Статистичний аналіз залежностей економічних показників типових підприємств для надання практичних рекомендацій по підвищенню продуктивності праці
МІНІСТЕРСТВО ОСВІТИ І НАУКИ УКРАЇНИ
ХМЕЛЬНИЦЬКИЙ НАЦІОНАЛЬНИЙ УНІВЕРСИТЕТ
Кафедра прикладної математики та соціальної
інформатики
КУРСОВА РОБОТА
Статистичний аналіз
залежностей економічних показників типових підприємств для надання практичних
рекомендацій по підвищенню продуктивності праці
КРПМ. 010061.00.00.00
Студент
групи ПМ - 10 - 1
С.С.
Григорук
Керівник
к. п.
н., доцент І.І. Ігнатьєва
2014р.
Вступ
У сучасному суспільстві з високим
рівнем розвитку науки та технологій, зокрема комп’ютерних, особливого значення
набуває вміння користуватись надбаннями сучасної техніки, використовувати для
підвищення рівня життя різноманітні методи науки. Тут потрібно не лише бути
добре обізнаним в тих чи інших методах, не лише знати про існування передових
технологій, але й вміти обрати серед існуючих найкращі, тобто найефективніші
для розв’язання певної конкретної задачі. Перед керівництвом підприємств за
умов жорсткої конкуренції на теренах сучасного, ще не повністю розвиненого
ринку за необхідності приймати максимально ефективні рішення виникає проблема:
в якому напрямку скеровувати діяльність підприємства, щоб забезпечити
оптимальний план виробництва; якими методами користуватись, щоб максимально
повно реалізувати виробничий потенціал підприємства.
Світ сучасних математичних знань має особливі інструменти для
вирішення подібних проблем. Існуючі статистичні методи дозволяють провести
досить повний аналіз діяльності підприємства та знайти шлях переходу від
існуючого стану до бажаного, тобто оптимізувати виробництво, забезпечити
максимальну ефективність функціонування.
Мета курсової роботи: надання
практичних рекомендацій щодо шляхів підвищення продуктивності праці.
Об’єкт дослідження: продуктивність
праці.
Предмет дослідження: підприємства.
Поставлена в роботі мета передбачає
необхідність вирішення таких завдань:
– за допомогою кластерного аналізу виділити типову
групу;
– визначити залежності між показниками за допомогою
кореляційного аналізу;
– побудувати регресійні моделі (парну, множинну
лінійну, множинну нелінійну) та визначити регресійне рівняння, що якнайкраще
аналітично описує залежність продуктивності праці від інших ознак;
– методами факторного аналізу визначити приховані
(латентні) ознаки, що мають вплив на результуючу ознаку;
– розробити рекомендації щодо підвищення продуктивності
праці підприємств даної галузі.
Для реалізації поставлених задач та проведення розрахунків
було використано наступні програмні продукти: Microsoft Office Excel, С#.
Дана робота складається з трьох розділів. У першому розділі
описано економічний зміст показників та сформульовано постановку задачі.
У другому містяться теоретичні відомості, за допомогою яких
реалізовувались поставлені завдання.
У третьому розділі проведено розрахунки та наведено
результати дослідження.
1. Опис
предметної області
.1 Економічний зміст показників
В управлінні підприємством або організацією, що здійснюють
будь-які види господарської діяльності в ринковому економічному середовищі,
застосовуються різні показники. Їх використання має відображати особливості
діяльності підприємства або організації, давати змогу вести певну аналітичну
роботу.
Тому будь-яке підприємство можна охарактеризувати такими
економічними показниками:
– продуктивність праці;
– індекс зниження собівартості
продукції;
– рентабельність;
– трудомісткість одиниці
продукції;
– питома вага робітників у
складі ПП;
– питома вага покупних виробів;
– коефіцієнт змінності
устаткування;
– премії і винагороди на одного
працівника;
– питома вага утрат від браку;
– фондовіддача;
– середньорічна чисельність ПП;
– середньорічна вартість ОВФ;
– середньорічний фонд
заробітної плати ПП;
– фондоозброєність праці;
– оборотність нормованих
оборотних коштів;
– оборотність ненормованих
оборотних коштів;
– невиробничі витрати.
Для даного дослідження обрано
наступні показники:
1) Продуктивність праці
Продуктивність праці - це показник трудової діяльності
<#"721044.files/image001.gif"> досліджуваних змінних на 53 об’єктах сукупності, що
аналізується, методами прикладного статистичного аналізу дослідити залежність
продуктивності праці (Y1) від премій і винагород на одного працівника (Х8),
питомої ваги утрат від браку (Х9), фондовіддачі (Х10), середньорічної
чисельності працівників підприємства (Х11), середньорічної вартості ОВФ (Х12),
невиробничих витрат (Х17), яка б дозволила найкращим чином надати практичні
рекомендації по підвищенню продуктивності праці Y1 за даними значень пояснюючих
змінних 
2.
Теоретична частина
2.1
Робастне статистичне оцінювання
2.1.1
Грубі помилки та методи їх виявлення
При дослідженні статистичних сукупностей даних часто
доводиться мати справу з даними, значення яких відрізняються від значень
основного масиву (помилки або викиди). При розв’язуванні завдань робастного
оцінювання виділяють два типи даних, що засмічують вихідну статистичну
сукупність.
До першого типу відносять дані, які неістотно відрізняються
від значень, що є типовими для сукупності. Такі дані не викликають значних
спотворень в аналітичних результатах і можуть опрацьовуватись традиційними
статистичними.
До другого типу відносять ті дані, які значно відхиляються
від типових даних сукупності. Їх називають грубими помилками. Вони підлягають
спеціальній обробці.
Причинами грубих помилок є:
– специфічні особливості окремих елементів досліджуваної
сукупності;
вони, як правило, призводять до випадкових відхилень;
– невірне групування або розбиття елементів на однорідні
підмножини, і,
як наслідок, неправильне зарахування окремих елементів до
досліджуваної сукупності;
– грубі помилки при реєстрації та опрацюванні даних.
Кожне зі значень, яке є підозрілим на помилковість,
перевіряється за допомогою спеціальних статистичних критеріїв.
Т-критерій Граббса. Даний критерій дозволяє здійснити
перевірку одного помилкового значення сукупності. Перевірка здійснюється за
наступним алгоритмом:
1) обчислення вибіркової середньої 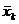 по
безпомилкових даних, тобто, тих даних, з яких вилучене підозріле на помилку
значення;
по
безпомилкових даних, тобто, тих даних, з яких вилучене підозріле на помилку
значення;
) обчислення вибіркового середньоквадратичного відхилення  по
по
безпомилкових даних;
) розрахунок спостереженого значення критерія:
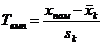 (2.1)
(2.1)
) знаходження за таблицею критичного значення критерія  при рівні
при рівні
значущості  та кількості безпомилкових даних
та кількості безпомилкових даних  . Якщо
. Якщо 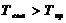 ,
то гіпотеза про помилковість досліджуваного значення приймається.
,
то гіпотеза про помилковість досліджуваного значення приймається.
Перевірка наступних підозрілих значень здійснюється після вилучення
помилки з сукупності. Перевагою даного критерія є його простота у застосуванні.критерій
Тіт’єна та Мура застосовується для перевірки групи значень на помилковість. В
такому випадку можливі наступні ситуації:
– помилки знаходяться у верхній частині ранжованого ряду
даних;
– помилки знаходяться у нижній частині ранжованого ряду
даних.
Розглянемо спочатку перший випадок. Алгоритмом:
1) обчислення вибіркової загальної середньої  по всіх даних сукупності;
по всіх даних сукупності;
) обчислення вибіркової середньої по
безпомилкових даних, тобто, тих даних, з яких вилучені підозрілі на помилку
значення;
3) розрахунок спостереженого значення критерія:
 (2.2)
(2.2)
де -кількість помилок.
Чисельник розраховується по безпомилкових даних, знаменник - по всіх
даних сукупності.
) знаходження за таблицею критичного значення критерія 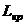 при рівні значущості ,
кількості вихідних даних
при рівні значущості ,
кількості вихідних даних  та кількості безпомилкових даних . Якщо
та кількості безпомилкових даних . Якщо  ,
то гіпотеза про помилковість досліджуваного значення приймається.
,
то гіпотеза про помилковість досліджуваного значення приймається.
Аналогічно критерій використовується у випадку розташування
групи помилок у нижній частині ранжованого ряду даних.критерій Тіт’єна та Мура
використовується у випадку розташування помилкових даних з обох кінців
ранжованої сукупності. Емпіричне значення критерію обчислюється за формулою:
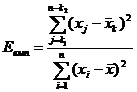 (2.3)
(2.3)
де  та
та  -
кількість підозрілих на помилковість значень у нижній та верхній частинах
ранжованого ряду даних,
-
кількість підозрілих на помилковість значень у нижній та верхній частинах
ранжованого ряду даних,
 -
безпомилкова середня, обчислена по відкинутих підозрілих значеннях з обох
кінців ряду;
-
безпомилкова середня, обчислена по відкинутих підозрілих значеннях з обох
кінців ряду;
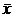 -
загальна середня.
-
загальна середня.
Емпіричне значення критерію порівнюється з критичним, знайденим за
відповідною таблицею при рівні значущості ,
кількості вихідних даних та кількості безпомилкових даних  . Гіпотеза про помилковість значень приймається, якщо
емпіричне значення менше за критичне.
. Гіпотеза про помилковість значень приймається, якщо
емпіричне значення менше за критичне.
2.1.2
Методи одержання стійких статистичних оцінок
Після знаходження помилок вирішується завдання оцінювання
параметрів вибіркової сукупності. При цьому помилкові дані або відкидаються,
або модифікуються. Далі будуть розглянуті два підходи робастного оцінювання
вибіркової середньої.
Формула середньої за Пуанкаре. Нехай у вихідній сукупності є  помилкових даних, розташованих у верхній частині
ранжованого ряду. Тоді вони вилучаються з сукупності. Однак щоб вилучення не
вплинуло істотно на зміну розрахованого значення стосовно істинного, з нижньої
частини вихідної сукупності також вилучається перших значень. Вибіркова середня тоді знаходиться за
формулою
помилкових даних, розташованих у верхній частині
ранжованого ряду. Тоді вони вилучаються з сукупності. Однак щоб вилучення не
вплинуло істотно на зміну розрахованого значення стосовно істинного, з нижньої
частини вихідної сукупності також вилучається перших значень. Вибіркова середня тоді знаходиться за
формулою
 (2.4)
(2.4)
Аналогічно здійснюється розрахунок стійкої середньої у випадку
розташування помилки у нижній частині ряду.
Якщо помилкові дані розташовані з обох кінців сукупності, вона
модифікується таким чином, щоб мінімізувати кількість безпомилкових даних, які
будуть вилучені з сукупності. Тобто, з одного кінця ранжованої сукупності
вилучаються всі помилкові дані, а з іншого - того, де їх було менше, крім
помилкових вилучаються і безпомилкові.
Наведений спосіб робастного оцінювання є досить простим, але має
недолік - значно скорочується вихідна сукупність даних.
Формула середньої за Вінзором. Обчислення середньої за Вінзором
передбачає попередню модифікацію вихідної сукупності даних. Нехай помилки у
кількостіодиниць розташовані у верхній частині впорядкованого
за зростанням ряду даних. Тоді всі помилкові значення замінюються на перше
безпомилкове значення у верхній частині сукупності  . Відповідним чином перетворюються дані у нижній
частині сукупності - перших значень
замінюються на значення
. Відповідним чином перетворюються дані у нижній
частині сукупності - перших значень
замінюються на значення  . Наведений процес перетворення сукупності називається
вінзорізацією даних. Тоді стійка середня обчислюється за загальною формулою
середньої для перетворених даних. Якщо вінзорізовані дані позначити через
. Наведений процес перетворення сукупності називається
вінзорізацією даних. Тоді стійка середня обчислюється за загальною формулою
середньої для перетворених даних. Якщо вінзорізовані дані позначити через  , то вираз для розрахунку має вигляд
, то вираз для розрахунку має вигляд
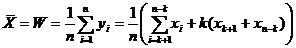 (2.5)
(2.5)
Аналогічно перетворюються дані у випадку розташування помилок
в нижній частині ранжованого ряду даних. Якщо помилки знаходяться в обох
частинах ряду, то вінзорізація відбувається таким чином, щоб максимально їх
виключити.
Формули стійких середніх за Пуанкаре та за Вінзором дають гарні
результати для сукупностей зі симетричним розподілом засмічень, коли грубі
помилки розташовані в обох кінцях ранжованої сукупності даних.
2.2
Ієрархічний кластерний аналіз
Кластерний аналіз - це сукупність методів, що дозволяють
класифікувати багатомірність спостереження за відсутності апріорної інформації
про розподіл генеральної сукупності з якої зроблено вибірку досліджуваних
об’єктів. Мета кластерного аналізу - утворення груп, схожих між собою об’єктів,
які називаються кластерами.
Кластерний аналіз призводить до розбиття на групи з
урахуванням всіх ознак одночасно. Методи кластерного аналізу: агломеративні,
диви зимні та ітераційні. Використається як спосіб вимірювання евклідова
відстань:
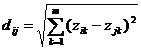 (2.4)
(2.4)
Оцінка розбиття на кластери проводиться за допомогою функціоналу якості
розбиття  . Використовуються наступні види функціоналів:
. Використовуються наступні види функціоналів:
– загальна сума внутрішньо - групових дисперсій
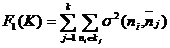 (2.5)
(2.5)
– загальна сума попарних внутрішньо - кластерних
відстаней між елементами:
 (2.6)
(2.6)
– узагальнена внутрішньо - класова дисперсія:
 (2.7)
(2.7)
де - кількість кластерів;
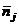 -
вектор середніх значень ознак об’єктів
-
вектор середніх значень ознак об’єктів 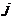 -го
кластера;
-го
кластера;
 -
дисперсія об’єктів -го кластера;
-
дисперсія об’єктів -го кластера;
 -
коваріаційна матриця об’єктів -го
кластера;
-
коваріаційна матриця об’єктів -го
кластера;
 -
кількість об’єктів, що належать -му
кластеру.
-
кількість об’єктів, що належать -му
кластеру.
Найкращим вважається таке розбиття, при якому функціонал досягає свого
екстремального (min) значення.
2.2.1 Агломеративні методи кластерного аналізу
Сутність методів: послідовне об’єднання двох найбільш подібних
кластерів в один, що містить в собі всі об’єкти.
Загальний алгоритм:
– кожен об’єкт розглядається як окремий кластер;
– обчислюється матриця відмінностей між об’єктами;
– на основі матриці відмінностей знаходяться два найбільш
близькі кластери;
– перераховується матриця відстаней між кластерами;
– процес повторюється з кроку 3 до утворення одного
кластера;
– визначається кількість кластерів, на які розіб’ється
вхідна сукупність шляхом аналізу відстаней між кластерами.
Існує загальна формула, яка дозволяє обчислити відстань між кластерами
незалежно від методу її оцінки. Нехай на деякому кроці в кластер  були об’єднані кластери:
були об’єднані кластери: 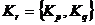 , то відстань від нього до деякого кластера
, то відстань від нього до деякого кластера 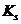 визначають за формулою:
визначають за формулою:
 (2.8)
(2.8)
Параметри 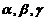 визначаються методом яким проводилося об’єднання.
Значення параметрів подано у таблиці 2.1.
визначаються методом яким проводилося об’єднання.
Значення параметрів подано у таблиці 2.1.
Таблиця 2.1 - Значення параметрів формули перерахунку відстані між
кластерами в залежності від методу оцінки їх близькості
|
Метод
|
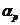   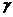
|
|
|
|
|
Ближнього сусіда
|
0,5
|
0,5
|
0
|
-0,5
|
|
Дальнього сусіда
|
0,5
|
0,5
|
0
|
0,5
|
Метод оцінки відстані між кластерами повинен обиратись з
урахуванням відомостей про існуючу структуру в сукупності об'єктів спостережень
або з урахуванням вимог до оптимізації обраного критерію якості кластеризації.
.2.2 Дивизимний метод кластерного аналіз
Дивизимний метод за процесом
розрахунків є протилежним агломеративному. Початково припускається, що всі
об'єкти належать одному кластеру.
Алгоритм методу:
1) обчислюється матриця відстаней;
2) знаходять два об'єкти,
відстань між якими найбільша, ці об'єкти утворять центри нових кластерів;
) решта об'єктів розподіляють
на два кластери за ступенем близькості їх до центрів;
) обраний кластер ділимо на 2
кластери згідно пунктів 2 - 4;
5) процедуру повторюємо поки не буде утворено  кластерів по одному об’єкту в кожному з них;
кластерів по одному об’єкту в кожному з них;
) найбільш доцільна кількість кластерів визначається на тому
кроці після якого зменшення відстані між кластерами приріст був найбільший.
Перевагою дивизимного методу є те, що
він не вимагає перерахунку матриці відстаней на кожному кроці.
2.2.3
Ітераційні методи кластерного аналізу
Суть ітераційних методів полягає в
тому, що процес класифікації починається із визначення початкових умов, тобто
кількості утворюваних кластерів та еталонів.
Метод -середніх належить до групи ітераційних методів
еталонного типу.
Алгоритм цього методу: нехай є спостережень,
кожне з яких характеризується ознаками.
Ці спостереження необхідно розбити на кластерів.
З точок відбирають випадковим чином або задають
виходячи з деяких апріорних міркувань точок
об’єктів, які обирають за “еталони”  .
.
З 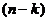 об’єктів, що залишилися, витягується точка
об’єктів, що залишилися, витягується точка  і перевіряється до якого з еталонів вона знаходиться
найближче. Для перевірки використовується одна з наведених метрик в таблиці
1.2.
і перевіряється до якого з еталонів вона знаходиться
найближче. Для перевірки використовується одна з наведених метрик в таблиці
1.2.
Таблиця 2.2 - Метрики
|
№
|
Назва
|
Формула
|
|
1
|
Евклідова відстань
|

|
|
2
|
Лінійна відстань (відстань міських кварталів)
|
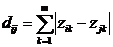
|
|
3
|
Відстань Мінковського
|

|
|
4
|
Супремум - норма
|
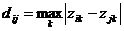
|
5 Відстань Махаланобіса 
|
де  коваріаційна матриця коваріаційна матриця
|
Початкова вага кожного кластера буде рівна 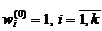 . Після приєднання елемента до якогось -го кластера, еталон цього кластера та його вага
перераховується за формулами
. Після приєднання елемента до якогось -го кластера, еталон цього кластера та його вага
перераховується за формулами
 ,
,

