Моделирование грузопотока на сортировочном узле
Моделирование грузопотока
на сортировочном узле
Введение
Транспорт наряду с другими отраслями является сферой
материального производства. Продукция транспорта специфична. В отличие от
продукции промышленных, сельскохозяйственных и других предприятий ее нельзя
ощутить физически и накапливать. Она одновременно производится и потребляется.
Продукцией транспорта является перевозка, перемещение грузов и пассажиров. Оно
осуществляется на разных стадиях производственного процесса: от начальной - при
перемещении сырья и материалов, до завершающей - при перемещении готовой
продукции потребителям. Это перемещение, превращая «незавершенный» продукт в
готовое к употреблению изделие, увеличивает его стоимость на сумму транспортных
затрат.
Железнодорожный транспорт занимает ведущее место среди других
видов транспорта. Железные дороги работают непрерывно в течение года и суток,
перевозят как мелкие партии груза, так и массовые потоки леса, топлива,
цемента, металла и других грузов.
Главное назначение железнодорожного транспорта - наиболее
полное удовлетворение предприятий, организаций и населения в перевозках с
обеспечением максимальных удобств, безопасности и сохранности пассажиров и
перевозимых грузов. В основу деятельности железных дорог должны быть положены
интересы клиента - пользователя услугами железнодорожного транспорта.
Клиент, в свою очередь, в условиях жесткой рыночной
конкуренции заинтересован, чтобы либо его продукция, либо продукция ему была бы
доставлена точно в срок, за кратчайшее время, с минимальными затратами, в
заданных объемах и номенклатуре. Понятно, что это вело бы, во-первых, к
уменьшению стоимости хранения товаров на складах отпуска и приема за счет
уменьшения времени хранения товаров и уменьшения размеров резервных запасов на
этих складах. А во-вторых, к снижению прямых издержек на перевозку грузов. В
конечном итоге это позволило бы снизить себестоимость производимых товаров и
долю стоимости их доставки от производителя до потребителя в конечной цене
товара.
Это возможно лишь при четкой, скоординированной работе
железнодорожного транспорта, которая предполагает организацию и осуществление
перевозок товаров неразрывно с накоплением, обработкой и передачей информации
как о самом перевозимом грузе (его виде, объеме, весе, типе и т.д.), так и об
условиях его транспортировки (в чем и как перевозить, условия перевозки и
хранения и т.п.), о маршруте перевозки, об условиях по расчетам за перевозку и
складированию (тарифы), о том, что происходит с грузом во время перевозки и
пр.; а также отлаженную работу сортировочных станций.
Под отлаженной работой сортировочных станций понимается
работа, обеспечивающая минимальное число переработок в пути следования и
простоя под накоплением и переработкой, ускорение доставки грузов и оборот
вагонов, интенсивное использование сортировочных устройств и маневровых средств
и экономичность перевозок.
1. Перевозочный процесс. Значение перевозок
1.1
Логистика на железнодорожном транспорте
Цель системы физического распределения
состоит в снижении затрат, связанных с перемещением готовой продукции от места
производства до места потребления и ее хранением в соответствии с требуемым
уровнем обслуживания потребителя. Цели логистики связаны с координацией
физического распределения и управления материальными ресурсами для снижения
затрат или улучшения обслуживания потребителя.
Основным объектом исследования, управления
и оптимизации в логистике является материальный поток. Информационные,
финансовые, сервисные потоки (так называемые потоки, сопутствующие
материальному) рассматриваются в подчиненном плане как генерируемые исследуемым
материальным потоком.
Логистика - это наука об управлении и
оптимизации материальных потоков, потоков услуг и связанных с ними
информационных и финансовых потоков для достижения поставленных перед ней
целей.
В наиболее общей постановке с позиций
логистики можно исследовать возникновение, преобразование или поглощение
материальных и сопутствующих потоков на определенном экономическом объекте,
функционирующем как система, т.е. реализующем поставленные перед ним цели и
рассматриваемом в этом смысле как единое целое.
Очевидно, что формой существования материальных потоков
должно быть движение конкретных видов продукции (материальных ресурсов,
незавершенного производства, готовой продукции) в процессах закупок,
производства и сбыта. Поэтому материальный поток можно определить как
находящиеся в состоянии движения материальные ресурсы, незавершенное
производство, готовая продукция, к которым применяются логистические операции
или функции, связанные с физическим перемещением в пространстве (погрузка,
разгрузка, затаривание, перевозка продукции, ее сортировка, консолидация,
разукрупнение и т.п.). Под материальными ресурсами мы будем понимать предметы
труда: сырье, основные и вспомогательные материалы, полуфабрикаты,
комплектующие изделия, сборочные единицы, топливо, запасные части,
предназначенные для ремонта и обслуживания технологического оборудования и
других основных фондов, отходы производства. Незавершенное производство - это
продукция, не законченная производством в пределах данного предприятия. Готовая
продукция - это продукция, полностью прошедшая производственный цикл на данном
предприятии, полностью укомплектованная, прошедшая технический контроль,
сданная на склад или отгруженная потребителю.
1.2
Материальные потоки и их параметры
Объектом исследования логистики как науки
является система материальных, информационных, финансовых и других потоков.
Принципиальное отличие логистического подхода от предшествующего ему управления
движением материальных ресурсов состоит в том, что теперь объектом управления
стал поток - множество объектов, воспринимаемое как единое целое.
Основные параметры, характеризующие поток,
следующие: начальный и конечный пункты, геометрия пути (траектория), длина пути
(мера траектории), скорость и время движения, промежуточные пункты,
интенсивность. Для работы с потоками необходима хотя бы самая простая
классификация. Остановимся на рассмотрении лишь тех характеристик, которые в
полной и достаточной степени описывают исследуемый материальный поток.
По отношению к рассматриваемой системе
исследуемый поток можно определить как внешний, т.к. он поступает в систему
извне и покидает ее пределы (рис. 1.1).
Внешний поток

Рис. 1.1
По степени непрерывности - дискретный,
т.к. он образуется объектами в виде отдельных грузов, перемещаемыми с
интервалами:
Р = 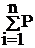 i (1.1)
i (1.1)
По степени регулярности поток можно классифицировать как
стохастический, потому что он характеризуется случайным характером параметров,
которые в каждый момент времени принимают определенную величину с известной
степенью вероятности:
Рf = fi = 1 (1.2)
Говоря о стабильности, хочется отметить, что поток подвержен
влиянию внешней среды. Различного рода задержки, связанные с нарушением графика
движения поездов, с авариями, крушениями, с нарушением ритма
погрузочно-разгрузочных работ и пр., вносят некоторые элементы нестабильности.
По степени периодичности: поток характеризуется постоянством
параметров через определенный период времени Т. Другое дело, что сам период
изменяется в заданном интервале.
p = f(T); (1.3)
По степени сложности: здесь определение не может быть однозначным.
Как известно, простые (дифференцированные) потоки состоят из
объектов одного вида, а сложные (интегрированные) потоки объединяют разнородные
объекты. В нашем случае отдельные простые потоки от отдельных отправителей в
месте обработки превращаются в сложный, получающийся суперпозицией простых:
р =  i (1.4)
i (1.4)
По степени управляемости: если говорить о системе управления этим
потоком, то величина управления определяется параметрами этого потока.
Но в рамках предложенной работы рассматриваются только параметры
создания модели материального потока в месте ее обработки. Вопрос же
управляющего воздействия со стороны системы управления в зависимости от
параметров опущен, т.е. мы определяем вход в систему управления и все. Другими
словами, мы говорим только о величине входного потока.
Итак, материальный поток - это продукция (в виде грузов, деталей,
товарно-материальных ценностей), рассматриваемая в процессе приложения к ней
различных логистических (транспортировка, складирование и др.) и
технологических (механообработка, сборка и др.) операций и отнесенная к
определенному временному интервалу.
Материальный поток внешний - материальный поток, протекающий во
внешней (по отношению к логистической системе) среде.
Материальный поток внутренний - материальный поток внутри данной
логистической системы.
Материальный поток входной - внешний материальный поток,
поступающий в данную логистическую систему из внешней среды.
Материальный поток выходной - внешний материальный поток,
поступающий из данной логистической системы во внешнюю среду.
Грузовой поток - количество грузов, перевезенных отдельными видами
транспорта в определенном направлении от пункта отправления до пункта
назначения за определенный период (обычно за год).
1.3
Организация и управление эксплуатационной работой
Железнодорожный транспорт занимает ведущее место среди других
видов транспорта. Железные дороги работают непрерывно в течение года и суток,
перевозят огромное количество грузов, вызывая бесконечное перемещение
материальных потоков.
Для оценки деятельности железных дорог используют
количественные и качественные показатели. Количественные показатели
характеризуют объемы перевозок пассажиров и грузов, а также работу подвижного
состава. К ним относятся: число перевезенных пассажиров, пассажирооборот, число
погруженных и выгруженных вагонов (погрузка и выгрузка), грузооборот, пробеги
вагонов, локомотивов, поездов, грузонапряженность и др.
Качественные показатели характеризуют
использование подвижного состава. К ним относятся: скорость движения поездов,
оборот вагона, среднесуточный пробег и производительность вагонов и
локомотивов, нагрузка вагона, производительность труда, стоимость перевозок.
Производительность труда и себестоимость
перевозок - это обобщающие показатели работы железных дорог, которые
характеризуют экономическую сторону эксплуатационной работы. Производительность
труда выражается числом тонно-километров нетто, приходящимся в среднем на
одного работника за единицу времени, например, за год, месяц. Себестоимость
перевозок - это сумма всех затрат, приходящихся на 10 т-км грузовых или 10
пасс-км пассажирских перевозок.
Основная работа по организации
перевозочного процесса выполняется на станциях: промежуточных, участковых,
сортировочных, грузовых и пассажирских. Здесь выполняются начальные и конечные
операции перевозочного процесса, сосредоточен основной контингент работников,
связанных с движением поездов и организацией перевозочного процесса.
1.4
Технология переработки вагонов на сортировочных станциях
Сортировочные станции предназначены для
массового расформирования и формирования грузовых поездов. При этом выполняется
техническое обслуживание составов перед расформированием и перед отправлением
поездов, а также смена локомотивов и локомотивных бригад. Кроме того, на
сортировочных станциях выполняются грузовые операции на грузовых пунктах
подъездных путей и станции.
Сортировочные станции размещаются в
крупных пунктах зарождения и погашения значительных вагонопотоков: транзитных
без переработки, транзитных с переработкой и местных.
Транзитные поезда без переработки принимаются
на специальные пути для транзитных поездов, проходят техническое и коммерческое
обслуживание, смену локомотивов и бригад.
Транзитные с переработкой и местные
вагонопотоки прибывают в виде поездов, подлежащих расформированию. Транзитные с
переработкой после накопления вагонопотока формируются в новые поезда и
отправляются по назначению. Местные поступают на грузовые пункты, проходят
грузовые операции, после чего в составах своего формирования отправляются по
назначению.
