Создание программного комплекса для повышения доступности и отказоустойчивости информационной системы, разрабатываемой на предприятии ЗАО 'Компания РОС'
Введение
В результате развития технологий компьютерных
сетей сегодня стало возможно создавать системы, состоящие из множества
компьютеров, объединенных высокоскоростными каналами связи и решать следующие 4
задачи:
1. Обеспечение доступа к удаленным ресурсам:
файловые хранилица, сервера печати, сервера баз данных, сервера, ERP и CRM
системы и прочее.
2. Обеспечение прозрачности доступа к
ресурсам: от пользователя необходимо скрыть тот факт, что ресурсы сети
физически находятся на разных компьютерах или распределены на некотором их
множестве.
. Обеспечение открытости: использование
служб, вызов которых предполагает использование стандартного синтаксиса и
семантики.
. Обеспечение масштабируемости: система
должна иметь возможность к легкому подключению к ней новых пользователей и
ресурсов; система может быть разнесена (или сильно разнесена) в пространстве;
система должна быть проста в управлении при работе во множестве административно
независимых организациях.
Для обеспечения выполнения всех 4-х задач в
настоящее время используются кластерные системы. Кластер - группа компьютеров
(узлов), объединённых высокоскоростными каналами связи и представляющая с точки
зрения пользователя единый аппаратный ресурс [1].
Использование кластерных систем позволяет решить
одну или одновременно 2 следующие задачи:
· Обеспечение повышенной доступности
ресурса: к сожалению, аппаратура, обеспечивающая реализацию основных
программных алгоритмов предоставляемого ресурса, и аппаратура, обеспечивающая
связь между узлами кластера может давать сбои (отключение электропитания, обрыв
кабеля, поломка механизмов чтения дисков и проч.), а многие ресурсы должны
предоставлять доступ в режиме 24\7, поэтому использование дублирующих или
частично дублирующих механизмов на различных узлах кластера способно решать
данную задачу.
· Обеспечение повышенной
производительности: позволяют увеличить скорость расчётов, разбивая задание на
параллельно выполняющиеся потоки. Используются в научных исследованиях [2].
В данном дипломном проекте рассматривается создание
кластерной системы, решающую первую из перечисленных задач.
1.
Специальная часть
1.1 Постановка задачи
Разработать программный комплекс для решения
задачи повышения отказоустойчивости проектируемой информационной системы в
оборонном, коммерческом и личном использовании.
Цель:
1. повышение надежности работы
информационной системы;
2. обеспечение функционирования
информационной системы в сети с большим уровнем помех.
Задачи:
·
разработать
программный комплекс, отслеживающий состояние сети, и исполнения алгоритма
поддержания работоспособности системы при изменении параметров сети.
Требования:
·
программный
комплекс должен реализовывать заданный механизм поддержания работоспособности
информационной системы;
·
программный
комплекс должен обеспечивать автоматическую и ручную режимы работы;
·
программный
комплекс должен функционировать под управлением ОС на базе BSD
4.4;
·
программный
комплекс должен быть реализован на языке C++;
·
программный
комплекс должен обеспечивать функцию журналирования своей работы;
·
работа
программного комплекса должна быть прозрачна для пользователя.
Входные данные:
Следующие входные данные должны вводиться
пользователем в процессе конфигурирования узла программного комплекса:
·
имя
кластера;
·
имя
узла;
·
доменное
имя центра - данное символьное обозначение присваивается узлу, который
назначается центром;
·
путь
к файлу журнала;
·
путь
к файлу сценария, исполняемого при назначении данного узла центром;
·
путь
к файлу сценария, исполняемого при назначении другого узла центром, замсто
данного узла.
Следующие входные данные устанавливаются
пользователем при желании:
·
вес
узла (приоритет выбора данного узла центром, если пользователь не указывает вес
узла - вес считается автоматически исходя из группы параметров: загруженность
процессора, нагрузка на канал ethernet, производительность НЖМД и проч.);
·
режим
работы узла (клиентский или серверный режим. В клиентском режиме данный
компьютер, на котором производиться инсталляция программного комплекса, не
имеет возможности становиться центром, а исключительно занимается
реконфигурацией системы, для доступа пользователю к ресурсам кластера. В
серверном же режиме, программный комплекс занимается мониторингом состояния
клстерной системы в целом, и, при необходимости, может становиться центром
системы.)
После конфигурирования узла и запуска
программного комплексного комплекса, пользователю предоставляется интерфейс
взаимодействия с помощью командной строки, с помощью которого пользователь
может выполнить следующие операции:
·
завершить
работу текущего узла;
·
сменить
текущий центр на иной;
·
запросить
информацию о конфигурации кластера (список узлов, их вес и параметры).
Выходные данные:
1. Журнал работы программного комплекса.
Данный журнал представляет собой текстовый
документ со следующей информацией, разделенной символом табуляции:
▪ Дата наступления события;
▪ Код события - внутренний код
события - для установления места возникновения события;
▪ Тип события - информационное
поле, обозначающее уровень произошедшего события(I - информационное, например,
подключение нового узла к кластеру, W - предупреждение, например, отключение
одного из узлов кластера (не являющегося центром), и E - ошибка, например,
отключение центрального узла кластера)
▪ Сообщение - тестовое поле, в
котором располагается комментарий о возникшем событии.
2. Результаты пользовательского запроса.
· Запрос на завершение работы узла. В
результате пользователю выдается строка подтверждающая успешность выполнения
данной команды.
· Запрос на смену центра на иной. В результате
пользователю выдается строка подтверждающая успешность выполнения данной
команды.
· Запрос на конфигурацию кластера. В
результате выполнения данной команды, пользователю выдается список узлов, с
параметрами, разделенными символом табуляции.
1.2 Аналитический обзор
Любая кластерная система повышенной доступности
должна обладать следующими тремя свойствами:
·
Непротиворечивость
·
Отказоустойчивость
·
Защищенность
Исходя из анализа решаемой задачи,
предполагается, что защита разрабатываемой кластерной системы ложится на
аппаратуру, поддерживающую функционирование данной кластерной системы и выходит
за рамки дипломного проекта. Однако, остальные свойства должны быть
реализованы.
1.2.1 Отказоустойчивость
Отказоустойчивость - это важная область построения
распределенных систем. Отказоустойчивость определяется как способность системы
маскировать появление ошибок и исправлять их. Другими словами, система
отказоустойчива, если она продолжает функционировать при наличии отказов.
Избыточность - это стандартный способ
обеспечения отказоустойчивости. Если избыточность применяется к процессам,
становится важным понятие группы процессов [3].
Группы процессов
Все группы процессов можно разделить в
соответствии с их внутренней структурой. В некоторых начальников нет и все
процессы равны между собой. В других - существует некое подобие иерархии, при
котором один из процессов является координатором, а все остальные процессы -
исполнители. В таком подходе при появлении запроса, он сначала отправляется
координатору, а затем координатор решает какой из исполнителей будет
обрабатывать запрос.
Любая из этих организаций имеет свои достоинства
и недостатки.
Одноранговая организация симметрична и не имеет
единой точки отказа. Если в одном из процессов обнаруживается ошибка, то группа
просто становиться меньше и продолжает обслуживание абонентских запросов.
Недостаток одноранговых групп состоит в том, что процесс принятия решения более
сложен. Так, например, чтобы принять какое-либо решение процессам необходимо
провести голосование, что влечет за собой дополнительные задержки и
необходимость дополнительных действий.
Иерархическая группа обладает противоположными
свойствами: пока координатор находится в рабочем состоянии он принимает все
решения по поводу обслуживания пользовательского запроса, при этом запрос
обслуживается системой с максимально возможной скоростью. Однако, потеря
координатора влечет за собой остановку всей группы, что приводит к отказу в
обслуживании абонентов.
Исходя из того, что разрабатываемая система
должна обеспечивать максимальную обработку пользовательских запросов и, наряду
с этим, избегать возможности в отказе от обработки пользовательских запросов,
то предлагается использование интегрированного решения: в нормальном состоянии
система представляет собой иерархическую группу процессов, обслуживающих
пользовательские запросы с максимальной скоростью, однако, при отказе
координатора, происходит общее голосование, на котором выбирается новый
координатор.
1.2.2 Алгоритмы
голосования
Алгоритм забияки
Когда один из процессов замечает, что
координатор больше не отвечает на запросы, то он инициирует голосование.
Процесс проводит голосование следующим образом:
·
Процесс
посылает всем процессам с большими, чем у него, номерами (номера присваиваются,
исходя, например, из порядка создания процессов, или из возможностей
вычислительной машины на которой выполняется данный процесс. Главное - чтобы
каждый процесс имел уникальный номер) сообщение ГОЛОСОВАНИЕ.
·
Далее
возможны два варианта развития событий:
·
если
никто не отвечает, то текущий процесс выигрывает голосование и становиться
координатором
·
если
один из процессов с большими номерами отвечает, то он становиться
координатором, а работа текущего процесса на этом заканчивается.
Кольцевой алгоритм
В данном алгоритме предполагается, что каждый
процесс знает о том, который процесс является его приемником, т.е. процессы
являются физически или логически упорядоченными. Когда один из процессов
обнаруживает, что координатор не функционирует, что он строит сообщение ГОЛОСОВАНИЕ,
содержащее его номер процесса и посылает его своему приемнику. Если приемник не
работает, что отправитель пропускает его и переходит к следующему элементу
