Створення компілятора
КУРСОВА РОБОТА
з дисципліни: “Системне
програмне забезпечення”
На тему: “Створення
компілятора”
ЗМІСТ
Вступ 3
. Короткі теоретичні
відомості 4
.1 Таблиці
ідентифікаторів 4
.1.1 Метод бінарного
дерева 5
.1.2 Хешування 6
.2 Лексичний
аналізатор 7
.3 Синтаксичний
аналізатор 9
.4 Генерація
об’єктного коду 11
. Таблиця передування 13
. Лістинг програм 15
. Результати роботи 144
Висновки 147
Перелік використаної
літератури 148
Вступ
Тема: Створення компілятора
Мета роботи: вивчення складових частин, основних принципів побудови і
функціонування компіляторів. Практичне освоєння методів побудови простих
компіляторів для заданої вхідної мови.
Завдання
Для програмної організації компілятора рекомендується
використовувати Borland Delphi:
Компілятор повинен складатися:
1) лексичний аналізатор
2) синтаксичний аналізатор
) оптимізатор
) генератор результуючого кода
Для побудови компілятора бажано використовувати методи
застосовані при виконанні лабораторної роботи.
Варіант - 5
) Тип констант: вісімкові
) Додаткові операції: >><<
) Оператори цикла: repeat <оператор> until
<вираз>
) Оптимізація: виключення зайвих операцій
) Тип даних: integer
) Тип коментарів: {коментарій}
1.
Короткі теоретичні відомості
1.1
Таблиці ідентифікаторів
Способи організації таблиць ідентифікаторів:
) прості і впорядковані списки
2) бінарне дерево
) хеш-адресація з ре хешуванням
) хеш-адресація за методом ланцюжків
) комбінація хеш-адресації зі списком або бінарним
деревом
Задача компілятора в тому, щоб зберігати інформації про кожний
елемент початкової програми і ати доступ до цієї інформації по імені елемента.
Для рішення цієї задачі служать таблиці ідентифікаторів. Таблиця складається з
набору полів даних (записів) кожне з яких відповідає одному елементу початкової
програми.
Компілятор поповнює записи таблиці ідентифікаторів по мірі
аналізу початкової програми із знаходженням в ній нових елементів, яки
вимагають розміщення в таблиці. Пошук інформації в таблиці виконується всякий
раз коли компілятору необхідні дані про той або інший елемент програми. Пошук
елементів в таблиці виконується компілятором набагато частіше ніж запис.
Кожному додаванню елемента в таблицю передує пошук, щоб пересвідчитися що немає
такого елемента в таблиці. На кожну операції пошуку елемента в таблиці компілятор
витрачає час і ,оскільки число елементів в початковій програмі може біти від
одного до сотень тисяч, цей час буде істотно впливати на загальний час
компіляції. Тому пошук має бути максимально швидким.
1.1.1
Метод бінарного дерева
В цьому методі кожний вузол дерева є елементом таблиці,
кореневим вузлом стає перший елемент, який компілятор зустрів при заповненні
таблиці. Дерево є бінарним, бо кожна вершина має не більше 2 гілок.
Компілятор працює з потоком вхідних даних, що містить
ідентифікатори.
Алгоритм роботи бінарного дерева:
) Перший - заноситься в вершину дерева, наступні
попадають в дерево за таким алгоритмом:
2) 1) вибрати черговий ідентифікатор з потоку, якщо
чергового нема, то побудова закінчена
) зробити поточним вузлом дерева кореневу вершину
) порівняти ім’я чергового ідентифікатора з іменем
ідентифікатора який міститься в поточному вузлі
) якщо ім’я чергового ідентифікатора менше - перейти
до кроку 5, якщо дорівнює - зупинити алгоритм, оскільки однакових
ідентифікаторів бути не повинно, інакше - перейти до кроку 7
) якщо у поточного вузла існує ліва вершина, то
зробити її поточним вузлом и повернутися до кроку 3, інакше - до кроку 8
) створити нову вершину, помістити в неї інформацію
про черговий ідентифікатор, зробити цю нову вершину лівою вершиною поточного
вузла і перейти до кроку 1
) якщо у поточного вузла є права вершина, то зробити
її поточним вузлом і повернутися до кроку 3, інакше - до кроку 8
) створити нову вершину, помістити в неї інформацію
про черговий ідентифікатор, зробити нову вершину правою вершиною поточного
вузла і перейти до кроку 1
Пошук називається бінарним тому, що на кожному кроці об’єм
розгляданої інформації скорочується в 2 рази, тобто шуканий символ порівнюється
з (n+1)/2 елементами в середині таблиці, якщо співпадінь немає, то
переглядається блок елементів пронумерованих від 1 до (n+1)/2-1 або від (n+1)/2
до n в залежності від того менше чи більше шуканий елемент порівнюваного, далі
процес повторюється над блоком вдвічі меншого розміру.
Число порівнянь і форма дерева залежить від порядку
надходження ідентифікаторів.
Недоліком також є необхідність зберігати 2 додаткові
посилання на ліву и праву гілки в кожному елементі дерева і робота з динамічним
виділенням пам’яті для побудови дерева.
1.1.2
Хешування
Для хешування використовується поняття хеш-функції і
хеш-адресації. Хеш-функція F відображає множини вхідних елементів R на множину
цілих невід’ємних чисел Z
>Z:F(r) = n, r є R, n є Z
Множина допустимих вхідних елементів називається областю
визначення функції F.
Множина значень хеш-функції - M є Z
Процес відображення області визначення хеш-функції на множину
значень - хешування, тобто відображення імен ідентифікаторів на множину цілих
невід’ємних чисел. Хеш-адресація полягає у використанні значення, яке видає
хеш-функція в якості комірки з деякого масиву даних.
Метод хешування дуже ефективний тому, що час розміщення
елемента в таблиці і час пошуку елемента в таблиці визначається лише часом
обчислення хеш-функції, який є на порядки меншим необхідного для багатократних
порівнянь елементів в таблиці.
При хешуванні кожний елемент таблиці записується в комірку,
адресу якої видає хеш-функція обчислена для цього елемента. Для занесення
будь-якого елемента в таблицю ідентифікаторів треба обчислити його хеш-функцію
і звернутися до потрібної комірки масиву даних. Для пошуку елемента в таблиці
треба обчислити функцію для шуканого елемента і перевірити чи не є задана нею
комірка масиву пустою, якщо комірка не пуста - знайдено.
Недоліки:
- неефективне використання об’єму пам’яті оскільки
пам’ять повинна виділятися під всю область значень хеш-функції, тоді як реально
зберігається набагато менше.
необхідність прийнятного вибору хеш-функції
1.2
Лексичний аналізатор
Лексичний аналізатор - це частина компілятора, яка читає
літери програми на вхідній мові і будує з них слова (лексеми) початкової мови.
На вхід лексичного аналізатора надходить текст початкової програми, а
інформація на виході передається синтаксичному аналізатору.
Лексема - структурна одиниця мови, яка складається з символів
мови і не містить в своєму складі інших структурних одиниць мови. Лексемами є
ідентифікатори, константи, ключові слова, знаки операції.
Етап лексичного аналізу програми введено за таких причин:
- спрощення робота з текстом початкової програми і
скорочення об’єму інформації, що надходить, оскільки лексичний аналізатор
структурує інформацію, що надходить і вилучає непотрібну інформацію
- для виділення і розбору лексем можливо застосовувати
легку і ефективну техніку аналізу
лексичний аналізатор відділяє конструктивно складний
синтаксичний аналіз від роботи з текстом початкової програми, це дає змогу при
переході від однієї версії мови до іншої внести незначні зміни в простий
лексичний аналізатор
Таблиця лексем
Результатом роботи лексичного аналізатора є перелік всіх
знайдених в початковій програмі лексем і додаткової службової інформації.
Таблиця лексем в кожному рядку містить інформацію про вид лексеми, її тип і
значення. Як правило в цій таблиці є 2 поля: тип лексеми, вказівник на
інформацію про лексеми. Не слід плутати таблицю лексем з таблицею
ідентифікаторів тому, що таблиця лексем фактично містить весь текст початкової
програми обробленої лексичним аналізатором.
В таблиці лексем будь-яка лексема може зустрічатися будь-яке
число раз, тоді як в таблиці ідентифікаторів кожна лексема зустрічається лише
один раз. До того ж таблиця ідентифікаторів містить лише ідентифікатори і
константи, а інших типів лексем в ній немає.
Лексеми обов’язково розміщені в тому ж порядку, що і в
початковій програмі, а в таблиці ідентифікаторів лексеми розміщені в порядку
зручному для пошуку.
Алгоритм роботи лексичного аналізатора:
1) переглядається вхідний потік символів програми на
початковій мові до знаходження чергового символу, який обмежує лексеми;
2) для вибраної частини вхідного потоку відбувається
розпізнавання лексеми;
) при успішному розпізнаванні інформація про виділену
лексему заноситься в таблицю лексем і алгоритм повертається на перший крок;
) при неуспішному розпізнаванні видається сповіщення
про помилку і наступні дії залежать від реалізації лексичного аналізатора: або
його виконання зупиняється або робиться спроба розпізнати наступну лексему
тобто крок 1;
Робота програми лексичного аналізатора продовжується до тих
пір, поки не будуть переглянуті всі символи програми на початковій мові з
вхідного потоку.
1.3 Синтаксичний аналізатор
компілятор хешування лексичний аналізатор
За ієрархією граматик Хамського є 4 головні групи мов і
граматик, що їх описують. Регулярні і контекстно-вільні граматики
використовуються при описі синтаксису мов програм. З допомогою регулярних
граматик описуються лексеми мови, а саме ідентифікатори, константи, службові
слова та ін. А на основі контекстно-вільних граматик будуються більш складні
синтаксичні конструкції: опис типів і змінних, арифметичні і логічні вирази,
керуючі оператори і повністю вся програма на вхідній мові.
Синтаксичний аналізатор - частина компілятора, яка
відповідає за виявлення і перевірку синтаксичної конструкції вхідної мови. В
задачу синтаксичного аналізатора входить:
1) знайти і виділити синтаксичні конструкції в тексті
початкової програми;
2) встановити тип і перевірити правильність кожної
синтаксичної конструкції;
) представити синтаксичні конструкції в виді зручному
для наступної генерації результуючої програми;
Синтаксичний аналізатор сприймає вихід лексичного аналізатора
і розбирає його у відповідності з граматикою вхідної мови, але в граматиці
вхідної мови програмування ,як правило, не уточнюється які конструкції треба
вважати лексемами і на практиці не існує правила того, які конструкції
розпізнає лексичний аналізатор,а які синтаксичний - це визначає сам розробник
компілятора, виходячи з синтаксису і семантики вхідної мови і технологічних
особливостей програм.
Головну роль у функціонування синтаксичного аналізатора грає
принцип побудови розпізнавача для контекстно-вільних мов. Оскільки перед
синтаксичним аналізатором стоять 2 основні задачі: перевірити правильність
конструкцій програми у виді вже виділених слів вхідної мови, перетворити її в
вид зручний для семантичної обробки і генерації коду, то одним із способів
синтаксичного розбору є дерево синтаксичного розбору.
Основою для побудови дерева є автомати з магазинною пам’яттю
(МП-автомати). МП-автомат, на відміну від звичайного кінцевого автомата,
має магазин (стек), в цей стек заносяться як правило термінальні і не
термінальні символи граматики мови. Перехід автомата з магазинною пам’яттю з
одного стану в інший залежить не тільки від вхідного символу,а ще і від одного
або кількох символів з вершини стека.
Отже конфігурація МП-автомата визначається 3 параметрами:
1) станом автомату;
2) поточним символом вхідного ланцюжка;
) вмістом стека;
При виконанні переходу автомату з однієї конфігурації в іншу
із стека вилучаються верхні символи, які відповідають умові переходу і додається
ланцюжок, який відповідає правилу переходу. Перший символ ланцюжка стає
вершиною стеку. Допускаються переходи при яких вхідний символ пропускається і
цей же символ буде вхідним символом при наступному переході (такі переходи
називаються l-переходами). Якщо при закінченні ланцюжка автомат знаходиться в одному з
заданих кінцевих станів, а стек пустий - ланцюжок вважається прийнятим і після
закінчення ланцюжка можуть бути зроблені l-переходи, інакше ланцюжок не
приймається. Автомат з МП називається недетермінованим, якщо при одній і
тій же його конфігурації можливий більш ніж 1 перехід, якщо ж з будь-якої
конфігурації автомата з МП при будь-якому вхідному символі можливий лише 1
перехід, то автомат з МП є детермінованим. Детерміновані автомати з МП
задають клас детермінованих контекстно-вільних мов для яких існують однозначні
контекстно-вільні граматики, саме цей клас мов лежить в основі синтаксичних
конструкцій всіх мов програмування тому, що будь-яка синтаксична конструкція
мови програмування повинна трактуватися компілятором однозначно.
1.4 Генерація об’єктного коду
Генерація об’єктного коду - це переведення компілятором
внутрішнього представлення початкової програми в ланцюжок символів вихідної
мови. Вихідною мовою компілятора, на відміну від транслятора, може бути або
асемблер, або об’єктний код. Генерація об’єктного коду виконується після
лексичного, синтаксичного і семантичного аналізу.
Компілятор виділяє закінчену синтаксичну конструкцію з тексту
початкової програми, генерує для неї фрагмент результуючого коду і записує цей
фрагмент в текст результуючої програми. Це повторюється для всіх синтаксичних
конструкцій в програмі. Аналізуються такі синтаксичні конструкції як блоки
операторів, описи процедур і функцій.
В лабораторній роботі результатом генерації коду є програма
на мові асемблера. Взагалі є такі форми внутрішнього представлення
програми:
1) структури зв’язних списків, що представляють синтаксичні
дерева;
2) багатоадресний код з явно іменованими результатами
(тетради);
) багатоадресний код з неявно іменованими результатами
(тріади);
) зворотній постфікс ний польський запис операції;
) асемблер ний код або машинні команди;
В кожному конкретному компіляторі розробник вибирає одну з
даних форм. В даній лабораторній роботі використовується 3 форма.
Тріада - запис операцій в формі з 3 складових: операція і 2
операнди.
<операція> (<операнд 1><операнд 2>)
Особливістю тріад є те, що один або обидва операнди можуть
бути посиланнями на іншу тріаду в тому випадку, якщо в якості операнда даної
тріади виступає результат іншої тріади, тому тріади послідовно нумерують для
зручності вказання посилань одних тріад на інші (в реалізації компілятора
можуть бути не номери, а вказівники). Тоді при зміні нумерації і порядка
слідування не треба змінювати посилання.
Приклад: A := B*C + D - B*10
. *(B, C)
2. +(1^, D)
. *(B, 10)
. -(^2, ^3)
. :=(A, ^4)
Тріади обчислюються послідовно одна за одною і результат
обчислення зберігається в тимчасовій пам’яті.
Тріади дуже зручні для переведення їх кода в асемблер ний,
але для тріад також потрібен алгоритм розподілу пам’яті для зберігання
проміжних результатів обчислень, оскільки тимчасові змінні тріадами не
використовуються (в цьому відмінність тріад від тетрад). Тріади не залежать від
архітектури обчислювальної системи на яку орієнтована результуюча програма. Це
машинно-незалежна форма внутрішнього представлення програми.
Переваги тріад:
1) вони є лінійною послідовністю операцій на відміну від
синтаксичного дерева;
2) займають менше пам’яті ніж тетроди і краще
оптимізуються ніж зворотній польський код;
) явно відображають взаємодію операцій між собою;
) результат обчислення тріад можна зберігати в
регістрах процесора, що зручно для оптимізації;
вони наближені до двоадресних машинних команд, які найбільше
поширені в наборах команд більшості комп’ютерів;
2.
Таблиця передування
|
|
pr.
|
end.
|
;
|
f
|
(
|
)
|
else
|
beg
|
end
|
rpt
|
until
|
a
|
c
|
:=
|
or
|
xor
|
and
|
<
|
>
|
=
|
<>
|
not
|
-
|
+
|
um
|
!
|
*
|
/
|
|
pr.
|
|
=
|
<
|
<
|
|
|
|
<
|
|
<
|
|
<
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
end.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
>
|
|
|
|
;
|
|
>
|
>
|
<
|
|
|
|
<
|
>
|
<
|
|
<
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if
|
|
|
|
|
=
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(
|
|
|
|
|
<
|
=
|
|
|
|
|
|
<
|
<
|
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
|
<
|
<
|
|
)
|
|
>
|
>
|
<
|
|
>
|
=
|
<
|
>
|
<
|
=
|
<
|
|
|
>
|
>
|
>
|
>
|
>
|
>
|
>
|
|
>
|
>
|
|
|
>
|
>
|
|
else
|
|
>
|
>
|
<
|
|
|
>
|
<
|
>
|
<
|
|
<
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
beg.
|
|
|
<
|
<
|
|
|
|
<
|
=
|
<
|
|
<
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
end
|
|
>
|
>
|
|
|
|
>
|
|
>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
repit
|
|
|
|
|
=
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
until
|
|
>
|
>
|
<
|
|
|
>
|
<
|
<
|
<
|
|
<
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
a
|
|
>
|
>
|
|
|
>
|
>
|
|
>
|
|
|
|
|
=
|
>
|
>
|
>
|
>
|
>
|
>
|
>
|
|
>
|
>
|
|
|
>
|
>
|
|
c
|
|
>
|
>
|
|
|
>
|
>
|
|
>
|
|
|
|
|
|
>
|
>
|
>
|
>
|
>
|
>
|
>
|
|
>
|
>
|
|
|
>
|
>
|
|
:=
|
|
>
|
>
|
|
<
|
|
>
|
|
>
|
|
|
<
|
<
|
|
|
|
|
|
|
|
|
|
<
|
<
|
<
|
|
<
|
<
|
|
or
|
|
|
|
|
<
|
>
|
|
|
|
|
|
<
|
<
|
|
>
|
>
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
|
<
|
<
|
|
xor
|
|
|
|
|
<
|
>
|
|
|
|
|
|
<
|
<
|
|
>
|
>
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
|
<
|
<
|
|
and
|
|
|
|
|
<
|
>
|
|
|
|
|
|
<
|
<
|
|
>
|
>
|
>
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
<
|
|
<
|
<
|
|
<
|
|
|
|
|
<
|
>
|
|
|
|
|
|
<
|
<
|
|
>
|
>
|
>
|
|
|
|
|
|
<
|
<
|
<
|
|
<
|
<
|
|
>
|
|
|
|
|
<
|
>
|
|
|
|
|
|
<
|
<
|
|
>
|
>
|
>
|
|
|
|
|
|
<
|
<
|
|
<
|
<
|
|
=
|
|
|
|
|
<
|
>
|
|
|
|
|
|
<
|
<
|
|
>
|
>
|
>
|
|
|
|
|
|
<
|
<
|
<
|
|
<
|
<
|
|
<>
|
|
|
|
|
<
|
>
|
|
|
|
|
|
<
|
<
|
|
>
|
>
|
>
|
|
|
|
|
|
<
|
<
|
<
|
|
<
|
<
|
|
not
|
|
|
|
|
=
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
|
|
>
|
>
|
|
<
|
>
|
>
|
|
>
|
|
|
<
|
<
|
|
>
|
>
|
>
|
>
|
>
|
>
|
>
|
|
>
|
>
|
<
|
|
>
|
>
|
|
+
|
|
>
|
>
|
|
<
|
>
|
>
|
|
>
|
|
|
<
|
<
|
|
>
|
>
|
>
|
>
|
>
|
>
|
>
|
|
>
|
>
|
<
|
|
>
|
>
|
|
um
|
|
>
|
>
|
|
<
|
>
|
>
|
|
>
|
|
|
<
|
<
|
|
>
|
>
|
>
|
>
|
>
|
>
|
>
|
|
>
|
>
|
<
|
|
>
|
>
|
|
!
|
<
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
*
|
|
>
|
>
|
|
<
|
>
|
>
|
|
>
|
|
|
<
|
<
|
|
>
|
>
|
>
|
>
|
>
|
>
|
>
|
|
>
|
>
|
<
|
|
>
|
>
|
|
/
|
|
>
|
>
|
|
<
|
>
|
>
|
|
>
|
|
|
<
|
<
|
|
>
|
>
|
>
|
>
|
>
|
>
|
>
|
|
>
|
>
|
<
|
|
>
|
>
|
3.
