Разработка и реализация алгоритма решения систем линейных алгебраических уравнений трехдиагонального вида на графическом вычислительном устройстве
Министерство
образования и науки Российской Федерации
Федеральное
государственное бюджетное образовательное учреждение высшего профессионального
образования «Самарский государственный аэрокосмический университет имени
академика С.П. Королева (национальный исследовательский университет)»
Факультет
информатики
Кафедра
технической кибернетики
Выпускная
квалификационная работа специалиста
на
тему: Разработка и реализация алгоритма решения систем линейных алгебраических
уравнений трёхдиагонального вида на графическом вычислительном устройстве
Самара,
2013
Реферат
Объектом исследования является метод циклической
редукции и алгоритм Томаса для решения СЛАУ с матрицей трехдиагонального вида.
Целью является разработка параллельного
алгоритма для реализации на графическом вычислительном устройстве.
Разработанные алгоритмы реализованы на GPU
с применением технологии CUDA. Проведено сравнение времени работы параллельного
(GPU) и
последовательного (CPU)
алгоритмов. Результаты представлены в виде таблиц и графиков, отображающих
зависимость ускорения вычислений, произведенных на GPU
от размеров сеточной области.
Введение
Развитие математики (теория разностных схем,
проекционные и вариационные методы и другое), физики (оптика, теория
теплопроводности, газовая динамика и другое) и моделирования приводит к
необходимости разработки новых способов решения различных задач вычислительной
физики. При исследовании некоторых из указанных задач возникает потребность в
рассмотрении трехдиагональных систем линейных алгебраических уравнений (СЛАУ).
При этом может потребоваться решение вплоть до
сотен или даже тысяч трехдиагональных систем, что может быть столь велико, что
при использовании однопроцессорного компьютера либо возникнут проблемы из-за
нехватки памяти, либо решение займет очень много времени. В связи с этим
возникает необходимость разработки параллельных алгоритмов решения
трехдиагональных систем.
Развитие вычислительных технологий
последние десятки лет шло быстрыми темпами. Настолько быстрыми, что уже сейчас
разработчики процессоров практически подошли к так называемому «кремниевому
тупику». Безудержный рост тактовой частоты стал невозможен в силу целого ряда
серьезных технологических причин.
В развитии
современных процессоров намечается тенденция к постепенному увеличению
количества ядер, что повышает возможности процессоров в параллельных
вычислениях. Однако уже давно имеются GPU, значительно превосходящие
центральные процессоры в данном отношении. Именно поэтому для определённых
задач применение GPU выгоднее, ведь они изначально сделаны для них.
Например, в
видеочипах NVIDIA основной блок - это мультипроцессор с восемью-десятью ядрами
и сотнями ALU в целом, несколькими тысячами регистров и небольшим количеством
разделяемой общей памяти. Кроме того, видеокарта содержит быструю глобальную
память с доступом к ней всех мультипроцессоров, локальную память в каждом
мультипроцессоре, а также специальную память для констант.
CUDA (англ. Compute Unified
Device Architecture) - технология GPGPU (англ. General-Purposecomputing on Graphics Processing Units), позволяющая
программистам реализовывать на упрощённом языке программирования Си алгоритмы, выполнимые на графических
процессорах ускорителей GeForce восьмого поколения и старше.
Часто при решении больших
трехдиагональных систем на GPU, возникает проблема нехватки памяти («разделяемая память»).
Поэтому, в рамках данной дипломной работы был разработан параллельный метод
решения трехдиагональных систем линейных алгебраических уравнений (СЛАУ),
решающий эту проблему.
Суть этого метода заключается в том, что для
больших систем наша стратегия состоит в расщеплении в маленькие системы,
которые могут затем быть решены основой нашего метода. Параллельная циклическая
редукция хорошо подходит для этого, каждый шаг расщепляет работу наполовину.
Поэтому, если вводить нагрузку (систему) в n раз большую, чем самая большая
нагрузка, которая помещается в разделяемую память, требуется log(n) шагов
параллельной циклической редукции для того, чтобы каждая подсистема уместилась
в разделяемую память.
1. Методы решения систем линейных
уравнений трехдигонального вида
1.1 Метод прогонки
Одним из часто встречающихся видов систем
линейных алгебраических уравнений является система
Ax=f
(1.1)
с ленточной матрицей A. В этом случае уравнения всегда могут быть упорядочены так,
что каждое неизвестное 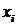 появляется только в
нескольких уравнениях, «соседних» с i-м
уравнением. Формально мы говорим, что матрица
появляется только в
нескольких уравнениях, «соседних» с i-м
уравнением. Формально мы говорим, что матрица 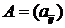 имеет верхнюю ширину
ленты q,
если
имеет верхнюю ширину
ленты q,
если 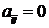 для
всех
для
всех 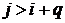 ,
и нижнюю ширину ленты р, если для всех
,
и нижнюю ширину ленты р, если для всех 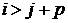 [8]. При q=p=1 такая
матрица называется трехдиагональной:
[8]. При q=p=1 такая
матрица называется трехдиагональной:
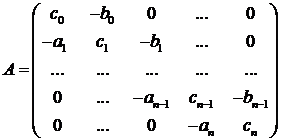 .
.
В системе (1.1) 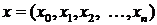 - вектор
неизвестных,
- вектор
неизвестных, 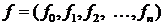 - вектор
правых частей.
- вектор
правых частей.
Данную систему можно переписать в
виде:
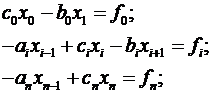 (1.2)
(1.2)
где 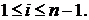
Пусть требуется найти решение этой
системы уравнений.
Специфика системы, в силу её
трехдиагональности, позволяет получить простые расчетные формулы для вычисления
решения [1].
Рассмотрим алгоритм решения системы
вида (1.2). Проведем исключение неизвестных в (1.2) для этого запишем систему в
следующем виде:
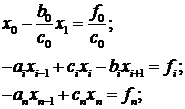 (1.3)
(1.3)
где
Произведем замену в первом уравнении
системы (1.3):
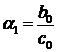 ;
; 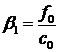 .
.
Возьмем первые два уравнения системы
(1.3):
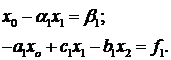
Умножим первое уравнение на 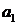 и сложим со
вторым уравнением получим:
и сложим со
вторым уравнением получим:
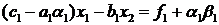 .
.
Разделим полученное уравнение на 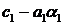 , тогда
будем иметь:
, тогда
будем иметь:
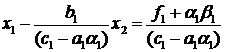 .
.
Произведем замену в уравнении:
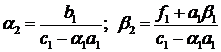 .
.
Тогда получим:
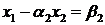 .
.
Остальные уравнения системы не
содержат 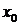 , поэтому на
этом первый шаг процесса исключения заканчивается. В результате выполненных
преобразований получим новую уменьшенную систему:
, поэтому на
этом первый шаг процесса исключения заканчивается. В результате выполненных
преобразований получим новую уменьшенную систему:
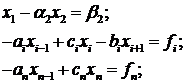 (1.4)
(1.4)
где 
Система (1.4) имеет аналогичную
системе (1.2) структуру и не содержит неизвестное . Если
решить эту систему, то потом неизвестное можно будет найти по следующей
формуле:
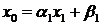 .
.