кольца или к следующему, пока не найдет работающий процесс. На каждом шаге
отправитель добавляет свой номер процесса к списку сообщений, активно продвигая
себя в качестве кандидата на координаторы.
В конце концов сообщение вернется к процессу,
который начал голосование. Процесс распознает это событие по приходу сообщения,
содержащего его номер процесса. В этот момент тип сообщения изменяется на
КООРДИНАТОР и вновь отправляется по кругу, сообщая всем процессам, кто стал
координатором (элемент списка с максимальным номером) и какие процессы входят в
новое кольцо. После того, как сообщение пройдет все кольцо оно удаляется и
процессы возвращаются к нормальной работе.
Выводы о выборе алгоритмов
голосования
К сожалению, предположить, что в разрабатываемой
системе процессы будут как-то упорядочены чрезвычайно трудно. Поэтому
единственной возможностью становиться выбор алгоритма Забияки, к тому же выбор
данного алгоритма позволяет достаточно просто организовать подключение новых
процессов (узлов кластера) в систему: достаточно просто инициализировать
голосование новым процессом, чтобы о нем узнал действующий координатор и повлек
за собой выбор нового координатора. Для увеличения эффективности работы
алгоритма при выборе нового координатора, когда подключается новый участник к
группе процессов, можно производить выбор координатора между текущим
координатором и подключаемым узлом (или группой узлов).
1.2.3 Непротиворечивость
Важным вопросом для распределенных систем
является репликация данных. Данные обычно реплицируются для повышения
надежности и увеличения производительности. Одна из основных проблем при этом сохранение
непротиворечивости реплик. Говоря менее формально, это означает, что если в
одну из копий вносятся изменения, то нам необходимо обеспечить, чтобы эти
изменения распространились и на остальные копии, иначе реплики не будут
одинаковы.
Типы хранилища
Основную проблему проектирования распределенных
хранилищ данных - это когда, где и кому размещать копии хранилища [3].
Постоянные реплики
Постоянные реплики можно рассматривать как
исходный набор реплик, образующих распределенное хранилище данных. Во многих
случаях число постоянных реплик невелико. Подобная же статическая организация
применяется и для создания распределенных баз данных. Базы данных могут быть
реплицированы и распределены по нескольким серверам, образующим вместе кластер
рабочих станций. О таких кластерах говорят как об архитектуре без
распределения, подчеркивая, что ни диски, ни оперативная память не используется
процессорами совместно. С другой стороны, базы данных могут распределяться и
возможно реплицироваться по множеству географически распределенных мест.
Реплики, инициируемые сервером
В противоположность постоянным репликам,
реплики, инициируемые сервером, являются копиями хранилища данных, которые
создаются для повышения производительности и создание которых инициируется
хранилищем данных.
Основу функционирования алгоритма динамической
репликации составляют два положения. Во-первых, репликация должна производиться
для уменьшения нагрузки на сервер. Во-вторых, конкретные файлы с сервера должны
перемещаться или реплицироваться на серверы, которые находятся наиболее близко
к клиентам, обращающимся к этим файлам.
Алгоритм функционирования реплик, инициируемых
сервером, таково: сервер подсчитывает количество обращений к данному файлу и
подсчитывает откуда исходят обращения. Как только число обращений достигает
определенного порога, сервер, исходя из набора данных о наиболее активных
клиентах, использующих данный файл, создает репликацию данного файла на
ближайшем к клиентам сервере. Как только число обращений падает ниже
определенного порога, репликация уничтожается.
Реплики, инициируемые клиентом
Еще один важный тип реплик - реплики,
создаваемые по инициативе клиентов. Инициируемые клиентом реплики часто
называют клиентскими кэшами. В сущности, кэш - это локальное устройство
хранения данных, используемое клиентом для временного хранения копии файлов,
запрошенных клиентом. В принципе, управление кэшем полностью возлагается на
клиента. Хранилище, из которого извлекаются данные, не делает ничего для того,
чтобы управлять клиентским кэшем.
Клиентский кэш используется исключительно для
увеличения скорости доступа клиентов к данным.
Выводы о выборе о типе
проектируемого хранилища
Проанализировав существующие методы организации
распределенных хранилищ можно сделать следующие выводы: использование реплик,
инициируемых сервером, в данном проекте представляется невозможным, т.к. такая
организация предполагает динамическое создание реплик, однако, хранилище данных
может выйти из строя (или может быть потеряна возможность соединения с
хранилищем) до того момента, как будет создана хотя бы 1 репликация.
Исходя из этого, можно предположить, что
наиболее подходящей схемой организации становится использование схемы
постоянных реплик, однако этот вариант так же полностью не удовлетворяет нашим
требованиям, т.к. предполагает изначально довольно низкую масштабируемость.
Поэтому существует возможность создания некоего подобия комбинированного
решения из алгоритмов постоянных реплик и реплик, инициируемых клиентом: при
подключении дополнительных узлов в кластер, подключаемый узел запрашивает
репликацию данных, затем участвует с остальными узлами в работе наравне.
Распространение обновлений
Операции обновления в распределенных и
реплицируемых хранилищах данных обычно инициируются клиентом, после чего
пересылаются на одну из копий. Оттуда обновление пересылается на все остальные
узлы кластера, обеспечивая тем самым, требование непротиворечивости. Существуют
различные аспекты проектирования, связанные с распространением обновлений.
Состояние и операции
Один из вопросов проектирования связан с тем,
что кластеры будут распространять. Существуют 3 основные возможности:
·
Распространение
извещения об обновлении. Данный подход предполагает распространение извещения о
несостоятельности данных на остальных узлах, помимо одно из узлов. Плюсом
такого подхода следует отметить крайне невысокую нагрузку на сеть - т.к.
передается исключительно извещение о несостоятельности данных. При
необходимости, остальные узлы запрашивают измененные данные, например, при
обращении клиента к ним. Однако, минусом такого подхода следует отметить крайне
низкую эффективность работы при наличии нестабильных каналов связи: при
отключении узла, хранящего обновленные копии файлов от общей сети - все
изменения не будут потеряны. Данный подход абсолютно недопустим в реализуемом
проекте.
·
Передавать
данные из одной копии в другую. Предполагается, что передаются именные данные.
Данный метод крайне эффективен при отношении большого количества операций
чтения к операциям записи. К сожалению, аналитически оценить соотношение
операций чтения к операциям записи мы не можем, поэтому использование данного
подхода так же представляется туманным.
·
Распространять
операцию обновления по всем копиям. Данный подход предполагает, что
пересылаются не модифицированные данные, а операции, которые следует произвести
на данными. Этот метод так же называется «активной репликацией». Основной
выигрыш от активной репликации состоит в том, что обновления удается передавать
с минимальными затратами на взаимодействие. Минусом же представляется то, что
если операции окажутся сложными, то каждой реплике может потребоваться большая
процессорная мощность для осуществления операции обновления. Исходя из того,
что минимизация производительности оборудования (а, в конечном счете, и его
стоимости) в данном проекте не является ключевым моментом, то данный метод
представляется самым эффективным.
Продвижение и извлечение
Другой вопрос проектирования заключается в том,
следует ли продвигать или извлекать обновления.
Протоколы, основанных на извлечении обновлений,
обычно называются клиентскими протоколами. Основаны на том, что клиент перед
попыткой чтения данных из кэша проверяет валидность этих данных и при
отрицательном результате запрашивает у хранилища актуальные данные. Т.к. Выше
было решено отказаться от использования пользовательских кэшей, то данный метод
представляется неэффективным.
Протоколы, основанные на продвижении обновлений,
обычно называют серверными протоколами. В данных протоколах обновления
распространяются по другим репликам, не ожидая поступления от других реплик
запросто на получение обновлений. Данный метод вполне подходит для решения
поставленной задачи.
1.2.4 Обзор существующих
разработок
Microsoft Cluster Services
В службе
Microsoft Cluster применяется
общее
хранилище
(shared storage). В такой конфигурации узлы кластера
подключены к одним и тем же системам дисковой памяти, как правило SAN (Storage
Area Network). Служба Microsoft Cluster поддерживает также двухузловые кластеры
на базе SCSI, в которых оба узла подключены по одной шине SCSI. Как в
конфигурациях на базе SAN, так и в SCSI каждый узел «видит» и может
использовать тома, определенные в подключенном хранилище данных, так, как будто
эти тома находятся на локально подключенном диске. Если первичный узел отказывает,
то резервный берет на себя управление томом данных (и другими ресурсами,
связанными с приложением, такими как IP-адреса, имена NetBIOS и имена общих
ресурсов) и запускает приложение. Эти системы должны разрешать конфликтные
ситуации между владельцами дисковых томов, чтобы в данный момент времени только
один сервер мог записывать данные на том. Для успешной работы кластера с общим
хранилищем данных необходимы безупречно совместимые друг с другом аппаратные
компоненты. Microsoft сертифицирует определенные аппаратные конфигурации и
публикует их в разделе кластеров каталога Windows Catalog (для Windows Server
2003) или в списке Hardware Compatibility List (HCL - для Windows 2000 Server)
[4].
Linux-HA и DRBD
Linux-HA предоставляет совпеременные
высоконадежные возможности для широкого спектра платформ, и поддерживает
несколько десятков тысяч различных критичных систем по всему миру. HA
