Разработка рекомендаций по совершенствованию модели безопасности компьютерной системы
Содержание
Введение
. Общая модель безопасного обмена информацией
.1 Основы криптологии
.2 Оценка надежности криптоалгоритмов
.3 Классификация методов шифрования информации
.4 Абсолютно стойкий шифр
.5 Задача аутентификации информации
.6 Защита от случайных искажений
.7 Контроль целостности с использованием криптографических
методов
.8 Выводы
. Определение вероятностных характеристик двоичного канала
.1 Постановка задачи
.2 Основные понятия помехоустойчивого кодирования
.3 Вероятностные характеристики при полностью известном
сигнале
.4 Прием сигналов с неопределенной фазой
.5 Выводы
. Оценка качества приема кодограмм со стиранием
.1 Оценка оптимального когерентного приема
.2 Оценка оптимального некогерентного приема
.3 Выводы
Заключение
Список используемых источников
Введение
Несанкционированный доступ к информации в компьютерных сетях превратился
сегодня в одну из серьезнейших проблем, стоящих на пути развития
телекоммуникационной среды и информационной инфраструктуры общества. Страны,
где вычислительные системы и компьютерные сети проникли во все сферы
человеческой деятельности, особенно страдают от последствий компьютерных
злоупотреблений.
В России, с развитием информационных технологий и общественных сетей
передачи данных, тоже начинает ощущаться важность создания и развития надежных
средств обеспечения информационной безопасности.
Обеспечение информационной безопасности в закрытых компьютерных системах
успешно разрабатываются на протяжении значительного периода времени.
Обеспечение безопасности в открытых компьютерных сетях, таких, как
Internet, не имеет долгой истории и мощной исследовательской базы. Отсутствие
некоторых обязательных требований к безопасности систем (которые присущи
закрытым компьютерным системам, обрабатывающим государственную конфиденциальную
информацию), компромиссный характер решений задач безопасности в открытых
сетях, вызванный функциональными требованиями к ним, разнообразие программного
обеспечения - все эти причины привели к отсутствию единой методологии решения
задач обеспечения безопасности в открытых компьютерных сетях.
Важнейшей характеристикой любой компьютерной системы независимо от ее
сложности и назначения становится безопасность циркулирующей в ней информации.
В первую очередь это объясняется все ускоряющимися темпами научно-технического
прогресса, результатом которого являются все более совершенные компьютерные
технологии. Их появление не только ставит новые проблемы обеспечения
безопасности, но и представляет, казалось бы, уже решенные вопросы в совершенно
новом ракурсе [3, 12]. Как отмечается в [4, 10, 16, 17], трудоемкости решения
задачи защиты информации также способствуют:
увеличение объемов информации, накапливаемой, хранимой и обрабатываемой с
помощью компьютерной техники;
сосредоточение в единых базах данных информации различного назначения и
принадлежности;
расширение круга пользователей, имеющих доступ к ресурсам компьютерной
системы и находящимся в ней массивам данных;
усложнение режимов функционирования технических средств компьютерной
системы;
увеличение количества технических средств и связей в АСОД;
наличие различных стилей программирования, появление новых технологий
программирования, затрудняющих оценку, качества используемых программных
продуктов.
Развивающиеся быстрыми темпами компьютерные технологии вносят большие
изменения в нашу жизнь. Информация - товар, который можно приобрести, продать,
обменять, а ее стоимость часто в сотни раз превосходит стоимость компьютерной
системы, в которой она хранится.
От степени безопасности информационных технологий в настоящее время
зависит благополучие, а порой и жизнь многих людей. Это плата за усложнение и
повсеместное распространение автоматизированных систем обработки информации.
Информационной безопасности в наше время уделяется очень большое
внимание. Создана большая нормативно-теоретическая база, формальные
математические методы которой обосновывают большинство понятий,
форулировавшихся ранее лишь с помощью словесных описаний. При этом разработчики
систем безопасности, реализующих различные способы и методы противодействия
угрозам информации, стараются максимально облегчить работу по администрированию
безопасности. Для этого большинством информационных систем используются
стандартные подходы, ставшие результатом накопления разработчиками систем
защиты опыта создания и эксплуатации подобных систем.
Целью создания любой системы безопасности является предупреждение
последствий умышленных (преднамеренных) и случайных деструктивных воздействий,
следствием которых могут быть разрушение, модификация или утечка информации, а
также дезинформация [10, 15]. В том случае, если объект атаки противника -
какой-то из компонентов системы (аппаратные средства или ПО), можно говорить о
прерывании, когда компонент системы становится недоступен, теряет
работоспособность или попросту утрачивается в результате обычной кражи;
перехвате и/или модификации, когда противник получает доступ к компоненту и/или
возможность манипулировать им; подделке, когда противнику удается добавить в
систему некий компонент или процесс (разрушающее программное воздействие),
файлы или записи в них [4]. Эффективная система безопасности должна
обеспечивать [10]:
секретность всей информации или наиболее важной ее части;
достоверность (полноту, точность, адекватность, целостность,
аутентичность) информации, работоспособность компонентов системы в любой момент
времени;
своевременный доступ пользователей к необходимой им информации и ресурсам
системы;
защиту авторских прав, прав собственников информации, возможностъ
разрешения конфликтов;
разграничение ответственности за нарушение установленных правил
информационных отношений;
оперативный контроль за процессами управления, обработки и обмена
информацией, так называемые средства контроля безопасности.
В рамках данной выпускной квалификационной работы будут проведены исследования,
посвященные разработке рекомендаций для механизмов защиты компьютерной системы.
Актуальность темы в современных условиях нельзя недооценить. Во-первых, с
развитием технологий повышается риск нарушения конфиденциальности информации.
Во-вторых, исходя из первого пункта, можно с уверенностью сказать, что модели
безопасности компьютерных систем требуют постоянных усовершенствований и
разработки рекомендаций, на основе актуальных на данный момент угроз.
Объектом исследования представленной выпускной квалификационной работы
является модель безопасности компьютерной системы.
Предметом исследования - совершенствование модели безопасности
компьютерной системы.
Цель работы - разработка рекомендаций по совершенствованию модели
безопасности компьютерной системы.
Достижению поставленной цели сопутствует практическое и теоретическое
решение, отраженное в содержании данной выпускной квалификационной работы,
следующих задач:
рассмотреть общую модель безопасного обмена информацией;
выявить вероятностные характеристики двоичного канала;
проанализировать прием кодограмм со стиранием;
разработать рекомендации по совершенствованию модели безопасности.
Работа состоит из введения, трех глав, заключения и списка литературы.
Введение содержит объект, предмет, цель и задачи исследования, а так же
обосновывает актуальность и практическое значение данной проблемы.
Первая глава раскрывает общую модель безопасного обмена информацией.
Рассматриваются основные теоретические вопросы надежности криптоалгоритма,
классификации методов шифрования и контроля целостности данных.
Во второй главе рассмотрены вопросы определения вероятностных
характеристик двоичного канала.
В третьей главе оценивается прием кодограмм со стиранием и рекомендации
по совершенствованию модели безопасности.
Заключение содержит основные выводы и подводит итог проделанной работы.
1. Общая
модель безопасного обмена информацией
1.1 Основы
криптологии
Основной целью криптографической защиты или криптографического закрытия
информации является защита от утечки информации, которая обеспечивается путем
обратимого однозначного преобразования сообщений или хранящихся данных в форму,
непонятную для посторонних, или неавторизованных лиц. Преобразование,
обеспечивающее криптозащиту, называется шифрованием. Защита от модификации
информации и навязывания ложных данных, т.е. имитозащита, обеспечивается
выработкой имитоприставки. Последняя представляет собой информационную
последовательность, полученную по определенным правилам из открытых данных и
ключа.
Исходным объектом является текст как упорядоченный набор из элементов
алфавита, представляющего конечное множество используемых для шифрования
информации знаков. Криптоалгоритмом или шифром является совокупность обратимых
преобразований множества открытых данных на множество зашифрованных данных,
заданных алгоритмом криптографического преобразования [7, 12].
Криптосистема состоит из пространства ключей, пространства открытых
текстов, пространства шифротекстов и алгоритмов зашифрования и расшифрования.
Раскрытие криптоалгоритма является результатом работы криптоаналитика,
приводящий к возможности эффективного определения любого зашифрованного с
помощью данного алгоритма открытого текста. Способность шифра противостоять
всевозможным попыткам его раскрытия, т.е. атакам на него определяет стойкость
криптоалгоритма.
1.2 Оценка
надежности криптоалгоритмов
Все современные шифры базируются на принципе Кирхгофа, согласно которому
секретность шифра обеспечивается секретностью ключа, а не секретностью
алгоритма шифрования. В некоторых ситуациях (например, в военных,
разведывательных и дипломатических ведомствах) нет никаких причин делать
общедоступным описание сути криптосистемы. Сохраняя такую информацию в тайне,
можно дополнительно повысить надежность шифра. Однако полагаться на секретность
этой информации не следует, так как рано или поздно она будет
скомпрометирована. Поэтому анализ надежности таких систем всегда должен
проводиться исходя из того, что противник имеет всю информацию о применяемом
криптоалгоритме, ему неизвестен только реально использованный ключ [6]. В связи
с вышеизложенным можно сформулировать общее правило: при создании или при
анализе стойкости криптосистем не следует недооценивать возможности противника.
Их лучше переоценить, чем недооценить.
Стойкость криптосистемы зависит от сложности алгоритмов преобразования,
длины ключа, а точнее, от объема ключевого пространство, метода реализации: при
программной реализации необходимо дополнительно защищаться от разрушающих
программных воздействий - закладок, вирусов и т. п. Хотя понятие стойкости
шифра является центральным в криптографии, количественная оценка
криптостойкости - проблема до сих пор нерешенная.
Методы оценки качества криптоалгоритмов, используемые на практике [7, 9]:
) всевозможные попытки их вскрытия;
) анализ сложности алгоритма дешифрования;
З) оценка статистической безопасности шифра.
В первом случае многое зависит от квалификации, опыта, интуиции
криптоаналитика и от правильной оценки возможностей противника. Обычно
считается, что противник знает шифр, имеет возможность его изучения, знает
некоторые характеристики открытых защищаемых данных, например тематику
сообщений, их стиль, стандарты, форматы и т.п. В [7] приводятся следующие
примеры возможностей противника:
противник может перехватывать все зашифрованные сообщения, но не имеет
соответствующих им открытых текстов;
противник может перехватывать все зашифрованные сообщения и добывать
соответствующие им открытые тексты;
противник имеет доступ к шифру (но не ключам) и поэтому может
зашифровывать и расшифровывать любую информацию.
Во втором случае оценку стойкости шифра заменяют оценкой минимальной
сложности алгоритма его вскрытия. Однако получить строго доказуемые оценки
нижней границы сложности алгоритмов рассматриваемого типа не представляется
возможным. Иными словами, всегда возможна ситуация, когда алгоритм вскрытия
шифра, сложность которого анализируется, оказывается вовсе не самым
эффективным.
Сложность вычислительных алгоритмов можно оценивать числом выполняемых
элементарных операций, при этом, естественно, необходимо учитывать их стоимость
и затраты на их выполнение. В общем случае то число должно иметь строгую нижнюю
оценку и выходить за пределы возможностей современных компьютерных систем.
Качественный шифр невозможно раскрыть способом более эффективным чем полный
перебор по всему ключевому пространству, при этом криптограф должен
рассчитывать только на то, что у противника не хватит времени и ресурсов, чтобы
это сделать.
Алгоритм полного перебора по всему ключевому пространству - это пример
так называемого экспоненциального алгоритма. Если сложность алгоритма
выражается неким многочленом (полиномом) от n, где п число элементарных операций, такой
алгоритм носит название полиномиального. Пример полиномиального алгоритма -
алгоритм умножения столбиком двух п -разрядных двоичных чисел, требующий
выполнения п2 элементарных, битовых, операций умножения [7].
В третьем случае считается, что надежная криптосистема с точки зрения
противника является «черным ящиком», входная и выходная информационные
последовательности которого взаимно независимы, при этом выходная зашифрованная
последовательность является псевдослучайной. Поэтому смысл испытаний
заключается в проведении статистических тестов, устанавливающих зависимости
изменений в зашифрованном тексте от изменений символов или битов в исходном
тексте или ключе, а также анализирующих, насколько выходная зашифрованная
последовательность по своим статистическим свойствам приближается к истинно
случайной последовательности. Случайность текста шифровки можно приближенно оценивать
степенью ее сжатия при использовании алгоритма Лемпела-Зива, применяемого в
архиваторах IВМ РС. Как отмечается в [9], если
степень сжатия больше 10% криптосистема несостоятельна.
