Анализ продажной цены автомобиля
Направление
«Экономика»
Квалификация
«Бакалавр экономики»
Кафедра
эконометрики и математических методов экономики
КУРСОВАЯ
РАБОТА
На тему:
Анализ продажной цены автомобиля
Оглавление
Введение
. Описание факторов рынка
подержанных автомобилей
.1 Статистическое описание
переменных
. Эконометрическое моделирование
исходных данных
.1 Первая конкурирующая модель
.2 Вторая конкурирующая модель
.3 Анализ остатков
.4 Третья модель регрессии с
добавленными фиктивными переменными наблюдений
.5 Построение утилитарной модели
.6 Проверка гипотезы об отсутствии
гетероскедастичности в остатках третьего уравнения регрессии
. Точечные и интервальные
внутри-выборочные прогнозы для продажной стоимости автомобилей
Выводы
Список использованной литературы
Введение
автомобиль стоимость
эконометрический регрессия
В курсовой работе рассматривается московский
сегмент российского вторичного рынка (подержанных) автомобилей марок Patriot и
Hunter, проданных за 2009-2010.
Предметом исследования является цена сделки
(продажи) подержанного автомобиля, как функция характеризующих факторов
(указаны далее). Объектом исследования является выборка значений этих факторов
для отечественных внедорожников УАЗ марок Patriot и Hunter по 132 сделкам.
Цель и задачи исследования: определение набора
конкурирующих моделей средней ожидаемой цены сделки как функции значений
выбранных факторов, точностное описание этих моделей, определение наилучшей из
них.
Методика исследования: определение состава
рыночных факторов формирования цены подержанных автомобилей, их статистический
анализ и эконометрическое моделирование в рамках моделей множественной линейной
регрессии.
Актуальность исследования определяется
устойчивостью спроса на подержанные автомобили этих марок, как в Московском
регионе, так и во всей России. При этом, для этих автомобилей важен именно
вторичный сегмент, т.к. в большинстве случаев все производственные дефекты им
уже выявлены и установлены в процессе первичной эксплуатации.
Следует отметить, что автомобили марки Patriot
пользуются спросом в основном у москвичей, имеющих большую семью, и выезжающих
регулярно за город. А автомобили марки Hunter более популярны у жителей
сельских частей московского региона.
1. Описание факторов рынка подержанных автомобилей
Аудиторская компания Pricewaterhouse Coopers
несколько лет подряд регулярно представляет доклады о состоянии дел на
автомобильном рынке России: подводит итоги и даёт собственный прогноз. В этом
году PwC впервые уделила пристальное внимание продажам подержанных машин, ведь
дальше не замечать этот растущий сектор уже нельзя. В 2013-м на вторичке было
реализовано 5,6 млн. автомобилей - на 4% больше, чем в 2012-м. По числу
регистраций бэушные легковушки опережают новые машины вдвое, и рост совершенно
точно продолжится.
Так называемых драйверов роста на рынке бэушных
машин - хоть отбавляй. Производители запустили спецпрограммы и теперь дают
дополнительные гарантии (примерами могут служить Mercedes-Benz StarClass, BMW
Premium Selection, Audi с пробегом :plus, Jaguar Selected, Skoda Plus). Крупные
дилеры создали подразделения, специализирующиеся на перепродажах (BlueFish,
Major Expert). Постепенно набирает популярность трейд-ин. Банки принялись
предлагать кредиты под автомобили с пробегом. Пышным цветом вторичный рынок
цветёт в Интернете, который теперь считается ключевым источником информации о
подержанных машинах. Кроме того, всё большую роль в секторе начинают играть
корпоративные парки, которым нужно продать автомобили, номинально отработавшие
срок.
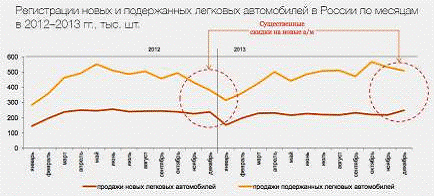
Наиболее ликвидными среди
секонд-хенда остаются автомобили в возрасте до пяти лет. Их доля постепенно
увеличивается и составляет 27% в общем объёме автопарка России (в Москве -
50,4%). Соответственно, у регионов, обладающих такой «молодой вторичкой»,
имеется наибольший потенциал роста. Лидирует, конечно же, Центральный
федеральный округ со столицей во главе. Другие стараются догонять (в Татарстане
«допятилетки» составляют 45,2% рынка, в Питере - 44,6%, в Самарской области и
Пермском крае - более 41%), но Москва непобедима - это крупнейший в стране
рынок старых и новых автомобилей.
В российской столице 87%
автомобильного секонд-хенда - иномарки. Официальные дилеры контролируют около
27% вторичного рынка (в России - лишь 4%), и их экспансия продолжается.
Преимуществом обладают те, кто способен собрать под одной крышей максимальное
количество подержанных машин. По брендам ситуация следующая: первое место в
Москве занимает продукция АвтоВАЗа (доля 10,6%), второе - Ford (6,1%), третье
делят Nissan и Toyota (по 5,9%). Далее в топ-10 следуют BMW (5,8%),
Mercedes-Benz (5,4%), Volkswagen (5,3%), Mitsubishi (4,3%), Hyundai (4,3%) и
Kia (3,6%).
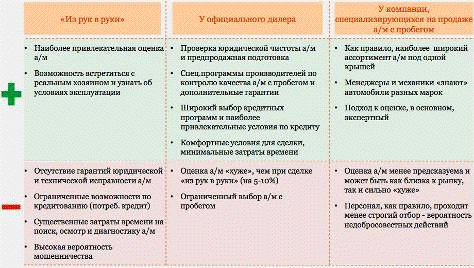
В прошлом году в столице было
продано около 500 тысяч автомобилей с пробегом, а зарегистрировано 290 000
бэушных машин. Это говорит о том, что почти половина перепроданных легковушек
отправилась в область и другие регионы. Всё дело в московских ценах, широте
ассортимента, высокой конкуренции (у дилеров больше возможностей дать хорошие
скидки), что и привлекает перекупщиков. Изменений в этом круговороте ожидать
вряд ли стоит. Прогноз PwC по «пробежному рынку» на 2014 год такой: количество
регистраций стабилизируется на нынешней отметке, доля дилеров на вторичке в
Москве вырастет до 30%, в России - до 5%.
