Разработка кодека кода Файра
Содержание
1. Введение
2. Выбор и обоснование кода
. Разработка кодирующего и
декодирующего устройства
.1 Синтез кодера
.1.1 Разработка структурной схемы
кодера
.1.2 Разработка функциональной схемы
кодера
.1.3 Разработка принципиальной схемы
кодера
.2 Синтез декодирующего устройства
.2.1 Разработка структурной схемы
декодера
.2.2 Разработка функциональной схемы
декодера
.2.3 Разработка принципиальной схемы
декодера
.2.4 Устранение временной задержки
при декодировании
Заключение
Литература
1.
Введение
При передаче и хранении информации по каналу
связи или при ее хранении в запоминающих устройствах возможно ее искажение за
счет помех или отказа ячеек памяти, что может привести к ошибочному ее
воспроизведению.
С искажениями сигнала можно бороться увеличивая соотношение
мощностей сигнал/помеха. Этого можно добиться увеличивая мощность самого
сигнала при постоянном уровне помех, однако это увеличение ведет к излучению и
чрезмерному потреблению энергии передающих системю. Самым эффективным методом
увеличения верности передачи информации является использование кодов,
исправляющих и обнаруживающих ошибки в принятом сообщении. Чаще всего для
проверки в сообщение вносится избыточность. Методы повышения надежности путем
введения избыточности широко используются и в различных технических
устройствах.
Сообщение, поступающее в устройство кодирования
(кодер), преобразуется в последовательность символов, называемую кодовым
словом. Кодовое слово передается по каналу связи (после модуляции) либо
хранится в запоминающем устройстве. В обоих случаях возможно искажение
информации. Сообщение, считанное с ЗУ или принятое из канала связи и прошедшее
через демодулятор, поступает на декодер, который использует заранее внесенную
избыточность для проверки и возможного исправления сообщения.
При передаче сообщения по каналу связи с большой
скоростью передачи помехи часто имеют длительность большую, чем время передачи
одного символа, поэтому может исказиться последовательность из нескольких
идущих подряд символов, образуя пакет ошибок - совокупность кодовых слов,
которые начинаются и заканчиваются ошибочными кодовыми символами, а внутри
могут быть ошибочные и неошибочные символы.
Широко используемыми кодами, исправляющими
пакеты ошибок, являются коды Файра, рассмотренные в данном курсовом проекте.
Код Файра еще в 60-е годы прошлого века использовался для защиты магнитных лент
и при воспроизведении их поврежденных частей, в старых кабельных системах при
возможности повреждения участка сообщения.
В данном курсовом проекте рассмотрен код Файра, подробно
рассмотрена структура его кодирующего и декодирующего устройств.
2.
Выбор и обоснование кода
Перед подачей кодовых слов в канал связи к ним
добавляют проверочные разряды, число которых зависит от числа информационных
разрядов, а так же от вида и кратности обнаруживаемых и исправляемых кодом
ошибок. Код, способный обнаруживать и исправлять возникающие в кодовых словах
ошибки, называется корректирующим.
Широкое распространение получили циклические
коды, в которых к блоку из k
информационных символов добавляется r
проверочных, в частности коды Файра, обнаруживающие и исправляющие одиночные
пакеты ошибок.
Циклические коды удобнее рассматривать,
представляя кодовое слово в виде полинома:
Q(x) = an-1xn-1
+ an-2xn-2 + … + a1x
+ a0
, (2.1)
где ai
- цифры системы счисления, чаще всего 0 и 1 (двоичная система счисления),
xi
- основание системы счисления.
Такое представление позволяет свести операции
над кодами к операциям над полиномами. При этом сложение и умножение
многочленов производится по модулю два. То есть сложение полиномов сводится к
сложению по модулю два коэффициентов для одинаковых степеней x,
а умножение - к перемножению степенных функций, при этом коэффициенты при одних
и тех же степенях складываются по модулю два.
Идея построения циклических кодом базируется на
использовании неприводимых полиномов - полиномов, которые не могут быть
представлены в виде произведения многочленов низших степеней.
Код Файра относится к циклическим кодам и
предназначен для коррекции пакетов ошибок разрядности b
и обнаружения пакетов разрядности l.
Порождающий полином кода Файра определяется по формуле:
g(x)
= ( xc+1)g1(x)
, (2.2)
где g1(x)
- неприводимый многочлен степени m,
c = 2b-1,
не делится на 2m-1.
Период двучлена ( xc+1)
равен с, то есть через i
= c остатки от деления
xi на (xc+1)
будут повторяться.
