Методи кластеризації: процедура Мак-Кіна, метод К-методів, сітчасті методи
ДЕРЖАВНА
ПОДАТКОВА СЛУЖБА УКРАЇНИ
НАЦІОНАЛЬНИЙ
УНІВЕРСИТЕТ ДЕРЖАВНОЇ ПОДАТКОВОЇ СЛУЖБИ УКРАЇНИ
Реферат
На
тему: «Методи кластеризації: процедура Мак-Кина, метод К-методів, сітчасті
методи»
Ірпінь
2013
Вступ
Кластерний аналіз (англ.
<#"662655.files/image001.gif"> - множина
об'єктів,  - множина
номерів (імен, міток) кластерів
<#"662655.files/image003.gif">. Є кінцева вибірка
<#"662655.files/image004.gif">. Потрібно
розбити вибірку
<#"662655.files/image005.gif">, а об'єкти
різних кластерів
<#"662655.files/image006.gif"> приписується номер кластера
<#"662655.files/image007.gif">.
- множина
номерів (імен, міток) кластерів
<#"662655.files/image003.gif">. Є кінцева вибірка
<#"662655.files/image004.gif">. Потрібно
розбити вибірку
<#"662655.files/image005.gif">, а об'єкти
різних кластерів
<#"662655.files/image006.gif"> приписується номер кластера
<#"662655.files/image007.gif">.
Алгоритм кластеризації - це
функція  , яка
будь-якому об'єкту
, яка
будь-якому об'єкту  ставить у
відповідність номер кластера
<#"662655.files/image010.gif">. Множина в деяких
випадках відома заздалегідь, проте частіше ставиться завдання визначити
оптимальне число кластерів
<#"662655.files/image011.gif">
ставить у
відповідність номер кластера
<#"662655.files/image010.gif">. Множина в деяких
випадках відома заздалегідь, проте частіше ставиться завдання визначити
оптимальне число кластерів
<#"662655.files/image011.gif">
Рис. 1
Аналіз середніх значень змінних для
кожного кластера дозволяє зробити висновок про те, що за ознакою Х1 кластери 1
і 3 мають близькі значення, тоді як кластер 2 має середнє значення набагато
менший, ніж у інших двох кластерах. Навпаки, за ознакою Х2 перший кластер має
саме мінімальне значення, тоді як 2-й і 3-й кластери мають вищі та близькі між
собою середні значення. Для ознак Х3-Х12 середні значення в кластері 1 значно
вище, ніж у кластерах 2 і 3. Нагадаємо, що дані 12 ознак були
лектронно-мікроскопічними характеристиками еритроцитів трьох груп дітей -
"Здорових", "С захворюванням щитовидної залози (до
лікування)" і "С захворюванням щитовидної залози (після
лікування)". Подальший аналіз цих і багатьох інших результатів
статистичного аналізу досліджуваного масиву дозволив встановити цікаві
взаємозв'язку захворювання щитовидної залози і електронномікроскопічних
характеристик еритроцитів крові.
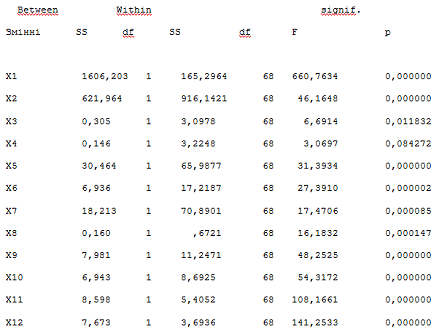
Наступна таблиця дисперсійного
аналізу результатів кластеризації на два кластери також показує необхідність
відхилення нульової гіпотези про рівність групових середніх майже за всіма 12
ознаками, за винятком змінної Х4, для якої досягнутий рівень значимості
виявився більше 5%.
Нижче наведені графік і таблиця
групових середніх для випадку кластеризації на два кластери. Ми пропонуємо
нашим читачам самостійно зробити порівняння середніх величин окремих ознак при
класифікації на 3 кластера, і на 2 кластери.
