Проектирование статистического пакета прикладных программ
Содержание
Введение
1. Обзор аналогов системы
2. Требования к пакету
3. Структура пакета
4. План реализации пакета
5. Управление версиями
Заключение
Список литературы
Введение
В рамках учебного процесса многие студенты сталкиваются с
необходимостью исследования больших объёмов данных, выявления зависимостей,
проведения статистических и маркетинговых исследований или построения моделей.
Это верно как для технических специальностей, так и для гуманитарных (например,
социология).
Всё вышесказанное имеет ещё большую актуальность при
проведении научных исследований.
Часть подобной работы можно выполнить с помощью связки
доступных программ и пакетов, но нередко гораздо удобнее, а то и просто
необходимо использовать единый инструмент обработки данных.
На рынке представлено множество программных продуктов,
реализующие необходимые функции, но полнофункциональные версии по-настоящему
универсальных и простых в освоении пакетов стоят немалых денег.
Целью работы является создание проекта разработки
статистического пакета, удовлетворяющего нашим требованиям.
Задачи, решаемые в рамках данной цели:
· обзор аналогов
проектируемой системы;
· разработка
структуры пакета;
· разработка
плана реализации проекта;
· выбор
инструментов разработки.
1.
Обзор аналогов системы
Самые популярные аналоги нашего будущего пакета,
представленные на рынке - программы SPSS и STATISTICA. Они являются наиболее универсальными. Также в
различных областях широко применяются программы SAS и MINITAB.
STATISTICA
В данный момент в продаже имеется русскоязычная версия STATISTICA 6 и англоязычная версия STATISTICA 10.
Обычно, когда мы говорим "пакет STATISTICA", мы подразумеваем
три основных модуля:
Базовый пакет STATISTICA Base - предоставляет обширный
выбор основных статистик в едином пакете в сочетании с мощностью,
производительностью и простотой использования технологии STATISTICA.
Линейные и Нелинейные Модели STATISTICA Advanced Linear/Non-Linear Models - большой набор самых
современных инструментов для моделирования и прогнозирования, включающий возможность
автоматического выбора модели и расширенные интерактивные средства
визуализации.
Многомерные разведочные технологии анализа STATISTICA Multivariate Exploratory Techniques - широкий выбор
разведочных технологий анализа различных типов данных в сочетании с богатыми
интерактивными средствами визуализации.
Эти три модуля составляют стандартную комплектацию пакета STATISTICA 6. Модули могут
приобретаться как единым пакетом, так и отдельно. При этом, для работы модулей STATISTICA Advanced Linear/Non-Linear Models и STATISTICA Multivariate Exploratory Techniques требуется наличие
базового пакета STATISTICA Base.
В версии STATISTICA 10 модули комплектуются немного иначе: можно
приобрести либо только STATISTICA Base, либо пакет STATISTICA Advanced, включающий в себя три
вышеперечисленных основых модуля и дополнительный модуль Power Analysis.
Также существуют дополнительные специализированные модули и
системы.
Анализ мощности STATISTICA Power Analysis является всесторонним
инструментом для планирования ваших исследований. Он помогает найти подходящий
размер выборки для вашего конкретного анализа. В модуле представлен широкий
спектр функций для анализа статистической мощности и вычисления размера
выборки.
Нейронные сети STATISTICA Neural Networks - единственный в мире
программный продукт для нейросетевых исследований, полностью переведенный на
русский язык. Кроме того, STATISTICA Neural Networks является богатой, мощной
и чрезвычайно быстрой средой анализа нейросетевых моделей, соответствует самым
современным технологиям и показывает наилучшие рабочие характеристики.
Уникальные возможности Мастера решений позволяют использовать систему не только экспертам
по нейронным сетям, но и новичкам в области нейросетевых вычислений.
Cистема Карты контроля качества STATISTICA Quality Control Charts предоставляет широкий
спектр аналитических методов управления качеством, а также контрольные карты
презентационного качества. Практически все многочисленные графики и их
параметры могут быть модифицированы и сохранены в качестве установок по
умолчанию или шаблонов для дальнейшего использования. Карты контроля качества STATISTICA включает мощные и
простые средства для создания совершенно новых аналитических процедур, которые
затем могут быть добавлены в модуль в качестве полноправных методов. Это
особенно полезно в случае интеграции пакета в существующую систему сбора и
обработки данных.
Система Анализ процессов STATISTICA Process Analysis состоит из двух модулей,
каждый из которых включает обширный набор технологий, таких как анализ пригодности
процесса, анализ повторяемости и воспроизводимости измерений, анализ Вейбулла,
выборочных планов и компонентов дисперсии для случайных эффектов.
Модуль Планирование экспериментов STATISTICA Design of Experiments предлагает исчерпывающий
набор процедур для построения и анализа экспериментальных планов, используемых
в промышленных исследованиях.
STATISTICA Data Miner представляет собой
инструмент аналитического исследования больших массивов информации с целью
выявления определенных закономерностей и систематических взаимосвязей между
переменными, которые затем можно применить к новым совокупностям данных.
