Распределение задач с помощью нитей по процессорам вычислительной системы заданной структуры
Министерство
образования и науки Российской Федерации
Государственное
образовательное учреждение высшего профессионального образования
«Московский
государственный технический университет имени Н.Э. Баумана»
Факультет
«Информатика и системы управления»
Кафедра
«Компьютерные системы и сети»
Расчетно-пояснительная
записка к курсовому проекту
Распределение
задач с помощью нитей по процессорам вычислительной системы заданной структуры.
Вычислительные
системы
Москва, 2013
Реферат
Объектом проектирования является вычислительная система.
Цель курсовой работы - найти оптимальное время решения задачи в узлах
вычислительной сети (ВС).
Для нахождения оптимального времени решения задачи необходимо разработать
алгоритм распределения вершин информационного графа по процессорам заданной
структуры вычислительной сети. В результате этого распределения, исходная
задача, должна решаться за минимально возможное время на данной ВС. Число
процессоров, при этом, должно быть минимизировано, с учетом обеспечения решения
задачи за минимальное время.
Материалы по курсовому проекту представлены в виде расчетно-пояснительной
записки.
Перечень сокращений, условных обозначений, символов, единиц и
терминов
ВС - вычислительная система,
ВМ - вычислительный модуль вычислитель,
ИЛГ - информационно-логическая граф-схема,
ИГ - информационная граф-схема.
Введение
В настоящее время тенденция использования многопроцессорных систем для
обработки данных возрастает.
Для эффективного использования таких систем необходимо:
· преобразовывать последовательные алгоритмы обработки данных в
параллельные;
· использовать специальные алгоритмы (планировщики), которые
позволят распределить операторы параллельных алгоритмов по процессорам
вычислительной сети.
По своей сути, планировщик является частью основного алгоритма и служит
для обеспечения эффективного выполнения основного алгоритма в условиях
конкретной ВС.
При этом алгоритмы-планировщики могут использовать различные критерии
оптимизации. Критериями оптимизации могут быть следующие параметры:
· минимизация времени выполнения задачи;
· минимизация числа процессоров для заданного времени
выполнения задачи;
· обеспечение максимальной эффективности использования
процессоров ВС;
· и др.
Разработка планировщиков связана с рядом сложностей, таких как:
· анализ большого количества условий;
· рассмотрение множества различных ситуаций, которые возникают
при распределении операторов по нитям и нитей по процессорам ВС;
· работа с большим количеством исходных данных.
Исходными данными для задач такого типа являются времена расчета отдельно
взятых операторов, объем передаваемых данных между ними и время, необходимое
для этих передач. Время, необходимое для передачи некоторого объема данных
между двумя параллельно выполняемыми операторами определяется структурой
конкретной ВС.
Разработка и совершенствование алгоритмов-планировщиков увеличит
быстродействие обработки данных на многопроцессорных системах.
В данной работе рассматриваются способы представления граф-схемы для
случайного алгоритма с заданными параметрами и методы отображения их на
структуре ВС (гиперкубе).
Конфигурации граф-схем позволяют представить в удобной форме все
существующие операторы последовательных языков программирования, а также
представлять схемы обмена данными между ВМ. На базе граф-схем создаются
различные схемы анализа параллельных алгоритмов: матрицы следования, множества
взаимно независимых операторов, внешние и внутренние замыкания в граф-схемах,
определения минимального количества ВМ, обеспечивающих минимальное время решения
задачи, построение нитей в граф-схемах алгоритмов решаемой задачи,
распределение нитей по ВМ и т.д.
1.
Теоретическая часть
1.1 Понятие о современных вычислительных системах
Система, представленная множеством описаний W={K,A}, где K - описание
конструкций ВС, А - описание алгоритма работы множества вычислительных модулей,
называется вычислительной. Описание К составляет множества значений {M,S}, где
М - множество базовых вычислительных устройств {mi}, i=0, ... , N-1, где под
базовыми вычислительными устройствами понимаются ЭВМ, процессоры, блоки памяти,
внешние устройства. S - сеть связей между множествами элементов базиса.
В конструкцию К должны быть заложены следующие принципы:
а) параллелизм при обработке информации, т.е. организация вычислений
одновременно на множестве вычислительных модулей М с организацией в случае
необходимости обмена данными через сеть S;
б) адаптация конфигурации сети S к решаемой задаче. Алгоритм А
обеспечивает наряду с требуемой обработкой управление одновременной работой
определённым множеством ВМ и необходимым обменом данными между ними.