Лістинг програм
. FormLab
unit FormLab4;, Messages, SysUtils, Classes, Graphics,
Controls,, Dialogs, StdCtrls, ComCtrls, Grids, ExtCtrls,, SyntSymb, Triads;
{ Типы возможных ошибок компилятора: файловая,
лексическая, синтаксическая, семантическая (триады)
или ошибок нет }= (ERR_FILE, ERR_LEX, ERR_SYNT,_TRIAD,
ERR_NO);= class(TForm): TPageControl;: TTabSheet;: TTabSheet;: TButton;:
TGroupBox;: TMemo;: TEdit;: TButton;: TButton;: TOpenDialog;: TStringGrid;:
TTabSheet;: TTreeView;: TTabSheet;: TGroupBox;: TSplitter;: TGroupBox;:
TSplitter;: TGroupBox;: TMemo;: TMemo;: TMemo;_C: TCheckBox;: TCheckBox;:
TTabSheet;: TMemo;: TCheckBox;BtnLoadClick(Sender:
TObject);BtnFileClick(Sender: TObject);EditFileChange(Sender:
TObject);BtnExitClick(Sender: TObject);FormCreate(Sender:
TObject);FormClose(Sender: TObject;Action: TCloseAction);
{ Список лексем }: TLexList;
{ Синтаксический стек }: TSymbStack;
{ Список триад }: TTriadList;
{ Имена файлов: входного, результата и ошибок
},sOutFile,sErrFile: string;
{ Функция записи стартовых данных в файл ошибок
}StartInfo(const sErrF: string);
{ Функция обработки командной строки
}ProcessParams(flOptC,flOptSame,flOptAsm: Boolean);
{ Процедура инициализации таблицы
для отображения списка лексем }InitLexGrid;
{ Процедура отображения синтаксического дерева
}MakeTree(nodeTree: TTreeNode;: TSymbol);
{ Процедура информации об ошибке }ErrInfo(const sErrF,sErr:
string;,iLen: integer);
{ Функция запуска компилятора }CompRun(const
sInF,sOutF,sErrF: string;symbRes: TSymbol;,flDelC,flDelSame,flOptC,,flOptAsm:
Boolean): TErrType;
{ Public declarations };: TCursovForm;
{$R *.DFM}FncTree, LexType, LexAuto, TrdType, TrdMake,
TrdAsm,;TCursovForm.InitLexGrid;
{ Процедура инициализации таблицы
для отображения списка лексем }GridLex do:= 2;[0,0] := '№
п/п';[1,0] := 'Лексема';[2,0] := 'Значение';[0,1] := '';[1,1] := '';[2,1] :=
'';;;TCursovForm.StartInfo(sErrF: string{имя файла ошибок});
{ Функция записи стартовых данных в файл ошибок },iCnt:
integer;{счетчик параметров и переменная цикла}: string;{суммарная командная
строка}
{ Запоминаем имя файла ошибок }:= sErrF;
{ Записываем в файл ошибок дату запуска компилятора
}(sErrFile,('--- %s ---',[DateTimeToStr(Now)]),0,0);
{ Берем количество входных параметров }:= ParamCount;
{ Обнуляем суммарную командную строку }:= ParamStr(0);
{ Записываем в суммарную командную строку
все параметры последовательно }i:=1 to iCnt do:= sTmp +' '+
ParamStr(i);
{ Записываем в файл ошибок суммарную командную строку
}(sErrFile,sTmp,0,0);;TCursovForm.ProcessParams(flOptC,flOptSame,flOptAsm:
Boolean{флаги});
{ Функция обработки командной строки },iCnt,iLen: integer;:
string;
{ Список для записи ошибок параметров }: TStringList;
{ Устанавливаем все флаги по умолчанию }:= True;:= True;:=
True;
{ Создаем список для записи ошибок параметров }:= TStringList.Create;
{ Берем количество входных параметров }:= ParamCount;
{ Обрабатываем все параметры, начиная со второго }i:=2 to
iCnt do
{ Берем строку параметра }:= ParamStr(i);
{ Берем длину строки параметра }:= Length(sTmp);
{ Если параметр слишком короткий или не начинается
со знака "-" - это неправильный параметр }(iLen
< 3) or (sTmp[1] <> '-') then
{ Запоминаем ошибку в список }.Add(Format('Неверный параметр
%d: "%s"!',
[i,sTmp]))
{ Иначе обрабатываем параметр в соответствии
с его типом (второй символ) }sTmp[2] of
{ Флаг оптимизации ассемблера }
'a','A': flOptAsm := (sTmp[3] = '1');
{ Флаг оптимизации методом свертки }
'c','C': flOptC := (sTmp[3] = '1');
{ Флаг оптимизации исключением лишних операций }
's','S': flOptSame := (sTmp[3] = '1');
{ Имя выходного файла }
'o','O': sOutFile := System.Copy(sTmp,3,iLen-2);
{ Имя файла ошибок }
'e','E': StartInfo(System.Copy(sTmp,3,iLen-2));
{ Параметр неизвестного типа }
{ Запоминаем ошибку в список }.Add(Format('Неверный параметр
%d: "%s"!',
[i,sTmp]));{case};{for};
{ Ставим имена файлов по умолчанию,
если они не были указаны в параметрах }sOutFile = '' then:=
ChangeFileExt(sInpFile,'.asm');sErrFile = ''
then(ChangeFileExt(sInpFile,'.err'));
{ Берем количество ошибок в параметрах }:= listErr.Count-1;
{ Запоминаем информацию обо всех ошибках }i:=0 to iCnt do
ErrInfo(sErrFile,listErr[i],0,0)
{ Освобождаем память, занятую списком ошибок
}listErr.Free;{try};;TCursovForm.FormCreate(Sender:
TObject);,flOptSame,flOptAsm: Boolean;: TSymbol;: TErrType;:= nil;:= '';:= '';
{ В начале выполнения инициализируем список лесем,
таблицу идентификаторов, синтаксический стек
и список триад };:= TLexList.Create;:= TSymbStack.Create;:=
TTriadList.Create;
{ Если указан параметр - не надо открывать окно,
надо сразу запускать компилятор
и обрабатывать входной файл }ParamCount > 0 then
{ Берем имя входного файла из первого параметра }:=
ParamStr(1);
{ Обрабатываем все остальные параметры
}(flOptC,flOptSame,flOptAsm);
{ Запускаем компилятор }:= CompRun(,sOutFile,sErrFile{входные
файлы},{ссылка на дерево разбора},{запоминать списки триад не надо},{флаг
удаления триад "C"},{флаг удаления триад "SAME"},{флаг
оптимизации по методу
свертки объектного кода },{флаг оптимизации исключ.
лишних операций},{флаг оптимизации команд
ассемблера});
{ Если не было файловых ошибок,
то надо завершать работу }iErr <> ERR_FILE then
Self.Close;;;TCursovForm.FormClose(Sender: TObject;Action: TCloseAction);
{ В конце выполнения очищаем список лесем,
таблицу идентификаторов, синтаксический стек
и список триад }.Free;.Free;.Free;;.Terminate;;TCursovForm.EditFileChange(Sender:
TObject);
{ Можно читать файл, только когда его имя не пустое }.Enabled
:= (EditFile.Text <> '');;TCursovForm.BtnFileClick(Sender:
TObject);FileOpenDlg.Execute then
{ Выбор имени файла с помощью стандартного диалога }.Text :=
FileOpenDlg.FileName;.Enabled := (EditFile.Text <>
'');;;TCursovForm.ErrInfo(const sErrF,sErr: string;,iLen: integer);
{ Процедура информации об ошибке }
{ Файл для записи информации об ошибке }: TextFile;
{ Если имя файла ошибок не пустое }sErrF <> '' then
{ Записываем информацию об ошибке в файл
}(fileErr,sErrF);FileExists(sErrF) then
Append(fileErr)Rewrite(fileErr);(fileErr,sErr);
{ и закрываем его }(fileErr);
выдаем сообщение об этом }(Format('Ошибка записи в файл
"%s"!'#13#10
+ 'Ошибка компиляции: %s!',
[sErrF,sErr]),,[mbOk],0);
{ Если имя файла ошибок пустое,
выводим информацию на экран }
{ Позиционируем список строк на место ошибки }.SelStart :=
iPos;.SelLength := iLen;
{ Выводим сообщение на экран }(sErr,mtWarning,[mbOk],0);
{ Отображаем позицию ошибки в списке строк }.SetFocus;;;
{ Функция запуска компилятора }TCursovForm.CompRun(sInF,{имя
входного файла},{имя результирующего файла}{имя файла ошибок}:string;symbRes:
TSymbol;{корень дерева разбора},{флаг записи триад в списки},{флаг удаления
триад типа ""},{флаг удаления триад типа ""},{флаг
оптимизации методом свертки},{флаг оптимизации методом
исключения лишних операций}{флаг оптимизации ассемблерного
кода}
: Boolean): TErrType;,iCnt,iErr: integer;: TLexem;,sAdd:
string;: TStringList;
{ Очищаем список лексем }.Clear;
{ Очищаем синтаксический стек }.Clear;
{ Очищаем список триад }.Clear;
{ Чтение файла в список строк }.Lines.LoadFromFile(sInF);:=
ERR_FILE;('Ошибка чтения файла!',mtError,[mbOk],0);;;
{ Анализ списка строк и заполнение списка лексем }:=
MakeLexList(ListIdents.Lines,listLex);iErr <> 0 then
{ Если анализ не успешный, выводим сообщение об ошибке }
{ Берем позицию ошибочной лексемы из
фиктивной лексемы в начале списка }(sErrF,('Неверная лексема
"%s" в строке %d!',
[listLex[0].LexInfoStr,iErr]),[0].PosAll,listLex[0].PosNum);
{ Результат - лексическая ошибка }:= ERR_LEX;
{ Добавляем в конец списка лексем информационную
лексему "конец строки" }ListIdents
do.Add(TLexem.CreateInfo('Конец строки',(Text),Lines.Count-1,0));
{ Строим дерево синтаксического разбора и
получаем ссылку на его корень }:=
BuildSyntList(listLex,symbStack);
{ Если эта ссылка содержит лексические данные,
значит была ошибка в месте, указанном лексемой }symbRes.SymbType
= SYMB_LEX then
{ Берем позицию ошибочной лексемы из
лексемы по ссылке }(sErrF,('Синтаксическая ошибка в строке %d
поз. %d!',
[symbRes.Lexem.StrNum+1,symbRes.Lexem.PosNum]),.Lexem.PosAll,0);
{ Освобождаем ссылку на лексему }.Free;:= nil;
{ Результат - синтаксическая ошибка }:= ERR_SYNT;
{ Иначе ссылка указывает на корень
синтаксического дерева }
{ Строим список триад по синтаксическому дереву }:=
MakeTriadList(symbRes,listTriad);
{ Если есть ссылка на лексему, значит была
семантическая ошибка }lexTmp <> nil then
{ Берем позицию ошибочной лексемы по ссылке
}(sErrF,('Семантическая ошибка в строке %d поз. %d!',
[lexTmp.StrNum+1,lexTmp.PosNum]),.PosAll,0);
{ Результат - семантическая ошибка }:= ERR_TRIAD;
{ Если есть ссылка пуста, значит триады построены }
{ Результат - "ошибок нет" }:= ERR_NO;
{ Если указан флаг, сохраняем общий список триад }flTrd
then.WriteToList(ListTriadAll.Lines);
{ Если указан флаг, выполняем оптимизацию
методом свертки объектного кода }flOptC then(listTriad);
{ Если указан флаг, удаляем триады типа "C" }flDelC
then(listTriad,TRD_CONST);;
{ Если указан флаг, сохраняем
список триад после оптимизации }flTrd
then.WriteToList(ListTriadConst.Lines);
{ Если указан флаг, выполняем оптимизацию
методом исключения лишних операций }flOptSame
then(listTriad);
{ Если указан флаг, удаляем триады типа "SAME"
}flDelSame then(listTriad,TRD_SAME);;
{ Если указан флаг, сохраняем
список триад после оптимизации }flTrd
then.WriteToList(ListTriadSame.Lines);
{ Распределяем регистры по списку триад }:=
MakeRegisters(listTriad);
{ Создаем и записываем список ассемблерных команд }:=
TStringList.Create;asmList do
{ Очищаем список ассемблерных команд };
{ Пишем заголовок программы }(Format('program
%s;',[NAME_PROG]));
{ Запоминаем перечень всех идентификаторов }:=
IdentList(',',NAME_INPVAR,NAME_FUNCT);sVars <> '' then
{ Если перечень идентификаторов не пустой,
записываем его с указанием типа данных
}('');('var');(Format(' %s: %s;',[sVars,NAME_TYPE]));;('');
{ Пишем заголовок функции }(Format('function %0:s(%1:s:
%2:s): %2:s;'
+' stdcall;',
[NAME_FUNCT,NAME_INPVAR,NAME_TYPE]));
{ Если регистров для хранения промежуточных
результатов не хватило и нужны временные
переменные, то заполняем их список }iCnt > 0
then('var');:= '';i:=0 to iCnt do:= Format('%s%d',[TEMP_VARNAME,i]);sVars = ''
then sVars := sAddsVars := sVars +','+ sAdd;;(Format(' %s:
%s;',[sVars,NAME_TYPE]));;
{ В тело функции записываем созданный список
команд ассемблера }('begin');('
asm');(#9'pushad'#9#9'{запоминаем регистры}');(listTriad,asmList,flOptAsm);(#9'popad'#9#9'{восстанавливаем
регистры}');(' end;');('end;');('');
{ Описываем одну входную переменную }(Format('var %s: %s;',
[NAME_INPVAR,NAME_TYPE]));('');
{ Заполняем тело главной программы }('begin');(Format('
readln(%s);',[NAME_INPVAR]));(Format(' writeln(%s(%s));',
[NAME_FUNCT,NAME_INPVAR]));(' readln;');('end.');{with};
{ Если установлен флаг, записываем список команд
в список для отображения на экране }flTrd
then.Lines.AddStrings(asmList);
{ Если имя результирующего файла не пустое,
записываем туда список всех команд }sOutF <> ''
then.SaveToFile(sOutF);Result :=
ERR_FILE;;asmList.Free;{try};;;;;TCursovForm.BtnLoadClick(Sender: TObject);
{ Процедура чтения и анализа файла },iCnt: integer;:
TErrType;: TSymbol;: TTreeNode;:= nil;
{ Очищаем таблицу отображения списка лексем
и синтаксическое дерево };.Items.Clear;.Clear;
{ Вызываем функцию компиляции }:= CompRun(.Text,'','',{задан
только входной файл}{указатель на дерево разбора},{Списки триад нужно
запоминать},_C.Checked
{флаг удаления триад "C"},.Checked
{флаг удаления триад "SAME"},{флаг оптимизации по
методу
свертки объектного кода },{флаг оптимизации исключ.
лишних операций},.Checked{флаг оптимизации
команд ассемблера});iRes > ERR_LEX then
{ Если не было лексической ошибки,
заполняем список лепксем }
{ Цикл по всем прочитанным лексемам }.RowCount :=
listLex.Count+1;:= listLex.Count-1;i:=0 to iCnt do
{ Первая колонка - номер }.Cells[0,i+1] := IntToStr(i+1);
{ Вторая колонка - тип лексемы }.Cells[1,i+1] :=(listLex[i].LexType);
{ Третья колонка - значение лексемы }.Cells[2,i+1] :=
listLex[i].LexInfoStr;;;(iRes > ERR_SYNT) and (symbRes <> nil) then
{ Если не было синтаксической ошибки,
заполняем дерево синтаксического разбора }
{ Записываем данные в корень дерева }:=
TreeSynt.Items.Add(nil,symbRes.SymbolStr);
{ Строим остальные элементы дерева от его корня
}(nodeTree,symbRes);
{ Раскрываем всё дерево }.Expand(True);
{ Позиционируем указатель на корневой элемент }.Selected :=
nodeTree;;iRes > ERR_TRIAD then
{ Если не было семантической ошибки,
то компиляция успешно запвершена }('Компиляция успешно
выполнена!',,[mbOk],0);.ActivePageIndex := 4;;;TCursovForm.MakeTree(
{ Процедура отображения синтаксического дерева }: TTreeNode;
{ссылка на корневой элемент отображаемой
части дерева на экране}: TSymbol
{ссылка на синтаксический символ, связанный
с корневым элементом этой части дерева});,iCnt: integer;:
TTreeNode;
{ Берем количество дочерних вершин для текущей }:=
symbSynt.Count-1;
{ Цикл по всем дочерним вершинам }i:=0 to iCnt do
{ Добавляем к дереву на экране вершину и
запоминаем ссылку на нее }:=
TreeSynt.Items.AddChild(nodeTree,[i].SymbolStr);
{ Если эта вершина связана с нетерминальным символом,
рекурсивно вызываем процедуру построения дерева
для нее }symbSynt[i].SymbType = SYMB_SYNT
then(nodeTmp,symbSynt[i]);;;TCursovForm.BtnExitClick(Sender: TObject);
{ Завершение работы с программой }.Close;;.