Дополнительная возможность STATISTICA Data Miner - STATISTICA Text Miner. Особенностью средств
добычи и отбора информации, а также других аналитических инструментов,
доступных в STATISTICA Text Miner, является то, что в качестве входных данных
можно использовать не только текстовые документы или веб-страницы, но также
ссылки, списки или кластеры. Анализируемая неструктурированная информация даже
может включать в себя непреобразованные битовые изображения, звуковые файлы и
т.д.
На рисунке 1 представлен пример интерфейса пакета STATISTICA.
статистический пакет прикладная программа
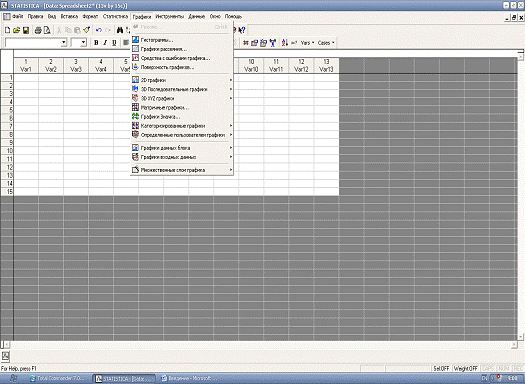
Рисунок 1 - Интерфейс STATISTICA
Стоимость базового модуля STATICTICA Base для образовательных
учреждений составляет около пятнадцати тысяч рублей за однопользовательскую
версию. Каждый модуль расширения стоит также от одного до нескольких десятков
тысяч рублей.
Пакет не требует высокой производительности от ПК
пользователя, однако работает только под управлением ОС семейства Windows (за исключением Windows 2000).
SPSS Statistics
Другой популярный статистический пакет - SPSS Statistics также представлен в виде
связанных модулей. После покупки компании корпорацией IBM в 2009 году, пакет стал
называться IBM SPSS Statistics. Последняя версия под номером 20 датируется
августом 2011 года.
Список модулей SPSS представлен ниже.
SPSS Statistics Base - это ключевой элемент
пакета SPSS Statistics, обеспечивающий доступ к данным, управление данными,
подготовку данных к анализу, анализ данных и создание отчетов.
В SPSS Advanced Models заложены процедуры, которые позволять
продвинуться за рамки базового анализа данных. В SPSS Advanced Models имеется мощный набор
методов одномерного и многомерного анализа для решения реальных практических
задач.
SPSS Bootstrapping упрощает тестирование
устойчивости и надежности моделей.
SPSS Categories применяется для решения следующих задач:
· Анализ больших, громоздких двухвходовых и
многовходовых таблиц;
· Работа с порядковыми и номинальными
переменными с использованием процедур, аналогичных обычным процедурам
регрессии, анализа главных компонент и канонической корреляции;
· Визуализация и исследование категориальных
данных.
Модуль SPSS Complex Samples предоставляет
специализированные средства планирования и статистики, которые требуются при
работе с данными выборочного обследования. Они позволяют сделать статистически
более правильные выводы о генеральной совокупности, учитывая план отбора при
проведении анализа. SPSS Complex Samples облегчает понимание и упрощает работу с данными
обследований на базе сложных выборок.
Совместный (Conjoint) анализ в SPSS Conjoint предоставляет
возможность оценки того, как отдельные атрибуты товаров и услуг оказывают
влияние на предпочтения покупателей. При помощи такого анализа можно оценивать
влияние на принятие решения каждого атрибута в контексте набора атрибутов
товаров или услуг, так как это делают покупатели, принимая решение о покупке.
SPSS Tables существенно облегчает процесс подытоживания
данных для подгрупп. Интерактивный интерфейс построения таблиц обновляется в
режиме реального времени, так что можно видеть, как будут выглядеть таблицы.
Также можно добавлять в таблицы тестовые статистики и изменять таблицы, чтобы
они были более понятными и наглядними. Построенные таблицы можно экспортировать
в Microsoft Word и Excel.
Дополнительный модуль SPSS Data Preparation предоставляет доступ к
новым процедурам, позволяющим значительно упростить этап подготовки данных. Используя этот
модуль, Вы сможете:
· выявлять нетипичные или
ошибочные значения в данных;
· изучать
структуру пропущенных данных;
· исследовать
распределение переменных.
SPSS Decision Trees автоматически строит
дерево. Нужно только указать целевую переменную, переменные-предикторы и
выбрать алгоритм построения дерева решений. Decision Trees автоматически просеивает
данные и находит статистически значимые группы. С помощью интуитивно понятных
древовидных диаграмм, графиков и таблиц Decision Trees можно просто и быстро
сегментировать данные. Представить результаты анализа можно в любом формате,
например, вывести информацию по каждому узлу в виде таблицы или графика либо их
комбинации.
Там, где получать выборки большого объема невозможно или
слишком дорого, SPSS Exact Tests позволит исследовать выборки малых объемов,
учитывая их специфику и не давая ошибочных результатов, как традиционные
критерии.
