Анализ тональности текстов на основе ДСМ-метода
Министерство
образования и науки РФ
Федеральное
государственное бюджетное образовательное учреждение высшего профессионального
образования
«Вятский
государственный гуманитарный университет»
ФАКУЛЬТЕТ
ИНФОРМАТИКИ, МАТЕМАТИКИ И ФИЗИКИ
Кафедра
прикладной математики и информатики
КУРСОВАЯ
РАБОТА
Анализ
тональности текстов на основе ДСМ-метода
Выполнил Вычегжанин Сергей
Владимирович
Научный руководитель
Котельников Евгений Вячеславович
Киров
2013
Содержание
Введение
Глава
1. Задача анализа тональности текстов
.1
Понятие анализа тональности текста
.1.1
Определение
.1.2
История
.1.3
Постановка задачи
.1.4
Применение
.2
ДСМ-метод
.2.1
Схема метода
.2.2
Описание метода
.2.3
Алгоритм поиска пересечений
.3
N-кратный скользящий контроль
.4
Метрики качества
.4.1
Правильность и ошибочность
.4.2
Точность и полнота
Глава
2. Практическое исследование ДСМ-метода
.1
Программная реализация
.1.1
Пользовательский интерфейс
.1.2
Входные данные
.1.3
Выходные данные
.2
Текстовая коллекция
.3
Эксперименты и результаты
.3.1
Оценка качества анализа тональности
.3.2
Оценка времени работы программы
Заключение
Библиографический
список
Приложение
Введение
В сети Интернет содержится огромное количество
разнообразных текстов, авторами которых являются обычные пользователи. Это
могут быть статьи в блогах, отзывы на продукты, сообщения в социальных сетях и
т. п. В этом контенте содержится большое количество ценной информации.
В компьютерной лингвистике существует отдельное
направление обработки естественно-языковых текстов - анализ тональности текстов
(sentiment analysis). Тональностью называется эмоциональная оценка, которая
выражена в тексте. Актуальность задачи определения тональности заключается в
том, что на основе текстовой информации можно оценить отношение общества к какому-либо
продукту или событию. Например, с помощью данного анализа можно оценить
успешность рекламной кампании, политических и экономических реформ; выявить
отношение прессы и СМИ к определенной персоне, к организации, к событию;
определить, как относятся потребители к определенной продукции, к услугам, к
организации. Такая информация представляет значительный интерес для
маркетологов, социологов, экономистов, политологов и всех тех специалистов,
деятельность которых зависит от мнений людей.
Существуют два основных подхода к решению задачи
анализа тональности текста: на основе словарей и на основе машинного обучения.
В первом подходе используются словари, содержащие слова и предложения, для
которых известна оценка выраженной в них тональности. Этот подход эффективен
при использовании больших словарей, но процесс их составления весьма
трудоемкий. Второй подход заключается в создании автоматического
классификатора, который использует коллекцию обучающих текстов. В основе этого
подхода лежат статистические методы. Подход эффективен при наличии большой
коллекции обучающих текстов.
Одним из логических методов анализа тональности
текстов является ДСМ-метод автоматического порождения гипотез. В [9]
отмечается, что преимуществом ДСМ-метода по сравнению со статистическими
методами является прозрачность и корректность процесса логического вывода,
хорошая интерпретируемость генерируемых гипотез, отсутствие необходимости
большого числа примеров для обучения.
Целью настоящей курсовой работы является
применение ДСМ-метода для определения тональности текстов. Обозначенная цель
достигается за счет решения следующих задач:
· изучение области анализа тональности
текстов;
· описание ДСМ-метода автоматического
порождения гипотез;
· программная реализация ДСМ-метода;
· проведение экспериментов по
определению тональности текстов;
· анализ результатов влияния
компонентов ДСМ-метода на качество определения тональности.
В первой главе приводится постановка задачи
анализа тональности текстов и примеры областей деятельности, в которых применяется
анализ тональности, рассматриваются теоретические аспекты ДСМ-метода
автоматического порождения гипотез, дается описание показателей, на основе
которых будет сделано заключение о качестве работы метода.
Во второй главе дается описание практической реализации
ДСМ-метода, приводятся результаты тестирования разработанной
программы-анализатора в виде таблиц и графиков.
В заключение работы приводится общий вывод по
полученным результатам и список использованной литературы.
Глава 1. Задача анализа тональности
текстов
.1 Понятие анализа тональности
текста
1.1.1 Определение
Анализ тональности текста (англ. sentiment
analysis, opinion
mining, sentiment
classification) - это
область компьютерной лингвистики, которая занимается изучением мнений и эмоций
в текстовых документах. Анализ тональности представляет собой текстовую
классификацию, т. е. процесс присвоения естественно-язычным текстам
тематической категории из определенного набора.
Под мнением (тональностью) понимают выраженное в
тексте эмоциональное отношение некоторого субъекта к определенному объекту [9].
Тональность может иметь одномерное или многомерное эмотивное пространство. В
одномерном пространстве существует одно измерение (одна шкала), в котором может
быть несколько значений - классов (двухбалльная, трехбалльная, n-балльная
шкалы). В многомерном пространстве несколько ортогональных измерений, например,
базовые эмоции - радость, счастье, страх, гнев и т.д.
1.1.2 История
В [5] отмечается, что автоматическая
классификация текстов имеет длительную историю, уходящую в начало 1960-х гг.
Вплоть до конца 1980-х гг. наиболее популярным подходом к классификации
документов была инженерия знаний (knowledge
engineering), заключающаяся в
ручном определении правил, содержащих знания экспертов о том, как определить, к
какой категории относится документ. В 1990-х гг. с бурным развитием
производства и доступности онлайн документов интерес к автоматической
классификации усилился. Новая тенденция, основанная на машинном обучении,
вытеснила предыдущий подход. Эта тенденция заключалась в том, что на основе
индуктивного процесса автоматически создается классификатор путем обучения с
помощью набора предварительно классифицированных документов, характеризующихся
одной или более категориями. Преимуществом является высокая эффективность и
значительное сохранение опыта экспертов.
Проблема автоматического распознавания мнений в
тексте оказалась предметом активных исследований за рубежом сравнительно
недавно - в 2000-х гг. В России таких работ до последнего времени было крайне
мало; только в 2012 году оценка тональности текста была выбрана одной из
главных тем конференции по компьютерной лингвистике «Диалог-2012» [10].
1.1.3 Постановка задачи
Целью анализа тональности является нахождение
мнений в тексте и определение их свойств. Существуют разные задачи в
зависимости от исследуемых свойств текстов, например, определение автора
мнения, т. е. кому принадлежит это мнение; определение темы, т. е. о чем
говорится во мнении; определение тональности, т. е. позиция автора относительно
объекта, о котором говорится во мнении.
Перед тем, как сформулировать обобщенную
постановку задачи анализа тональности, формально определим понятие мнения. В
соответствии с [3] мнение обозначим множеством вида
 ,(1)
,(1)
где  (entity) - сущность (объект), по
отношению к аспектам которой выражается мнение;
(entity) - сущность (объект), по
отношению к аспектам которой выражается мнение;  (aspect) - i-й аспект
сущности (свойство объекта), по отношению которому выражается мнение;
(aspect) - i-й аспект
сущности (свойство объекта), по отношению которому выражается мнение; 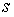 (sentiment)
- тональность мнения по отношению к i-му аспекту
сущности
(sentiment)
- тональность мнения по отношению к i-му аспекту
сущности 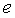 ;
;  (holder) -
выразитель мнения (субъект);
(holder) -
выразитель мнения (субъект);  (time) - время выражения мнения.
Если мнение выражается по отношению к сущности в целом, а не к отдельному её
аспекту, то устанавливается
(time) - время выражения мнения.
Если мнение выражается по отношению к сущности в целом, а не к отдельному её
аспекту, то устанавливается  .
.
Обобщенную задачу анализа
тональности можно сформулировать в следующем виде: в заданном тексте 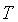 найти все
мнения вида (1).
найти все
мнения вида (1).
Приведем несколько основных вариантов
задач анализа тональности, описанных в работе [9].
. Определение исключительно
тональности текста.
Данная формулировка задачи анализа
тональности является наиболее простой. Рассматривается только тональность мнения,
которое выражено в тексте (часто предполагается, что оно единственное); при
этом остальные компоненты множества (1) не выделяются или считаются известными.
Обычно тональность  представлена
определенной шкалой. Выделяют следующие типы шкал:
представлена
определенной шкалой. Выделяют следующие типы шкал:
) Двухзначная шкала. Шкала
тональности имеет только два значения -положительная тональность и
отрицательная.
) Трехзначная шкала. К предыдущим
двум вариантам добавляется третье значение - нейтральное, которое может
обозначать либо отсутствие тональности, либо одновременное наличие как
положительной, так и отрицательной тональности.
) Многозначная шкала. Шкала
тональности имеет более 3 значений. Существует множество вариантов таких шкал,
отличающихся количеством значений тональности и наличием нейтрального значения.
. Определение тональности, субъекта
и объекта
В данном варианте задачи кроме
тональности мнения
определяется выразитель  мнения,
субъект и объект , по
отношению к которому выражается мнение. Выражение (1) в данном случае принимает
вид:
мнения,
субъект и объект , по
отношению к которому выражается мнение. Выражение (1) в данном случае принимает
вид:
 .
.
Для решения задачи в такой
постановке кроме методов определения тональности требуется также применение
методов извлечения сущностей из текста.
. Определение мнения в целом
Мнение рассматривается как полное
выражение (1), т. е. по сравнению с предыдущим вариантом кроме выделения
сущности (объекта
мнения) требуется определение её аспектов 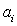 .
