Нелинейная организация данных
1. Нелинейная организация данных
1.1 Древовидная организация данных
Нелинейная организация данных - это множество записей, каждая
из которых связана с произвольным количеством предшествующих и последующих
записей. Наиболее используемыми вариантами нелинейной организации данных
являются деревья и нелинейные списки.
Деревом называется множество записей, расположенных по
уровням по следующим правилам: на первом уровне расположена только одна запись
(корень дерева), к любой записи i-го уровня ведет адрес связи только от одной
записи (i-1) - го уровня. Количество уровней в дереве называется рангом. Для
выполнения задания воспользуемся данным алгоритмом построения упорядоченного
бинарного дерева:
1. Первая запись массива с ключом А1
становится корнем дерева;
2. Значение ключа второй записи А2
сравнивается с А1, находящемся в корне дерева;
. Если А2 < А1, то вторая
запись помещается на левой от корня ветви, в противном случае - на правой
ветви;
. Далее на каждом шаге создается упорядоченное дерево
из первых i записей;
5. Выбор места i-й записи массива в дереве производится
следующим образом. Ключ Аi сравнивается с корневым значением и
выполняется переход по левому адресу, если А1 > Аi.
Если А1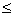 Аi, то по правому адресу.
Ключ, записанный по этому адресу, сравнивается с Аi, и снова
организуется переход по левому или правому адресу до нахождения свободного
места. Если требуемый адрес не заполнен, то он должен адресовать запись с
ключом Аi.
Аi, то по правому адресу.
Ключ, записанный по этому адресу, сравнивается с Аi, и снова
организуется переход по левому или правому адресу до нахождения свободного
места. Если требуемый адрес не заполнен, то он должен адресовать запись с
ключом Аi.
Задание 1. Построить упорядоченное
бинарное дерево со следующими значениями ключевых признаков и подравнять их
(приложить подробный протокол подравнивания со всеми итерациями и описаниями
их): 62, 30, 70, 85, 35, 96, 26, 18, 47, 66, 42, 34, 71, 54, 93.
Построим упорядоченное бинарное дерево для записей с
ключевыми признаками: 62, 30, 70, 85, 35, 96, 26, 18, 47, 66, 42, 34, 71, 54,
93 (рис. 2.1).
Упорядоченное бинарное дерево построено следующим образом:
1. Первая запись с ключом 62 становится корнем дерева;
2. Значение ключа второй записи 30 сравнивается с 62
(30 < 62), запись помещаем на левой от корня ветви;
. Далее сравниваем ключ третей записи 70 с коревым
значением 62 (70 > 62), запись помещаем на правой от корня ветви;
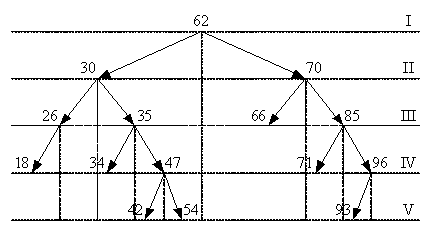
Рисунок 2.1 - Упорядоченное бинарное дерево
4. Сравниваем ключ 85 с коревым значением 62 (85 > 62),
выполняется переход по правому адресу, далее сравниваем значение 85 со
значением 70 (85 > 70), запись помещаем на правой ветви;
5. Сравниваем ключ 35 с коревым значением 62 (35 <
62), выполняется переход по левому адресу, далее сравниваем значение 35 со
значением 30 (35 > 30), запись помещаем на правой ветви;
. Сравниваем ключ 96 с коревым значением 62 (96 >
62), выполняется переход по правому адресу, далее сравниваем значение 96 со
значением 70 (96 > 70), выполняется переход по правому адресу, далее
сравниваем значение 96 со значением 85 (96 > 85), запись помещаем на правой
ветви;
. Сравниваем ключ 26 с коревым значением 62 (26 <
62), выполняется переход по левому адресу, далее сравниваем значение 26 со
значением 30 (26 < 30), запись помещаем на левой ветви;
. Сравниваем ключ 18 с коревым значением 62 (18 <
62), выполняется переход по левому адресу, далее сравниваем значение 18 со
значением 30 (18 < 30), выполняется переход по левому адресу, сравниваем