Сеть S должна обеспечивать в каждый момент времени требуемый обмен
данными между вычислительными модулями. Наиболее подходящей для этой цели
является сеть по полному графу, т.е. связь каждого вычислительного модуля с
каждым. Построение такой сети для большого количества вычислительных модулей,
содержащихся в современных ВС, является сложной и дорогостоящей процедурой. В
связи с чем, разрабатываются различные типы и конфигурации сетей, в которых
обеспечиваются связи в зависимости от различных требований. Очевидно, что в
таких сетях, как правило, возникает необходимость транзитной передачи
информации с помощью вычислительных модулей, попадающих в контур передачи
информации. Такие передачи, естественно, требуют дополнительных затрат времени,
в связи с чем возникает задача минимизации этих затрат c помощью выбора
конструкций тех или иных разновидностей сетей с учетом структуры решаемых
задач. Вследствие этого проблему выбора графа межмодульных связей необходимо
рассматривать в нескольких аспектах:
· минимизация времени выполнения межмодульных обменов;
· максимизация числа одновременно выполняемых обменов;
· максимальная сохранность связности при выходах из строя ВМ и
линий.
.2 Структура ВС типа «Обобщенный nD-куб»
Реализация обмена с помощью структуры типа «Обобщенный nD- куб»
представлена на рисунке 1.
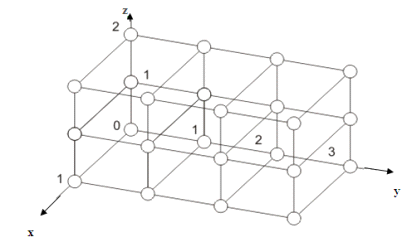
Рисунок 1 - Схема представления обобщенного 3-х мерного гиперкуба 2х4х3
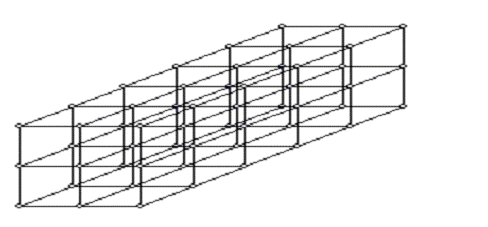
Рисунок 2 - Схема представления обобщенного 3-х мерного гиперкуба 3х3х6
Структура вычислительной системы типа «Обобщенный nD-куб» описывается
графом GS =(М, S*), где М - множество вычислительных модулей, определяемых
вершинами графа, М ={mi}, i = 0, … , N-1, 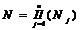 . По каждой координате j, j=1,…,n
вводятся точки Nj={0,1, ... ,
Nj-1}, где Nj - размерность куба по координате j. Множество вершин графа ВС
определяется декартовыми произведениями [N1]
. По каждой координате j, j=1,…,n
вводятся точки Nj={0,1, ... ,
Nj-1}, где Nj - размерность куба по координате j. Множество вершин графа ВС
определяется декартовыми произведениями [N1]  [N2] …[Nn], |N1|·|N2|·…·|Nn|=N. Две вершины
соединяются ребром, если декартовы произведения, определяющие эти вершины,
отличаются друг от друга на 1.
[N2] …[Nn], |N1|·|N2|·…·|Nn|=N. Две вершины
соединяются ребром, если декартовы произведения, определяющие эти вершины,
отличаются друг от друга на 1.
1 Основные определения, необходимые для разработки
алгоритма распределения программных модулей по вычислительным модулям
вычислительной сети
Вершина - оператор ИЛГ заданной задачи.
Вес вершины (P) - время расчета вершины на i-ом процессоре.
Степень вершины (Vi) - количество узлов, находящиеся от i-ой вершины на
минимальном расстоянии.
Коэффициент передачи (pA) - время передачи между узлами ВС.
Комплексный узел - транзитный узел ВС.
Время старта вершины (sT) - время старта расчета вершины в существующем
разбиении вершин между процессорами.
Время финиша вершины (fT) - время финиша расчета вершины в существующем
разбиении вершин между процессорами.
Нить - набор из одной или нескольких вершин, которые последовательно
рассчитываются на одном процессоре.
Множество нитей (Т) - совокупность всех нитей заданного ИЛГ.
Пучок нитей ({Pz}) - множество связанных между собой нитей.
Таблица связей к-ой нити (TSk) - совокупность нитей, связанных с
k-ой нитью (имеет Sk элементов).
Массив связей (MS) - упорядоченное множество связей всех нитей одного пучка.