А что же новые автомобили? Выиграть
бой у секонда им пока не светит. По подсчётам аналитиков PwC, в этом году
российский авторынок упадёт на 3% - до 2,5 млн. машин. Хуже других придётся
продавцам импортируемых новых легковушек: их объёмы просядут на 12% (сейчас это
ниша примерно в 10 тысяч машин, преимущественно японских). Отечественный
автопром уйдёт в минус на 6%, тогда как производителей иномарок в России
ожидает небольшой рост - на 4%. Причины дальнейшего падения рынка - это
негативный макроэкономический фон (снижение темпов роста экономики, падение
курса рубля, сокращение бюджетных расходов) и умеренно-пессимистические
настроения потребителей.
Фактор, способствующий росту
авторынка, по мнению аналитиков PwC, всего один - это поступление в продажу
новых моделей массового сегмента. В то же время сдерживать реализацию машин
будут четыре мощных фактора - рост цен на автомобили и топливо (вследствие
повышения налога на добычу полезных ископаемых, акцизов на топливо и
общемирового подорожания нефти), валютные колебания, а также сокращение
государственных расходов и инвестиций.
Тем не менее долгосрочный прогноз
PwC не изменился: эксперты по-прежнему считают, что к 2025 году российский
авторынок вырастет до 3,6 млн. машин и перегонит германский. Причём постепенные
подвижки в этом направлении, то есть умеренный рост, можно ожидать уже в
2015-м. Некоторые признаки стабилизации наблюдаются с середины прошлого года -
благодаря программе льготного кредитования.
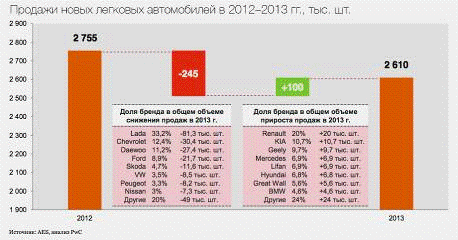
Фирма Pricewaterhouse Coopers
подвела собственные итоги прошлого года для автомобильного рынка нашей страны.
По её калькуляциям вышло, что продажи в штучном выражении упали на 5,5% (с 2755
до 2610 машин), а в денежном - на 3% (с 71 до 69 млрд. долларов). Аналитики признаются,
что прогноз на 2013-й был более оптимистичным, но перегрев оказался сильнее.
Единственной сектором, где был зафиксирован рост продаж, стали иномарки
российского производства - их доля выросла до 50% от всех проданных новых
легковушек.
В 2013 году на глобальном авторынке
локомотивами роста были Китай (+15,7%, или 17,9 млн. шт.) и США (+7,6%, или
15,56 млн. шт.), которые сумели улучшить у себя экономическую обстановку. В
остальных странах БРИКС продажи снизились: в Бразилии и Индии из-за выросших
ставок по кредитам, высокой инфляции и растущей задолженности населения,
подорожания топлива. В России - отчасти из-за неопределённости в экономике.
Кстати, Олимпиада в Сочи повлияла на
рынок - южные регионы получили деньги и принялись покупать машины. Однако
ожидать от спортивного праздника подспорья в дальнейшем не стоит. Как и
рассчитывать на то, что спрос на новые автомобили подстегнут санация банков,
падение рубля и подобные неприятности: вряд ли люди массово понесут спасать
свои сбережения в автосалоны. Надежда на то, что негативный макроэкономический
фон сменится на нейтральный, новинки наведут шороху, возобновится льготное
кредитование, разовьются корпоративные парки, а потребительская уверенность,
самая низкая за несколько лет, всё-таки вырастет.
.1 Статистическое описание
переменных
|
Фиктивные
переменные
|
Описание
|
Фиктивные
переменные
|
Описание
|
|
D1
|
ABS
|
D30
|
Обогрев
сидений
|
|
D2
|
Airbag
боковые
|
D31
|
Омыватель
фар
|
|
D3
|
Airbag
д/водителя
|
D32
|
Отделка
под дерево
|
|
D4
|
Airbag
д/пассажира
|
D33
|
Парктроник
|
|
D5
|
Airbag
оконные
|
D34
|
Подлокотник
передний
|
|
D6
|
ESP
|
D35
|
Противотуманные
фары
|
|
D7
|
Handsfree
|
D36
|
Разд.
спинка задн. сидений
|
|
D8
|
Авт.
упр. светом
|
D37
|
Регул.
сид. вод. по высоте
|
|
D9
|
Антипробуксовочная
система
|
D38
|
Регул.
сид. пасс. по высоте
|
|
D10
|
Ау
диоподготовка
|
D39
|
Регулировка
руля
|
|
D11
|
Багажник
на крыше
|
D40
|
Салон
(велюр)
|
|
D12
|
Блокировка
заднего диф.
|
D41
|
Салон
(кожа)
|
|
D13
|
Бортовой
компьютер
|
D42
|
Сигнализация
|
|
D14
|
ГУР
|
D43
|
Сотовый
телефон
|
|
D15
|
Д/о
багажника
|
D44
|
Тонированные
стекла
|
|
D16
|
Д/о
бензобака
|
D45
|
Фаркоп
|
|
D17
|
Датчик
дождя
|
D46
|
Центральный
замок
|
|
D18
|
Иммобилайзер
|
D47
|
Электроантенна
|
|
D19
|
Катализатор
|
D48
|
Электрозеркала
|
|
D20
|
Климат-контроль
|
D49
|
Электропривод
вод. сиденья (есть)
|
|
D21
|
Кондиционер
|
D50
|
Электропривод
вод. сиденья (с памятью)
|
|
D22
|
Корректор
фар
|
D51
|
Электропривод
пасс. сиденья
|
|
D23
|
Круиз-контроль
|
D52
|
Электростекла
(все)
|
|
D24
|
Ксеноновые
фары
|
D53
|
Электростекла
(передние)
|
|
D25
|
Лебедка
|
D54
|
Магнитола
(есть)
|
|
D26
|
Легкосплавные
диски
|
D55
|
Магнитола
(с CD)
|
|
D27
|
Люк
|
D56
|
Магнитола
(с MP3)
|
|
D28
|
Навигационная
система
|
D57
|
CD-чейнджер
(есть)
|
|
D29
|
Обогрев
зеркал
|
D58
|
CD-чейнджер
(с MP3)
|
2. Эконометрическое моделирование исходных
данных
И так, мы располагаем 129 наблюдениями
переменных, из которых 2 количественные, продажа стоимости автомобиля и его
пробег, 3 различные качественные бинарные переменные, 1 качественную переменную
с 4 градациями, которую используем в виде набора 3-х “бинарных” переменных (см.
параграф 2 предыдущей главы).
Мы так же будем использовать две дополнительных
переменные LN_price и LN_run. Первая, в нашем случае приводит к нормальности
распределения зависимой случайной переменной. Вторая - даёт простое
представление о функции эластичности цены автомобиля по его пробегу.
