|
828
|
128
|
956
Вычислим
оценки коэффициентов связи: 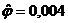 , , 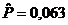 , , 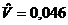 , , 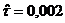 , , 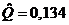 , , 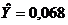 , , 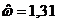 , ,  , , 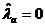 , , 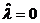 , , 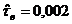 , ,  . .
По
малым значениям коэффициентов связи мы можем судить о независимости признаков.
Выполнение задания 2
Рассчитаем теоретические частоты в таблице сопряжённости:
Таблица 2 - теоретические частоты в таблице сопряжённости.
|
Знакомы
|
Не знак.
|
Уклонилсь
|
|
|
Участвуют
|
446,04234
|
393,84589
|
94,1117697
|
934
|
|
Не участвуют
|
64,948349
|
57,34801
|
13,703641
|
136
|
|
Затруднились
|
53,009314
|
46,806097
|
11,1845893
|
111
|
|
564
|
498
|
119
|
1181
|
Проверим
гипотезу  (о независимости значения признака «Знакомы с
программами депутатов» от готовности участия в выборах), используя критерий
«Хи-квадрат». (о независимости значения признака «Знакомы с
программами депутатов» от готовности участия в выборах), используя критерий
«Хи-квадрат».  , , 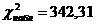 . . 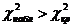 , значит, гипотезу о независимости отвергаем на уровне
значимости 0,05. , значит, гипотезу о независимости отвергаем на уровне
значимости 0,05.
Вычислим
оценки коэффициентов связи: 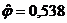 , , 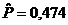 , , 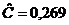 , , 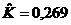 , ,  , , 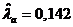 , , 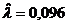 , , 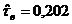 , , 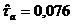 , , 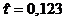 . .
По
значениям коэффициентов связи делаем вывод - существует слабая связь между
значениями признаков «Знакомы с программами депутатов» и «Готовность к участию
в выборах». Исходя из значения коэффициентов  и и 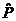 , можем сделать вывод о наличии связи средней силы. , можем сделать вывод о наличии связи средней силы.
Построим
доверительные интервалы для коэффициентов связи: 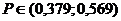 , ,
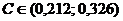 , ,  , ,  , , 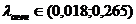 . .
Выполнение задания 3
Насыщенная модель имеет вид
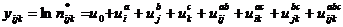
Рассчитаем
параметры для насыщенной модели и проверим их значимость:
|
Коэф-ты
|
|
Нормир.
|
Значим?
|
|
u0
|
4,332103
|
83,79929
|
Значим
|
|
u1(a)
|
-0,0162
|
-0,31341
|
Незначим
|
|
u1(b)
|
0,485375
|
9,388996
|
Значим
|
|
u1(с)
|
0,944783
|
18,27569
|
Значим
|
|
u2(a)
|
0,016202
|
0,313415
|
Незначим
|
|
u2(b)
|
-0,48538
|
-9,389
|
Значим
|
|
u2(с)
|
-0,94478
|
-18,2757
|
Значим
|
|
u11(ab)
|
0,063678
|
1,23178
|
Незначим
|
|
u11(aс)
|
-0,055
|
-1,06399
|
Незначим
|
|
u11(bс)
|
0,088763
|
1,717014
|
Незначим
|
|
u12(ab)
|
-0,06368
|
-1,23178
|
Незначим
|
|
u12(aс)
|
0,055004
|
1,063994
|
Незначим
|
|
u12(bс)
|
-0,08876
|
-1,71701
|
Незначим
|
|
u21(ab)
|
-0,06368
|
-1,23178
|
Незначим
|
|
u21(aс)
|
0,055004
|
1,063994
|
Незначим
|
|
u21(bc)
|
-0,06368
|
-1,23178
|
Незначим
|
|
u22(aс)
|
0,063678
|
1,23178
|
Незначим
|
|
u22(ab)
|
-0,055
|
-1,06399
|
Незначим
|
|
u22(bс)
|
0,088763
|
1,717014
|
Незначим
|
|
u111(abc)
|
0,125212
|
2,422067
|
Значим
|
|
u112(abc)
|
-0,12521
|
-2,42207
|
Значим
|
|
u121(abc)
|
-0,12521
|
-2,42207
|
Значим
|
|
u122(abc)
|
0,125212
|
2,422067
|
Значим
|
|
u211(abc)
|
-0,12521
|
-2,42207
|
Значим
|
|
u212(abc)
|
0,125212
|
2,422067
|
Значим
|
|
u221(abc)
|
0,125212
|
2,422067
|
Значим
|
|
u222(abc)
|
-0,12521
|
-2,42207
|
Значим
|
Из таблицы следует, что значимое влияние на исследуемые показатели
оказывают факторы «Удовлетворённость сроками» и «Удовлетворённость качеством»,
а также взаимодействие всех трёх факторов (включая «Клиенты фирмы»).
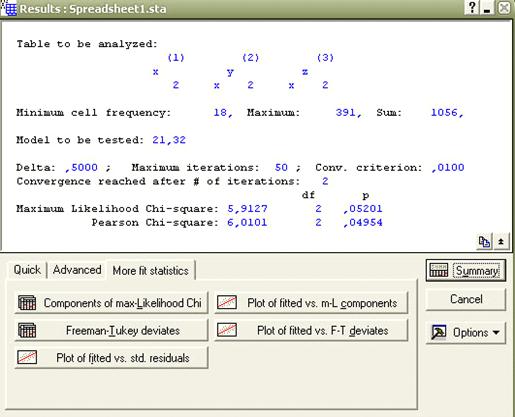
Рисунок 1 - проверка модели AB/BC в программном пакете Statistica
Среди
ненасыщенных иерархических моделей наиболее адекватной является модель AB/BC.