Необходимые условия стойкости криптосистемы, проверяемые
статистическими методами:
отсутствие статистической зависимости между входной и выходной
последовательностями
выходная последовательность по своим статистическим свойствам должна быть
похожа на истинно случайную последовательность;
при неизменной входной информационной последовательности незначительное
изменение ключа должно приводить к существенному изменению выходной
последовательности;
при неизменном ключе незначительное изменение входной последовательности
должно приводить к существенному изменению выходной последовательности;
отсутствие зависимости между ключами, последовательно используемыми в
процессе шифрования.
В каждой конкретной ситуации выбор криптоалгоритма определяется
следующими факторами:
особенностью защищаемой информации;
особенностями среды хранения или передачи информации;
ценностью информации, характером защищаемых секретов, временем
обеспечения секретности;
объемами информации, скоростью ее передачи, степенью оперативности ее
предоставления пользователю;
возможностями собственников информации, владельцев средств сбора,
обработки, хранения и передачи информации по ее защите;
характером угроз, возможностями противника.
1.3
Классификация методов шифрования информации
На рисунке 1.1 показаны основные объекты изучения классической
криптографии, где А и В - законные пользователи, W - противник или криптоаналитик.
Учитывая, что схема на рисунке 1.1,а фактически является частным случаем схемы
на рисунке 1.1,б при В=А, в дальнейшем будет рассматриваться
только она.
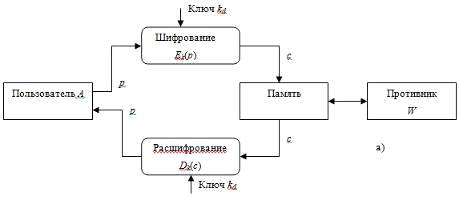
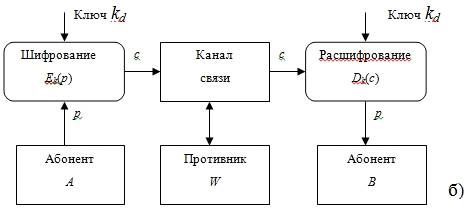
Рисунок 1.1
Процедуры зашифрования (encryption) и расшифрования (decryption) можно представить в следующем виде:
с=Ek(p);
p=Dk(c);
где p и с - открытый (р1аintеxt) и зашифрованный (сiрhertext) тексты,
ke и
kd - ключи зашифрования и расшифрования;
Ek и Dk функции зашифрования с ключом ke и расшифрования с ключом kd соответственно, причем для любого
открытого текста p справедливо
Dk(Ek(p))=p.
На рисунке 1.2 приведена классификация методов шифрования информации.
Различают два типа алгоритмов шифрования: симметричные (с секретным ключом) и
асимметричные (с открытым ключом). В первом случае обычно ключ расшифрования
совпадает с ключом зашифрования, т.е.
ke=kd=k
либо знание ключа зашифрования позволяет легко вычислить ключ расшифрования.
В асимметричных алгоритмах такая возможность отсутствует: для зашифрования и
расшифрования используются разные ключи, причем знание одного из них не дает
практической возможности определить другой. Поэтому, если получатель В информации
сохраняет в секрете ключ расшифрования, ключ зашифрования может быть сделан
общедоступным.
В процессе шифрования информация делится на порции величиной от одного до
сотен бит. Как правило, поточные шифры оперируют с битами открытого и закрытого
текстов, а блочные - с блоками фиксированной длины. Но главное отличие между
этими двумя методами заключается в том, что в блочных шифрах для шифрования
всех порций используется один и тот же ключ, а в поточных - для каждой порции
используется свой ключ той же размерности. Иначе говоря, в поточных шифрах
имеет место зависимость результата шифрования порции информации от ее позиции в
тексте, а в некоторых случаях и от результатов шифрования предыдущих порций
текста. Таким образом, при реализации поточной криптосистемы возникает
необходимость в элементах памяти, изменяя состояние которых можно вырабатывать
последовательность (поток) ключевой информации. Блочную же криптосистему можно
рассматривать как зависящую от ключа.
1.4
Абсолютно стойкий шифр
Простейшей и в то же время наиболее надежной изо всех схем шифрования
является так называемая схема однократного использования, изобретение которой
чаще всего связывают с именем Г.С. Вернама [13]. Формируется m-разрядная случайная двоичная
последовательность - ключ шифра, известный отправителю и получателю сообщения.
Отправитель производит побитовое сложение по модулю 2 ключа и m-разрядной двоичной
последовательности, соответствующей передаваемому сообщению
сi=piki, i=1,…,
m.
где pi, ki и сi -
очередной i-й бит соответственно исходного
сообщения, ключа и зашифрованного сообщения, m - число бит исходного текста. Процесс расшифрования
сводится к повторной генерации ключевой последовательности и наложению ее на
зашифрованные данные. Уравнение расшифрования имеет вид
pi=ciÅki, i=1,…, m.
К. Шенноном доказано, что если ключ является фрагментом истинно случайной
двоичной последовательности с равномерным законом распределения, причем длина
ключа равна длине исходного сообщения и используется этот ключ только один раз,
после чего уничтожается, такой шифр является абсолютно стойким, его невозможно
раскрыть, даже если криптоаналитик располагает неограниченным запасом времени и
неограниченным набором вычислительных ресурсов. Противнику известно только
зашифрованное сообщение, при этом все различные ключевые последовательности
возможны и равновероятны, а значит, возможны и любые сообщения, т.е.
криптоалгоритм не дает никакой информации об открытом тексте.
Целью противника может являться раскрытие криптосистемы, нахождение
ключа, в крайнем случае дешифрование какого-либо закрытого сообщения. По К.
Шеннону, в совершенно секретных криптосистемах после анализа закрытых текстов
апостериорные вероятности возможных открытых текстов остаются такими же, какими
были их априорные вероятности [6].
Необходимые и достаточные условия абсолютной стойкости шифра:
полная случайность ключа;
равенство длин ключа и открытого текста;
однократное использование ключа.
Абсолютная стойкость рассмотренной схемы оплачивается слишком большой
ценой: она чрезвычайно дорогая и непрактичная. Основной ее недостаток - это
равенство объема ключевой информации и суммарного объема передаваемых
сообщений. Существует большое число модификаций представленной схемы, наиболее
известная из которых основана на использовании одноразовых шифровальных
блокнотов.
Таким образом, построить эффективный криптоалгоритм можно, лишь
отказавшись от абсолютной стойкости. Возникает задача разработки такого
теоретически нестойкого шифра, для вскрытия которого противнику потребовалось
бы выполнить такое число операций, которое неосуществимо на современных и
ожидаемых в ближайшей перспективе вычислительных средствах за разумное время. В
первую очередь представляет интерес схема, использующая ключ небольшой
разрядности, который в дальнейшем выполняет функцию «зародыша», порождающего
значительно более длинную ключевую последовательность - генератора
псевдослучайных кодов. Последовательность называется псевдослучайной, если по
своим статистическим свойствам она неотличима от истинно случайной
последовательности, но в отличие от последней является детерминированной, т.е.
знание алгоритма ее формирования дает возможность ее повторения необходимое
число раз [12]. В общем случае символы исходного алфавита в цифровом виде и
символы гаммы складываются по модулю числа элементов алфавита. Возможно
использование при гаммировании и других логических операций.
1.5 Задача
аутентификации информации
Задача аутентификации обрабатываемых массивов данных позволяет
потребителю обеспечить гарантии, во-первых, целостности информации и,
во-вторых, ее авторства. Можно предположить, что задачу аутентификации можно
решить обычным шифрованием. Искажения, внесенные в зашифрованные данные,
становятся очевидными после расшифрования только в случае большой избыточности
исходных данных. В общем случае требование избыточности данных может не
выполняться, а это означает, что после расшифрования модифицированных данных
они по-прежнему могут поддаваться интерпретации. Таким образом, свойства
секретности и подлинности информации в общем случае могут не совпадать. При
использовании симметричной криптосистемы факт успешного расшифрования данных,
зашифрованных на секретном ключе, может подтвердить их авторство лишь для
самого получателя. Третий участник информационного обмена, арбитр, при
возникновении споров не сможет сделать однозначного вывода об авторстве
информационного массива, так как его автором может быть каждый из обладателей
секретного ключа, а их как минимум, двое.
Необходим контроль целостности потока сообщений. На всех этапах своего
жизненного цикла информация может подвергаться случайным и умышленным
разрушающим воздействиям. Для обнаружения случайных искажений информации
применяются корректирующие коды, которые в некоторых случаях позволяют не
только зафиксировать факт наличия искажений информации, но и локализовать и
исправить эти искажения. Умышленные деструктивные воздействия чаще всего имеют
место при хранении информации в памяти компьютера и при ее передаче по каналам
связи. При этом полностью исключить возможность несанкционированных изменений в
массивах данных не представляется возможным. Крайне важно оперативно обнаружить
такие изменения, так как в этом случае ущерб, нанесенный законным
пользователям, будет минимальным. Целью противника, навязывающего ложную
информацию, является выдача ее за подлинную, поэтому своевременная фиксация
факта наличия искажений в массиве данных сводит на нет все усилия
злоумышленника. Следовательно, под имиттозащитой понимают не исключение
возможности несанкционированных изменений информации, а совокупность методов,
позволяющих достоверно зафиксировать их факты, если они имели место.
Для обнаружения искажений в распоряжении законного пользователя должна
быть некоторая процедура проверки T(p), дающая на выходе 1, если в массиве
данных p отсутствуют искажения, или 0, если
такие искажения имеют место. Для ограничения возможностей противника по подбору
информационной последовательности p¢, p¢¹ p, такой, что T(p¢)=1, идеальная процедура такой проверки должна обладать
следующими свойствами:
невозможность найти такое сообщение p¢ способом более эффективным, чем
полный перебор по множеству допустимых значений p;
вероятность успешно пройти проверку у случайно выбранного сообщения p¢ не должна превышать заранее
установленного значения.
Вследствие того, что в общем случае все возможные значения p могут являться допустимыми, второе
требование требует внесения избыточности в защищаемый массив данных. При этом
чем больше разница N
между размером преобразованного избыточного p* и размером исходного массивов p, тем меньше вероятность принять
искаженные данные за подлинные. Она составляет величину 2-N.
Варианты внесения избыточности с использованием шифрования (рисунок 1.2),
с формированием контрольного кода (рисунок 1.3) и с формированием контрольного
кода и зашифрованием (рисунок 1.4) схематично показаны на рисунке 1.2-1.4.

Рисунок 1.2

Рисунок 1.3

Рисунок 1.4
В роли неповторяющегося блока данных nrb может выступать метка времени, порядковый номер
сообщения и т.п. В роли контрольного кода могут выступать имитоприставка или
электронная подпись. Имитоприставкой называют контрольный код, который
формируется и проверяется с помощью одного и того же секретного ключа.
Использование блока nrb
позволяет контролировать целостность потока сообщений, защищая от повтора,
задержки, переупорядочения или их утраты. Целостность потока сообщений можно
также контролировать, используя зашифрование со сцеплением сообщений.
Самый естественный способ преобразования информации с внесением избыточности
- это добавление к исходным данным контрольного кода s фиксированной разрядности N, вычисляемого как некоторая функция
от этих данных
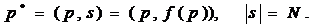
Выделение
исходных данных из преобразованного массива p* является
простым отбрасыванием контрольного кода s. Проверка
целостности заключается в вычислении для содержательной части p*
полученного массива данных контрольного кода s=f(p)
и сравнения его с переданным значением s. Если они
совпадают, сообщение считается подлинным, в противном случае - ложным:
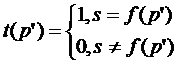
Функция
f формирования контрольного кода должна удовлетворять
следующим требованиям:
она
должна быть вычислительно необратимой;
у
противника должна отсутствовать возможность сформировать ложный массив данных с
корректно вычисленным контрольным кодом.
Второе
свойство можно обеспечить двумя способами: либо сделать функцию f
зависимой от некоторого секретного параметра (ключа), либо пересылать
контрольный код отдельно от защищаемых данных. Простейшим примером кода s
является контрольная сумма блоков массива данных, однако такое преобразование
непригодно для имитозащиты, т.к. контрольная сумма не зависит от взаимного
расположения блоков.
1.6 Защита
от случайных искажений
Основным средством защиты информации от случайных искажений являются
помехоустойчивые коды. Наиболее ярким представителем являются CRC- коды (cyclic redundancy code). Циклические коды обладают рядом достоинств:
высокая достоверность обнаружения искажений;
зависимость контрольного кода не только от всех бит анализируемой
информационной последовательности, но и от их взаимного расположения;
высокое быстродействие, связанное с получением контрольного кода в
реальном масштабе времени;
простота аппаратной реализации и удобство интегрального исполнения;
простота программной реализации.
