Автоматизация преобразования структурированных данных в корпоративном правовом портале
Министерство образования Республики
Беларусь
Учреждение образования
"Гомельский государственный
университет имени Франциска Скорины"
Физический факультет
Кафедра автоматизированных систем
обработки информации
Автоматизация преобразования
структурированных данных в корпоративном правовом портале
Дипломный проект
Исполнитель: студент группы Ф-57 Ходьков Е.И.
Научный руководитель: ассистент кафедры АСОИ
Говорушкина Н.А.
Гомель, 2012
Содержание
Введение
1. Описание технических и программных требований
1.1 Постановка задачи
1.2 Структура разрабатываемого приложения
1.3 Основные рабочие процессы в проектируемом продукте
2. Выбор технологий реализации web-приложения
2.1 Общие сведения об используемых технологиях
3. Проектирование и создание исходных данных
3.1 Написание необходимой документации
3.2 Реализация процессинговой части Web-приложения
3.3 Примеры выходных данных и работа с системой
Заключение
Список использованных источников
Приложения
Введение
В настоящее время пользователи сети Интернет нуждаются в
быстром и качественном доступе к юридической информации. Большинство
существующих ресурсов не могут предложить полноценный функционал, который бы
отвечал требованиям унифицированного представления данных.
Целью дипломного проекта являлась разработка системы
автоматизации преобразования структурированных данных в корпоративном правовом
портале. В процессе достижения цели в дипломном проекте решались следующие
задачи: выбор программных средств реализации проекта, ознакомление с предметной
областью, определение проблемы и выработка требований, разработка проекта
приложения, реализация приложения, оформление сопроводительной документации.
Разработанный программный комплекс позволяет решить данную
проблему, предоставить пользователю сайта возможность получить необходимые ему
правовые документы в понятной, доступной форме с возможностью выбора формата
представления данных. Организация поддержки различных типов информации
юридического характера, хранящейся в виде структурированных данных, форматирование
конечных документов в зависимости от их типа, легкая навигация в рамках
создаваемой системы - все эти черты нашли отражение в процессе разработки
дипломного проекта.
Основное преимущество автоматизации - это сокращение
избыточности хранимых данных, и, следовательно, экономия объема используемой
памяти, устранение возможности возникновения противоречий из-за хранения в
разных местах сведений об одном и том же объекте, увеличение степени
достоверности информации и увеличение скорости обработки информации; излишнее
количество внутренних промежуточных документов.
приложение портал программное средство
В первой главе была четко поставлена задача для дипломного
проекта, выполнен поиск оптимального пути ее решения, а также выделены основные
рабочие процессы в разрабатываемом продукте.
Во второй главе обосновывается выбор и подробное описание
технических и программных средств, необходимых для решения поставленной задачи,
их особенности, основные преимущества. Предпочтение было отдано использованию
локального сервера, на базе которого будет построено бизнес-приложение. В нем
найдут применение различные технологии, основной упор сделан на следующие языки
разметки и трансформации: XSLT, XSL-FO, XML, HTML, CSS.
Третья глава содержит информацию о функционировании уже готового
программного продукта, описание основных особенностей автоматизированного
комплекса и руководство пользователя по работе с ним.
1. Описание
технических и программных требований
1.1
Постановка задачи
Главной задачей дипломного проекта являлась разработка
бизнес-приложения, которое сможет извлекать необходимую информацию,
представленную в виде структурированных данных, и с помощью дальнейшего
форматирования с применением специализированных языков трансформации
представлять эти данные пользователю системы. Приложение должно удовлетворять
ряду условий:
для функционирования системы требуется наличие локального
сервера, который способен не только обеспечивать обработку действий
пользователя, но и поддерживать функции интерпретации языков XSLT и XSL-FO;
исходные данные должны быть структурированы (формат XML), иметь одинаковую
сущность и единообразное форматирование ввиду четких и строгих требований,
предъявляемых к информации юридического характера;
информация должна представляться конечному пользователю в
нескольких видах - в формате гипертекста, а также в текстовом и PDF-формате, причем их
внешний вид должен быть максимально идентичным;
приложение должно предоставлять пользователю возможность
переходить по различным разделам сайта и получать интересующую его информацию в
любом доступном виде;
приложение должно предоставлять пользователю возможность
вручную изменять путь к необходимым файлам, если это необходимо;
пользователь должен иметь возможность распечатать информацию
или переслать ее по электронной почте.
1.2 Структура
разрабатываемого приложения
Юридическая информация должна быть представлена в строгом
виде. Любые законодательные акты и другие правовые документы должны
отображаться в строгом соответствии с требованиями, предъявляемыми к ним. В
этой связи появляется необходимость введения унификации исходных данных,
используемых для последующего отображения пользователю. Использование
структурированного типа данных позволяет использовать единый подход к хранению,
пересылке информации и ее визуальному отображению. Иерархическая система
структурированных данных позволяет легко получить доступ к любому необходимому
элементу, получить его содержимое и в результате форматирования вывести на
экран. Схема работы такой системы приведена на рисунке 1.
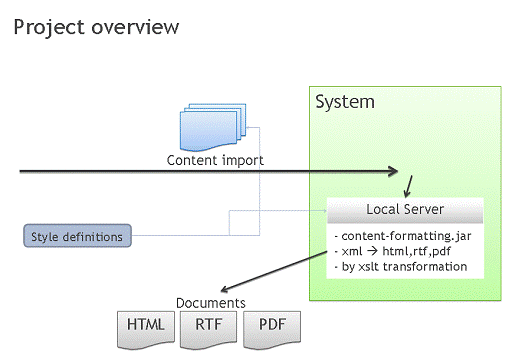
Рисунок 1 - Принцип работы веб-приложения
Таким образом, мы видим, что данные независимы от системы и
могут изменяться. Также может подвергаться изменению и сама структура файлов,
что потребует внесения изменений в обработчик исходных файлов. Пользователь
может получить доступ к сайту при помощи двух способов. Первый - обращение
через локальный сервер, предназначенный для аутентификации. После ввода логина
и пароля (если они верны) сервер генерирует токен (уникальная последовательность
цифр и букв в нашем случае) и затем при помощи Access API обращается к удаленному
серверу платформы для вставки сгенерированного токена. Для этого необходимо
использование надежного и защищенного локального сервера, который одновременно
будет выполнять функцию парсера для исходного контента. Затем пользователь
перенаправляется на часть сайта платформы, доступную для всех пользователей,
где происходит проверка токена из базы с токеном в GET-параметре запроса. И в
зависимости от полученного результата пользователю выдается список доступных
правовых документов или страница с сообщением об ошибке аутентификации. Второй
способ - получение письма с заранее сгенерированной ссылкой, в которой уже
прописан токен. Письмо может быть отправлено после перехода запроса на страницу
с документом в новое состояние. Также пользователи могут инициировать начало
процесса отправкой письма на заранее известный адрес. После перехода и
идентификации на публичной части платформы пользователь может совершить
разрешенные ему действия.
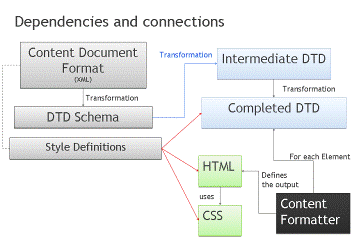
Рисунок 2 - Схема процесса отображения документа на сайте
Далее можно определить основные моменты жизненного цикла
любого документа, который доступен пользователю веб-приложения (рисунок 2).
Необходимая пользователю юридическая информация хранится в виде набора
структурированных данных в заранее определенном формате, например XML. Каждый файл в заданно
формате должен строго соответствовать определенному набору правил, что в данном
случае регулируется наличием DTD-схемы, которая отвечает за проверку корректности
структуры исходного документа. Общее содержание отдельных элементов исходного
файла также регламентируется задокументированным набором стилистических
требований, которые затем находят применения при конечном отображении
документов (рисунок 3). Ввиду существования различных видов правовых актов,
законов и иных документов к одним и тем же структурным элементов таких данных
ним могут применяться отличные друг от друга стилистические требования, что
требует разделения форматирования документов, относящихся к разным юридическим
группам.
Если же взглянуть на систему с точки зрения разработчика, то
он увидит ее подобным образом, как представлено на рисунке 4. Если заказчик
требует внесения определенных изменения, он формирует ряд запросов. Затем
выясняется, каким образом их лучше всего разрешить - со стороны исходных данных
или их обработчика. Для тестирования предлагаемых решений используется
локальный сервер. Если варианты устранения проблемы проходят успешную апробацию,
то выпускается новая версия системы.