Она имеет вид 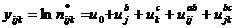 Рассчитаем теоретические частоты и оценки
коэффициентов в модели AB/BC. Рассчитаем теоретические частоты и оценки
коэффициентов в модели AB/BC.
Теоретические
частоты в трёхмерной таблице сопряжённости:
|
Удовл. сроками
|
Удовл. кач-вом
|
|
|
Да
|
Нет
|
|
Орг-ии
|
Да
|
385,53299
|
48,46701
|
|
Нет
|
91,029851
|
15,97015
|
|
Частные лица
|
Да
|
314,46701
|
39,53299
|
|
Нет
|
136,97015
|
24,02985
|
Получим
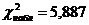 , , 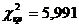 . . 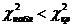 , следовательно, данная ненасыщенная модель адекватна
исходным данным. , следовательно, данная ненасыщенная модель адекватна
исходным данным.
Рассчитаем
параметры для данной ненасыщенной модели:
|
Коэф-ты
|
|
Нормир.
|
Значим?
|
|
u0
|
4,330562
|
83,00143
|
Значим
|
|
u11(ab)
|
0,153081
|
2,934013
|
Значим
|
|
u11(bс)
|
0,083319
|
1,596935
|
Незначим
|
|
u12(ab)
|
-0,15308
|
-2,93401
|
Значим
|
|
u12(bс)
|
-0,08332
|
-1,59693
|
Незначим
|
|
u21(ab)
|
-0,15308
|
-2,93401
|
Значим
|
|
u21(bс)
|
-0,08332
|
-1,59693
|
Незначим
|
|
u22(ab)
|
0,153081
|
-2,93401
|
Значим
|
|
u22(bс)
|
0,083319
|
2,934013
|
Значим
|
Из таблицы следует, что значимое влияние на результативный показатель
оказывает взаимодействие факторов «Клиенты фирмы» и «Удовлетворённость
сроками».
1.2
Непараметрические методы проверки гипотез об однородности распределения двух
совокупностей
Исходные данные представляют собой повторные парные наблюдения или
попарно связанные выборки, то есть когда для каждого объекта Oi (i=1,n)
имеется два значения: xi и yi («до обработки» и «после обработки»).
Ставится задача выяснить, есть ли эффект «обработки».
Решение такой задачи сводится к проверке гипотезы об однородности
распределения совокупностей Х и Y.
. С помощью критерия Хи-квадрат проверяется гипотеза о согласии
распределений совокупностей Х и Y.
Рассматриваются зависимые выборки Х и Y объемом n.
Выберем распределение FX(x) случайной величины Х за
теоретическое и проверим гипотезу о согласии распределений совокупностей Х и Y. Выдвинем гипотезы:

Для
проверки этой гипотезы воспользуемся критерием χ2:
 . .
При
n→∞ эта статистика распределена по закону χ2 с числом степеней свободы ν=n-1.
2. С помощью рангового критерия Вилкоксона и критерия знаков Фишера
проверяется гипотеза об отсутствии эффекта «обработки».
Решение задачи об определении влияния эффекта «обработки» сводится к
проверке гипотезы об однородности распределения двух зависимых совокупностей X и Y.
Рассматривается модель вида:
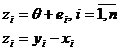 , ,
где
θ
- неизвестный параметр, характеризующий
сдвиг совокупности; ei, i=1,n - ненаблюдаемая случайная величина, характеризующая
отклонения zi и θ.
Выдвигаются
гипотезы:
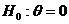 (совокупности
Х и Y не различаются по характеристике положения), (совокупности
Х и Y не различаются по характеристике положения), 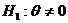 (совокупности Х и Y различаются по
характеристике положения) (совокупности Х и Y различаются по
характеристике положения)
Проверка
нулевой гипотезы осуществляется с помощью критерия знаковых рангов Вилкоксона и
критерия знаков Фишера.
При
проверки гипотезы Н0 с помощью критерия знаковых рангов Вилкоксона на еi
накладываются следующие ограничения:
1) все еi i=1,n, взаимонезависимы;
2) еi принадлежат непрерывно совокупности
(не обязательно одной и той же), симметричной относительно нуля.
Статистика положительных ранговых знаков Вилкоксона имеет вид:
 , ,
где
Ri - ранги |zi| в совокупности, упорядоченной
по увеличению абсолютных разностей; 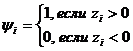 . .
Если zi=0, то эти значения исключаются, в
результате чего объем выборки n уменьшается.
При объеме выборки n→∞
статистика имеет нормальный закон распределения:
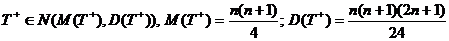
Для
проверки гипотезы также может использоваться критерий знаков Фишера. В
этом случае на еi накладываются следующие ограничения:
.
Все еi взаимно независимы;
.
Все ei извлечены из непрерывной (не обязательно одной и той
же) совокупности, имеющей медиану, равную нулю.
Критерий
знаков Фишера накладывает на параметры ei более слабые
ограничения, следовательно, критерий знаковых рангов Вилкоксона более мощный.
Для
построения критерия Фишера определяются счетчики  . .
Статистика
знаков Фишера имеет вид: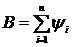 . .
Значения
критических точек этой статистики затабулированы.
В
условиях справедливости нулевой гипотезы статистика  имеет асимптотическое стандартное нормальное
распределение. имеет асимптотическое стандартное нормальное
распределение.
3. Если гипотеза об отсутствии эффекта «обработки» отвергнута, необходимо
оценить параметр, характеризующий сдвиг совокупности.
