Разработка анализирующей части компилятора языка С
Министерство образования и науки
Российской Федерации
Федеральное государственное бюджетное
образовательное учреждение высшего профессионального образования
«Магнитогорский государственный
технический университет им Г.И. Носова»
Кафедра вычислительной техники и
прикладной математики
Курсовая работа по дисциплине:
«Теория языков программирования и
методы трансляции»
на тему
«Разработка анализирующей части
компилятора языка С»
Выполнил:
студент гр. АВ-09
Габдрахманов
И.А.
г. Магнитогорск, 2013
Оглавление
Введение
1. Лексический анализатор
2. Синтаксический
анализатор
3. Семантический
анализатор
Заключение
Библиографический список
Введение
Анализирующая часть выполняет проверку исходной программы на соответствие
грамматике языка, правилам семантики и построение внутреннего представления.
Анализирующая часть включает в себя 3 анализатора: лексический, синтаксический
и семантический.
Компилятор переводит программы с одного языка на другой. Входом
компилятора служит цепочка символов, составляющая исходную программу на языке
программирования 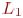 . Выход компилятора (объектная программа) также представляет
собой цепочку символов, но принадлежащую другому языку
. Выход компилятора (объектная программа) также представляет
собой цепочку символов, но принадлежащую другому языку  , например, языку некоторого
компьютера. При этом сам компилятор написан на языке
, например, языку некоторого
компьютера. При этом сам компилятор написан на языке  , возможно, отличающемся от первых
двух. Будем называть язык исходным языком, язык - целевым языком, а язык - языком реализации. Таким образом,
можно говорить о компиляторе как об отображении множества в множество , т.е.
, возможно, отличающемся от первых
двух. Будем называть язык исходным языком, язык - целевым языком, а язык - языком реализации. Таким образом,
можно говорить о компиляторе как об отображении множества в множество , т.е. 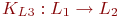 .
.
1. Лексический анализатор
Основная задача лексического анализа - разбить входной текст, состоящий
из последовательности одиночных символов, на последовательность слов, или
лексем, т.е. выделить эти слова из непрерывной последовательности символов. Все
символы входной последовательности с этой точки зрения разделяются на символы,
принадлежащие каким-либо лексемам, и символы, разделяющие лексемы
(разделители). В некоторых случаях между лексемами может и не быть разделителей.
Обычно все лексемы делятся на классы. Примерами таких классов являются
числа (целые, восьмеричные, шестнадцатиричные, действительные и т.д.),
идентификаторы, строки. Отдельно выделяются ключевые слова и символы пунктуации
(иногда их называют символы-ограничители). Как правило, ключевые слова - это
некоторое конечное подмножество идентификаторов.
Лексический анализатор построен с использованием GNU Flex - генератора
лексических анализаторов. Входным файлом для Flex является файл c.l, содержащий
описание лексики языка. Lex-файл состоит из трех секций - блока определений,
блока правил и блока кода на Си. Блоки разделяются c помощью строк, содержащих
%%.
Блок определений включает в себя описания именованных регулярных
выражений в формате: имя выражение. Каждое выражение описывается в отдельной
строке.
([Pp][+-]?{D}+)
Блок правил содержит правила для определения принадлежности лексемы
классу языка в формате: «регулярное выражение» { код на си, обрабатывающий
лексему и возвращающий ее класс }
Каждое правило располагается в отдельной строке. Пример правила для
определения десятичной константы:
[1-9]{D}*{IS}?
В процессе создания лексического анализатора командой lex c.l из
Lex-файла генерируется код на C, содержащийся в файле c.lexer.c. Данный файл
содержит функцию yylex(), которая и выполняет лексический анализ программы.
После каждого вызова функция возвращает тип лексемы из входного потока, либо 0,
в случае его окончания, а также помещает в переменную yytext текст лексемы.
Кроме того, в каких-либо других внешних (extern) переменных может находиться
информация о лексеме, полученная из пользовательского кода на С. Для корректной
работы данной функции переменная yyin должна указывать на открытый файл с
исходным текстом программы.