значение 18 со значением 26 (18 < 26), запись помещаем на левой ветви;
. Сравниваем ключ 47 с коревым значением 62 (47 <
62), выполняется переход по левому адресу, далее сравниваем значение 47 со
значением 30 (47 > 30), выполняется переход по правому адресу, сравниваем
значение 47 со значением 35 (47 > 35), запись помещаем на правой ветви;
. Сравниваем ключ 66 с коревым значением 62 (66 >
62), выполняется переход по правому адресу, далее сравниваем значение 66 со
значением 70 (66 < 70), запись помещаем на левой ветви;
. Сравниваем ключ 42 с коревым значением 62 (42 <
62), выполняется переход по левому адресу, далее сравниваем значение 42 со
значением 30 (42 > 30), выполняется переход по правому адресу, сравниваем
значение 42 со значением 35 (42 > 35), выполняется переход по правому
адресу, сравниваем значение 42 со значением 47 (42 < 47), запись помещаем на
левой ветви;
. Сравниваем ключ 34 с коревым значением 62 (34 <
62), выполняется переход по левому адресу, сравниваем значение 34 со значением
30 (34 > 30), выполняется переход по правому адресу, сравниваем значение 34
со значением 35 (34 < 35), запись помещаем на левой ветви;
. Сравниваем ключ 71 с коревым значением 62 (71 >
62), выполняется переход по правому адресу, далее сравниваем значение 71 со
значением 70 (71 > 70), выполняется переход по правому адресу, далее
сравниваем значение 71 со значением 85 (71 < 85), запись помещаем на левой
ветви;
. Сравниваем ключ 54 с коревым значением 62 (54 <
62), выполняется переход по левому адресу, далее сравниваем значение 54 со
значением 30 (54 > 30), выполняется переход по правому адресу, сравниваем
значение 54 со значением 35 (54 > 35), выполняется переход по правому
адресу, сравниваем значение 54 со значением 47 (54 > 47), запись помещаем на
правой ветви;
. Сравниваем ключ 93 с коревым значением 62 (93 >
62), выполняется переход по правому адресу, далее сравниваем значение 93 со
значением 70 (93 > 70), выполняется переход по правому адресу, далее
сравниваем значение 93 со значением 85 (93 > 85), выполняется переход по
правому адресу, сравниваем значение 93 со значением 96 (93 < 96), запись
помещаем на левой ветви.
На рисунке 2.1 записи со значениями 62, 30, 70, 35, 85, 47
являются полными, т. к. у них заполнены два адреса связи; записи со значениями
26, 96 с одним адресом - неполные; записи 18, 34, 42, 54, 66, 71, 93 с двумя
незаполненными адресами - концевые.
Ранг данного упорядоченного дерева равен 5, т. к. количество
уровней в дереве 5.
Ранг упорядоченного бинарного дерева можно сократить с
помощью специальных преобразований - подравниваний. Если для некоторой записи
длины ее ветвей различаются не более чем на единицу, то она называется
сбалансированной. Бинарное дерево называется подравненным, если все его записи
являются сбалансированными. Для того чтобы подравнять бинарное дерево
необходимо для каждой несбалансированной записи найти соседнюю слева запись,
если у нее левая ветвь длиннее правой, или найти соседнюю справа запись, если правая
ветвь длиннее. Найденная соседняя запись помещается на место
несбалансированной, а сама несбалансированная запись заново включается в
дерево.
В упорядоченном бинарном дереве (рис. 2.1),
несбалансированной записью является запись 70, т. к. у этой вершины разница
ветвей равна 2 (длина левой ветви равна 1, длина правой ветви - 3,
следовательно, 3 - 1 = 2). Все остальные вершины являются сбалансированными.
итерация. Подравняем вершину со значением 70. На место
вершины 70 ставим вершину со значением 85 вместе со всеми вытекающими из нее
вершинами (71, 96, 93), далее перераспределяем вершину 66, затем
перераспределяем вершину 70 (рис. 2.2).