Рисунок 3 - Применения форматирования к исходным данным
Гибкая методология разработки программного обеспечения
позволяет успешно вести разработку как небольших, так и средних проектов и
реализации их в рамках единой сети правовых порталов. Система реализует
фундамент для отображения любой юридической информации, позволяет описывать
требования любого уровня, планировать состав документов и реализовывать их
обработку.
Вся информация по процессу разработки доступна в одном месте,
в связи с чем существенно упрощается контроль процесса разработки участниками
проекта, заказчик также может контролировать процесс разработки или даже
принимать в нем участие в части формирования пожеланий и управления
приоритетами реализации или исправления ошибок.
Вы можете работать над проектом в любое время суток, в любом
удобном для вас месте, где есть интернет, вся информация по проекту, артефакты
и сведения по ходу его выполнения у вас всегда будут под рукой. Не нужно
пересылать или переносить документы с одного компьютера на другой. Используемая
система управления процессом разработки повышает степень контролируемости
разработки, что является одним из важных критериев для заказчика, повышает его
уверенность в успехе выполнения проекта.
Система реализована в форме Web-приложения. Не нужно
устанавливать какое-либо приложение, заниматься дополнительным
администрированием и безопасностью. Все что нужно пользователю - это
Web-браузер и доступ в интернет.
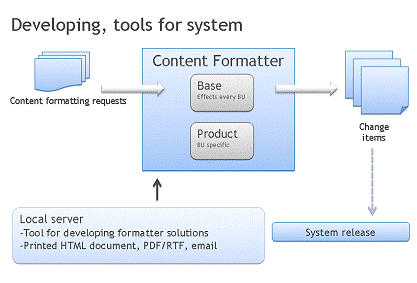
Рисунок 4 - Схема отладки системы
1.3 Основные
рабочие процессы в проектируемом продукте
Основными рабочими процессами являются: переход по меню
доступных документов, выбор отображаемого документа, выбор формата отображаемого
документа. Стоит заметить, что при работе с первым процессом область страницы,
в которой визуализируется документ, не изменяется до тех пор, пока пользователь
не выбрал информацию для отображения. Также следует добавить, что пользователь
всегда будет получать отформатированные данные в HTML-формате. Если же он
захочет сохранить данные в формате PDF или RTF, для этого на странице присутствуют
соответствующие ссылки (рисунок 5).
Enter the system. Пользователь открывает
стартовую страницу проекта. Перед ним - древовидная структура документов.
Select the doc. Выбрав ту или иную
категорию юридических документов пользователь может далее определить, какой
конкретно документ ему нужно открыть для дальнейшего изучения.
HTML View. После выбора документа через
меню он отображается в соответствующей панели интернет-страницы в HTML-формате. В этот момент,
после нажатия на ссылку, происходит обращения системы к серверу, он ссылается
на документ, к которому желает получить доступ пользователь. Поскольку он хранится
в XML-формате, происходит
динамическое преобразование с помощью внутренних ресурсов, созданных
разработчиком. На выходе пользователь получает лишь конечный HTML-код, который с помощью
браузера и CSS-файла с таблицами стилей представлен в наиболее удобном для
изучения виде.
PDF View. Из режима просмотра HTML-документа пользователь
может получить его в формате PDF при переходе по соответствующей ссылке.
RTF View. Из режима просмотра HTML-документа пользователь
может получить его в формате RTF при переходе по соответствующей ссылке.

Рисунок 5 - Общий процесс обращения пользователя к документу
2. Выбор
технологий реализации web-приложения
2.1 Общие
сведения об используемых технологиях
Для наиболее быстрого и эффективного решения поставленной
задачи необходимо выбрать подходящий сервис для бизнес-приложения.
Также понадобится локальный сервер, который будет отвечать за
аутентификацию пользователей. Это позволит снизить затраты, связанные с
покупкой лицензий.
На сервере для аутентификации предполагается использование
небольшого web-приложения, которое будет отвечать за авторизацию пользователей
(ранее зарегистрированных в системе) и перенаправление их на сайт сервиса
облачных вычислений. Также он будет удаленно создавать токены, которые будут в
дальнейшем использоваться для идентификации пользователей.
Для решения задач на стороне локального сервера было решено
использовать такие технологии, как Java, J2EE, MySQL, а также другие языки для front-end части.-
объектно-ориентированный язык программирования, разработанный компанией Sun
Microsystems (в последующем, приобретённой компанией Oracle). Приложения Java
обычно компилируются в специальный байт-код, поэтому они могут работать на
любой виртуальной Java-машине (JVM) независимо от компьютерной архитектуры.Platform,
Enterprise Edition, сокращенно Java EE (до версии 5.0 - Java 2 Enterprise
Edition или J2EE) - набор спецификаций и соответствующей документации для языка
Java, описывающей архитектуру серверной платформы для задач средних и крупных
предприятий.
Спецификации детализированы настолько, чтобы обеспечить
переносимость программ с одной реализации платформы на другую. Основная цель
спецификаций - обеспечить масштабируемость приложений и целостность данных во
время работы системы. J2EE во многом ориентирована на использование её через
веб как в интернете, так и в локальных сетях. Вся спецификация создаётся и
утверждается через JCP (Java Community Process) в рамках инициативы Sun
Microsystems Inc.EE является промышленной технологией и в основном используется
в высокопроизводительных проектах, в которых необходима надежность,
масштабируемость, гибкость.
Для функционирования системы в качестве локального сервера
был выбран Apache Cocoon, не только предоставляющий полноценный инструментарий для
реализации проекта, но и одновременно являющийся процессором, поддерживающим
языки трансформации исходных данных.
Сами исходные данные в виду необходимости их
структурированного представления будут храниться в XML формате и проверяться на
соответствии заданной разработчиком с учетом требований заказчика DTD схеме.
Для трансформации данных были выбраны языки XSLT и XSL-FO, которые позволяют
представить информацию, извлеченную из структурированных данных и представить
ее в форматах HTML и PDF (RTF) соответственно.
При выводе информации в формате HTML потребуется
использование CSS стилей для более точного соответствия отображаемых данных
спецификации, предоставляемой заказчиком. Что касается PDF (RTF), то в них необходимое
форматирование задается на уровне языка XSL-FO.
Использование языков XSLT и XSL-FO в комбинации с
применением сервера Apache Cocoon позволяет реализовать функцию печати данных, а
также их пересылки по электронной почте и все это на уровне веб-приложения.
Сервер Apache Cocoon
Apache Cocoon, часто называемый просто Cocoon, - программный
каркас для разработки веб-приложений. Он ориентирован на использование XML и
построен с использованием языка программирования Java. Гибкость, завязанная на
использование XML, позволяет публиковать содержимое в различных форматах,
включая XML, PDF и WML. В частности, на основе данного программного каркаса
создана мощная система управления содержимым Apache Lenya. Cocoon также широко
используется как средство хранения данных, а также как промежуточное
программное обеспечение для передачи данных между системами.2 от Apache XML
Project является гибкой системой Web-публикации, в основе которой лежат
повторно используемые компоненты. Несмотря на то, что концепция многократного
использования компонент присутствует во многих системах, Cocoon выделяется
простотой интерфейсов взаимодействия компонент. Каждая компонента принимает на
вход и возвращает XML, и такой подход работает.2 является системой публикации
XML. Что же это на самом деле значит? Это не база данных, в которой хранятся
XML-данные, и не сервер приложений J2EE, который подготавливает контент для
web-сервера. Cocoon 2 архитектурно располагается на промежуточном уровне и
представляет собой среду обработки контента. Контент обрабатывается системой
компонент, структуру которой как раз и строит разработчик. Рассмотрим простой
пример. Предположим, к некоторому XML-документу, сохраненному в файле (file.
xml), применяется XSL-преобразование (stylesheet. xsl) для получения результата
в виде HTML. Система компонент Cocoon, соответствующая данной задачи, показана
на рисунке 6.
Любая система компонент начинается с генератора. На рисунке 5
генератор анализирует файл и создает поток событий SAX. Вторым элементом в
рассматриваемой системе компонент является XSL-процессор. В нашем случае,
процессор преобразований применяет XSL-преобразование (stylesheet. xsl) к
XML-документу, полученному от генератора. Результатом его также является
SAX-поток. На выходе системы находится сериализатор. Он прерывает поток и
выдает результата преобразования в качестве HTTP-ответа. Подобную трехуровневую
систему компонент можно применять для создания множества или даже всех страниц
разрабатываемого сайта. Этот пример может показаться слишком простым, поскольку
две компоненты из трех являются крайними компонентами, однако, он хорошо
иллюстрирует общую идею.