Процедуру повторюємо з другого кроку. Процес закінчується тоді, коли не
залишається вільних елементів.
2.3
Кореляційний аналіз
Кореляційний аналіз представляє собою
інструмент, який дозволяє кількісно оцінити зв’язки між великим числом
взаємодіючих економічних явищ - при цьому, деякі з них невідомі. Схема
складання прогнозу полягає в зборі даних про значення залежних змінних, їх
аналізі на предмет наявності зв’язку і, якщо такий зв’язок існує, необхідно
оцінити тісноту цього зв’язку, це і є кореляція.
Кореляційний аналіз проводиться за
наступною схемою:
З метою встановлення залежностей між
параметрами будують попарні кореляційні поля. Обчислюють точкові оцінки
числових характеристик за формулою

для того, щоб знайти коефіцієнти кореляції.
Коефіцієнт кореляції обчислюється за формулою:
 (2.9)
(2.9)
Обчислюють коефіцієнт детермінації за
формулою:
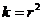 (2.10)
(2.10)
За допомогою якого встановлюють
найсильніші та найслабші зв’язки між параметрами. Обчислюють точкові оцінки умовних
середніх квадратичних відхилень за формулою:
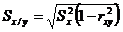 (2.11)
(2.11)
Обчислюють точкові оцінки часткових коефіцієнтів кореляції. Для цього
записують кореляційну матрицю:
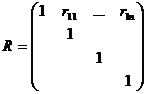 (2.12)
(2.12)
Обчислюють точкові оцінки
коефіцієнтів кореляції за формулою:
 (2.13)
(2.13)
де 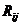 - алгебраїчні доповнення до кореляційної матриці.
- алгебраїчні доповнення до кореляційної матриці.
Якщо значення часткових коефіцієнтів кореляції менші від значень
квадратичних коефіцієнтів кореляції, то можна зробити висновок про те, що при
виключенні одного з параметрів зв’язок між іншими параметрами слабшає. Це
говорить про те, що той параметр що виключається посилює кореляцію між іншими
змінними.
Обчислюють часткові коефіцієнти детермінації. Якщо часткові коефіцієнти
детермінації менші за квадратичні (парні), то це свідчить про те, що тісна
залежність, яку показали обчислення парних коефіцієнтів обумовлено частково або
повністю дією на цю пару інших фіксованих випадкових величин. Якщо частковий
коефіцієнт детермінації більший за парний, то фіксовані компоненти послаблюють
зв’язок.
Обчислюють точкові оцінки залишкових дисперсій при фіксованих  значеннях за формулою:
значеннях за формулою:
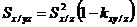 (2.14)
(2.14)
Обчислюють точкові оцінки множинних коефіцієнтів детермінації та
кореляції за формулами:
 (2.15)
(2.15)
Коефіцієнти показують залежність
однієї величини від усіх інших.
Перевіряють за рівнем значущості 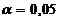 значимість
множинних коефіцієнтів детермінації в генеральній сукупності.
значимість
множинних коефіцієнтів детермінації в генеральній сукупності.  Спочатку обчислюють емпіричне значення критерію за
формулою:
Спочатку обчислюють емпіричне значення критерію за
формулою:
 (2.16)
(2.16)
За таблицею розподілу Фішера знаходять критичні значення критерію  . Якщо критичне значення менше ніж емпіричне, то
. Якщо критичне значення менше ніж емпіричне, то  відхиляється, якщо навпаки, то приймається. Якщо
коефіцієнт не значимий, то в генеральній сукупності залежність відсутня.
відхиляється, якщо навпаки, то приймається. Якщо
коефіцієнт не значимий, то в генеральній сукупності залежність відсутня.
2.3.1
Мультиколінеарність
При моделюванні багатьох соціально-економічних явищ та
процесів виникає задача виявлення та оцінки зв’язку між ними. У багатьох
дослідженнях виявляється, що деяка результативна ознака змінюється під впливом
не одного, а кількох факторів.
Одна з передумов застосування методу найменших квадратів до
оцінки параметрів лінійних багатофакторних моделей - це відсутність лінійних
зв’язків між незалежними змінними моделі. Якщо такі зв’язки існують, то це
явище називають мультиколінеарність.
Суть мультиколінеарності полягає в тому, що в багатофакторній
регресійній моделі дві або більше незалежних змінних пов’язані між собою
лінійною залежністю або, іншими словами, мають високий ступінь кореляції:
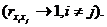
Наявність мультиколінеарності створює певні проблеми при розробці
моделей. Насамперед, визначник матриці спостережень 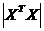 наближається до нуля, і оператор оцінювання за
звичайним МНК стає надзвичайно чутливий до похибок вимірювань і похибок
обчислень. При цьому МНК оцінки можуть мати значне зміщення відносно дійсних
оцінок узагальненої моделі, а в деяких випадках можуть стати взагалі
беззмістовними.
наближається до нуля, і оператор оцінювання за
звичайним МНК стає надзвичайно чутливий до похибок вимірювань і похибок
обчислень. При цьому МНК оцінки можуть мати значне зміщення відносно дійсних
оцінок узагальненої моделі, а в деяких випадках можуть стати взагалі
беззмістовними.
Найповніше дослідити мультиколінеарність дає змогу алгоритм
Фаррара-Глобера:
) нормалізування змінних 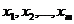 економетричної
моделі:
економетричної
моделі:
 (2.17)
(2.17)
де n - кількість спостережень;- кількість незалежних змінних;
 -
дисперсія
-
дисперсія  незалежної змінної;
незалежної змінної;
 -
середнє значення фактора Хі.
-
середнє значення фактора Хі.
2) обчислення кореляційної матриці:
 , (2.18)
, (2.18)
де R - кореляційна матриця.
Однак на основі цієї залежності не можна стверджувати, що отриманий
зв'язок є явищем мультиколінеарності. Якщо діагональні елементи матриці 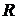 не дорівнюють одиниці, то на діагоналі цієї матриці
потрібно проставити одиниці, а до решти елементів додати різницю між одиницею й
значенням діагонального елемента.
не дорівнюють одиниці, то на діагоналі цієї матриці
потрібно проставити одиниці, а до решти елементів додати різницю між одиницею й
значенням діагонального елемента.
) визначення визначника кореляційної матриці  . Обчислення критерю
. Обчислення критерю 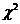 :
:
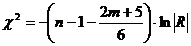 (2.19)
(2.19)
Порівняти це значення з табличним при 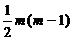 ступенях
свободи і рівні значущості
ступенях
свободи і рівні значущості  (якщо
(якщо
 , то в масиві незалежних змінних існує
мультиколінеарність).
, то в масиві незалежних змінних існує
мультиколінеарність).
) визначення матриці похибок: 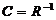 .
.
) розрахунок F критерію:
 , (2.20)
, (2.20)
Значення критеріїв порівняти з табличним при  і
і  ступенях
свободи й рівня значущості (якщо
ступенях
свободи й рівня значущості (якщо
 , то відповідна незалежна змінна мультиколінеарна з
іншими).
, то відповідна незалежна змінна мультиколінеарна з
іншими).
6) розрахування коефіцієнтів детермінації та часткових
коефіцієнтів кореляції, які характеризують щільність зв’язку між двома змінними
за умови, що інші змінні не впливають на цей зв'язок.
) обчислення t критерію
 (2.21)
(2.21)
Значення критеріїв порівняти з табличним при (m-n) ступенях свободи та
рівні значущості 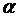 (якщо
(якщо 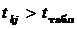 ,
то то між незалежними змінними існує мультиколінеарність).
,
то то між незалежними змінними існує мультиколінеарність).
Якщо 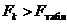 , то певна змінна залежить від усіх інших незалежних
змінних і треба вирішити питання про її виключення з переліку змінних. Якщо
, то певна змінна залежить від усіх інших незалежних
змінних і треба вирішити питання про її виключення з переліку змінних. Якщо 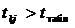 то
то  і
і
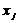 щільно пов’язані між собою. Аналізуючи F і t
критерій, робимо висновок, яку зі змінних треба виключити з моделі.
щільно пов’язані між собою. Аналізуючи F і t
критерій, робимо висновок, яку зі змінних треба виключити з моделі.
2.4
Регресійний аналіз
Кількісний вплив факторів 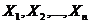 на
результативний показник
на
результативний показник 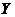 вивчається за допомогою регресійного аналізу, який
дозволяє встановити вид аналітичної залежності між ознаками
вивчається за допомогою регресійного аналізу, який
дозволяє встановити вид аналітичної залежності між ознаками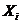 та оцінити
параметри моделі.
та оцінити
параметри моделі.
2.4.1
Парна лінійна регресія
Модель будується на основі кореляційного аналізу. У загальному вигляді
регресійна модель між факторною ознакою  та
результативною ознакою
та
результативною ознакою  з врахуванням фактора випадкових величин (помилок)
з врахуванням фактора випадкових величин (помилок)  записується у вигляді:
записується у вигляді:
 (2.22)
(2.22)
де  і
і 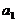 -
невідомі параметри регресійної моделі.
-
невідомі параметри регресійної моделі.
Задача регресійного аналізу полягає у відшуканні невідомих параметрів і рівняння
регресії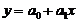 . При цьому необхідно досягти “найкращої”
апроксимації. Найчастіше при цьому користуються методом найменших квадратів, що
передбачає мінімізацію виразу:
. При цьому необхідно досягти “найкращої”
апроксимації. Найчастіше при цьому користуються методом найменших квадратів, що
передбачає мінімізацію виразу:
 ,
,
де  - фактичні (емпіричні), а
- фактичні (емпіричні), а 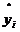 - розрахункові (теоретичні) значення результативної
ознаки.
- розрахункові (теоретичні) значення результативної
ознаки.
Невідомі параметри і
можна знайти із системи нормальних рівнянь:
 (2.23)
(2.23)
Необхідно розрахувати базисні середні та залишкову дисперсію.
Для визначення значущості моделі за 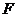 -
критерієм Фішера необхідно обчислити розрахункове значення:
-
критерієм Фішера необхідно обчислити розрахункове значення:
 . (2.24)
. (2.24)
Табличне значення критерію Фішера для рівня значущості 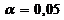 та числа ступенів свободи
та числа ступенів свободи  становить
становить 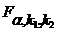 .
.
Якщо 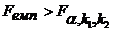 , то побудована модель адекватна статистичним даним,
якщо
, то побудована модель адекватна статистичним даним,
якщо 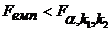 , то модель неадекватна.
, то модель неадекватна.
Для перевірки перевіряють значущість параметрів за 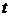 - критерієм Стьюдента необхідно розрахувати
розрахункове значення критерію.
- критерієм Стьюдента необхідно розрахувати
розрахункове значення критерію.
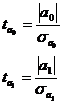 (2.25)
(2.25)
Якщо  більші
більші 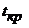 ,то
параметри моделі значущі.
,то
параметри моделі значущі.
2.4.2
Парна нелінійна регресія
На практиці часто зустрічаються економетричні моделі з нелінійною
залежністю між показником  та фактором
та фактором  .
.
За методикою оцінок параметрів парну нелінійну регресію поділяють на
два типи:
– нелінійна за факторами, але
лінійна за невідомими параметрами;
– нелінійна за факторами та
параметрами.
Найчастіше використовують такі парні
нелінійні моделі:
1) поліноміальна: 
) гіперболічна: 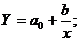
) логарифмічна: 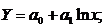
) степенева: 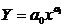
) показникова: 
) експоненціальна: 
Лінеаризуємо дану модель. Далі
працюємо з нею як зі звичайною парною лінійною регресією.
2.4.3
Множинна лінійна регресія
У реальному житті при аналізі соціально-економічних явищ та
процесів має місце багатомірний їх опис, тобто є необхідність використовувати в
аналізі велике число показників (параметрів або ознак). Для опису таких
процесів застосовується множинна регресія.
Загальний вигляд рівняння множинної регресії:
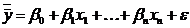 (2.26)
(2.26)
Параметри моделі оцінюються методом найменших квадратів.
Алгоритм виконання множинної лінійної регресії:
1) Знаходження добутку:
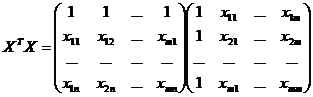 ,
,
де - об’єм вибірки.
2) Обчислення:
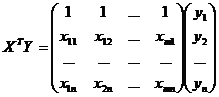 .
.
) Знаходження 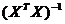 .
.
) Збчислення оцінки для коефіцієнта регресії:
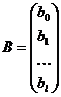 за
формулою
за
формулою  .
.
5) Записується оцінка для рівняння регресії, яка має
вигляд:
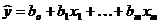 .
.
) Перевіряється значущість одержаного рівняння регресії
(перевірка наадекватність одержаної моделі). Висувають дві гіпотези:  - рівняння регресії не значуще,
- рівняння регресії не значуще,  - рівняння регресії значуще.
- рівняння регресії значуще.
Знаходиться
 ,
,

де - сума квадратів відхилень значень результуючої ознаки
у регресії
 ,
,
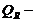 сума
квадратів відхилень значень регресії від нуля
сума
квадратів відхилень значень регресії від нуля
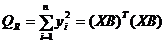 .
.
Застосовується - критерій:
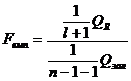 (2.27)
(2.27)
 кількість
незалежних змінних, - об’єм вибірки.
кількість
незалежних змінних, - об’єм вибірки.
Порівнюється 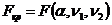 , яке визначається при рівні значущості і ступенях свободи
, яке визначається при рівні значущості і ступенях свободи 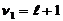 ,
,
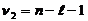 з
з  .
.
Якщо  , то нульова гіпотеза відхиляється, дана модель
значима в генеральні сукупності, тобто хоча б одне значення з
, то нульова гіпотеза відхиляється, дана модель
значима в генеральні сукупності, тобто хоча б одне значення з  .
.
Якщо 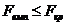 , тоді приймається нульова гіпотеза, що свідчить про
неадекватність моделі в реальному процесі. У випадку, якщо приймається нульова
гіпотеза, то наступний пункт можна не робити.
, тоді приймається нульова гіпотеза, що свідчить про
неадекватність моделі в реальному процесі. У випадку, якщо приймається нульова
гіпотеза, то наступний пункт можна не робити.
7) Якщо нульова гіпотеза відхилилась, то перевіряємо
значущість кожного коефіцієнта регресії окремо. Для цього знаходять оцінку для
залишкової дисперсії
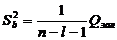 .
.
Знайти оцінку коваріаційної матриці вектора 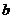 :
:

Перевіряється значущість коефіцієнта регресії:

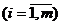

За t-критерієм Стьюдента
 (2.28)
(2.28)
 ,
,
 ,
приймається (
,
приймається (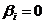 ),
),
 відхиляється
(
відхиляється
( ).
).
Якщо хоча б один з коефіцієнтів не значимий, переходимо до покрокового
регресійного аналізу.
8) В моделі регресії не враховуються доданки, які містять
не значимий коефіцієнт регресії, проводиться перерахунок моделі наступним
чином. З вхідних даних виключаються значення фактора, який має не значимий
коефіцієнт регресії, будується множинна лінійна регресійна модель.
9) У випадку, коли всі коефіцієнти значимі,
перевіряється ступінь впливу залишків на регресійну модель, тобто обчислюється
кореляційне відношення:
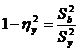 (2.29)
(2.29)
Якщо кореляційне відношення 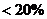 ,
то модель можна використовувати на практиці. Якщо
,
то модель можна використовувати на практиці. Якщо  - є значний вплив випадкових факторів.
- є значний вплив випадкових факторів.
2.4.4
Множинна нелінійна регресія
Найбільш розповсюджені моделі
нелінійної регресії:
– адитивні - моделі, величина результуючої ознаки яких
дорівнює сумі відповідних значень факторів. До адитивних моделей відносяться:
1) 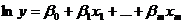 ;
;
)  ;
;
) 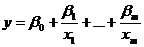 ;
;
– мультиплікативні - моделі, в яких величина
результуючої ознаки дорівнює добутку відповідних значень факторних ознак. До
мультиплікативних моделей відносяться
а) 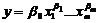 ;
;
б)  .
.
Лінеаризація - це перехід від нелінійної моделі до лінійної.
Якщо модель адитивна, то:
1)  ,
,  ;
;
) 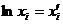 ,
,  ;
;
)  , .
, .
Якщо модель мультиплікативна, то спочатку застосовується
логарифмування, тобто зведення до адитивної моделі:
а) 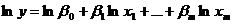 ,
, 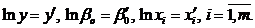 ;
;
б) 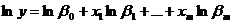 ,
, 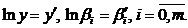 .
.
Алгоритм побудови моделі представлений далі.
Нехай модель мультиплікативна виду:
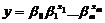 .
.
1) проводимо лінеаризацію функції:
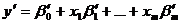 ;
;
2) лінеаризуємо вхідні дані;
3) виконуємо усі дії по побудові множинної лінійної
регресії моделі відповідно до пункту (2.4.2);
4) знаходимо  ,тобто експоненціюємо;
,тобто експоненціюємо;
) знаходимо  ,
тобто
,
тобто 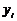 шукається з моделі одержаної в пункті 3;
шукається з моделі одержаної в пункті 3;
) перевіряємо адекватність та знаходимо допустиму область.
2.5 Факторний аналіз
.5.1 Сутність завдання факторного
аналізу
Сутність методів факторного аналізу полягає в переході від
опису деякої множини досліджуваних об'єктів, заданої великим набором непрямих
безпосередньо вимірюваних ознак, до їх опису меншим числом максимально
інформативних глибинних змінних, що відображають найбільш істотні властивості
явища. Такого роду змінні, що називаються факторами, є деякими функціями
початкових ознак. В більшості випадків фактори являють собою латентні (скриті)
ознаки, які не підлягають прямому вимірюванню, але здійснюють безпосередній
вплив на досліджуване явище чи процес.
Фактор є розрахунковою змінною, тобто якоюсь новою характеристикою
об'єктів, що вивчаються. Опис фактора в термінах його зв'язку з набором
початкових ознак відшуковується у вигляді так званої факторної матриці, або
матриці факторних навантажень розмірністю  ,
де - кількість вихідних ознак, а - число факторів. Основою для побудови факторної
матриці служить кореляційна матриця. Вона відображає ступінь взаємозв'язку між
кожною парою ознак, тоді як факторна матриця характеризує ступінь зв'язку між
кожною з даних ознак і факторів,
виявлених в процесі аналізу. При цьому значення обирається
виходячи з двох умов: повинне бути багато менше за , а рівень втрат в інформації достатньо малим.
,
де - кількість вихідних ознак, а - число факторів. Основою для побудови факторної
матриці служить кореляційна матриця. Вона відображає ступінь взаємозв'язку між
кожною парою ознак, тоді як факторна матриця характеризує ступінь зв'язку між
кожною з даних ознак і факторів,
виявлених в процесі аналізу. При цьому значення обирається
виходячи з двох умов: повинне бути багато менше за , а рівень втрат в інформації достатньо малим.
Факторна матриця дозволяє виділити для кожного фактора групу
параметрів, найтісніше з ним зв'язаних. Тим самим відкривається можливість
зіставити фактори один з одним, дати їм змістовне тлумачення і найменування,
тобто навести інтерпретацію факторів.
2.5.2 Постановка
завдання факторного аналізу
Нехай є набір стандартизованих вихідних ознак  ,
, 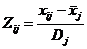 .
Необхідно замінити ці ознаки іншими
.
Необхідно замінити ці ознаки іншими 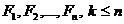 .
Нові ознаки називають факторами. При цьому виходять з припущення, що початкові
ознаки є результатом дії деяких спільних чинників, в ролі яких і будуть
виступати нові фактори. Загальна модель факторного аналізу має такий вигляд:
.
Нові ознаки називають факторами. При цьому виходять з припущення, що початкові
ознаки є результатом дії деяких спільних чинників, в ролі яких і будуть
виступати нові фактори. Загальна модель факторного аналізу має такий вигляд:
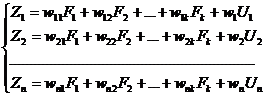 (2.30)
(2.30)
Ознаки  відображають характерні риси вихідних ознак і
називаються характерностями.
відображають характерні риси вихідних ознак і
називаються характерностями.  -
факторні ознаки, відображають спільні риси вхідних ознак.
-
факторні ознаки, відображають спільні риси вхідних ознак.  - факторні навантаження (показують частку загального
фактора у вихідній ознаці
- факторні навантаження (показують частку загального
фактора у вихідній ознаці 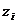 ).
Значення факторних навантажень коливаються в межах від -1 до 1. Чим ближчі вони
за модулем до 1, тим зв’язок між фактором та ознакою щільніший. Якщо величина
факторного навантаження додатна, то вплив фактора на ознаку позитивний, інакше
- негативний.
).
Значення факторних навантажень коливаються в межах від -1 до 1. Чим ближчі вони
за модулем до 1, тим зв’язок між фактором та ознакою щільніший. Якщо величина
факторного навантаження додатна, то вплив фактора на ознаку позитивний, інакше
- негативний.
Лінійність взаємозв’язку у факторній моделі є припущенням, оскільки в
дійсності основні параметри, що визначають соціально-економічні явища,
взаємодіють більш складно. Тому модель факторного аналізу є першим наближенням
до відображення реальних процесів.
Матричний запис факторної моделі:
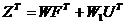 ,
,
де  - матриця реалізацій вихідних ознак розмірності (m´n);
- матриця реалізацій вихідних ознак розмірності (m´n);
 -
матриця факторних навантажень, спільностей розмірності (n´k);
-
матриця факторних навантажень, спільностей розмірності (n´k);
-
матриця реалізацій факторів, розмірності (m´ k);
 -
діагональна матриця факторних навантажень характерностей, розмірності (n´ n);
-
діагональна матриця факторних навантажень характерностей, розмірності (n´ n);
 -
матриця реалізацій характерностей, розмірності (m´n);
-
матриця реалізацій характерностей, розмірності (m´n);
Кожне рівняння системи (2.31) можна подати у вигляді:
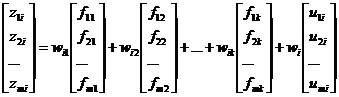 .
.
Залежність між компонентами ознак та факторів її можна записати таким
чином:
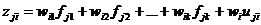 ,
,
де 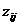 - -те
значення
- -те
значення  -ї ознаки;
-ї ознаки;
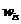 -
факторне навантаження
-
факторне навантаження  -го фактора;
-го фактора;
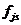 -
-те значення -того
фактора;
-
-те значення -того
фактора;
 -
факторне навантаження характерності -ї
ознаки;
-
факторне навантаження характерності -ї
ознаки;
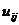 -
-те значення характерності -ї ознаки;
-
-те значення характерності -ї ознаки;

Одержані фактори будуються таким чином, щоб вони були взаємно
некорельовані між собою та характерностями.
 (2.33)
(2.33)
При проведенні перетворень враховано ознаку ортогональності, що 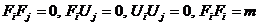 .
.
Дисперсія вихідної ознаки:
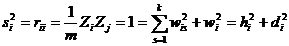 ,
,
де 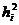 - частка дисперсії ознаки , яка пояснюється відібраними факторами;
- частка дисперсії ознаки , яка пояснюється відібраними факторами;
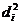 -
відображає частку характерного фактора в дисперсії.
-
відображає частку характерного фактора в дисперсії.
Основним завданням факторного аналізу є пояснення відібраними факторами
якомога більшої частки дисперсії вхідних ознак. Факторне навантаження виражає кореляцію між факторами і ознакою, і 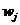 між характерністю і ознакою.
між характерністю і ознакою.
2.5.3
Метод головних компонент
Метод головних компонент відноситься до компонентного аналізу і є
самостійним методом багатомірного статистичного аналізу. Даний метод дозволяє
за вихідними ознаками побудувати узагальнених ознак, які називаються головними
компонентами і являють собою штучні змінні, що є лінійними комбінаціями
вихідних ознак.
Властивості головних компонент:
а) їх кількість дорівнює кількості вихідних ознак;
б) вони є ортогональними;
в) вони є стандартизованими;
г) вони впорядковані таким чином, що перша головна
компонента пояснює
найбільшу частку дисперсії вхідних ознак. Наступна найбільшу
частку дисперсії, що залишилась непоясненою першою компонентою.
На практиці для аналізу беруть, як правило, тільки ті
компоненти, сумарна частка дисперсії яких не менше 80%, а інші відкидаються як
такі, що не значимі.
Алгоритм методу головних компонент:
1) Обчислюється матриця стандартизованих ознак .
) Обчислюється кореляційна матриця стандартизованих ознак 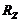 .
.
) Обчислюється матриця власних значень:
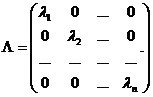
та матриця нормованих власних векторів
 .
.
4) Обчислюємо матрицю факторних навантажень:
 (2.31)
(2.31)
5) За матрицею власних значень обчислюється частка
дисперсії (власне значення це і є дисперсія).
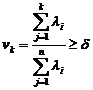 (2.32)
(2.32)
6) Обчислюється матриця значень факторів:
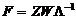 (2.33)
(2.33)
) За початковими та
одержаною будуємо регресійну модель лінійну.
Склад компоненти визначається за коефіцієнтом інформованості:
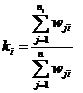 (2.34)
(2.34)
Набір пояснюючих ознак вважається задовільним, якщо величина
коефіцієнта інформованості становить не менше 0,75.
2.5.4
Метод головних факторів
При знаходженні факторів за методом головних факторів передбачається
, що характерності вже відомі. Це означає, що в кореляційній матриці R
діагональні елементи виражають лише спільності, а тому менші одиниці. Метод
головних факторів полягає в знаходженні такої матриці факторних навантажень W,
яка задовольняє співвідношенню:
WWT = R - H12 = R¢, (2.35)
де H - діагональна матриця, що виражає характерність;¢ - редукована матриця
кореляцій.
Матриця факторних навантажень знаходиться з точністю до
ортогонального перетворення.
На практиці редукцію вихідної кореляційної матриці можна
провести декількома способами:
– методом найбільшої кореляції - діагональний елемент
замінюється на найбільше по відповідному рядку (стовпчику) недіагональне
значення коефіцієнта кореляції;
– методом Барта - для кожного рядка спочатку знаходиться
середнє значення коефіцієнта кореляції; якщо воно порівняно велике, то
діагональний елемент замінюється трохи більшим за найбільше по рядку значення
коефіцієнта кореляції, а якщо воно порівняно мале, то діагональний елемент
замінюється трохи меншим за найбільше по рядку значення коефіцієнта кореляції.
– методом тріад - діагональний елемент обчислюється за
формулою
 , (2.36)
, (2.36)
де rik та ris - найбільші по рядку значення коефіцієнта
кореляції.
Оцінка значущості кореляційної матриці може проводитись за
критерієм Уілкіса c2 .
Спостережене значення критерію обчислюється за формулою
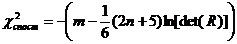 . (2.37)
. (2.37)
Це значення порівнюється з критичним для c2 - розподілу, знайденим при заданому рівні значущості
a та кількості ступенів вільності n =n(n-1)/2. Значущість кореляційної матриці
підтверджується, якщо спостережене значення перевищує критичне
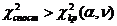 .
.
Достатність виділених факторів може бути перевірена за критерієм Лоулі c2 .
Спостережене значення критерію обчислюється за формулою
 . (2.38)
. (2.38)
де R+ - матриця залишкових кореляцій, значущість якої перевіряється;¢ - вихідна редукована матриця.
Критичне значення знаходиться при заданому рівні значущості a та кількості ступенів вільності
n
=((n-k)2 -n- k) /2
де k - кількість виділених головних факторів. Ця кількість є
достатньою, якщо спостережене значення критерію менше за критичне:
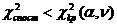 .
.
Отже, алгоритм обчислень за методом головних факторів має
наступний вигляд:
1) обчислення матриці стандартизованих ознак: X®Z;
2) обчислення кореляційної матриці стандартизованих
ознак: Z®R;
) обчислення редукованої кореляційної матриці: R®R¢;
) обчислення першого власного значення l1 та відповідно йому
нормованого власного вектора V1 редукованої кореляційної матриці: R¢®(l1, V1);
) обчислення вектора факторних навантажень першого
фактора F1: (l1,V1)®W1;
) обчислення матриці залишкових кореляцій : (R¢, W1) ® R1;
) перевірка значущості матриці залишкових кореляцій.
Якщо вона значуща, то ітераційний процес продовжується.
Інтерпретація одержаних факторів здійснюється наведеному
розглянутому підходу при розгляді методу головних компонент.
3 Практична частина
.1 Робастне статистичне оцінювання
З метою виявлення грубих помилок у вибірковій сукупності було
проведено робастне статистичне оцінювання.
У вхідній сукупності даних є значення, які значно
відхиляються від інших. Для перевірки результативного показника та кожного з
факторів на наявність грубих помилок було проранжовано вхідні дані (Додаток B).
Візуально проаналізувавши проранжовані дані визначено, що
значні відхилення значень є у всіх факторах. У таблиці 3.1.1 подано порядкові
номери підозрілих на помилку значень у вибірці початкових даних.
Таблиця 3.1.1 - Підозрілі елементи
|
Порядковий номер підозрілого елемента
|
Фактор, в якому присутній підозрілий елемент
|
|
52
|
Y1
|
|
18
|
X9
|
|
29
|
X8 , X10
|
|
31
|
X17
|
|
15
|
X11
|
|
25
|
X11, X12
|
|
39
|
X11
|
|
37
|
X11, X12
|
|
38
|
X11
|
|
49
|
X8
|
|
50
|
X11
|
Для того, щоб перевірити чи підозрілі елементи є грубими
помилками застосовано критерії:
· Т-критерій Граббса для факторів Y1,
X9, X10, X17;
· L-критерій Тітьєна та Мура для
фактора X12;
· Е-критерій Тітьєна та Мура для
факторів X8 та X11.
Результат перевірки вхідних даних на грубі помилки занесені
до таблиці 3.1.2.
Таблиця 3.1.2 - Результати робастного оцінювання
Y1 
X8 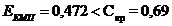
X9 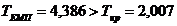
X10 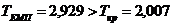
X11 
|
Значення помилкові
|
|
|
X12
|
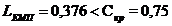
|
X17 
Аналіз результатів таблиці показує, що з даної вибіркової
сукупності необхідно виключити 52-ге підприємство, оскільки воно є помилковим у
результуючій ознаці.
Знайдено середні вибіркові за Пуанкаре (формула 2.4),
Вінзором (формула 2.5) та описовою статистикою Excel. Результати занесено до
таблиці 3.1.3.
Таблиця 3.1.3 - Середні вибіркові
|
Фактори
|
Середнє вибіркове за Пуанкаре
|
Середнє вибіркове за Вінзором
|
Описова статистика Excel
|
|
Y1
|
7,93
|
7,881
|
7,970
|
|
X8
|
1,068
|
1,034
|
1,072
|
|
X9
|
0,470
|
0,477
|
0,486
|
|
X10
|
1,534
|
1,520
|
1,526
|
|
X11
|
14742,805
|
13728,491
|
14707,792
|
|
X12
|
80,929
|
84,579
|
91,876
|
|
X17
|
19,570
|
19,570
|
19.570
|
Аналіз даних таблиці показує, що значення середніх для
фактора X17 є однаковими, оскільки у даній сукупності відсутні помилкові значення.
Таким чином, у результаті проведеного робастного
статистичного оцінювання було проаналізовано дану вибіркову сукупність та
висунуто гіпотези про помилковість значень, які візуально відрізняються від
основної групи (Таблиця 3.1.1)
У результаті перевірки за Т-критерієм Граббса, L-критерієм та
Е-критерієм Тітьєна та Мура гіпотеза про помилковість даних підтвердилася для
підприємств у факторах: Y1 (продуктивність праці), X8 (премії та винагороди на
одного працівника), X9 (питома вага утрат від браку), X10 (фондовіддача), X11
(середньорічна чисельність ПП), X12 (середньорічна вартість ОВФ).
Спираючись на отримані результати було прийнято рішення про
виключення з генеральної сукупності 52-ге підприємство, оскільки воно є
помилковим в результуючій ознаці.
Оцінено параметри вибіркової сукупності за формулами
вибіркової середньої за Пуанкаре та Вінзором, а також за пакетом аналізу Excel
(Таблиця 3.1.3).
.2 Ієрархічний кластерний аналіз
З метою виділення типової групи підприємств було проведено
кластерний аналіз.
Групування об’єктів проведено трьома методами:
агломеративним, дивизимним та ітераційним методами. Для цього було використано
програмний продукт на C# (Додаток C).
За алгоритмами агломеративного методу (п. 2.2.1), дивизимного
методу (п. 2.2.2) та ітераційного методу (п. 2.2.3) вибіркову сукупність було
розбито на два кластери
Оцінку розбиття на кластери було проведено за допомогою
функціоналу якості розбиття - загальна сума попарних внутрішньогрупових
дисперсій (2.5).
Функціонал досягає свого мінімального значення для розбиття
за ітераційним методом. Отже, до типової групи увійшло 41 підприємство:

Таблиця 3.2.1 - Результати кластерного аналізу
|
Назва методу
|
Кластери
|
Значення функціоналу якості
|
Агломеративний метод дальнього сусіда 
|
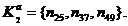 302887415,4 302887415,4
|
|
Дивизимний метод 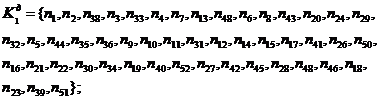
|
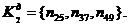 302887415,4 302887415,4
|
|
Ітераційний метод k - середніх 
|
 112549992,3 112549992,3
|
|
Дану типову групу будемо використовувати для подальшого
дослідження.
3.3 Кореляційний аналіз
Проведено попередню оцінку наявності
лінійного зв’язку за допомогою кореляційних полів. (Додаток Е)
Побудувавши кореляційні поля залежності результуючого
показника від кожного з факторів, а також факторів між собою бачимо, що лінійна
залежність спостерігається між такими парами:і X11 - продуктивність праці та
середньорічна чисельність ПП (Рисунок Е.4);та X10 - продуктивність праці та
фондовіддача (Рисунок Е.3);і X12 - продуктивність праці та середньорічна
вартість ОВФ (Рисунок Е.5);і X12 - премії та винагороди на одного працівника та
середньорічна вартість ОВФ (Рисунок Е.10);і X17 - питома вага утрат від браку
та невиробничі витрати (Рисунок Е.15);і X12 - середньорічна чисельність ПП та
середньорічна вартість ОВФ (Рисунок Е.19).
Коефіцієнти кореляції обчислено за формулою (2.9): Матриця
парних коефіцієнтів кореляції має вигляд:
Таблиця 3.3.1- Парні коефіцієнти кореляції
|
Y1
|
X8
|
X9
|
X10
|
X11
|
X12
|
X17
|
|
Y1
|
1,000
|
0,119
|
0,121
|
0,254
|
0,185
|
0,270
|
-0,015
|
|
X8
|
0,119
|
1,000
|
0,121
|
-0,047
|
0,258
|
0,572
|
-0,342
|
|
X9
|
0,121
|
0,121
|
1,000
|
-0,273
|
0,194
|
0,306
|
-0,400
|
|
X10
|
0,254
|
-0,047
|
-0,273
|
1,000
|
0,078
|
-0,257
|
0,033
|
|
X11
|
0,185
|
0,258
|
0,194
|
0,078
|
1,000
|
0,741
|
-0,041
|
|
X12
|
0,270
|
0,572
|
0,306
|
-0,257
|
0,741
|
1,000
|
-0,139
|
|
X17
|
-0,015
|
-0,342
|
-0,400
|
0,033
|
-0,041
|
-0,139
|
1,000
|
Коефіцієнт детермінації обчислено за формулою (2.10). Матриця
парних коефіцієнтів детермінації має вигляд:
Таблиця 3.3.2 - Парні коефіцієнти детермінації
|
Y1X8X9X10X11X12X17
|
|
|
|
|
|
|
|
|
Y1
|
1,000
|
0,014
|
0,015
|
0,065
|
0,034
|
0,073
|
0,000
|
|
X8
|
0,014
|
1,000
|
0,015
|
0,002
|
0,067
|
0,327
|
0,117
|
|
X9
|
0,015
|
0,015
|
1,000
|
0,074
|
0,038
|
0,094
|
0,160
|
|
X10
|
0,065
|
0,002
|
0,074
|
1,000
|
0,006
|
0,066
|
0,001
|
|
X11
|
0,034
|
0,067
|
0,038
|
0,006
|
1,000
|
0,548
|
0,002
|
|
X12
|
0,073
|
0,327
|
0,094
|
0,066
|
0,548
|
1,000
|
0,019
|
|
X17
|
0,000
|
0,117
|
0,160
|
0,001
|
0,002
|
0,019
|
1,000
|
За результатами перевірки на мультиколінеарність (Додаток F)
було виключено фактори Х12 - середньорічна чисельність ОВФ та Х17 - невиробничі
витрати.
Тоді матриця парних коефіцієнтів кореляції має вигляд:
Таблиця 3.3.3 - Матриця парних коефіцієнтів кореляції
|
Y1
|
X8
|
X9
|
X10
|
X11
|
|
Y1
|
1,000
|
0,014
|
0,015
|
0,065
|
0,034
|
|
X8
|
0,014
|
1,000
|
0,015
|
0,002
|
0,067
|
|
X9
|
0,015
|
0,015
|
1,000
|
0,074
|
0,038
|
|
X10
|
0,065
|
0,002
|
0,074
|
1,000
|
0,006
|
|
X11
|
0,034
|
0,067
|
0,038
|
0,006
|
1,000
|
Визначено оцінки параметрів семивимірного
нормального закону розподілу - вектори середніх арифметичних і стандартних
відхилень, матриці парних коефіцієнтів кореляції та детермінації.
Таблиця 3.3.4 - Середні арифметичні
та стандартні відхилення
|
Y1
|
X8
|
X9
|
X10
|
X11
|
|
Середнє
|
7,129
|
1,014
|
0,525
|
10683,805
|
|
Стандартне відхилення
|
1,773
|
0,715
|
0,373
|
0,415
|
4707,697
|
Обчислено точкові оцінки числових характеристик за формулою
:

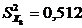

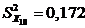

Визначено елементи матриці часткових коефіцієнтів кореляції
за формулою (2.13).
Матриця часткових коефіцієнтів кореляції має вигляд
Таблиця 3.3.5 - Матриця часткових коефіцієнтів кореляції
|
Y1
|
X8
|
X9
|
X10
|
X11
|
|
Y1
|
1,000
|
-0,087
|
0,168
|
-0,289
|
0,107
|
|
X8
|
-0,087
|
1,000
|
-0,041
|
-0,073
|
-0,234
|
|
X9
|
0,168
|
-0,041
|
1,000
|
0,323
|
0,181
|
|
X10
|
-0,289
|
-0,073
|
0,323
|
1,000
|
-0,108
|
|
X11
|
0,107
|
-0,234
|
0,181
|
-0,108
|
1,000
|
Таблиця 3.3.6 - Матриця часткових коефіцієнтів детермінації:
|
Y1X8X9X10X11
|
|
|
|
|
|
|
Y1
|
1,000
|
0,008
|
0,028
|
0,083
|
0,011
|
|
X8
|
0,008
|
1,000
|
0,002
|
0,005
|
0,055
|
|
X9
|
0,028
|
0,002
|
1,000
|
0,104
|
0,033
|
|
X10
|
0,083
|
0,005
|
0,104
|
1,000
|
0,012
|
|
X11
|
0,011
|
0,055
|
0,033
|
0,012
|
1,000
|
Перевіримо часткові коефіцієнти кореляції на значущість. З таблиці  - статистики Фішера-Ієйтса для числа знаходимо
проміжок для критичного значення
- статистики Фішера-Ієйтса для числа знаходимо
проміжок для критичного значення 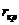 .
З межами проміжку для критичного значення -статистики
порівнюємо модулі точкових оцінок часткових коефіцієнтів кореляції. Якщо
значення більше за верхню межу, то
.
З межами проміжку для критичного значення -статистики
порівнюємо модулі точкових оцінок часткових коефіцієнтів кореляції. Якщо
значення більше за верхню межу, то  - відхиляється, а якщо менше за нижню межу -
приймається. Якщо потрапляє в проміжок, то може
бути відхилено.
- відхиляється, а якщо менше за нижню межу -
приймається. Якщо потрапляє в проміжок, то може
бути відхилено.
Значення - статистики Фішера-Ієйтса рівне: верхня межа - 0,325,
нижня межа - 0,304. Значення часткового коефіцієнта вибираємо більше, ніж
0,304.
Таблиця 3.3.7 - Перевірка на значущість часткових коефіцієнтів
кореляції
|
Номер коефіцієнта
|
Значення коефіцієнта
|
|
r1,8
|
-0,087
|
|
r1,9
|
0,168
|
|
r1,10
|
-0,289
|
|
r1,11
|
0,107
|
|
r8,9
|
-0,041
|
|
r8,10
|
-0,073
|
|
r8,11
|
-0,234
|
|
r9,10
|
0,323
|
|
r9,11
|
0,181
|
|
r10,11
|
-0,108
|
|
rкр
|
0,304
|
Таким чином, значущими є частковий коефіцієнт кореляції між факторами 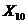 та
та  :
: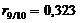
Для значущих коефіцієнтів кореляції знайдено довірчі інтервали. Таким
чином, частковий коефіцієнт кореляції r9,10 знаходиться в межах 
Оскільки значення часткових коефіцієнтів кореляції менші за
значення парних між факторами Y1 та X8 , Y1 та X11, X8 та X11, X9 та X11, X10
та X11 то при виключенні фактора X12 зв’язок між цими факторами слабшає. Це
свідчить про те, що саме цей фактор посилює кореляцію між даними змінними.
Значення часткових коефіцієнтів детермінації між факторами Y1
та X10, X8 та X10, X9 та X10, X10 та X11 більші, ніж значення парних коефіцієнтів.
Це означає, що фіксовані компоненти послаблюють зв’язок між парами даних
факторів.
Обчислено точкові оцінки множинних коефіцієнтів кореляції та
детермінації за формулами (2.14˗2.15) для того, щоб виявити
залежності між однією ознакою з усіма іншими (Таблиця 3.3.7). Дані коефіцієнти
детермінації перевірено на значимість.
Таблиця 3.3.8 - Точкові оцінки множинних коефіцієнтів
кореляції та детермінації без мультиплікативного фактора
|
Ознака
|
Коефіцієнт кореляції
|
Коефіцієнт детермінації
|
Емпіричне значення критерію Фішера
|
Критичне значення критерію Фішера
|
|
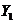 0,3550,1261,2942,634 0,3550,1261,2942,634
|
|
|
|
|
|
 0,2850,0810,794 0,2850,0810,794
|
|
|
|
|
|
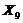 0,3850,1481,569 0,3850,1481,569
|
|
|
|
|
|
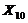 0,4120,1701,842 0,4120,1701,842
|
|
|
|
|
|
 0,3510,1231,261 0,3510,1231,261
|
|
|
|
|
Таким чином маємо, що не значущими є всі коефіцієнти
детермінації, оскільки
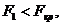
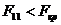 і
і
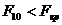 ,
, 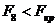 ,
,
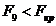
Таким чином, провівши кореляційний аналіз було побудовано кореляційні
поля (додаток Е), проаналізувавши які було висунуто гіпотези, що кореляційний
зв’язок існує між парами:і X11 - продуктивність праці та середньорічна
чисельність ПП (Рисунок Е.4);та X10 - продуктивність праці та фондовіддача
(Рисунок Е.3);і X12 - продуктивність праці та середньорічна вартість ОВФ
(Рисунок Е.5);і X12 - премії та винагороди на одного працівника та середньорічна
вартість ОВФ (Рисунок Е.10);і X17 - питома вага утрат від браку та невиробничі
витрати (Рисунок Е.15);і X12 - середньорічна чисельність ПП та середньорічна
вартість ОВФ (Рисунок Е.19).
Обчислено матрицю парних коефіцієнтів кореляції (таблиця 3.3.1).
Значення коефіцієнтів кореляції підтверджують високу залежність між
факторами Y1 та X10  , Y1 і X12
, Y1 і X12 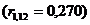 ,
X8 і X12
,
X8 і X12  , X9 і X17
, X9 і X17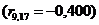 ,
X11 і X12
,
X11 і X12 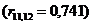 , що підтверджує висунуті гіпотези. Між факторами Х11
та Х17
, що підтверджує висунуті гіпотези. Між факторами Х11
та Х17 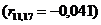 , Х10 та Х17
, Х10 та Х17 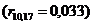 ,
Y1 та X17
,
Y1 та X17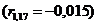 , існує слабка залежність.
, існує слабка залежність.
Визначник матриці парних коефіцієнтів кореляції близький до нуля, що
означає, що між незалежними змінними існує мультиколінеарність. Згідно
алгоритму Фаррара-Глобера та економічного змісту факторів, було визначено, що
для усунення мультиколінеарності необхідно виключити змінні Х12 - середньорічна
чисельність ОВФ та Х17 - невиробничі витрати.
Перераховано матрицю парних коефіцієнтів кореляції (1.1).
Також обчислено матрицю часткових коефіцієнтів кореляції (таблиця
3.3.2)
Оскільки значення часткових коефіцієнтів кореляції менші за значення
парних між факторами Y1 та X8 , Y1 та X11, X8 та X11, X9 та X11, X10 та X11 то
при виключенні фактора X12 зв’язок між цими факторами слабшає. Це свідчить про
те, що саме цей фактор посилює кореляцію між даними змінними.
Значення часткових коефіцієнтів детермінації між факторами Y1 та X10,
X8 та X10, X9 та X10, X10 та X11 більші, ніж значення парних коефіцієнтів. Це
означає, що фіксовані компоненти послаблюють зв’язок між парами даних факторів.
За - статистикою Фішера-Ієйтса перевірено значущість
часткових коефіцієнтів кореляції та визначено, що значущим є коефіцієнт між
факторами Х9 та Х10 (Таблиця 3.3.7).
Знайдено точкові оцінки п’яти коефіцієнтів множинної кореляції та
детермінації (Таблиця 3.3.8).
За F - критерієм Фішера перевірено значущість множинних коефіцієнтів
детермінації (Таблиця 3.3.8). Усі коефіцієнти детермінації виявились не
значимими. Оскільки множинні коефіцієнти не значимі, то в
сукупності відсутня лінійна залежність між результативним показником та
незалежними змінними.
3.4
Регресійний аналіз
З метою встановлення аналітичної залежності між ознаками X та
Y та надання практичних рекомендацій щодо підвищення продуктивності праці,
проведено регресійний аналіз.
3.4.1
Парна лінійна регресія
Для побудови парної лінійної регресії
вибрано фактор який краще впливає на результативну ознаку за результатами
кореляційного аналізу. Найтісніший зв'язок існує між фактором Х10 -
фондовіддача та результативної ознакою Y1 - продуктивність праці.
Знайдено оцінки параметрів регресії за методом найменших
квадратів. Модель має вигляд:

Перевірено на значимість дане рівняння регресії за F - критерієм
Фішера.
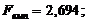
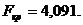
Оскільки  , то рівняння регресії не значиме, тобто за даною
моделлю не можна робити прогноз.
, то рівняння регресії не значиме, тобто за даною
моделлю не можна робити прогноз.
3.4.2
Парна нелінійна регресія
Побудовано парну нелінійну регресію. За методом найменших
квадратів знайдено оцінки параметрів регресії. Дана регресія має вигляд:
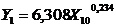
За критерієм Фішера перевірено дану модель на значущість.
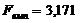
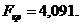
Оскільки, , то рівняння регресії незначиме. За даною моделлю не
можна робити прогноз.
3.4.3
Множинна лінійна регресія
Побудовано модель вигляду (2.26).
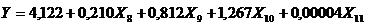
Перевірено дану модель на значущість.
Знайдено емпіричне значення критерію Фішера.

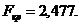
Оскільки, , то модель неадекватна статистичним даним і її не
можна використовувати для прогнозування.
3.4.4
Множинна нелінійна регресія
Побудовано адитивну модель вигляду
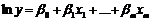 . (3.1)
. (3.1)
Зробимо лінеаризацію
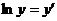 .
.
Використовуючи алгоритм множинної
лінійної регресії знайдемо оцінки параметрів моделі. Отже, отримана модель має
вигляд:

За критерієм Фішера перевірено дану модель на адекватність.

Оскільки, , то рівняння регресії незначиме. За даною моделлю не
можна робити прогноз.
Побудуємо адитивну нелінійну модель вигляду
 (3.2)
(3.2)
Знайдено оцінки параметрів моделі. Модель має вигляд:

Дану модель перевірено на адекватність за критерієм Фішера.
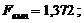
Оскільки, , то рівняння регресії незначиме. За даною моделлю не
можна робити прогноз.
Побудуємо адитивну модель вигляду
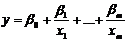 (3.3)
(3.3)
Знайдено оцінки параметрів регресії. Отримано модель вигляду:

Дану модель перевірено на адекватність за критерієм Фішера.
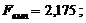
Оскільки, , то рівняння регресії незначиме. За даною моделлю не
можна робити прогноз.
Побудовано мультиплікативну модель вигляду
 (3.4)
(3.4)
Знайдено оцінки параметрів даної регресії. Отримано модель
наступного вигляду:

Дану модель перевірено на адекватність за критерієм Фішера.
Таблиця 3.3.9 - Результати
регресійного аналізу
|
Назва регресії
|
Регресійна модель
|
Значення критерію Фішера
|
Кореляційне відношення
|
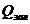
|
Парна лінійна регресія 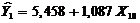

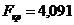
|
Fемп< Fкр (неадекватна)0,746117,670
|
|
|
|
Парна нелінійна регресія 
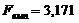
|
Fемп< Fкр (неадекватна)0,947119,185
|
|
|
|
Множинна лінійна регресія 
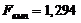

|
Fемп< Fкр (неадекватна)0,874109,988
|
|
|
|
Множинна нелінійна регресія (адитивна) 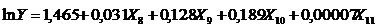

|
Fемп< Fкр (неадекватна)0,899113,135
|
|
|
|
Множинна нелінійна регресія (адитивна) 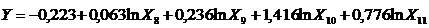
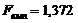
|
Fемп< Fкр (неадекватна)0,868109,164
|
|
|
|
Множинна нелінійна регресія (адитивна) 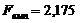
|
Fемп< Fкр (неадекватна)0,805101,316
|
|
|
|
Множинна нелінійна регресія (мультиплікативна) 

|
Fемп< Fкр (неадекватна)0,896112,739
|
|
|
|
Множинна нелінійна регресія (мультиплікативна) 
|
Fемп< Fкр (неадекватна)0,899113,135
|
|
|
|

Оскільки, , то рівняння регресії незначиме. За даною моделлю не
можна робити прогноз.
Побудовано модель вигляду
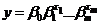 (3.5)
(3.5)
Знайдено оцінки параметрів моделі. Маємо наступну модель:

За критерієм Фішера дану модель перевірено на значущість.