Для переработки вагонопотоков станции
имеют соответствующие устройства: парк прибытия (ПП), сортировочная горка (Г),
сортировочный парк (СП), вытяжные пути, парк отправления (ПО), грузовые пункты,
локомотивное и вагонное депо и др. Предпочтительнее последовательное
расположение основных парков: ПП, СП, ПО. Крупные сортировочные станции могут
иметь 2 сортировочные системы, включающие в себя перечисленные основные парки и
горку. В этом случае станция называется двухсторонней. Могут быть также станции
с параллельным и комбинированным расположением парков.
Для расформирования составов между парками
приема и сортировочным располагается сортировочная горка, представляющая собою
возвышение, с которого отдельные вагоны или группы вагонов, называемые
отцепами, скатываются под действием силы тяжести на разные пути сортировочного
парка по своим назначениям.
Процесс расформирования-формирования
составов на горке наиболее сложный и интенсивный, поэтому горка оснащена
комплексом средств автоматизации, включающим в себя горочную автоматическую
централизацию, устройства автоматизированного регулирования скорости роспуска и
др.
О поездах, прибывающих на станцию в
расформирование, поступает информация в виде телеграмм-натурных листов. При
подходе поезда дежурный по станции извещает работников, участвующих в
обработке. Телетайпист, находящийся во входной горловине парка прибытия,
списывает номера вагонов и передает в станционный технологический центр (СТЦ),
где они сверяются с данными ранее полученной телеграммы-натурного листа и
документами, поступившими с поезда. Техническое обслуживание состава начинается
при движении прибывающего поезда и продолжается после его остановки,
закрепления и отцепки поездного локомотива. При осмотре состава выявляются
технические и коммерческие неисправности, которые нельзя устранить немедленно.
Информация о таких вагонах передается в СТЦ для корректировки сортировочного
листа.
По окончании технического и коммерческого
осмотров вагонов установленное ранее ограждение снимают, к составу прицепляется
горочный локомотив и состав надвигается вагонами вперед на горку для
расформирования. Расформированием, в котором участвуют горочные операторы,
составители, расцепляющие состав, машинисты горочных локомотивов, руководит
дежурный по горке. В процессе расформирования на путях сортировочного парка
происходит накопление новых составов в соответствии с назначениями плана
формирования.
При накоплении вагонов на полный состав
согласно норме маневровый диспетчер, который руководит работой всей станции,
планирует и регулирует процесс составообразования, дает указание дежурному по
парку формирования или составителю о формировании поезда. При этом вагоны
сортируются по группам, которые затем объединяются (при формировании группового
или сборного поезда). Между вагонами с опасными или негабаритными грузами, а
также вагонами с людьми и другими вагонами в поезде в соответствии с правилами
должны быть представлены порожние вагоны. После окончания формирования состав
переставляется в парк отправления, где производятся технический и коммерческий
осмотры состава и устранение обнаруженных неисправностей. При перестановке
состава телетайпист поста, расположенного между сортировочным парком и парком
отправления, списывает номера вагонов и передает их в СТЦ и в
информационно-вычислительный центр, на основании чего составляется натурный
лист на отправляемый поезд.
После окончания осмотра и ремонта вагонов
снимается ограждение, навешиваются хвостовые сигналы, к составу прицепляется
поездной локомотив, производится проба тормозов, машинисту вручаются
перевозочные документы и справка о тормозах и поезд отправляется. Об
отправлении поезда дежурный по станции парка отправления сообщает поездному
диспетчеру с указанием номера поезда и локомотива, времени отправления,
назначения состава, массы, числа вагонов и условной длины.
Вагоны, с которыми на станциях выполняются
грузовые операции, называются местными. С этими вагонами связаны начальные и
конечные операции перевозочного процесса, т.е. погрузка и выгрузка грузов.
Местные вагоны поступают на станцию в
составах, прибывающих в расформирование, отправляются в поездах своего
формирования после выполнения грузовых операций. В процессе обработки они
проходят те же операции, что и транзитные с переработкой с добавлением
операций, связанных с погрузкой и выгрузкой. Местные вагоны могут проходить
одну операцию - только погрузку (или только выгрузку) или две операции -
выгрузку, а затем погрузку.
В процессе расформирования состава местные
вагоны направляются на специальный путь сортировочного парка, где они
накапливаются для подачи к местам погрузки и выгрузки. Документы на них
передаются в товарную контору. Подаются вагоны под выгрузку или погрузку по
установленному заранее графику или оперативному плану по указанию маневрового
диспетчера или дежурного по станции. После окончания грузовых операций местные
вагоны убирают от грузовых фронтов и направляют на соответствующие пути
сортировочного парка согласно назначениям погрузки. Документы из товарной
конторы передаются в СТЦ для накопления в соответствии с планом формирования.
Перед подачей под погрузку при техническом
и коммерческом осмотрах устанавливается пригодность вагонов для перевозки
груза. На каждую отправку груза - мелкую, повагонную или маршрутную, а также
комплект контейнеров грузоотправитель составляет накладную - основной грузовой
перевозочный документ. Накладная сопровождает груз на всем пути следования и
выдается грузополучателю вместе с грузом на станции назначения.
1.5
План формирования вагонопотоков
На сети дорог тысячи станций принимают,
грузят и отправляют грузы в самые разные пункты. Загруженные и подготовленные к
отправлению вагоны должны быть сформированы в поезда и как можно быстрее
доставлены к месту назначения. Вагоны включают в поезда по определенной
системе, обеспечивающей минимальные число переработок в пути следования и
простоя под накоплением и переработкой, ускорение доставки грузов и оборот
вагонов, интенсивное использование сортировочных устройств и маневровых средств
и экономичность перевозок. Все это достигается правильным распределением
сортировочной работы между станциями.
При разработке указанной системы
необходимы данные о размерах перевозок, такие как грузопоток, вагонопоток.
Грузопоток - это масса груза в тоннах,
отправляемая станцией в каком-либо направлении за определенное время (сутки,
месяц, год).
Вагонопоток - число вагонов, следующих по
линии в каком-либо направлении за определенный промежуток времени, обычно за
сутки. Среднесуточное число вагонов на одной станции или участке назначением на
другую станцию или участок называют струей вагонопотока. Число вагонов в каждой
струе вагонопотока зависит от рода перевозимого груза, грузоподъемности вагонов
и ее использования.
Вагонопотоки определяют среднесуточным
числом вагонов со всеми родами грузов или с одним грузом - при выполнении
частных расчетов (определение количества отправительских маршрутов,
установление вместимости погрузочно-разгрузочных фронтов и др.). Имея данные о
груженых вагонопотоках, устанавливают также размеры порожних вагонопотоков. На
основании этого определяют размеры движения, рассчитывают пропускную и
перерабатывающую способности железнодорожных устройств, строят графики
движения. Результаты расчетов вагонопотоков изображают в виде диаграмм и косой
таблицы, а также ступенчатого графика вагонопотоков по направлениям движения.
Организация вагонопотоков, устанавливающая
наиболее рациональный путь следования груженых и порожних вагонопотоков по
направлениям сети, устанавливается в итоге планом формирования поездов, который
утверждается МПС или начальником дороги (для местных вагонопотоков). План
формирования устанавливает род и назначение поездов и групп вагонов,
формируемых станциями. В нем для каждой станции указываются категории
отправляемых поездов, станции их расформирования и назначения вагонов,
включаемых в составы, род подвижного состава поездов из порожних вагонов.
План формирования предусматривает
группировку вагонов в поезда по назначениям следования (до одной и той же
станции выгрузки или расформирования) или по роду подвижного состава (для
порожних поездов). Порядок формирования составов из вагонов определенных
назначений называется специализацией поездов. Грузовые поезда классифицируют по
условиям формирования, дальности следования и роду перевозок, состоянию
включаемых в них вагонов, числу групп в составе.
По условиям формирования грузовые поезда
делятся на отправительские и ступенчатые маршруты, организуемые на станциях
погрузки, а также поезда, формируемые на сортировочных, участковых и грузовых
станциях без участия грузоотправителей (технические маршруты).
Отправительские маршруты формируют из
вагонов, погруженных одним или несколькими грузоотправителями на подъездных
путях или в местах общего пользования. Ступенчатые маршруты могут быть
организованы как одним отправителем на нескольких станциях, так и несколькими отправителями
на одной или нескольких станциях или подъездных путях. Отправительские и
ступенчатые маршруты следуют либо на одну станцию или участок, либо в
«распыление», т.е. расформировываются на какой-то сортировочной станции и затем
развозятся местными поездами к местам выгрузки.
По дальности следования и роду перевозок
грузовые поезда могут быть скорые и ускоренные, сквозные, участковые, сборные,
вывозные, передаточные, хозяйственные. Скорые и ускоренные имеют обычно
уменьшенную норму массы и длины и повышенную маршрутную скорость, например,
рефрижераторные и контейнерные поезда, поезда для перевозки скоропортящихся и
других грузов, требующих срочной доставки.
Сквозные поезда проходят без переработки
через одну или несколько участковых или сортировочных станций; участковые
следуют без изменения состава по одному участку; сборные предназначены для
развоза и сбора вагонов по промежуточным станциям участка; вывозные поезда
отправляют с сортировочных и участковых станций до некоторых промежуточных
станций и обратно; передаточные поезда служат для передачи вагонов между
станциями железнодорожного узла.
По состоянию включаемых вагонов поезда
делятся на груженые, порожние и комбинированные (из груженых и порожних
вагонов), а по числу групп в составе - на одногруппные и групповые.
План формирования разрабатывают по двум
основным направлениям: организация отправительских и ступенчатых маршрутов с
мест погрузки, и организация технических маршрутов с сортировочных и участковых
станций.
При маршрутных перевозках учитывают
достаточность погрузочно-выгрузочных средств у отправителей и получателей.
Дополнительные затраты на организацию маршрутов по сравнению с немаршрутным
отправлением на станциях погрузки и выгрузки не должны превышать экономии в
пути следования от проследования маршрутов без переработки на сортировочных и
участковых станциях. Значительный эффект дает маршрутизация технологических
перевозок, например, угля, железной руды и других массовых грузов. Широкое
применение при этом находят так называемые кольцевые маршруты.
При организации вагонопотоков с
технических станций (составлении плана формирования поездов на сортировочных и
участковых станциях) необходимо достичь рациональной организации в поезда
вагонопотоков, не охваченных отправительской маршрутизацией, т.е. такого
распределения переработки вагонов между сортировочными и участковыми станциями,
при котором достигается быстрейшая доставка грузов с наименьшими затратами
средств. Вначале составляется план формирования одногруппных поездов, а затем
выявляют возможность его улучшения групповой специализацией.
