Розробка алгоритму та його програмна реалізація для комп’ютеризованої системи оптимального розподілу квазістохастичного ресурсу
Міністерство освіти та науки
України
Криворізький інститут
Кременчуцького університету
економіки, інформаційних технологій та управління
Кафедра Технічної кібернетики
ДИПЛОМНА РОБОТА
зі спеціальності
.091402 “Гнучкі
комп’ютеризовані системи та робототехніка“
ПОЯСНЮВАЛЬНА ЗАПИСКА
“Розробка алгоритму та його програмна
реалізація для комп’ютеризованої системи оптимального розподілу
квазістохастичного ресурсу”
Студент групи ГКС-03-д Сумченко Ірина Леонідівна
Керівник роботи доц., к.т.н. Євтушенко Олександр Іванович
Завідувач кафедри ТК доц., к.т.н. Старіков О.М.
Кривий Ріг
Анотація
Метою даної дипломної роботи є розробка алгоритму
оптимального розподілу квазістохастичного ресурсу. Використання алгоритму
реалізується на прикладі автоматичного складання розкладу в учбових закладах.
Застосування алгоритму дозволяє підвищити оперативність обробки інформації,
покращити ефективність і точність роботи. Реалізація алгоритму здійснена в
середовищі Mathemetica 5.0.
Аннотация
Целью данной дипломной работы является разработка алгоритма оптимального распределения
квазистохастического ресурса. Программная реализация алгоритма производится на примере
автоматического составления расписания в учебных учреждениях. Использование
алгоритма позволяет повысить оперативность обработки информации, улучшить
эффективность и точность работы. Алгоритм реализован в среде Mathemetica 5.0.
summary
purpose of the given degree work is development of algorithm
of optimum distribution casual resource. Program realization of algorithm is
made on an example of automatic drawing up of the schedule in educational
establishments. Use of algorithm allows to raise efficiency of processing of
the information, to improve efficiency and accuracy of work. The algorithm is
realized in Mathemetica 5.0 environment.
ЗМІСТ
Вступ
1 Постанова задачі
1.1 Найменування та галузь
застосування
1.2 Підстава для створення
1.3 Характеристика
розробленого програмного забезпечення
.4 Мета й призначення
1.5 Загальні вимоги до
розробки
1.6 Джерела розробки
2 Дослідження систем
автоматичного розподілу ресурсу
2.1 Програма «Розклад ПРО»
2.2 Програми «Коледж» і «Коледж Плюс»
3 Огляд інструментів, що використовуються для
реалізаціі алгоритму
3.1 Поняття випадкового ресурсу й випадкового
попиту
.1.1 Опис
стохастичних величин у термінах математичної статистики
3.1.2. Групування
даних в аспекті розвязуваної задачі
3.2 Основні методи
оптимізації
3.2.1 Загальна
характеристика оптимізаційних задач
3.2.2. Постановка
задачі оптимізації
3.2.3 Види
обмежень
3.2.4 Критерії оптимальності
3.2.5 Класифікація
задач
3.2.6 Методи
рішення задач оптимізації
4 Програмна
реалізація та опис функціональних можливостей алгоритму
4.1 Алгоритм
розподілу
4.2 Введеня даних.
Способи вводу
4.2.1 Формування
списку ресурсу
4.2.2 Формування
списку попиту
4.3 Генерація
функцій користувача
4.3.1 Розрахункові
функції
4.3.2 Функції
виводу інформації
5 Економічне
обґрунтування доцільності розробки програмного продукту
.1
Організаційно-економічна частина
5.2 Розрахунок
витрат праці на розробку алгоритму
.3 Розрахунок
витрат на ручну обробку інформації
.4 Економічний
ефект від використання алгоритму
6 Охорона праці
6.1 Аналіз
небезпечних та шкідливих факторів на робочому місці оператора ПК
6.2 Заходи щодо
нормалізації шкідливих та небезпечних факторів на робочому місці оператора ПК
6.2.1 Захист від
електромагнітних випромінювань та уражень електричним струмом
6.2.2 Захист від
шуму та вібрації
6.2.3 Заходи щодо
забезпечення чистого повітряного середовища
6.2.4 Захист від
рентгенівського випромінювання
6.2.5 Забезпечення
раціонального освітлення
.3 Пожежна безпека
Заключення
Список літератури
Додаток А - Вихідний текст алгоритму
Додаток Б - Перелік змінних та функцій
Додаток В - Бази даних ресурсу й попиту
ВСТУП
Робота присвячена створенню програмної моделі алгоритму
оптимального розподілу квазістохастичного ресурсу. До розгляду даної теми
приводять різні потреби, починаючи від систем керування вогнем, закінчуючи
системами розподілу транспорту по випадкових замовленнях.
Одне з можливих застосувань даної розробки є проблема
складання розкладу у вузах. Розклад занять регламентує трудовий ритм, впливає
на творчу віддачу викладачів, тому його можна розглядати як фактор оптимізації
використання обмежених трудових ресурсів - викладацької сполуки. Технологію же
розробки розкладу варто сприймати не тільки як трудомісткий технічний прогрес
або об'єкт автоматизації з використанням ЕОМ, але і як акцію оптимального
керування. Таким чином, це - проблема розробки оптимальних розкладів занять у
вузах з очевидним економічним ефектом. Рішення даної проблеми на сьогоднішній
день містить у собі ряд труднощів. По-перше, процес складання розкладу
ускладнюється великою кількістю критерій та обмежень, тому що учасники
навчального процесу різноманітні. По-друге, процес складання розкладу може мати
величезну кількість варіантів рішення, при цьому необхідно вибрати найбільш
оптимальний. Вручну перебрати всі припустимі варіанти й вибрати з них найліпший
практично не можливо.
Крім того, існують ще й специфічні для кожного вузу вимоги до
функціональних можливостей програмного продукту. Створити уніфіковане програмне
забезпечення не надається можливим, з погляду економічної доцільності; а
вартість створення спеціалізованого програмного продукту в сторонніх
розроблювачів невиправдано велика.
Метою роботи є підвищення ефективності використання
випадкового ресурсу, шляхом автоматизації й оптимізації процесу розподілу
елементів попиту. Проблема розглянута на прикладі складання розкладу в
навчальних установах.
Основу алгоритму оптимального розподілу становить
кластеризація даних. Кластер являє собою множину елементів, обраних із
загального списку за заданними параметрами. Виявлення кластерів та їх подальше
використання дозволяє спростити процес обробки даних і оптимізувати процес
розподілу елементів.
Реалізація алгоритму проводиться в середовищі СКМ
Mathemetica. Пакет Mathemetica має величезну обчислювальну потужність і
дозволяє реалізовувати найскладніші алгоритми.
У результаті виконання роботи були сформовані текстові файли,
що містять вихідні дані по ресурсу й попиту, зроблене моделювання елементів
попиту й елементів випадкового ресурсу, моделювання розподілу, розроблена
демоверсія реалізації алгоритму. Використання алгоритму оптимального розподілу
в процесі складання розкладу дозволить підвищити оперативність обробки
інформації, поліпшити ефективність і точність роботи.
1. ПОСТАНОВА
ЗАДАЧІ
1.1
Найменування та галузь застосування
Найменування розробки: Алгоритм оптимізації розподілу
квазістохастичного ресурсу. Алгоритм системи може бути використаний для
автоматизації процесу складання розкладу в учбових закладах.
1.2
Підстава для створення
Підставою для розробки є наказ № 65Са-01 від 29 жовтня 2007
р. по Криворізькому інституту КУЕІТУ.
Початок робіт: 30.10.07. Закінчення робіт: 01.06.08.
1.3
Характеристика розробленого програмного забезпечення
Алгоритм автоматизації був реалізований в середовищі Mathematica 5.0.
До складу системи входять:
· 1_spisok.nb - файл,що містить перелік всіх
функцій, використаних для реалізації алгоритму;
· 2_realiz.nb - файл, що містить функцію
оптимального розподілу елементів ресурсу.
.4
Мета й призначення
Метою даного проекту є створення алгоритму програмної моделі
розкладу у вузі, що дозволила б ефективно вирішувати завдання автоматичного
складання розкладу, відбираючи найбільш оптимальні варіанти, і володіла б
гнучкістю (від створення бази даних до її змін із часом) для адаптації системи
в рамках конкретного практичного завдання.
1.5
Загальні вимоги до розробки
Вимоги до програмного забезпечення:
· Робота в середовищі операційних
систем Windows 98/ME/2000/XP;
· Відсутність додаткових вимог до
розміщення здійснених файлів;
· Додаткове програмне забезпечення: установка пакету Mathematica 5.0.
Мінімальні вимоги до апаратного забезпечення:
· IBM-сумісний комп'ютер, не нижче
Pentium IІ, RAM-512Mb, SVGA-800*600*16bit;
· Вільний простір на жорсткому диску не
менш 2Мб;
.6
Джерела розробки
Джерелами розробки дипломної роботи є:
· довідкова література;
· наукова література;
· технічна література;
· програмна документація.
2. ДОСЛІДЖЕННЯ СИСТЕМ АВТОМАТИЧНОГО РОЗПОДІЛУ РЕСУРСУ
Оляд систем розподілу ресурсу проводимо на прикладі программ
автоматичного складання розкладу в учбових закладах.
Розклад занять в учбовій установі - це один з найважливіших
видів планування навчально-виховної роботи й основний організаційний документ,
що визначає роботу колективу викладачів і студентів, адміністрації й установи в
цілому. Якість розкладу в значній мірі визначає якість навчального процесу.
Складання розкладу регламентується цілим рядом нормативних
документів і методик. Методичні рекомендації зі складання розкладу містять у
собі не тільки педагогічні, організаційні, але й гігієнічні вимоги.
У сукупності ж зі складністю деяких варіантів навчальних
планів дотримання всіх пропонованих вимог при складанні розкладу являє собою
для завуча складне й трудомістке завдання, що іноді ускладнюється специфікою
установи (індивідуальні вимоги викладачів до днів і годиннам роботи, особливо з
боку викладачів-адміністраторів і викладачів-сумісників; певні дні й годинни
проведення занять; обмежене число кабінетів; використання технічних засобів
навчання; двозмінна робота установи; наявність трьох і більше
класів-комплектів; перевантаження окремих викладачів і багато чого іншого).
У той же час, зберігається головна вимога до розкладу -
створення найкращих умов для ефективних занять учнів і праці викладачів. При
цьому необхідний облік ступеня професійної майстерності кожного викладача,
стилю й методів його роботи, орієнтації кожного кабінету на ті або інші предмети.
Від завуча потрібне знання всіх особливостей навчального процесу, щоб правильно
сформулювати їх у вигляді вимог до майбутнього розкладу.
Використання комп'ютера дозволяє автоматизувати рутинну
частину праці завучів по переборі величезного числа можливих варіантів
розкладу. Крім того, застосування ПЭВМ дає можливість ще до складання розкладу
скористатися ефективним математичним апаратом аналізу вихідних даних і вимог,
що дозволяє заздалегідь виявити сховані в них конфліктні ситуації й одержати
рекомендації з їхнього дозволу.
На сьогоднішній день існує ряд програм, які допомагають
автоматизувати процес складання розкладу й кожний зі своїми особливостями.
2.1 Програма «Розклад ПРО»
Компанія «Дігсі» розробляє програмне забезпечення й для
комерційних структур і для індивідуальних користувачів. Розклад ПРО, мабуть,
займає проміжне положення між індивідуальним використанням і корпоративним.
Області застосування програми чітко визначені, що випливає із
самої назви. Продукт орієнтований на вчителів, завучей та директорів шкіл,
котрі постійно зіштовхуються з проблемою складання та редагування розклаюу.
Крім того, програма охоплює склад викладачів інститутів та університетів,
представників деканатів, відповідальних за складання розкладу занять. Взагалі,
програма призначена для всіх людей, котрі задіяні в складанні розкладу.
Кожний з викладачів може також використати її для складання
своїх індивідуальних розкладів-пам'яток по своїх уроках (парам). Крім того,
зменшується ризик втрати записів за розкладом, що досить великий, якщо
інформація зберігається на паперових носіях.
Програма «Розклад ПРО» призначена для зручного й швидкого
складання розкладу занять шкіл та вузів у ручному й автоматичному режимах. У
будь-який момент можна внести зміни в розклад і роздрукувати його, а також
легко й зручно експортувати таблицю в Excel.
Програма проста й зручна у використанні. Вона дозволяє
викладачам і вчителям значно скоротити час складання шкільних або інститутських
розкладів при мінімальних витратах зусиль.
Функції програми:
• уведення даних для складання розкладу в загальній панелі
"Керування";
• паралельне завдання даних для складання розкладу:
кабінетів, викладачів,
груп;
• уведення даних про погодинне навантаження на кожен день
тижня для всіх викладачів;
• автоматичне інформування про недостатній об'єм даних для
складання
розкладу;
• зберігання даних розкладів за попередні роки;
• експорт готового до редагування розкладу в MS Excel;
• друк розкладу в режимі "по групах";
• друк розкладу в режимі "по викладачах".
Основна технологія роботи представлена в деревоподібній
структурі "Керування" - необхідно пройти послідовно по
"гілках" цього дерева зверху вниз. Кожний варіант розкладу
розглядається як окремий проект. Увівши один раз вхідні дані, можна надалі робити
копію проекту й працювати (редагувати або експериментувати) з нею.
Програма підтримує два режими керування даними: ручний і
автоматичний.
Ручний режим.
Призначений для досвідчених викладачів, у яких склалися свої
технології складання розкладу і яким потрібний лише зручний інструмент для цих
технологій. У цьому режимі програма виводить чисту таблицю, у яку методом
"перетягнути й кинути" потрібно заносити відповідні предмети. Всі
обмеження, задані на етапі уведення вихідних даних програма відображає на
екрані або відслідковує при роботі.
Автоматичний режим.
Оскільки строгих алгоритмів складання розкладу не існує, то в
цьому режимі пропонуються лише варіанти автоматичного розрахунку. Прийнятним
можна вважати варіант, у якому немає нерозподілених Предметів і "дір"
у Груп. Після одержання прийнятного варіанта можна редагувати його в ручному
режимі.
Вивести на друк готовий розклад по групах або по викладачах
можна безпосередньо із програми, скориставшись меню "Файл". Якщо
необхідно додаткове оформлення зовнішнього вигляду розкладу, можна зробити
експорт результатів в Microsoft Excel.
Вхідні дані.
Всі початкові дані, які пізніше будуть використані програмою
для побудови розкладу, повинні бути уведені в розділі «Вхідні дані». Головне
вікно програми в цьому режимі виглядає так:

Необхідно послідовно пройти по розділах вікна Керування
зверху вниз, заповнюючи відповідні Списки й проставляючи необхідні Зв'язки.
Програма розрахована для складання розкладу занять як шкіл,
так і вузів, при цьому прийнята термінологія вузів. Можна рекомендувати
наступну аналогію:
o Семестр - чверть;
o Спеціальність - паралель (перші
класи,...);
o Потік - профіль (спеціалізація,...);
o Група - конкретний клас.
Якщо вибрати сам розділ «Вхідні дані», то можна задати
загальні параметри такі, як мова інтерфейсу програми й період автоматичного
збереження в секундах.
Процес складання розкладу містить у собі наступні кроки:
) Створюємо новий проект (Файл -> Новий проект) і
відразу зберігаємо його (Файл - Зберегти). У цьому прикладі для проекту задане
ім'я «Старт». Вибираємо розділ «Навчальний заклад» і вводимо назву (у прикладі
- «Школа»). Назва Навчального закладу й ім'я файлу проекту відображаються в
заголовку вікна програми. Обов'язково потрібно задати параметри семестру за
замовчуванням. Натискаємо кнопку «Редагувати настроювання семестру».

)
До параметрів семестру відносяться:
o кількість тижнів у семестрі -
обов'язковий параметр, без нього розрахунок Розкладу неможливий;
o періодичність повторення розкладу -
актуально для інститутів, де є поняття «плаваюча пара»;
o кількість занять у кожний із днів
тижня.
Для редагування кількості занять у день потрібно клацнути
мишкою на рядку в таблиці, після чого стане доступна панель «Тиждень». У ній
можна вводити кількість годин безпосередньо із клавіатури або використовуючи
кнопки зі стрілками поруч із потрібним днем.
У прикладі задані 2 тижні в семестрі й по 4 години на кожний
з п'яти днів тижня.

3) У розділі Кабінети задається Список Кабінетів
(загальних і спеціалізованих). Список автоматично сортується за алфавітом у
зростаючому порядку. Клацнувши за назвою Списку можна поміняти порядок
сортування на зворотній. Щоб додати в Список Кабінетів нове значення, необхідно
задати режим Додати (Режим коректування Списку (Додавання, Видалення,
Редагування) можуть викликатися з Головного меню, кнопками Панелі інструментів,
з Контекстного меню. У новому полі, що з'явилося, уводимо назву Кабінету (у
прикладі - «Студія»).

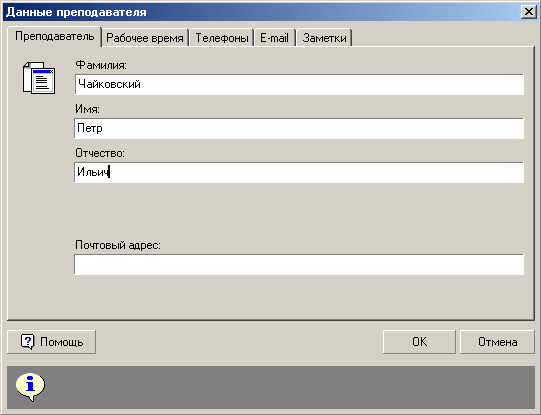
4) У розділі Викладачі формується Список Викладачів.
Список автоматично сортується за алфавітом у зростаючому порядку. Клацнувши за
назвою Списку можна поміняти порядок сортування на зворотний. Режими
коректування Списку (Додати, Видалити, Редагувати) можуть викликатися тими ж
способами, що й у розділі Кабінетів. Щоб додати нове значення в Список
Викладачів, необхідно задати режим Додати. У результаті відкривається вікно
діалогу із вкладками: Викладач, Робочий час , Телефони, E-mail, Замітки. У
найпростішому випадку заповнюємо тільки першу вкладку.
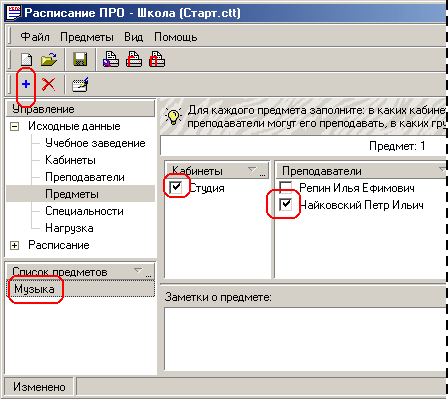
5) У розділі Предмети формується Список Предметів.
Список автоматично сортується за алфавітом у зростаючому порядку. Клацнувши за
назвою Списку можна поміняти порядок сортування на зворотний. Режими
коректування Списку (Додавання, Видалення, Редагування) викликаються тими ж
способами, що й у попередніх кроках. Вибравши розділ «Предмети», задаємо режим
Додати. У новому полі, що з'явилося, уводимо назву Предмета (у прикладі -
«Музика»). І відразу проставляємо потрібні Зв'язки (у прикладі відзначений
Викладач «Чайковський»).
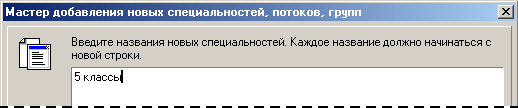
6) У розділі Спеціальності задається деревоподібна
структура Груп (класів). Список автоматично сортується за алфавітом у
зростаючому порядку. Клацнувши за назвою Списку можна поміняти порядок
сортування на зворотний. Вибравши розділ «Спеціальності», задаємо режим Додати.
У вікні діалогу додавання об'єктів відзначаємо пункт «Додати нові
спеціальності» (у цей момент доступна тільки ця можливість).

7) Вводимо назву Спеціальності (у прикладі - «5 класи»).
Натискаємо кнопку Далі, у наступному вікні натискаємо кнопку Готово.
8) Знову задаємо режим Додати. У вікні діалогу додавання
об'єктів тепер відзначаємо пункт «Додати нові потоки». Натискаємо кнопку Далі.

9) Уводимо назву Потоку (у прикладі - «Загальний»).
Натискаємо кнопку Далі, у наступному вікні натискаємо кнопку Готово.

10) Ще раз задаємо режим Додати. У вікні діалогу
додавання об'єктів відзначаємо пункт «Додати нові групи».

11) Вводимо назву першої Групи (у прикладі - «Клас 5а»),
натискаємо клавішу ENTER , потім уводимо назву другої Групи (у прикладі - «Клас
5б»).

12) Задамо потрібні Зв'язки. Активізуємо (клацаємо за
назвою) Спеціальність (у прикладі це «5 класи»). У вікні Зв'язків відзначаємо
всі Предмети й всіх Викладачів.

13)
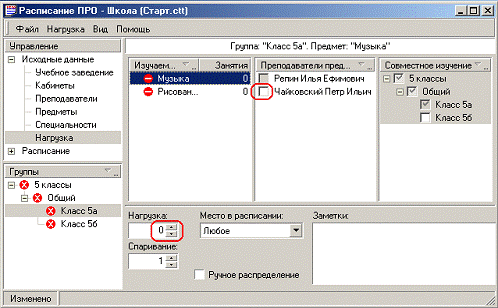
У розділі Навантаження задається Навантаження і її властивості:
o Число годин у Семестрі (поле
«Навантаження»);
o Пріоритет предмета (поле «Місце в
розкладі»);
o Спарювання годин за обраним
предметом.
Слід зазначити, що навантаження задається на Групу, а не на
Потік або Спеціальність. Це дає гнучкість при завданні «складних» предметів.
Вибравши розділ «Навантаження», активізуємо (клацаємо за
назвою) Групу (Клас 5а), потім Предмет (Музика). Предмет позначений значком  . Це означає, що не задано число
годин по даному Предмету. Вводимо потрібне число в поле «Навантаження» - знизу
екрана. Значок поруч із Предметом міняється на
. Це означає, що не задано число
годин по даному Предмету. Вводимо потрібне число в поле «Навантаження» - знизу
екрана. Значок поруч із Предметом міняється на  . Це означає, що не зазначено
Викладача даного Предмета. Відзначаємо потрібного Викладача (відповідно до
заданних раніше Зв'язків будуть доступні тільки певні Викладачі, у прикладі -
Чайковський).
. Це означає, що не зазначено
Викладача даного Предмета. Відзначаємо потрібного Викладача (відповідно до
заданних раніше Зв'язків будуть доступні тільки певні Викладачі, у прикладі -
Чайковський).
14) Вибираємо підрозділ «По групах», розділу «Розклад». У
головному меню вибираємо пункт Створити розклад (на Панелі інструментів є
відповідна кнопка). У діалозі, що відкрився, можна настроїти параметри обмежень
пошуку Розкладу. Рекомендується залишати параметри, задані за замовчуванням,
тому просто натискаємо кнопку OК. Запускається процес розрахунку Розкладу, при
цьому виводиться діалогове вікно. У якому відображається хід процесу. Перервати
процес пошуку можна в будь-який момент.

