Разработка системы анализа Log-файлов
РЕФЕРАТ
СИСТЕМЫ АНАЛИЗА, СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ
ДАННЫХ, WEB-СЕРВЕР, LOG-ФАЙЛЫ.
Объектом разработки дипломной работы является
система, предназначения для обработки логов, а так же выбор аналитики для
качественного анализа логов
Целью работы является разработка системы,
способной хранить и обрабатывать большие объемы статистических данных
результатов работы web-сервера.
В результате выполнения дипломной работы
спроектирована и разработана база данных для хранения статистики, разработаны
графический интерфейс и создано 4 отчета статистики.
ОБОЗНАЧЕНИЯ И СОКРАЩЕНИЯ
|
CLF
|
Common
Log Format
|
|
URL
|
Единый
указатель ресурсов
|
|
NCSA
|
National
Center for Supercomputing Application (Национальный центр суперкомпьютерных
приложений
|
|
URI
|
Uniform
Resource Identifie
|
|
БД
|
База
данных
|
|
SQL
|
Structured
Query Language
|
|
PSQL
|
Procedural
Structured Query Language
|
ВВЕДЕНИЕ
файл программирование конвенция
кроссплатформленость
Современное общество невозможно представить без
интернета. Число пользователей интернета растёт темпами, опережающими любые
возможности ручного анализа. В России, за период с 2011 по 2013, число
пользователей возросло с 52 процентов до 62 процентов. Для эксперта оказывается
невозможным охватить такое количество данных, а так же применение классических
методов анализа, требующие от него формулирования гипотез или создания
обучающих данных. При этом корректное получение данных о поведении
пользователей на сайте необходимо для улучшения структуры сайта, его
наполняемости, устранение ошибок в структуре, созданию криптостойкой защите и
качественное обеспечение пользователей той информации, которая необходима
именно ему.
Современная интеграция интернета прослеживается
во всех сферах деятельности человека. Основной причиной роста интеграции
интернета послужила простота и скорость, с которой можно осуществлять операции
через интернет. В результате текущей динамике произошли серьезные изменения в
общении с конечными пользователями, а так же появилась возможность
персонифицировать предложения для каждого посетителя.
Целью моей дипломной работы ознакомиться с
современными средствами анализа log-файлов, структурой и правилами ведения
логов, а так же разработать систему для анализа этих файлов.
Основные этапы анализа. Анализ существующих
решений.
Основные этапы анализа.
Процесс автоматического изучения характеристик
доступа пользователей к серверам может включать изучение наиболее популярных
путей решения, нахождении ассоциативных правил, созданию кластеризации. Для
решения данных задач можно использовать существующие технические документы, в
частности собираются огромные объемы информации, автоматически создаваемой
серверами и оседающих в журналах регистрации. Источником информации может также
являться ссылочный журнал, в котором хранится информация для каждой страницы,
на которую осуществляется ссылка, журналы браузеров и регистрационные данные
пользователей, собранные CGI-сценариями. Извлечение знаний и последовательный
анализ принято разделять на две части:
РАЗРАБОТКА СИСТЕМЫ АНАЛИЗА LOG-ФАЙЛОВ
content mining описывает автоматический поиск
информационных ресурсов в интернете и включает в себя добычу содержимого из
веб-данных. Аналогом content mining является метод интеллектуального анализа
данных для реляционных баз данных( Data mining), так как существует возможность
найти похожие типы знаний из неструктурированных данных, находящихся в
веб-документах. Веб-документ в себе может содержать несколько типов данных:
Текст.
Мультимедийные данные (изображение, аудио,
видео).
Метаданные.
Гиперссылки.
Существуют различные методы поиска информации в
интернете. Наиболее распространенным методом является поиск на основе ключевых
слов. Традиционные поисковые системы имеют сканеры для поиска и сбора полезной
информации, методы индексирования для хранения информации и обработки запросов,
чтобы пользователь мог получить более точную информацию. Технология web content
mining выходит за рамки традиции технологии Information Retrieval или
сокращенно IR. Под IR понимается процесс неструктурированной документальной
информации, удовлетворяющей информационным потребностям и так же наука об этом
поиске.
В web content mining существует два подхода:
агентный и ориентированный на базу.
Первый подход включает такие системы:
Интеллектуальные поисковые агенты.
Фильтрация информации / классификация.
Персонифицированные агенты сети.
Второй подход включает систмы:
Многоуровневые базы данных.
Систему веб-запросов ( Web Query Systems).usage
mining.usage mining - это процесс добычи полезной информации из
пользовательских журналов доступа, прокси-сервера, браузерных журналов и
пользовательских сессионных данных. Целью такого анализа является выявлений
предпочтений пользователей при использовании ресурсов сети интернет. В данном
методе производится анализ следующей информации:
История просмотра страниц пользователем.