Максимальное число символов в кодовой комбинации
n равно наименьшему
общему кратному c и (2m-1),
то есть:
n = c·(2m
-
1). (2.3)
Число проверочных символов в кодовом слове
r = c
+ m. (2.4)
Коды Файра используются для обнаружения и
коррекции одиночных пакетов ошибок длины p,
разделенных интервалом в L
≥(n-p).
Для исправления пакетов ошибок длиной p
требуется не менее (3b
- 1) проверочных разрядов.
Найдем основные параметры заданного кода Файра:
По условию задания образующий полином
g(x)=(x9+1)(x5+x2+1).
(2.5)
Преобразуем его к следующему виду:
g(x)
= x14 +
x11 +
x9 +
x5 +
x2
+ 1. (2.6)
Максимальное число разрядов в кодовой
комбинации:
n = c·(2m
-
1) = 9·(25 - 1) = 279
Число проверочных разрядов в слове
r = c
+ m = 9 + 5 = 14
Число информационных разрядов в слове
k= n
- r = 279 - 14 = 265
Для коррекции пакетов ошибок длиной p
= 5 требуется не менее 3b-1
проверочных символов. В случае заданного кода (b=5)
это условие выполняется:
b-1 =3·5-1=14
3.
Разработка кодирующего и декодирующего устройства
.1
Синтез кодера
.1.1
Разработка структурной схемы кодера
При кодировании разделенным кодом существует два
варианта построения кодирующего устройства в зависимости от соотношения между k
и r :
1) если k
> r, то кодер
реализуется по порождающему полиному g(x)
2) если k
<r, то кодер
реализуется по проверочному полиному h(x)
Так как в случае заданного кода k
> r (265 > 14), то
кодирование будем осуществлять по порождающему полиному.
Кодовое слово принадлежит коду, если оно делится
на порождающий полином g(x).
Для реализации разделимого кода, удовлетворяющего этому условию можно
воспользоваться описанным ниже способом.
Многочлен Q(x),
соответствующий k-разрядной
информационной последовательности, умножается на xr,
где r = n
- k (эквивалентно
дописыванию r нулей к
информационной последовательности). Далее произведение Q(x)·xr
делится на генераторный полином g(x):
[Q(x)
· xn-k]
/ g(x)
= С + R(x)/g(x),
(3.1)
где R(x)
- некоторый остаток. Умножим обе части на g(x)
и перенесем остаток в левую часть:
Q(x)
· xn-k
+
R(x)
= С·g(x).
(3.2)
Так как С - целое, то Q(x)
· xr
+
R(x)
делится на g(x),
а значит является кодовым словом.
Таким образом, циклический код, в частности код
Файра, можно строить, приписывая к каждой комбинации информационных символов
остаток от деления соответствующей последовательности на образующий многочлен
кода:
F(x) = Q(x)·xr/g(x) +
Q(x)·xr .
Кодирование идет по следующему принципу:
информационные символы в течении k
тактов поступают одновременно на вход формирователя проверочных символов (ФПС),
где осуществляется деление входной последовательности на порождающий полином
(рис. 1), и на выход кодера (при этом ключи КЛ1 и КЛ2 замкнуты, а КЛ3 разомкнут).
Через k тактов в ФПС
образуется r проверочных
символов; тогда ключ 1 и ключ 2 размыкаются, в ФПС прекращается деление
информационной последовательности на генераторный полином, а ключ 2 замыкается,
после чего схема производит еще r
тактов, выдавая проверочные символы из ячеек ФПС на выход кодера.
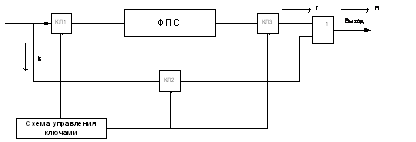
Рис. 1 - Структурная схема
кодирующего устройства.
На основании вышесказанного можно
выделить основные блоки и элементы устройства кодирования:
1) ФПС - формирователь проверочных
символов
2) КЛ1 - ключ, который управляет
поступлением информации в схему формирования проверочных символов.
) КЛ2 - ключ, отвечающий за выдачу в
канал инфомационных символов.
) КЛ3 - ключ, управляющий выдачей в канал
проверочных символов, сформированных в ФПС.
) Схема управления ключами - формирует
сигналы управления ключами.
) Коммутатор - схема “или” - предназначен
для согласования линий.
Структурная схема кодирующего устройства
изображена на рис. 1.
3.1.2 Разработка
функциональной схемы кодера
Как уже было упомянуто в пункте 3.1.1 данной
пояснительной записки, основу кодирующих и декодирующих устройств циклических
кодов составляют линейные переключательные схемы. Они состоят из следующих
основных элементов: триггерной ячейки (рис. 2,а) и сумматора по модулю два
(рис. 2,б).