К системе (1.4) можно опять
применить описанный выше способ исключения неизвестных. Таким образом, на
втором шаге будет исключено неизвестное 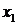 , на третьем
, на третьем 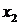 и так
далее. В результате l-го шага придем к системе для
неизвестных
и так
далее. В результате l-го шага придем к системе для
неизвестных 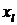 ,
, 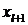 , …,
, …, 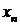 :
:
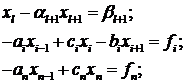 (1.5)
(1.5)
где 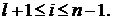
А так же получим формулы для
нахождения (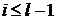 ):
):
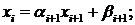 (1.6)
(1.6)
где 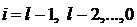 .
.
Коэффициенты 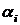 и
и 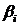 находятся
по следующим формулам:
находятся
по следующим формулам:
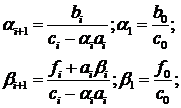
Полагая в системе (1.5) 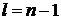 , получим
систему для и
, получим
систему для и 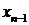 :
:
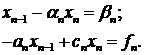
Из этой системы найдем и :
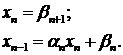
Объединяя эти равенства с равенством
(1.6) для случая , получим
окончательные формулы для нахождения неизвестных:
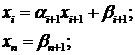 (1.7)
(1.7)
где 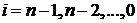 ;
;
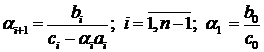 ; (1.8)
; (1.8)
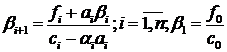 . (1.9)
. (1.9)
Формулы (1.7-1.9) описывают метод
прогонки. Коэффициенты и называются
прогоночными коэффициентами, формулы (1.8, 1.9) описывают прямой ход прогонки,
а (1.7) - обратный ход.
Для устойчивости метода прогонки
знаменатели дробей не должны обращаться в нуль. Достаточным условием этого
являяются неравенства
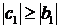 ,
,  ;
;
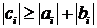 .
.
Подсчет арифметический действий в
(1.7) - (1.9) показывает, что реализация метода прогонки по этим формулам
требует 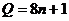 арифметических
действий[1].
арифметических
действий[1].
В рассмотренном методе
правой прогонки определение производится
последовательно справа налево.
Общий последовательный алгоритм правой прогонки
состоит из следующей последовательности шагов:
Шаг 1. Задать начальные значения коэффициентов a,
b,
c и правых
частей уравнений f.
Шаг 2. Рассчитать для прямого
хода прогонки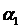 и
и 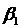 .
.
Шаг 3. Рассчитать значения
прогоночных коэффициентов 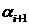 и
и 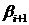
Шаг 4. Найти значение .
Шаг 5. Используя формулу 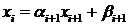 найти
остальные неизвестные.
найти
остальные неизвестные.
Аналогично выписываются формулы
левой прогонки .
Рассчитываются прогоночные
коэффициенты:
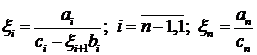 ; (1.10)
; (1.10)
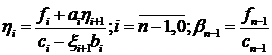 . (1.11)
. (1.11)
И неизвестные:
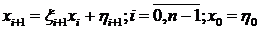 (1.12)
(1.12)
Общий последовательный алгоритм
левой прогонки состоит из шагов аналогичных шагам правой прогонки.
1.2 Метод встречных прогонок
Иногда оказывается удобно
комбинировать правую и левую прогонки, получая так называемый метод встречных
прогонок. Этот метод целесообразно применять, если надо найти только одного
неизвестное или группу идущих подряд неизвестных. В этом методе в области 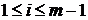 вычисляются
прогоночные коэффициенты
вычисляются
прогоночные коэффициенты 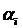 ,
, 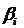 по формулам
(1.8, 1.9) и в области
по формулам
(1.8, 1.9) и в области 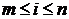 коэффициенты
коэффициенты
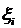 ,
, 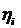 по формулам
(1.10, 1.11).
по формулам
(1.10, 1.11).
Выпишем формулы (1.7) и (1.12) для
обратного хода правой и левой прогонок для 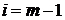 . Получим систему:
. Получим систему:
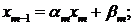
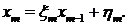
Из которой найдем 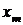 :
:
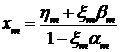 .
.
Используя найденное , по формуле
(1.6) для  найдем
последовательно
найдем
последовательно 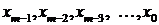 , а по формуле
(1.12) для
, а по формуле
(1.12) для 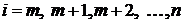 вычислим
остальные
вычислим
остальные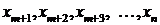 .
.
Итак, формулы метода встречных
прогонок имеют вид:
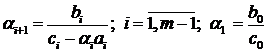 ; (1.8)
; (1.8)
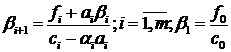 . (1.9)
. (1.9)
 ; (1.10)
; (1.10)
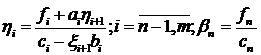 . (1.11)
. (1.11)
для прогоночных
коэффициентов и


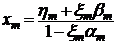
для определения решения.
1.3 Метод циклической редукции
Вернемся к СЛАУ вида (1.1) и
рассмотрим метод циклической редукции применительно к указанной системе.
Перепишем систему (1.1) в виде
(1.12):
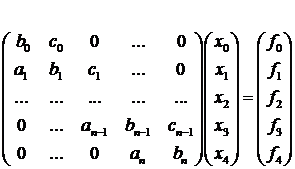 .
.
Идея метода циклической редукции
состоит в последовательном исключении из уравнений системы (1.12) неизвестных сначала с
нечетными номерами i , затем из оставшихся уравнений с номерами i ,
кратными 2, затем 4 и так далее [2].

Рисунок 1 - Схема циклической
редукции
На каждой итерации прямого хода
редукции рассматриваются тройки уравнений. Каждый шаг процесса исключения
уменьшает число неизвестных, и если  где
где  , то в результате процесса
исключения останется одно уравнение, из которого можно найти
, то в результате процесса
исключения останется одно уравнение, из которого можно найти 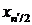 . На рисунке
1 изображена схема циклической редукции
. На рисунке
1 изображена схема циклической редукции
На первой итерации алгоритма тройка
рассматриваемых уравнений для системы (1.12) выглядит следующим образом:
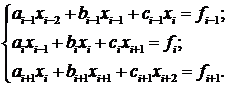 (1.13)
(1.13)
Специальные конечные
уравнения будут корректно включены, если мы установим 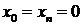 .Если первое из этих уравнений умножить на
.Если первое из этих уравнений умножить на 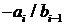 , а последнее на
, а последнее на 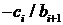 и эти три уравнения
сложить, все ссылки на переменны.
и эти три уравнения
сложить, все ссылки на переменны. 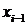 и
и 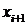 уничтожаются.
уничтожаются.
Тогда получаем:
 .
.
Произведем следующие замены:

Тогда получаем:
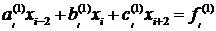 .
(1.14)
.
(1.14)
Уравнение (1.14) имеет отношение к
каждой второй переменной, и, если они написаны для 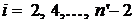 , являются
трехдиагональным множеством уравнений того же вида, что и исходные уравнения
(1.13), но с другими коэффициентами
, являются
трехдиагональным множеством уравнений того же вида, что и исходные уравнения
(1.13), но с другими коэффициентами 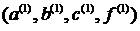 . В грубом
приближении число уравнений было поделено пополам. Вполне понятно, что процесс
можно рекурсивно повторять до тех пор, пока после
. В грубом
приближении число уравнений было поделено пополам. Вполне понятно, что процесс
можно рекурсивно повторять до тех пор, пока после 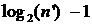 уровней
редукции остается только центральное уравнение для
уровней
редукции остается только центральное уравнение для 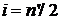 :
:
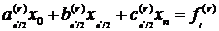 .
.
где настроечный индекс 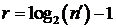 указывает
уровень редукции. Поскольку
указывает
уровень редукции. Поскольку 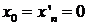 , решение для центрального уравнения
получается посредством деления
, решение для центрального уравнения
получается посредством деления
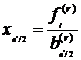 .