Последовательность просмотра.usage mining
включает в себя следующие составляющие:
Предварительная обработка
Операционная идентификация.
Инструменты обнаружение шаблонов.
Инструменты анализа шаблонов.
Статистика фиксирует идентификационные данные
веб-пользователей вместе с их поведением на сайте. В зависимости от вида
данных, результатом работы могут являться:
Данные веб-сервера.
Данные серверных приложений.
Данные прикладного уровня.
Сбор информации.
В дипломной работе применяется метод анализа,
основанный на web usage mining. В частности сбор информации происходит на
уровне сервера и представляет собой отбор информации из журналов web-сервера.
Данный способ используется наиболее часто, поскольку без лишних накладных
ресурсов можно получить достаточно полную картину работы пользователя с
сервером, к тому же, для этого метода уже существуют заранее накопленные
данные. Все современные серверы автоматически ведут логирование или
журнализацию; при этом данные журналы занимают достаточно мало места и могут
храниться годами. Для дальнейшего рассмотрения необходимо понять, что
представляет из себя журнал сервера, принцип заполнения его сервером и какую
именно информацию он хранит.
Журнал сервера должен отвечать требованиям
стандарта Common Log Format (CLF). В переводе дословно с английского CLF -
общий формат регистрации, также известный как NCSA Common Log Format. Под
аббревиатурой NCSA имеется ввиду National Center for Supercomputing Application
или в переводе на русский язык Национальный центр суперкомпьютерных приложений.
Рассмотрим типовую конфигурацию лог файла
веб-сервера apache:
"%h %l %u %t \"%r\" %>s
%b"
Строка формата состоит процентных директив,
каждый из которых указывает веб-серверу на необходимость вывод конкретной
информации.
Рассмотри на примере, что же обозначают наши
директивы.
Пример лога, записанный в формате CLF:
.168.1.1 - - [28/Apr/2013:20:58:02 +0400]
"GET / HTTP/1.1" 200 44
«192.168.1.1» выводится параметром «%h».
Это IP-адрес клиента (удалённый хост), который
сделал запрос на сервер. Стандартная конфигурация использует журналирование
постпроцесса, в частности такие как logresolve, дословно означает «журнал
решения», для определения хостов. IP-адрес представленный здесь, не обязательно
будет являться адресом компьютера, на котором пользователь сидит. Если между
пользователем и сервером используется прокси-сервер, то это будет адрес
прокси-сервера, а не исходной машины.
« - »выводится параметром «%L»
«Дефис» на выходе указывает, что запрашиваемая
информация недоступна. Данный параметр указывает на имя пользователя (Identd).
Эта информация ненадежна и практически никогда не может быть использована,
кроме как на жестко контролируемых внутренними сетями. По умолчанию в
настройках веб-сервера Apache данный параметр не определяет.
« - »выводится параметром «%U»
Это идентификатор лица, запрашивающий документ
при помощи аутентификации HTTP. Если код состояния запроса имеет значение 401,
то этому значению не следует доверять, так как пользователь не
аутентифицирован. Так же, если документ не защищен паролем, то вместо имени
пользователя будет выводится « - ».
[28/Apr/2013:20:58:02 +0400] выводит директива
«%Т»
Время сервера, когда был получен запрос. Формат
выводимой даты: [День/ месяц / год / часы:минуты:секунды зону].
Данный параметр указывает на строку запроса от
клиента. Данная строка содержит много полезной информации. Первое- метод,
используемый клиентом получать информации, а так же используемый протокол.
Второе - это ресурс, который клиент запросил. В веб-серверах существует
возможность редактирование списка выводимых данных данным параметром.
«200» выводит параметр «%>s»
Это код состояния, который сервер посылает
обратно клиенту. Эта информация очень ценна, потому что он показывает,
состояние ответа на запрос:
Успешно выполнены - коды, начинающиеся с 2.
Перенаправления - коды, начинающиеся с 3.
Ошибки, вызванные клиентом -коды, начинающиеся с
4
Ошибки в сервере -коды, начинающиеся с 5
Большинство современных веб-серверов, в том
числе apache и ngnix, позволяют администраторам какие поля должны включаться в
журнал, а какие - нет. Самые распространенные из дополнительных полей:
Обратившиеся приложение
Единый указатель ресурсов (URL) документа
Значение cookies.