а) 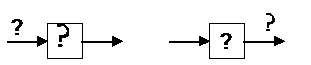
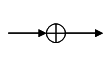 б)
б)
Рис. 2
Рассмотрим процесс работы схемы деления
полиномов, используемой при реализации схемы ФПС.
Общий вид схемы, реализующей деление
многочлена 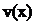 на
на 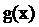 , приведен
на рис.3.
, приведен
на рис.3.
Рис. 3
Рассмотрим работу данной схемы на
примере : пусть требуется разделить 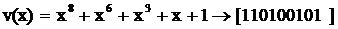 на
на 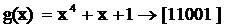 . Соответствующая схема приведена на
рис.4.
. Соответствующая схема приведена на
рис.4.

Рис. 4
Вначале устройство памяти содержит
нули. Выходной символ принимает значения, равные 0 на первых 4-х (r) сдвигах,
пока первый входной символ не достигнет конца регистра сдвига. Эти первые
сдвиги не имеют аналогий при делении столбиком (рис.5,а ).
а)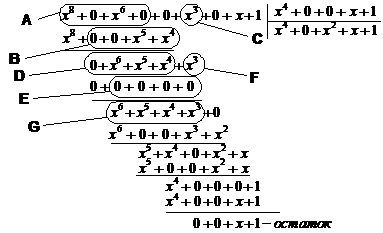 б)
б)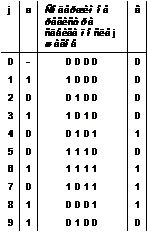
Рис. 5
Для каждого коэффициента частного 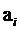 необходимо
(как при делении столбиком) вычесть из делимого многочлен
необходимо
(как при делении столбиком) вычесть из делимого многочлен 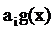 . Это
вычитание осуществляется с помощью обратной связи. Так, после 4-го шага
содержимое регистра сдвига соответствует многочлену, обозначенному на рис.5а
буквой A. Обратной связи соответствует многочлен, обозначенный буквой B, а
входу -многочлен C, сносимый при делении столбиком. После 5-го шага содержимому
регистра сдвига соответствует многочлен, обозначенный D. После всех девяти (n) сдвигов на
выходе - младший коэффициент частного от деления, а в регистре сдвига -
остаток.
. Это
вычитание осуществляется с помощью обратной связи. Так, после 4-го шага
содержимое регистра сдвига соответствует многочлену, обозначенному на рис.5а
буквой A. Обратной связи соответствует многочлен, обозначенный буквой B, а
входу -многочлен C, сносимый при делении столбиком. После 5-го шага содержимому
регистра сдвига соответствует многочлен, обозначенный D. После всех девяти (n) сдвигов на
выходе - младший коэффициент частного от деления, а в регистре сдвига -
остаток.
Таким образом, операция деления
полиномов реализуема на линейной переключательной схеме, с соответствующим
образом заведенными обратными связями, расположение которых соответствуют
степеням элементов полинома-делителя. Общий вид кодера для заданного кода
приведен на рис. 6.

Рис. 6 - Схема кодера.
Существует два варианта построения
схем деления полиномов: с вынесенными сумматорами и со встроенными сумматорами.
Данная схема построена по схеме деления полиномов с вынесенными сумматорами,
так как такой вариант является наиболее целесообразным. Это связано с тем, что
в реальных регистрах сумматоры между ячейками не встроены, а следовательно
реализация схемы со встроенными сумматорами сопряжена с большими трудностями,
чем реализация схемы с вынесенными, где все они устанавливаются на одну линию
обратной связи (см. рис. 6 ). Таким образом, ячейкам 1..14 соответствуют выходы
регистра сдвига, между которыми соответствующим образом в линию обратной связи
поставлены сумматоры по модулю два. код файр декодирование
информация
Элементами функциональной схемы
являются:
1) ФПС - формирователь проверочных символов
(осуществляет деление полинома Q(x)·xr на образующий полином g(x), делимое в виде кодовой комбинации, представляющей полином Q(x)·xr подается на вход
регистра сдвига, а полином g(x) вводится в регистр в виде соответствующим образом
подобранной структуры обратных связей через сумматоры).
2) КЛ1 - ключ, который управляет
поступлением информации в схему формирования проверочных символов.
) КЛ2 - ключ, отвечающий за выдачу в
канал инфомационных символов.
) КЛ3 - ключ, управляющий выдачей в канал
проверочных символов, сформированных в ФПС.
) Коммутатор - схема “или” - предназначен
для согласования линий.
) Сумматоры по модулю 2.
) Схема управления ключами - формирует
сигналы управления ключами.
Функциональная схема кодера приведена в
приложении 1.