2. FncTree
unit FncTree;
{ Модуль, обеспечивающий работу с комбинированной таблицей
идентификаторов, построенной на основе хэш-функции и
бинарного дерева }TblElem;
{ Функция начальной инициализации хэш-таблицы }InitTreeVar;
{ Функция освобождения памяти хэш-таблицы }ClearTreeVar;
{ Функция удаления дополнительной информации в таблице
}ClearTreeInfo;
{ Добавление элемента в таблицу идентификаторов
}AddTreeVar(const sName: string): TVarInfo;
{ Поиск элемента в таблице идентификаторов }GetTreeVar(const
sName: string): TVarInfo;
{ Функция, возвращающая количество операций сравнения
}GetTreeCount: integer;
{ Функция записи всех имен идентификаторов в одну строку
}IdentList(const sLim,sInp,sOut: string): string;
{ Минимальный и максимальный элементы хэш-таблицы
(охватывают весь диапазон значений хэш-функции) }_MIN =
Ord('0')+Ord('0');_MAX = Ord('z')+Ord('z');: array[HASH_MIN..HASH_MAX] of
TVarInfo;
{ Массив для хэш-таблицы }: integer;
{ Счетчик количества сравнений }GetTreeCount: integer;:=
iCmpCount;;IdentList(const sLim,sInp,sOut: string): string;
{ Функция записи всех имен идентификаторов в одну строку }:
integer; { счетчик идентификаторов }: string; { стока для временного хранения
данных }
{ Первоначально строка пуста }:= '';
{ Цикл по всем идентификаторам в таблице }i:=HASH_MIN to
HASH_MAX do
{ Если ячейка таблицы пустая, то добавлять ничего
не нужно, }HashArray[i] = nil then sAdd := ''
{ иначе вычисляем добавочную часть строки }sAdd :=
HashArray[i].GetElList(sLim,sInp,sOut);
{ Если добавочная часть строки не пуста,
то добавляем ее в общую строку через разделитель }sAdd
<> '' thenResult <> '' then Result := Result + sLim + sAddResult :=
sAdd;;{for};;VarHash(const sName: string): longint;
{ Хэш функция - сумма кодов первого и среднего
символов строки }:= (Ord(sName[1])
+ Ord(sName[(Length(sName)+1) div 2])
HASH_MIN) mod (HASH_MAX-HASH_MIN+1)+HASH_MIN;Result <
HASH_MIN then Result := HASH_MIN;;InitTreeVar;
{ Начальная инициализация хэш-таблицы -
все элементы пустые }i : integer;i:=HASH_MIN to HASH_MAX do
HashArray[i] := nil;;ClearTreeVar;
{ Освобождение памяти для всех элементов хэш-таблицы }i :
integer;i:=HASH_MIN to HASH_MAX do[i].Free;[i] := nil;;;ClearTreeInfo;
{ Удаление дополнительной информации для всех
элементов хэш-таблицы }i : integer;i:=HASH_MIN to HASH_MAX
doHashArray[i] <> nil then HashArray[i].ClearAllInfo;;AddTreeVar(const
sName: string): TVarInfo;
{ Добавление элемента в хэш-таблицу и дерево }iHash: integer;
{ Обнуляем счетчик количества сравнений }:= 0;
{ Вычисляем хэш-адрес с помощью хэш-функции }:=
VarHash(Upper(sName));HashArray[iHash] <> nil then:=
HashArray[iHash].AddElCnt(sName,iCmpCount):= TVarInfo.Create(sName);[iHash] :=
Result;;;GetTreeVar(const sName: string): TVarInfo;iHash: integer;:= 0;:=
VarHash(Upper(sName));HashArray[iHash] = nil then Result := nil:=
HashArray[iHash].FindElCnt(sName,iCmpCount);
{ Вызов начальной инициализации таблицы
при загрузке модуля };
{ Вызов освобождения памяти таблицы при выгрузке модуля };.
3. TblElem
unit TblElem;
{ Модуль, описывающий структуру данных элементов
таблицы идентификаторов }
{ Класс для описания некоторых данных,
связанных с элементом таблицы }= class(TObject)SetInfo(iIdx:
integer; iInfo: longint);; abstract;GetInfo(iIdx: integer): longint;;
abstract;Info[iIdx: integer]: longintGetInfo write SetInfo; default;;
{ Класс для описания элемента хэш-таблицы }= class(TObject)
{ Имя элемента }: string;
{ Дополнительная информация (для будущего использования)}:
TAddVarInfo;
{ Ссылки на меньший и больший элементы
для организации бинарного дерева },maxEl: TVarInfo;
{ Конструктор создания элемента хэш-таблицы }Create(const sN:
string);
{ Деструктор для освобождения памяти, занятой элементом
}Destroy; override;
{ Функция заполнения дополнительной информации элемента
}SetInfo(pI: TAddVarInfo);
{ Функции для удаления дополнительной информации
}ClearInfo;ClearAllInfo;
{ Свойство "Имя элемента" }VarName: string read
sName;
{ Свойство "Дополнительная информация"
(для будущего использования) }Info: TAddVarInfo read pInfo
write SetInfo;
{ Функции для добавления элемента в бинарное дерево
}AddElCnt(const sAdd: string;iCnt: integer): TVarInfo;AddElem(const sAdd:
string): TVarInfo;
{ Функции для поиска элемента в бинарном дереве
}FindElCnt(const sN: string;iCnt: integer): TVarInfo;FindElem(const sN:
string): TVarInfo;
{ Функция записи всех имен идентификаторов
в одну строку }GetElList(const sLim,sInp,sOut: string):
string;;Upper(const x:string): string;SysUtils;
{ Условная компиляция: если определено имя REGNAME,
то имена переменных считаются регистрозависимыми,
иначе - регистронезависимыми }
{$IFDEF REGNAME}Upper(const x:string): string;Result :=
UpperCase(x); end;
{$ELSE}Upper(const x:string): string;Result := x; end;
{$ENDIF}TVarInfo.Create(const sN: string);
{ Конструктор создания элемента хэш-таблицы }
{ Вызываем конструктор базового класса TObject }Create;
{ Запоминаем имя элемента и обнуляем все ссылки }:= sN;:=
nil;:= nil;:= nil;;TVarInfo.Destroy;
{ Деструктор для освобождения памяти, занятой элементом }
{ Освобождаем память по каждой ссылке
(если она не нулевая), при этом в дереве рекурсивно
будет освобождена память для всех элементов };.Free;.Free;
{ Вызываем деструктор базового класса TObject
}Destroy;;TVarInfo.GetElList(const sLim{разделитель списка},,sOut{имена, не
включаемые в строку}: string): string;
{ Функция записи всех имен идентификаторов в одну строку
}sAdd: string;
{ Первоначально строка пуста }:= '';
{ Если элемент таблицы не совпадает с одним
из невключаемых имен, то его нужно включить в строку
}(Upper(sName) <> Upper(sInp))(Upper(sName) <> Upper(sOut)) then
Result := sName;
{ Если есть левая ветвь дерева }minEl <> nil then
{ Вычисляем строку для этой ветви }:= minEl.GetElList(sLim,sInp,sOut);
{ Если она не пустая, добавляем ее через разделитель }sAdd
<> '' thenResult <> '' then Result := Result + sLim + sAddResult :=
sAdd;;;
{ Если есть правая ветвь дерева }maxEl <> nil then
{ Вычисляем строку для этой ветви }:=
maxEl.GetElList(sLim,sInp,sOut);
{ Если она не пустая, добавляем ее через разделитель }sAdd
<> '' thenResult <> '' then Result := Result + sLim + sAddResult :=
sAdd;;;;TVarInfo.SetInfo(pI: TAddVarInfo);
{ Функция заполнения дополнительной информации элемента }:=
pI;;TVarInfo.ClearInfo;
{ Функция удаления дополнительной информации элемента
}.Free;:= nil;;TVarInfo.ClearAllInfo;
{ Функция удаления дополнительной информации элемента
и его связок }minEl <> nil then minEl.ClearAllInfo;maxEl
<> nil then maxEl.ClearAllInfo;.Free;:= nil;;TVarInfo.AddElCnt(const
sAdd: string;iCnt: integer): TVarInfo;
{ Функция добавления элемента в бинарное дерево
с учетом счетчика сравнений }i: integer;
{ Увеличиваем счетчик сравнений }(iCnt);
{ Сравниваем имена нового и текущего элемента
(одной функцией!) }:=
StrComp(PChar(Upper(sAdd)),PChar(Upper(sName)));i < 0 then
{ Если новый элемент меньше, смотрим ссылку
на меньший элемент }
{ Если ссылка не пустая, рекурсивно вызываем функцию
добавления элемента }minEl <> nil then:=
minEl.AddElCnt(sAdd,iCnt)
{ Если ссылка пустая, создаем новый элемент
и запоминаем ссылку на него }:= TVarInfo.Create(sAdd);:=
Result;;
{ Если новый элемент больше, смотрим ссылку
на больший элемент }i > 0 then
{ Если ссылка не пустая, рекурсивно вызываем функцию
добавления элемента }maxEl <> nil then:=
maxEl.AddElCnt(sAdd,iCnt)
{ Если ссылка пустая, создаем новый элемент
и запоминаем ссылку на него }:= TVarInfo.Create(sAdd);:=
Result;;
{ Если имена совпадают, то такой элемент уже есть
в дереве - это текущий элемент }Result :=
Self;;TVarInfo.AddElem(const sAdd: string): TVarInfo;
{ Функция добавления элемента в бинарное дерево
без учета счетчика сравнений }iCnt: integer;:=
AddElCnt(sAdd,iCnt);;TVarInfo.FindElCnt(const sN: string;iCnt: integer):
TVarInfo;
{ Функция поиска элемента в бинарном дереве
с учетом счетчика сравнений }i: integer;
{ Увеличиваем счетчик сравнений }(iCnt);
{ Сравниваем имена искомого и текущего элемента
(одной функцией!) }:=
StrComp(PChar(Upper(sN)),PChar(Upper(sName)));i < 0 then
{ Если искомый элемент меньше, смотрим ссылку
на меньший элемент }
{ Если ссылка не пустая, рекурсивно вызываем для нее
функцию поиска элемента, иначе элемент не найден }minEl
<> nil then Result := minEl.FindElCnt(sN,iCnt)Result := nil;i > 0 then
{ Если искомый элемент больше, смотрим ссылку
на больший элемент }
{ Если ссылка не пустая, рекурсивно вызываем для нее
функцию поиска элемента, иначе элемент не найден }maxEl
<> nil then Result := maxEl.FindElCnt(sN,iCnt)Result := nil;
{ Если имена совпадают, то искомый элемент
найден - это текущий элемент }Result :=
Self;;TVarInfo.FindElem(const sN: string): TVarInfo;
{ Функция поиска элемента в бинарном дереве
без учета счетчика сравнений }iCnt: integer;:=
FindElCnt(sN,iCnt);;.
4. LexElem
unit LexElem;
{ Модуль, описывающий структуру элементов таблицы лексем
}Classes, TblElem, LexType;
{ Структура для информации о лексемах }= recordLexType:
TLexType of_VAR: (VarInfo: TVarInfo);_CONST: (ConstVal: integer);_START:
(szInfo: PChar);;
{ Структура для описания лексемы }= class(TObject)
{ Информация о лексеме }: TLexInfo;
{ Позиция лексемы в исходном тексте программы },iPos,iAllP:
integer;
{ Конструкторы для создания лексем разных
типов}CreateKey(LexKey: TLexType;,iSt,iP: integer);CreateVar(VarInf: TVarInfo;,iSt,iP:
integer);CreateConst(iVal: integer;,iSt,iP: integer);CreateInfo(sInf:
string;,iSt,iP: integer);Destroy; override;
{ Свойства для получения информации о лексеме }LexType:
TLexType read LexInfo.LexType;VarInfo: TVarInfo read LexInfo.VarInfo;ConstVal:
integer read LexInfo.ConstVal;
{ Свойства для чтения позиции лексемы
в исходном тексте программы }StrNum: integer read
iStr;PosNum: integer read iPos;PosAll: integer read iAllP;
{ Текстовая информация о типе лексемы }LexInfoStr: string;
{ Имя для лексемы-переменной }VarName: string;;
{ Структура для описания списка лексем }= class(TList)
{ Деструктор для освобождения памяти
при уничтожении списка }Destroy; override;
{ Процедура очистки списка }Clear; override;
{ Процедура и свойство для получения информации
о лексеме по ее номеру }GetLexem(iIdx: integer):
TLexem;Lexem[iIdx: integer]: TLexem read GetLexem;;;SysUtils,
LexAuto;TLexem.CreateKey(LexKey: TLexType;,iSt,iP: integer);
{ Конструктор создания лексемы типа "ключевое
слово" }Create;.LexType := LexKey;
{ запоминаем тип ключевого слова }:= iSt; { запоминаем
позицию лексемы }:= iP;:= iA;;TLexem.CreateVar(VarInf: TVarInfo;,iSt,iP:
integer);
{ Конструктор создания лексемы типа "ключевое
слово" }Create;.LexType := LEX_VAR; { тип - "переменная" }
{ запоминаем ссылку на таблицу идентификаторов }.VarInfo :=
VarInf;:= iSt; { запоминаем позицию лексемы }:= iP;:=
iA;;TLexem.CreateConst(iVal: integer;,iSt,iP: integer);
{ Конструктор создания лексемы типа "константа"
}Create;.LexType := LEX_CONST; { тип - "константа" }
{ запоминаем значение константы }.ConstVal := iVal;:= iSt; {
запоминаем позицию лексемы }:= iP;:= iA;;TLexem.CreateInfo(sInf:
string;,iSt,iP: integer);
{ Конструктор создания информационной лексемы
}Create;.LexType := LEX_START; { тип - "доп. лексема" }
{ выделяем память для информации }.szInfo :=
StrAlloc(Length(sInf)+1);
{ запоминаем информацию }(LexInfo.szInfo,sInf);:= iSt; {
запоминаем позицию лексемы }:= iP;:= iA;;TLexem.Destroy;
{ Освобождаем занятую память,
если это информационная лексема }LexType = LEX_START then
StrDispose(LexInfo.szInfo);Destroy;;TLexem.VarName: string;
{ Функция получения имени лексемы типа "переменная"
}:= VarInfo.VarName;;TLexem.LexInfoStr: string;
{ Текстовая информация о типе лексемы }LexType of_VAR: Result
:= VarName;
{ для переменной - ее имя }_CONST: Result :=
IntToStr(ConstVal);
{ для константы - значение }_START: Result :=
StrPas(LexInfo.szInfo);
{ для инф. лексемы - информация }Result :=
LexTypeInfo(LexType);
{ для остальных - имя типа };;TLexList.Clear;
{ Процедура очистки списка }i: integer;
{ Уничтожаем все элементы списка }i:=Count-1 downto 0 do
Lexem[i].Free;Clear; { вызываем функцию базового класса };TLexList.Destroy;
{ Деструктор для освобождения памяти
при уничтожении списка }; { Уничтожаем все элементы списка }
{ Вызываем деструктор базового класса
}Destroy;;TLexList.GetLexem(iIdx: integer): TLexem;
{ Получение лексемы из списка по ее номеру }:=
TLexem(Items[iIdx]);;.