.
1.1.4 Применение
Анализ тональности текста является одним из
перспективных направлений компьютерной лингвистики. Это направление
искусственного интеллекта позволяет извлекать разнообразную информацию,
находящуюся в форме текста на естественном языке.
Автоматическое распознавание тональности текстов
находит широкое применение в различных сферах деятельности человека. Приведем
несколько примеров из работы [9].
. Маркетинговые исследования. Проводятся для
разнообразных целей, включая изучение потребительских предпочтений, измерение
степени удовлетворения потребностей потребителей, определение эффективности
распространения продуктов или услуг.
2. Финансовые рынки. В работе [1]
говорится, что о каждом акционерном обществе существуют многочисленные
публикации новостей, статьи, блоги и сообщения в Твиттере. Система анализа тональности
может использовать эти источники для нахождения статей, в которых обсуждаются
такие общества, и извлекать отзывы, что позволит создать автоматическую
торговую систему. Одной из таких систем является «The Stock Sonar»
(<#"699222.files/image014.gif">
Рис. 1 - Схема ДСМ-метода классификации текстов
Для реализации ДСМ-метода используются три
основных компонента: словарь, обучающая коллекция текстов и классифицируемые
тексты. Словарь и обучающая коллекция используются для формирования множества гипотез,
характеризующих принадлежность текста к определенному классу. Гипотезы
сравниваются с фрагментами классифицируемых текстов на предмет совпадения. По
результатам сравнения делается заключение об эмоциональной категории этих
текстов.
Словарь может быть сформирован как автоматически
(содержит без исключения все слова из обучающей коллекции), так и вручную
(содержит только слова, имеющие явно выраженную эмоциональную окраску).
Обучающая коллекция составляется из текстов,
тональность которых известна. Классифицируемая коллекция содержит тексты,
тональность которых неизвестна и ее требуется определить.
1.2.2 Описание метода
ДСМ-метод - это метод автоматического порождения
гипотез. Был предложен В. К. Финном в конце 1970-х гг. Свое название метод
получил от инициалов известного английского философа, логика и экономиста Джона
Стюарта Милля. ДСМ-метод представляет собой формализацию правдоподобных
рассуждений, которая позволяет на основе анализа имеющихся данных формировать
гипотезы о том, какими свойствами могут обладать рассматриваемые объекты.
ДСМ-метод - это синтез трех познавательных процедур - эмпирической индукции,
структурной аналогии и абдукции. В данной работе мы рассмотрим только два этапа
этого метода - этапы индукции и аналогии.
В соответствии с [8] будем использовать
следующие условные обозначения: О - множество объектов предметной
области, Р - множество свойств этих объектов, С - множество
характеристик объектов, являющихся возможными причинами свойств, V -
множество истинностных оценок объектов.
На вход ДСМ-метод подается множество изучаемых
объектов и информация о наличии или отсутствии у них определенных свойств.
Кроме того, имеется ряд целевых признаков, каждый из которых разбивает исходное
множество объектов на четыре непересекающихся подмножества:
объекты, про которые известно, что они обладают
данным признаком,
объекты, про которые известно, что они не
обладают данным признаком,
объекты, для которых существуют аргументы как
за, так и против того, что они обладают данным признаком,
объекты, о которых неизвестно, обладают они этим
признаком или нет.
В задаче определения тональности
текста с двумя эмоциональными категориями множество О содержит
исследуемые тексты; множество Р состоит из одного элемента (свойства)  ,
обозначающего положительную тональность текста (отсутствие этого свойства
означает, что тональность текста отрицательна); множество С включает
характеристики, отвечающие за представление текстов, например характеристика
может быть отдельным словом или словосочетанием; множество
,
обозначающего положительную тональность текста (отсутствие этого свойства
означает, что тональность текста отрицательна); множество С включает
характеристики, отвечающие за представление текстов, например характеристика
может быть отдельным словом или словосочетанием; множество
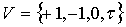 ,
,
где +1 означает, что объект обладает
свойством  , -1
означает, что объект не обладает свойством , 0 - наличие противоречия (т. е.
имеются аргументы как за, так и против того, что объект обладает свойством ),
, -1
означает, что объект не обладает свойством , 0 - наличие противоречия (т. е.
имеются аргументы как за, так и против того, что объект обладает свойством ), 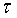 -
отсутствие информации о свойстве ) [9].
-
отсутствие информации о свойстве ) [9].
Множество текстов О состоит
из трех подмножеств: тексты положительной тональности (+1), тексты
отрицательной тональности (-1) и тексты, тональность которых требуется
определить (-тексты).
Первые два подмножества образуют обучающую коллекцию текстов, третье
подмножество - тестовую коллекцию.
Идея ДСМ-метода заключается в
следующем. Сначала составляется коллекция текстов, для которых точно известна
эмоциональная окраска. На основе имеющейся коллекции производится обучение
классификатора. Оно заключается в формировании гипотез (этап индукции).
Гипотеза представляет собой пересечение текстов коллекции. С помощью
соответствующего алгоритма находят всевозможные пересечения текстов. Для каждой
эмоциональной категории формируется отдельное множество гипотез.
Далее следует этап аналогии.
Сформированные гипотезы поочередно сравниваются в -текстами.
Если гипотеза содержатся в обрабатываемом тексте, то она помечается каким-либо
образом. После того, как все гипотезы проверены на совпадение с текстом, можно
выделить множество помеченных гипотез. Такое множество выделяется в каждой эмоциональной
категории. На последнем этапе остается сделать заключение, к какому классу
отнести -текст. В
задаче определения тональности текста используется достаточно большое
количество характеристик объектов (порядка 104) и порожденных
гипотез (порядка 104-106) [9]. Вследствие этого
происходят многочисленные совпадения характеристик как положительных гипотез,
так и отрицательных с -текстами,
т. е. имеют место множественные конфликты. Для выхода из этой ситуации
используется функция разрешения конфликтов. В качестве критериев, позволяющих
присвоить тональность -текстам,
можно рассматривать:
а) суммарное количество гипотез
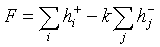 ,
,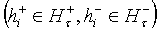 ,(2)
,(2)
где 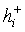 ,
,  - положительные и отрицательные
гипотезы соответственно;
- положительные и отрицательные
гипотезы соответственно; 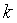 -
коэффициент, учитывающий дисбаланс количества положительных и отрицательных
текстов,
-
коэффициент, учитывающий дисбаланс количества положительных и отрицательных
текстов,
б) суммарное количество
характеристик во всех гипотезах,
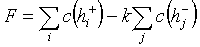 ,(3)
,(3)
где  - количество характеристик гипотезы
,
- количество характеристик гипотезы
,
в) суммарное количество родителей
всех гипотез
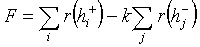 ,(4)
,(4)
где  - количество родителей гипотезы ,
- количество родителей гипотезы ,
г) произведение количества
характеристик на количество родителей
 ,(5)
,(5)
д) взвешенное среднее арифметическое
числа характеристик, т. е. отношение произведения количества характеристик на
количество родителей к общему количеству родителей гипотез одного класса
 ,(6)
,(6)
е) взвешенное среднее арифметическое
числа родителей, т. е. отношение произведения количества характеристик на
количество родителей к общему количеству характеристик гипотез одного класса
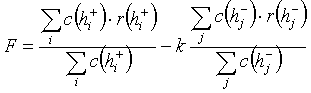 .(7)
.(7)
Значение, возвращаемое данной
функцией, определяет категорию обрабатываемого текста.
1.2.3 Алгоритм поиска пересечений
На этапе индукции для того, чтобы установить
сходства объектов, осуществляется поиск всех общих фрагментов объектов.
Доказано, что для бинарного представления характеристик такая задача является NР-полной
[2]. Для поиска всех общих фрагментов мы будем использовать алгоритм Норриса,
который имеет линейную сложность от числа общих фрагментов, является
инкрементным и одним из самых эффективных среди аналогичных методов [9].
Приведем описание алгоритма Норриса
в соответствии с [8]. Пусть у нас имеется набор множеств (объектов). Введем на
этом наборе множеств какой-нибудь линейный порядок и зафиксируем его. На 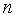 -ном шаге
для -ного
объекта алгоритм дополняет набор пересечений, построенных для предыдущих
-ном шаге
для -ного
объекта алгоритм дополняет набор пересечений, построенных для предыдущих  множеств,
пересечениями каждого множества этого набора с -ным объектом.
множеств,
пересечениями каждого множества этого набора с -ным объектом.
Обозначим через 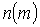 номер
множества
номер
множества 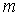 (сами множества
и их пересечения будем обозначать маленькими буквами, а подмножество номеров
множеств - большими буквами).
(сами множества
и их пересечения будем обозначать маленькими буквами, а подмножество номеров
множеств - большими буквами).
Пусть  - множество понятий, полученных при
обработке первых
- множество понятий, полученных при
обработке первых  множеств.
Очевидно, что
множеств.
Очевидно, что 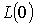 пусто.
пусто.
Ниже приведен псевдокод алгоритма
поиска максимальных пересечений подмножеств.