старейшее, обладающее наибольшими возможностями и наилучше протестированное
решение среди свободно распространяемых продуктов. По стандарту проекта оно
всегда компилируется без сообщений и не критичных ошибках (warnings). Исходный
код периодически оценивается экспертами по компьютерной безопасности.
Оно предоставляет возможности мониторинга узлов
кластера и приложений, предоставляет современную модель зависимостей,
основанную на правилах размещения ресурсов на узлах кластера. Когда случает
сбой, или происходит изменение в правилах, то используются определенные
пользователем правила для перемещения ресурсов внутри кластера.
Возможности:
·
Работает
на всех известных Linux платформах
·
Автоматически
определяет сбои в работе узлов кластера
·
Современные
возможности описания зависимостей между ресурсами позволяют стартовать ресурсы
быстро и в правильном порядке
·
Поддреживает
как co-location, так и anti-colocation правила
·
Распределение
ресурсов позволяют вам разместить приложения точно там, где вам требуется,
основываясь на зависимостях между ресурсами; правилах, определенных
администратором; параметрах узлов кластера, определенных администратором и
правилами размещения
·
Точное
управление ресурсами может включать определённые пользователями атрибуты,
которые позволяют управлять переключением ресурсов между узлами
·
Правила
позволяют определять временные зависимости. Это означает что вы можете
определять разные правила для разного времени. Например можно задать правило,
согласно которому возвращение переключенного ресурса на основной узел буде
происходить только в ночное время
·
Простая
для понимания и внедрения система управления приложениями. Большинство
приложений не требуют дополнительных скриптов для базового управления.
·
Возможность
группирования ресурсов предоставляет простое управление для комплексных
приложений
·
Активный
fencing
механизм (STONITH) предоставляет возможность гарантированной целостности
данных даже в случаях не стандартных сбоев
·
Графический Интерфейс Пользователя GUI упрощает управление
кластером
·
Свободное распространение исключает зависимость от производителя и
предоставляет большую гибкость и стабильность
·
Специальная поддержка кластерных приложений с использование
ресурсов-клонов позволяет одному приложению работать на нескольких узлах
кластера
·
Встроенная простая поддержка LVS распределения нагрузки
·
Встроенная простая поддержка ClusterIP распределения
нагрузки
·
Встроенная простая поддержка DRBD механизма
репликации данных
·
Специальная
поддержка синхронизации в режиме master/slave предоставляет надежную
целостность данных
·
Известность
и надежная репутация в Linux сообществе
·
Работает
на отдельных серверах для предоставления простого механизма старта, остановки и
мониторинга приложений
·
Поддерживает
географически распределенные кластера, включая надежно переключение ресурсов
·
Также
доступно для FreeBSD, OpenBSD и Solaris. Портируемо на другие POSIX платформы
[5]
Oracle
RAC
Опция Real
Application
Clusters (RAC)
позволяет строить отказоустойчивые и хорошо масштабируемые серверы баз данных
на основе объединения нескольких вычислительных систем. В архитектуре RAC
экземпляры СУБД Oracle одновременно выполняются на нескольких объединенных в
кластер системах, производя совместное управление общей базой данных. По
существу, с точки зрения приложения - это единая СУБД. Такой подход позволяет
достичь исключительно высокой готовности и масштабируемости любых приложений.
Гибкость и эффективность планирования ресурсов позволяют наращивать мощности до
любого уровня по требованию, по мере изменения потребностей
бизнеса.используется для создания корпоративных сетей распределенной обработки данных.
Такие сети строятся из большого количества стандартизованных недорогих
компонентов: процессоров, серверов, сетевых устройств и устройств хранения
данных. RAC - это программный продукт и технология, позволяющая объединить все
эти компоненты в эффективную вычислительную систему всей организации. RAC и
Grid-технологии дают возможность радикально снизить эксплуатационные затраты и
обеспечить новый уровень гибкости, делая корпоративные системы более
адаптивными, гибкими и динамичными. Динамическое обеспечение узлами,
устройствами хранения, центральными процессорами и оперативной памятью
позволяет быстро и эффективно гарантировать необходимые уровни сервиса при
одновременном снижении затрат за счет лучшего использования ресурсов. Кроме
того, архитектура RAC полностью прозрачна для приложения, работающего с
кластерной базой данных - не требуется никаких модификаций приложения для его
развертывания в среде RAC.
Масштабируемость
RAC дает пользователям возможность добавлять в
кластер новые узлы при возрастании требований к ресурсам, производить
постепенное увеличение мощности системы при оптимизации затрат на оборудование.
При использовании вместе с СУБД Oracle 11g сформированные с помощью
Grid-технологии пулы стандартных недорогих компьютеров и модульных систем хранения
данных делают это решение еще более гибким. Процесс наращивания ресурсов
становится значительно более простым и быстрым, поскольку при необходимости
расширения к кластеру можно добавлять новые узлы вместо того, чтобы заменять
существующие более мощными. Технология Cache Fusion, реализованная в Real
Application Clusters, и поддержка InfiniBand, предусмотренная в СУБД Oracle
11g, позволяют почти линейно наращивать пропускную способность системы без
каких-либо изменений в приложениях.
Высокая готовность
Другое ключевое преимущество кластерной
архитектуры на основе Oracle RAC - присущая ей устойчивость к отказам за счет
наличия множества узлов. Поскольку физические узлы работают независимо друг от
друга, отказ одного или нескольких узлов не оказывает влияния на работу
остальных узлов кластера. Аварийное переключение сервиса может быть произведено
на любой узел Grid. В самой крайней ситуации система на базе Real Application
Clusters способна поддерживать работу базы данных даже при отказе всех узлов за
исключением одного. Подобная архитектура позволяет прозрачно вводить в действие
узлы или выводить их из работы, например, для технического обслуживания, в то
время как остальная часть кластера будет продолжать поддерживать работу СУБД.
RAC имеет встроенные средства интеграции с сервером приложений Oracle
Application Server 11g для аварийного переключения пулов соединений. Благодаря
этому приложение получает информацию об отказе немедленно, не тратя десятки
минут ожидания до истечения тайм-аута TCP-соединения. Приложение может
немедленно предпринять подходящие действия по восстановлению. Средства
балансировки нагрузки позволяют перераспределить нагрузку равномерно между
ресурсами Grid.
Баланс нагрузки
RAC поддерживает новую абстракцию, получившую
название сервиса. Сервисы представляют классы пользователей базы данных или
приложений. Задание и применение бизнес-политик к сервисам позволяет разрешать
такие проблемы, как выделение узлов на периоды пиковых вычислительных нагрузок
или автоматическое устранение последствий отказа сервера. Это гарантирует
предоставление системных ресурсов в требуемый период времени и там, где это
необходимо для решения поставленных задач.
Единый стек кластерного ПО
Oracle Database Enterprise Edition 11g и Опция
Real Application Clusters составляют полный комплект ПО управления и
функционирования кластера. Кластерное программное обеспечение Oracle
(Clusterware) предоставляет все необходимые возможности, требуемые для работы
кластера, включая учет узлов, службы сообщений и блокировки. В связи с тем, что
оно представляет собой полностью интегрированный стек с общими API событий и
управления, им можно централизованно управлять с помощью OEM. Нет необходимости
приобретения дополнительного кластерного ПО других производителей. Кластерное
ПО имеет единый интерфейс и единую функциональность для всех поддерживаемых
Oracle платформ.
Выводы
К сожалению, анализ данной разработки можно
завершить уже на данном этапе, т.к. текущая разработка не подходит в качестве
решения поставленной задачи по нескольким параметрам:
· требуется отдельные средства для
организации общего хранилища
· требуется использование операционной
системы Microsoft Windows 2000\2003\2008, что недопустимо в проекте
· число узлов кластера не может
превышать 8
Данная реализация в определенном приближении
решает поставленные задачи, однако, система реплицирования DRDB не имеет
портированной версии под операционную систему на базе BSD 4.4, которая
используется в проекте. К тому же система ориентирована в первую очередь на
работу с отключаемыми (мобильными) клиентами, чего не требуется в проектируемой
системе, хотя в определенной доработке может быть использовано в проекте. К
тому же, данная система не по всем параметрам удовлетворяет выбранным выше
характеристикам системы, поэтому может быть сделан вывод о неприменимости
использования данной системы в проекте.
Для улучшения наглядности проведенного мной
анализа, составлена таблица 1.1 на основании аналогов и критерий, по которым
видны достоинства и недостатки каждого.
Таблица 1.1 - Сводная таблица анализа
существующих средств.
|
Аналоги
Критерии
|
Microsoft Cluster Services
|
Linux-HA + DRBD
|
Oracle RAC
|
Разрабатываемый программный комплекс
|
|
Функционирование
под управление ОС на базе BSD 4.4
|
-
|
+-
|
+
|
+
|
|
Реализация
заданного механизма поддержания работоспособности ИС
|
-
|
+
|
-
|
+
|
|
Реализация
механизма журналирования
|
+
|
+
|
-
|
+
|
|
Возможность
работы в сетях с высоким уровнем помех
|
-
|
-
|
-
|
+
|
|
Прозрачность
работы программного комплекса
|
+
|
+
|
+
|
+
|
Исходя из отсутствия аналога по всем параметрам,
мной было принято решение создать собственный программный комплекс, отвечающий
всем перечисленным выше требованиям.
1.3 Разработка программного
комплекса и описание алгоритма
1.3.1 Структура
программного комплекса
На рисунке 1.3.1.1 представлена структурная
схема программного комплекса, отражающая модули, из которых состоит программный
комплекс, и схему взаимодействия между ними.

