Работа с регулярными выражениями
ВВЕДЕНИЕ
регулярный алгебраический программа
Регулярные выражения (РВ) - это очень удобная форма записи так называемых
регулярных или автоматных языков. Поэтому РВ используются в качестве входного
языка во многих системах, обрабатывающих цепочки.
В
замкнутом полукольце всех
языков в алфавите
всех
языков в алфавите 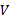 рассмотрим
подалгебру, порожденную множеством, которое состоит из пустого языка, языка
рассмотрим
подалгебру, порожденную множеством, которое состоит из пустого языка, языка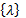 , всех
языков
, всех
языков  (каждый
из которых содержит единственную однобуквенную цепочку), и замкнутую
относительно итерации. Эта подалгебра, обозначаемая
(каждый
из которых содержит единственную однобуквенную цепочку), и замкнутую
относительно итерации. Эта подалгебра, обозначаемая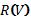 , есть
полукольцо с итерацией. Оно играет важнейшую роль в теории формальных языков.
Его называют полукольцом регулярных языков.
, есть
полукольцо с итерацией. Оно играет важнейшую роль в теории формальных языков.
Его называют полукольцом регулярных языков.
Алгебраические
операции над регулярными языками удобно представлять с помощью, так называемых
регулярных выражений. Каждое регулярное выражение представляет (или обозначает)
некоторый регулярный язык.
Конечный
автомат (КА) - это преобразователь, который позволяет сопоставить входу
соответствующий выход, причем выход этот может зависеть не только от текущего
входа, но и от того, что происходило раньше, от предыстории работы конечного
автомата.
1. ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
.1 Операторы
регулярных выражений
Как говорилось выше: регулярные выражений обозначают (задают, или
представляют) языки. В качестве примера рассмотрим регулярное выражений 01* +
10*. Оно определяет язык всех цепочек, состоящих либо из одного нуля, за
которым следует любое количество единиц, либо из одной единицы, за которой
следует произвольное количество нулей.
Существуют три операции над языками, соответствующими операторам
регулярных выражений:
. Объединение двух языков L и M, обозначаемое L M - это множество цепочек, которые содержатся либо в L, либо в M, либо в обоих языках.
M - это множество цепочек, которые содержатся либо в L, либо в M, либо в обоих языках.
. Конкатенация языков L и M - множество цепочек, которые можно
образовать путем дописывания к любой цепочке из K любой цепочки из M. Например, если L =
{001, 10, 111} и M
= {ε, 001}, то L.M, или просто LM -
это {001,10,111, 001001, 10001, 111001}. Первые три цепочки в LM - это цепочки из L, соединенные с ε.
Поскольку ε
является единицей
(нейтральным элементом) для операции конкатенации, результирующие цепочки,
будут такими же, как и цепочки из L.
. Итерация (“звездочка”, или замыкание Клини) языка L обозначается L* и представляет собой множество всех
тех цепочек, которые можно образовать путем конкатенации любого количества
цепочек из L. При этом допускаются повторения,
т.е. одна и та же цепочка из L
может быть выбрана для конкатенации более одного раза. Например, если L = {0,1}, то L* - это все цепочки, состоящие из нулей и единиц. Если L = {0,11}, то в L* входят цепочки из нулей и единиц,
содержащие четное количество единиц, например 011, 11110, ε.
1.2 Построение регулярных выражений
Все алгебры начинаются с некоторых элементарных выражений. Обычно это
константы и/или переменные. Применяя определенный набор операторов к этим
элементарным выражений и уже построенным выражениям, можно конструировать более
сложные выражения. Обычно необходимо так же иметь некоторые методы
группирования операторов и операндов, например, с помощью скобок.
Алгебра
регулярных выражений строится по такой же схеме: используются константы и
переменные для обозначения языков и операторы для обозначения трёх операций из
раздела 1.1. Регулярные выражения можно определить рекурсивно. В этом
определении не только характеризуются правильные регулярные выражения, но и для
каждого регулярного выражения  описывается
представленный им язык, который обозначается через
описывается
представленный им язык, который обозначается через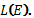
Базис
состоит из трех частей:
.
