Особенности программной реализации моделей всех подсистем операционной системы
Содержание
Введение
. Исследовательская
часть
.1 Алгоритм
замещения страниц «LRU»
.2 Алгоритм
диспетчеризации процессов SRT
.3 Принцип
организации одновременной работы процессов
.4 Связная
последовательность индексов файловых блоков
. Конструкторская
часть
.1 Проектирование
подсистемы управления памятью
.2 Проектирование
подсистемы управления процессами
.3 Подсистема
управления внешними запоминающими устройствами
. Технологическая
часть
Заключение
Список
использованных источников и литературы
Введение
Курсовая работа по дисциплине «Операционные системы» представляет собой
программную модель операционной системы, состоящей из следующих основных
подсистем любой операционный системы: подсистема управления памятью, подсистема
управления внешними запоминающими устройствами (ВЗУ), подсистема управления
процессами, а также механизмы, синхронизирующие работу всех подсистем и
обеспечивающие параллельную работу системы.
Пояснительная записка состоит из 30 листов и содержит 5 частей:
исследовательская часть
конструкторская часть
технологическая часть
список использованных источников и литературы
В исследовательской части описан алгоритм замещения страниц «LRU», алгоритм диспетчеризации процессов
SRT, принцип организации одновременной
работы процессов и особенности организации записи и считывания информации на
ВЗУ с использованием типа связи между файловыми блоками (ФБ) «Связная
последовательность индексов».
В конструкторской части отражаются основные этапы проектирования и
особенности программной реализации моделей всех подсистем ОС.
В технологической части приводятся основные принципы взаимодействия
пользователя с программной моделью ОС, в том числе пользовательский интерфейс.
В списке использованных источников и литературы указаны ссылки на
литературные источники.
1. Исследовательская часть
1.1 Алгоритм замещения страниц «LRU»
В основе неплохого приближения к оптимальному алгоритму лежит наблюдение,
что страницы, интенсивно используемые несколькими последними командами, будут,
скорее всего, снова востребованы следующими несколькими командами. И наоборот,
долгое время невостребованные страницы наверняка еще долго так и останутся
невостребованными. Эта мысль наталкивает на вполне осуществимый алгоритм: при
возникновении ошибки отсутствия страницы нужно избавиться от той страницы,
которая длительное время не была востребована. Эта стратегия называется
замещением наименее востребованной страницы - LRU (Least Recently
Used).
Теоретически реализовать алгоритм LRU вполне возможно, но его практическая реализация
дается нелегко. Для его полной реализации необходимо вести связанный список
всех страниц, находящихся в памяти. В начале этого списка должна быть только
что востребованная страница, а в конце - наименее востребованная. Сложность в
том, что этот список должен обновляться при каждом обращении к памяти. Для
поиска страницы в списке, ее удаления из него и последующего перемещения этой
страницы вперед потребуется довольно много времени, даже если это будет
возложено на аппаратное обеспечение (если предположить, что такое оборудование
можно создать).
Тем не менее существуют другие способы реализации LRU с использованием специального
оборудования. Сначала рассмотрим самый простой из этих способов. Для его
реализации аппаратное обеспечение необходимо оснастить 64-разрядным счетчиком
С, значение которого автоматически увеличивается после каждой команды. Кроме
этого, каждая запись в таблице страниц должна иметь достаточно большое поле,
чтобы содержать значение этого счетчика. После каждого обращения к памяти
текущее значение счетчика С сохраняется в записи таблицы страниц, относящейся к
той странице, к которой было это обращение. При возникновении ошибки отсутствия
страницы операционная система проверяет все значения счетчика в таблице
страниц, чтобы найти наименьшее из них. Та страница, к чьей записи относится
это значение, и будет наименее востребованной.
Теперь рассмотрим второй алгоритм работы аппаратного обеспечения LRU. В машине, имеющей п страничных
блоков, аппаратное обеспечение LRU
может поддерживать изначально нулевую матрицу п на п битов. Как только будет
обращение к страничному блоку k,
аппаратура сначала устанавливает все биты строки k в 1, а затем обнуляет все биты столбца k. В любой момент времени строка с
наименьшим двоичным значением относится к наименее востребованной странице,
строка со следующим наименьшим значением относится к следующей наименее
востребованной странице, и т. д. На рис. 3.16 показана работа этого алгоритма
для четырех страничных блоков, к которым обращение происходит в следующем порядке:
0123210323.