5. LexAuto
unit LexAuto; {!!! Зависит от входного языка !!!}
{ Модуль, обеспечивающий построение таблицы лексем
по исходному тексту программы }Classes, TblElem, LexType,
LexElem;
{ Функция создания списка лексем по исходному
тексту программы }MakeLexList(listFile: TStrings;: TLexList):
integer;SysUtils, FncTree;
{ Перечень всех возможных состояний конечного автомата }=
(_START,AP_IF1,AP_IF2,AP_NOT1,AP_NOT2,AP_NOT3,_ELSE1,AP_ELSE2,AP_ELSE3,AP_ELSE4,AP_END2,AP_END3,_PROG1,AP_PROG2,AP_PROG3,AP_PROG4,AP_OR1,AP_OR2,_BEGIN1,AP_BEGIN2,AP_BEGIN3,AP_BEGIN4,AP_BEGIN5,_XOR1,AP_XOR2,AP_XOR3,_AND1,AP_AND2,AP_AND3,_REPEAT1,AP_REPEAT2,AP_REPEAT3,AP_REPEAT4,AP_REPEAT5,_COMM,AP_COMMSG,AP_ASSIGN,AP_VAR,AP_CONST,_UNTIL1,AP_UNTIL2,AP_SIGN,AP_LT,AP_FIN,AP_ERR);MakeLexList(listFile:
TStrings;: TLexList): integer;
{ Функция создания списка лексем по исходному
тексту программы },j,iCnt,iStr, { Переменные и счетчики
циклов },{ Счетчик общего количества входных символов }
{ Переменные для запоминания позиции начала лексемы },iStart:
integer;: TAutoPos;{ Текущее состояние конечного автомата }
{ Строки для временного хранения результатов },sTmp: string;
{ Несколько простых процедур для работы со списком лексем
}AddVarToList(posNext: TAutoPos; iP: integer);
{ Процедура добавления переменной в список }
{ Выделяем имя переменной из текущей строки }:=
System.Copy(sCurStr,iStart,iP-iStart);
{ При создании переменной она сначала заносится
в таблицу идентификаторов, а потом ссылка на нее -
в таблицу лексем
}.Add(TLexem.CreateVar(AddTreeVar(sTmp),,i,iStart));:= j;:= iAll-1;:=
posNext;;AddVarKeyToList(keyAdd: TLexType;: TAutoPos);
{ Процедура добавления переменной и
разделителя в список }
{ Выделяем имя переменной из текущей строки }:=
System.Copy(sCurStr,iStart,j-iStart);
{ При создании переменной она сначала заносится
в таблицу идентификаторов, а потом ссылка на нее -
в таблицу лексем
}.Add(TLexem.CreateVar(AddTreeVar(sTmp),,i,iStart));
{ Добавляем разделитель после переменной
}.Add(TLexem.CreateKey(keyAdd,iAll,i,j));:= j;:= iAll-1;:=
posNext;;StrBinToInt(S : string) : integer;, li, mi :
integer;:=length(S);li>8 then begin:= AP_ERR;:=8;;:=1;:=0;ii := li downto 1
do beginS[ii] of
'0':;
'1': Result:=Result+mi;begin:=0;:=
AP_ERR;;;;:=mi*2;;;AddConstToList(posNext: TAutoPos; iP: integer);
{ Процедура добавления константы в список }
{ Выделяем константу из текущей строки }:= System.Copy(sCurStr,iStart,iP-iStart);
{ Заносим константу в список вместе с ее значением
}.Add(TLexem.CreateConst(StrBinToInt(sTmp),,i,iStart));:= j;:=
iAll-1;posCur<>AP_ERR then:= posNext;;AddConstKeyToList(keyAdd:
TLexType;: TAutoPos);
{ Процедура добавления константы и разделителя в список }
{ Выделяем константу из текущей строки }:=
System.Copy(sCurStr,iStart,j-iStart);
{ Заносим константу в список вместе с ее значением
}.Add(TLexem.CreateConst(StrBinToInt(sTmp),iStComm,,iStart));
{ Добавляем разделитель после константы
}.Add(TLexem.CreateKey(keyAdd,iAll,i,j));:= j;:= iAll-1;posCur<>AP_ERR
then:= posNext;;AddKeyToList(keyAdd: TLexType;: TAutoPos);
{ Процедура добавления ключевого слова или
разделителя в список
}.Add(TLexem.CreateKey(keyAdd,iStComm,i,iStart));:= j;:= iAll-1;:=
posNext;;Add2KeysToList(keyAdd1,keyAdd2: TLexType;: TAutoPos);
{ Процедура добавления ключевого слова и
разделителя в список
}.Add(TLexem.CreateKey(keyAdd1,iStComm,i,iStart));.Add(TLexem.CreateKey(keyAdd2,iAll,i,j));:=
j;:= iAll-1;:= posNext;;KeyLetter(chNext: char; posNext: TAutoPos);
{ Процедура проверки очередного символа ключевого слова
}sCurStr[j] of
':': AddVarToList(AP_ASSIGN,j);
'-': AddVarKeyToList(LEX_SUB,AP_SIGN);
'+': AddVarKeyToList(LEX_ADD,AP_SIGN);
'*': AddKeyToList(LEX_MUL,AP_SIGN);
'/': AddKeyToList(LEX_DIV,AP_SIGN);
'=': AddVarKeyToList(LEX_EQ,AP_SIGN);
'>': AddKeyToList(LEX_GT,AP_SIGN);
'<': AddVarToList(AP_LT,j);
'(': AddKeyToList(LEX_OPEN,AP_SIGN);
')': AddKeyToList(LEX_CLOSE,AP_START);
'{': posCur := AP_COMMSG;
';': AddVarKeyToList(LEX_SEMI,AP_START);
' ',#10,#13,#9: AddVarToList(AP_START,j);sCurStr[j] = chNext
then posCur := posNextsCurStr[j] in ['0'..'9','A'..'Z','a'..'z','_']posCur :=
AP_VARposCur := AP_ERR;{case list};;KeyFinish(keyAdd: TLexType);
{ Процедура проверки завершения ключевого слова }sCurStr[j]
of
'-': Add2KeysToList(keyAdd,LEX_UMIN,AP_SIGN);
'+': Add2KeysToList(keyAdd,LEX_ADD,AP_SIGN);
'*': AddKeyToList(LEX_MUL,AP_SIGN);
'/': AddKeyToList(LEX_DIV,AP_SIGN);
'=': Add2KeysToList(keyAdd,LEX_EQ,AP_SIGN);
'>': Add2KeysToList(keyAdd,LEX_GT,AP_SIGN);
'<': AddKeyToList(keyAdd,AP_LT);
'(': AddKeyToList(LEX_OPEN,AP_SIGN);
')': AddKeyToList(LEX_CLOSE,AP_START);
'{': posCur := AP_COMMSG;
';': Add2KeysToList(keyAdd,LEX_SEMI,AP_START);
'0'..'9','A'..'Z','a'..'z','_': posCur := AP_VAR;
' ',#10,#13,#9: AddKeyToList(keyAdd,AP_SIGN);posCur :=
AP_ERR;{case list};;
{ Обнуляем общий счетчик символов и результат функции }:=
0;:= 0;:= 0;
{ Устанавливаем начальное состояние конечного автомата }:=
AP_START;
{ Цикл по всем строкам входного файла }:=
listFile.Count-1;i:=0 to iCnt do
{ Позиция начала лексемы - первый символ }:= 1;
{ Цикл по всем символам текущей строки }:=
Length(sCurStr);:=0;(j);
{ Увеличиваем общий счетчик символов }(iAll);
{ Моделируем работу конечного автомата в зависимости
от состояния КА и текущего символа входной строки }posCur
of_START:
{ В начальном состоянии запоминаем позицию
начала лексемы }:= j;:= iAll-1;sCurStr[j] of
'b': posCur := AP_BEGIN1;
'i': posCur := AP_IF1;
'p': posCur := AP_PROG1;
'e': posCur := AP_ELSE1;
'r': posCur := AP_REPEAT1;
'u': posCur := AP_UNTIL1;
'o': posCur := AP_OR1;
'x': posCur := AP_XOR1;
's': posCur := AP_SHL1;
'a': posCur := AP_AND1;
'n': posCur := AP_NOT1;
':': posCur := AP_ASSIGN;
'-': AddKeyToList(LEX_SUB,AP_SIGN);
'+': AddKeyToList(LEX_ADD,AP_SIGN);
'*': AddKeyToList(LEX_MUL,AP_SIGN);
'/': AddKeyToList(LEX_DIV,AP_SIGN);
'=': AddKeyToList(LEX_EQ,AP_SIGN);
'>': AddKeyToList(LEX_GT,AP_SIGN);
'<': posCur := AP_LT;
'(': AddKeyToList(LEX_OPEN,AP_SIGN);
')': AddKeyToList(LEX_CLOSE,AP_START);
'{': posCur := AP_COMMSG;
';': AddKeyToList(LEX_SEMI,AP_START);
'0'..'9': posCur := AP_CONST;
'A'..'Z','c','f'..'h','j'..'m',
'q'..'r','t'..'v','y','z','_': posCur := AP_VAR;
' ',#10,#13,#9: ;posCur := AP_ERR;{case list};;_SIGN:
{ Состояние, когда может встретиться
унарный минус }:= j;:= iAll-1;sCurStr[j] of
'b': posCur := AP_BEGIN1;
'i': posCur := AP_IF1;
'p': posCur := AP_PROG1;
'e': posCur := AP_ELSE1;
'w': posCur := AP_REPEAT1;
'd': posCur := AP_UNTIL1;
'o': posCur := AP_OR1;
'x': posCur := AP_XOR1;
's': posCur := AP_SHL1;
'a': posCur := AP_AND1;
'n': posCur := AP_NOT1;
'-': AddKeyToList(LEX_UMIN,AP_SIGN);
'(': AddKeyToList(LEX_OPEN,AP_SIGN);
')': AddKeyToList(LEX_CLOSE,AP_START);
'{': posCur := AP_COMMSG;
'0'..'9': posCur := AP_CONST;
'A'..'Z','c','f'..'h','j'..'m',
'q'..'r','t'..'v','y','z','_': posCur := AP_VAR;
' ',#10,#13,#9: ;posCur := AP_ERR;{case list};;_LT:
{ Знак меньше или знак неравенства? }sCurStr[j] of
'b': AddKeyToList(LEX_LT,AP_BEGIN1);
'i': AddKeyToList(LEX_LT,AP_IF1);
'p': AddKeyToList(LEX_LT,AP_PROG1);
'e': AddKeyToList(LEX_LT,AP_ELSE1);
'r': AddKeyToList(LEX_LT,AP_REPEAT1);
'u': AddKeyToList(LEX_LT,AP_UNTIL1);
'o': AddKeyToList(LEX_LT,AP_OR1);
'x': AddKeyToList(LEX_LT,AP_XOR1);
's': AddKeyToList(LEX_LT,AP_SHL1);
'a': AddKeyToList(LEX_LT,AP_AND1);
'n': AddKeyToList(LEX_LT,AP_NOT1);
'>': AddKeyToList(LEX_NEQ,AP_SIGN);
'-': Add2KeysToList(LEX_LT,LEX_UMIN,AP_SIGN);
'(': Add2KeysToList(LEX_LT,LEX_OPEN,AP_SIGN);
'0'..'9': AddKeyToList(LEX_LT,AP_CONST);
'A'..'Z','c','f'..'h','j'..'m','q'..'r','t'..'v',
'y','z','_': AddKeyToList(LEX_LT,AP_VAR);
' ',#10,#13,#9: AddKeyToList(LEX_LT,AP_SIGN);posCur :=
AP_ERR;{case list};_ELSE1:
{ "else", или же "end", или переменная? }sCurStr[j]
of
'l': posCur := AP_ELSE2;
'n': posCur := AP_END2;
':': AddVarToList(AP_ASSIGN,j);
'-': AddVarKeyToList(LEX_SUB,AP_SIGN);
'+': AddVarKeyToList(LEX_ADD,AP_SIGN);
'*': AddKeyToList(LEX_MUL,AP_SIGN);
'/': AddKeyToList(LEX_DIV,AP_SIGN);
'=': AddVarKeyToList(LEX_EQ,AP_SIGN);
'>': AddKeyToList(LEX_GT,AP_SIGN);
'<': AddVarToList(AP_LT,j);
'(': AddKeyToList(LEX_OPEN,AP_SIGN);
')': AddKeyToList(LEX_CLOSE,AP_START);
'{': posCur := AP_COMMSG;
';': AddVarKeyToList(LEX_SEMI,AP_START);
'0'..'9','A'..'Z','a'..'k','m',
'o'..'z','_': posCur := AP_VAR;
' ',#10,#13,#9: AddVarToList(AP_START,j);posCur :=
AP_ERR;{case list};_IF1: KeyLetter('f',AP_IF2);_IF2: KeyFinish(LEX_IF);_ELSE2:
KeyLetter('s',AP_ELSE3);_ELSE3: KeyLetter('e',AP_ELSE4);_ELSE4:
KeyFinish(LEX_ELSE);_OR1: KeyLetter('r',AP_OR2);_OR2:
KeyFinish(LEX_OR);_UNTIL1: KeyLetter('o',AP_UNTIL2);_UNTIL2:
KeyFinish(LEX_UNTIL);_XOR1: KeyLetter('o',AP_XOR2);_XOR2:
KeyLetter('r',AP_XOR3);_XOR3: KeyFinish(LEX_XOR);_AND1:
KeyLetter('n',AP_AND2);_AND2: KeyLetter('d',AP_AND3);_AND3:
KeyFinish(LEX_AND);_NOT1: KeyLetter('o',AP_NOT2);_NOT2:
KeyLetter('t',AP_NOT3);_NOT3: KeyFinish(LEX_NOT);_PROG1:
KeyLetter('r',AP_PROG2);_PROG2: KeyLetter('o',AP_PROG3);_PROG3:
KeyLetter('g',AP_PROG4);_PROG4: KeyFinish(LEX_PROG);_REPEAT1: KeyLetter('h',AP_REPEAT2);_REPEAT2:
KeyLetter('i',AP_REPEAT3);_REPEAT3: KeyLetter('l',AP_REPEAT4);_REPEAT4:
KeyLetter('e',AP_REPEAT5);_REPEAT5: KeyFinish(LEX_REPEAT);_BEGIN1:
KeyLetter('e',AP_BEGIN2);_BEGIN2: KeyLetter('g',AP_BEGIN3);_BEGIN3:
KeyLetter('i',AP_BEGIN4);_BEGIN4: KeyLetter('n',AP_BEGIN5);_BEGIN5:
KeyFinish(LEX_BEGIN);_END2: KeyLetter('d',AP_END3);_END3:
{ "end", или же "end.", или переменная?
}sCurStr[j] of
'-': Add2KeysToList(LEX_END,LEX_UMIN,AP_SIGN);
'+': Add2KeysToList(LEX_END,LEX_ADD,AP_SIGN);
'*': AddKeyToList(LEX_MUL,AP_SIGN);
'/': AddKeyToList(LEX_DIV,AP_SIGN);
'=': Add2KeysToList(LEX_END,LEX_EQ,AP_SIGN);
'>': Add2KeysToList(LEX_END,LEX_GT,AP_SIGN);
'<': AddKeyToList(LEX_END,AP_LT);
'(': AddKeyToList(LEX_OPEN,AP_SIGN);
')': AddKeyToList(LEX_CLOSE,AP_START);
'{': posCur := AP_COMMSG;
';': Add2KeysToList(LEX_END,LEX_SEMI,AP_START);
'.': AddKeyToList(LEX_FIN,AP_START);
'0'..'9','A'..'Z','a'..'z','_'::= AP_VAR;
' ',#10,#13,#9: AddKeyToList(LEX_END,AP_SIGN);posCur :=
AP_ERR;{case list};_ASSIGN:sCurStr[j] of
'=': AddKeyToList(LEX_ASSIGN,AP_SIGN);posCur := AP_ERR;{case
list};_VAR:sCurStr[j] of
':': AddVarToList(AP_ASSIGN,j);
'-': AddVarKeyToList(LEX_SUB,AP_SIGN);
'+': AddVarKeyToList(LEX_ADD,AP_SIGN);
'*': AddKeyToList(LEX_MUL,AP_SIGN);
'/': AddKeyToList(LEX_DIV,AP_SIGN);
'=': AddVarKeyToList(LEX_EQ,AP_SIGN);
'>': AddVarKeyToList(LEX_GT,AP_SIGN);
'<': AddVarToList(AP_LT,j);
'(': AddKeyToList(LEX_OPEN,AP_SIGN);
')': AddKeyToList(LEX_CLOSE,AP_START);
'\': posCur := AP_COMMSG;
';': AddVarKeyToList(LEX_SEMI,AP_START);
'0'..'9','A'..'Z','a'..'z','_'::= AP_VAR;
'^': AddVarToList(AP_COMM,j);
' ',#10,#13,#9: AddVarToList(AP_START,j);posCur :=
AP_ERR;{case list};_CONST:sCurStr[j] of
':': AddConstToList(AP_ASSIGN,j);
'-': AddConstKeyToList(LEX_SUB,AP_SIGN);
'+': AddConstKeyToList(LEX_ADD,AP_SIGN);
'*': AddKeyToList(LEX_MUL,AP_SIGN);
'/': AddKeyToList(LEX_DIV,AP_SIGN);
'=': AddConstKeyToList(LEX_EQ,AP_SIGN);
'>': AddConstKeyToList(LEX_GT,AP_SIGN);
'<': AddConstToList(AP_LT,j);
'(': AddKeyToList(LEX_OPEN,AP_SIGN);
')': AddKeyToList(LEX_CLOSE,AP_START);
'}': posCur := AP_COMMSG;
';': AddConstKeyToList(LEX_SEMI,AP_START);
'0'..'9': posCur := AP_CONST;
' ',#10,#13,#9: AddConstToList(AP_START,j);posCur :=
AP_ERR;{case list};_COMM:sCurStr[j] of
'\': if (j<iStr)and(sCurStr[j+1]=')') then begin:=
AP_START;(j);(iAll);;{case list};_COMMSG:sCurStr[j] of
'}': if (j<iStr)and(sCurStr[j+1]=')') then begin:=
AP_SIGN;(j);(iAll);;{case list};{case pos};
{ Проверяем, не достигнут ли конец строки }j = iStr then
{ Конец строки - это конец текущей лексемы }posCur of_IF2: AddKeyToList(LEX_IF,AP_SIGN);_PROG4:
AddKeyToList(LEX_PROG,AP_START);_ELSE4: AddKeyToList(LEX_ELSE,AP_START);_BEGIN5:
AddKeyToList(LEX_BEGIN,AP_START);_REPEAT5: AddKeyToList(LEX_REPEAT,AP_SIGN);_END3:
AddKeyToList(LEX_END,AP_START);_OR2: AddKeyToList(LEX_OR,AP_SIGN);_UNTIL2:
AddKeyToList(LEX_UNTIL,AP_SIGN);_XOR3: AddKeyToList(LEX_XOR,AP_SIGN);_AND3:
AddKeyToList(LEX_AND,AP_SIGN);_NOT3: AddKeyToList(LEX_AND,AP_SIGN);_LT:
AddKeyToList(LEX_LT,AP_SIGN);_FIN: AddKeyToList(LEX_FIN,AP_START);_CONST:
AddConstToList(AP_START,j+1);_ASSIGN: posCur :=
AP_ERR;_IF1,AP_PROG1,AP_PROG2,AP_PROG3,_ELSE1,AP_ELSE2,AP_ELSE3,AP_XOR1,AP_XOR2,_OR1,AP_UNTIL1,AP_AND1,AP_AND2,AP_NOT1,AP_NOT2,_REPEAT1,AP_REPEAT2,AP_REPEAT3,AP_REPEAT4,_END2,AP_BEGIN1,AP_BEGIN2,AP_BEGIN3,AP_BEGIN4,_VAR:
AddVarToList(AP_START,j+1);{case pos2};;
{ Проверяем не была ли ошибка в лексемах }posCur = AP_ERR
then
{ Если была ошибка, вычисляем позицию
ошибочной лексемы }:= (j - iStart)+1;
{ и запоминаем ее в виде фиктивной лексемы в начале
списка для детальной диагностики ошибки
}.Insert(0,.CreateInfo('Недопустимая лексема',iStart,i,iStart));
{ Если ошибка, прерываем цикл };;j=iStr;
{ В конце строки увеличиваем общий счетчик символов
на 2: конец строки и возврат каретки }(iAll,2);
{ Если ошибка, запоминаем номер ошибочной строки
и прерываем цикл }posCur = AP_ERR then:= i+1;;;;
{ Если комментарий не был закрыт, то это ошибка }posCur in
[AP_COMM,AP_COMMSG] then.Insert(0,.CreateInfo('Незакрытый
комментарий',,iCnt,iAll-iStComm));:= iCnt;not (posCur in
[AP_START,AP_SIGN,AP_ERR]) then
{ Если КА не в начальном состоянии -
это неверная лексема }.Insert(0,.CreateInfo('Незавершенная
лексема',iStart,iCnt,iStart));:= iCnt;;;.