План формирования устанавливает
назначения, в которые станция должна формировать поезда. Назначением плана
формирования называется конечная станция, где состав поезда подвергается
расформированию. Для каждого направления, примыкающего к технической станции,
может быть выделено от одного до нескольких назначений. Чем больше число
назначений плана формирования, тем больше вагонов простаивает в ожидании
поступления замыкающих групп, следовательно, увеличение числа назначений
вызывает увеличение простоя вагонов под накоплением. Зато появляется
возможность формировать больше поездов на дальние расстояния без переработки на
нескольких технических станциях.
2. Моделирование - инструмент исследования сложных объектов
систем массового обслуживания
В настоящее время нельзя назвать область человеческой
деятельности, в которой в той или иной степени не использовались бы методы
моделирования. Особенно это относится к сфере управления различными системами,
где основными являются процессы принятия решений на основе получаемой
информации.
Замещение одного объекта другим с целью получения информации
о важнейших свойствах объекта-оригинала с помощью объекта-модели называется
моделированием.
Моделирование базируется на некоторой аналогии реального и
мысленного эксперимента. Аналогия − основа для объяснения изучаемого
явления, однако, критерием истины может служить только практика, только опыт.
Хотя современные научные гипотезы могут создаваться чисто теоретическим путём,
но по сути базируются на широких теоретических знаниях. Для объяснения реальных
процессов выдвигаются гипотезы, для подтверждения которых ставится эксперимент.
В широком смысле под экспериментом можно понимать некоторую процедуру
организации и наблюдения каких-то явлений, которые осуществляют в условиях,
близких к естественным, либо имитируют их.
Различают пассивный эксперимент, когда исследователь
наблюдает протекающий процесс, и активный, когда наблюдатель вмешивается и
организует протекание процесса. Естественно, что предпочтение отдаётся второму
виду эксперимента, поскольку именно на его основе удаётся выявить критические
ситуации, получить наиболее интересные закономерности, обеспечить возможность
повторения эксперимента в различных точках и т.д.
2.1
Общая характеристика проблемы моделирования систем
В основе моделирования лежат информационные процессы,
поскольку само создание модели базируется на информации о реальном объекте. В
процессе реализации модели получается информация о данном объекте, одновременно
в процессе эксперимента с моделью вводится управляющая информация, существенное
место занимает обработка полученных результатов, т.е. информация лежит в основе
всего процесса моделирования.
Таким образом, моделирование может быть определено как
представление объекта моделью для получения информации об этом объекте путём
проведения экспериментов с его моделью.
Надо иметь в виду, что любой эксперимент может иметь
существенное значение только при специальной его обработке и обобщении.
Единичный эксперимент никогда не может быть решающим для подтверждения
гипотезы, проверки теории.
При системном подходе к моделированию систем необходимо
прежде всего четко определить цель моделирования. Поскольку невозможно
полностью смоделировать реально функционирующую систему (систему-оригинал),
создается модель под поставленную проблему. Таким образом, применительно к
вопросам моделирования цель возникает из требуемых задач моделирования, что
позволяет в конечном итоге правильно подойти к выбору критерия и оценить, какие
элементы войдут в создаваемую модель.
Применительно к нашей работе цель определяется как создание
модели грузопотока на сортировочном узле. При этом учитываются следующие важные
моменты, необходимые для создания точной, правдоподобной модели, максимально
приближенной к реальному объекту:
количество различных грузов и интенсивность их прохождения
различны;
исследуемый материальный поток характеризуется следующими
свойствами: сложный, стохастический, дискретный, нестабильный.
Если цель моделирования ясна, то возникает следующая
проблема, а именно проблема построения модели, которое оказывается возможным,
если имеется информация или выдвинуты гипотезы относительно структуры,
алгоритмов и параметров исследуемого объекта. На основании их изучения
осуществляется идентификация объекта. В настоящее время широко применяют
различные способы оценки параметров: по методу наименьших квадратов, по методу
максимального правдоподобия, байесовские, марковские оценки.
2.2
Классификация видов моделирования систем
В основе моделирования лежит теория подобия, которая
утверждает, что абсолютное подобие может иметь место лишь при замене одного
объекта другим точно таким же. При моделировании абсолютное подобие не имеет
место и стремятся к тому, чтобы модель достаточно хорошо отображала исследуемую
сторону функционирования объекта. Поэтому в качестве одного из первых признаков
классификации видов моделирования можно выбрать степень полноты модели и
разделить модели в соответствии с этим признаком на полные, неполные и
приближенные. В основе полного моделирования лежит полное подобие, которое
проявляется как во времени, так и в пространстве. Для неполного моделирования
характерно неполное подобие модели изучаемому объекту. В основе приближенного
моделирования лежит приближенное подобие, при котором некоторые стороны
функционирования реального объекта не моделируются совсем.
В зависимости от характера изучаемых процессов в системе все
виды моделирования могут быть разделены на детерминированные и стохастические,
статические и динамические, дискретные, непрерывные и дискретно-непрерывные.
Детерминированное моделирование отображает детерминированные процессы, т.е.
процессы, в которых предполагается отсутствие всяких случайных воздействий;
стохастическое моделирование отображает вероятностные процессы и события. В
этом случае анализируется ряд реализаций случайного процесса и оцениваются
средние характеристики, т.е. набор однородных реализаций. Статическое
моделирование служит для описания поведения объекта в какой-либо момент
времени, а динамическое моделирование отражает поведение объекта во времени.
Дискретное моделирование служит для описания процессов, которые предполагаются
дискретными, соответственно непрерывное моделирование позволяет отразить непрерывные
процессы в системах, а дискретно-непрерывное моделирование используется для
случаев, когда хотят выделить наличие как дискретных, так и непрерывных
процессов.
2.3
Основные подходы к построению математических моделей систем
Для исследования характеристик процесса функционирования
любой системы математическими методами, включая машинные, должна быть проведена
формализация этого процесса, т.е. построена математическая модель.
Исходной информацией при построении математических моделей
процессов функционирования систем служат данные о назначении и условиях работы
исследуемой (проектируемой) системы S. Эта информация определяет основную цель
моделирования системы S и позволяет сформулировать требования к разрабатываемой
математической модели М. Причём уровень абстрагирования зависит от круга тех
вопросов, на которые исследователь системы хочет получить ответ с помощью
модели, и в какой-то степени определяет выбор математической схемы.
Математическую схему можно определить как звено при переходе
от содержательного к формальному описанию процесса функционирования системы с
учётом воздействия внешней среды, т.е. имеет место цепочка «описательная модель
− математическая схема − математическая модель».
Каждая конкретная система S характеризуется набором
свойств, под которыми понимаются величины, отражающие поведение моделируемого
объекта (реальной системы) и учитывающие условия её функционирования во
взаимодействии с внешней средой Е. При построении математической модели системы
необходимо решить вопрос об её полноте. Полнота модели регулируется, в
основном, выбором границы «система S − среда Е». Также должна быть решена задача
упрощения модели, которая помогает выделить основные свойства системы, отбросив
второстепенные. Причём отнесение свойств системы к основным или второстепенным
существенно зависит от цели моделирования системы.
Под математическим моделированием будем понимать процесс
установления соответствия данному реальному объекту некоторого математического
объекта, называемого математической моделью, и исследование этой модели,
позволяющее получать характеристики рассматриваемого реального объекта. Вид
математической модели зависит как от природы реального объекта, так и от задач
исследования объекта и требуемой достоверности и точности решения этой задачи. Любая
математическая модель, как и всякая другая, описывает реальный объект лишь с
некоторой степенью приближения к действительности. Математическое моделирование
для исследования характеристик процессам функционирования систем можно
разделить на аналитическое, имитационное и комбинированное.
Для аналитического моделирования характерно то, что процессы
функционирования элементов системы записываются в виде некоторых функциональных
соотношений (алгебраических, интегрально-дифференциальных, конечно-разностных и
т.п.) или логических условий. Аналитическая модель может быть исследована
следующими методами: а) аналитическим, когда стремятся получить в общем виде
явные зависимости для искомых характеристик; б) численным, когда, не умея
решать уравнений в общем виде, стремятся получить числовые результаты при
конкретных начальных данных; в) качественным, когда, не имея решения в явном
виде, можно найти некоторые свойства решения (например, оценить устойчивость
решения).
Наиболее полное исследование процесса функционирования
системы можно провести, если известны явные зависимости, связывающие искомые
характеристики с начальными условиями, параметрами и переменными системы S. Однако такие
зависимости удаётся получить только для сравнительно простых систем. При
усложнении систем исследование их аналитическим методом наталкивается на
значительные трудности, которые часто бывают непреодолимыми. Поэтому, желая
использовать аналитический метод, в этом случае идут на существенное упрощение
первоначальной модели, чтобы иметь возможность изучить хотя бы общие свойства
системы. Такое исследование на упрощенной модели аналитическим методом помогает
получить ориентировочные результаты для определения более точных оценок другими
методами. Численный метод позволяет исследовать по сравнению с аналитическим
методом более широкий класс систем, но при этом полученные решения носят
частный характер.
При имитационном моделировании реализующий модель алгоритм
воспроизводит процесс функционирования системы во времени, причем имитируются
элементарные явления, составляющие процесс, с сохранением их логической
структуры и последовательности протекания во времени, что позволяет по исходным
данным получить сведения о состояниях процесса в определённые моменты времени,
дающие возможность оценить характеристики системы S.
Основным преимуществом имитационного моделирования по
сравнению с аналитическим является возможность решения более сложных задач.
Имитационные модели позволяют достаточно просто учитывать такие факторы, как
наличие дискретных и непрерывных элементов, нелинейные характеристики элементов
системы, многочисленные случайные воздействия и др., которые часто создают
трудности при аналитических исследованиях. Имитационное моделирование −
зачастую единственный практически доступный метод получения информации о
поведении системы, особенно на этапе её проектирования.
2.4
Организация машинного моделирования систем
Сегодня наиболее эффективным методом исследования больших
систем является машинное моделирование. Моделирование с использованием средств
вычислительной техники позволяет исследовать механизм явлений, протекающих в
реальном объекте с большими или малыми скоростями, когда в натурных
экспериментах трудно (или невозможно) проследить за изменениями, происходящими
в течение короткого времени, или когда получение достоверных результатов
сопряжено с длительным экспериментом. При необходимости машинная модель дает
возможность как бы «растягивать» или «сжимать» реальное время, так как машинное
моделирование связано с понятием системного времени, отличного от реального.
Существуют общие положения, применяемые ко всем случаям
машинного моделирования. Даже в тех случаях, когда конкретные способы
моделирования отличаются друг от друга и имеются различные модификации моделей,
в практике моделирования систем можно сформулировать общие принципы, которые
могут быть положены в основу методологии машинного моделирования
Процесс моделирования системы S сводится к выполнению
подэтапов, сгруппированных в виде трех этапов: построение концептуальной модели
системы и ее формализация; алгоритмизация модели системы и ее машинная
реализация; получение и интерпретация результатов моделирования системы.