Циклический код гарантирует обнаружение либо исправление ошибок заданной
степени кратности. Если кратность ошибок превышает заданное значение, то
применяемый код может их не обнаружить, что делает непригодным для защиты от
умышленных искажений информации.
Контроль целостности осуществляется с помощью генератора CRC -кода, построенного на основе
регистра сдвига с обратными связями, реализованными в соответствии с
характеристическим многочленом. Исходное состояние ячеек памяти регистра
выбирается нулевым. Анализируемая двоичная последовательность преобразуется в
короткий (обычно в 16- или 32-разрядный) двоичный код - CRC -код. Значение полученного CRC -кода сравнивается с эталонным
значением, полученным заранее для последовательности без искажений. По
результатам сравнения делается вывод о наличии или отсутствии искажений в
анализируемой последовательности.
Рассмотрим
схему генератора CRC-кода с характеристическим многочленом  . Под регистром сдвига понимают электронную схему,
позволяющую вырабатывать последовательность, определенную линейным рекуррентным
уравнением [16]. Физическая реализация электронной схемы составляется из двух
элементов. Один из этих элементов называют сумматором, второй - задержкой или
ячейкой памяти (рисунок 1.5)
. Под регистром сдвига понимают электронную схему,
позволяющую вырабатывать последовательность, определенную линейным рекуррентным
уравнением [16]. Физическая реализация электронной схемы составляется из двух
элементов. Один из этих элементов называют сумматором, второй - задержкой или
ячейкой памяти (рисунок 1.5)

Рисунок 1.5
Сумматор имеет два входа и один выход. Если на оба входа сумматора
подаются одинаковые сигналы (0 и 0 или 1 и 1), то на выход подается 0; если на
входы подаются разные сигналы (0 и 1 или 1 и 0), то на выход передается 1.
Таким образом, сумматор реализует двоичную функцию - сумму по модулю 2.
Задержка имеет один вход и один выход. Ячейка памяти работает по тактовым
импульсам: она запоминает информацию, поступающую на ее вход, на выход ячейки
поступает информация, задержанная на один такт (предшествующее состояние
ячейки).
Самыми простыми схемами, используемыми в качестве базовых при построении
других, более стойких, поточных шифров, являются линейные регистры сдвига
(ЛРС), представляющие из себя несколько (от 20 до 100) ячеек памяти, в каждой
из которых может храниться один бит информации. Совокупность бит, находящихся в
данный момент в ЛРС, называется его состоянием. Для выработки очередного бита
циркулирующей последовательности, т.е. гаммы, ЛРС при поступлении тактового
импульса производит один цикл преобразований, называемый тактом. Схематично
линейный регистр сдвига показан на рисунке 1.6.
Рисунок 1.6
Число бит, охваченных в ЛРС обратной связью, называется его разрядностью.
На вход генератора поступает анализируемая двоичная последовательность длиной m
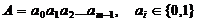
Ее
можно представить в полиномиальном виде
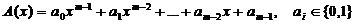
Тогда
процесс получения CRC-кода эквивалентен делению входного многочлена A(x)
на характеристический многочлен генератора CRC-кода j(x). Если
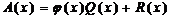 ,
,
где
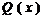 и
и 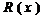 -
соответственно частное и остаток, то коэффициенты многочлена появляются на выходе регистра, а коэффициенты
многочлена остаются в регистре генератора после прохождения всей
последовательности A. Иначе говоря, CRC-код s
в точности равен коду остатка R, т.е. s(x)=R(x).
-
соответственно частное и остаток, то коэффициенты многочлена появляются на выходе регистра, а коэффициенты
многочлена остаются в регистре генератора после прохождения всей
последовательности A. Иначе говоря, CRC-код s
в точности равен коду остатка R, т.е. s(x)=R(x).
Состояние
ячейки на каждом такте зависит входной последовательности и от номера данного
такта в общей процедуре контроля. Пример работы ЛРС, показанного на рисунке
1.5, при входной кодограмме «100110101111000» и установке исходного состояния
«0000» представлен в таблице 1.1
Таблица
1.1
|
№ такта
|
Вход
|
Яч 1
|
Яч 2
|
Яч 3
|
Яч 4
|
Выход
|
|
|
0
|
0
|
0
|
0
|
|
|
1
|
1
|
1
|
0
|
0
|
0
|
0
|
|
2
|
0
|
0
|
1
|
0
|
0
|
0
|
|
3
|
0
|
0
|
0
|
1
|
0
|
0
|
|
4
|
1
|
0
|
0
|
0
|
1
|
0
|
|
5
|
1
|
0
|
0
|
0
|
0
|
1
|
|
6
|
0
|
0
|
0
|
0
|
0
|
0
|
|
7
|
1
|
1
|
0
|
0
|
0
|
0
|
|
8
|
0
|
0
|
1
|
0
|
0
|
0
|
|
9
|
1
|
1
|
0
|
1
|
0
|
0
|
|
10
|
1
|
0
|
1
|
0
|
1
|
0
|
|
11
|
1
|
0
|
0
|
1
|
0
|
1
|
|
12
|
1
|
0
|
0
|
0
|
1
|
0
|
|
13
|
0
|
1
|
0
|
0
|
0
|
1
|
|
14
|
0
|
0
|
1
|
0
|
0
|
0
|
|
15
|
0
|
0
|
0
|
1
|
0
|
0
|
Поскольку состояние ячеек ненулевое, то в кодограмме имеются ошибки.
Для CRC-генератора справедлив принцип
суперпозиции: реакция линейного устройства на сумму двух входных воздействий
равна сумме реакций на каждое входное воздействие в отдельности. Входную
последовательность можно представить суммой по модулю 2 разрешенной
последовательности B
и вектора ошибки e:
A=B+e.
Применяя принцип суперпозиции, получим равенство
sA=sB+se.
Таким образом, необходимым и достаточным условием пропуска искажений является
равенство se=0, которое имеет место тогда и
только тогда, когда многочлен e(x) нацело делится на многочлен j(x).
Пусть N -
разрядность CRC-кода и e¹0, т.е. в анализируемой
последовательности длиной m
есть искажения. Рассмотрим достоверность метода, т.е. условия, при которых se=0. При m=N+1,
когда степень многочлена e(x) меньше либо равна N, существует только один многочлен e(x), нацело делящийся на многочлен j(x), это e(x)=j(x),
а значит в этом случае Ne=1.
При m=N+2 существует уже 3 многочлена e(x) степени меньшей или равной N+1 нацело делящиеся на многочлен j(x), это e(x)=j(x),
e(x)=j(x)×x, e(x)=j(x)×(x+1), а значит Ne=3. В общем случае при m>N
справедливо
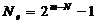 .
.
Учитывая,
что общее число искажений в последовательности длиной m
равно 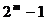 , для доли обнаруживаемых искажений Pd
получаем соотношение
, для доли обнаруживаемых искажений Pd
получаем соотношение
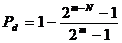
На
практике m>>N, 2m>>1,
2m-N>>1. Тогда
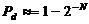 (при N=16
Pd=0,99998).
(при N=16
Pd=0,99998).
Таким
образом, доля обнаруживаемых искажений не зависит от длины анализируемой
последовательности, а определяется лишь разрядностью контрольного кода.
1.7
Контроль целостности с использованием криптографических методов
Можно выделить два основных криптографических подхода к решению задачи
защиты информации от несанкционированных изменений данных:
формирование с помощью функции зашифрования Ek блочного шифра кода аутентификации сообщений - MAC (Message Authentification Code);
формирование с помощью необратимой функции сжатия h(x) (хеш-функции) информации кода обнаружения
манипуляций с данными - MDC
(Manipulation Detection Code).
Код аутентификации сообщений (MAC) используется для защиты при передаче данных с
использованием секретного ключа, что требует предварительного распределения
ключей. Контрольный код хранится вместе с защищаемыми данными и у противника
отсутствует возможность его вычисления.
Имитоприставка ГОСТ 28147-89 является классическим примером кода MAC. Код аутентификации может
формироваться в режимах сцепления блоков шифротекста CBC (Ciphertext Block Chaining) или обратной связи по шифротексту CBF (Ciphertext Feedback), обеспечивающих зависимость
последнего блока шифротекста от всех блоков открытого текста. В случае
использования преобразования Ek
для выработки контрольного текста требования к нему несколько отличаются от
требований при его использовании для зашифрования поскольку не требуется
свойство обратимости, а также криптостойкость может быть снижена, например, за
счет уменьшения числа раундов шифрования. В случае выработки кода MAC преобразование всегда выполняется в
одну сторону, при этом в распоряжении противника есть только зависящий от всех
блоков открытого текста контрольный код, в то время как при зашифровании у него
имеется набор блоков шифротекста, полученных с использованием одного секретного
ключа. Схема алгоритма формирования MAC показана на рисунке 1.7.

Рисунок 1.7
Код обнаружения манипуляций с данными - MDC используется при разовой передаче данных для контроля
целостности хранимой информации. Поскольку контрольный код передается отдельно
от защищаемых данных, необходим аутентичный канал для его передачи. Поскольку
секретной информации нет, то у противника имеется возможность вычисления
контрольного кода.
MDC
есть результат действия хеш-функции. Иначе говоря, MDC это хеш-образ сообщения p, к которому применили хеш-функцию, т.е. s=h(p).
Основное требование к хеш-функции состоит в том, чтобы не существовало способа
определения массива данных p,
имеющего заданное значение хеш-образа h(p),
отличного от перебора по всему множеству возможных значений p. Наиболее простой способ построения
хеш-функции основан на использовании вычислительной необратимости относительно
ключа k функции зашифрования Ek любого блочного шифра. Даже при
известных блоках открытого p и
закрытого текстов c=
Ek (p) ключ k не может быть определен иначе, как перебором по множеству всех возможных
значений. Таким образом, схема формирования хеш-образа сообщения p, обладающая гарантированной
стойкостью, равной стойкости используемого шифра, может быть следующей:
) массив данных p
разбивается на блоки фиксированного размера, равного размеру ключа çk÷ используемого блочного шифра, т.е.
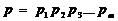 ,
,
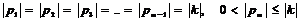 ;
;
2) если последний блок pm неполный, он дополняется каким-либо образом до нужного размера çk÷;
) хеш-образ сообщения вычисляется по алгоритму
 ,
,
где
s0 - синхропосылка, обычно выбирают s0=0.
Задача
подбора массива данных
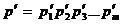
под
заданный контрольный код s эквивалентна системе уравнений, которую необходимо
решить для определения ключа для заданных блоков открытого и закрытого (в
режиме простой замены) сообщений. Однако в рассматриваемой ситуации нет
необходимости решать всю систему
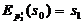 ,
, 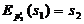 , …,
, …, 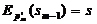 ;
;
достаточно
решить только одно уравнение
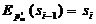
относительно
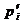 , остальные блоки массива могут быть произвольными. Но
и эта задача в случае использования надежной функции Ek
вычислительно неразрешима.
, остальные блоки массива могут быть произвольными. Но
и эта задача в случае использования надежной функции Ek
вычислительно неразрешима.
Приведенная
схема формирования MDC не учитывает наличия так называемых побочных ключей
шифра. Если для 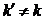 имеет место равенство
имеет место равенство
 ,
,
где
pi - некоторый блок открытого текста, то такой код k и
является побочным ключом, т.е. ключом, дающим при зашифровании блока pi
точно такой же результат, что и истинный ключ k.
Обнаружение противником побочного ключа при дешифровании сообщения не является
особым успехом, так как на этом найденном побочном ключе он не сможет правильно
расшифровать другие блоки закрытого текста, учитывая, что для различных блоков
побочные ключи в общем случае также различны. В случае выработки кода MDC
ситуация прямо противоположна: обнаружение побочного ключа означает, что
противник нашел такой ложный блок данных p¢, использование
которого не изменяет контрольного кода.
Для
уменьшения вероятности навязывания ложных данных в результате нахождения
побочных ключей при преобразовании применяются не сами блоки исходного
сообщения, а результат их расширения по некоторому алгоритму. Под расширением Ext(pi)
понимается процедура получения блока данных большего размера из блока данных
меньшего размера. Схема алгоритма формирования MDC
(хеш-образа сообщения p) представлена на рисунке 1.8.

Рисунок 1.8
1.8 Выводы
Проблема реализации методов защиты информации имеет два аспекта:
разработку средств, реализующих криптографические алгоритмы, методику
использования этих средств.
Каждый из рассмотренных криптографических методов могут быть реализованы
либо программным, либо аппаратным способом.
Возможность программной реализации обуславливается тем, что все методы
криптографического преобразования формальны и могут быть представлены в виде
конечной алгоритмической процедуры.