Рисунок 6 - Пример обработки исходного документа на сервере Cocoon
Главным преимуществом является то, что в исходном файле можно
явно выделить бизнес-логику документа. В данном случае мы никак не используем
JDBC API, напротив, контент исходного документа начинает отражать исходную
бизнес-задачу.2 состоит из трех основных компонент: первая - генератор, который
создает поток XML SAX. Этот поток может быть создан на основе файла из
локальной файловой системы, на основе XML-данных из базы данных или внешней
системы, или как-нибудь иначе. Вторая компонента - процессор преобразований,
который изменяет поток XML. В качестве этой компоненты могут использоваться
XSL, SQL, SOAP, LDAP или пользовательские процессоры.
Главное требование заключается в возможности обрабатывать
входящий поток XML и выводить также поток XML. В роли третьей компоненты
выступает сериализатор, который терминирует поток XML и создает физическую
репрезентацию контента в соответствующем формате. Таким форматом может быть не
только HTTP, но и любой графический формат, операция записи в локальный файл и
т.д.
XML как средство хранения структурированных данных
XML (англ. eXtensible Markup Language - расширяемый язык
разметки; произносится) - рекомендованный Консорциумом Всемирной паутины язык
разметки, фактически представляющий собой свод общих синтаксических правил. XML
- текстовый формат, предназначенный для хранения структурированных данных
(взамен существующих файлов баз данных), для обмена информацией между программами,
а также для создания на его основе более специализированных языков разметки
(например, XHTML). XML является упрощённым подмножеством языка SGML.
Правильно построенный документ соответствует всем общим
правилам синтаксиса XML, применимым к любому XML-документу. И если, например,
начальный тег не имеет соответствующего ему конечного тега, то это неправильно
построенный документ XML. Документ, который неправильно построен, не может
считаться документом XML; XML-процессор (парсер) не должен обрабатывать его
обычным образом и обязан классифицировать ситуацию как фатальная ошибка.
Действительный документ дополнительно соответствует некоторым
семантическим правилам. Это более строгая дополнительная проверка корректности
документа на соответствие заранее определённым, но уже внешним правилам, в
целях минимизации количества ошибок, например, структуры и состава данного,
конкретного документа или семейства документов. Эти правила могут быть
разработаны как самим пользователем, так и сторонними разработчиками, например,
разработчиками словарей или стандартов обмена данными. Обычно такие правила
хранятся в специальных файлах - схемах, где самым подробным образом описана
структура документа, все допустимые названия элементов, атрибутов и многое
другое. И если документ, например, содержит не определённое заранее в схемах
название элемента, то XML-документ считается недействительным; проверяющий
XML-процессор (валидатор) при проверке на соответствие правилам и схемам обязан
(по выбору пользователя) сообщить об ошибке.
Данные два понятия не имеют достаточно устоявшегося
стандартизированного перевода на русский язык, особенно понятие valid, которое
можно также перевести, как имеющий силу, правомерный, надёжный, годный, или
даже проверенный на соответствие правилам, стандартам, законам. Некоторые
программисты применяют в обиходе устоявшуюся кальку "Валидный".
Годом рождения XML можно считать 1996 год, в конце которого
появился черновой вариант спецификации языка, или 1998 год, когда эта
спецификация была утверждена. А началось всё с появления в 1986 году языка
SGML.(англ. Standard Generalized Markup Language - стандартный обобщённый язык
разметки) заявил о себе как гибкий, комплексный и всеохватывающий мета-язык для
создания языков разметки. Несмотря на то, что понятие гипертекста появилось в
1965 году, SGML не имеет гипертекстовой модели. Создание SGML можно с
уверенностью назвать попыткой объять необъятное, так как он объединяет в себе
такие возможности, которые крайне редко используются все вместе. В этом и
состоит его главный недостаток - сложность и, как следствие, дороговизна этого
языка ограничивает его использование только крупными компаниями, которые могут
позволить себе купить соответствующее программное обеспечение и нанять
высокооплачиваемых специалистов. Кроме того, у небольших компаний редко
возникают настолько сложные задачи, чтобы привлекать к их решению SGML.
Наиболее широко SGML применяется для создания других языков
разметки, именно с его помощью был создан язык разметки гипертекстовых
документов - HTML, спецификация которого была утверждена в 1992 году. Его
появление было связано с необходимостью организации стремительно
увеличивающегося массива документов в сети Интернет. Бурный рост количества
подключений к Интернету и, соответственно, веб-серверов повлек за собой такую
потребность в кодировке электронных документов, с которой не мог справиться
SGML вследствие высокой трудности освоения. Появление HTML - очень простого
языка разметки - быстро решило эту проблему: лёгкость в изучении и богатство
средств оформления документов сделали его самым популярным языком для
пользователей Интернет. Но, по мере роста количества и изменения качества
документов в Сети, росли и предъявляемые к ним требования, и простота HTML
превратилась в его главный недостаток. Ограниченность количества тегов и полное
безразличие к структуре документа побудили разработчиков в лице консорциума W3C
к созданию такого языка разметки, который был бы не столь сложен, как SGML, и
не настолько примитивен, как HTML. В результате на свет появился язык XML,
сочетающий в себе простоту HTML, логику разметки SGML и удовлетворяющий
требованиям Интернета.
Достоиства:
язык разметки, позволяющий стандартизировать вид
файлов-данных, используемых компьютерными программами, в виде текста, понятного
человеку;
поддерживает Юникод;
в формате XML могут быть описаны такие структуры данных, как
записи, списки и деревья;
это самодокументируемый формат, который описывает структуру и
имена полей так же как и значения полей;
имеет строго определённый синтаксис и требования к анализу,
что позволяет ему оставаться простым, эффективным и непротиворечивым.
Одновременно с этим, разные разработчики не ограничены в выборе экспрессивных
методов (например, можно моделировать данные, помещая значения в параметры
тегов или в тело тегов, можно использовать различные языки и нотации для
именования тегов и т.д.);
формат, основанный на международных стандартах;
иерархическая структура XML подходит для описания практически
любых типов документов, кроме аудио и видео мультимедийных потоков, растровых
изображений, сетевых структур данных и двоичных данных;
представляет собой простой текст, свободный от лицензирования
и каких-либо ограничений;
не зависит от платформы;
является подмножеством SGML (который используется с 1986
года). Уже накоплен большой опыт работы с языком и созданы специализированные
приложения;
не накладывает требований на порядок расположения атрибутов в
элементе и вложенных элементов разных типов, что существенно облегчает
выполнение требований обратной совместимости;
в отличие от бинарных форматов, XML содержит метаданные об
именах, типах и классах описываемых объектов, по которым приложение может
обработать документ неизвестной структуры (например, для динамического
построения интерфейсов);
имеет реализации парсеров для всех современных языков
программирования;
существует стандартный механизм преобразования XSLT,
реализации которого встроены в браузеры, операционные системы, веб-серверы;
поддерживается на низком аппаратном, микропрограммном и
программном уровнях в современных аппаратных решениях.
Регулирование структуры XML файла с помощью DTD-схемы
DTD (англ. Document Type Definition определение типа
документа) включает в себя два понятия. Термин, который используется для
описания схемы документа или его части языком схем DTD. Язык схем DTD (DTD
schema language) - искусственный язык, который используется для записи
фактических синтаксических правил метаязыков разметки текста SGML и XML. С
момента его внедрения другие языки схем для спецификаций, такие как XML Schema
и RELAX NG, выпускаются с дополнительной функциональностью.
Из-за определённых отличий между XML и SGML, применение DTD
также имеет некоторые особенности в зависимости от целевого документа.описывает
схему документа для конкретного языка разметки посредством набора объявлений
(объектов-параметров, элементов и атрибутов), которые описывают его класс (или
тип) с точки зрения синтаксических ограничений этого документа. Также DTD может
объявлять конструкции, которые всегда необходимы для определения структуры
документа, но, зато, могут влиять на интерпретацию определённых документов.
Объявление объекта-параметра определяет макрос определённого
типа, на который можно ссылаться и который может быть развернут где-нибудь в
DTD. Эти макросы могут не появляться в самом документе, а быть только в DTD.
Если на объект-параметр ссылаются по имени их DTD, то он разворачивается в
строку, в которой указано содержимое этого объекта.
Объявления элементов образовывают перечень разрешенных
названий элементов в документе, а также определяют информацию относительно
тегов (являются ли они обязательными) и модели содержимого для каждого
элемента. С каждым элементом DTD-документа можно сопоставить список атрибутов.
Для этого используется директива! ATTLIST, в которой указываются имя элемента,
с которым может быть сопоставлен список атрибутов и параметры каждого атрибута:
его имя, тип и свойства по умолчанию. Чтобы связать документ с определённым
DTD, необходимо в начале текста документа указать элемента Объявление Типа
Документа.
Языки трансформации XSLT и XSL-FO
XSLT (eXtensible Stylesheet Language Transformations) - язык преобразования XML-документов. Спецификация
XSLT входит в состав XSL и является рекомендацией W3C.
При применении таблицы стилей XSLT, состоящей из набора
шаблонов, к XML-документу (исходное дерево) образуется конечное дерево, которое
может быть сериализовано в виде XML-документа, XHTML-документа (только для XSLT
2.0), HTML-документа или простого текстового файла. Правила выбора (и, отчасти,
преобразования) данных из исходного дерева пишутся на языке запросов
XPath.имеет множество различных применений, в основном в области
web-программирования и генерации отчётов. Одной из задач, решаемых языком XSLT,
является отделение данных от их представления, как часть общей парадигмы MVC (англ.
Model-view-controller). Другой стандартной задачей является преобразование
XML-документов из одной XML-схемы в другую.разработан рабочей группой XSL
Консорциума Всемирной паутины.
Версия 1.0 была одобрена в качестве рекомендации 16 ноября
1999 года. После выхода первой версии начались работы над версией 1.1, но в
2001 году они были прекращены, а рабочая группа XSL присоединилась к рабочей
группе XQuery для совместной работы над XPath 2.0. Впоследствии XPath 2.0
послужил основой при разработке XSLT версии 2.0.
Версия 2.0 была одобрена в качестве рекомендации 23 января
2007 года. Несмотря на то, что версия 2.0 является последней, версия 1.0
продолжает использоваться очень широко. В простейшем случае XSLT-процессор
получает на входе два документа - входной XML-документ и таблицу стилей XSLT -
и создает на их основе выходной документ.
Язык XSLT является декларативным, а не процедурным. Вместо
определения последовательности исполняемых операторов, этот язык определяет
правила, которые будут применяться во время преобразования. Само преобразование
ведется по фиксированному алгоритму.
В первую очередь XSLT процессор разбирает файл преобразования
и строит XML дерево входного файла. Затем он ищет шаблон, который лучше всего
подходит для корневого узла и вычисляет содержимое найденного шаблона.
Инструкции в каждом шаблоне могут либо напрямую говорить XSLT процессору
"создай здесь такой-то тег", либо говорить "обработай другие
узлы по тому же правилу, что и корневой узел".
Более подробно этот алгоритм, в чём-то нетривиальный,
описывается ниже, хотя многие из его экзотических деталей опущены. Каждый
XSLT-процессор должен выполнить различные шаги для подготовки к трансформации.
Прочитать таблицу стилей XSLT с помощью XML-парсера и
перевести его содержимое в дерево узлов (дерево таблицы стилей), согласно
модели данных XPath. Синтаксические ошибки "времени компиляции"
определяются на этой стадии. Таблицы стилей могут быть модульными, поэтому все
включения (инструкции xsl: include, xsl: import) также будут обработаны на этой
стадии с целью объединить все шаблонные правила и иные элементы из других
таблиц стилей в единое дерево таблицы стилей.
Прочитать входные данные XML с помощью XML-парсера, перевести
его содержимое в дерево узлов (исходное дерево), согласно модели данных XPath.
XML-документ может ссылаться на другие XML-источники с помощью вызова функций
document (). Эти вызовы обычно обрабатываются во время выполнения, так как их
расположение может являться вычисляемым, а вызовы соответствующих функций могут
не происходить вовсе. (Пример выше не ссылается на какие-либо другие
документы.)
Удалить пустые узлы из таблицы стилей XSLT, кроме тех,
которые являются потомками от элементов xsl: text. Это позволяет исключить
появление "лишних" пробелов.
Удалить пустые текстовые узлы из исходного дерева, если
инструкции xsl: strip-space присутствуют в исходном документе. Это позволяет
исключить появление "лишних" пробелов. (Пример выше не использует эту
возможность)
Пополнить XSLT-дерево тремя правилами, которые предоставляют
поведение по умолчанию для любых типов узлов, которые могут быть встречены при
обработке. Первое правило - для обработки корневого узла; оно даёт инструкцию
процессору обработать каждого потомка корневого узла. Второе правило - для
любых текстовых узлов или узлов атрибутов; он даёт команду процессору сделать
копию этого узла в результирующем дереве. Третье правило - для всех узлов
комментария и узлов-инструкций обработки; никакой операции не производится.
Шаблоны, явно заданные в XSLT, могут перекрывать часть или все шаблоны-правила,
заданные по умолчанию. Если шаблон не содержит явных правил, встроенные правила
будут применены для рекурсивного обхода исходного дерева и только текстовые
узлы будут скопированы в результирующее дерево (узлы атрибутов не будут достигнуты,
так как они не являются "детьми" их родительских узлов). Полученный
таким образом результат обычно нежелателен, так как он является просто
конкатенацией всех текстовых фрагментов из исходного XML-документа.
Затем процессор проделывает следующие шаги для получения и
сериализации результирующего дерева: создаёт корневой узел результирующего
дерева, обрабатывает корневой узел исходного дерева. Процедура обработки узла
описана ниже, сериализует результирующее дерево, если необходимо, согласно
подсказкам, описанным инструкцией xsl: output.
При обработке узла производятся следующие действия.
Производится поиск наиболее подходящего шаблона правила. Это достигается
проверкой соответствия шаблона (который является выражением XPath) для каждого
правила, указывая узлы, для которых правило может быть применено. Каждому
шаблону процессором назначается относительный приоритет и старшинство для
облегчения разрешения конфликтов. Порядок шаблонных правил в таблице стилей
также может помочь разрешению конфликтов между шаблонами, которые соответствуют
одинаковым узлам, но это не оказывает влияния на порядок, в котором узлы будут
обрабатываться.
Template rule contents are instantiated. Элементы в пространстве
имён XSLT (обычно имеющие префикс xsl:) трактуются как инструкции и имеют
специальную семантику, которая указывает на то, как они должны
интерпретироваться. Одни предназначены для добавления узлов в результирующее
дерево, другие являются управляющими конструкциями. Не XSLT-элементы и
текстовые узлы, обнаруженные в правиле, копируются, "дословно", в
результирующее дерево. Комментарии и управляющие инструкции игнорируются.
Инструкция xsl: apply-templates при её обработке приводит к
выборке и обработке нового набора узлов. Узлы идентифицируются с помощью
выражения XPath. Все узлы обрабатываются в том порядке, в котором они
содержатся в исходном документе.расширяет библиотеку функций XPath’s и
позволяет определять XPath-переменные. Эти переменные имеют разную область
видимости в таблице стилей, в зависимости от того, где они были определены и их
значения могут задаваться за пределами таблицы стилей. Значения переменных не
могут быть изменены во время обработки.
Хотя эта процедура может показаться сложной, однако она
делает XSLT по возможностям похожей на другие языки web-шаблонов. Если таблица
стилей состоит из единственного правила, предназначенного для обработки
корневого узла, в результат просто копируется всё содержимое шаблона, а
XSLT-инструкции (элементы "xsl: …") заменяются вычисляемым
содержимым. XSLT предлагает даже специальный формат ("literal result
element as stylesheet") для таких простых, одношаблонных трансформаций.
Однако, возможность определять отдельные шаблоны и правила сильно увеличивает
гибкость и эффективность XSLT, особенно при генерации результата, который очень
похож на исходный документ.FO (англ. eXtensible Markup Language Formatting
Objects - объекты форматирования языка таблиц стилей для XML) - рекомендованный
Консорциумом Всемирной паутины язык разметки типографских макетов и иных
предпечатных материалов. XSL-FO является частью XSL, наряду с XSLT и XPath.
В отличие от комбинации HTML и CSS, XSL-FO - это
унифицированный язык представления. Он не имеет семантической разметки в том
смысле в каком она используется в HTML. И, в отличие от CSS, который модифицирует
представление по умолчанию для внешнего HTML или XML-документа, он сохраняет
все данные документа внутри себя.
Документ XSL-FO - это XML файл, в котором хранятся данные для
печати или вывода на экран (например, просто текст). Эти данные находятся внтури
тегов fo: block, fo: table, fo: simple-page-master и д. р., где указаны
отступы, переводы строк и т.д.
Общая идея использования XSL-FO состоит в том, что
пользователь создаёт документ, не в FO, но в виде XML. Это может быть,
например, XHTML или DocBook, хотя возможно использование буквально любого
XML-языка. Затем, пользователь применяет XSLT-преобразование, либо написав его
самостоятельно, либо взяв готовое, подходящее к этому типу документа. Этот XSLT
преобразует XML в XSL-FO.
После того как документ на XSL-FO получен, он передаётся
приложению, которое носит название FO-процессор. Эта программа конвертирует
XSL-FO-документ в какой-либо читаемый и/или печатаемый формат. Наиболее часто
используется преобразование в PDF либо PS; некоторые FO-процессоры могут давать
на выходе RTF-файлы либо просто показывать документ в окне.
Использование HTML и CSS
HTML (Hyper Text Markup Language) - "язык гипертекстовой
разметки", предназначенный для создания и просмотра Web-страниц в Сети.-
это универсальный язык для функциональной классификации различных частей
документа в соответствии с их назначением. Другими словами, HTML показывает,
какая часть документа является заголовком, а какая - текстом, какую часть
текста надо выделить, и где должны располагаться графические изображения.
Сущность HTML заключается в том, что после разметки документа
и выделения его различных частей можно быть уверенным: документ будет красиво и
правильно отображаться в любом браузере и на любом компьютере.- это язык
разметки, с помощью которого можно создать и просмотреть Web-страницы в Сети. В
HTML каждый тег (дополнительные служебные символы) - эта команда, указывающая
браузеру, как ему отображать Web-страницу. Для создания своего Web-сайта, и к
тому же интересного, вы не сможете обойтись без HTML.html обладает
многочисленными достоинствами:
гибкость. Работу над Web-узлом можно продолжать даже вдали от
компьютера. Используя HTML, разработчик перестаете зависеть от конкретной
программы, которая может оказаться недоступной в данный момент;
упрощение отладки. Поскольку разработчик сам написал
HTML-текст, ему будет проще отладить его и найти необходимые решения, если
что-то не работает;
независимость.html не привязан к конкретной фирме или
программе, поэтому нет необходимости беспокоиться о том, что фирма-разработчик
прекратит свое существование и оставит вас в безвыходном положении.
CSS это язык стилей, определяющий отображение HTML-документов. Например, CSS работает с шрифтами,
цветом, полями, строками, высотой, шириной, фоновыми изображениями, позиционированием
элементов и многими другими вещами.
HTML может (неправильно) использоваться для
оформления web-сайтов. Но CSS предоставляет большие возможности и более точен
и проработан. CSS, на сегодняшний день, поддерживается всеми браузерами (программами
просмотра).
Разница между CSS и HTML в следующем: HTML используется для
структурирования содержимого страницы, а CSS используется для
форматирования этого структурированного содержимого. Язык HTML используется только для
вывода структурированного текста.используется создателями и посетителями web-страниц для задания
цветов, шрифтов, расположения и других аспектов представления документа.
Основное назначение, для которого технология CSS была разработана, это
разделение содержимого (написанного на HTML или другом языке разметки) и
представления документа (написанного на CSS). Это разделение может увеличить
доступность документа, предоставить большую гибкость и возможность управления
его представлением, а также уменьшить сложность и повторяемость в структурном
содержимом. Кроме того CSS позволяет представлять один и тот же документ в
различных стилях или методах вывода, таких как экранное представление, печать,
чтение голосом (специальным голосовым браузером или программой чтения с
экрана), или при выводе устройствами, использующими Шрифт Брайля.при
отображении страницы может быть взята из различных источников:
авторские стили (информация стилей, предоставляемая автором
страницы) в виде внешних таблиц стилей, то есть отдельного файла. css, на
который делается ссылка в документе;
встроенных стилей - блоков CSS внутри самого HTML
документа;стилей, когда в HTML-документе информация стиля для одного элемента
указывается в его атрибуте style;
пользовательские стили;
локальный CSS-файл, указанный пользователем в настройках
браузера, переопределяющий авторские стили, и применяемый ко всем документам;
стиль браузера;
стиль, используемый браузером по умолчанию для представления
элементов.
Стандарт CSS определяет приоритеты, в порядке которых
применяются правила стилей, если для какого-то элемента подходят несколько
правил одновременно. Это называется "каскадом", в котором для правил
рассчитываются приоритеты или "веса", что делает результаты
предсказуемыми.
У CSS достаточно простой синтаксис. Таблица стилей состоит из
набора правил. Каждое правило, в свою очередь, состоит из одного или нескольких
селекторов, разделенных запятыми и блока определений. Блок определений же
обрамляется фигурными скобками, и состоит из набора свойств и их значений.
Преимущества CSS:
управление отображением множества документов с помощью одной
таблицы стилей;
более точный контроль над внешним видом страниц;
различные представления для разных носителей информации
(экран, печать, и т.д.);
сложная и проработанная техника дизайна.
3.
Проектирование и создание исходных данных
3.1 Написание
необходимой документации
Первым этапом проектирования данного проекта стоит считать
написание документации, которая будет регламентировать правила создания XML-файлов, поскольку в них
содержатся данные, используемые для последующего вывода на экран. Помимо этого
для проверки структуры XML-файлов на соответствие заданным требования
следует использовать DTD-схему, в которой будут строго и однозначно
заданы допустимые для построения валидных XML-файлов теги, а также атрибуты,
которые можно применять для описания каждого из тегов. Такой подход позволит
добиться единообразия исходных данных, которые затем при помощи системы будут
предоставляться конечному пользователю в удобном для него виде.
Рисунок 7 - Демонстрация примера отображения HTML-страницы
На рисунке 7 показано, как в документе Word задано форматирование
исходного файла, преобразованного обработчиком и затем показанного конечному
пользователю в браузере. Текст, отображенный на голубом фоне, является
сгенерированным, его появлением регламентируется соответствующими
файлами-обработчиками. Все остальные данные находятся в исходном XML-файле и добавляются на
страницы из определенных участков этого файла в соответствии с требованиями,
изложенными в документации (рисунок 8).