В качестве конкурирующих, мы будем рассматривать
модели для логарифма цены (LN_price), использующие либо переменную пробег
(run), либо его лоарифм (LN_run) в составе объясняющих переменных. Дальнейшему
улучшению подвергнется наилучшая из них.
Так же, дополнительно, мы построим аналогичную
простую модель зависимости непосредственно для цены (price) автомобиля.
Последняя модель, возможно менее пригодна с точки зрения теории, но весьма
удобна на практике, как для быстрого отсева явно не пригодных предложений, так
и для использования простыми обывателями, которые вряд ли помнят что такое
логарифм.
В процессе анализа автором было исследовано 5
типов моделей, первые две модели использовали непосредственно возраст
автомобиля эта зависимость оказалась в обоих случаях существенно не линейной.
Кроме того они показались автору бесперспективными для дальнейшего улучшения.
Эти модели в дальнейшем не использовались и в работе не описывались.
Этот факт привел к необходимости введения замены
переменной year на фиктивную переменную. Все модели используют mark, state,
power и константу.
2.1 Первая конкурирующая модель
Далее мы будем рассматривать две модели, сначала
для LN_price, а потом отдельно построим модель для цены (price) нужной в
систему ее практической полезности (утилитарности).
Первая модель содержит переменную run в качестве
фактора, вторая - переменную LN_run.
_PRICE = C + C1 х
MARK + C2 x STATE + C3 x POWER + x DUM2_YEAR + C5 x DUM2_YEAR + C6 x DUM4_YEAR
+ C7 x RUN + EPSILON.
Где:
C - константа,
C1 - C7 - коэффициенты уравнения,- случайная
составляющая.
Результат оценивания первой модели дан в таблице
3.
Таблица 3. Вывод в пакете EViews результатов
оценивания первой пробной конкурирующей модели регрессии.
|
Dependent Variable: LN_PRICE
|
|
|
|
Method: Least Squares
|
|
|
|
Date: 05/13/13
Time: 18:25
|
|
|
|
Sample: 1 132
|
|
|
|
Included observations: 130
|
|
|
|
Variable
|
Coefficient
|
Std. Error
|
t-Statistic
|
Prob.
|
|
C
|
12.79760
|
0.127811
|
100.1295
|
0.0000
|
|
MARK
|
-0.179599
|
0.040512
|
-4.433281
|
0.0000
|
|
STATE
|
0.127830
|
0.048364
|
2.643105
|
0.0093
|
|
POWER
|
0.233384
|
0.112824
|
2.068564
|
0.0407
|
|
DUM2_YEAR
|
-0.107976
|
0.049881
|
-2.164681
|
0.0324
|
|
DUM3_YEAR
|
-0.324490
|
0.071259
|
-4.553654
|
0.0000
|
|
DUM4_YEAR
|
-0.344819
|
0.068436
|
-5.038564
|
0.0000
|
|
RUN
|
-3.35E-06
|
7.68E-07
|
-4.360340
|
0.0000
|
|
R-squared
|
0.647120
|
Mean dependent var
|
12.76526
|
|
Adjusted R-squared
|
0.626873
|
S.D. dependent var
|
0.349080
|
|
S.E. of regression
|
0.213232
|
Akaike info criterion
|
-0.193304
|
|
Sum squared resid
|
5.547107
|
Schwarz criterion
|
-0.016840
|
|
Log likelihood
|
20.56476
|
Hannan-Quinn criter.
|
-0.121601
|
|
F-statistic
|
31.96096
|
Durbin-Watson stat
|
0.527893
|
|
Prob(F-statistic)
|
0.000000
|
|
|
Далее мы представим соответствующие объяснения,
связанные с интерпретацией вывода результатов оценивания для нашего первого
пробного уравнения регрессии.
В выводе результатов оценивания в Eviews в
первом столбце, помеченном “Variable”, в верхнем блоке таблицы 2 приводится
список объясняющих (независимых) переменных, входящих в матрицу исходных
данных.
Эта матрица состоит из восьми столбцов (первого
столбца из единиц, второго столбца из значений фиктивной переменной mark и
т.д., и последнего столбца из значений переменной run.) 130 строк - каждая
соответствует своему номеру наблюдения.
Таким образом, число оцениваемых параметров в
данной регрессии равно 8.
Объем выборки равен 130 наблюдений, (в выводе
результатов оценивания смотри Included observations: 130).
В столбце, помеченном “Coefficient” [],
отображаются оцененные коэффициенты регрессии нашего пробного уравнения.
Коэффициент с - это свободный член, который
имеет значение основного уровня прогнозирования, когда все другие объясняющие
переменные нулевые.
В столбце “Std. Error” [], показывается
оцененные стандартные ошибки для оценок коэффициентов.
Стандартные ошибки измеряют статистическую
надежность оценок коэффициентов - чем больше стандартные ошибки, тем больше
статистический шум в оценках.
Если ошибки распределены нормально, то
существует приблизительно 2 шанса из 3, что истинный коэффициент регрессии
находится в пределах одной стандартной ошибки от оцененного коэффициента, и
приблизительно 95 шансов из 100, что истинный коэффициент находится в пределах
двух стандартных ошибок от оцененного коэффициента.статистика [] (в столбце
“t-Statistic”) мы вычислили как отношение оцененного коэффициента регрессии к
его стандартной ошибке, и применяется для тестирования нулевой гипотезы, что
истинный коэффициент регрессии равен нулю.
Значение статистики R-квадрат (R-squared) служит
оценкой измерения, насколько хорошо из построенной регрессии прогнозируются
внутри выборочные значения объясняемой (зависимой) переменной, и,
следовательно, является измерителем качества соответствия модели наблюдаемым
данным.
Одна из проблем при применении в измерении
качества соответствия модели наблюдаемым данным состоит в том, что при
добавлении в модель новых регрессоров, значение никогда не уменьшится. Или
всегда можно получить значение равное единице, если включить столько
независимых регрессоров, сколько в выборке имеется наблюдений. В нашем случае
такой опасности нет.
Для скорректированного (Adjusted R-squared) [],
обычно обозначаемого как, на обычный при добавлении регрессоров в модель
налагается штраф, который не вносит свой вклад в объяснительную мощность
модели.
Стандартная ошибка регрессии (S.E. of
regression) [] является итоговой статистикой на основе оцененной дисперсии
остатков. статистика [] (F-statistic), применяется для тестирования нулевой
гипотезы, все коэффициенты наклона в регрессии (за исключением свободного
члена) равны нулю.значение, предоставленное ниже F-статистики
(Prob(F-statistic)) [], является предельным уровнем значимости F-критерия.