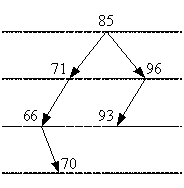
Рисунок 2.2 - Подравнивание вершины 70
итерация. На рисунке 2.2, видно, что несбалансированной
записью является запись 71, т. к. у этой вершины разница ветвей равна 2 (длина
левой ветви равна 2, длина правой ветви - 0, следовательно, 2 - 0 = 2). Все
остальные вершины являются сбалансированными.
Подравняем вершину. На место вершины 71 ставим вершину со
значением 66 вместе с вытекающей из нее вершиной 70, далее перераспределяем
вершину 71 (рис. 2.3).
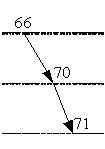
Рисунок 2.3 - Подравнивание вершины 71
3 итерация. Из рисунка 2.3, видно, что несбалансированной
записью является запись 66, у этой вершины разница ветвей равна 2 (длина левой
ветви равна 0, длина правой ветви - 1, следовательно, 2 - 0 = 2). Все остальные
вершины являются сбалансированными.
Выполним подравнивание вершины. На место вершины 66 ставим
вершину со значением 70 вместе с вытекающей из нее вершиной 71, далее
перераспределим вершину 70 (рис. 2.4).
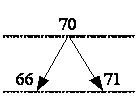
Рисунок 2.4 - Подравнивание вершины 66
В результате преобразований получаем подравненное бинарное
дерево, т. к. все его записи являются сбалансированными (рис. 2.5).
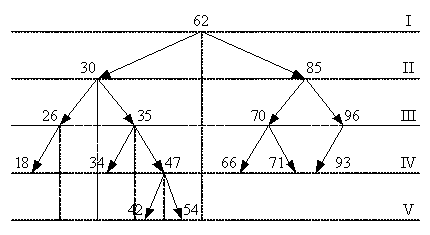
Рисунок 2.5 - Итоговое подравненное бинарное дерево
Задание 2. Проставить в вершинах
бинарного дерева ключевые признаки от 1 до 12 так, чтобы дерево стало
упорядоченным (подравнивать не надо) (рис. 2.6).
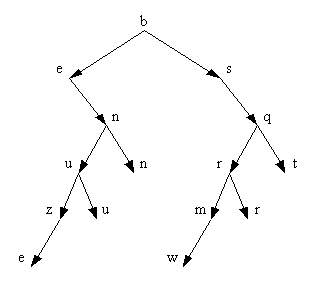
Рисунок 2.6 - Пример головоломки
Проставляя в вершинах бинарного дерева ключевые признаки,
учитывалось то, что записи, обозначенные одинаковыми буквами, имеют равные
значения. По левой ветви располагаются записи с меньшими значениями, по правой
ветви - с большими. В итоге получили упорядоченное бинарное дерево (рис. 2.7).
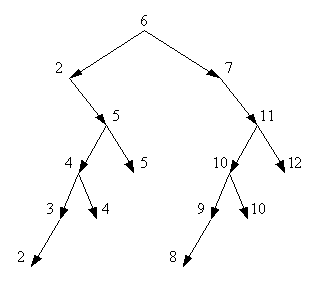
Рисунок 2.7 - Упорядоченное бинарное дерево
1.2
Нелинейные списковые структуры данных
Нелинейный список - множество элементов, каждый из которых
может быть либо записью, либо списком. Структуру списка выражают формулой, в
которой записи помечаются буквами, а списки заключаются в круглые скобки.
Список, включенный в другой список, называется подсписком. Адреса связей,
принадлежащие каждой записи, образуют звено связи. В звене связи
однонаправленного списка два адреса: первый указывает на следующий элемент
списка, второй - на подсписок или запись. Списковые структуры данных могут иметь
два вида представления: с помощью аналитической записи и графической
интерпретации структуры списка.
Аналитическая запись списковой структуры строится по
следующим правилам:
1. В качестве элемента сложного списка может выступать
список любой структуры, который может являться подсписком данного списка;
2. Каждый подсписок заключается в круглые скобки;
. Элементы списка записываются последовательно один за
другим согласно порядку их следования и отделяются друг от друга запятыми;
. Для идентификации (обозначения) элементов списка
могут использоваться как заглавные, так и прописные буквы.