Оскільки, , то рівняння регресії незначиме. За даною моделлю не
можна робити прогноз.
Таким чином, з метою встановлення виду аналітичної залежності між
ознаками X та Y, було проведено регресійний аналіз.
Було побудовано вісім регресійних моделей, а саме: парної лінійної та
парної нелінійної регресії, множинної лінійної та 5 моделей множинної
нелінійної регресій (Таблиця 3.3.9).
За результатами перевірки на значущість моделей за критерієм
Фішера, виявлено, що всі моделі не адекватні (Таблиця 3.3.9). Також було
обчислено кореляційні відношення для перевірки ступеня впливу неврахованих
факторів (Таблиця 3.3.9). Оскільки всі кореляційні відношення становлять більше
20%, то це свідчить про те, необхідно надати інформацію про інші показники
діяльності підприємства.
.5 Факторний аналіз
3.5.1 Метод головних компонент
Метод головних компонент дозволяє за
вихідними ознакам побудувати узагальнені ознаки, які називаються головними
компонентами, і за допомогою регресійного аналізу виявити форму залежності
результуючої ознаки від знайдених головних компонент.
Було використано алгоритм методу
головних компонент (2.5.3), стандартизовано початкові значення (Додаток F) та
обчислено кореляційну матрицю стандартизованих ознак (Таблиця G.1). Обчислено
матрицю власних значень та матрицю нормованих власних векторів (Таблиця 3.5.1).
Таблиця 3.5.1 - Матриця нормованих
власних значень та власних векторів
|
V8
|
V9
|
V10
|
V11
|
V12
|
V17
|
|
λ
|
2,354
|
1,269
|
1,044
|
0,805
|
0,410
|
0,118
|
|
1
|
0,446
|
-0,083
|
0,324
|
0,638
|
0,419
|
0,326
|
|
2
|
0,362
|
0,501
|
-0,075
|
-0,544
|
0,560
|
0,051
|
|
3
|
-0,179
|
-0,449
|
0,708
|
-0,359
|
0,284
|
-0,234
|
|
4
|
0,456
|
-0,485
|
-0,095
|
-0,403
|
-0,312
|
0,536
|
|
5
|
0,584
|
-0,255
|
-0,205
|
0,068
|
-0,044
|
-0,738
|
|
6
|
-0,297
|
-0,489
|
-0,581
|
0,029
|
0,575
|
0,064
|
За (2.31) обчислено матрицю факторних
навантажень (Таблиця 3.5.2)
Таблиця 3.5.2 - Матриця факторних
навантажень
|
F1
|
F2
|
F3
|
F4
|
F5
|
F6
|
|
X8
|
0,685
|
-0,094
|
0,331
|
0,572
|
0,269
|
0,112
|
|
Х9
|
0,555
|
0,565
|
-0,076
|
-0,488
|
0,359
|
0,017
|
|
Х10
|
-0,275
|
-0,506
|
0,723
|
-0,322
|
0,182
|
-0,080
|
|
Х11
|
0,700
|
-0,547
|
-0,097
|
-0,362
|
-0,200
|
0,184
|
|
X12
|
0,896
|
-0,287
|
-0,210
|
0,061
|
-0,028
|
-0,254
|
|
X17
|
-0,456
|
-0,551
|
-0,593
|
0,026
|
0,368
|
0,022
|
Також обчислено частку пояснюючої
дисперсії за(2.32).
Таблиця 3.5.3 - Частка пояснюючої дисперсії
|
Ознака
|
F1
|
F3
|
F4
|
F5
|
F6
|
|
Накопичена сума
|
2,35
|
3,62
|
4,67
|
5,47
|
5,88
|
6,000
|
|
Частка дисперсії
|
39,23%
|
60,39%
|
77,78%
|
91,19%
|
98,03%
|
100,00%
|
Для дослідження відібрано лише чотири перші головні
компоненти, оскільки вони пояснюють 77,78% дисперсії вхідних ознак, що
прийнятно для нас.
Відібрано значення факторів для пояснення головних компонент
(Таблиця 3.5.4)
Таблиця 3.5.4 - Відбір інформативних факторів
|
Латентні ознаки
|
|
F1
|
F2
|
|
|
Фактор
|
Значення факторного навантаження
|
Відсоток
|
Фактор
|
Значення факторного навантаження
|
Відсоток
|
Фактор
|
Значення факторного навантаження
|
Відсоток
|
|
X12
|
0,896
|
25,129%
|
Х9
|
0,565
|
22,150%
|
X10
|
0,723
|
35,641%
|
|
Х11
|
0,700
|
44,745%
|
Х17
|
0,551
|
43,769%
|
X17
|
0,593
|
64,863%
|
|
Х8
|
0,685
|
63,938%
|
X11
|
0,547
|
65,221%
|
X8
|
0,331
|
81,148%
|
|
Х9
|
0,555
|
79,493%
|
X10
|
0,506
|
85,067%
|
X12
|
0,210
|
91,486%
|
|
X17
|
0,456
|
92,288%
|
X12
|
0,287
|
96,322%
|
X11
|
0,097
|
96,250%
|
|
X10
|
0,275
|
100%
|
X8
|
0,094
|
100%
|
X9
|
0,076
|
100%
|
Відібрано компоненти за допомогою коефіцієнта інформативності
(2.34) і в результаті отримано чотири латентних ознаки:- латентна ознака, яка
включає: середньорічну вартість ОВФ (Х12), середньорічну чисельність ПП (Х11),
премії та винагороди на одного працівника (Х8) та питому вагу утрат від браку
(Х9).- латентна ознака, яка включає: питому вагу утрат від браку (Х9),
невиробничі витрати (Х17), середньорічну чисельність ПП (Х11) та фондовіддачу
(Х10)- латентна ознака, яка включає: фондовіддачу (Х10), невиробничі витрати (Х17)
та премії та винагороди на одного працівника (Х8).
Обчислено матрицю значень головних компонент за формулою
(2.33) та подано у таблиці G.5.
Побудовано факторну модель за допомогою алгоритму пункту
(2.4.2) та перевірено на адекватність. Модель за критерієм Фішера є
неадекватною, тому її не можна використовувати для прогнозування (Таблиця
3.5.2)
Модель має наступний вигляд:
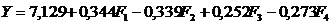 (3.9)
(3.9)
3.5.2 Метод головних факторів
Було використано алгоритм методу головних факторів (2.5.4),
стандартизовано початкові значення (Додаток F) та обчислено редуковану
кореляційну матрицю стандартизованих ознак (Таблиця H.1). Обчислено матрицю
власних значень та матрицю нормованих власних векторів (Таблиця 3.5.5).
Таблиця 3.5.5 - Матриця нормованих
власних значень та власних векторів редукованої кореляційної матриці
|
V8
|
V9
|
V10
|
V11
|
V12
|
V17
|
|
λ
|
1,989
|
0,757
|
0,443
|
0,308
|
-0,161
|
-0,210
|
|
1
|
0,434
|
0,143
|
0,631
|
-0,406
|
0,303
|
0,370
|
|
2
|
0,299
|
0,485
|
-0,403
|
0,350
|
0,625
|
0,022
|
|
3
|
-0,134
|
-0,312
|
0,552
|
0,527
|
0,380
|
-0,399
|
|
4
|
0,506
|
-0,531
|
-0,134
|
0,438
|
-0,178
|
0,469
|
|
5
|
0,626
|
-0,187
|
-0,138
|
-0,282
|
-0,062
|
-0,686
|
|
6
|
-0,239
|
-0,575
|
-0,313
|
-0,405
|
0,581
|
0,116
|
Обчислено матрицю залишкових кореляцій (Таблиця H.3)
Перевіримо значущість матриці залишкових кореляцій за
критерієм Уілкіса c2 (формула 2.37)
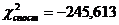

Оскільки  <
< 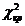 ,
то дана кореляційна матриця незначуща.
,
то дана кореляційна матриця незначуща.
Перевіримо, чи кількість вибраних факторів є достатньою за критерієм
Лоулі (2.38)
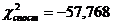

Оскільки  < ,
то кількість відібраних факторів є достатньою.
< ,
то кількість відібраних факторів є достатньою.
За аналогічним принципом відібрано фактори для пояснення даного
головного фактору (Таблиця 3.5.6)
Таблиця 3.5.6 - Відбір інформативних факторів для F1
|
Фактори
|
Факторне навантаження
|
Відсотки
|
|
X12
|
0,883
|
27,984%
|
|
Х11
|
0,714
|
50,619%
|
|
Х8
|
0,611
|
70,002%
|
|
Х9
|
0,421
|
83,352%
|
|
X17
|
-0,337
|
94,026%
|
|
X10
|
-0,188
|
100%
|
- латентна ознака, яка включає: середньорічну вартість ОВФ
(Х12), середньорічну чисельність ПП (Х11), премії та винагороди на одного
працівника (Х8).
Обчислено матрицю значень головних факторів (Таблиця .Н.5).
Побудовано факторну модель за допомогою алгоритму пункту
(2.4.2).
Модель за критерієм Фішера є неадекватною, тому
використовувати дану модель для прогнозування не можна (Таблиця 3.5.2)
Модель має наступний вигляд:
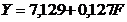 (3.10)
(3.10)
Таким чином, було здійснено факторний аналіз за допомогою методу
головних компонент та методу головних факторів.
Для дослідження відібрано лише чотири перші головні компоненти,
оскільки вони пояснюють 77,78% дисперсії вхідних ознак. (Таблиця 3.5.3).
Також відібрано значення факторів для пояснення даних головних
компонент так, щоб коефіцієнт інформативності становив не менше 70%.(Таблиця
3.5.4). В результаті отримано наступні латентні ознаки:- латентна ознака, яка
включає фактори: Х12 - середньорічна вартість ОВФ (25,129%), Х11 -
середньорічна чисельність ПП (19,616%), Х8 - премії та винагороди на одного
працівника (19,193%) та Х9 - питома вагу утрат від браку (15,554%).- латентна
ознака, яка включає фактори: Х9 - питома вагу утрат від браку (22,150%), Х17 -
невиробничі витрати (21,619%), Х11 - середньорічна чисельність ПП (21,451%) та
Х10 - фондовіддача (19,847%)- латентна ознака, яка включає фактори: Х10 -
фондовіддача (35,641%), Х17 - невиробничі витрати (29,222%) та Х8 - премії та
винагороди на одного працівника (16,284%).
Таблиця 3.5.7 - Результати факторного аналізу
|
Назва регресії
|
Регресійна модель
|
Значення критерію Фішера
|
Кореляційне відношення
|

|
Регресія за методом головних компонент 


|
Fемп< Fкр (неадекватна)0,882110,983
|
|
|
|
Регресія за методом головних факторів 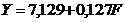