Определяются точечные и интервальные оценки параметра сдвига θ.
Точечная оценка θ Ходжеса-Лемана, основанная на статистике знаковых
рангов Вилкоксона, рассчитывается по формуле:
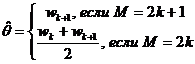 , ,
где
М=n(n+1)/2; wj, j=1,M - упорядоченные по возрастанию средние значения  . .
Проверяются
гипотезы 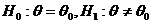 . Для этого необходимо при реализации критерия
Вилкоксона рассматривать не zi, а . Для этого необходимо при реализации критерия
Вилкоксона рассматривать не zi, а 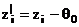 . .
Если
гипотеза не отвергается, необходимо построить доверительный интервал для
статистики θ
с надежностью γ:
Строится
упорядоченная совокупность 
Границы
доверительного интервала (θl; θu)
определяются следующим образом: 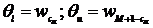
При
объеме выборки n→∞ статистика Вилкоксона распределена
нормально, поэтому число сα находится
по формуле
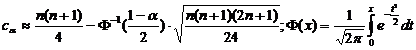 . .
Выполнение задания 4
Имеем зависимые совокупности.
Проверим
гипотезу 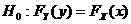 (об однородности распределения совокупности до и после
обработки) с помощью критерия (об однородности распределения совокупности до и после
обработки) с помощью критерия 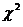 . .
Получаем
 , ,  .
Поскольку , гипотезу Н0 отвергаем, следовательно, распределения
совокупностей неоднородны. Оценим параметр сдвига. .
Поскольку , гипотезу Н0 отвергаем, следовательно, распределения
совокупностей неоднородны. Оценим параметр сдвига.
Выдвинем
гипотезу .
Вычислим
значения статистик Фишера и Вилкоксона:
Wilcoxon Matched Pairs Test (Spreadsheet1) Marked
tests are significant at p <,05000
|
Valid
|
T
|
Z
|
p-level
|
|
Y & X
|
10
|
4,000000
|
2,191691
|
0,028403
|
Sign Test (Spreadsheet1) Marked tests are significant at p
<,05000
|
No. of
|
Percent
|
Z
|
p-level
|
|
Y & X
|
9
|
77,77778
|
1,333333
|
0,182422
|
Так как критерий Вилкоксона является более мощным, то мы отвергаем
гипотезу Н0 об отсутствии эффекта обработки.
Найдём
сдвиг. M - чётное, значит 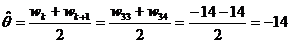 Получим
оценку сдвига. Следовательно, работа со специальными упражнениями ускорила
решение примеров в среднем на 14 секунд. Получим
оценку сдвига. Следовательно, работа со специальными упражнениями ускорила
решение примеров в среднем на 14 секунд.
Вычислим
значения статистик Фишера и Вилкоксона с учётом сдвига:
Sign Test (Spreadsheet1) Marked tests are significant
at p <,05000
|
No. of
|
Percent
|
Z
|
p-level
|
|
X & Y-Teta
|
9
|
55,55556
|
0,000000
|
1,000000
|
Wilcoxon Matched Pairs Test (Spreadsheet1) Marked tests are
significant at p <,05000
|
Valid
|
T
|
Z
|
p-level
|
|
X & Y-Teta
|
10
|
19,00000
|
0,414644
|
0,678403
|
Так
как значения статистик Фишера и Вилкоксона больше 0,05, следовательно, оценка
сдвига 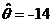 адекватна. адекватна.
Найдём
доверительный интервал для эффекта обработки с доверительной вероятностью γ=0,95. Вычислим 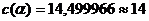 . Находим
границы доверительного интервала . Находим
границы доверительного интервала  . .
Выполнение
задания 5
Имеем
независимые совокупности.
Проверим
гипотезу (об однородности распределения совокупности до и после
обработки) с помощью критерия .
Получаем 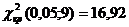 , , 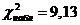 . . 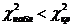 , следовательно, гипотезу об однородности
распределения совокупности до и после обработки принимаем. , следовательно, гипотезу об однородности
распределения совокупности до и после обработки принимаем.
Wald-Wolfowitz Runs Test (Spreadsheet2.sta) By
variable 2 Marked tests are significant at p <,05000
|
Valid N - Group 1
|
Valid N - Group 2
|
Mean - Group 1
|
Mean - Group 2
|
Z
|
p-level
|
Z adjstd
|
p-level
|
No. of - Runs
|
No. of - ties
|
|
1
|
10
|
8
|
8,500000
|
6,750000
|
0,054708
|
0,956371
|
-0,191478
|
0,848151
|
10
|
5
|
Kolmogorov-Smirnov Test (Spreadsheet2.sta) By variable 2
Marked tests are significant at p <,05000
|
Max Neg - Differnc
|
Max Pos - Differnc
|
p-level
|
Mean - Group 1
|
Mean - Group 2
|
Std.Dev. - Group 1
|
Valid N - Group 1
|
Valid N - Group 2
|
|
1
|
-0,025000
|
0,450000
|
p > .10
|
8,500000
|
6,750000
|
2,173067
|
2,492847
|
10
|
8
|
Mann-Whitney U Test (Spreadsheet2.sta) By variable 2 Marked
tests are significant at p <,05000
|
Rank Sum - Group 1
|
Rank Sum - Group 2
|
U
|
Z
|
p-level
|
Z - adjusted
|
p-level
|
Valid N - Group 1
|
Valid N - Group 2
|
2*1sided - exact p
|
|
1
|
114,0000
|
57,00000
|
21,00000
|
1,688194
|
0,091375
|
1,701415
|
0,088866
|
10
|
8
|
0,101102
|
0,848>0,05, 0,1>0,05, 0,089>0,05,
следовательно, гипотезу 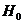 принимаем. принимаем.