После обращения к странице 0 возникает ситуация, показанная на рис. 1, а.
После обращения к странице 1 возникает ситуация, показанная на рис. 1, б, и т.
д.
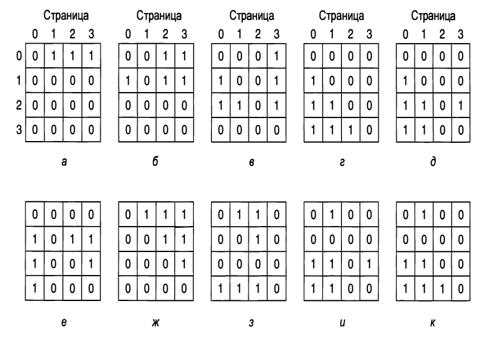
Рис. 1. Использование алгоритмом LRU матрицы при обращении к страницам в
следующем порядке: 0, 1, 2, 3, 2, 1, 0, 3, 2, 3.
При всей принципиальной возможности реализации предыдущего алгоритма LRU вряд ли найдется машина, обладающая
нужным оборудованием. Скорее всего, нам понадобится решение, которое может быть
реализовано в программном обеспечении. Одно из возможных решений называется
алгоритмом нечастого востребования - NFU (Not Frequently Used). Для его реализации потребуется программный счетчик
с начальным нулевым значением, связанный с каждой страницей. При каждом
прерывании от таймера операционная система сканирует всё находящиеся в памяти
страницы. Для каждой страницы к счетчику добавляется значение бита R, равное 0 или 1. Счетчики позволяют
приблизительно отследить частоту обращений к каждой странице. При возникновении
ошибки отсутствия страницы для замещения выбирается та страница, чей счетчик
имеет наименьшее значение.
Основная проблема при использовании алгоритма NFU заключается в том, что он никогда ничего не забывает.
К примеру, при многопроходной компиляции те страницы, которые интенсивно
использовались при первом проходе, могут по прежнему сохранять высокие значения
счетчиков и при последующих проходах. Фактически если на первый проход
затрачивается больше времени, чем на все остальные проходы, то страницы,
содержащие код для последующих проходов, могут всегда иметь более низкие
показатели счетчиков, чем страницы, использовавшиеся при первом проходе.
Вследствие этого операционная система будет замещать нужные страницы вместо
тех, надобность в которых уже отпала.
К счастью, небольшая модификация алгоритма NFU позволяет достаточно
близко подойти к имитации алгоритма LRU. Модификация состоит из двух частей.
Во-первых, перед добавлением к счетчикам значения бита R их значение сдвигается
на один разряд вправо. Во-вторых, значение бита R добавляется к самому левому,
а не к самому правому биту.
На рис. 2 показано, как работает модифицированный алгоритм, известный как
алгоритм старения. Предположим, что после первого прерывания от таймера бит R
для страниц от 0 до 5 имеет, соответственно, значения 1, 0, 1, 0, 1 и 1 (для
страницы 0 оно равно 1, для страницы 1 - 0, для страницы 2 - 1, и т. д.). Иными
словами, между прерываниями от таймера, соответствующими тактам 0 и 1, было
обращение к страницам 0, 2, 4 и 5, в результате которого их биты R были
установлены в 1, а у остальных страниц их значение осталось равным 0. После
того как были смещены значения шести соответствующих счетчиков и слева было
вставлено значение бита R, они приобрели значения, показанные на рис. 2, а. В
четырех оставшихся столбцах показаны состояния шести счетчиков после следующих
четырех прерываний от таймера.