Ключи КЛ1,
КЛ2 и КЛ3 реализуются в виде двухвходового элемента «И». Наличием уровня
логической единицы или логического нуля на одном из входов элемента можно закрывать
и открывать ключ (рис 7).
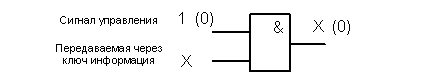
Рис. 7
Двухвходовый коммутатор
представляет собой двухвходовую схему «ИЛИ».
Формирователь проверочных символов
представляет собой сдвиговый регистр с последовательным вводом и параллельным
выводом информации. ФПС имеет обратную связь через пять сумматоров по модулю
два. Число ячеек сдвигающего регистра равно степени образующего полинома, т.е. r = 14 ячеек
памяти.
Схема управления ключами построена
на девятиразрядном счетчике, двух девятивходовых элементах «И», семи инверторах
и JK-триггере.
Схема работает следующим образом: счетчик считает поступающие на него импульсы fтакт и выдает на
свой выход соответствующую посчитанному количеству импульсов двоичную
комбинацию. На элементы «И» через инверторы и напрямую заводятся выходы
счетчика так, что как только счетчик выдаст необходимую комбинацию, элемент «И»
будет иметь на своем выходе единицу. В свою очередь, выход одного элемента «И»
заведен на вход J (от англ. «jerk» -толчок),
а другого на вход K (от англ. «kill» - убить) JK-триггера
(изначально установлен в единичное состояние). В случае заданного кода элементы
«И» настроены на появление на выходе счетчика чисел (265)10 =
(100001001)2 и (279) 10 = (100010111)2 . На рис. 8 приведены
временные диаграммы, поясняющие работу схемы управления ключами. Через 279
тактов (период работы схемы) происходит сброс счетчика в нулевое состояние
подачей сигнала на его вход сброса R и описанный
выше процесс повторяется.


Рис 8 - Временные диаграммы сигналов
управления ключами.
Из рис. 8 видно, что для управления
ключами КЛ1 и КЛ2 используется прямой выход триггера, а для КЛ3 - инверсный.
За 265 тактов
в регистре образуется остаток от деления полиномов. После 265 такта ключи КЛ1 и
КЛ2 размыкаются, а ключ КЛ3 замыкается. С этого
момента формирователь в течение 14 тактов выдает
сформировавшиеся в нем проверочные символы на выход кодера. После 279 такта ФПС
содержит только нули и процесс подачи информационных символов повторяется.
Таким образом, период работы схемы составляет 279 тактов.
3.1.3
Разработка принципиальной схемы кодера
По условию задания тактовая частота равна 200
МГц. Кодер построим на базе быстродействующих КМОП микросхем серии КР1554
(аналогичная зарубежная серия MC74AC
- Advanced ). Напряжение
питания микросхем серии КР1554 - от 2 до 6 В. Рабочий температурный интервал
-45...+85 С. Ток, потребляемый в статическом режиме, по нормам технических
условий не превышает 4 мкА для простых микросхем и 8 мкА для микросхем средней
степени интеграции. Все микросхемы этой серии отличаются очень высокой
нагрузочной способностью - при высоком логическом уровне на выходе, напряжении
питания 4,5 В и выходном напряжении 3,86 В выходной вытекающий ток не менее 24
мА. Максимально допустимая емкость - 500 пФ.
Время задержки на вентиль равно 4 нс.
) Для построения формирователя проверочных
символов нам понадобятся две микросхемы КР1554ИР8, в одной из которых задействованы
все 8 выходом, в другой используются только 3 из них.
Микросхема представляет собой восьмиразрядный
сдвиговый регистр с последовательной загрузкой и параллельной выгрузкой.
Наличие двух входов загрузки А и &А позволяет использовать один из них в качестве
управляющего загрузкой данных низкий уровень на одном из них запрещает
прохождение сигнала со второго. Низкий уровень на входе R
устанавливает все выходы микросхемы в 0.
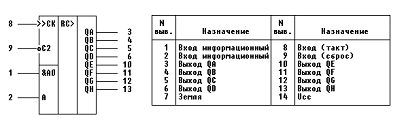
Рис. 9 - Микросхема КР1554ИР8.
Две микросхемы КР1554ЛП5 - «4 двухвходовых
элемента исключающее или» используется для реализации пяти сумматоров по модулю
два - одна микросхема помещена в цепь обратной связи после регистра сдвига, а
вторая устанавливается на вход схемы и из нее используется только один элемент.
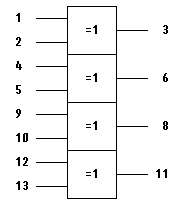
Рис. 10 - Микросхема КР1554ЛП5 .