.
Теперь оставшиеся неизвестные могут
быть найдены из процедуры замещения. Поскольку нам известны , 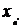 и
и 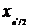 , то неизвестные промежуточные
значения могут быть найдены из уравнений на уровне
, то неизвестные промежуточные
значения могут быть найдены из уравнений на уровне 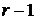 ,
использовав
,
использовав
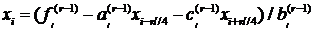
для 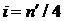 и
и 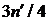 . Замещение процедуры повторяется до
тех пор, пока окончательно с помощью исходных уравнений не будут найдены все
нечетные неизвестные.
. Замещение процедуры повторяется до
тех пор, пока окончательно с помощью исходных уравнений не будут найдены все
нечетные неизвестные.
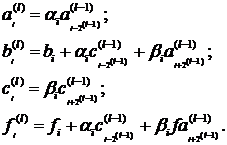
Где 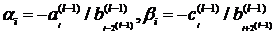 и
и
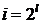 с
шагом
с
шагом 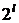 до
до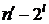 , с
первоначальными значениями
, с
первоначальными значениями 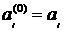 ,
, 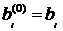 и
и
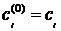 с
последующим замещением решения для
с
последующим замещением решения для 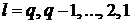 из
из
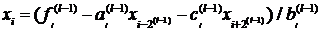 , (1.15)
, (1.15)
где 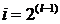 с
шагом
с
шагом 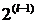 до
до
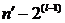 и
, когда они
имеют место.
и
, когда они
имеют место.
Диаграмма маршрутизации этого
алгоритма изображена на рисунке Рисунок 2 для 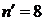 . Для удобства обозначим вектор
. Для удобства обозначим вектор 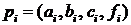 .
.
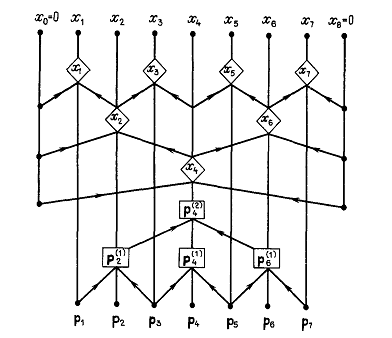
Рисунок 2 - Диаграмма маршрутизации алгоритма
циклической редукции
решение линейный уравнение
трехдигональный
Общий последовательный алгоритм циклической
редукции состоит из следующей последовательности шагов:
Шаг 1. Задать начальные значения коэффициентов a,
b,
c и правых
частей уравнений f.
Шаг 2. Пересчитать для каждого шага редукции
значения коэффициентов a
и c.
Шаг 3. Пересчитать для каждого шага редукции
значения правых частей уравнений f.
Шаг 4. Решить систему, полученную на последнем
шаге редукции. Найти значения двух неизвестных.
Шаг 5. Пересчитать для каждого шага редукции
значения оставшихся неизвестных.
2. Параллельные алгоритмы решения
систем линейных алгебраических уравнений трехдиагонального вида
В первом разделе были рассмотрены
последовательные алгоритмы решения систем алгебраических уравнений с
трехдиагональными матрицами. Однако с появлением многопроцессорных
вычислительных комплексов стало актуальным создание параллельных алгоритмов
решения таких систем, основанных как на ранее известных последовательных
алгоритмах (методы прогонки, циклической редукции), так и алгоритмов,
изначально создававшихся как параллельные (метод декомпозиции области).
Существует классификация, разделяющая параллельные алгоритмы на алгоритмы с
функциональной декомпозицией и с декомпозицией данных [8].
В [1] опубликованы традиционно используемые в
вычислительной практике алгоритмы, основанные на декомпозиции данных, при
которой производится распределение матрицы системы между процессорами вычислительного
комплекса, позволяющее каждому процессору решать свою подсистему.
Функциональная декомпозиция основывается на особенностях разностной или
проекционной задачи, приводящей к исследуемой системе линейных уравнений.
Из представленных далее алгоритмов к первому
виду (декомпозиция данных) следует отнести метод декомпозиции области и метод
циклической редукции. Алгоритмы прогонки относятся к виду, основанному на
функциональной декомпозиции.
2.1 Параллельный
алгоритм встречных прогонок
Рассмотрим двухзадачный алгоритм, основанный на
методе встречных прогонок [7].
Функциональная декомпозиция задается спецификой
метода встречных прогонок, в котором прогоночные коэффициенты (a,
b и h, z)
вычисляются с двух сторон по направлению к центру матрицы А. Так как
вычисления двух пар коэффициентов прогонки независимы, то их можно находить
параллельно.
Произведем разбиение одномерной
сеточной области w1 на 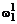 и
и 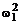 , где нижний
индекс при
, где нижний
индекс при 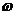 - это
размерность области, а верхний - номер процессора, как это показано на рисунке
3. Вычисления разделим на три шага, соответствующие прямому (рисунок 3а),
обратному (рисунок 3в) ходу встречных прогонок и обмену данными между процессорами
(рисунок 3б).
- это
размерность области, а верхний - номер процессора, как это показано на рисунке
3. Вычисления разделим на три шага, соответствующие прямому (рисунок 3а),
обратному (рисунок 3в) ходу встречных прогонок и обмену данными между процессорами
(рисунок 3б).
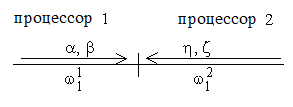
Рисунок 3а - Прямой ход прогонок
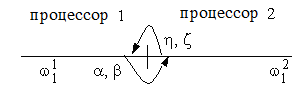
Рисунок 3б - Обмен данными между задачами

Рисунок 3в - Обратный ход прогонок
В течение прямого хода прогонок первый процессор
находит прогоночные коэффициенты a, b,
второй процессор - h, z. Далее,
первый процессор передает второму пару чисел a, b,
необходимых для запуска обратного хода прогонки на втором процессоре, который в
это время производит аналогичную передачу, необходимую первому процессору. На
третьем шаге оба процессора одновременно реализуют обратный ход прогонок,
находя решение СЛАУ.
Ускорение такого алгоритма можно оценить
величиной [4]:
 ;
;
где M
- размерность СЛАУ, С1Mtа
- длительность расчета по последовательному алгоритму, если tа
- время производства одной арифметической операции с плавающей точкой, tк=tу+tп
- длительность одной коммуникации между процессорами (tу
- время установки на обмен, tп
- время передачи или приема (считаем их равными) одного пакета по сети). При
пакетной модели передачи данных время передачи разного объема информации
остается константой до тех пор, пока объем передаваемого массива не превысит
размер пакета. Здесь это условие соблюдается (передается всего пара чисел), в
дальнейшем также будем полагать его верным. К сожалению, этот подход нельзя
развить для большего количества задач (алгоритм не масштабируем [10]), если сеточная область w одномерна.
2.2 Метод декомпозиции области
Ограничение на масштабируемость предыдущего
алгоритма сужает область его применения. Рассмотрим масштабируемый алгоритм,
основанный на декомпозиции области [5]. Пусть имеется система уравнений вида:
Ax=b;
где А - трехдиагональная матрица
размера n×n;
n=pq+p-1
для некоторых целых p
и q (p>q).