|
Fемп< Fкр (неадекватна)0,956120,320
|
|
|
|
Також факторний аналіз було проведено за допомогою методу
головних факторів. За критерієм Лоулі перевірено чи кількість відібраних
факторів є достатньою.
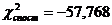
Оскільки < ,
то кількість відібраних факторів є достатньою.
В результаті було відібрано одну латентну ознаку:- латентна ознака, яка
включає фактори: Х12 - середньорічна вартість ОВФ (27,619%), Х11 -
середньорічна чисельність ПП (22,635%), Х8 - премії та винагороди на одного
працівника (19,383%).
Побудовано дві регресійні моделі та перевірено їх на адекватність
(Таблиця 3.5.2). За результатами перевірки критерієм Фішера дані моделі є
неадекватними. Також було обчислено кореляційні відношення для перевірки впливу
неврахованих факторів. У зв’язку з тим, що кореляційні відношення складають
більше 20%, то існує великий вплив неврахованих факторів.
3.6 Практичні рекомендації
У ході роботи було проведено статистичний аналіз впливу
факторів на продуктивність праці.
Використовуючи лише наявні фактори, які впливають на розвиток
підприємства, ми не можемо надати ніяких практичних рекомендацій щодо шляхів
підвищення продуктивності праці. Це означає, що існує потреба в наданні
додаткової інформації для отримання результату.
Поза межами дослідження залишилося 52-ге підприємство,
оскільки значення його економічних показників значно відрізняються від основної
групи.
Значну різницю між даними підприємствами та 52-гим
підприємством можна пояснити, як специфічну особливість окремого елемента
досліджуваної сукупності.
Висновки
У даній курсовій роботі за допомогою статистичних методів
було здійснено аналіз підприємств по підвищенню рівня продуктивності праці.
Для розробки практичних рекомендацій
по підвищенню продуктивності праці використано такі фактори, як премії та
винагороди на одного працівника, питома вага утрат від браку, фондовіддача,
середньорічна чисельність ПП, середньорічна вартість ОВФ та невиробничі
витрати.
За отриманими даними 53 підприємств
(Додаток А) було проведено дослідження .
Щоб вилучити дані, що значно
відхиляються від значень основного масиву було проведено робастне статистичне
оцінювання в результаті якого вилучено 52 підприємство.
За допомогою методів кластерного аналізу, генеральну
сукупність було розділено на дві групи, елементи в яких розташовуються на
мінімальній відстані один від одного. Групу з найбільшою кількістю елементів
обрано для подальшої роботи. Така група є типовою і складається з 41
підприємства. (Додаток D). Інші підприємства, а саме: 1, 2, 3, 4, 7, 13, 24,
25, 37, 38, 39, було вилучено з основного масиву даних. Підприємства типової
групи були використані для подальшого аналізу та розробки рекомендацій.
Для дослідження лінійних зв’язків між змінними було проведено
кореляційний аналіз. Визначено, що висока залежність існує між факторами: Y1 та
X10 , Y1 і X12 ,
X8 і X12 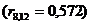 , X9 і X17,
X11 і X12 , що підтверджує висунуті гіпотези. Між факторами Х11
та Х17 , Х10 та Х17 ,
Y1 та X17 існує слабка залежність. При перевірці на
мультиколінеарність було виключено змінні Х12 - середньорічна чисельність ОВФ
та Х17 - невиробничі витрати. Знайдено точкові оцінки п’яти коефіцієнтів
множинної кореляції та детермінації Усі коефіцієнти детермінації виявились не
значимими, тобто в сукупності відсутня лінійна залежність між результативним
показником та незалежними змінними.
, X9 і X17,
X11 і X12 , що підтверджує висунуті гіпотези. Між факторами Х11
та Х17 , Х10 та Х17 ,
Y1 та X17 існує слабка залежність. При перевірці на
мультиколінеарність було виключено змінні Х12 - середньорічна чисельність ОВФ
та Х17 - невиробничі витрати. Знайдено точкові оцінки п’яти коефіцієнтів
множинної кореляції та детермінації Усі коефіцієнти детермінації виявились не
значимими, тобто в сукупності відсутня лінійна залежність між результативним
показником та незалежними змінними.
З метою встановлення виду аналітичної залежності між ознаками
X та Y, було проведено регресійний аналіз.
Було побудовано вісім регресійних моделей, а саме: парної
лінійної та парної нелінійної регресії, множинної лінійної та 5 моделей
множинної нелінійної регресій.
За результатами перевірки моделей за критерієм Фішера,
виявлено, що всі моделі не адекватні (Таблиця 3.3.9). Оскільки всі кореляційні
відношення становлять більше 20% (Таблиця 3.3.9), то це свідчить про те,
необхідно надати інформацію про інші показники діяльності підприємства.
Здійснено факторний аналіз за допомогою методу головних
компонент та методу головних факторів.
В результаті проведення факторного аналізу методом головних
компонент отримано наступні приховані фактори:- латентна ознака, яка включає
фактори: Х12 - середньорічна вартість ОВФ (25,129%), Х11 - середньорічна
чисельність ПП (19,616%), Х8 - премії та винагороди на одного працівника
(19,193%) та Х9 - питома вагу утрат від браку (15,554%).- латентна ознака, яка
включає фактори: Х9 - питома вагу утрат від браку (22,150%), Х17 - невиробничі
витрати (21,619%), Х11 - середньорічна чисельність ПП (21,451%) та Х10 -
фондовіддача (19,847%)- латентна ознака, яка включає фактори: Х10 -
фондовіддача (35,641%), Х17 - невиробничі витрати (29,222%) та Х8 - премії та
винагороди на одного працівника (16,284%).
В результаті проведення факторного аналізу методом головних
факторів було відібрано одну латентну ознаку:- латентна ознака, яка включає
фактори: Х12 - середньорічна вартість ОВФ (27,619%), Х11 - середньорічна
чисельність ПП (22,635%), Х8 - премії та винагороди на одного працівника
(19,383%).
Побудовано дві регресійні моделі та перевірено їх на
адекватність (Таблиця 3.5.7). За результатами перевірки критерієм Фішера дані
моделі є неадекватними. Кореляційні відношення є досить великими, що свідчить
про великий вплив неврахованих факторів.
За результатами проведеного аналізу було визначено, що для
надання практичних рекомендацій щодо шляхів підвищення продуктивності праці
існує потреба в наданні додаткової інформації для отримання результату.
агломеративний кластерний регресія факторний
Перелік
посилань
1.
Башнянин Г.І., Лазур П.Ю, Медведєв В.С. Політична економія. - Київ, 2002.
2.
Григорук П.М. Економетричне моделювання. Конспект лекцій / П.М. Григорук.
Хмельницький 2005. - с.123
3.
Мандель И.Д. Кластерный анализ / И.Д. Мандель.-Москва: Финансы и статистика,
1988.-176с.
. Мороз
В.С., Мороз В.В. Економетрія. - Хмельницький, 2000.
Додаток
А
Таблиця А.1 - Вхідні дані
|
№ п-ва
|
Y1
|
X8
|
X9
|
X10
|
X11
|
X12
|
X17
|
|
1
|
9,26
|
1,23
|
0,23
|
1,45
|
26006
|
167,70
|
17,72
|
|
2
|
9,38
|
1,04
|
0,39
|
1,30
|
23935
|
186,10
|
18,39
|
|
3
|
12,11
|
1,80
|
0,43
|
1,37
|
22589
|
220,50
|
26,46
|
|
4
|
10,81
|
0,43
|
0,18
|
1,65
|
21220
|
169,30
|
22,37
|
|
5
|
9,35
|
0,88
|
0,15
|
1,91
|
7394
|
39,53
|
28,13
|
|
6
|
9,87
|
0,57
|
0,34
|
1,68
|
11586
|
40,41
|
17,55
|
|
7
|
8,17
|
1,72
|
0,38
|
1,94
|
26609
|
103,00
|
21,92
|
|
8
|
9,12
|
1,70
|
0,09
|
1,89
|
7801
|
37,02
|
19,52
|
|
9
|
5,88
|
0,84
|
0,14
|
1,94
|
11587
|
45,74
|
23,99
|
|
10
|
6,30
|
0,60
|
0,21
|
2,06
|
9475
|
40,07
|
21,76
|
|
11
|
6,22
|
0,82
|
0,42
|
1,96
|
10811
|
45,44
|
25,68
|
|
12
|
5,49
|
0,84
|
0,05
|
1,02
|
6371
|
41,08
|
18,13
|
|
13
|
6,50
|
0,67
|
0,29
|
1,85
|
26761
|
136,1
|
25,74
|
|
14
|
6,61
|
1,04
|
0,48
|
4210
|
42,39
|
21,21
|
|
15
|
4,32
|
0,66
|
0,41
|
0,62
|
3557
|
37,39
|
22,97
|
|
16
|
7,37
|
0,86
|
0,62
|
1,09
|
14148
|
101,80
|
16,38
|
|
17
|
7,02
|
0,79
|
0,56
|
1,60
|
9872
|
47,55
|
13,21
|
|
18
|
8,25
|
0,34
|
1,76
|
1,53
|
5975
|
32,61
|
14,48
|
|
19
|
8,15
|
1,6
|
1,31
|
1,4
|
16662
|
103,3
|
13,38
|
|
20
|
8,72
|
1,46
|
0,45
|
2,20
|
9166
|
38,95
|
13,69
|
|
21
|
6,64
|
1,27
|
0,50
|
1,32
|
15118
|
81,32
|
16,66
|
|
22
|
8,10
|
1,58
|
0,77
|
1,48
|
11429
|
67,26
|
15,06
|
|
23
|
5,52
|
0,68
|
1,20
|
0,68
|
6462
|
59,92
|
20,09
|
|
24
|
9,37
|
0,86
|
0,21
|
2,30
|
24628
|
107,30
|
15,98
|
|
25
|
13,17
|
1,98
|
0,25
|
1,37
|
49727
|
512,60
|
18,27
|
|
26
|
6,67
|
0,33
|
0,15
|
1,51
|
11470
|
53,81
|
14,42
|
|
27
|
5,68
|
0,45
|
0,66
|
1,43
|
19448
|
80,83
|
22,76
|
|
28
|
5,22
|
0,74
|
0,74
|
1,82
|
18963
|
59,42
|
15,41
|
|
29
|
10,02
|
0,03.
|
0,32
|
2,62
|
9185
|
36,96
|
19,35
|
|
30
|
8,16
|
0,99
|
0,89
|
1,75
|
17478
|
91,43
|
16,83
|
|
31
|
3,78
|
0,24
|
0,23
|
1,54
|
6265
|
17,16
|
30,53
|
|
32
|
6,48
|
0,57
|
0,32
|
2,25
|
8810
|
27,29
|
17,98
|
|
33
|
10,44
|
1,22
|
0,54
|
1,07
|
17659
|
184,30
|
22,09
|
|
34
|
7,65
|
0,68
|
0,75
|
1,44
|
10342
|
58,42
|
18,29
|
|
35
|
8,77
|
1,00
|
0,16
|
1,40
|
8901
|
59,40
|
26,05
|
|
36
|
7,00
|
0,81
|
0,24
|
1,31
|
8402
|
49,63
|
26,2
|
|
37
|
11,06
|
1,27
|
0,59
|
1,12
|
32625
|
391,30
|
17,26
|
|
38
|
9,02
|
1,14
|
0,56
|
1,16
|
31160
|
258,60
|
18,83
|
|
39
|
13,28
|
1,89
|
0,63
|
0,88
|
46461
|
75,66
|
19,7
|
|
40
|
9,27
|
0,67
|
1,10
|
1,07
|
13833
|
123,70
|
16,87
|
|
41
|
6,70
|
0,96
|
0,39
|
1,24
|
6391
|
37,21
|
14,63
|
|
42
|
6,69
|
0,67
|
0,73
|
1,49
|
11115
|
53,37
|
22,17
|
|
43
|
9,42
|
0,98
|
0,28
|
2,03
|
6555
|
32,87
|
22,62
|
|
44
|
7,24
|
1,16
|
0,10
|
1,84
|
11085
|
45,63
|
26,44
|
|
45
|
5,39
|
0,54
|
0,68
|
1,22
|
9484
|
48,41
|
22,26
|
|
46
|
5,61
|
1,23
|
0,87
|
1,72
|
3967
|
13,58
|
19,13
|
|
47
|
5,59
|
0,78
|
0,49
|
1,75
|
15283
|
63,99
|
18,28
|
|
48
|
6,57
|
1,16
|
0,16
|
1,46
|
20874
|
104,60
|
28,23
|
|
49
|
6,54
|
4,44
|
0,85
|
1,60
|
19418
|
222,10
|
12,39
|
|
50
|
4,23
|
1,06
|
0,13
|
1,47
|
3351
|
25,76
|
11,64
|
|
51
|
5,22
|
2,13
|
0,49
|
1,38
|
6338
|
29,52
|
8,62
|
|
52
|
11,03
|
2,20
|
0,79
|
1,39
|
11795
|
78,11
|
19,41
|
Додаток В
Таблиця В.1 - Проранжовані вхідні дані
|
№
|
Y1
|
№
|
X8
|
№
|
X9
|
№
|
X10
|
№
|
X11
|
№
|
X12
|
№
|
X17
|
|
31
|
3,78
|
29
|
0,03
|
12
|
0,05
|
15
|
0,62
|
50
|
3351
|
46
|
13,58
|
51
|
8,62
|
|
50
|
4,23
|
31
|
0,24
|
8
|
0,09
|
23
|
0,68
|
15
|
3557
|
31
|
17,16
|
50
|
|
15
|
4,32
|
26
|
0,33
|
52
|
0,09
|
14
|
0,88
|
46
|
3967
|
50
|
25,76
|
49
|
12,39
|
|
51
|
5,22
|
18
|
0,34
|
44
|
0,1
|
39
|
0,88
|
14
|
4210
|
32
|
27,29
|
17
|
13,21
|
|
28
|
5,22
|
4
|
0,43
|
50
|
0,13
|
12
|
1,02
|
18
|
5975
|
51
|
29,52
|
19
|
13,38
|
|
45
|
5,39
|
27
|
0,45
|
9
|
0,14
|
33
|
1,07
|
31
|
6265
|
18
|
32,61
|
20
|
13,69
|
|
12
|
5,49
|
45
|
0,54
|
5
|
0,15
|
40
|
1,07
|
51
|
6338
|
43
|
32,87
|
26
|
14,42
|
|
23
|
5,52
|
6
|
0,57
|
26
|
0,15
|
16
|
1,09
|
12
|
6371
|
29
|
36,96
|
18
|
14,48
|
|
47
|
5,59
|
32
|
0,57
|
35
|
0,16
|
37
|
1,12
|
41
|
6391
|
8
|
37,02
|
41
|
14,63
|
|
46
|
5,61
|
10
|
0,6
|
48
|
0,16
|
38
|
1,16
|
23
|
6462
|
41
|
37,21
|
22
|
15,06
|
|
27
|
5,68
|
15
|
0,66
|
4
|
0,18
|
45
|
1,22
|
43
|
6555
|
15
|
37,39
|
28
|
15,41
|
|
9
|
5,88
|
13
|
0,67
|
10
|
0,21
|
41
|
1,24
|
5
|
7394
|
20
|
38,95
|
24
|
15,98
|
|
11
|
6,22
|
40
|
0,67
|
24
|
0,21
|
2
|
1,3
|
8
|
7801
|
5
|
39,53
|
16
|
16,38
|
|
10
|
6,3
|
42
|
0,67
|
1
|
0,23
|
36
|
1,31
|
36
|
8402
|
10
|
40,07
|
21
|
16,66
|
|
32
|
6,48
|
23
|
0,68
|
31
|
0,23
|
21
|
1,32
|
32
|
8810
|
6
|
40,41
|
30
|
16,83
|
|
13
|
6,5
|
34
|
0,68
|
36
|
0,24
|
3
|
1,37
|
35
|
8901
|
12
|
41,08
|
40
|
16,87
|
|
49
|
6,54
|
28
|
0,74
|
25
|
0,25
|
25
|
1,37
|
20
|
9166
|
52
|
41,99
|
37
|
17,26
|
|
48
|
6,57
|
47
|
0,78
|
43
|
0,28
|
51
|
1,38
|
29
|
9185
|
14
|
42,39
|
6
|
17,55
|
|
14
|
6,61
|
17
|
0,79
|
13
|
0,29
|
53
|
1,39
|
10
|
9475
|
11
|
45,44
|
1
|
17,72
|
|
21
|
6,64
|
36
|
0,81
|
29
|
0,32
|
19
|
1,4
|
45
|
9484
|
44
|
45,63
|
32
|
17,98
|
|
26
|
6,67
|
11
|
0,82
|
32
|
0,32
|
35
|
1,4
|
52
|
9756
|
9
|
45,74
|
12
|
18,13
|
|
42
|
6,69
|
9
|
0,84
|
6
|
0,34
|
52
|
1,41
|
17
|
9872
|
17
|
47,55
|
25
|
18,27
|
|
41
|
6,7
|
12
|
0,84
|
7
|
0,38
|
27
|
1,43
|
34
|
10342
|
45
|
48,41
|
47
|
18,28
|
|
36
|
7
|
16
|
0,86
|
2
|
0,39
|
34
|
1,44
|
11
|
10811
|
36
|
49,63
|
34
|
18,29
|
|
17
|
7,02
|
24
|
0,86
|
41
|
0,39
|
1
|
1,45
|
44
|
11085
|
42
|
53,37
|
2
|
18,39
|
|
44
|
7,24
|
5
|
0,88
|
15
|
0,41
|
48
|
1,46
|
42
|
11115
|
26
|
53,81
|
38
|
18,83
|
|
16
|
7,37
|
41
|
0,96
|
11
|
0,42
|
50
|
1,47
|
22
|
11429
|
34
|
58,42
|
46
|
19,13
|
7,65
|
43
|
0,98
|
3
|
0,43
|
22
|
1,48
|
26
|
11470
|
35
|
59,4
|
29
|
19,35
|
|
22
|
8,1
|
30
|
0,99
|
20
|
0,45
|
42
|
1,49
|
6
|
11586
|
28
|
59,42
|
53
|
19,41
|
|
19
|
8,15
|
35
|
1
|
14
|
0,48
|
26
|
1,51
|
9
|
11587
|
23
|
59,92
|
8
|
19,52
|
|
30
|
8,16
|
2
|
1,04
|
47
|
0,49
|
18
|
1,53
|
53
|
11795
|
47
|
63,99
|
39
|
19,7
|
|
7
|
8,17
|
14
|
1,04
|
51
|
0,49
|
31
|
1,54
|
40
|
13833
|
22
|
67,26
|
23
|
20,09
|
|
18
|
8,25
|
50
|
1,06
|
21
|
0,5
|
17
|
1,6
|
16
|
14148
|
39
|
75,66
|
52
|
20,1
|
|
20
|
8,72
|
38
|
1,14
|
33
|
0,54
|
49
|
1,6
|
21
|
15118
|
53
|
78,11
|
14
|
21,21
|
|
35
|
8,77
|
44
|
1,16
|
17
|
0,56
|
4
|
1,65
|
47
|
15283
|
27
|
80,83
|
10
|
21,76
|
|
38
|
9,02
|
48
|
1,16
|
38
|
0,56
|
6
|
1,68
|
19
|
16662
|
21
|
81,32
|
7
|
21,92
|
|
8
|
9,12
|
52
|
1,21
|
37
|
0,59
|
46
|
1,72
|
30
|
17478
|
30
|
91,43
|
33
|
22,09
|
|
1
|
9,26
|
33
|
1,22
|
16
|
0,62
|
30
|
1,75
|
33
|
17659
|
16
|
101,8
|
42
|
22,17
|
|
40
|
9,27
|
1
|
1,23
|
39
|
0,63
|
47
|
1,75
|
28
|
18963
|
7
|
103
|
45
|
22,26
|
|
5
|
9,35
|
46
|
1,23
|
27
|
0,66
|
28
|
1,82
|
49
|
19418
|
19
|
103,3
|
4
|
22,37
|
|
24
|
9,37
|
21
|
1,27
|
45
|
0,68
|
44
|
1,84
|
27
|
19448
|
48
|
104,6
|
43
|
22,62
|
|
2
|
9,38
|
37
|
1,27
|
42
|
0,73
|
13
|
1,85
|
48
|
20874
|
24
|
107,3
|
27
|
22,76
|
|
43
|
9,42
|
20
|
1,46
|
28
|
0,74
|
8
|
1,89
|
4
|
21220
|
40
|
123,7
|
15
|
22,97
|
|
6
|
9,87
|
22
|
1,58
|
34
|
0,75
|
5
|
1,91
|
3
|
22589
|
13
|
136,1
|
9
|
23,99
|
|
29
|
10,02
|
19
|
1,6
|
22
|
0,77
|
7
|
1,94
|
2
|
23935
|
1
|
167,7
|
11
|
25,68
|
|
33
|
10,44
|
8
|
1,7
|
53
|
0,79
|
9
|
1,94
|
24
|
24628
|
4
|
169,3
|
13
|
25,74
|
|
4
|
10,81
|
7
|
1,72
|
49
|
0,85
|
11
|
1,96
|
1
|
26006
|
33
|
184,3
|
35
|
26,05
|
|
53
|
11,03
|
3
|
1,8
|
46
|
0,87
|
43
|
2,03
|
7
|
26609
|
2
|
186,1
|
36
|
26,2
|
|
37
|
11,06
|
39
|
1,89
|
30
|
0,89
|
10
|
2,06
|
13
|
26761
|
3
|
220,5
|
44
|
26,44
|
|
3
|
12,11
|
25
|
1,98
|
40
|
1,1
|
20
|
2,2
|
38
|
31160
|
49
|
222,1
|
3
|
26,46
|
|
25
|
13,17
|
51
|
2,13
|
23
|
1,2
|
32
|
2,25
|
37
|
32625
|
38
|
258,6
|
5
|
28,13
|
|
39
|
13,28
|
53
|
2,2
|
19
|
1,31
|
24
|
2,3
|
39
|
46461
|
37
|
391,3
|
48
|
28,23
|
|
52
|
49
|
4,44
|
18
|
1,76
|
29
|
2,62
|
25
|
49727
|
25
|
512,6
|
31
|
30,53
|
Додаток
С
System;System.Collections.Generic;System.IO;System.Linq;System.Text;System.Windows.Forms;MSExcel
= TcKs.MSOffice.Excel;ClusterAnalysis
{ public partial class MainForm : Form
{ private double[,] distance_matrix, matrix_d;int size;bool
isDalnySusid = false;MainForm()
{
InitializeComponent();.Threading.Thread.CurrentThread.CurrentCulture = new
System.Globalization.CultureInfo( "ru-RU" );
}Button1Click(object sender, EventArgs e)
{(distance_matrix, size);
}GetRowNameBySize(int index)
{ const int a_code = (int) 'A';int z_code = (int) 'Z';result
= "";(index > z_code-a_code)
{= ((char) (a_code + index/(z_code-a_code) - 1)).ToString();
}+= ((char) (a_code +
index%(z_code-a_code)-index/(z_code-a_code))).ToString()result;
}[,] ObjectArrayToDoubleArray(ref object[,] arr, int size)
{ var result = new double[size, 7];(int i = 0; i < size;
i++)
{ for (int j = 0; j < 7; j++)[i, j] = (double) arr[i + 1,
j + 1];
} return result;
} double[,] CalculateDistanceMatrix(ref double[,] matrix, int
size)
{ double[,] result = new double[size,size];tmp_distance,
tmp_sum;[] avarageForColumn = new double[7], sigma = new double[7];[,] z = new
double[size, 7];
// Середнє значення для кожного стовпця(int i = 0; i < 7;
i++) { tmp_sum = 0.0;(int j = 0; j < size; j++)_sum += matrix[j, i];[i] =
tmp_sum / size;
} // Виправлене сер. квадратичне відхилення(int i = 0; i <
7; i++)
{ tmp_sum = 0;(int j = 0; j < size; j++)_sum += Math.Pow(matrix[j,
i] - avarageForColumn[i], 2);[i] = Math.Sqrt((tmp_sum * size) / (size - 1.0));
} // Створення тимчасової матриці Z(int i = 0; i < size;
i++)(int j = 0; j < 7; j++)[i, j] = (matrix[i, j] -
avarageForColumn[j])/sigma[j];
//WriteMatrixToOutout(ref z, size, " STANDART MATRIX
");(int i = 0; i < size; i++)
{ for (int j = 0; j < i; j++)
{ tmp_distance = GetDistanceFor(ref z, i, j);[i, j] =
tmp_distance;[j, i] = tmp_distance;
} }result; }double GetDistanceFor(ref double[,] matrix, int
row1, int row2)
{ double tmp_distance = 0;(int i = 0; i < 7; i++)
{ tmp_distance += (matrix[row1, i] - matrix[row2,
i])*(matrix[row1, i] - [row2, i]); }Math.Sqrt(tmp_distance);
} double GetDistanceFor(double[] row1, double[] row2)
{ double tmp_distance = 0; for (int i = 0; i < 7; i++)
{ tmp_distance += (row1[i] - row2[i]) * (row1[i] - row2[i]);
} return Math.Sqrt(tmp_distance);
}[] Aglomerative(double[,] matrix, int size)
{ double min;index_i = 0, index_j = 0;= radioButton2.Checked;
//contains all clusters (if elem length>0 cluster exist)[]
clusters = new string[size];(int i = 0; i < size; i++)[i] = (i +
1).ToString();method = (isDalnySusid) ? "ДАЛЬНЬОГО СУСІДА" :
"БЛИЖНЬОГО СУСІДА"; WriteTextToLog("\n
============== АГЛОМЕРАТИВНИЙ МЕТОД ("+method+") ================
\n");(size > 1)
{ min = Min(ref matrix, size, ref index_i, ref
index_j);(index_j < index_i)(ref index_i, ref index_j);=
MargeTwoClusters(matrix, index_i, index_j, size, ref clusters);-;
//WriteMatrixToOutout(ref matrix, size, "MARGED MATRIX [" + (index_i
+ 1) + "," + (index_j + 1) + "]");("> Dmin is
" + min + ". Marged clusters [" + (index_i+1) + "," +
(index_j+1) + "].\n " +(ref clusters));
} MessageBox.Show("It seems like ok!");new[]
{" ", " "};
}[] Dyvyzuvny(double[,] matrix, int size)
{ var clusters = new List<int[]>(size);[] startCluster
= new int[size];(int i = 0; i < size; i++)[i] =
i;.Add(startCluster);("\n ============== ДИВИЗИВНИЙ МЕТОД ===============
\n");(clusters.Count<size)
{ SplitCluster(ref clusters, ref matrix);(ref clusters);
}.Show("It seems like ok!");new[] { " ",
" " };
}SplitCluster(ref List<int[]> clusters, ref double[,]
matrix)
{ double max = double.MinValue;index_i = 0, index_j = 0,
cluster_index = 0;(var i = 0; i < clusters.Count; i++)
{ for (int j = 0; j < clusters[i].Length - 1; j++)
{ for (int k = j + 1; k < clusters[i].Length; k++)
{ if (matrix[clusters[i][j], clusters[i][k]] > max)
{ max = matrix[clusters[i][j], clusters[i][k]];_i = j;_j =
k;_index = i;
} }
} }(string.Format("> Dmax is {0}, center of new
clusters {1} {2}, current cluster - {3}", max, index_i+1, index_j+1,
cluster_index+1));[] curr_cluster = clusters[cluster_index];<int>
newcluster1 = new List<int>(), newcluster2= new
List<int>();.RemoveAt(cluster_index);(curr_cluster.Length)
{ case
1:;2:.Add(curr_cluster[0]);.Add(curr_cluster[1]);;:(int j = 0; j <
curr_cluster.Length; j++)
{(GetDistanceFor(ref matrix, j, index_i) <=
GetDistanceFor(ref matrix, j, index_j))
newcluster1.Add(curr_cluster[j]);.Add(curr_cluster[j]);
};
}.Add(newcluster1.ToArray());.Add(newcluster2.ToArray());
// WriteClustersToOutput(ref clusters);
}
/// <summary>
/// Search and return min value of matrix without diagonal
/// </summary>
/// <param name="matrix">matrix to
search</param>
/// <param name="size">matrix
size</param>
/// <param name="index_i">row of min in
matrix</param>
/// <param name="index_j">column of min in
matrix</param>
/// <returns></returns>static double Min(ref
double[,] matrix, int size, ref int index_i, ref int index_j)
{ double min = double.MaxValue;(int i = 0; i < size; i++)
{ for (int j = 0; j < i; j++)
{ if (matrix[i, j] < min)
{ min = matrix[i, j];_i = i;_j = j;
}
} } return min;
} /// <summary>
/// Marge two clusters in distance matrix and return new
distance matrix
/// </summary>
/// <param name="matrix">matrix with
distances from clusters</param>
/// <param name="cluster1">index of lower
cluster</param>
/// <param name="cluster2">index of bigest
cluster</param>
/// <param name="size">Dimention of current
matrix</param>
/// <returns>New matrix with marged rows (cluser1,
cluster2) </returns>[,] MargeTwoClusters(double[,] matrix, int cluster1,
int cluster2, int size, ref string[] clusters) { clusters[cluster1] += "
" + clusters[cluster2];[] clusters_new = new string[size-1];
//leave minimum of two cluster to one (horizontal,
vertical)(int i = 0; i < size; i++)
{ if (!isDalnySusid)
{ if (matrix[i, cluster1] > matrix[i, cluster2])[i,
cluster1] = matrix[i, cluster2];(matrix[cluster1, i] > matrix[cluster2,
i])[cluster1, i] = matrix[cluster2, i];
} else
{ if (matrix[i, cluster1] < matrix[i, cluster2])[i,
cluster1] = matrix[i, cluster2];(matrix[cluster1, i] < matrix[cluster2,
i])[cluster1, i] = matrix[cluster2, i];
} }[cluster1, cluster1] = 0;
//create new matrix with marged 2 clusters[,] result = new
double[size-1,size-1];(int i = 0; i < size-1; i++)
{(int j = 0; j < size-1; j++)
{ result[i, j] = i < cluster2
? (j < cluster2 ? matrix[i, j] : matrix[i, j + 1])
: (j < cluster2 ? matrix[i + 1, j] : matrix[i + 1, j +
1]);
} clusters_new[i] = i < cluster2
? clusters[i]
: clusters[i + 1];
} clusters = clusters_new;result;
} /// <summary>
/// Write matrix to log.txt
/// </summary>
/// <param name="matrix">matrix to
write</param>
/// <param name="size">size of
matrix</param>
/// <param name="text">additional
text</param>WriteMatrixToOutout(ref double[,] matrix, int size, string
text)
{ var sw = new
StreamWriter("log.txt",true);.WriteLine(" =================
"+text+" ================= ");(int i = 0; i < size; i++)
{ for (int j = 0; j < 7; j++).Write(matrix[i, j] +
"\t\t");.WriteLine();
} sw.Close();
}WriteClustersToOutput(ref List<int[]> cluster)
{sw = new StreamWriter("log.txt", true);(int i = 0;
i < cluster.Count; i++)
{ sw.Write("K"+(i+1)+"={");(int j = 0; j
< cluster[i].Length; j++).Write((cluster[i][j] + 1) + "
");.Write("} ");
} sw.WriteLine();.Close();
}WriteClustersToOutput(ref List<List<int>>
cluster)
{sw = new StreamWriter("log.txt", true);(int i = 0;
i < cluster.Count; i++)
{.Write("K" + (i + 1) + "={");(int j = 0;
j < cluster[i].Count; j++).Write((cluster[i][j] + 1) + "
");.Write("} ");
} sw.WriteLine();.Close(); } WriteTextToLog(string text)
{sw = new StreamWriter("log.txt",
true);.WriteLine(text);.Close();
} void SwapVars(ref int var1, ref int var2)
{ var tmp = var1;= var2;= tmp;
} string GlueCurrentClusters(ref string[] clusters)
{ var result = String.Empty;(int i = 0; i <
clusters.Length; i++)+= "K" + (i + 1) + "={" + clusters[i]
+ "} ";result;
} private void button2_Click(object sender, EventArgs e)
{ Dyvyzuvny(distance_matrix, size);
} private void button3_Click(object sender, EventArgs e)
{ using (var app = MSExcel.Application.CreateApplication())
{ var book1 = app.Workbooks.Open(Environment.CurrentDirectory
+ "/test1.xls");sheet1 = (MSExcel.Worksheet)book1.Worksheets[1];
//get matrix sizesizeCell = sheet1.GetRange("A1",
"A1");= (int)(double)(sizeCell.Value2);.Text = size + "x7";
//Console.WriteLine("26 is " +
GetRowNameBySize(26));
//Console.WriteLine("53 is " +
GetRowNameBySize(53));left_border = "G" + (size + 2);[,]
initial_matrix =
(object[,])(sheet1.GetRange("A2",
left_border).Value2);_d = ObjectArrayToDoubleArray(ref initial_matrix,
size);_matrix = CalculateDistanceMatrix(ref matrix_d, size);.Quit();
}.MSOffice.Common.WrapperHelper.GCCollect();.Enabled =
true;.Enabled = true;.Enabled = true;.Enabled = true;_caption.Enabled =
true;.Enabled = true;.Enabled = true;.Enabled = true;.Enabled = true;.Enabled =
true;.Enabled = true;
//Clear file before writingsw = new
StreamWriter("log.txt");.Write("");.Close();
//WriteMatrixToOutout(ref distance_matrix, size, "
STANDART MATRIX");
}void button4_Click(object sender, EventArgs e)
{ int numOfClusters =
(int)numericUpDown1.Value;numOfIterations = (int) numericUpDown2.Value;(matrix_d,
size, numOfClusters, numOfIterations);
}[] Iteratyvny(double[,] matrix, int size, int numOfClusters,
int numOfIterations)
{ //set centres of clusters to first elementscentres = new
List<double[]>(numOfClusters);("\n ================ ІТЕРАТИВНИЙ
================== \n"); var tmp_center = new double[7];clusters = new
List<List<int>>(numOfClusters);clusters_old =
string.Empty;clusters_current = string.Empty;(int i = 0; i < numOfClusters;
i++)
{ clusters.Add(new List<int>{i});(int j = 0; j < 7;
j++)_center[j] = matrix[i, j];.Add(tmp_center); } min_distance =
double.MaxValue, currDistance;cluster_index = 0, start_point = numOfClusters +
1,numOfAllIteration = numOfIterations;(numOfIterations > 0)
{ for (var i = start_point; i < size; i++)
{ for (var j = 0; j < numOfClusters; j++)
{ currDistance = GetDistanceFor(centres[j], GetRowById(ref
matrix, i));(currDistance <= min_distance)
{ min_distance = currDistance;_index = j;
} }_distance = double.MaxValue;[cluster_index].Add(i);
centres[cluster_index] = AvarageOfTwo(centres[cluster_index], GetRowById(ref
matrix, i));
}("> Iteration number - " + (numOfAllIteration -
numOfIterations));(ref clusters);-;_point = 0;_current = ClustersToString(ref
clusters);(String.Compare(clusters_current, clusters_old,
StringComparison.Ordinal) == 0)
{ MessageBox.Show("Last iterations the same as this.
Stop");new[] { "", "" };
}_old = ClustersToString(ref clusters);(var i = 0; i <
numOfClusters; i++)[i].Clear();
}.Show("Iterations out!");new[] {"",
""};
}ClustersToString(ref List<List<int>> cluster)
{str = new StringBuilder();(int i = 0; i < cluster.Count;
i++)
{.Append("K" + i + "={");(int j = 0; j
< cluster[i].Count; j++).Append(cluster[i][j]+"
");.Append("}");
} return str.ToString();
} double[] GetRowById(ref double[,] matrix, int id)
{ var current_row = new double[7];(int i = 0; i < 7;
i++)_row[i] = matrix[id, i];current_row;
}[] AvarageOfTwo(double[] row1, double[] row2)
{ var result = new double[7];(int i = 0; i < 7; i++)[i] =
(row1[i] + row2[i])/2.0;result;
}
}
}
Додаток
D
Таблиця D.1 - Типові підприємства
|
№ п-ва
|
Y1
|
X8
|
X9
|
X10
|
X11
|
X12
|
X17
|
|
5
|
9,35
|
0,88
|
0,15
|
1,91
|
7394
|
39,53
|
28,13
|
|
6
|
9,87
|
0,57
|
0,34
|
1,68
|
11586
|
40,41
|
17,55
|
|
8
|
9,12
|
1,7
|
0,09
|
1,89
|
7801
|
37,02
|
19,52
|
|
9
|
5,88
|
0,84
|
0,14
|
1,94
|
11587
|
45,74
|
23,99
|
|
10
|
6,3
|
0,6
|
0,21
|
2,06
|
9475
|
40,07
|
21,76
|
|
11
|
6,22
|
0,82
|
0,42
|
1,96
|
10811
|
45,44
|
25,68
|
|
12
|
5,49
|
0,84
|
0,05
|
1,02
|
6371
|
41,08
|
18,13
|
|
14
|
6,61
|
1,04
|
0,48
|
0,88
|
4210
|
42,39
|
21,21
|
|
15
|
4,32
|
0,66
|
0,41
|
0,62
|
3557
|
37,39
|
22,97
|
|
16
|
7,37
|
0,86
|
0,62
|
1,09
|
14148
|
101,8
|
16,38
|
|
17
|
7,02
|
0,79
|
0,56
|
1,6
|
9872
|
47,55
|
13,21
|
|
18
|
8,25
|
0,34
|
1,76
|
1,53
|
5975
|
32,61
|
14,48
|
|
19
|
8,15
|
1,6
|
1,31
|
1,4
|
16662
|
103,3
|
13,38
|
|
20
|
8,72
|
1,46
|
0,45
|
2,2
|
9166
|
38,95
|
13,69
|
|
21
|
6,64
|
1,27
|
0,5
|
1,32
|
15118
|
81,32
|
16,66
|
|
22
|
8,1
|
1,58
|
0,77
|
1,48
|
11429
|
67,26
|
15,06
|
|
23
|
5,52
|
0,68
|
1,2
|
0,68
|
6462
|
59,92
|
20,09
|
|
26
|
6,67
|
0,33
|
0,15
|
1,51
|
11470
|
53,81
|
14,42
|
|
27
|
5,68
|
0,45
|
0,66
|
1,43
|
19448
|
80,83
|
22,76
|
|
28
|
5,22
|
0,74
|
0,74
|
1,82
|
18963
|
59,42
|
15,41
|
|
29
|
10,02
|
0,03
|
0,32
|
2,62
|
9185
|
36,96
|
19,35
|
|
30
|
8,16
|
0,99
|
0,89
|
1,75
|
17478
|
91,43
|
16,83
|
|
31
|
3,78
|
0,24
|
1,54
|
6265
|
17,16
|
30,53
|
|
32
|
6,48
|
0,57
|
0,32
|
2,25
|
8810
|
27,29
|
17,98
|
|
33
|
10,44
|
1,22
|
0,54
|
1,07
|
17659
|
184,3
|
22,09
|
|
34
|
7,65
|
0,68
|
0,75
|
1,44
|
10342
|
58,42
|
18,29
|
|
35
|
8,77
|
1
|
0,16
|
1,4
|
8901
|
59,4
|
26,05
|
|
36
|
7
|
0,81
|
0,24
|
1,31
|
8402
|
49,63
|
26,2
|
|
40
|
9,27
|
0,67
|
1,1
|
1,07
|
13833
|
123,7
|
16,87
|
|
41
|
6,7
|
0,96
|
0,39
|
1,24
|
6391
|
37,21
|
14,63
|
|
42
|
6,69
|
0,67
|
0,73
|
1,49
|
11115
|
53,37
|
22,17
|
|
43
|
9,42
|
0,98
|
0,28
|
2,03
|
6555
|
32,87
|
22,62
|
|
44
|
7,24
|
1,16
|
0,1
|
1,84
|
11085
|
45,63
|
26,44
|
|
45
|
5,39
|
0,54
|
0,68
|
1,22
|
9484
|
48,41
|
22,26
|
|
46
|
5,61
|
1,23
|
0,87
|
1,72
|
3967
|
13,58
|
19,13
|
|
47
|
5,59
|
0,78
|
0,49
|
1,75
|
15283
|
63,99
|
18,28
|
|
48
|
6,57
|
1,16
|
0,16
|
1,46
|
20874
|
104,6
|
28,23
|
|
49
|
6,54
|
4,44
|
0,85
|
1,6
|
19418
|
222,1
|
12,39
|
|
50
|
4,23
|
1,06
|
0,13
|
1,47
|
3351
|
25,76
|
11,64
|
|
51
|
5,22
|
2,13
|
0,49
|
1,38
|
6338
|
29,52
|
8,62
|
|
52
|
11,03
|
2,2
|
0,79
|
1,39
|
11795
|
78,11
|
19,41
|
Додаток
Е
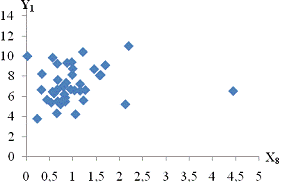
Рисунок Е.1 - Кореляційне поле для Y1
та фактора Х8