Константы ε
и Ø Являются регулярными выражениями, определяющими языки {ε} и Ø, соответственно,
т.е. .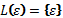 и
и 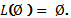
.
Если 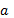 -
произвольный символ, то -
регулярное выражение, определяющее язык
-
произвольный символ, то -
регулярное выражение, определяющее язык . Т.е.
. Т.е. 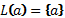 .
.
.
Переменная, обозначенная прописной курсивной буквой, например, 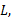 представляет
произвольный язык.
представляет
произвольный язык.
1.3
Лексический анализ
Одним из наиболее ранних применений регулярных выражений было
использование их для спецификации компонента компилятора, называемого
“лексическим анализатором”. Этот компонент сканирует исходную программу и
распознает все лексемы, т.е. подцепочки последовательных символов, логически
составляющие единое целое. Типичными примерами лексем являются ключевые слова и
идентификаторы, но существует и множество других примеров.
Unix-команда
lex и ее GNU-версия flex
получают на вход список регулярных выражений в стиле UNIX, за каждым из которых в фигурных скобках следует код,
указывающий, что должен делать лексический анализатор, если найдет экземпляр
такой лексемы. Такая система называется генератором лексического анализатора,
поскольку на ее вход поступает высокоуровневое описание лексического
анализатора и по этому описанию она создает функцию, которая представляет собой
работающий лексический анализатор.
Такие команды, как lex и flex, оказались очень удобными, поскольку
мощность нотации регулярных выражений необходима и достаточна для описания
лексем. Эти команды способны использовать процедуру преобразования регулярного
выражения в детерминированный конечный автомат для того чтобы генерировать
эффективную функцию, разбивающую исходную программу на лексемы. Они превращают
задачу построения лексического анализатора в “послеобеденную работу”, тогда как
создания этих основанных на регулярных выражениях средств построение
лексического анализатора вручную могло занимать несколько месяцев. Кроме того,
если по какой-либо причине возникает необходимость модифицировать лексический
анализатор, то намного проще изменить одно или два регулярных выражения, чем
забираться внутрь загадочного когда, чтобы исправить дефект.
Общая проблема, для решения которой технология регулярных выражений
оказалась весьма полезной, заключается в описании нечетко определенного класса образцов
в тексте. Нечеткость описания, в сущности, является гарантией того, что с
самого начала нет нужды корректно и полно описывать образцы. Не исключено, что
мы никогда не сможем получить точное и полное описание. С помощью регулярных
выражений можно не прилагая больших усилий, описывать такие образцы и быстро
изменять эти описания, если результат нас не устраивает. Кроме того,
“компилятор” для регулярных выражений годен и для преобразования записываемых
выражений в выполнимый код.
2.2
Постановка задачи и выбор среды разработки
Для того, чтобы закрепить усвоенные знания необходимо на практике
продемонстрировать работу регулярных выражений. Как было сказано пунктом выше,
основным применение регулярных выражений связано с поиском в тексте образцов
или шаблонов. Например, данная технология может использоваться в web-сервисах: предположим, из текста
необходимо извлечь данные о логинах пользователей некого сайта, записанных в
определенном формате. Данный формат, можно использовать как шаблон или образец,
и с помощью регулярных выражений, извлечь сведения о пользователях не составит
труда.
После того, как задача была сформулирована, необходимо определиться с
наиболее подходящей средой разработки. Данную задачу, можно интерпретировать
как построение конечного автомата, для распознавания регулярных выражений. С
данной точки зрения, наиболее всего подходят среды разработки C/C++. Данные IDE
предпочтительнее в силу того, что обладают всеми необходимыми средствами для
решения поставленной задачи. Для C++
существует собрание библиотек, которое расширяет функциональность данного
языка, в частности boost/regex имеет всю необходимую
функциональность для фильтрации, поиска, разбора и обработки текста.
2.3
Тестирование и отладка программы
Для того чтобы проверить правильность работы программы и оправдать выбор
среды разработки, необходимо провести тестирование программы. Как говорилось
при постановке задачи, программа будет извлекать из текста данные по некоторому
шаблону. Для примера, создадим программу, которая будет проверять текст, и в
случае если найдет конструкцию .regtest,
будет извлекать слово, написанное перед точкой.
