Метод кодирования Хаффмана
Содержание
Содержание
Введение
1. Описание метода
кодирования Хаффмана
. Среда разработки Delphi
версии 7.0
.1 Основные понятия
объектно-ориентированного программирования
. Описание программы,
разработанной в Delphi
7.0
. Реализация на Delphi
метода кодирования Хаффмана
Заключение
Литература
Введение
Сжатие информации - проблема,
имеющая достаточно давнюю историю, гораздо более давнюю, нежели история
развития вычислительной техники, которая (история) обычно шла параллельно с
историей развития проблемы кодирования и шифровки информации.
Все алгоритмы сжатия оперируют
входным потоком информации, минимальной единицей которой является бит, а
максимальной - несколько бит, байт или несколько байт.
Целью процесса сжатия, как
правило, есть получение более компактного выходного потока информационных
единиц из некоторого изначально некомпактного входного потока при помощи
некоторого их преобразования.
Основными техническими
характеристиками процессов сжатия и результатов их работы являются:
степень сжатия (compress rating)
или отношение (ratio) объемов исходного и результирующего потоков;
скорость сжатия - время,
затрачиваемое на сжатие некоторого объема информации входного потока, до
получения из него эквивалентного выходного потока;
качество сжатия - величина,
показывающая на сколько сильно упакован выходной поток, при помощи применения к
нему повторного сжатия по этому же или иному алгоритму.
Кодирование Хаффмана является
простым алгоритмом для построения кодов переменной длины, имеющих минимальную
среднюю длину. Этот весьма популярный алгоритм служит основой многих
компьютерных программ сжатия текстовой и графической информации. Некоторые из
них используют непосредственно алгоритм Хаффмана, а другие берут его в качестве
одной из ступеней многоуровневого процесса сжатия. Метод Хаффмана производит
идеальное сжатие (то есть, сжимает данные до их энтропии), если вероятности
символов точно равны отрицательным степеням числа 2. Алгоритм начинает строить
кодовое дерево снизу вверх, затем скользит вниз по дереву, чтобы построить
каждый индивидуальный код справа налево (от самого младшего бита к самому
старшему). Начиная с работ Д.Хаффмана 1952 года, этот алгоритм являлся
предметом многих исследований.
1. Описание метода кодирования Хаффмана
Метод сжатия информации на основе двоичных
кодирующих деревьев был предложен Д. А. Хаффманом в 1952 году задолго до
появления современного цифрового компьютера. Обладая высокой эффективностью, он
и его многочисленные адаптивные версии лежат в основе многих методов,
используемых в современных алгоритмах кодирования. Код Хаффмана редко
используется отдельно, чаще работая в связке с другими алгоритмами кодирования.
Метод Хаффмана является примером построения кодов переменной длины, имеющих
минимальную среднюю длину. Этот метод производит идеальное сжатие, то есть
сжимает данные до их энтропии, если вероятности символов точно равны
отрицательным степеням числа 2.
Этот метод кодирования состоит из двух основных
этапов:
. Построение оптимального кодового дерева.
. Построение отображения код-символ на основе
построенного дерева.
Алгоритм основан на том, что некоторые символы
из стандартного 256-символьного набора в произвольном тексте могут встречаться
чаще среднего периода повтора, а другие - реже. Следовательно, если для записи
распространенных символов использовать короткие последовательности бит, длиной
меньше 8, а для записи редких символов - длинные, то суммарный объем файла
уменьшится. В результате получается систематизация данных в виде дерева
(«двоичное дерево»).
Пусть A={a1,a2,...,an}
- алфавит из n различных
символов, W={w1,w2,...,wn}
- соответствующий ему набор положительных целых весов. Тогда набор бинарных
кодов C={c1,c2,...,cn},
такой что:
- ci
не является префиксом для cj,
при i!=j;
минимальна (|ci|
длина кода ci)
называется минимально-избыточным префиксным
кодом или иначе кодом Хаффмана.
Бинарным деревом называется ориентированное
дерево, полустепень исхода любой из вершин которого не превышает двух.
Вершина бинарного дерева, полустепень захода
которой равна нулю, называется корнем. Для остальных вершин дерева полустепень
захода равна единице.