.3
Дисперсионный анализ
.3.1
Параметрический дисперсионный анализ
Дисперсионный анализ предназначен для проверки наличия зависимости
нормально распределенной результативной случайной величины Y от нескольких факторов (факторных
величин), а именно для выявления причинно-следственной связи между вариацией
факторов и вариацией результативных признаков. Суть дисперсионного анализа
состоит в разложении дисперсии признака на составляющие, обусловленные влиянием
конкретных факторов и проверке гипотез о значимости их влияния. Модели
дисперсионного анализа будем классифицировать:
1) в зависимости от числа факторов - на однофакторные, двухфакторные
и т.д.;
2) по природе факторов - на детерминированные (М1), случайные
(М2) и смешанные, в зависимости от того какими являются уровни факторов.
Однофакторный анализ
Пусть
требуется проверить наличие влияния на результативный признак одного
контролируемого фактора А, имеющего m уровней 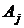 , , 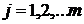 .
Наблюдаемые значения результативного признака Y на каждом
из фиксированных уровней обозначим .
Наблюдаемые значения результативного признака Y на каждом
из фиксированных уровней обозначим 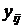 , , 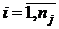 , где , где 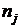 - число
объектов наблюдения. Любое наблюдение можно
представить в виде - число
объектов наблюдения. Любое наблюдение можно
представить в виде
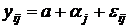 , , 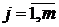 , , , ,
где
а - генеральная средняя результативного признака; 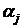 - влияние (эффект) фактора на j-ом
уровне; - влияние (эффект) фактора на j-ом
уровне; 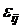 - случайные величины (остатки), отражающие влияние на
Y всех неконтролируемых факторов. - случайные величины (остатки), отражающие влияние на
Y всех неконтролируемых факторов.
Относительно
будем предполагать, что они распределены нормально и
удовлетворяют следующим условиям: 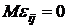 ; ; 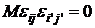 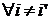 или или 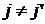 ; ; 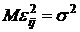 - остаточная дисперсия. - остаточная дисперсия.
В
зависимости от изучаемой модели относительно предполагаем:
модель М1 - - фиксированные величины, такие что 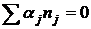 и основная гипотеза H0: и основная гипотеза H0:  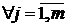 , то есть нет влияния фактора А на Y; , то есть нет влияния фактора А на Y;
модель
М2 - - случайные величины, удовлетворяющие условиям - 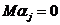 ; ; 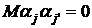  ; ; 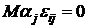 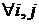 ; ; 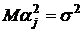 -
факторная дисперсия. Основная гипотеза H0: -
факторная дисперсия. Основная гипотеза H0: 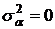 : нет
влияния фактора А на Y. : нет
влияния фактора А на Y.
Для
проверки основной гипотезы дисперсионного анализа, утверждающей, что нет
влияние фактора А (уровней фактора А) на изменение
результативного признака, вычислим следующие статистики
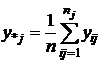 -
групповые средние (средние уровней ); -
групповые средние (средние уровней );
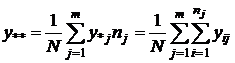 - общая
средняя результативного признака, - общая
средняя результативного признака,
где
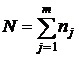 . .
Определим
две дисперсии: межгрупповую (дисперсию групповых средних) или факторную,
обусловленную влиянием изучаемого фактора и внутригрупповую (остаточную),
величина которой рассматривается как случайная. Необходимые суммы квадратов
отклонений обозначим:
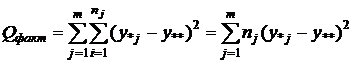 -
факторная сумма квадратов отклонений; -
факторная сумма квадратов отклонений;
 -
остаточная сумма квадратов отклонений; -
остаточная сумма квадратов отклонений;
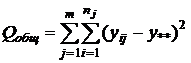 - общая
сумма квадратов отклонений. - общая
сумма квадратов отклонений.
Легко
проверить 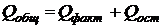
Несмещенные
оценки общей, факторной и остаточной дисперсий
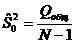 ; ;  ; ; 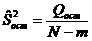 . .
Если
влияние фактора отсутствует, то  и и 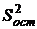 можно рассматривать как независимые оценки дисперсии можно рассматривать как независимые оценки дисперсии 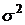 всей совокупности. Наоборот, если фактор оказывает
существенное влияние на результативный признак, то отношение : будет расти и превзойдет некоторый критический
предел. Таким образом, первоначальную гипотезу Н0 можно заменить такой Н0: всей совокупности. Наоборот, если фактор оказывает
существенное влияние на результативный признак, то отношение : будет расти и превзойдет некоторый критический
предел. Таким образом, первоначальную гипотезу Н0 можно заменить такой Н0:
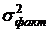 = =  . Для
проверки нулевой гипотезы рассмотрим статистику: . Для
проверки нулевой гипотезы рассмотрим статистику:
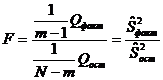 , ,
распределенную,
очевидно, по закону Фишера-Снедекора со 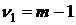 и и 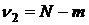 степенями свободы. Если степенями свободы. Если 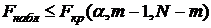 ,
то гипотеза не отвергается, то есть влияние фактора А на результативный
признак не доказано. Если ,
то гипотеза не отвергается, то есть влияние фактора А на результативный
признак не доказано. Если  , то Н0 отвергается и с вероятностью ошибки , то Н0 отвергается и с вероятностью ошибки 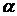 можно утверждать: влияние фактора А на
результативный признак существенно. можно утверждать: влияние фактора А на
результативный признак существенно.