Алгоритм основан на разбиении множества
неизвестных на непересекающиеся подмножества Di
и множество разделителей Si,
как это показано на рисунке 4:
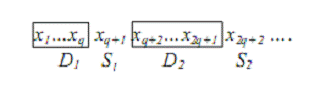
Рисунок 4 - Разбиение множества неизвестных
Затем переменные переупорядочиваются путем
присвоения последних индексов элементам множества S,
что приводит к системе стреловидного вида:
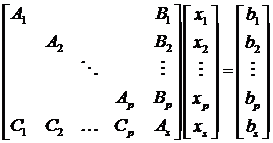 (2.1)
(2.1)
Вводя следующие обозначения Al=diag(A1…Ap), BT=(B1…Bp), C=(C1…Cp), xl=(x1…xp), bl=(b1…bp), описанную
выше систему можно представить в виде:
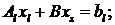 (2.2)
(2.2)
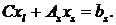 (2.3)
(2.3)
Предположив, что матрица Al
невырожденная, умножим уравнение (2.3) на C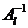 и вычтем
полученное из уравнениия (2.2):
и вычтем
полученное из уравнениия (2.2):
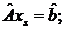 (2.4)
(2.4)
где 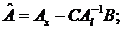
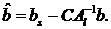
Как только будет решена система
(2.4) относительно xs, остальные
неизвестные можно найти из систем:
Alxi=
bl
- Bxs;
где 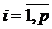 .
.
Данные системы можно решать
независимо друг от друга. Кроме того, слагаемые CB и Cb также можно
находить независимо. Схема алгоритма декомпозиции областей представлена на
рисунке 5:

Рисунок 5 - Схема алгоритма декомпозиции области
Ускорение алгоритма оценивается величиной:
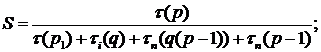
где 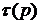 - время решения исходной системы,
- время решения исходной системы,  - число
матриц на первом процессоре,
- число
матриц на первом процессоре, 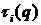 - время глобальной рассылки
массива, состоящей из q элементов, τn - время
пересылки одного пакета по сети.
- время глобальной рассылки
массива, состоящей из q элементов, τn - время
пересылки одного пакета по сети.
2.3 Параллельный алгоритм правой
прогонки
Рассмотрим схему распараллеливания метода
прогонки при использовании p потоков. Пусть нужно решить
трехдиагональную систему линейных уравнений
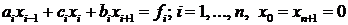
с использованием p параллельных
потоков.
Применим блочный подход к разделению
данных: пусть каждый поток обрабатывает m=n/p строк
матрицы A, т.е. k-й поток обрабатывает строки с номерами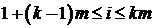 . кратно
числу потоков, в общем случае изменится только число уравнений в последнем
потоке. Ниже, на рисунке 6, представлено разделение данных для трех потоков в
случае системы из 12 уравнений.
. кратно
числу потоков, в общем случае изменится только число уравнений в последнем
потоке. Ниже, на рисунке 6, представлено разделение данных для трех потоков в
случае системы из 12 уравнений.
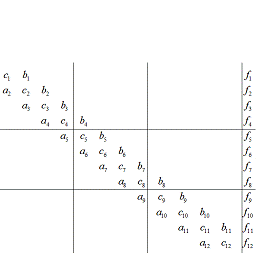
Рисунок 6 - Разделение данных для трех потоков
системы из 12 уравнений
В пределах полосы матрицы,
обрабатываемой k-м потоком, можно организовать исключение
поддиагональных элементов матрицы (прямой ход метода). Для этого осуществляется
вычитание строки i, умноженной на константу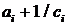 , из строки
, из строки  с тем,
чтобы результирующий коэффициент при неизвестной в ()-й строке
оказался нулевым. Если исключение первым потоком поддиагональных переменных не
добавит в матрицу новых коэффициентов, то исключение поддиагональных элементов
в остальных потоках приведет к возникновению столбца отличных от нуля
коэффициентов: во всех блоках (кроме первого) число ненулевых элементов в
строке не изменится, но изменится структура уравнений.
с тем,
чтобы результирующий коэффициент при неизвестной в ()-й строке
оказался нулевым. Если исключение первым потоком поддиагональных переменных не
добавит в матрицу новых коэффициентов, то исключение поддиагональных элементов
в остальных потоках приведет к возникновению столбца отличных от нуля
коэффициентов: во всех блоках (кроме первого) число ненулевых элементов в
строке не изменится, но изменится структура уравнений.
Модификации также подвергнутся элементы вектора
правой части. Рисунок 7 иллюстрирует данный процесс, чертой сверху отмечены
элементы, которые будут модифицированы.

Затем выполняется обратный ход алгоритма -
каждый поток исключает наддиагональные элементы, начиная с последнего.

Рисунок 8 - Иллюстрация обратного
хода параллельной прогонки
После выполнения обратного хода матрица стала
блочной. Исключим из нее внутренние строки каждой полосы, в результате получим
систему уравнений относительно части исходных неизвестных, частный вид которой
представлен на рисунке 9.
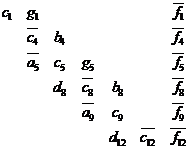
Рисунок 9 - Вид матрицы после
исключения внутренних строк
Рассмотренный способ
распараллеливания уже дает хорошие результаты, но можно использовать лучшую
стратегию исключения неизвестных. Прямой ход нового алгоритма будет таким же, а
во время обратного хода каждый поток исключает наддиагональные элементы, начиная
со своего предпоследнего, и заканчивая последним для предыдущего потока.
Рисунок 10 иллюстрирует данный процесс.
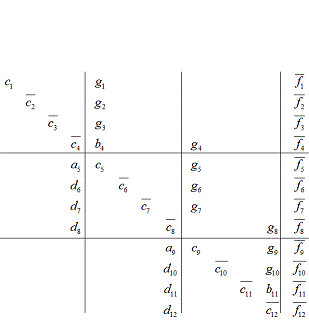
Рисунок 10 - Иллюстрация
модифицированного обратного хода параллельной прогонки
Изменение порядка исключения переменных в
обратном ходе алгоритма приводит к тому, что можно сформировать вспомогательную
задачу меньшего размера. Исключим из матрицы все строки каждой полосы, кроме
последней, в результате получим систему уравнений относительно части исходных
неизвестных, частный вид которой представлен ниже.
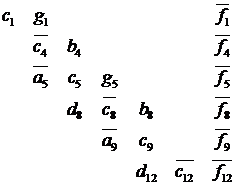
Рисунок 11 - Вид матрицы после
исключения всех внутренних строк кроме последней
Даная система будет содержать всего p уравнений,
и также будет трехдиагональной. Ее можно решить последовательным методом
прогонки (так как для систем с общей памятью число потоков p будет не
слишком велико, применять для решения вспомогательной системы даже параллельный
метод встречной прогонки нецелесообразно). После того, как эта система будет
решена, станут известны значения неизвестных на нижних границах полос
разделения данных. Далее можно за один проход найти значения внутренних
переменных в каждом потоке.
2.4 Параллельный
алгоритм циклической редукции
Описанный выше способ выполнения циклической
редукции имеет наименьшее число скалярных арифметических операций и,
следовательно, является наилучшим вариантом для последовательного компьютера
[2].
На матрицах процессоров желательно поддерживать
параллелизм на как можно более высоком уровне, и поддержание параллелизма на
уровне п во всей фазе редукции
достигается другим методом выполнения циклической редукции. На последнем уровне
редукции решения для всех переменных отыскиваются параллельно, за исключением
центрального значения в циклической редукции и фаза замещения не требуется. Так
как этот метод наиболее пригоден для паракомпьютера, назовем его параллельным
вариантом циклической редукции.
Диаграмма маршрутизации для
параллельного варианта показана на рисунке 12. Для удобства обозначим вектор .