Пусть Т- бинарное дерево, А=(0,1)- двоичный
алфавит и каждому ребру Т-дерева приписана одна из букв алфавита таким образом,
что все ребра, исходящие из одной вершины, помечены различными буквами. Тогда
любому листу Т-дерева можно приписать уникальное кодовое слово, образованное из
букв, которыми помечены ребра, встречающиеся при движении от корня к
соответствующему листу. Особенность описанного способа кодирования в том, что
полученные коды являются префиксными.
Очевидно, что стоимость хранения
информации, закодированной при помощи Т-дерева, равна сумме длин путей из корня
к каждому листу дерева, взвешенных частотой соответствующего кодового слова или
длиной взвешенных путей:  , где
, где  - частота
кодового слова длины
- частота
кодового слова длины 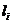 во входном
потоке. Рассмотрим в качестве примера кодировку символов в стандарте ASCII. Здесь
каждый символ представляет собой кодовое слово фиксированной(8 бит) длины,
поэтому стоимость хранения определится выражением
во входном
потоке. Рассмотрим в качестве примера кодировку символов в стандарте ASCII. Здесь
каждый символ представляет собой кодовое слово фиксированной(8 бит) длины,
поэтому стоимость хранения определится выражением 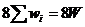 , где W- количество
кодовых слов во входном потоке.
, где W- количество
кодовых слов во входном потоке.
Поэтому стоимость хранения 39
кодовых слов в кодировке ASCII равна 312, независимо от
относительной частоты отдельных символов в этом потоке. Алгоритм Хаффмана
позволяет уменьшить стоимость хранения потока кодовых слов путем такого подбора
длин кодовых слов, который минимизирует длину взвешенных путей. Будем называть
дерево с минимальной длиной путей деревом Хаффмана.
Классический алгоритм Хаффмана
на входе получает таблицу частот встречаемости символов в сообщении. Далее на
основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево).
1. Символы входного
алфавита образуют список свободных узлов. Каждый лист имеет вес, который может
быть равен либо вероятности, либо количеству вхождений символа в сжимаемое
сообщение;
2. Выбираются два
свободных узла дерева с наименьшими весами;
. Создается их родитель
с весом, равным их суммарному весу;
. Родитель добавляется в
список свободных узлов, а два его потомка удаляются из этого списка;
. Одной дуге, выходящей
из родителя, ставится в соответствие бит 1, другой - бит 0;
. Шаги, начиная со
второго, повторяются до тех пор, пока в списке свободных узлов не останется
только один свободный узел. Он и будет считаться корнем дерева.
Допустим, у нас есть следующая
таблица частот, которая изображена на рис. 1.
Рисунок 1 - Таблица частот
На первом шаге из листьев
дерева выбираются два с наименьшими весами - Г и Д. Они присоединяются к новому
узлу- родителю, вес которого устанавливается 5+6= 11. Затем узлы Г и Д
удаляются из списка свободных. Узел Г соответсвует ветви 0 родителя, узел Д-
ветви 1.
На следующем шаге то же происходит
с узлами Б и В, так как теперь эта пара имеет самый меньший вес в дереве.
Создается новый узел с весом 13, а узлы Б и В удаляются из списка свободных.
После всего этого дерево кодирования выглядит так, как показано на рис. 2.

Рисунок 2 - Дерево кодирования Хаффмана после
второго шага
На следующем шаге «наилегчайшей» парой
оказываются узлы Б/В и Г/Д.
Для них еще раз создается родитель, теперь уже с
весом 24. Узел Б/В соответствует ветви 0 родителя, Г/Д - ветви 1.
На последнем шаге в списке свободных осталось
только 2 узла - это узел А и узел Б (Б/В)/(Г/Д). В очередной раз создается
родитель с весом 39, и бывшие свободные узлы присоединяются к разным его
ветвям.
Поскольку свободным остался только один узел, то
алгоритм посотроения дерева кодирования Хаффмана завершается. Окончательное
дерево представлено на рис. 3.

Рисунок 3 - Окончательное дерево кодирования
Хаффмана
Каждый символ, входящий в сообщение, определяется
как конкатенация нулей и единиц, сопоставленных ребрам дерева Хаффмана, на пути
от корня к соответствующему листу.
Для данной таблицы символов коды Хаффмана будут
выглядеть, как показано на рисунке 4.