15) Можна переглянути Розклад по Викладачах. Для цього в
структурі «Керування» потрібно клацнути на гілці «По викладачах» і відзначити
Викладачів, які будуть відображені в таблиці.
)

Вимоги до системи:
ОС: Win 95/98/NT/2000/XP: 32 Mb
Простір на диску: 10 Mb
2.2 Програми
«Коледж» і «Коледж Плюс»
Програма «Коледж» і «Коледж Плюс» є розвитком лінійки
продуктів Хронограф 3.0.
Дані продукти призначені для автоматизації планування й
організації навчального процесу установ початкової й середньої професійної
освіти (ППО й СПО).
Програма «Коледж», ціна якої становить 12000 руб призначена
для установ, що не мають значних проблем зі складанням розкладу занять. Містить
у собі базовий набір функцій для складання розкладу занять, а також
повнофункціональні модулі для формування звітних форм за результатами
навчального процесу (звіти про вичитування годин).
Програма «Коледж Плюс», ціна - 16000 руб є найбільш повною
версією з існуючої лінії продуктів. Призначена для установ зі складним процесом
складання розкладу занять. Дозволяє вирішувати завдання оптимального формування
груп учнів, містить розширений функціонал для створення розкладу занять,
ураховує проблеми з недоліком аудиторій.
Пакети орієнтовані на керівників установ, відповідальних за
організацію й контроль якості навчально-виховного процесу.
Принципи роботи із програмним пакетом «Коледж»
Організація введення й обробки даних у програмному пакеті
«Коледж» здійснюється в 3 етапи:. Введення інформації про навчальний період і
призначення періодів
навчання по різних проектах розкладу.
У процесі роботи з програмою «Коледж» користувач може задати
кілька навчальних періодів.
Для кожного періоду створити кілька проектів розкладу, і
вказати кожному проекту відрізок часу, у плині якого по ньому буде вироблятися
навчання.
Користувач може змінити список свят, і у випадку влучення
свята на робочий день перенести роботу освітньої установи з даного дня на
будь-який іншій.

II. Створення проекту розкладу (за допомогою
автоматичного алгоритму й ручного редактора).
Створення проекту розкладу в пакеті «Коледж» здійснюється в 2
модулях:
Перший модуль. Введення даних учбової установи (як вручну,
так і з можливістю імпорту основних облікових даних з MS Excel).
Введення даних учбової установи в пакеті «Коледж» здійснюється
за допомогою послідовного проходження наступних етапах:
) Введення даних про учбову установу.
У даному екрані необхідно:
Задати періодичність розкладу від 1 до 4 тижнів;
Вибрати робочі дні тижня учбової установи;
Задати реквізити учбової установи;
Відкоригувати, при необхідності, розклад дзвінків.

2) Склад груп.
У даному екрані необхідно:
Ввести список груп по всім курсам і вказати графік їхньої
роботи;
Створити списки груп, що вчаться, вказавши їхнє прізвище,
ім'я, по батькові й стать.

3)
Тижнева сітка годин.
У даному екрані необхідно:
Привести заданий список предметів у відповідність зі
специфікою установи утворення із вказівкою їх профілізацїї;
Зробити ранжирування в балах труднощів для кожного предмета;
Визначити навантаження й кількість груп для профілів
предметів у кожній паралелі й класі.

4) Розподіл учнів по групах.
У даному екрані необхідно:
Призначити учнів у ту або іншу підгрупу, по всіх предметах,
для яких заданий розподіл на підгрупи в рамках обраної групи.

5)
Дані про викладачів.
У даному екрані необхідно:
Ввести список викладачів учбової установи;
Вказати спеціалізацію викладачів;
Вказати профілі викладання по відповідних предметах;
Задати сумісництво;
Ввести табельний номер і педагогічний розряд викладачів, для
одержання шаблона звіту «Тарифікаційний список».

6) Інформація про кабінети.
У даному екрані необхідно:
Ввести список кабінетів учбової установи;
Вказати місткість і поверх кабінету;
Закріпити кабінет за предметом або викладачем;
Задати графік попередньої зайнятості кабінетів по годинниках
і/або дням.

7) Графік роботи викладачів.
У даному екрані необхідно:
Призначити викладачам безумовно-вільні від занять годинники
й/або дні;
Вказати плановане навантаження викладача для можливості
використання надалі автоматичного розподілу навантаження;
Задати загальну кількість робочих днів викладача в тиждень
без вказівки конкретних неробочих днів.

8) Розподіл навантаження.
Даний екран дозволяє вводити інформацію в 3 режимах:
По викладачах;
По предметах;
По групах.
У кожному з режимів можна:
Призначити/перепризначити викладача в обрану групу або
підгрупу по обраному предмету;
Задати потокові й спарені години;
Автоматично розподілити навантаження викладачів відповідно до
заданого планованого навантаження.

Другий модуль. Складання розкладу (за допомогою автоматичного
алгоритму й ручного редактора).
Складання розкладу в пакеті «Коледж» здійснюється в Екрані
складання розкладу, що має 4 режими відображення:
Основний;
Клас;
Відображення по навчальних одиницях;
Перерозподіл учнів по підгрупах.
При роботі в будь-якому режимі користувач може редагувати
частково складений розклад, переносячи поставлені заняття з уроку на урок.
У будь-який момент заповнення тижневої сітки розкладу
користувач може перейти в автоматичний режим розміщення занять. Алгоритм роботи
Автомата інтерактивний, тобто має на увазі численні переходи від автоматичного
режиму складання розкладу до ручного й назад.. Оперативне керування
навчальним процесом (за допомогою організації необхідних замін у готовому
розкладі).
Оперативне керування навчальним процесом у пакеті «Коледж»
здійснюється на базі складеного розкладу учбової установи в 2 екранах:
1. Екран «Заміни»
При роботі в даному екрані користувач вибирає дату, і вказує
відсутніх викладачів, після чого може їх замінити, виходячи з необхідних
критеріїв. Програма надає користувачеві широкий набір фільтрів, для вибору
замінного викладача й дозволяє створити власні критерії відбору.
Після вибору дати й замінного викладача, даний екран містить:
замінного викладача, критерій відбору для заміни, робоче поле (інформація про
всіх викладачів, що підходять критеріям відбору), розклад замінного викладача,
розклад обраного в робочому полі викладача.
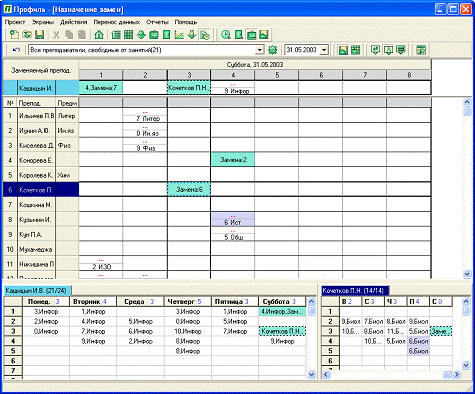
2. Екран «Зошит замін»
Даний екран являє собою повний список запланованих і вже
проведених замін.
У кожному рядку Робочого поля вікна Зошит замін зазначені:
дата, день тижня й номер замінного уроку;
прізвище замінного викладача;
група, для якої запланована заміна;
предмет, по якому повинен був проводитися замінний урок;
кабінет, у якому повинне було бути проведене замінне заняття;
ім'я й табельний номер викладача, що заміняє.

На кожному етапі роботи, по мірі введення й підготовки даних
користувач може одержати необхідні звіти. Окремої уваги заслуговують звіти про
вичитування годин для викладачів і груп за будь-який відрізок часу. Всі звіти можуть
бути як надруковані, так і експортовані для приведення у відповідність із
необхідним форматом у МS Excel.
На базі створеної інформації в програмі передбачена
можливість створення сайту установи утворення.
Розглянуті програми складання розклади зручні й прості у
використанні, мають ряд достоїнств і однозначно необхідні в організації
навчального процесу. Недоліком даних програм є складне перенастроювання під
специфічні для кожного вузу вимоги до функціональних можливостей програмного
продукту, при цьому вартість створення такого продукту в сторонніх
розроблювачів невиправдано велика.
3.
ОГЛЯД ІНСТРУМЕНТІВ, ЩО ВИКОРИСТОВУЮТЬСЯ ДЛЯ РЕАЛІЗАЦІЇ АЛГОРИТМУ
3.1 Поняття випадкового ресурсу й випадкового попиту
Математична (або теоретична) статистика опирається на методи
й поняття теорії ймовірностей, але вирішує в певному змісті зворотні завдання.
У теорії ймовірностей розглядаються випадкові величини з
заданим розподілом або випадкові експерименти, властивості яких цілком відомі.
Предмет теорії ймовірностей - властивості й взаємозв'язки цих
величин(розподілів). Але звідки беруться знання про розподіли й імовірності в
практичних експериментах? Основна проблема полягає в тому, що висновки
доводиться робити за результатами кінцевого числа спостережень. Точні висновки
про розподіл можна робити лише тоді, коли проведене нескінченне число
випробувань, що нездійсненно. Математична статистика дозволяє за результатами
кінцевого числа експериментів робити більш-менш точні висновки про розподіли
випадкових величин, спостережуваних у цих експериментах.
Поняття випадкової величини.
Якщо результатом випробування є випадкова подія, що приймає
числове значення, то говорять про випадкову величину.
Випадковою величиною називається змінна величина, що залежно
від результату випробування випадково приймає одне значення з безлічі можливих
значень.
Випадкова величина, що приймає різні значення, які можна
записати у вигляді кінцевої або нескінченної послідовності, називається
дискретною випадковою величиною. Приклади: число очків, що випали при киданні
гральної кістки; число народжених дітей у родині; число куль, які можна дістати
з урни й т.д. Випадкова величина, що може приймати всі значення з деякого
числового проміжку, називається безперервною випадковою величиною.
Приклади: приріст ваги свійської тварини за місяць є
випадкова величина, що може прийняти значення з деякого проміжку; прогнозована
температура повітря по області й т.д.
Характеристики випадкової величини.
Математичним очікуванням М (Х) дискретної випадкової величини
Х називається сума добутків всіх можливих значень величини Х на відповідні
ймовірності:
М(Х) = x1· p1 + x2· p2 + … + xn· pn ,
де x1, x2, …, xn - випадкові величини, що відповідають повній
групі подій, тобто p1 + p2 + … + pn = 1...
Дисперсією D (X) дискретної випадкової величини Х називається
математичне очікування квадрата відхилення випадкової величини Х від її
математичного очікування:
D(X) = M [(X - M(X))2] або D(X) = M (X2) - M2(X).
Середнім квадратичним відхиленням σ
(Х) випадкової
величини Х називається корінь квадратний з її дисперсії:
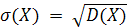 .
.
Інтегральною функцією розподілу безперервної випадкової величини Х
називається функція F(x), рівна ймовірності того, що Х прийняла значення, менше
х:
F(x) = P(X < x).
Диференціальною функцією розподілу безперервної випадкової
величини Х (або її щільністю ймовірності) називається функція f(x), рівна
похідної інтегральної функції:
f(x) = F '(x).
Математичним очікуванням безперервної випадкової величини Х з
щільністю ймовірності f(x) називається величина невласного інтеграла (якщо він
сходиться):

Дисперсією безперервної випадкової величини Х, математичне
очікування якої М (Х) = а й функція f(x) є щільністю ймовірності, називається
величина невласного інтеграла (якщо він сходиться):

Для безперервної випадкової величини Х середнє квадратичне
відхилення s(Х) визначається як і для дискретної величини.
.1.1 Опис стохастичних величин у термінах математичної
статистики
Основні поняття математичної статистики.
Часто експеримент являє собою чорний ящик, що видає лише
якісь результати, по яких потрібно зробити висновок про властивості самого
експерименту. Спостерігач має набір числових (або їх можна зробити числовими)
результатів, отриманих повторенням того самого випадкового експерименту в
однакових умовах.
При цьому виникають, наприклад, наступні питання:
. Якщо ми спостерігаємо одну випадкову величину - як за набором її значень у декількох
досвідах зробити як можна більше точний висновок про її розподіл?
. Якщо ми спостерігаємо одночасно прояв двох (або
більше) ознак, тобто маємо набір значень декількох випадкових величин - що можна сказати про їх залежність? Є
вона чи ні? А якщо є, то яка ця залежність?
Часто буває можливо висловити якісь припущення про розподіл,
захованому в «чорному ящику», або про його властивості. В цьому випадку за
експерементальними даними потрібно підтвердити або спростувати ці припущення
(«гіпотези»). При цьому треба пам'ятати, що відповідь «так» або «ні» може бути
дана лише з певним ступенем вірогідності, і чим довше ми можемо продовжувати
експеримент, тим точніше можуть бути висновки. Найбільш сприятливої для
дослідження виявляється ситуація, коли можна впевнено стверджувати про деякі
властивості спостережуваного експерименту - наприклад, про наявність
функціональної залежності між спостережуваними величинами, про нормальність
розподілу, про його симетричність, про наявність у розподілу щільності або про його
дискретний характер, і т.д.
Отже, про (математичну) статистику має сенс згадувати, якщо
o є випадковий експеримент, властивості
якого частково або повністю невідомі,
o ми вміємо відтворювати цей
експеримент у тих самих умовах якесь (а краще - яке завгодно) число раз.
Прикладом такої серії експериментів може служити соціологічне
опитування, набір економічних показників або, нарешті, послідовність гербів і
решок при тысячекратном підкиданні монети.
Основні поняття вибіркового методу.
Нехай ξ : Ω > R - випадкова величина,
спостережувана у випадковому експерименті. Передбачається, що імовірнісний
простір заданий (і не буде нас цікавити).
Будемо вважати, що провівши n раз цей експеримент в однакових
умовах, ми одержали числа X1, X2, …, Xn - значення цієї випадкової величини в
першому, другому, і т.д. експериментах. Випадкова величина ξ має деякий розподіл F, що
нам частково або повністю невідомий.
Розглянемо докладніше набір X = (X1, …, Xn), названий
вибіркою.
У серії вже зроблених експериментів вибірка - це набір чисел.
Але якщо цю серію експериментів повторити ще раз, то замість цього набору ми
одержимо новий набір чисел. Замість числа X1 з'явиться інше число - одне зі
значень випадкової величини ξ. Тобто X1 (і X2, і X3, і т.д.)
- змінна величина, що може приймати ті ж значення, що й випадкова величина ξ,
і так само часто
(з тими ж імовірностями). Тому до досліду X1 - випадкова величина, однаково
розподілена з ξ, а після досліду - число, що ми
спостерігаємо в даному першому експерименті, тобто одне з можливих значень
випадкової величини X1.
Вибірка X = (X1, …, Xn) об'єму n - це набір з n незалежних і
однаково розподілених випадкових величин («копій ξ»), що мають, як і ξ, розподіл F.
Вибірковий розподіл.
Розглянемо реалізацію вибірки на одному елементарному результаті
ω0
- набір чисел X1
= X1 (ω0), …, Xn = Xn (ω0). На підходящому імовірнісному
просторі введемо випадкову величину ξ*, що приймає значення X1, …, Xn
з імовірностями по 1/n (якщо якісь зі значень збіглися, складемо ймовірності
відповідне число раз). Таблиця розподілу ймовірностей і функція розподілу
випадкової величини ξ* виглядають так:

Розподіл величини ξ* називають емпіричним або
вибірковим розподілом.
Обчислимо математичне очікування й дисперсію величини ξ* і введемо позначення для
цих величин:

Точно так само обчислимо й момент порядку k:

У загальному випадку позначимо через  величину:
величину:

Якщо при побудові всіх введених нами характеристик вважати вибірку X1,
…, Xn набором випадкових величин, то й самі ці характеристики -  -
cтануть величинами випадковими. Ці характеристики вибіркового розподілу
використовують для оцінки (наближення) відповідних невідомих характеристик
дійсного розподілу.
-
cтануть величинами випадковими. Ці характеристики вибіркового розподілу
використовують для оцінки (наближення) відповідних невідомих характеристик
дійсного розподілу.
Причина використання характеристик розподілу ξ* для оцінки характеристик дійсного розподілу ξ (або X1) - у близькості цих розподілів при
більших n.
Розглянемо, для приклада, n підкидань правильного кубика. Нехай Xi €
{1, …, 6} - кількість очків, що випали при i-му кидку, i = 1, …, n. Припустимо,
що одиниця у вибірці зустрінеться n1 раз, двійка - n2 разів і т.д. Тоді
випадкова величина ξ* буде
приймати значення 1, …, 6 з імовірностями n1/n, …, n6/n відповідно. Але ці
пропорції з ростом n наближаються до 1/6 відповідно до закону більших чисел.
Тобто розподіл величини ξ * у деякому змісті зближається із дійсним розподілом
числа очків, що випадають при підкиданні правильного кубика.
Емпірична функція розподілу.
Оскільки невідомий розподіл F можна описати, наприклад, його функцією
розподілу F(y) = P (X1 < y), побудуємо по вибірці «оцінку» для цієї функції.
Емпіричною функцією розподілу, побудованої по вибірці X =(X1, …,Xn)
об'єму n, називається випадкова функція 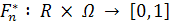 ,
при кожному y Є R рівна
,
при кожному y Є R рівна

Інакше кажучи, при будь-якому y значення F(y), рівне дійсної
ймовірності випадковій величині X1 бути менше y, оцінюється часткою елементів
вибірки, менших y.
Якщо елементи вибірки X1, …, Xn упорядкувати по зростанню (на кожному
елементарному результаті), вийде новий набір випадкових величин, називаний
варіаційним рядом

Тут

Елемент X(k), k = 1, …, n називається k-м членом варіаційного ряду або
k-ою порядковою статистикою.
Іншою характеристикою розподілу є таблиця (для дискретних розподілів)
або щільність (для абсолютно безперервних). Емпіричним, або вибірковим аналогом
таблиці або щільності є так звана гістограмма.
Гістограмма будується за групованими даними. Передбачувану область
значень випадкової величини (або область вибіркових даних) ділять незалежно від
вибірки на деяку кількість інтервалів (не обов'язково однакових). Нехай A1, …,
Ak -інтервали на прямій, називані інтервалами угруповання. Позначимо для j = 1,
…, k через νj число елементів вибірки, що потрапили в
інтервал Aj:

На кожному з інтервалів Aj будують прямокутник, площа якого пропорційна
νj.
Загальна площа всіх прямокутників
повинна дорівнювати одиниці. Нехай lj - довжина інтервалу Aj. Висота fj
прямокутника над Aj дорівнює:

.1.2 Групування даних в аспекті розв'язуваної задачі
Якщо об'єм вибірки дуже великий, часто працюють не з елементами
вибірки, а із групованими даними. Приведемо ряд понять, пов'язаних з
угрупованням. Для простоти будемо ділити область вибіркових даних на k
однакових інтервалів A1, …, Ak довжини Δ:

Як колись, нехай νj - число елементів вибірки, що потрапили в інтервал Aj
, і ωj
- частота влучення в інтервал Aj
(оцінка ймовірності влучення в інтервал):

На кожному з інтервалів Aj будують прямокутник з висотою fj = ωj/Δ
і одержують гістограмму.
Розглянемо середини інтервалів: 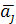 = αj-1 + Δ/2 - середина Aj. Набір
= αj-1 + Δ/2 - середина Aj. Набір
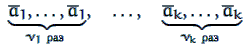
можна вважати «огрубленною» вибіркою, у якій всі Xi, що попадають в
інтервал Aj, замінені на .
По цій вибірці можна побудувати такі ж (але більше грубі) вибіркові
характеристики, що й по вихідній (позначимо їх так само), наприклад вибіркове
середнє