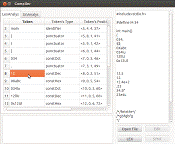
Рисунок 1 - пример работы лексического анализатора (без ошибок)

Рисунок 2 - пример работы лексического анализатора (с ошибками)
2. Синтаксический анализатор
Синтаксический анализ - это процесс, который определяет, принадлежит ли
некоторая последовательность лексем языку, порождаемому грамматикой. В
принципе, по любой грамматике можно построить синтаксический анализатор, но
грамматики, используемые на практике, имеют специальную форму. Например,
известно, что для любой контекстно-свободной грамматики может быть построен
анализатор, сложность которого не превышает O(n3) для входной строки длины n,
но в большинстве случаев по заданному языку программирования мы можем построить
такую грамматику, которая позволит сконструировать и более быстрый анализатор.
Анализаторы реально используемых языков обычно имеют линейную сложность; это
достигается, например, за счет просмотра исходной программы слева направо с
заглядыванием вперед на один терминальный символ (лексический класс).
Вход синтаксического - последовательность лексем и таблицы, например,
таблица внешних представлений, которые являются выходом лексического
анализатора.
Выход синтаксического анализатора - дерево разбора и таблицы, например,
таблица идентификаторов и таблица типов, которые являются входом для следующего
просмотра компилятора (например, это может быть просмотр, осуществляющий
контроль типов).
Для реализации синтаксического анализатора выбран генератор анализаторов
GNU Bison. На входе данного генератора - описание грамматики в БНФ, на выходе -
анализирующий модуль на языке Си.интегрирован с Flex и полученный с его помощью
анализатор использует в качестве входа результаты вызовов функции
yylex().(bison)-файл состоит из трех секций - описания токенов, описания
грамматики и кода на Си.
Описание токенов содержит просто список возможных типов токенов. При
генерации кода каждому типу токенов будет присвоено уникальное значение типа
yylval, которое и возвращает yylex().
Описание грамматики содержит в себе набор правил в БНФ и код на Си,
например, для построения дерева разбора, обрабатывающий каждое правило.
Пример:
_expression /* Ok */
: postfix_expression { $$ = $1; }
| INC_OP unary_expression { $$ = makeTreeNode($1, $2); }
| DEC_OP unary_expression { $$ = makeTreeNode($1, $2); }
| unary_operator cast_expression { $$ = makeTreeNode($1, $2);
}
| SIZEOF unary_expression { $$ = makeTreeNode($1, $2); }
| SIZEOF '(' type_name ')' { $$ = makeTreeNode($1, $3); }
;
Переменные $1, $2 и т. д. в коде на Си соответствуют токенам в выражении,
переменная $$ - результат, который будет использован при обработке выражения
более высокого уровня. При сборке анализирующей части получается файл
c.parser.h, содержащий LR-анализатор на языке Си. Анализатор запускается
вызовом функции yyparse(). По завершении анализа функция возвращает 0, если
программа не содержит синтаксических ошибок, либо 1, если ошибки есть.
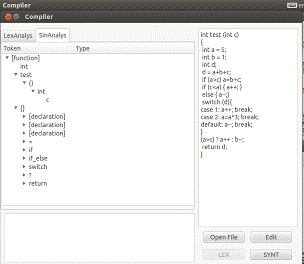
Рисунок 3 - пример работы лексического анализатора
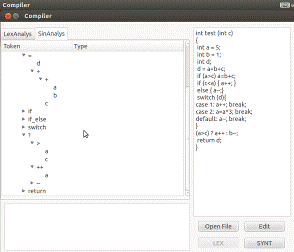
Рисунок 4 -разбор управляющей конструкции
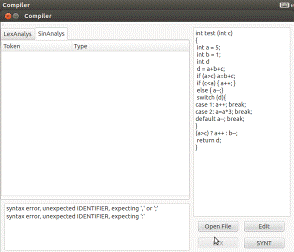
Рисунок 5 - пример работы синтаксического анализатора (с ошибками)
3. Семантический анализатор
Фаза контроля типов проверяет, удовлетворяет ли программа контекстным
условиям. Главной составляющей контекстных условия является "правильное
использование" программой типов данных, предоставляемых входным языком,
т.е. корректность выражений, встречающихся в программе, с точки зрения
использования типов. Данная задача включает нахождение объявления в программе
каждого используемого идентификатора, и проверку корректности его появления в
использующем контексте.