Рисунок 4 - Коды Хаффмана
Наиболее частый символ сообщения А закодирован
наименьшим количеством бит, а наиболее редкий символ Д - наибольшим. Стоимость
хранения кодированного потока, определенная как сумма длин взвешенных путей,
определится выражением 15*1+7*3+6*3+6*3+5*3=87, что существенно меньше
стоимости хранения входного потока (312).
Поскольку ни один из полученных кодов не
является префиксом другого, они могут быть однозначно декодированы при чтении
их из потока.
Алгоритм декодирования предполагает просмотр
потоков битов и синхронное перемещение от корня вниз по дереву Хаффмана в
соответствии со считанным значением до тех пор, пока не будет достигнут лист,
то есть декодировано очередное кодовое слово, после чего распознавание
следующего слова вновь начинается с вершины дерева.
Классический алгоритм Хаффмана имеет один
существенный недостаток. Для восстановления содержимого сжатого сообщения
декодер должен знать таблицу частот, которой пользовался кодер. Следовательно,
длина сжатого сообщения увеличивается на длину таблицы частот, которая должна
посылаться впереди данных, что может свести на нет все усилия по сжатию
сообщения. Кроме того, необходимость наличия полной частотной статистики перед
началом собственно кодирования требует двух проходов по сообщению: одного для
построения модели сообщения (таблицы частот и дерева Хаффмана), другого- для
собственно кодирования.
2. Среда разработки Delphi
версии 7.0
кодирование хаффман
программа delphi
История возникновения Delphi
уходит своими корнями в далекие 60-е годы прошлого века.
Язык Паскаль (послуживший
основой для написания Delphi),
был разработан профессором Н.Виртом в конце 60-х годов специально для обучения
программированию студентов. В числе студентов этого выдающегося профессора
Цюрихского университета были Ф.Каин и А.Хейлсберг. Каин позднее основал
корпорацию Borland.
Под руководством этих двух студентов язык Паскаль был превращен в мощное
средство разработки программ любой сложности.
Первым продуктом Borland
для семейства Windows
стала среда разработки Delphi
1, она была разработана для создания программ под Windows
3.1.
Появление новой версии Delphi
2 существенно отличило среду разработки от предыдущих продуктов. Данная версия
была разработана ужу под 32-разядные операционные системы Windows
95 и Windows
NT 4.
Следующие версии Delphi
(3, 4, 5, б, 7) являлись следствием постепенного развития среды разработки -
улучшались существующие компоненты, добавлялись новые возможности, большое
внимание уделялось программированию баз данных и программ для глобальной сети Internet.
Так же можно сказать, что Delphi
иногда именуется еще как и Object
Pascal.
Так же одной из инноваций можно
считать интеграция в Delphi
технологии .Net от Microsoft.
Казалось бы, что следующею
версию Delphi логично
было бы назвать 9, а на самом деле она называется Borland
Delphi 2005. Давай те
разберемся почему. Из основных особенностей среды разработки Delphi
2005 можно отметить то, что новая среда разработки объединила в себе весь опыт
программирования и создания специальных продуктов для разработки программною
обеспечения. В Delphi
2005 можно создавать программы для платформы Win32,
а можно создавать программы под перспективную платформу .Net.
Кроме того, до седьмой версии использовался язык программирования основанный на
языкеPascal. В новой
версии осуществлен возможность разработки программ на нескольких языках (Delphi,
C++, Java),
чего раньше не было ни в одной подобно среде разработки. Если так же к
вышеперечисленному добавить, что в Delphi
2005 добавлено много новых компонентов и инструментов, то становиться понятно
почему новая версия вышла под таким специфическим названием.
Версия Delphi 7 (2001 год) стала последней и
наиболее развитой версией среды, реализованной для платформы Win32. В ней, в
частности, появился компилятор для .NET, пока в консольном варианте. Добавилось
множество компонентов и Мастеров, автоматизирующих создание сетевых приложений.
Была продолжена поддержка кроссплатформной технологии создания программ на базе
Delphi и Kylix.
.1 Основные понятия объектно-ориентированного
программирования
Объектно-ориентированное программирование (ООП)
зародилось в языках программирования Паскаль, Ада, С++. До появления ООП
технология создания компьютерных программ базировалась на процедурном
программировании, в котором основой программ являлись функции и процедуры, т.е.
действия. Созданная т.о. компьютерная программа отличалась четким алгоритмом
работы - последовательностью действий по достижению поставленной цели. В ООП
основной точкой опоры при проектировании программы является - объект. Программа
ООП - это не последовательность операторов, а совокупность объектов и способов
их взаимодействия. Обмен информацией между объектами происходит посредством
сообщений.
