Разработка нейросетевой технологии и программного продукта авторизации пользователя
МИНИСТЕРСТВО
ОБРАЗОВАНИЯ И НАУКИ
РОССИЙСКОЙ
ФЕДЕРАЦИИ
Федеральное
государственное бюджетное образовательное учреждение
высшего
профессионального образования
«КУБАНСКИЙ
ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ»
(ФГБОУ ВПО
КубГУ)
Кафедра
информационных технологий
ДИПЛОМНАЯ
РАБОТА
РАЗРАБОТКА
НЕЙРОСЕТЕВОЙ ТЕХНОЛОГИИ И ПРОГРАММНОГО ПРОДУКТА АВТОРИЗАЦИИ ПОЛЬЗОВАТЕЛЯ
Работу выполнил:
М.Б. Ревякин
Специальность:
010200 «Прикладная
математика и
информатика»
Научный
руководитель
к. ф. - м. н.,
доцент Ю.В. Кольцов
Нормоконтроллер
А.В. Харченко
Краснодар
2013
Реферат
Дипломная работа 55 с., 2 ч., 8 рис., 11 табл.,
18 источников
Объектом исследования являются возможности
применения искусственных нейронных сетей для решения задачи биометрической
идентификации личности на основе её динамических характеристик.
Цель работы состоит в разработке программного
продукта, осуществляющего идентификацию и авторизацию личности на основе её
клавиатурного почерка.
В процессе работы было разработано приложение,
обладающее доступным графическим интерфейсом пользователя, отвечающее
поставленным задачам.
Ключевые слова: ИСКУССТВЕННАЯ НЕЙРОННАЯ СЕТЬ,
БИОМЕТРИЯ, БИБЛИОТЕКА QT,
ИДЕНТИФИКАЦИЯ, АУТЕНТИФИКАЦИЯ, КЛАВИАТУРНЫЙ ПОЧЕРК.
Содержание
Введение
. Общие принципы работы систем
биометрической идентификации личности
.1 Структуры систем биометрической
идентификации личности по особенности воспроизведения действий
.2 Особенности применения
нейросетевых решающих правил в системах биометрической идентификации
.3 Измерение близости образа к биометрическому
эталону мерой Хемминга
.4 Евклидова мера близости к центру
биометрического эталона
.5 Линейное разделение пространства
контролируемых параметров (персептрон)
.6 Проблемы обучения искусственных
нейронных сетей
. Описание и реализация программного
продукта
.1 Постановка задачи
.2 Программные инструменты,
примененные при разработке приложения
.2.1 Кросс-платформенная библиотека
Qt
.2.2 Библиотека классов
BPNeuralNetwork
.2.3 Модель прямого ввода ОС Windows
Raw Input
.2.4 Система управления базами данных
SQLite
.3 Описание базы данных
.4 Структура нейронной сети и формат
данных
.5 Описание ключевых моментов
реализации приложения
.5.1 Разработка графического
интерфейса
.5.2 Работа с базами данных
средствами Qt
.5.3 Многопоточная работа приложения
.6 Основные принципы взаимодействия
пользователя с системой
Заключение
Список использованных источников
Введение
Бурный рост информатизации общества, рост
доступности персональных компьютеров, увеличение объемов денежных операций с
использованием ПК, развитие информационных коммуникаций типа Internet
существенно повысили требования к уровню достоверности и защищенности
информации каждого участника информационного сообщества.
Информационное сообщество адекватно отвечает
подобным запросам, разрабатывая все более сложные, надежные и эффективные
средства защиты.
Актуальность разработки биометрических систем
безопасности состоит в том, что они позволят существенно уменьшить влияние
человеческого фактора на защитные механизмы. Подобные системы должны
самостоятельно узнавать своего пользователя и подчиняться только ему.
Решение проблемы разработки подобных систем
классическими средствами, например, статистической обработкой данных, может
оказаться бесперспективным в связи с тем, что в вопросах биометрической
идентификации часто приходится использовать множество плохих данных. В этом
плане перспективным оказывается использование искусственных нейронных сетей.
В последние десятилетия в мире активно
развивается новая прикладная область математики, специализирующаяся на искусственных
нейронных сетях (ИНС). Актуальность исследований в этом направлении
подтверждается массой различных применений ИНС. Искусственные нейронные сети
способны решать широкий круг задач распознавания образов, идентификации,
прогнозирования, оптимизации, управления сложными объектами.
Целью дипломной работы является разработка
нейросетевой технологии и программного продукта, осуществляющего биометрическую
идентификацию личности посредством ее клавиатурного почерка.
1. Общие принципы работы систем биометрической
идентификации личности
.1 Структуры систем биометрической
идентификации личности по особенности воспроизведения действий
Биометрические системы, простроенные на анализе
особенностей воспроизведения голоса, рукописного и клавиатурного почерка, имеют
много общего. Это позволяет использовать одну обобщенную блок-схему для
описания всех биометрических систем этого класса, которая приведена на рисунке
1.1 и отображает основные этапы обработки информации [1].
Первым этапом обработки является преобразование
неэлектрических величин (координат конца пера, звукового давления, положения
рук) в электрические сигналы. Далее эти сигналы оцифровываются и вводятся в
процессор, осуществляющий программную обработку данных.

Рисунок 1.1 - Обобщенная блок схема
биометрических систем идентификации личности на основе динамических
характеристик
При программной обработке выполняется
масштабирование амплитуд входных сигналов, приводящее их к некоторому
эталонному значению.
Кроме этого, осуществляется приведение сигналов
к единому масштабу времени, дробление сигналов на отдельные фрагменты с
последующим сдвигом фрагментов сигнала до оптимального совмещения с эталонным
расположением.
После приведения к эталонному значению масштабов
и сдвига фрагментов сигналов осуществляется вычисление вектора функционалов
(вектора контролируемых параметров 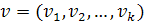 ).
Как правило, вычисляются линейные функционалы, но нет запретов и на вычисление
более сложных нелинейных функционалов [1].
).
Как правило, вычисляются линейные функционалы, но нет запретов и на вычисление
более сложных нелинейных функционалов [1].
Перечисленные выше пять первых блоков обработки
информации работают по одним и тем же алгоритмам, независимо от режима работы
самой биометрической системы. Именно по этой причине они образуют
последовательное соединение блоков без ветвлений. Режим работы системы
(обучение или аутентификация) определяет совокупность операций, далее
осуществляемых с измеренным вектором параметров .
В случае если биометрическая система находится в
режиме обучения, векторы параметров 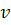 поступают
в блок правил обучения, который формирует биометрический эталон личности. Так
как динамические образы личности обладают существенной изменчивостью, для
формирования биометрического эталон требуется несколько примеров реализаций
одного и того же образа. В простейшем случае биометрический эталон может
формироваться в виде двух векторов: вектора математических ожиданий
контролируемых параметров
поступают
в блок правил обучения, который формирует биометрический эталон личности. Так
как динамические образы личности обладают существенной изменчивостью, для
формирования биометрического эталон требуется несколько примеров реализаций
одного и того же образа. В простейшем случае биометрический эталон может
формироваться в виде двух векторов: вектора математических ожиданий
контролируемых параметров 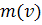 и вектора
дисперсий этих параметров
и вектора
дисперсий этих параметров 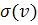 .
.
В режиме аутентификации вектор контролируемых
параметров , полученный из
предъявленного образа, сравнивается решающим правилом с биометрическим
эталоном. Если предъявленный вектор оказывается близок к биометрическому
эталону, принимается положительное аутентификационное решение. При значительных
отличиях предъявленного вектора и его биометрического эталона осуществляется
отказ в аутентификации. Если протокол аутентификации не слишком жесткий, то
пользователю предоставляются дополнительные попытки повторной аутентификации.
Следует подчеркнуть, что вид используемого
системой решающего правила и вид биометрического эталона неразрывно связаны.
Можно считать, что при разработке системы разработчик задается некоторым
решающим правилом и уже оно однозначно определяет вид биометрического эталона
или биометрических данных личности. Формально можно считать, что возможно
существование достаточно большого числа видов различных решающим правил,
соответственно, должно существовать множество различных видом биометрических
эталонов. Однако это не так и на практике используется весьма ограниченное
число достаточно эффективных решающих правил и малое число соответствующих им
биометрических эталонов.
1.2 Особенности применения
нейросетевых решающих правил в системах биометрической идентификации
Обычно деление алгоритма принятия решения на
само решающее правило и биометрический эталон идентифицируемой личности не
вызывает особых затруднений. В этом плане, пожалуй, исключением является
искусственные нейронные сети. Для искусственных нейронных сетей такие параметры
как число входов нейрона, число нейронов, вид функции возбуждения, число слоев
сети, вид связей в сети, скорее всего следует рассматривать как параметры
структуры решающего правила. Значения нейровесов и значения смещающих
коэффициентов, полученные для конкретной личности, следует рассматривать как
параметры некоторого биометрического эталона, предназначенного для
нейросетевого решающего правила с конкретной структурой [1].
Еще одной особенностью нейросетевых решающих
правил является существенное перераспределение вычислительных ресурсов,
затрачиваемых на обучение и аутентификацию. Как правило, оказывается, что
обучение нейронных сетей требует существенно больше вычислительных ресурсов в
сравнении с аутентификацией (самим принятием решения) [3, 4]. Для большинства
классических решающих правил формирование биометрического эталон вообще
является тривиальной задачей, не требующей особых ресурсов, и сводится к
вычислению математических ожиданий и дисперсий. Для нейросетевого принятия
решения настройка весовых коэффициентов сети - это далеко не простая задача,
которая подчас не может быть решена в рамках приемлемых затрат вычислительных
ресурсов. Автомат, настраивающий искусственную нейронную сеть на реальных
биометрических данных, часто попадает в тупики обучения, требующие огромных
затрат вычислительных ресурсов для последующего выхода из них [2]. Для того
чтобы исключить попадание настраивающего нейросеть автомата в тупики обучения,
следует уметь эти тупики отслеживать и обходить их стороной, экономя тем самым
затрачиваемые на обучение ресурсы.