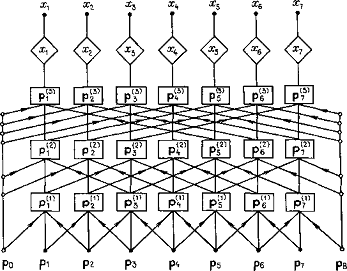
Рисунок 12 - Диаграмма маршрутизации алгоритма
параллельного циклической редукции
На каждом уровне уравнения редукции
для всех п уравнений решаются
параллельно. Трудность возникает тогда, когда требуются данные, которые не
попадают в описанный диапазон  . Однако
можно увидеть, что правильный результат получается, если принять
. Однако
можно увидеть, что правильный результат получается, если принять
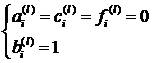 (2.5)
(2.5)
для 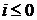 и
и
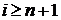 ,
или
,
или 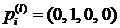 .
.
Добавив эти специальные значения в
изначальную систему получим уравнение
 для и
; (2.6)
для и
; (2.6)
которое дает правильные значения при
попадании в систему (1.13). Теперь можем рассматривать либо решение исходного
конечного множества уравнений, либо, как вариант, решение расширенного
бесконечного множества с коэффициентами (2.5). Это равнозначно только
суммирующим уравнениям, таким как (2.6), вне диапазона исходной задачи. Любая
точка зрения равно справедлива, но последняя больше подходит для параллельного
варианта циклической редукции, так как она описывает необходимые значения  и
и 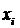 . вне
первоначально обозначенной задачи. После подсчета (фактически требуются только
значения
. вне
первоначально обозначенной задачи. После подсчета (фактически требуются только
значения 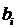 и
и 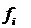 ). Значение х
получается из уравнения (1.15):
). Значение х
получается из уравнения (1.15):
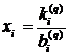 .
.
Члены х
в правой части уравнения (1.15) отсутствуют, так как на этом уровне редукции
они лежат вне диапазона и по
уравнению (2.2) равны нулю.
Число операций в алгоритме
параллельной циклической редукции составляет:
 ;
;
где ,  [2].
[2].
Недостатком данного алгоритма
является то, что его нельзя использовать для любого числа уравнений в системе.
3. Разработка алгоритма для
реализации на GPU
В предложенном алгоритме
предполагается проведение вычислений, на центральном процессорном устройстве (CPU) и на графическом
процессорном устройстве (GPU), то есть, на так называемой гетерогенной вычислительной среде.
Вычисления, которые можно произвести независимо, будут выполняться на GPU. Участки, которые
нельзя распараллелить, будут выполняться на СPU. Запускать параллельные
участки кода на графическом устройстве позволяет технология CUDA.
.1 Основные
возможности и особенности технологии CUDA
Технология CUDA -
это программно-аппаратная вычислительная архитектура NVIDIA, основанная на
расширении языка Си, которая даёт возможность организации доступа к набору
инструкций графического ускорителя и управления его памятью при организации
параллельных вычислений. CUDA помогает реализовывать алгоритмы, выполнимые на
графических процессорах видеоускорителей GeForce восьмого поколения и старше (серии
GeForce 8, GeForce 9, GeForce 200), а также Quadro и Tesla.
Хотя трудоёмкость
программирования GPU при помощи CUDA довольно велика, она ниже, чем с ранними
GPGPU решениями. Такие программы требуют разбиения приложения между несколькими
мультипроцессорами подобно MPI программированию, но без разделения данных,
которые хранятся в общей видеопамяти. И так как CUDA программирование для
каждого мультипроцессора подобно OpenMP программированию, оно требует хорошего
понимания организации памяти.
Программно-аппаратная архитектура
для вычислений на GPU компании NVIDIA отличается от предыдущих моделей GPGPU
тем, что позволяет писать программы для GPU на языке Си со стандартным
синтаксисом, указателями и необходимостью в минимуме расширений для доступа к
вычислительным ресурсам видеочипов. CUDA не зависит от графических API, и
обладает некоторыми особенностями, предназначенными специально для вычислений
общего назначения.
Модель программирования в CUDA
предполагает группирование потоков. Потоки объединяются в блоки потоков (thread
block) - одномерные или двумерные сетки потоков, взаимодействующих между собой
при помощи разделяемой памяти и точек синхронизации. Программа (ядро, kernel)
исполняется над сеткой (grid) блоков потоков (thread blocks). Эта модель
представлена на рисунке 13.
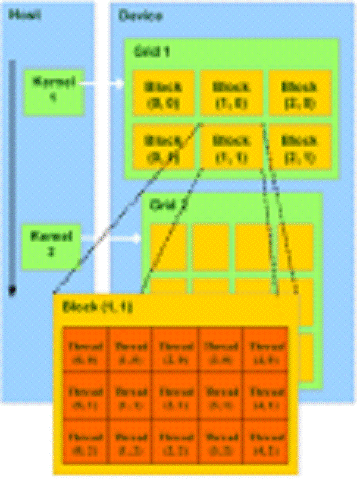
Рисунок 13
- Модель программирования в CUDA
Модель памяти в
CUDA отличается возможностью побайтной адресации, поддержкой как gather, так и
scatter. Доступно довольно большое количество регистров на каждый потоковый
процессор, до 1024 штук. Доступ к ним очень быстрый, хранить в них можно
32-битные целые или числа с плавающей точкой.
Каждый поток имеет
доступ к шести типам памяти, что отображено на рисунке 14.
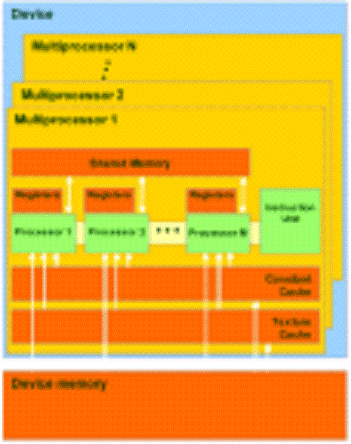
Рисунок 14 - Виды памяти в CUDA
Глобальная память -
самый большой объём памяти, доступный для всех
мультипроцессоров на видеочипе, размер составляет от 256 мегабайт до 1.5
гигабайт на текущих решениях. Обладает высокой пропускной способностью, более
100 гигабайт/с для топовых решений NVIDIA, но очень большими задержками в
несколько сот тактов. Не кэшируется, поддерживает обобщённые инструкции, и
обычные указатели на память.
Локальная память -
это небольшой объём памяти, к которому имеет доступ
только один потоковый процессор. Она относительно медленная - такая же, как и
глобальная.
Разделяемая память -
это 16-килобайтный блок памяти с общим доступом для
всех потоковых процессоров в мультипроцессоре. Эта память весьма быстрая, такая
же, как регистры. Она обеспечивает взаимодействие потоков, управляется
разработчиком напрямую и имеет низкие задержки. Преимущества разделяемой
памяти: использование в виде управляемого программистом кэша первого уровня,
снижение задержек при доступе исполнительных блоков к данным, сокращение
количества обращений к глобальной памяти.
Память констант -
область памяти объемом 64 килобайта, доступная только
для чтения всеми мультипроцессорами. Она кэшируется по 8 килобайт на каждый
мультипроцессор. Довольно медленная - задержка в несколько сот тактов при
отсутствии нужных данных в кэше.
Текстурная память -
блок памяти, доступный для чтения всеми
мультипроцессорами. Выборка данных осуществляется при помощи текстурных блоков
видеочипа, поэтому предоставляются возможности линейной интерполяции данных без
дополнительных затрат. Кэшируется по 8 килобайт на каждый мультипроцессор.