) Для построения устройства управления ключами
необходим счетчик на 9 разрядов, 7 инверторов, 2 элемента реализующих функцию
«9И», и один JK-триггер.
Счетчик построим, используя 3 микросхемы
КР1554ИЕ10, соединенные по схеме наращивания разрядности (рис. 11). Микросхема
представляет собой четырехразрядный двоичный счетчик с асинхронным сбросом,
дешифрующим счетным выходом, с возможностью синхронной установки в произвольное
состояние от нуля до пятнадцати. В качестве запоминающего элемента используется
JK триггер с внутренней задержкой. Счетчик имеет вход синхронизации С, вход
установки нуля R, четыре информационных входа Dl - D4, входы разрешения счета
VI, разрешения предварительной записи V2, разрешения переноса P1, четыре выхода
Ql-Q4 и выход
переноса информации Р2 Счетчик устанавливается в предварительное состояние при
наличии на входе разрешения V2 низкого уровня В этом случае разрешена подача
сигналов на входы JK триггеров через информационные входы Dl -D4. Информация
передается на выходы при поступлении положительного фронта тактового импульса
на вход синхронизации. Операция счета происходит при наличии на входах VI, P1,
V2, R высокого уровня. Схема устанавливается в нулевое состояние при подаче на
вход R напряжения низкого
уровня. В режиме записи на шины V2 подается низкий уровень, R - высокий, а
состояния входов VI и PI могут быть любыми. Для переноса импульса в следующий
каскад предусмотрена специальная схема с входом разрешения переноса P1 и
выходом Р2. При подаче на вход схемы пятнадцатого счетного импульса на выходе
появляется высокий уровень. После шестнадцатого импульса, когда счетчик
обнуляется, выход Р2 снова переходит в состояние низкого уровня Следовательно, на
каждые шестнадцать счетных импульсов формируется один импульс переноса на вход
счетчика старшего разряда. Условное обозначение, таблица истинности и схема
наращивания разрядности для данной микросхемы приведены на рис. 11.
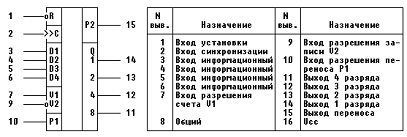
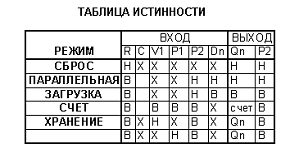
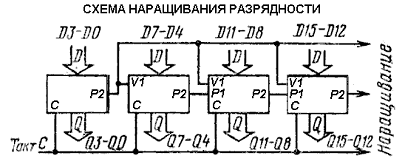
Рис. 11 - Микросхема КР1554ИЕ10.
При построении кодера используется три схемы
КР1554ЛН1 (рис. 12). Данная схема представляет собой набор из шести инверторов.
Первая схема служит для правильного задания комбинации, на которую будет
реагировать триггер, переключая свое состояние и устанавливается перед
элементом «9И». Так как для задания необходимо 7 инверторов, то необходимо
поставить еще одну микросхему КР1554ЛН1, один из инвертирующих элементов
которой будет использован с той же целью, что и элементы первой микросхемы, а
второй будет использован для заведения сигнала сброса счетчиков при комбинации,
соответствующей числу 279 (это связано с тем, что элемент «9И» выдаст в этот
момент единицу, а вход сброса счетчиков инверсный ). На изображении элементы
этой микросхемы разнесены по принципиальной схеме, а не изображены единым
блоком согласно ГОСТу о правилах выполнения схем. Третья микросхема используется
при реализации элемента «9И».
Рис. 12 - Микросхема КР1554ЛН1.
Для реализации схемы «9И» используем 2
микросхемы КР1554ЛА4 (рис. 13), состоящей из трех элементов 3И-НЕ, микросхему
КР1554ЛН1 (необходимо установить, так как КР1554ЛА4 имеет инверсные выходы) и
схему, объединяющие предыдущие ступени схемы «9И» - микросхему КР1554ЛИ6 (рис.
14) - 2 элемента 4-И, в каждом элементе которой используется по 3 входа (на
неиспользуемый вход заводится единица). Таким образом, на первом элементе
микросхемы КР1554ЛИ6 появится логическая единица при комбинации на счетчике,
соответствующей числу 265, а на втором - 279.
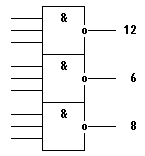
Рис. 13 - Микросхема КР1554ЛА4.
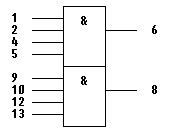
Рис. 14 - Микросхема КР1554ЛИ6.