Рисунок 8 - Описание различных элементов страницы
Мы видим таблицу, в которой четко регламентировано, что
должно появляться в качестве того или иного элемента. В первом столбце
перечисляются различные компоненты, из которых построен конечный документ. Во
втором столбце содержится путь, по которому данные, относящиеся к каждому
конкретному компоненту, содержатся в исходном файле. Это необходимо для
конфигурации процессинговых файлов, чтобы для каждого элемента XML-документа на HTML-страницу выводилось
именно та информация, которая соответствует ему. Третий столбец содержит
дополнительную информацию для страниц, отображаемых на английском языке
(специально сгенерированный текст или дополнительные символы, которыми следует
разделять отдельные участки одного элемента в зависимости от указанных правил).
В четвертом столбце содержится специализированная информация для отображения на
другом языке, в данном случае - на французском.
В другом документе рассматривается описание тех же элементов,
но уже с точки зрения их конкретного оформления с использованием атрибутов CSS (рисунок 9)
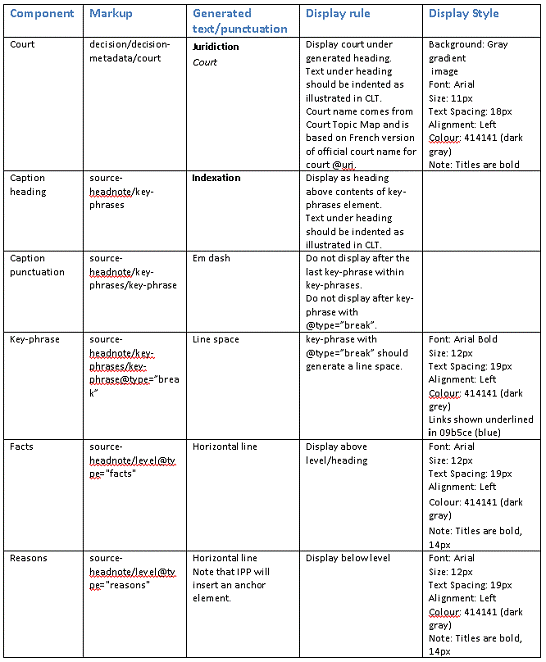
Рисунок 9 - Описание стилевых атрибутов элементов
Здесь в первом столбце отображено название элементов, второй
столбец содержит прямой путь к компоненту в исходном XML-файле. Третий столбец
описывает дополнительно генерируемый текст, в четвертом находится описание
правил отображение элементов, а в пятом - их стилевые атрибуты.
Создание
DTD-схемы
DTD описывает схему документа для конкретного языка разметки
посредством набора объявлений (объектов-параметров, элементов и атрибутов),
которые описывают его класс (или тип) с точки зрения синтаксических ограничений
этого документа. Также DTD может объявлять конструкции, которые всегда
необходимы для определения структуры документа, но, зато, могут влиять на
интерпретацию определённых документов.
Таким образом, для создания исходных файлов, используемых в
проекте, необходимо наличие DTD-схемы, которая будет регламентировать правила
построения таких документов. После документирования всех требований,
предъявляемых к исходным данным, на их основе создается DTD-схема, в которой
указано, какие элементы и их атрибуты можно использовать для хранения и
передачи информации обработчику. Примеры определения некоторых элементов
приведены на рисунке 10.