 := пустое множество;
:= пустое множество;
For i := 1 To <
количество множеств  > Do Begin
> Do Begin
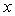 := <очередное множество >;
:= <очередное множество >;
For j := 1 To < размер
множества > Do Begin
//  - понятие из множества
- понятие из множества
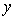 := очередное пересечение из ;
:= очередное пересечение из ;
 := номера множеств ,
составляющих пересечение ;
:= номера множеств ,
составляющих пересечение ;
// если является
подмножеством
If  Then
Then
// добавляем к номерам, входящим в , номер 

// иначе, если не является
подмножеством
Else Begin
// найдем пересечение множеств и
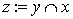 ;
;
f := false; // флаг
совпадения  с одним из
множеств в
с одним из
множеств в
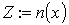 ; // номер родителя пересечения
; // номер родителя пересечения
k := 1;
While (k <=
<размер множества >) And (not f) Do Begin
:= очередное пересечение из ;
:= номера множеств ,
составляющих пересечение ;
If 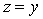 Then Begin
Then Begin
;:= true;;Begin
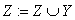 ;(k);;;not f Then
;(k);;;not f Then
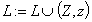 ; // добавляем новое понятие в
; // добавляем новое понятие в
End;
End;
f := false; // флаг,
показывающий, является ли подмножеством
// некоторого множества из 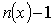
q := 1;
While (q <= ) And (not f) Do Begin
:= очередное множество ;
If  Then
Then
f := true
Else(q);;not
f Then
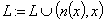 ;
;
End;
1.3 N-кратный
скользящий контроль
автоматический тональность текст программный
Приведем описание метода перекрестной проверки
согласно справочнику [4]. Перекрестная проверка (кросс-валидация) - это
статистический метод оценки и сравнения обучающих алгоритмов путем деления
данных на два сегмента: один сегмент используется для обучения системы, другой
- для ее проверки. Базовой формой перекрестной проверки является N-кратный
скользящий контроль (N-fold
cross-validation).
При проведении N-кратного
скользящего контроля все имеющиеся данные разбивают на N
равных (или приблизительно равных) по размеру частей (блоков). Обычно N
задают равным 5 или 10. Каждый из N
блоков поочерёдно объявляется контрольным (тестовым), остальные N-1
блоков объявляются обучающими (тренировочными). Производится обучение
классификатора по обучающим блокам, а затем осуществляется классификация
объектов в контрольном блоке. Процедура обучения повторяется N
раз, в результате все объекты оказываются классифицированными как контрольные
ровно по одному разу, и как обучающие по (N-1)
раз.
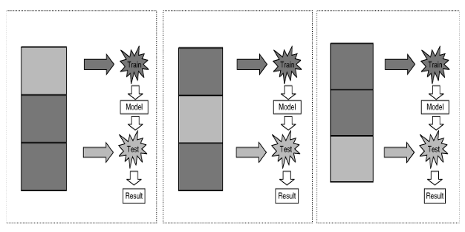
Рис. 2 - Процедура 3-кратной перекрестной
проверки
Для оценки качества работы классификатора
используют заранее определенную метрику, например, точность (precision).
Итоговую оценку точности классификации вычисляют как среднее арифметическое
значение точности по всем циклам. Таким образом, процедура перекрестной
проверки позволяет максимально полно использовать имеющиеся выборочные данные
для оценки качества автоматической классификации.
Обычно перекрестная проверка используется в
ситуациях, когда необходимо оценить, насколько предсказывающая модель способна
работать на практике. Необходимо отметить, что недостатком процедуры
перекрестного контроля являются высокие вычислительные затраты, поскольку в
каждом цикле необходимо проводить обучение классификатора.
1.4 Метрики качества
Для оценки эффективности ДСМ-метода будем
пользоваться следующими метриками - правильность (accuracy),
точность (precision),
полнота (recall) и F1-мера
(F1-measure).
Эти метрики легко рассчитать на основании
таблицы сопряженности, которая составляется для каждого класса отдельно.
Таблица 1 - Таблица сопряженности
|
Категория
|
Экспертная
оценка
|
|
Positive
|
Negative
|
|
Оценка
классификатора
|
Positive
|
TP
|
FP
|
|
Negative
|
FN
|
TN
|
В таблице содержится информация о том, сколько
раз система приняла верное и сколько раз неверное решение по объектам заданного
класса. Условные обозначения категорий:(true
positives) - объекты,
которые классификатор отнес к позитивному классу и которые действительно
принадлежат позитивному классу; TN (true
negative) - объекты,
которые классификатор отнес к негативному классу и которые действительно
принадлежат негативному классу;(false
positive) - объекты,
которые классификатор ошибочно отнес к позитивному классу, хотя на самом деле
они относятся к негативному классу;(false
negative) - объекты,
которые классификатор ошибочно отнес к негативному классу, хотя на самом деле
они относятся к позитивному классу.
Описание основных метрик приведем в соответствии
с [5].
1.4.1 Правильность и ошибочность
На практике не бывает систем, абсолютно точно
определяющих правильные соотношения классов и принадлежащих им объектов.
Классификатор будет работать с ошибками относительно тестовой выборки. Для
оценки успешности сопоставления классов и объектов используется метрика
правильности:
 ,(8)
,(8)
где в числителе - количество
объектов, по которым классификатор принял правильное решение, в знаменателе -
размер классифицируемой выборки. Для оценки процента ошибок используется метрика
ошибочности:
 ,(9)
,(9)
где в числителе - количество
объектов, по которым классификатор принял ошибочное решение. Это метрика
используется не так часто в задачах текстовой классификации.
1.4.2 Точность и полнота
Точность P
и полнота R являются
метриками, которые используются при оценке большей части систем анализа
информации. Иногда они используются сами по себе, иногда в качестве базиса для
производных метрик, таких как F1-мера.
Точность системы в пределах класса - это доля
объектов действительно принадлежащих данному классу относительно всех объектов,
которые система отнесла к этому классу. Эта метрику можно представить как
степень «разумности» системы. Полнота системы - это доля найденных
классификатором объектов, принадлежащих классу, относительно всех объектов
этого класса в тестовой выборке. Данную метрику можно представить как степень
полноты системы.
Метрика точности определяется формулой
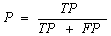 .(10)
.(10)
Метрика точности характеризует,
сколько полученных от классификатора положительных ответов являются
правильными. Чем больше точность, тем меньше число ложных попаданий. Но эта
метрика не дает представление о том, все ли правильные ответы вернул
классификатор. Для этого существует метрика полноты, определяемая формулой
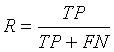 .(11)
.(11)
Метрика полноты характеризует
способность классификатора «угадывать» положительные ответы в тестовой выборке.
Отметим, что ложно-положительные ответы никак не влияют на эту метрику.
1.4.3 F1-мера
Метрики точности и полноты дают достаточно
исчерпывающую характеристику классификатора. Понятно, что чем выше точность и
полнота, тем лучше. Если повышать полноту, делая классификатор более
«оптимистичным», это приведет к понижению точности из-за увеличения числа
ложно-положительных ответов. Если же делать классификатор более
«пессимистичным», то при росте точности произойдет одновременное падение
полноты из-за отбраковки какого-то числа правильных ответов.
В реальной жизни максимальная точность и полнота
не достижимы одновременно, поэтому приходится искать некоторый баланс. С этой
целью вводится метрика, которая объединяет в себе информацию о точности и
полноте классификатора. Она получила название F1-мера
и фактически является средним гармоническим величин P и R:
 .(12)
.(12)
В данной формуле придается
одинаковый вес точности и полноте, поэтому F1-мера будет снижаться одинаково
при уменьшении точности.
Глава 2. Практическое исследование
ДСМ-метода
2.1 Программная реализация
Для написания программы-анализатора был
использован язык программирования C#.
2.1.1 Пользовательский интерфейс
Программа реализована в виде консольного
приложения. Запуск осуществляется из командной строки Windows.
Синтаксис команды запуска исполняемого файла представлен на рис. 3.

Рис. 3 - Синтаксис команды запуска приложения
По умолчанию коэффициент дисбаланса 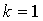 , количество
блоков для перекрестной проверки
, количество
блоков для перекрестной проверки  .
.
2.1.2 Входные данные
Словарь хранится в текстовом файле Dictionary.txt.
Исходные тексты для обучения и классификации
располагаются в следующих директориях:
/SourceTexts/MinusSamples
- обучающие негативные тексты,
/SourceTexts/PlusSamples
- обучающие позитивные тексты,
/SourceTexts/TauSamples
- тексты, тональность которых требуется определить.
Тексты после обработки программой Mystem
помещаются в директории:
/NormalizedTexts/MinusSamples
- нормализованные негативные тексты,
/NormalizedTexts/PlusSamples
- нормализованные позитивные тексты,
/NormalizedTexts/TauSamples
- нормализованные тексты, тональность которых требуется определить.
2.1.3 Выходные данные
Результаты процедуры кросс-валидации содержатся
в текстовом файле ResultsCrossValidation.txt, результаты классификации - в
файле ResultsClassification.txt.
2.1.4 Диаграмма классов и структуры
данных
Диаграмма классов изображена на рис. 4.

Рис. 4 - Диаграмма классов
В программе используются следующие
пользовательские структуры данных:
o Структура Hypothesis
содержит информацию о признаках, характеризующих гипотезу, родителях этих
признаков и классе тональности, к которому принадлежит данная гипотеза.
struct Hypothesis
{
// Множество признаковHashSet<int>
setValues;
// Множество родителейHashSet<int>
setParents;
// Класс гипотезы:
// '-' - отрицательный,
// '+' - положительныйchar type;
}
o Структура TextInfo
содержит характеристики текста: имя файла, множество слов из текста, содержащихся
в словаре, и класс тональности текста.
public struct TextInfo
{
// Имя файла, содержащего текстstring name;
// Множество слов из словаря, содержщихся в
текстеHashSet<int> setValues;
// Класс текста:
// '-' - отрицательный,
// '+' - положительный
// 't' - неопределенной тональностиchar type;
}
Поле setValues
содержит индексы слов, присутствующих в тексте.
o Структура EffectMeasure
описывает метрики качества.
struct EffectMeasure
{
// Точностьdouble precission;
// Полнотаdouble recall;
// F1-мераdouble f1_measure;
// Правильностьdouble accuracy;
}
Приведем описание классов и реализованных в них
методов.