Если
влияние фактора доказано, то можно проверить гипотезы:
1) Н0: 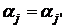 - о
равенстве двух средних выбранных уровней с помощью статистики - о
равенстве двух средних выбранных уровней с помощью статистики
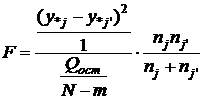 , ,
распределенной
по закону Фишера-Снедекора с 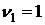 и и
2) При проверке гипотезы Н0: а=а0 используется:
в
случае модели М1 статистика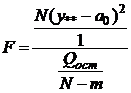 , имеющая
F - распределение с и ; , имеющая
F - распределение с и ;
в
случае модели М2 и  статистика статистика 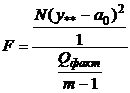 , имеющая
F - распределение с и , имеющая
F - распределение с и  . .
Несмещенную
точечную оценку для факторной дисперсии, в случае отклонения нулевой гипотезы,
можно уточнить 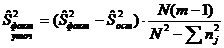 . .
Интервальная
оценка для 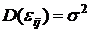 с надежностью с надежностью 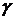
 . .
Двухфакторный
дисперсионный анализ
Будем
исследовать влияние двух факторов А и В на результативный
нормально распределенный признак Y; 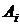 , , 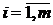 ; ; 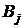 , ,  - уровни
факторов. Рассмотрим два случая. - уровни
факторов. Рассмотрим два случая.
I. Пусть каждой
паре уровней факторов и соответствует
одно наблюдаемое значение результативного признака , то есть наблюденные значение можно представить в
виде таблицы с двумя входами.
Таблица
3.1
|
Аi Bj
|
B1
|
B2
|
…
|
Bl
|
|
А1
|
y11
|
y12
|
…
|
y1l
|
|
А2
|
y21
|
y22
|
…
|
y2l
|
|
…
|
…
|
…
|
…
|
…
|
|
Аm
|
ym1
|
ym2
|
…
|
yml
|
В
этом случае модель дисперсионного анализа будем рассматривать в виде:  , где а - общая генеральная средняя; - независимые нормально распределенные остатки, с и , где а - общая генеральная средняя; - независимые нормально распределенные остатки, с и 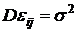 , ,  ; ;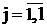 ; ; 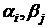 -
отклонения от а, обусловленные влиянием соответствующих уровней факторов
А и В. -
отклонения от а, обусловленные влиянием соответствующих уровней факторов
А и В.
Если
уровни факторов и фиксированные
(модель М1), то 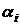 и и 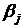 есть
неслучайные величины, удовлетворяющие очевидным условиям есть
неслучайные величины, удовлетворяющие очевидным условиям 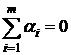 ; ; 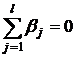 . .
Нулевые
гипотезы формулируются в виде:
Н0: 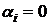 , ; Н0: , ; Н0: 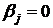 , ,  ; ;
Если
уровни факторов и случайные,
то и будем
считать независимыми между собой и с случайными
величинами распределенными нормально с 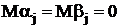 и и 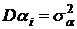 ; ;  .
Отсутствие влияния уровней факторов на изменения результативного признака -
нулевые гипотезы - формально записывается в виде: .
Отсутствие влияния уровней факторов на изменения результативного признака -
нулевые гипотезы - формально записывается в виде:
Н0: ; Н0:
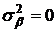 . .
Если
уровни фактора А - случайные, а В - фиксированные (смешанная
модель), то независимые между собой и с случайные величины с 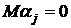 , ; -
неслучайные величины, удовлетворяющие условию , ; -
неслучайные величины, удовлетворяющие условию 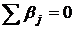 . Нулевые
гипотезы об отсутствии влияния уровней факторов на изменения результативного
признака формулируются в виде: . Нулевые
гипотезы об отсутствии влияния уровней факторов на изменения результативного
признака формулируются в виде:
Н0: ; Н0:
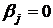 , . , .
Аналогично
строится смешанная модель, в которой фактор А имеет фиксированные
уровни, а фактор В - случайные.
Построим
разложение:
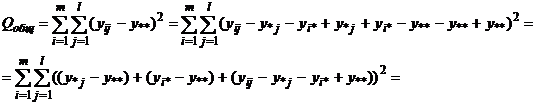
 
где
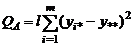 ; ; 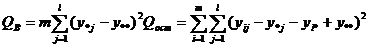 ; ;
 Для
проверки нулевой гипотезы об отсутствии влияния одного из факторов Для
проверки нулевой гипотезы об отсутствии влияния одного из факторов  рассматриваем статистику рассматриваем статистику , (где , (где 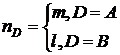 ),
распределенную, очевидно, по закону Фишера-Снедекора с ),
распределенную, очевидно, по закону Фишера-Снедекора с 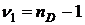 и и 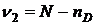 степенями
свободы. степенями
свободы.
II. В общем
случае, когда для каждой пары уровней и имеется n(n>1)
наблюдений.
|
Аi Bj
|
B1
|
B2
|
…
|
Bl
|
|
А1
|
y111, y112,…,
y11n
|
y121, y122,…,
y12n
|
…
|
y1l1, y1l2,…,
y1ln
|
|
А2
|
y211, y212,…,
y21n
|
y221, y222,…,
y22n
|
…
|
y2l1, y2l2,…,
y2ln
|
|
…
|
…
|
…
|
…
|
…
|
|
Аm
|
ym11, ym12,…,
ym1n
|
ym21, ym22,…,
ym2n
|
…
|
yml1, yml2,…,
ymln
|
Модель
дисперсионного анализа представим в виде , , , , 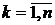 , где , где 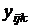 - к-ое наблюдение результативного признака для
i-го уровня фактора А и j-го
уровня фактора В; а - общая генеральная средняя; - отклонения от а, обусловленные влиянием
соответствующих уровней Аi и Вj; - к-ое наблюдение результативного признака для
i-го уровня фактора А и j-го
уровня фактора В; а - общая генеральная средняя; - отклонения от а, обусловленные влиянием
соответствующих уровней Аi и Вj;
 - отклонения от а, обусловленные совместным
влиянием уровней факторов А и В; - отклонения от а, обусловленные совместным
влиянием уровней факторов А и В; 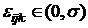 и
независимы между собой. и
независимы между собой.