1.3 Измерение близости образа к
биометрическому эталону мерой Хемминга
Описанная обобщенная блок-схема системы
биометрической аутентификации (идентификации) во многом носит абстрактный
характер. Наполним эту блок-схему конкретным содержанием, задавшись одним из
самых простых решающих правил и меру Хемминга [5]. Будем считать, что система
идентификации осуществляет измерение вектора ,
состоящего из 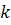 существенно
коррелированных биометрических параметров. Кроме того, будем считать, что
личность на этапе идентификации предъявила
существенно
коррелированных биометрических параметров. Кроме того, будем считать, что
личность на этапе идентификации предъявила 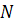 своих
динамических образов, и соответственно, мы имеем реализаций
векторов
своих
динамических образов, и соответственно, мы имеем реализаций
векторов 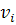 .
.
Проанализировав имеющиеся реализации векторов
биометрических параметров, мы можем найти характерный для личности интервал
изменения каждого конкретного параметра  .
Если теперь при попадании параметра
.
Если теперь при попадании параметра  в
интервал присваивать
в
интервал присваивать
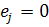 ,
а при выпадении из интервала присваивать
,
а при выпадении из интервала присваивать
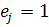 ,
то мы получим вектор Хемминга. Для «Своего» этот вектор должен состоять
практически из одних нулей. Для «Чужого», предъявляющего иные биометрические
параметры, вектор Хемминга будет иметь много несовпадений (много единиц).
,
то мы получим вектор Хемминга. Для «Своего» этот вектор должен состоять
практически из одних нулей. Для «Чужого», предъявляющего иные биометрические
параметры, вектор Хемминга будет иметь много несовпадений (много единиц).
Для рассматриваемого случая биометрическим
эталоном, зафиксированным при обучении, являются значения минимумов и
максимумов измеряемых параметров. Тогда абсолютное значение расстояния Хемминга
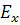 до
биометрического эталона следует определить как общее число выпадений измерений
за интервалы допустимых значений биометрического эталона. Расстояние Хемминга всегда
не отрицательно и может изменяться от 0 до (где
-
число контролируемых биометрических параметров).
до
биометрического эталона следует определить как общее число выпадений измерений
за интервалы допустимых значений биометрического эталона. Расстояние Хемминга всегда
не отрицательно и может изменяться от 0 до (где
-
число контролируемых биометрических параметров).
Число примеров при обучении биометрической
системы может существенно варьироваться. Как правило, биометрические системы,
анализирующие динамические образы, опираясь на меру Хемминга, способны
удовлетворительно работать при их обучении на 5…7 примерах, однако для их
хорошей работы требуется порядка 20…30 примеров [1]. При этом, использование
более 50…60 примеров для обучения системы перестает приносить ощутимые
преимущества.
Следует отметить, что задание в биометрическом
эталоне интервалов допустимых значений измеряемых параметров может
осуществляться различными способами. На малых обучающих выборках целесообразно
осуществлять прямое вычисление минимума и максимума измеренных значений
контролируемых параметров. При объеме обучающей выборки в пять и более примеров
становится целесообразным вычисление математического ожидания значений
параметров 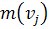 и их дисперсий
и их дисперсий 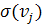 .
А этом случае значение минимальной и максимальной границ принято вычислять
следующим образом:
.
А этом случае значение минимальной и максимальной границ принято вычислять
следующим образом:
 , (1.1)
, (1.1)
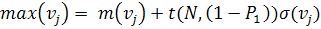 , (1.2)
, (1.2)
где 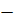 число
использованных при обучении примеров;
число
использованных при обучении примеров; 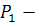 заданное
значение вероятности ошибок первого рода (в этих операциях
заданное
значение вероятности ошибок первого рода (в этих операциях  принимают
равным 0,1);
принимают
равным 0,1); 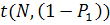 - коэффициенты
Стьюдента, которые приведены в таблице 1.1) [7].
- коэффициенты
Стьюдента, которые приведены в таблице 1.1) [7].
Таблица 1.1 - Коэффициенты Стьюдента
|
Число
примеров
|
Вероятность
ошибки первого рода -  (вероятность
отказа подлинному автору в аутентификации) (вероятность
отказа подлинному автору в аутентификации)
|
|
0,1
|
0,05
|
0,03
|
0,025
|
0,02
|
0,015
|
0,01
|
0,005
|
0,0025
|
|
2
|
3,07
|
6,31
|
10,56
|
12,5
|
15,9
|
21,21
|
31,82
|
63,7
|
127,3
|
|
3
|
1,88
|
2,92
|
3,89
|
4,3
|
4,85
|
5,64
|
6,97
|
9,92
|
14,1
|
|
4
|
1,63
|
2,35
|
2,95
|
3,18
|
3,48
|
3,82
|
4,54
|
5,84
|
7,54
|
|
5
|
1,53
|
2,13
|
2,60
|
2,78
|
2,99
|
3,25
|
3,75
|
4,6
|
5,6
|
|
6
|
1,47
|
2,01
|
2,44
|
2,57
|
2,75
|
3,01
|
3,37
|
4,03
|
4,77
|
|
7
|
1,43
|
1,94
|
2,31
|
2,45
|
2,61
|
2,83
|
3,14
|
3,71
|
3,32
|
|
8
|
1,41
|
1,89
|
2,24
|
2,36
|
2,51
|
2,72
|
3
|
3,5
|
4,03
|
|
9
|
1,39
|
1,86
|
2,19
|
2,37
|
2,45
|
2,63
|
2,9
|
3,36
|
3,83
|
|
10
|
1,38
|
1,83
|
2,15
|
2,26
|
2,4
|
2,57
|
2,82
|
3,25
|
3,69
|
|
12
|
1,36
|
1,8
|
2,09
|
2,16
|
2,33
|
2,49
|
2,72
|
3,11
|
3,49
|
|
14
|
1,35
|
1,77
|
2,06
|
2,14
|
2,28
|
2,43
|
2,65
|
3,01
|
3,37
|
|
21
|
1,33
|
1,73
|
1,99
|
2,09
|
2,19
|
2,33
|
2,53
|
2,85
|
3,15
|
|
41
|
1,3
|
1,68
|
1,93
|
2,02
|
2,12
|
2,25
|
2,42
|
2,7
|
2,97
|
|
∞
|
1,28
|
1,65
|
1,89
|
1,96
|
2,06
|
2,18
|
2,33
|
2,58
|
2,81
|
При вычислении математического ожидания
контролируемого параметра может использоваться обычная формула [6]
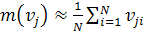 . (1.3)
. (1.3)
Основным недостатком (1.3) является то, что при
обучении приходится помнить значения всех измеренных ранее параметров. Эта
проблема усугубляется тем, что в неопределенном будущем может понадобиться
дообучение биометрической системе и, следовательно, при использовании (1.3)
приходится хранить все данных обучении неопределенно долго. Более удобным для
реализации является рекуррентное вычисление математического ожидания:
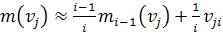 . (1.4)
. (1.4)
При использовании (1.4) приходится помнить
только общее число уже использованных примеров и текущее значение
математического ожидания. На каждом последующем шаге появляется новое значение
математического ожидания и запоминается 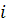 число учтенных
примеров [17].
число учтенных
примеров [17].
Аналогичная ситуация возникает и при вычислении
дисперсии контролируемых параметров. Если хранятся все значения измеренных
параметров, то может быть использована обычная форма вычисления:
 . (1.5)
. (1.5)
При необходимости экономии памяти используется
рекуррентное вычисление дисперсии:
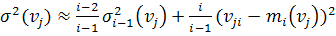 . (1.6)
. (1.6)
После того как сформирован биометрический
эталон, возможна реализация процедур аутентификации зарегистрированного
пользователя. При осуществлении процедур аутентификации “Свой” пользователь
достаточно редко ошибается и, соответственно, мера Хемминга оказывается малой.
Иначе обстоит дело при попытках аутентифицироваться “Чужих”. Для “Чужого”
ошибки оказываются гораздо более частыми. Эта типовая ситуация иллюстрируется
рисунке 1.2, где приведен пример гистограмм “Свой” - “Чужой” биометрической
системы контроля динамики регистрируемого сигнала.

Рисунок 1.2 - Пример гистограмм распределения
значений меры Хемминга
Гистограмма получена для меры Хемминга,
построенной на контроле 80 параметров [1]. Из рисунка 1.2 видно, что для
«Своего» наиболее вероятным отклонением является значение  и
зафиксированное значение меры Хемминга не превосходит 5. Для «Чужого»,
пытающегося подстроить динамику сигнала, мера Хемминга принимает значения от 7
и выше. В качестве разделяющего порога областей «Свой» «Чужой» может быть
принято непопадание в заданные интервалы 6 контролируемых параметров.
и
зафиксированное значение меры Хемминга не превосходит 5. Для «Чужого»,
пытающегося подстроить динамику сигнала, мера Хемминга принимает значения от 7
и выше. В качестве разделяющего порога областей «Свой» «Чужой» может быть
принято непопадание в заданные интервалы 6 контролируемых параметров.
Этот пример соответствует хорошему разделению
областей «Свой» и «Чужой» с достаточно примитивным решающим правилом. Для того
чтобы задать порог, разделяющий эти области, необходимо вычислить значения
математического ожидания меры Хемминга для области «Свой», дисперсию для этой
же области. Тогда можно воспользоваться следующими соотношениями [1]:
«Свой» если 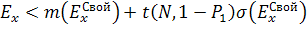 ,
(1.7)
,
(1.7)
«Чужой» если 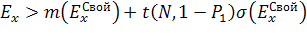 ,
(1.8)
,
(1.8)
где 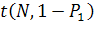 -
коэффициенты Стьюдента;
-
коэффициенты Стьюдента;  - число примеров
при обучении;
- число примеров
при обучении; 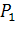 - заданная
вероятность ошибки первого рода для системы в целом (обычно принимается
- заданная
вероятность ошибки первого рода для системы в целом (обычно принимается  .
.
Следует подчеркнуть, что (1.7), (1.8) корректны
только для закона распределения значений меры Хемминга, близкого к нормальному
закону. Нормализация этого закона осуществляется при условии достаточно
большого числа контролируемых параметров 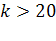 и
выборе достаточно узких диапазонов допустимых значений параметров
биометрического эталона. Искусственное сужение диапазонов осуществлено в
формулах (1.1), (1.2) увеличением вероятности ошибки с
обычной величины 0,01 до 0,1. Опыт показал, что оптимальным является растяжение
области «Свой» с тем, чтобы она занимала от 20% до 40% области возможных
значений меры Хемминга [1]. Это соотношение, с одной стороны, позволяет иметь
закон распределения значений области «Свой», близкий к нормальному, а с другой
стороны, корректно осуществлять сбор информации аудита безопасности путем
наблюдения за поведением «Своих» и «Чужих».