Если p-значение меньше уровня значимости,
например, меньше 0,05, то при тестировании совместная нулевая гипотеза, что все
коэффициенты наклона равны нулю, отклоняется.
В нашей первой пробной модели p-значение равно нулю,
и, таким образом, мы отклоняем нулевую гипотезу, что все коэффициенты нашей
регрессии равняются нулю.
На этом мы завершаем соответствующие объяснения,
связанные с интерпретацией вывода результатов оценивания в таблице 2.
Все коэффициенты этого уравнения регрессии
являются значимыми на уровне 95% и имеют хорошо экономически интерпретируемые
знаки коэффициентов регрессии.
Например, при более раннем годе выпуска
автомобиля его продажная стоимость при прочих равных условиях снижается.
Значение статистики R-квадрат для этого
уравнения равно 0,647, и, следовательно, 64,7% вариации переменной продажная
стоимость автомобиля объясняется независимыми переменными, включенными в правую
часть первого уравнения регрессии. И это значение дает нам вывод о приемлимом
качестве соответствия модели наблюдаемым данным.
Наше первое пробное уравнение регрессии включает
все имеющиеся у нас переменные, и является линейным, как по параметрам, так и
по переменным.
.2 Вторая конкурирующая модель
Вторая модель, как уже говорилось, содержит
переменную LN_run
вместо run.
(В этом случае коэффициент C7
равен значению эластичности цены по пробегу.)
LN_PRICE = C + C1 + MARK + C2 x
STATE + C3 x POWER +x DUM2_YEAR + C5 x DUM2_YEAR + C6 x DUM4_YEAR
+ C7 x LN_RUN + EPSILON.
Где: C - константа, : C7 - коэфф. уравнения,-
случайная составляющая.
Результат оценивания модели 1 приведен в таблице
4.
Таблица 4. Вывод в пакете EViews результатов
оценивания второй модели регрессии.
|
Dependent
Variable: LN_PRICE
|
|
|
|
Method:
Least Squares
|
|
|
|
Date:
05/14/13 Time: 13:13
|
|
|
|
Sample:
1 132
|
|
|
|
Included
observations: 130
|
|
|
|
Variable
|
Coefficient
|
Std.
Error
|
t-Statistic
|
Prob.
|
|
C
|
12.98790
|
0.177811
|
75.41157
|
0.0000
|
|
MARK
|
-0.177773
|
0.043512
|
-4.118829
|
0.0001
|
|
STATE
|
0.151773
|
0.050503
|
3.005213
|
0.0032
|
|
POWER
|
0.252834
|
0.120396
|
2.100022
|
0.0378
|
|
DUM2_YEAR
|
-0.127819
|
0.073501
|
-2.401951
|
0.0178
|
|
DUM3_YEAR
|
-0.395957
|
0.069468
|
-5.387070
|
0.0000
|
|
DUM4_YEAR
|
-0.346358
|
0.069468
|
-6.137505
|
0.0000
|
|
LN_RUN
|
-3.31247
|
0.014015
|
-2.229596
|
0.0276
|
|
R-squared
|
0.608096
|
Mean
dependent var
|
12.76526
|
|
Adjusted
R-squared
|
0.585610
|
S.D.
dependent var
|
0.349080
|
|
S.E.
of regression
|
0.224714
|
Akaike
info criterion
|
-0.088414
|
|
Sum
squared resid
|
6.160549
|
Schwarz
criterion
|
0.088049
|
13.74694
|
Hannan-Quinn
criter.
|
0.016711
|
|
F-statistic
|
27.04295
|
Durbin-Watson
stat
|
0.489251
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
Второе уравнение, в отличие от первого, содержит
переменную LN_RUN вместо переменной RUN.
Сравнение результатов с результатами первой
модели, говорит о том, что эта модель имеет меньшую прогностическую силу.
Это означает, что на рынке данных авто
эластичность [] цены по пробегу (коэффициент C7) нельзя считать постоянной.
Для анализа эластичности рынка, требуется больше
данных, желательно, равномерно распределенных по всему диапазону пробега. К
тому же этот анализ требует отдельного самостоятельного исследования.
В нашей работе мы не будем проводить такое
исследование, потому что такая задача перед автором не ставилась.
Из двух моделей для дальнейшего анализа, мы выберем
первую.
.3 Анализ остатков
Проверка на гетероскедактичность [;;]
остатков показала наличие средней (R-squared = 0.42) зависимости квадратов
остатков от зависимой величины.
А тест на зависимость остатков от исходных
переменных дал отрицательный результат. Данное оценивание не приводится. Модель
зависимости дана ниже.
EPSILON2 = 45.18038 - 7.425410 x
LN_price
+ 0.304176 x
LN_price
+ EPSILON1,
F-statistic = 45.40328 (Prob. F-Stat
= 0.00000)
Через LN_price
обозначена вторая степень переменной LN_price,
а через EPSILON
- остатки этой регрессии.
Эта зависимость является значимой. Об этом
свидетельствуют значения критериев (F-statistic
= 45.40328 Prob. F-Stat
= 0.00000).
Но эта зависимость не очень существенна (R-squered
=0,41).
Не приводя аналогичных расчетов, отметим лишь
то, что увеличение степени полинома по переменной LN_price
улучшает эту зависимость не существенно.
Однако, как будет понятно из дальнейшего, не
стоит торопиться с выводами и переходить сразу к взвешенной регрессии.
Попробуем поступить по-другому - построить
модель, учитывающую дополнительный анализ исходных данных на наличие выбросов.
Рассмотрим график остатков регрессии и определим
наиболее выделяющееся значения (выбросы):
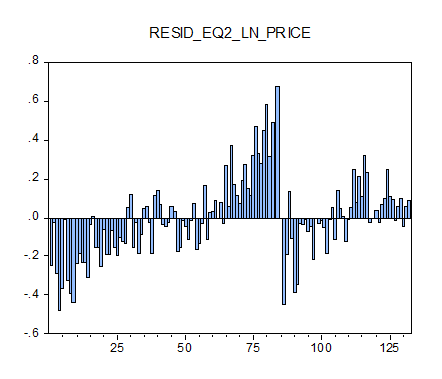
Рисунок 3. График значений остатков регрессии
для второго уравнения (по оси абсцисс - номера наблюдений упорядоченных по
возрастанию логарифма цены).