Если
уровни факторов Аi и Вj
фиксированные (модель М1), то отклонения и - неслучайные величины, удовлетворяющие условиям:; ; 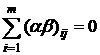 ; ; 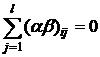 . .
Сформулируем
гипотезы об отсутствии влияния:
фактора
А - Н0: 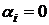 ; ;
фактора В - Н0: ; ; ; ;
фактора В - Н0: ; ;
совместного
влияния факторов А и В - Н0:  ;;. ;;.
В
случае модели М2 и есть
независимые между собой и с 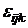 случайные
величины, распределенные нормально с нулевым математическим ожиданием и с
дисперсиями случайные
величины, распределенные нормально с нулевым математическим ожиданием и с
дисперсиями 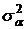 , , 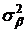 и и 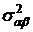 . Сформулируем нулевые гипотезы от отсутствии влияния: . Сформулируем нулевые гипотезы от отсутствии влияния:
фактора
А - Н0: ; фактора В - Н0: ;
совместного
влияния факторов А и В - Н0: 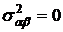 . .
Для
смешанной модели, когда, к примеру, уровни фактора А случайные, а
фактора В - фиксированные, отклонения и независимые между собой и с нормально распределены случайные величины с нулевыми
математическими ожиданиями, с дисперсиями и , при этом 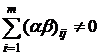 , а , а 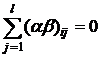 ; . ; .
Нулевые
гипотезы об отсутствии влиянием факторов имеют вид:
фактора
А - Н0: ; фактора В - Н0: ; ;
совместного
влияния факторов А и В - Н0:  .` .`
Аналогично
строится другая смешанная модель. Разложив, как и при n=1, общую сумму квадратов на составляющие:
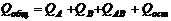 , ,   ; ;  ; ; 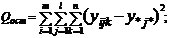
Приведем
в нижеследующей таблице схему проверки основных гипотез для различных моделей
двухфакторного дисперсионного анализа.
|
Вариации
|
Сумма квадратов
|
Число степеней свободы
|
Несмещенные оценки
дисперсий
|
М1
|
М2
|
Смешанная модель
|
|
|
|
|
|
|
А - случай
|
В - случай
|
|
|
|
|
Fнабл.
|
Fнабл.
|
Fнабл.
|
Fнабл.
|
|
А В АВ Остат.
|
QА QВ QАВ Qост
|
m-1 l-1 (m-1)(l-1)
ml(n-1)
|
1 QА/(m-1)
2 QВ/(l-1) 3 QАВ/(m-1)(l-1) 4 Qост/ml(n-1)
|
1 : 4 2 : 4 3 :
4
|
1 : 3 2 : 3 3 :
4
|
1 : 4 2 : 3 3 :
4
|
1 : 3 2 : 4 3 :
4
|
1.3.2
Непараметрический дисперсионный анализ
Непараметрический дисперсионный анализ предназначен для проверки наличия
зависимости количественной результативной случайной величины Y от нескольких факторов (факторных
величин), а именно для выявления причинно-следственной связи между вариацией
факторов и вариацией результативных признаков. Среди факторов будем различать
случайные и неслучайные величины, измеряемые в любой из шкал: интервальной,
порядковой или номинальной. При этом, в отличие от параметрического
дисперсионного анализа, закон распределения случайной величины Y отличен от нормального.
Однофакторный непараметрический дисперсионный анализ
Для проверки однородности распределения более двух независимых
совокупностей используется дисперсионный анализ. Непараметрическими
альтернативами однофакторного дисперсионного анализа являются критерии
Краскела-Уоллеса и медианный тест.
Исходными данными являются выборки из k независимых генеральных совокупностей объемами n1,n2,…,nk.
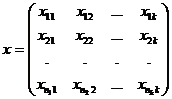 , ,
где
xij - значение признака для i-го объекта
наблюдения, извлеченного из j-й генеральной совокупности; j=1,k; i=1,nj.
Рассматривается
модель вида
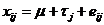 , ,
где
µ - неизвестная общая средняя; τj - эффект j-го
«наблюдения»; eij - случайные величины.
При
этом 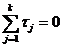 , а все eij - взаимонезависимы, извлечены из одной и той же
генеральной совокупности. , а все eij - взаимонезависимы, извлечены из одной и той же
генеральной совокупности.
Ставится
задача: выяснить, влияют ли уровни качественного признака на значения
результативного показателя. Другими словами, являются ли распределения k
независимых случайных величин однородными. Для этого выдвигается гипотеза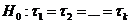
При
справедливости гипотезы Н0 все выборки можно объединить в одну, поскольку
распределение k случайных величин является однородным. Если
альтернативная гипотеза имеет вид 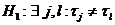 , то для
проверки нулевой гипотезы используются критерий Краскела-Уоллеса и медианный
тест. Если альтернативная гипотеза , то для
проверки нулевой гипотезы используются критерий Краскела-Уоллеса и медианный
тест. Если альтернативная гипотеза 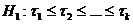 , где
хотя бы одно из неравенств строгое, то для проверки нулевой гипотезы
используется критерий Джонкхиера. , где
хотя бы одно из неравенств строгое, то для проверки нулевой гипотезы
используется критерий Джонкхиера.