2. Распределение операторов по ВМ вычислительной системы с
распределенной памятью для информационно-логической граф-схемы
При построении плана распределения операторов по ВМ вычислительной
системы с распределённой памятью для информационной граф-схемы возникают
определённые трудности, связанные с передачей информации через транзитные ВМ.
Сущность метода заключается в том, что на первом этапе создаются нити без учёта
обмена информацией между ВМ. Затем при построении нитей в моменты обмена
данными длины нитей корректируются на время обмена информацией в данной точке.
Вначале получаем модифицированные веса вершин в виде pm,j=pj+qj,i ,где pj - вес
j-й вершины, qj,i - вес дуги, исходящей из j-й вершины. При использовании
транзитных ВМ модифицированный вес возрастает на qj,i(n-1), где n - количество
используемых транзитных процессоров.
Структура ВС с общей памятью. Применяется в многопроцессорных
системах и не используется в многомашинных системах
Коммуникационная сеть вырождается в общую шину. Дополнительно
к преимуществу структуры общей шины данная структура обладает тем достоинством,
что обмен информацией между процессорами не требует дополнительных операций, а
осуществляется благодаря доступу процессора к памяти.
Системы с общей оперативной памятью образуют современный
класс ВС - многопроцессорных супер-ЭВМ. Одинаковый доступ всех
процессоров к программам и данным представляет широкие возможности организации
параллельного вычислительного процесса (параллельных вычислений).
Отсутствуют потери реальной производительности на межпроцессорный (между
задачами, процессами и т.д.) обмен данными (рис.3)

Рисунок 3 - Вычислительная система с общей памятью
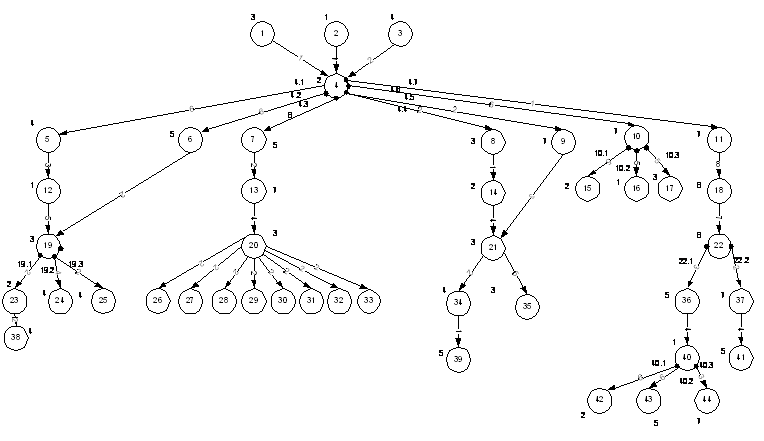
Рисунок
4 - Граф-схема параллельного алгоритма
2.1 Построение матрицы следования ИЛГ
Основным инструментом анализа граф-схем алгоритмов служит матрица следования,
а также различные её модификации. Матрица следования - это транспонированная
матрица смежности. Использование матрицы следования вместо матриц смежности
объясняется удобством размещения и анализа граф-схем.
Для
удобства присвоим постоянный идентификатор - Si i {1, 2. …,
n}.Матрица S - квадратная - количество строк и столбцов совпадает с количеством
вершин граф-cхемы. В матрица S i - ой вершине графа G ставятся в соответствие i
- ые столбец и строка этой матрицы. Если существует связь по управлению:
{1, 2. …,
n}.Матрица S - квадратная - количество строк и столбцов совпадает с количеством
вершин граф-cхемы. В матрица S i - ой вершине графа G ставятся в соответствие i
- ые столбец и строка этой матрицы. Если существует связь по управлению:  , то элемент матрицы равен (i,j) = j.n, при j →
i образуется (i,j) = 1. Остальные элементы матрицы S равны 0.
, то элемент матрицы равен (i,j) = j.n, при j →
i образуется (i,j) = 1. Остальные элементы матрицы S равны 0.
Для
заданной матрицы Si размера m отражения весов вершин вводится понятие
расширенной матрицы следования SRi: прибавляется дополнительно k столбцов с
номерами m+1, …, m+k, где k - размерность вектора весов вершин граф - схемы.
Построим
расширенные матрицы следования для нашей граф - схемы. (Таблица 1 Приложение
4.1).
Построим
матрицу следования с указанием весов дуг и вершин (SDR) для данной ИЛГ (Таблица
2 Приложение 4.2).