або вибіркову дисперсію

Крива, що з'єднує крапки (α0, 0), (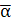 1, f1), …, (k, fk), (αk, 0), називається полігоном (частот). На відміну від
гистограммы полігон - безперервна функція (ламана).
1, f1), …, (k, fk), (αk, 0), називається полігоном (частот). На відміну від
гистограммы полігон - безперервна функція (ламана).
Кластеризація.
Величезні обсяги інформації можна зробити доступними для сприйняття,
якщо вміти розбивати джерела інформації на тематичні групи, тим самим відразу ж
відкидаючи множини даних з мало-релевантних груп. Такий процес угруповання даних
здійснюється за допомогою кластеризацїї або класифікації.
Необхідно чітко розуміти різницю між класифікацією й кластеризаціею
даних. Класифікація це віднесення кожного елемента в певний клас із заздалегідь
відомими параметрами, отриманими на етапі навчання. Число класів строго
обмежено. Кластеризація - автоматична розбивка елементів деякої множини на
кластери - підмножини (групи), залежно від їхньої схожості. Кількість кластерів
може бути довільним або фіксованим. Є 2 основних методи кластеризацїї: декомпозиція
(поділ, k-кластеризація) - у цьому випадку кожний об'єкт зв'язаний тільки з
однією групою, ієрархічна кластеризація - у цьому випадку кожна група більшого
розміру складається із груп меншого розміру.
У кластеризацїї існує велика кількість практичних застосувань як в
інформатиці так і в інших областях. Прикладами застосування можуть служити:
o Аналіз даних;
o Добування й пошук інформації;
o Угруповання й розпізнавання об'єктів.
Так само кластеризація сама по собі є важливою формою
абстракції даних.
Крім того, кластеризація є розділом сучасної теоретичної
інформатики й у цій області можна одержати ряд цікавих дослідницьких
результатів.
Формальні визначення.
Об'єкт - елементарна група даних, з якою оперують алгоритми
кластеризацїї.
Кожному об'єкту ототожнюється вектор характеристик.= (x1, …
xd)
Компоненти xi є окремими характеристиками об'єкта.
Кількість характеристик d визначають розмірність простору
характеристик.
Множина, що складається із всіх векторів характеристик
позначимо æ.
Відстань d(xi, xj) між об'єктами xi і xj - результат
застосування обраної метрики в просторі характеристик.
Загальна схема кластеризацїї.
Кластеризація даних містить у собі наступні етапи:
. Виділення вектора характеристик.
Для початку необхідно вибрати властивості, які характеризують
об'єкти. Ними можуть бути кількісні характеристики (координати, інтервали...),
якісні характеристики (кольори, статус...) і т.д.
Потім варто спробувати зменшити розмірність простору
характеристичних векторів, тобто виділити найбільш важливі властивості
об'єктів. Зменшення розмірності прискорює процес кластеризацїї й у ряді
випадків дозволяє візуально оцінювати її результати.
Виділені характеристики варто нормалізувати. Далі всі об'єкти
представляються у вигляді характеристичних векторів.
. Визначення метрики.
Вибір метрики необхідний для визначення близькості об'єктів.
Метрика вибирається залежно від:
o простору, у якому розташовані
об'єкти;
o неявних характеристик кластерів.
. Розбивка об'єктів на групи.
. Подання результатів.
Результати кластеризацїї повинні бути представлені в зручному
для обробки виді.
Класифікація алгоритмів кластеризацїї.
. Ієрархічні алгоритми.
Результатом роботи ієрархічних алгоритмів є дендограмма
(ієрархія), що дозволяє розбити вихідну множину об'єктів на будь-яке число кластерів.
Два найбільш популярні алгоритми:
Single-link - на кожному кроці поєднує два кластери з
найменшою відстанню між двома будь-якими представниками.
Complete-link - на кожному кроці поєднує два кластери з
найменшою відстанню між двома найбільш вилученими представниками.
Кластеризация як задача оптимізації.
Кластеризацію можна розглянути як задачу побудови оптимальної
розбивки об'єктів на групи. При цьому оптимальність може бути визначена як
вимога мінімізації середноквадратичної помилки розбивки:
 ,
,
де cj - «центр мас» кластера j. «Центр мас» кластера - крапка в
просторі характеристичних векторів із середніми для даного кластера значеннями
характеристик.
2. k-Means алгоритм.
Даний алгоритм складається з наступних кроків:
) Випадково вибрати k крапок, що є початковими
«центрами мас» кластерів (будь-які k з n об'єктів, або взагалі k випадкових
крапок);
) Віднести кожний об'єкт до кластера з найближчим
«центом мас»;
) Перерахувати «центри мас» кластерів відповідно до
поточного членства;
) Якщо критерій зупинки алгоритму не вдоволений,
повернуться до другого кроку.
Як критерій зупинки звичайно вибирають один із двох:) Відсутність
переходу об'єктів із кластера в кластер на кроці 2.) Мінімальна зміна
середноквадратичної помилки.
Алгоритм чутливий до початкового вибору «центрів мас».
. Мінімальне покриваюче дерево.
Даний метод робить ієрархічну кластеризацию «зверху - дониз».
Спочатку всі об'єкти містяться в один кластер. Потім на кожному кроці один із
кластерів розбивається на два, так щоб відстань між ними було максимальною.
. Метод найближчого сусіда.
Цей метод є одним з найстарших методів кластеризацїї. Він був
створений в 1987 році. Він простий і найменш оптимальний із всіх представлених.
Для кожного об'єкта поза кластером здійснюється наступне:
) Знаходимо його найближчого сусіда, кластер якого
визначений.
) Якщо відстань до цього сусіда менше порога, то
відносимо його в той же кластер. Інакше з розглянутого об'єкта створюється ще
один кластер.
Далі розглядається результат і при необхідності збільшується
поріг.
. Нечітка кластеризація.
Чітка (непересічна) кластеризація - кластеризація, при якій
кожний xi з æ відноситься тільки до одного
кластеру.
Нечітка кластеризація - кластеризація, при якій для кожного
xi з æ визначається fi,k. fi,k - значення, що показує ступінь
приналежності xi до кластера j.
Алгоритм нечіткої кластеризации наступний:
Необхідно вибрати початкову нечітку розбивку n об'єктів на k
кластерів шляхом вибору матриці приналежності U розміром n×k.
Звичайно Uij ℮
[0, 1].
Використовуючи матрицю U, знайти значення критерію нечіткої
помилки.
Перегрупувати об'єкти з метою зменшення цього значення
критерію нечіткої помилки.
Вертатися в пункт 2 доти, поки зміни матриці U не стануть незначними.
Кластеризація великих об'ємів даних.
При кластеризацїї великих об'ємів даних звичайно використають
k-Means або гібридні модифікації.
Якщо множина об'єктів не вміщується в основну пам'ять, можна:
o проводити кластеризацію за принципом
«розділяй і пануй», шляхом вилучення підмножин, проведення кластеризацїї
усередині них і наступною роботою тільки з одним представником кожного
кластера;
o використати потокові (on-line)
алгоритми (наприклад, модифікація методу найближчого сусіда);
o використати паралельні обчислення.
Застосування кластеризацїї.
Використання кластеризацїї спрощує роботу з інформацією, тому
що:
o досить працювати тільки з k
представниками кластерів;
o легко знайти «схожі» об'єкти - такий пошук застосовується в ряді
пошукових движків;
o відбувається автоматична побудова
каталогів.
Також наочне подання кластерів дозволяє зрозуміти структуру
множини об'єктів æ у просторі.
.2 Основні методи оптимізації
3.2.1 Загальна характеристика оптимізаційних задач
Пошуки оптимальних рішень привели до створення спеціальних
математичних методів і вже в 18 столітті були закладені математичні основи
оптимізації (варіаційне обчислення, чисельні методи й ін). Однак до другої
половини 20 століття методи оптимізації в багатьох галузях науки й техніки
застосовувалися дуже рідко, оскільки практичне використання математичних
методів оптимізації вимагало величезної обчислювальної роботи, що без ЕОМ
реалізувати було вкрай важко, а в ряді випадків - неможливо. Особливо більші
труднощі виникали при рішенні задач оптимізації процесів у хімічній технології
через велику кількість параметрів і їхнього складного взаємозв'язку між собою.
При наявності ЕОМ задача помітно спрощується.
Терміном "оптимізація" у літературі позначають
процес або послідовність операцій, що дозволяють одержати уточнене рішення.
Хоча кінцевою метою оптимізації є відшукання найкращого або
"оптимального" рішення, звичайно доводиться задовольнятися
поліпшенням відомих рішень, а не доведенням їх до досконалості. Тому під
оптимізацією розуміють скоріше прагнення до досконалості, що, можливо, і не
буде досягнуто.
Необхідність прийняття найкращих рішень так само стара, як
саме людство. Споконвіку люди, приступаючи до здійснення своїх заходів,
роздумували над їхніми можливими наслідками й приймали рішення, вибираючи тим
або іншому образу залежні від них параметри - способи організації заходів. Але
до пори, до часу рішення могли прийматися без спеціального математичного
аналізу, просто на основі досвіду й здорового глузду.
Візьмемо приклад: людина вийшла ранком з будинку, щоб їхати
на роботу. По ходу справи йому доводиться прийняти цілий ряд рішень: чи брати
із собою парасольку? У якім місці перейти вулицю? Яким видом транспорту
скористатися? І так далі. Зрозуміло, всі ці рішення людин приймає без
спеціальних розрахунків, просто опираючись на наявний у нього досвід і на
здоровий глузд. Для обґрунтування таких рішень ніяка наука не потрібна, так
навряд чи знадобиться й надалі.
Однак візьмемо інший приклад. Допустимо, організується робота
міського транспорту. У нашому розпорядженні є якась кількість транспортних
засобів. Необхідно прийняти ряд рішень, наприклад: яка кількість і які
транспортні засоби направити по тім або іншому маршруті? Як змінювати частоту
проходження машин залежно від часу доби? Де розмістити зупинки? І так далі.
Ці рішення є набагато більше відповідальними, чим рішення
попереднього приклада. У силу складності явища наслідку кожного з них не
настільки ясні; для того, щоб уявити собі ці наслідки, потрібно провести
розрахунки. А головне, від цих рішень набагато більше залежить. У першому
прикладі неправильний вибір рішення зачепить нтереси однієї людини; у другому -
може відбитися на діловому житті цілого міста.
Звичайно, і в другому прикладі при виборі рішення можна діяти
інтуїтивно, опираючись на досвід і здоровий глузд. Але рішення виявляться
набагато більше розумними, якщо вони будуть підкріплені кількісними,
математичними розрахунками. Ці попередні розрахунки допоможуть уникнути
тривалого й дорогого пошуку правильного рішення "на дотик".
Найбільш складно стщїть справа із прийняттям рішень, коли
мова йде про заходи, досвіду в проведенні яких ще не існує й, отже, здоровому
глузду не на що обпертися, а інтуїція може обдурити. Нехай, наприклад,
складається перспективний план розвитку озброєння на кілька років уперед.
Зразки озброєння, про які може йти мову, ще не існують, ніякого досвіду їхнього
застосування немає. При плануванні доводиться опиратися на велику кількість
даних, стосовних не стільки до минулого досвіду, скільки до передбачуваного
майбутнього. Обране рішення повинне по можливості вберегти нас від помилок,
пов'язаних з неточним прогнозуванням, і бути досить ефективним для широкого
кола умов. Для обґрунтування такого рішення приводиться в дію складна система
математичних розрахунків.
Взагалі, чим складніше организуемое захід, чим більше
вкладається в нього матеріальних засобів, чим ширше спектр його можливих
наслідків, тим менш припустимі так звані "вольові" рішення, що не
опираються на науковий розрахунок, і тим більше значення одержує сукупність
наукових методів, що дозволяють заздалегідь оцінити наслідку кожного рішення,
заздалегідь відкинути неприпустимі варіанти й рекомендувати ті, які
представляються найбільш вдалими.
Практика породжує все нові й нові задачі оптимізації причому
їхня складність росте. Потрібні нові математичні моделі й методи, які
враховують наявність багатьох критеріїв, проводять глобальний пошук оптимуму.
Інакше кажучи, життя змушує розвивати математичний апарат оптимізації.
Реальні прикладні задачі оптимізації дуже складні. Сучасні
методи оптимізації далеко не завжди справляються з рішенням реальних задач без
допомоги людини. Не icнує,
поки такої теорії, що врахувала б будь-які особливості функцій, що описують
постановку задачі. Варто віддавати перевагу таким методам, якими простіше
управляти в процесі рішення задачі.
Отже, оптимізація - цілеспрямована діяльність, що полягає в
одержанні найкращих результатів при відповідних умовах.
Сфера застосування методів оптимізації:
o розробка прогнозу;
o планування;
o інвестування;
o складання розкладу робіт;
o керування транспортними потоками;
o визначення оптимальної стратегії в
конкурентній боротьбі;
o виявлення вузьких місць, меж
рентабельності, стійкості бізнесу;
o призначення об'єктів однієї групи
об'єктам іншої групи;
o рішення систем рівнянь в економічних
і інженерних задачах.
.2.2 Постановка задачі оптимізації
Постановка задачі оптимізації припускає існування конкуруючих
властивостей процесу, наприклад:
кількість продукції - "витрати сировини"
кількість продукції - "якість продукції"
Вибір компромісного варіанта для зазначених властивостей і
являє собою процедуру рішення оптимизаційної задачі.
При постановці задачі оптимізації необхідно:
. Наявність об'єкта оптимізації й мети оптимізації. При цьому
формулювання кожної задачі оптимізації повинно вимагати екстремального значення
лише однієї величини, тобто одночасно системі не повинне приписуватися два й
більше критерій оптимізації, тому що практично завжди экстремум одного критерію
не відповідає экстремуму іншого. Типовий приклад неправильної постановки задачі
оптимізації:
"Одержати максимальну продуктивність при мінімальній
собівартості". Помилка полягає в тім, що ставиться задача пошуку оптимуму
2-х величин, що суперечать один одному по своїй суті.
Правильна постановка задачі могла бути наступна:
а) одержати максимальну продуктивність при заданій
собівартості;
б) одержати мінімальну собівартість при заданій
продуктивності;
У першому випадку критерій оптимізації - продуктивність, а в
другому - собівартість.
. Наявність ресурсів оптимізації, під якими розуміють
можливість вибору значень деяких параметрів об'єкта оптимізації. Об'єкт повинен
мати певні ступені волі - керуючими впливами.
. Можливість кількісної оцінки величини оптимызацыъ, оскільки
тільки в цьому випадку можна порівнювати ефекти від вибору тих або інших
керуючих впливів.
. Облік обмежень.
.2.3 Види обмежень
Незважаючи на те, що прикладні задачі ставляться до зовсім
різних областей, вони мають загальну форму. Всі ці задачі можна класифікувати
як задачі мінімізації функції f(x) N-мірного векторного аргументу x = (x1,
x2,..., xn), компоненти якого задовольняють системі рівнянь hk(x) = 0, набору
нерівностей gi(x) ≥ 0, а також обмежені зверху й знизу, тобто xi(u) ≥
xi ≥ xi(l). У наступному викладі функцію f(x) будемо називати цільовою
функцією, рівняння hk(x) = 0 - обмеженнями у вигляді рівностей, а нерівності
gi(x) ≥ 0 - обмеженнями у вигляді нерівностей.
Задача загального виду:
мінімізувати f(x) при обмеженнях
hk(x) = 0, k = 1, ..., K,(x) ≥ 0, j = 1, ..., J,(u) ≥
xi ≥ xi(l), I = 1, ..., N
називається задачею оптимізації з обмеженнями або задачею
умовної оптимізації. Задача, у якій немає обмежень, тобто
J = K = 0;(u) = xi(l) = ∞, i=1, ..., N,
називається оптимізаційною задачею без обмежень або задачею
безумовної оптимізації.
.2.4 Критерії оптимальності
Звичайно величина оптимізації пов'язана з економічністю
роботи розглянутого об'єкта (апарат, цех, завод). Оптимізуємий варіант роботи
об'єкта повинен оцінюватися якоюсь кількісною мірою - критерієм оптимальності.
Критерієм оптимальності називається кількісна оцінка
оптимізуємої якості об'єкта.
На підставі обраного критерію оптимальності складається
цільова функція, що представляє собою залежність критерію оптимальності від
параметрів, що впливають на її значення. Вид критерію оптимальності або
цільової функції визначається конкретною задачею оптимізації.
Таким чином, задача оптимізації зводиться до знаходження
экстремума цільової функції.
Найбільш загальною постановкою оптимальної задачі є вираження
критерію оптимальності у вигляді економічної оцінки (продуктивність,
собівартість продукції, прибуток, рентабельність). Однак у приватних задачах
оптимізації, коли об'єкт є частиною технологічного процесу, не завжди вдається
або не завжди доцільно виділяти прямий економічний показник, який би повністю
характеризував ефективність роботи розглянутого об'єкта. У таких випадках
критерієм оптимальності може служити технологічна характеристика, що побічно
оцінює економічність роботи агрегату (час контакту, вихід продукту, ступінь
перетворення, температура). Наприклад, установлюється оптимальний температурний
профіль, тривалість циклу - "реакція - регенерація". Але в кожному
разі будь-який критерій оптимальності має економічну природу.
Розглянемо більш докладно вимоги, які повинні пред'являтися
до критерію оптимальності.
. Критерій оптимальності повинен виражатися кількісно.
. Критерій оптимальності повинен бути єдиним.
. Критерій оптимальності повинен відбивати найбільш
істотні сторони процесу.
. Бажано щоб критерій оптимальності мав ясний фізичний
зміст і легко розраховувався.
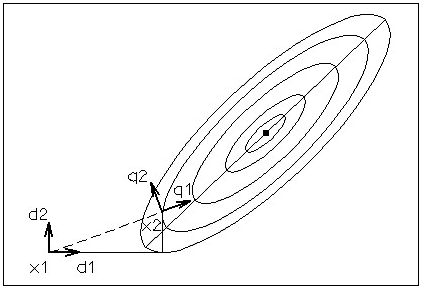
Будь-який оптимізуємий об'єкт схематично можна представити в
такий спосіб:

Мал. 3.1 О
б'єкт оптимізації
Позначення: Y - виходи об'єкта;- контрольовані вхідні
параметри;- регульовані вхідні параметри керуючі параметри;- неконтрольовані
впливи.
При постановці конкретних задач оптимізації критерій
оптимальності повинен бути записаний у вигляді аналітичного вираження. У тому
випадку, коли випадкові збудження невеликі і їхній вплив на об'єкт можна не
враховувати, критерій оптимальності може бути представлений як функція вхідних,
вихідних і керуючих параметрів:
R = R(X1, X2,...,XN, Y1,Y2,...,YN, U1,U2,..., UN)
Тому що Y=f (U), то при фіксованих Х можна записати:= R(Ui)
При цьому будь-яка зміна значень керуючих параметрів подвійно
позначається на величині R:
прямо, так як керуючі параметри безпосередньо входять до
вираження критерію оптимізації;
побічно - через зміну вихідних параметрів процесу, які
залежать від керуючих.
Якщо ж випадкові збудження досить великі і їх необхідно
враховувати, то варто застосовувати експериментально - статистичні методи, які
дозволять одержати модель об'єкта у вигляді функції:
Y = j(Xi,Ui)
яка справедлива тільки для вивченої локальної області. Тоді
критерій оптимальності прийме наступний вид:
R = R(X,U)
У принципі, для оптимізації замість математичної моделі можна
використати й сам об'єкт, однак оптимізація досвідченим шляхом має ряд істотних
недоліків:
а) необхідний реальний об'єкт;
б) необхідно змінювати технологічний режим у значних межах,
що не завжди можливо;
в) тривалість випробувань і складність обробки даних.
Наявність математичної моделі (за умови, що вона досить
надійно описує процес) дозволяє значно простіше вирішити задачу оптимізації
аналітичним або чисельним методами.
У задачах оптимізації розрізняють прості й складні критерії
оптимізації.
Критерій оптимальності називається простим, якщо потрібно
визначити экстремум цільової функції без завдання умов на які-небудь інші
величини. Такі критерії звичайно використаються при рішенні приватних задач
оптимізації (наприклад, визначення максимальної концентрації цільового
продукту, оптимального часу перебування реакційної суміші в апарату й т.п.).
Критерій оптимальності називається складним, якщо необхідно
встановити экстремум цільової функції при деяких умовах, які накладаються на
ряд інших величин (наприклад, визначення максимальної продуктивності при
заданій собівартості, визначення оптимальної температури при обмеженнях по
термостійкості каталізатора й ін.).
Процедура рішення задачі оптимізації обов'язково включає,
крім вибору керуючих параметрів, ще й установлення обмежень на ці параметри
(термостійкість, вибухобезпечність, потужність перекачувальних пристроїв).
Обмеження можуть накладатися як по технологічним, так і по економічних
міркуванням.
Отже, для рішення задачі оптимізації необхідно:
а) скласти математичну модель об'єкта оптимізації:
Y = f(X,U)
б) вибрати критерій оптимальності й скласти цільову функцію:
R = φ(Y) = F(X,U)
в) установити можливі обмеження, які повинні накладатися на
змінні:
ψi(X,U) = 0
ψi(X,U) < 0
г) вибрати метод оптимізації, що дозволить знайти
екстремальні значення шуканих величин.
Прийнято розрізняти задачі статичної оптимізації для
процесів, що протікають у сталих режимах, і задачі динамічної оптимізації.
У першому випадку вирішуються питання створення й реалізації
оптимальної моделі процесу, у другому - задачі створення й реалізації системи
оптимального керування процесом при несталих режимах експлуатації.
.2.5 Класифікація задач
Задачі оптимізації можна класифікувати відповідно до виду
функцій f, hk, gi і розмірністю вектора x. Задачі без обмежень, у яких x являє
собою одномірний вектор, називаються задачами з один змінної й становлять
найпростіший, але разом з тим досить важливий підклас оптимізаційних задач.
Задачі умовної оптимізації, у яких функції hk, і gi є лінійними, звуться
задачами з лінійними обмеженнями.
В таких задачах цільові функції можуть бути або лінійними,
або нелінійними. Задачі, які містять тільки лінійні функції вектора
безперервних змінних x, називаються задачами лінійного програмування; у задачах
цілочислового програмування компоненти вектора x повинні приймати тільки цілі
значення.
Задачі з нелінійною цільовою функцією й лінійними обмеженнями
іноді називають задачами нелінійного програмування з лінійними обмеженнями.
Оптимізаційні задачі такого роду можна класифікувати на основі структурних
особливостей нелінійних цільових функцій. Якщо f(x) - квадратична функція, то
ми маємо справу із задачею квадратичного програмування; якщо f(x) є відношення
лінійних функцій, то відповідна задача зветься до задачі дробно - лінійного
програмування, і т.д. Ділення оптимізаційних задач на ці класи становить
значний інтерес, оскільки специфічні особливості тих або інших задач відіграють
важливу роль при розробці методів їхнього рішення (Мал. 3.2).

Мал. 3.2 Класифікація задач математичного програмування:
.2.6 Методи рішення задач оптимізації.
Задачі одномірної мінімізації являють собою найпростішу
математичну модель оптимізації, у якій цільова функція залежить від однієї
змінної, а припустимою множиною є відрізок речовинної осі:(x) → min , x
належить [a, b].
Максимізація цільової функції (f(x) → max) еквівалентна
мінімізації протилежної величини ( -f(x) → min ), тому, не применшуючи
спільності можна розглядати тільки задачі мінімізації.
До математичних задач одномірної мінімізації приводять
прикладні задачі оптимізації з однією керованою змінною. Крім того,
необхідність у мінімізації функцій однієї змінної виникає при реалізації деяких
методів рішення більш складних задач оптимізації.
Для рішення задачі мінімізації функції f(x) на відрізку [a,
b] на практиці, як правило, застосовують наближені методи. Вони дозволяють
знайти рішення цієї задачі з необхідною точністю в результаті визначення
кінцевого числа значень функції f(x) і її похідних у деяких точках відрізка [a,
b]. Методи, що використовують тільки значення функції і не потребують
обчислення її похідних, називаються прямими методами мінімізації.
Більшим достоїнством прямих методів є те, що від цільової
функції не потрібно диференціювання й, більш того, вона може бути не задана в
аналітичному виді. Єдине, на чому засновані алгоритми прямих методів
мінімізації, це можливість визначення значень f(x) у заданих точках.
Розглянемо найпоширеніші на практиці прямі методи пошуку
точки мінімуму. Самою слабкою вимогою на функцію f(x), що дозволяє використати
ці методи, є її унімодальність. Тому далі будемо вважати функцію f(x)
унімодальною на відрізку [a, b].
Метод перебору.
Метод перебору або рівномірного пошуку є найпростішим із
прямих методів мінімізації й полягає в наступному. Розіб'ємо відрізок [a,b] на
n рівних частин точками ділення:
xi =  ,
i = 0, ... n
,
i = 0, ... n
Обчисливши значення F(x) у точках xi, шляхом порівняння знайдемо точку
xm, де m - це число від 0 до n, таку, що(xm) = min F(xi) для всіх i від 0 до n.
Погрішність визначення точки мінімуму xm функції F(x) методом перебору
не перевершує величини eps =  .
.
Метод ділення навпіл.
Розглянемо функцію F, що потрібно мінімізувати на інтервалі [a1, b1].
Припустимо, що F строго квазівипукла. Очевидно, що найменше число обчислень
значень функції, які необхідні для скорочення інтервалу невизначеності,
дорівнює двом. Однієї зі стратегій є вибір цих двох крапок симетрично на
відстані eps > 0 від середини інтервалу. Тут число eps настільки мало, щоб
довжина нового інтервалу невизначеності eps+(b1-a1)/2 була досить близькою до
теоретичного значення (b1-a1)/2, і в той же час таке, щоб значення функції в
цих двох точках були помітні.
Алгоритм дихотомічного методу для мінімізації квазівипуклої фунції на
інтервалі [a1,b1].
Початковий етап.
Вибрати константу розрізнення 2еps > 0 і припустиму кінцеву довжину
інтервалу невизначеності l > 0. Нехай [a1,b1] - початковий інтервал
невизначеності. Покласти k = 1 і перейти до основного етапу.
Основний етап.
Крок 1. Якщо bk-ak < l, то зупинитися; точка мінімуму належить
інтервалу [ak,bk]. У противному випадку обчислити