Стандартный анализ выбросов [;] дал
результаты, приведенные в таблице
Таблица 4. Значения всех
рассматриваемых переменных для пяти наблюдений с наибольшими по абсолютному
значению остатками регрессии для второго уравнения.
|
Номер наблюд.
|
Перем. price
|
Перем. ln_price
|
Перем. mark
|
Перем. year
|
Перем. state
|
Перем. power
|
Перем. run (км.)
|
|
84
|
850 тыс. руб.
|
13.6530
|
1
|
1
|
1
|
1
|
2500
|
|
80
|
650 тыс. руб.
|
13.3847
|
1
|
2
|
1
|
1
|
24000
|
|
82
|
700 тыс. руб
|
13.4588
|
1
|
1
|
1
|
1
|
4500
|
|
4
|
260 тыс. руб
|
12.4684
|
1
|
1
|
1
|
1
|
10000
|
|
86
|
140 тыс. руб
|
11.8494
|
0
|
3
|
0
|
1
|
116000
|
Теперь посмотрим на таблицу 4
значений всех рассматриваемых переменных для пяти наблюдений с наибольшими по
абсолютному значению остатками регрессии для второго уравнения.
Четыре наблюдения относятся к
автомобилям марки Hunter
с мощностью 128 л. с., в отличном состоянии, и только одно последнее наблюдение
относится к автомобилям марки Patriot, 2006г. выпуска, 128 л. с., в хорошем
состоянии (см. значения по переменным mark, year,
power, state
в таблице 4).
Первый автомобиль в таблице 4
(под номером 84) имеет положительный максимальный по модулю остаток регрессии.
Этот автомобиль 2008г. выпуска, его продажная стоимость максимальна и
составляет 850 тыс. рублей (для сравнений см. описательные статистики в таблице
1). Все значения переменных для этого автомобиля в классе автомобилей марки Hunter
имеют самые лучшие значения, в том числе и пробег в км., поскольку он прошел
обкатку 2500 км., и обычно за этот пробег выявляются и устраняются все его
недостатки.
Второй автомобиль в таблице 4
(под номером 80) имеет второй положительный максимальный остаток регрессии.
Этот автомобиль 2007г. выпуска и его продажная стоимость составляет 650 тыс.
рублей. Все значения переменных для этого автомобиля для этого автомобиля в
классе автомобилей марки Hunter
также имеют самые лучшие значения, за исключением 2007г. выпуска и пробега
24000 км.
Третий автомобиль в таблице 4
(под номером 82) 2008г. выпуска имеет третий положительный максимальный остаток
регрессии. Его продажная стоимость составляет 700 тыс. рублей. Все значения
переменных для этого автомобиля для этого автомобиля в классе автомобилей марки
Hunter также имеют самые
лучшие значения, за исключением пробега, равного 4500 км.
Четвертый автомобиль в таблице
4 (под номером 4) имеет отрицательный максимальный остаток регрессии. Его
продажная стоимость составляет 260 тыс. рублей. Все значения переменных для
этого автомобиля в классе автомобилей марки Hunter
также имеют самые лучшие значения, за исключением пробега, составляющего 10000
км.
Пятый автомобиль в классе
автомобилей марки Patriot в таблице 4 (под номером 86) имеет отрицательный
максимальный остаток регрессии. Его продажная стоимость по сравнению с другими
автомобилями небольшая и составляет 140 тыс. рублей. Он имеет 2006г. выпуска и
большой пробег, составляющий 116000 км.
.4 Третья модель регрессии с
добавленными фиктивными переменными наблюдений
Эти пять наблюдений (автомобилей) плохо
описываются нашей второй моделью регрессии (имеют наибольшие по абсолютному
значению остатки), поскольку имеют свои особенности, и, по-видимому, эти
наблюдения сильно ухудшают качество нашей модели для всех остальных наблюдений.
Поэтому, чтобы проверить наше последнее
предположение, мы введем пять новых соответствующих фиктивных переменных,
которые обозначим как dum84,
dum80, dum82,
dum4 и dum86,
в соответствии с номером наблюдения. Все фиктивные переменные имеют нулевые
значения, за исключением значения, равного единице, которое проставлено в
соответствующий номер наблюдения.
Эти пять наблюдений будут анализироваться как
отдельные явления и соответствующие коэффициенты - это изменение LN_price
для этих явлений, но отношение к “общей” картине, т.е. набору данных из
которого эти наблюдения. Все фиктивные переменные имеют нулевые значения, за
исключением значения, равного единице, которое проставлено в соответствующий
номер наблюдения.
После первого прогона регрессии, не трудно
заметить, что наблюдения 4, 80, 82, 84,86 существенно выделяются. Из них цена
сделки 4 и 86 явно занижены, а сделок 80, 82 и 84 явно завышены. Например,
сделка 84 с УАЗом Hunter
годовалого и с пробегом 2500 км представляется мало вероятной, а трех годичный
УАЗом Patriot
с
пробегом 100000 км, был продан за 140000 рублей. К примеру, цена аналогичного
автомобиля Niva составляла
300000 рублей. Скорей всего эти 5 сделок были совершены в особых условиях,
информация о которых отсутствует. Выделив эти наблюдения каждое по отдельности
путем ведения соответствующих фиктивных переменных, получим следующий результат
(смотри таблицу 5):
В таблице 5 приведен вывод в пакете EViews
результатов оценивания третьей модели регрессии с добавленными фиктивными
переменными наблюдений. Прежде всего, отметим, что все коэффициенты регрессии
этого уравнения значимы.
Таблица 5. Вывод в пакете EViews результатов
оценивания третьей модели регрессии.
|
Dependent
Variable: LN_PRICE
|
|
|
|
Method:
Least Squares
|
|
|
|
Date:
05/15/13 Time: 15:21
|
|
|
|
Sample:
1 132
|
|
|
|
Included
observations: 130
|
|
|
|
Variable
|
Coefficient
|
Std.
Error
|
t-Statistic
|
Prob.
|
|
C
|
12.66378
|
0.105021
|
120.5837
|
0.0000
|
|
MARK
|
-0.220201
|
0.035894
|
-6.134738
|
0.0000
|
|
STATE
|
0.116289
|
0.041017
|
2.835149
|
0.0054
|
|
POWER
|
0.363213
|
0.097242
|
3.735144
|
0.0003
|
|
DUM2_YEAR
|
-0.101235
|
0.042501
|
-2.381912
|
0.0188
|
|
DUM4_YEAR
|
-0.342298
|
0.057943
|
-5.907472
|
0.0000
|
|
DUM3_YEAR
|
-0.301499
|
0.061127
|
-4.932346
|
0.0000
|
|
DUM84
|
0.737169
|
0.185649
|
3.970764
|
0.0001
|
|
DUM80
|
0.632533
|
0.184907
|
3.420810
|
0.0009
|
|
DUM82
|
0.548817
|
0.185626
|
2.956579
|
0.0038
|
|
DUM4
|
-0.425621
|
0.185609
|
-2.293101
|
0.0236
|
|
DUM86
|
-0.539456
|
0.192717
|
-2.799213
|
0.0060
|
|
RUN
|
-2.90E-06
|
6.59E-07
|
-4.403834
|
0.0000
|
|
R-squared
|
0.756043
|
Mean
dependent var
|
12.76526
|
|
Adjusted
R-squared
|
0.731022
|
S.D.