2.2 Определение ранних сроков окончания выполнения операторов
При исследовании граф-схем алгоритмов одними из основных характеристик
являются ранние сроки окончания выполнения операторов. Имея эти величины, можно
построить планы выполнения операторов с учётом распределения операторов по ВМ.
Необходимо подчеркнуть, что на основе граф-схемы алгоритма, можно определить:
) Частичную упорядоченность выполнения алгоритма.
) Веса операторов pj, j = 1, …, m (обычно - времена выполнения процедур).
) Началом отсчёта времени решения задачи является начало выполнения
операторов, являющихся входами в алгоритм.
) Тк - это путь максимальной длины в граф-схеме ( это максимальное время,
за которое может быть решена данная задача).
Ранний
срок окончания выполнения оператора - это время на оси отсчёта времени, равное
t1, j = 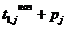 , j = 1 . . .m, где
, j = 1 . . .m, где 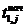 - время начала
выполнения j-ого оператора, pj - время выполнения j-ого оператора, полученное
при минимальном времени решения задачи Т=Тк.
- время начала
выполнения j-ого оператора, pj - время выполнения j-ого оператора, полученное
при минимальном времени решения задачи Т=Тк.
Каждая
строка диаграммы может служить нитью для загрузки в процессор. Таким образом,
получилось 7 нитей:
={3,4,5,12,19,23,38}={2,6,16,24}={1,7,13,20,27~34}={8,14,21,35,39,43}={9,17,36,42}={10,15,38,41}={11,18,22,37,40,44}
ак
как рассматривается ВС с общей памятью, обмена данными через каналы связи между
процессорами нет, и количество нитей меньше, чем число процессоров, поэтому распределение
нитей между ВМ может осуществляться, например, следующим образом: первая нить
загружается в первый ВМ, вторая - во второй и т. д.
По алгоритму, приведенному в Приложении 2, определим ранние сроки
окончания выполнения операторов и построим их диаграмму.
Учёт
времён передачи информации осуществляется, используя следующие соотношения: для
развёртки- p,j=qi,j+pj, где j= - номера
операторов, образующих развёртку; для свёртки- pj= qj,i +pj где j=- номера
операторов, образующих cвёртку. С помощью матрицы следования с указанными
весами дуг и вершин модифицированные веса вершин можно вычислить следующим
образом: если в i-й строке найдено одно число, то вес i-й
вершины модифицируется к виду: рi:=pi+qji; если в i-й строке
найдено несколько чисел, то веса вершин модифицируются к виду рj:=pj+qi,j, j={}, где j
- номера столбцов, в которых найдены числа, qi,j -
множество весов дуг, принадлежащих i-й строке.
- номера
операторов, образующих развёртку; для свёртки- pj= qj,i +pj где j=- номера
операторов, образующих cвёртку. С помощью матрицы следования с указанными
весами дуг и вершин модифицированные веса вершин можно вычислить следующим
образом: если в i-й строке найдено одно число, то вес i-й
вершины модифицируется к виду: рi:=pi+qji; если в i-й строке
найдено несколько чисел, то веса вершин модифицируются к виду рj:=pj+qi,j, j={}, где j
- номера столбцов, в которых найдены числа, qi,j -
множество весов дуг, принадлежащих i-й строке.
Таблица 3- Ранние сроки окончания выполнения операторов
|
№
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
|
T
|
3
|
1
|
4
|
6
|
10
|
11
|
11
|
9
|
13
|
13
|
13
|
11
|
18
|
11
|
15
|
14
|
16
|
21
|
|
№
|
19
|
20
|
21
|
22
|
23
|
24
|
25
|
26-33
|
34
|
35
|
36
|
37
|
38
|
39
|
40
|
41
|
42
|
43
|
44
|
|
Т
|
14
|
21
|
16
|
29
|
16
|
18
|
18
|
37
|
20
|
19
|
34
|
36
|
22
|
25
|
35
|
41
|
37
|
40
|
42
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
После того, как ы определили ранние сроки выполнения операторов, постоим
диаграммы ранних сроков выполнения данных операторов.
Паузы, возникшие на 2, 16, 19, 20 моментах времени
связаны с синхронизацией вычислений, определяемой структурой рассматриваемой
граф-схемы. Общее время решения этой задачи составляет 42 условных единиц.
Анализируя представленный способ построения плана
решения задач на ВС, можно сделать вывод, что достаточно простыми средствами
можно построить достаточно эффективную процедуру организации решения
параллельных задач на ВС.