Класс Program
отвечает за подготовку данных к обработке и вывод результатов в файл. Методы
класса:
o BuildHashSet
- формирует множество слов, содержащихся в тексте;
o LoadDictionary
- загружает словарь из файла Dictionary.txt;
o NormText
- осуществляет нормализацию текстов, т. е. переводит каждое слово в начальную
форму;
o PrintResultCrossValidation
- выполняет вывод метрик качества в файл ResultsCrossValidation.txt;
o PrintResultClassifications
- выполняет вывод метрик качества в файл ResultsClassifications.txt;
o RandomSort
- выполняет сортировку обучающих текстов в случайном порядке.
Класс TextNormalizer
отвечает за нормализацию текстов. Методы класса:
o CreateProcess
- создает новый процесс (запускает морфологический анализатор Mystem
от Яndex);
o Normalize
- производит нормализацию текстов в заданной директории.
Класс CrossValidator
отвечает за перекрестную проверку обучающей модели. Методы класса:
o CalcKoeff
- рассчитывает метрики качества анализа тональности;
o ProcessTexts
- осуществляет перекрестную проверку (делит множество текстов на равнее части;
поочередно одну из частей выбирает в качестве контрольной, остальные - в
качестве обучающих);
Класс JsmProcessor
отвечает за этапы ДСМ-метода. Методы класса:
o Analogy
- выполняет процедуру аналогии;
o Classification
- определяет класс тональности текста;
o ConflictResolution,
…, ConflictResolution6 - функции
разрешения конфликтов на основе различных критериев;
o Induction
- выполняет процедуру индукции (алгоритм Норриса поиска пересечений текстов).
2.2 Текстовая коллекция
Перед проведением эксперимента была
составлена коллекция отзывов пользователей сети Интернет о фильмах с
использованием сайта <#"699222.files/image066.gif">. Полученные результаты представлены
в табл. 2 и табл. 3.
Таблица 2 - Результаты тестирования
ДСМ-метода в зависимости от словаря и частей речи при использовании функции
разрешения конфликтов на основе количества гипотез
|
Параметры
|
Метрики
качества
|
|
Часть
речи
|
Словарь
|
Precision
|
Recall
|
F1-measure
|
Accuracy
|
|
Прил.
|
Авт.
|
0,915
|
0,890
|
0,902
|
0,896
|
|
Ручной
|
0,918
|
0,892
|
0,904
|
0,898
|
|
Сущ.
|
Авт.
|
0,433
|
0,868
|
0,573
|
0,711
|
|
Ручной
|
0,769
|
0,859
|
0,805
|
0,885
|
|
Гл.
|
Авт.
|
0,775
|
0,841
|
0,806
|
0,816
|
|
Ручной
|
0,704
|
0,808
|
0,749
|
0,779
|
|
Прил.
+ Сущ.
|
Авт.
|
0,716
|
0,966
|
0,822
|
0,850
|
|
Ручной
|
0,956
|
0,927
|
0,940
|
0,941
|
|
Прил.
+ Гл.
|
Авт.
|
0,916
|
0,898
|
0,906
|
0,902
|
|
Ручной
|
0,927
|
0,929
|
0,928
|
0,925
|
|
Сущ.
+ Гл.
|
Авт.
|
0,616
|
0,940
|
0,741
|
0,801
|
|
Ручной
|
0,903
|
0,852
|
0,888
|
|
Прил.
+ Сущ. + Гл.
|
Авт.
|
0,778
|
0,964
|
0,860
|
0,876
|
|
Ручной
|
0,918
|
0,972
|
0,944
|
0,945
|
|
Все
части речи
|
Авт.
|
0,768
|
0,921
|
0,833
|
0,850
|
|
Ручной
|
0,907
|
0,944
|
0,924
|
0,925
|
Таблица 3 - Результаты тестирования ДСМ-метода в
зависимости от словаря и частей речи при использовании функции разрешения
конфликтов на основе произведения количества характеристик на количество
родителей
|
Параметры
|
Метрики
качества
|
|
Часть
речи
|
Словарь
|
Precision
|
Recall
|
F1-measure
|
Accuracy
|
|
Прил.
|
Авт.
|
0,882
|
0,861
|
0,871
|
0,868
|
|
Ручной
|
0,931
|
0,855
|
0,890
|
0,881
|
|
Сущ.
|
Авт.
|
0,685
|
0,723
|
0,699
|
0,706
|
|
Ручной
|
0,692
|
0,789
|
0,735
|
0,813
|
|
Гл.
|
Авт.
|
0,762
|
0,768
|
0,764
|
0,766
|
|
Ручной
|
0,835
|
0,768
|
0,795
|
0,800
|
|
Прил.
+ Сущ.
|
Авт.
|
0,787
|
0,843
|
0,814
|
0,820
|
|
Ручной
|
0,933
|
0,893
|
0,912
|
0,911
|
|
Прил.
+ Гл.
|
Авт.
|
0,872
|
0,845
|
0,858
|
0,855
|
|
Ручной
|
0,935
|
0,840
|
0,884
|
0,875
|
|
Сущ.
+ Гл.
|
Авт.
|
0,771
|
0,790
|
0,779
|
0,781
|
|
Ручной
|
0,839
|
0,873
|
0,855
|
0,862
|
|
Прил.
+ Сущ. + Гл.
|
Авт.
|
0,848
|
0,857
|
0,852
|
0,854
|
|
Ручной
|
0,947
|
0,878
|
0,911
|
0,907
|
|
Все
части речи
|
Авт.
|
0,684
|
0,889
|
0,770
|
0,798
|
|
Ручной
|
0,952
|
0,880
|
0,914
|
0,909
|
На основании этой информации, проведем анализ
влияния отдельных составляющих ДСМ-метода на качество распознавания тональности
текстов.
а) Влияние словаря
В табл. 4 приведены размеры словаря по каждой
части речи, а на рис. 5 эти данные представлены в виде диаграммы.
Автоматический словарь формировался путем добавления из текстов обучающей
коллекции всех слов без исключения. Ручной словарь составлялся из
автоматического путем удаления слов с нейтральной окраской.
Таблица 4 - Размер словаря
|
Параметры
|
Размер
словаря
|
Параметры
|
Размер
словаря
|
|
Часть
речи
|
Словарь
|
|
Часть
речи
|
Словарь
|
|
|
Прил.
|
Авт.
|
1280
|
Прил.
+ Гл.
|
Авт.
|
2014
|
|
Ручной
|
757
|
|
Ручной
|
1041
|
|
Сущ.
|
Авт.
|
1142
|
Сущ.
+ Гл.
|
Авт.
|
1876
|
|
Ручной
|
294
|
|
Ручной
|
578
|
|
Гл.
|
Авт.
|
734
|
Прил.
+ Сущ. + Гл.
|
Авт.
|
3156
|
|
Ручной
|
284
|
|
Ручной
|
1335
|
|
Прил.
+ Сущ.
|
Авт.
|
2422
|
Все
части речи
|
Авт.
|
3409
|
|
Ручной
|
1050
|
|
Ручной
|
1379
|

Рис. 5 - Размер словаря
Использование ручного словаря в большинстве
случаев позволило получить более высокие оценки. Улучшение оценок составило от
1% до 77% по табл. 2 и от 1% до 39% по табл. 3. Среднее улучшение показателей
представлено в табл. 5. Незначительное ухудшение наблюдается по метрике
полноты. Улучшение связано с тем, что словарь, составленный вручную, содержит
слова с наиболее ярко выраженной эмоциональной окраской, и практически не
содержит слов с нейтральной окраской. Благодаря отсутствию нейтрально
окрашенных слов формирующиеся гипотезы более точно характеризуют тональность.
Таблица 5 - Среднее улучшение оценок при
использовании ручного словаря по сравнению с автоматическим
|
Источник
усредняемых данных
|
Метрика
|
|
Precision
|
Recall
|
F1-measure
|
Accuracy
|
|
Табл.
2
|
11,4%
|
-0,39%
|
5,7%
|
4,1%
|
|
Табл.
3
|
11,6%
|
3%
|
7,4%
|
7,6%
|
Таблица 6 - Количество сформированных гипотез
(при использовании функции разрешения конфликтов на основе количества гипотез)
|
Параметры
|
Количество
гипотез
|
|
Часть
речи
|
Словарь
|
Положительные
|
Отрицательные
|
|
Прил.
|
Авт.
|
2958
|
3046
|
|
Ручной
|
2161
|
1932
|
|
Сущ.
|
Авт.
|
5290
|
9758
|
|
Ручной
|
718
|
1234
|
|
Гл.
|
Авт.
|
3663
|
4155
|
|
Ручной
|
1204
|
1378
|
|
Прил.
+ Сущ.
|
Авт.
|
12146
|
18907
|
|
Ручной
|
2988
|
3307
|
|
Прил.
+ Гл.
|
Авт.
|
9193
|
9828
|
|
Ручной
|
3754
|
3601
|
|
Сущ.
+ Гл.
|
Авт.
|
13660
|
22201
|
|
Ручной
|
1850
|
2676
|
|
Прил.
+ Сущ. + Гл.
|
Авт.
|
23713
|
34850
|
|
Ручной
|
4584
|
5280
|
|
Все
части речи
|
Авт.
|
72412
|
113258
|
|
Ручной
|
6217
|
6874
|
Наряду с повышением качества снизилось время
работы программы. Это вызвано уменьшением количества слов в ручном словаре по
сравнению с автоматическим, и как следствие, снижением времени поиска
пересечений текстов. В табл. 6 этот факт подтверждается уменьшением количества
гипотез.