Критерий
Краскела-Уоллеса проверяет однородность распределения k случайных
величин при альтернативной гипотезе сдвига. Критерий имеет вид: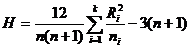 , где , где 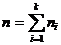 Ri -
сумма рангов i-й выборки, i=1,k. Ri -
сумма рангов i-й выборки, i=1,k.
При
справедливости нулевой гипотезы и ni≥5, k≥4
аппроксимируется распределением «Хи-квадрат» с числом степеней свободы υ=k-1.
Медианный
тест обладает меньшей мощностью и основан на подсчете числа наблюдений каждой
выборки, которые попадают выше или ниже общей медианы выборок, и вычисляет
затем значение статистики «Хи-квадрат» для таблицы сопряженности 2*k,
где k - число рассматриваемых случайных величин.
Двухфакторный непараметрический дисперсионный анализ
Непараметрический двухфакторный дисперсионный анализ - обобщение схемы
повторных парных наблюдений, когда имеется k наблюдений на каждом из n объектов.
Исходные данные:
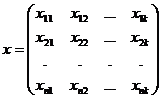
Рассмотрим
модель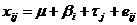 , где µ - неизвестная общая средняя; , где µ - неизвестная общая средняя; 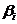 - влияние i-го наблюдения на значение
количественного признака; τj - эффект j-го «наблюдения»; eij -
случайные величины. - влияние i-го наблюдения на значение
количественного признака; τj - эффект j-го «наблюдения»; eij -
случайные величины.
При
этом , 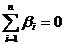 , а все eij -
взаимонезависимы, извлечены из одной и той же генеральной совокупности. , а все eij -
взаимонезависимы, извлечены из одной и той же генеральной совокупности.
Ставится
задача: проверить, являются ли распределения k независимых
случайных величин однородными. Для этого выдвигается гипотеза
Если
альтернативная гипотеза имеет вид , то для
проверки нулевой гипотезы используются критерий Фридмана.
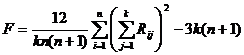 , ,
где
 - ранг i-го объекта по j-му признаку.
Критерий Фридмана при справедливости Н0 аппроксимируется распределением
«Хи-квадрат» с числом степеней свободы n-1. - ранг i-го объекта по j-му признаку.
Критерий Фридмана при справедливости Н0 аппроксимируется распределением
«Хи-квадрат» с числом степеней свободы n-1.
Если
альтернативная гипотеза , где хотя бы одно из неравенств строгое, то для
проверки нулевой гипотезы используется критерий Пейджа.
Выполнение задания 6
С помощью программы STADIA
проверим гипотезу Н0: стаж работы не влияет на производительность рабочего.
Получим следующие результаты:
-ФАКТОРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ. Файл:
Пропущн=3 3
параметрический
Источник Сум.квадр Ст.своб Ср.квадр F Значимость Сила влияния
Факт.1 391,5 3 130,5 10,54 0,0018 0,2091
Остат. 136,2 11 12,38
Общая 527,7 14 37,7(фактор1)=10,54, Значимость=0,0018, степ.своб = 3,11
Гипотеза 1: <Есть влияние фактора на отклик>
Параметры модели:
Среднее = 154,5, доверит.инт.=8,651
Эффект1 = -4,867, доверит.инт.=15,82
Эффект2 = -4,783, доверит.инт.=13,7
Эффект3 = 1,667, доверит.инт.=12,25
Эффект4 = 8,467, доверит.инт.=15,82
Парные сравнения Шеффе
Переменные Разность Интервал Значим Гипотеза H1
-2 0,08333 8,802 0,9999
-3 6,533 8,416 0,1508
-4 13,33 9,41 0,006413 Да
-3 6,45 7,731 0,1143
-4 13,25 8,802 0,004314 Да
-4 6,8 8,416 0,1297
До 5, 5-10 - 10-15, 15-20: 9,892 7,031 0,006076 Да
Следовательно, гипотезу Н0 отвергаем.
Найдём
оценку остаточной дисперсии. Сначала вычислим 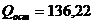 . Затем
найдём несмещённую оценку остаточной дисперсии: . Затем
найдём несмещённую оценку остаточной дисперсии: 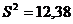 . Затем с
доверительной вероятностью γ=0,99 найдём
доверительный интервал для остаточной дисперсии. Получаем интервал [5,09; 52,37]. . Затем с
доверительной вероятностью γ=0,99 найдём
доверительный интервал для остаточной дисперсии. Получаем интервал [5,09; 52,37].
Воспользуемся
КОП «Дисперсионный анализ».
Предположим,
что фактор имеет случайные уровни (α=0,05).
Однофакторный
дисперсионный анализ
Нулевая
гипотеза: альфа j=0
-----------мещенные
оценкифакт = 391,517; Q ост = 136,217; Q общ = 527,733
-------------
Неcмещенные
оценкифакт = 130,506; S ост = 12,383
-------------наблюденное
= 10,539критическое = 3,59
-----------
Нулевая
гипотеза отвергается, есть влияние фактора
Предположим,
что фактор имеет фиксированные уровни (α=0,01).