Рисунок 1.3.1.1 - Структурная схема программного
комплекса
Модуль инициализации (INIT)
Задачи, решаемые модулем инициализации, состоят
в запуске остальных модулей программного комплекса, отслеживания аварийного
завершения остальных модулей с помощью сигналов операционной системы и передачи
пользовательских запросов программному комплексу. При приходе сообщения о завершении
работы одного из модулей, модуль инициализации пытается перезапустить данный
процесс и записать сообщение в журнал о данном событии. Если запись в журнал
невозможна (не функционирует модуль журналирования или модуль обслуживания
сообщений), то модуль инициализации записывает сообщение о наступлении такого
события в локальный журнал (файл). Схема работы данного модуля представлена на
рисунке 1.3.1.1.1.

Рисунок 1.3.1.1.1 - Алгоритм работы модуля
инициализации
Модуль обслуживания сообщений
Все модули программного комплекса
взаимодействуют между собой через очередь сообщений - тип межпроцессного
взаимодействия, предоставляемого операционной системой. Основная задача модуля
обслуживания сообщений - это пересылка сообщения от одного модуля другому.
Схема работы модуля представлена на рисунке 1.3.1.2.1.

Рисунок 1.3.1.2.1 - Алгоритм работы модуля
обслуживания сообщений
Модуль журналирования
Модуль журналирования решает задачу сохранения
событий системы, присылаемых ему другими модулями программного комплекса. Схема
работы данного модуля представлена на рисунке 1.3.1.3.1.

Рисунок 1.3.1.3.1 - Алгоритм работы модуля
журналирования
Модуль широковещательной рассылки
информации
Основной задачей данного модуля является
рассылка информации о существовании данного узла в сеть и данных о весе
текущего узла.
Модуль обнаружения узлов в сети
Основная задача, решаемая данным модулем - это
прослушивание сети на наличие информации от модулей широковещательной рассылки
информации других узлов кластера в сети. При обнаружении такой информации,
модуль обнаружения узлов в сети отправляет сообщение о наступлении такого
события модулю управления состоянием узла с информацией о весе удаленного узла.
Модуль обслуживания клиентского
подключения
Данный модуль используется для диагностики
работоспособности узла, который в данный момент является центром кластера,
пересылки сообщений от центра локальному модулю управления состоянием узла и
запрошенных данных от локального узла к центру кластера. При обрыве соединения
с центром, данный модуль сообщает о наступлении такого события модулю
управления состоянием узла.
Модуль обслуживания клиентских
подключений
Данный модуль используется для диагностики
работоспособности узлов, которые в данный момент подключены к текущему
центральному узлу кластера, пересылки сообщений от центрального узла кластера
остальным узлам и получения данных, запрошенных центральным узлом, от остальных
узлов кластера. При обнаружении обрыва соединения с одним из узлов, данный
модуль сообщает о наступлении такого события локальному модулю управления
состоянием узла.
Модуль управления состоянием узла
Данный модуль представляет собой головной
процесс управления программным комплексом, который занимается отработкой всех
событий, происходящих в программном комплексе. Схема функционирования
представлена на рисунке 1.3.1.8.1.

Рисунок 1.3.1.8.1 - Алгоритм работы модуля
управления состоянием узла.

Рисунок 1.3.1.8.2 - Алгоритм исполнения
сообщения от модуля инициализации.

Рисунок 1.3.1.8.3 - Алгоритм исполнения
сообщения от модуля обнаружения узлов в сети.