В качестве триггера будем использовать
микросхему КР1554ТВ9, условное обозначение и таблица истинности которой
приведена на рис. 15.
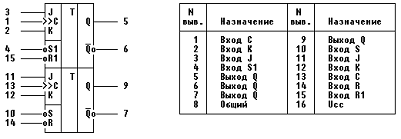
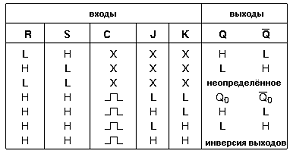
Рис. 15 - Микросхема КР1554ТВ9.
Микросхема представляет собой два независимых
тактируемых JK триггера с
установкой в 0 и 1. Считывание информации со входов J и К происходит во время
положительного перепада на входе С. Наличие низкого уровня на входах R и S
одновременно дает неопределенное состояние на выходах. Перед началом работы
схемы триггер должен быть установлен в единичное состояние. Подача на его входы
J и K
сигналов с элементов «9И» запирает его на соответствующее количество тактов в
состоянии лог. 0 либо лог. 1.
) Ключи реализуются на микросхеме КР1554ЛИ2,
состоящей из четырех элементов 2И (рис. 16).
Рис. 16 - Микросхема К1554ЛИ2.
)Микросхема КР1554ЛЛ1 (рис. 17) содержит четыре
элемента «ИЛИ», один из которых используется для реализации выходного
коммутирующего устройства.
Рис. 17 - Микросхема КР1554ЛЛ1.
Принципиальная схема кодирующего устройства
приведена в приложении 2.
3.2
Синтез декодирующего устройства
3.2.1
Разработка структурной схемы декодера
При декодировании циклических кодов наибольшее
распространение получили 2 способа декодирования: синдромное и мажоритарное (по
принципу большинства). Мажоритарное декодирование привлекает простотой
описания, однако для заданного кода имеет сложную схемную реализацию и, к тому
же не все циклические коды допускают такое декодирование. Построим синдромный
декодер кода Файра, для корректировки пакетной ошибки длиной p=5.
При декодировании кода Файра наиболее
целесообразно использовать устройство декодирования, в котором для обнаружения
и последующего исправления ошибок полином, соответствующий принятой кодовой
комбинации, делится на порождающий полином g(x).
Это удобно, так как при декодировании используются те же регистры сдвига, что и
при кодировании.
Схема декодирования работает по следующему
принципу. Принятое сообщение последовательно поступает на буферный регистр (БР)
и делитель принятого полинома на образующий полином .
При декодировании используется два следующих
свойства синдрома ошибок S(x)(остатка
от деления принятого слова на g(x)):
1) Пусть S(x)
- синдром кодовой комбинации F(x),
тоесть остаток от деления F(x)
на образующий полином g(x).
Тогда синдром циклического сдвига F(x)
получается в результате одного сдвига формирователя синдрома, в котором
первоначально содержится синдром S(x).
2) Если в комбинации ошибок, которая может
быть исправлена все ошибки расположены в r=n-k
старших разрядах, то синдром совпадает с последовательностью ошибок e(x).
То есть, если пакет длиной p
ограничен p старшими разрядами
слова, то в p справа
расположенных ячейках памяти делителя на g(x),
вычисляющих S(x),
находится e(x).
А в (n-k-p)
разрядах регистра будут расположены нулевые символы. Если же пакет ошибок
расположен в другом месте последовательности, то после сдвигов он все равно
займет p старших разрядов
буфера, p символов синдрома
старшего порядка совпадут с пакетом ошибок.
Число тактов, необходимых для исправления пакета
ошибок равно 2·n. В течение
первой половины тактов производится запись принятой комбинации в буферный
регистр разрядности n и
формирование синдрома разрядности r.
После этого осуществляется еще n
тактов, за которые происходит считывание из регистра и исправление ошибок. Если
не зафиксируется нулевое значение младших разрядов генератора, то это значит,
что длина пакета ошибок больше p,
ошибка не может быть исправлена.
Из вышесказанного можно сделать вывод, что схему
декодера можно подразделить на следующие основные блоки:
1) генератор синдрома ошибок -
предназначен для деления принятого сообщения на генераторный полином;
2) буферный регистр - служит для
предварительной записи принятой последовательности символов и представляет
собой обычный сдвиговый регистр с последовательным вводом;
3) схема обнаружения ошибок по виду синдрома -
контролирует присутствие пакета ошибок только в p
старших разрядах ;
4) схема коррекции и управления вводом
и выводом информации из генератора синдрома - предназначена для исправления
ошибок в принятом сообщении;
Структурная схема декодирующего устройства
представлена на риc. 18.