Рисунок Е 2 - Кореляційне поле для
показника показника Y1 та фактора Х9
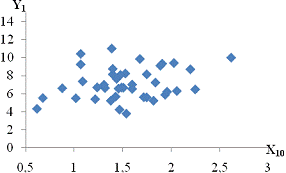
Рисунок В.3 - Кореляційне поле для
показника Y1 та фактора Х10
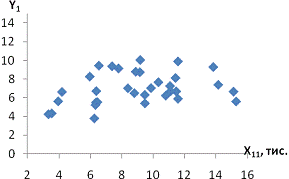
Рисунок В.4 - Кореляційне поле для
показника Y1 та фактора Х11
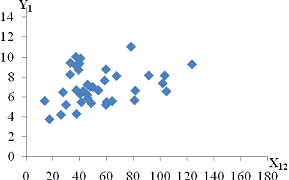
Рисунок В.5 - Кореляційне поле для
показника Y1 та фактора Х12
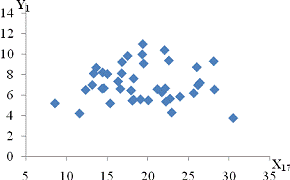
Рисунок В.6 - Кореляційне поле для
показника Y1 та фактора Х17
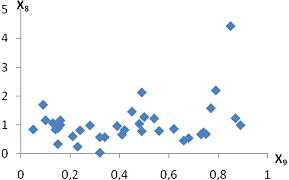
Рисунок В.7 - Кореляційне поле для
фактора Х8 та фактора Х9