Однофакторный
дисперсионный анализ
Нулевая
гипотеза: дисперсия альфа =0
-----------мещенные
оценкифакт = 391,517; Q ост = 136,217; Q общ = 527,733
-------------
Неcмещенные
оценкифакт = 130,506; S ост = 12,383
-------------наблюденное
= 10,539критическое = 6,22
-----------
Нулевая
гипотеза отвергается, есть влияние фактора
При
α=0,05
проверим гипотезу о существенности
влияния фактора на втором и третьем уровнях на результативный признак, т.е,
гипотезу о равенстве математических ожиданий второй и третьей группы
наблюдённых значений. 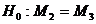 . .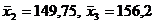 . Fнабл=7,47, Fкр(0,05;1;11)=4,84
следовательно, гипотезу H0 отвергаем на данном уровне значимости. . Fнабл=7,47, Fкр(0,05;1;11)=4,84
следовательно, гипотезу H0 отвергаем на данном уровне значимости.
Затем
при α=0,05
проверим гипотезу о значении
математического ожидания: H0:m=m0=155 (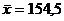 ). Будем
строить двухстороннюю критическую область. ). Будем
строить двухстороннюю критическую область.
Для
модели М1 имеем:. Fнабл=0,26, Fкр(0,05;1;11)=4,84,
следовательно, гипотезу H0 принимаем на данном уровне значимости.
Для
модели М2 имеем:. Fнабл=0,025, Fкр(0,05;1;11)=10,13,
следовательно, гипотезу H0 принимаем на данном уровне значимости.
Выполнение
задания 7
Проверим
гипотезу о влиянии факторов на результативную переменную при различных
комбинациях случайности/фискированности факторов с помощью КОП «Дисперсионный анализ».
Оба
фактора имеют случайные уровни:
Двухфакторный
(бесповторный)дисперсионный анализ
Н0
(влияние А): дисперсия (А)j=0H0(влияние В): дисперсия(В)i=0
-----------мещенные
оценки (фактор А)факт = 10,889; Q ост = 64,444; Q общ = 258,222
-------------
Неcмещенные
оценкифакт = 5,444; S ост = 10,741
-------------наблюденное
= 0,507критическое = 10,92
Нет
оснований отвергнуть гипотезу об отсутствии влияния фактора А
-----------мещенные
оценки (фактор В)факт = 182,889; Q ост = 64,444; Q общ = 258,222
-------------
Неcмещенные
оценкифакт = 91,444; S ост = 10,741
-------------наблюденное
= 8,514критическое = 10,92
-----------
Нет
оснований отвергнуть гипотезу об отсутствии влияния фактора B
При
остальных комбинациях случайности/фиксированности факторов получаем те же
оценки смещённых и несмещённых оценок дисперсий, критических и наблюдённых
значений статистики Фишера, меняются только нулевые гипотезы.
Фактор
А имеет случайные уровни, фактор В - фиксированные уровни:
Двухфакторный
(бесповторный)дисперсионный анализ
Н0
(влияние А): дисперсия (А)j=0Н0(влияние В): альфа(В)i=0
-----------
Нет
оснований отвергнуть гипотезу об отсутствии влияния фактора А
-----------
Нет
оснований отвергнуть гипотезу об отсутствии влияния фактора B
Фактор
А имеет фиксированные уровни, фактор В - случайные уровни:
Двухфакторный
(бесповторный)дисперсионный анализ
Н0
(влияние А): альфа(А)j=0Н0(влияние В): дисперсия(В)i=0
-----------
Нет
оснований отвергнуть гипотезу об отсутствии влияния фактора А
-----------
Нет
оснований отвергнуть гипотезу об отсутствии влияния фактора B
Оба
фактора имеют фиксированные уровни:
Двухфакторный
(бесповторный) дисперсионный анализ
логлинейный модель гипотеза дисперсионный
Н0
(влияние А): альфа(А)j=0Н0(влияние В): альфа(В)i=0
-----------
Нет
оснований отвергнуть гипотезу об отсутствии влияния фактора А
-----------
Нет
оснований отвергнуть гипотезу об отсутствии влияния фактора B
Выполнение
задания 8
Проверим
гипотезу (об однородности распределения совокупностей) на основе
критерия Краскелла-Уоллиса в программном пакете Statistica:
Kruskal-Wallis ANOVA by Ranks; immuno (Spreadsheet1)
Independent (grouping) variable: Group № Kruskal-Wallis test: H ( 3, N= 30)
=12,38319 p =,0062
|
Code
|
Valid
|
Sum of
|
|
1
|
1
|
5
|
35,5000
|
|
2
|
2
|
7
|
101,5000
|
|
3
|
3
|
8
|
101,0000
|
|
4
|
4
|
10
|
227,0000
|
Так как p=0,0062<0,05, гипотезу об
однородности распределения отвергаем.
Выполнение задания 9
Проверим
гипотезу (об однородности распределения совокупностей) на
основе критерия Фридмана в программном пакете Statistica:
Friedman ANOVA and Kendall Coeff. of Concordance
(Spreadsheet6) ANOVA Chi Sqr. (N = 3, df = 3) = 8,111111 p = ,04377 Coeff. of
Concordance = ,90123 Aver. rank r = ,85185
|
Average
|
Sum of
|
Mean
|
Std.Dev.
|
|
Plenka1
|
2,000000
|
6,00000
|
2,000000
|
|
|
Plenka2
|
1,166667
|
3,50000
|
1,333333
|
0,577350
|
|
Plenka3
|
3,833333
|
11,50000
|
3,333333
|
0,577350
|
|
Plenka4
|
3,000000
|
9,00000
|
2,666667
|
0,577350
|
p=0,04377<0,05,
следовательно, гипотезу об однородности распределения отвергаем.
Похожие работы на - Непараметрические методы проверки статистических гипотез
|