и
выборе достаточно узких диапазонов допустимых значений параметров
биометрического эталона. Искусственное сужение диапазонов осуществлено в
формулах (1.1), (1.2) увеличением вероятности ошибки с
обычной величины 0,01 до 0,1. Опыт показал, что оптимальным является растяжение
области «Свой» с тем, чтобы она занимала от 20% до 40% области возможных
значений меры Хемминга [1]. Это соотношение, с одной стороны, позволяет иметь
закон распределения значений области «Свой», близкий к нормальному, а с другой
стороны, корректно осуществлять сбор информации аудита безопасности путем
наблюдения за поведением «Своих» и «Чужих».
1.4 Евклидова мера близости к центру
биометрического эталона
Наиболее привычным для большинства инженеров
является использование линейного Евклидова пространства и измерение параметров
в виде их проекции на ортонормированную систему координат. Евклидова мера
расстояния между некоторым вектором 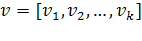 и
центром биометрического эталона
и
центром биометрического эталона  в ортогональной
системе координат находится следующим образом [18]:
в ортогональной
системе координат находится следующим образом [18]:
 . (1.9)
. (1.9)
В векторной форме выражение (1.9) будет
выглядеть несколько иначе:
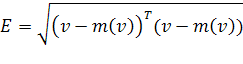 . (1.10)
. (1.10)
Как показывает практика, вычисление Евклидовой
меры дает достаточно хорошие результаты только в действительно ортогональных
системах координат для векторов со слабо коррелированными компонентами. К
сожалению, задача ортогонализации системы измеряемых биометрических параметров
далеко не тривиально и в реальных биометрических системах решается только в
первом приближении. Если же система учитываемых биометрических признаков не
ортогональна, то расстояние до центра биометрического эталона вычисляется через
соответствующий вариант квадратичной формы
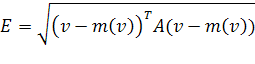 , (1.11)
, (1.11)
где 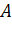 -
положительно определенная квадратная матрица, описывающая взаимосвязь проекции
осей неортогональной системы координат.
-
положительно определенная квадратная матрица, описывающая взаимосвязь проекции
осей неортогональной системы координат.
Из линейной алгебры [8, 18] известно, что любая
система координат может быть ортогонализирована некоторым линейным
преобразованием
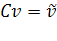 , (1.12)
, (1.12)
Где  -
матрица ортогонализующего преобразования;
-
матрица ортогонализующего преобразования;  -
новые координаты вектора в новой ортогональной системе координат.
-
новые координаты вектора в новой ортогональной системе координат.
В новой ортогональной системе координат
Евклидова мера будет вычисляться следующим образом:
 , (1.13)
, (1.13)
где 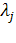 -
характеристические числа положительно определенной матрицы квадратичной
формы (1.11), записанной в исходной системе координат.
-
характеристические числа положительно определенной матрицы квадратичной
формы (1.11), записанной в исходной системе координат.
Следует отметить, что выражение (1.13)
соответствует крайне важному понятию взвешенной Евклидовой меры. Взвешивание
появляется либо при ортогонализации исходно неортогональной системы координат
(1.10), либо является следствием минимизации ошибки вычислений в неортогональной
системе.
Для неортогональных систем координат
использование соотношений (1.9) и (1.10) может приводить к большим ошибкам,
причем эти ошибки подчас оказываются одного знака [1]. Например, для всех точек
I и III
четверти координаты в неортогональной системе могут быть меньше по сравнению с
ортогональной системой. Это приводит к занижению расстояний и может быть
скорректировано с помощью введения некоторых поправочных коэффициентов 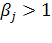 .
Для точек в II и IV четвертях та же косоугольная система дает завышение
значения длин, и оно должно быть скорректировано значениями поправочных
коэффициентов
.
Для точек в II и IV четвертях та же косоугольная система дает завышение
значения длин, и оно должно быть скорректировано значениями поправочных
коэффициентов 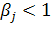 .
.
Точное значение Евклидовой меры дает только
квадратичная форма (1.11), учитывающая комбинационное влияние не нулевых
взаимных проекций осей. Соотношения вида (1.9), (1.10) комбинационных
составляющих не учитывают и, соответственно, с их использованием возможно
только приближенная оценка:
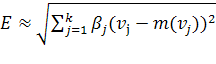 , (1.14)
, (1.14)
где 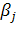 -
положительные весовые коэффициенты, минимизирующие значение ошибки
-
положительные весовые коэффициенты, минимизирующие значение ошибки 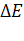 для
наиболее вероятных значений вектора
для
наиболее вероятных значений вектора 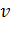 .
.
Задача подбора весовых коэффициентов не
имеет строгого решения, обычно их подбирают, стремясь сохранить их произведение
близким к единице:
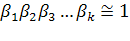 . (1.15)
. (1.15)
В случае использования в биометрических системах
Евклидовой взвешенной меры расстояния роль биометрического эталона играют
вектор математического ожидания значений параметров и вектор весовых
коэффициентов.
1.5 Линейное разделение пространства
контролируемых параметров (персептрон)
Одним из наиболее популярных на сегодня решающих
правил является использование линейных разделяющих функций.
Розенблат [9] дал доказательство теоремы о
возможности обучения персептронов, осуществляющих деление многомерного
пространства значений признаков некоторой гиперплоскостью.
Персептрон описывается следующими уравнениями
[3]:
«Свой» при 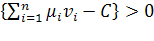 ,
(1.16)
,
(1.16)
«Чужой» при 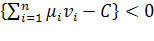 ,
(1.17)
,
(1.17)
где 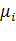 -
весовые коэффициенты, подбираемые при настройке персептрона (при его обучении
на примерах); С - смещающая гиперплоскость постоянная составляющая (подбирается
при настройке).
-
весовые коэффициенты, подбираемые при настройке персептрона (при его обучении
на примерах); С - смещающая гиперплоскость постоянная составляющая (подбирается
при настройке).
Персептрон или искусственный нейрон может быть
представлен как сумматор входных сигналов и некоторый нелинейный элемент
(пороговый элемент - компаратор). Отклик сумматора (линейная часть персептрона)
может быть записан в обычной форме [3]:
 . (1.18)
. (1.18)
Аналогично отклик линейной части персептрона
может быть записан в векторной форме:
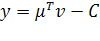 , (1.19)
, (1.19)
где 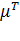 -
вектор строка из
-
вектор строка из 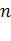 коэффициентов
весового суммирования; - вектор столбец из
измеренных
биометрических параметров.
коэффициентов
весового суммирования; - вектор столбец из
измеренных
биометрических параметров.
Удобнее всего рассматривать суть персептронов,
реализующих линейные разделяющие правила, на их простейшем варианте с двумя
входами. В этом случае задача синтеза оптимального решающего правила сводится к
проведению на плоскости прямой, наилучшим образом разделяющей множества
биометрических параметров "Свой" и "Чужой". Пример решения
этой задачи приведен на рисунке 1.3
Рисунок иллюстрирует тот факт, что путем
вращения и сдвига исходной системы координат иногда удается добиться полного
разделения областей "Свой" и "Чужой", разместив их в разных
четвертях новой системы координат. Следует подчеркнуть, что на рисунке (1.3)
изображена достаточно простая ситуация с одинаковыми корреляционными связями
параметров областей "Свой" и "Чужой", последнее несколько
упрощает задачу в силу параллельности главных осей эллипса "Свой" и
эллипса "Чужой". Для ситуации равных корреляционных связей внутри
вектора биометрических параметров поиск оптимального поворота системы координат
совпадает с решением задачи декорреляции биометрических параметров [1].
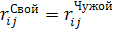 (1.20)
(1.20)
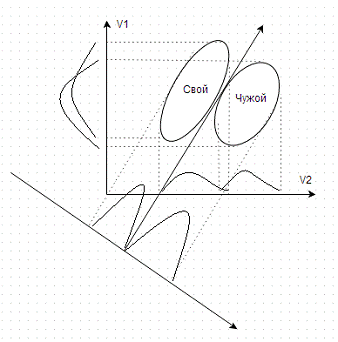
Рисунок 1.3 - Декоррелирующий поворот системы
координат, позволяющий добиться линейной разделимости множеств
Для получения оптимального преобразования
системы координат необходимо домножить вектор входных параметров на соответствующую
декорреляционную матрицу 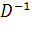 , ослабляя,
насколько это возможно, взаимное влияние биометрических параметров [1]:
, ослабляя,
насколько это возможно, взаимное влияние биометрических параметров [1]:
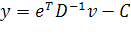 , (1.21)
, (1.21)
где 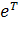 -
вектор-строка единичных весовых коэффициентов.
-
вектор-строка единичных весовых коэффициентов.
Соотношение (1.20) эквивалентно получению
весовых коэффициентов персептрона (нейрона) суммированием элементов
декоррелирующей матрицы:
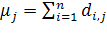 , (1.22)
, (1.22)
где  -
элементы декоррелирующей матрицы ;
-
элементы декоррелирующей матрицы ;
 -
номер строки элемента матрицы;
-
номер строки элемента матрицы; 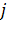 - номер столбца
соответствующего элементов матрицы .
- номер столбца
соответствующего элементов матрицы .
Следует подчеркнуть, что основным достоинством
процедуры вычисления весовых коэффициентов персептрона (нейрона) вида (1.22)
является ее детерминированность. Детерминированность вычислительных процедур
является весьма важным свойством для биометрических систем, так как эти системы
должны гарантированно обучаться на нескольких предъявленных примерах и поиск
весовых коэффициентов должен быть осуществлен за достаточно малый интервал
времени. Процедуры декорреляции, построенные на обращении матриц или их
ортогональном разложении, имеют квадратичную сложность, в то время как другие
известные алгоритмы, построенные на подборе параметров, имеют экспоненциальную
сложность по отношению к числу входов нейрона.