При построении временных диаграмм выполнения операторов необходимо
учитывать, что они строятся для информационно-логической граф-схемы, и не все
операторы будут выполнены. Это можно сделать, например, с помощью динамического
плана, состояние которого изменяется каждый раз, как только выполняется
очередной логический оператор.
Для рассматриваемой граф-схемы временные диаграммы будут выглядеть, как
показано на рисунках 4-9:
.3 Распределение нитей на структуре типа обобщенный гиперкуб
По условию задан обобщенный трехмерный гиперкуб 3х3х6, на рисунке 21 для
примера представлен гиперкуб 2х3х3.
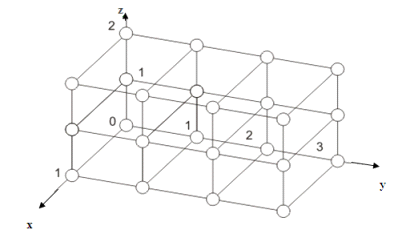
Рисунок 21 - Схема представления обобщенного 3-х мерного гиперкуба 2х4х3
вычислительный система обобщенный гиперкуб
Для построения матрицы дистанций для гиперкуба необходимо перенумеровать
его вершины. Нумерация показана в таблице 2:
Таблица 4 - Нумерация вершин гиперкуба.
|
Координата ВМ (x,y,z)
|
000
|
001
|
002
|
003
|
004
|
010
|
011
|
012
|
013
|
014
|
020
|
021
|
022
|
023
|
024
|
|
Номер ВМ
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
Координата ВМ (x,y,z)
|
030
|
031
|
032
|
033
|
034
|
040
|
041
|
042
|
043
|
044
|
100
|
101
|
102
|
103
|
104
|
|
Номер ВМ
|
16
|
17
|
18
|
19
|
20
|
21
|
22
|
23
|
24
|
25
|
26
|
27
|
28
|
29
|
30
|
|
Координата ВМ (x,y,z)
|
110
|
111
|
112
|
113
|
114
|
120
|
121
|
122
|
123
|
124
|
130
|
131
|
132
|
133
|
134
|
|
Номер ВМ
|
31
|
32
|
33
|
34
|
35
|
36
|
37
|
38
|
39
|
40
|
41
|
42
|
43
|
44
|
45
|
|
Координата ВМ (x,y,z)
|
140
|
141
|
142
|
143
|
144
|
200
|
201
|
202
|
203
|
204
|
210
|
211
|
212
|
213
|
214
|
|
Номер ВМ
|
46
|
47
|
48
|
49
|
50
|
51
|
52
|
53
|
54
|
55
|
56
|
57
|
58
|
59
|
60
|
|
Координата ВМ (x,y,z)
|
220
|
221
|
222
|
223
|
224
|
230
|
231
|
232
|
233
|
234
|
240
|
241
|
242
|
243
|
244
|
|
Номер ВМ
|
61
|
62
|
63
|
64
|
65
|
66
|
67
|
68
|
69
|
70
|
71
|
72
|
73
|
74
|
75
|
Далее строится матрица дистанций, в которой расстояния указываются в
минимальном числе промежуточных связей между соответствующими вычислительными
модулями. В связи с большим размером матрицы дистанций, содержащей 5625
элементов (75х75), целиком она не приводится. Минимальную сумму расстояний до
остальных модулей имеет 38-й модуль (это очевидно, так как данный модуль
находится в геометрическом центре вычислительной системы). Сумма расстояний для
него равна 230. Приведу часть матрицы дистанций для этого вычислительного
модуля (см. таблицу 3):
Таблица 5 - Расстояния от 38-го вычислительного модуля до остальных ВМ.