Рисунок 1.3.1.8.4 - Алгоритм исполнения
сообщения от модуля обслуживания клиентского подключения.

Рисунок 1.3.1.8.5 - Алгоритм исполнения
сообщения от модуля обслуживания клиентских подключений.
1.3.2 Режимы работы
программного комплекса
Клиентский режим
В данном режиме функционирования программного
комплекса на узле функционируют в активном режиме следующие модули:
· Модуль обнаружения узлов в сети
· Модуль обслуживания сообщений
· Модуль инициализации
· Модуль управления состоянием узла
При работе узла в клиентском режиме программный
комплекс отслеживает изменения в конфигурации кластера (в основном, изменение
центрального узла кластера), и производит перенастройку конфигурации узла для корректного
доступа к ресурсам кластера (производит запуск соответствующего скрипта,
который, например, меняет файл /etc/hosts).
Серверный активный режим
Узел может работать в данном режиме, только если
он является в данный момент центром кластера, в активном режиме функционируют
следующие модули:
· Модуль широковещательной рассылки
информации
· Модуль управления состоянием узла
· Модуль инициализации
· Модуль обслуживания сообщений
· Модуль журналирования
· Модуль обнаружения узлов в сети
· Модуль обслуживания клиентских
подключений
В процессе функционирования узла в данном
режиме, модуль обнаружения узлов в сети постоянно исследует сеть на наличие
информации о других узлах, находящихся в серверном активном режиме,
одновременно с этим рассылая сообщения о себе в сеть. Если такой узел найден,
то информация об узле отправляется в модуль управления состоянием узла, в
котором заявленный вес удаленного узла сравнивается с весом текущего узла, при
выполнении такого условия, что вес удаленного узла больше веса текущего узла,
происходит переключения текущего узла в серверный пассивный режим и подключение
к удаленному узлу как к центру кластера, в противном случае событие
игнорируется.
Серверный пассивный режим
При работе в данном режиме узел представляется
клиентом к центральному узлу кластера, и функционируют следующие модули:
· Модуль управления состоянием узла;
· Модуль обслуживания сообщений;
· Модуль инициализации;
· Модуль журналирования;
· Модуль обслуживания клиентского
подключения.
В данном режиме, узел постоянно отслеживает
наличие подключения с центральным узлом кластера и, при обрыве соединения,
переходит в серверный активный режим.
1.3.3 Алгоритм
функционирования программного комплекса
Алгоритм инициализации узла
После успешной инсталляции и конфигурации узла
кластера, запуск осуществляется в следующей последовательности:
· Осуществляется запуск модуля
инициализации;
· Модуль инициализации создает очередь
сообщений и осуществляет запуск модулей в следующей последовательности:
. Модуль обслуживания сообщений (в
активном режиме);
. Модуль журналирования (в активном
режиме);
. Модуль широковещательной рассылки
информации (в режиме ожидания);
. Модуль обнаружения узлов в сети (в
режиме ожидания);
. Модуль обслуживания клиентских
подключений (в режиме ожидания);
. Модуль обслуживания клиентского
подключения (в режиме ожидания);
· Узел переводится в клиентский или
активный серверный режим (исходя из параметров конфигурации).
Алгоритм перехода в активный
серверный режим
Переход в активный серверный режим осуществляется
по следующему алгоритму:
· Модуль обслуживания клиентского
подключения соединяется с локальным модулем обслуживания клиентских
подключений;
· Модуль обслуживания клиентских
подключений переводится в активный режим;
· Модуль обнаружения узлов в сети переводится
в активный режим;
· Модуль широковещательной рассылки
информации переводится в активный режим;
· Событие перехода в активный
серверный режим фиксируется модулем журналирования.
Алгоритм перехода в пассивный
серверный режим
Переход в пассивный серверный режим
осуществляется по следующему алгоритму:
· Всем подключенным клиентам
отсылается сообщение на переключение на другой сервер;
· Модуль обслуживания клиентского
подключения соединяется с удаленным модулем обслуживания клиентских
подключений;
· Модуль обслуживания клиентского
подключения подключается к новому центру;
· Модуль обслуживания клиентских
подключений переводится в режим ожидания;
· Модуль обнаружения узлов в сети
переводится в режим ожидания;
· Модуль широковещательной рассылки
информации переводится в режим ожидания;
· Событие перехода в пассивный
серверный режим фиксируется модулем журналирования.
1.4 Разработка
пользовательского интерфейса
Исходя из того, что данный программный комплекс
используется, в большинстве случаев, на серверных платформах под управлением BSD
UNIX, то для
обеспечения удобства администрирования и работы программного комплекса, был
разработан удобный пользовательский интерфейс, обеспечивающий взаимодействие с
программным комплексом через командную строку.
1.4.1 Конфигурирование
программного комплекса
Конфигурирование осуществляется с помощью любого
текстового редактора, например, vi.
Файл конфигурации представляет собой набор строк типа «Параметр» = «Значение»,
что позволяет быстро и удобно сконфигурировать инсталляцию программного
комплекса под собственные нужды.

Рисунок 1.4.1.1 - Процесс конфигурации
программного комплекса.
1.4.2 Взаимодействие с
программным комплексом
Взаимодействие с программным комплексом
осуществляется с помощью системы параметров и их значений, указываемых при
запуске исполняемого файла программного комплекса. Список допустимых команд
управления описан в пункте «1.7. Разработка руководства оператора».

Рисунок 1.4.2.1 - Процесс взаимодействия с
программным комплексом.
1.5 Текст программы
В связи с большим объемом, текст программы
предъявлен в Приложении 1.
1.6 Анализ тестовых
испытаний программного блока
В постановке задачи был задан ряд функций,
которые должен выполнять программный комплекс, поэтому я решил проводить
тестовые испытания, исходя из каждой заявленной функции. Проверка будет
считаться завершенной в том случае, если вышеперечисленная последовательность действий
оператора будет соответствовать выполнению данной функции. [13]
1.6.1 Проверка
корректного функционирования системы, состоящей из одного элемента
Схема теста
Осуществляется запуск программного комплекса на
одном узле. В качестве ресурса, предоставляемого кластером, выбран web-сервер
Apache.
Ожидаемый результат
Программный комплекс корректно инициализируется
и выводит соответствующее сообщение. Доступ к web-сайту
с клиента осуществляется корректно.
Полученный результат
Результат инициализации программного комплекса
представлен на рисунке 1.6.1.3.1.

Рисунок 1.6.1.3.1 - Результат инициализации
программного комплекса.
Доступ к web-сайту
с клиента осуществляется корректно.
Результат теста
Тест пройден полностью.
1.6.2 Проверка
корректной отработки и реконфигурации системы при подключении нового узла или
группы узлов
Схема теста
К системе, состоящей из двух узлов, подключается
сначала дополнительный узел, затем группа узлов, состоящая так же из двух
узлов.

Рисунок 1.6.2.1.1 - Схема теста. А - подключение
1 узла, Б - подключение группы узлов.
Ожидаемый результат
Система определит изменение конфигурации сети и
выберет новый центр. Доступ к web-сайту
не нарушится при изменении центра.
Полученный результат
В ходе теста система корректно отработала
изменение в конфигурации кластера, о чем свидетельствуют рисунки 1.6.2.3.1,
1.6.2.3.2, 1.6.2.3.3.

Рисунок 1.6.2.3.1 -Конфигурация кластера первой
группы узлов.

Рисунок 1.6.2.3.2 -Конфигурация кластера второй
группы узлов.
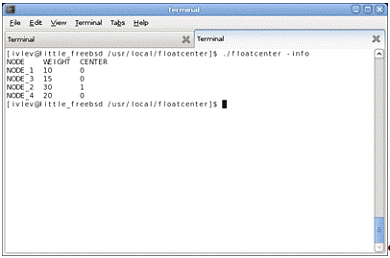
Рисунок 1.6.2.3.2 -Конфигурация кластера после
объединения групп.
Доступ к web-сайту
с клиента осуществляется корректно.
Результат теста
Тест пройден полностью.
1.6.3 Проверка
корректной отработки и реконфигурации системы при отключении узла или группы
узлов
Схема теста
Системы, состоящие из 3 и 4 узлов
соответственно, разделяются на системы, состоящие из 2 и 1, и 2 и 2 узлов,
соответственно.
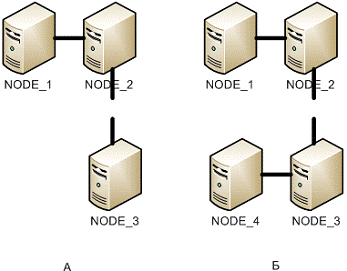
Рисунок 1.6.2.1.1 - Схема теста. А - отключение
1 узла, Б - отключение группы узлов.
Ожидаемый результат
Система определит изменение конфигурации сети и
выберет новый центр. Доступ к web-сайту
не нарушится при изменении центра с двух клиентов, подключенных к разным
группам узлов.
Полученный результат
В ходе теста система корректно отработала
изменение в конфигурации кластера, о чем свидетельствуют рисунки 1.6.3.3.1,
1.6.3.3.2, 1.6.3.3.3.

Рисунок 1.6.3.3.1 -Конфигурация исходного
кластера.