6. LexType
unit LexType; {!!! Зависит от входного языка !!!}
{ Модуль, содержащий описание всех типов лексем }
{ Возможные типы лексем в программе }=
(LEX_PROG, LEX_FIN, LEX_SEMI, LEX_IF, LEX_OPEN,
LEX_CLOSE,_ELSE, LEX_BEGIN, LEX_END, LEX_REPEAT, LEX_UNTIL, LEX_VAR,_CONST,
LEX_ASSIGN, LEX_OR, LEX_XOR, LEX_AND,_LT, LEX_GT, LEX_EQ, LEX_NEQ,
LEX_NOT,_SUB, LEX_ADD,LEX_MUL,LEX_DIV, LEX_UMIN, LEX_START);
{ Функция получения строки наименования типа лексемы
}LexTypeName(lexT: TLexType): string;
{ Функция получения текстовой информации о типе лексемы
}LexTypeInfo(lexT: TLexType): string;LexTypeName(lexT: TLexType): string;
{ Функция получения строки наименования типа лексемы }lexT
of_OPEN: Result := 'Открывающая скобка';_CLOSE: Result := 'Закрывающая
скобка';_ASSIGN: Result := 'Знак присвоения';_VAR: Result :=
'Переменная';_CONST: Result := 'Константа';_SEMI: Result :=
'Разделитель';_ADD,LEX_SUB,LEX_MUL,LEX_DIV,LEX_UMIN,LEX_GT,LEX_LT,LEX_EQ,_NEQ:
Result := 'Знак операции';Result := 'Ключевое слово';;;LexTypeInfo(lexT:
TLexType): string;
{ Функция получения текстовой информации о типе лексемы }lexT
of_PROG: Result := 'prog';_FIN: Result := 'end.';_SEMI: Result := ';';_IF:
Result := 'if';_OPEN: Result := '(';_CLOSE: Result := ')';_ELSE: Result :=
'else';_BEGIN: Result := 'begin';_END: Result := 'end';_REPEAT: Result :=
'repeat';_UNTIL: Result := 'until';_VAR: Result := 'a';_CONST: Result :=
'c';_ASSIGN: Result := ':=';_OR: Result := 'or';_XOR: Result := 'xor';_AND:
Result := 'and';_LT: Result := '<';_GT: Result := '>';_EQ: Result := '=';_NEQ:
Result := '<>';_NOT: Result := 'not';_ADD: Result := '+';_MUL: Result :=
'*';_DIV: Result := '/';_SUB,_UMIN: Result := '-';Result := '';;;.
7. SyntRyle
unit SyntRule; {!!! Зависит от входного языка !!!}
{ Модуль, содержащий описание матрицы предшествования и
правил грамматики }LexType, Classes;_LENGTH = 7; { максимальная длина правила
(в расчете на символы грамматики) }_NUM = 30; { общее
количество правил грамматики }
{ Матрица операторного предшествования }:
array[TLexType,TLexType] of char =
( {pr. end. ; if ( ) else beg end rpt until a c := or xor and
< > = <> not - + um ! * /}
{pr.} (' ','=','<','<',' ',' ',' ','<',' ','<','
','<',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' '),
{end.}(' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ','
',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ','>',' ',' '),
{;} (' ','>','>','<',' ',' ','
','<','>','<',' ','<',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ','
',' ',' ',' ',' '),
{if} (' ',' ',' ',' ','=',' ',' ',' ',' ',' ',' ',' ',' ','
',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' '),
{(} (' ',' ',' ',' ','<','=',' ',' ',' ',' ','
','<','<','
','<','<','<','<','<','<','<','<','<','<','<','
','<','<'),
{)} (' ','>','>','<','
','>','=','<','>','<','=','<',' ','
','>','>','>','>','>','>','>',' ','>','>',' ','
','>','>'),
{else}(' ','>','>','<',' ','
','>','<','>','<',' ','<',' ',' ',' ',' ',' ',' ',' ',' ',' ','
',' ',' ',' ',' ',' ',' '),
{beg.}(' ',' ','<','<',' ',' ',' ','<','=','<','
','<',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' '),
{end} (' ','>','>',' ',' ',' ','>',' ','>',' ','
',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' '),
{repeat}(' ',' ',' ',' ','=',' ',' ',' ',' ',' ',' ',' ','
',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' '),
{until} (' ','>','>','<',' ','
','>','<','<','<',' ','<',' ',' ',' ',' ',' ',' ',' ',' ',' ','
',' ',' ',' ',' ',' ',' '),
{a} (' ','>','>',' ',' ','>','>',' ','>',' ','
',' ',' ','=','>','>','>','>','>','>','>','
','>','>',' ',' ','>','>'),
{c} (' ','>','>',' ',' ','>','>',' ','>',' ','
',' ',' ',' ','>','>','>','>','>','>','>','
','>','>',' ',' ','>','>'),
{:=} (' ','>','>',' ','<',' ','>',' ','>','
',' ','<','<',' ',' ',' ',' ',' ',' ',' ',' ',' ','<','<','<','
','<','<'),
{or} (' ',' ',' ',' ','<','>',' ',' ',' ',' ','
','<','<','
','>','>','<','<','<','<','<','<','<','<','<','
','<','<'),
{xor} (' ',' ',' ',' ','<','>',' ',' ',' ',' ','
','<','<',' ','>','>','<','<','<','<','<','<','<','<','<','
','<','<'),
{and} (' ',' ',' ',' ','<','>',' ',' ',' ',' ','
','<','<','
','>','>','>','<','<','<','<','<','<','<','<','
','<','<'),
{<} (' ',' ',' ',' ','<','>',' ',' ',' ',' ','
','<','<',' ','>','>','>',' ',' ',' ',' ','
','<','<','<',' ','<','<'),
{>} (' ',' ',' ',' ','<','>',' ',' ',' ',' ','
','<','<',' ','>','>','>',' ',' ',' ',' ','
','<','<','<',' ','<','<'),
{=} (' ',' ',' ',' ','<','>',' ',' ',' ',' ','
','<','<',' ','>','>','>',' ',' ',' ',' ','
','<','<','<',' ','<','<'),
{<>} (' ',' ',' ',' ','<','>',' ',' ',' ',' ','
','<','<',' ','>','>','>',' ',' ',' ',' ','
','<','<','<',' ','<','<'),
{not} (' ',' ',' ',' ','=',' ',' ',' ',' ',' ',' ',' ',' ','
',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' '),
{-} (' ','>','>',' ','<','>','>',' ','>','
',' ','<','<',' ','>','>','>','>','>','>','>','
','>','>','<',' ','<','<'),
{+} (' ','>','>',' ','<','>','>',' ','>','
',' ','<','<',' ','>','>','>','>','>','>','>','
','>','>','<',' ','<','<'),
{um} (' ','>','>',' ','<','>','>',' ','>','
',' ','<','<',' ','>','>','>','>','>','>','>','
','>','>','<',' ','>','>'),
{!} ('<',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ','
',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' ',' '),
{*} (' ','>','>',' ','<','>','>',' ','>','
',' ','<','<',' ','>','>','>','>','>','>','>','
','>','>','<',' ','<','<'),
{/} (' ','>','>',' ','<','>','>',' ','>','
',' ','<','<',' ','>','>','>','>','>','>','>','
','>','>','<',' ','<','<')
)
);
{ Правила исходной грамматики }: array[1..RULE_NUM] of string
=
('progEend.','E','E;E','E;','if(B)EelseE','if(B)E',
'beginEend','repeat(B)untilE','a:=E','BorB','BxorB','B',
'BandB','B','E<E','E>E','E=E','E<>E','(B)','not(B)',
'E-E','E+E','E','-E','E','(E)','a','c',
'E*E','E/E');MakeSymbolStr(iRuleNum: integer): string;
{ Функция корректировки отношений предшествования
для расширения матрицы предшествования }CorrectRule(cRule:
char; lexTop,lexCur: TLexType;: TList): char;SyntSymb;MakeSymbolStr(iRuleNum:
integer): string;iRuleNum in [10..20] then Result := 'B'Result := 'E';;CorrectRule(cRule:
char; lexTop,lexCur: TLexType;: TList): char;j: integer;
{ Корректируем отношение для символа "else", если в
стеке
не логическое выражение }:= cRule;(cRule = '=') and (lexTop =
LEX_CLOSE)(lexCur = LEX_ELSE) then:= TSymbStack(symbStack).Count-1;(j >
2)(TSymbStack(symbStack)[j-2].SymbolStr <> 'B')Result := '>';;;.
8. SyntSymb
unit SyntSymb;
{ Модуль, обеспечивающий выполнение функций синтаксического
разбора с помощью алгоритма "сдвиг-свертка" на
основе
матрицы операторного предшествования }Classes, LexElem,
SyntRule;
{ Два типа символов: терминальные (лексемы)
и нетерминальные (синтаксические) }= (SYMB_LEX, SYMB_SYNT);
{ Структура данных для информации о символе грамматики }=
record
{ Тип символа - терминальный или нетерминальный }SymbType:
TSymbKind of
{ Для терминального символа - ссылка на лексему }_LEX:
(LexOne: TLexem);
{ Для нетерминального символа - ссылка на список
символов, из которых он был построен }_SYNT: (LexList:
TList);;
{ Предварительное описание класса "Символ" }=
class;
{ Массив символов, составляющих правило грамматики }=
array[0..RULE_LENGTH] of TSymbol;
{ Структура, описывающая грамматический символ }=
class(TObject)
{ Информация о символе }: TSymbInfo;
{ Номер правила, по которому создан символ }: integer;
{ Конструктор создания терминального символа
на основе лексемы }CreateLex(Lex: TLexem);
{ Конструктор создания нетерминального символа
на основе правила и массива символов }CreateSymb(iR,iSymbN:
integer;SymbArr: TSymbArray);
{ Деструктор для удаления символа }Destroy; override;
{ Функция получения символа из правила по порядковому
номеру символа }GetItem(iIdx: integer): TSymbol;
{ Функция, возвращающее количество символов
в исходном правиле }Count: integer;
{ Функция, формирующая строковое представление символа
}SymbolStr: string;
{ Свойства символа на основе описанных выше
функций и данных }
{ Свойство, возвращающее тип символа }SymbType: TSymbKind
read SymbInfo.SymbType;
{ Свойство, возвращающее ссылку на лексему
для терминального символа }Lexem: TLexem read SymbInfo.LexOne;
{ Свойство, возвращающее символа из правила
по порядковому номеру символа }Items[iIdx: integer]: TSymbol
read GetItem;;
{ Свойство, возвращающее номер правила }Rule: integer read
iRuleNum;;
{ Структура, описывающая синтаксический стек }= class(TList)
{ Деструктор для удаления стека }Destroy; override;
{ Функция очистки стека }Clear; override;
{ Функция выборки символа по порядковому номеру
от конца стека }GetSymbol(iIdx: integer): TSymbol;
{ Функция помещения в стек входящей лексемы }Push(lex:
TLexem): TSymbol;
{ Свойство для выборки символа по порядковому номеру
от вершины стека }Symbols[iIdx: integer]: TSymbol read
GetSymbol;;
{ Функция, возвращающая самую верхнюю лексему в стеке
}TopLexem: TLexem;
{ Функция, выполняющая свертку и помещающая новый символ
на вершину стека }MakeTopSymb: TSymbol;;
{ Функция, выполняющая алгоритм "сдвиг-свертка"
}BuildSyntList(const listLex: TLexList;: TSymbStack): TSymbol;LexType,
LexAuto;TSymbol.CreateLex(Lex: TLexem);
{ Конструктор создания терминального символа
на основе лексемы }
{ Вызываем конструктор базового класа }Create;
{ Ставим тип символа "терминальный" }.SymbType :=
SYMB_LEX;
{ Запоминаем ссылку на лексему }.LexOne := Lex;
{ Правило не используется, поэтому "0" }:=
0;;TSymbol.CreateSymb(iR{номер правила},{кол-во исходных символов}:
integer;SymbArr: TSymbArray{массив исходных символов});
{ Конструктор создания нетерминального символа
на основе правила и массива символов }i: integer;
{ Вызываем конструктор базового класа }Create;
{ Ставим тип символа "нетерминальный" }.SymbType :=
SYMB_SYNT;
{ Создаем список для хранения исходных символов }.LexList :=
TList.Create;
{ Переносим все исходные символы в список
в обратном порядке }i:=iSymbN-1 downto 0
do.LexList.Add(SymbArr[i]);
{ Запоминаем номер правила }:= iR;;TSymbol.GetItem(iIdx:
integer): TSymbol;
{ Функция получения символа из правила
по порядковому номеру символа }:=
TSymbol(SymbInfo.LexList[iIdx]);TSymbol.Count: integer;
{ Функция, возвращающее количество символов
в исходном правиле }:= SymbInfo.LexList.Count;;TSymbol.SymbolStr:
string;
{ Функция, формирующая строковое представление символа }
{ Если это нетерминальный символ, формируем его
представление в зависимости от номера правила }SymbType =
SYMB_SYNT then:= MakeSymbolStr(iRuleNum)
{ Если это терминальный символ, формируем его
представление в соответствии со строковым
представлением лексемы }Result :=
Lexem.LexInfoStr;;TSymbol.Destroy;
{ Деструктор для удаления символа }i:
integer;SymbInfo.SymbType = SYMB_SYNT then
{ Если это нетерминальный символ }SymbInfo.LexList do
{ Удаляем все его исходные символы из списка }i:=Count-1
downto 0 do TSymbol(Items[i]).Free;
{ Удаляем список символов };;
{ Вызываем деструктор базового класа
}Destroy;;TSymbStack.Destroy;
{ Деструктор для удаления синтаксического стека }
{ Очищаем стек };
{ Вызываем деструктор базового класа
}Destroy;;TSymbStack.Clear;
{ Функция очистки синтаксического стека }i: integer;
{ Удаляем все символы из стека }i:=Count-1 downto 0 do
TSymbol(Items[i]).Free;
{ Вызываем функцию базового класса }Clear;;TSymbStack.GetSymbol(iIdx:
integer): TSymbol;
{ Функция выборки символа по порядковому номеру
от конца стека }:= TSymbol(Items[iIdx]);;TSymbStack.TopLexem:
TLexem;
{ Функция, возвращающая самую верхнюю лексему
в синтаксическом стеке }i: integer;:= nil;
{ Для всех символов начиная от вершины стека }i:=Count-1
downto 0 do
{ Если это терминальный символ }Symbols[i].SymbType =
SYMB_LEX then
{ Берем ссылку на лексему }:= Symbols[i].Lexem;
{ Прекращаем поиск };;;TSymbStack.Push(lex: TLexem): TSymbol;
{ Функция помещения лексемы в синтаксический стек }
{ Создаем новый терминальный символ }:=
TSymbol.CreateLex(lex);
{ Добавляем его в стек }(Result);;TSymbStack.MakeTopSymb:
TSymbol;
{ Функция, выполняющая свертку и помещающая новый символ
на вершину стека.
Результат функции:- если не удалось выполнить свертку, иначе
ссылка
на новый нетерминальный символ - если свертка выполнена }:
TSymbol; {текущий символ стека}: TSymbArray;
{массив для запоминания символов правила},iSymbN: integer;
{счетчик символов стеке и счетчик символов в правиле}:
string; {строковое представление правила}
{ Функция добавления символа в правило }AddToRule(const sStr:
string;{строка символа}: TSymbol{тек. символ});
{ Устанавливаем ссылку на текущий символ }:= sym;
{ Добавляем очередной символ в массив символов правила
}[iSymbN] := Symbols[i];
{ Добавляем его в строковое представление правила
(слева!) }:= sStr + sRuleStr;
{ Удаляем символ из стека }(i);
{ Увеличиваем счетчик символов в правиле }(iSymbN);;:= nil;
{ Сбрасываем счетчик символов в правиле и
обнуляем текущий символ }:= 0;:= nil;
{ Строковое представление правила пустое }:= '';
{ Выполняем алгоритм для всех символов,
начиная с вершины стека }i:=Count-1 downto 0 do
{ Если это нетерминальный (синтаксический) символ
}Symbols[i].SymbType = SYMB_SYNT then
{ Добавляем его в правило, текущий символ при этом
не меняется }(Symbols[i].SymbolStr,symCur)
{ Если это терминальный символ и
текущий символ пустой }symCur = nil then
{ Добавляем его в правило и делаем текущим
}(LexTypeInfo(Symbols[i].Lexem.LexType),[i])
{ Если это терминальный символ и он связан
отношением "=" с текущим символов
}GramMatrix[Symbols[i].Lexem.LexType,.Lexem.LexType] = '=' then
{ Добавляем его в правило и делаем текущим
}(LexTypeInfo(Symbols[i].Lexem.LexType),[i])
{ Иначе прерываем цикл, дальше искать не нужно };
{ Если превышена максимальная длина правила,
цикл прекращаем }iSymbN > RULE_LENGTH then Break;;
{ Если выбран хотя бы один символ из стека }iSymbN <> 0
then
{ Ищем простым перебором правило, у которого строковое
представление совпадает с построенным
строковым представлением }i:=1 to RULE_NUM doGramRules[i] =
sRuleStr then
{ Если правило найдено, создаем новый
нетерминальный символ }:=
TSymbol.CreateSymb(i,iSymbN,SymbArr);
{ И добавляем его в стека }(Result);
{ Прерываем цикл поика правил };;
{ Если не был создан новый символ (правило не найдено),
надо удалить все исходные символы, это ошибка }Result = nil
theni:=0 to iSymbN-1 do SymbArr[i].Free;;;BuildSyntList(listLex:
TLexList{входная таблица лексем};: TSymbStack{стек для работы алгоритма}
): TSymbol;
{ Функция, выполняющая алгоритм "сдвиг-свертка".