Рисунок 10 - Задание правил DTD-схемы
В данном случае рассматриваются элементы xhtml: tr, xhtml:
th и xhtml: td, которые логически соответствуют строке, заголовку и
ячейке таблицы. После объявления элемента указывается перечень компонентов,
которые могут являться его потомками. Далее после ключевого определения <!
ATTLIST следует перечисление атрибутов, которые могут применяться к
описываемому элементу, указывается их типа и значение по умолчанию, если оно
используется.
Таким образом создана база, которая сможет выступать в
качестве основы для построения комплексных структурированных данных. Так как
главной целью создания портала является представления различной информации
юридического характера, то от разработчика требуется добиться одинакового
подхода при отображения схожих данных, чтобы пользователь мог легко
ориентироваться в программной среде и заниматься веб-серфингом документов,
относящихся к одному правовому полю (например, законодательным актам или
указам).
Однако при создании исходных структурированных данных мы не
должны учитывать интересы конечного пользователя. Главная задача - предоставить
информацию в таком виде, чтобы проектировщик XSLT-обработчиков смог в
дальнейшем извлечь ее и в зависимости от типа представленного документа
(сведения о котором будут храниться в исходном файле) дифференцировать
дальнейший процессинг информации.
Пример
исходного XML-файла
Далее рассмотрим, что же представляет собой стандартный XML-файл, который выступает
в роли хранилища данных, используемых затем для вывода на экран. Процесс
создания исходного документа должен учитывать описанные выше требования,
касательно структуры файла и стилевых атрибутов каждого из используемых
элементов. Данные будут обрабатываться позже посредством функциональных
возможностей языков трансформации XSLT и XSLF-FO. На данном этапе от разработчика требуется
грамотно и последовательно перенести информацию, изложенную в обычной
электронной форме, в структурированные данные, не теряя при этом логическую
нагрузку на каждый из элементов, описанных как в сопровождающей документации,
так и в DTD-схеме проекта. Следует отметить, что DTD-схема должна находиться
в одной папке с исходными данными, чтобы они могли проверяться на соответствие
ей.
Каждый исходный документ имеет единообразную структуру,
которая начинается с объявления XML-спецификации:
<? xml version='1.0' encoding='UTF-8'? >
За ней следует привязка схемы DTD, использующейся при
валидации файла на корректность структуры:
<! DOCTYPE xml-document PUBLIC "- // DiplomaProject // DTD Ruling-Format: Document XML // EN" " Diploma_Project. dtd">
Далее могут указывать требования, предъявляемые непосредственно
к DTD-схеме, такие как ее
версия и др. Указывается идентификационный номер исходного документа.
После этого начинается структурное описание самого документа
в соответствии со всеми спецификациями по его построению. Пример такого XML-файла показан на рисунке
11.