і перейти до кроку 2.
Крок2. Якщо F(pk) < F(qk), покласти a[k+1]=ak і b[k+1]=qk. У
противному випадку покласти a[k+1]=pk і b[k+1]=bk. Замінити k на k+1 і перейти
до кроку 1.
Методи безумовної мінімізації функцій багатьох змінних.
Задача безумовної оптимізації складається в знаходженні мінімуму або
максимуму функції під час відсутності яких-небудь обмежень. Незважаючи на те що
більшість практичних задач оптимізації містить обмеження, вивчення методів
безумовної оптимізації важливо з декількох точок зору. Багато алгоритмів
рішення задачі з обмеженнями припускають відомість її до послідовності задач
безумовної оптимізації. Інший клас методів заснований на пошуку підходящого
напрямку й наступної мінімізації уздовж цього напрямку. Обґрунтування методів
безумовної оптимізації може бути природно поширене на обґрунтування процедур
рішення задач із обмеженнями.
Методи безумовної мінімізації функцій багатьох змінних містить у собі
багатомірний пошук без використання похідних і пошук, що використає похідні.
Багатомірний пошук без використання похідних.
Розглянемо методи рішення мінімізації функції декількох змінних f, які
опираються тільки на обчислення значень функції f(x), не використовують
обчислення похідних, тобто прямі методи мінімізації. Важливо відзначити, що для
застосування цих методів не потрібно не тільки диференціювання цільової
функції, але навіть аналітичного завдання. Потрібно лише мати можливість
обчислювати або вимірювати значення f у довільних точках. Такі ситуації часто
зустрічаються в практично важливих задачах оптимізації. В основному всі описані
методи полягають у наступному. При заданому векторі х визначається припустимий
напрямок d. Потім, відправляючись із крапки х, функція f мінімізується уздовж
напрямку d одним з методів одномірної мінімізації. Задача лінійного пошуку
полягає в мінімізації f(x+lym·d) при умові, що lym належить L, де L задається в
формі L = E1, L = {lym: lym ≥ 0} або L = {l: a ≤ lym ≤ b}.
Будем вважати, що точка мінімума lym існує. Однак в реальних задачах це
припущення може не виконуватися. Оптимальне значення цільової функції в задачі
лінійного пошуку може бути не обмежене або оптимальне значення функції кінцеве,
але не досягається не при якому lym.
Багатомірний пошук без використання похідних реалізується з
використанням наступних методів: циклічного покоординатного спуску; Хука й
Дживса; Розенброка; мінімізації по правильному симплексі; пошуку точки мінімуму
по деформованому симплексу.
Метод циклічного покоординатного спуску.
У цьому методі як напрямки пошуку використовуються координатні вектори.
Метод циклічного покоординатного спуску здійснює пошук уздовж напрямків d1,
..., dn, де dj - вектор, всі компоненти якого, за винятком j-ого, дорівнюють
нулю. Таким чином, при пошуку по напрямку dj міняється тільки змінна xj, у той
час як всі інші змінні залишаються зафіксованими.
Алгоритм циклічного покоординатного спуску.
Початковий етап.
Вибрати eps > 0, що буде використовуватися для зупинки алгоритму, і
взяти в якості d1, ..., dn координатні напрямки. Вибрати початкову точку x1,
покласти y1 = x1, k=j=1 і перейти до основного етапу.
Основний етап.
Крок 1. Покласти lymj рівним оптимальному рішенню задачі мінімізації
f(yj+lym·dj) при умові, що lym належить E1. Покласти y[j+1]= yj+lymj·dj. Якщо j
< n, то замінити j на j+1 і повернутися до кроку 1. Якщо j=n, то перейти до
кроку 2.
Крок 2. Покласти x[k+1] = y[n+1]. Якщо || x[k+1] - xk || < eps, то
зупинитися. У противному випадку покласти y1= x[k+1], j=1, замінити k на k+1 і
перейти до кроку 1.
Метод Хука й Дживса.
Метод Хука й Дживса здійснює два типи пошуку - пошук, що досліджує, і
пошук за зразком. Перші дві ітерації процедури показані на малюнку 3.3.
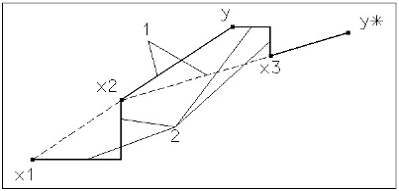
Мал. 3.3 Метод Хука й Дживса: 1-пошук за зразком; 2- пошук, що
досліджує, уздовж координатних осей.
При заданому початковому векторі x1 пошук, що досліджує, по
координатних напрямках приводить у точку x2 . Наступний пошук за зразком у
напрямку x1- x2 приводить у точку y. Потім, досліджуючий пошук, що починається
із точки y, дає точку x3. Наступний етап пошуку за зразком уздовж напрямку x3-
x2 дає y*. Потім процес повторюється.
Алгоритм Хука й Дживса з використанням одномірної мінімізації.
Розглянемо варіант методу, що використовує одномірну мінімізацію уздовж
координатних напрямків d1,..., dn і напрямків пошуку за зразком.
Початковий етап.
Вибрати число eps > 0 для зупинки алгоритму. Вибрати початкову
крапку x1, покласти y1= x1, k=j=1 і перейти до основного етапу.
Основний етап.
Крок 1. Знайти lymj - оптимальне рішення задачі мінімізації f(yj+lym ·
dj) при умові що lym належить E1. Покласти y[j+1]= yj+lymj·dj. Якщо j < n,
то замінити j на j+1 и повернутися до кроку 1. Якщо j = n, то покласти x[k+1] =
y[n+1]. Якщо ||x[k+1] - xk|| < eps , то зупинитися; у противному випадку
перейти до кроку 2.
Крок 2. Покласти d = x[k+1] - xk і знайти lym - оптимальне рішення
задачі мінімізації f(x[k+1]+lym·d) при умові lym належить E1. Покласти y1=
x[k+1]+lym·d, j=1, замінити k на k+1 и перейти до кроку 1.
Метод Розенброка.
Розглянемо варіант методу із застосуванням одномірної мінімізації. На
кожній ітерації процедура здійснює ітеративний пошук уздовж n лінійно
незалежних і ортогональних напрямків. Коли отримана нова точка наприкінці
ітерації, будується нова множина ортогональних векторів. На малюнку 3.4 нові
напрямки позначені через q1 і q2.
Мал. 3.4 Побудова нових напрямків пошуку в методі Розенброка.
Побудова напрямків пошуку.
Нехай d1,..., dn - лінійно незалежні вектори, по нормі рівні одиниці.
Будемо вважати, що ці вектори взаємно ортогональні, тобто (di · dj) = 0 для i
!= j. Починаючи з поточної точки xk, цільова функція послідовно мінімізується
вздовж кожного з напрямків, в результаті чого отримується точка x[k+1]. Слід
зазначити, що x[k+1]- xk = Sum(lymj · dj), де lymj - довжина кроку по напрямку
dj. Новий набір напрямків q1,..., qn будується за допомогою процедури
Грамма-Шмідта наступним шляхом:
aj = 
 =
bj /|| bj ||.
=
bj /|| bj ||.
Нові напрямки побудовані в такий спосіб є лінійно незалежними й
ортогональними.
Алгоритм методу Розенброка з мінімізацією по напрямку.
Початковий етап.
Нехай eps > 0 - скаляр, використовуваний у критерії зупинки. Вибрати
в якості d1,..., dn координатні напрямки, початкову точку x1, покласти y1= x1,
k=j=1 і перейти до основного етапу.
Основний етап.
Крок 1. Знайти lymj - оптимальне рішення задачі мінімізації f(yj+lymj ·
dj) при умові lym належить E1 и покласти y[j+1]= yj+lymj · dj. Якщо j < n,
то замінити j на j+1 и повернутися до кроку 1. В іншому випадку перейти до
кроку 2.
Крок 2. Покласти x[k+1]= y[n+1]. Якщо ||x[k+1] - xk|| < eps, то
зупинитися. У противному випадку покласти y1= x[k+1], замінити k на k+1
покласти j=1 і перейти до кроку 3.
Крок 3. Побудувати нову множину лінійно незалежних і взаємно
ортогональних напрямків відповідно до процедури Грамма-Шмідта. Позначити нові
напрямки d1,..., dn і повернутися до кроку 1.
Мінімізация по правильному симплексу.
Правильним симплексом у просторі En називається множина з n+1
рівновіддалених один від одного точок (вершин симплекса). Відрізок, що з'єднує
дві вершини, називається ребром симплекса.
У просторі E2 правильним симплексом є сукупність вершин
рівностороннього трикутника, а в E3 - правильні тетраедри. Якщо x0 - одна з
вершин правильного симплекса в En, то координати інших n вершин x1,..., xn
можна знайти, наприклад, по формулах:
xji =  (1)
(1)
де d1 = a(sqrt(n+1) - 1) / n · sqrt(2), d2 = a(sqrt(n+1) + n - 1) / n ·
sqrt(2), a - довжина ребра.
Вершину x0 симплекса, побудованого по формулах (1), будемо називати
базовою. В алгоритмі симплексного методу використовується наступна важлива
властивість правильного симплекса. По відомому симплексі можна побудувати новий
симплекс шляхом відбиття якої-небудь вершини, наприклад, xk симетрично щодо
центра ваги xc інших вершин симплекса. Нова й стара вершини y і xk пов'язані
співвідношенням:

де 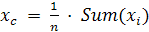 для
всіх i!=k.
для
всіх i!=k.
В результаті одержуємо новий симплекс із тим же ребром і вершинами
y=2xс-xk, xi, i=0,...,n, i!=k. У такий спосіб відбувається переміщення
симплекса в просторі. На малюнку 3.5 представлена ілюстрація цієї властивості
симплекса для двовимірної області.

Мал. 3.5 Побудова нового симплекса в Е2 відбиттям точки х2.
Пошук точки мінімуму функції f(x) за допомогою правильних симплексів
виробляється в такий спосіб. На кожній ітерації порівнюються значення функції у
вершинах симплекса. Потім проводиться описана вище процедура відбиття для тієї
вершини, у якій f(x) приймає найбільше значення. Якщо у відбитій вершині
виходить менше значення функції, то переходять до нового симплекса. Якщо ж
спроба відбиття не приводить до зменшення функції, то скорочують довжину ребра
симплекса, наприклад, удвічі й будують новий симплекс із цим ребром. У якості
базової вибирають ту вершину x0 старого симплекса, у якій функція принимет
мінімальне значення. Пошук точки мінімуму f(x) закінчують, коли або ребро
симплекса, або різниця між значеннями функції у вершинах симплекса стають
досить малими.
Алгоритм мінімізації по правильному симплексу.
Початковий етап.
Вибрати параметр точності eps, базову точку x0, ребро a і побудувати
початковий симплекс по формулах (1). Обчислити f(x0).
Основний етап.
Крок 1. Обчислити значення f(x) у вершинах симплекса x1,..., xn.
Крок 2. Упорядкувати вершини симплекса x0,..., xn так, щоб(x0) ≤
f(x1) ≤ ... ≤ f (x[n-1]) ≤ f(xn).
Крок 3. Перевірити умову (1/n)Sum[f(xi)-f(x0)]2 < eps2, i=[1,n].
Це одне з можливих умов зупинки. При його виконанні
"дисперсія" значень f(x) у вершинах симплекса стає менше e2, що, як
правило, відповідає або малому ребру a симплекса, або влученню точки мінімуму
x* усередину симплекса, або тому й інший одночасно.
Якщо ця умова виконана, то обчислення припинити, думаючи x*= x0. У
противному випадку перейти до кроку 4.
Крок 4. Знайти xс і виконати відбиття вершини xn : y = 2 · xс- xn. Якщо
f(y) < f(xn), то покласти xn = y і перейти до кроку 2. Інакше - перейти до
кроку 5.
Крок 5. Перейти до нового правильного симплекса із удвічі меншим
ребром, вважаючи базовою вершиною x0. Інші n вершин симплеска знайти по формулі
xi=( xi+ x0)/2, i=1,..., n. Перейти до кроку 1.
Пошук крапки мінімуму по деформованому симплексу.
Алгоритм мінімізації по правильному симплексі можна модифікувати,
додавши до процедури відбиття при побудові нового симплекса процедури стиску й
розтягання. А саме, положення нової вершини y замість вершини xn, що відповідає
найбільшому значенню функції, знаходиться порівнянням і вибором найменшого
серед значень цільової функції в точках:
= xс - a(xc - xn), 0 < a < 1;= xc + a(xc - xn), 0 < a <1;
(2)= xc + b(xc - xn), b приблизно дорівнює 1;= xc + g(xc - xn), g<1.
Геометрична ілюстрація цих процедур для двовимірного простору наведена
на малюнку 3.6.

Мал. 3.6 Пробні точки z1, z2, z3, z4 для переходу до нового симплекса
Так як величина a належить інтервалу (0;1), то вибір точок z1 і z2
відповідає стиску симплекса; b приблизно дорівнює 1, тому вибір точки z3
відповідає відбиттю, а g >1 і вибір точки z4 приводить до розтягання
симплекса.
Необхідно відзначити, що при деформаціях втрачається властивість
правильності вихідного симплекса.
На практиці добре зарекомендував себе наступний набір параметрів a =
1/2, b = 1, g = 2.
Алгоритм методу пошуку точки мінімуму функції по деформованому
симплексу.
Початковий етап.
Вибрати параметр точності eps, параметри a, b і g, базову точку x0,
параметр a і побудувати початковий симплекс. Обчислити значення функції f(x0).
Основний етап.
Крок 1. Обчислити значення функції у вершинах симплекса x1,..., xn.
Крок 2. Упорядкувати вершини симплекса x0,..., xn так, щоб(x0) ≤
f(x1) ≤ ... ≤ f (x[n-1]) ≤ f(xn).
Крок 3. Перевірити умову (1/n)Sum[f(xi)-f(x0)]2 < eps2, i=[1,n].
Це одне з можливих умов зупинки. При його виконанні
"дисперсія" значень f(x) у вершинах симплекса стає менше e2, що, як
правило, відповідає або малому ребру a симплекса, або влученню точки мінімуму
x* усередину симплекса, або тому й іншому одночасно.
Якщо ця умова виконана, то обчислення припинити, думаючи x*= x0. У
противному випадку перейти до кроку 4.
Крок 4. Знайти xс і пробні точки zk , k=1,...,4 по формулах (2). Знайти
f(z*) = minf(zk). Якщо f(z*) < f(xn), то покласти xn = z* і перейти до кроку
2. Інакше - перейти до кроку 5.
Крок 5. Зменшити симплекс, думаючи xi = (xi+ x0)/2, i=1,...,n перейти
до кроку 1.
Багатомірний пошук, що використовує похідні.
Нехай функція f(x) диференційована в Еn . У цьому розділі розглядається
ітераційна процедура мінімізації виду:= x[k-1] + lym[k] · dk, k=1,... ,
де напрямок убування dk визначається тим або іншом способом з
урахуванням інформації про частки похідних функції f(x), а величина кроку
lym[k] >0 така, що(xk) < f(xk-1), k=1,2,....
Тому що функція передбачається диференційованою, то у якості критерію
зупинки у випадку нескінченної ітераційної послідовності { xk }, як правило,
вибирають умову ||grad(f(xk))|| < eps, хоча, зрозуміло, можуть бути
використані й інші критерії.
Багатомірний пошук, що використовує похідні містить у собі метод
найшвидшого спуску.
Метод найшвидшого спуску.
Метод найшвидшого спуску є одним з найбільш фундаментальних процедур
мінімізації диференційованої функції декількох змінних. Вектор d називається
напрямком спуска для функції f у точці x, якщо існує таке d > 0, що f(x+lym
· d) < f(x) для всіх lym, що належать інтервалу (0, d).
У методі найшвидшого спуску здійснюється рух уздовж напрямку d, для
якого ||d|| = 1 і яке мінімізує наведену вище межу. Якщо f диференційована в
точці x і grad(f(x)) != 0, те -grad(f(x))/||grad(f(x))|| є напрямком
найшвидшого спуску. У зв'язку з цим метод найшвидшого спуску іноді називають
градієнтним методом.
Алгоритм методу найшвидшого спуску.
При заданій точці x алгоритм найшвидшого спуску полягає в реалізації
лінійного пошуку уздовж напрямку -grad(f(x))/||grad(f(x))|| або, що те ж саме,
уздовж напрямку -grad(f(x)).
Початковий етап. Нехай eps > 0 - константа зупинки. Вибрати
початкову точку x1, покласти k =1 і перейти до основного етапу.
Основний етап. Якщо ||grad(f(x))|| < eps , то зупинитися; у
противному випадку покласти dk = -grad(f(x)) і знайти lym[k] - оптимальне
рішення задачі мінімізації f(xk + lym · dk) при lym ≥ 0. Покласти
x[k+1]=xk+lym[k] · dk, замінити k на k+1 и повторити основний етап.
Застосування алгоритмів мінімізації функцій багатьох змінних.
Алгоритми безумовної мінімізації функцій багатьох змінних можна
порівнювати й досліджувати як з теоретичної, так і з експериментальної точок
зору.
Перший підхід може бути реалізований повністю тільки для досить
обмеженого класу задач, наприклад, для сильно опуклих квадратичних функцій. При
цьому можливий широкий спектр результатів від одержання нескінченної
мінімізуючої послідовності в методі циклічного покоординатного спуска до
збіжності не більш ніж за n ітерацій у методі сполучених напрямків.
Потужним інструментом теоретичного дослідження алгоритмів є теореми про
збіжність методів. Однак, як правило, формулювання таких теорем абстрактні, при
їхньому доказі використовується апарат сучасного функціонального аналізу. Крім
того, найчастіше непросто встановити зв'язок отриманих математичних результатів
із практикою обчислень. Справа в тому, що умови теорем важкоперевіряємі в
конкретних задачах, сам факт збіжності мало що дає, а оцінки швидкості
збіжності неточні й неефективні. При реалізації алгоритмів також виникає багато
додаткових обставин, строгий облік яких неможливий (помилки округлення,
наближене рішення різних допоміжних задач і т.д.) і які можуть сильно вплинути
на хід процесу.
Тому на практиці часто порівняння алгоритмів проводять за допомогою
обчислювальних експериментів при рішенні так званих спеціальних тестових задач.
Ці задачі можуть бути як з малим, так і з більшим числом змінних, мати різний
вигляд нелінійності. Вони можуть бути складені спеціально й виникати із
практичних додатків, наприклад задача мінімізації суми квадратів, рішення
систем нелінійних рівнянь і т.п.
4.
ПРОГРАМНА РЕАЛІЗАЦІЯ ТА ОПИС ФУНКЦІОНАЛЬНИХ МОЖЛИВОСТЕЙ АЛГОРИТМУ
.1 Алгоритм розподілу
Алгоритм розподілу елементів попиту по випадково сформованому
ресурсі складається з наступних блоків:

. Формування множини, що містить елементи ресуру.
2. Формування множини, що містить елементи попиту.
. Чи закінчився список попиту?
. Виключення із загального ресурсу елементів, які
неможливо використати при розподілі поточного елемента попиту.
. Чи можна сформувати новий кластер?
. Отримання повідомлення про невдалий розподіл
поточного елемента попиту.
. Формування кластера, що містить елементи вільного
ресурсу по необхідних параметрах елемента поточного попиту. Для даної мети
використаються заздалегідь сформовані функції.
. Чи містить кластер необхідну кількість елементів?
. Розподіл поточного елемента попиту по елементах
кластера. При цьому елемент ресурсу в загальному масиві заміняється сполученням
поточного елемента попиту й елемента ресурсу.
.2 Введення даних. Способи вводу.
4.2.1 Формування списку ресурсу
Ресурс являє собою 4-мірний масив, що складається з 0 і 1,
розподілених випадковим шляхом. Значення 0 вказує на вільний елемент ресурсу,
значення 1 - зайнятий елемент.
Співвідношення зайнятих та вільних елементів ресурсу
представлено наступною діаграмою (Мал. 4.1):

Масив ресурсу відображає зайнятість аудиторій на всі дні семестру,
на кожній з пар. Текстовий файл dano.txt зберігає початкові значення елементів
масиву ресурсу. Щоб використати дані файлу в робочому файлі, необхідно його
імпортувати. Для цього використовуємо функцію пакета Mathematica - Import.
У загальному виді функція записується в такий спосіб:[“file”,
“format”] - де в якості “file” необхідно вказати повний шлях імпортованого
файлу, а в якості “format” - формат імпортованого файлу.

Для визначення розмірності масиву М використовуємо вбудовану
функцію пакета Mathematica - Dimensions. Параметром даної функції є розглянутий
масив - М. Значення розмірності масиву М привласнимо змінній d.
Щоб кожному значенню масиву d відповідала окрема змінна,
використовуємо цикл Do. Загальний вид циклу:[expr, {i, imin, imax}] - у циклі з
лічильником i, починаючи з imin і до imax з кроком рівним 1 виконується
вираження expr.
Таким чином, кожна зі змінних (d1, d2, d3, d4) буде
відповідати певному параметру: d1 - кількість тижнів у семестрі; d2 - кількість
всіх аудиторій; d3 - кількість навчальних днів у тиждень; d4 - кількість пар у
день. Надалі ці змінні можна буде використати для перебору елементів масиву
ресурсу.

Для визначення кількості всіх зайнятих аудиторій використаємо
функцію пакета Mathematica - Sum. У загальному виді функція виглядає:[f, {i,
imin, imax}, {j, imin, jmax}, …] - визначення суми значень вираження f,
перебираючи елементи i, j,..., починаючи з min до max із кроком 1.
Функція Sum підраховує суму всіх елементів масиву М. Так як
масив М складається з 0 і 1 (0 - аудиторія вільна, 1 - аудиторія зайнята), то
функція Sum визначить кількість зайнятих аудиторій.

Для визначення вільного ресурсу необхідно від загального
ресурсу відняти зайнятий ресурс.
Загальний ресурс визначаємо перемноживши значення розмірності
вихідної матриці М. % - вказує на результат попереднього вираження, тобто від
загального ресурсу віднімаємо суму зайнятих аудиторій.

Щоб виразити в процентному співвідношенні вільний ресурс
необхідно знайти відношення вільного ресурсу до загального й помножити на 100%:

Створимо новий масив μμ, розмірністю вихідного
масиву М. Масив μμ складається з тих же значень, що й
масив М.
У новому масиві μμ замінимо ячейки рівні 0 на
змінні A{i, j, k, z} з індексами, які відповідають координатам ячейки. Ячейки
рівні 1 - очистимо.
Для реалізації даного завдання використаємо цикл For для
перебору елементів масиву μμ.
У пакеті Mathematica цикл For записується з наступними
параметрами:[start, test, incr, body] - спочатку один раз обчислюється
вираження start, потім по черзі обчислюються вираження в body і incr до тих
пір, поки умова test не перестане давати логічне значення True.
Використовуючи вкладені цикли For, здійснюємо перебір всіх
елементів масиву М. У тілі циклу застосовуємо оператор умови If. Загальний
вид:[condition, t, f] - Якщо умова (condition) є істина, тоді виконується дія
t, інакше - f.
За допомогою умови If порівнюємо кожне значення елемента
масиву М з 1. Якщо умова істина, тоді елементу масиву μμ с тими ж координатами
привласнюємо порожнє значення - {}. Якщо ж умова - неправда, тоді елементу
масиву μμ привласнюємо змінну А с відповідними
індексами (i, j, k, z) - які дорівнюють координатам поточнї ячейки.
Перебравши всі елементи масиву М и здійснивши всі задані
заміни, у підсумку одержимо новий масив μμ, у якому наочно видно вільні
елементи ресурсу.

Створимо масив, що складається тільки зі змінних A{i, j, k,
z}, тобто масив буде містити тільки елементи вільного ресурсу. Для цього в
пакеті Mathematica можна скористатися функцією Flatten[ ]. В якості параметра
вказується масив, що буде обробляти функція.
Новому масиву привласнимо ім'я fμ.
Запис: fμ
= Flatten[μμ] формує масив, у якому функція Flatten [ ] виключає порожні
значення - {} і залишає змінні A{i, j, k, z}
Сформуємо масив ffμ, шляхом перетворення
попереднього масиву, таким чином, щоб індекси {i, j, k, z} змінної А,
перебували на одному рівні зі змінною. Тобто масив ffμ повинен містити тільки
змінні А і набір масивів з відповідними індексами змінної А. Для цієї мети в
пакеті Mathematica скористаємося функцією Level[expr, levelspec]. Дана функція
представляє список всіх підвиражень значення expr на рівнях levelspec.
У програмі як параметри функції Level використаємо ім'я
попереднього масиву - fμ, значення рівня задаємо - {2}.

Сформуємо загальний список ресурсу. Кожний з елементів масиву
ресурсу являє собою підмножину параметрів - {i, j, k, z}. Кожне зі значень
визначають: i - порядковий номер тижня; j - індекс аудиторії; k - порядковий
номер дня тижня; z - порядковий номер пари в день.
Для створення подібного масиву в пакеті Mathematica можна
використати функцію Cases [expr, pattern ]. У параметрах функції необхідно
вказати ім'я масиву (expr) з якого будуть відбиратися елементи, що відповідають
зазначеному зразку(pattern).
Зміннійresurs привласнимо масив, що утворився. Це й буде
загальний список ресурсу, який можна буде використати для складання розкладу.
Для визначення довжини масиву ресурсу використаємо функцію
Length[].

Для того щоб масив ресурсу зберігся в первісному вигляді,
експортуємо його в окремий файл формату текст (Resurs.txt). Пакет Mathematica
містить вбудовану функцію Export, що і реалізує дане завдання. Загальний
вид:[“file”, expr, “format”] - як параметри функції необхідно вказати ім'я
створюваного файлу, вираження, яке потрібно експортувати у файл і формат файлу.

Щоб скористатися даними файлу Resurs.txt , необхідно його
імпортувати в робочий файл. Для цього використовується функція Import. Як
параметри функції Import необхідно вказати повний шлях до імпортованого файлу й
формат файлу.
Використання функції Import дозволяє в будь-який момент часу
переглянути загальний список ресурсу й порівняти його з поточними
перетвореннями. Також це допомагає в процесі створення алгоритму не акцентувати
увагу на всіх вищеописаних функціях при створенні списку ресурсу.

.2.2 Формування списку попиту
Список попиту являє собою одномірний масив, що складається з
підмножин - {i, j, k, z, r}. Кожне значення підмножини відповідає певному
параметру: i - вид аудиторії необхідний для проведення заняття , j - індекс
дисципліни, k - індекс викладача, z - необхідна кількість пар для проведення
заняття, r - індекс групи.