б) Влияние частей речи
Проведенные испытания показали, что из трех
наиболее многочисленных групп частей речи (прил., сущ., гл.) наилучшие оценки
качества определения тональности достигаются при использовании имен
прилагательных. В табл. 7 приведены результаты улучшения оценок при
использовании имен прилагательных по сравнению с другие частями речи. Сравнение
проведено по результатам испытаний с ручным словарем.
Таблица 7 - Улучшение оценок при использовании
имен прилагательных по сравнению с другими частями речи (при использовании
ручного словаря)
|
Источник
данных
|
Часть
речи, с которой проводилось сравнение
|
Метрика
|
|
|
Precision
|
Recall
|
F1-measure
|
Accuracy
|
|
Табл.
2
|
сущ.
|
19,4%
|
3,8%
|
12,3%
|
1,5%
|
|
гл.
|
30,4%
|
10,4%
|
20,7%
|
15,3%
|
|
Табл.
3
|
сущ.
|
34,5%
|
8,4%
|
21,1%
|
8,4%
|
|
гл.
|
11,5%
|
11,3%
|
11,9%
|
10,1%
|
Объединение прилагательных с другими частями
речи позволило получить еще более высокие оценки. Наилучшие и близкие между
собой оценки были достигнуты при комбинациях:
· по данным табл. 2 - прил. + сущ.,
прил. + сущ. + гл.;
· по данным табл. 3 - прил. + сущ.,
прил. + сущ. + гл., все части речи.
Данный эксперимент показал, что наибольший вклад
в качество определения тональности текста вносят прилагательные.
в) Совместное влияние словаря и частей речи
По данным табл. 2 и 3 наименее хорошие
результаты показало использование сущ. и автоматического словаря. Наилучшие
результаты (строки, выделенные серым цветом) были достигнуты при использовании
сочетаний ручного словаря и прил. + сущ., прил. + сущ. + гл., всех частей речи.
2. Результаты эксперимента в зависимости от
функции разрешения конфликтов
В процессе эксперимента для каждого -текста на
основе совпадений характеристик определялись множества подходящих положительных
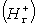 и
отрицательных
и
отрицательных  гипотез.
Затем эти гипотезы поступали на вход функции разрешения конфликтов
гипотез.
Затем эти гипотезы поступали на вход функции разрешения конфликтов  , которая на
основе заданного критерия присваивала тексту определенную тональность. Для
разрешения конфликтов использовались функции, приведенные в п. 1.2.2.
Компьютерный эксперимент проводился при коэффициенте естественного дисбаланса
, которая на
основе заданного критерия присваивала тексту определенную тональность. Для
разрешения конфликтов использовались функции, приведенные в п. 1.2.2.
Компьютерный эксперимент проводился при коэффициенте естественного дисбаланса  . Результаты
представлены в табл. 8.
. Результаты
представлены в табл. 8.
Таблица 8 - Результаты работы
ДСМ-метода в зависимости от функции разрешения конфликтов
|
Критерий
функции разрешения конфликтов
|
Метрики
качества
|
|
Precision
|
Recall
|
F1-measure
|
Accuracy
|
|
Суммарное
количество гипотез
|
0,950
|
0,906
|
0,927
|
0,919
|
|
Суммарное
количество характеристик во всех гипотезах
|
0,919
|
0,915
|
0,917
|
0,911
|
|
Суммарное
количество родителей у всех гипотез
|
0,940
|
0,850
|
0,892
|
0,882
|
|
Произведение
количества характеристик на количество родителей
|
0,932
|
0,843
|
0,885
|
0,874
|
|
Взвешенное
среднее арифметическое числа характеристик
|
0,941
|
0,844
|
0,889
|
0,879
|
|
Взвешенное
среднее арифметическое числа родителей
|
0,717
|
0,679
|
0,696
|
0,691
|
Данные табл. 8 были получены при использовании
ручного словаря с прилагательными. На основании этих можно заключить, что
функция разрешения конфликтов влияет на качество определения тональности
текстов. Лучшие результаты показала функция разрешения конфликтов на основе
суммарного количества гипотез.
2.3.2 Оценка времени работы
программы
В процессе проведения экспериментов было
замерено фактическое время работы программы-анализатора в зависимости от
количества обучающих текстов. Оценка временной сложности программы в целом
определяется алгоритмом поиска пересечений текстов. Так как задача поиска общих
фрагментов текстов является NP-полной,
то время работы программы с увеличением числа обучающих текстов растет по
экспоненциальной зависимости. При проведении эксперимента по замеру времени
использовался ручной словарь с прилагательными. На рис. 6 изображен график
зависимости времени работы программы от количества текстов.
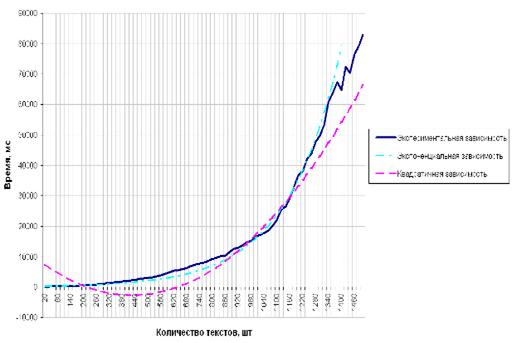
Рис. 6 - Время работы программы-анализатора
При помощи метода наименьших квадратов построено
два приближения исследуемой зависимости (рис. 6). Для рассмотренного набора
входных данных наиболее точной оказалась экспоненциальная зависимость.
В табл. 9 приведено время работы программы для
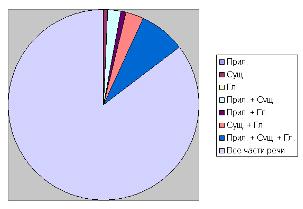
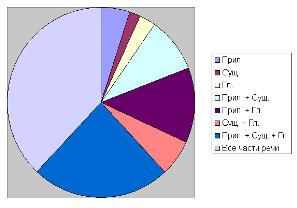
различных частей речи и словарей, а на рис. 7 и рис. 8 эти данные представлены
в виде диаграмм.
Таблица 9 - Время работы программы-анализатора
(при использовании функции разрешения конфликтов на основе количества гипотез)
|
Параметры
|
Время
работы, мин
|
Параметры
|
Время
работы, мин
|
|
Часть
речи
|
Словарь
|
|
Часть
речи
|
|
|
Прил.
|
Авт.
|
0,145
|
Прил.
+ Гл.
|
Авт.
|
1,006
|
|
Ручной
|
0,082
|
|
Ручной
|
0,210
|
|
Сущ.
|
Авт.
|
0,705
|
Сущ.
+ Гл.
|
Авт.
|
3,505
|
|
Ручной
|
0,035
|
|
Ручной
|
0,104
|
|
Гл.
|
Авт.
|
0,230
|
Прил.
+ Сущ. + Гл.
|
Авт.
|
9,128
|
|
Ручной
|
0,045
|
|
Ручной
|
0,396
|
|
Прил.
+ Сущ.
|
Авт.
|
2,381
|
Все
части речи
|
Авт.
|
98,880
|
|
Ручной
|
0,159
|
|
Ручной
|
0,633
|
 а
а
 б
б
Рис. 7 - Время работы программы-анализатора (в
мс): а - автоматический словарь; б - ручной словарь
На рис. 8 изображена диаграмма времени работы
программы с ручным словарем в процентном отношении ко времени работы с
автоматическим словарем.
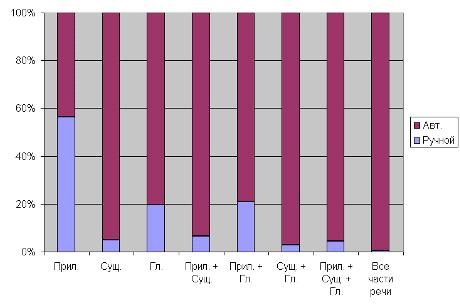
Рис. 8 - Время работы программы с ручным
словарем в процентном отношении ко времени работы с автоматическим словарем
Полученные результаты показывают, что при
использовании ручного словаря скорость работы программы существенно больше, чем
в случае автоматического словаря. При этом качество распознавания тональности
выше.
Заключение
В процессе выполнения курсовой работы был изучен
ДСМ-метод автоматического порождения гипотез, применяемый для анализа
тональности текстов, выполнена программная реализация этого метода и проведен
ряд компьютерных экспериментов. Исследование было направлено на выявление
влияния компонентов ДСМ-метода на качество распознавания тональности текстов.
Изучалось влияние словаря, частей речи и функции разрешения конфликтов. Анализ
полученных результатов позволил сделать следующие выводы:
o словарь, составленный вручную, по
сравнению с автоматическим словарем дает улучшение значения метрик качества
вследствие отсечения множества слов с нейтральной окраской, а также увеличивает
скорость работы программы;
o наибольший вклад в качество
определения тональности вносят имена прилагательные вследствие частого
употребления и содержания ярко выраженной эмоциональной окраски;
o разные функции разрешения конфликтов
дают разное качество определения тональности.
Таким образом, ДСМ-метод показал хорошие
результаты по определению тональности отзывов о фильмах. На основании
экспериментов можно сказать, что одним из путей повышения производительности
метода является качественное составление словарей эмоциональной лексики.
Библиографический список
1. Feldman
R. Techniques and Applications for Sentiment Analysis // Communications of the
ACM. 2013. Vol. 56, №4. P. 82-89.
2. Kuznetsov
S.O., Obiedkov S.A. Comparing Perfomance of Algorithms for Generating Concept
Lattices // Journal of Experimental and Theoretical Artificial Intelligence.