При добавлении дополнительных полей к Common Log
Format (CLF) образуется Combined Log Format, или комбинированный формат
журнала. Данный формат является точно таким же, как и Common Log Format, с
добавлением двух полей. Каждое дополнительное поле использует процент директивы
- %{заголовок}i. В заголовке может использоваться любой HTTP заголовок запроса
Рассмотрим типовую настройку конфигурации
комбинированного лога:
"%h %l %u %t \"%r\"
%>s %b \"%{Referer}i\" \"%{User-agent}i\""
Пример комбинированного
лога:
.0.0.1 - frank [10/Oct/2000:13:55:36
-0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
"#"656690.files/image001.gif">
Рисунок 1 - Пример отчёта в
Webalizer
Analog
Разработчик: Стивен Тернер.
Сайт программы #"656690.files/image002.gif">
Рисунок 2 - Пример отчета Analog
AWStats
Разработчик: Laurent Destailleur.
Сайт программы #"656690.files/image003.gif">
Рисунок 3 - Пример отчета AWStat
Log Analyzer представляет собой
профессиональное решение для анализа серверных лог-файлов. Данное решение
исследует логи на стороне клиента и поддерживает работу с лог-файлами не только
в форматах IIS и Apache, но и в нестандартных форматах. Пакет поставляется в
трех редакциях: бесплатной Lite и платных Standard и Professional.
Возможности бесплатной версии
ограничены получением основных данных о посещаемости сайта, представляемых в
виде 23 базовых отчетов. С их помощью можно узнать, с каких поисковых систем
(имеется поддержка свыше 430 поисковых систем и каталогов, включая национальные
системы самых разных стран) и по каким фразам приходят посетители (рис. 5), а
также проанализировать трафик со ссылающихся сайтов и выявить ошибки в работе
исследуемого сайта.
Версия Standard обеспечивает
генерацию уже 33 отчетов, которые могут быть дополнительно настроены путем
внедрения фильтров. Информация в данных отчетах позволяет не только представить
общую картину посещаемости сайта, но и подробно изучить приходящих на него
посетителей, а также проанализировать работу роботов. В частности, можно
узнать, откуда они приходят, выявить интересы (на какие страницы чаще всего
приходят, что загружают, по каким ссылкам щелкают), сколько времени находятся
на сайте, с каких страниц чаще всего уходят и т.д. Кроме того, AlterWind Log Analyzer
Standard позволяет подробно анализировать результаты рекламных кампаний и
выявлять наиболее предпочтительные в плане прихода рефереров ресурсы.
Количество базовых отчетов в версии
Professional - 52, и их также можно перестраивать посредством применения
фильтрации. Помимо этого данная версия содержит неограниченное число шаблонов
отчетов (для сравнения в версии Standard шаблон всего один) - это позволяет для
каждой из повторяющихся задач создать свой собственный шаблон с определенными
настройками и фильтрами, что в дальнейшем существенно упростит и ускорит
процесс получения требуемых статистических данных. Кроме того, версия
Professional позволяет дополнительно генерировать отчеты, требуемые для
оптимизации сайта под поисковые системы, его продвижения и анализа pay-per
click-программ. В частности, с ее помощью можно не только увидеть историю
переходов по сайту, глубину поиска и время пребывания на нем, но и проследить
названные данные с учетом поисковых фраз, сайтов-рефереров и URLs.
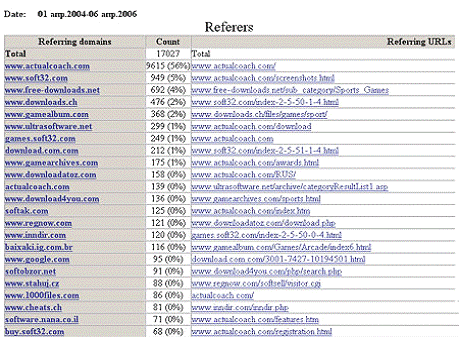
Рисунок 4 - Пример отчета AlterWind
Log Analyzer
Разработчик: Semonitor
Сайт программы
#"656690.files/image005.gif">
Рисунок 5 - Пример отчета Semonitor
Требования к создаваемой системе.
Выбор инструментов реализации. Описание общей архитектуры.
Требования к создаваемой системе
Приведенная в отчетах статистика
отличается максимально возможной полнотой и позволяет проанализировать работу
проекта и выявить имеющиеся проблемы. На основе анализа существующих систем
можно сделать вывод о том, какими свойствами должно обладать создаваемая
система.
Кроссплатформленость. Система должна
работать под различными ОС, так как веб-сервера работают под управлением
операционных систем Windows и Unix.
Гибкость. Данное свойство позволит
системе при создании дополнительных модулей легко добавлять в существующую
систему.