При аппаратной реализации все процедуры шифрования и дешифрования
выполняются специальными электронными схемами. Наибольшее распространение
получили модули, реализующие комбинированные методы. При этом непременным
компонентом всех аппаратно реализуемых методов является гаммирование. Это
объясняется тем, что метод гаммирования удачно сочетает в себе высокую
криптостойкость и простоту реализации.
Основным достоинством программных методов реализации защиты является их
гибкость, т.е. возможность быстрого изменения алгоритмов шифрования. Основным
же недостатком программной реализации является существенно меньшее
быстродействие по сравнению с аппаратными средствами (примерно в 10 раз).
В последнее время стали появляться комбинированные средства шифрования,
так называемые программно-аппаратные средства. В этом случае в компьютере
используется своеобразный “криптографический сопроцессор” - вычислительное
устройство, ориентированное на выполнение криптографических операций (сложение
по модулю, сдвиг и т.д.). Меняя программное обеспечения для такого устройства,
можно выбирать тот или иной метод шифрования. Такой метод объединяет в себе
достоинства программных и аппаратных методов.
Таким образом, выбор типа реализации криптозащиты для конкретной ИС в
существенной мере зависит от ее особенностей и должен опираться на всесторонний
анализ требований, предъявляемых к системе защиты информации.
Задача аутентификации обрабатываемых массивов данных позволяет
потребителю обеспечить гарантии целостности информации и ее авторства. Свойства
секретности и подлинности информации в общем случае могут не совпадать.
Необходим контроль целостности потока сообщений. На всех этапах своего
жизненного цикла информация может подвергаться случайным и умышленным
разрушающим воздействиям.
Для обнаружения случайных искажений информации применяются корректирующие
коды, которые в некоторых случаях позволяют не только зафиксировать факт
наличия искажений информации, но и локализовать и исправить эти искажения.
Крайне важно оперативно обнаружить такие изменения, так как в этом случае
ущерб, нанесенный законным пользователям, будет минимальным. Под имиттозащитой
понимают не исключение возможности несанкционированных изменений информации, а
совокупность методов, позволяющих достоверно зафиксировать их факты, если они
имели место. Для этого требуется внесение избыточности в защищаемый массив
данных.
2.
Определение вероятностных характеристик двоичного канала
.1
Постановка задачи
При
обмене информацией между абонентами по двоичному каналу связи восстановление
переданного сообщения осуществляется посредством поэлементного приема сигналов
и последующим анализом двоичной кодограммы. Вероятность ошибочного приема
кодограммы зависит как от вероятности ошибочного приема одиночного символа, так
и величины избыточности кодограммы. Введение в модель канала связи решения на
стирание элементарного символа уменьшает вероятность ошибки его восстановления
[11, 21]. Для оценки степени влияния стирания на вероятность ошибочного приема
кодограммы необходимо определить аналитическое выражение для вероятности ошибки
и вероятности стирания элементарного символа (0 или 1). При использовании
радиоканала информация передается на заданном интервале [0, T]
радиоимпульсами 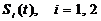 [20]
[20]
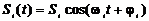 , (2.1)
, (2.1)
где
в зависимости от вида модуляции может дискретно изменяться либо амплитуда
радиоимпульса (Si), либо несущая частота (ωi),
либо начальная фаза (φi).
Затраченная энергия для каждого сигнала определяется выражением
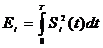 . (2.2)
. (2.2)
Качество
приема тем лучше, чем больше затраченная энергия. Обычно используют сигналы,
имеющие равные энергии E1=E2=E. Коэффициент их взаимной корреляции, определяемый
выражением
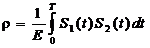 , (2.3)
, (2.3)
где
ρ=-1
при фазоманипулированных сигналах и ρ=0 при частотно-манипулированных сигналах. При
воздействии аддитивной помехи  типа
«белый шум» со спектральной плотностью мощности
типа
«белый шум» со спектральной плотностью мощности  формируется
смесь
формируется
смесь  , которая подвергается оптимальной обработке y(T),
алгоритм и схема которой определяется по критерию максимального правдоподобия
[20, 21]
, которая подвергается оптимальной обработке y(T),
алгоритм и схема которой определяется по критерию максимального правдоподобия
[20, 21]
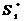
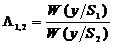
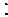
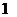 , (2.4)
, (2.4)
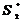
где
- 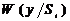 - функции правдоподобия соответствующих сигналов.
- функции правдоподобия соответствующих сигналов.
Решение
принимается в пользу наиболее вероятного сигнала. Чем больше информации
известно о входном сигнале, тем лучше качество приема. Прежде, чем определять
вероятностные характеристики в каналах со стиранием для одиночного символа при
различной степени неопределенности параметров несущего колебания, рассмотрим
основные понятия помехоустойчивого кодирования.
2.2
Основные понятия помехоустойчивого кодирования
Кодирование с исправлением ошибок основывается на использовании
избыточности [5, 8]. Под избыточностью понимается наличие в кодовой комбинации
некоторого числа проверочных (избыточных) символов, определенным образом
связанных с информационными. Проверочные символы используются для того, чтобы
подчеркнуть индивидуальность элемента сообщения. Их всегда выбирают так, чтобы
сделать маловероятной потерю элементом сообщения его индивидуальности при
воздействии помех.
Для исправления ошибок в n- разрядной двоичной кодовой
последовательности не все 2n возможных кодограмм представляют элементы
сообщения. Так, если М - объем алфавита, k=log2М -
количество информационных символов, r - количество проверочных символов, n=k+r - разрядность кодограммы
помехоустойчивого кода, то М=2k - это количество используемых
(разрешенных) для передачи кодограмм, а остальные 2n-2k неиспользуемые кодограммы
или запрещенные. В связи с этим, помехоустойчивые коды обозначаются, как
правило, как (n, k) коды. Мера эффективности помехоустойчивого
кода определяется отношением R=k/n и называется скоростью
кода. Доля избыточных символов в помехоустойчивом коде определяется как 1-R.
Для исправления ошибок достаточно определить, к какому подмножеству
относится принятая кодограмма. Исправление ошибок происходит не во всех
случаях, а только тогда, когда под действием ошибок в дискретном канале
принятая кодограмма остается в том же подмножестве, центром которой является
передаваемая кодограмма. Если же принятая кодограмма в результате ошибок
переходит в другое подмножество, то декодер примет решение в пользу другой
разрешенной кодограммы. Итак, наличие на выходе дискретного канала запрещенной
кодограммы свидетельствует об ошибках, а принадлежность ее к установленному
подмножеству позволяет ошибки исправить.
При изучении свойств помехоустойчивых кодов, как правило, используют
понятие кодового расстояния dмин. Расстояние между двумя кодограммами
(расстояние Хемминга) определяется как число разрядов, в которых эти кодограммы
отличаются друг от друга. Кодовое расстояние характеризует список разрешенных
кодограмм, и представляет минимально возможное расстояние из расстояний
Хемминга между любыми парами разрешенных кодограмм. Для примитивного кода (не
обладающего корректирующими способностями) dмин=1.
Корректирующие способности помехоустойчивого кода определяются
количеством гарантированно обнаруживаемых или исправляемых ошибок.
Для того, чтобы в коде с обнаружением ошибок одна из разрешенных
кодограмм не трансформировалась в другую, минимальное кодовое расстояние должно
быть тем больше, чем больше t - кратность обнаруживаемых ошибок.
Аналогично в случае кодов исправляющих ошибки. Кратность исправляемых ошибок
обозначим g. Установим
соотношения между dмин и t, или g. Если dмин задано, а произошло t=dмин
ошибок, то возможна трансформация одной разрешенной кодограммы в другую. При t<dмин
такой трансформации не произойдет. Поэтому связь между dмин и t
можно записать формулой
dмин³t+1. (2.5)
Если
произошло 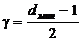 ошибок, то исправить их можно используя то
обстоятельство, что полученные кодограммы сосредоточены в одном подмножестве.
Следовательно, выражением, связывающим dмин и g, будет
ошибок, то исправить их можно используя то
обстоятельство, что полученные кодограммы сосредоточены в одном подмножестве.
Следовательно, выражением, связывающим dмин и g, будет
dмин³2g+1. (2.6)
Формулы,
устанавливающие зависимости между dмин t и , имеют
простую геометрическую интерпретацию, приведенную на рисунке 2.1:
-
запрещенные кодограммы; - разрешенные кодограммы.
Рисунок
2.1 -Геометрическая интерпретация корректирующих способностей кодов
Вероятность
появления фиксированной комбинации для n-разрядной
кодограммы из i ошибок равна p0i(1-p0)n-i.
p0 - вероятность ошибки одиночного символа. Заметим,
что при p0<0,5 выполняется неравенство
(1-p0)n>p0(1-p0)n-1>p02(1-p0)n-2>...
. (2.7)
Следовательно,
появление фиксированной одиночной ошибки более вероятно, чем фиксированной
комбинации двух ошибок, и так далее. Это значит, что декодер принимает решение
в пользу ближайшей по расстоянию Хемминга разрешенной кодограммы, вероятность
передачи которой максимальна. Декодер, реализующий это правило декодирования,
является декодером максимального правдоподобия, и в указанных предположениях он
минимизирует вероятность ошибок декодирования принятой кодограммы [22]. В этом
смысле такой декодер является оптимальным.
Процесс
выбора решения может быть описан математически при помощи таблицы декодирования
(см. таблицу 1.1). Разрешенные кодограммы образуют первую строку этой таблицы.
Решения об ошибке, принимаемые декодером, задаются перечнем запрещенных
кодограмм, которые приведены под разрешенными кодограммами. Они перечисляются в
порядке возрастания кратности ошибки. Характеристикой ошибок, описанных в
таблице 1, может служить вектор ошибок е, записываемый в виде двоичной
последовательности той же разрядности, что и кодовые комбинации, и единицы
которой показывают позиции, на которых произошла ошибка.
Предположим,
что в качестве разрешенных кодограмм для передачи восьми элементов сообщения
выбраны:
B1 - 00000; B2
- 00111; B3 - 01001; B4 - 01110.
B5 - 10010; B6
- 10101; B7 - 11011; B8 - 11100.
В
примере dмин=2, что позволяет гарантированно обнаруживать однократные
ошибки.
Таблица
1 - Таблица декодирования
00000
00111 01001 01110 10010 10101 11011 11100
00110
01000 01111 10011 10100 11010 11101
00101
01011 01100 10000 10111 11001 11110
00011
01101 01010 10110 10001 11111 11000
01111
00001 00110 11010 11101 10011 10100
10111
11001 11110 00010 00101 01011 01100
00100 01010 01101 10001 10110 11000 11111
Составим
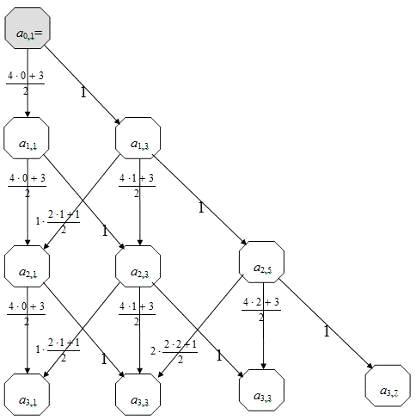
таблицу декодирования, записав запрещенные кодограммы под разрешенными. Их
будет 258=24 шт. Так для первой строки таблицы 1 вектор ошибок е1
равен 00001; для второй строки е2=00010; и далее е3=00100; е4=01000;
е5=10000; е6=01001.
При однократной ошибке любая кодограмма будет отличаться от разрешенных
(строки 2-6), это свидетельствует о наличии ошибок, но только при векторе
ошибки е=00100 (строка 4) она будет отождествлена с переданной
кодограммой. Все остальные кодограммы при однократных ошибках имеют
неоднозначное соответствие, каждая имеет по два варианта, например кодограмма
00001 может быть отождествлена с кодограммой 00000 (первый столбец), либо 01001
(третий столбец). Таким образом, в таблице декодирования (таблица 1.1) записано
8 разрешенных кодограмм, 8 запрещенных кодограмм, однозначно исправляющих
однократные ошибки и 8 пар запрещенных кодограмм, имеющих неоднозначное
расположение в таблице декодирования. При двукратных ошибках получающиеся
кодограммы либо идентифицируются как однократные ошибки (например, для вектора
ошибки е=00011 они показаны в последней подчеркнутой строке), либо
переходят в другую разрешенную кодограмму, например вектор ошибки е=01001
переводит кодограмму из третьего столбца в первый.
Таким образом, данный пример подтверждает, что код с dмин=2
гарантирует обнаружение однократной ошибки.
Алгоритм декодирования по методу максимального правдоподобия заключается
в следующем:
. После получения n - разрядной кодограммы В* она
складывается по mod 2 последовательно со всеми разрешенными кодограммами и
вычисляются векторы ошибок ei.