Объектом назовем понятие, абстракцию или любой
предмет с четко очерченными границами, который имеет смысл в контексте
рассматриваемой прикладной проблемы. Объекты могут наследовать характеристики и
поведение других объектов, называемых родительскими или предками. Наличие
механизма наследования является самым существенным различием между обычным
программированием на Pascal ООП программированием в Delphi.
Взаимодействие между объектами осуществляется с
помощью сообщений. Объект может посылать сообщения другим объектам или
принимать сообщения от них.
Сообщением является совокупность данных
определенного типа, передаваемых объектом-отправителем объекту-получателю, имя
которого указывается в сообщении. Объект-получатель реагирует на сообщение
выполнением некоторого метода, имя которого тоже может быть указано в
сообщении, либо никак не реагирует.
Совокупность данных и методов их чтение и записи
называются свойством. Свойства объектов можно устанавливать в процессе
проектирования, а также можно изменять программно во время выполнения
программы. (В процессе проектирования приложений в среде программирования
Delphi можно просматривать значения некоторых из этих данных в окне Инспектора
Объектов и изменять эти значения).
Основным понятием ООП является понятие класса -
это множество объектов, которые обладают внутренними свойствами, присущими любому
объекту класса. Причем специфика класса проводится путем определения его
внутренних свойств (классообразующие признаки). Он выступает в качестве
объектного типа данных. Классы имеют поля (как тип данных Record), свойства
(напоминающие поля, но имеющие дополнительные описания) и методы (подпрограммы,
которые обрабатывают поля и свойства класса). Базовым классом для всех объектов
в Delphi, является класс TObject. Он инкапсулирует основные функции,
свойственные всем объектам Delphi. Все классы в Delphi являются прямыми или
косвенными наследниками этого класса.
Каждый конкретный класс имеет свои особенности
поведения и характеристики, определяющих этот класс. Например, класс
геометрических фигур можно разделить на два подкласса: плоские и объемные
фигуры. Плоские фигуры могут иметь вершины и не иметь их. Плоскими фигурами, не
имеющими вершин, являются окружности и эллипсы.
Наследование - это отношение между классами, при
котором класс использует структуру или поведение другого класса (одиночное
наследование), или других (множественное наследование) классов. Наследование
вводит иерархию "общее/частное", в которой подкласс наследует от
одного или нескольких более общих суперклассов. Подклассы обычно дополняют или
переопределяют унаследованную структуру и поведение. Наследование - это
средство получения новых типов данных (классов) из уже существующих типов,
называемых базовыми классами. При этом повторно используется существующий код.
Порождённый класс образуется из базового путем добавления или изменения кода.
При этом новый класс сохраняет все свойства старого: данные объекта базового
класса включаются в данные производного объекта , а методы базового класса
могут быть вызваны для объекта производного класса, причем они будут
выполняться над данными включенного в объект базового класса. Иначе говоря,
новый класс наследует как данные старого класса, так и методы их обработки.
3. Описание программы, разработанной в Delphi
7.0
Разработаем программу, на примере, рассмотренном
в пункте 1.
Создадим дерево Хаффмана для выражения
"гааггабабадавввадабгааггабабаддаввваббд".
Суть построения двоичного дерева такова: получив
строку, кодировщик должен создать таблицу частот, то есть список всех символов
с частотой их повторения.
На рабочем поле Form1
создадим кнопки Button1Click, Button2Click и Button3Click под названием
соответственно «Рассчитать таблицу частот», «Кодировка» и «Очистить все»,
добавим таблицу StringGrid1, в которой будет отображаться таблица частот, а так
же создадим поле memo1
и memo2, в которых будут
показаны результаты выражения и кодировки. Еще добавим компонент OpenDialod,
с помощью которого происходит открытие файла. Внешний вид Form1
показан на рисунке 5.