Обеспечение быстрого доступа к
статистическим данным.
Обеспечение безопасности доступа к
данным
Выбор инструментов реализации.
Рассмотрим подробнее способы
достижения требований изложенных в прошлой главе. Кроссплатформенность и
гибкость можно выполнить, написав программное обеспечение на C++, Delphi и
Python. Клиентское приложение было принято решение писать на
Python.высокоуровневый язык программирования общего назначения, ориентированный
на повышение производительности разработчика и читаемости кода. Синтаксис ядра
Python минималистичен. В то же время стандартная библиотека включает большой
объём полезных функций.[6]
Основные характеристики:
Свободное распространение. Python
распространяется совершенно свободно в соответствии с открытой либеральной
лицензией. Исходные коды могут использоваться любым образом, даже встраиваться
в проприетарные продукты и продаваться.
Многофункциональность языка. Python
является многоцелевым языком программирования, поэтому на нем могут
разрабатываться игры, сайты, локальные приложения, программы управления
оборудованием и многое другое.
Высокая скорость разработки
проектов. Объем кода на Python в три и более раз меньше, чем для аналогичных
проектов на C, C++ и Java, поэтому разработка проектов на Python гораздо
интенсивнее. Кроме того, код на Python выполняется, минуя компиляцию и
линковку.
Качество и простота сопровождения
кода, написанного на Python. Код, написанный на Python, отличается ясностью и
удобочитаемостью по сравнению с кодом на других языках программирования.
Ясность кода на Python позволяет существенно сократить количество ошибок и
повысить таким образом качество.
Переносимость кода. Python
реализован на стандартизованном ANSI C, поэтому он может быть скомпилирован и
запущен под всеми основными операционными системами. Скрипты, написанные на
Python, исполняются на самых разных устройствах, включая карманные компьютеры.
Большая часть кода на Python исполняется в исходном виде под любой из поддерживаемых
операционных систем: MS DOS, MS Windows, Linux, FreeBSD, Solaris, Mac OS, OS/2,
QNX, VMS, BeOS, VxWorks, Windows Mobile, Symbian, iPod и других.
Библиотеки. В Python имеется
обширная коллекция стандартных библиотек, которые могут быть использованы в
скрипте, включая библиотеки по работе с сетью и регулярными выражениями. Кроме
того, скрипт на Python может выполняться с использованием ваших собственных и
любых сторонних библиотек, включая NumPy (аналог MathLab), PyGame (игры и
анимация), PIL (графика), PyRo (робот), NLTK (анализ фраз естественных языков).
Гибкость и интеграция. Python
позволяет вызывать функции из библиотек, написанных на C или C++, а также
вызывать функции, написанные на Python, из программ на C и C++. Есть
возможность интеграции и с Java-компонентами. В Python имеется прикладной
интерфейс C API, который позволяет организовать указанные вызовы.[7]
Для обеспечение быстрого доступа к
статистическим данным необходимо выбрать СУБД. Среди некоммерческих стоит
выделить две: PostgreSQL и Firebird. Для создаваемой системы была выбрана СУБД
Firebird.- реляционная СУДБ, обладает многоверсионной архитектурой,
обеспечивающей параллельную обработку оперативных и аналитических запросов (это
возможно потому, что читающие пользователи не блокируют пишущих), компактность
(дистрибутив 5Mb), высокую эффективность и мощную языковую поддержку для
хранимых процедур и триггеров. [4][5] СУДБ легко работает с большими базами
данных. Среди минусов можно отметить отсутствие кеша результатов запросов и
отсутствие полнотекстовых индексов.
Основные характеристики Firebird
Полная поодержка хранимых процедур и
триггеров.
Транзакции, полностью совместимые с
концепцией ACID.
Ссылочная целостность.
Версионная архитектура.
Очень небольшой размер.
Мощный внутренний язык для написания
хранимых процедур и триггеров (PSQL).
Поддержка внешних пользовательских
функций (UDF).практически не требует работы системного администратора или
позволяет свести ее к минимуму.
Почти не требует настройки -
использовать СУБД можно сразу же после ее установки!
Огромное интернет-сообщество
пользователей и разработчиков, множество мест, где вы можете получить быструю и
бесплатную помощь.
Возможность распространения
встроенной в приложение (embedded) версии - замечательно подходит для создания
каталогов на CD-ROM, однопользовательских и пробных версий программ.
Десятки специализированных
приложений от сторонних разработчиков, включая средства администрирования,
репликации, и так далее.
Безопасная запись данных (careful
write) - быстрое восстановление после сбоев, отсутствие необходимости в
журналировании транзакций!