. Подсчитывается число единиц в каждом векторе ошибок.
. Декодер отождествляет принятую кодограмму В* той разрешенной
кодограмме, для которой вектор ошибок имеет наименьшее число единиц.
Множество разрешенных кодовых слов в таблице декодирования (первая строка
таблицы 1) является подмножеством множества всех 2n кодограмм
разрядностью n. В процессе построения таблицы декодирования множество
кодограмм разрядностью n разбивается на подмножества (столбцы таблицы
декодирования). Причем сначала выписываются запрещенные кодограммы с одиночной
ошибкой, как самой вероятной, затем кодограммы с двумя ошибками и так далее.
В случае, когда код исправляет g ошибок, подмножества являются непересекающимися, а число
запрещенных кодограмм Ne в столбце должно удовлетворять неравенству [1,
22]
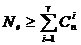 , (2.8)
, (2.8)
где
Cni=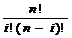 - число сочетаний из n элемнтов
по i.
- число сочетаний из n элемнтов
по i.
Неравенство
(2.8) следует непосредственно из того, что имеется ровно 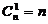 запрещенных кодограмм, отличающихся от разрешенной в
одной позиции,
запрещенных кодограмм, отличающихся от разрешенной в
одной позиции, 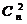 запрещенных кодограмм, отличающихся в двух позициях и
так далее.
запрещенных кодограмм, отличающихся в двух позициях и
так далее.
Теперь
можно связать избыточность кода с числом ошибок, которые им исправляются.
Заметим сначала, что число всевозможных кодограмм 2n, а каждый столбец
таблицы 1 содержит Ne запрещенных кодограмм. Поэтому число разрешенных
кодограмм должно удовлетворять неравенству
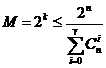 . (2.9)
. (2.9)
шифрование информация криптоалгоритм кодирование
Это
неравенство называется границей Хэмминга или границей сферической упаковки.
Равенство в (2.9) достигается только для так называемых совершенных кодов.
Число известных совершенных кодов очень невелико. Коды, гарантированно
исправляющие одну ошибку относят к кодам Хемминга. Для них условие (2.9)
преобразуется к виду
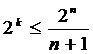 . (2.10)
. (2.10)
При
исследовании кодов с исправлением ошибок интерес представляет вероятность
появления на выходе декодера ошибочной последовательности. При независимых
ошибках на основании теоремы Бернулли вероятность появления в n -
разрядной кодограмме ровно m ошибок определяется биномиальным
распределением
P(m,
n)=Cnmp0m(1-p0)n-m, при 0£m£n. (2.11)
Если
приведенный в таблице 1 код используется исключительно для обнаружения ошибок,
то вероятность правильного приема равна (1-p0)5.
Необходимо
заметить, что для различных каналов свойства помехоустойчивых кодов могут использоваться
по-разному. Ранее предполагалось, что канал связи двоичный симметричный. В
двоичном симметричном канале со стираниями может рассматриваться режим только
исправления стертых символов, так как получение стертого символа уже
свидетельствует об ошибке. Определим возможности корректирующих кодов в
отношении исправления стертых символов. Предположим, что стирания отдельных
символов - события независимые, число стертых символов в кодограмме (кратность
стираний) обозначим через tс и допустим, что все нестертые символы
приняты правильно. При этом, приняв кодограмму с tс стираниями, образуем
укороченный код разрядностью (n-tс). Для этого во всех разрешенных кодограммах
необходимо вычеркнуть разряды, стертые в принятой кодограмме.
Для
того, чтобы кодограммы укороченного кода были различны, расстояние между ними
должно быть не менее единицы. Это позволяет исправить tс ошибок, так как
известно местонахождение стертых символов. Вернемся к таблице 1. Вычеркивание в
различных сочетаниях одного, двух или трех разрядов образуют укороченный код,
разрешенные кодограммы которого отличаются не менее чем на единицу. И только
вычеркивание четырех разрядов приводит к неоднозначности укороченного кода.
Если вычеркнуть последние четыре разряда получим код: первый элемент - 1,
второй - 0, третий - 1, четвертый - 0, из которого следует, что однозначно
отождествить принятую кодограмму одной из разрешенных нельзя. При вычеркивании
трех разрядов (последних) получим укороченный код: первый элемент - 11, второй
- 00, третий - 10, четвертый - 01, то есть возможно однозначное сопоставление
принятой кодограммы одной из разрешенных в укороченном коде. Таким образом, при
допущенных ограничениях возможно не менее tс=dмин стираний.
Наличие в системе передачи данных обратного канала с решающей обратной
связью позволяет, используя помехоустойчивый код с обнаружением ошибок, достичь
заданной вероятности ошибки порционально расходуя избыточность. Предполагается,
что всякий избыточный код всегда имеет большую избыточность, чем это необходимо
для обнаружения и исправления ошибок, потому что избыточностью обладают все
кодограммы, а ошибки содержат только некоторые из них. Это объясняется
случайностью помехи, в некоторые моменты времени отношение сигнал/шум создает
ошибки, а в некоторые - нет. А так как избыточность, необходимая для
обнаружения ошибок, меньше избыточности, необходимой для их исправления, то для
избежания изменений избыточности (понимай для увеличения скорости передачи
информации) часто ограничиваются применением обнаруживающих кодов, а сохранение
верности осуществляют, используя обратную связь.
2.3
Вероятностные характеристики при полностью известном сигнале
Рассмотрим двоичный гауссовский канал. Одномерная плотность распределения
шума в фиксированный момент времени tk имеет нормальный закон распределения с нулевым
средним значением [20]
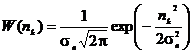 . (2.12)
. (2.12)
При
наличии аддитивной смеси среднее значение становится равным значению
действующего сигнала
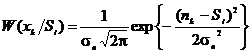 , (2.13)
, (2.13)
Наибольшее
количество информации о случайном процессе на заданном интервале времени
заключено в многомерном законе распределения. В этом случае разобьем интервал
наблюдения [0, T] на k равноотстоящих отсчетов с шагом 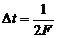 , где F - максимальная частота
спектра шума, т.е. энергетический спектр шума в этом случае имеет вид,
представленный на рисунке 2.2.
, где F - максимальная частота
спектра шума, т.е. энергетический спектр шума в этом случае имеет вид,
представленный на рисунке 2.2.
Рисунок
2.2 - Энергетический спектр шума
Значения
шума в выбранных отсчетах n(tk) будут
некоррелированы и в каждом сечении распределены по нормальному закону с
дисперсией 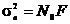 , определяемой мощностью шума. Тогда многомерная
плотность распределения для k совместных
отсчетов примет вид
, определяемой мощностью шума. Тогда многомерная
плотность распределения для k совместных
отсчетов примет вид
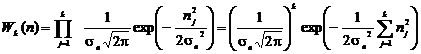 . (2.14)
. (2.14)
При
условии действия сигнала si(tj) шум будет определяться как разность n(tj)=x(tj)si(tj),
где si(tj) выступает как математическое ожидание смеси x(tj).
Закон изменения формы сигнала si(tj) известен. Следовательно, функция правдоподобия для k
сечений примет вид
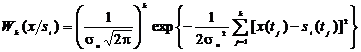 , (2.15)
, (2.15)
а
отношение правдоподобия после сокращения одинаковых сомножителей перед
экспонентой запишется в виде
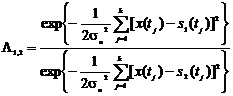
Или
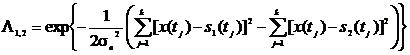 . (2.16)
. (2.16)
Учтем,
что 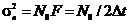 . Тогда
получим
. Тогда
получим
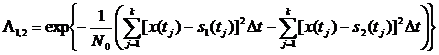 . (2.17)
. (2.17)
Для
увеличения количества информации о случайном процессе на интервале [0, T]
устремим число отсчетов к бесконечности k®¥. Тогда получим
Dt®0, x(tj)®x(t), si(tj)®si(t), а суммирование переходит в интегрирование. Таким
образом
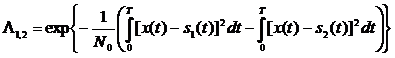 . (2.18)
. (2.18)
После
возведения в квадрат и приведения подобных членов, получим
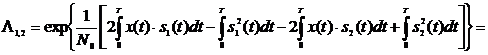
 .
.
Тогда
отношение правдоподобия предстанет в виде
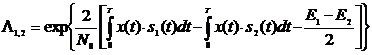 . (2.19)
. (2.19)
Прологорифмируем
обе части неравенства (2.4), что можно сделать вследствие монотонности функции
логарифма. Домножив обе части неравенства на положительную величину N0,
и перенеся известные значения Ei в правую часть неравенства окончательно получим
правило решения оптимального приемника
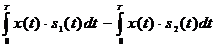
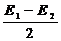 (2.20)
(2.20)
Приемник
состоит из дух ветвей корреляционного приема, каждый из которых включает в себя
генератор копии полезного сигнала, перемножитель и интегратор, а также
вычитающего устройства и решающего устройства. На входе решающего устройства
формируется разностное напряжение
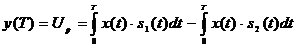 ,
,
которое
сравнивается с порогом 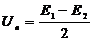 . Если разностное напряжение превышает порог, то
решение принимается в пользу первого сигнала, в противном случае - в пользу
второго сигнала.
. Если разностное напряжение превышает порог, то
решение принимается в пользу первого сигнала, в противном случае - в пользу
второго сигнала.
Схема оптимальной корреляционной обработки представлена на рисунке 2.3.
Схема состоит из перемножителей (П), интеграторов (И), генераторов копии
сигналов (ГКi),
вычитающего устройства (ВУ) и решающего устройства (РУ).
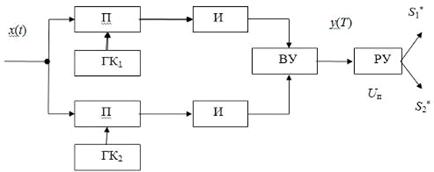
Рисунок 2.3 - Оптимальная схема обработки одиночного символа
Поскольку входная смесь распределена по нормальному закону, а схема
обработки является линейной, то плотность распределения разностного напряжения
на входе решающего устройства также будет гауссовской и примет вид
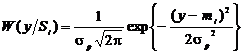 , (2.21)
, (2.21)
где
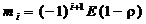 - среднее значение смеси регулярной составляющей,
- среднее значение смеси регулярной составляющей, 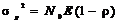 - дисперсия или мощность помехи, что изображено на
рисунке 2.4.
- дисперсия или мощность помехи, что изображено на
рисунке 2.4.
Рисунок
2.4 - Условные плотности распределения смеси входе решающего устройства
При выборе нулевого порога решающего устройства значение вероятности
ошибки приема одиночного символа p определяется как среднее значение между переходными вероятностями P(S2*/S1)
и P(S1*/S2)
с учетом вероятностей появления исходных сигналов P(S1),
P(S2)

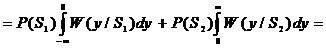
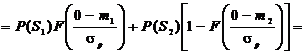
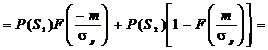
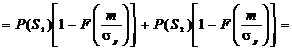
 , (2.22)
, (2.22)
где
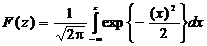 - интеграл вероятности;
- интеграл вероятности; 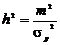 - отношение сигнал шум.
- отношение сигнал шум.
В
двоичном симметричном канале со стиранием решение на стирание принимается,
когда значение разности напряжения находится в пределах от 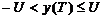 , причем
, причем  .
.
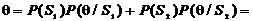
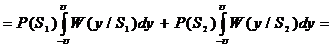
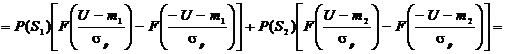
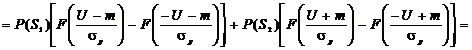
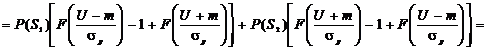
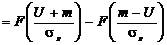 , (2.23)
, (2.23)
а
значение вероятности ошибки
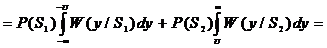
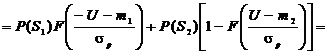
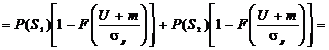
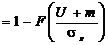 . (1.24)
. (1.24)
Введем
обозначение 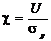 . В подобной ситуации значение вероятности ошибки p
и вероятности стирания
. В подобной ситуации значение вероятности ошибки p
и вероятности стирания 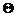 определятся выражениями:
определятся выражениями:
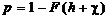 , (2.25)
, (2.25)
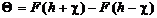 . (2.26)
. (2.26)
Если
применить функцию [2]
 , (2.27)
, (2.27)
то
искомые вероятности примут вид
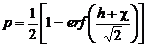 , (2.28)
, (2.28)
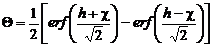 . (2.29)
. (2.29)
2.4 Прием
сигналов с неопределенной фазой
Поскольку начальная фаза радиоимпульса вследствие воздействия помех может
существенно измениться, то следует рассмотреть случай, когда начальная фаза
приходящего сигнала неизвестна и может принимать любое значение на интервале
(0, 2π).