|
Номер ВМ
|
1
|
2
|
3
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
Расстояние
|
5
|
4
|
3
|
4
|
5
|
4
|
3
|
2
|
3
|
4
|
3
|
2
|
1
|
2
|
3
|
|
Номер ВМ
|
16
|
17
|
18
|
19
|
20
|
21
|
22
|
23
|
24
|
25
|
26
|
27
|
28
|
29
|
30
|
|
Расстояние
|
4
|
3
|
2
|
3
|
4
|
5
|
4
|
3
|
4
|
5
|
4
|
3
|
2
|
3
|
4
|
|
Номер ВМ
|
31
|
32
|
33
|
34
|
35
|
36
|
37
|
38
|
39
|
40
|
41
|
42
|
43
|
44
|
45
|
|
Расстояние
|
3
|
2
|
1
|
2
|
3
|
2
|
1
|
0
|
1
|
2
|
3
|
2
|
1
|
2
|
3
|
|
Номер ВМ
|
46
|
47
|
48
|
49
|
50
|
51
|
52
|
53
|
54
|
55
|
56
|
57
|
58
|
59
|
60
|
|
Расстояние
|
4
|
3
|
2
|
3
|
4
|
5
|
4
|
3
|
4
|
5
|
4
|
3
|
2
|
3
|
4
|
|
Номер ВМ
|
61
|
62
|
63
|
64
|
65
|
66
|
67
|
68
|
69
|
70
|
71
|
72
|
73
|
74
|
75
|
|
Расстояние
|
3
|
2
|
1
|
2
|
3
|
4
|
3
|
2
|
3
|
4
|
5
|
4
|
3
|
4
|
5
|
Необходимо
отметить, что сумма расстояний от выбранного модуля до остальных может быть
получена аналитически, без нахождения расстояний до каждого отдельного
вычислительного модуля. Рассмотрим пример трёхмерного гиперкуба,
соответствующий решаемой задаче. Пусть 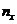 ,
,  ,
, 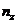 - число
вычислительных модулей по осям x, y
и z соответственно,
- число
вычислительных модулей по осям x, y
и z соответственно, 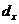 ,
, 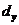 ,
,  - размер
гиперкуба по осям x, y и z соответственно,
- размер
гиперкуба по осям x, y и z соответственно, 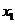 ,
,  ,
, 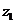 -
координаты выбранного вычислительного модуля. Тогда число вычислительных
модулей по осям x, y и z, расположенных на одинаковом расстоянии от
выбранного, равно соответственно:
-
координаты выбранного вычислительного модуля. Тогда число вычислительных
модулей по осям x, y и z, расположенных на одинаковом расстоянии от
выбранного, равно соответственно: 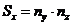 ,
, 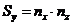 ,
,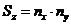 .
.
Тогда
сумма всех расстояний будет равна:
 .(1)
.(1)
Для
38-го вычислительного модуля согласно формуле (1) сумма расстояний: 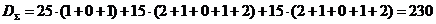 , что совпадает с полученным результатом.
, что совпадает с полученным результатом.
Таким
образом, оптимальным для размещения первой нити является 38-й вычислительный
модуль. Для размещения всех нитей необходимо 10 вычислительных модулей. 38-й
вычислительный модуль связан с 6 другими модулями. Таким образом, 6 нитей
загружаются в 13-й, 33-й, 37-й, 38-й, 39-й, 43-й и 63-й вычислительные модули,
а оставшиеся 3 - в 32-й, 34-й и 42-й модули (см рисунок 10), так как расстояние
до 38-го ВМ до этих модулей равно 2:
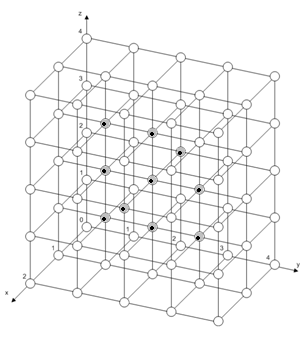
Рисунок 22 - Распределение нитей по вычислительным модулям ВС структуры
«обобщенный гиперкуб».
Заключение
В ходе проектирования были решены задачи нахождения ранних сроков
окончания выполнения операторов; построения нитей решения задачи в соответствии
с заданной граф-схемой; распределения нитей по ВС, с учетом времени передачи
между операторами и между процессорами.
В результате проделанной работы можно сделать вывод, что «Алгоритм
распределения программных модулей по узлам ВС» работает верно и позволяет
оптимизировать время и число необходимых процессоров для решения поставленной
задачи. Данный алгоритм применим для различных топологий ВС, для
неограниченного количества операторов. Таким образом, «Алгоритм распределения
программных модулей по узлам ВС» является универсальным.
Список
используемой литературы
1. Руденко Ю.М., Волкова Е.А. Вычислительные системы.
Москва, НИИ РЛ МГТУ им. Н.Э.Баумана, 2010.
2. Корнеев В.В. Параллельные вычислительные
системы, Издательство НГТУ, 1999.
. Хорошевский В.Г. Архитектура вычислительных систем,
МГТУ им. Н.Э. Баумана, 2008.
4. Руденко Ю.М. Новый подход к
изображению схем алгоритмов для вычислительных систем. Информатика и системы
управления в ХХ1 веке. Сборник трудов №7 молодых учёных, аспирантов, и
студентов - М,: МГТУ им. Н.Э. Баумана, 2009. 167-181 с.