При определении графической структуры списка внешние скобки
всегда отбрасываются, каждой открытой скобке находится соответствующая ей
закрытая скобка; элементы, заключенные в скобки, являются подсписками и
объявляются сложными элементами. Элементы, обозначенные буквами, объявляются
простыми.
Задание 3. Списковая структура
задана аналитическим выражением. Построить графическую интерпретацию данного
списка:
((b, (a, (c, (n)), b), (b, a)), a, (b, (a,
())))
Построим графическую интерпретацию данного списка.
1. Отбросив внешние скобки, перенумеруем оставшиеся
скобки в данном списке:
2.
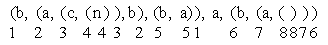
3. Из списка выделяются три элемента, обозначим их:
§ сложный элемент, Подсписок 1 - (b, (a, (c, (n)), b), (b, a));
§ сложный элемент, Подсписок 2 - (b, (a, ())).
4. На первом уровне проставим три звена связи для этих
элементов (рис. 2.8).
5. На втором уровне раскроем сложные элементы:
· Подсписок 1 содержит три элемента:
§ простой элемент - b;
§ сложный элемент, Подсписок 3 - (a, (c, (n)), b);
§ сложный элемент, Подсписок 4 - (b, a).
· Подсписок 2 содержит два элемента:
§ простой элемент - b;
§ сложный элемент, Подсписок 5 - (a, ()).
Таким образом, на втором уровне в графической интерпретации
будут звенья связи трех элементов из Подсписка 1 и двух элементов из Подсписка
2 (всего 5).
6. На третьем уровне раскроем Подсписок 3, Подсписок 4
и Подсписок 5:
· Подсписок 3 содержит три элемента:
§ простой элемент - a;
§ сложный элемент, Подсписок 6 - (c, (n));
§ простой элемент - b.
· Подсписок 4 содержит два элемента:
§ простой элемент - b;
§ простой элемент - a.
· Подсписок 5 содержит два элемента:
§ простой элемент - a;
§ сложный элемент, Подсписок 7 - ().
На третьем уровне в графической интерпретации будут звенья
связи трех элементов из Подсписка 3, двух элементов из Подсписка 4 и Подсписка
5 (всего 7).
7. На четвертом уровне раскроем Подсписок 6, он
содержит два элемента:
§ простой элемент - с;
§ сложный элемент, Подсписок 8 - (n).
На четвертом уровне в графической интерпретации будут звенья
связи двух элементов из Подсписка 6.
8. На пятом уровне раскроем Подсписок 8, он содержит
один простой элемент - n.
На пятом уровне в графической интерпретации будет звено связи
одного элемента из Подсписка 8.
9. На шестом уровне проставим собственные значения
записей: a, b, c, n.
10. Далее, адреса связей каждого звена по уровням
соединяются с соответствующими элементами, им подчиненными.
Графическая интерпретация списка ((b, (a, (c, (n)), b), (b, a)), a, (b, (a, ()))) представлена на
рисунке 2.8.
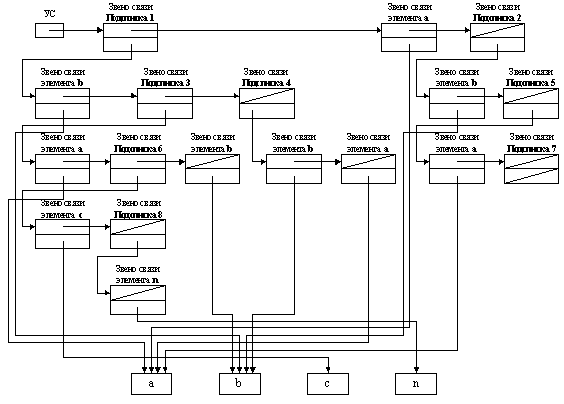
Рисунок 2.8 - Графическая интерпретация списка
2.
Методы ускоренного доступа к данным
2.1 Адресные функции
Ускорение доступа к данным достигается применением
принципиальных методов размещения информации и ее поиска либо путем создания
массивов вспомогательной информации о хранимых данных. Расстановка записей
происходит в соответствии с адресными функциями двух видов: i = A - c и i = ОСТ (A/m).