dependent var
|
0.349080
|
|
S.E.
of regression
|
0.181044
|
Akaike
info criterion
|
-0.485517
|
|
Sum
squared resid
|
3.834889
|
Schwarz
criterion
|
-0.198763
|
|
Log
likelihood
|
44.55860
|
Hannan-Quinn
criter.
|
-0.368999
|
|
F-statistic
|
30.21607
|
Durbin-Watson
stat
|
0.957412
|
|
Prob(F-statistic)
|
0.000000
|
|
|
|
Полученное новое уравнение удовлетворяет всем
требованиям и его коэффициенты подсчитаны так, что наши пять наблюдений на них
не влияют.
.5 Построение утилитарной модели
Попробуем теперь построить практический полезную
(утилитарную) модель, которой можно использовать для экспресс анализа на данном
рынке. А так же для расчета продажной цены автомобиля среднестатистического
обывателя.
PRICE = C + C1 + MARK + C2 x STATE +
C3 x POWER + x DUM2_YEAR + C5 x DUM2_YEAR + C6 x DUM4_YEAR
+ C7 x RUN + EPSILON.
Все коэффициенты этой модели значимы на 95%,
кроме коэффициента при C4 (мощность), он значим на 88% уровне вероятности, но
не нормальность распределения (остатков) дает нам основания предполагать, что
вероятность существенно выше и соответственно, не дает оснований выбрасывать данное
слагаемое.
Таблица 6.
Результаты оценивания
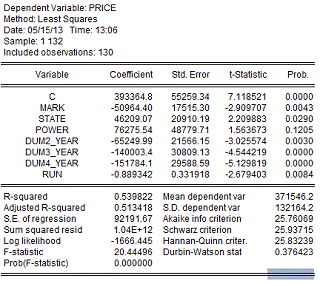
Да, это модель обладает меньшей прогностической
силой R*2 = 0,54, но с другой стороны хорошо интерпретируется средняя цена
автомобиля, которая составляет 393000 рублей (округлено), автомобиль Hunter на
51000 дешевле. Отличное состояние увеличивает цену на 46000 по сравнению с
хорошим состоянием, двигатель в 128 л.с. на 76000 дороже.
Иными словами результат можно истолковать
следующим образом: Средняя цена автомобиля марки Patriot в хорошем состоянии, с
двигателем в 98 л.с., 2008 года выпуска, без пробега стоит 393000.
Более мощный двигатель увеличивает цены
автомобиля на 76000.
Двух годовая марка стоит на 65000 меньше, трех
годовая еще на 14000, четырех годовая еще на 15000.
Каждые 1000 км пробега уменьшают цену автомобиля
на 900 рублей. То есть это модель коррелирует с ценой предложения на рынке на
70%, что вполне допустимо для обывателя и оставляет 30% для торга. Эта модель
может быть построена для каждой марки отдельно, но это не является нашей
задачей.
2.6 Проверка гипотезы об отсутствии
гетероскедастичности в остатках третьего уравнения регрессии
Если остатки регрессии являются н.о.р.
(независимыми и одинаково распределенными) остатками, то по теореме
Гаусса-Маркова [] применение метода наименьших квадратов (МНК) приводит к
состоятельным и эффективным оценкам коэффициентов регрессии.
Предположение о н.о.р.
несправедливо, если остатки регрессии не распределены одинаково или независимо
(или то и другое).
“Когда дисперсия остатков
регрессии, условная по регрессорам, изменяется по наблюдениям, то предположение
об одинаковом распределении остатков “регрессии” несправедливо.
Это явление, известное как
гетероскедастичность (остатки регрессии статистически могут быть зависимы и
имеют неравные дисперсии), противоположна гомоскедастичности (остатки регрессии
независимы и имеют равные дисперсии).
В случае справедливости
предположения нормальности и однородности распределения остатков регрессии
предполагается, что остатки условно гомоскедастичны: о дисперсии ошибок в
регрессорах у нас нет никакой информации.
Если справедливо предположение о нулевом
условном среднем, 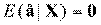 , но остатки
регрессии не являются н.о.р. остатками, то применение МНК все еще приводит к
состоятельным оценкам коэффициентов регрессии, но они являются неэффективными.
, но остатки
регрессии не являются н.о.р. остатками, то применение МНК все еще приводит к
состоятельным оценкам коэффициентов регрессии, но они являются неэффективными.
В этом случае выборочное распределение оценок
коэффициентов регрессии асимптотически (для больших выборок) все еще будет
подчиняться нормальному закону распределения со средним значением в точке
истинных значений коэффициентов, но оцененная ковариационная матрица оценок
коэффициентов регрессии, не будет являться состоятельной оценкой”. []
Теперь с помощью теста
Бреуша-Пагана-Годфрея [2] (Breusch-Pagan-Godfrey)
проверим нулевую гипотезу о гомоскедастичности остатков третьего уравнения
регрессии (остатки регрессии имеют равные дисперсию).
Вместе со значениями этих двух
статистик в пакете Eviews также приводится значение F-статистики.
(Для теста на избыточность состава переменных во вспомогательной регрессии).
Вывод в пакете Eviews
результатов тестирования остатков третьей регрессии по Бреушу-Пагану-Годфрею
для проверки нулевой гипотезы отсутствия гетероскедастичности против
альтернативной гипотезы присутствия гетероскедастичности представлен в таблице
6.
Значение основной ЛМ-статистики
Бреуша-Пагана-Годфрея, обозначенное в верхнем блоке вывода в пакете Eviews как Scaled
explained
SS, равно 41,39 с p-значением,
равным нулю.
Две другие вспомогательные статистики F-статистика
и статистика Кроенкера [] (в выводе пакета Eviews в таблицы 5 они помечены как F-statistic
и Obs*R-squared),
которые представлены для сравнения, также имеют соответствующие p-значения.
Таблица 7. Результат
тестирования остатков на гетероскедастичность.
|
Heteroskedasticity Test:
Breusch-Pagan-Godfrey
|
|
F-statistic
|
4.024856
|
Prob.
F(12,117)
|
0.0000
|
|
Obs*R-squared
|
37.98452
|
Prob.
Chi-Square(12)
|
0.0002
|
|
Scaled
explained SS
|
41.39384
|
Prob.