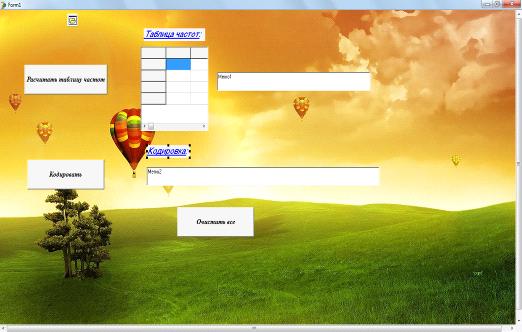
Рисунок 5- Внешний вид Form1
В корневой папке программы создадим текстовый
файл, в котором напишем созданное выражение
«гааггабабадавввадабгааггабабаддаввваббд».
На начальном этапе итерационного цикла создаем
процедуру tablica,
в которой сначала описываем открытие текстового файла следующим образом:
Form1.opendialog1.Filter:='текстовые
файлы|*txt|все|*';Form1.openDialog1.Execute
and
fileexists(Form1.opendialog1.Filename)then.memo1.Lines.LoadFromFile(Form1.openDialog1.FileName)
else MessageDlg('что- то не так с
файлом',mtwarning,[mbOk],0);:=Form1.memo1.text;
На рисунке 6 показано , как программа будет
выглядеть при открытии файла.

Рисунок 6 - Внешний вид программы при открытии
файла
Создание таблицы частот происходит по следующему
принципу: символы, встречающиеся в текстовом файле, выписываются в столбец в
порядке убывания вероятностей (частоты) их появления. Два последних символа
объединяются в один с суммарной вероятностью. Из полученной новой вероятности и
вероятностей новых символов, не использованных в объединении, формируется новый
столбец в порядке убывания вероятностей, а две последние вновь объединяются.
Это продолжается до тех пор, пока не останется одна вероятность, равная сумме
вероятностей всех символов, встречающихся в файле.
Листинг тег-кода таблицы частот:
krs:=0;i:=1 to length(s1) do
begin:=0;j:=1 to krs dos1[i]=s[j] then:=j;jjj>0 then
c[jjj]:=c[jjj]+1begin:=krs+1;[krs]:=s1[i];[krs]:=1;;;.StringGrid1
.colcount:=3;.StringGrid1 .rowcount:=krs+1;i:=1 to krs do
begin.stringgrid1.cells [1,i]:=s[i];.stringgrid1.cells [2,i]:=inttostr(c[i]);;
При нажатии кнопки Button1Click
осуществляется вызов процедуры tablica.
В результате чего происходит считывание текстового файла и загрузка его в поле memo1.
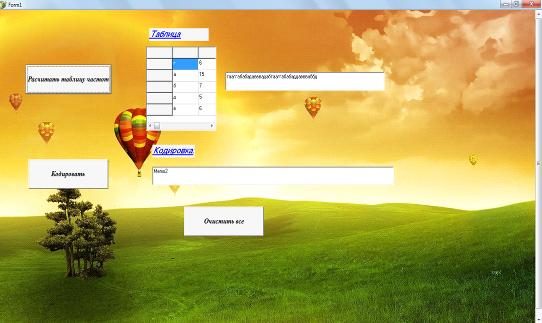
Рисунок 7 - Расчет таблицы частот и заполнение
поля memo1
При этом в корневой папке программы создается
текстовый файл с названием «таблица», в котором отображается рассчитанная
таблица частот. В программе это описано следующим образом:
assignfile(f,'таблица.txt');(f);i:=1
to krs do(f,s[i],' ',inttostr(c[i]));
closefile(f);
Теперь, когда дерево создано, можно вычислить
коды (битовые цепочки для кодирования исходных чисел) и закодировать данные.
Опираясь на рисунок 8, нужно уяснить, что вычисление кода числа начинается от
корня дерева. Для вычисления кода, необходимо, двигаясь по дереву от корня к
числу в исходной таблице, подсчитать число пройденных узлов. Это значение будет
равно длине битовой цепочки кода. И проследить для каждого узла повороты, если
поворот в узле осуществляется налево, то в цепочке битов устанавливается
значение 0, если направо - 1.