Большое количество средств доступа к
базе данных: native/API, драйверы dbExpress, ODBC, OLEDB, .Net provider,
JDBC-драйвер, модули для Python, PHP, Perl, и так далее.
Поддержка большинства
распространенных операционных систем, включая Windows, Linux, Solaris, MacOS.
Инкрементные бэкапы.
Билды для 32- и 64-разрядных ОС.
Полная реализация курсоров в PSQL.
Триггеры на коннект и транзакции.
Временные таблицы [8]
Описание общей архитектуры.
Общая архитектура создаваемой
системы состоит из 4 блоков:
Система анализа.
СУБД.
Показ статистических данных.файл
сервера.
На следующем рисунке показано
схематическое взаимодействие компонентов внутри системы:
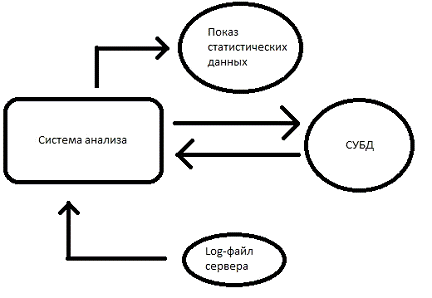
Рисунок 6 - Общая архитектура
системы
Взаимодействие компонентов внутри системы:
В системе анализа указывается путь хранении
log-файла сервера. Подгружается файл.
Осуществляется парсинг подгружаемого файла, с
заполнением данных в СУБД.
Для отображение статистических данных,
пользователей выбирает необходимый отчет. После вызова отчета, система анализа
обращается в базу за необходимыми данными.
После того, как были выбраны необходимые данные,
пользователю показывается конечный результат выполнения отчета или в виде HTML-
страницы или в exel-формате.
Описание инструментов и метода реализации.
Конвенции программирования.
В высококачественном программировании должна
быть очевидна связь между концептуальной целостностью архитектуры и её
низкоуровневой реализации. Реализация должна соответствовать высокоуровневой
архитектуре и обладать внутренней согласованностью. В этом заключается смысл
принципов конструирования, определяющих конвенции именования переменных,
классов, методов, а так еж форматирования кола и оформления переменных.
При разработке сложной программы архитектурные
принципы вносят в программу структурный баланс, а принципы конструирования -
низкоуровневую гармонию, при наличии которой каждый класс определяется как
неотъемлемая часть общего плана. Любая крупная программа требует применения
контролирующей структуры, унифицирующей аспекты языка программирования. Красота
крупной структуры частично заключается в том, как в её отдельных компонентах
выражены особенности архитектуры. Без унификации программа будет смесью
небрежных вариаций стиля, заставляющих прилагать дополнительные усилия только
для того, чтобы различия в стиле кодирования, которые вполне можно было
избежать. Одно из условий успешного программирования - устранение ненужных
вариаций, позволяющее сосредоточиться на действительно необходимых вариациях.
[9]
Конвенции разработки Firebird.
Имена всех объектов должны отражать способ их
использования.
Имена генераторов состоят из буквы «G» нижнего
подчеркивания и наименования первичного ключа для генерации чьего значения
используется генератор. Имена генераторов используемых для других целей
начинаются с «GEN_» далее используется любое имя отражающее назначение
генератора.
Имена триггеров имею формат
«TR_<ИМЯ_ТАБЛИЦЫ>_<Время срабатывания>_<Доплнительная_информация>».
Где Время срабатывания буквы BI (перед вставкой), AI (после вставки), BU(до
обновления), AU(после обновления), BD(до удалени), AD(после удаления).
Имена таблиц, используемых для хранения данных,
начинаются с префикса «S_», тем самым обозначая, что таблицы используются для
статического хранения данных. Таблицы, используемые для хранения справочников,
маркируются префиксом «L_». Таблицы, хранящие часто изменяемые данные,
обозначаются префиксом «D_».
Имена хранимых процедур начинаются с префиксов
«REP_» и «W_».
Префикс «REP_» обозначает, что процедура
производит лишь чтение данных. Префиксом «W_» маркируются процедуры
производящие изменения в БД.
Типы данных в таблицах описываются строго
прописанными доменами.
Записи из таблиц не удаляются, для пометки
записи как удаленная используется поле статус, которое заполняется подходящим
значением из таблицы статусов записей.
В каждой таблице в качестве первичного ключа
используется целочисленное поле.
В каждой таблице существуют два поля, хранящие
информацию о дате последнего изменения записи и о пользователе, который
последним производил изменение, поля имеют фиксированные имена LASTDATE и
USRNAME.