В настоящее время известно более сотни алгоритмов
стохастического итерационного подбора значений весовых коэффициентов [10],
однако каждый из них следует с осторожностью применять в биометрии с
определенной осторожностью. Применение итерационных методов случайного подбора
весовых коэффициентов линейной части нейрона, во-первых, может длиться
неограниченное время (зацикливание), во-вторых, могут быть получены ошибочные
значения коэффициентов, соответствующие одному из локальных минимумов функции
настройки. Все это делает случайные методы настройки (подбора) нейровесов  нежелательными
в биометрических системах, так как они достаточно часто приводят систему в один
из возможных тупиков настройки.
нежелательными
в биометрических системах, так как они достаточно часто приводят систему в один
из возможных тупиков настройки.
Кроме того, различные методы случайного подбора
(поиска) коэффициентов следует
рассматривать лишь как способы некоторого сокращения времени полного перебора
всех возможных комбинаций значений нейровесов. С этой точки зрения
детерминированные процедуры вычисления нейровесов через синтез декоррелирующей
матрицы и суммирование ее элементов всегда будут иметь максимально возможную
скорость "поиска" решения.
Следует обратить особое внимание на то, что все
проведенные выше рассуждения относятся к достаточно простой ситуации, когда
области "Свой" и "Чужой" имеют одинаковые коэффициенты
внутренней корреляции между параметрами (главные оси эллипсов обоих областей
параллельны). Эта простейшая ситуация не приводит к неопределенности при
синтезе матрицы декорреляции по исходным
корреляционным матрицам 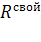 и
и 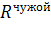 в
силу их полной тождественности [1].
в
силу их полной тождественности [1].
Неопределенность возникает только в том случае,
когда 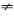 .
В этом случае преобразование системы координат для устранения корреляционных
связей биометрических параметров подлинного пользователя не может привести к
аналогичному результату для других пользователей. Выход из этой неоднозначной
ситуации состоит в усреднении корреляционных матрицы областей «Свой» и «Чужой».
.
В этом случае преобразование системы координат для устранения корреляционных
связей биометрических параметров подлинного пользователя не может привести к
аналогичному результату для других пользователей. Выход из этой неоднозначной
ситуации состоит в усреднении корреляционных матрицы областей «Свой» и «Чужой».
Можно показать, что для областей «Свой» и
«Чужой», соответствующих многомерному нормальному закону распределения значений
и имеющих разные коэффициенты корреляции между одноименными параметрами,
оптимальным будет являться преобразование системы координат, диагонализирующее
следующую корреляционную матрицу:
 +
+ 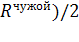 .
(1.23)
.
(1.23)
При диагонализации матрицы (1.23) получается
новая система координат
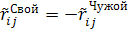 . (1.24)
. (1.24)
Естественно, что стартовые условия для синтеза
декоррелирующей матрицы в виде (1.23) оказываются достаточно точны только для
нормального многомерного закона распределения значений. Однако с ростом
размерности матриц необходимость в гипотезе о нормальном распределении
ослабевает, так как сказывается эффект нормализации суммы большого числа
случайных отклонений. Сказывается то, что диагонализация корреляционной матрицы
выполняется не сама по себе, а только с целью последующего суммирования
линейной частью персептрона.
Кроме подбора весовых коэффициентов
искусственного нейрона (персептрона) еще одной важной задачей является
правильный выбор смещающей постоянной составляющей. Произвольное изменение
значения постоянной составляющей приводит
к появлению множества параллельных разделяющих прямых. Необходимо, исходя из
некоторых соображений, выбрать одну из множества разделяющих прямых. В общем
случае эта задача оказывается неоднозначной и достаточно сложной, но она имеет
простое точное решение в рамках гипотезы нормального закона распределения
плотностей  и
и  .
Если гипотеза нормального закона хорошо выполняется, то постоянная может
быть найдена путем проведения разделяющей линии через точку равновероятных
ошибок первого и второго рода [1].
.
Если гипотеза нормального закона хорошо выполняется, то постоянная может
быть найдена путем проведения разделяющей линии через точку равновероятных
ошибок первого и второго рода [1].
Точка равновероятных ошибок первого рода (отказ
подлинному владельцу биометрии) и ошибок второго рода (пропуск злоумышленника)
находится, исходя из условия
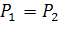 , (1.25)
, (1.25)
где -
площадь хвоста распределения «Свой», отсеченного справа порогом 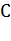 ;
;
 -
площадь хвоста распределения «Чужой», отсеченного слева порогом .
-
площадь хвоста распределения «Чужой», отсеченного слева порогом .
В свою очередь, выполнения (1.25) можно легко
добиться, зная значения весовых коэффициентов 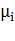 .
Для этого достаточно предъявить почти настроенному персептрону несколько
примеров подлинных биометрических образов и математическое ожидание
.
Для этого достаточно предъявить почти настроенному персептрону несколько
примеров подлинных биометрических образов и математическое ожидание 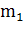 и
стандарт отклонения
и
стандарт отклонения  области «Свой».
Кроме того, необходимо предъявить почти настроенному персептрону несколько
образов биометрии «Чужой» и вычислить для них математическое ожидание
области «Свой».
Кроме того, необходимо предъявить почти настроенному персептрону несколько
образов биометрии «Чужой» и вычислить для них математическое ожидание 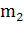 и
стандарт отклонения
и
стандарт отклонения 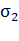 . После этого точка
равновероятных ошибок находится путем деления отрезка
. После этого точка
равновероятных ошибок находится путем деления отрезка  пропорционально
стандартам и .
Расстояние до точки от центра
биометрического эталона может быть вычислено следующим образом:
пропорционально
стандартам и .
Расстояние до точки от центра
биометрического эталона может быть вычислено следующим образом:
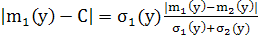 . (1.26)
. (1.26)
Аналогично может быть вычислено расстояние от
проекции разделяющей линейной функции (дискриминанты) до центра второй области
«Чужой»:
 . (1.27)
. (1.27)
Очевидно, что, пользуясь уравнениями (1.26),
(1.27), нетрудно найти положение проекции линейной разделяющей функции
(гиперплоскости), близкое к оптимальному. При необходимости положение проекции
разделяющей линии дополнительно может быть уточнено путем требуемого изменения
соотношения между вероятностями ошибок первого и второго рода. Проекция линии
(гиперплоскости) может быть сдвинута в любую сторону из точки равновероятных
ошибок.
1.6 Проблемы обучения искусственных
нейронных сетей
Нейронные сети (линейные и нелинейные) являются
естественным способом поиска общего решения через объединение множества частных
решений, полученных по группам биометрических данных. Основной проблемой
применения искусственных нейронных сетей является их обучение или проблема
поиска значений нейровесов нейронов и коэффициентов смещения.
Под обучением нейронной сети биометрической
системы будем понимать процесс предъявления ей примеров группы биометрических
образов «Свой» и «Чужой», а также подбор весов нейронов с тем, чтобы сеть могла
с заданной вероятностью ошибок разделять эти две группы биометрических образов.
На сегодня известно порядка сотни алгоритмов обучения искусственных нейронных
сетей [10, 11]. Все известные алгоритмы обучения сетей следует разделить на два
больших класса:
· обучение с учителем;
· самообучение сетей без учителя.
Наиболее важным для биометрии является обучении
с учителем, причем обучение с квалифицированным и добросовестным учителем,
искренне желающим обучить систему. Изначально учитель должен предоставить
системе достоверную и достаточно полную информацию о вариантах воспроизведения
распознаваемого биометрического образа. Если учитель недобросовестен и преднамеренно
дает искаженные образы, то биометрическая система в принципе не должна на них
обучаться. В этом случае биометрическая система должна сама отказаться от
обучения, задокументировав свой отказ от обучения и избежав тем самым
преднамеренной или неумышленной компрометации.
Обучение без учителя на сегодня представляет для
биометрии достаточно абстрактный интерес. На сегодня нет примеров эффективного
практического применения обучения без учителя существующих биометрических
систем [1].
Следует подчеркнуть, что функция отказа от
обучения «Не могу обучиться» является стандартной для различных программных
пакетов обучения искусственных нейронных сетей. Однако при этом, как правило,
на функцию отказа от обучения разработчики пакета сваливают все свои огрехи. Как
следствие, функция отказа постоянно срабатывает, перекладывая ответственность
за принятое решение на учителя. В биометрических системах этого делать нельзя,
так как системы должны быть максимально дружественны по отношению к
пользователю. Они должны снимать с пользователя (учителя) интеллектуальную
нагрузку. В этом плане пакеты настройки нейросети биометрических систем должны
кардинально отличаться от аналогичных универсальных пакетов. Программы
настройки нейросети биометрических систем должны быть гораздо более
корректными, более глубоко и детально анализировать качество исходного
материала и возможные тупики настройки. Кроме того, они должны гарантировать
вполне определенное качество обучения и не вводить в заблуждение «потенциальных
пользователей» завышенными или заниженными показателями.
Учитывая отмеченное выше, можно утверждать, что
биометрические программы настройки нейросетей должны быть построены на
тщательном анализе различных дефектов исходных компонент процесса обучения. Они
должны быть способны численно измерять значения дефектов, если требуется
обходить выявленные и измеренные дефекты однозначно и быстро, осуществляя
процесс обучения.
2. Описание и реализация
программного продукта
.1 Постановка задачи
Необходимо разработать программный продукт,
предназначенный для осуществления аутентификации пользователя на основе
динамических характеристик его биометрии, в частности на основе его
особенностей ввода данных с клавиатуры. Такое программное обеспечение в
процессе своего функционирования должно решать следующие основные задачи:
- чтение данных с клавиатуры и
выявление особенностей ввода текста пользователем;
- выполнение идентификации
пользователя;
- выполнение аутентификации
пользователя.
Кроме того, разрабатываемое приложение должно
отвечать следующим требованиям:
- наличие понятного пользователю
графического интерфейса;
- обеспечение возможности хранения
данных, полученных от пользователя на протяжении всего времени работы
приложения; исключение необходимости осуществления повторного ввода данных,
необходимых для функционирования приложения;
- обеспечение функционирования
приложения для любого количества пользователей;
- обеспечение возможности исключения
пользователя из списка пользователей, успешно аутентифицируемых системой;
- наличие функционала для уточнения
особенностей ввода текста пользователем с целью повышения точности его
аутентификации;
- осуществление контроля любых попыток
аутентификации пользователей.