Для выделения полной
энергии радиоимпульса используется квадратурная обработка с базовыми сигналами,
преобразованными по Гильберту [17]. В данном случае могут использоваться сигналы
с частотной манипуляцией, коэффициент взаимной корреляции у которых нулевой.
Следовательно, по одной ветви приема будет регулярная составляющая, а по другой
ветви приема чистый шум.
Схема оптимальной некогерентной обработки представлена на рисунке 2.5.
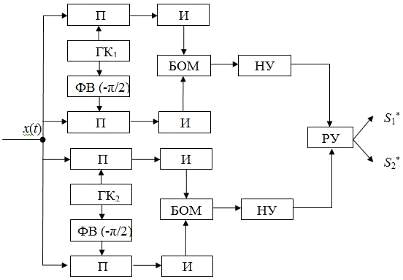
Рисунок 2.5 - Квадратурная схема реализации оптимального приема
дискретных сообщений при неопределенной фазе сигнала
Схема состоит из перемножителей (П), интеграторов (И), генераторов копии
сигналов (ГКi),
фазовращателей (ФВ), блоков определения модуля корреляционного интеграла (БОМ),
нелинейных устройств (НУ) и решающего устройства (РУ).
Плотность распределения огибающей A узкополосного случайного процесса распределена по
закону Райса
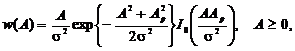 (2.30)
(2.30)
где
Ap - амплитуда регулярной составляющей сигнала; σ2 - дисперсия переменной составляющей;  - модифицированная функция Бесселя нулевого порядка.
- модифицированная функция Бесселя нулевого порядка.
Следовательно,
наличие сигнала дает распределение огибающей корреляционного интеграла V1
по закону Райса, а при отсутствии сигнала V0 по закону
Рэлея.
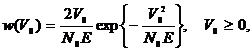 (2.31)
(2.31)
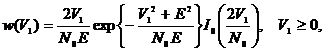 (2.32)
(2.32)
где
переменная V0 без регулярной составляющей имеет дисперсию 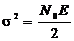 , а переменная V1 имеет
регулярную составляющую E и ту же дисперсию. Условные плотности распределения
вероятности огибающих на входе решающего устройства изображены на рисунке 2.6.
, а переменная V1 имеет
регулярную составляющую E и ту же дисперсию. Условные плотности распределения
вероятности огибающих на входе решающего устройства изображены на рисунке 2.6.
Для
двоичной системы алгоритм оптимального некогерентного приема сводится к
проверке одного неравенства
V1>V0.
(2.33)
При
его выполнении регистрируется 1, в противном случае - 0.
Рисунок
2.6 - Условные плотности распределения вероятности огибающих на входе решающего
устройства
При выборе нулевого значения дополнительного порога стирания (U=0) значение вероятности ошибки
приема одиночного символа p
определяется
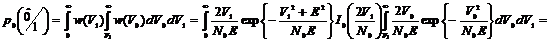

 . (2.34)
. (2.34)
Функция
под знаком интеграла представляет собой закон Райса для переменной 2V1
с регулярной составляющей E и дисперсией N0E,
а это значит, что интеграл в (2.34) равен 1. Тогда
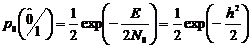 , (2.35)
, (2.35)
где
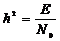 - отношение сигнал шум.
- отношение сигнал шум.
В
двоичном симметричном канале со стиранием решение на стирание принимается,
когда значение разности напряжения находится в пределах 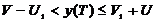 , причем
, причем 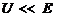 .
Обозначим нормированное значение порога стирания
.
Обозначим нормированное значение порога стирания 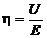 . Тогда
вероятность стирания
. Тогда
вероятность стирания
 , (2.36)
, (2.36)
а
вероятность ошибки
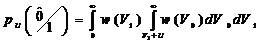 . (2.37)
. (2.37)
Следовательно,
можно записать
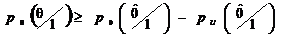 . (2.38)
. (2.38)
Определим
вероятность ошибки при наличии стирания.
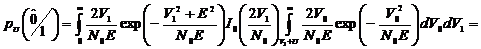
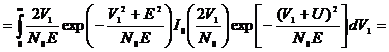
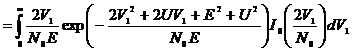 . (2.39)
. (2.39)
Введем
новую переменную
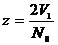 . (2.40)
. (2.40)
Тогда
с учетом введенных обозначений получим
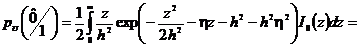
 . (2.41)
. (2.41)
Представим
модифицированную функцию Бесселя нулевого порядка разложением в ряд [18]
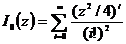 . (2.42)
. (2.42)
Тогда
искомая вероятность примет вид
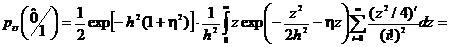
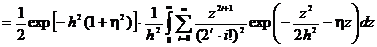 . (2.43)
. (2.43)
После
перестановки операций интегрирования и суммирования получим
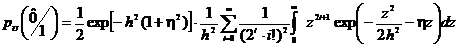 . (2.44)
. (2.44)
Учитывая
выражение для определенного интеграла
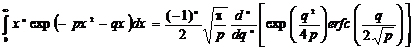 , (2.45)
, (2.45)
в
котором
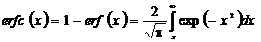 , (2.46)
, (2.46)
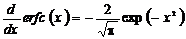 , (2.47)
, (2.47)
после
введения обозначений  ,
, 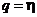 ,
, 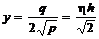 ,
, 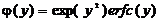 получим
получим
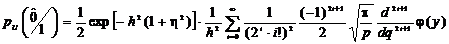 . (2.48)
. (2.48)
Определим
производные функции φ(y)
нечетного порядка
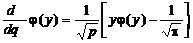 ;
;
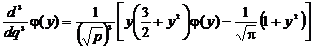 ;
;
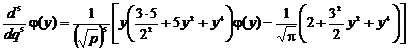 ;
;
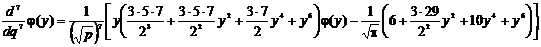 .
.
Таким
образом, нечетную производную функции φ(y) можно
представить с использованием коэффициентов полинома переменной y
в виде
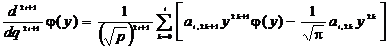 , (2.49)
, (2.49)
где
ai,j - коэффициенты полинома.
Следующая
производная нечетного порядка имеет вид
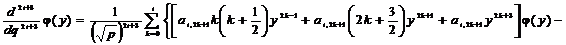
 . (2.50)
. (2.50)
Выпишем
слагаемые для различных значений переменной k
k=0: 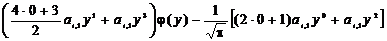 ,
,
k=1: 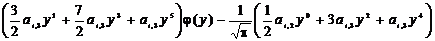 ,
,
k=2: 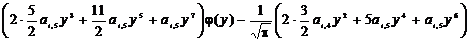 ,
,
k=3: 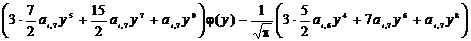 ,
,
k=4: 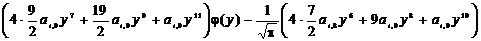 ,
,
k=5: 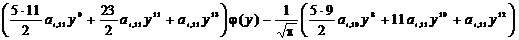 ,
,
k=6: 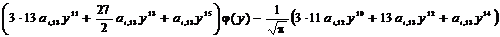
В
общем виде коэффициенты связаны соотношениями
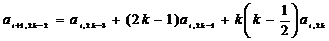 , (2.51)
, (2.51)
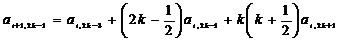 , (2.52)
, (2.52)
причем,
при k=1 будут иметь место равенства
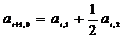 ,
,
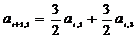 ,
,
а
при k=i коэффициенты ai,2i+1=1,
ai,2i=1 и будут иметь место равенства
 ,
,
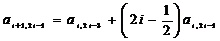 .
.
Коэффициенты
нечетных степеней связаны только с нечетными коэффициентами предшествующих
производных, а четных степеней как с четными, так и с нечетными, поэтому
сначала определим зависимость коэффициентов нечетных степеней от порядка
производной. Качество связей нечетных коэффициентов представлены на рисунке
2.8.
Виды
связей между коэффициентами представлены на рисунке 2.7.

Рисунок
2.7 - Виды связей между коэффициентами полинома
Рисунок
2.8 - Качество связей нечетных коэффициентов
Исходный
коэффициент  и коэффициенты высших степеней
и коэффициенты высших степеней  . Коэффициенты предыдущей степени (j=1)
. Коэффициенты предыдущей степени (j=1)
 . (2.53)
. (2.53)
Используя
выражение для суммы членов арифметической прогрессии
 , (2.54)
, (2.54)
Получим
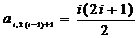 . (2.55)
. (2.55)
Предшествующий
коэффициент (j=2) можно получить из предыдущего
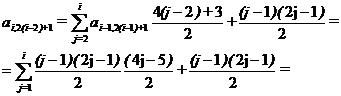
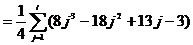 . (2.56)
. (2.56)
С
учетом сумм квадратов и кубов целых чисел
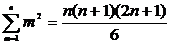 , (2.56)
, (2.56)
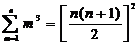 (2.57)
(2.57)
выражение
для предшествующего коэффициента примет вид
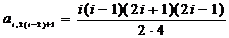 . (2.58)
. (2.58)
Полагая,
что
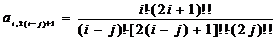 , (2.59)
, (2.59)
после
замены k=i-j получим зависимость коэффициента нечетной степени от
его положения в таблице
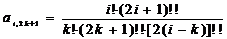 . (2.60)
. (2.60)
Учитывая,
что двойной факториал можно представить через однократный
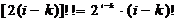 , (2.61)
, (2.61)
нечетные
коэффициенты можно представить через биномиальные коэффициенты
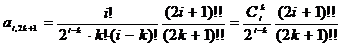 . (2.62)
. (2.62)
где
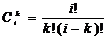 - число сочетаний из i по k.
- число сочетаний из i по k.
Определим
коэффициенты четных степеней. Качество связей четных коэффициентов представлено
на рисунке 2.8
Исходный
коэффициент 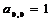 и коэффициенты высших степеней
и коэффициенты высших степеней 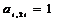 . Заметим, что
. Заметим, что  .
.
Рассчитаем
коэффициенты четных степеней из нескольких слагаемых, начиная с наибольшей
степени. Коэффициенты предыдущей степени отстоят на j позиций.
Тогда имеет место равенство
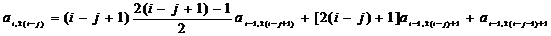 . (2.63)
. (2.63)
Рассчитаем
известные слагаемые
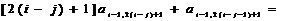
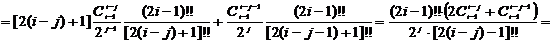
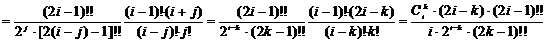 .
.
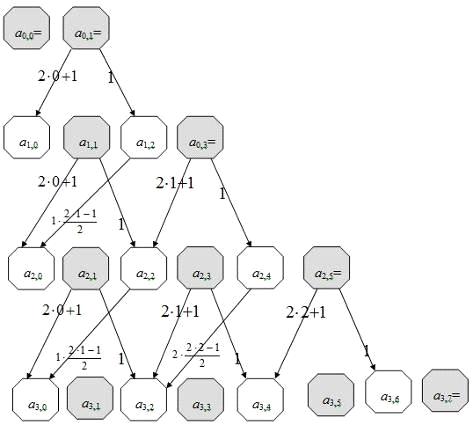
Рисунок
2.8 - Качество связей четных коэффициентов
Связь
четных коэффициентов осуществляется через два смещения (∆j=2),
поэтому первоначально определим коэффициенты в порядке возрастания нечетной
переменной j, а затем по четной
j=1:
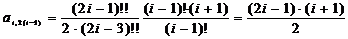 ;
;
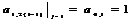 ;=3:
;=3: 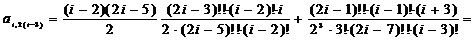
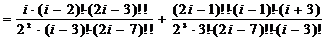 ;
;
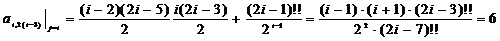 ;=5:
;=5: 
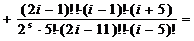
 ;
;
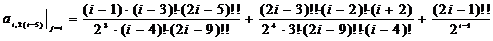 ;=7:
;=7: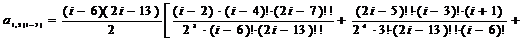
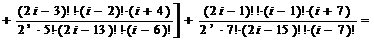
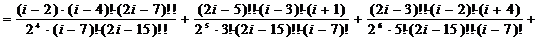
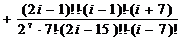 ;=2:
;=2: 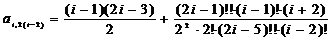 ;=4:
;=4: 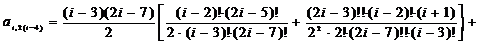
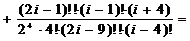
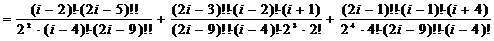 ;
;
j=6: 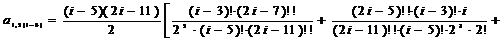
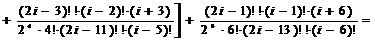
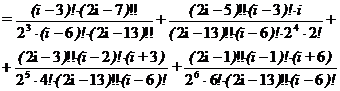 .