2002. Vol. 14.
3. Liu
B. Sentiment Analysis and Opinion Mining. Morgan & Claypool Publishers,
2012.
4. Refaeilzadeh
P., Tang L., Liu H. Encyclopedia of Database Systems // Springer, US. 2009.
. Sebastiani
F. Machine learning in Automated Text Categorization // ACM Computing Surveys. 2002.
Vol. 34. P.
1-47.
6. Автоматическое
порождение гипотез в интеллектуальных системах / под ред. В. К. Финна. - М.:
Либроком, 2009. - 528 с.
. ДСМ-метод
автоматического порождения гипотез / под ред. О. М. Аншакова. - М.: Либроком,
2009. - 432 с.
. Кожунова
О. С. Технология разработки семантического словаря системы информационного
мониторинга // Автореферат диссертации на соискание ученой степени кандидата
технических наук. - М., 2009. - 21 с.
. Котельников
Е. В. Распознавание эмоциональной составляющей в текстах: проблемы и подходы /
Е. В. Котельников, М. В. Клековкина, Т. А. Пескишева, О. А. Пестов; под. ред.
С. М. Окулова. - Киров: Изд-во ВятГГУ, 2012. - 103 с.
. Котельников
Е. В., Пескишева Т. А., Пестов О. А. Параллельный выбор параметров
классификатора для анализа тональности текстов // Вопросы современной науки и
практики. Университет им. В.И. Вернадского. Тамбов: ГОУ ВПО ТГТУ, 2012. С.
67-74.
Приложение
Файл
Program.csSystem;System.Collections.Generic;System.Linq;System.Text;System.IO;System.Collections;System.Diagnostics;JSM_VS
{
/// <summary>
/// Гипотезы
/// </summary>struct
Hypothesis
{
/// <summary>
/// Множество признаков
///
</summary>HashSet<int> setValues;
/// <summary>
/// Множество родителей
///
</summary>HashSet<int> setParents;
/// <summary>
/// Класс гипотезы:
/// '-' - отрицательный,
/// '+' - положительный
/// </summary>char type;
}
/// <summary>
/// Описание текстов
/// </summary>struct TextInfo
{
/// <summary>
/// Имя файла, содержащего текст
/// </summary>string name;
/// <summary>
/// Множество слов из словаря, содержщихся
в тексте
///
</summary>HashSet<int> setValues;
/// <summary>
/// Класс текста:
/// '-' - отрицательный,
/// '+' - положительный
/// 't' - неопределенной тональности
/// </summary>char type;
}
/// <summary>
/// Метрики качества
/// </summary>struct
EffectMeasure
{
/// <summary>
/// Точность
/// </summary>double
precission;
/// <summary>
/// Полнота
/// </summary>double recall;
/// <summary>
/// F1-мера
/// </summary>double
f1_measure;
/// <summary>
/// Правильность
/// </summary>double accuracy;
//public int countPlusHyp; //
Количество положительных гипотез
//public int countMinusHyp; //
Количество отрицательных гипотез
}Program
{
/// <summary>
/// Загрузка словаря
/// </summary>
/// <param
name="words"></param>void
LoadDictionary(Dictionary<string, int> words)
{sr = new
StreamReader("dictionary.txt", Encoding.GetEncoding(1251));numWord =
0;(!sr.EndOfStream)
{str = sr.ReadLine();++;.Add(str,
numWord);
}.Close();
}
/// <summary>
/// Сортировка массива примеров в случайном
порядке
/// </summary>
/// <param
name="arrayOfSet"></param>void RandomSort(TextInfo[]
arrayOfSet)
{rand = new Random();(int i = 0; i
< arrayOfSet.Length; i++)
{index1 = rand.Next(0,
arrayOfSet.Length - 1);index2 = rand.Next(0, arrayOfSet.Length - 1);temp =
arrayOfSet[index1];[index1] = arrayOfSet[index2];[index2] = temp;
}
}
/// <summary>
/// Нормализация исходных текстов
/// </summary>void NormText()
// Нормализуем положительные
текстыsrcText = new TextNormalizer();.Normalize("SourceTexts\\PlusSamples",
"NormalizedTexts\\PlusSamples");
// Нормализуем отрицательные
тексты.Normalize("SourceTexts\\MinusSamples",
"NormalizedTexts\\MinusSamples");
// Нормализуем
тау-тексты.Normalize("SourceTexts\\TauSamples",
"NormalizedTexts\\TauSamples");
}
/// <summary>
/// Построение массива из множеств
слов, содержащихся в каждом тексте
/// </summary>
/// <param
name="dict"></param>
/// <param
name="dirName"></param>
/// <param
name="samples"></param>void
BuildHashSet(Dictionary<string, int> dict, string dirName,TextInfo[]
samples, char type)
{diNormText = new
DirectoryInfo(dirName);[] fiNormText = diNormText.GetFiles();= new
TextInfo[fiNormText.Length];(int i = 0; i < fiNormText.Length;
i++)[i].setValues = new HashSet<int>();(int i = 0; i <
fiNormText.Length; i++)
{sr = new StreamReader(dirName +
"\\" + fiNormText[i].Name,.GetEncoding(1251));[i].name =
fiNormText[i].Name;(!sr.EndOfStream)
{str = sr.ReadLine();[] masStr =
str.Split('=',
',');(dict.ContainsKey(masStr[0]))[i].setValues.Add(dict[masStr[0]]);
}[i].type = type;.Close();
}
}void
PrintResultCrossValidation(string description, EffectMeasure koeff, long time)
{sw = new
StreamWriter("ResultsCrossValidation.txt", false,
Encoding.GetEncoding(1251));.WriteLine(description);.WriteLine("Preccision
= {0:d3}", koeff.precission.ToString());.WriteLine("Recall =
{0:d3}", koeff.recall.ToString());.WriteLine("F1-measure =
{0:d3}", koeff.f1_measure.ToString());.WriteLine("Accuracy =
{0:d3}", koeff.accuracy.ToString());.WriteLine("Time processing =
{0}", time.ToString());.Close();
}void
PrintResultClassification(char[] resClassification, TextInfo[] tauSamples, long
time)
{sw = new
StreamWriter("ResultsClassification.txt", false,
Encoding.GetEncoding(1251));(int i = 0; i < tauSamples.Length;
i++).WriteLine("{0} {1}", tauSamples[i].name,
resClassification[i]);.WriteLine("Time processing = {0}",
time.ToString());.Close();
}void Main(string[] args)
{error =
false;imbalance;typeFuncResolution;index = 0;(args.Length > 0 &&
args.Length <= 5)
{
// Вызов справки(index <
args.Length && args[index] == "-help")
{= true;
}
// Проверка необходимости
нормализации текстов(!error && index < args.Length &&
args[index] == "-n")
{();++;
}
// Тип функции разрешения конфликтов
{=
int.Parse(args[index]);(typeFuncResolution < 1 && typeFuncResolution
> 6)
{= true;.WriteLine("Ошибка!
Неверно задан номер функции разрешения конфликтов");
}++;
}
{= 1;
}
// Коэффициент дисбаланса
{= double.Parse(args[index]);++;
}
{= 1;
}timer = new Stopwatch();<string,
int> dict = new Dictionary<string, int>();(dict);
// Массив множеств, содержащий в
i-той ячейке номера слов из словаря, входящих в i-тый текст[] plusSamples,
minusSamples, tauSamples;(dict, "NormalizedTexts\\PlusSamples", out
plusSamples, '+');(dict, "NormalizedTexts\\MinusSamples", out minusSamples,
'-');(dict, "NormalizedTexts\\TauSamples", out tauSamples, 't');
// Проверка необходимости проведения
процедуры кросс-валидации(!error && index < args.Length &&
args[index][0] == '-' && args[index][1] == 'c')
{
// Запускаем таймер.Start();[] str =
args[index].Split('/');numBlocks = 5;(str.Length > 2)
{= true;.WriteLine("Ошибка!
Неверно задан параметр перекресной проверки");
}if (str.Length == 2)
{
{= int.Parse(str[1]);(numBlocks <
2 || numBlocks > Math.Min(plusSamples.Length, minusSamples.Length))
{= true;.WriteLine("Ошибка!
Количество блоков должно быть в диапазоне от {0} до {1}",
"2",.Min(plusSamples.Length, minusSamples.Length));
}
}
{= true;.WriteLine("Ошибка!