2.2 Программные инструменты,
примененные при разработке приложения
В рамках поставленной задачи было разработано
приложение, отвечающее перечисленным требованиям. Для этого были применены
следующее программное обеспечение и технологии:
- язык программирования C++;
- среда разработки Visual
Studio 2010;
- Qt:
кросс-платформенный инструментарий разработки ПО;
- библиотека классов BPNeuralNetwork;
- Raw
Input: модель прямого
ввода ОС Windows;
- встраиваемая база данных SQLite.
Разработка прототипа приложения была
осуществлена ранее в виде нескольких отдельных утилит, консольных приложений,
частично решающих перечисленные выше требования. В качестве языка
программирования применялся язык программирования общего назначения C++,
с использованием объектно-ориентированной парадигмы.
2.2.1 Кросс-платформенная библиотека
Qt
Перед началом разработки полноценного
приложения, отвечающего озвученным выше требованиям, было принято решение
продолжать разработку на языке C++.
В качестве инструментария для создания графического интерфейса была выбрана
кросс-платформенная библиотека разработки программного обеспечения Qt,
разработкой которого в данный момент продолжает заниматься финская компания Digia.
Библиотека Qt
в первую очередь предназначена для разработки программного обеспечения на языке
программирования C++, однако
также существуют её «привязки» ко многим другим языкам программирования, таким
как Python, Ruby,
Java, PHP
и другие.
Qt позволяет
запускать написанное с его помощью программное обеспечение в большинстве
современных операционных систем путём простой компиляции программы для каждой операционной
системы без изменения исходного кода. Включает в себя все основные классы,
которые могут потребоваться при разработке прикладного программного
обеспечения, начиная от элементов графического интерфейса и заканчивая классами
для работы с сетью, базами данных и XML. Qt является полностью
объектно-ориентированным, легко расширяемым и поддерживающим технику
компонентного программирования.
Отличительная особенность Qt
от других библиотек - использование Meta
Object Compiler
(MOC) - предварительной
системы обработки исходного кода (в общем-то, Qt
- это библиотека не для чистого C++,
а для его особого наречия, с которого и «переводит» MOC
для последующей компиляции любым стандартным C++
компилятором). MOC
позволяет во много раз увеличить мощь библиотек, вводя такие понятия, как слоты
и сигналы. Кроме того, это позволяет сделать код более лаконичным. Утилита MOC
ищет в заголовочных файлах на C++
описания классов, содержащие макрос Q_OBJECT,
и создаёт дополнительный исходный файл на C++,
содержащий метаобъектный код [12].
Qt позволяет
создавать собственные плагины и размещать их непосредственно в панели
визуального редактора. Также существует возможность расширения привычной
функциональности виджетов, связанной с размещением их на экране, отображением,
перерисовкой при изменении размеров окна.
2.2.2 Библиотека классов BPNeuralNetwork
Для моделирования искусственной нейронной сети
применялись возможности самописной библиотеки BPNeuralNetwork.
Она представляет собой библиотеку классов, реализующих искусственную нейронную
сеть, моделирующую персептрон. Она содержит классы Neuron,
Layer и NeuralNet,
которые моделируют сущности нейрон, слой и нейронная сеть соответственно.
Поскольку библиотека написана с применением объектно-ориентированной парадигмы,
то она предоставляет возможности для расширения её функциональности путем
наследования перечисленных классов и разработки собственных реализаций
нейронных сетей. Так, в состав библиотеки входят классы NeuronBP,
LayerBP и NeuralNetBP,
которые реализуют частный случай персептрона - многослойный персептрон по
Румельхарту.
Обучение такого персептрона проводится по методу
обратного распространения ошибки, являющегося градиентным алгоритмом обучения с
учителем.
На рисунке 2.1 представлена UML-диаграмма
библиотеки BPNeuralNetwork.
2.2.3 Модель прямого ввода ОС Windows
Raw
Input
В операционной системе Microsoft Windows
ловушкой, или хуком (hook) называется механизм перехвата событий с
использованием особой функции (таких как передача сообщений Windows, ввод с мыши
или клавиатуры) до того, как они дойдут до приложения. Эта функция может затем
реагировать на события и, в некоторых случаях, изменять или отменять их [13].
Эта модель перехвата сообщений имеет ряд
недостатков с точки зрения разработчиков приложений. Так, для получения ввода
от нестандартного устройства приложение должно выполнить значительное число
операций: открыть устройство, периодически его опрашивать, заботиться о
возможности параллельного использования устройства другим приложением и т.д.

Рисунок 2.1 - UML-диаграмма
библиотеки классов BPNeuralNetwork
Поэтому в последних версиях операционной системы
Windows была предложена альтернативная модель ввода, названная моделью прямого
ввода, упрощающая разработку приложений, использующих нестандартные устройства
ввода [14].
Модель прямого ввода отличается от оригинальной
модели ввода Windows. В обычной модели приложение получает устройство -
независимый ввод в форме сообщений (таких как WM_CHAR), которые посылаются окнам
приложения. В модели прямого ввода приложение должно зарегистрировать
устройства, от которых оно хочет получать ввод. Далее приложение получает
пользовательский ввод через сообщение WM_INPUT. Поддерживается два способа
передачи данных - стандартный и буферизированный; для интерпретации введенных
данных приложению нужно получить информацию о природе устройства ввода, что
можно сделать с помощью функции GetRawInputDeviceInfo.
В виду ряда достоинств новой модели прямого
ввода - простоты реализации и эффективности - именно она была использована для
реализации клавиатурного перехватчика.
2.2.4 Система управления базами
данных SQLite
SQLite - легковесная встраиваемая реляционная
база данных. Она не использует парадигму клиент-сервер, то есть движок SQLite
не является отдельно работающим процессом, с которым взаимодействует программа,
а предоставляет библиотеку, с которой программа компонуется и движок становится
составной частью программы. Таким образом, в качестве протокола обмена
используются вызовы функций (API) библиотеки SQLite. Такой подход уменьшает
накладные расходы, время отклика и упрощает программу. SQLite хранит всю базу
данных (включая определения, таблицы, индексы и данные) в единственном
стандартном файле на том компьютере, на котором исполняется программа. Простота
реализации достигается за счёт того, что перед началом исполнения транзакции
записи весь файл, хранящий базу данных, блокируется; ACID-функции достигаются в
том числе за счёт создания файла журнала.
База данных SQLite
была использована при разработке приложения для организации длительного
хранения информации о характеристиках ввода текста пользователями, структуре
нейронной сети, ее весах и другой информации. Описание структуры базы данных
будет рассмотрено в следующих разделах.
Предпочтение SQLite
перед другими системами управления базами данных обусловлено такими факторами,
как простота использования, наличие драйверов для SQLite
в Qt по умолчанию.
Кроме того, движок SQLite
и интерфейс к ней реализованы в одной библиотеке, что увеличивает скорость
выполнения запросов. Такой сервер часто называют встроенным. Встроенный сервер
имеется у других СУБД, например, у MySQL,
однако его использование требует лицензионных отчислений.
2.3 Описание базы данных
В процессе разработки приложения, отвечающего
требованиям, перечисленным ранее, были создана база данных, основным
содержанием которой являются 9 таблиц, предназначенных для хранения
разнообразной информации, необходимой для корректной работы приложения.
При первом запуске приложения большая часть
таблиц не содержит данных, при этом содержимое некоторых таблиц не подлежит
обновлению в процессе работы с приложением; такие таблицы должны быть
«инициализированы» ранее. Таким образом, дистрибутив приложения
распространяется с подготовленной базой данных.
Рассмотрим подробнее структуру разработанной
базы данных.
Таблица 2.1 - Структура таблицы Users
|
Поле
|
Тип
|
Описание
|
|
Id
|
Integer
|
Идентификатор
пользователя
|
|
Name
|
Varchar
|
Имя
пользователя
|
В таблице 2.1 описана структура таблицы Users.
Эта таблица хранит информацию о зарегистрированных пользователях системы. До
тех пор пока в таблице Users
информация о пользователе отсутствует, он не может приступить к процессам его
идентификации или аутентификации.
Таблица 2.2 - Структура таблицы KeyCombinations
|
ПолеТипОписание
|
|
|
|
Id
|
Integer
|
Идентификатор
буквосочетания
|
|
Сombination
|
Varchar
|
Двухбуквенная
строка-значение
|
В таблице 2.2 описана структура таблицы KeyCombinations.
Эта таблица хранит информацию о буквосочетаниях, набор которых пользователем
контролируется приложение с целью уточнения его особенностей набора текста. В
данной таблице хранится только пятьдесят значений, которые являются наиболее
частыми буквосочетаниями русского языка. Информация из таблицы частотности
двухбуквенных буквосочетаний [15] была отсортирована по абсолютной частоте, что
позволило получить информацию о группе наиболее вероятных сочетаний: ст, то,
но, на, по, ен, ни, ко, ра, ов, не, ро, пр, ал, го, ре, ос, ли, ка, во, ер, та,
от, ва, ор, ол, ет, те, ом, ан, ел, од, ть, ла, он, ле, ло, ес, ат, ри, ль, де,
ог, ве, ны, ти, за, ит, ск, да.
Решение об ограничении количества контролируемых
параметров обосновывается необходимостью минимизировать количество неизвестных
значений, которые в дальнейшем интерпретируются нейронной сетью как отсутствие
сигнала, т.е. поступают на её входы в виде нулевых значений. При этом частота,
с которой выбранные буквосочетания встречаются в текстах на русском языке,
позволяет достаточно быстро считать необходимые для предсказуемой работы
нейронной сети данные.
В таблице 2.3 описана структура таблицы
KeyPressSessions. Эта таблица хранит информацию о сессиях набора текста
пользователем. Добавление новых значений в таблицу происходит в процессе
считывания характеристик клавиатурного почерка пользователя. Потребность в
создании сущности сессии набора текста появилась в связи с необходимостью
выделения информации об особенностях ввода текста в отдельные примеры для
обучения нейронной сети.