Співвідношення занять за їх видами виражено діаграмою (Мал
4.2):

Мал. 4.2 Співвідношення занять
Так як протягом семестру попит є відносно постійним, то для
зручності роботи з масивом, експортуємо його значення в окремий файл, формату
текст. Привласнимо йому ім'я NewSpros.txt.
Дане завдання реалізуємо з використанням функції Export. Як
параметри функції вказуємо ім'я створюваного файлу, дані які потрібно
експортувати в окремий файл і формат цього файлу.

Щоб скористатися даними файлу NewSpros.txt, необхідно його
імпортувати в робочий файл. У пакеті Mathematica використаємо функцію Import.
Як параметри функції вказуємо повний шлях до імпортованого файлу й формат
файлу.
Використання функції Import дозволяє в будь-який момент часу
переглянути загальний список попиту, виконати необхідні дії над ним,
редагувати.

.3 Генерація функцій користувача
4.3.1 Розрахункові функції
Створення кластерів.
Формування розкладу вимагає перебору всіх елементів попиту й
розподіл їх по існуючому ресурсі, дотримуючись всіх обмежень і критерій.
Варіантів таких розподілів величезна кількість. Вручну перебрати всі практично
неможливо.
Якщо ж перебирати всі можливі варіанти з використання ЕОМ,
по-перше, цей процес забере якийсь час, а по-друге, не раціонально перебирати
таку велику кількість елементів.
Для рішення проблеми використаємо метод формування й
використання кластерів. Кластер являє собою масив даних, обраних із загального
списку за заданим критерієм. Таким чином, відмовившись від послідовного
перебору всіх елементів загального списку ресурсу, перебір кластерів зменшує
час і число варіантів розподілу попиту по ресурсу, тим самим оптимізує цей
процес.
Створимо функцію в результаті роботи, якої формується
кластер, що містить вільні елементи ресурсу. Елементи ресурсу відбираються по
заданих днях тижня, з деякою періодичністю.
У пакеті Mathematica створимо функцію з параметрами. Ім'я
функції привласнимо aT1. Як
параметр вкажемо порядковий номер дня до якого необхідно формувати кластер і з
якою періодичністю перебирати дні.
Використаємо функцію пакета Mathematica - Block. У загальному
виді функція має вигляд:[{x, y,...}, expr], де {x, y,...} - локальні змінні,
еxpr - тіло функції.
У якості локальної змінної використаємо змінну r - для
перебору днів тижня.
У тілі функції використаємо вкладені цикли For. Функція
починає перебір елементів ресурсу починаючи з понеділка й до дня (D_),
зазначеного в параметрах функції aT1. У вкладених циклах перебираються тижні, обмежуючи число тижнів змінною
d1, описаною вище. Потім здійснюється перебір по індексах аудиторій. Кількість
аудиторій обмежена змінною d2, описаною вище. Далі перебір по парах у день ,
обмежуючи їхню кількість змінною d4. В останньому вкладеному циклі здійснюється
перебір по днях тижня. Але на відміну від попередніх циклів, де крок дорівнював
1, крок перебору днів тижня (р_) задається з використанням параметра функції aT1, тобто вказується з якою
періодичністю варто перебрати елементи.
Сформувавши в такий спосіб деякі значення {i, j, k, z} і скориставшись
функцією Cases можна створити список елементів, обраних із загального масиву
ресурсу по заданих параметрах.
Функція Join у пакеті Mathematica дозволяє об'єднати в один
масив всі списки, що формуються на етапах виконання функції aT1.
У загальному виді функція Join має вигляд:[list1, list2, ...]
- де list1, list2 - списки, які необхідно об'єднати в один масив.
В результаті виконання функції aT1 формується кластер, що містить
елементи вільного ресурсу із заданою періодичністю в днях, починаючи з понеділка
кожного тижня й до зазначеного дня.

Якщо необхідно відібрати елементи з періодичністю 5 днів,
починаючи з понеділка й до середи, тоді функція aT1 запишеться в такий спосіб:

Створимо функцію, результатом роботи якої, є формування
кластера, що містить вільні елементи ресурсу. Елементи кластера відповідають
наступним параметрам: дотримується періодичність (р_); елементи відбираються,
починаючи з понеділка кожного тижня й до зазначеного дня (D_); у списку тільки
задані індекс аудиторії (а_) і порядковий номер пари в день на якій буде
проводитися заняття (para_).
У пакеті Mathematica створимо функцію з ім'ям аТ2, для
виклику якої необхідно вказати всі перераховані вище параметри.
Опис функції аТ2 здійснюємо з використанням вбудованої
функції пакета Mathematica - Block. У якості локальної змінної використаємо
змінну r - для перебору днів тижня.
У тілі функції описуємо вкладені цикли For. Функція починає
перебір елементів списку ресурсу, починаючи з понеділка й до зазначеного в
параметрах функції дня тижня (D_). Для кожного дня тижня формується окремий
масив з ім'ям APrbeg. Індекс rbeg відповідає порядковому номеру дня тижня.
Викликавши функцію аТ2 і запросивши APrbeg, де rbeg задати конкретне значення
дня тижня, можна одержати кластер вільного ресурсу із заданими параметрами для
певного дня тижня.
Далі здійснюється перебір по тижнях, обмежуючи їхнє число
змінною d1, описаної вище. Потім провадиться перебір по днях тижня, обмеживши
число днів змінною d3. В останньому вкладеному циклі крок, з яким перебираються
елементи, задається з використанням параметра функції аТ2 (р_).
Так як в параметрах функції аТ2 можна вказати необхідний
індекс аудиторії (а_) і порядковий номер пари для проведення заняття (para_),
то ці ж значення використаються при створенні зразка вибірки в параметрах
функції Cases - {i, a, r, para}.
Функція Join дозволяє об'єднати в один масив всі списки, що
формуються на етапах виконання тіла функції аТ2. Змінна allT зберігає загальний список обраних
елементів.
Таким чином, формується кластер, що містить елементи ресурсу
із заданими параметрами періодичності, необхідного індексу аудиторії,
порядкового номера пари в день і дня до якого здійснюється вибірка.

Якщо необхідно відібрати елементи з періодичністю 5 днів,
починаючи з понеділка й до п'ятниці, по індексу аудиторії 1 для першої пари,
тоді функція аТ2 запишеться в такий спосіб:

Створимо функцію, результатом роботи якої є формування
кластера, що містить значення елементів вільного ресурсу із заданою
періодичністю, параметрами аудиторії й дня тижня до якого здійснюється вибірка
елементів.
У пакеті Mathematica створимо функцію з ім'ям аТ3, для виклику
якої необхідно вказати наступні параметри: періодичність з якою відбираються
дні (р_), порядковий номер дня тижня для якого провадиться вибірка (D_) і
індекс аудиторії, у якій необхідно проводити заняття (а_).
Використаємо функцію пакета Mathematica - Block. У якості
локальної змінної використаємо змінну r - для перебору днів тижня.
У тілі функції опишемо вкладені цикли For. Функція здійснює
перебір елементів ресурсу, починаючи з понеділка й до дня (D_), зазначеного в
параметрах функції аТ3. Потім провадиться перебір по тижнях, обмежуючи їхнє
число змінною d1. Далі реалізується перебір по парах у день, обмеживши їхню
кількість змінною d4. В останньому вкладеному циклі здійснюється перебір по
днях тижня. При цьому крок, з яким перебираються елементи в циклі, задається з
використанням параметра функції (р_).
Вказавши в параметрах функції аТ3 індекс необхідної
аудиторії, можна задати зразок вибірки в параметрах функції Cases - {i, a, r,
z}.
Використовуючи функцію Join поєднуємо всі підмножини, що
формуються на етапах виконання тіла функції аТ3.
При формуванні підмножини елементів для кожного дня тижня
(понеділка, вівторка й т.д.) використаємо змінну Arbeg. Індекс rbeg відповідає
порядковому номеру дня тижня. Викликавши функцію аТ3 і запросивши Arbeg, де
rbeg конкретне значення дня тижня, можна одержати кластер вільного ресурсу із
заданими параметрами для певного дня тижня. Але, крім цього, у результаті
роботи функції аТ3 формується загальний кластер, що містить список обраних
елементів вільного ресурсу з певними параметрами для всіх необхідних днів
тижня.

Якщо необхідно відібрати елементи з періодичністю 5 днів,
починаючи з понеділка й до середи, по індексу аудиторії 2, тоді функція аТ3
запишеться в такий спосіб:

Створимо функцію, в результаті роботи якої формується
кластер, що містить елементи вільного ресурсу з наступними параметрами:
періодичність днів, вказівка дня тижня до якого здійснюється вибірка й
необхідна кількість пар в тиждень для проведення занять.
У пакеті Mathematica створимо функцію з ім'ям arasp4, для
виклику якої необхідно задавати параметри: періодичність, з якої будуть
перебирати дні тижня (р_); порядковий номер дня тижня, до якого буде
провадитися вибірка елементів (D_) і необхідна кількість пар для проведення
заняття на тиждень (k_).
Для реалізації даного завдання в пакеті Mathematica
використаємо функцію Block. У якості локальної змінної використаємо змінну r -
для перебору днів тижня.
У тілі функції використаємо вкладені цикли For. Перший цикл
здійснює перебір елементів ресурсу, починаючи з понеділка й до дня (D_),
зазначеного в параметрах функції arasp4. Для кожного дня тижня формується
окрема підмножина rasprbeg. Індекс відповідає порядковому номеру дня тижня. Викликавши
функцію arasp4 і запросивши rasprbeg, де rbeg привласнити конкретне значення
дня тижня, можна одержати кластер вільного ресурсу із заданими параметрами для
окремого дня тижня.
У другому циклі перебираються тижні семестру, починаючи з
першої й до останньої, значення якої зберігається в змінній d1. В останньому
вкладеному циклі здійснюється перебір по днях тижня, де крок перебору елементів
задається з використанням параметра функції (р_).
Таким чином, формуються деякі значення {i, _, r, _}, де «_»
відповідає будь-якому значенню, що знаходиться на цьому місці. {i, _, r, _}
можна використати як зразок у параметрах функції Cases.
Пакет Mathematica дозволяє використати функцію Cases з
додатковими параметрами, у яких можна вказати кількість елементів вибірки. У
функції це й буде змінна (k_), що задається як параметри функції arasp4.
Функція Join поєднує підмножини, що формуються на етапах
виконання тіла функції arasp4.
В результаті, задаючи необхідні параметри при виконанні
функції arasp4, формується кластер, яким можна маніпулювати в процесі складання
розкладу.

Якщо необхідно відібрати елементи з періодичністю 5 днів,
починаючи з понеділка й до п'ятниці, у кількості 2 пар у тиждень, тоді функція
arasp4 запишеться в такий спосіб:

Створимо функцію, у результаті роботи якої, формується
кластер, що містить елементи вільного ресурсу з параметрами: необхідного
порядкового номера дня тижня й кількості пар для проведення занятть на тиждень.
У пакеті Mathematica створимо функцію з ім'ям Klaster1 для
виклику якої необхідно задавати наступне: день тижня (den_) і необхідну
кількість пар на тиждень (kvo_).
Для реалізації даного завдання в пакеті Mathematica
скористаємося функцією Block. У якості локальної змінної використаємо змінну r
- для перебору днів тижня.
У тілі функції використаємо вкладені цикли For. Перший цикл
здійснює перебір елементів ресурс по тижнях, обмежуючи кількість тижнів змінною
d1, описаної вище. У другому циклі проводиться перебір по днях тижня, обмежуючи
їхнє число змінною d3. При цьому крок перебору елементів задається не 1, як у
попередньому циклі, а зі збільшенням на 5. Такий крок дозволяє здійснювати
вибірку з необхідною періодичністю. У циклі перебір починаємо з дня, зазначеного
в параметрах функції Klaster1.
За допомогою функції Cases реалізуємо вибірку по заданому
зразку. В якості зразка сформуємо наступне вираження {i, _, r, _} - де i, r -
задані параметри (i - порядковий номер тижня, r - порядковий день тижня). Функцію
Cases використаємо з додатковими параметрами, у яких можна вказати кількість
елементів, що відбирають, по заданому зразку.
За допомогою функції Join поєднуємо підмножини, що формуються
на етапах виконання функції Klaster1.
У результаті виконання функції, задаючи необхідні параметри,
формується кластер, що містить значення вільного ресурсу, що задовольняють
задані умови. Сформований у такий спосіб кластер можна використати при
складанні розкладу.

Якщо необхідно відібрати елементи ресурсу для вівторка, у
кількості 2 пар у тиждень, тоді функція Klaster1 запишеться в такий спосіб:

Створимо функцію, в результаті роботи якої здійснюється
розподіл заданого попиту по заздалегідь сформованому ресурсу. При цьому є
необхідність вказати порядковий номер дня тижня, з якого починається розподіл.
В пакеті Mathematica для рішення поставленого завдання
створимо функцію з ім'ям Rasp. Для виклику функції необхідно задати в якості
параметру порядковий номер дня тижня, з якого починається розподіл попиту по
ресурсу (dned_).
Функцію Rasp опишемо за допомогою функції пакета Mathematica
- Block. Локальні змінні, які буде використовувати функція не передбачені, тому
на їхньому місці вкажемо порожню множину - { }.
У тілі функції використаємо вкладені цикли For. Перший цикл
здійснює перебір по елементах масиву попиту, починаючи з першого й до
останнього. Останній елемент списку попиту визначається за допомогою функції
Length. Функція повертає довжину списку, ім'я якого вказанно в параметрах
функції.
Другий цикл здійснює перебір по днях тижня, починаючи з дня,
зазначеного в параметрах функції Rasp. Тіло циклу складається з наступних
операторів: при кожному кроці формується порожній кластер { }. Потім за допомогою
оператора If порівнюємо кількість пар поточного елемента попиту з кількістю
тижнів у семестрі. Якщо кількість пар обраної дисципліни менше кількості тижнів
у семестрі, тоді формується кластер Kl з використанням функції Klaster1,
описаної вище. При цьому в параметрах функції Klaster1 необхідно вказати
кількість обраних елементів ресурсу рівне 1. Якщо ж умова не виконується тоді
формується кластер Kl з використанням функції Klaster1, але при цьому кількість
обраних елементів ресурсу рівне 2.
Далі, використовуючи оператор If, здійснюємо перевірку,
порівнюючи кількість пар обраної дисципліни з довжиною кластера, що
сформувався, Kl (Довжина визначається за допомогою функції Length). Якщо умова
задовольняється, тоді виконується цикл за допомогою функції For. У циклі
перебираються заняття обраної дисципліни, починаючи з першого й до останнього,
вираженим четвертим параметром у значенні елемента попиту. У тілі циклу
виконуємо наступні дії: змінній f привласнюємо значення позиції в якій
перебуває зазначений елемент. Для визначення позиції елемента в списку в пакеті
Mathematica використаємо функцію Position. Загальний вид функції:[list, expr] -
повертає значення позиції вираження expr у списку list.
Наступний оператор тіла циклу - це заміна елемента вільного
ресурсу на об'єднання елементів ресурсу й обраного попиту. Для цього
використовується функція ReplacePart. Загальний вид функції:[list, expr, pos] -
повертає список елементів list, у якому вираження expr заміняє елемент, що
знаходиться в позиції pos.
Загальному масиву ресурсу (resurs) привласнимо масив, у якому
за допомогою функції ReplacePart заміняємо елементи, що знаходяться в позиції f
об'єднанням обраного елемента попиту з ресурсом. Об'єднання здійснюємо за
допомогою функції Join.
Останнім оператором тіла циклу є присвоєння змінної beg,
значення при якому здійснюється вихід із циклу, у якому перебираються дні
тижня. Таким чином, реалізується перехід до наступного елемента попиту і його
подальший розподіл по ресурсу.
Якщо ж умова If, у якому порівнюється кількість пар обраної
дисципліни з довжиною кластера, що сформувався (Kl), не виконується, тоді для
цієї ж дисципліни формується новий кластер для наступного дня тижня.
Таким чином, при виконанні функції Rasp здійснюється розподіл
дисциплін по ресурсу. При цьому здійснюється перетворення початкового виду
масиву ресурсу, у якому на деяких позиціях встановлені об'єднання елементів
попиту й ресурсу.

Якщо необхідно розподілити попит по ресурсу, починаючи з
понеділка, тоді функція Rasp запишеться в такий спосіб:

Сформуємо масив, що складається з розподілених елементів
попиту по ресурсу. Масиву привласнимо ім'я gotovo. За допомогою функції Cases
здійснимо вибірку з перетвореного масиву resurs елементів за зразком {{_, _, _,
_, _},{_, _, _, _}}.

При необхідності можна здійснити вибірку по заданому елементу
попиту. Для реалізації даного завдання в пакеті Mathematica використаємо
функцію Cases.
Як джерело-масив використаємо масив resurs. В якості зразка,
за яким буде здійснюватися вибірка, можна скористатися наступним вираженням: {
{2, 5, 1, 6, 2}, {_, _, _, _} }, де значення {2, 5, 1, 6, 2} є певним елементом
попиту й відбір буде проводитися тільки для даного елементу.

За допомогою функції Length можна визначити кількість
розподілених пар для заданої дисципліни. Для цього як параметри функції Length
вкажемо значення попереднього вираження (%).

Описана вище, функція Rasp має недолік у тім, що при
розподілі не враховується необхідність наявності певної аудиторії для
проведення конкретного заняття.
Співвідношення вільних аудиторій за їх видами представлено
діаграмою (Мал.4.3).

Мал. 4.3 Співвідношення аудиторій
Для рішення цього завдання створимо функцію, в результаті
роботи якої формується кластер, що містить елементи вільного ресурсу. Значення
кластера є елементами ресурсу, призначеного для проведення занять, що вимагають
наявності комп'ютерів.
У пакеті Mathematica створимо функцію kks. Для виклику
функції необхідно вказати, як параметр, ім'я масиву з якого буде здійснюватися
вибірка (www_).
Тіло функції kks опишемо за допомогою функції пакета
Mathematica - Block. Так як локальних змінних у функції не передбачено, то на
місці їхнього опису залишаємо порожнюя множуну - { }. У тілі функції
використаємо цикл For. Даний цикл здійснює перебір по індексах аудиторій. У
базі даних аудиторії з індексами 1 - 5 є аудиторіями в наявності яких є
комп'ютери. Тому перебір у циклі проводиться від аудиторії з індексом 1 і до
аудиторії з індексом 5.
У тілі циклу за допомогою функції Cases реалізуємо вибірку
елементів. Як параметри функції вказуємо ім'я масиву, з яким буде працювати
функція. Ім'я масиву передається з параметрів функції kks (www_). Як зразок у
функції Cases використаємо вираження: {_, j, _, _}, де j виступає конкретним
значенням аудиторії.
За допомогою функції Join поєднуємо підмножини, що формуються
на етапах виконання функції kks.
У підсумку одержуємо масив з ім'ям vub, що містить елементи
вільного ресурсу, призначеного для проведення занять потребуючих наявності
комп'ютерів.

Якщо задати як масив-джерело ім'я масиву resurs, тоді функція
kks запишеться в такий спосіб:

Створимо функцію, у результаті роботи якої формується
кластер, що містить елементи вільного ресурсу. Значення кластера є елементами
ресурсу, призначеного для проведення занять з дисципліни - Електроніка та
мікросхемотехніка.
У пакеті Mathematica створимо функцію el. Для виклику функції
необхідно вказати, в якості параметру, ім'я масиву з якого буде здійснюватися
вибірка (www_).
Тіло функції el опишемо за допомогою функції пакета
Mathematica - Block. Так як локальних змінних у функції не передбачено, то на
місці їхнього опису залишаємо порожню множину - { }. У тілі функції
використаємо цикл For. Даний цикл здійснює перебір по індексах аудиторій. У
базі даних аудиторія з індексом 6 є аудиторією для проведення занятть з
дисципліни електроніка та мікросхемотехніка.
У тілі циклу за допомогою функції Cases реалізуємо вибірку
елементів. Як параметри функції вказуємо ім'я масиву, з яким буде працювати функція.
Ім'я масиву передається з параметрів функції el (www_). Як зразок у функції
Cases використаємо вираження: {_, j, _, _}, де j виступає конкретним значенням
аудиторії.
За допомогою функції Join поєднуємо підмножини, що формуються
на етапах виконання функції el.
У підсумку одержуємо масив з ім'ям vub, що містить елементи
вільного ресурсу, призначеного для проведення занять з дисципліни - Електроніка
й мікросхемотехніка.

Якщо задати як масив-джерело ім'я масиву resurs, тоді функція
el запишеться в такий спосіб:

Створимо функцію, в результаті роботи якої формується
кластер, що містить елементи вільного ресурсу. Значення кластера є елементами
ресурсу, призначеного для проведення лабораторних робіт з фізики.
У пакеті Mathematica створимо функцію fiz. Для виклику
функції необхідно вказати, в якості параметру, ім'я масиву з якого буде
здійснюватися вибірка (www_).
Тіло функції fiz опишемо за допомогою функції пакета
Mathematica - Block. Так як локальних змінних у функції не передбачено, то на
місці їхнього опису залишаємо порожню множину - { }.
У тілі функції використаємо цикл For. Даний цикл здійснює
перебір по індексах аудиторій. У базі даних аудиторія з індексом 7 є аудиторією
для проведення лабораторних робіт з фізики.
У тілі циклу за допомогою функції Cases реалізуємо вибірку
елементів. Як параметри функції вказуємо ім'я масиву, з яким буде працювати
функція. Ім'я масиву передається з параметрів функції fiz (www_). Як зразок у
функції Cases використаємо вираження: {_, j, _, _}, де j виступає конкретним
значенням аудиторії.
За допомогою функції Join поєднуємо підмножини, що формуються
на етапах виконання функції fiz.
У підсумку одержуємо масив з ім'ям vub, що містить елементи
вільного ресурсу, призначеного для проведення лабораторних робіт з фізики.
Якщо задати як масив-джерело ім'я масиву resurs, тоді функція
fiz запишеться в такий спосіб:

Створимо функцію, в результаті роботи якої формується
кластер, що містить елементи вільного ресурсу. Значення кластера є елементами
ресурсу, призначеного для проведення лабораторних робіт з хімії.
В пакеті Mathematica створимо функцію him. Для виклику
функції необхідно вказати, як параметр, ім'я масиву з якого буде здійснюватися
вибірка (www_).
Тіло функції him опишемо за допомогою функції пакета
Mathematica - Block. Так як локальних змінних у функції не передбачено, то на
місці їхнього опису залишаємо порожню множину - { }.
У тілі функції використаємо цикл For. Даний цикл здійснює
перебір по індексах аудиторій. У базі даних аудиторії з індексами 8 - 9 є
аудиторіями для проведення лабораторних робіт з хімії.
У тілі циклу за допомогою функції Cases реалізуємо вибірку
елементів. Як параметри функції вказуємо ім'я масиву, з яким буде працювати
функція. Ім'я масиву передається з параметрів функції him (www_). Як зразок у
функції Cases використаємо вираження: {_, j, _, _}, де j виступає конкретним
значенням аудиторії.
За допомогою функції Join поєднуємо підмножини, що формуються
на етапах виконання функції him.
У підсумку одержуємо масив з ім'ям vub, що містить елементи
вільного ресурсу, призначеного для проведення лабораторних робіт з хімії.