Chi-Square(12)
|
0.0000
|
|
Test
Equation:
|
|
|
Dependent
Variable: RESID^2
|
|
|
Method:
Least Squares
|
|
|
Date:
05/16/13 Time: 11:10
|
|
|
Sample:
1 132
|
|
|
Included
observations: 130
|
|
|
Variable
|
Coefficient
|
Std.
Error
|
t-Statistic
|
Prob.
|
|
C
|
-0.030726
|
0.024893
|
-1.234327
|
0.2196
|
|
MARK
|
0.045033
|
0.008508
|
5.293059
|
0.0000
|
|
STATE
|
0.013190
|
0.009722
|
1.356701
|
0.1775
|
|
POWER
|
0.060343
|
0.023049
|
2.618020
|
0.0100
|
|
DUM2_YEAR
|
-0.024596
|
0.010074
|
-2.441479
|
0.0161
|
|
DUM4_YEAR
|
-0.032814
|
0.013734
|
-2.389215
|
0.0185
|
|
DUM3_YEAR
|
-0.054954
|
0.014489
|
-3.792851
|
0.0002
|
|
DUM84
|
-0.087765
|
0.044004
|
-1.994463
|
0.0484
|
|
DUM80
|
-0.062519
|
0.043828
|
-1.426445
|
0.1564
|
|
DUM82
|
-0.087704
|
0.043999
|
-1.993340
|
0.0486
|
|
DUM4
|
-0.087538
|
0.043995
|
-1.989735
|
0.0490
|
|
DUM86
|
0.028846
|
0.045679
|
0.631480
|
0.5290
|
|
RUN
|
-3.02E-08
|
1.56E-07
|
-0.193652
|
0.8468
|
|
R-squared
|
0.292189
|
Mean
dependent var
|
0.029499
|
|
Adjusted
R-squared
|
0.219593
|
S.D.
dependent var
|
0.048576
|
|
S.E.
of regression
|
0.042913
|
Akaike
info criterion
|
|
|
Sum
squared resid
|
0.215454
|
Schwarz
criterion
|
|
|
Log
likelihood
|
231.7034
|
Hannan-Quinn
criter.
|
|
|
F-statistic
|
4.024856
|
Durbin-Watson
stat
|
|
|
Prob(F-statistic)
|
0.000032
|
|
|
В нижнем блоке вывода в таблице
7 представлены результаты оценивания соответствующей вспомогательной регрессии,
необходимой для вычисления значений трех названных статистик.
P-значение
основной ЛМ-статистики Бреуша-Пагана-Годфрея, равное нулю, говорит нам о том,
что нулевую гипотезу отсутствия гетероскедастичности следует отклонить. Таким
образом, принимается альтернативная гипотеза о наличие гетероскедастичности в
остатках регрессии третьего уравнения.
Тест показывает практическое присутствие
гетероскедастичности, хотя и слабой (R-squared
=0.3), но объясняющим переменным.
Для объяснения зависимой переменной продажная
стоимость автомобиля третье уравнение регрессии выбрано нами как “наилучшее”.
Переоценку коэффициентов регрессии с помощью
взвешиваной регрессии этом случае я считаю ненужной, потому, что
гетероскедактичность слаба, а оценки все равно состоятельны и несмещенные.
3. Точечные и интервальные внутри-выборочные
прогнозы для продажной стоимости автомобилей
Для каждого внутри-выборочного наблюдения
программа EViews вычисляет точечные прогнозные значения объясняемой (зависимой)
переменной, используя оцененные значения коэффициентов регрессии и значения
экзогенных переменных в правой части уравнения регрессии.
Для нашей третьей модели регрессии мы получили
следующее оцененное уравнение (в круглых скобках значения стандартных ошибок
коэффициентов, смотри таблицу 7):
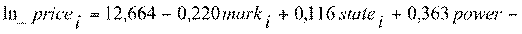
(0,077) (0,049) (0,036) (0,064)
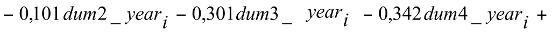
(0,052) (0,058) (0,061)

(0,062) (0,051) (0,062) (0,062) (0,062)
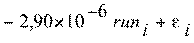 ,
, 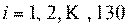 ,
(
,
(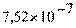 )
)
где dum3_power - взаимодействие 2006г. выпуска
автомобиля с его мощностью, то есть автомобили 2006г. выпуска с мощностью 128
л. с.
Для каждого внутри-выборочного наблюдения программа
EViews вычисляет точечные прогнозные значения логарифмической продажной
стоимости автомобиля 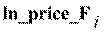 ,
, 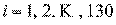 ,
используя формулу, в которой среднее значение остатка
,
используя формулу, в которой среднее значение остатка 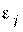 полагается
равным нулю.
полагается
равным нулю.
Согласно классическим учебникам [;;],
точечные прогнозы делаются с ошибкой, где ошибка - это просто разность между
фактическим и прогнозным значением, то есть остаток .
Если модель специфицирована правильно, то существуют два источника ошибки
прогноза: неопределенность в остатках и неопределенность в коэффициентах
регрессии.
Стандартное измерение этой вариации -
стандартная ошибка регрессии (помеченная в выводе результатов оценивания
уравнения “S.E.
of regression”).
Неопределенность в остатках обычно является самым большим источником ошибки
прогноза.
Второй источник ошибки прогноза - это
неопределенность в коэффициентах. Оцененные коэффициенты уравнения регрессии
отклоняются от истинных (теоретических) коэффициентов регрессии случайным образом.
Эффект влияния неопределенности в коэффициентах
зависит от переменных. Чем больше экзогенные переменные отклоняются от своих
средних значений, тем ниже точность прогнозов.
Вариабельность прогнозов измеряется стандартными
ошибками прогнозов. Для невзвешенного уравнения регрессии стандартные ошибки
прогнозов вычисляются по формуле:
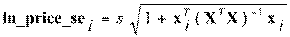
где 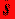 -
стандартная ошибка регрессии. Эти стандартные ошибки объясняются как
неопределенностью остатков (первый член под корнем в правой части уравнения),
так и неопределенностью коэффициентов (второй член под корнем).
-
стандартная ошибка регрессии. Эти стандартные ошибки объясняются как
неопределенностью остатков (первый член под корнем в правой части уравнения),
так и неопределенностью коэффициентов (второй член под корнем).
Точечные прогнозы, построенные из линейной
модели регрессии, оцененной методом наименьших квадратов, оптимальны в том
смысле, что они имеют наименьшую дисперсию прогноза среди прогнозов, сделанных
с помощью линейных несмещенных оценок коэффициентов регрессии. Далее, если
остатки распределены по нормальному закону, то ошибки прогнозов тоже. Тогда с
помощью t-распределения, и легко можно получить интервалы прогнозов.