Адресной функцией называется зависимость i = f(А), где i -
номер (адрес) записи; А - значение ключевого атрибута.
Адресная функция может вырабатывать одинаковое значение i для
значений ключей, принадлежащих разным записям, которые называются синонимами.
Простейшая адресная функция имеет вид: i = А - с, где с -
константа.
Необходимо определить минимальное значение ключевого атрибута
Аmin и максимальное значение Аmax. Тогда с = Аmin
- 1. Необходимый участок памяти для данных должен иметь размер [Аmax
- Аmin + 1] - запись. Записи-синонимы связываются в цепочки с
помощью адресов связи, они занимают дополнительную (резервную) память.
Недостатком адресной функции вида i = А - с является большой
объем неиспользуемой памяти, если Аmax - Аmin много
больше, чем количество записей М исходного массива.
Задание 4. Построить адресную
функцию вида i = A - c, согласно выбранному
варианту.
34, 36, 21, 27, 33, 37, 30, 38, 39, 28, 36, 29,
37, 29, 30, 35, 32
Рассмотрим размещение записей согласно адресной функции i = A - c. Для этого определим
минимальное значение ключевого атрибута Amin и максимальное значение Amax.
Amin = 21, Amax = 39.
Так как c = Amin - 1, тогда получаем c = 21 - 1 = 20,
следовательно, i = A - 20.
Необходимый участок памяти для данных должен иметь размер [Amax - Amin + 1] - запись: [Amax - Amin + 1] = 39 - 21 + 1 = 19
записей.
Определим размещение записей согласно адресной функции, i = A - с:
i = 34 - 20 = 14
i = 36 - 20 = 16
i = 21 - 20 = 1
i = 27 - 20 = 7
i = 33 - 20 = 13
i = 37 - 20 = 17
i = 30 - 20 = 10
i = 38 - 20 = 18 = 39 - 20 = 19 = 28 - 20 = 8 = 36 - 20 = 16 = 29 - 20 = 9 = 37 - 20 = 17 = 29 - 20 = 9= 32 - 20 =
12
Организация данных записей изображена на рисунке 3.1.
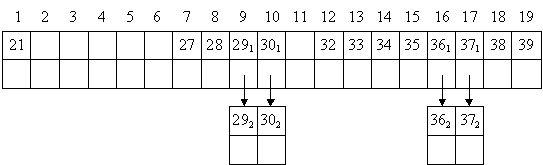
Рисунок 3.1 - Организация записей в соответствии с адресной
функцией вида i = A - с
Указанного выше недостатка (большой объем неиспользуемой
памяти) лишена адресная функция вида i = ОСТ (А/m), где m - целое число; ОСТ -
остаток от деления А на m.
Значение m принимается равным простому числу, которое
непосредственно больше либо меньше числа записей М: m = М ± 1. Выделяются две зоны
памяти - основная и резервная. Основная зона содержит m записей. Резервная зона
предназначена для размещения записей-синонимов. При формировании данных согласно
адресной функции сначала производится заполнение основной зоны. Если при этом
позиция основной зоны, полученная при вычислении, уже занята, то текущая запись
помещается в резервную зону и адресуется из позиции основной зоны. В дальнейшем
при такой ситуации наращивается цепочка записей в резервной зоне.
Задание 5. Построить адресную
функцию вида i = ОСТ (A/m), согласно выбранному варианту.
77, 89, 20, 41, 82, 36, 56, 45, 89, 22, 26, 82,
37, 82, 57, 83, 42
Рассмотрим исходный массив, значение m принимается равным простому числу, которое непосредственно больше
либо меньше числа записей M: 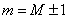 .
.
Определим число записей M и
значение m: M = 17, m =17 - 1 = 16.
Таким образом, адресная функция примет вид: i = ОСТ (A/16).