Якщо задати як масив-джерело ім'я масиву resurs, тоді функція
him запишеться в такий спосіб:

Створимо функцію при роботі якої формується кластер, що
містить елементи вільного ресурсу, призначеного для проведення лекційних
занять.
В пакеті Mathematica створимо функцію з ім'ям leks. Для
виклику функції необхідно вказати, як параметр, ім'я масиву з якого буде
здійснюватися вибірка (www_).
Тіло функції leks опишемо за допомогою функції пакета
Mathematica - Block. Так як локальних змінних у функції не передбачено, то на
місці їхнього опису залишаємо порожню множину - { }.
У тілі функції використаємо цикл For. Даний цикл здійснює
перебір по індексах аудиторій. У базі даних аудиторії з індексами 10 - 37 є
аудиторіями для проведення лекцій.
У тілі циклу за допомогою функції Cases реалізуємо вибірку
елементів. Як параметри функції вказуємо ім'я масиву, з яким буде працювати
функція. Ім'я масиву передається з параметрів функції leks (www_). Як зразок у
функції Cases використаємо вираження: {_, j, _, _}, де j виступає конкретним
значенням аудиторії.
За допомогою функції Join поєднуємо підмножини, що формуються
на етапах виконання функції leks.
В результаті роботи функції leks одержуємо масив з ім'ям vub,
що містить елементи вільного ресурсу, призначеного для проведення лекцій.

Якщо задати як масив-джерело ім'я масиву resurs, тоді функція
leks запишеться в такий спосіб:

Створимо функцію при роботі якої формується кластер, що
містить елементи вільного ресурсу, призначеного для проведення практичних
занять.
У пакеті Mathematica створимо функцію з ім'ям prs. Для
виклику функції необхідно вказати, в якості параметру, ім'я масиву з якого буде
здійснюватися вибірка (www_).
Тіло функції prs опишемо за допомогою функції пакета
Mathematica - Block. Так як локальних змінних у функції не передбачено, то на
місці їхнього опису залишаємо порожню множину - { }.
У тілі функції використаємо цикл For. Цикл здійснює перебір
по індексах аудиторій. У базі даних аудиторії з індексами 38 - 40 є аудиторіями
для проведення практичних занять.
У тілі циклу за допомогою функції Cases реалізуємо вибірку
елементів. Як параметри функції вказуємо ім'я масиву, з яким буде працювати
функція. Ім'я масиву передається з параметрів функції prs (www_). Як зразок у
функції Cases використаємо вираження: {_, j, _, _}, де j виступає конкретним
значенням аудиторії.
За допомогою функції Join поєднуємо підмножини, що формуються
на етапах виконання функції prs.
В результаті роботи функції prs одержуємо масив з ім'ям vub,
що містить елементи вільного ресурсу, призначеного для проведення практичних
занять.

Якщо задати як масив-джерело ім'я масиву resurs, тоді функція
prs запишеться в такий спосіб:

Необхідно відзначити, у функціях kks[www_], el[www_],
iz[www_], him[www_], leks[www_], prs[www_], описаних вище, значення індексів
аудиторій задаються згідно попередньо сформованої в певному порядку бази даних.
База даних аудиторій являє собою впорядкований по індексах
список можливих до використання аудиторій. Список ділиться на блоки по
призначенню аудиторій для проведення певних дисциплін.
Створимо функцію, у результаті роботи якої, формується
кластер, що містить елементи вільного ресурсу. Елементи кластера відбираються
із заданого масиву-джерела даних для певного дня тижня, при цьому задається
необхідна кількість пар для проведення заняття на тиждень.
У пакеті Mathematica створимо функцію з ім'ям Klaster. Для
виклику функції необхідно вказати наступні параметри: масив-джерело даних
(masiv_), порядковий номер дня тижня для якого необхідно провести відбір (r_),
необхідну кількість пар для проведення занять по певній дисципліні в тиждень
(kvo_).
Тіло функції Klaster опишемо за допомогою функції пакета
Mathematica - Block. Локальних змінних у функції не передбачено, тому на місці
їхнього опису залишаємо порожню множину - { }.
У тілі функції використаємо цикл For. Цикл здійснює перебір
по тижнях, починаючи з першого й закінчуючи останнім, котрий визначений
змінноюї d1, описаної вище.
У тілі циклу реалізуються наступні дії: змінній chet
привласнюємо 1. Дана змінна необхідна для контролю кількості пар по заданій
дисципліні в тиждень. Наступним оператором циклу є вкладений цикл For, що
здійснює перебір по парах у день. У тілі вкладеного циклу виконуємо оператор
умови If. За допомогою умовного оператора здійснюємо перевірку на кількість пар
по дисципліні в тиждень. Якщо ж змінна chet, що змінюється при роботі функції
Klaster не перевищує заданий параметр функції (kvo_), тоді за допомогою функції
Cases проводимо вибірку елементів. У параметрах функції Cases вказуємо ім'я
масиву-джерела (masiv_); зразок, по якому відбираються елементи {i, _, r, z} і
їхню кількість (1). Результат вибірки заносимо в змінну τ. Далі, використовуючи ще
один оператор If здійснюємо перевірку отриманого результату, що перебуває в
змінній τ. Якщо змінна не дорівнює порожній
безлічі, тоді використовуючи функцію Join формуємо загальний масив кластера,
шляхом об'єднання елементів. Після проводимо нарощування змінної chet, щоб не
вийти за межі, визначені в параметрах функції Klaster.
Таким чином, викликавши функцію Klaster і задавши необхідні
параметри, формується кластер, що містить елементи вільного ресурсу із заданими
параметрами.

Якщо необхідно відібрати елементи ресурсу для понеділка, у
кількості 3 пар у тиждень, тоді функція Klaster запишеться в такий спосіб:

Створимо функцію, в результаті роботи якої, здійснюється
розподіл дисциплін по необхідних аудиторіях. При цьому можна вказати, з якого
дня тижня необхідно почати розподіл.
В пакеті Mathematica створимо функцію з ім'ям Rasp1. Для
виклику функції необхідно вказувати як параметр день тижня, з якого потрібно
почати розподіл (dned_).
Формування тіла функції Rasp1опишемо за допомогою функції
пакета Mathematica - Block. Так як локальні змінні у функції використовуватися
не будуть, то на їхньому місці опису вкажемо порожню множину - { }.
У тілі функції використаємо цикл For. Цикл здійснює перебір
елементів масиву попиту, починаючи з першого й до останнього. Останній елемент
списку попиту визначаємо за допомогою функції Length. У тілі циклу змінній est
привласнимо 0. Дана змінна необхідна для визначення невдалого розподілу. Потім
змінній ррр привласнимо значення результату роботи функції Which.
Функція Which є вбудованою функцією пакета Mathematica і
являє собою умовний оператор з деяким числом порівнянь.
У функції Rasp1 оператор Which реалізує наступні порівняння:
якщо перше значення в елементі попиту дорівнює 1 (тобто дисципліна для
проведення заняття вимагає аудиторію з наявністю комп'ютера ), тоді змінній ррр
буде привласнений кластер, сформований за допомогою функції kks[www_], описаної
вище. Якщо перше значення в елементі попиту дорівнює 2 (тобто необхідна
аудиторія для проведення лабораторного заняття по дисципліні - Електроніка та мікросхемотехніка
), тоді змінній ррр буде привласнений кластер, сформований за допомогою функції
el[www_]. Якщо перше значення в елементі попиту дорівнює 3 (тобто необхідна
аудиторія для проведення лабораторного заняття по фізиці ), тоді змінній ррр
буде привласнений кластер, сформований за допомогою функції fiz[www_]. Якщо
перше значення в елементі попиту дорівнює 4 (тобто необхідна аудиторія для
проведення лабораторного заняття по хімії), тоді змінній ррр буде привласнений
кластер, сформований за допомогою функції him[www_]. Якщо перше значення в
елементі попиту дорівнює 5 (тобто необхідна аудиторія для проведення лекцій),
тоді змінній ррр буде привласнений кластер, сформований за допомогою функції
leks[www_]. Якщо ж перше значення в елементі попиту дорівнює 6 (тобто необхідна
аудиторія для проведення практичних занять), тоді змінній ррр буде привласнений
кластер, сформований за допомогою функції prs[www_]. Наступний оператор циклу -
вкладений цикл For. Цикл здійснює перебір по днях тижня, починаючи із дня зазначеного
в параметрах функції Rasp1. У тілі вкладеного циклу використовується умовний
оператор If. Оператор здійснює порівняння четвертого значення елемента попиту
(тобто значення, що визначає кількість пар по дисципліні на семестр) зі змінною
d1, що визначає кількість тижнів у семестрі. Якщо кількість пар по дисципліні
не перевищує кількість тижнів у семестрі, тоді змінній Kl привласнюється
значення кластера, сформованого за допомогою функції Klaster [masiv_, r_,
kvo_], описаної вище. При цьому параметри функції Klaster [masiv_, r_, kvo_]
наступні: як масив-джерело даних використається масив, сформований на
попередньому етапі (ррр); день тижня для якого здійснюється вибірка передається
із циклу (beg); кількість пар для дисципліни на тиждень визначено 1.
Якщо ж умова не виконується, тобто кількість пар для певної
дисципліни більше кількості тижнів у семестрі, тоді змінної Kl привласнимо
значення кластера, формування якого здійснюється за допомогою тієї ж функції
Klaster [masiv_, r_, kvo_] з тими ж параметрами, тільки замість проведення
одного заняття в тиждень, вкажемо 2.
Потім за допомогою оператора If здійснюємо порівняння
четвертого значення елемента попиту (тобто значення, що визначає кількість пара
по дисципліні на семестр) з кількістю елементів масиву Kl, сформованого на
попередньому етапі. Кількість елементів масиву Kl визначаємо за допомогою
функції Length. Якщо умова (If) виконується, тоді реалізуємо розподіл,
використовуючи цикл For. Цикл здійснює перебір по порядкових номерах пар
дисципліни. У тілі циклу змінній f за допомогою функції Position передаємо
значення позиції елемента масиву Kl у масиві ресурсу (resurs). Потім за
допомогою функції ReplacePart перетворимо масив ресурсу (resurs) у такий
спосіб: заміняємо елемент, що перебуває в позиції f, об'єднанням (Join)
елемента попиту й ресурсу.
Якщо розподіл поточної дисципліни зроблено, то необхідно
перейти до наступного елемента попиту й почати розподіл для нього. Для цього
необхідно вийти із циклу по перебору днів. За для цієї мети привласнимо змінній
beg значення 6. І так як розподіл вдався, значення змінної est змінюємо на 1.
Якщо розподіл не вдався, то виводиться відповідне
повідомлення. Для цього використається умовний оператор If. Якщо змінна est
дорівнює 0, тоді за допомогою функції Print виводимо повідомлення: «Не вдалося
розподілити елемент попиту» і вказуємо сам елемент. Інакше залишаємо змінну est
без змін.
Таким чином, у результаті роботи функції Rasp1 здійснюється
розподіл попиту по ресурсу із заданими умовами.

Якщо необхідно здійснити розподіл, починаючи з понеділка,
тоді функція Rasp1 прийме вигляд:

Функція Rasp1 здійснює розподіл дисциплін по аудиторіях не
враховуючи те, що той самий викладач не може проводити заняття в той самий день
на одній і тій же парі, але в різних аудиторіях. Теж саме стосується й груп
студентів. Група не може одночасно займатися декількома дисциплінами. Для
вирішення цієї проблеми створимо нову функцію.
У пакеті Mathematica функції привласнимо ім'я Rasрred. Для
виклику функції необхідна вказати порядковий день тижня з якого потрібно почати
розподіл (dned_).
Формування тіла функції Rasрred опишемо за допомогою функції
пакета Mathematica - Block. Так як локальні змінні у функції використовуватися
не будуть, то на їхньому місці опису вкажемо порожню множину - { }.
У тілі функції змінній beg привласнимо результат роботи
функції Which. Змінна beg необхідна для зберігання порядку перебору днів тижня.
Функція Which реалізує наступні умови: якщо змінна dned, зазначена в параметрах
функції Rasрred дорівнює 1 (тобто розподіл необхідно почати з понеділка), тоді
змінній beg буде привласнений масив dd, сформований заздалегідь. Масив dd являє
собою набір чисел від 1 до 5.

Якщо змінна dned дорівнює 2 (тобто розподіл потрібно почати з
вівторка), тоді змінна beg одержить результат роботи функції RotateLeft. Дана
функція змінює порядок розташування чисел у масиві, шляхом зрушення вліво. Загальний
вид функції: RotateLeft [expr, n] - елементи вираження expr зрушуються вліво на
n позицій.Функція RotateRight [expr, n] змінює порядок розташування чисел у
масиві, шляхом зрушення вправо.
Використовуючи RotateLeft і RotateRight у функції Which
формуємо масив з необхідним порядком розташування днів.
Наступний оператор тіла функції - цикл For. Цикл здійснює
перебір елементів масиву попиту, починаючи з першого й до останнього. Останній
елемент списку попиту визначаємо за допомогою функції Length.
У тілі циклу змінним U, T, vse привласнимо порожню множину -
{ }. Потім змінній tch привласнимо масив, сформований за допомогою функції
Cases. Функція здійснює вибірку елементів з масиву resurs за зразком {{_, _,
spros[[p]][[3]], _, _}, {_, _, _, _}}, де spros[[p]][[3]] вказує на поточне
значення індексу викладача. Тобто здійснюється вибірка вже розподілених
елементів попиту по індексу викладача. Далі використаємо цикл For. У циклі
реалізуємо перебір елементів, сформованого на попередньому етапі масиву tch. У
тілі циклу змінної tchudel привласнимо порожню множину { }. Використовуючи
функцію Cases здійснимо вибірку з масиву попиту resurs елементів за зразком
{tch[[m]][[2]][[1]], _, tch[[m]] [[2]] [[3]], tch[[m]] [[2]] [[4]]}, де
tch[[m]][[2]][[1]], tch[[m]] [[2]] [[3]], tch[[m]] [[2]] [[4]] - конкретні
значення елементів попиту. Результат вибірки збережемо в змінній tchudel.
Множини tchudel, що формуються в циклі, об'єднаємо в єдиний масив U. Для цього
використаємо функцію пакета Mathematica - Union. Таким чином, здійснюється
вибір елементів ресурсу по викладачах, для яких розподіл поточного попиту
неможливо.
Подібним способом здійснюємо вибір елементів попиту по
групах, для яких розподіл поточного попиту неможливо. Змінній st привласнимо
масив, сформований за допомогою функції Cases. Функція здійснює вибірку
елементів з масиву resurs за зразком {{_, _, _, _, spros[[p]][[5]]}, {_, _, _,
_}}, де spros[[p]][[5]] вказує на поточне значення індексу групи. Тобто
здійснюється вибірка вже розподілених елементів попиту по індексу групи. Далі
використаємо цикл For. У циклі реалізуємо перебір елементів, сформованого на
попередньому етапі масиву st. У тілі циклу змінній studel привласнимо порожню
множуну { }. Використовуючи функцію Cases здійснимо вибірку з масиву попиту
resurs елементів за зразком {st[[k]][[2]][[1]], _, st[[k]] [[2]] [[3]], st[[k]]
[[2]] [[4]]}, де st[[k]] [[2]][[1]], st[[k]] [[2]] [[3]], st[[k]] [[2]] [[4]] -
конкретні значення елементів попиту. Результат вибірки збережемо в змінній
studel. Множини studel, що формуються в циклі, об'єднаємо в єдиний масив T.
Сформований масив U і масив Т об'єднаємо за допомогою функції
Union у єдиний масив з ім'ям vse. Це буде масив ресурсу, для якого неможливе
розподіл поточного елемента попиту.
Далі змінній ррр привласнимо значення результату роботи
функції Which. Оператор Which реалізує наступні порівняння: якщо перше значення
в елементі попиту рівняється 1 (тобто дисципліна для проведення заняття вимагає
аудиторію з наявністю комп'ютера ), тоді змінній ррр буде привласнений кластер,
сформований за допомогою функції kks[www_], описаної вище. Як масив-джерело
(www_) у цьому випадку й у наступних, використаємо вираження Сomplement[resurs,
vse]. За допомогою функції пакета Mathematica - Сomplement виключаємо із
загального масиву ресурсу елементи для яких розподіл за поточним елементом
попиту неможливо.
Якщо перше значення в елементі попиту рівняється 2 (тобто
необхідна аудиторія для проведення лабораторного заняття по дисципліні -
Електроніка й мікросхемотехніка ), тоді змінній ррр буде привласнений кластер,
сформований за допомогою функції el[www_].
Якщо перше значення в елементі попиту рівняється 3 (тобто
необхідна аудиторія для проведення лабораторного заняття по фізиці ), тоді
змінній ррр буде привласнений кластер, сформований за допомогою функції
fiz[www_].
Якщо перше значення в елементі попиту рівняється 4 (тобто
необхідна аудиторія для проведення лабораторного заняття по хімії), тоді
змінній ррр буде привласнений кластер, сформований за допомогою функції
him[www_].
Якщо перше значення в елементі попиту рівняється 5 (тобто
необхідна аудиторія для проведення лекцій), тоді змінній ррр буде привласнений
кластер, сформований за допомогою функції leks[www_].
Якщо ж перше значення в елементі попиту рівняється 6 (тобто
необхідна аудиторія для проведення практичних занять), тоді змінній ррр буде
привласнений кластер, сформований за допомогою функції prs[www_].
Змінній est привласнимо 0. Дана змінна необхідна для
визначення невдалого розподілу.
Наступний оператор циклу - вкладений цикл For. Цикл здійснює
перебір по днях тижня, використовуючи масив beg, сформований раніше. У тілі
вкладеного циклу змінної Kl привласнимо значення результату роботи функції
Which. Оператор Which реалізує наступні порівняння: якщо четверте значення
елемента попиту (тобто значення, що визначає кількість пар по дисципліні на
семестр) менше змінної d1, що визначає кількість тижнів у семестрі, тоді
змінній Kl привласнимо значення кластера, сформованого за допомогою функції
Klaster [masiv_, r_, kvo_], описаної вище. При цьому параметри функції Klaster
[masiv_, r_, kvo_] наступні: як масив-джерело даних використовується масив,
сформований на попередньому етапі (ррр); день тижня для якого здійснюється
вибірка передається із циклу (beg); кількість пар для дисципліни на тиждень
визначено 1.
Якщо четверте значення елемента попиту не перевищує значення
2·d1, де d1 - кількість тижнів на семестр, тоді змінній Kl привласнимо значення
кластера, сформованного за допомогою функції Klaster [masiv_, r_, kvo_],
описаної вище. При цьому параметри функції Klaster [masiv_, r_, kvo_] наступні:
як масив-джерело даних використовується масив, сформований на попередньому
етапі (ррр); день тижня для якого здійснюється вибірка передається із циклу
(beg); кількість пар для дисципліни на тиждень визначено 2.
Аналогічним способом здійснюємо наступну перевірку кількості
пар по дисципліні на семестр з кількістю тижнів і формуємо кластери з
відповідними параметрами.
Потім за допомогою оператора If здійснюємо порівняння
четвертого значення елемента попиту (тобто значення, що визначає кількість пар
по дисципліні на семестр) з кількістю елементів масиву Kl, сформованого на
попередньому етапі. Кількість елементів масиву Kl визначаємо за допомогою
функції Length. Якщо умова (If) виконується, тоді реалізуємо розподіл,
використовуючи цикл For. Цикл здійснює перебір по порядкових номерах пар
дисципліни. У тілі циклу змінній f за допомогою функції Position передаємо
значення позиції елемента масиву Kl у масиві ресурсу (resurs). Потім за
допомогою функції ReplacePart перетворимо масив ресурсу (resurs) у такий
спосіб: заміняємо елемент, що перебуває в позиції f, об'єднанням (Join)
елемента попиту й ресурсу.
Якщо розподіл поточної дисципліни зроблено, то необхідно
перейти до наступного елемента попиту й почати розподіл для нього. Для цього
необхідно вийти з циклу по перебору днів. З цією метою привласнимо змінній beg
значення 6. І так як розподіл вдався, значення змінної est змінюємо на 1.
Якщо розподіл не вдався, то виводиться відповідне
повідомлення. Для цього використається умовний оператор If. Якщо змінна est
дорівнює 0, тоді за допомогою функції Print виводимо повідомлення: «Не вдалося
розподілити елемент попиту» і вказуємо сам елемент. Інакше залишаємо змінну est
без змін.
Таким чином, у результаті роботи функції Raspred здійснюється
розподіл попиту по ресурсу із заданими умовами.



Якщо необхідно здійснити розподіл, починаючи з понеділка,
тоді функція Raspred прийме вигляд:

4.3.2 Функції виводу інформації
Логіко-функціональна схема роботи користувача з системою
представлена наступною блок-схемою:

1. Ввод користувачем дня з якого необхідно почати розподіл
(1 - Пн, 2 - Вт, 3 - Ср, 4 - Чт, 5 - Пт)
. Вивести таблицю розкладу за групами?
. Вивести таблицю розкладу за викладачами?
. Вивести загальну таблицю розкладу?
. Друк таблиці розкладу за групами.
. Друк таблиці розкладу за викладачами.
. Друк загальної таблиці розкладу.
. Чи влаштовує користувача сформований розклад?
При наявності сформованого розкладу можна створити функцію,
результатом роботи якої є вивод на екран розкладу по заданому індексу аудиторії
на весь семестр.
У пакеті Mathematica створимо функцію з ім'ям class. Для
виклику функції необхідно в якості параметру вказати індекс аудиторії (_ind).
Тіло функції class опишемо за допомогою вбудованої функції
пакета Mathematica - Block. Так як локальних змінних у функції не передбачено,
то на місці їхнього опису залишаємо порожню множцну - { }.
У тілі функції використаємо оператор Print для виводу
повідомлення для якої аудиторії виводиться розклад. Потім формуємо таблицю, що
складається з нулів, розмірністю 9 × 1 × 5
× 6. Для
цього використаємо функцію Table. Таблиці привласнимо ім'я cl. Далі
використаємо цикл For. Цикл здійснює перебір по тижнях. Кількість тижнів
обмежено змінною d1, описаної вище. У тілі циклу використаємо вкладений цикл по
перебору днів тижня, починаючи з першого й до останнього, визначеного змінною
d3. У тілі вкладеного циклу реалізуємо ще один вкладений цикл For, що здійснює
перебір по парах у день. Кількість пар визначена змінною d4. Таким чином,
перебираючи елементи масиву cl кожному значенню привласнимо вираження масиву
ltab з тими ж координатами номера тижня, дня й пари в день, а індекс аудиторії
відповідає значенню, зазначеному в параметрах функції class. Масив ltab являє
собою список, що містить дані про зайняті й вільні елементи ресурсу, виражених
у вигляді 0 і 1 (0 - вільний, 1 - зайнятий), а також розподілених елементів
попиту, виражених у вигляді даних про назву дисципліни, прізвище викладача й
групи студентів.
Використовуючи функцію пакета Mathematica - TableForm
представимо дані масиву cl у табличній формі.

Якщо задати як параметр функції cl індекс аудиторії 2, тоді
результатом роботи функції буде наступна таблиця:

Можна також реалізувати вивод по індексу тижня. Для цього в
пакеті Mathematica створимо функцію з ім'ям nedelja. Для виклику функції
необхідно, як параметр вказати індекс тижня (_ind).
Тіло функції nedelja опишемо за допомогою вбудованої функції
пакета Mathematica - Block. Так як локальних змінних у функції не передбачено,
то на місці їхнього опису залишаємо порожню множину - { }.
У тілі функції використаємо оператор Print для виводу
повідомлення для якого тижня виводиться розклад. Потім формуємо таблицю, що
складається з нулів, розмірністю 45 × 1 × 5
× 6. Для
цього використаємо функцію Table. Таблиці привласнимо ім'я cl. Далі
використаємо цикл For. Цикл здійснює перебір по аудиторіях. Кількість аудиторій
обмежено змінною d2, описаної вище. У тілі циклу використаємо вкладений цикл по
перебору днів тижня, починаючи з першого й до останнього, визначеного змінною
d3. У тілі вкладеного циклу реалізуємо ще один вкладений цикл For, що здійснює
перебір по парах у день. Кількість пар визначено змінною d4. Таким чином,
перебираючи елементи масиву cl кожному значенню привласнимо вираження масиву
mout з тими ж координатами номера аудиторії, дня й пари в день, а індекс тижня
відповідає значенню, зазначеному в параметрах функції nedelja. Масив mout є
результатом транспонування матриці ltab , що містить дані про зайняті й вільні
елементи ресурсу, виражених у вигляді 0 і 1 (0 - вільний, 1 - зайнятий), а
також розподілених елементів попиту, виражених у вигляді даних про назву
дисципліни, прізвище викладача й групи студентів.
Використовуючи функцію пакета Mathematica - TableForm
представимо дані масиву cl у табличній формі.