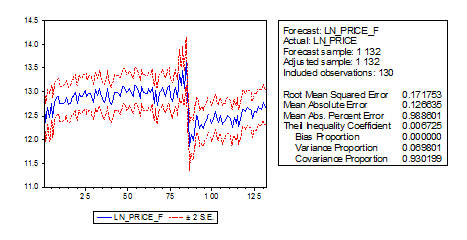
Рисунок 4. Точечные и 95%-ые интервальные
внутри-выборочные прогнозы для логарифмической продажной стоимости автомобилей
с таблицей статистических результатов оценивания прогнозов.
На рисунке 4 представлен график точечных и
95%-ых интервальных внутри-выборочных прогнозов для логарифмической продажной
стоимости автомобилей с таблицей статистических результатов оценивания качества
прогнозирования логарифмической продажной стоимости автомобилей.
На графике верхняя и нижняя кривая соответствуют
верхним и нижним границам 95%-ых доверительных интервалов, а срединная кривая
соответствует точечным прогнозам.
В таблице, справа от графика, первые две
статистики ошибок прогнозов зависят от масштаба зависимой переменной. Их
следует применять для сравнения прогнозов из разных моделей по правилу: чем
меньше ошибка, тем лучше способность прогнозирования модели. Это
среднеквадратичная ошибка прогнозов (Root Mean Squared
Error в таблице) и
средняя абсолютная ошибка прогнозов (Mean
Absolute
Error).
Оставшиеся две статистики, средняя абсолютная
ошибка прогноза в процентах (Mean
Abs. Persent
Error) и коэффициент
неравенства Тейла (Theil
Inequality
Coefficient), не зависят от
масштаба зависимой переменной. Коэффициент неравенства Тейла всегда лежит между
нулем и единицей, где нуль указывает на точное совпадение прогнозных и
фактических значений.
Доля (в среднеквадратичной ошибке прогнозов)
систематической ошибки прогнозов (Bias
Proportion) говорит нам,
насколько далеко среднее значение прогнозов от среднего значения фактического
ряда.
Доля (в среднеквадратичной ошибке прогнозов)
дисперсии прогнозов (Variance
Proportion) говорит нам,
насколько далеко вариация прогнозов от вариации фактического ряда.
Доля (в среднеквадратичной ошибке прогнозов)
ковариации прогнозных и фактических значений (Covariance
Proportion) измеряет
остающиеся несистематические ошибки прогнозов.
Отметим, что доля систематической ошибки, доля
дисперсии и доля ковариации прогнозов в сумме составляют единицу.
Если прогнозы “хороши”, то доля систематической
ошибки и доля дисперсии прогнозов должны быть маленькими, так что большая часть
в среднеквадратичной ошибке прогнозов была бы сконцентрирована на доле
ковариации прогнозов и фактических значений.
Значения статистик оценивания качества
прогнозирования в таблице свидетельствуют о хорошем качестве подобранной
модели. Например, значение доля систематической ошибки прогнозов равна нулю.
Это показывает, что среднее значение прогнозов полностью отслеживает среднее
значение зависимой переменной.
Значение статистики R-квадрат для нашего
“наилучшего” третьего уравнения регрессии равно 0,756, то есть почти 76%
дисперсии переменной логарифмическая продажная стоимость автомобиля объясняется
независимыми переменными, включенными в правую часть этого уравнения регрессии.
Следовательно, 24% дисперсии переменной логарифмическая продажная стоимость
автомобиля имеющимися у нас независимыми переменными не объясняется. И это
визуально отражается на графике рисунке 5.
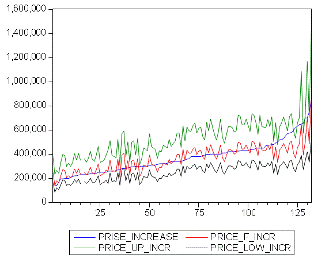
Рисунок 5. Фактические значения и точечные
прогнозные значения продажной стоимости автомобилей в рублях с верхней и нижней
границами для 95%-ых доверительных интервалов.
PRICE_INCREASE
- наблюденное значение.
PRICE _F_INCR
- предсказанное значение.
PRICE_UP_INCR
- верхняя 95% доверительная граница.
PRICE_LOW_INCR
- нижняя 95% доверительная граница.
На графике рисунка 5 верхняя и нижняя кривая
соответствуют верхним и нижним границам 95%-ых доверительных интервалов, а две
срединных кривых соответствуют значениям точечных прогнозов и фактическим
значениям продажной стоимости автомобилей в рублях, причем фактическим
значениям продажной стоимости автомобилей в рублях соответствует более гладкая
кривая. Для визуального удобства по оси абсцисс наблюдения также упорядочены по
возрастанию фактических значений продажной стоимости автомобилей в рублях.
Отметим, что все фактические
значения продажной стоимости автомобилей в руб. попадают в 95%-ые доверительных
интервалы прогнозов, за исключением четырех фактических значений с наибольшими
продажными стоимостями в рублях из 130 фактических значений.
Выводы
Проведенное исследование говорит о том, что:
. Отобранные факторы являются существенными в
формировании структуры цены предложения при продаже поддержанного автомобиля,
хотя и не определяют ее полностью.
. Наиболее точна и пригодна для анализа модель
логарифма цены.
. Существенное значение имеет анализ выбранных
данных с выделением выбросов и последующим переоцениваем модели.
. Учет выбросов существенно повышает
прогностическую силу модели.
. Достигнутая точность модели (R-squared = 0,74)
представляет автору близкой к оптимальной на рынке.
. Наблюдается гетероскедактичность остатков
регрессии (хотя и слабая в нашем случае). Этот факт следует учитывать при
расширении объёма исследования.
. В дальнейшем, следует обратить внимание так же
и на выявленную зависимость квадрата остатков от объясняемой переменной.
. Вполне практически пригодной для решения
узкого, но важного круга задач оказалась и модель простой регрессии и
непосредственно для цены автомобиля.
Эту модель я назвал утилитарной.
Список использованной литературы
1. Основы эконометрики.
Прикладная статистика. С.А. Айвазян, В.С. Мхитарян. М.: Юнити 2001.
2. Эконометрика. Начальный
курс (7-ое издание). Катышев П.К., Магнус Я.Р., Пересецкий А. А. М.:Дело, 2005.
. Путеводитель по
современной эконометрике. Вербик М. Пер. с англ. В.А. Банников. Научн. ред. и
предисл. С.А. Айвазян. - М.: Научная книга, 2008."Библиотека Солев".
4. http://www.gks.ru/
5. http://www.uaz.ru/