Определим размещение записей согласно адресной функции, i = ОСТ
(A/m):
i = ОСТ
(77/16) = 13= ОСТ (89/16) = 9= ОСТ (20/16) = 4= ОСТ (41/16) = 9= ОСТ (82/16) = 2= ОСТ (36/16) = 4= ОСТ (56/16) = 8= ОСТ (45/16) = 13= ОСТ (89/16) = 9= ОСТ (22/16) = 6= ОСТ (26/16) = 10= ОСТ (82/16) = 2= ОСТ (37/16) = 5= ОСТ (82/16) = 2= ОСТ (57/16) = 9 = ОСТ (83/16) = 3
i = ОСТ (42/16) = 10
нелинейный бинарный доступ индексируемый
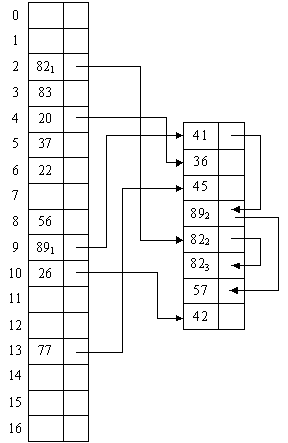
Рисунок 3.2 - Организация записей в соответствии с адресной
функцией вида i = ОСТ (A/m)
Таким образом, доступ к требуемым записям может
осуществляться не только путем сравнения искомого значения ключа с ключами
записей, извлекаемых из массива по определенному алгоритму, но и в результате
вычисления местоположения требуемой записи. Как было выше показано, можно
использовать специальную расстановку записей в памяти компьютера, которая
нарушает типичную при последовательной организации данных упорядоченность
записей по значениям ключевого атрибута.
2.2 Способы организации индексируемого массива
Индексом называется набор адресов и ключей записей, которые
выбираются из основного массива по определённому закону. Отдельный элемент
набора индексов также называется индексом, хотя это не соответствует значению
слова index-список.
Существует несколько различных способов организации
индексируемого массива. Рассмотрим два из них - это индексно-последовательный
массив и рандомизированный индекс.
Индексно-последовательный массив представляет собой
последовательный массив индексов, в который из основного массива выносится
информация о записях, номера которых образуют арифметическую прогрессию с шагом
d > 1, причем первый индекс адресует первую запись. Основной массив,
дополненный таким индексом, обычно называется индексно-последовательным.
Индексы такого типа называются К - индексами (от слова «ключ»).
Шаг арифметической прогрессии для К - индексов равен: 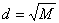 , где M - количество элементов в исходном массиве.
, где M - количество элементов в исходном массиве.
Рандомизированный индекс. Если ключи записей, информация о которых
выносится в индекс, приближенно образуют арифметическую прогрессию, получаем
ситуацию с адресной функцией для индекса (рандомизация индекса), причём первый
индекс адресует первую запись.
Индексы такого типа называются А - индексами (от слова
«адрес»).
Точное описание рандомизированного индекса состоит в следующем. А
- индекс с номером i хранит адрес записи основного массива, ключ которой равен
или непосредственно больше значения: 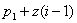 , где z - константа (шаг арифметической прогрессии), р1
- значение ключа первой записи основного массива.
, где z - константа (шаг арифметической прогрессии), р1
- значение ключа первой записи основного массива.
Точной формулы для шага арифметической прогрессии z для А -
индексов не существует, используют формулу: 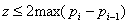 , где pi - значение ключа i-й записи.
, где pi - значение ключа i-й записи.
Задание 6. Построить А - и К - индексы. Вставку провести с учетом значения
55 и удаление с учетом значения 36.
, 52, 33, 66, 29, 36, 34, 41, 38, 37, 23, 34, 29, 33, 24, 57, 35
Упорядочим по возрастанию исходный массив. Массив будет иметь
следующий вид (рис. 3.3, а). Для построения А - и К - индексов вычислим шаг
арифметической прогрессии d, z.
Вычислим шаг арифметической прогрессии для К - индексов:
M = 17, 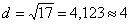 . Получаем К - индексы (рис. 3.3. б).
. Получаем К - индексы (рис. 3.3. б).
Вычислим шаг арифметической прогрессии для А - индексов:
max (52 - 41) = 11, 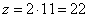 .
.
Определим А - индексы, используя формулу 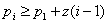 , где pi - значение ключа i-й записи, p1 - значение ключа первой записи, z - шаг арифметической прогрессии:
, где pi - значение ключа i-й записи, p1 - значение ключа первой записи, z - шаг арифметической прогрессии:
z = 22;
p1 = 23, А1
= 0100;
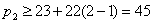 (т. к. в исходном массиве такого значения ключа нет, то выберем
следующее большее, т.е. 52), А2 = 0114. Получаем А - индексы (рис.