Результат функции:
нетерминальный символ (корень синтаксического дерева),
если разбор был выполнен успешно;
терминальный символ, ссылающийся на лексему, где была
обнаружена ошибка, если разбор выполнен с ошибками. },iCnt:
integer; {счетчик лексем и длина таблицы лексем}: TLexem;
{ссылка на дополнительную начальную лексему}: TLexType;{тип
текущей лексемы}: char;{текущее отношение предшествования}:= nil;
{ Вычисляем длину входной таблицы лексем }:= listLex.Count-1;
{ Создаем дополнительную лексему "начало строки"
}:= TLexem.CreateInfo('Начало файла',0,0,0);
{ Обнуляем счетчик входных лексем }:= 0;
{ Цикл по всем лексемам от начала
до конца таблицы лексем }i<=iCnt do
{ Получаем тип лексемы на вершине стека }:=
symbStack.TopLexem.LexType;
{ Если на вершине стека начальная лексема,
а текущая лексема - конечная,
то алгоритм разбора завершен }(lexTCur =
LEX_START)(listLex[i].LexType = LEX_START) then Break;
{ Смотрим отношение лексемы на вершине стека
и текущей лексемы в строке }:=
GramMatrix[lexTCur,listLex[i].LexType];
{ Корректируем отношение. Если корректировка матрицы
предшествования не используется, то функция должна
вернуть то же самое отношение }:=
CorrectRule(cRule,lexTCur,[i].LexType,symbStack);cRule of
'<','=': { Надо выполнять сдвиг (перенос) }
{ Помещаем текущую лексему в стек }.Push(listLex[i]);
{ Увеличиваем счетчик входных лексем }(i);;
'>': { Надо выполнять свертку }symbStack.MakeTopSymb = nil
then
{ Если не удалось выполнить свертку }
{ Запоминаем текущую лексему как место ошибки }:=
TSymbol.CreateLex(listLex[i]);
{ Прерываем алгоритм };;
{ Отношение не установлено - ошибочная ситуация }
{ Запоминаем текущую лексему как место ошибки }:=
TSymbol.CreateLex(listLex[i]);
{ Прерываем алгоритм };;{case};{repeat};
{ Если алгоритм прошел без ошибок }Result = nil then
{ Проверяем, что в стеке осталось только 2 символа
}symbStack.Count = 2 then
{ Если да, то верхний символ -
результат синтаксического разбора }:= symbStack[1]
{ Иначе это ошибка - отмечаем последнюю лексему
как место ошибки }Result :=
TSymbol.CreateLex(listLex[iCnt]);;
{ Уничтожаем временную начальную лексему }.Free;;;.
9. TrdOpt
unit TrdOpt;
{ Модуль реализующий два алгоритма оптимизации:
оптимизация путём свёртки объектного кода;
оптимизация за счёт исключения лишних операций. }Classes,
TblElem, LexElem, TrdType, Triads;
{ Информационная структура для таблицы идентификаторов,
предназначенная для алгоритма свёртки объектного кода }=
class(TAddVarInfo)
{ Поле для записи значения переменной }: longint;
{ Конструктор для создания структуры }Create(iInfo: longint);
{ Функции для чтения и записи информации }GetInfo(iIdx:
integer): longint; override;SetInfo(iIdx: integer; iInfo: longint);;;
{ Информационная структура для таблицы идентификаторов,
предназначенная для алгоритма исключения лишних операций }=
class(TAddVarInfo)
{ Поле для записи числа зависимости переменной }: longint;
{ Конструктор для создания структуры }Create(iInfo: longint);
{ Функции для чтения и записи информации }GetInfo(iIdx:
integer): longint; override;SetInfo(iIdx: integer; iInfo: longint);;;
{ Процедура оптимизации методом свёртки объектного кода
}OptimizeConst(listTriad: TTriadList);
{ Процедура оптимизации методом
исключения лишних операций }OptimizeSame(listTriad:
TTriadList);SysUtils, FncTree, LexType, TrdCalc;TConstInfo.Create(iInfo:
longint);
{ Конструктор создания информационной структуры
для свёртки объектного кода }Create;:= iInfo;;TConstInfo.SetInfo(iIdx:
integer;: longint);
{ Функция записи инфоримации }:=
iInfo;;TConstInfo.GetInfo(iIdx: integer): longint;
{ Функция чтения инфоримации }:= iConst;;TestOperConst(Op:
TOperand; listTriad: TTriadList;iConst: integer): Boolean;
{ Функция проверки того, что операнд является константой
и получения его значения в переменную iConst }pInfo:
TConstInfo;:= False;
{ Выборка по типу операнда }Op.OpType of_CONST:
{ Если оператор - константа, то всё просто... }:=
Op.ConstVal;:= True;;_VAR:
{ Если оператор - переменная }
{ тогда проверяем наличие у нее
информационной структуры }:=
TConstInfo(Op.VarLink.Info);pInfo <> nil then
{ и если такая структура есть,
берём ее значение }:= pInfo[0];:= True;;;_LINK:
{ Если оператор - ссылка на триаду }
{ то он является константой,
если триада имеет тип "CONST"
}listTriad[Op.TriadNum].TrdType = TRD_CONST:=
listTriad[Op.TriadNum][1].ConstVal;:= True;;;{case};;OptimizeConst(listTriad:
TTriadList);
{ Процедура оптимизации методом свёртки объектного кода
},j,iCnt,iOp1,iOp2: integer;: TOpArray;: TTriad;
{ Очищаем информационные структуры
таблицы идентификаторов };
{ Заполняем операнды для триады типа "CONST"
}[1].OpType := OP_CONST;[2].OpType := OP_CONST;[2].ConstVal := 0;:=
listTriad.Count-1;
{ Для всех триад списка выполняем алгоритм }i:=0 to iCnt do:=
listTriad[i];Trd.TrdType in TriadLineSet then
{ Если любой операнд линейной триады ссылается
на триаду типа "CONST",
то берём и запоминаем её значение }j:=1 to 2 do(Trd[j].OpType
= OP_LINK)(listTriad[Trd.Links[j]].TrdType = TRD_CONST).OpTypes[j] :=
OP_CONST;.Values[j] :=[Trd.Links[j]][1].ConstVal;;Trd.TrdType = TRD_IF then
{ Если первый операнд условной триады ссылается
на триаду типа "CONST",
то берём и запоминаем её значение }(Trd[1].OpType = OP_LINK)(listTriad[Trd.Links[1]].TrdType
= TRD_CONST).OpTypes[1] := OP_CONST;.Values[1]
:=[Trd.Links[1]][1].ConstVal;;Trd.TrdType = TRD_ASSIGN then
{ Если второй операнд триады присвоения
ссылается на триаду типа "CONST",
то берём и запоминаем её значение }(Trd[2].OpType =
OP_LINK)(listTriad[Trd.Links[2]].TrdType = TRD_CONST).OpTypes[2] :=
OP_CONST;.Values[2] :=[Trd.Links[2]][1].ConstVal;;;
{ Если триада помечена ссылкой, то линейный участок
кода закончен - опять очищаем информационные
структуры таблицы идентификаторов }Trd.IsLinked then
ClearTreeInfo;
{ Если триада имеет тип "присвоение" }Trd.TrdType =
TRD_ASSIGN then
{ И если её второй операнд - константа
}TestOperConst(Trd[2],listTriad,iOp2) then
{ запоминаем его значение в информационной
структуре переменной }[1].VarLink.Info :=
TConstInfo.Create(iOp2);
{ Если триада - одна из линейных операций }Trd.TrdType in
TriadLineSet then
{ И если оба её операнда - константы
}TestOperConst(Trd[1],listTriad,iOp1)TestOperConst(Trd[2],listTriad,iOp2) then
{ тогда вычисляем значение операции }[1].ConstVal
:=(Trd.TrdType,iOp1,iOp2);
{ запоминаем его в триаде типа "CONST",
которую записываем в список
вместо прежней триады }.Items[i] :=
TTriad.Create(TRD_CONST,Ops);
{ Если на прежнюю триаду была ссылка,
сохраняем её }[i].IsLinked := Trd.IsLinked;
{ Уничтожаем прежнюю триаду }.Free;;;;;TDepInfo.Create(iInfo:
longint);
{ Конструктор создания информационной структуры
для чисел зависимости }Create;:=
iInfo;;TDepInfo.SetInfo(iIdx: integer; iInfo: longint);
{ Функция записи числа зависимости }:=
iInfo;;TDepInfo.GetInfo(iIdx: integer): longint;
{ Функция чтения числа зависимости }:=
iDep;;CalcDepOp(listTriad: TTriadList;: TOperand): longint;
{ Функция вычисления числа зависимости
для операнда триады }:= 0;
{ Выборка по типу операнда }Op.OpType of_VAR:
{ Если это переменная - смотрим ее информационную
структуру, и если такая структура есть,
то берем оттуда число зависимости }Op.VarLink.Info <>
nil then Result :=.VarLink.Info.Info[0];_LINK:
{ Если это ссылка на триаду,
то берем число зависимости триады }:=
listTriad[Op.TriadNum].Info;{case};;CalcDep(listTriad: TTriadList;: TTriad):
longint;
{ Функция вычисления числа зависимости триады }iDepTmp:
longint;:= CalcDepOp(listTriad,Trd[1]);:= CalcDepOp(listTriad,Trd[2]);
{ Число зависимости триады есть на единицу большее,
чем максимальное из чисел зависимости её операндов }iDepTmp
> Result then Result := iDepTmp+1Inc(Result);.Info :=
Result;;OptimizeSame(listTriad: TTriadList);
{ Процедура оптимизации методом исключения
лишних операций },j,iStart,iCnt,iNum: integer;: TOpArray;:
TTriad;
{ Ставим начало линейного участка равным
началу списка триад }:= 0;
{ Очищаем информационные структуры
таблицы идентификаторов };:= listTriad.Count-1;
{ Заполняем операнды для триады типа "SAME"
}[1].OpType := OP_LINK;[2].OpType := OP_CONST;[2].ConstVal := 0;
{ Для всех триад списка выполняем алгоритм }i:=0 to iCnt do:=
listTriad[i];
{ Если триада помечена ссылкой, то линейный участок
кода закончен - опять очищаем информационные
структуры таблицы идентификаторов,
и запоминаем начало нового линейного участка }Trd.IsLinked
then;:= i;;
{ Если любой операнд триады ссылается на триаду
типа "SAME", то переставляем ссылку на предыдущую,
совпадающую с ней триаду }j:=1 to 2 doTrd[j].OpType = OP_LINK
then:= Trd[j].TriadNum;listTriad[iNum].TrdType = TRD_SAME then.Links[j] :=
listTriad[iNum].Links[1];;
{ Если триада типа "присвоение",
то запоминаем число зависимости переменной }Trd.TrdType =
TRD_ASSIGN then[1].VarLink.Info := TDepInfo.Create(i+1);
{ Если триада - одна из линейных операций }Trd.TrdType in
TriadLineSet then
{ Вычисляем число зависимости триады }(listTriad,Trd);
{ На всем линейном участке ищем совпадающую с ней
триаду с таким же числом зависимости }j:=iStart to i-1
doTrd.IsEqual(listTriad[j])(Trd.Info = listTriad[j].Info) then
{ Если такая триада найдена, запоминаем
ссылку на нее }[1].TriadNum := j;
{ запоминаем её в триаде типа "SAME", которую
записываем в список вместо прежней триады }.Items[i]
:=.Create(TRD_SAME,Ops);
{ Если на прежнюю триаду была ссылка,
сохраняем её }[i].IsLinked := Trd.IsLinked;
{ Уничтожаем прежнюю триаду }.Free;
{ Прерываем поиск };;;{if};{for};;.
10. Triads
unit Triads;
{ Модуль, обеспечивающий работу с триадами
и списком триад }Classes, TblElem, LexElem, TrdType;
{ Предварительное описание класса триад }= class;
{ Типы операндов: константа, переменная,
ссылка на другую триаду }= (OP_CONST, OP_VAR, OP_LINK);
{ Структура данных для описания операнда в триадах }= record
{ Тип операнда }OpType: TOpType of_CONST: (ConstVal:
integer);
{ для константы - её значение }_VAR: (VarLink: TVarInfo);
{ для переменной - ссылка на элемент
таблицы идентификаторов }_LINK: (TriadNum: integer);
{ для триады - номер триады };
{ Массив операндов из двух элементов }= array[1..2] of
TOperand;
{ Структура данных для описания триады }= class(TObject)
{ Тип триады }: TTriadType;
{ Массив операндов }: TOpArray;
{ Дополнительная информация для оптимизирующих алгоритмов }:
longint;
{ Флаг наличия ссылки на эту триаду }: Boolean;
{ Конструктор для создания триады }Create(Typ: TTriadType;
const Ops: TOpArray);
{ Функции для чтения и записи операндов }GetOperand(iIdx:
integer): TOperand;SetOperand(iIdx: integer; Op: TOperand);
{ Функции для чтения и записи ссылок на другие триады
}GetLink(iIdx: integer): integer;SetLink(iIdx: integer; TrdN: integer);
{ Функции для чтения и записи типа операндов }GetOpType(iIdx:
integer): TOpType;SetOpType(iIdx: integer; OpT: TOpType);
{ Функции для чтения и записи значений констант
}GetConstVal(iIdx: integer): integer;SetConstVal(iIdx: integer; iVal: integer);
{ Свойства триады, основанные на описанных выше
функциях }TrdType: TTriadType read TriadType;Opers[iIdx:
integer]: TOperand read GetOperandSetOperand; default;Links[iIdx: integer]:
integer read GetLinkSetLink;OpTypes[iIdx: integer]: TOpType read
GetOpTypeSetOpType;Values[iIdx: integer]: integer read GetConstValSetConstVal;
{ Функция, проверяющая совпадение (эквивалентность)
двух триад }IsEqual(Trd1: TTriad): Boolean;
{ Функция, формирующая строковое представление триады
}MakeString(i: integer): string;;
{ Класс для описания списка триад и работы с ним }=
class(TList)
{ Процедура очистки списка и деструктор
для удаления списка }Clear; override;Destroy; override;
{ Процедура вывода списка триад в список строк
для отображения списка триад }WriteToList(list: TStrings);
{ Процедура удаления триады из списка }DelTriad(iIdx:
integer);
{ Функция получения триады из списка по её номеру
}GetTriad(iIdx: integer): TTriad;
{ Свойство списка триад для доступа к нему
по номеру триады }Triads[iIdx: integer]: TTriad read
GetTriad;;;
{ Процедура удаления из списка триад
всех триад заданного типа }DelTriadTypes(listTriad:
TTriadList;: TTriadType);SysUtils, FncTree, LexType;TTriad.Create(Typ:
TTriadType;Ops: TOpArray);
{ Конструктор создания триады }i: integer;
{ Вызываем конструктор базового класса }Create;
{ Запоминаем тип триады }:= Typ;
{ Запоминаем два операнда триады }i:=1 to 2 do Operands[i] :=
Ops[i];
{ Очищаем поле дополнительной информации
и поле внешней ссылки }:= 0;:= False;;TTriad.GetOperand(iIdx:
integer): TOperand;
{ Функция получения данных об операнде триады
по его номеру }:= Operands[iIdx];;TTriad.SetOperand(iIdx:
integer; Op: TOperand);
{ Функция записи данных операнда триады по его номеру }[iIdx]
:= Op;;TTriad.GetLink(iIdx: integer): integer;
{ Функция получения ссылки на другую триаду из операнда
по его номеру }:=
Operands[iIdx].TriadNum;;TTriad.SetLink(iIdx: integer; TrdN: integer);
{ Функция записи номера ссылки на другую триаду
в операнд по его номеру }[iIdx].TriadNum :=
TrdN;;TTriad.GetOpType(iIdx: integer): TOpType;
{ Функция получения типа операнда по его номеру }:=
Operands[iIdx].OpType;;TTriad.GetConstVal(iIdx: integer): integer;
{ Функция записи типа операнда по его номеру }:=
Operands[iIdx].ConstVal;;TTriad.SetConstVal(iIdx: integer; iVal: integer);
{ Функция получения значения константы в операнде
по его номеру }[iIdx].ConstVal :=
iVal;;TTriad.SetOpType(iIdx: integer; OpT: TOpType);
{ Функция записи значения константы в операнд
по его номеру }[iIdx].OpType := OpT;;IsEqualOp(const Op1,Op2:
TOperand): Boolean;
{ Функция проверки совпадения (эквивалентности)
двух операндов }
{ Операнды равны, если совпадают их типы }:= (Op1.OpType =
Op2.OpType);
{ и значения в зависимости от типа }Result thenOp1.OpType
of_CONST: Result := (Op1.ConstVal = Op2.ConstVal);_VAR: Result := (Op1.VarLink
= Op2.VarLink);_LINK: Result := (Op1.TriadNum =
Op2.TriadNum);;;TTriad.IsEqual(Trd1: TTriad): Boolean;
{ Функция, проверяющая совпадение (эквивалентность)
двух триад }
{ Триады эквивалентны, если совпадают их типы }:= (TriadType
= Trd1.TriadType)
{ и оба операнда
}IsEqualOp(Operands[1],Trd1[1])IsEqualOp(Operands[2],Trd1[2]);;GetOperStr(Op:
TOperand): string;
{ Функция формирования строки для отображения
оператора триады }Op.OpType of_CONST: Result :=
IntToStr(Op.ConstVal);_VAR: Result := Op.VarLink.VarName;_LINK: Result := '^'+
IntToStr(Op.TriadNum+1);{case};;TTriad.MakeString(i: integer): string;:=
Format('%d:'#9'%s (%s, %s)',
[i+1,TriadStr[TriadType],(Opers[1]),GetOperStr(Opers[2])]);;TTriadList.Destroy;
{ Деструктор для удаления списка триад }
{ Очищаем список триад };
{ Вызываем деструктор базового класса
}Destroy;;TTriadList.Clear;
{ Процедура очистки списка триад }i: integer;
{ Освобождаем память для всех триад из списка }i:=Count-1
downto 0 do TTriad(Items[i]).Free;
{ Вызываем функцию базового класса
}Clear;;TTriadList.DelTriad(iIdx: integer);
{ Функция удаления триады из списка триад }
{ Если это не последняя триада }iIdx < Count-1 then
{ и если на нее есть ссылка - переставляем
флаг ссылки на предыдущую }(Items[iIdx+1]).IsLinked
:=(Items[iIdx+1]).IsLinkedTTriad(Items[iIdx]).IsLinked;
{ Освобождаем память триады }(Items[iIdx]).Free;
{ Удаляем ссылку на триаду из списка
}(iIdx);;TTriadList.GetTriad(iIdx: integer): TTriad;
{ Функция выборки триады из списка по её номеру }:=
TTriad(Items[iIdx]);;TTriadList.WriteToList(list: TStrings);
{ Процедура вывода списка триад в список строк
для отображения списка триад },iCnt: integer;
{ Очищаем список строк }.Clear;:= Count-1;
{ Для всех триад из списка триад }i:=0 to iCnt do
{ Формируем строковое представление триады
и добавляем его в список строк
}.Add(TTriad(Items[i]).MakeString(i));;DelTriadTypes(listTriad: TTriadList;:
TTriadType);
{ Процедура удаления из списка триад всех триад
заданного типа },j,iCnt,iDel: integer;: TList;: TTriad; {
список для запоминания изменений
индексов триад }
{ Вначале изменение индекса нулевое }:= 0;:=
listTriad.Count-1;
{ Создаем список для запоминания изменений
индексов триад }:= TList.Create;
{ Для всех триад списка выполняем запоминание
изменений индекса }i:=0 to iCnt do
{ Запоминем изменение индекса данной триады
}.Add(TObject(iDel));
{ Если эта триада удаляемого типа,
то увеличиваем изменение индекса }listTriad[i].TriadType =
TrdType then Inc(iDel);;
{ Для всех триад списка изменяем индексы ссылок }i:=iCnt
downto 0 do:= listTriad[i];
{ Если эта триада удаляемого типа, то удаляем ее
}Trd.TriadType = TrdType then listTriad.DelTriad(i)
{ Иначе для обоих операндов триады смотрим,
не является ли он ссылкой }j:=1 to 2 doTrd[j].OpType =
OP_LINK then
{ Если операнд является ссылкой на триаду,
уменьшаем её индекс }.Links[j] :=.Links[j] -
integer(listNum[Trd.Links[j]]);;
{ Уничтожаем список для запоминания
изменений индексов триад }listNum.Free;;;.