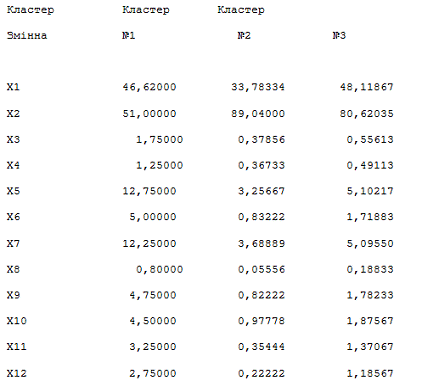
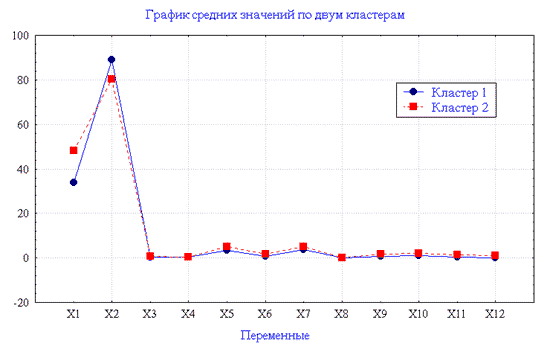
Рис. 2
У тому випадку, коли дослідник не
має можливості заздалегідь визначитися з найбільш імовірним числом кластерів,
він змушений повторити розрахунки, задаючи різне їх число, подібно до того, як
це було зроблено нами вище. А потім, порівнюючи отримані результати між собою,
зупинитися на одному з найбільш прийнятних варіантів кластеризації.
Метод К-методів
Кластеризація зображення
методом k-середніх полягає у наступному: будується деяка цільова функція
<http://uk.wikipedia.org/wiki/%D0%A6%D1%96%D0%BB%D1%8C%D0%BE%D0%B2%D0%B0_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D1%96%D1%8F>
Ф(°), що виражає якість поточного розбиття зображення на k кластерів із
центрами у точках Сі, і=1,…,n; k - задано.
Вибравши в початковий момент
центри кластерів
<http://uk.wikipedia.org/wiki/%D0%9A%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80_(%D1%96%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0)>
довільним чином, далі для кожного пікселя зображення ітеративно <http://uk.wikipedia.org/wiki/%D0%86%D1%82%D0%B5%D1%80%D0%B0%D1%86%D1%96%D1%8F>
визначаємо його приналежність до одного із k кластерів і обчислюємо нові
значення для центрів кластерів, намагаючись при цьому мінімізувати функцію
Ф(°).
Алгоритм
<http://uk.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC>
методу «Кластеризація за схемою к-середніх»:
вибрати k інформаційних точок
в якості центрів кластерів поки не завершиться процес зміни центрів кластерів;
зіставити кожну інформаційну
точку з кластером, відстань до центра якого мінімальна;
переконатися, що в кожному
кластері міститься хоча б одна точка. Для цього кожний порожній кластер
потрібно доповнити довільною точкою, що розташована «далеко» від центра
кластера;
центр кожного кластера
замінити середнім від елементів кластера;
кінець.
Сітчасті методи
При вирішенні завдань, пов'язаних з
моніторингом навколишнього середовища, часто виникає необхідність кластеризації
великих масивів даних при відсутності будь-яких апріорних відомостей про
шуканих класах. У цих умовах доцільно застосовувати так звані сіткові
(grid-based) алгоритми кластеризації, що використовують сітку з фіксованим
кроком. Обчислювальна складність таких алгоритмів визначається числом елементів
сітковою структури і практично не залежить від кількості класифікуються
об'єктів. Крім того, вони дозволяють виділяти кластери складної форми без
будь-яких припущень про структуру даних. Однак результати кластеризації при
цьому істотно залежать від вибору кроку сітки, що значно ускладнює їх практичне
застосування. Для вирішення цієї проблеми в останні роки активно розвиваються
сіточні методи, засновані на використанні не однієї, а на декількох сіток з
фіксованим кроком. У даній роботі пропонується алгоритм кластеризації,
використовує проміжні результати, отримані алгоритмом CCA на послідовності
сіток з фіксованими кроками. Алгоритм кластеризації CCA ґрунтується на введенні
клітинної структури в просторі ознак і розбитті клітин на класи, використовуючи
оцінку щільності розподілу даних. Кінцевий результат визначається за допомогою
ансамблевого методу, заснованого на побудові узгодженої матриці відмінностей.
Після обчислення узгодженої матриці відмінностей для знаходження підсумкового
рішення застосовується метод побудови дендрограмми, заснований на
агломеративного кластеризації. Алгоритм дозволяє виділяти багатомодові кластери
складної форми і формувати рішення, стійке до зміни кроку сітки.
Висновки
Ми розглянули коротко основні
поняття кластерного аналізу і кластеризації. Детально розглянули кілька
методів, кожен з яких застосовується в наш час і кожен з яких є ефективним в
якихось особливих випадках, і кожен має недоліки.
Література
кластеризація метод кін
1. Журавлев
Ю.И., Рязанов В.В., Сенько О.В. Распознавание. Математические методы.
Программная система. Практические применения.
2. Шуметов
В.Г. Шуметова Л.В. Кластерный анализ: подход с применением ЭВМ. - Орел:
ОрелГТУ, 2000. - 118 с.
. Загоруйко
Н.Г. Прикладные методы анализа данных и знаний. М., 2010.