5. Руденко Ю.М. Построение плана
выполнения параллельных алгоритмов на базе граф-схем. Аэрокосмические
технологии. Научные материалы МНТК - 2009. Реутов - Москва 2009. 179=181с.
. Руденко Ю.М. Учёт
зависимостей программных модулей по данным и последовательностям их выполнения
при параллельных вычислениях. Известия высших учебных заведений. Поволжский
регион. Технические науки. № 3 (11), 2009. 67-75 с.
Приложение 1
Алгоритм построения нитей
1. Просматриваем матрицу SDR по строкам сверху вниз. Если
просмотрены все строки, то - конец алгоритма.
2. Если
в i-й строке найдено одно число, то вес i-й
вершины модифицируется к виду: рi:=pi+qj,i .
Если в i-й строке найдено несколько чисел, то веса вершин
модифицируются следующим образом: рj:=pj+qi,j ,j={ }, где ,j -
множество столбцов, в которых найдены числа, qi,j -
множество весов дуг, принадлежащих i-й
строке .
}, где ,j -
множество столбцов, в которых найдены числа, qi,j -
множество весов дуг, принадлежащих i-й
строке .
3. Используя модифицированные веса, с помощью алгоритма
6.1.1 вычисляем ранние сроки окончания выполнения операторов.
4. Вычисленные ранние сроки окончания выполнения
операторов служат основой для построения диаграммы загрузки ВМ. Каждая строка
диаграммы может служить нитью для загрузки в процессор.
Приложение 2
Алгоритм вычисления ранних сроков окончания выполнения
операторов
1. Вычислим t1,j: =0, где j
:=1,…,RS. RS - размер
матрицы следования
2. Просматриваются строки матрицы S сверху вниз, выбирается
первая необработанная строка матрицы, и осуществляется переход к следующему
шагу, если обработаны все строки, то - конец алгоритма.
. Если выбрана j-я строка, не содержащая единичных элементов,
то вычисляем t1,j: = pj , где pj - вес j-го
оператора и переходим на шаг 5.
. Если j-я строка содержит единичные элементы, то вычисляется
t1,j:
=  + pj,
+ pj,
где
max , берётся по множеству времён t1,j , где jq
- номера элементов j-й
строки, равных единице. Если в множестве
, где jq
- номера элементов j-й
строки, равных единице. Если в множестве 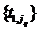 есть
нулевые элементы, то выполняется шаг 6, иначе выполняется шаг 5.
есть
нулевые элементы, то выполняется шаг 6, иначе выполняется шаг 5.
5. Обработанная j-я строка исключается из рассмотрения.
Осуществляется переход на шаг 3.
. Выбираем столбец j:=jq и переходим на шаг 3.
Примечание: пункт 6 алгоритма 6.1.1 используется для нетреугольной
матрицы S
Приложение 3
Алгоритм распределения программных модулей по узлам
Вычислительной сети.
1. Задана ВС с N вычислительных модулей, нумеруемых
как {0,1,…,N-1}.
Предполагается, что мощность множества удовлетворяет потребность в количестве
ВМ для решения поставленной задачи предполагаемым методом.
2. Количество нитей W. Множество нитей Т.
. Вычислим матрицу расстояний между вычислительными
модулями.

Минимальное расстояние между двумя ВМ равно 1, максимальное -
N-2.
. Для определения показателя близости ВМ определим сумму
столбцов матрицы R.  j=1,2,…,N. При j=1 показатель близости наилучший.
j=1,2,…,N. При j=1 показатель близости наилучший.
5. Упорядочим St(j) в порядке возрастания
. Построим диаграмму ранних сроков окончания
выполнения операторов с указанием связей между операторами, с учетов времени
передачи между операторами. Образуем множества несвязных между собой пучков
нитей {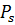 }; S={0,1,…,q}.
}; S={0,1,…,q}.
7. Среди
множеств { } найдем множество {
} найдем множество {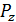 }, имеющее нить
}, имеющее нить 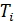 с
максимальным количеством элементов в множестве
с
максимальным количеством элементов в множестве 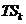 (таблице связей к-й нити). Предположим таблица связей
имеет
(таблице связей к-й нити). Предположим таблица связей
имеет  элементов.
элементов.
Примечание: таких множеств нитей может быть несколько, и
тогда выбирается любое из них.
. Составим из связей между нитями множества {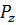 } массив MS и обнулим все его элементы.
} массив MS и обнулим все его элементы.
9. Если
степень i-й вершины вычислительной сети есть 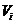 , то сравниваем и .
, то сравниваем и .
. Если
 , то нить размещается в узле i,
и переходим к шагу 12, иначе следующий шаг.