11. TrdAsm
unit TrdAsm;
{ !!! Зависит от целевой вычислительной системы !!! }
{ Модуль распределения регистров и построения ассемблерного
кода по списку триад }Classes, TrdType, Triads;
{ Префикс наименования временных переменных }_VARNAME =
'_Tmp';
{ Количество доступных регистров процессора }_PROCREG = 6;
{ Функция распределения регистров и временных переменных
для хранения промежуточных результатов триад
}MakeRegisters(listTriad: TTriadList): integer;
{ Функция построения ассемблерного кода по списку триад
}MakeAsmCode(listTriad: TTriadList;: TStrings;: Boolean):
integer;SysUtils;MakeRegisters(listTriad: TTriadList): integer;
{ Функция распределения регистров и временных переменных
для хранения промежуточных результатов триад.
Результат: количество необходимых временных переменных }
{ Счетчики и переменные циклов },j,iR,iCnt,iNum : integer;
{ Динамический массив для запоминания занятых регистров }:
TList;:= 0;
{ Создаем массив для хранения занятых регистров }:=
TList.Create;listReg <> nil then
{ Обнуляем информационное поле у всех триад
}i:=listTriad.Count-1 downto 0 do[i].Info := 0;
{ Цикл по всем триадам. Обязательно с конца списка!
}i:=listTriad.Count-1 downto 0 do
{ Цикл по всем (2) операндам }j:=1 to 2 do
{ Если триада - линейная операция, или "IF"
(первый операнд), или прсвоение (второй операнд)
}((listTriad[i].TrdType in TriadLineSet)(listTriad[i].TrdType = TRD_IF) and (j
= 1)(listTriad[i].TrdType = TRD_ASSIGN) and (j = 2))
{ и при этом операндом является ссылка
на другую триаду }(listTriad[i][j].OpType = OP_LINK) then
{ Запорминаем номер триады, на которую ссылка }:=
listTriad[i][j].TriadNum;
{ Если этой триаде еще не назначен регистр, и если
это не предыдущая триада,
то надо ей назначить регистр }(listTriad[iNum].Info = 0) and
(iNum <> i-1) then
{ Количество назначенных регистров
в массиве регистров }:= listReg.Count-1;
{ Цикл по всему массиву назначенных регистров }iR:=0 to iCnt
do
{ Если область действия регистра за пределами
текущей триады, то этот регистр свободен и
можно его использовать }longint(listReg[iR]) >= i then
{ Запоминаем новую область действия регистра
(iNum) }[iR] := TObject(iNum);
{ Назначаем регистр триаде с номером iNum }[iNum].Info :=
iR+1;
{ Прерываем цикл по массиву регистров };;;
{ Если не один из использованных регистров
не был назначен, надо брать новый регистр
}listTriad[iNum].Info = 0 then
{ Добавляем запись в массив регистров, указываем
ей область действия iNum }.Add(TObject(iNum));
{ Назначаем новый регистр триаде с номером iNum }[iNum].Info
:= listReg.Count;;;;
{ Результат функции:
количество записей в массиве регистров - 1,
за вычетом количества доступных регистрв процессора }:=
listReg.Count - (NUM_PROCREG-1);listReg.Free;;;GetRegName(iInfo: integer):
string;
{ Функция наименования регистров процессора }iInfo of
: Result := 'al';
: Result := 'bl';
: Result := 'dl';
: Result := 'ah';
: Result := 'bh';
: Result := 'ch';
: Result := 'dh';
: Result := 'si';
: Result := 'di';
{ Если это не один из регистров - значит,
даем имя временной переменной }Result :=('%s%d',[TEMP_VARNAME,iInfo-NUM_PROCREG]);{case};;GetOpName(i:
integer; listTriad: TTriadList;: integer): string;
{ Функция наименования операнда триады- номер триады в
списке;- список триад;- номер операнда триады }: integer; {номенр триады по
ссылке}: TTriad; {текущая триада}
{ Запоминаем текущую триаду }:= listTriad[i];
{ Выборка наименования операнда в зависимости от типа
}Triad[iOp].OpType of
{ Если константа - значение константы }_CONST: Result :=
IntToStr(Triad[iOp].ConstVal);
{ Если переменная - ее имя из таблицы идентификаторов
}_VAR::= Triad[iOp].VarLink.VarName;
{ Если имя совпадает с именем функции,
заменяем его на Result функции }Result = NAME_FUNCT then
Result := NAME_RESULT;;
{ Иначе - это регистр для временного хранения
результатов триады }
{ Запоминаем номер триады }:= Triad[iOp].TriadNum;
{ Если это предыдущая триада, то операнд не нужен }iNum = i-1
then Result := ''
{ Берем номер регистра, связанного с триадой }:=
listTriad[iNum].Info;
{ Если регистра нет, то операнд не нужен }iNum = 0 then
Result := ''
{ Иначе имя операнда - это имя регистра }Result :=
GetRegName(iNum);;;{case};;MakeMove(const sReg,{имя регистра},{предыдущая
команда}{предыдущая величина в al}: string;: Boolean{флаг оптимизации}):
string;
{ Функция, генерящая код занесения значения в регистр al }
{ Если операнд был только что выгружен из al,
или необходимое значение уже есть в аккумуляторе,
нет необходимости записывать его туда снова
}(Pos(Format(#9'mov'#9'%s,al',[sReg]),sPrev) = 1)(sVal = sReg) then:=
'';;;flagOpt then
{ Если оптимизация команд включена }
{ Если значение = 0, то заносим его с помощью XOR }sReg = '0'
thensVal = '-1' then:= #9'inc'#9'al'sVal = '1' then:= #9'dec'#9'al':=
#9'xor'#9'al,al'
{ Если = 1 - двумя командами: XOR и INC }sReg = '1' thensVal
= '-1' then:= #9'neg'#9'al'sVal = '0' then:= #9'inc'#9'al':=
#9'xor'#9'al,al'#13#10#9'inc'#9'al';
{ Если = -1 - двумя командами: XOR и DEC }sReg = '-1'
thensVal = '1' then:= #9'neg'#9'al'sVal = '0' then:= #9'dec'#9'al':=
#9'xor'#9'al,al'#13#10#9'dec'#9'al';
{ Иначе заполняем al командой MOV }Result :=
Format(#9'mov'#9'al,%s',[sReg]);
{ Если оптимизация команд выключена,
всегда заполняем al командой MOV }Result :=
Format(#9'mov'#9'al,%s',[sReg]);;MakeOpcode(i: integer;{номер текущей триады}:
TTriadList;{список триад}sOp,sReg,{код операции и операнд},{предыдущая
команда}{предыдущая величина в al}: string;: Boolean{флаг оптимизации}):
string;
{ Функция, генерящая код линейных операций над al }Triad:
TTriad;{текущая триада}
{ Запоминаем текущую триаду }:= listTriad[i];
{ Если оптимизация команд включена }flagOpt then
{ Если операнд = 0 }sReg = '0' thenTriad.TrdType of
{ Для команды AND результат всегда = 0 }_AND::=
MakeMove('0',sPrev,sVal,flagOpt);
{ Для OR, "+" и "-" ничего не надо делать
}_OR,TRD_ADD,TRD_SUB, TRD_MUL, TRD_DIV: Result := #9#9;
{ Иначе генерим код выполняемой операции }Result :=
Format(#9'%s'#9'al,%s',[sOp,sReg]);{case};
{ Если операнд = 1 }sReg = '1' thenTriad.TrdType of
{ Для команды OR результат всегда = 1 }_OR::=
MakeMove('1',sPrev,sVal,flagOpt);
{ Для AND ничего не надо делать }_AND: Result := #9#9;
{ Для "+" генерим операцию INC }_ADD: Result :=
#9'inc'#9'al';
{ Для "-" генерим операцию DEC }_SUB: Result :=
#9'dec'#9'al';_MUL: Result := #9'mul'#9'al';_DIV: Result := #9'div'#9'al';
{ Иначе генерим код выполняемой операции }Result :=
Format(#9'%s'#9'al,%s',[sOp,sReg]);{case};
{ Если операнд = -1 }sReg = '-1' thenTriad.TrdType of
{ Для "+" генерим операцию DEC }_ADD: Result :=
#9'dec'#9'al';
{ Для "-" генерим операцию INC }_SUB: Result :=
#9'inc'#9'al';
{ Для "*" генерим операцию MUL }_MUL: Result :=
#9'mul'#9'al';
{ Для "/" генерим операцию DIV }_DIV: Result :=
#9'div'#9'al';
{ Иначе генерим код выполняемой операции }Result :=
Format(#9'%s'#9'al,%s',[sOp,sReg]);{case};;
{ Если оптимизация команд выключена,
всегда генерим код выполняемой операции };
{ Добавляем к результату информацию о триаде
в качестве комментария }:= Result + Format(#9'{ %s }',
{ Функция построения ассемблерного кода по списку триад
},iCnt: integer;{счетчик и переменная цикла}: string;{строка для имени
регистра},sVal: string;
{строки для хранения предыдущей команды и значения
al}TakePrevAsm;
{ Процедура, выделяющая предыдущую команду и значение al
из списка результирующих команд }j: integer;:=
listCode.Count;j > 0 then:= listCode[j-1];:=
StrPas(PChar(listCode.Objects[j-1]));:= '';:= '';;;MakeOper1(const sOp,{код
операции}: string;{код доп. операции}: integer{номер операнда в триаде});
{ Функция генерации кода для унарных операций }sReg{строка
для имени регистра}: string;
{ Берем предыдущую команду и значение из al };
{ Запоминаем имя операнда }:= GetOpName(i,listTriad,iOp);
{ Если имя пустое, операнд уже есть в регистре al
от выполнения предыдущей триады, иначе его нужно
занести в al - вызываем функцию генерации кода }sReg <>
'' then:= MakeMove(sReg,sPrev,sVal,flagOpt);sReg <> '' then
listCode.Add(sReg);;
{ Генерим непосредственно код операции }.Add(Format(#9'%s'#9'al'#9'{
%s }',
[sOp,listTriad[i].MakeString(i)]));
{ Если есть доп. операция, генерим ее код }sAddOp <> ''
then.Add(Format(#9'%s'#9'al,1',[sAddOp]));
{ Если триада связана с регистром, запоминаем результат в
этом регистре }listTriad[i].Info <> 0 then:=
GetRegName(listTriad[i].Info);
{ При этом запоминаем, что сейчас находится в al
}.AddObject(Format(#9'mov'#9'%s,al',[sReg]),(PChar(sReg)));;;MakeOper2(const
sOp,{код операции}: string{код доп. операции});
{ Функция генерации кода для бинарных арифметических
и логических операций }sReg1,sReg2{строки для имен
регистров}: string;
{ Берем предыдущую команду и значение из al };
{ Запоминаем имя 1 операнда }:= GetOpName(i,listTriad,1);
{ Запоминаем имя 2 операнда }:= GetOpName(i,listTriad,2);
{ Если имя первого операнда пустое, значит он уже
есть в регистре al от выполнения предыдущей триады -
вызываем функцию генерации кода для второго операнда }(sReg1
= '') or (sReg1 = sVal)
then.Add(MakeOpCode(i,listTriad,sOp,sReg2,,sVal,flagOpt))
{ Если имя второго операнда пустое, значит он уже
есть в регистре al от выполнения предыдущей триады -
вызываем функцию генерации кода для первого операнда }(sReg2
= '') or (sReg2 = sVal)
then.Add(MakeOpCode(i,listTriad,sOp,sReg1,,sVal,flagOpt));
{ Если есть доп. операция, генерим ее код
(когда операция несимметричная - например "-")
}sAddOp <> '' then.Add(Format(#9'%s'#9'al',[sAddOp]));
{ Если оба операнда не пустые, то надо:
сначала загрузить в al первый операнд;
сгенерить код для обработки второго операнда. }:=
MakeMove(sReg1,sPrev,sVal,flagOpt);sReg1 <> '' then
listCode.Add(sReg1);.Add(MakeOpCode(i,listTriad,sOp,sReg2,,sVal,flagOpt));;
{ Если триада связана с регистром, запоминаем результат в
этом регистре }listTriad[i].Info <> 0 then:=
GetRegName(listTriad[i].Info);
{ При этом запоминаем, что сейчас находится в al
}.AddObject(Format(#9'mov'#9'%s,al',[sReg1]),(PChar(sReg1)));;;MakeCompare(const
sOp: string
{флаг операции сравнения});
{ Функция генерации кода для операций сравнения
}sReg1,sReg2{строки для имен регистров}: string;
{ Берем предыдущую команду и значение из al };
{ Запоминаем имя 1 операнда }:= GetOpName(i,listTriad,1);
{ Запоминаем имя 2 операнда }:= GetOpName(i,listTriad,2);
{ Если имя первого операнда пустое, значит он уже
есть в регистре al от выполнения предыдущей триады -
сравниваем al со вторым операндом }sReg1 = ''
then.Add(Format(#9'cmp'#9'al,%s'#9'{ %s }',
[sReg2,listTriad[i].MakeString(i)]))
{ Если имя второго операнда пустое, значит он уже
есть в регистре al от выполнения предыдущей триады -
сравниваем al с первым операндом в обратном порядке }sReg2 =
'' then.Add(Format(#9'cmp'#9'%s,al'#9'{ %s }',
[sReg1,listTriad[i].MakeString(i)]))
{ Если оба операнда не пустые, то надо:
сначала загрузить в al первый операнд;
сравнить al со вторым операндом. }:=
MakeMove(sReg1,sPrev,sVal,flagOpt);sReg1 <> '' then
listCode.Add(sReg1);.Add(Format(#9'cmp'#9'al,%s'#9'{ %s }',
[sReg2,listTriad[i].MakeString(i)]));;
{ Загружаем в младший байт al 1 или 0
в зависимости от флага сравнения }.Add(Format(#9'set%s'#9'al',[sOp]));
(* Один из вариантов кода:
{ Преобразуем 8 младших бит в 16 бит }.Add(#9'cbw');
{ Преобразуем 16 младших бит в 32 бита }.Add(#9'cwde'); *)
(* Другой вариант: *).Add(#9'and'#9'al,1');
{ Если триада связана с регистром, запоминаем результат в
этом регистре }listTriad[i].Info <> 0 then:=
GetRegName(listTriad[i].Info);
{ При этом запоминаем, что сейчас находится в al
}.AddObject(Format(#9'mov'#9'%s,al',[sReg1]),(PChar(sReg1)));;;
{ Тело основной функции }
{ Берем количество триад в списке }:= listTriad.Count-1;
{ Цикл по всем триадам от начала списка }i:=0 to iCnt do
{ Если триада помечена, создаем локальную метку
в списке команд ассемблера }listTriad[i].IsLinked
then.Add(Format('@M%d:',[i+1]));
{ Генерация кода в зависимости от типа триады }listTriad[i].TrdType
of
{ Код для триады IF }_IF:
{ Если операнд - констата (это возможно
в результате оптимизации) }listTriad[i][1].OpType = OP_CONST
then
{ Условный переход превращается в безусловный,
если константа = 0, }listTriad[i][1].ConstVal = 0 then.Add(Format(#9'jmp'#9'@M%d'#9'{
%s }',
[listTriad[i][2].TriadNum+1,[i].MakeString(i)]));
{ а иначе вообще генерить код не нужно. }
{ Если операнд не константа }
{ Берем имя первого операнда }:= GetOpName(i,listTriad,1);
{ Если имя первого операнда пустое,
значит он уже есть в регистре al
от выполнения предыдущей триады }sR = '' then
{ тогда надо выставить флаг "Z", сравнив al
сам с собой, но учитывая, что предыдущая
триада для IF - это либо сравнение, либо
логическая операция, это можно опустить}
(* listCode.Add(#9'test'#9'al,al') *)
{ иначе надо сравнить al с операндом
}.Add(Format(#9'cmp'#9'%s,0',[sR]));
{ Переход по обратному условию "NOT Z"
на ближайшую метку }.Add(Format(#9'jnz'#9'@F%d'#9'{ %s }',
[i,listTriad[i].MakeString(i)]));
{ Переход по прямому условию на дальнюю метку
}.Add(Format(#9'jmp'#9'@M%d',
[listTriad[i][2].TriadNum+1]));
{ Метка для ближнего перехода }.Add(Format('@F%d:',[i]));;;
{ Код для бинарных логических операций }_OR:
MakeOper2('or','');_XOR: MakeOper2('xor','');_AND: MakeOper2('and','');
{ Код для операции NOT (т.к. NOT(0)=FFFFFFFF,
то нужна еще операция: AND al,1 }_NOT:
MakeOper1('not','and',1);
{ Код для операций сравнения по их флагам }_LT:
MakeCompare('l');_GT: MakeCompare('g');_EQ: MakeCompare('e');_NEQ:
MakeCompare('ne');
{ Код для бинарных арифметических операций }_ADD:
MakeOper2('add','');_SUB: MakeOper2('sub','neg');_MUL:
MakeOper2('mul','');_DIV: MakeOper2('div','');
{ Код для унарного минуса }_UMIN: MakeOper1('neg','',2);
{ Код для операции присвоения }_ASSIGN:
{ Берем предыдущую команду и значение из al };
{ Берем имя второго операнда }:= GetOpName(i,listTriad,2);
{ Если имя первого операнда пустое,
значит он уже есть в регистре al
от выполнения предыдущей триады }sR <> '' then
{ иначе генерим код загрузки операнда в al }:= MakeMove(sR,sPrev,sVal,flagOpt);sVal
<> '' then listCode.Add(sVal);;
{ Из al записываем результат в переменную
с именем первого операнда }:=
listTriad[i][1].VarLink.VarName;sVal = NAME_FUNCT then sVal := NAME_RESULT;:=
Format(#9'mov'#9'%s,al'#9'{ %s }',
[sVal,listTriad[i].MakeString(i)]);
{ При этом запоминаем, что было в al
}.AddObject(sVal,TObject(PChar(sR)));;
{ Код для операции безусловного перехода }_JMP:
listCode.Add((#9'jmp'#9'@M%d'#9'{ %s }',
[listTriad[i][2].TriadNum+1,[i].MakeString(i)]));
{ Код для операции NOP }_NOP:
listCode.Add(Format(#9'nop'#9#9'{ %s }',
[listTriad[i].MakeString(i)]));{case};{for};:=
listCode.Count;;.