На этапе построения концептуальной модели Мк и ее
формализации проводится исследование моделируемого объекта с точки зрения
выделения основных составляющих процесса его функционирования, определяются
необходимые аппроксимации и получается обобщенная схема модели S, которая преобразуется в
машинную модель Мм на втором этапе моделирования путем
последовательной алгоритмизации и программирования модели. Последний третий
этап моделирования системы сводится к проведению согласно полученному плану
рабочих расчетов с использованием выбранных программно-технических средств,
получению и интерпретации результатов моделирования системы S с учетом воздействия
внешней среды Е. Очевидно, что при построении модели и ее машинной реализации
при получении новой информации возможен пересмотр ранее принятых решений, то
есть процесс моделирования является итерационным. Рассмотрим содержание каждого
из этапов более подробно.
2.4.1
Построение концептуальной модели
На первом этапе машинного моделирования - построения
концептуальной модели Мк системы S - формулируется модель и
строится ее формальная схема, т.е. основным назначением этого этапа является
переход от содержательного описания объекта к ее математической модели, другими
словами, процессу формализации.
Модель должна быть адекватной, иначе невозможно получить
положительные результаты моделирования, т.е. исследование процесса
функционирования системы на неадекватной модели вообще теряет смысл.
Далее дается четкая формулировка задачи исследования
конкретной системы S и основное внимание уделяется таким вопросам, как признание
существования задачи и необходимости машинного моделирования, выбор методики
решения задачи с учетом имеющихся ресурсов, определение масштаба задачи и
возможности разбиения ее на подзадачи.
Необходимо также ответить на вопрос о приоритетности решения
различных подзадач, оценить эффективность возможных математических методов и
программно-технических средств их решения. Тщательная проработка этих вопросов
позволяет сформулировать задачу исследования и приступить к ее реализации. При
этом возможен пересмотр начальной постановки задачи в процессе моделирования.
Проведение анализа задачи моделирования способствует
преодолению возникающих в дальнейшем трудностей при ее решении методом
моделирования. На рассматриваемом этапе основная работа сводится именно к
проведению анализа, включая: выбор критериев оценки эффективности процесса функционирования
системы S;
выбор возможных методов идентификации; выполнение предварительного анализа
содержания второго этапа алгоритмизации модели системы и ее машинной
реализации.
После постановки задачи моделирования системы S определяются требования к
информации, из которой получают качественные и количественные исходные данные,
необходимые для решения этой задачи. Эти данные помогают глубоко разобраться в
сущности задачи, методах ее решения.
При этом необходимо помнить, что именно от качества исходной
информации об объекте моделирования существенно зависят как адекватность
модели, так и достоверность результатов моделирования.
Для этого же этапа характерно выдвижение гипотез и принятие
предположений. Гипотезы при построении модели системы S служат для заполнения
«пробелов» в понимании задачи исследователем. Выдвигаются также гипотезы
относительно возможных результатов моделирования системы S, справедливость которых
проверяется при проведении машинного эксперимента. Предположения
предусматривают, что некоторые данные неизвестны или их нельзя получить.
Предположения могут выдвигаться относительно известных данных, которые не
отвечают требованиям решения поставленной задачи. Предположения дают
возможность провести упрощения модели в соответствии с выбранным уровнем
моделирования. При выдвижении гипотез и принятии предположений учитываются
следующие факторы: объем имеющейся информации для решения задачи; подзадачи,
для которых информация недостаточна; ограничения на ресурсы времени для решения
задачи; ожидаемые результаты моделирования.
Таким образом, в процессе работы с моделью системы S возможно многократное
возвращение к этому подэтапу в зависимости от полученных результатов
моделирования и новой информации об объекте.
Для оценки качества процесса функционирования моделируемой
системы S
необходимо выбрать некоторую совокупность критериев оценки эффективности, т.е.
в математической постановке задача сводится к получения соотношения для оценки
эффективности как функции параметров и переменных системы. Эта функция
представляет собой поверхность отклика в исследуемой области изменения
параметров и переменных и позволяет определить реакцию системы.
На этапе построения концептуальной модели осуществляется
определение процедур аппроксимации.
Для аппроксимации реальных процессов, протекающих в системе S, обычно использую три
вида процедур: детерминированную, вероятностную, определения средних значений.
При детерминированной процедуре результаты моделирования
однозначно определяются по данной совокупности входных воздействий, параметров
и переменных системы S. В этом случае отсутствуют случайные элементы, влияющие на
результаты моделирования. Вероятностная процедура применяется в том случае,
когда случайные элементы влияют на характеристики процесса функционирования системы
S и когда необходимо
получить информацию о законах распределения выходных переменных. Процедура
определения средних значений используется тогда, когда при моделировании
системы интерес представляют средние значения выходных переменных при наличии
случайных элементов.
И, наконец, описание концептуальной модели системы. На этом
подэтапе построения модели системы описывается концептуальная модель Мк
в абстрактных терминах и понятиях; дается описание модели с использованием
типовых математических схем; принимается выбор процедуры аппроксимации реальных
процессов при построении модели. Таким образом, на этом подэтапе проводится
подробный анализ задачи, рассматриваются возможные методы ее решения и дается
детальное описание концептуальной модели Мк, которая затем
используется на втором этапе моделирования.
2.4.2
Алгоритмизация модели и ее машинная реализация
На этом этапе математическая модель, сформированная на первом
этапе, воплощается в конкретную машинную модель. Этот этап представляет собой
этап практической деятельности, направленной на реализацию идей и
математических схем в виде машинной модели Мк процесса
функционирования системы S.
Удобной формой представления логической структуры моделей
процессов функционирования систем и машинных программ является схема. На
различных этапах моделирования составляются обобщенные и детальные логические
схемы моделирующих алгоритмов, а также схемы программ.
Логическая схема моделирующего алгоритма представляет собой
логическую структуру модели процесса функционирования системы. Она указывает
упорядоченную во времени последовательность логических операций, связанных с
решением задачи моделирования.
Схема программы отображает порядок программной реализации
моделирующего алгоритма с использованием конкретного математического
обеспечения. Схема программы представляет собой интерпретацию логической схемы
моделирующего алгоритма разработчиком программы на базе конкретного
алгоритмического языка.
Обобщенная схема моделирующего алгоритма задает общий порядок
действий при моделировании системы без каких-либо уточняющих деталей. Она
показывает, что необходимо выполнить на очередном шаге моделирования, например,
обратиться к датчику случайных чисел.
Детальная схема моделирующего алгоритма содержит уточнения,
отсутствующие в обобщенной схеме. Она показывает не только, что необходимо
выполнить на очередном шаге моделирования, но и как это выполнить.
Построение логической схемы модели. Рекомендуется строить
модель по блочному принципу, т.е. в виде некоторой совокупности стандартных блоков.
Построение модели системы из таких блоков обеспечивает необходимую гибкость в
процессе ее эксплуатации, особенно на стадии машинной отладки. При построении
блочной модели проводится разбиение процесса функционирования системы на
отдельные достаточно автономные подпроцессы. Таким образом, модель
функционально подразделяется на подмодели, каждая из которых в свою очередь
может быть разбита на еще более мелкие элементы. Блоки такой модели бывают двух
типов: основные и вспомогательные. Каждый основной блок соответствует
некоторому реальному подпроцессу, имеющему место в моделируемой системе S, а вспомогательные блоки
представляют собой лишь составную часть машинной модели, они не отражают
функции моделируемой системы и необходимы лишь для машинной реализации,
фиксации и обработки результатов моделирования.
Наличие логической схемы модели позволяет построить схему
программы, которая должна отражать разбиение модели на блоки, подблоки;
особенности программирования модели; проведение необходимых изменений; возможности
тестирования программы; форму представления входных и выходных данных.
При достаточно подробной схеме программы, которая отражает
все операции логической схемы модели, можно приступать к программированию
модели.
Проверку достоверности программы на этапе машинной реализации
модели необходимо проводить обратным переводом программы в исходную схему;
проверкой отдельных частей программы при решении различных тестовых задач;
объединением всех частей программы и проверкой ее в целом на контрольном примере
моделирования варианта системы S.
Здесь же необходимо проверить оценки затрат машинного времени
на моделирование. Полезно также получить достаточно простую аналитическую
аппроксимацию зависимости затрат машинного времени от количества реализаций,
что позволит правильно сформулировать требования к точности и достоверности
результатов моделирования.
2.4.3
Получение и интерпретация результатов моделирования
На третьем этапе моделирования − этапе получения и
интерпретации результатов моделирования − ПК используется для проведения
рабочих расчетов по составленной и отлаженной программе. Результаты этих
расчетов позволяют проанализировать и сформулировать выводы о характеристиках
процесса функционирования моделируемой системы S.
При реализации моделирующих алгоритмов на ПК вырабатывается
информация о состояниях процесса функционирования исследуемых систем. Эта
информация является исходным материалом для определения приближенных оценок
искомых характеристик, получаемых в результате машинного эксперимента, то есть
критериев оценки. Критерием оценки будем называть любой количественный
показатель, по которому можно судить о результатах моделирования системы.
Критериями оценки могут служить показатели, получаемые на основе процессов,
действительно протекающих в системе, или получаемых на основе специально
сформированных функций этих процессов.
Таким образом, весь процесс моделирования проводится в три
этапа. На первом этапе главное - построение концептуальной модели и ее
формализация. Концептуальная модель в нашем случае - создание входа в систему
массового обслуживания (СМО), определение параметров входного интерфейса СМО
(рис. 2.1).
Концептуальная модель

Рис. 2.1
На втором этапе создаем алгоритм модели, выбираем в качестве
инструмента моделирования язык программирования ВС++, разрабатываем ГСА,
которые представляют собой интерпретацию логической схемы моделируемого
алгоритма.
Непосредственно моделирование осуществляем в две стадии.
Первая - определение основных статистических характеристик простых, отдельно
взятых материальных потоков, которые на второй стадии - стадии создания модели
грузопотока методом суперпозиции превращаются в сложный.
На заключительном этапе получения и интерпретации результатов
проводим эксперименты, анализируем результаты, изучаем свойства модели.
3. Описание основных конструкций языка С++
Разработка программного обеспечения на практике является
довольно непростым процессом. Требуется учесть все тонкости и нюансы как всего
программного комплекса в целом, так и его отдельных частей. Системный подход к
программированию основывается на том, что поставленная перед разработчиком
задача предварительно разбивается на пару-тройку менее крупных вопросов,
которые, в свою очередь, делятся еще на несколько менее сложных задач, и так до
тех пор, пока самые мелкие задачи не будут решены с помощью стандартных
процедур. Таким образом осуществляется так называемая функциональная
декомпозиция.
Язык программирования С++ построен на базе языка С, но в
отличие от него позволяет программисту разрабатывать программы (или приложения)
с использованием как традиционного структурного, так и
объектно-ориентированного подхода.