Таблица 2.3 - Структура таблицы KeyPressSessions
|
Поле
|
Тип
|
Описание
|
|
Id
|
Integer
|
Идентификатор
сессии
|
|
UserId
|
Integer
|
Идентификатор
пользователя
|
|
DataAdded
|
Date
|
Дата
создания
|
Таблица 2.4 - Структура таблицы KeyPressData
|
Поле
|
Тип
|
Описание
|
|
Id
|
Integer
|
Идентификатор
характеристики
|
|
SessionId
|
Integer
|
Идентификатор
сессии
|
|
CombinationId
|
Integer
|
Идентификатор
буквосочетаний
|
|
TimeValue
|
Integer
|
Временной
интервал между нажатиями клавиш буквосочетания
|
В таблице 2.4 описана структура таблицы KeyPressData.
Данная таблица предназначена для хранения характеристик клавиатурного почерка
пользователей. Для каждой характеристики указывается текущая сессия,
идентификатор буквосочетания, а также временной интервал в миллисекундах между
отпусканием одной клавиши и нажатием следующей. Очевидно, значения в поле TimeValue
могут принимать отрицательные значения, что характерно для пользователей,
обладающих техникой слепой печати.
В процессе заполнения данными таблицы KeyPressData
осуществляется контроль за объемом полученных данных для текущей сессии. Если
для большей части буквосочетаний данные уже предоставлены, происходит создание
очередной сессии (сущность KeyPressSessions). Сохранение последующих временных
интервалов осуществляется с указанием идентификатора вновь созданной сессии.
В таблице 2.5 описана структура таблицы NeuralNets,
которая предназначена для хранения общей информации о нейронной сети, такой как
её наименование и дата создания.
Таблица 2.5 - Структура таблицы NeuralNets
|
Поле
|
Тип
|
Описание
|
|
Id
|
Integer
|
Идентификатор
нейронной сети
|
|
Name
|
Varchar
|
Наименование
|
|
DateCreated
|
Date
|
Дата
создания
|
Таблица 2.6 - Структура таблицы NeuralNetSettings
|
Поле
|
Тип
|
Описание
|
|
Id
|
Integer
|
Идентификатор
веса
|
|
NetId
|
Integer
|
Идентификатор
нейронной
сети
|
|
LayerNum
|
Integer
|
Номер
слоя
|
|
NeuronFrom
|
Integer
|
Номер
нейрона предыдущего слоя
|
|
NeuronTo
|
Integer
|
Номер
нейрона текущего слоя
|
|
WeightValue
|
Float
|
Значение
веса
|
В таблице 2.6 описана структура таблицы NeuralNetSettings,
которая предназначена для хранения весов обученной сети. Её заполнение
осуществляется после каждого удачного обучения нейронной сети в приложении.
В таблице 2.7 описана структура таблицы
NeuralNetDetails. Она хранит описание структуры каждой нейронной сети таблицы NeuralNets.
Таблица 2.7
- Структура таблицы NeuralNetDetails
|
Поле
|
Тип
|
Описание
|
|
Id
|
Integer
|
Идентификатор
значения
|
|
NetId
|
Integer
|
Идентификатор
нейронной
сети
|
|
LayerNum
|
Integer
|
Номер
слоя
|
|
NeuronCount
|
Integer
|
Количество
нейронов в слое LayerNum
|
Таблица 2.8 - Структура таблицы NeuralNetUsers
|
Поле
|
Тип
|
Описание
|
|
Id
|
Integer
|
Идентификатор
соотношения
|
|
NetId
|
Integer
|
Идентификатор
нейронной
сети
|
|
UserId
|
Integer
|
Идентификатор
пользователя
|
|
OutputNum
|
Integer
|
Номер
выхода, соответствующего пользователю с идентификатором UserId
|
В таблице 2.8 описана структура таблицы NeuralNetUsers.
Эта таблица предназначена для хранения соответствия между пользователями и
выходами нейронной сети. Наличие такой информации необходимо в связи с тем, что
в приложении существует возможность обучения нейронной сети (идентификации) на
примерах произвольных пользователей системы, данные о клавиатурном почерке
которых внесены в базу данных.
В таблице 2.9 описана структура таблицы UserAuthentications.
Она предназначена для хранения данных об успешных аутентификациях пользователей
в системе. Вместе с информацией о том, какой пользователь был аутентифицирован,
когда это произошло, в таблицу записывается информация о том, на сколько
процентов нейронная сеть была уверена в предоставленном результате
аутентификации.
В таблице 2.10 описана структура таблицы TextFragments.
Данная таблица с простой структурой предназначена для хранения текстов, которые
отображаются в приложении для удобства пользователя во время его работы с
модулями предъявления особенностей набора текста и аутентификации. Данные этой
таблицы не подлежат обновлению в приложении, поэтому таблица должна быть
заполнена данными до начала работы с программой.
Таблица 2.9 - Структура таблицы UserAuthentications
|
Поле
|
Тип
|
Описание
|
|
Id
|
Integer
|
Идентификатор
авторизации
|
|
UserId
|
Integer
|
Идентификатор
пользователя
|
|
AccessDate
|
Date
|
Дата-время
авторизации
|
|
Accurancy
|
Float
|
Точность,
с которой пользователь был распознан нейронной сетью
|
Таблица 2.10 - Структура таблицы TextFragments
|
Поле
|
Тип
|
Описание
|
|
Id
|
Integer
|
Идентификатор
авторизации
|
|
Text
|
Text
|
Текст
|
2.4 Структура нейронной сети и
формат данных
биометрический идентификация
нейронный сеть
Для решения задачи распознавания клавиатурного
почерка средствами библиотеки классов BPNeuralNetwork
была применена искусственная нейронная сеть типа персептрон, обучение которой
осуществлялось на основе алгоритма обратного распространения ошибки. Была
выбрана следующая структура сети:
- пятьдесят нейронов во входном слое;
- десять нейронов во внутреннем слое;
- по одному нейрону для каждого
пользователя в выходном слое.
Обучающие данные формируются следующим образом:
за каждым входом закрепляется одно из буквосочетаний, которые находятся в
таблице KeyCombinations
базы данных, т.е. контролируемое приложением. В процессе прямого
распространения сигнала в нейронной сети на ее входы подаются временные
значения, полученные от пользователей для соответствующего буквосочетания,
нормализованные относительно отрезка [-1;1]. Каждый выходной нейрон в процессе
обучения учится принимать значения 0 или 1 по следующему правилу:
 , (2.1)
, (2.1)
где i
- номер пользователя, которому принадлежит входной вектор значений.
2.5 Описание ключевых моментов
реализации приложения
Разработка приложения велась с применением
возможностей библиотеки Qt
версии 4.8.0. Она разделена на большое количество модулей, из которых были
использованы следующие:
· QtCore - классы ядра библиотеки,
используемые другими модулями;
· QtGui - компоненты графического
интерфейса;
· QtSql - набор классов для работы с
базами данных с использованием языка структурированных запросов SQL.
Модуль QtCore содержит базовую функциональность,
основные классы библиотеки, используемые во всех остальных модулях. Модуль QtGui
применен для разработки графического интерфейса пользователя.
Функциональность модуля QtSql
позволила избежать зависимости от особенностей реализации конкретного
интерфейса доступа к базе данных. Разработанное приложение работает с базой
данных SQLite, однако,
все что требуется для перехода к использованию другой базы данных - это замена
драйвера доступа к базе данных, при этом практически никаких изменений кода не
потребуется.
Кроме того, применение классов модуля QtSql
позволило упростить решение некоторых других задач.
2.5.1 Разработка графического
интерфейса
С целью упрощения разработки пользовательского
интерфейса использовалась кросс-платформенная среда Qt
Designer, которая входит в
состав дистрибутива Qt
framework. Она позволяет
разрабатывать графические интерфейсы пользователя при помощи ряда инструментов.
Существует панель инструментов «Панель виджетов», в которой доступны для использования
элементы интерфейса - виджеты, такие как, например, «выпадающий список»
ComboBox, «поле ввода» LineEdit, «кнопка» PushButton и многие другие. Каждый
виджет имеет свой набор свойств, определяемый соответствующим ему классом
библиотеки Qt. Свойства виджета могут быть изменены при помощи «Редактора
свойств». Для каждого класса свойств виджета существует свой специализированный
редактор [16]. Характерной особенностью Qt Designer является поддержка
визуального редактирования сигналов и слотов.
Созданное в Qt
Designer представление
сохраняется в файл в XML-формате,
который подлежит конвертации в C++
код при помощи утилиты uic.
В результате будет получен модуль, содержащий код создания и инициализации
элементов графического интерфейса. Для того чтобы воспользоваться полученным
модулем в собственной программе, необходимо его импортировать и вызвать метод
класса, содержащегося в методе, передав ему в качестве параметра собственную
реализацию виджета Qt.
В качестве примера рассмотрим реализацию
главного окна приложения. В библиотеке Qt
существует класс QMainWindow,
предназначенный для реализации главного приложения. Главное окно предоставляет
структуру для создания пользовательского интерфейса приложения. QMainWindow
имеет собственный компоновщик, в который можно добавлять панель инструментов,
строку меню и строку состояния. Компоновщик имеет центральную область, которая
может быть занята любым стандартным или пользовательским виджетом.
Для того чтобы получить разработать собственный
виджет (в частности, главное окно приложения), необходимо наследовать класс,
обладающий базовой функциональностью, а затем реализовать необходимую
функциональность, добавляя новые методы или переопределяя существующие.
class VisKeyRec : public QMainWindow
{_OBJECT
public:(QWidget *parent = 0,
Qt::WFlags flags = 0);
~VisKeyRec();
// собственные методы и поля …
private:
Ui::VisKeyRecClass
ui;
// приватные методы и поля …
private
slots:on_actionAddUser_triggered();
signals:dbSelected(QString);
};
В коде, представленном выше, осуществляется
объявление собственного класса, реализующего функциональность главного окна.
Скрытое поле с класса Ui::VisKeyRecClass
является классом, полученным с помощью Qt
Designer. Объект ui
содержит метод setipUi(QWidget*),
который должен быть вызван в конструкторе класса главного окна, в результате
чего произойдет наполнение класса виджетами, указанными при конструировании
пользовательского интерфейса.