Рисунок 8 - Окончательное дерево кодирования
Хаффмана
Длительность передачи каждого отдельного кода
ti, очевидно, может быть найдена следующим образом: ti = ki •  , где ki -
количество элементарных сигналов (бит) в коде символа i. В соответствии с
приведенными выше правилами получаем следующую таблицу кодов:
, где ki -
количество элементарных сигналов (бит) в коде символа i. В соответствии с
приведенными выше правилами получаем следующую таблицу кодов:
|
А
|
01
|
|
Б
|
100
|
|
В
|
101
|
|
Г
|
110
|
|
Д
|
111
|
Рисунок 9 - Кодировка символов
Рассмотрим описание процедуры кодирования:
for i:=1 to krs do
begin[i]:=s[i];[i]:=true;[i]:='';;:=krs;n1:=fmin(krs,c,f);[n1]:=false;:=fmin(krs,c,f);:=rod[n1];:=rod[n2];i:=1
to krs dorod[i]=r1 then begin[i]:='1'+kod[i];[i]:=r2;rod[i]=r2 then kod[i]:='0'+kod[i];[n2]:=c[n2]+c[n1];:=kvo-1;kvo=1;i:=1
to length(s1) doj:=1 to krs do begins1[i]=s[j] then s2:=s2+kod[j];;
Полученный результат записывается в поле memo2:
Form1.memo2.text:=s2;
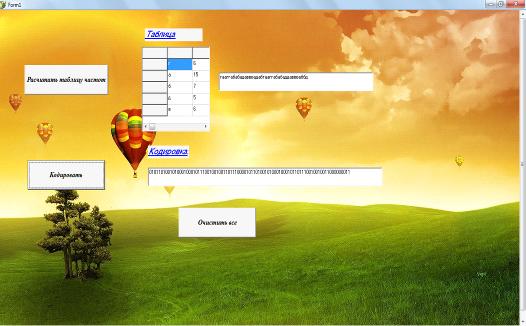
Рисунок 10 - Кодировка выражения
При этом в корневой папке программы создается
текстовый файл с названием «кодировка», в котором отображается рассчитанная
таблица частот. В программе это описано следующим образом:
assignfile(ff,'кодировка.txt');(ff);
writeln(ff,s2);(ff);
Итак, нам удалось сжать выражение, где стоимость
хранения входного потока равна 312бит в 87 бит.
В дополнении к программе, была создана кнопка
«очистить все», которая позволяет очистить таблицу частот, поля memo1
и memo2. Для этого
создана кнопка Button3Click.
Рассмотрим листинг тег-кода:
for i:=0 to Form1.ComponentCount-1
do(Form1.Components[i] is TMemo)then (Form1.Components[i] as
TMemo).Clear;(Form1.Components[i] is TEdit)then (Form1.Components[i] as
TEdit).Text:='';;k := 0 to StringGrid1.RowCount - 1 doj := 0 to
StringGrid1.ColCount - 1 do.Cells[j, k] := '';
Таким образом, при нажатии кнопки «Очистить все»
внешний вид программы станет, как при начальном этапе, изображенном на рисунок
5.
В итоге, корневая папка будет иметь следующие
файлы, показанные на рисунке 11.

Рисунок 11 - Корневая папка
4. Реализация на Delphi метода кодирования
Хаффмана
Листинг программы:
const nmax=250;masbol= Array
[1..1000] of boolean;maschast= Array [1..1000] of integer;: TForm1;
{$R *.dfm}s1:string;:string;: array
[1..nmax] of string;s: array [1..nmax] of char;: array [1..nmax] of char;:
maschast;:byte;tablica;jjj,i,j:integer; var f:textfile;.opendialog1.Filter:='текстовые
файлы|*txt|все|*';Form1.openDialog1.Execute
and
fileexists(Form1.opendialog1.Filename)then.memo1.Lines.LoadFromFile(Form1.openDialog1.FileName)
else MessageDlg('что- то не так с
файлом',mtwarning,[mbOk],0);
s1:=Form1.memo1.text;:=0;i:=1 to
length(s1) do begin:=0;j:=1 to krs dos1[i]=s[j] then:=j;jjj>0 then
c[jjj]:=c[jjj]+1begin:=krs+1;[krs]:=s1[i];[krs]:=1;;;.StringGrid1
.colcount:=3;.StringGrid1 .rowcount:=krs+1;i:=1 to krs do
begin.stringgrid1.cells [1,i]:=s[i];.stringgrid1.cells
[2,i]:=inttostr(c[i]);;(f,'таблица.txt');(f);i:=1
to krs do(f,s[i],' ',inttostr(c[i]));(f);;TForm1.Button1Click(Sender:
TObject);;;fmin(k:integer;v:maschast;f:masbol):integer;imin,min,i:integer;:=32767;:=0;i:=1
to k dof[i] and (min>v[i]) then begin:=v[i];:=i;;:=imin;;TForm1.Button2Click(Sender:
TObject);n1,n2,i,j,kvo:integer;,r2:char;:masbol;:textfile;i:=1 to krs do