Как известно, любая программа представляет собой некую
последовательность инструкций в машинных кодах, управляющих поведением
определенного вычислительного средства. Для упрощения процесса разработки
программного обеспечения (ПО) создана не одна сотня языков программирования.
Каждый из них имеет сильные и слабые стороны и призван решать ряд определенных
задач.
Все существующие средства программирования можно разделить на
две основные категории:
языки программирования низкого уровня;
языки программирования высокого уровня.
К первой группе относят семейство языков Ассемблера. Эти
средства разработки программного обеспечения позволяют получить наиболее
короткий и быстродействующий код. Однако процесс программирования на языке
низкого уровня − занятие весьма кропотливое, утомительное и занимает
гораздо больше времени, чем при использовании языка высокого уровня. Кроме того,
программы, написанные на Ассемблере, достаточно тяжелы для восприятия,
вследствие чего вероятность возникновения ошибок в них значительно выше.
В свою очередь, этих недочетов лишены языки программирования
высокого уровня, к которым относится и С++. Вместе с тем, данной группе языков
присущи недостатки другого рода, например такие, как значительное увеличение
размера и времени выполнения исполняемого модуля.
Программное обеспечение, разработанное с использованием С++ и
представленное ниже, включает идентификаторы, ключевые слова, функции,
переменные, константы, операторы, выражения, массивы и ряд других элементов.
Директивы препроцессора представляют собой команды
компилятору, которые позволяют управлять компиляцией программы и сделать ее код
более понятным. Все директивы начинаются с символа #. Перед начальным
символом # и вслед за ним могут располагаться пробелы. Директивы
обрабатываются во время первой фазы компиляции специальной программой - препроцессором.
Первая строка программы (#include<iostream.h>) подключает
заголовочный файл iostream.h, содержащий объявления функций и переменных для потокового
вода\вывода. В С++ стандартный поток ввода связан с константой cin, а поток вывода −
с константой cout (для использования этих констант подключается заголовочный файл iostream.h).
Любая программа на С++ обязательно включает в себя функцию main, с которой и начинает
свое выполнение.
3.1
Типы данных С++
Суть фактически любой программы сводится к вводу, хранению,
модификации и выводу некоторой информации. Для того, чтобы программа могла на
протяжении своего выполнения сохранять определенные данные, используются
переменные и константы.
Переменная − объект программы, занимающий в общем
случае несколько ячеек памяти, призванный хранить данные. Переменная обладает
именем, размером и рядом других атрибутов.
Объявление переменной начинается с ключевого слова,
определяющего его тип, за которым следует собственно имя переменной и
(необязательно) инициализация − присвоение начального значения. Хотя
начальная инициализация и не является обязательной при объявлении переменной,
все же рекомендуется инициализировать переменные начальным значением. Если
этого не сделать, переменная изначально может принять непредсказуемое значение.
Переменные могут быть объявлены как внутри тела какой-нибудь
функции, так и за пределами любой из них.
Переменные, объявленные внутри тела функции, называются
локальными. Такие переменные размещаются в стеке программы и действуют только
внутри той функции, в которой объявлены. Как только управление возвращается
вызывающей функции, память, отводимая под локальные переменные, освобождается.
Каждая переменная характеризуется областью действия, областью
видимости и временем жизни.
Под областью действия переменной понимают область программы,
в которой переменная доступна для использования.
С этим понятием тесно связано понятие области видимости
переменной. Если переменная выходит из области действия, она становится
невидимой. С другой стороны, переменная может находиться в области действия, но
быть невидимой. Переменная находится в области видимости, если к ней можно
получить доступ (с помощью операции разрешения видимости, в том случае, если
она непосредственно не видима).
Временем жизни переменной называется интервал выполнения
программы, в течение которого она существует.
Локальные переменные имеют своей областью видимости функцию
или блок, в которых они объявлены. В то же время область действия локальной
переменной может исключать внутренний блок, если в нем объявлена переменная с
тем же именем. Время жизни локальной переменной определяется временем
выполнения блока или функции, в которой она объявлена.
Это означает, например, что в разных функциях могут
использоваться переменные с одинаковыми именами совершенно независимо друг от
друга.
Глобальные переменные же объявляются вне тела какой-либо из
функций и действуют на протяжении выполнения всей программы. Такие переменные
доступны в любой из функций программы, которая описана после объявления
глобальной переменной. Отсюда следует вывод, что имена локальных и глобальных
переменных не должны совпадать. Если глобальная переменная не
проинициализирована явным образом, она инициализируется значением 0.
Область действия глобальной переменной совпадает с областью
видимости и простирается от точки ее описания до конца файла, в котором она
объявлена. Время жизни глобальной переменной − постоянное, то есть
совпадает с временем выполнения программы.
Вообще говоря, использование глобальных переменных при
написании программы не желательно. Применение их оправдано только в случае
крайней необходимости, так как содержимое таких переменных может быть изменено
внутри тела любой функции, что чревато серьезными ошибками при работе
программы.
Рассмотрим типы данных, которые задействованы в программе.
Целочисленные переменные (типа int), как следует из
названия, призваны хранить целые значения, и могут быть знаковыми и
беззнаковыми. Символьный тип данных char используется для построения более сложных
конструкций, таких, как строки, символьные массивы. Данные типа char также могут быть
знаковыми и беззнаковыми. Для представления чисел с плавающей запятой применяем
тип данных float. Этот тип используется для хранения не очень больших дробных
чисел. Переменная типа void не имеет значения и служит для согласования
синтаксиса.
Константы, так же как и переменные, представляют собой
область памяти для хранения данных с тем лишь отличием, что значение,
присвоенное константе первоначально, не может быть изменено на протяжении всей
программы.
3.2
Выражения и операторы
Для осуществления манипуляций с данными С++ располагает
широким набором операций. Операции представляют собой некоторое действие,
выполняемое над операндом (операндами). К базовым арифметическим операциям
можно отнести операции сложения(+), вычитания(-), умножения(*), деления(/). Для
эффективного использования возвращаемого операциями значения предназначен
оператор присваивания(=) и его модификации: сложение с присваиванием(+=),
вычитание с присваиванием(-=), умножение с присваиванием(*=) и соответственно
деление с присваиванием(/=).
Как и в Ассемблере, в С++ имеется эффективное средство
увеличения и уменьшения значения операнда на единицу − унарные операторы
инкремента(++) и декремента(-).
3.3
Управление выполнением программы
Некоторые задачи требуют от программы принятия решения в
зависимости от различных ситуаций. Язык программирования С++ обладает
исчерпывающим набором конструкций, позволяющим управлять порядком выполнения
отдельно взятых ветвей программы. Например, мы можем передать управление в ту
или иную часть программы в зависимости от результатов проверки некоторого
условия.
Для осуществления ветвления в программе используются условный
оператор if и оператор if с ключевым словом else.
Оператор if производит ветвление программы в зависимости от
результата проверки некоторого условия на истинность.
Оператор if_else имеет следующий вид:
if (проверяемое условие)
предложение 1;
else
предложение 2;
предложение 3;
Если проверяемое условие выполняется, осуществляется переход
к предложению 1 с последующим переходом к предложению 3. В случае, когда
проверяемое условие принимает ложное значение, программа выполнит ветвь,
содержащую предложение 2, а затем перейдет к предложению 3.
Следует отметить, что комбинация if_else позволяет значительно упростить
код программы.
Еще одно замечание: часто проверяемое условие представляет
собой проверку значения некоторой целочисленной переменной. Тогда если эта
переменная принимает ненулевое значение, то результатом вычисления условного
выражения будет true, и произойдет переход на выполнение предложения, указанного за
оператором if. Поэтому в программе можно встретить записи вида:
if (! х)
{
// если х == 0
…
}
Например:
if (! D = b*b - a)
{
…
}
Эта запись означает: присвоить переменной D вычисленное значение (b*b-a), и если переменная D приняла ненулевое
значение, выполнить блочный оператор {…}. Обычно в подобных случаях компилятор
выдает предупреждение о вероятно ошибочном использовании оператора присвоения
вместо сравнения.
Следующим мощным механизмом управления ходом
последовательности выполнения программы является использование циклов.
Цикл задает многократное прохождение по одному и тому же коду
программы (итерации). Он имеет точку вхождения, проверочное условие и
(необязательно) точку выхода. Цикл, не имеющий точки выхода, называется
бесконечным. Для бесконечного цикла проверочное условие всегда принимает
истинное значение.
Проверка условия может осуществляться перед выполнением
(циклы for, while) или после окончания (do - while) тела цикла.
Циклы могут быть вложенными друг в друга произвольным
образом.
Синтаксис цикла for имеет вид:
for (выражение 1; выражение 2; выражение 3)
оператор или блок операторов;
Этот оператор работает следующим образом. Сначала выполняется
выражение 1, если оно присутствует в конструкции. Затем вычисляется величина
выражения 2 (если оно присутствует) и, если полученный результат принял
истинное значение, выполняется тело цикла (оператор или блок операторов). В
противном случае выполнение цикла прекращается и осуществляется переход к
оператору, следующему непосредственно за телом цикла.
После выполнения тела цикла вычисляется выражение 3, если оно
имеется в конструкции, и осуществляется переход к пункту вычисления величины
выражения 2.
Выражение 1 чаще всего служит в качестве инициализации
какой-нибудь переменной, выполняющей роль счетчика итераций.
Выражение 2 используется как проверочное условие и на
практике часто содержит выражения с операторами сравнения. По умолчанию
величина выражения 2 принимает истинное значение.
Выражение 3 служит для приращения значения счетчика циклов
либо содержит выражение, влияющее, каким бы то ни было образом, на проверочное
условие.
Если выражение представляет собой константу с истинным
значением, тело цикла будет выполняться всегда и, следовательно, мы имеем дело
с бесконечным оператором. Цикл также окажется бесконечным, когда условие,
определенное в выражении изначально, истинно и нигде далее в теле цикла не
изменяется. Такой вариант возможен как таковой, но в представленной программе
не используется.
Как и для оператора for, если в цикле должны синхронно изменяться
несколько переменных, которые зависят от переменной цикла, вычисление их
значений можно поместить в проверочное выражение оператора while, воспользовавшись
оператором «запятая».
Как и многие другие языки высокого уровня, С++ предоставляет
возможность работы с наборами однотипных данных − массивами. Отдельная
единица таких данных, входящих в массив, называется элементом массива. В
качестве элементов массива могут выступать данные любого типа (один тип данных
для каждого массива), а также указатели на однотипные данные. Массивы бывают
одно- и многомерными.
Поскольку все элементы массива имеют один тип, они также
обладают одинаковым размером. Использованию массива в программе предшествует его
объявление, резервирующее под массив определенное количество памяти. При этом
указывается тип элементов массива, имя массива и его размер.
3.4
Динамическое выделение массивов
В программе каждая переменная может размещаться в одном из
трех мест: в области данных программы, в стеке или в свободной памяти.