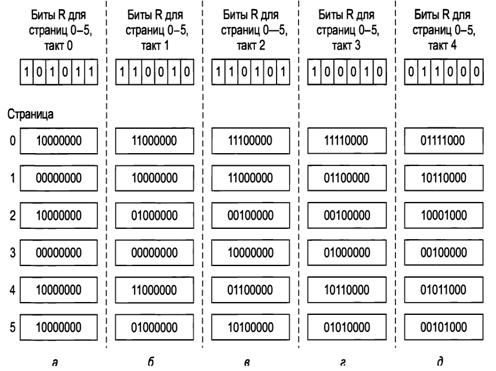
Рис. 2. Алгоритм старения является программной моделью алгоритма LRU. Здесь показаны шесть страниц в
моменты пяти таймерных прерываний, обозначенных буквами от а до д.
операционный
псевдопараллельный диспетчеризация память
При возникновении ошибки отсутствия страницы удаляется та страница, чей
счетчик имеет наименьшее значение. Очевидно, что у страницы, к которой не было
При возникновении ошибки отсутствия страницы удаляется та страница, чей счетчик
имеет наименьшее значение. Очевидно, что у страницы, к которой не было
обращений за, скажем, четыре прерывания от таймера, в ее счетчике будет четыре
ведущих нуля, и поэтому значение ее счетчика будет меньшим, чем у счетчика
страницы, к которой не было обращений в течение трех прерываний от таймера.
Этот алгоритм отличается от алгоритма LRU двумя особенностями. Рассмотрим
страницы 3 и 5 на рис. 2, д. Ни к одной из них за два прерывания от таймера не
было ни одного обращения, но к обеим было обращение за прерывание от таймера,
предшествующее этим двум. В соответствии с алгоритмом LRU если страница должна
быть удалена, то мы должны выбрать одну из этих двух страниц. Проблема в том,
что мы не знаем, к какой из них обращались в последнюю очередь между тактом 1 и
тактом 2. При записи только одного бита за интервал между двумя прерываниями от
таймера мы утратили возможность отличить более раннее обращение от более
позднего. Все, что мы можем сделать, - это удалить страницу 3, поскольку к
странице 5 также было обращение двумя тактами ранее, а к странице 3 такого
обращения не было. Второе различие между алгоритмом LRU и алгоритмом старения
заключается в том, что в алгоритме старения счетчик имеет ограниченное
количество бит (в данном примере - 8 бит), которое сужает просматриваемый им
горизонт прошлого. Предположим, что у каждой из двух страниц значение счетчика
равно нулю. Все, что мы можем сделать, - это выбрать одну из них произвольным
образом. В действительности вполне может оказаться, что к одной из этих страниц
последнее обращение было 9 тактов назад, а ко второй - 1000 тактов назад. И это
обстоятельство установить невозможно. Но на практике 8 бит вполне достаточно,
если между прерываниями от таймера проходит примерно 20 мс. Если к странице не
было обращений в течение 160 мс, то она, наверное, уже не так важна.
1.2 Алгоритм диспетчеризации процессов SRT
Важнейшей частью операционной системы, непосредственно влияющей на
функционирование вычислительной машины, является подсистема управления
процессами. Процесс (или по-другому, задача) - абстракция, описывающая
выполняющуюся программу. Для операционной системы процесс представляет собой
единицу работы, заявку на потребление системных ресурсов. Подсистема управления
процессами планирует выполнение процессов, то есть распределяет процессорное
время между несколькими одновременно существующими в системе процессами, а
также занимается созданием и уничтожением процессов, обеспечивает процессы
необходимыми системными ресурсами, поддерживает взаимодействие между
процессами.
Если в операционной системе планирование осуществляется только в
вынужденных ситуациях, говорят, что имеет место невытесняющее (nonpreemptive)
планирование. Если планировщик принимает и вынужденные, и невынужденные
решения, говорят о вытесняющем (preemptive) планировании. Термин
"вытесняющее планирование" возник потому, что исполняющийся процесс
помимо своей воли может быть вытеснен из состояния исполнение другим процессом.