Рисунок 1.6.3.3.2 -Конфигурация кластера первой
группы узлов.
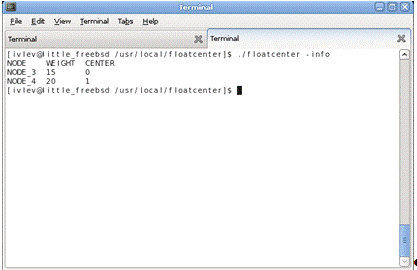
Рисунок 1.6.3.3.3 - Конфигурация кластера второй
группы узлов.
Доступ к web-сайту
с клиентов осуществляется корректно. У клиента, подключенного ко второй группе
узлов (группа, которая оказалась, отключена от центра), был заметен
кратковременный сбой при попытке доступа к web-сайту.
Результат теста
Тест пройден полностью.
1.6.4 Проверка
корректной работы системы при наличии многочисленных помех в линиях связи
Схема теста
Проводятся тесты, аналогичные двум предыдущим
тестам. Уровень ошибок на линиях связи устанавливается равным 50%.
Ожидаемый результат
Аналогичные результаты двух предыдущих тестов.
Полученный результат
Результат теста
Тест пройден полностью.
1.6.5 Проверка
журналирования событий системы
Схема теста
Выполняется тест по подключению группы узлов к
существующему кластеру, и отслеживаются изменения в файлах журналов.
Ожидаемый результат
Изменения конфигурации кластера должны быть
отражены в журнале работы системы.
Полученный результат
На рисунке 1.6.4.3.1 представлен файл журнала
узла NODE_2. На
рисунке видно, что система при инициализации перевелась в серверный активный
режим, затем корректно подключила 1 узел, и остальную группу узлов, при
изменении конфигурации кластера.
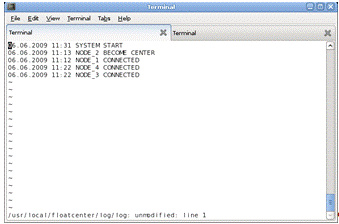
Рисунок 1.6.4.3.1 - Файл журнала узла NODE_2.
Результат теста
Тест пройден полностью.
1.6.5 Проверка
корректного исполнения команд оператора при работе в ручном режиме
функционирования системы
Схема теста
Оператор вводит команды в следующей
последовательности:
· Запрос информации о конфигурации
кластера
· Исполнение команды на изменение
центра
· Запрос информации о конфигурации
кластера
Ожидаемый результат
Второй запрос информации должен показать
изменение положения центра. Доступ к сайту с клиента не должен быть нарушен.
Полученный результат
Тест выполнен в полной мере, результаты теста
представлены на рисунках 1.6.5.3.1, 1.6.5.3.2, 1.6.5.3.3.

Рисунок 1.6.5.3.1 - Результат запроса информации
о конфигурации кластера до изменения положения центра.

Рисунок 1.6.5.3.2 - Исполнение команды на
изменение .положения центра.

Рисунок 1.6.5.3.3 - Результат запроса информации
о конфигурации кластера после изменения положения центра.
Результат теста
Тест пройден полностью.
1.6.6 Результаты
тестовых испытаний
Для наглядности результаты тестовых испытаний
предъявим в виде таблицы 1.6.6.1, где будут перечислены проводимые тестовые
испытания и отмечен положительный или отрицательный результат каждого вида
испытания.
Таблица 1.6.6.1- Результаты тестовых испытаний
|
Проводимые
тестовые испытания
|
Результаты
испытаний
|
|
Корректное
функционирование системы, состоящей из одного элемента
|
+
|
|
Корректное
отработка и переконфигурирование системы при подключении нового элемента в
существующую конфигурацию
|
+
|
|
Корректное
отработка и переконфигурирование системы при подключении группы элементов в
существующую конфигурацию
|
+
|
|
Корректное
отработка и переконфигурирование системы при отключении элемента от
существующей конфигурации
|
+
|
|
Корректное
отработка и переконфигурирование системы при отключении группы элементов от существующей
конфигурации
|
+
|
|
Корректная
работа системы при наличии многочисленных помех в линиях связи
|
+
|
|
Журналирование
событий системы
|
+
|
|
Корректное
исполнение команд оператора при работе в ручном режиме функционировании
системы
|
+
|
1.7 Разработка руководства
оператора
1.7.1 Назначение
программы
Функциональное назначение
Функциональным назначением программного
комплекса является повышение отказоустойчивости и доступности вычислительной
сети.
Эксплуатационное назначение
Программный комплекс должен эксплуатироваться в
профильных подразделениях на объектах Заказчика.
Конечными пользователями программного комплекса
должны являться сотрудники профильных подразделений объектов Заказчика.
Состав функций
Программный комплекс обеспечивает возможность
выполнения перечисленных ниже функций:
1. Реализация
заданного механизма поддержания работоспособности информационной системы;
2. Обеспечение
ручного и автоматического режимов работы;
3. Журналирование
событий, происходящих в системе.
1.7.2 Условия выполнения
программы
Климатические условия эксплуатации
Климатические условия эксплуатации, при которых
должны обеспечиваться заданные характеристики, должны удовлетворять
требованиям, предъявляемым к техническим средствам в части условий их
эксплуатации.
Минимальный состав технических
средств
В состав технических средств должен
входить IBM-совместимый персональный компьютер (ПЭВМ), включающий в себя:
·
процессор Pentium-IV с тактовой частотой - 3,2 ГГц;
·
оперативную память объемом 1 Гб;
Минимальный состав программных средств
Система функционирует под
управлением ОС FreeBSВ версии 7.0.
1.7.3 Требования к
пользователю
Для работы программного комплекса в ручном
режиме требуется минимум один конечный пользователь (оператор).
Конечный пользователь программного комплекса
(оператор) должен обладать практическими навыками работы с интерфейсом
командной стройки операционной системы.
1.7.4 Выполнение
программного комплекса
Установка и конфигурация
программного комплекса
Для установки программного комплекса необходимо:
1. скопировать исполняемый файл «floatcenter»
в каталог на жестком диске, создать файл журнала и конфигурационных параметров;
2. Файл конфигурационных параметров
представляет собой текстовый файл со строками «Параметр=Значение» (Пример
представлени на рисунке 1.7.4.1).
Список допустимых параметров:
· CLUSTER_NAME
- имя кластера (символьное имя);
· NODE_NAME
- имя узла (символьное имя);
· CENTER_NAME
- доменное имя центра (символьное имя);
· SCRIPT_BECOME_CENTER
- путь к файлу сценария, запускаемого при присвоении данному узлу статуса
«центра»;
· SCRIPT_BECOME_USUAL
- путь к файлу сценария, запускаемого при присвоении данному узлу статуса
рядового узла;
· LOG
- путь к файлу журнала;
· NODE_WEIGHT
- вес узла (числовое значение);
· MODE
- режим работы (допустимые значения: SERVER,
CLIENT)
3. Установить разрешения на чтение и запись
файл журнала, исполнение исполняемого файла программного комплекса и чтения
файла конфигурации.

Рисунок 1.7.4.1. - Процесс конфигурации
программного комплекса.
Взаимодействие программным
комплексом
Запуск:
Для запуска программного комплекса необходимо
выполнить следующую команду:
> ./floatcenter
-start
Останов:
Для останова программного комплекса необходимо
выполнить следующую команду:
> ./floatcenter
-stop
Получение информации о конфигурации
кластера:
Для получения информации о конфигурации кластера
необходимо выполнить следующую команду:
> ./floatcenter
-into
Переназначение центра:
Для переназначения центра необходимо выполнить
следующую команду:
> ./floatcenter
-change <ИМЯ_УЗЛА>
1.7.5 Сообщения
оператору
В процессе работы программного комплекса могут
выдаваться диагностические сообщения о некорректной работе программного
комплекса (ошибках), которые необходимо передать разработчику.
Основными же сообщения оператору являются:
1. Сообщение о недостаточных правах на
чтение\запись в файл журнала;
2. Сообщение о недостаточных правах на
чтение файла параметров;
. Сообщения, подтверждающие выполнение
команды (рисунок 1.7.5.1).

Рисунок 1.7.5.1. - Подтверждение выполнения
команды.
При попытке выполнить недопустимую команду, ее
исполнение игнорируется.
2.
Экологическая часть и безопасность жизнедеятельности
2.1 Исследование
возможных опасных и вредных факторов, возникающих при работе с ЭВМ, и их
воздействие на пользователей
Любой производственный процесс, в том числе и
работа с вычислительной техникой, сопряжен с появлением опасных и вредных
факторов.
Опасным называется фактор, воздействие которого
на человека вызывает травму, то есть внезапное повреждение организма в
результате воздействия внешних факторов.
Вредным называется фактор, длительное
воздействие которого на человека, приводит к профессиональным заболеваниям.
[17]
Факторы различаются в зависимости от источника
возникновения.
2.1.1 Исследование
возможных опасных и вредных факторов, возникающих при работе с ЭВМ
Питание ЭВМ производится от сети 220В. Так как
безопасным для человека напряжением является напряжение 40В, то при работе на
ЭВМ опасным фактором является поражение электрическим током.
В дисплее ЭВМ высоковольтный блок строчной
развертки и выходного строчного трансформатора вырабатывает высокое напряжение
до 25кВ для второго анода электронно - лучевой трубки. А при напряжении от 5 до
300
кВ
возникает рентгеновское излучение различной жесткости, которое является вредным
фактором при работе с ПЭВМ (при 15 - 25 кВ возникает мягкое рентгеновское
излучение).
Развертка ЭЛТ создается напряжением с частотой:
·
85
Гц (кадровая развертка);
·
42
кГц (строчная развертка).
Следовательно, пользователь попадает в зону
электромагнитного излучения низкой частоты, которое является вредным фактором.
Во время работы компьютера дисплей создает
ультрафиолетовое излучение, при повышении плотности которого > 10 Вт/м2,
оно становиться для человека вредным фактором. Его воздействие особенно
сказывается при длительной работе с компьютером.
Во время работы компьютера вследствие явления
статического электричества происходит электризация пыли и мелких частиц,
которые притягивается к экрану.
Вывод:
При эксплуатации перечисленных элементов
вычислительной техники могут возникнуть следующие опасные и вредные факторы:
·
поражение
электрическим током;
·
рентгеновское
излучение;
·
электромагнитное
излучение;
·
ультрафиолетовое
излучение;
·
статическое
электричество.
2.1.2 Анализ влияния
опасных и вредных факторов на пользователя
Влияние электрического тока
Электрический ток, воздействуя на человека,
приводит к травмам. Такими травмами являются:
· Общие травмы:
·
судорожное
сокращение мышц, без потери сознания;
·
судорожное
сокращение мышц, с потерей сознания;
·
потеря
сознания с нарушением работы органов дыхания и кровообращения;
·
состояние
клинической смерти;
·
Местные
травмы:
·
электрические
ожоги;
·
электрический
знак;
·
электро-автольмия.
Проходя через тело человека, электрический ток
оказывает следующие воздействия:
·
термическое
(нагрев тканей и биологической среды);
·
электролитическое
(разложение крови и плазмы);
·
биологическое
(способность тока возбуждать и раздражать живые ткани организма);
·
механическое
(возникает опасность механического травмирования в результате судорожного
сокращения мышц).
Наиболее опасным переменным током является ток
20 - 100 Гц. Так как компьютер питается от сети переменного тока частотой 50 Гц,
то этот ток является опасным для человека. [18, 19]
Влияние рентгеновского излучения
В организме происходит:
·
торможение
функций кроветворных органов;
·
нарушение
нормальной свертываемости крови и т.д.
Влияние электромагнитных излучений
низкой частоты
Электромагнитные поля с частотой 60 Гц и выше
могут инициировать изменения в клетках животных (вплоть до нарушения синтеза
ДНК). В отличие от рентгеновского излучения, электромагнитные волны обладают
необычным свойством: опасность их воздействия при снижении интенсивности не
уменьшается, мало того, некоторые поля действуют на клетки тела только при
малых интенсивностях или на конкретных частотах. Оказывается переменное
электромагнитное поле, совершающее колебания с частотой порядка 60 Гц,
вовлекает в аналогичные колебания молекулы любого типа, независимо от того,
находятся они в мозге человека или в его теле. Результатом этого является
изменение активности ферментов и клеточного иммунитета, причем сходные процессы
наблюдаются в организмах при возникновении опухолей.
Влияние ультрафиолетового излучения
Ультрафиолетовое излучение - электромагнитное
излучение в области, которая примыкает к коротким волнам и лежит в диапазоне
длин волн ~ 200 - 400 нм.
Различают следующие спектральные области:
·
200
- 280 нм - бактерицидная область спектра.
·
280
- 315 нм - Зрительная область спектра (самая вредная).
·
315
- 400 нм - Оздоровительная область спектра.
Синий люминофор экрана монитора вместе с
ускоренными в электронно-лучевой трубке электронами являются источниками ультрафиолетового
излучения. Воздействие ультрафиолетового излучения сказывается при длительной
работе за компьютером. Основными источниками поражения являются глаза и кожа.
Энергетической характеристикой является
плотность потока мощности [Вт/м2].
Биологический эффект воздействия определяется
внесистемной единицей [эр]. 1 эр - это поток (280 - 315 нм), который
соответствует потоку мощностью 1 Вт.
Воздействие ультрафиолетового излучения
сказывается при длительной работе за компьютером. Максимальная доза облучения:
·
7,5
мэр·ч/м2 за рабочую смену;
·
60
мэр·ч/ м2 в сутки.
При длительном воздействии и больших дозах могут
быть следующие последствия:
·
серьезные
повреждения глаз (катаракта);
·
рак
кожи;
·
кожно-биологический
эффект (гибель клеток, мутация, канцерогенные накопления);
·
фототоксичные
реакции.
Влияние статического электричества
Результаты медицинских исследований показывают,
что электризованная пыль может вызвать воспаление кожи, привести к появлению
угрей и даже испортить контактные линзы. Кожные заболевания лица связаны с тем,
что наэлектризованный экран дисплея притягивает частицы из взвешенной в воздухе
пыли, так, что вблизи него «качество» воздуха ухудшается и оператор вынужден
работать в более запыленной атмосфере. Таким же воздухом он и дышит.
Особенно стабильно электростатический эффект
наблюдается у компьютеров, которые находятся в помещении с полами, покрытыми
синтетическими коврами.
При повышении напряженности поля Е
>
15
кВ/м,
статическое электричество может вывести из строя компьютер. [22]
Вывод:
Из анализа воздействий опасных и вредных
факторов на организм человека следует необходимость защиты от них.
2.2 Способы защиты
пользователей от воздействия на них опасных и вредных факторов
.2.1 Методы и средства
защиты от поражения электрическим током
В помещении вычислительного центра существует
опасность прикосновения одновременно к предметам, имеющим соединения с землей,
и металлическому корпусу электрооборудования.
Как основной способ борьбы с опасностью
поражения электрическим током (от поражения напряжением прикосновения)
используется зануление.
Зануление - это преднамеренное соединение
нетоковедущих металлических частей, которые могут оказаться под напряжением в
результате повреждения изоляции, с нулевым защитным проводником (применяется в
трехфазных сетях с заземленной нейтралью в установках до 1000 вольт, см. рис.
2.1). [19]