Рисунок В.8 - Кореляційне поле для Х8
та фактора Х10

Рисунок В.9 - Кореляційне поле для
фактора Х8 та фактора Х11

Рисунок В.10 - Кореляційне поле для
фактора Х8 та фактора Х12
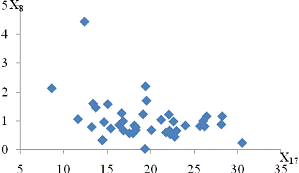
Рисунок В.11 - Кореляційне поле для фактора Х8 та фактора Х17

Рисунок В.12 - Кореляційне поле для
фактора Х9 та фактора Х10
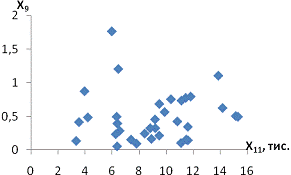
Рисунок В.13 - Кореляційне поле для
фактора Х9 та фактора Х11
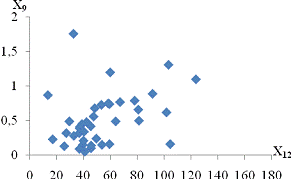
Рисунок В.14 - Кореляційне поле для
фактора Х9 та фактора Х12

Рисунок В.15 - Кореляційне поле для
фактора Х9 та фактора Х17
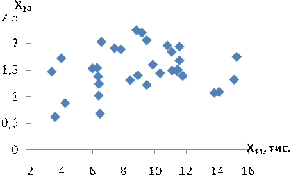
Рисунок В.16 - Кореляційне поле для
фактора Х10 та фактора Х11

Рисунок В.17 - Кореляційне поле для фактора Х10 та фактора
Х12
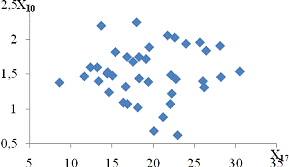
Рисунок В.18 - Кореляційне поле для
фактора Х10 та фактора Х17

Рисунок В.19 - Кореляційне поле для
для фактора Х11 та фактора Х12
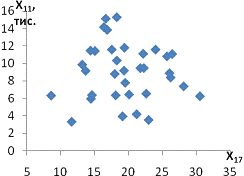
Рисунок В.20 - Кореляційне поле для
фактора Х11 та фактора Х17
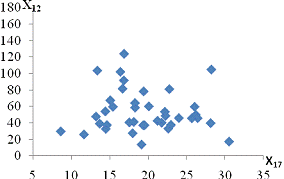
Рисунок В.21 - Кореляційне поле для
фактора Х12 та фактора Х17
Додаток F
Перевірено фактори на мультиколінеарність. Для цього обчислено
визначник матриці парних коефіцієнтів кореляції 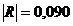
Оскільки визначник матриці близький до нуля, то це свідчить
про наявність мультиколінеарності.
За алгоритмом Фаррара-Глобера перевірено між якими факторами
існує мультиколінеарність.
Для цього нормалізуємо змінні за формулою (2.17).
Матрицю нормалізованих змінних транспонуємо та знайдемо
кореляційну матрицю.
Визначник матриці 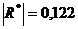 .
.
Обчислимо емпіричне значення критерію 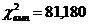 .
Критичне значення
.
Критичне значення .
.
Оскільки фактичне значення критерію більше за табличне, то робимо
висновок, що серед незалежних змінних існує мультиколінеарність.
Розраховано F-статистику.
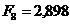

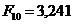
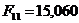
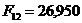
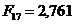
Табличне значення критерію Фішера 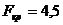 .
.
Оскільки 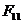 >
> та
та 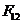 >,
то фактори
>,
то фактори 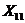 та
та 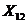 мультиколінеарні
з іншими.
мультиколінеарні
з іншими.
Також розраховано коефіцієнт детермінації.
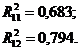
Обчислено емпіричні значення t - статистики.

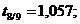
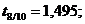


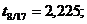
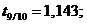






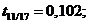
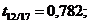
Критичне значення  .
.
Оскільки  >
> ,
,
 >,
>,
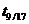 >,
то між факторами та ,
>,
то між факторами та ,
 та
та  ,
та
,
та 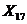 існує
мультиколінеарність.
існує
мультиколінеарність.
Проаналізувавши значення F-статистики, коефіцієнта детермінації та t -
статистики визначено, що найкраще серед факторів
та виключити фактор оскільки
дана величина є менш керованою, ніж величина .
Перерахувавши кореляційну матрицю та емпіричне значення критерію
Пірсона маємо:
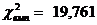 ;
;
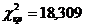 .
.
Отже, між незалежними змінними існує мультиколінеарність.
Аналогічним чином розраховано F-статистику уже для 5
факторів.
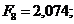

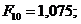
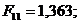
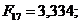
Критичне значення критерію 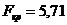 .
.
Обчислено коефіцієнти детермінації.
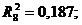
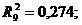
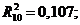


Оскільки за допомогою F-статистики не можна визначити які
саме фактори є мультиколінеарними, то обчислено значення t - статистики.
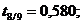
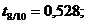
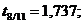


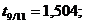

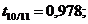


Критичне значення критерію 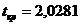 .
.
Оскільки, 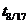 >
, >,
то між факторами
>
, >,
то між факторами 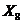 та ,
та,
існує мультиколінеарність.
та ,
та,
існує мультиколінеарність.
Проаналізувавши значення F-статистики, коефіцієнта детермінації та t -
статистики визначено, що найкраще виключити фактор , оскільки він є менш керованим ніж інші фактори.
Перерахувавши кореляційну матрицю, обчислено емпіричне значення
критерію 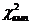 для 4 факторів.
для 4 факторів.
 ;
;
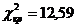 .
.
Оскільки <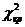 ,
то в масиві незалежних змінних не існує мультиколінеарності.
,
то в масиві незалежних змінних не існує мультиколінеарності.
Додаток G
Таблиця F.1 - Стандартизовані дані
|
№ п-ва
|
Z1
|
Z8
|
Z9
|
Z10
|
Z11
|
Z12
|
Z17
|
|
5
|
1,252
|
-0,187
|
-1,006
|
0,896
|
-0,699
|
-0,521
|
1,730
|
|
6
|
1,545
|
-0,620
|
-0,496
|
0,342
|
0,192
|
-0,499
|
-0,361
|
|
8
|
1,123
|
0,959
|
-1,167
|
0,848
|
-0,612
|
-0,582
|
0,028
|
|
9
|
-0,704
|
-0,243
|
-1,033
|
0,969
|
0,192
|
-0,370
|
0,912
|
|
10
|
-0,468
|
-0,579
|
-0,845
|
1,258
|
-0,257
|
-0,507
|
0,471
|
|
11
|
-0,513
|
-0,271
|
-0,281
|
1,017
|
0,027
|
-0,377
|
1,246
|
|
12
|
-0,924
|
-0,243
|
-1,274
|
-1,249
|
-0,916
|
-0,483
|
-0,247
|
|
14
|
-0,293
|
0,036
|
-0,120
|
-1,586
|
-1,375
|
-0,451
|
0,362
|
|
15
|
-1,584
|
-0,495
|
-0,308
|
-2,213
|
-1,514
|
-0,573
|
0,710
|
|
16
|
0,136
|
-0,215
|
0,255
|
0,736
|
0,992
|
-0,593
|
|
17
|
-0,062
|
-0,313
|
0,094
|
0,149
|
-0,172
|
-0,326
|
-1,219
|
|
18
|
0,632
|
-0,942
|
3,315
|
-0,019
|
-1,000
|
-0,689
|
-0,968
|
|
19
|
0,576
|
0,819
|
2,107
|
-0,333
|
1,270
|
1,029
|
-1,185
|
|
20
|
0,897
|
0,624
|
-0,201
|
1,595
|
-0,322
|
-0,535
|
-1,124
|
|
21
|
-0,276
|
0,358
|
-0,067
|
-0,526
|
0,942
|
0,495
|
-0,537
|
|
22
|
0,547
|
0,791
|
0,658
|
-0,140
|
0,158
|
0,153
|
-0,853
|
|
23
|
-0,907
|
-0,467
|
1,812
|
-2,068
|
-0,897
|
-0,025
|
0,141
|
|
26
|
-0,259
|
-0,956
|
-1,006
|
-0,068
|
0,167
|
-0,174
|
-0,980
|
|
27
|
-0,817
|
-0,788
|
0,363
|
-0,260
|
1,862
|
0,483
|
0,669
|
|
28
|
-1,077
|
-0,383
|
0,577
|
0,680
|
1,759
|
-0,037
|
-0,784
|
|
29
|
1,630
|
-1,375
|
-0,550
|
2,608
|
-0,318
|
-0,583
|
-0,005
|
|
30
|
0,581
|
-0,033
|
0,980
|
0,511
|
1,443
|
0,740
|
-0,504
|
|
31
|
-1,889
|
-1,082
|
-0,791
|
0,005
|
-0,939
|
-1,064
|
2,204
|
|
32
|
-0,366
|
-0,620
|
-0,550
|
1,716
|
-0,398
|
-0,818
|
-0,276
|
|
33
|
1,867
|
0,288
|
0,041
|
-1,128
|
1,482
|
2,996
|
0,536
|
|
34
|
0,294
|
-0,467
|
0,604
|
-0,236
|
-0,073
|
-0,062
|
-0,215
|
|
35
|
0,925
|
-0,019
|
-0,979
|
-0,333
|
-0,379
|
-0,038
|
1,319
|
|
36
|
-0,073
|
-0,285
|
-0,765
|
-0,550
|
-0,485
|
-0,275
|
1,348
|
|
40
|
1,207
|
-0,481
|
1,543
|
-1,128
|
0,669
|
1,524
|
-0,496
|
|
41
|
-0,242
|
-0,075
|
-0,362
|
-0,718
|
-0,912
|
-0,577
|
-0,938
|
|
42
|
-0,248
|
-0,481
|
0,550
|
-0,116
|
0,092
|
-0,184
|
0,552
|
|
43
|
1,292
|
-0,047
|
-0,657
|
1,186
|
-0,877
|
-0,682
|
0,641
|
|
44
|
0,062
|
0,204
|
-1,140
|
0,728
|
0,085
|
-0,372
|
1,396
|
|
45
|
-0,981
|
-0,662
|
0,416
|
-0,767
|
-0,255
|
-0,305
|
0,570
|
|
46
|
-0,857
|
0,302
|
0,926
|
0,439
|
-1,427
|
-1,151
|
-0,049
|
|
47
|
-0,868
|
-0,327
|
-0,094
|
0,511
|
0,977
|
0,074
|
-0,217
|
|
48
|
-0,315
|
0,204
|
-0,979
|
-0,188
|
2,165
|
1,060
|
1,750
|
|
49
|
-0,332
|
4,789
|
0,873
|
0,149
|
1,855
|
3,914
|
-1,381
|
|
50
|
-1,635
|
0,064
|
-1,060
|
-0,164
|
-1,558
|
-0,855
|
-1,529
|
|
51
|
-1,077
|
1,560
|
-0,094
|
-0,381
|
-0,923
|
-0,764
|
-2,126
|
|
52
|
2,200
|
1,658
|
0,712
|
-0,357
|
0,236
|
0,417
|
0,006
|
Додаток H
Таблиця G.1 - Кореляційна матриця
стандартизованих ознак
|
Z8
|
Z9
|
Z10
|
Z11
|
Z12
|
Z17
|
|
Z8
|
1,000
|
0,121
|
-0,047
|
0,258
|
0,572
|
-0,342
|
|
Z9
|
0,121
|
1,000
|
-0,273
|
0,194
|
0,306
|
-0,400
|
|
Z10
|
-0,047
|
-0,273
|
1,000
|
0,078
|
-0,257
|
0,033
|
|
Z11
|
0,258
|
0,194
|
0,078
|
1,000
|
0,741
|
-0,041
|
|
Z12
|
0,572
|
0,306
|
-0,257
|
0,741
|
1,000
|
-0,139
|
|
Z17
|
-0,342
|
-0,400
|
0,033
|
-0,041
|
-0,139
|
1,000
|
Таблиця G.5 - Матриця значень головних
компонент
|
№ п-ва
|
F1
|
F2
|
F3
|
|
5
|
-1,138
|
-1,124
|
-0,178
|
|
6
|
-0,400
|
-0,124
|
0,365
|
|
8
|
-0,504
|
-0,545
|
1,135
|
|
9
|
-0,688
|
-1,223
|
0,208
|
|
10
|
-0,875
|
-0,814
|
0,609
|
|
11
|
-0,641
|
-0,978
|
0,005
|
|
12
|
-0,634
|
0,560
|
-0,527
|
|
14
|
-0,483
|
1,113
|
-1,067
|
|
15
|
-0,764
|
1,255
|
-1,816
|
|
16
|
0,835
|
0,276
|
-0,766
|
|
17
|
-0,025
|
0,683
|
0,772
|
0,138
|
2,560
|
0,228
|
|
19
|
1,773
|
0,745
|
0,224
|
|
20
|
-0,134
|
-0,024
|
2,095
|
|
21
|
0,722
|
-0,131
|
-0,127
|
|
22
|
0,672
|
0,558
|
0,545
|
|
23
|
0,230
|
1,996
|
-1,705
|
|
26
|
-0,334
|
0,043
|
0,300
|
|
27
|
0,494
|
-0,878
|
-1,106
|
|
28
|
0,606
|
-0,395
|
0,598
|
|
29
|
-1,150
|
-0,911
|
1,562
|
|
30
|
0,970
|
-0,336
|
0,276
|
|
31
|
-1,613
|
-0,586
|
-1,234
|
|
32
|
-0,887
|
-0,407
|
1,391
|
|
33
|
1,703
|
-1,102
|
-1,738
|
|
34
|
0,031
|
0,536
|
-0,214
|
|
35
|
-0,580
|
-0,703
|
-0,872
|
|
36
|
-0,709
|
-0,415
|
-1,082
|
|
40
|
1,231
|
0,755
|
-1,134
|
|
41
|
-0,332
|
1,062
|
0,238
|
|
42
|
-0,147
|
0,089
|
-0,558
|
|
43
|
-0,952
|
-0,508
|
0,709
|
|
44
|
-0,074
|
-0,682
|
-1,371
|
|
45
|
-1,010
|
-0,307
|
0,471
|
|
46
|
0,724
|
-0,598
|
1,111
|
|
47
|
0,275
|
0,184
|
-0,565
|
|
48
|
-1,403
|
0,558
|
-2,308
|
|
49
|
1,383
|
3,891
|
-1,110
|
|
50
|
1,170
|
-0,704
|
1,118
|
|
51
|
1,685
|
0,323
|
1,489
|
|
52
|
0,117
|
0,919
|
0,138
|
Додаток
K
Таблиця Н.1 - Редукована кореляційна матриця стандартизованих
ознак
|
Z8
|
Z9
|
Z10
|
Z11
|
Z12
|
Z17
|
|
Z8
|
0,572
|
0,121
|
-0,047
|
0,258
|
0,572
|
-0,342
|
|
Z9
|
0,121
|
0,400
|
-0,273
|
0,194
|
0,306
|
-0,400
|
|
Z10
|
-0,047
|
-0,273
|
0,273
|
0,078
|
-0,257
|
0,033
|
|
Z11
|
0,258
|
0,194
|
0,078
|
0,741
|
0,741
|
-0,041
|
|
Z12
|
0,572
|
0,306
|
-0,257
|
0,741
|
0,741
|
-0,139
|
|
Z17
|
-0,342
|
-0,400
|
0,033
|
-0,041
|
-0,139
|
0,400
|
Таблиця Н.3 - Матриця залишкових кореляцій
|
Z8
|
Z9
|
Z10
|
Z11
|
Z12
|
Z17
|
|
Z8
|
0,198
|
-0,137
|
0,068
|
-0,179
|
0,032
|
-0,136
|
|
Z9
|
-0,137
|
0,223
|
-0,193
|
-0,107
|
-0,066
|
-0,258
|
|
Z10
|
0,068
|
-0,193
|
0,237
|
0,212
|
-0,091
|
-0,030
|
|
Z11
|
-0,179
|
-0,107
|
0,212
|
0,231
|
0,110
|
0,200
|
|
Z12
|
0,032
|
-0,066
|
-0,091
|
0,110
|
-0,039
|
0,158
|
|
Z17
|
-0,136
|
-0,258
|
-0,030
|
0,200
|
0,158
|
0,287
|
Таблиця Н.5 - Матриця значень фактора F1
|
№ п-ва
|
F1
|
№ п-ва
|
F1
|
|
5
|
-2,248
|
30
|
2,149
|
|
6
|
-0,835
|
31
|
-3,347
|
|
8
|
-1,025
|
32
|
-1,847
|
|
9
|
-1,262
|
33
|
3,928
|
|
10
|
-1,736
|
34
|
-0,020
|
|
11
|
-1,209
|
35
|
-1,109
|
|
12
|
-1,447
|
36
|
-1,436
|
|
14
|
-1,231
|
40
|
2,558
|
|
15
|
-1,841
|
41
|
-0,907
|
|
16
|
1,780
|
42
|
-0,323
|
|
17
|
-0,180
|
43
|
-1,973
|
|
18
|
-0,173
|
44
|
-1,230
|
|
19
|
3,665
|
45
|
-0,728
|
|
20
|
-0,328
|
46
|
-1,526
|
|
21
|
1,580
|
47
|
0,500
|
|
22
|
1,323
|
48
|
1,640
|
|
23
|
0,157
|
49
|
8,512
|
|
26
|
-0,699
|
50
|
-1,728
|
|
27
|
1,250
|
51
|
0,369
|
|
28
|
1,368
|
52
|
1,915
|
|
29
|
-2,304
|
|
|