Ниже представлен скриншот выполнения работы программы reg1.cpp. Данная программа будет проверять строку “one.regtesttwothree”.
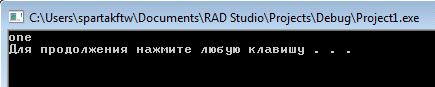
Рисунок 1. Результат работы программы reg1.cpp
Данная программа работает не совсем корректно, точнее не совсем по тому
плану, который был поставлен в постановке задачи. Если предоставить программе
на проверку строку вроде “onetwo.regtestthree”, то результат будет следующим.

Рисунок 2. Тестирование reg1.cpp
Как видно из рис. 2, программа извлекла весь текст строки, написанный до
.regtest, а по условию необходимо было
извлечь лишь одно слово перед .regtest.
Поэтому данная программа работает не совсем корректно. Для того, чтобы
полностью удовлетворить требованиям к задаче, была разработана вторая версия
программы - reg2.cpp.
Предоставим reg2.cpp строку “onetwo.regtestthree”
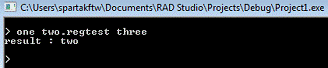
Рисунок 3. Результат работы reg2.cpp
Программа корректно обработала данную строку и вывела необходимые данные.
Попробуем усложнить задачу, и введем строку “testmy.regtestprogramplease.regtest”.

Рисунок 4. Тестирование reg2.cpp
Как видно из рис.4 программа reg2.cpp корректно обрабатывает исходные
данные, и извлекает необходимую информацию.
В ходе тестирования приложений reg1.cpp и reg2.cpp
было установлено, что оба приложения работают корректно, однако программа reg2.cpp наиболее точно выполняет указанные требования в
постановке задачи. Листинги обеих программ можно найти в приложениях А и Б.
2.4 Возможная
модификация приложений
В качестве возможного изменения и модификации программ reg1.cpp и reg2.cpp можно рассмотреть работу
непосредственно с файлами, для более удобного предоставления результата. Так же
возможно создание более удобного и дружелюбного интерфейса для работы с
пользователем.
ЗАКЛЮЧЕНИЕ
В ходе выполнения данной работы, были рассмотрены основные принципы
работы с регулярными выражениями, а также способы их построения.
Регулярные выражения подчиняются многим алгебраическим законам арифметики,
хотя есть и различия. Объединение и конкатенация ассоциативны, но только
объединение коммутативно Конкатенация дистрибутивна относительно объединения.
Объединение идемпотентно.
Также были разработаны две программы на основе регулярных выражений, для
поиска в тексте необходимой информации. Данные приложения были протестированные
и проверены на правильность функционирования.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Хопкрофт, Д. Введение в теорию автоматов, языков и
вычислений, 2-е изд. / Д. Хопкрофт, Э. Мотвани, Р. Ульман - М.: Издательский
дом “Вильямс”, 2002. - 528 с.
. СТО ЮУрГУ 04-2008 Стандарт организации. Курсовое и
дипломное проектирование. Общие требования к содержанию и оформлению /
составители: Т.И. Парубочая, Н.В. Сырейщикова, В.И. Гузеев, Л.В. Винокурова. -
Челябинск: Изд-во ЮУрГУ, 2008. - 56 с.
. Молчанов, А.Ю. Системное программное обеспечение: Учебник
для вузов / А.Ю. Молчанов. - СПб.: Питер, 2006. - 396 с.
ПРИЛОЖЕНИЯ
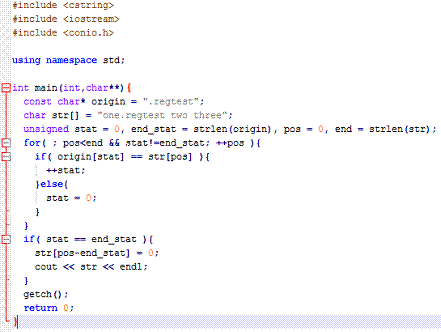
Приложение А
Листинг
программы reg1.cpp
Приложение Б
Листинг
программы reg2.cpp