Каждой переменной в программе память может отводиться либо
статически, то есть в момент загрузки программы, либо динамически − в
процессе выполнения программы. Если массив объявлен статически, значения всех
его элементов хранятся в стековой памяти или области данных программы. Если
количество элементов массива невелико, такое размещение оправдано. Однако
довольно часто возникают случаи, когда в стековой памяти, содержащей локальные
переменные и вспомогательную информацию, недостаточно места для размещения всех
элементов большого массива, как, например, в нашем случае. Тогда для хранения
данных приходится использовать динамическую память. Чтобы разместить в памяти
некоторый динамический объект, для него необходимо предварительно выделить в
памяти соответствующее место. По окончании работы с объектом выделенную для его
хранения память требуется освободить.
Выделение динамической памяти под объект в программе
осуществляется при помощи выражения new, а освобождение выделенных ресурсов памяти
производится выражением delete.
Операторы new и delete имеют две формы:
управление динамическим размещением в памяти единичного
объекта;
динамическое размещение массива объектов.
Форма оператора delete должна обязательно соответствовать форме
оператора new для данного объекта: если выделение памяти проводилось для
единичного объекта (new), освобождение памяти также должно осуществляться для единичного
объекта (delete). Для массива объектов используются соответственно операторы new[] и delete[].
Таким образом с помощью языка программирования ВС++ были
реализованы две программы, листинги и результаты работы которых представлены в
приложении.
4. Теория вероятностей и математическая статистика
4.1
Случайные величины
В науке, практической деятельности людей и в быту каждодневно
создаются такие положения, когда возникает массовый спрос на обслуживание
какого-либо специального вида, причем обслуживающая организация, располагая
лишь ограниченным числом обслуживающих единиц, не всегда способна немедленно
удовлетворять все поступающие заявки. Примеры такой ситуации хорошо известны
каждому. Очереди у магазинных и билетных касс, в буфетах, парикмахерских и
т.д.; невозможность получить билет на нужный поезд из-за его переполнения; задержка
в посадке самолетов, вызываемая отсутствием свободных посадочных площадок;
задержка в ремонте потерпевших аварию станков из-за нехватки ремонтных бригад -
все эти и многие другие аналогичные, хорошо известные примеры, несмотря на
существенные различия их реального содержания, с формальной стороны очень
близки друг другу. Во всех подобных случаях перед теорией встает, в сущности,
одна основная задача: установить с возможной точностью взаимную зависимость
между числом обслуживающих единиц и качеством обслуживания. При этом качество
обслуживания в различных случаях, естественно, измеряется различными
показателями. Большей частью таким показателем служит либо процент заявок,
получающих отказ (процент пассажиров, не получивших билетов на данный поезд),
либо среднее время ожидания начала обслуживания (очереди различного рода).
Разумеется, качество обслуживания во всех случаях тем выше, чем больше число
обслуживающих единиц; однако столь же очевидно, что чрезмерный рост этого числа
сопряжен с излишним расходом сил и материальных средств; практически поэтому
вопрос обычно ставится так, что сначала устанавливается необходимый уровень
качества обслуживания, а затем находится минимальное число обслуживающих
единиц, при котором этот уровень может быть достигнут.
4.1.1
Определение и задание случайной величины
Случайной называют величину, которая в результате испытания
примет одно и только одно возможное значение, наперед не известное и зависящее
от случайных причин, которые заранее не могут быть учтены.
Будем далее обозначать случайные величины прописными буквами X, Y, Z, а их возможные значения
- соответствующими строчными буквами х, у, z. Например, если
случайная величина X имеет три возможных значения, то они будут обозначены так: x1, х2, х3.
Целесообразно различать случайные величины, принимающие лишь
отдельные, изолированные значения, и случайные величины, возможные значения
которых сплошь заполняют некоторый промежуток.
Дискретной (прерывной) называют случайную величину, которая
принимает отдельные, изолированные возможные значения с определенными
вероятностями. Число возможных значений дискретной случайной величины может
быть конечным или бесконечным.
Непрерывной называют случайную величину, которая может
принимать все значения из некоторого конечного или бесконечного промежутка.
Очевидно, число возможных значений непрерывной случайной величины бесконечно.
На первый взгляд может показаться, что для задания дискретной
случайной величины достаточно перечислить все ее возможные значения. В
действительности это не так: случайные величины могут иметь одинаковые перечни
возможных значений, а вероятности их - различные. Поэтому для задания
дискретной случайной величины недостаточно перечислить все возможные ее
значения, нужно еще указать их вероятности.
Законом распределения дискретной случайной величины называют
соответствие между возможными значениями и их вероятностями; его можно задать
таблично, аналитически (в виде формулы) и графически.
При табличном задании закона распределения дискретной
случайной величины первая строка таблицы содержит возможные значения, а вторая
- их вероятности:
X х1 х2… хn
р р1 p2… рn
Приняв во внимание, что в одном испытании случайная величина
принимает одно и только одно возможное значение, заключаем, что события X = x1, X = х2,…, Х= хn образуют полную группу;
следовательно, сумма вероятностей этих событий равна единице:
p1+ p2 +… +pn = 1
Если множество возможных значений X бесконечно (счетно), то
ряд р1 + р2+… сходится и его сумма равна единице.
4.1.2
Математическое ожидание дискретной случайной величины
Закон распределения полностью характеризует случайную
величину с вероятностной точки зрения. Но при решении ряда практических задач
нет необходимости знать все возможные значения случайной величины и
соответствующие им вероятности, а удобнее пользоваться некоторыми
количественными показателями, которые давали бы в сжатой форме достаточную
информацию о случайной величине. Такие показатели называются числовыми
характеристиками случайной величины. Основными из них являются математическое
ожидание, дисперсия, среднее квадратическое отклонение.
Математическое ожидание характеризует положение случайной
величины на числовой оси, определяя собой некоторое среднее значение, около
которого сосредоточены все возможные значения случайной величины. Поэтому математическое
ожидание иногда называют просто средним значением случайной величины.
Хотя математическое ожидание дает о случайной величине
значительно меньше сведений, чем закон ее распределения, но для решения
некоторых задач знание математического ожидания оказывается достаточным.
Математическим ожиданием дискретной случайной величины называют
сумму произведений всех ее возможных значений на их вероятности. При этом
должно удовлетворяться требование абсолютной сходимости ряда: 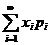 .
.
Пусть случайная величина X может
принимать только значения xl, х2,…, xn, вероятности которых соответственно равны
pl, p2,…, рn. Тогда математическое ожидание М (X) случайной величины X
определяется равенством
М (X) = х1р1 + х2р2
+ … + хnрn. (4.1)
Из определения следует, что математическое ожидание дискретной
случайной величины есть неслучайная (постоянная) величина.
Доказано, что средняя арифметическая наблюдаемых во время
испытаний значений случайной величины приближается к ее математическому ожиданию
при большом числе испытаний. При проведении серий испытаний средние
арифметические наблюдаемых значений случайной величины, вычисленные для каждой
серии, колеблются около математического ожидания этой случайной величины. При
этом колебание становится меньше с увеличением числа испытаний в серии, и все
вычисленные средние приближаются к постоянной величине − математическому
ожиданию. Это свойство называется свойством устойчивости средних.
4.1.3
Дисперсия дискретной случайной величины
Легко указать такие случайные величины, которые имеют
одинаковые математические ожидания, но различные возможные значения.
Таким образом, зная лишь математическое ожидание случайной
величины, еще нельзя судить ни о том, какие возможные значения она может
принимать, ни о том, как они рассеяны вокруг математического ожидания. Другими
словами, математическое ожидание полностью случайную величину не характеризует.
По этой причине наряду с математическим ожиданием вводят и
другие числовые характеристики. Так, например, для того чтобы оценить, как
рассеяны возможные значения случайной величины вокруг её математического
ожидания, пользуются, в частности, числовой характеристикой, которую называют
дисперсией.
Прежде чем перейти к определению дисперсии, введём понятие
отклонения случайной величины от её математического ожидания.
Пусть X - случайная величина и М (X) - её математическое
ожидание. Рассмотрим в качестве новой случайной величины разность X−М(Х).
Отклонением, называют разность между случайной величиной и ее
математическим ожиданиям.
Пусть закон распределения X известен:
X x1 x2… хn
p p1 p2… pn
Напишем закон распределения отклонения. Для того чтобы
отклонение приняло значение х1−М(Х), достаточно, чтобы
случайная величина приняла значение x1. Вероятность же этого события равна р1;
следовательно, и вероятность того, что отклонение примет значение х1−М
(X), также равна р1.
Аналогично обстоит дело и для остальных возможных значений отклонения.
Таким образом, отклонение имеет следующий закон
распределения:
X − М(Х) x1 −M(X) х2 −М(Х)… хn−М(Х)
P p1 p2… pn
На практике часто требуется оценить рассеяние возможных
значений случайной величины вокруг ее среднего значения.
На первый взгляд может показаться, что для оценки рассеяния
проще всего вычислить все возможные значения отклонения случайной величины и
затем найти их среднее значение. Однако такой путь ничего не даст, так как
среднее значение отклонения, т.е. М [X - М (X)], для любой случайной величины равно нулю. Это
свойство объясняется тем, что одни возможные отклонения положительны, а другие
- отрицательны; в результате их взаимного погашения среднее значение отклонения
равно нулю. Эти соображения говорят о целесообразности заменить возможные
отклонения их абсолютными значениями или их квадратами. Так и поступают на
деле. Правда, в случае, когда возможные отклонения заменяют их абсолютными
значениями, приходится оперировать с абсолютными величинами, что приводит
иногда к серьезным затруднениям. Поэтому чаще всего идут по другому пути, т.е.
вычисляют среднее значение квадрата отклонения, которое и называют дисперсией.
Дисперсией (рассеянием) дискретной случайной величины
называют математическое ожидание квадрата отклонения случайной величины от ее
математического ожидания:
D(X) = M [X−М(Х)]2
(4.2)
Пусть случайная величина задана законом распределения
X x1 x2… хn
p p1 p2… pn
Тогда квадрат отклонения имеет следующий закон распределения:
[X−М (Х)]2 [х1−М (Х)]2
[х2−М (Х)]2… [хn−М (Х)]2
p p1 p2… pn
По определению дисперсии,
D (X) = М [X−М (Х)]2 = [х1−М (Х)]2p1+ [х2−М
(Х)] p2+ … +[хn−М (Х)]2pn
Таким образом, для того чтобы найти дисперсию, достаточно
вычислить сумму произведений возможных значений квадрата отклонения на их
вероятности.
Для вычисления дисперсии часто бывает удобно пользоваться
следующей теоремой: дисперсия равна разности между математическим ожиданием
квадрата случайной величины X и квадратом ее математического ожидания:
D (X) = M (X2) − [M(X)]2 (4.3)
Недостатком дисперсии является то, что она имеет размерность
квадрата случайной величины и ее нельзя геометрически интерпретировать.