Рисунок 2.1 - Защитное зануление
Для защиты используется нулевой защитный провод.
В сеть вставляется предохранитель (автомат). Принцип защиты пользователей при
занулении заключается в отключении сети за счет тока короткого замыкания,
который вызывает перегорание предохранителя и отключает сеть.
При нормальном режиме работы сети ток, текущий
через человека, можно рассчитать по формуле 2.1.
Iч = Uф/(Rч+r0) (2.1)
где Iч - ток, протекающий через
человека [А];ф - фазовое напряжение (Uф = 220 В), [В];ч
- сопротивление тела человека (Rч = 1000 Ом), [Ом];0 -
сопротивление заземлителя (сопротивление обуви ~ 10 Ом), [Ом];
Так как r0 << Rч -
следовательно, сопротивление заземлителя можно в расчет не брать. Получается,
что практически все Uф применено к телу человека и, следовательно,
получается по формуле 2.2:
Iч = Uф/Rч (2.2)
Iч = 220/1000 = 0,22 А
Допустимые значения приложенного напряжения и
протекающего через человека тока соответственно равны 36 В и 0,006 А.
Полученные же при расчете цифры горазда превосходят эти значения (220 В и 0,22
А).
Рассчитаем ток короткого замыкания (Iкз)
по формуле 2.3 при срабатывании защитной схемы зануления и параметры
предохранителя (Iном), используемого в схеме.
(2.3)
где Uф - фазное напряжение сети
питания (Uф = 220 В), [В];
rТ
- паспортная величина сопротивления обмотки трансформатора, (rТ
= 0,312 Ом), [Ом].
Rобщ = r1
+ r2
+ r3 (2.4)
где (2.5)
ρ - удельное
сопротивление нулевого защитного проводника (для меди ρ
= 0,0175 Ом·м), [Ом·м];- длина проводника, [м];- площадь поперечного сечения
нулевого защитного проводника (S
= 1 мм2), [мм2].
Возьмем l1
= 850 м, l2
= 150 м, l3
= 70 м;
r1
= 0,0175·850/1 = 14,875 Ом
r2
= 0,0175·150/1 =2,625 Ом
r3
= 0,0175·70/1 = 1,225 Ом
Rобщ
= 14,875 Ом + 2,625 Ом + 1,225 Ом = 18,725 Ом
По величине Iкз
определим, с каким Iном
необходимо в цепь питания ЭВМ включать автомат.
, следовательно (2.6)
Где k - коэффициент, указывающий тип защитного
устройства (в зависимости от типа автомата: k=3 для автомата с электромагнитным
расщепителем).
ном
= 11,68 А / 3 = 3,9 А
Вывод:
Для отключения ПЭВМ от сети в случае короткого
замыкания или других неисправностей в цепь питания ПЭВМ необходимо ставить
автомат с Iном = 4 А. алгоритм
программный пользователь интерфейс
2.2.2 Методы и средства
защиты от рентгеновского излучения
Существует 3 основных способа защиты от
рентгеновского излучения:
·
время
(работа не более 4 часов);
·
расстояние
(не менее 50 см от экрана);
·
экранирование.
Необходимо придерживаться строгого графика
работы - время работы за компьютером не должно превышать половины рабочей смены
(4 часа).
Для рентгеновского излучения - предельно
допустимая доза для людей, которые постоянно или временно работают
непосредственно с источником ионизирующих излучений не должна превышать D = 0,5
бэр/год в год.
Определим уровень мощности дозы на различных
расстояниях от экрана монитора по формуле 2.7:
Рri = Р0·е-·r
(2.7)
гдеР0 - мощность дозы излучения на
расстоянии 5 см от экрана, мкР/ч; rj - уровень мощности
рентгеновского излучения на заданном расстоянии, мкР/ч;- расстояние от экрана,
см;
- коэффициент ослабления воздухом
рентгеновских лучей, см-1.
Для расчета возьмем = 3,14·10-2 см-1.
Таблица 2.1 - Зависимость уровня мощности дозы
от расстояния до источника
|
r, см
|
5
|
10
|
30
|
40
|
50
|
60
|
|
Рrj,
мкР/ч
|
100
|
73
|
53
|
39
|
28
|
21
|
Принимая среднее расстояние между пользователем
и монитором за 60 см и зная, что годовая доза рентгеновского излучения опасная
для здоровья равна 0,5Р - можно рассчитать по формуле 2.8 реальную дозу
радиации получаемую пользователем за год:
Dr
= Di
·
n · n1
·
n2
(2.8)
где Dr - доза радиации за год;-
нормируемое ежедневное время работы за монитором равное 4ч; 1 -
количество рабочие дней в неделю (5 дней); 2 - количество рабочих
недель в году (в среднем 43 недели); i - мощность дозы
рентгеновского излучения на расстоянии 60 cм;
r
= 15,2 · 4 · 5 · 43 = 0,013Р (бэр).
,013Р < 0,5Р (предельно допустимая доза 0,5Р
значительно превосходит полученное значение дозы).
Вывод:
Оператору рекомендуется находиться от монитора
на расстоянии не менее 60 см.
2.2.3 Методы и средства
защиты от ультрафиолетового излучения
Для защиты от ультрафиолетового излучения:
·
защитный
фильтр или специальные очки (толщина стекол 2мм, насыщенных свинцом);
·
одежда
из фланели и поплина;
·
побелка
стен и потолка (ослабляет на 45-50%).
·
мощность
люминисцентных ламп не должна превышать 40 Вт
2.2.4 Методы и средства
защиты от электромагнитных полей низкой частоты
Защита от электромагнитных излучений
осуществляется временем, расстоянием, экранированием:
·
время
работы - не более 4 часов;
·
расстояние
- не менее 50 см от источника;
·
экранирование.
Относительно электромагнитных излучений низкой
частоты можно отметить, что в современных мониторах нижний предел спектра
смещен в сторону высоких частот посредством увеличения частоты кадровой
развертки до 90 - 120Гц и значительно превышает наиболее опасную частоту - 60
Гц.
Чтобы уменьшить опасность надо:
·
не
работать с открытой ЭВМ;
·
соблюдать
расстояния между соседними ЭВМ (не < 1,5м)
·
исключить
пребывание сбоку от монитора (≥ 1,2 м).
2.2.5 Методы и средства
защиты от статического электричества
Электростатические поля вызывают скопление пыли,
попадающей на лицо и глаза оператора.
Норма: 15 кВ/м.
Защита от статического электричества и вызванных
им явлений осуществляется следующими способами:
·
наличие
контурного заземления;
·
использование
нейтрализаторов статического электричества;
·
скорость
подвижного воздуха в помещении должна быть не более 0,2 м/с;
·
отсутствие
синтетических покрытий;
·
ежедневная
влажная уборка помещения вычислительного центра для уменьшения количества пыли;
·
проветривание
без присутствия пользователя. [21,22]
Вывод:
Выбранные методы и способы защиты от опасных и
вредных факторов обеспечивают защиту пользователей, работающих с вычислительной
техникой.
2.3 Эргономические
требования к рабочим местам пользователей
Выполнение эргономических рекомендаций по
эксплуатации компьютеров позволяет значительно снизить вредные воздействия
находящихся в эксплуатации ПЭВМ. В первую очередь безопасность при работе с
ПЭВМ может быть обеспечена за счет рационального размещения компьютеров в
помещениях, оптимальной с точки зрения эргономики организации рабочего дня
пользователей, а также за счет применения средств повышения контраста
изображения и защиты от бликов на экране, электромагнитных излучений и
электростатического поля.
Рекомендации охватывают следующий круг вопросов:
· Требования к помещениям и оборудованию рабочих
мест.
· Рекомендации по защите пользователей
от излучений ПЭВМ.
2.3.1 Требования к
помещениям, оборудованию рабочих мест и освещенности
Помещения должны иметь естественное и
искусственное освещение. Желательна ориентация оконных проемов на север или
северо-восток. Оконные проемы должны иметь регулируемые жалюзи или занавеси,
позволяющие полностью закрывать оконные проемы. Занавеси следует выбирать
одноцветные, гармонирующие с цветом стен, выполненные из плотной ткани и
шириной в два раза больше ширины оконного проема. Для дополнительного
звукопоглощения занавеси следует подвешивать в складку на расстоянии 15
20
см
от стены с оконными проемами. [18, 23]
Рабочие места по отношению к световым проемам
должны располагаться так, чтобы естественный свет падал сбоку, преимущественно
- слева.
Для устранения бликов на экране, также как
чрезмерного перепада освещенности в поле зрения, необходимо удалять экраны от
яркого дневного света.
Рабочие места должны располагаться от стен с
оконными проемами на расстоянии не менее 1 м.
Освещенность на рабочем месте с ПЭВМ должна быть
не менее 300 лк.
Поверхность пола в помещениях должна бать
ровной, без выбоин, нескользкой, удобной для чистки и влажной уборки, обладать
антистатическими свойствами. [20]
Рекомендуемый микроклимат в помещениях при
работе с ПЭВМ:
·
температура
19 21С;
·
относительная
влажность воздуха 55 62%.
Площадь на одно рабочее место должна составлять
примерно 6 м2 (объем - не меньше 20м3). Конструкция
рабочего места пользователя ПЭВМ (при работе сидя) должна обеспечивать
поддерживание оптимальной рабочей позы с такими эргономичными характеристиками:
·
ступня
ног - на полу или на подставке для ног;
·
бедра
- в горизонтальной плоскости;
·
предплечье
- вертикально;
·
локти
- под углом 70 - 90
к вертикальной плоскости;
·
запястья
согнуты под углом не больше 20
относительно горизонтальной плоскости;
·
наклон
головы - 15 - 20
относительно вертикальной плоскости;
·
монитор
должен располагаться напротив глаз пользователя и на оптимальном расстоянии от
них, но не ближе 60 см. [20,23,24]
2.3.2 Рекомендации по
защите пользователей от излучений ПЭВМ
Если в помещении эксплуатируется более одного
компьютера, то следует учесть, что на пользователя одного компьютера могут воздействовать
излучения от других ПЭВМ, в первую очередь со стороны боковых и задних стенок
дисплея. Учитывая, что от излучения со стороны экрана дисплея можно защититься
применением специальных фильтров, необходимо, чтобы пользователь размещался от
боковых и задних стенок других дисплеев на расстоянии не менее 1,5 м. [18]
На мониторы рекомендуется устанавливать защитные
фильтры, обеспечивающие защиту от вредных воздействий монитора в
электромагнитном спектре и позволяющие уменьшить блик от электронно-лучевой
трубки, а также повысить читаемость символов.
2.4 Выводы
Соблюдение перечисленных методов и способов
защиты от опасных и вредных факторов, а также соблюдение эргономических
требований позволяют обеспечить полную безопасность пользователя при работе с
вычислительной техникой.
Заключение
В результате проделанной работы был разработан
программный комплекс для решения задачи повышения отказоустойчивости
проектируемой информационной системы в оборонном, коммерческом и личном
использовании.
Учитывая требования:
• программный комплекс должен реализовывать
заданный механизм поддержания работоспособности информационной системы;
• программный комплекс должен обеспечивать
автоматическую и ручную режимы работы;
• программный комплекс должен функционировать
под управлением ОС на базе BSD 4.4;
• программный комплекс должен быть реализован
на языке C++;
• программный комплекс должен обеспечивать
функцию журналирования своей работы;
• работа программного комплекса должна быть
прозрачна для пользователя.
Программный комплекс был внедрен в
научно-исследовательскую деятельность ЗАО «Компания РОС» на этапе создания
комплексного имитационно-моделирующего стенда.
Список
использованной литературы
1. Статья “Кластер
(группа компьютеров)” / Википедия: Свободная энциклопедия.-http://ru.wikipedia.org/wiki/%D0%9A%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80_(%D0%B3%D1%80%D1%83%D0%BF%D0%BF%D0%B0_%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%BE%D0%B2)
2. Статья “Кластер
(группа серверов)” / Википедия: Свободная энциклопедия.- http://ru.wikipedia.org/wiki/%D0%9A%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80_(%D0%B3%D1%80%D1%83%D0%BF%D0%BF%D0%B0_%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%BE%D0%B2)