Медленная, как глобальная - сотни тактов задержки при отсутствии данных в кэше.
Естественно, что
глобальная, локальная, текстурная и память констант - это физически одна и та
же память, известная как локальная видеопамять видеокарты. Их отличия в
различных алгоритмах кэширования и моделях доступа. Центральный процессор может
обновлять и запрашивать только внешнюю память: глобальную, константную и
текстурную. Структура памяти изображена на рисунке 15.
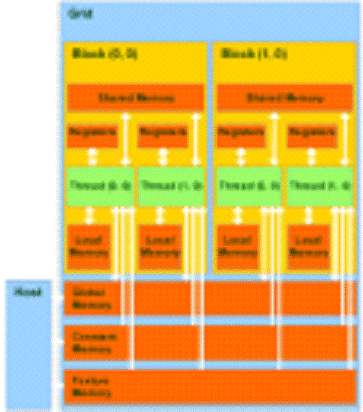
Рисунок 15 - Модель памяти в CUDA
3.2 Реализация разработанного
алгоритма на GPU
В этой части представлен
многошаговый метод для решения больших трехдиагональных систем на ГПУ. Ранее большие
трехдиагональные системы не могли быть эффективно решены в связи с ограничением
размера разделяемой памяти на чипе. Суть этого метода заключается в том, что
для больших систем наша стратегия состоит в расщеплении в маленькие системы,
которые могут затем быть решены основой нашего метода.
Для разделения системы на более
мелкие подсистемы хорошо подходит параллельная циклическая редукция, каждый ее
шаг расщепляет работу наполовину. Поэтому, если вводить нагрузку (систему) в n
раз большую, чем самая большая нагрузка, которая помещается в разделяемую
память, требуется log(n) шагов параллельной циклической редукции для того,
чтобы каждая подсистема уместилась в разделяемую память. После разделения,
получившиеся системы решаются с помощью алгоритма Томаса (прогонки).
Разработанный алгоритм*
продемонстрирован схематически на рисунке 16 для случая, когда в системе 8
уравнений.

Рисунок 16 -
Схема разработанного алгоритма
На входе мы имеем одну
трехдиагональную систему линейных уравнений, состоящую из восьми уравнений. На
первом этапе данная система разбивается на две подсистемы, состоящих из четырех
уравнений, по строению эти системы аналогичны первой. При необходимости
разбиение можно продолжать до того момента, когда подсистемы будут помещаться в
разделяемую память GPU. На последнем этапе полученные системы решаются с помощью метода
прогонки.
В ходе работы над реализацией
алгоритма было принято решение запускать два ядра - функции, которые
выполняются на ГПУ.
Первое ядро осуществляет
редукцию, разбивая систему до размеров, которые умещаются в разделяемую память GPU. Редукция осуществляется до уровня 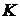 . При этом должно
соответствовать условию:
. При этом должно
соответствовать условию:
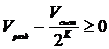 ;
;
где 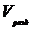 объем
разделяемой памяти в одном блоке,
объем
разделяемой памяти в одном блоке, 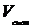 объем памяти
необходимый для хранения исходной задачи.
объем памяти
необходимый для хранения исходной задачи.
Для реализации алгоритма
редукции необходимо, чтобы каждому уравнению соответствовала своя нить, однако
количество нитей в одном блоке ограничено, поэтому для реализации данного
алгоритма на каждую систему необходимо выделить
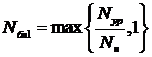 ;
;
где 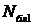 -
количество блоков,
-
количество блоков,  количество
уравнений в системе,
количество
уравнений в системе,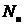 максимально
возможное количество нитей в одном блоке, а общее количество выделенных блоков
составит:
максимально
возможное количество нитей в одном блоке, а общее количество выделенных блоков
составит:
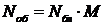 ;
;
где  общее
количество выделенных блоков, а
общее
количество выделенных блоков, а 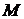 количество решаемых
систем.
количество решаемых
систем.
Второе ядро решает
каждую полученную редуцированную систему методом прогонки. В этом ядре каждой
системе соответствует свой блок. Количество блоков можно рассчитать по формуле:
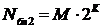 .
.

Рисунок 17 - Схема
реализации алгоритма на вычислительной системе
Ниже изложен алгоритм реализации разработанного
метода с использованием одного ГПУ.
.Инициализация исходных массивов данных.
. Выделение глобальной памяти на GPU
под массивы коэффициентов a, b, c, f
и
массив неизвестных x.
. Передача массивов коэффициентов a, b,
c, f
на
GPU.
4. Вызов ядра. Разделение системы на более
мелкие.
. Вызов ядра, решающего каждую полученную
редуцированную систему методом прогонки.
.Передача результирующего x
вектора на CPU.
Чтобы функции выполнялись не
процессором, а устройством, они имеют квалификатор __global__.
Объявление функции ядра,
осуществляющего алгоритм редукции, может иметь следующий вид:
__global__ void
reduction( float *a, float *b, float *c,float *f) { thread =
blockIdx.x*N+threadIdx.x+1;block = blockIdx.x;(int i=0; i<K; i++) { min =
thread-pow(2.0, i);max = thread+pow(2.0, i);(min<block*N+1)
min=0;(max>(block+1)*N) max=0;
float
alfa=-a[thread]/b[min];
float
betta=-c[thread]/b[max];
float zn0=alfa*a[min];
float
zn1=b[thread]+alfa*c[min]+betta*a[max];
float zn2=betta*c[max];
float
zn3=f[thread]+alfa*f[min]+betta*f[max];
__threadfence();
a[thread]=zn0;
b[thread]=zn1;
c[thread]=zn2;
f[thread]=zn3;
}
}
Вызов ядра из основной программы
осуществляется следующим образом:
<<<M,N/int(pow(2.0,
D))>>>(dev_a, dev_b, dev_c, dev_f).
Для работы с устройством
использовались следующие встроенные функции:
выделение памяти на устройстве:
((void**) &dev_a,
(N*M+1)*sizeof(float));
освобождения памяти на устройстве:
cudaFree( dev_a);
пересылка данных с ЦПУ на ГПУ:
(dev_a,a,(N*M+1)*sizeof(float),cudaMemcpyHostToDevice);
- пересылка данных с ГПУ на ЦПУ:
(a,dev_a,(N*M+1)*sizeof(float),cudaMemcpyDeviceToHost);
4. Исследования
алгоритмов
Исследования алгоритмов будем проводить на
вычислительной системе с графическим вычислительным устройством GeForce
GT 540M,
ЦПУ Intel
Core i5-2410М
2,3 Ггц, операционной системой Microsoft Windows 7 с установленным драйвером
NVIDIA CUDA Version 4.0.
Будем использовать как разделяемую, так и
глобальную память GPU.
Глобальную память GPU,
так как она имеет большой объем, будет удобно использовать для разделения
системы на части, а разделяемая будет применяться для решения полученных в ходе
разбиения новых систем.
В этом разделе будем сравнивать разработанный
параллельный алгоритм исполняемый на GPU
с последовательным алгоритмом прогонки на CPU
для потока задач, представляющих из себя системы алгебраических уравнений с
трехдиагональной матрицей. Для получения результатов будем изменять размеры
сеточной области. Сначала зафиксируем число систем и будем изменять количество
уравнений в системе, а затем зафиксируем количество уравнений в системе и будем
изменять число систем. Результаты (время работы алгоритма) сравним со временем
выполнения последовательного алгоритма на CPU
и отобразим графически.