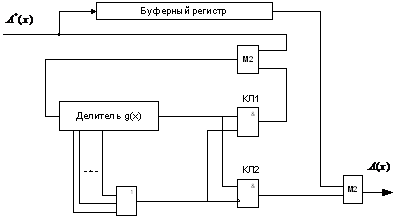
Рис 18 - Структурная схема декодера.
3.2.2
Разработка функциональной схемы декодера
В соответствии с разделом 3.2.1 данной
пояснительной записки, структурными блоками декодера являются:
1) n
-разрядный буферный регистр;
2) r
-разрядный генератор синдрома ;
) блок обнаружения ошибок;
) ключевая схема;
) блок коррекции .
Буферный регистр построен на основе регистрах
сдвига. В течение n тактов в
него последовательно поступает n-разрядное
кодовое слово (в случае заданного кода n
= 279 ). Затем, в течение последующих n
тактов, регистр выдаёт разряды принятого кодового слова на вход сумматора по
модулю два, установленного перед выходом схемы.
Генератор синдрома представляет собой делитель
на порождающий полином g(x)
и является сдвиговым регистром с последовательным вводом и параллельным выводом
информации. Генератор имеет обратную связь через пять сумматоров по модулю два.
Число ячеек сдвигающего регистра равно степени образующего полинома, т.е. r
= 14 ячеек памяти.
Ключи, как и в кодере выполняются на
двухвходовых элементах «И», однако в данной схеме управление может
осуществляться без использования счетчиков, лишь в соответствии с принципом
работы декодера (при помощи внутренних сигналов схемы).
Согласно предыдущему разделу, в процессе работы
схеме нужно обнаружить ситуацию, когда в p
старших разрядах генератора синдрома будет находиться пакет ошибок, a младшие
(n-k-p) разряды будут
содержать нули. Для обнаружения ситуации, когда в младших разрядах отсутствуют
единицы используется многовходовой элемент «ИЛИ».
Схема работает следующим образом:
n тактов на вход
схемы поступает принятое кодовое слово A*(x),
которое может содержать ошибки. A*(x)
одновременно заводится на генератор синдрома (делитель на g(x)
) и в буферный регистр. Через n
тактов в делителе сформирован синдром ошибки принятого слова. Если выполняется
условие содержания пакета ошибок в p=5
старших разрядах и отсутствия единиц в 9 младших разрядах, то 9-ти входовый
элемент «ИЛИ» выдает на свой выход ноль и тем самым открывает ключ КЛ2 и
закрывает ключ КЛ1. Это приводит к разрыву цепи обратной связи схемы деления на
g(x)
и выводу сформированного синдрома, сосредоточенного в 5 старших разрядах на
выходной сумматор по модулю два. Таком образом, происходит суммирование
сформированного синдрома, который совпадает с вектором ошибок, с информационной
последовательностью из буферного регистра, а точнее с искаженным пакетом
символов, находящихся в этот момент непосредственно на выходе регистра.
Функциональная схема декодера приведена в
приложении 3.
3.2.3
Разработка принципиальной схемы декодирующего устройства
При построении принципиальной схемы декодера
воспользуемся той же серией интегральных микросхем, что и при построении кодера
- КР1554.
Схема генератора синдрома в декодере идентична
схеме формирователя проверочных символов в кодере, выполняет ту же операцию и
построена из тех же микросхем (микросхемы КР1554ИР8 - рис. 9 , КР1554ЛП5
- рис. 10). Еще одна микросхема КР1554ЛП5 используется для реализации
входного и выходного сумматоров.
Буферный регистр должен осуществлять приём и
хранение информационных символов принятой кодовой комбинации на время,
необходимое генератору синдрома для проверки наличия ошибок. Буферный регистр
должен быть рассчитан на приём 279 разрядов. Для обеспечения такой разрядности
используем 35 регистров КР1554ИР8 (рис. 9).
Схема контроля отсутствия единиц в младших
разрядах реализуется с использованием микросхемы КР1554ЛЕ4 - трех элементов
3ИЛИ-НЕ (рис. 19) и микросхемы КР1554ЛН1 (рис. 12).
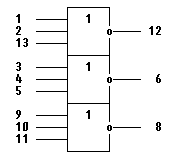
Рис. 19 - Микросхема КР1554ЛЕ4..
Ключи, так же как и в кодере реализованы на
микросхемах КР1554ЛИ2 (рис. 16).