. Распределенные
системы. Принципы и парадигмы / Э. Таненбаум, М. Ван Стеен. Спб.: Питер, 2009. - 877 с.
4. Технические страницы портала компании Microsoft.
<http://technet.microsoft.com/en-us/default.aspx>
. Официальная страница проекта Linux-HA. -
<http://www.linux-ha.org/>
6. Джесс Либерти,
Брэдли Джонс Освой самостоятельно C++ за 21 день.- М.: Вильямс, 2007.- 784 с.
7. Э. Таненбаум
Компьютерные сети.- СПб.: Питер, 2007.- 992 с.
. Официальный
сайт компании Лидер computers. Статья Компьютерные сети.- М.,
http://www.leader-comp.ru/computer-network.html
. Официальная
страница проета FreeBSD - http://www.freebsg.org
. Официальная
страница проекта OpenNet - http://www.opennet.ru
11. Microsoft SQL Server 2000/ М.Ф.Гарсиа, Дж.Рединг, Э.Уолен, С.А.ДаЛюк - Спб: ЭКОМ, 2004
- 976 стр.
. FreeBSD.
Подробное руководство. Издание 2 / Майкл Лукас - Спб: Символ-Плюс, 2009г. - 864
стр.
13. ГОСТ 19.301-79
Программа и методика испытаний. Требования к содержанию и оформлению. - Введ.
01.01.81 - Группа Т55.
14. ГОСТ 19.505-79
Руководство оператора. Требования к содержанию и оформлению. - Введ. 01.01.80 -
Группа Т55.
. ГОСТ 19.201-78
Техническое задание. Требования к содержанию и оформлению. - Введ. 01.01.80 -
Группа Т55.
. ГОСТ 19.701-90
Схемы алгоритмов, программ данных и систем. - Введ. 01.01.92 - Группа Т5.
. ГОСТ
12.0.003-86. Опасные и вредные производственные факторы.
. Сибаров Ю. Г. и
др. Охрана труда на ВЦ.- М.,
1989.
. ГОСТ
12.1.030-81. Электробезопасность. Защитное заземление, зануление.
. САНПиН-1340-03.
Гигиенические требования к персональным ЭВМ и организации работы.
. ГОСТ ССБТ
12.1.045-84. Электростатические поля. Допустимые условия на рабочем месте.
. ГОСТ ССБТ
12.1.124-84. Средства защиты от статического электричества.
. ФЗ РФ №181.
1999 г. «Об основах охраны труда в РФ».
. Трудовой кодекс
РФ
Приложение
1
Текст программы
Головной
модуль
#include
"../conf/config.h"
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include
<../classes/cmessenger.h>CBrain: public IMessenger
{:();FuncOnMsgRcv(Message msg);OnStoppingAll();Init();
~CBrain();:voice_pid, ear_pid, nose_pid,
finger_pid, head_pid;*messenger;ppid;stopping_all;p_started;
};
#include
"cbrain.h"::CBrain()
{_pid = 2;_pid = 2;_pid = 2;_pid =
2;= getpid();_all = false;_started = 0;("---=== Welcome to BRAIN
===---\n");("Starting services...\n");("BRAIN PID=%d\n",ppid);("Starting
voice...\n");_pid = fork();(voice_pid < 0) {("Brain: error calling
fork()");;
} else if (voice_pid == 0)
{(execl(VOICE_EXE, NULL) < 0) {("Brain: error calling execl()");
}
}("VOICE
PID=%d\n",voice_pid);("Starting ear...\n");_pid = fork();(ear_pid
< 0) {("Brain: error calling fork()");;
} else if (ear_pid == 0)
{(execl(EAR_EXE, NULL) < 0) {("Brain: error calling execl()");
}
}("EAR
PID=%d\n",ear_pid);("Starting nose...\n");_pid =
fork();(nose_pid < 0) {("Brain: error calling fork()");;
} else if (nose_pid == 0)
{(execl(NOSE_EXE, NULL) < 0) {("Brain: error calling execl()");
}
}("NOSE
PID=%d\n",nose_pid);("Starting finger...\n");_pid =
fork();(finger_pid < 0) {("Brain: error calling fork()");;
} else if (finger_pid == 0) {(execl(FINGER_EXE,
NULL) < 0) {("Brain: error calling execl()");
}
}("FINGER
PID=%d\n",finger_pid);("---=== Log of IPC ===---\n");= new
CMessenger();
}CBrain::OnStoppingAll()
{(p_started == 0) {>stoplisten();
}
}CBrain::Init()
{>setExObjOnMsgRcv(this);>startlisten();
}CBrain::FuncOnMsgRcv(Message msg)
{pid;status;(msg.datab.cmd)
{CMD_STOP_ALL:>sendmessage(finger_pid,
CMD_FINGER_STOP);(1);>sendmessage(nose_pid,
CMD_NOSE_STOP);>sendmessage(ear_pid,
CMD_EAR_STOP);>sendmessage(voice_pid, CMD_VOICE_STOP);_all = true;;SAY_STARTED:(&msg.datab.data,
&pid, msg.datab.size);("%d : PID = %d : Started!\n",
msg.datab.pid, pid);_started++;;SAY_PAUSED:(&msg.datab.data, &pid,
msg.datab.size);("%d : PID = %d : Paused!\n", msg.datab.pid, pid);;SAY_CONTINUED:(&msg.datab.data,
&pid, msg.datab.size);("%d : PID = %d : Continued!\n",
msg.datab.pid, pid);;SAY_STOPPED:(&msg.datab.data, &pid,
msg.datab.size);("%d : PID = %d : Stopped!\n", msg.datab.pid,
pid);_started--;(stopping_all)();;CMD_NOSE_CONTINUE:>sendmessage(nose_pid,
CMD_NOSE_CONTINUE);;CMD_NOSE_PAUSE:>sendmessage(nose_pid,
CMD_NOSE_PAUSE);;CMD_NOSE_STOP:>sendmessage(nose_pid,
CMD_NOSE_STOP);(&status);;CMD_VOICE_CONTINUE:>sendmessage(voice_pid,
CMD_VOICE_CONTINUE);;CMD_VOICE_PAUSE:>sendmessage(voice_pid, CMD_VOICE_PAUSE);;CMD_VOICE_STOP:>sendmessage(voice_pid,
CMD_VOICE_STOP);(&status);;CMD_EAR_CONTINUE:>sendmessage(ear_pid,
CMD_EAR_CONTINUE);;CMD_EAR_PAUSE:>sendmessage(ear_pid,
CMD_EAR_PAUSE);;CMD_EAR_STOP:>sendmessage(ear_pid,
CMD_EAR_STOP);(&status);;CMD_FINGER_CONNECT:>sendmessage(finger_pid,
CMD_FINGER_CONNECT, msg.datab.data,
msg.datab.size);;CMD_FINGER_RECONNECT:>sendmessage(finger_pid,
CMD_FINGER_RECONNECT, msg.datab.data,
msg.datab.size);;CMD_FINGER_DISCONNECT:>sendmessage(finger_pid,
CMD_FINGER_DISCONNECT);;CMD_FINGER_STOP:>sendmessage(finger_pid,
CMD_FINGER_STOP);(&status);;INFO_EAR_SOMEBODY_HAS_BIGGER_WEIGHT:>sendmessage(nose_pid,
CMD_NOSE_CONNECT_CLIENTS_TO_ANOTHER_SERVER, msg.datab.data,
msg.datab.size);>sendmessage(nose_pid, CMD_NOSE_PAUSE);>sendmessage(ear_pid,
CMD_EAR_PAUSE);>sendmessage(voice_pid,
CMD_VOICE_PAUSE);>sendmessage(head_pid, CMD_HEAD_BECOME_PASSIVE,
msg.datab.data,
msg.datab.size);;INFO_FINGER_SERVER_LOST:>sendmessage(nose_pid,
CMD_NOSE_CONTINUE);>sendmessage(ear_pid, CMD_EAR_CONTINUE);>sendmessage(voice_pid,
CMD_VOICE_CONTINUE);>sendmessage(head_pid, CMD_HEAD_BECOME_ACTIVE);;
}
}::~CBrain()
{>deletequeue();messenger;
}
#include
"cbrain.h"main(int argc, char *argv[])
{* brain = new CBrain();>Init();
delete brain;0;
}
Модуль
широковещательной рассылки информации:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <../conf/config.h>
#include <sys/wait.h>
#include <signal.h>
#include
<../interfaces/ibroadcastserver.h>CBroadcastServer{:(int
port);startlisten();stoplisten();messagereceived(char* msg, int
len);SetExObjOnMsgReceived(IBroadcastServer* lExObjOnMsgReceived);
~CBroadcastServer();:sock;cpid;sockaddr_in
sa;* ExObjOnMsgReceived;
};
#include
"cbroadcastserver.h"::CBroadcastServer(int port)
{.sin_addr.s_addr =
INADDR_ANY;.sin_port = htons(BROADCAST_PORT);= -1;
}CBroadcastServer::SetExObjOnMsgReceived(IBroadcastServer*
lExObjOnMsgReceived)
{= lExObjOnMsgReceived;
}CBroadcastServer::messagereceived(char*
msg, int len)
{>FuncOnMsgReceived(msg, len);
}CBroadcastServer::startlisten()
{optval = 1;=
socket(PF_INET,SOCK_DGRAM,IPPROTO_UDP);(setsockopt(sock, SOL_SOCKET,
SO_BROADCAST, &optval, sizeof optval) == -1) {("CBroadcastServer:
Error calling setsockopt()");;
}(bind(sock,(struct sockaddr
*)&sa, sizeof(struct sockaddr)) != 0) {("CBroadcastServer: Error
calling bind()");;
}= fork();(cpid < 0)
{("CBroadcastServer: Error calling fork()");;
} else if (cpid == 0) {(1)
{msg[MAX_MSG_SIZE];recsize;_t fromlen;= sizeof(sa);((recsize = recvfrom(sock,
(void *)msg, MAX_MSG_SIZE, 0, (struct sockaddr *)&sa, &fromlen)) <
0) {("CBroadcastServer: Error calling recvfrom()");;
}(msg, recsize);
}
}
}CBroadcastServer::stoplisten()
{(cpid > 0) {(cpid, SIGHUP);status;(&status);(sock);
}= -1;
}::~CBroadcastServer()
{();
}
Модуль
обслуживания
сообщений:
#include
"../conf/config.h"
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <strings.h>
#include <unistd.h>
#define CMD_STOP_ALL 0
#define SAY_STARTED 1
#define SAY_PAUSED 2
#define SAY_CONTINUED 3
#define SAY_STOPPED 4
#define CMD_VOICE_CONTINUE 10
#define CMD_VOICE_PAUSE 11
#define CMD_VOICE_STOP 12
#define CMD_EAR_CONTINUE 20
#define CMD_EAR_PAUSE 21
#define CMD_EAR_STOP 22
#define
INFO_EAR_SOMEBODY_HAS_BIGGER_WEIGHT 200
#define CMD_NOSE_CONTINUE 30
#define CMD_NOSE_PAUSE 31
#define CMD_NOSE_STOP 32
#define
CMD_NOSE_CONNECT_CLIENTS_TO_ANOTHER_SERVER 300
#define INFO_NOSTRILL_CLIENT_LOST
350
#define CMD_NOSTRILL_DISCONNECT 360
#define CMD_NOSTRILL_SENDDATA 361
#define CMD_FINGER_CONNECT 40
#define CMD_FINGER_DISCONNECT 41
#define CMD_FINGER_RECONNECT 42
#define CMD_FINGER_STOP 43
#define INFO_FINGER_SERVER_LOST 400
#define INFO_FINGER_CONNECT 401
#define INFO_FINGER_DISCONNECT 402
#define CMD_HEAD_CONTINUE 50
#define CMD_HEAD_PAUSE 51
#define CMD_HEAD_STOP 52
#define CMD_HEAD_BECOME_ACTIVE 500
#define CMD_HEAD_BECOME_PASSIVE 501
#include
<../interfaces/imessenger.h>CMessenger{:();startlisten();startlisten(int
pid);stoplisten();messagereceived(Message msg);sendmessage(long
lcmd);sendmessage(long lcmd, char* data, int data_sz);sendmessage(int pid, long
lcmd, void* data, int data_sz);sendmessage(int pid, long
lcmd);setExObjOnMsgRcv(IMessenger* lExObjOnMsgRcv);deletequeue();
~CMessenger();:msgid;cont;*
ExObjOnMsgRcv;
};
#include
"cmessenger.h"::CMessenger()
{_t key;((key = ftok(KEY_FILE, 'A'))
< 0) {("CMessenger: error calling ftok()");;
}((msgid = msgget(key, 0666 |
IPC_CREAT)) < 0) {("CMessenger: error calling msgget()");;
}= false;= NULL;
}CMessenger::setExObjOnMsgRcv(IMessenger*
lExObjOnMsgRcv)
{= lExObjOnMsgRcv;
}CMessenger::startlisten()
{msg;.mtype = BRAIN_MSG_ID;=
true;(cont) {(msgrcv(msgid, &msg, sizeof(msg), msg.mtype, 0) < 0)
{("CMessenger: error calling msgrcv()");;
}(msg);
};
}CMessenger::startlisten(int pid)
{msg;.mtype = pid;= true;(cont)
{(msgrcv(msgid, &msg, sizeof(msg), msg.mtype, 0) < 0)
{("CMessenger: error calling msgrcv()");;
}(msg);
};
}CMessenger::stoplisten()
{= false;;
}CMessenger::messagereceived(Message
msg)
{(ExObjOnMsgRcv != NULL)
{>FuncOnMsgRcv(msg);
}
}CMessenger::sendmessage(long lcmd)
{msg;.mtype =
BRAIN_MSG_ID;.datab.cmd = lcmd;(msg.datab.data, MAX_MSG_DATA_SIZE);.datab.size
= 0;.datab.pid = getpid();(msgsnd(msgid, (void *)&msg, sizeof(msg.datab),
0) !=0) {("CMessenger: Error calling msgsnd()");;
};
}CMessenger::sendmessage(long lcmd,
char* data, int data_sz)
{msg;.mtype =
BRAIN_MSG_ID;.datab.cmd = lcmd;.datab.size = data_sz;.datab.pid =
getpid();(msg.datab.size > MAX_MSG_DATA_SIZE) {("CMessenger: Error
trying to send message: data to send is too large!");;
}(data, msg.datab.data,
data_sz);(msgsnd(msgid, (void *)&msg, sizeof(msg.datab), 0) !=0)
{("CMessenger: Error calling msgsnd()");;
};
}CMessenger::sendmessage(int pid,
long lcmd, void* data, int data_sz)
{msg;.mtype = pid;.datab.cmd =
lcmd;.datab.size = data_sz;.datab.pid = getpid();(msg.datab.size >
MAX_MSG_DATA_SIZE) {("CMessenger: Error trying to send message: data to
send is too large!");;
}(data, msg.datab.data,
data_sz);(msgsnd(msgid, (void *)&msg, sizeof(msg.datab), 0) !=0)
{("CMessenger: Error calling msgsnd()");;
};
}CMessenger::sendmessage(int pid,
long lcmd)
{msg;.mtype = pid;.datab.cmd =
lcmd;(msg.datab.data, MAX_MSG_DATA_SIZE);.datab.size = 0;.datab.pid =
getpid();(msgsnd(msgid, (void *)&msg, sizeof(msg.datab), 0) !=0)
{("CMessenger: Error calling msgsnd()");;
};
}CMessenger::deletequeue()
{(msgctl(msgid, IPC_RMID, 0) < 0)
{("CMessenger: error calling msgctl()");;
}
}::~CMessenger()
{
}