Так как в разработанном алгоритме решения
трехдиагональных систем линейных алгебраических уравнений для разбиения больших
систем на малые используется метод циклической редукции, проведем эксперименты
для разных степеней разбиения системы. Зафиксируем значения M
и N и будем изменять
степень разбиения системы k.
Результат запишем в виде таблицы и графика (для лучшей наглядности)
4.1 Исследования ускорения алгоритма
Проведем исследования алгоритма, зафиксируем
количество систем M, а количество уравнений N будем изменять. В
таблице 1 представлены результаты исследования отношения времени выполнения
вычислений последовательного алгоритма на CPU
(TCPU) ко времени
выполнения вычислений разработанного алгоритма на GPU
(TGPU) от
размеров сеточной области. Число систем уравнений равняется 300, 500 и 700 для
одних и тех же N
.
Таблица 1
|
q
|
M
=700
|
M
=500
|
M
=300
|
|
1
|
0,25
|
0,1625
|
0,0825
|
|
2
|
0,275
|
0,55
|
0,195
|
|
3
|
0,75
|
0,675
|
0,475
|
|
4
|
1,475
|
1,825
|
1,225
|
|
5
|
3,75
|
3,25
|
1,55
|
|
6
|
7
|
2,325
|
|
7
|
7,0425
|
6,3
|
5,25
|
|
8
|
9,75
|
8
|
6,05
|
|
9
|
9
|
8,125
|
8
|
|
10
|
9,225
|
8,9
|
8,95
|
|
11
|
8,5
|
9,175
|
8,5
|
|
12
|
8,75
|
9,025
|
8,975
|
|
12
|
8,625
|
9,1
|
9,2
|
Для иллюстрации приведенных в
таблице 6 данных на рисунке 18 приведен график зависимости ускорения S алгоритма
от 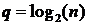 .
.
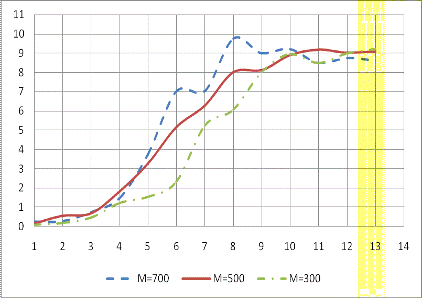
Рисунок 18
На графике, изображенном на рисунке
18, видно, что при небольшой размерности систем (до 23) ускорение
меньше единицы, то есть разработанный алгоритм для GPU работает
медленнее, чем последовательный. Это связано с
затратами времени на выделение памяти на GPU
и последующим копирование в нее исходных данных копирование превышают выигрыш в
скорости выполнения арифметических операций.
На больших же размерах
системы алгоритм эффективен, так как ускорение больше единицы. Из графика
видно, что ускорение увеличивается с ростом числа уравнений. Но при размерности
210 и 213 ускорение начинает колебаться около девяти. Это
объясняется ограничением роста производительности <#"656526.files/image189.gif">
Рисунок 19
Из рисунка 19 видны границы
эффективного применения алгоритма. Можно сделать выводы, что при увеличении
количества систем отношение времени выполнения вычислений последовательного
алгоритма на CPU (TCPU) ко времени
выполнения вычислений разработанного алгоритма на GPU (TGPU) возрастает
с увеличением числа решаемых систем. При количестве систем до 100, ускорение
меньше единицы. А значит, параллельный алгоритм работает медленнее, чем
последовательный, что связано с неполной загруженностью. На больших же количествах систем алгоритм эффективен, так как ускорение
больше единицы. Из графика видно, что при количестве систем больше 350,
ускорение начинает колебаться около 9. Это объясняется ограничением роста
производительности
<#"656526.files/image187.gif">.

Рисунок 20
Из рисунка видно, что чем больше
степень разбиения, тем меньше ускорение, получаемое разработанным алгоритмом.
Это можно объяснить тем, что на разбиение требуется дополнительное время,
которое снижает ускорение, кроме того из-за разбиения падает загруженность
нитей, что тоже негативно сказывается на ускорении. Однако это разбиение
необходимо производить при превышении максимального рамера системы,
помещающейся в разделяемую память.
Заключение
В рамках данной работы был разработан и
исследован параллельный алгоритм решения систем линейных алгебраических
уравнений, заключающийся в разделении больших систем для их последующего помещения
в разделяемую память GPU.
Приведены результаты работы алгоритма в виде
таблиц и графиков зависимости ускорения вычислений от размеров сеточной
области.
Для алгоритма, в ходе экспериментов, было
установлено, что при размерности систем N
в пределах от 25 до 213 ускорение изменяется от 1 до 3,5.
Так же было установлено, что при количестве систем M
в пределах от 100 до 600 ускорение изменяется от 1 до 3,5. Это говорит о том,
что в данных диапазонах размерностей сеточной области лучше воспользоваться параллельным
алгоритмом на GPU, чем
последовательным на CPU.Также
было выяснено, что при N>210
M>400 ускорение начинает колебаться около 3,5. Было
выяснено, что разбиение системы оказывает негативное влияние на ускорение
разработанного алгоритма, однако оно необходимо для использования разделяемой
памяти при больших размерностях систем.
Список использованных
источников
1 Самарский, А.А. Методы решения
сеточных уравнений [Текст]/А.А. Самарский, Е.С. Николаев. - М.: Наука, 1978. -
592 с.
2 Хокни Р., Джессхоуп К.
Параллельные ЭВМ. Архитектура, программирование и алгоритмы: Пер. с англ. - М.:
Радио и связь, 1986. - 392
Головашкин, Д.Л. Методы
параллельных вычислений. Часть 2. [Текст]: учебное пособие/Д.Л. Головвкашкин,
С.П. Головашкина. - Самар. гос. аэрокосм. ун-т. - Самара, 2003. - 103 с.
Ортега, Дж. Введение
в параллельные и векторные методы решения линейных систем/ Дж.Ортега. - М. :
Мир, 1991. - 364 с.
Ярмушкин, С.В. Исследование
параллельных алгоритмов решения трехдиагональных систем линейных уравнений [Текст]/С.В.
Ярмушкин, Д.Л. Головашкин//Вестн. Сам. гос. техн. ун-та. Сер. Физ.-мат. науки.
- 2004. - вып. 26. - С. 78-82.
6 Hockney R.W., Jesshope
C.R. Parallel Computers 2. Architecture, Programming and Algorithms. - Adam
Hilger, Bristol and Philadelphia, 1988. - 625 p.
7 Головашкин, Д.Л.
Параллельные алгоритмы решения сеточных уравнений трехдиагонального вида,
основанные на методе встречных прогонок [Текст]/Д.Л. Головашкин //
Математическое моделирование. - 2005. - Том 17, № 11. - С. 118-128.
Голуб, Дж. Матричные
вычисления [Текст]/Дж. Голуб, Ч. Ван Лоун. - М.: Мир, 1999. - 548 с.
Бахвалов, Н.С. Численные
методы [Текст]: учебное пособие для физмат. специальностей вузов/Н.С. Бахвалов,
Н.П. Жидков, Г.М. Кобельков. - М.: Физматлит, 2002. - 630 с.
Головашкин, Д.Л.
Параллельные алгоритмы метода циклической прогонки [Текст]/Д.Л. Головашкин,
М.В. Филатов//Компьютерная Оптика. - ИСОИ РАН, Самараю - 2005. - вып. 27. - С.