3.3. в).
(т. к. в исходном массиве такого значения ключа нет, то выберем
следующее большее, т.е. 52), А2 = 0114. Получаем А - индексы (рис.
3.3. в).

Рисунок 3.3 - Основной массив организации данных (а); К - индексы
с учетом корректировки (б); А - индексы с учетом корректировки (в)
При корректировке записей индексы также должны изменяться:
всегда К - индексы и реже А - индексы. При включении новой записи с ключом q
определяем К - индекс, такой, что Ki-1 £ q < Ki,
где i - номер К - индекса. Затем всем К - индексам с номером i и больше
присваиваем значения ключей и адресов тех записей, которые непосредственно
предшествуют ранее зафиксированным в этих индексах записям основного массива.
Аналогично при удалении записи с ключом q всем К - индексам с номером i и
больше присваиваем значения ключей и адресов тех записей, которые
непосредственно следуют за ранее указанными в этих индексах записями основного
массива. При корректировке массива изменяются меньше значений А - индексов, чем
К - индексов. Значения К - и А - индексов представлены с учетом изменений на
рисунке 3.3 (б, в).
Таким образом, А - индексы целесообразнее К - индексов - они
характеризуются меньшим объемом памяти, необходимым для их размещения, а также
более быстрым поиском при достаточно большом количестве элементов в массиве.
Заключение
При выполнении курсового проекта были изучены теоретические
основы методов и средств описания экономических информационных систем.
Про нелинейную организацию данных необходимо отметить, что по
критерию времени формирования данных бинарное дерево имеет определенные
преимущества перед последовательным массивом, несмотря на то, что процессы
формирования описываются одинаковыми формулами. По времени поиска последовательный
массив и бинарное дерево предпочтительнее списка. Минимальное время
корректировки характерно для бинарного дерева, а минимальный объем памяти - для
последовательного массива.
Анализ методов организации данных показал, что не существует
абсолютно безупречного метода. Поэтому надо выбирать метод организации данных,
исходя из конкретных поставленных перед проектировщиком БД задач. Необходимо
учесть то, что минимальное время (формирования, поиска, корректировки) обычно
считается более важным критерием, чем объем минимальной дополнительной памяти,
и тогда лучшим методом организации данных считается упорядоченное бинарное
дерево.
Что же касается ускорения доступа к данным, то оно
достигается применением принципиальных методов размещения и поиска информации,
либо путем создания массивов вспомогательной информации о хранимых данных. При
использовании адресных функций наиболее рационально использовать адресную
функцию вида i = ОСТ (A/m) при рассмотрении данных, когда [Amax - Amin]
намного больше, чем количество записей исходного массива М, в то время адресная
функция вида i = A - c потребует большие объемы неиспользуемой, но
зарезервированной памяти.
При организации индексируемого массива целесообразнее
использовать А - индексы, так как они характеризуются меньшим объемом памяти,
необходимым для их размещения, более быстрым поиском при достаточно большом
числе записей в массиве, а также более простой корректировкой массива.
Для достижения цели курсового проекта, поставленные задачи
решены в полном объеме.
Выполнение данного курсового проекта позволило получить
необходимые знания, способствующие успешному изучению дисциплин, относящихся к
проектированию и организации компьютерной обработки экономических данных и
внедрению автоматизированных информационных технологий в экономике.
Список литературы
1. Исакова А.И. Теория экономических информационных
систем: Учебное пособие. - Томск: Томский межвузовский центр дистанционного
образования, 2001. - 124 с.
2. Мишенин А.И. Теория экономических информационных
систем: Учебник. - М.: Финансы и статистика, 1993. - 370 с.
. Семенов М.И., Трубилин И.Т., Лойко В.И., Барановская
Т.П. Автоматизированные информационные технологии в экономике. Учебник. - М.:
Финансы и статистика, 2001. - 416 с.: ил.
. Якубайтис Э.А. Информационные сети и системы.
Справочная книга. - М.: Финансы и статистика, 1996. - 368 с.