Якщо задати як параметр функції nedelja індекс тижня 2, тоді
результатом роботи функції буде наступна таблиця:

5.
ЕКОНОМІЧНЕ ОБҐРУНТУВАННЯ ДОЦІЛЬНОСТІ РОЗРОБКИ ПРОГРАМНОГО ПРОДУКТУ
.1 Організаційно-економічна
частина
Розробка програмного забезпечення залишається дотепер досить
трудомістким процесом. Організація
й планування процесу розробки програмного продукту або програмного комплексу
при традиційному методі планування передбачає виконання наступних робіт:
o формування складу виконуваних робіт і
угруповання їх по стадіях розробки;
o розрахунок трудомісткості виконання
робіт;
o установлення професійного складу й
розрахунок кількості виконавців;
o визначення тривалості виконання
окремих етапів розробки;
o побудова календарного графіка
виконання розробки;
o контроль виконання календарного
графіка.
Трудомісткість розробки програмної продукції залежить від
ряду факторів, основними з яких є наступні: ступінь новизни розроблювального
програмного комплексу, складність алгоритму його функціонування, обсяг
використовуваної інформації, вид її подання й спосіб обробки, а також рівень
використовуваної алгоритмічної мови програмування. Всі перераховані фактори впливають
на процес формування ціни продукту, що з економічної точки зору є найбільш
важливим моментом для розроблювача.
Програмні продукти являють собою досить специфічний товар з
безліччю властивих їм особливостей. Багато їхніх особливостей проявляються й у методах
розрахунків ціни на них. На розробку програмного продукту середньої складності
звичайно потрібні досить незначні засоби. Однак, при цьому вона може дати
економічний ефект, що значно перевищує ефект від використання досить дорогих систем.
Варто підкреслити,
що у програмних продуктів практично відсутній процес фізичного старіння й
зношування. Для них основні витрати доводяться на розробку зразка, тоді як
процес тиражування являє собою, звичайно, порівняно нескладну й недорогу
процедуру копіювання магнітних носіїв і супровідної документації.
Цей програмний продукт призначений для автоматизації процесу
складання розкладу в учбових закладах різних рівнів.
Алгоритм проекту реалізуємо в системі Mathematica.
Необхідні для розробки програмного продукту засоби
обчислювальної техніки: персональна ЕОМ на базі процесора Pentium IV с тактовою
частотою 2,1 Мгц, 512 Мб оперативної пам’яті, HDD 40 Гб, дисковод для
компакт-дисків 4-х швидкісний.
Для роботи системі необхідно:
ПЕОМ на базі Intel-сумісного процесора п’ятого покоління с
частотою не менш ніж 433Мгц, с ОЗУ рівним 64Мб, що оснащена SVGA-відеоадаптером
та монітором 17” та вільним дисковим простором не менш ніж 30Мб.
5.2 Розрахунок витрат праці на розробку програмного продукту
Економічна доцільність розробки полягає в економії
працезатрат і часу.
Таблиця 5.1
Затрати на матеріали
|
№ п/п
|
Найменування
матеріалу
|
Витрати, шт.
|
Ціна грн./шт.
|
Сума грн.
|
|
1
|
Допоміжна
література
|
1
|
15
|
15
|
|
2
|
Диск CD-R
|
2
|
2
|
4
|
|
Разом 19
|
Таблиця 5.2
Затрати на устаткування та програмне забезпечення
|
№ п/п
|
Наименування
матеріала
|
Расход, шт.
|
Ціна, грн./шт.
|
Сума, грн.
|
|
1
|
Компьютер класу
Pentium IV
|
1
|
3000
|
3000
|
|
2
|
Система Mathematica
|
1
|
5000
|
5000
|
|
3
|
Запропонована
программа
|
1
|
300
|
300
|
|
|
|
|
Ітого:
|
Зо= 8300
|
Амортизація складає 25% в квартал від остаточної вартості,
т.е. :
А = Фост * На, де Фост - остаточна вартість на початок
кварталу, На - норма амортизації.квартал 8300 * 0,25 =2075 грн.квартал (8300 - 2075) * 0,25 = 1556,25 грн.квартал (8300 - 2075 - 1556,25) * 0,25 = 1167,19 грн.квартал (8300 - 2075 - 1556,25 - 1167,19) * 0,25 = 875,39 грн.
ІТОГО амортизація = 5673,83 грн.
Таблиця 5.3
Основна зарабітня платня розробників ПП
|
№ п/п
|
Виконавці
|
Трудоємкість, чол.
дн.
|
Оклад, грн.
|
Затрати по з/п,
грн.
|
|
1
|
Програміст
|
7
|
1200
|
400,00
|
Додаткова зарабітня платня розробників ІС складає 20 % від
основної зарабітньої платні:
400,00*
0,20 = 80,00 грн.
Фонд зарабітньої плати являє суму основної і додаткової
зарабітньої плати:
400,00+ 80,00 = 480,00 грн.
Відрахування на соціальні кошти складає 39% від фонду оплати
праці:
80,00 * 0,39 = 187,20 грн.
Накладні витрати складають 250 % від велечини основної
зарабітної платні:
400,00* 2,5 = 1000,00 грн.
Таблиця 5.4
Калькуляція
|
№ п/п
|
Найменування статей
витрат
|
Витрати, грн.
|
|
1
|
Амортизація
|
5673,83
|
|
2
|
Витратні матеріали
|
19
|
|
3
|
Основна заробітня
платня розробників
|
400,00
|
|
4
|
80,00
|
|
5
|
Відрахування на
соціальне страхування
|
187,2
|
|
6
|
Накладні витрати
|
1000,00
|
|
Ітого витрат: Зк= 7360,03
|
5.3 Витрати на ручну обробку інформації
Витрати на ручну обробку інформації рахуються
за формулою:
Зр = Оn * Ц * Гд / Нв , де
Оn - об’єм інформації, обрабляємої вручну, Мбайт;
Ц - вартість одного часу роботи, грн./год;
Гд - коефіцієнт, який враховує додаткові затрати часу на
логічні операції при ручній обробці інформації;
Нв - норма вироботки, Мбайт/ год.
В цьому випадку:
Оn = 5 Мбайт (загальний об’єм даних, що обробляються);
Ц = 5,95 грн./ год; (1000/21/8)
Гд = 2.5 (встановлено експерементально);
Нв = 0.005 Мбайт / год.
З цього слідує, що витрати на ручну обробку інформації будуть
рівні:
Зр = 5 * 5,95 * 2,5 / 0,005 = 14875,00 грн.
5.4 Економічний ефект від використання алгоритму
Витрати на автоматизовану обробку інформації розраховуються
по наступній формулі:
 ,
де
,
де
 -
час автоматичної обробки, год.;
-
час автоматичної обробки, год.;
 -
вартість однієї години машинного часу, грн. /год;
-
вартість однієї години машинного часу, грн. /год;
 -
час роботи оператора, год.;
-
час роботи оператора, год.;
 -
вартість однієї години роботи оператора, грн. /год.
-
вартість однієї години роботи оператора, грн. /год.
Для нашого випадку:= 0,083 год,
Номінальний фонд робочого часу розраховується по формулі :
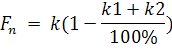
к - кількість відпрацьованих годин за рік;
k1 - щоденні втрати 9-10% (відпустка, декретна
відпустка й ін.)
k2
- внутрішні втрати робочого часу,
1- 2% (пільгові години, перерви й т. п).
к
= д * р * м
д - середнья кількість робочих днів у місяці = 21;
р - тривалість роботи оператора з програмою в день = 1;
м - кількість робочих місяців у році = 11;
К
= 21 * 1 * 11 = 231

Час роботи оператора = 207 годин на рік
Вартість однієї години машинного часу дорівнює:
Цм = Цэ*Р
Цэ - вартість 1кВт електроенергії (0,2436грн)
Р - споживана потужність комп'ютера в годину 160Вт
Цм=0,2436*0,16=0,04грн/год
Отже, витрати на автоматизованну обробку інформації будуть
рівні:
За = 0,083 * 0,04 + 207 * (0,04 + 5,36) = 1117,8 грн.
Таким чином, річна економія від впровадження продукту дорівнює:
Эу = Зр - За - Зк,
Эу = 14875,00 - 1117,8 - 7360,03= 6397,17 грн.
Економічний ефект від користування програмним забеспеченням
за рік рахується по формулі, грн.:
Эг = Эу - Ен * Зо , де
Эг = 6397,17 - 0,2 * 8300 = 4737,17 грн.
Ен - нормативний коефіцієнт ефективності капітальних уложень
= 0,2.
Ефективність розробки може бути оцінена за формулою:
Эр = Эг × 0,4/Зк.
Эр = 4737,17 * 0,4/7360,03 = 0,26
Оскільки Эр > 0.20, розробка є економічно доцільною.
Вартісна оцінка результатів застосування програмного
забезпечення за розрахунковий період Т визначається за формулою:
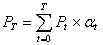 ,
,
де Т - розрахунковий період;
Рt - вартісна оцінка результатів t розрахункового періоду, грн.;
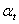 -
функція, що дисконтує, яка вводиться з метою приведення всіх витрат і
результатів до одного моменту часу.
-
функція, що дисконтує, яка вводиться з метою приведення всіх витрат і
результатів до одного моменту часу.
Дисконтирующа функція має вигляд:
at = 1 / (1 + р) t , де
at - дисконтирующа функція, яка вводиться з метою приведення
усіх витрат і результатів до одному моменту години.
р - коефицієнт дисконтирування (р = Ен = 0.2).
Таким чином:
 .
.
Якщо програмне забезпечення замінює ручну працю, отже, набір корисних
результатів у принципі не змінюється. Як оцінка результатів застосування
програмного забезпечення в рік береться різниця (економія) витрат, виникающих в
результаті користування програмним забезпеченням, т.ч. РT = Эу.
Передбачається, що дана розробка без змін і доробок буде
використовуватися протягом трьох років. Тоді вартісна оцінка результатів
застосування програмного забезпечення (економія) за розрахунковий період Т = 3
роки складає:

6.
ОХОРОНА ПРАЦІ
Охорона праці - це система законодавчих актів,
соціально-економічних, організаційних і лікувально-профілактичних заходів і
засобів, що забезпечують безпеку, збереження здоров'я і працездатності людини в
процесі праці.
Законодавство України про охорону праці складається із
загальних законів України та спеціальних законодавчих актів. Загальними
законами України, що визначають основні положення з охорони праці є Конституція
України, Закон України «Про охорону праці», Кодекс законів про працю (КЗпП),
Закон України «Про загальнообов'язкове державне соціальне страхування від
нещасного випадку на виробництві та професійного захворювання, які спричинили
втрату працездатності»
Крім загальних законів України, правові відносини у сфері
охорони праці регулюються спеціальними законодавчими актами, указами і
розпорядженнями Президента України, рішеннями уряду України, нормативними
актами міністерств та інших центральних органів державної виконавчої влади.
Сьогодні проводиться значна робота з питань вдосконалення законодавчої бази з
питань охорони праці, адаптації українського законодавства з охорони праці до
вимог Європейського Союзу.
Закон України «Про охорону праці» визначає основні положення
щодо реалізації конституційного права громадян на охорону їх життя і здоров'я в
процесі трудової діяльності, регулює за участю відповідних державних органів
відносини між власником підприємства, установи і організації або уповноваженим
ним органом і працівником з питань безпеки, гігієни праці та виробничого
середовища і встановлює єдиний порядок організації охорони праці в Україні.
Кодекс законів про працю України регулює трудові відносини
всіх працівників, сприяючи зростанню продуктивності праці, поліпшенню якості
роботи, підвищенню ефективності суспільного виробництва і піднесенню на цій
основі матеріального і культурного рівня життя трудящих, зміцненню трудової
дисципліни і поступовому перетворенню праці на благо суспільства в першу
життєву потребу кожної працездатної людини.
Основні вимоги гігієни та санітарії відображені в законі
України «Про забезпечення санітарного та епідемічного благополуччя населення».
Параметри мікроклімату на робочих місцях регламентовані ГОСТ 12.1.005-88 та ДСН
3.3.6.042-99, а норми штучного та природного освітлення визначені будівельними
нормами та правилами СНиП ІІ-4-79/85.
Пожежна безпека визначена законом України «Про пожежну
безпеку» та «Правилами про пожежну безпеку в Україні». Забезпечення пожежної безпеки є невід'ємною
частиною державної діяльності щодо охорони життя та здоров'я людей,
національного багатства і навколишнього природного середовища. Закон України
«Про пожежну безпеку» визначає загальні правові, економічні та соціальні основи
забезпечення пожежної безпеки на території України, регулює відносини державних
органів, юридичних і фізичних осіб у цій галузі незалежно від виду їх
діяльності та форм власності.
.1
Аналіз небезпечних та шкідливих факторів на робочому місці оператора ПК
Фактори виробничого середовища впливають на функціональний стан і
працездатність оператора. Існує поділ виробничих факторів на небезпечні й
шкідливі. Небезпечний виробничий фактор - це виробничий фактор, вплив якого в
певних умовах приведе до травми або до іншому раптовому погіршенню здоров'я.
Вплив же шкідливого виробничого фактору в певних умовах приведе до захворювання
або зниження працездатності.
Небезпечні й шкідливі виробничі фактори підрозділяються за природою дії
на наступні групи: фізичні, хімічні, біологічні, психофізичні. Перші три групи
включають вплив виробничою технікою й робітничим середовищем. Психофізіологічні
фактори характеризують зміни стану людини під впливом ваги й напруженості
праці. Включення їх у систему факторів виробничої небезпеки обумовлене тим, що
надмірні трудові навантаження в підсумку можуть також привести до захворювань.
Оператор ЕОМ може зіткнутися з наступними фізично небезпечними й
шкідливими факторами:
o підвищенні значення електричного
струму, статичної електрики та рівня електромагнітних випромінювань;
o підвищений рівень рентгенівських
випромінювань;
o підвищений рівень шуму;
o несприятливі мікрокліматичні умови;
o недостатнє або надмірне освітлення.
До психофізичних небезпечних і шкідливих виробничих факторів
можна віднести: фізичні перевантаження (статичні й динамічні), нервово-психічні
перевантаження (розумова напруга й перенапруга, монотонність праці, емоційні
перевантаження, стомлення, емоційний стрес, емоційне перевантаження).
Той самий небезпечний і шкідливий виробничий фактор по природі
своєї дії може відноситися одночасно до різних груп, перерахованих вище.
Відповідно діючим нормативним документам (СН 512-78 та
ДСанПіН 3.3.2.007-98) площа приміщення 13,0 м²;
об’єм - 20 м³.
Стіна, стеля,
підлога приміщення виготовляються з матеріалів, дозволених для оформлення
приміщень санітарно-епідеміологічним наглядом. Підлога приміщення вкрита
діелектричним килимком, випробуваним на електричну міцність.
Висота робочої поверхні столу для оператора ПЕОМ - 690 мм,
ширина повинна забезпечувати можливість виконання операцій в зоні досягнення
моторного ходу; висота столу 725 мм, ширина 800 мм, глибина 900 мм. Простір для
ніг: висота 600 мм, ширина 500 мм, глибина на рівні колін 500 мм, на рівні
витягнутої ноги 650мм.
Ширина й глибина сидіння 400 мм, висота поверхні сидіння 450
мм, кут нахилу поверхні від 15º вперед до 5º
назад. Поверхня
сидіння плоска, передній край закруглений.
Заземлення конструкцій, які знаходяться в приміщенні надійно
захищені діелектричними щитками. В приміщенні з ПЕОМ кожен день проводиться
вологе прибирання.
Мікроклімат виробничих приміщень і стан повітряної середи в
робочій зоні - головні чинники, які визначають умови праці. Основні параметри
мікрокліматичних умов - температура, вологість, швидкість руху повітря і
барометричний тиск впливають на теплообмін і загальний стан організму людини.
На організм людини і обладнання ПЕОМ великий вплив виявляє
відносна вологість. При відносній вологості повітря більш 75-80% знижується
опір ізоляції, змінюються робочі характеристики елементів, зростає
інтенсивність відмов елементів ПЕОМ. Швидкість руху повітря і запиленість
повітряного середовища виявляють вплив на функціональну діяльність людини і
роботу приладів ПЕОМ.
Одним з найважливіших фізіологічних механізмів організму є
терморегуляція, що залежить від мікрокліматичних умов навколишньої середи.
Терморегуляція підтримує тепловий баланс організму людини при різноманітних
метеорологічних умовах і тяжкості роботи, що виконується за рахунок звуження
або розширення поверхні кровоносних судин і відповідної роботи потових залоз.
Несприятливий мікроклімат в процесі роботи викликає
недомагання і втому організму, порушує нервову і розумову діяльність, сприяє
зниженню спостережливості і швидкості реакції.
При роботі на ПЕОМ людина наражається на шумовий вплив з боку
багатьох джерел, наприклад, шум викликаний роботою принтера (70 дБ),
вентиляторів і кондиціонерів (до 100 дБ).
Діючи на слуховий аналізатор, шум змінює функціональний стан
багатьох систем органів людини внаслідок взаємодії між ними через центральну
нервову систему. Це виявляє вплив на органи зору людини, вестибулярний апарат і
рухові функції, а також призводить до зниження мускульної дієздатності. При
роботі в умовах шуму спостерігається підвищена втомлюваність і зниження
дієздатності, погіршується увага і мовна комутація, створюються передумови до
помилкових дій працюючих.
Небезпечний і шкідливий вплив на людей здійснюють електричний
струм, електричні дуги, електромагнітні поля, що проявляються у вигляді
електротравм і професійних захворювань. Ступінь небезпечного й шкідливого
впливів на людину електричного струму, електричної дуги, електромагнітних полів
залежить від: роду й величини напруги й струму; частоти електричного струму;
шляхи проходження струму через тіло людини; тривалості впливу на організм
людини; умов зовнішнього середовища.
Електронно-променеві трубки, які працюють при напрузі понад 6
кВ є джерелами „м’якого” рентгенівського випромінювання. При напрузі понад 10
кВ рентгенівське випромінювання виходить за межі скляного балону і розсіюється
в навколишньому просторі виробничого приміщення.
Шкідливий вплив рентгенівських променів зв’язаний з тим, що,
проходячи через біологічну тканину, вони викликають в тканині іонізацію молекул
тканинної речовини, що може призвести до порушення міжмолекулярних зв’язків, що
в свою чергу, призводить до порушення нормальної течії біохімічних процесів і
обміну речовин.
Освітлення робочого місця - найважливіший фактор створення
нормальних умов праці. Освітленню варто приділяти особливу увагу, тому що при
роботі з монітором найбільшу напругу одержують очі.
Недостатнє освітлення робочих місць - одна з причин низької
продуктивності праці. В цьому випадку очі працюючого сильно напружені, важко
розрізняють предмети, у людини знижується темп і якість роботи, погіршується
загальний стан.
6.2
Заходи щодо нормалізації шкідливих та небезпечних факторів на робочому місці
оператора ПК
Одна
з найважливіших задач охорони праці - забезпечення безпеки працюючих, тобто
забезпечення такого стану умов праці, при якому виключено дію на працюючих
небезпечних і шкідливих виробничих чинників.
6.2.1
Захист від електромагнітних випромінювань та уражень електричним струмом
На сьогоднішній день основним засобом захисту від
електромагнітних випромінювань, що застосовуються в обчислювальній техніці є
екранування джерел випромінювання. Сьогодні всі монітори, що випускаються, а
також блоки живлення мають корпус, виконаний зі спеціального матеріалу, що
практично повністю затримує проходження електромагнітного випромінювання.
Застосовуються також спеціальні екрани, що зменшують ступінь впливу
електромагнітних і рентгенівських променів на оператора.
Для зниження електромагнітного впливу на людину-оператора
використовуються також раціональні режими роботи, при яких норма роботи на ПЕОМ
не повинна перевищувати 50 % робочого часу.
Гранично допустимі рівні напруги дотику і струмів при
експлуатації і ремонті обладнання забезпечені:
― застосуванням малої напруги;
― ізоляцією струмоведучих
мереж;
― обґрунтуванням і оптимальним
вибором елементної бази, що виключає передумови поразки електричним струмом;
― правильного компонування,
монтажу приладів і елементів;
― дотриманням умов безпеки при
настанові і заміні приладів і інше.
Захист від небезпечних впливів електричного струму при
експлуатації обчислювальних комплексів забезпечені:
― застосування захисного
заземлення або обнуління;
― ізоляцією струмопровідних
частин;
― дотриманням умов безпеки при
настанові і заміні агрегатів;
― надійним контактним
сполученням з урахуванням перепаду кліматичних параметрів.
Для усунення причин утворення статичного заряду
застосовуються провідні матеріали для покриття підлоги, панелей, робочих
столів, стільців. Для зниження ступеня електризації і підвищення провідності
діелектричних поверхонь підтримується відносна вологість повітря на рівні
максимально допустимого значення.
На робочих місцях всі металеві та електропровідні неметалеві
обладнання заземлені.
.2.2
Захист від шуму та вібрації
Ефективне рішення проблеми захисту від впливу шуму
досягається проведенням комплексу заходів, в які входить ослаблення
інтенсивності цього шкідливого виробничого чинника в джерелах і на шляху
розповсюдження звукових хвиль.
Зниження виробничого шуму в приміщеннях, де розміщені ПЕОМ,
досягається за рахунок акустичної обробки приміщення - зменшення енергії
відбитих хвиль, збільшення еквівалентної площі звукопоглинаючих поверхонь,
наявність в приміщеннях штучних звукопоглиначів.
З метою зниження шуму в самих джерелах встановлюються
віброгасячі і шумогасячі прокладки або амортизатори.
В якості засобів звукопоглинання застосовуються не горючі або
тяжко горючі спеціальні перфоровані плити, панелі, мінеральна вата з
максимальним коефіцієнтом поглинання в межах частот 31.5-8000 Гц.
6.2.3 Заходи щодо забезпечення чистого
повітряного середовища
Для створення нормальних умов роботи програмістів і
операторів ПЕОМ в машинному залі використовується система кондиціювання, що
забезпечує необхідні оптимальні мікрокліматичні параметри і чистоту повітря.
В холодні періоди року температура повітря, швидкість його руху
і відносна вологість повітря відповідно складають: 22-24 С°; 0,1 м/с; 40-60%; в теплі
періоди року температура повітря - 23-25 Сº;
відносна
вологість 40-60 %; швидкість руху повітря - 0,1 м/с.
.2.4 Захист від рентгенівського випромінювання
Електронно-променеві трубки, магнетрони, тиратрони та інші
електровакуумні прилади, що працюють при напрузі вище 6 кВ, є джерелами
„м’якого” рентгенівського випромінювання.
При технічній експлуатації апаратури, в якій напруга вище 15
кВ, використовують засоби захисту для відвертання рентгенівського опромінення
операторів і інженерно-технічних робітників, бо при такій напрузі рентгенівське
випромінювання розсіюється в навколишньому просторі виробничого приміщення.
Засобами захисту від „м’якого” рентгенівського випромінювання
є застосування поляризаційних екранів, а також використання в роботі моніторів,
що мають біо-керамічне покриття і низький рівень радіації.
В якості засобів захисту від чинності м’яких рентгенівських
променів застосовуються екрани з сталевого листа (0,5-1 мм) або алюмінію (3
мм), спеціальної гуми.
Для відвертання розсіювання рентгенівського випромінювання по
виробничому приміщенню встановлюють захисні огорожі з різноманітних захисних
матеріалів, наприклад, свинцю або бетону.
6.2.5 Забезпечення раціонального освітлення
При правильно розрахованому і виконаному освітленні очі
працюючого за комп’ютером протягом тривалого часу зберігають здатність добре
розрізняти предмети не втомлюючись. Це сприяє зниженню професійного
захворювання очей, підвищується працездатність.
Штучне освітлення в приміщеннях експлуатації ПЕОМ
реалізується системою загального рівномірного освітлення.
У виробничих і адміністративно-суспільних приміщеннях, у
випадках переважної роботи з документами, допускається застосування системи комбінованого
освітлення (до загального освітлення додатково встановлюються світильники
місцевого освітлення, призначені для освітлення зони розташування документів).
Освітленість на поверхні стола в зоні розміщення робочого
документа повинна бути 300 - 500 лк, також допускається установка світильників
місцевого освітлення для підсвічування документів, але з такою умовою, щоб воно
не створювало відблисків на поверхні екрана й не збільшувало освітленість
екрана більш ніж на 300 лк.
Як джерела світла при штучному висвітленні повинні
застосовуватися переважно люмінесцентні лампи типу ЛБ. Допускається
застосування ламп накалювання у світильниках місцевого освітлення.
Для розрахунку штучного освітлення найчастіше використовують
метод світлового потоку.
Розрахунок за даним способом зводитися до визначення необхідної кількості
світильників N для установки в приміщеннях, що визначається по формулі:

Де: Ф - світловий
потік лампи, люмен;
Е - нормована освітленість, люкс;
kз - коефіцієнт запасу (для
люмінесцентних ламп kз = 1,1);
S - площа освітлювального
приміщення, м2;
Z - коефіцієнт мінімальної освітленості (для люмінесцентних ламп
Z = 1,1);
N - кількість електричних ламп;
η - коефіцієнт використання
світлового потоку.
Значення коефіцієнта використання освітлювальної установки η визначають залежно від типу
світильника, коефіцієнтів відбиття стелі, стін і підлоги, а також від індексу
приміщення і, що характеризує співвідношення розмірів освітлюваного приміщення.
Показник приміщення обчислюють по формулі:
Де: L і b - довжина та ширина приміщення, м;
hn - висота підвісу світильника
над робітничою поверхнею, м.
В приміщенні з розмірами L = 6 м, b = 4 м, h = 3 м робітнича поверхня знаходиться на
рівні 0,8 м від полу, тому hn = 2,2 м.
Отже, показник приміщення рівний:

По довіднику визначаємо величину коефіцієнту використання
світлового потоку η = 0,45 для і = 1,1 та коефіцієнтів
відбивання світла - 70%, 50%, 30%.
Для освітлення використовується люмінесцентна лампа типу ЛБ,
потужністю 40 Вт, світловий потік лампи 3000 лм. При загальному типі освітлення
значення Е = 300 лк.
Підставимо всі отримані дані в формулу і визначимо необхідну
кількість світильників:

За результатами проведених розрахунків можна зробити висновок
про те, що небезпечні і шкідливі виробничі чинники, діючи в робочій зоні,
знаходяться в межах допустимих норм і їх вплив на організм працюючих не
приносить істотної шкоди здоров’ю.
6.3
Пожежна безпека
В системі заходів, направлених на охорону державної і
особистої власності громадян, відвертання впливу на людей небезпечних чинників
пожежі і вибуху, питання пожежної і вибухової безпеки займають важливе місце.
По класифікації по пожежній небезпеці приміщення з ПЕОМ
відносяться до категорії В (відповідно до СНиП 2.09.02-85), що характеризуються
наявністю твердих горючих і тяжко горючих речовин і матеріалів, а також
легкозаймистих матеріалів.
Пожежі на обчислювальних центрах становлять особливу
небезпеку, тому що сполучені з великими матеріальними втратами. Як відомо,
пожежа може виникнути при взаємодії горючих речовин, окислювача й джерела
запалювання. У приміщеннях обчислювальних центрів присутні всі три фактори,
необхідні для виникнення пожежі.
Виникнення пожежі в розглянутому приміщенні найбільш ймовірно
із причин несправності електроустаткування, до яких відносяться: іскріння в
місцях з'єднання електропроводки, короткі замикання в мережі, перевантаження
дротів і обмоток трансформаторів, перегрів джерел безперебійного харчування й
інші фактори. Тому підключення комп'ютерів до мережі необхідно провадити через
розподільні щити, що дозволяють провадити автоматичне відключення навантаження
при аварії.
Особливістю сучасних ЕОМ є дуже висока щільність розташування
елементів електронних схем, висока робоча температура процесора й мікросхем
пам'яті. Отже, вентиляція й система охолодження, передбачені в системному блоці
комп'ютера повинні бути постійно в справному стані, тому що в противному
випадку можливий перегрів елементів, що не виключає їхнє запалення.
Надійна робота окремих елементів і електронних схем у цілому
забезпечується тільки в певних інтервалах температури, вологості й при заданих
електричних параметрах. При відхиленні реальних умов експлуатації від
розрахункових, також можуть виникнути пожаронебезпечні ситуації.
Оскільки при займанні электропристрої можуть перебувати під
напругою, то використовувати воду й піну для гасіння пожежі неприпустимо,
оскільки це може привести до електричних травм. Іншою причиною, по якій
небажане використання води, є те, що на деякі елементи ЕОМ неприпустиме
потрапляння вологи. Тому для гасіння пожеж у розглянутому приміщенні можна
використати або порошкові склади, або установки вуглекислотного гасіння. Але
оскільки останні призначені тільки для гасіння невеликих вогнищ загоряння, то
область їхнього застосування обмежена. Тому для гасіння пожеж у цьому випадку
застосовуються порошкові склади, тому що вони мають наступні властивості:
діелектрики, практично не токсичні, не роблять корозійного впливу на метали, не
руйнують діелектричні лаки.
Установки порошкового пожежогасіння можуть бути як
переносними, так і стаціонарними, причому стаціонарні можуть бути з ручним,
дистанційним і автоматичним включенням.
Первинні засоби пожежегасіння: ручні вогнегасники в кількості
2 шт.
Засоби гасіння загорання й пожежі, які можуть бути ефективно
використані в початковій стадії пожежі: внутрішні пожежні крани, кошми, пісок.
Для виявлення пожеж в приміщенні встановлені датчики, що
спрацьовують при появі диму, підвищенні температури і відкритого вогню.
Для профілактики пожежної безпеки організується навчання
виробничого персоналу (обов'язковий інструктаж із правил пожежної безпеки не
рідше одного разу в рік), видання необхідних інструкцій з доведенням їх до
кожного працівника установи, випуск і вивіска плакатів із правилами пожежної
безпеки й правилами поведінки при пожежі. Також необхідна наявність планів, що
інформують людей про розташування аварійних виходів з будинку у випадку
виникнення пожежі, плану евакуації людей в аварійних ситуаціях.
ЗАКЛЮЧЕННЯ
В процесі виконання дипломного проекту був розроблений
алгоритм оптимального розподілу квазістохастичного ресурсу.
Розроблений алгоритм є способом оптимального розподілу
елементів ресурсу. При створенні відповідного інтерфейсу даний алгоритм можна
використати для різних потреб. Наприклад, вирішувати транспортні задачі,
завдання диспетчирізації, складання розкладів і т.д.
Використання алгоритму в програмних продуктах дозволяє:
· Підвищити оперативність обробки
інформації;
· Поліпшити ефективність роботи;
· Зменшити обсяг паперових носіїв;
· Підвищити точність роботи.
Реалізація даного проекту була проведена із залученням такого
потужного і в той же час простого середовища програмування як система
Mathematica 5.0. Система завдяки своїм вбудованим функціям, таким як Cases, Join, Union, Complement дозволяє спростити алгоритм обробки
даних, оперуючи не кожним окремим елементом, а сформованими кластерами. Кластер
являє собою деяку множину елементів, відібраних з загального масиву за певною
ознакою. Виявлення кластерів та подальше їх вико ристання в алгоритмі заощаджує
ресурси пам'яті й час в процесі перебору варіантів розподілу.
В дипломному проекті реалізація алгоритму впроваджувалася на
прикладі складання розкладу занять в учбових закладах. Залучення розробленого
алгоритму до процесу формування розкладу дозволило скоротити до декількох
хвилин час, витрачений на сам процес формування, враховуючи всі критерії та
умови щодо розпділу аудиторій, дисциплін, груп і т.д. Крім того, у користувача
залишається можливість відкорегувати отриманий розклад за власними побажаннями.
СПИСОК ЛІТЕРАТУРИ
1. Айзерман М.А., Алескеров Ф.Т. Выбор вариантов:
основы теории. - М.: Наука, Гл. ред. физ.-мат.лит., 1990. С. 52-58
2. Алексеев В.М., Тихомиров В.М., Фомин С.В.
Оптимальное управление. М., Наука, 1994.
. Бахвалов Н.С., Н.П.Жидков, Г.М.Кобельков,
Численные методы. Наука, 1990.
. Белкин А.Р., Левин М.Ш. Принятие решений:
комбинаторные методы аппроксимации информации. - М.: Наука, Гл. ред. физ.-мат.
лит., 1990. - 226 с.
. Воеводин В.В., Вычислительные основы линейной
алгебры. Наука, 1989.
. Волошин Г.Я. Методы оптимизации в экономике:
Питер, 2004.
. Голуб Дж., Ван-Лоун Ч. Матричные вычисления -
М.: Мир, 1999. - С. 223.
. Дж.Форсайт, М.Малькольм, К.Моулер, Машинные
методы математических вычислений. Мир, 1980.
. Зайцев М.Г. Методы оптимизации управления :
Компьютерно-ориентированный подход. Изд.2, испр. - М.: Киев, 2000.
. Каханер Д., Моулер К., Нэш С. Численные
методы и прграммное обеспечение. - М.: Мир, 1998, 575 стр.
. Кормен, Лейзерсон, Ривест. Алгоритмы:
построение и анализ. _ М.: МЦМО, 1999.
. Краснощеков П.С., Петров А.А. Принципы
построения моделей. Изд. 2-е, пересмотр. и дополнен. - М.: Фазис: ВЦ РАН, 2000.
- С. 203.
. Кульбак С. Теория информации и статистика. -
М.: Наука, 1967, 404 стр.
. Лебедев В.И. Функциональный анализ и
вычислительная математика -М.: ФИЗМАТЛИТ, 2000, 296 с.
. Люстерник Л.А., Соболев В.И. Краткий курс
функционального анализа. - М.: Высшая школа, 1989.
. Марчук Г.И. Методы вычислительной математики.
М.: Наука, 1991.
. Математическая логика и теория алгоритмов.
Учебное пособие. Тверь: Изд-во ТГТУ. 2005
. Математическое программирование. Учебное
пособие. Новосибирск: Изд-во СГУПС. 2005
. Математическая статистика. Учебное пособие.
М.: МЗ - Пресс. 2004. (Естеств.н. Мат. Информ.)
. Натансон И.П. Конструктивная теория функций.
М.-Л.: Гос. изд-во техн.-теор.лит., 1949.
. Немнюгин С.А. Программирование - CПб.: Питер, 2000.
. Принятие решений в многокритериальной среде:
количественный подход. 2. испр., доп.изд. М.: ФИЗМАТЛИТ. 2005
. Соболь И.М., Статников Р.Б. Выбор оптимальных
параметров в задачах со многими критериями. М.: Наука, 1991.
. Стронгина Р.Г. Высокопроизводительные параллельные
вычисления на кластерных системах, Материалы второго Международного
научно-практического семинара. - Нижний Новгород, 2002. - 351с.
. Теория вероятностей и математическая
статистика. Учебник для студентов высших педагогических учебных заведений. М.:
Высш. шк. 2005.
. Треногин В.А, Функциональный анализ. М.,
Наука, 1993.
. Фурсиков А.В. Оптимальное управление
распределёнными системами. Теория и приложения. Новосибирск, Научная книга,
1999.
. Ширяев А.Н. Вероятность. М.: Наука, 1980.
. Штоер P. Многокритериальная оптимизация.
Теория, вычисления и приложения. М.: Радио и связь, 1992.
30. G.H.Golub, Ch. Van Loan, Matrix Computations,
The Hopkins University Press, 1989.
Додаток А
Вихідний текст алгоритму






квазістохастичний
алгоритм mathemetica
Додаток Б
Перелік змінних та функцій
М - масив, що містить
значення вільних і зайнятих аудиторій на весь семестр;- розмірність масиву М;-
кількість тижнів у семестрі;- кількість всіх аудиторій;- кількість навчальних
днів у тиждень;- кількість пар у день;- кількість вільних аудиторій;
μμ
- масив, що містить елементи
вільного ресурсу, представлених у вигляді змінної A{i, j, k, z} і зайнятого
ресурсу, представлених у вигляді порожньої безлічі - {};
fμ
- масив, що складається тільки з
елементів вільного ресурсу, представлених у вигляді змінних A{i, j, k, z};-
масив, що містить загальний список вільного ресурсу;- масив, що містить
загальний список попиту;
аТ1 [p_, D_] -
функція формування кластера, що містить елементи вільного ресурсу, із заданою
періодичністю (р_), починаючи з понеділка кожного тижня й до зазначеного дня
(D_);
аТ2 [p_, D_, а_,
para_] - функція формування кластера, що містить елементи вільного ресурсу, із
заданою періодичністю (р_), дня тижня до якого здійснювалася вибірка (D_),
необхідного індексу аудиторії (а_) і порядкового номера пари для проведення
заняття (para_);
аТ3 [p_, D_, а_] -
функція формування кластера, що містить елементи вільного ресурсу, із заданою
періодичністю (р_), дня тижня до якого здійснювалася вибірка (D_), необхідного
індексу аудиторії (а_);[p_, D_, k_] - функція формування кластера, що містить
елементи вільного ресурсу, із заданою періодичністю (р_), дня тижня до якого
здійснювалася вибірка (D_), необхідної кількості пар для проведення заняття на
тиждень;[den_, kvo_] - функція формування кластера, що містить елементи
вільного ресурсу, для зазначеного дня тижня (den_) і необхідної кількості пар у
тиждень (kvo_);[dned_] - функція розподілу елементів попиту по ресурсу,
починаючи із зазначеного дня (dned_). Функція не враховує необхідність певної
аудиторії для проведення конкретного заняття;- масив, що складається з
розподілених елементів попиту по ресурсу;[www_] - функція формування кластера,
що містить елементи вільного ресурсу, призначених для проведення занять з
наявністю комп'ютерів;[www_] - функція формування кластера, що містить елементи
вільного ресурсу, призначених для проведення занять по дисципліні - Електроніка
й мікросхемотехніка;[www_] - функція формування кластера, що містить елементи
вільного ресурсу, призначених для проведення лабораторних занять по
фізиці;[www_] - функція формування кластера, що містить елементи вільного
ресурсу, призначених для проведення лабораторних занять по хімії;[www_] -
функція формування кластера, що містить елементи вільного ресурсу, призначених
для проведення лекційних занять;[www_] - функція формування кластера, що
містить елементи вільного ресурсу, призначених для проведення практичних
занять;[masiv_, r_, kvo_] - функція формування кластера, що містить елементи
вільного ресурсу, обирані з масиву-джерела (masiv_) для зазначеного дня тижня
(den_) і необхідної кількості пар у тиждень (kvo_);[dned_] - функція розподілу
елементів попиту по ресурсі, починаючи із зазначеного дня (dned_);[dned_] -
функція розподілу елементів попиту по ресурсі, починаючи із зазначеного дня
(dned_) із заданими параметрами;[ind_] - функція виводу розкладу для ладанної
аудиторії (ind_).
Додаток В
Бази даних ресурсу й
попиту
Список аудиторій:
|
1
|
202(5) - к/к
|
|
16
|
309а(5)
|
|
31
|
502(21)
|
|
2
|
211(5) - к/к
|
|
17
|
310(5)
|
|
32
|
505(21) - история
|
|
3
|
409(5) - к/к
|
|
18
|
312(5)
|
|
33
|
512(21)
|
|
4
|
411(5) - к/к
|
|
19
|
314(5)
|
|
34
|
513(21)
|
|
5
|
413(5) - к/к
|
|
20
|
403(5) - химия
|
|
35
|
14(7)
|
|
6
|
207а(5) - лб
|
|
21
|
410(5)
|
|
36
|
43(УК)
|
|
7
|
210(5) - физика
|
|
22
|
202(21) - матем.
|
|
37
|
45(УК)
|
|
8
|
402(5) - химия
|
|
23
|
203(21) - матем.
|
|
38
|
405(21)
|
|
9
|
408(5) - аналит
химия
|
|
24
|
207(21) - нач.
геометр.
|
|
39
|
406(21)
|
|
10
|
209(5)
|
|
25
|
208(21)
|
|
40
|
407(21)
|
|
11
|
203(5)
|
|
26
|
209(21) - нач.
геометр.
|
|
41
|
508(21)
|
|
12
|
204(5)
|
|
27
|
402(21)
|
|
42
|
509(21)
|
|
13
|
301(5)
|
|
28
|
403(21)
|
|
43
|
41(УК)
|
|
14
|
302(5)
|
|
29
|
409(21)
|
|
44
|
44(УК)
|
|
15
|
307(5)- детали
машин
|
|
30
|
410(21)
|
|
45
|
48(УК)
|
Список викладачів та груп:
|
1
|
Гончар М.(ФСЕД)
|
|
23
|
Кислова (ФСЕД)
|
|
1
|
ММ - 07д
|
|
2
|
Кодинец (ФСЕД)
|
|
24
|
Васильев (ТК)
|
|
2
|
ММ - 06д
|
|
3
|
Чичкан (Ф)
|
|
25
|
Сушенцев (ТК)
|
|
3
|
ММ - 05д
|
|
4
|
Яцунок (ФСЕД)
|
|
26
|
Фарионова (ТК)
|
|
4
|
ММ - 04д
|
|
5
|
Трайно (ФСЕД)
|
Супрунова (ТК)
|
|
5
|
ГКС - 07д
|
|
6
|
Батареев (ТК)
|
|
28
|
Чудык (ТК)
|
|
6
|
ГКС - 06д
|
|
7
|
Китова (ФСЕД)
|
|
29
|
Шайда (ТК)
|
|
7
|
ГКС - 05д
|
|
8
|
Кормер (ФСЕД)
|
|
30
|
Сосюк (ТК)
|
|
8
|
ГКС - 04д
|
|
9
|
Евтушенко (М)
|
|
31
|
Корнилов (ТК)
|
|
9
|
ФП - 07д
|
|
10
|
Приходько (М)
|
|
32
|
Кузьменко (Ф)
|
|
10
|
ФП - 06д
|
|
11
|
Грибенко (М)
|
|
33
|
Гончар В.Н. (Ф)
|
|
11
|
ФП - 05д
|
|
12
|
Мец (М)
|
|
34
|
Гончаренко В. (Ф)
|
|
12
|
ФП - 04д
|
|
13
|
Вдовиченко И.В.
(ФСЕД)
|
|
35
|
Скиба (Ф)
|
|
|
|
|
14
|
Чернявская (М)
|
|
36
|
Манякика (Ф)
|
|
|
|
|
15
|
Задорожняя (М)
|
|
37
|
Политыкин (Ф)
|
|
|
|
|
16
|
Климович (ФСЕД)
|
|
38
|
Мельниченко (Ф)
|
|
|
|
|
17
|
Олейник (М)
|
|
39
|
Закутская (Ф)
|
|
|
|
|
18
|
Гончаренко В. (М)
|
|
40
|
Мазурок (Ф)
|
|
|
|
|
19
|
Даценко (ТК)
|
|
41
|
Чепурная (Ф)
|
|
|
|
|
20
|
Захарова (ТК)
|
|
42
|
Романец (ФСЕД)
|
|
|
|
|
21
|
Седин (ФСЕД)
|
|
43
|
Лукаш (Ф)
|
|
|
|
|
22
|
Вдовиченко И.Н.
(ТК)
|
|
44
|
Клименко (Ф)
|
|
|
|
Список дисциплін:
|
1
|
Філософія
|
|
41
|
Електроніка та мікросхемотехніка
|
|
2
|
Основи психолог.та
педагог.
|
|
42
|
Елементи та
пристрої інтегр.систем
|
|
3
|
Іноземна мова
|
|
43
|
Теорія електр.та
магн.кіл
|
|
4
|
Фізичне виховання
|
|
44
|
Систем.програмування
|
|
5
|
Фізика
|
|
45
|
ТАУ
|
|
6
|
Інформатика
|
|
46
|
Робототехніка та
мехатрон.
|
|
7
|
Вища математика
|
|
47
|
Проектування баз
даних
|
|
8
|
Хімія
|
|
48
|
Проектування
комп.ГКС
|
|
9
|
Соціологія
|
|
49
|
Комп.електроніка
|
|
10
|
Теорет.та
прикл.механіка
|
|
50
|
Основи менеджменту
|
|
11
|
Фізика
конденс.сталну матер.
|
|
51
|
Основи
інформ.процес.в роб.
|
|
12
|
Металознавство
|
|
52
|
Проектув.гнучких
інтегр.систем
|
|
13
|
Теплотехніка
|
|
53
|
Релігієзнавство
|
|
14
|
Кристалограф.,
кристалохім.
|
|
54
|
Інформ.мережа
Інтернет
|
|
15
|
Електротехн.та
електроніка
|
|
55
|
Економіка та
орг.виробництва
|
|
16
|
Основи
наук.дослід.і орг.
|
|
56
|
АСНД
|
|
17
|
Економіка
підприємства
|
|
57
|
Корпор.інформ.системи
|
|
18
|
Теоретичні основи
легування
|
|
58
|
web -програмування
|
|
19
|
Маркетинг.ценов.политика
|
|
59
|
Українська культура
|
|
20
|
Фіз.властивості і
методи д.
|
|
60
|
Сучас.укр.мова
|
|
21
|
Безпека
життєдіяльності
|
|
61
|
Основи екол.та
безп.життєд.
|
|
22
|
Основи екології
|
|
62
|
Історія
заруб.літератури
|
|
23
|
Теор.і
практ.терміч.обробки
|
|
63
|
Основи теорії
мовн.комунік
|
|
24
|
Украін.та
світов.ринок мет.
|
|
64
|
Латинська мова
|
|
25
|
Збір, перер.і реал.
ВМР
|
|
65
|
Практичн.курс
друг.ін.мови
|
|
26
|
Діагнос.і
дефект.матер.
|
|
66
|
Фонетика
основн.ін.мови
|
|
27
|
Матем.модел.та
оптим.
|
|
67
|
Практичн.грам.осн.ін.мови
|
|
28
|
Методи
локал.поверх.обр
|
|
68
|
Аналіт.чит.та
розмов.практик.
|
|
29
|
Спеціальні сталі і
сплави
|
|
69
|
Логіка
|
|
30
|
Охорона праці
|
|
70
|
Вступ до
перекладознав.
|
|
31
|
Плануван.і
упр.марк.мет.
|
|
71
|
Лінгво країн др.ін.мови
|
|
32
|
Ділова українська
мова
|
|
72
|
Порівнял.грам.ін.та
укр.мови
|
|
33
|
Алгоритмічні мові
та програм.
|
|
73
|
Термінологія
осн.ін.мови
|
|
34
|
Інженерна та
комп.графіка
|
|
74
|
Практ.переклад з
осн.ін.мови
|
|
35
|
Організація та
функц.ЕОМ
|
|
75
|
Політологія
|
|
36
|
Основи диск.математики
|
|
76
|
Екон.осн.марк.і
менедж.
|
|
37
|
Метрологія і
вимірювання
|
|
77
|
Переклад і
ред.ком.докум.
|
|
38
|
Теорія інформ.та
кодування
|
|
78
|
Соціолоінг
пробл.варіатив.
|
|
39
|
Теорія ймовірності
та мат.статист.
|
|
79
|
Грамат.проблеми
перекл.
|
|
40
|
Матем.прогр.та
досл.опер.
|
|
80
|
Комп.лексикогр.і
перекл.
|