Всем триггерам, работающим с одной таблицей и
имеющим одинаковое время срабатывания, присваивается уникальный приоритет
кратный 100.
Наименования входных переменных должно
начинаться с префикса «IN_» выходных - «OUT_». Внутренние переменные начинаются
с префикса «V_».
Описание архитектуры БД.
База состоит из 5 основных таблиц.
Таблица IP адресов L_IP в которой хранится
информация об IP адресах, с которых осуществлялся заход на сайт. Таблица
состоит из следующих полей: целочисленного идентификатора записи (первичный
ключ), IP адрес, дата захода на web-ресурс, внешний ключ, связывающий с
таблицей L_USERS, внешний ключ, связывающий с таблицей L_METOD
Таблица пользователей, заходивших на веб-ресурс,
L_USERS состоит из целочисленного идентификатора записи (первичный ключ), имя
пользователя (может быть null), ссылку, откуда совершен данный заход, внешний
ключ, связывающий с таблицей L_USER_AGENT.
Таблица L_METOD состоит из целочисленного
идентификатора записи (первичный ключ), метод, используемый пользователем
получать информацию; ресурс, к которому пользователь обратился; внешний ключ,
связывающий с таблицей S_HTTP_CODE
Таблица S_HTTP_CODE состоит из целочисленного
идентификатора записи (первичный ключ), кодов состояния, имени состояния.
Таблица L_USER_AGENT состоит из целочисленного
идентификатора записи (первичный ключ), используемый браузер, операционная
система пользователя.
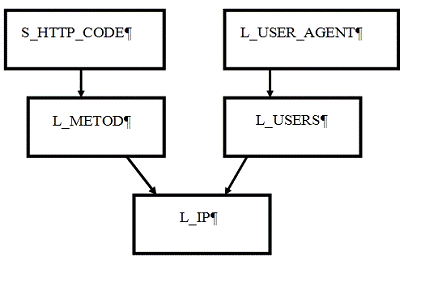
Рисунок 7 - Схематическая связь в
таблице
Создание хранимых процедур.
Для написание процедур в СУБД
Firebird используется PSQL - расширение языка SQL. Основными элементами в
расширение PSQL являются циклы и логические операторы.
Объявление действия совершаемого над
процедурой, в скобках перечисляются входные параметры процедуры.
CREATE OR
ALTER PROCEDURE PROCEDURE_NAME ()
В конструкции в скобках RETURNS ()
перечисляются выходные параметры которые будут выведены процедурой после вызова
команды SUSPEND. Команды BEGIN и END обозначают конец и начало блока с текстом
процедуры._NUMBER = 0;
Объявляем массив, который будем
обрабатывать.
FORla.ID_ANSWER,
la.IS_CORRECT, la.TEXT, la.SCOREL_ANSWER lala.ID_QUERY = :IN_QUESTION_NUMBER
Переменные, которым будут
присваиваться значения из массива.
INTO
:OUt_ID_ANSWER, :OUT_IS_CORRECT, :OUT_TEXT, :OUT_SCORE
DO BEGIN
Тело цикла с инкрементом счетчика и
выводом информации.
OUT_NUMBER =
OUT_NUMBER +1;;
END
Тонкости разработки на Python.
Кроссплатформленость
Не у каждого рядового пользователя
на компьютере будет установлен интерпретатор Python с нужными библиотеками. Для
решение данной проблемы существует приложение под названием py2exe.
Для конвертирования необходимо
создать файл setup.py в директории, где находится программа написанная на
Python.
from
distutils.core import
setuppy2exe(=[{"script":"analiz.py"}],={"py2exe":
{"includes":["sip"]}}
)
После этого запускаем упаковку командой:
setup.py py2exe
После выполнения команды, в каталоге
где находилась наша программа создается 2 папки: build и dist. Основная
проблема при выполнении данной процедуры - это увеличение объема программы.
Уменьшить объем приложения можно 4
способами:
Самое действенное. Сжать библиотеки
upx. Консольное приложение. Работает элементарно. На вход передается файл, оно
его сжимает.
Удалить unicodedata.pyd, bz2.pyd,
select.pyd, w9xpopen.exe. Веса немного, но, как минимум, в проекте станет
меньше файлов
Если в setup.py указать опцию
optimize:2, то модули будут компилироваться в .pyo (python optimized code), а
не в .pyc (python compiler script). Это не дает большого эффекта, но кто знает,
может Вам повезет)
И наконец, можно подчистить
library.zip от неиспользованных модулей и кодировок. Только аккуратно.[11]
Работа с exсel
В своей дипломной работе стояла
задача выводить данные как в виде html страниц, так и в формату exсel. Для
реализации данного условия стандартных библиотек, входящих в интерпретатор
python было недостаточно. Существует 3 дополнительные библиотеки для работ с
exсel:- дает возможность читать файлы Excel.- создание и заполнение файлов
Excel.- набор утилит для расширения возможности предыдущих 2 библиотек.