Рисунок 11 - Исходный XML-документ
Как можно видеть, документ обладает четкой древовидной
структурой, у каждого элемента может быть несколько потомком, что позволяет
добиться глубокой вложенности в случае необходимости создания сложной структуры
данных. Следует обратить внимание на то, что огромная роль уделяется именно
правильному представлению данных.
На приведенном выше рисунке непосредственный текст документа
изображен черным шрифтом. Это именно та информация, которую получает конечный
пользователь и которого она интересует.
Синим шрифтом выделены структурные элементы, которые
используются для построения исходного документа. Правила их использования
регламентированы DTD-схемой, привязанной к документу.
Красный шрифт используется для выделения атрибутов каждого
отдельного элемента (нода). Перечень допустимых для применения атрибутов
содержится в DTD-схеме. Фиолетовый шрифт применяется, чтобы выделить значения
атрибутов.
Таким образом, мы можем заметить, что в исходном документе
встречаются 4 типа данных, каждый из которых несет определенную логическую
нагрузку и его присутствие обязательно в каждом источнике информации этого
проекта.
Настройка
и использование сервера Apache Cocoon
Cocoon 2 от Apache XML Project является гибкой системой
Web-публикации, в основе которой лежат повторно используемые компоненты.
Несмотря на то, что концепция многократного использования компонент
присутствует во многих системах, Cocoon выделяется простотой интерфейсов
взаимодействия компонент. Каждая компонента принимает на вход и возвращает XML,
и такой подход работает.2 является системой публикации XML. Что же это на самом
деле значит? Это не база данных, в которой хранятся XML-данные, и не сервер
приложений J2EE, который подготавливает контент для web-сервера. Cocoon 2
архитектурно располагается на промежуточном уровне и представляет собой среду
обработки контента. Контент обрабатывается системой компонент, структуру
которой как раз и строит разработчик.
Любая система компонент начинается с генератора. Генератор
анализирует файл и создает поток событий SAX. Вторым элементом в
рассматриваемой системе компонент является XSL-процессор. В нашем случае,
процессор преобразований применяет XSL-преобразование (stylesheet. xsl) к
XML-документу, полученному от генератора. Результатом его также является
SAX-поток. На выходе системы находится сериализатор. Он прерывает поток и
выдает результата преобразования в качестве HTTP-ответа. Подобную трехуровневую
систему компонент можно применять для создания множества или даже всех страниц
разрабатываемого сайта. Этот пример может показаться слишком простым, поскольку
две компоненты из трех являются крайними компонентами, однако, он хорошо
иллюстрирует общую идею.
На рисунке 12 показан случай, более приближенный к реальной
жизни. Страницы, содержащие статический и динамический контент, поступают из
базы данных. К предыдущей схеме добавлена новая компонента - SQL-процессор. SQL-процессор обрабатывает SQL-выражения, включенные в
исходный XML-документ, и заменяет их на результат выборки, опять же
оформленный в виде XML-фрагмента.

Рисунок 12 - Принцип работы сервера Apache Cocoon
Например, если в исходном документе (в file. xml) содержится следующая
информация:
<guest-list>
<sql: execute-query>
<sql: query>CONCAT (lastName, ', ',
firstName) as name, ageguest WHERE status = ARRIVING;
</sql: query>
</sql: execute-query>
</guest-list>оответствующим результатом действия
SQL-процессора будет примерно следующее:
<guest-list>
<row-set>
<row>
<name>Bush, George</name>
<age>56</age>
</row>
<row>
<name>Jackson, Michael</name>
<age>42</age>
</row>
<row>
<name>Einstein, Albert</name>
<age>105</age>
</row>
</row-set>
</guest-list>
Главным преимуществом является то, что в исходном файле можно
явно выделить бизнес-логику документа. В данном случае мы никак не используем
JDBC API, напротив, контент исходного документа начинает отражать исходную
бизнес-задачу.
Предположим теперь, что в локальной базе данных находится
список символов акций, которые мы хотим использовать при отображении текущих
цен на рынке. Подобная страница может являться составной частью какого-нибудь
портала наподобие Yahoo. Эту бизнес-задачу можно решить с помощью
многокомпонентной системы, показанной на рисунке 13.

Рисунок 13 - Включение в систему SOAP-процессора
Допустим, что в SOAP-процессор поступает следующий фрагмент
XML-кода:
<soap: query url="#"650569.files/image014.gif">
Рисунок 14 - Структура файла
document-xhtml-renderer-scion-view. xsl
Возвращаемся к документу doc-view-specific. xsl. Здесь
находится один из наиболее важным участком обработчика, а именно, темплейт,
отвечающий за создание структуры документа для различных типов юридических
данных. В темплейте "atlas-document-body-structure" в зависимости от
переменной, в которой содержатся данные об идентификации типа юридической
информации, строится своя индивидуальная структура HTML-страницы и в дальнейшем
вызываются специфические обработчики (рисунок 15).

Рисунок 15 - Структура темплейта "atlas-document-body-structure"
Посредством вызова инструкции <xsl:
apply-templates/> происходит обращение ко всем другим обработчикам,
которые найдут в исходном документе элементы, подходящие под их условия.
Использование инструкции <xsl: call-template/> приводит к вызову
специального темплейта с изначально заданным именем.
Далее приведем пример, как строится секция заголовка для
одного из документов (рисунок 16).

Рисунок 16 - Создание секции заголовка
На рисунке представлены 3 взаимосвязанных темплейта. В первом
из них строится общая структура секции заголовка, создаются блоки-контейнеры,
вызывается обработчик для отображения текста главного заголовка после чего
инструкция <xsl: call-template name="metadata-grey-box-law"/>
вызывает отображение панели с метаданными - "дэшбоард" - своего рода
информационное меню HTML-страницы.
Далее формируется кнопка-список для перехода к секциям "Related Matter" с использованием
возможностей JavaScript, для чего создается пустой блок-контейнер в третьем из
приведенных выше темплейтов. Затем внутри первого обработчика вызывается второй
темплейт, который отвечает за отображение дополнительной текстовой информации
после "дэшбоарда". Подобным образом устроена работа и других
обработчиков, например, отвечающего за преобразование элементов wkdoc: level (рисунок 17).

Рисунок 17 - Структура темплейта "wkdoc: level"
Следующий темплейт иллюстрирует процесс создания
информационного меню для документов типа Newsletter (рисунок 18). Данный
обработчик находится в файле value-add-html. xsl.

Рисунок 18 - Структура темплейта
"metadata-grey-box-news"
Здесь применяется более сложный механизм, наряду с блочной
структурой представления данных также используется и табличная. За
форматирование отвечает закрепленный за проектом CSS-файл, который с
использованием изображений и специализированных атрибутов позволяет добиться
получения необходимого результата оптимальным способом. Также вызывается
специализированный темплейт для отображения даты, хранящейся в документе, в
формате, который зависит от языка. То есть, в случае, если исходный файл
содержит параметр, указывающий на английский язык, будет применено иное
форматирование, нежели в случае использования французского языка. На рисунке 19
показано, как происходит обработка и создание заголовков различных уровней для
элементов h1,
находящихся в исходных данных, которые относятся к типу документов "GAD" (doc-agency).

Рисунок 19 - Обработка элементов h1 из документов типа GAD
Еще одним часто встречающимся элементом является "para". Его обработка
происходит в файле paragraph-html. xsl (рисунок 20).

Рисунок 20 - Обработка элементов para
Создание
XSL-FO темплейтов
Аналогичным образом происходит процесс создания обработчиков
на языке трансформации XSL-FO, который отвечает за отображение преобразованных
исходных данных в форматах PDF и RTF. Пользователь получает возможность при просмотре
HTML-страницы в веб-браузере
скачать изучаемый документ в одном из предложенных форматов.
Всего в системе используется порядка 20 XSL-FO-файлов, отвечающих за
различные аспекты функционирования системы в режимах RTF и PDF, начиная от обработки
небольших структурных элементов исходного документа, заканчивая реализацией
общего представления документа для его последующей отправки посредством
электронной почты. Стартовой точкой системы является файл document-fo-skeleton.
xsl (рисунок 21). Он содержит точку входа в исходный документ (<xsl:
template match="/">).

Рисунок 21 - Структура файла
document-xhtml-renderer-scion-view. xsl
В случае вызова данного темплейта происходит построение HTML-страницы, вызов других
темплейтов для дальнейшей обработки исходного документа, подключение файлов с
кодом JavaScript, подключение CSS-файла, формирование тела страницы и ее блочной
структуры.
Следующим вызывается файла print-xhtml-specific. xsl,
который включает в себя другие необходимые темплейты и подключает обработчики
из других файлов проекта:
<xsl: include href="document-xhtml-list-renderer.
xsl"/>
<xsl: include href="document-xhtml-commons.
xsl"/>
<xsl: include href="doc-heading. xsl"/>
<xsl: include href="value-add-html. xsl"/>
<xsl: include href="document-xhtml-renderer.
xsl"/>
<xsl: include href="xhtml-page-start-element.
xsl"/>
<xsl: include href="xhtml-footer. xsl"/>
<xsl: include href="xhtml-print-header. xsl"/>
<xsl: include
href="xhtml-print-document-body-structure. xsl"/>
<xsl: include href="doc-notes-html. xsl" />
<xsl: include href="all-formats. xsl"/>
<xsl: include href="break-html. xsl"/>
Таким образом, строится структура проекта, в котором
обработка практически каждого элемента заканчивается вызовом обработчиков для
всех вложенных в него элементов. Так происходит до тех пор, пока процессор не
добирается до конца каждой ветки структурного дерева, после чего переходит к
следующему ответвлению документа.
Возвращаемся к документу doc-view-specific. xsl. Здесь
находится один из наиболее важным участком обработчика, а именно, темплейт,
отвечающий за создание структуры документа для различных типов юридических
данных. В темплейте "atlas-document-body-structure" в зависимости от
переменной, в которой содержатся данные об идентификации типа юридической
информации, строится своя индивидуальная структура HTML-страницы и в дальнейшем
вызываются специфические обработчики (рисунок 22).
Посредством вызова инструкции <xsl:
apply-templates/> происходит обращение ко всем другим обработчикам,
которые найдут в исходном документе элементы, подходящие под их условия.
Использование инструкции <xsl: call-template/> приводит к вызову
специального темплейта с изначально заданным именем.
Можно сделать вывод о том, что принцип построения обработчика
в обоих языках (XSLT и XSL-FO) имеет много общих черт, что ускоряет процесс разработки
приложения после создания первой части.
Существенным отличием между этими языками трансформации является
то, что в XSLT существует возможность подключить внешний CSS-файл с настройками
форматирования генерируемых HTML-документов. Очевидно, что при создании PDF и RTF документов такая функция
нереализуема, что вынуждает разработчика напрямую задавать параметры
форматирования выходных данных в самих темплейтах при помощи атрибутов
элементов, идентичных тем, что используются в CSS.