Неверно задано количество блоков");
}
}(!error)
{
// Средние показатели
эффективностиaverAffectMeasure = new
EffectMeasure();(plusSamples);(minusSamples);cv = new
CrossValidator();.ProcessTexts(plusSamples, minusSamples, ref
averAffectMeasure, numBlocks,, typeFuncResolution);.Stop();("Average value
on " + numBlocks.ToString() + " tests:",, timer.ElapsedMilliseconds);.Reset();++;
}
}
// Проверка необходимости
классификации тау-текстов(!error && index < args.Length &&
args[index] == "-t")
{.Start();jp = new JsmProcessor();
// Список гипотез<Hypothesis>
plusHypotheses = new List<Hypothesis>();<Hypothesis> minusHypotheses
= new List<Hypothesis>();
//
Индукция.Induction(plusHypotheses, plusSamples);.Induction(minusHypotheses,
minusSamples);<Hypothesis>[] coincidedHyp;
// Аналогия.Analogy(plusHypotheses,
minusHypotheses, tauSamples, out coincidedHyp);[] resClassification = new
char[tauSamples.Length];
// Классификация
тау-текстов.Classification(resClassification, coincidedHyp, imbalance,
typeFuncResolution);.Stop();(resClassification, tauSamples,
timer.ElapsedMilliseconds);++;
}(!error && index <
args.Length)
{.WriteLine("Ошибка! Команда
содержит неизвестные параметры или последовательность параметров задана
неверно");= true;
}
}
{.WriteLine("Ошибка! Неверное
количество параметров");= true;
}(error)
{.WriteLine("Синтаксис
команды:");.WriteLine("JSM_VS [-n] [f] [k] [-c/b] [-t]
[-help]");.WriteLine("\t-n\tвыполнить нормализацию
текстов");.WriteLine("\tf\tтип функции разрешения конфликтов (по
умолчанию 1)");.WriteLine("\t\t1\tна основе суммарного кол-ва
гипотез");.WriteLine("\t\t2\tна основе суммарного кол-ва характеристик");.WriteLine("\t\t3\tна
основе суммарного кол-ва родителей");.WriteLine("\t\t4\tпроизведение
кол-ва характеристик на кол-во
родителей");.WriteLine("\t\t5\tвзвешенное среднее арифметическое
числа характеристик");.WriteLine("\t\t6\tвзвешенное среднее
арифметическое числа родителей");.WriteLine("\tk\tкоэффициент
дисбаланса (+) и (-) текстов (по умолчанию
1)");.WriteLine("\t-с\tвыполнить перекрестную
проверку");.WriteLine("\t\tb\tколичество блоков (по умолчанию
5)");.WriteLine("\t-t\tвыполнить распознавание
t-текстов");.WriteLine("\t-help\tвызвать справку по команде");
}.WriteLine("Программа успешно
выполнена!");
}
}
}
Файл
TextNormalizer.csSystem;System.Collections.Generic;System.Linq;System.Text;System.IO;System.Runtime.InteropServices;JSM_VS
{TextNormalizer
{struct PROCESS_INFORMATION
{IntPtr hProcess;IntPtr hThread;uint
dwProcessId;uint dwThreadId;
}struct STARTUPINFO
{uint cb;string lpReserved;string
lpDesktop;string lpTitle;uint dwX;uint dwY;uint dwXSize;uint dwYSize;uint
dwXCountChars;uint dwYCountChars;uint dwFillAttribute;uint dwFlags;short
wShowWindow;short cbReserved2;IntPtr lpReserved2;IntPtr hStdInput;IntPtr
hStdOutput;IntPtr hStdError;
}
[DllImport("kernel32.dll")]extern
bool CreateProcess(string lpApplicationName, string lpCommandLine, IntPtr
lpProcessAttributes, IntPtr lpThreadAttributes,bInheritHandles, uint
dwCreationFlags, IntPtr lpEnvironment,lpCurrentDirectory, ref STARTUPINFO
lpStartupInfo, out PROCESS_INFORMATION lpProcessInformation);
/// <summary>
/// Процедура нормализации текстов
/// </summary>
/// <param
name="source"></param>
/// <param
name="destination"></param>void Normalize(string source,
string destination)
{diSource = new
DirectoryInfo(source);diDestination = new DirectoryInfo(destination);[]
fiSource = diSource.GetFiles();(int i = 0; i < fiSource.Length; i++)si = new
STARTUPINFO();_INFORMATION pi = new PROCESS_INFORMATION();fileInPath = source +
"\\" + fiSource[i].Name;
// Опции программы mystem
// n - построчный режим; каждое
слово печатается на новой строке
// l - не печатать исходные
словоформы, только леммы и граммемы
// i - печатать грамматическую
информациюoptions = " -nli ";fileOutPath = destination +
"\\" + "norm_" + fiSource[i].Name;("mystem.exe",
"mystem.exe " + fileInPath + options + fileOutPath,.Zero, IntPtr.Zero,
false, 0, IntPtr.Zero, null, ref si, out pi);
}
}
}
}
Файл
CrossValidation.csSystem;System.Collections.Generic;System.Linq;System.Text;JSM_VS
{CrossValidator
{
/// <summary>
/// Вычисление метрик эффективности
анализа
/// </summary>
/// <param name="resForPlusTestCollect"></param>
/// <param
name="resForMinusTestCollect"></param>
/// <param
name="koeff"></param>void CalcKoeff(char[]
resForPlusTestCollect, char[] resForMinusTestCollect, ref EffectMeasure koeff)
{TP = 0, FP = 0, TN = 0, FN = 0;(int
i = 0; i < resForPlusTestCollect.Length; i++)
{(resForPlusTestCollect[i] ==
'+')++;if (resForPlusTestCollect[i] == '-')++;
}(int i = 0; i <
resForMinusTestCollect.Length; i++)
{(resForMinusTestCollect[i] ==
'-')++;if (resForMinusTestCollect[i] == '+')++;
}.precission = (double)TP /
(double)(TP + FP);.recall = (double)TP / (double)(TP + FN);.accuracy =
(double)(TP + TN) / (double)(TP + TN + FN + FP);.f1_measure = 2 *
koeff.precission * koeff.recall / (koeff.precission + koeff.recall);
}
/// <summary>
/// Запуск процедуры кросс-валидации
/// </summary>
/// <param
name="plusSamples"></param>
/// <param
name="minusSamples"></param>
/// <param
name="averAffectMeasure"></param>
/// <param
name="n"></param>
/// <param
name="imbalance"></param>void ProcessTexts(TextInfo[]
plusSamples, TextInfo[] minusSamples,EffectMeasure averAffectMeasure, int n,
double imbalance, int typeFuncResolution)
{(int i = 0; i < n; i++)
{
// Тестовая коллекция[]
plusTestCollection = null;[] minusTestCollection = null;
// Обучающая коллекция[]
plusTrainingCollection = null;[] minusTrainingCollection = null;sizePlusBlock =
plusSamples.Length / n;sizeMinusBlock = minusSamples.Length /
n;(plusSamples.Length - (i + 1) * sizePlusBlock >= sizePlusBlock
&&.Length - (i + 1) * sizeMinusBlock >= sizeMinusBlock)
{
// Инициализация тестовой коллекции=
new TextInfo[sizePlusBlock];= new TextInfo[sizeMinusBlock];(int j = 0; j <
sizePlusBlock; j++)[j] = plusSamples[i * sizePlusBlock + j];(int j = 0; j <
sizeMinusBlock; j++)[j] = minusSamples[i * sizeMinusBlock + j];
// Инициализация обучающей
коллекции= new TextInfo[plusSamples.Length - sizePlusBlock];= new
TextInfo[minusSamples.Length - sizeMinusBlock];(int j = 0; j < i *
sizePlusBlock; j++)[j] = plusSamples[j];(int j = (i + 1) * sizePlusBlock; j
< plusSamples.Length; j++)[j - sizePlusBlock] = plusSamples[j];(int j = 0; j
< i * sizeMinusBlock; j++)[j] = minusSamples[j];(int j = (i + 1) *
sizeMinusBlock; j < minusSamples.Length; j++)[j - sizeMinusBlock] =
minusSamples[j];
}
{
// Инициализация тестовой коллекции=
new TextInfo[plusSamples.Length - i * sizePlusBlock];= new
TextInfo[minusSamples.Length - i * sizeMinusBlock];(int j = 0; j <
plusSamples.Length - i * sizePlusBlock; j++)[j] = plusSamples[i * sizePlusBlock
+ j];(int j = 0; j < minusSamples.Length - i * sizeMinusBlock; j++)[j] =
minusSamples[i * sizeMinusBlock + j];
// Инициализация обучающей
коллекции= new TextInfo[i * sizePlusBlock];= new TextInfo[i *
sizeMinusBlock];(int j = 0; j < i * sizePlusBlock; j++)[j] =
plusSamples[j];(int j = 0; j < i * sizeMinusBlock; j++)[j] =
minusSamples[j];
// Список гипотез<Hypothesis>
plusHypotheses = new List<Hypothesis>();<Hypothesis>
minusHypotheses = new List<Hypothesis>();jp = new JsmProcessor();
//
Индукция.Induction(plusHypotheses, plusTrainingCollection);.Induction(minusHypotheses,
minusTrainingCollection);<Hypothesis>[]
coincidedHypForPlusSamples;<Hypothesis>[] coincidedHypForMinusSamples;
// Аналогия.Analogy(plusHypotheses,
minusHypotheses, plusTestCollection, out coincidedHypForPlusSamples);.Analogy(plusHypotheses,
minusHypotheses, minusTestCollection, out coincidedHypForMinusSamples);
// Обработка примеров
классификатором
// '+' - пример положительный
// '-' - пример отрицательный
// 'n' - класс примера не
определен[] resForPlusTestCollection = new char[plusTestCollection.Length];[]
resForMinusTestCollection = new
char[minusTestCollection.Length];.Classification(resForPlusTestCollection,
coincidedHypForPlusSamples, imbalance,
typeFuncResolution);.Classification(resForMinusTestCollection, coincidedHypForMinusSamples,
imbalance, typeFuncResolution);koeff = new
EffectMeasure();(resForPlusTestCollection, resForMinusTestCollection, ref
koeff);(i < n)
{.precission +=
