Java: Русские буквы и не только…
Java: Русские буквы и не только...
Введение
Некоторые
проблемы настолько сложны, что нужно быть очень умным и очень хорошо
информированным, чтобы не быть уверенным в их решении.
Лоренс
Дж. Питер
Peter's Almanac
Кодировки
Когда
я только начинал программировать на языке C, первой моей программой (не считая
HelloWorld) была программа перекодировки текстовых файлов из основной кодировки
ГОСТ-а (помните такую? :-) в альтернативную. Было это в далёком 1991-ом году. С
тех пор многое изменилось, но за прошедшие 10 лет подобные программки свою
актуальность, к сожалению, не потеряли. Слишком много уже накоплено данных в
разнообразных кодировках и слишком много используется программ, которые умеют
работать только с одной. Для русского языка существует не менее десятка
различных кодировок, что делает проблему ещё более запутанной.
Откуда
же взялись все эти кодировки и для чего они нужны? Компьютеры по своей природе
могут работать только с числами. Для того чтобы хранить буквы в памяти
компьютера надо поставить в соответствие каждой букве некое число (примерно
такой же принцип использовался и до появления компьютеров - вспомните про ту же
азбуку Морзе). Причём число желательно поменьше - чем меньше двоичных разрядов
будет задействовано, тем эффективнее можно будет использовать память. Вот это
соответствие набора символов и чисел собственно и есть кодировка. Желание любой
ценой сэкономить память, а так же разобщённость разных групп компьютерщиков и
привела к нынешнему положению дел. Самым распространённым способом кодирования
сейчас является использование для одного символа одного байта (8 бит), что
определяет общее кол-во символов в 256. Набор первых 128 символов
стандартизован (набор ASCII) и является одинаковыми во всех распространённых
кодировках (те кодировки, где это не так уже практически вышли из
употребления). Англицкие буковки и символы пунктуации находятся в этом
диапазоне, что и определяет их поразительную живучесть в компьютерных системах
:-). Другие языки находятся не в столь счастливом положении - им всем
приходится ютиться в оставшихся 128 числах.
Unicode
В
конце 80-х многие осознали необходимость создания единого стандарта на
кодирование символов, что и привело к появлению Unicode. Unicode - это попытка
раз и навсегда зафиксировать конкретное число за конкретным символом. Понятно,
что в 256 символов тут не уложишься при всём желании. Довольно долгое время
казалось, что уж 2-х то байт (65536 символов) должно хватить. Ан нет -
последняя версия стандарта Unicode (3.1) определяет уже 94140 символов. Для
такого кол-ва символов, наверное, уже придётся использовать 4 байта (4294967296
символов). Может быть и хватит на некоторое время... :-)
В
набор символов Unicode входят всевозможные буквы со всякими чёрточками и
припендюльками, греческие, математические, иероглифы, символы псевдографики и
пр. и пр. В том числе и так любимые нами символы кириллицы (диапазон значений
0x0400-0x04ff). Так что с этой стороны никакой дискриминации нет.
Если
Вам интересны конкретные кода символов, для их просмотра удобно использовать
программу "Таблица символов" из WinNT. Вот, например, диапазон
кириллицы:
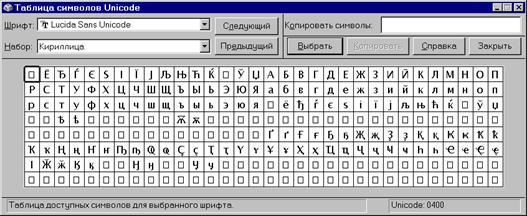
Если
у Вас другая OS или Вас интересует официальное толкование, то полную раскладку
символов (charts) можно найти на официальном сайте Unicode
(#"#">http://people.comita.spb.ru/