Этих недостатков лишено среднее квадратическое отклонение
случайной величины, которое представляет собой положительный квадратный корень
из дисперсии:
σ(X) = √ D(X) (4.4)
4.2
Определение вероятности события
Для количественного сравнения между собой
событий по степени возможности их появления вводится определенная мера, которая
называется вероятностью события.
Вероятностью события называется численная
мера степени объективной возможности появления этого события.
Если опыт сводится к схеме случаев, то
вероятность появления некоторого события вычисляется как отношение числа
случаев, благоприятствующих появлению этого события, к общему числу случаев.
Это и есть классическое определение вероятности события.
На практике же часто классическое определение
вероятности неприменимо по двум причинам:
во-первых, классическое определение
вероятности предполагает, что общее число случаев должно быть конечно. На самом
же деле, оно зачастую неограниченно;
во-вторых, часто невозможно представить
исходы опыта в виде равновозможных и несовместных событий.
Было замечено, что частота появления
событий, не сводящихся к схеме случаев, при многократно повторяющихся опытах
имеет тенденцию стабилизироваться около какой-то постоянной величины. Это
свидетельствует о том, что данные события также обладают определенной степенью
объективной возможности появления в опыте, меру которой можно представить в
виде относительной частоты или частости.
При большом числе испытаний частость
стремится воспроизвести вероятности в пределе при большом числе опытов должна
практически совпадать с ней. Это положение носит название закона больших чисел.
На основе этого возникло понятие
статической вероятности события, под которой понимается относительная частота
появления события в произведенных опытах.
4.5
Построение вариационных рядов
Установление закономерностей, которым
подчиняются массовые случайные явления, основано на изучении статистических
данных − сведений о том, какие значения принял в результате наблюдений
интересующий исследователя признак.
4.5.1
Вариационные ряды
Для
изучения результатов наблюдений прежде всего необходимо их сгруппировать по
некоторому признаку. В дальнейшем различные наблюдавшиеся значения признака
условимся называть вариантами, а под варьированием понимать изменение значений
признака у наблюдаемых элементов.
Число, показывающее, сколько раз
встречается вариант в ряде наблюдений, называется частотой варианта (mx).
Для изучения результатов наблюдений можно
использовать не частоту варианта, а долю ее в сумме всех частот (wx), которая равна
отношению частоты (mx) к общему числу наблюдений (n), т.е. wx= mx/n. Такая величина
называется частостью.
Таблица, позволяющая судить о
распределении частот (или частостей) между вариантами, называется дискретным
вариационным рядом.
Если просмотр первичных данных не позволил
составить представление о варьировании значений признака, то, рассматривая
вариационный ряд, можно сделать выводы, например, о том, что значение
исследуемого признака колеблется между двумя определенными величинами, что
наиболее часто встречается некоторое конкретное значение этого признака и т.д.
Наряду с понятием частоты используется понятие накопленной частоты
( ). Накопленная частота показывает, сколько
наблюдалось элементов со значением признака, меньшим или равным х. Отношение
накопленной частоты к общему числу наблюдений называется накопленной частостью
(w
). Накопленная частота показывает, сколько
наблюдалось элементов со значением признака, меньшим или равным х. Отношение
накопленной частоты к общему числу наблюдений называется накопленной частостью
(w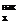 ). Очевидно, что w=/n.
). Очевидно, что w=/n.
Значения, принимаемые признаком, могут отличаться одно от другого
на сколь угодно малую величину, т.е. признак может принять любое значение в
некотором числовом интервале. Такие признаки называются непрерывными. В этом
случае трудно выявить характерные черты варьирования значений признака. А если
к тому же велико число вариантов, построение дискретного вариационного ряда
также не даст желаемых результатов. Тогда используют интервальную частоту. Эта
частота показывает, сколько наблюдалось элементов со значением признака,
принадлежащим тому или иному интервалу.
Таблица, позволяющая судить о распределении частот (или частостей)
между интервалами варьирования значений признака, называется интервальным
вариационным рядом.
Интервальный вариационный ряд строят по данным наблюдений за
непрерывным признаком, а также за дискретным, если велико число наблюдавшихся
вариантов. Дискретный вариационный ряд строят только для дискретного признака.
4.5.2
Построение интервального вариационного ряда
Для построения интервального вариационного
ряда необходимо определить величину интервала, установить полную шкалу
интервалов, в соответствии с ней сгруппировать результаты наблюдений.
Для определения оптимальной величины
интервала (h),
т.е. такой, при которой построенный интервальный ряд не был бы слишком
громоздким и, в то же время, позволял выявить характерные черты
рассматриваемого явления, будем использовать формулу Стэрджеса:
h = (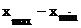 )/(1+3,322 lq n), (4.5)
)/(1+3,322 lq n), (4.5)
где  − соответственно максимальная и
минимальная варианты. Если h оказывается
дробным числом, то за величину интервала следует взять либо ближайшее целое
число, либо ближайшую несложную дробь.
− соответственно максимальная и
минимальная варианты. Если h оказывается
дробным числом, то за величину интервала следует взять либо ближайшее целое
число, либо ближайшую несложную дробь.
За начало первого интервала будем принимать величину, равную (хmin - h/2). Тогда, если аi - начало i - го интервала, то ai = xmin - h/2; a2 = a1+h; a3 = a2+h и т.д. Построение интервалов продолжают
до тех пор, пока начало следующего по порядку интервала не будет равным или
большим xmax.
После установления шкалы интервалов будем приступать к группировке
результатов наблюдений. В интервал включаются варианты большие, чем нижняя
граница интервала и меньшие или равные верхней границе интервала.
4.5.3
Графическое изображение вариационных рядов
Графическое изображение вариационного ряда
позволяет представить в наглядной форме закономерности варьирования значений
признака. Наиболее широко используются такие виды графического изображения
вариационных рядов, как полигон и гистограмма.
Полигоном частот называют ломаную, отрезки
которой соединяют точки (х1; n1), (x2; n2),…, (xk\ nk). Для построения
полигона частот на оси абсцисс откладывают варианты xi, а на оси ординат - соответствующие им
частоты ni. Точки (хi; ni), соединяют отрезками
прямых и получают полигон частот.
Полигоном относительных частот называют
ломаную, отрезки которой соединяют точки (x1; w1), (x2; w2),…, (xk; wk). Для построения
полигона относительных частот на оси абсцисс откладывают варианты xi, а на оси ординат - соответствующие им
относительные частоты wi. Точки (xi; wi) соединяют отрезками
прямых и получают полигон относительных частот.
На рис. 4.1 изображен полигон
относительных частот следующего распределения:
X 1,5 3,5 5,5 7,5
W 0.1 0.2 0.4 0.3
Гистограмма служит для изображения только
интервального вариационного ряда. Для ее построения в прямоугольной системе
координат по оси абсцисс откладывают отрезки, изображающие интервалы
варьирования, и на этих отрезках, как на основании, строят прямоугольники с
высотами, равными частотам (или частостям) соответствующего интервала.
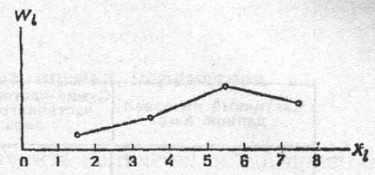
Рис. 4.1
В результате получается ступенчатая
фигура, состоящая из прямоугольников, которая и называется гистограммой (рис.
4.2).
Гистограмма
частот

Рис. 4.2
Средние величины, характеризуя вариационный ряд одним числом,
не отражают изменчивости наблюдавшихся значений признака, т.е. вариацию.
Простейшим показателем вариации является вариационный размах (Rв), равный разности между
наибольшим и наименьшим вариантами, т.е.
Rв = xmax - xmin (4.6)
Однако вариационный размах весьма
приближенный показатель вариации, так как он почти не зависит от изменения
вариантов, а крайние варианты, которые используются для его вычисления, как
правило, ненадежны.
4.3 Простейший поток
событий. Распределение Пуассона
Потоком событий называют последовательность событий, которые
наступают в случайные моменты времени. Примерами потоков служат поступление
вызовов на АТС, последовательность отказов элементов, приход грузовых поездов
на станцию и многие другие.
Среди свойств, которыми могут обладать потоки, выделим
свойства стационарности, отсутствия последействия и ординарности.
Свойство стационарности характеризуется тем, что вероятность
появления k
событий на любом промежутке времени зависит только от числа k и от длительности t промежутка и не зависит
от начала его отсчета; при этом различные промежутки времени предполагаются
непересекающимися.
Итак, если поток обладает свойством стационарности, то
вероятность появления k событий за промежуток времени длительности t есть функция, зависящая
только от k
и t.
Свойство отсутствия последействия характеризуется тем, что
вероятность появления k событий на любом промежутке времени не зависит от того,
появлялись или не появлялись события в моменты времени, предшествующие началу
рассматриваемого промежутка. Другими словами, условная вероятность появления k событий на любом
промежутке времени, вычисленная при любых предположениях о том, что происходило
до начала рассматриваемого промежутка (сколько событий появилось, в какой
последовательности), равна безусловной вероятности. Таким образом, предыстория
потока не сказывается на вероятности появления событий в ближайшем будущем.
Итак, если поток обладает свойством отсутствия последействия,
то имеет место взаимная независимость появлений того или иного числа событий в
непересекающиеся промежутки времени.
Свойство ординарности характеризуется тем, что появление двух
и более событий за малый промежуток времени практически невозможно. Другими
словами, вероятность появления более одного события пренебрежимо мала по
сравнению с вероятностью появления только одного события.
Итак, если поток обладает свойством ординарности, то за
бесконечно малый промежуток времени можем появиться не более одного события.
Простейшим (пуассоновским) называют поток событий, который
обладает свойствами стационарности, отсутствия последействия и ординарности.
Часто на практике трудно установить,
обладает ли поток перечисленными выше свойствами. Поэтому были найдены и другие
условия, при соблюдении которых поток можно считать простейшим или близким к
простейшему. В частности, установлено, что если поток представляет собой сумму
очень большого числа независимых стационарных потоков, влияние каждого из
которых на всю сумму (суммарный поток) ничтожно мало, то суммарный поток (при
условии его ординарности) близок к простейшему.
Интенсивностью потока a называют среднее число
событий, которые появляются в единицу времени.
Если постоянная интенсивность потока
известна, то вероятность появления k событий простейшего потока за время
длительностью t
определяется формулой Пуассона:
Pt(k) = (at)k×e-at/k (4.7)
Закон Пуассона описывает число событий k, происходящих за
одинаковые промежутки времени при условии, что события происходят независимо
друг от друга с постоянной средней интенсивностью. При этом число испытаний
велико, а вероятность появления события в каждом испытании мала. Поэтому закон
Пуассона называется еще законом распределения редких явлений.
Параметром распределения Пуассона является
величина a, характеризующая интенсивность появления событий в n испытаниях. На рис. 4.3
приведены многоугольники распределения Пуассона, соответствующие различным
значениям интенсивности.