koeff.precission;.recall += koeff.recall;.f1_measure +=
koeff.f1_measure;.accuracy += koeff.accuracy;
}(i == n - 1)
{.precission =
averAffectMeasure.precission / n;.recall = averAffectMeasure.recall /
n;.f1_measure = averAffectMeasure.f1_measure / n;.accuracy =
averAffectMeasure.accuracy / n;
}
}
}
}
}
Файл JsmProcessor.csSystem;System.Collections.Generic;System.Linq;System.Text;JSM_VS
{JsmProcessor
{
/// <summary>
/// Функция разрешения конфликтов
гипотез (количество гипотез)
/// </summary>
/// <param
name="coincidedHyp"></param>
/// <param
name="k"></param>
/// <returns></returns>char
ConflictResolution(List<Hypothesis> coincidedHyp, double k)
{countPlusHyp = 0, countMinusHyp =
0;(int i = 0; i < coincidedHyp.Count; i++)(coincidedHyp[i].type ==
'+')++;++;res = (double)countPlusHyp - k * (double)countMinusHyp;(res >
0)'+';if (res < 0)'-';'n';
}
/// <summary>
/// Функция разрешения конфликтов
гипотез (суммарное количество характеристик во всех гипотезах)
/// </summary>
/// <param
name="coincidedHyp"></param>
/// <param
name="k"></param>
///
<returns></returns>char ConflictResolution2(List<Hypothesis>
coincidedHyp, double k)
{countPlusValue = 0, countMinusValue
= 0;(int i = 0; i < coincidedHyp.Count; i++)(coincidedHyp[i].type == '+')+=
coincidedHyp[i].setValues.Count;+= coincidedHyp[i].setValues.Count;res =
countPlusValue - k * countMinusValue;(res > 0)'+';if (res < 0)'-';'n';
}
/// <summary>
/// Функция разрешения конфликтов
гипотез (суммарное количество родителей всех гипотез)
/// </summary>
/// <param
name="coincidedHyp"></param>
/// <param
name="k"></param>
///
<returns></returns>char ConflictResolution3(List<Hypothesis>
coincidedHyp, double k)
{countPlusParent = 0,
countMinusParent = 0;(int i = 0; i < coincidedHyp.Count;
i++)(coincidedHyp[i].type == '+')+= coincidedHyp[i].setParents.Count;+=
coincidedHyp[i].setParents.Count;res = countPlusParent - k *
countMinusParent;(res > 0)'+';if (res < 0)'-';'n';
}
/// <summary>
/// Функция разрешения конфликтов
гипотез (произведение количества характеристик на количество родителей)
/// </summary>
/// <param
name="coincidedHyp"></param>
/// <param
name="k"></param>
///
<returns></returns>char ConflictResolution4(List<Hypothesis>
coincidedHyp, double k)
{countPlusHyp = 0, countMinusHyp =
0;(int i = 0; i < coincidedHyp.Count; i++)(coincidedHyp[i].type == '+')+=
coincidedHyp[i].setValues.Count * coincidedHyp[i].setParents.Count;+=
coincidedHyp[i].setValues.Count * coincidedHyp[i].setParents.Count;res =
countPlusHyp - k * countMinusHyp;(res > 0)'+';if (res < 0)'-';'n';
}
/// <summary>
/// Функция разрешения конфликтов
гипотез (отношение произведения количества характеристик на количество
родителей
/// к общему количеству
характеристик в совпавших с текстом гипотезах одного класса)
/// </summary>
/// <param
name="coincidedHyp"></param>
/// <param
name="k"></param>
///
<returns></returns>char ConflictResolution5(List<Hypothesis>
coincidedHyp, double k)
{commonNumValuesPlusHyp = 0,
commonNumValuesMinusHyp = 0;(int i = 0; i < coincidedHyp.Count;
i++)(coincidedHyp[i].type == '+')+= coincidedHyp[i].setValues.Count;+=
coincidedHyp[i].setValues.Count;countPlusHyp = 0, countMinusHyp = 0;(int i = 0;
i < coincidedHyp.Count; i++)(coincidedHyp[i].type == '+')+=
coincidedHyp[i].setValues.Count * coincidedHyp[i].setParents.Count;+=
coincidedHyp[i].setValues.Count * coincidedHyp[i].setParents.Count;res = (double)countPlusHyp
/ (double)commonNumValuesPlusHyp -* (double)countMinusHyp /
(double)commonNumValuesMinusHyp;(res > 0)'+';if (res < 0)'-';'n';
}
/// <summary>
/// Функция разрешения конфликтов
гипотез (отношение произведения количества характеристик на количество
родителей
/// к общему количеству родителей в
совпавших с текстом гипотезах одного класса)
/// </summary>
/// <param
name="coincidedHyp"></param>
/// <param
name="k"></param>
///
<returns></returns>char ConflictResolution6(List<Hypothesis>
coincidedHyp, double k)
{commonNumParentsPlusHyp = 0,
commonNumParentsMinusHyp = 0;(int i = 0; i < coincidedHyp.Count;
i++)(coincidedHyp[i].type == '+')+= coincidedHyp[i].setParents.Count;+=
coincidedHyp[i].setParents.Count;countPlusHyp = 0, countMinusHyp = 0;(int i =
0; i < coincidedHyp.Count; i++)(coincidedHyp[i].type == '+')+=
coincidedHyp[i].setValues.Count * coincidedHyp[i].setParents.Count;+=
coincidedHyp[i].setValues.Count * coincidedHyp[i].setParents.Count;res =
(double)countPlusHyp / (double)commonNumParentsPlusHyp* (double)countMinusHyp /
(double)commonNumParentsMinusHyp;(res > 0)'+';if (res < 0)'-';'n';
/// <summary>
/// Функция классификации текстов
/// </summary>
/// <param
name="res"></param>
/// <param
name="coincidedHyp"></param>
/// <param
name="k"></param>
/// <param
name="typeFuncResolution"></param>void Classification(char[]
res, List<Hypothesis>[] coincidedHyp, double k, int typeFuncResolution)
{(int i = 0; i <
coincidedHyp.Length; i++)(typeFuncResolution)
{1:(coincidedHyp[i], k);[i] =
ConflictResolution(coincidedHyp[i], k);;2:(coincidedHyp[i], k);[i] =
ConflictResolution(coincidedHyp[i], k);;3:(coincidedHyp[i], k);[i] =
ConflictResolution(coincidedHyp[i], k);;4:(coincidedHyp[i], k);[i] =
ConflictResolution(coincidedHyp[i], k);;5:(coincidedHyp[i], k);[i] =
ConflictResolution(coincidedHyp[i], k);;6:(coincidedHyp[i], k);[i] =
ConflictResolution(coincidedHyp[i], k);;
}
}
/// <summary>
/// Процедура индукции
/// <param
name="hypotheses"></param>
/// <param name="setSamples"></param>void
Induction(List<Hypothesis> hypotheses, TextInfo[] setSamples)
{(int i = 0; i <
setSamples.Length; i++)
{hypCount1 = hypotheses.Count;(int j
= 0; j < hypCount1; j++)
{
// Находим пересечение очередного
объекта с текущей гипотезой<int> newIntersection = new
HashSet<int>();.UnionWith(setSamples[i].setValues);.IntersectWith(hypotheses[j].setValues);
// Если пересечение совпадает с
текущей гипотезой,
// то добавляем объект в список
родителей гипотезы(hypotheses[j].setValues.Count == newIntersection.Count
&&[j].setValues.SetEquals(newIntersection))
{[j].setParents.Add(i);
}
// иначе проверяем в какие ещё
гипотезы входит найденное пересечение// для определения всех родителей новой
гипотезы
{newHyp = new
Hypothesis();.setValues = new HashSet<int>();.setValues.UnionWith(newIntersection);.setParents
= new
HashSet<int>();.setParents.UnionWith(hypotheses[j].setParents);.setParents.Add(i);.type
= hypotheses[j].type;hypCount2 = hypotheses.Count;k = 0;(k < hypCount2)
{(hypotheses[k].setValues.Count ==
newHyp.setValues.Count &&[k].setValues.SetEquals(newHyp.setValues))
{[k].setParents.UnionWith(newHyp.setParents);;
}
{(hypotheses[k].setValues.SetEquals(newHyp.setValues)).setParents.UnionWith(hypotheses[k].setParents);
}++;
}(k == hypCount2).Add(newHyp);
}
}q = 0;(q < i)
{<int> newIntersection = new
HashSet<int>();.UnionWith(setSamples[i].setValues);.IntersectWith(setSamples[q].setValues);(newIntersection.Count
== setSamples[i].setValues.Count
&&[i].setValues.SetEquals(newIntersection))
{;
}++;
}(q == i)
{newHyp = new
Hypothesis();.setValues = new
HashSet<int>();.setValues.UnionWith(setSamples[i].setValues);.setParents
= new HashSet<int>();.setParents.Add(i);.type =
setSamples[i].type;.Add(newHyp);
}
}
}
/// <summary>
/// Процедура аналогии
/// </summary>
/// <param
name="plusHypotheses"></param>
/// <param
name="minusHypotheses"></param>
/// <param
name="setSamples"></param>
/// <param
name="coincidedHyp"></param>void
Analogy(List<Hypothesis> plusHypotheses, List<Hypothesis>
minusHypotheses,[] setSamples, out List<Hypothesis>[] coincidedHyp)
{= new
List<Hypothesis>[setSamples.Length];(int i = 0; i <
coincidedHyp.Length; i++)[i] = new List<Hypothesis>();(int i = 0; i <
setSamples.Length; i++)
{
// Поиск совпадений с положительными
гипотезами(int j = 0; j < plusHypotheses.Count; j++)
{<int> intersection = new
HashSet<int>();.UnionWith(setSamples[i].setValues);.IntersectWith(plusHypotheses[j].setValues);(intersection.SetEquals(plusHypotheses[j].setValues))[i].Add(plusHypotheses[j]);
}
// Поиск совпадений с отрицательными
гипотезами(int j = 0; j < minusHypotheses.Count; j++)
{<int> intersection = new
HashSet<int>();.UnionWith(setSamples[i].setValues);.IntersectWith(minusHypotheses[j].setValues);(intersection.SetEquals(minusHypotheses[j].setValues))[i].Add(minusHypotheses[j]);
}