Понятно, что мы не можем убедиться в правильности использования типов в
какой-нибудь конструкции до тех пор, пока не определим типы всех ее составных
частей. Например, для того, чтобы выяснить правильность оператора присваивания
мы должны знать типы его получателя (левой части) и источника (правой части).
Для того, чтобы выяснить, каков тип идентификатора, являющегося, например, получателем
присваивания, мы должны понять, каким образом этот идентификатор был объявлен в
программе.
Каждое вхождение идентификатора в программу является либо определяющим,
либо использующим. Под определяющим вхождением идентификатора понимается его
вхождение в описание, например, int i. Все остальные вхождения являются
использующими, например, i = 5 или i+13.
Цель идентификации идентификаторов, определить тип использующего
вхождения идентификатора. Эта задача может быть полностью или частично решена
на фазе синтаксического анализа. Все зависит от того, может ли использующее
вхождение идентификатора встретиться в программе до определяющего вхождения или
нет. Если все определяющие вхождения идентификаторов должны быть расположены
текстуально перед использующими вхождениями, то мы можем выполнить
идентификацию на фазе синтаксического анализа. Если же нет, то на фазе
синтаксического анализа мы можем обработать определяющие вхождения
идентификаторов и только на следующем просмотре текста программы выполнить
собственно идентификацию.
Семантический анализатор реализован методом рекурсивного спуска. Просмотр
ведется от начала дерева.
Алгоритм для одного уровня следующий:
Последовательно просматриваем каждый узел дерева данного уровня. Если это
объявление переменной, определение пользовательского типа или функции -
добавляем его в соответствующую таблицу. Если это выражение - рекурсивно
разбираем его, восходящим методом. Сначала определяются типы операндов в листах
поддерева, затем - типы узлов-операций первого уровня и т. д., пока не будет
получен тип выражения, находящегося на рассматриваемом уровне.
Если это конструкция языка - условный оператор, цикл, блок - рекурсивно
выполняем его обработку по тем же правилам. При вызове рекурсивного обработчика
для такой конструкции в него передаются копии таблиц идентификаторов, функций и
типов.
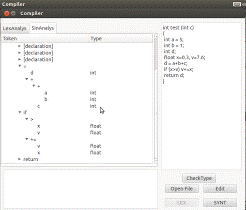
Рисунок 6 - пример работы семантического анализатора (без ошибок)

Рисунок 7 - пример работы семантического анализатора (с ошибками)
компилятор анализатор грамматика язык
Заключение
В данной работе раскрыт вопрос о написании анализирующей части
компилятора для языка высокого уровня, а именно: лексический анализатора,
синтаксический анализатора и семантический анализатора.
В результате, программа отвечает поставленным перед ней целям: проверка
правильности синтаксиса программы, проверка соответствия типов, а также
нахождение синтаксических и семантических ошибок, в случае, если таковые
имеются.
Библиографический список
1) Ахо А.В. - Компиляторы: принципы, технологии и
инструментарий, 2-е изд. Э Пер. с англ. - ООО «И.Д. Вильямс», 2008. - 1184 с.
2) flex lexical analyser - Wikipedia, the free encyclopedia // Wikipedia, the free encyclopedia [Электронный ресурс] / Wikimedia Foundation - Электрон. дан. - 2001-2013 - Режим
доступа: http://en.wikipedia.org/wiki/Flex_lexical_analyser, свободный. - Загл. с экрана.
3) GNU Bison
- Wikipedia, the free encyclopedia // Wikipedia, the free encyclopedia [Электронный ресурс] / Wikimedia Foundation - Электрон. дан. - 2001-2013 - Режим
доступа: http://en.wikipedia.org/wiki/GNU_Bison, свободный. - Загл. с экрана.