Распределение
Пуассона
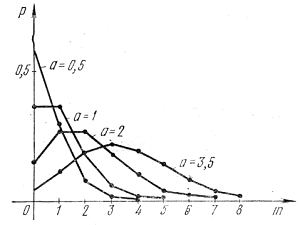
Рис. 4.3
Формула Пуассона отражает свойства
стационарности, отсутствия последействия и ординарности, поэтому ее можно
считать математической моделью простейшего потока.
4.4
Статистическая проверка статистических гипотез
Установление закономерностей, которым
подчинены массовые случайные явления, основано на изучении методами теории
вероятностей статистических данных - результатов наблюдений.
Первая задача математической статистики -
указать способы сбора и группировки статистических сведений, полученных в
результате наблюдений или в результате специально поставленных экспериментов.
Вторая задача математической статистики -
разработать методы анализа статистических данных в зависимости от целей
исследования. Сюда относятся:
оценка неизвестной вероятности события;
оценка неизвестной функции распределения; оценка параметров распределения, вид
которого известен; оценка зависимости случайной величины от одной или
нескольких случайных величин и др.;
проверка статистических гипотез о виде
неизвестного распределения или о величине параметров распределения, вид
которого известен.
Итак, задача математической статистики
состоит в создании методов сбора и обработки статистических данных для
получения научных и практических выводов.
Часто необходимо знать закон распределения
генеральной совокупности. Если закон распределения неизвестен, но имеются
основания предположить, что он имеет определенный вид (назовем его А),
выдвигают гипотезу: генеральная совокупность распределена по закону А. Таким
образом, в этой гипотезе речь идет о виде предполагаемого распределения.
Возможен случай, когда закон распределения
известен, а его параметры неизвестны. Если есть основания предположить, что
неизвестный параметр в равен определенному значению Q0, выдвигают гипотезу: Q = Q0. Таким образом, в этой
гипотезе речь идет о предполагаемой величине параметра одного известного
распределения.
Статистической называют гипотезу о виде
неизвестного распределения, или о параметрах известных распределений.
Например, статистическими являются
гипотезы:
генеральная совокупность распределена по
закону Пуассона;
дисперсии двух нормальных совокупностей
равны между собой.
В первой гипотезе сделано предположение о
виде неизвестного распределения, во второй - о параметрах двух
известных распределений.
Наряду с выдвинутой гипотезой рассматривают
и противоречащую ей гипотезу. Если выдвинутая гипотеза будет отвергнута, то
имеет место противоречащая гипотеза. По этой причине эти гипотезы целесообразно
различать. Нулевой (основной) называют выдвинутую гипотезу Н0.
Конкурирующей (альтернативной) называют
гипотезу Н1, которая противоречит нулевой.
Различают гипотезы, которые содержат
только одно и более одного предположений.
Проверка гипотезы о предполагаемом законе
неизвестного распределения производится так же, как и проверка гипотезы о
параметрах распределения, т.е. при помощи специально подобранной случайной
величины - критерия согласия.
Критерием согласия называют критерий
проверки гипотезы о предполагаемом законе неизвестного распределения.
Имеется несколько критериев согласия: c2 («хи квадрат»), Пирсона,
Колмогорова, Смирнова и др. Ограничимся описанием применения критерия Пирсона к
проверке гипотезы о распределении Пуассона генеральной совокупности (критерий
аналогично применяется и для других распределений, в этом состоит его
достоинство). С этой целью будем сравнивать эмпирические (наблюдаемые) и
теоретические (вычисленные в предположении) частоты.
Обычно эмпирические и теоретические
частоты различаются. Возможно, что расхождение случайно (незначимо) и
объясняется либо малым числом наблюдений, либо способом их группировки, либо
другими причинами. Возможно, что расхождение частот неслучайно (значимо) и
объясняется тем, что теоретические частоты вычислены исходя из неверной
гипотезы о распределении генеральной совокупности.
Критерий Пирсона отвечает на вопрос:
случайно ли расхождение частот? Правда, как и любой критерий, он не доказывает
справедливость гипотезы, а лишь устанавливает на принятом уровне значимости ее
согласие или несогласие с данными наблюдений.
Итак, пусть по выборке объема n получено эмпирическое
распределение:
варианты х1 х2 х3… хi
эмпирические частоты n1 n2 n3… ni
Допустим, что в предположении
распределения Пуассона генеральной совокупности вычислены теоретические частоты
n¢i. При уровне значимости a требуется проверить
нулевую гипотезу: генеральная совокупность распределена по закону Пуассона.
В качестве критерия проверки нулевой
гипотезы примем случайную величину
c2=  (4.8)
(4.8)
Эта величина случайная, так как в
различных опытах она принимает различные, заранее не известные значения. Ясно,
что чем меньше различаются эмпирические и теоретические частоты, тем меньше
величина критерия, и, следовательно, он в известной степени характеризует
близость эмпирического и теоретического распределений.
Заметим, что возведением в квадрат разностей частот устраняют
возможность взаимного погашения положительных и отрицательных разностей.
Делением на  достигают уменьшения каждого из слагаемых;
в противном случае сумма была бы настолько велика, что приводила бы к
отклонению нулевой гипотезы даже и тогда, когда она справедлива. Разумеется,
приведенные соображения не являются обоснованием выбранного критерия, а лишь
пояснением.
достигают уменьшения каждого из слагаемых;
в противном случае сумма была бы настолько велика, что приводила бы к
отклонению нулевой гипотезы даже и тогда, когда она справедлива. Разумеется,
приведенные соображения не являются обоснованием выбранного критерия, а лишь
пояснением.
Доказано, что при  закон распределения случайной величины независимо от того, какому
закону распределения подчинена генеральная совокупность, стремится к закону
распределения c2 с k степенями свободы. Поэтому случайная величина обозначена через c2, а сам критерий называют критерием согласия «хи квадрат».
закон распределения случайной величины независимо от того, какому
закону распределения подчинена генеральная совокупность, стремится к закону
распределения c2 с k степенями свободы. Поэтому случайная величина обозначена через c2, а сам критерий называют критерием согласия «хи квадрат».
Число степеней свободы находят по равенству k = s-1-r, где s - число групп (частичных интервалов) выборки; r - число параметров предполагаемого распределения, которые оценены
по данным выборки.
Обозначим значение критерия, вычисленное по данным наблюдений,
через c2 набл и сформулируем правило проверки нулевой гипотезы: для того чтобы
при заданном уровне значимости проверить нулевую гипотезу Н0 (генеральная
совокупность распределена по закону Пуассона), надо сначала вычислить
теоретические частоты, затем наблюдаемое значение и по таблице критических
точек распределения c2, по заданному уровню значимости a и числу степеней свободы k = s - 2 найти критическую точку c2кр (a; k).
Если c2 набл < c2кр - нет оснований отвергнуть
нулевую гипотезу.
Если c2 набл > c2кр - нулевую гипотезу отвергают.
Таким образом, на третьем, заключительном этапе моделирования -
этапе проведения экспериментов и интерпретации результатов была выдвинута
гипотеза о том, что моделируемый поток распределен по закону Пуассона.
Проверку гипотезы о предполагаемом законе неизвестного
распределения проведем при помощи специально подобранной случайной величины -
критерия согласия.
Для проверки гипотезы необходимо сравнение теоретических и
эмпирических вероятностей. Эмпирические - получены в результате наблюдений.
Теоретические же рассчитываются по формуле Пуассона.
Вычислим c2набл., для чего составим расчетную таблицу.
Таблица 4.1. Результаты расчета
|
i
|
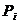  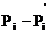 ( ( )2()2/ )2()2/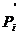
|
|
|
|
|
|
1
|
0,53
|
0,55
|
-0,02
|
0,0004
|
0,0007
|
|
2
|
0,36
|
0,33
|
0,03
|
0,0006
|
0,0018
|
|
3
|
0,08
|
0,01
|
0,07
|
0,0049
|
0,49
|
|
4
|
0,03
|
0,02
|
0,01
|
0,0001
|
0,005
|
|
5
|
0,003
|
0,004
|
-0,001
|
0,000001
|
0,0003
|
|
6
|
0,002
|
0,001
|
0,001
|
0,000001
|
0,001
|
|
S
|
|
|
|
|
0,499
|
По таблице критических точек распределения c2 (прил. 5), по уровню
значимости a=0,95 и по числу степеней свободы k=4 находим c2кр (0,95; 4)=0,711.
Так как c2набл<c2кр - нет оснований
отвергнуть нулевую гипотезу. Другими словами, расхождение эмпирических и теоретических
вероятностей незначимое. Следовательно, данные наблюдений согласуются с
гипотезой о распределении Пуассона исследуемого потока.
Список источников
железнодорожный вагон математический массив
1. Семенов
В.М., Маликов И.А. Транспортная логистика: Краткий терминологический словарь. -
СПб., 1998. - 217 с.
2. Гаджинский
А.М. Основы логистики: - Учебное пособие, М.: ИВЦ «Маркетинг», 1995. - 253 с.
3. Информационные
технологии на железнодорожном транспорте: Учебник для вузов ж.-д. транспорта /
Э.К. Лецкий, В.И. Панкратов, В.В. Яковлев и др.; Под ред. Э.К. Лецкого, Э.С.
Поддавашкина, В.В. Яковлева. - М., 2000. - 680 с.
4. Железные
дороги. Общий курс: Учебник для вузов / М.М. Филипов, М.М. Уздин, Ю.И. Ефименко
и др.; Под ред. М.М. Уздина. - М., 1991. - 259 с.
. Советов
Б.Я., Яковлев С.А. Моделирование систем. - М.: Высшая школа, 1985. - 178 с.
. Денисов
А.А., Колесников Д.Н. Теория больших систем управления. - Л.: Энергоиздат,
1987. - 234 с.
. Бусленко
Н.П. Метод статистического моделирования. - М.: Наука, 1989. - 240 с.
. Хинчин
А.Я. Работы по математической теории массового обслуживания. - М.: Мир, 1990. -
236 с.
. Хинчин
А.Я. Основные законы теории вероятностей. - М.: Высшая школа, 1989. - 234 с.
. Холл
М. Комбинаторика. - М.: Мир, 1989. - 185 с.
. Гмурман
В.Е. Теория вероятностей и математическая статистика. - М.: Высшая школа, 1998.
- 479 с.
. Правила
перевозок опасных грузов по железной дороге. / Под ред. Т.И. Якушкина. - М.:
Транспорт, 1995. - 252.
. Определение
цены проектируемых технических средств. - Методические указания к выполнению
экономической части дипломного проекта и курсовой работы студентами
электротехнического факультета и факультета автоматики и телемеханики. Грязнова
Л.П., Акользина Г.И. Омский институт инженеров железнодорожного транспорта - 26
с.
. СТП
ОмИИТ - 10 - 91. Курсовой и дипломный проекты. Основные положения. ОмИИТ,
-1993. - 9 с.