Рисунок 22 - Структура темплейта "atlas-document-body-structure"
Ввиду описанной выше особенности языка XSL-FO, построение заголовком
происходит несколько иным образом. Все параметры блочных (fo: block) и инлайновых (fo: inline) элементов задаются в
самих файлах XSL-FO, как показано на рисунке 23.
Подобным образом устроена работа и других обработчиков,
например, отвечающего за преобразование элементов wkdoc: level и их вывод в форматах PDF и RTF (рисунок 24).
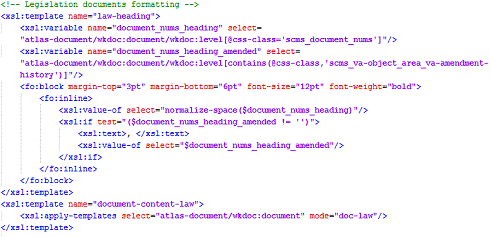
Рисунок 23 - Создание секции заголовка

Рисунок 24 - Структура темплейта "wkdoc: level"
Следующий темплейт иллюстрирует процесс создания
информационного меню для документов типа Newsletter (рисунок 25). Данный
обработчик находится в файле doc-heading-fop. xsl.

Рисунок 25 - Структура темплейта "newsMetadata"
Здесь в различных блочных элементах происходит обращение
обработчика к конкретным компонентам исходного файла и извлечение текстовой
информации для ее последующего отображения.
На рисунке 26 показано, как происходит обработка и создание
заголовков различных уровней для элементов h1, находящихся в исходных
данных, которые относятся к типу документов "Legislation" (doc-law).

Рисунок 26 - Обработка элементов h1 из документов типа Legislation
Еще одним часто встречающимся элементом является "para". Его обработка
происходит в файле paragraph-fo. xsl (рисунок 27).

Рисунок 27 - Обработка элементов para
Подключение
и использование CSS
Для корректного отображения выходных данных на HTML-странице в соответствии
с заданными требованиями к проекту подключается CSS-файл. Он функционирует в
системе локального сервера, подключается в XSLT-темплейте, отвечающем за
обработку загрузочного нода, а подключение к нему происходит динамически во
время отображения веб-страницы в браузере.
Это открывает возможность оперативного редактирования CSS-документа в процессе
разработки проекта в случае возникновения соответствующей необходимости.
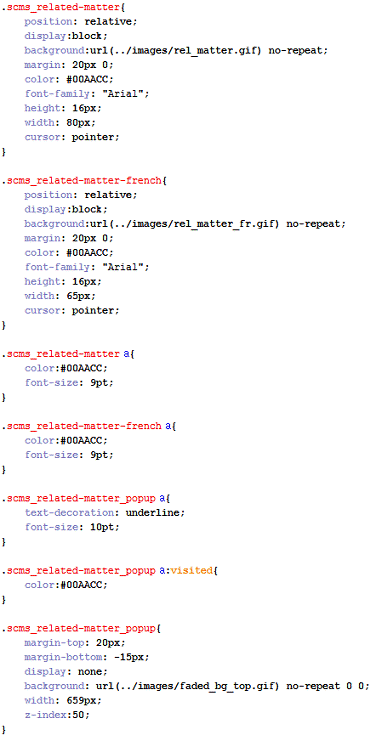
Рисунок 28 - Фрагмент файла docDisplay. Css
В данном проекте использовалась таблица стилей docDisplay. css, длина которой в
конечном итоге превысила 2000 строк ввиду большого количества различных
документов, поддерживаемых в проекте, а также разнообразия элементов,
используемых в них (рисунок 28).
Применение
JavaScript
Для реализации дополнительного функционала использовался JavaScript (рисунок 29). При
нажатии на кнопку Related Matter над ней появляется всплывающее окно, содержимое
окна сдвигается наверх.

Рисунок 29 - Функционал JavaScript
При фокусе курсора на всплывающем окне, возможен скроллинг в
пределах окна, при этом возможность прокрутки самой страницы блокируется. При
фокусе курсора вне пределов всплывающего окна возвращается стандартный
функционал. Реализация данной возможности показана на рисунке 30.

Рисунок 30 - Код функции блокировки скроллинга на языке JavaScript
3.3 Примеры
выходных данных и работа с системой
Функционирующая система с подключением локального сервера,
всех дополнительных библиотек, обработчиков и с реализацией главного меню
выглядит следующим образом (рисунок 31).

Рисунок 31 - Готовая реализация проекта
С помощью меню пользователь может перемещаться по документам
и открывать необходимую ему информацию (рисунок 32). Для этого введена
дифференциация по типу документов, по подключенной библиотеке, по виду
юрисдикции и языку исходных данных.
Рисунок 32 - Использование меню
Реализация возможностей JavaScript показана на рисунке 33
на примере использования кнопок "Related Matter" и "History". При нажатии
открываются всплывающие окна.

Рисунок 33 - Демонстрация работы JavaScript в разработанной системе
На рисунке 34 представлен пример реализации специального
информационного меню, которое содержит дополнительную информацию, касающуюся
каждого конкретного документа.

Рисунок 34 - Информационное меню
Одной из главных особенностей проекта являлась возможность
презентации данных конечному пользователю сразу в нескольких форматах, что
показано на рисунках 35-37.