3.2.4
Устранение временной задержки при декодировании
Из логики построения декодера видно, что данной
схеме для декодирования n
символов необходимо 2n
тактов. При этом входная последовательность должна быть разделена «прокладкой»
из n нулей, иначе
символы, поступающие на вход схемы генератора синдрома будут искажать уже
посчитанный синдром для находящейся в буферном регистре информационной
последовательности. Постановка ключа на вход схемы и его размыкание на вторые n
тактов (с момента начала поступления информации на декодер), приведут к потере
непрерывно поступающей информации. Задержка в n
тактов является весьма существенной (в нашем случае 279 тактов информация
должна фактически «стоять» на входе декодера и не поступать на обработку).
Рассмотрим возможные варианты решения данной
проблемы.
Одним из способов уменьшения времени работы
декодирующего устройства является применение второго декодера, абсолютно
идентичного построенному. В этом случае, поступающая информация должна
поочередно, каждые 279 тактов поступать то на один, то на второй декодер. Таким
образом, первые 279 значений информационной последовательности поступают на
вход первого декодера, в нем формируется синдром ошибки и этот декодер готов к
исправлению ошибок. Начиная с 280 такта на протяжении очередных 279 тактов,
последовательность A*(x)
поступает уже не на первый, а на второй декодер, и одновременно с этим, первый
декодер корректирует находящуюся в нем информацию. К тому моменту, когда первый
декодер обработает первые n
бит сообщения, во втором уже сформируется синдром ошибки для вторых n
бит. Следовательно, попеременно направляя входную последовательность то на один
декодер, то на второй можно обрабатывать непрерывный поток информации без
необходимости задержки на n
тактов, что сильно увеличивает пропускную способность декодера. Несмотря на
простоту данного решения, оно приводит к большим аппаратурным затратам, что
свидетельствует о неоптимальности данного метода.
Рассмотрим еще один вариант устранения временной
задержки. Если проанализировать работу декодера, то становится понятно, что
единственной причиной, которая не позволяет подавать входную декодируемую
последовательность непрерывно является невозможность подачи этой
последовательности на вход схемы генерации синдрома. Такая подача приведет к
искажению уже посчитанного для предыдущей комбинации синдрома. Напрашивается
вывод, что этот синдром необходимо сохранять в устройстве, отдельном от схемы
генерации синдрома и производить корректирование находящейся в буферном
регистре последовательности уже из этого устройства хранения, а на вход схемы
генерации синдрома при этом подавать новую последовательность.
Схема, соответствующая данному методу приведена
в приложении 7. Схема работает следующим образом: в течении первых n
тактов входная последовательность поступает на генератор синдрома и на буферный
регистр. Счетчик отсчитывает 279 тактов и на мгновение замыкает ключи
КЛ3..КЛ17, происходит запись синдрома в дублирующую схему хранения, в ней же в
дальнейшем производится его анализ на предмет появления пакетной ошибки по
алгоритму, описанному в предыдущем пункте. После записи происходит обнуления
ячеек памяти откуда был считан остаток от деления на g(x)
и на генератор синдрома можно подавать следующую последовательность
закодированных символов. К моменту, когда в ГС сформируется остаток от деления
новопоступившей последовательности, дублирующая схема исправит пакетные ошибки,
записанной в нее ранее информации. В буфере в этот момент будет содержаться
новая последовательность (предыдущая исправлена и выдана на выход декодера).
Затем ключи опять замыкаются, производится сохранение синдрома и процесс
повторяется.
Заключение
В данном курсовом проекте разработан кодек кода
Файра. Этот код относится к помехоустойчивым кодам, предназначенным для
обнаружения и коррекции одиночных пакетов ошибок. Код Файра весьма широко
распространен, благодаря просто схемной реализации кодека. Особенно широко коды
Файра используются при необходимости последовательной обработки информации,
например хранение информации на магнитных лентах.
Однако, применение кодов Файра приводит к
значительным временным затратам на обнаружение и коррекцию ошибок. Поскольку
такты, затрачиваемые на обнаружение, совпадают с операцией считывания, то в
этой части процесса декодирования задержки не возникает. Исправление ошибок
определяет задержку в устройстве декодирования, особенно заметную при большой
разрядности контролируемых слов, что может оказаться совершенно неприемлемым
для быстродействующих систем. Данную задачу можно решить, прибегая к
параллельной обработке поступающей информации, однако, при этом резко
увеличиваются аппаратные затраты по сравнению с последовательной обработкой.
Альтернативный вариант решения этой задачи был предложен в данном курсовом
проекте.
Литература
2.
Конопелько
В.К., Лосев В.В., Надежное хранение информации в полупроводниковых запоминающих
устройствах - М.: Радио и связь, 1986.
3.
Блейхут
Р.Э., Теория и практика кодов, контролирующих ошибки.- М.: Мир,1986.
4.
Колесник
В.Д, Мирончиков Е.Т., Декодирование циклических кодов -М.: Связь, 1968.