begin[i]:=s[i];[i]:=true;[i]:='';;:=krs;n1:=fmin(krs,c,f);[n1]:=false;:=fmin(krs,c,f);:=rod[n1];:=rod[n2];i:=1
to krs dorod[i]=r1 then begin[i]:='1'+kod[i];[i]:=r2;rod[i]=r2 then[i]:='0'+kod[i];[n2]:=c[n2]+c[n1];:=kvo-1;kvo=1;i:=1
to length(s1) doj:=1 to krs do begins1[i]=s[j]
then:=s2+kod[j];;.memo2.text:=s2;(ff,'кодировка.txt');(ff);(ff,s2);(ff);;TForm1.Button3Click(Sender:
TObject);i,k,j :integer;i:=0 to Form1.ComponentCount-1 do(Form1.Components[i]
is TMemo)then (Form1.Components[i] as TMemo).Clear;(Form1.Components[i] is
TEdit)then (Form1.Components[i] as TEdit).Text:='';;k := 0 to
StringGrid1.RowCount - 1 doj := 0 to StringGrid1.ColCount - 1 do.Cells[j, k] :=
'';
end;.
Заключение
В данной курсовой работе была поставлена задача
разработать программу для классического метода кодирования Хаффмана на Delphi
версии 7.0.
Первым такой алгоритм опубликовал Дэвид Хаффман
(David Huffman) [1] в 1952 году. Алгоритм Хаффмана двухпроходный. На первом
проходе строится частотный словарь и генерируются коды. На втором проходе
происходит непосредственно кодирование.
Стоит отметить, что за 50 лет со дня
опубликования, код Хаффмана ничуть не потерял своей актуальности и значимости.
Так с уверенностью можно сказать, что мы сталкиваемся с ним, в той или иной
форме (дело в том, что код Хаффмана редко используется отдельно, чаще работая в
связке с другими алгоритмами), практически каждый раз, когда архивируем файлы,
смотрим фотографии, фильмы, посылаем факс или слушаем музыку.
Кодирование Хаффмана является простым алгоритмом
для построения кодов переменной длины, имеющих минимальную среднюю длину. Этот
весьма популярный алгоритм служит основой многих компьютерных программ сжатия
текстовой и графической информации. Некоторые из них используют непосредственно
алгоритм Хаффмана, а другие берут его в качестве одной из ступеней
многоуровневого процесса сжатия.
Суть данного алгоритма заключается в построении
двоичного дерева с узловыми элементами из символов входного алфавита. И чем
больше вероятность появления символа в тексте, тем ближе он к корню. Каждой
ветви назначается «вес» - битовый ноль или единица. Кодирование каждого символа
осуществляется проходом по дереву и выбором одной из двух ветвей, начиная с
корня дерева и заканчивая листом с нужным символом.
Метод Хаффмана широко используется, но
постепенно вытесняется арифметическим сжатием. Свою роль в этом сыграло то, что
закончились сроки действия патентов, ограничивающих использование
арифметического сжатия. Кроме того, алгоритм Хаффмана не является оптимальным.
Он приближает относительные частоты появления символа в потоке частотами,
представляющими собой отрицательные степени двойки, в то время как
арифметическое сжатие дает лучшую степень приближения частоты.
Литература
1.
Методические указания для студентов, обучающихся на специальности
230700(Информационный сервис). Е.Р. Пантелеев, М.М. Хаджар, 2004, 25 с.;
.
Фундаментальные алгоритмы с структуры данных в Delphi: Пер. с англ. /Джулиан М.
Бакнел. - СПб: ООО «ДиаСофтЮП», 2003.- 560 с.;
.
Жоголев Е.А. Ж. 78 Технология программирования. - Научный Мир, 2004, 216 с.
.
Семенюк В. В. Экономное кодирование дискретной информации. - СПб.: СПб ГИТМО
(ТУ), 2001;
.
Материалы с сайтов:
http://vmg.pp.ua/books/КопьютерыИсети/;
http://www.codenet.ru/progr/alg/huffman/;
-
http://www.getinfo.ru/;
wikipedia.org/;
-
http://udelphi7.gym5cheb.ru/.