Рисунок 35 - HTML-презентация документа типа GAD

Рисунок 36 - PDF-презентация документа типа GAD

Рисунок 37 - RTF-презентация документа типа GAD
Для выхода из приложения достаточно закрыть окно браузера.
Заключение
Результатом дипломного проекта стал готовый к эксплуатации
web-проект. Была успешно реализована задача Автоматизации преобразования
структурированных данных в корпоративном правовом портале. Данное приложение
является удобным стартовым инструментарием, на основе которого можно создавать
более сложные приложения.
В процессе выполнения дипломного проекта были выбраны
необходимые для решения задачи технологические средства. Для функционирования
системы использовался локальный сервер Apache Cocoon, одновременно являющийся
процессором, поддерживающим языки трансформации исходных данных. Сами исходные
данные ввиду необходимости их структурированного представления хранятся в XML-формате и проверяться на
соответствии заданной разработчиком с учетом требований заказчика DTD схеме. Для трансформации
данных были выбраны языки XSLT и XSL-FO, которые позволяют представить информацию,
извлеченную из структурированных данных и представить ее в форматах HTML и PDF (RTF) соответственно. В HTML-реализации проекта нашли
применение возможности языка JavaScript.
Основная цель создания данного проекта - это строгое
представление пользователю юридической информации посредством использования
браузера, как средства доступа к данным. Поскольку правовые документы должны
отображаться в четком соответствии с требованиями, предъявляемыми к ним, была
внедрена унификация исходных данных, используемых для последующего отображения
пользователю. Применение структурированного типа данных позволило избрать
единый подход к хранению, пересылке информацию и ее визуальному отображению.
Приложение готово к использованию, его интерфейса интуитивно
понятен, работа с сайтом не вызовет затруднений даже у начинающих
пользователей. Применение перечисленных выше технологий позволило добиться
наилучшей реализации поставленной задачи.
Список
использованных источников
1. Экель, Б. Thinking in Java / Брюс Экель
// Питер, 1987. - С.15-30, 99-243.
2. Хабибуллин,
И. Разработка Web-служб средствами Java / Ильдар Хабибуллин // БХВ-Петербург. -
Санкт-Петербург, 2003. - С.25-133.
. Флэнаган,
Д. Java Справочник / Дэвид Флэнаган // Символ. - М., 2004. - С.214-221,
879-951.
. Фаулер,
М. Архитектура корпоративных программных приложений / М. Фаулер - М.:
"Вильямс", 2007 - 544 с.
. Ноутон,
П. Java 2. Наиболее полное руководство. / П. Ноутон, Г. Шилдт - СПб.:
БХВ-Петербург, 2005 - 1072 с
. Тидвелл,
Д.Г. Разработка пользовательских интерфейсов: Пер. с англ. / Д.Г. Тидвелл. -
П.: Питер, 2008. - 416 с.
. Буч,
Г. Объектно-ориентированное программирование с примерами применения / Г. Буч -
М.: Конкорд, 1992 - 567 с.
. XSLT
Tutorial [Электронный ресурс]. - 2011. - В режиме доступа: http://www.w3schools.com/xsl/. - Дата доступа: 24.02.2011.
. XPath,
XQuery, and XSLT Functions [Электронный ресурс]. - 2012. - В режиме доступа: http://www.w3schools.com/xpath/xpath_functions. asp. - Дата доступа: 10.03.2012.
. Cocoon
Tutorial [Электронный ресурс]. - 2012. - В режиме доступа: http://cocoon. apache.org/2.1/tutorial/index.html. - Дата доступа: 18.03.2012.
. XSL-FO
Input [Электронный ресурс]. - 2012. - В режиме доступа: http://xmlgraphics. apache.org/fop/fo.html. - Дата доступа: 26.03.2012.
. Модели
данных для индексации текстовых и графических информационных ресурсов [Электронный
ресурс]. - В режиме
доступа: http://listenbook. narod.ru/Pi-104/Mir_104. htm#_Toc223342930. - Дата
доступа: 02.04.2012.
13. iXBT.com - ваш основной источник
информации [Электронный ресурс]. - 2012. - В режиме доступа:
http://www.ixbt.com/. - Дата доступа: 03.04.2012.
. Википедиа
[Электронный ресурс]. - 2012. - В режиме доступа: http://ru. wikipedia.org/. -
Дата доступа: 10.04.2012.
Приложения
Приложение А
Пример XSLT-темплейтов:
<xsl: template match="wkdoc: level
[contains (@css-class,'scms_question-answer')] // para [contains
(@css-class,'scms_para')] ">
<xsl: call-template
name="put-anchor-marker-for-id"/>
<xsl: choose>
<xsl: when
test="$is-doctype-agency">
<xsl: choose>
<xsl: when test="ancestor:: wkdoc: level
[@css-class='scms_question'] ">
<p>
<xsl: apply-templates select="."
mode="find-num"/>
<xsl: apply-templates/>
</p>
</xsl: when>
<xsl: when test="ancestor:: wkdoc: level
[@css-class='scms_answer'] ">
<p>
<xsl: apply-templates select="."
mode="find-num"/>
<xsl: apply-templates/>
</p>
</xsl: when>
</xsl: choose>
</xsl: when>
<xsl: otherwise>
<xsl: apply-templates select="."
mode="find-num"/>
<xsl: apply-templates/>
</p>
</xsl: otherwise>
</xsl: choose>
</xsl: template>
<xsl: template match="span">
<xsl: choose>
<xsl: when test="@css-class">
<span>
<xsl: attribute name="class">
<xsl: value-of
select="@css-class"/>
</xsl: attribute>
<xsl: apply-templates/>
</span>
</xsl: when>
<xsl: otherwise>
<xsl: apply-templates/>
</xsl: otherwise>
</xsl: choose>
</xsl: template>
<xsl: template match="span [contains
(@css-class,'scms_term')] ">
<xsl: choose>
<xsl: when test="ancestor:: para
[preceding-sibling:: h1 [contains (@css-class,'scms_heading')]] ">
<xsl: apply-templates/>
</xsl: when>
<xsl: otherwise>
<span>
<xsl: apply-templates/>
</span>
</xsl: otherwise>
</xsl: choose>
</xsl: template>
<xsl: template match="wkdoc: level
[$is-doctype-agr-leg and contains (@css-class,'scms_document_nums')]
/para">
<xsl: variable name="sub-class"
select=" // sub-class/@sub-class"/>
<xsl: call-template
name="put-anchor-marker-for-id"/>
<xsl: choose>
<xsl: when
test="$sub-class='protocol'">
<xsl: apply-templates select="* [not
(contains (@css-class,'scms_num'))] "/>
</xsl: when>
<xsl: when
test="$sub-class='treaty'">
<xsl: apply-templates select="* [not
(contains (@css-class,'scms_type_print'))] "/>
</xsl: when>
</xsl: choose>
</xsl: template>
Пример XSL-FO-темплейтов:
<xsl: template
name="block-params">
<xsl: if test="fill">
<xsl: attribute
name="text-align-last">justify</xsl: attribute>
</xsl: if>
<xsl: if test="@align='center' or
@align='right'">
<xsl: attribute
name="text-align">
<xsl: value-of select="@align"/>
</xsl: attribute>
</xsl: if>
<xsl: if test="parent:: wkdoc: document
and $superClass='law'">
<xsl: attribute
name="margin-left">0.22in</xsl: attribute>
</xsl: if>
</xsl: template>
<xsl: template match="para/span [
($is-doctype-news) and contains (@css-class,'scms_type_report')] "
priority="1"/>
<xsl: template match="para [contains
(@css-class,'scms_type_attribution')] ">
<fo: block margin-top="3pt"
margin-bottom="6pt" text-align="right"
font-style="italic">
<xsl: text> - </xsl: text>
<xsl: apply-templates/>
</fo: block>
</xsl: template>
<xsl: template match="para [contains
(@css-class,'scms_type_caseref')] ">
<xsl: choose>
<xsl: when test="count (span [contains
(@css-class,'scms_text')]) gt 1">
<xsl: for-each select="span [contains
(@css-class,'scms_text')] ">
<fo: block text-align="right">
<xsl: apply-templates/>
</fo: block>
</xsl: for-each>
</xsl: when>
<xsl: otherwise>
<fo: block text-align="right">
<xsl: apply-templates/>
</fo: block>
</xsl: otherwise>
</xsl: choose>
</xsl: template>
<xsl: template match="wkdoc: level
[contains (@css-class,'scms_prov-body')] ">
<fo: block margin-left="0">
<xsl: apply-templates/>
</fo: block>
</xsl: template>
<xsl: template match="wkdoc: level
[contains (@css-class,'scms_attribution')] ">
<fo: block font-family="Verdana"
font-size="1.1em">
<xsl: apply-templates/>
</fo: block>
</xsl: template>
Пример CSS-селектров:_history-notes{:
relative;: block;: url (. /images/history. gif) no-repeat;: 20px 0;:
#00AACC;family: "Arial";: 16px;: 80px;: pointer;
}
. scms_history-notes-french{: relative;: block;:
url (. /images/history_fr. gif) no-repeat;: 20px 0;: #00AACC;family: "Arial";:
16px;: 65px;: pointer;
}
. scms_history-notes a{: #00AACC;size: 9pt;
}
. scms_history-notes-french a{: #00AACC;size:
9pt;
}
. scms_history-notes_popup a{decoration:
underline;size: 10pt;
}
. scms_history-notes_popup a: visited{: #00AACC;
}
. scms_history-notes_popup{top: 20px;bottom: -
15px;: none;: url (. /images/faded_bg_top. gif) no-repeat 0 0;: 659px;index:
50;
}
. scms_history-notes_popup_bgheader{: url (.
/images/rel_mat_header. gif) repeat-x;: 7px 12px;left: 2px;
}
. scms_history-notes_popup_header{: url (.
/images/history_letter. gif) no-repeat;: white;size: 10pt;: 0 23px;
}
. scms_history-notes_popup_content{: black;left:
35px;right: 50px;size: 10pt;x: hidden;y: auto;height: 169px;
}
. scms_history-notes_popup_background{:
20px;bottom: 24px;: url (. /images/faded_bg_bottom. gif) no-repeat 0 bottom;
}
. scms_history-notes_popup. scms_prov-para{left:
8px;
}
. scms_history-notes_popup. scms_subpara{left:
12px;
}
. scms_history-notes_popup. scms_subsection{left:
14px;
}
. scms_history-notes_popup. scms_prov-para,
. scms_history-notes_popup. scms_item,
. scms_history-notes_popup. scms_subpara,
. scms_history-notes_popup. scms_clause,
. scms_history-notes_popup. scms_subclause,
. scms_history-notes_popup. scms_section,
. scms_history-notes_popup. scms_subsection{:
static;
}
Пример JavaScript-функционала:showPopup = function
(id) {element = document. getElementById (id). previousSibling;(element.
nodeType! == 1) {= element. previousSibling;
}(element. style. display === 'block') {. body.
scrollTop - = (element. offsetHeight + 5);. documentElement. scrollTop - =
(element. offsetHeight + 5);. style. display = 'none';
} else {. style. display = 'block';. body.
scrollTop += (element. offsetHeight + 5);. documentElement. scrollTop +=
(element. offsetHeight + 5);
}element;
};generateList = function () {blocks = document.
getElementsByTagName ('div'),= [],= document. createDocumentFragment (),,=
document. getElementById ('relatedMatterList'),= 1,currentPopup,= {
'scms_related-matter': 'Related Matter ',
'scms_related-matter-french':
'Références '
};(var i = 0, l = blocks. length; i < l; i++)
{(hasClass (blocks [i], 'scms_related-matter') || hasClass (blocks [i],
'scms_related-matter-french')) {= document. createElement ('a');. innerHTML =
linkTitles [blocks [i]. className] + linkCounter++;
(function (link) {. onclick = function ()
{element = document. getElementById (link. id). previousSibling;(element.
nodeType! == 1) {= element. previousSibling;
}(element. style. display = 'none') {= showPopup
(link. id);
};. body. scrollTop = document. documentElement.
scrollTop = currentPopup. offsetTop;
}
}) (blocks [i]);. appendChild (tmpLink);
}
}. appendChild (fragment);
};hasClass (ele,cls) {ele. className. match (new
RegExp (' (\\s|^) '+cls+' (\\s|$) '));
}init () {popups = document. getElementsByTagName
('div');
// quit if this function has already been
called(arguments. callee. done) return;
// flag this function so we don't do the same
thing twice. callee. done = true;
// kill the timer(_timer) clearInterval
(_timer);();
};