, то нить размещается в узле i,
и переходим к шагу 12, иначе следующий шаг.
. Если
 то образуется комплексный узел, в котором один
вычислитель основной, остальные являются передающими звеньями.
то образуется комплексный узел, в котором один
вычислитель основной, остальные являются передающими звеньями.
12. Определим
с какой нитью из множества {Pz} связана 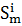 нить
нить  .
Пусть это будет нить
.
Пусть это будет нить 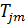 =(max∩Tj), TjϵT.
=(max∩Tj), TjϵT.
. Нить
занимает узел jm вычислительной
сети на минимально возможном расстоянии от узла i.
. Образуем
последовательность входящих и исходящих связей i-ой нити
с , S1,S2,…,Sd (1) из множества MS.
. Пусть
связь Sm ,где mϵ{1,2,..d},
в нити 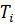 связывает оператор
связывает оператор  с
оператором
с
оператором  нити .Тогда,
если связь входящая, то если sT(γ) ≥ fT(α) + r(i,jm)*ρA,
то переходим на шаг 17, иначе Pγ=Pγ+ r(i,jm)*ρA.
нити .Тогда,
если связь входящая, то если sT(γ) ≥ fT(α) + r(i,jm)*ρA,
то переходим на шаг 17, иначе Pγ=Pγ+ r(i,jm)*ρA.
Если связь исходящая, то если Sm =0, то
Pα=Pα+
r(i,jm)*ρA,
иначе если sT(γ) < fT(α),
то
sT(γ) = fT(α).
. Если Sm - входящая связь, то все операторы в нити , начиная с оператора 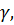 сдвинуты по оси времени вправо на
величину r(i,j)*
ρA. Иначе, аналогично в нити сдвинуты все операторы, начиная с .
сдвинуты по оси времени вправо на
величину r(i,j)*
ρA. Иначе, аналогично в нити сдвинуты все операторы, начиная с .
17. Связь Sm=1 в массиве связей всех нитей MS.
. Из последовательности (1) берем следующую связь для
рассмотрения, пусть m=m+1 и обозначим эту связь Sm. Если m≤d, то перейти к шагу 15, иначе шаг 19.
19. TSk= TSk|Tjm, если TSk≠0, то переходим к шагу 12,
иначе шаг 20.
. Уменьшим количество нерассмотренных нитей на 1, то
есть W=W-1.
Если W=0, то переходим к п.17, иначе выбираем из оставшихся нитей множества {Pz} нить с максимальным числом связей.
Пусть эта нить и переходим к шагу 12.
. Исключить из рассмотрения множества {} и переномеровать множество {}; S={0,1,…,q-1}. Если {}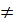 0, то перейти к шагу 7, иначе шаг 22.
0, то перейти к шагу 7, иначе шаг 22.
22. Конец алгоритма.
Матрица следования
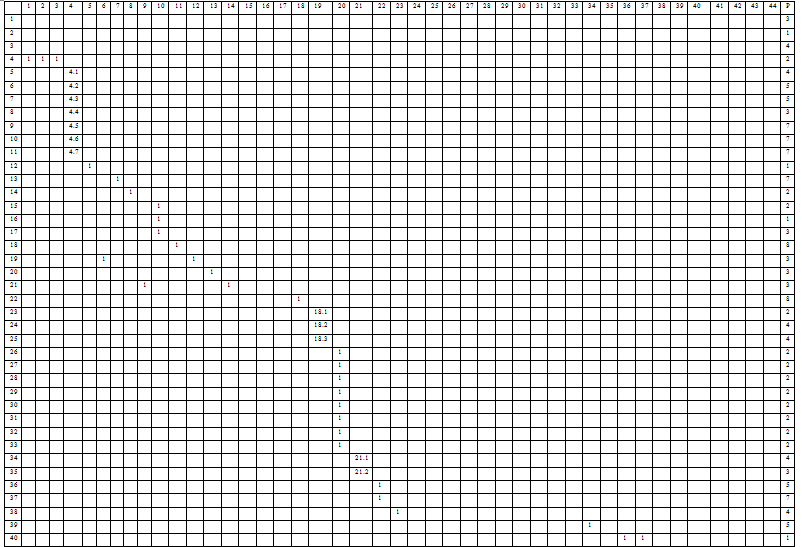

Таблица 2 - Расширенная матрица следования с указанием весов дуг и вершин
(SDR) данного ИЛГ.

Матрица дистанций для ВС структуры гиперкуб 3*3*6.