123-130.
Приложение
Исходный код программы
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <vector>
#include "CTimer.h"
#include <time.h>
#define M (500)
#define N (1024)
#define K (0)
#define D (0)
__global__ void reduction( float *a, float *b,
float *c,float *f) { thread = (blockIdx.x/int(pow(2.0, D)))*N*int(pow(2.0, D))+threadIdx.x+1;block
= blockIdx.x/int(pow(2.0, D));(int i=0; i<K; i++) { min = thread-pow(2.0,
i);max = thread+pow(2.0, i);(min<block*N*int(pow(2.0, D))+1)
min=0;(max>(block+1)*N*int(pow(2.0, D))) max=0;
float alfa=-a[thread]/b[min];
float betta=-c[thread]/b[max];
float zn0=alfa*a[min];
float zn2=betta*c[max];
float zn3=f[thread]+alfa*f[min]+betta*f[max];
__threadfence();[thread]=zn0;
b[thread]=zn1;
c[thread]=zn2;
f[thread]=zn3;
}
__syncthreads();
}
__global__ void sweep( float *a, float *b, float
*c, float *f, float *test, int shareDim) { temp[N*M];block =
blockIdx.x;first=(block/int(pow(2.0, K)))*N+(block%int(pow(2.0, K))+1);xDim =
N/int(pow(2.0, K));redDim = int(pow(2.0, K));(int i=0; i<xDim; i++){next =
first+i*redDim;[i]=a[next];[i+xDim ]=b[next];[i+2*xDim ]=c[next];[i+3*xDim
]=f[next];
}[xDim*4]=-temp[2*xDim]/temp[xDim];[xDim*4+xDim-1]=temp[3*xDim]/temp[xDim];(int
i=1; i<xDim-1;
i++){[xDim*4+i]=-temp[2*xDim+i]/(temp[i]*temp[xDim*4+i-1]+temp[xDim+i]);[xDim*4+xDim-1+i]=(temp[3*xDim+i]-temp[i]*temp[xDim*4+xDim-1+i-1])/(temp[i]*temp[xDim*4+i-1]+temp[xDim+i]);
} i
=xDim-1;[i]=(temp[3*xDim+i]-temp[i]*temp[xDim*4+xDim-1+i-1])/(temp[i]*temp[xDim*4+i-1]+temp[xDim+i]);(int
i=xDim-2; i>-1; i--){[i]=temp[i+1]*temp[xDim*4+i-1+1]+temp[xDim*4+xDim-1+i-1+1];
}(block==0){(int i=0; i< shareDim; i++) {
[i]=temp[i];
}
}();
}main(void){Time;Time1;shareDim = N/int(pow(2.0,
K))*4+(N/int(pow(2.0, K))-1)*2;* a = (float*)malloc((M*N+1)*sizeof(float));* b
= (float*)malloc((M*N+1)*sizeof(float));* c =
(float*)malloc((M*N+1)*sizeof(float));* f =
(float*)malloc((M*N+1)*sizeof(float));* test =
(float*)malloc((M*N)*sizeof(float));[0]=0; b[0]=1; c[0]=0; f[0]=0;(int i=1;
i<N*M+1; i++){[i]=(rand()%5 + 1);
}(int i=1; i<N*M+1; i++){[i]=(rand()%9 + 10);
}(int i=1; i<N*M+1; i++){[i]=(rand()%5 + 1);
}(int i=1; i<N*M+1; i++){[i]=(rand()%9 + 1);
}(int i=0; i<M; i++){[1+i*N]=0; c[N+i*N]=0;
} * a1 = (float*)malloc((M*N)*sizeof(float));*
b1 = (float*)malloc((M*N)*sizeof(float));* c1 = (float*)malloc((M*N)*sizeof(float));*
f1 = (float*)malloc((M*N)*sizeof(float));(int i=1; i<N*M+1; i++) {
[i-1]=a[i];[i-1]=c[i];[i-1]=b[i];[i-1]=f[i];
}
//cudaEvent_t start3, stop3;
//cudaEventCreate (&start3);
//cudaEventCreate (&stop3);*dev_a, *dev_b,
*dev_c, *dev_f, *dev_test;((void**) &dev_test,
(M*N)*sizeof(float));(dev_test,
test,(M*N)*sizeof(float),cudaMemcpyHostToDevice);((void**) &dev_a,
(N*M+1)*sizeof(float));((void**) &dev_b, (N*M+1)*sizeof(float));((void**)
&dev_c, (N*M+1)*sizeof(float));((void**) &dev_f,
(N*M+1)*sizeof(float));(dev_a,
a,(N*M+1)*sizeof(float),cudaMemcpyHostToDevice);(dev_b,
b,(N*M+1)*sizeof(float),cudaMemcpyHostToDevice);(dev_c,
c,(N*M+1)*sizeof(float),cudaMemcpyHostToDevice);(dev_f,
f,(N*M+1)*sizeof(float),cudaMemcpyHostToDevice);<<<M,N/int(pow(2.0,
D))>>>(dev_a, dev_b, dev_c, dev_f);.Start();<<<M*int(pow(2.0,
K)),1, shareDim*sizeof(float)>>>(dev_a, dev_b, dev_c, dev_f, dev_test,
shareDim);();.End();(test,
dev_test,(shareDim)*sizeof(float),cudaMemcpyDeviceToHost);(a,
dev_a,(N*M+1)*sizeof(float),cudaMemcpyDeviceToHost);(b,
dev_b,(N*M+1)*sizeof(float),cudaMemcpyDeviceToHost);(c,
dev_c,(N*M+1)*sizeof(float),cudaMemcpyDeviceToHost);(f,
dev_f,(N*M+1)*sizeof(float),cudaMemcpyDeviceToHost);
printf("%lf
",test[0]);("\n");("----------------------\n");* x1 =
(float*)malloc((N*M)*sizeof(float));* alfa =
(float*)malloc((N-1)*sizeof(float));* betta =
(float*)malloc((N-1)*sizeof(float));.Start();(int flag=0; flag<M;
flag++){[0]=-c1[flag*N]/b1[flag*N];[0]=f1[flag*N]/b1[flag*N];(int j=1; j<N-1;
j++){[j]=-c1[flag*N+j]/(alfa[+j-1]*a1[flag*N+j]+b1[flag*N+j]);[j]=(f1[flag*N+j]-a1[flag*N+j]*betta[j-1])/(alfa[j-1]*a1[flag*N+j]+b1[flag*N+j]);
}j=N-1;[flag*N+j]=(f1[flag*N+j]-a1[flag*N+j]*betta[j-1])/(alfa[j-1]*a1[flag*N+j]+b1[flag*N+j]);(int
i=N-2; i>-1; i--)[flag*N+i]=alfa[i]*x1[flag*N+i+1]+betta[i];
}.End();
//-----------------------------------------------------------------------
/*("\n");(int i=0; i<N/2; i++){
printf("%lf---%lf "
,x1[i*2],test[i]);("\n");
}
*/("---------\n");("\n");::cout
<< Time.GetTimeInSeconds() << " seconds" <<
std::endl;("\n");::cout << Time1.GetTimeInSeconds() <<
" seconds" << std::endl;("\n");("%lf "
,Time1.GetTimeInSeconds()/Time.GetTimeInSeconds());
//printf(" ### Total CPU
time:\t%.6f\n\n", 1.0*ev_time/CLOCKS_PER_SEC);(a);(b);(c);(f);(a1);(b1);(c1);(f1);(test);(x1);(alfa);(betta);("pause");
}