.
Для
нечетных сдвигов коэффициенты можно выразить суммой
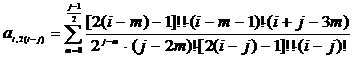 , (2.64)
, (2.64)
а
для четных сдвигов с дополнительным слагаемым
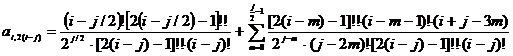 . (2.65)
. (2.65)
Если
ввести дополнительную функцию,
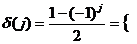
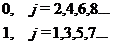 (2.66)
(2.66)
то
четные коэффициенты можно записать выражением
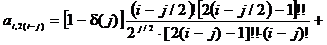
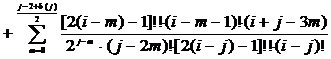 . (2.67)
. (2.67)
Ошибочная
вероятность примет вид
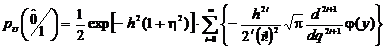 ; (2.68)
; (2.68)
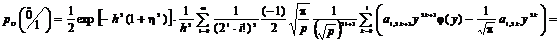
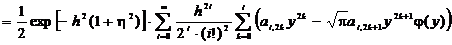 . (2.69)
. (2.69)
Поменяем
порядок суммирования элементов
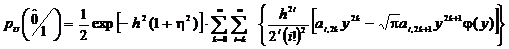 . (2.70)
. (2.70)
При
k=0 результат суммирования по четным коэффициентам дает
экспоненту
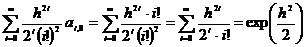 , (2.71)
, (2.71)
что
при отсутствии стирания (η=0)
приводит к исходному выражению
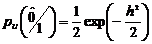 . (2.72)
. (2.72)
Тогда
после перегруппировки с точностью до девятой производной, используя разложение
в ряд, получим
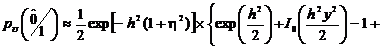
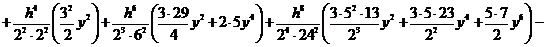

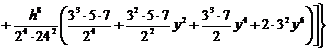
Подставляя
значение 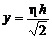 получим
получим
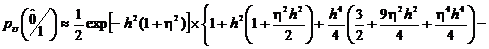
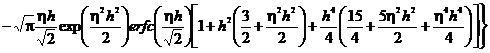 . (2.73)
. (2.73)
Определим
вероятность стирания.
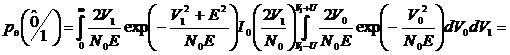
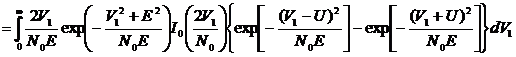 . (2.74)
. (2.74)
С
учетом решения по определению вероятности ошибки получим
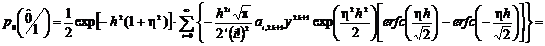
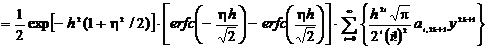 . (2.75)
. (2.75)
2.5 Выводы
При обмене информацией между абонентами по двоичному каналу связи
восстановление переданного сообщения осуществляется посредством поэлементного
приема сигналов и последующим анализом двоичной кодограммы. Вероятность
ошибочного приема кодограммы зависит как от вероятности ошибочного приема
одиночного символа, так и величины избыточности кодограммы. Введение в модель
канала связи решения на стирание элементарного символа уменьшает вероятность
ошибки его восстановления. Для оценки степени влияния стирания на вероятность
ошибочного приема кодограммы необходимо определить аналитическое выражение для
вероятности ошибки и вероятности стирания элементарного символа (0 или 1). При
воздействии аддитивной помехи типа «белый шум» формируется смесь, которая
подвергается оптимальной обработке, алгоритм и схема которой определяется по
критерию максимального правдоподобия. Решение принимается в пользу наиболее
вероятного сигнала. Чем больше информации известно о входном сигнале, тем лучше
качество приема.
Кодирование с исправлением ошибок основывается на использовании
избыточности. Под избыточностью понимается наличие в кодовой комбинации
некоторого числа проверочных символов, определенным образом связанных с
информационными. Проверочные символы используются для того, чтобы подчеркнуть
индивидуальность элемента сообщения. При передаче по дискретному каналу одной
из разрешенных кодограмм она под действием помехи может превратиться в одну из
запрещенных, что позволяет декодеру обнаруживать наличие ошибок. С этой целью в
основу помехоустойчивого кодирования положено разбиение всего множества
кодограмм на непересекающиеся подмножества с центрами, совпадающими с
разрешенными кодограммами.
Для исправления ошибок достаточно определить, к какому подмножеству
относится принятая кодограмма. Исправление ошибок происходит не во всех
случаях, а только тогда, когда под действием ошибок в дискретном канале
принятая кодограмма остается в том же подмножестве, центром которой является
передаваемая кодограмма. Если же принятая кодограмма в результате ошибок
переходит в другое подмножество, то декодер примет решение в пользу другой
разрешенной кодограммы. В двоичном симметричном канале со стираниями может
рассматриваться режим только исправления стертых символов, так как получение
стертого символа уже свидетельствует об ошибке. Так как известно местонахождение
стертых символов, то при определенных ограничениях возможное число стираний
может достигнуть кодовое расстояния.
Соотношение между вероятностью ошибки одиночного символа и вероятностью
его стирания зависят от отношения сигнал шум и величины выбранного порога
стирания. Кроме того, это отношение зависит от способа обработки сигнала. Для
гауссовского канала при полностью известных параметрах сигнала осуществляется
когерентная корреляционная обработка, в результате которой плотность
вероятности процесса на входе решающего устройства распределена по нормальному
закону, а вероятности ошибки и стирания одиночного символа вычисляется по
формулам (2.28), (2.29). При отсутствии информации о начальной фазе
радиоимпульса плотность вероятности огибающей процесса на входе решающего
устройства распределена по закону Райса, а вероятности ошибки и стирания
одиночного символа вычисляется по формулам (2.35), (2.62), (2.67), (2.69),
(2.75).
3. Оценка
качества приема кодограмм со стиранием
Введение в модель канала связи решения на стирание элементарного символа
уменьшает вероятность ошибки восстановления кодограммы. Поскольку
корректирующие способности помехоустойчивых кодов по восстановлению стертых
символов за счет знания места нахождения стираний больше, чем ошибочно принятых,
то можно определить оптимальное значение порога для границы на подобное
решение.
Оценить
вероятность ошибки приема n-разрядной кодограммы при использовании
помехоустойчивого (n, k) кода с кодовым расстоянием d,
который позволяет гарантированно восстановить до τ=d-1
стертых символов и исправить до 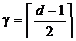 ошибочно
принятых символов можно воспользовавшись выражением [ 20 ]
ошибочно
принятых символов можно воспользовавшись выражением [ 20 ]
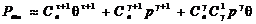 . (3.1)
. (3.1)
3.1 Оценка
оптимального когерентного приема
Рассмотрим
двоичный симметричный гауссовский канал со стиранием с независимым потоком
ошибок. При отсутствии стирания (с нулевым значением порога решающего
устройства) отношение сигнал-шум составляет величину  , а вероятность ошибки приема одиночного символа p0
определяется выражением
, а вероятность ошибки приема одиночного символа p0
определяется выражением
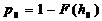 (3.2)
(3.2)
где
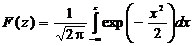 - интеграл вероятности.
- интеграл вероятности.
Возможный
диапазон изменения (3.2) представлен на рисунке 3.1.
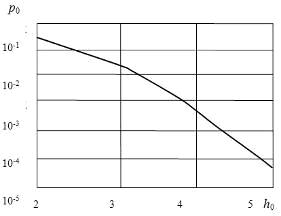
Рисунок
3.1 - Вероятность ошибки приема одиночного символа
В
двоичном симметричном канале решение на стирание принимается, в случае, если
после оптимальной обработки значение напряжения y находится
в пределах 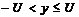 . Нормируем значение выбранного порога относительно
среднеквадратического отклонения обработанной оптимальным образом смеси σy
и введем обозначение
. Нормируем значение выбранного порога относительно
среднеквадратического отклонения обработанной оптимальным образом смеси σy
и введем обозначение 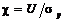 . С учетом стирания для одиночного символа значение
вероятности ошибки p и вероятности стирания
. С учетом стирания для одиночного символа значение
вероятности ошибки p и вероятности стирания 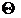 определятся
выражениями:
определятся
выражениями:
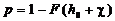 , (3.3)
, (3.3)
 . (3.4)
. (3.4)
Графики
зависимостей вероятности ошибки кодограммы от величины порога стирания при
различных h0 приведены на рисунке 3.2. Пунктирная линия
соответствует значению n=2, а сплошная линия n=5.
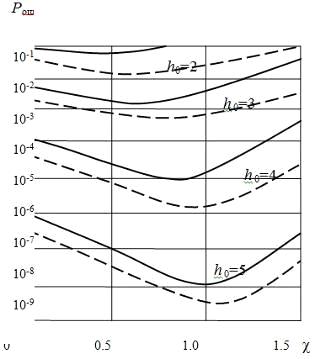
Рисунок
3.2 - Вероятность ошибки кодограммы
Имеется
оптимальное значение порога стирания, обеспечивающего минимум вероятности
ошибки кодограммы.
Условие
экстремума запишется в виде
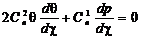 .
.
С
учетом частных производных
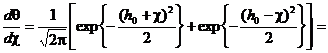
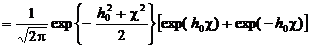
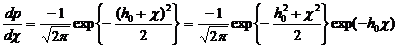
условие
экстремума функции можно записать в виде
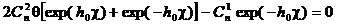 .
.
Будем
использовать приближенное значение интеграла Лапласа
 .
.
Обозначим
коэффициент  и переменную
и переменную 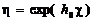 . В результате
уравнение для экстремума перепишем в виде
. В результате
уравнение для экстремума перепишем в виде
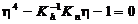
где
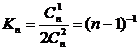
Решение
уравнения четвертой степени неполного вида при больших значениях отношений
сигнал-шум получим
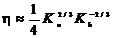 ,
,
а
возвращаясь к старой переменной будем иметь
 .
.
Проведя
логарифмирование обеих частей равенства, можно определить оптимальное значение
порога стирания

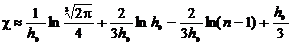 . (3.5)
. (3.5)
Основная
составляющая зависимости выбранного значения порога стирания от отношения
сигнал-шум - прямопророрциональная.
Расчет
оптимального порога χopt
для различных значений n и h0 представлены в таблице 2.
Таблица
2 - Оптимальный порог
|
χopt
(d=2,
τ=1, γ=0)
|
|
h=2
|
h=3
|
h=4
|
h=5
|
|
n=10
|
0,26
|
0,486
|
0,686
|
0,871
|
|
n=20
|
0,164
|
0,401
|
0,621
|
0,819
|
|
n=30
|
0,121
|
0,354
|
0,585
|
0,79
|
|
n=40
|
0,096
|
0,56
|
0,77
|
|
n=50
|
0,079
|
0,297
|
0,54
|
0,754
|
|
n=60
|
0,068
|
0,277
|
0,524
|
0,741
|
|
n=70
|
0,059
|
0,26
|
0,511
|
0,73
|
|
n=80
|
0,052
|
0,246
|
0,499
|
0,721
|
|
n=90
|
0,047
|
0,233
|
0,489
|
0,713
|
|
n=100
|
0,043
|
0,233
|
0,48
|
0,705
|
Значения выигрыша в вероятности ошибки кодограммы при оптимальном пороге
(χ=χopt) по сравнению с принятием решения по
одному порогу (χ=0) как показатель β=Pош(χ=0)/Pош(χ=χopt) представлены в таблице 3.