Для задачи дипломной работы
использовал библиотеку xlwt. Пример кода для создания excel файла:
font0.bold =
True style0 = xlwt.XFStyle() style0.= font0 style1 = xlwt.()
style1.num_format_str = 'D-MMM-YY' wb = xlwt.() ws = wb.add_sheet('A Test
Sheet') .write(0, 0, 'Test', style0) .write(1, 0, datetime.now(),style1)
.write(2, 0, 1) ws.write(2, 1, 1) .write(2, 2, xlwt.Formula("A3+B3"))
wb.save('example.xls')
ЗАКЛЮЧЕНИЕ
В современном мире существует
большое количество лог-анализаторов, которые предоставляют возможность получать
информацию о веб-ресурсе. Однако, как показал проведенный анализ популярных
анализаторов, обновления большинства бесплатных анализаторов практически не
происходит, а версии устарели.
На основе анализа существующих
решений были сформулированы концепции разрабатываемой системы, на основе
которой была спроектирована архитектура разрабатываемой системы.
Была спроектированы структура базы
данных, используемая в системе. С учетом специфики использования системы, для
хранения больших объемов данных.
СПИСОК ИСПОЛЬЗУЕМОЙ ЛИТЕРАТУРЫ
1. Щербин
А.А. Исследование и разработка метода автоматической классификации поведения
пользователей Интернет / А.А. Щербин - Москва: 2007. - 87 с.
2. The
Apache Software Foundation (2012). Apache HTTP server Documentation. URL:
http://httpd.apache.org/docs/ [10 сентября]
. Социологи
подсчитали число пользователей интернета в России URL:
http://lenta.ru/news/2013/03/16/internet/ [15 апреля]
4. Firebird:
About Firebird 25 января
2013. URL:http://www.firebirdsql.org/en/about-firebird/ [4 февраля
2013]
. iBase.ru
| Firebird 18 марта 2012
URL:http://www.ibase.ru/firebird.htm [26 октября
2012]
6. Программирование
на Phyton. Преимущества. 10 ноября 2010. URL:http://www.weblearn.ru/2010/11/programmirovanie-na-phyton-preimushhestva.
[ 21 сентября 2012]
. Узнайте
все о Firebird за 2 минуты 23 сентября 2011.
URL:http://www.firebirdnews.org/docs/fb2min_ru.html [1 октября 2012]
. Макконелл
С. Совершенный код. Мастер-класс / Пер. с англ. - М. : Издательство «Русская
редакция», 2012 - 896 стр. : ил.
. Марк
Лутц Изучаем Python. / Пер. с англ. - М. : Издательство «Символ-Плюс» 2011 -
1280 стр. : ил.
10. The
Webalizer. URL: http://www.webalizer.org/ [10 октября
2012]
11. Analog.
URL:http://www.analog.cx/ [11 октября 2012]
12. Awstat
official web site. URL:http://awstats.sourceforge.net/ [15 октября
2012]
. AlterWind
Log Analyzer URL: http://www.alterwind.ru/ [18 октября
2012]
14. Semonitor
URL:http://www.semonitor.ru/ [20 октября 2012]
ПРИЛОЖЕНИЕ
Исходный код парсера
class NodeList():__init__(self,
*args):.elements = [].add(*args)add(self, *args):arg in
args:.elements.append(arg)remove(self, *args):arg in args:arg in self:
self.elements.remove(arg)add_to(self, pos, arg):_list = self.elements_list =
[]i in range(len(old_list)+1):i < pos: new_list.append(old_list[i])i == pos:
new_list.append(arg): new_list.append(old_list[i-1]).elements =
new_listforeach(self, func, deep=False):_return = NodeList()node in
self:func(node): to_return.add(node)node.nodeType == 1 and
deep:_return.add(*node.foreach(func, True))to_returnbyName(self, name,
deep=False):self.foreach(lambda x: x.nodeType == 1 and x.name == name,
deep)withAttr(self, name, deep=False):self.foreach(lambda x: x.nodeType == 1
and name in x.attributes, deep)byAttr(self, name, value,
deep=False):self.foreach(lambda x: x.nodeType == 1 and name in x.attributes and
x.attributes[name] == value, deep)__getitem__(self,
index):self.elements[index]__bool__(self):bool(self.elements)__len__(self):len(self.elements)BondedList(NodeList):__init__(self,