В результате указанных операций будет получен
класс, содержащий необходимые элементы пользовательского интерфейса. В
дальнейшем от программиста требуется разработка поведения размещенных элементов
интерфейса, осуществления взаимодействия объектов между собой.
Механизм сигналов и слотов Qt
предназначен для связывания объектов друг с другом, коммуникации между собой.
Связанным объектам нет необходимости что-либо "знать" друг о друге.
Сигналы и слоты гораздо удобнее механизма функций обратного вызова (callbacks)
и четко вписываются в концепцию ООП.
Для использования этого механизма объявление
класса должно содержать специальный макрос Q_OBJECT на следующей строке после
ключевого слова class:
class MyClass {_OBJECT:
//...
};
Сигнал срабатывает в том момент, когда
происходит определенное событие. Слот - это функция, которая вызывается в ответ
на определенный сигнал. Виджеты Qt имеют большое количество предопределенных
сигналов и слотов, при этом разработчик всегда можем создать собственные
сигналы и слоты в своих классах.
Например, собственный сигнал может быть
определен следующим образом:
class MyClass: public QObject
{_OBJECT:
//...
signals:
void
mySignal();
};
Для того чтобы инициировать сигнал (выслать
сигнал) нужно использовать ключевое слово emit.
void MyClass ::sendMySignal()
{mySignal();
}
Также, сигналы могут использовать параметры для
передачи дополнительной информации.
Для соединения сигналов и слотов можно
использовать статический метод connect, определенный в классе QObject. В общем
виде соединение выглядит следующим образом:
connect(sender, SIGNAL(signal),
receiver, SLOT(slot));
и receiver - это указатели на QObject, signal и
slot - сигнатуры сигнала и слота.
Пример соединения:
QObject::connect(spinBox,
SIGNAL(valueChanged(int)),slider, SLOT (setValue(int)));
В приведенном выше примере, сигнал, возникающий
при каждом изменении объекта spinbox, связывается с соответствующим слотом
объекта slider. Вызов слота slider.setValue(int) происходит автоматически при
каждом возникновении сигнала spinBox.valueChanged(int).
Существует множество различных вариантов
соединения сигналов и слотов.
Один сигнал может быть соединен со многими
слотами:
connect(slider,
SIGNAL(valueChanged(int)),spinBox, SLOT(setValue (int)));(slider,
SIGNAL(valueChanged(int)),this, SLOT(updateStatusBar Indicator(int)));
При возникновении сигнала, слоты вызываются один
за другим, порядок не определен.
Множество сигналов могут быть соединены с
единственным слотом:
connect(sender0,
SIGNAL(overflow()),receiver1, SLOT(handleMath Error()));(sender1,
SIGNAL(divisionByZero()),receiver1, SLOT(handleMath Error()));
Сигналы могут быть соединены между собой:
connect(sender1,
SIGNAL(function1()),receiver, SIGNAL(function2()));
При возникновении первого сигнала, автоматически
генерируются все связанные сигналы. Не считая этого, соединение сигнал-сигнал
неотличимо от соединения сигнал-слот.
Любой элемент графического интерфейса в Qt
может быть отдельным окном. Разработка остальных модулей приложения
осуществляется аналогичным образом. Для них в качестве контейнеров были
использованы собственные классы-наследники qt-классов
QWidget и QDialog.
Класс QWidget является базовым для всех объектов
пользовательского интерфейса.
Виджет - это элементарный объект
пользовательского интерфейса: он получает события мыши, клавиатуры и другие
события от оконной системы и рисует свое изображение на экране. Виджет, не
встроенный в родительский виджет, называется окном. Обычно окно имеет рамку и
полосу с заголовком, хотя используя соответствующие флаги окна можно создать
окно без такого внешнего оформления. В Qt QMainWindow и разнообразные подклассы
QDialog являются наиболее распространёнными типами окон.
Каждый конструктор виджета принимает один или
два стандартных аргумента:*parent = 0 является родителем нового виджета. Если
он равен 0 (по умолчанию), новый виджет будет окном. Если нет, то он будет
потомком для parent, и будет подчиняться геометрии родителя parent (за
исключением случая, когда вы назначите ему флаг Qt::Window, как флаг
окна).::WindowFlags f = 0 (там, где это возможно) устанавливает флаги окна;
значение по умолчанию подходит почти для всех виджетов, но, например, чтобы
получить окно без рамки, предусмотренной системой, необходимо использовать
специальные флаги.
2.5.2 Работа с базами данных
средствами Qt
Qt дает возможность создания
платформо-независимых приложений для работы с базами данных, используя
стандартные СУБД. Qt включает драйвера для Oracle, Microsoft SQL Server, Sybase
Adaptive Server, IBM DB2, PostgreSQL, MySQL и ODBC-совместимых баз данных.
Работа с базами данных в Qt происходит на
различных уровнях:
Слой драйверов - Включает классы QSqlDriver,
QSqlDriverCreator, QSqlDriverCreatorBase, QSqlDriverPlugin и QSqlResult. Этот
слой предоставляет низкоуровневый мост между определенными базами данных и
слоем SQL API.
Слой SQL API - Этот слой предоставляет доступ к
базам данных. Соединения устанавливаются с помощью класса QSqlDatabase.
Взаимодействие с базой данных осуществляется с помощью класса QSqlQuery. В
дополнение к классам QSqlDatabase и QSqlQuery слой SQL API опирается на классы
QSqlError, QSqlField, QSqlIndex и QsqlRecord.
Например, следующий код демонстрирует установку
соединения с базой данных SQLite,
где переменная name
хранит адрес файла базы данных:
db =
QSqlDatabase::addDatabase("QSQLITE");.setDatabaseName(name);
(!db.open())
{
// код обработки ошибки соединения
}
Слой пользовательского интерфейса - этот слой
связывает данные из базы данных с дата-ориентироваными виджетами. Сюда входят
такие классы, как QSqlQueryModel, QSqlTableModel и QSqlRelationalTableModel.
При разработки приложения был использован класс
QSqlQueryModel. Этот класс предоставляет модель данных в режиме только для
чтения для результата SQL-запроса.
Модель используется как источник данных для виджетов отображения информации в
табличном виде. В частности, такой подход в приложении использовался для
отображения информации об имеющихся в базе данных пользователях и нейронных
сетях.
Для того чтобы отобразить набор записей,
соответствующий результату запроса, необходимо предварительно настроить модель:
QSqlQuerModel
usersModel->setQuery(getUsersQuery());
// set model columns
view>setHeaderData(1, Qt::Horizontal, tr("Имя пользователя"),
Qt::DisplayRole);
// прочая настройка модели
После чего нужно указать созданный объект в
качестве модели представления данных:
userTableView->setModel(usersModel);>show();
Класс QSqlQuery
обеспечивает интерфейс для выполнения SQL
запросов и навигации по результирующей выборке.
Для выполнения SQL
запросов, просто создают объект QSqlQuery
и вызывают QSqlQuery::exec().
Например, вот так:
QSqlQuery query;.prepare("SELECT
COUNT(*) FROM KeyCombinations");.exec();
Конструктор QSqlQuery
принимает необязательный аргумент QSqlDatabase,
который уточняет, какое соединение с базой данных используется. Если его не
указать, то используется соединение по умолчанию. Если возникает ошибка, exec()
возвращает false. Доступ к
ошибке можно получить с помощью QSqlQuery::lastError().
QSqlQuery
предоставляет единовременный доступ к результирующей выборке одного запроса.
После вызова exec(),
внутренний указатель QSqlQuery
указывает на позицию перед первой записью. Если вызвать метод QSqlQuery::next()
один раз, то он переместит указатель к первой записи. После этого необходимо
повторять вызов next(),
чтобы получать доступ к другим записям, до тех пор пока он не вернет false.
Вот типичный цикл, перебирающий все записи по порядку:
while (query.next())
{combination =
query.value(0).toInt();count = query.value(0).toInt();() << combination
<< count;
}
QSqlQuery
может выполнять не только SELECT,
но также и любые другие запросы. Следующий пример вставляет запись в таблицу,
используя INSERT:
QSqlQuery
query;
query.exec("INSERT INTO
NeuralNetDetails (netId, layerNum, neuronCount) VALUES (1, 2, 3)");
2.5.3 Многопоточная работа
приложения
Поскольку обучение нейронной сети - достаточно
долгий процесс, требующий существенных затрат процессорного времени, то во
избежание замораживания графического интерфейса во время обучения нейронной
сети были применены возможности потоков Qt.
Qt предоставляет поддержку потоков в виде платформо-независимых потоковых классов,
потокобезопасного способа отправки событий и возможности установки соединений
сигнал-слот между потоками. Это облегчает создание переносимых многопоточных
приложений и использование преимуществ многопроцессорных машин.
Экземпляр QThread представляет собой поток и
предоставляет средства для запуска потока функцией start(), которая будет
выполнять переопределенный QThread::run(). Реализация run() для потока - такая
же точка входа, что и функция main() для приложения. Весь код выполняется в
стеке вызовов, который начинается в функции run(), выполняющей новый поток, а
заканчивается при завершении потока, когда происходит возврат из функции.
QThread испускает сигналы, сообщающие о начале или окончании выполнения потока.
Для создания потока создается подкласс QThread и
переопределяется его функция run().
class NeuralNetTeachThread : public
QThread
{_OBJECT:setNet(NeuralNetBP* value)
{= value;
}:*net;run()
{>TeachOffLine();epochCount;res =
net->GetTeachStatus(epochCount);(netTeached(res == 0));
}:netTeached(bool);
};
Таким образом, обучение нейронной сети было
вынесено в отдельный поток, выполняющийся параллельно и позволяющий
пользователю продолжить работу с графическим интерфейсом, работающим в основном
потоке.
2.6 Основные принципы взаимодействия
пользователя с системой
Для начала работы с программой необходимо
указать местоположение файла базы данных, в котором хранится необходимая для
работоспособности приложения информация, а также записи о существующих
пользователях и их характеристиках, если работа с приложением осуществлялась
ранее.
Для этого необходимо выбрать пункт меню «Файл» -
«Указать местоположение БД», либо нажать «Ctrl-O».
На рисунке 2.2 отображен диалога открытия файл базы данных.