12. TrdCalc
unit TrdCalc; {!!! Зависит от входного языка !!!}
{ Модуль, вычисляющий значения триад при свертке операций
}TrdType;
{ Функция вычисления триады по типу и значениям
двух операндов }CalcTriad(Triad: TTriadType;,iOp2: integer):
integer;CalcTriad(Triad: TTriadType;,iOp2: integer): integer;
{ Функция вычисления триады по типу и значениям
двух операндов }:= 0;Triad of_OR: Result := (iOp1 or iOp2)
and 1;_XOR: Result := (iOp1 xor iOp2) and 1;_AND: Result := (iOp1 and iOp2) and
1;_NOT: Result := (not iOp1) and 1;_LT: if iOp1<iOp2 then Result := 1 else
Result := 0;_GT: if iOp1>iOp2 then Result := 1 else Result := 0;_EQ: if
iOp1=iOp2 then Result := 1 else Result := 0;_NEQ: if iOp1<>iOp2 then
Result := 1 else Result := 0;_ADD: Result := iOp1 + iOp2;_SUB: Result := iOp1 -
iOp2;_MUL: Result := iOp1 * iOp2;_DIV: Result := iOp1 / iOp2;_UMIN: Result :=
-iOp2;;;.
13. TrdMake
unit TrdMake; {!!! Зависит от входного языка !!!}
{ Модуль, обеспечивающий создание списка триад на основе
структуры синтаксического разбора }LexElem, Triads,
SyntSymb;MakeTriadList(symbTop: TSymbol;: TTriadList): TLexem;
{ Функция создания списка триад начиная от корневого
символа дерева синтаксического разбора.
Функция возвращает nil при успешном выполнении, иначе
она возвращает ссылку на лексему, где произошла ошибка
}LexType, TrdType;GetLexem(symbOp: TSymbol): TLexem;
{ Функция, проверяющая является ли операнд лексемой
}symbOp.Rule of
{ Если правил нет, это лексема! }
: Result := symbOp.Lexem;
{ Если дочерний символ построен по правилу №27 или 28,
то это лексема }
,28: Result := symbOp[0].Lexem;
{ Если это арифметические скобки, надо проверить,
не является ли лексемой операнд в скобках }
,26: Result := GetLexem(symbOp[1])
{ Иначе это не лексема }Result :=
nil;;;MakeTriadListNOP(symbTop: TSymbol;: TTriadList): TLexem;
{ Функция создания списка триад начиная от корневого
символа дерева синтаксического разбора (без добавления
триады NOP в конец списка) }: TOpArray; { массив операндов
триад },iIns2,iIns3: integer; { переменные для запоминания
индексов триад в списке }MakeOperand({номер
операнда},{порядковый номер символа в синт. конструкции},{минимальная позиция
триады в списке},{номер лексемы, на которой
позиционировать ошибку}: integer;iIns: integer{индекс триады
в списке}): TLexem;
{ Функция формирования ссылки на операнд }lexTmp: TLexem;
{ Проверяем, является ли операнд лексемой }:=
GetLexem(symbTop[iSymOp]);lexTmp <> nil then
{ Если да, то берем имя операнда в зависимости от типа
}lexTmp doLexType = LEX_VAR thenVarInfo.VarName = NAME_RESULT then
{ Проверяем, что переменная имеет допустимое имя }:=
lexTmp;;;
{ Если это переменная, то запоминаем ссылку
на таблицу идентификаторов }[iOp].OpType :=
OP_VAR;[iOp].VarLink := VarInfo;LexType = LEX_CONST then
{ Если это константа, то запоминаем её значение }[iOp].OpType
:= OP_CONST;[iOp].ConstVal := ConstVal;
{ Иначе это ошибка, возвращаем лексему как указатель
на место ошибки }:= lexTmp;;;:= iMin;:= nil;
{ иначе это синтаксическая конструкция }
{ Вызываем рекурсивно функцию создания списка триад }:=
MakeTriadListNOP(symbTop[iSymOp],listTriad);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Запоминаем индекс триады }:= listTriad.Count;
{ Если индекс меньше минимального (сисок не менялся) -
это ошибка }iIns <= iMin then:= symbTop[iSymErr].Lexem;;;
{ Запоминаем ссылку на предыдущую триаду }[iOp].OpType :=
OP_LINK;[iOp].TriadNum := iIns-1;;;MakeOperation(: TTriadType{тип создаваемой
триады}): TLexem;
{ Функция создания списка триад для линейных операций }
{ Создаем ссылку на первый операнд }:=
MakeOperand(1{op},0{sym},listTriad.Count,
{sym err},iIns1);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Создаем ссылку на второй операнд }:=
MakeOperand(2{op},2{sym},iIns1,
{sym err},iIns2);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Создаем саму триаду с двумя ссылками на операнды
}.Add(TTriad.Create(Trd,Opers));;
{ Тело главной функции. Начинаем с выбора типа правила
}symbTop.Rule of
:{'if(B)EelseE'}
{ Полный условный оператор }
{ Запоминаем ссылку на первый операнд
(условие "if(B)") }:=
MakeOperand(1{op},2{sym},listTriad.Count,
{sym err},iIns1);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Второй операнд - ссылка на триаду, номер которой
пока не известен }[2].OpType := OP_LINK;[2].TriadNum := 0;
{ Создаем триаду типа "IF"
}.Add(TTriad.Create(TRD_IF,Opers));
{ Запоминаем ссылку на второй операнд
(раздел "(B)E") }:= MakeOperand(2{op},4{sym},iIns1,
{sym err},iIns2);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Заполняем операнды для триады типа "JMP",
которая должна быть в конце раздела "(B)E" }[1].OpType
:= OP_CONST;[1].ConstVal := 1;
{ Второй операнд - ссылка на триаду, номер которой
пока не известен }[2].OpType := OP_LINK;[2].TriadNum := 0;
{ Создаем триаду типа "JMP"
}.Add(TTriad.Create(TRD_JMP,Opers));
{ Для созданной ранее триады типа "IF" ставим
ссылку в конец последовательности триад,
созданной для раздела "(B)E" }[iIns1].Links[2] :=
iIns2+1;
{ Запоминаем ссылку на третий операнд
(раздел "elseE") }:=
MakeOperand(2{op},6{sym},iIns2,
{sym err},iIns3);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Для созданной ранее триады типа "JMP" ставим
ссылку в конец последовательности триад,
созданной для раздела "elseE" }[iIns2].Links[2] :=
iIns3;;
:{'if(B)E'}
{ Неполный условный оператор }
{ Запоминаем ссылку на первый операнд
(условие "if(B)") }:=
MakeOperand(1{op},2{sym},listTriad.Count,
{sym err},iIns1);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Второй операнд - ссылка на триаду, номер которой
пока не известен }[2].OpType := OP_LINK;[2].TriadNum := 0;
{ Создаем триаду типа "IF"
}.Add(TTriad.Create(TRD_IF,Opers));
{ Запоминаем ссылку на второй операнд
(раздел "(B)E") }:= MakeOperand(2{op},4{sym},iIns1,
{sym err},iIns2);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Для созданной ранее триады типа "IF" ставим
ссылку в конец последовательности триад,
созданной для раздела "(B)E" }[iIns1].Links[2] :=
iIns2;;
:{'repeat(B)doE'}
{ Оператор цикла "repeat" }
{ Запоминаем ссылку на первый операнд
(условие "repeat(B)") }:= listTriad.Count;:=
MakeOperand(1{op},2{sym},iIns3,
{sym err},iIns1);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Второй операнд - ссылка на триаду, номер которой
пока не известен }[2].OpType := OP_LINK;[2].TriadNum := 0;
{ Создаем триаду типа "IF"
}.Add(TTriad.Create(TRD_IF,Opers));
{ Запоминаем ссылку на второй операнд
(раздел "doE") }:= MakeOperand(2{op},5{sym},iIns1,
{sym err},iIns2);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Заполняем операнды для триады типа "JMP", которая
должна быть в конце раздела "doE" }[1].OpType :=
OP_CONST;[1].ConstVal := 1;
{ Второй операнд - ссылка на начало созданного
списка триад }[2].OpType := OP_LINK;[2].TriadNum := iIns3;
{ Создаем триаду типа "JMP" }.Add(TTriad.Create(TRD_JMP,Opers));
{ Для созданной ранее триады типа "IF" ставим
ссылку в конец последовательности триад,
созданной для раздела "doE" }[iIns1].Links[2] :=
iIns2+1;;
:{'a:=E'}
{ Оператор присвоения }
{ Если первый операнд не является переменной,
то это ошибка }symbTop[0].Lexem.LexType <> LEX_VAR
then:= symbTop[0].Lexem;;;
{ Если имя первого операнда совпадает с именем
параметра, то это семантическая ошибка
}(symbTop[0].Lexem.VarName = NAME_INPVAR)(symbTop[0].Lexem.VarName =
NAME_RESULT) then:= symbTop[0].Lexem;;;
{ Создаем ссылку на первый операнд - переменную }[1].OpType
:= OP_VAR;[1].VarLink := symbTop[0].Lexem.VarInfo;
{ Создаем ссылку на второй операнд }:=
MakeOperand(2{op},2{sym},listTriad.Count,
{sym err},iIns1);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Создаем триаду типа "присвоение"
}.Add(TTriad.Create(TRD_ASSIGN,Opers));;
{ Генерация списка триад для линейных операций }
:{'BorB'} Result := MakeOperation(TRD_OR);
:{'BxorB'} Result := MakeOperation(TRD_XOR);
:{'BandB'} Result := MakeOperation(TRD_AND);
:{'E<E'} Result := MakeOperation(TRD_LT);
:{'E>E'} Result := MakeOperation(TRD_GT);
:{'E=E'} Result := MakeOperation(TRD_EQ);
:{'E<>E'} Result := MakeOperation(TRD_NEQ);
:{'E-E'} Result := MakeOperation(TRD_SUB);
:{'E+E'} Result := MakeOperation(TRD_ADD);
:{'E*E'} Result := MakeOperation(TRD_MUL);
:{'E/E'} Result := MakeOperation(TRD_DIV);
:{not(B)}
{ Создаем ссылку на первый операнд }:=
MakeOperand(1{op},2{sym},listTriad.Count,
{sym err},iIns1);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Второй операнд для унарной операции NOT
не имеет значения }[2].OpType := OP_CONST;[2].ConstVal := 0;
{ Создаем триаду типа "NOT"
}.Add(TTriad.Create(TRD_NOT,Opers));;
:{uminE}
{ Создаем ссылку на второй операнд }:=
MakeOperand(2{op},1{sym},listTriad.Count,
{sym err},iIns1);
{ Если произошла ошибка, прерываем выполнение }Result
<> nil then Exit;
{ Первый операнд для унарной операции "-"
должен быть 0 }[1].OpType := OP_CONST;[1].ConstVal := 0;
{ Создаем триаду типа "UMIN"
}.Add(TTriad.Create(TRD_UMIN,Opers));;
{ Для логических, арифметических или операторных скобок
рекурсивно вызываем функцию для второго символа }
,7,19,26:{'progEend.','beginEend','(E)','(B)'}:=
MakeTriadListNOP(symbTop[1],listTriad);
{ Для списка операторов нужно рекурсивно вызвать
функцию два раза }
:{E;E}:= MakeTriadListNOP(symbTop[0],listTriad);Result
<> nil then Exit;:= MakeTriadListNOP(symbTop[2],listTriad);;
{ Для лексем ничего делать не нужно }
,28: Result := nil;
{ Во всех остальных случаях нужно рекурсивно вызвать
функцию для первого символа }Result :=
MakeTriadListNOP(symbTop[0],listTriad);{case Rule};;
MakeTriadList(symbTop: TSymbol;: TTriadList): TLexem;
{ Функция создания списка триад начиная от корневого
символа дерева синтаксического разбора }: integer;:
TOpArray;: TTriad;
{ Создаем список триад }:=
MakeTriadListNOP(symbTop,listTriad);
{ Если произошла ошибка, прерываем выполнение,
иначе продолжаем... }Result = nil thenlistTriad do
{ Создаем пустую триаду "NOP" в конце списка
}[1].OpType := OP_CONST;[1].ConstVal := 0;[2].OpType := OP_CONST;[2].ConstVal
:= 0;(TTriad.Create(TRD_NOP,Opers));
{ Для всех триад в списке расставляем флаг ссылки }i:=Count-1
downto 0 do:= Triads[i];Trd.TrdType in [TRD_IF,TRD_JMP] then
{ Если триада типа "переход" ("IF" или
"JMP")
и ссылается на другую триаду,
то ту триаду надо пометить }Trd.OpTypes[2] = OP_LINK
then[Trd.Links[2]].IsLinked := True;;;;;.
14. TrdType
unit TrdType; {!!! Зависит от входного языка !!!}{ Модуль для
описания допустимых типов триад }_PROG = 'myCursov';_INPVAR = 'InpVar';_RESULT
= 'Result';_FUNCT = 'CompileTest';_TYPE = 'word';
{ Типы триад, соответствующие типам допустимых операций,
а также три дополнительные типа триад:
CONST - для алгоритма свёртки объектного кода;
SAME - для алгоритма исключения лишних операций;
NOP (No OPerations) - для ссылок на конец списка триад.
}= (TRD_IF, TRD_OR, TRD_XOR, TRD_AND, TRD_NOT,_LT, TRD_GT,
TRD_EQ, TRD_NEQ,_ADD, TRD_SUB, TRD_MUL, TRD_DIV, TRD_UMIN, TRD_ASSIGN,_JMP,
TRD_CONST, TRD_SAME, TRD_NOP);
{ Массив строковых обозначений триад
для вывода их списка на экран }= array[TTriadType] of
string;: TTriadStr =
('if','or','xor','and','not',
'<','>','=','<>','+','-','-',':=',
'jmp','C','same','nop', '*','/',);
{ Множество триад, которые являются линейными операциями }:
set of TTriadType =
[TRD_OR, TRD_XOR, TRD_AND, TRD_NOT, TRD_ADD, TRD_SUB,_LT,
TRD_GT, TRD_EQ, TRD_NEQ, TRD_UMIN, TRD_MUL, TRD_DIV];.
4.
Результати роботи
Вихідний стан
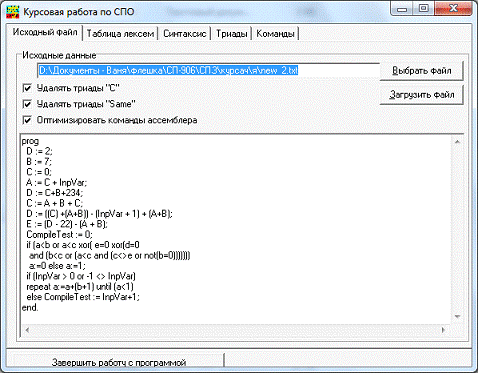
Таблиця лексем
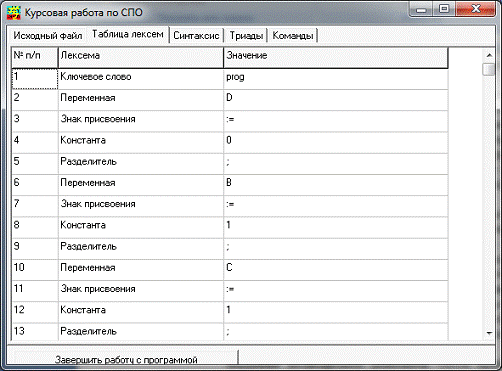
Синтаксичне дерево
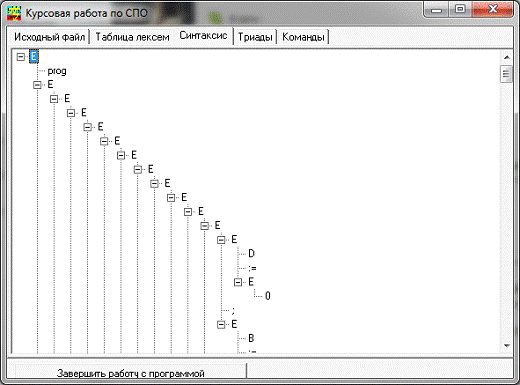
Тріади:
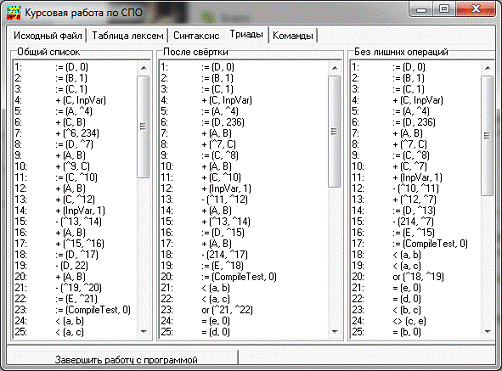
Команди
Висновки
Під час виконання даної курсової роботи я розглянула основні
складові частини компілятора, практично дослідила основні принципи побудови і
функціонування компіляторів. Освоїла методи побудови простих
компіляторів для заданої вихідної мови.
Перелік
використаної літератури
1. Гордеев А. В. Молчанов Л. Ю. Системное
программное обеспечение, - СПб.: Питер. 2002. - 734с.
2. Кампапиец Р. II. Манькоп Е. В., Филатов Н. Е.
Системное программирование. Основы построения трансляторов: Учеб. пособие для
высших и средних учебных заведений. - СПб.: КОРОНА Принт, 2000. - 256 с.
. Архангельский А.Я. Программирование в Delphi
6 - М.: ЗАО «Издательство БИНОМ», 2003. - 1120 с., ил.
. Системное программное обеспечение.
Лабораторный практикум/ А.Ю. Молчанов- СПб.: Питер, 2005.- 284 с.