Таблица 3 - Значения
выигрыша
|
β
(d=2,
τ=1, γ=0)
|
|
h=2
|
h=3
|
h=4
|
h=5
|
|
n=10
|
1,449
|
3,439
|
13,541
|
78,343
|
|
n=20
|
1,244
|
2,623
|
10,044
|
57,795
|
|
n=30
|
1,168
|
2,273
|
8,505
|
48,733
|
|
n=40
|
1,129
|
2,065
|
7,58
|
43,274
|
|
n=50
|
1,104
|
1,925
|
6,941
|
39,504
|
|
n=60
|
1,088
|
1,821
|
6,465
|
36,69
|
|
n=70
|
1,076
|
1,741
|
6,091
|
34,479
|
|
n=80
|
1,066
|
1,677
|
5,787
|
32,68
|
|
n=90
|
1,059
|
1,624
|
5,533
|
31,177
|
|
n=100
|
1,053
|
1,578
|
5,316
|
29,895
|
Значение вероятности ошибки для кодов (7, 4) сплошной линией и (15, 11)
пунктирной линией представлены на рисунке 3.3
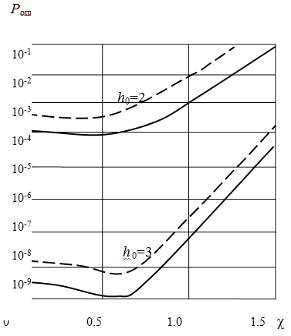
Рисунок 3.3 - Значение вероятности ошибки
Значение вероятности ошибки кодограммы также имеет минимальное значение.
Оптимальное значение порога стирания для значения h0=2 составляет величину χ=0,4, а для значения h0=3 составляет величину χ=0,57,
при этом значение
выигрыша в вероятности ошибки по сравнению со случаем одного порога в решающем
устройстве с ростом h0
увеличивается от β=1,187 до β=1,648 для кода (7, 4), а для кода (15, 11)
от величины β=1,193 до β=1,649.
3.2 Оценка
оптимального некогерентного приема
При некогерентном приеме, когда начальная фаза высокочастотного
заполнения радиоимпульса неизвестна и не может быть измерена с достаточной
степенью точности вследствие большой скорости ее изменения, вероятность
ошибочного приема кодограммы от относительного значения порога стирания η
при фиксированном
отношении сигнал - шум h
и разрядности кодограммы n
для кода с проверкой на четность по характеру аналогична случаю когерентного
приема. Числовые значения вероятности ошибки при нулевом значении порога и
минимальное значение с соответствующим значением оптимального порога
представлены в таблице 4
Таблица 4 - Вероятности ошибки кодограмм кодов (2, 1) и (5, 4)
|
n=2
|
n=5
|
|
Pош(η=0)
|
Pошmin
|
ηопт
|
Pош(η=0)
|
Pошmin
|
ηопт
|
|
h=2
|
0,131
|
0,064
|
0,22
|
0,296
|
0,218
|
0,14
|
|
h=3
|
0,011
|
2,271∙10-3
|
0,21
|
0,027
|
9,644∙10-3
|
0,15
|
|
h=4
|
3,354∙10-4
|
1,899∙10-5
|
0,20
|
8,383∙10-4
|
8,414∙10-5
|
0,16
|
|
h=5
|
3,725∙10-6
|
3,964∙10-8
|
0,19
|
9,311∙10-6
|
1,764∙10-7
|
0,17
|
Значения выигрыша в вероятности ошибки кодограммы при оптимальном пороге
(η=
ηopt) по сравнению с принятием решения по
одному порогу (η=0) как показатель β=Pош(η=0)/Pош(η= ηopt) представлены в таблице 5
Таблица 5 - Значения выигрыша при некогерентной обработке
|
β
(d=2, τ=1, γ=0)
|
|
h=2
|
h=3
|
h=4
|
h=5
|
|
n=10
|
1,159
|
2,16
|
7,224
|
38,051
|
|
n=20
|
1,058
|
1,694
|
5,393
|
28,213
|
|
n=30
|
1,026
|
1,525
|
4,593
|
23,52
|
|
n=40
|
1,012
|
1,418
|
4,141
|
21,228
|
При некогерентной обработке вероятность ошибки кодограммы для нулевого
порога стирания больше, чем при когерентной обработке, а значение выигрыша для
оптимального порога стирания меньше.
3.3 Выводы
Оценить эффективность процесса обмена информацией на основе циклических
кодов можно значением вероятности ошибки восстановления кодограммы. В каналах с
независимым появлением ошибок в элементарных символах эта вероятность зависит
от отношения сигнал-шум, корректирующих способностей используемых кодов и
способа обработки сигнала. Однако уменьшить вероятность ошибки кодограммы при
выбранном отношении сигнал-шум можно введением в канал связи режима стирания.
За счет знания места стертого символа значение корректирующих способностей
используемого кода возрастает, что приводит к появлению оптимального значения
порога решающего устройства, обеспечивающего режим стирания одиночных символов.
Сравнение вероятности ошибки восстановления искаженной кодограммы циклического
кода при оптимальном пороге стирания с режимом отсутствия стираний, показывает,
что существует выигрыш в эффективности восстановления принятой кодограммы и его
величина возрастает с увеличением отношения сигнал-шум. При некогерентной
обработке сигнала по сравнению с когерентной обработкой характер изменения
вероятности ошибки кодограммы сохраняется, но качественные показатели
ухудшаются.
Заключение
При обмене информацией между абонентами по двоичному каналу связи
восстановление переданного сообщения осуществляется посредством поэлементного
приема сигналов и последующим анализом двоичной кодограммы. Вероятность
ошибочного приема кодограммы зависит как от вероятности ошибочного приема
одиночного символа, так и величины избыточности кодограммы. Введение в модель
канала связи решения на стирание элементарного символа уменьшает вероятность
ошибки его восстановления. При воздействии аддитивной помехи типа «белый шум»
формируется смесь, которая подвергается оптимальной обработке, алгоритм и схема
которой определяется по критерию максимального правдоподобия. Решение
принимается в пользу наиболее вероятного сигнала. Чем больше информации
известно о входном сигнале, тем лучше качество приема.
Кодирование с исправлением ошибок основывается на использовании
избыточности. В двоичном симметричном канале со стираниями может
рассматриваться режим только исправления стертых символов, так как получение
стертого символа уже свидетельствует об ошибке. Так как известно
местонахождение стертых символов, то при определенных ограничениях возможное
число стираний может достигнуть кодового расстояния.
Получена аналитическая зависимость вероятности ошибки одиночного символа
и вероятности стирания от значения выбранного порога стирания. Соотношение
между вероятностью ошибки одиночного символа и вероятностью его стирания
зависят от отношения сигнал шум и величины выбранного порога стирания. Кроме
того, это отношение зависит от способа обработки сигнала. Для гауссовского
канала при полностью известных параметрах сигнала осуществляется когерентная
корреляционная обработка, в результате которой плотность вероятности процесса
на входе решающего устройства распределена по нормальному закону. При
отсутствии информации о начальной фазе радиоимпульса плотность вероятности
огибающей процесса на входе решающего устройства распределена по закону Райса
при наличии сигнала и по закону Релея при его отсутствии.
Оценить эффективность процесса обмена информацией на основе циклических
кодов можно значением вероятности ошибки восстановления кодограммы. В каналах с
независимым появлением ошибок в элементарных символах эта вероятность зависит
от отношения сигнал-шум, корректирующих способностей используемых кодов и
способа обработки сигнала. Однако уменьшить вероятность ошибки кодограммы при
выбранном отношении сигнал-шум можно введением в канал связи режима стирания.
За счет знания места стертого символа значение корректирующих способностей используемого
кода возрастает, что приводит к появлению оптимального значения порога
решающего устройства, обеспечивающего режим стирания одиночных символов.
Сравнение вероятности ошибки восстановления искаженной кодограммы циклического
кода при оптимальном пороге стирания с режимом отсутствия стираний, показывает,
что существует выигрыш в эффективности восстановления принятой кодограммы и его
величина возрастает с увеличением отношения сигнал-шум. При некогерентной
обработке сигнала по сравнению с когерентной обработкой характер изменения
вероятности ошибки кодограммы сохраняется, но качественные показатели
ухудшаются.
Поставленные во введении задачи, соответствующие цели выпускной
квалификационной работы, были достигнуты.
Рассмотрена общая модель безопасного обмена информацией в первой главе.
Во второй главе выявлены вероятностные характеристики двоичного канала.
Третья глава содержит анализ приема кодограмм со стиранием и рекомендации
по совершенствованию модели безопасности.
Разработанные рекомендации по совершенствованию модели безопасности
компьютерной системы могут применяться на практике для обеспечения лучшей
защиты конфиденциальных и секретных данных на предприятиях.
Потребность в защите данных возрастает с каждым днем в современном
обществе. Не осталось такой сферы человеческой деятельности, которой бы не
касалось обеспечение безопасности информации разного рода. Поэтому проблема,
затронутая в настоящей выпускной квалификационной работе, является
злободневной, а ее актуальность молниеносно возрастает.
Список
используемых источников
1. Андерсон Д.А. Дискретная математика и комбинаторика: Пер.
с англ. - М.: Издательский дом «Вильямс», 2003. - 960 с.
2. Анке Е., Эмде Ф., Леш Ф.
Специальные функции. Формулы, графики, таблицы. - М.: Наука Главная редакция физико
- математической литературы, 1968. - 344 с.
3. Анин Б.Ю. Защита компьютерной информации.- СПб.: БХВ -
Санкт-Петербург, 2000. - 256 c.
. Анохин М.И., Варноский М.П., Сидельников В.М., Ященко В.В.
Криптография в банковском деле.- М.: МИФИ, 1987.
. Аршинов М.Н., Садовский Л.Е. Коды и математика (рассказы о
кодировании).- М.: Наука Главн. ред. физ. мат. лит., 1983.
. Брассар Ж. Современная криптология. Пер. с англ. М.:
Полимед, 1999. - 296 с
. Введение в криптографию. Под общей ред. В.В. Ященко. СПб:
Питер, 2001. - 288 с
. Габидулин Э.М., Афанасьев В.Б. Кодирование в
радиоэлектронике. - М.: Радио и связь, 1986. - 176 с.
. Жельников В. Криптография от папируса до компьютера. М.: ABF, 1996. - 312 с
. Зиммерман Ф.Р. PGP: концепция безопасности и уязвимые места. Пер с англ. \\ Компьютера.
1997. №48. С. 36-40, 42-51.
11. Зяблов В.В. Исправление стираний
в двоичных линейных кодах // В кн.: Передача дискретных сообщений по каналам с
группирующимися ошибками.- М., 1972. - С. 34-38.
12. Иванов М.Д. Криптографические методы защиты информации в
компьютерных системах и сетях.- М.: Кудиц-образ, 2001. - 368 с.
13. Интегралы и ряды. Специальные
функции. Прудников А.П., Брычков Ю.А., Маричев Ф.И. - М.: Наука Главная
редакция физико - математической литературы, 1983. - 752 с.
14. Кнут Д.,Э. Искусство программирования, том 2.
Получисленные алгоритмы, 3-е изд.: Пер. с англ.: Уч. пос.- М.: Издательский дом
«Вильямс», 2001. - 832 с.
. Конев И.Р., Беляев А.В. Информационная безопасность
предприятия. - СПб.: БХВ-Петербург, 2003. - 752 с.
. Мельников В.В. Защита информации в компьютерных системах.
-М.: Финансы и статистика. Электроинформ, 1997. - 364 с.
. Моисеенков И. Основы безопасности компьютерных систем \\
КомпьютерПресс. 1991, №10. С. 19-24, №11. С. 7-21.
18. Осмоловский С.А. Стохастические
методы защиты информации. -М.: Радио и связь, 2003.
19. Петров А.А. Компьютерная безопасность. Криптографические
методы защиты.- М.: ДМК, 2000. - 320 с.
20. Теория электрической связи:
Учебник для вузов / А.Г. Зюко, Д.Д. Кловский, В.И. Коржик, М.В. Назаров; Под
ред. Д.Д. Кловского. - М.: Радио и связь, 1998. - 432 с.
21. Шварцман В.О., Емельянов Г.А. Теория передачи дискретной
информации. Учебник для вузов связи. - М.: Связь, 1979. - 424 с.
. Яблонский С.В. Введение в дискретную математику: Учебн.
Пособие для вузов / Под ред. В.А. Садовничего. - 3-е изд., стер. - М.: Высш.
шк., 2002. - 384 с.