Рисунок 2.2 - Диалог открытия файла базы данных
До тех пор, пока не будет выбран нужный файл,
работа с приложением невозможна, поскольку все пункты меню, кроме пункта
«Указать местоположение БД» и «Выход», будут оставаться недоступными.
После того, как необходимый файл будет выбран, в
главном окне приложения отобразится список зарегистрированных пользователей,
если они существуют.
На рисунке 2.3 отображено главное окно
приложения после выбора базы данных.
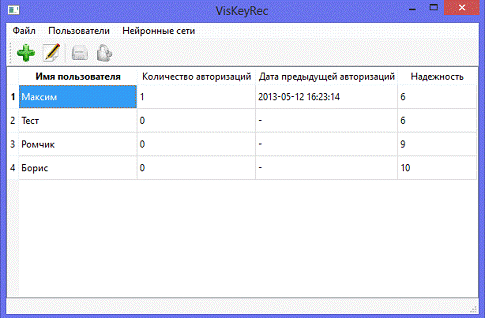
Рисунок 2.3 - Главное окно приложения после
открытия файла базы данных
Для каждого пользователя отображается такая
информация как имя пользователя, количество успешных авторизаций, дата
последней авторизаций и такой параметр как «надежность», которая означает
количество завершенных сессий набора текста, т.е. групп параметров,
характеризующих особенности клавиатурного почерка пользователя.
Для того, чтобы добавить нового пользователя,
необходимо выбрать пункт меню «Пользователи» - «Добавить», либо нажать «Ctrl-N».
После этого в появившемся диалоговом окне нужно ввести имя добавляемого
пользователя и нажать кнопку «Ok».
После этого зарегистрированный пользователь будет отображен в списке
пользователей.
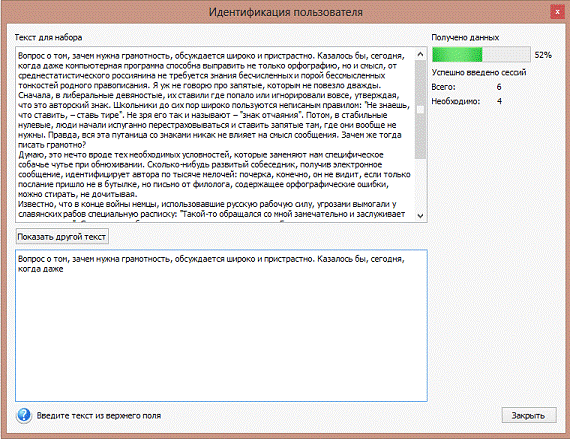
Рисунок 2.4 - Окно модуля предъявления
клавиатурного почерка
Для того чтобы отредактировать имя пользователя
нужно выбрать пункт меню «Пользователи» - «Редактировать», либо нажать «Ctrl-E».
Пункт меню будет доступен только в том случае, если выбран конкретный
пользователь в списке.
Для того чтобы пользователь мог быть в
дальнейшем идентифицирован программой, ему необходимо предоставить фрагменты
собственного клавиатурного почерка. Для этого предназначен модуль
«Идентификация», который доступен при выборе пункта меню «Пользователи» -
«Идентификация», либо по нажатию «Ctrl-I»,
либо по нажатию пиктограммы с изображением клавиши на панели инструментов.
На рисунке 2.4 отображено окно модуля
предъявления клавиатурного почерка.
В данном окне отображается текст для набора и
информацию о прогрессе. Для того чтобы осуществить идентификацию биометрической
системой, пользователю необходимо набрать как минимум 4 сессии, что отображено
в графе «Необходимо».
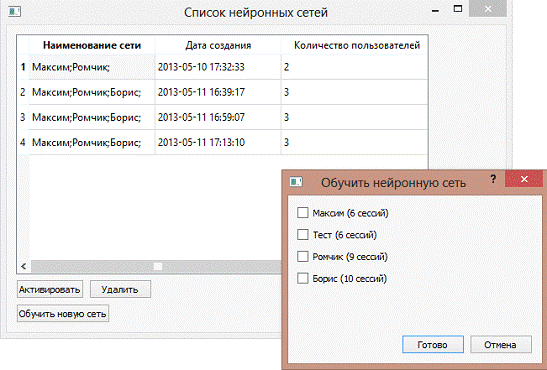
Рисунок 2.5 - Модуль работы с нейронными сетями
Текст, отображаемый в верхней части окна, можно
сменить. Для этого нужно нажать на кнопку «Показать другой текст».
Для завершения работы с модулем нужно нажать
кнопку «Закрыть».
После того, как пользователь ввел необходимый
объем текста, можно приступить к процедуре его идентификации, т.е. обучению
нейронной сети. Список обученных нейронных сетей доступ по выбору пункта меню
«Нейронные сети» - «Открыть список».
В новом окне отображается список обученных ранее
нейронных сетей. Существует возможность их удаления по нажатию на кнопку
«Удалить». Для обучения новой сети нужно нажать на кнопку «Обучить новую».
После чего в диалоговом окне необходимо выбрать пользователей, идентификация
которых должна быть выполнена.
На рисунке 2.5 представлено окно со списком
обученных ранее нейронных сетей, а также диалог выбора пользователей.
После того, как новая нейронная сеть будет
обучена, она будет добавлена в список.
Для того, чтобы иметь возможность выполнить
аутентификацию пользователей на основе одной из обученных сетей, необходимо
выбрать одну из сетей в списке и нажать кнопку «Активировать».
После выбора нейронной сети в главном окне
приложения станет доступен пункт меню «Пользователи» - «Авторизация». При
выборе этого пункта откроется окно с текстом, в котором пользователю необходимо
набрать небольшое количество текста. Данные от пользователя поступают на входы
нейронной сети, отклик которой интерпретируется как успешная либо не успешная
попытка авторизации, по результатам которой на экран будет выведено
информационное сообщение.
Заключение
В рамках данной дипломной работы автором был
разработан программный продукт, предназначенный для осуществления идентификации
и аутентификации личности на основе ее клавиатурного почерка. С целью
разработки графического интерфейса пользователя были изучены и применены
возможности современной кросс-платформенной библиотеки Qt,
что существенно упростило процесс разработки, позволило получить практически
полностью платформо-независимый программный код.
В процессе работы над приложением была применена
объектно-ориентированная парадигма программирования. Такой подход позволил
реализовать принцип модульности программного кода, что должно положительно
сказаться на удобстве и скорости дальнейшей разработки и простоте поддержки
реализованного программного продукта.
Разработанное программное обеспечение позволяет
наглядно продемонстрировать перспективность применения биометрии в задачах
увеличения безопасности хранения и доступа к персональным данным.
Дальнейшая работа над разработанным приложением
должна решать такие задачи, как обеспечение фоновой аутентификации во все время
работы пользователей с персональным компьютером, а также интеграция модуля
авторизации пользователей с системой авторизации операционной системы.
Список использованных источников
1. Иванов
А.И. Нейросетевые алгоритмы биометрической идентификации личности. - М.:
Радиотехника, 2004. - 144 с.: ил.
. Яхъяева
Г.Э. Нечеткие множества и нейронные сети: Учебное пособие. - Интернет-Университет
Информационных Технологий; БИНОМ. Лаборатория знаний, 2006. - 316 с.: ил.,
табл.
3. Хайкин
С. Нейронные сети: полный курс, 2-е издание. : Пер. с англ. - М. : Издательский
дом "Вильямс", 2006. - 1104 с. : ил. - Парал. тит. англ.
4. Осовский
С. Нейронные сети для обработки информации / Пер. с польского И.Д. Рудинского.
- М.: Финансы и статистика, 2002. - 344 с.: ил.
5. Распознавание
образов: состояние и перспективы. / Верхаген К., Дейн Р., Йостен Й., Вербак П.
- М.: Радио и связь, 1985. - 104с.
. Гмурман
В.Е. Теория вероятностей и математическая статистика: Учеб. пособие для вузов.
- 10 изд., стер. - М.: Высш. шк., 2004. - 479 с.: ил.
. Коэффициенты
Стьюдента [Электронный ресурс] / Статья - Электрон. дан.
. Белман
Р. Введение в теорию матриц. - М.: Наука, 1969
. Розенблат
Ф. Принципы нейродинамики. - М.: Мир, 1965, 196с.
10. Уоссермен
Ф. Нейрокомпьютерная техника: Теория и практика. - М.: Мир, 1992, 240с.
11. Горбань
А.Н. Обучение нейронных сетей. - М.: СП ПараГраф, 1990, 156 с.
12. Qt
Documentation
Archive [Электронный
ресурс] / Документация Qt-
Электрон. дан. - Режим доступа: http://doc.qt.digia.com/,
свободный - Загл. с экрана - Яз. англ.
. Клавиатурные
шпионы. Варианты реализации кейлоггеров в ОС Windows. Часть II [Электронный
ресурс] / Документация Qt-
Электрон. дан. - Режим доступа:
http://www.securelist.com/ru/analysis/204007541/
Klaviaturnye_shpiony_Varianty_realizatsii_keyloggerov_v_OS_Windows_Chast_II,
свободный - Загл. с экрана - Яз. рус.
14. Raw
Input [Электронный
ресурс] / Документация прямого ввода - Электрон. дан. - Режим доступа: http://msdn.microsoft.com/en-us/library/windows/desktop/
ms645536(v=vs.85).aspx
свободный - Загл. с экрана - Яз. англ.
. Частотность
двухбуквенных сочетаний [Электронный ресурс] / Статья - Электрон. дан. - Режим
доступа: http://dict.ruslang.ru/freq.php?act=
show&dic=freq_2letters,
свободный - Загл. с экрана - Яз. рус.
16. Qt
Designer
Manual [Электронный
ресурс] / Документация Qt
Designer - Электрон. дан. -
Режим доступа: http://qt-project.org/doc/qt-4.8/designer-manual.html, свободный
- Загл. с экрана - Яз. англ.
17. Рекуррентные
соотношения для дисперсии и математического ожидания [Электронный ресурс] /
Статья - Электрон. дан. - Режим доступа: http://www.nntu.ru/RUS/fakyl/VECH/metod/metod9/part5.htm,
свободный - Загл. с экрана - Яз. англ.
18. Ильин
В.А. Линейная алгебра / В.А. Ильин, Э.Г. Позняк М.: Наука - Физматлит, 1999