Невытесняющее планирование используется, например, в MS Windows 3.1 и ОС
Apple Macintosh. При таком режиме планирования процесс занимает столько
процессорного времени, сколько ему необходимо. При этом переключение процессов
возникает только при желании самого исполняющегося процесса передать управление
(для ожидания завершения операции ввода-вывода или по окончании работы). Этот
метод планирования относительно просто реализуем и достаточно эффективен, так
как позволяет выделить большую часть процессорного времени для работы самих
процессов и до минимума сократить затраты на переключение контекста. Однако при
невытесняющем планировании возникает проблема возможности полного захвата
процессора одним процессом, который вследствие каких-либо причин (например,
из-за ошибки в программе) зацикливается и не может передать управление другому
процессу. В такой ситуации спасает только перезагрузка всей вычислительной
системы.
Вытесняющее планирование обычно используется в системах разделения
времени. В этом режиме планирования процесс может быть приостановлен в любой
момент исполнения. Операционная система устанавливает специальный таймер для
генерации сигнала прерывания по истечении некоторого интервала времени -
кванта. После прерывания процессор передается в распоряжение следующего
процесса. Временные прерывания помогают гарантировать приемлемое время отклика
процессов для пользователей, работающих в диалоговом режиме, и предотвращают
"зависание" компьютерной системы из-за зацикливания какой-либо
программы.
Планирование по принципу SRT («по наименьшему остающемуся времени»)
относится к вытесняющему планированию.
По принципу SRT всегда выполняется процесс, имеющий минимальное оценочное
время до завершения, причем с учетом новых поступающих процессов. Выполняющийся
процесс может быть прерван при поступлении нового процесса, имеющего более
короткое оценочное время работы. Чтобы механизм SRT был эффективным, необходимы
достаточно точные оценки будущего, причем разработчик системы должен
позаботиться о мерах против неправильного использования прикладными
программистами особенностей стратегий планирования. Механизм SRT должен следить
за текущим временем обслуживания выполняющегося задания и обрабатывать
возникающие прерывания. Поступающие в систему небольшие процессы будут
выполняться почти немедленно. Реализация принципа SRT требует, чтобы
регистрировались истекшие времена обслуживания, а это приводит к увеличению
накладных расходов. Теоретически принцип SRT обеспечивает минимальные времена
ожидания.
1.3 Принцип организации одновременной работы процессов
Для организации псевдопараллельной работы с каждым из процессов
ассоциируется сегмент памяти, основное назначение которого заключается в
сохранении информации, необходимой для возобновления его работы в дальнейшем.
Эта информация называется контекстом процесса, а сегмент памяти, в котором она
сохраняется, называется сегментом состояния задачи TSS (от англ. Task State Segment - сегмент состояния задачи). Формат TSS в наиболее общем виде приведён на
рис. 3.

Рис.
3. Формат TSS.
Когда
работа процесса A прерывается готовым к выполнению процессом Б, то
процесс А сохраняет свой контекст в своём TSS, а процесс Б
загружает свой контекст из своего. Процесс Б может в свою очередь быть прерван
процессом В и т.д. (рис. 4.).
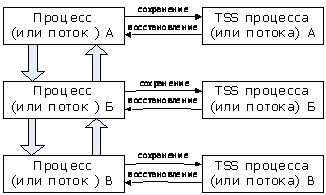
Рис.
4. Организация псевдопараллельной работы процессов.
Селектор
TSS работающего в данный момент процесса помещается в
программно недоступный регистр задачи центрального процессора (для
процессоров Intel - регистр TR). Последовательность
прерванных процессов, с целью возобновления их работы в дальнейшем,
объединяется в односвязный список - селектор TSS прерванного
процесса помещается в поле обратной связи TSS работающего
в данный момент процесса (рис. 5).

Рис.
5. Организация связанного списка из TSS.
Переключение
с одного процесса на другой заключается в использовании команды безусловного
перехода или команды вызова процедуры (для процессоров Intel - jmp и
call соответственно) с логическим адресом, селектор
которого индексирует дескриптор TSS нового процесса (рис.6).

Рис.
6. Формат дескриптора TSS.
Ещё
одним способом переключения на новый процесс (как правило, на более
привилегированный) является использование в этих командах логического адреса
шлюза задачи. Формат дескриптора шлюза задачи в наиболее общем виде приведён на
рис. 7.

Рис.
7. Формат дескриптора шлюза задачи
Рис. 8.