parent):.__init__(self).common_parent = parentadd(self, *args):arg in
args:self:[-1].nextSibling = arg.previousSibling = self[-1].parent =
self.common_parent.add(self, arg)remove(self, *args):arg in args:arg in self:=
self.elements.index(arg)self[i].previousSibling is not
None:[i].previousSibling.nextSibling = self[i].nextSiblingself[i].nextSibling
is not None:[i].nextSibling.previousSibling =
self[i].previousSibling.remove(self, arg)add_to(self, pos, arg):.parent =
self.common_parentpos == 0:[0].previousSibling = arg.nextSibling = self[0]pos
< len(self):[pos].previousSibling = arg.nextSibling =
self[pos][pos-1].nextSibling = arg.previousSibling = self[pos-1]pos ==
len(self):[pos-1].nextSibling = arg.previousSibling = self[pos-1].add_to(self,
pos, arg)Node():= None= None=
Noneremove(self):self.nextSibling:.nextSibling.previousSibling =
self.previousSiblingself.previousSibling:.previousSibling.nextSibling =
self.nextSiblingself.parent:.parent.childNodes.remove(self)insertBefore(self,
node):self.parent is not None:=
self.parent.childNodes.elements.index(self).parent.childNodes.add_to(index,
node)insertAfter(self, node):self.parent is not None:=
self.parent.childNodes.elements.index(self).parent.childNodes.add_to(index+1,
node)TextNode(Node):__init__(self, content=''):.content =
contentComment(TextNode):= 8= 'comment'__init__(self,
content=''):.__init__(self, content)Text(TextNode):= 3= 'text'__init__(self,
content=''):.__init__(self, content)Element(Node):= 1= 'element'=
True__init__(self, name=''):.name = name.attributes = {}.childNodes =
BondedList(parent=self)squeeze(self):self.parent is not None:= self.parent=
parent.childNodes.elements.index(self)= self.childNodes.remove()node in
children:.childNodes.add_to(pos, node)+= 1foreach(self, func,
deep=True):self.childNodes.foreach(func, deep)byName(self, name,
deep=True):self.childNodes.byName(name, deep)withAttr(self, name,
deep=True):self.childNodes.withAttr(name, deep)byAttr(self, name, value, deep=True):self.childNodes.byAttr(name,
value, deep)
Приложение Б. Исходный код GUI.
# -*- coding: utf-8 -*-sysPyQt4
import QtCore,
QtGuiAnyWidget(QtGui.QWidget):__init__(self,*args):.QWidget.__init__(self,*args)=
QtGui.QHBoxLayout(self)= QtGui.QFrame(self) # Фрейм.setFrameShape(QtGui.QFrame.StyledPanel).setFrameShadow(QtGui.QFrame.Raised)=
QtGui.QGridLayout(frame) # Менеджер
размещения
элементов
во
фрейме=
QtGui.QLabel(u"Метка",frame)
# Текстовая
метка..addWidget(label,0,0)_edit
= QtGui.QLineEdit(u"Винни Пух",
frame) # Строковое поле
ввода..addWidget(ln_edit,0,1)_group
= QtGui.QGroupBox(u"Выбор из
двух",
frame) # Рамка с
надписью
вокруг
группы
элементов._lay
= QtGui.QVBoxLayout(radio_group) # Менеджер
размещения
элементов
в
рамке.=
QtGui.QRadioButton(u"Первый",
radio_group) # Два зависимых=
QtGui.QRadioButton(u"Второй",
radio_group) # переключателя.setChecked(True)_lay.addWidget(radio1)_lay.addWidget(radio2).addWidget(radio_group,1,0,3,1)
combo = QtGui.QComboBox(frame) # Поле ввода с
раскрывающимся списком.
combo.addItem(u"Пятачок").setEditable(True).addWidget(combo,1,1)=
QtGui.QSpinBox(frame).setValue(5) ..addWidget(spin,2,1)=
QtGui.QCheckBox(u"Пометка",
frame) # Независимый переключатель.setCheckState(QtCore.Qt.Checked).addWidget(check,3,1)=
QtGui.QProgressBar(frame) # индикатор
прогресса.setValue(70).setOrientation(QtCore.Qt.Horizontal).addWidget(progress,4,0,1,2)_lay
= QtGui.QHBoxLayout()= QtGui.QPushButton(u"Ок",
frame)= QtGui.QPushButton(u"Отмена",
frame)_lay.addWidget(button1)_lay.addWidget(button2).addLayout(btn_lay,5,0,1,2).addWidget(frame)__name__=="__main__":=
QtGui.QApplication(sys.argv)= AnyWidget().show().exit(app.exec_())