Когда необходимо строить прогностические модели, а обычная
регрессия методом наименьших квадратов накладывает слишком много ограничений,
на помощь придет SPSS Regression Models, в котором реализовано
применение сложных моделей при помощи большого набора процедур нелинейного
моделирования.
SPSS Forecasting - это наиболее мощный инструмент для
анализа хронологической информации, построения моделей и выявления тенденций. В
SPSS Forecasting можно быстро и без
лишних усилий строить прогнозы и модели временных рядов.
При помощи SPSS Missing Values можно легко проверять
данные с различных точек зрения и получать диагностические отчеты, помогающие
обнаруживать закономерности в распределении пропущенных значений. После этого
можно исследовать итоговые статистики и заполнять пропущенные значения при
помощи статистических алгоритмов.
Модуль SPSS Neural Networks содержит нелинейные
процедуры моделирования, позволяющие обнаруживать более сложные взаимосвязи в
данных. Процедуры этого модуля являются дополнением традиционных статистических
методов, содержащихся в SPSS Statistics Base и дополнительных модулях
к нему. Используя методы data mining модуля SPSS Neural Networks, возможно обнаруживать
новые зависимости, а затем подтверждать их значимость с помощью традиционных
статистических методов.
SPSS по праву считают одним из лидеров среди
универсальных статистических пакетов, он имеет удобные и разнообразные
графические средства, подробнуй справочную систему и по мощности не уступает
более дорогостоящим программам, таким, как SAS.
Однако и цена самого пакета SPSS не слишком мала. Базовая
комплектация начинается с тысячи долларов США.
На рисунке 2 представлено начало работы с программой - ввод
переменных.
Рисунок 2 - Интерфейс SPSS Statistics
Как несложно заметить, интерфейсы рассмотренных пакетов во
многом схожи. Мы пойдем проторенным путём, и по возможности не будем
придумывать новые интерфейсные решения. Это позволит нам облегчить
использование нашего пакета пользователями уже знакомыми с вышеописанными
аналогами.
2. Требования
к пакету
Итак, каким же должен быть наш пакет? Как было отмечено выше,
интерфейс нашего пакета должен быть похож на известные аналоги, чтобы облегчить
его использование для пользователей, знакомых с популярными коммерческими
статистическими пакетами, а также для пользователей с нетехническим образованием
и вместе с тем учесть опыт ведущих производителей подобного программного
обеспечения.
Пакет будет построен по модульному принципу, что позволит
дополнять и развивать его функционал по мере необходимости. Так как пакет будет
открытым, это позволит ему стать для студентов технических специальностей не
только инструментом для исследований, но и платформой для совершенствования
навыков программирования. То есть любой студент или преподаватель сможет
дописать какой-то модуль, обеспечив нужный функционал. Также модульность
позволит в случае успеха пакета создавать для него коммерческие расширения.
В качестве среды разработки была выбрана Microsoft Visual Studio Express. Выбранный язык
программирования: Microsoft Visual C#. Версия Express является бесплатной и на
начальном этапе её функционал вполне устраивает нас. В будущем возможен переход
на платную полноценную версию. В качестве СУБД будем использовать Microsoft SQL Server Express, который также
бесплатен.
Опираясь на мощный фундамент, который составляют унаследованные
характеристики, C# содержит ряд важных новшеств. Например, в состав элементов языка
C# включены такие понятия,
как делегаты (представители), индексаторы, добавлен синтаксис, поддерживающий
атрибуты; упрощено создание компонентов за счёт исключения проблем, связанных с
COM; язык C# предлагает средства
динамического обнаружения ошибок, обеспечения безопасности и управляемого
выполнения программ. Таким образом, C# сочетает первозданную мощь C++ с типовой
безопасностью Java, которая обеспечивается наличием механизма контроля типов и
корректным использованием шаблонных классов.
Использование этого набирающего популярность современного
языка программирования, продвигаемого одной из крупнейших софтверных корпораций
в мире, позволит избежать трудностей с поддержкой и доработкой пакета в
будущем.
3. Структура
пакета
Что же должен уметь делать наш пакет? Разделим требования на
несколько частей.
Во-первых, это базовые функции работы с данными, такие, как:
· сортировка данных по
переменной (по каскаду переменных);
· отбор данных
по фильтру;
· расслаивать данные по
категориям переменной (группам), всем и выбранным;
· отмена отбора по фильтру
и расслоение;
· заполнение данных для
новой переменной;
· вычисление математических
функций и заполнение новой переменной вычисленными значениями.
Во-вторых, функции частотного анализа:
· расчет частот
(абсолютных, относительных (в долях и %), накопленных, с учетом ошибок);
· расчет числовых
характеристик с учетом типа шкал (мода, медиана, минимальное значение,
максимальное значение, размах, дисперсия, СКО, асимметрия, эксцесс).
В-третьих, метод проверки гипотез:
· о равенстве средних двух
выборок;
· о равенстве среднего
выборки константе;
· о равенстве дисперсий
двух выборок;
· о равенстве
дисперсии константе.
И наконец методы статистического анализа:
· определение взаимосвязи
между двумя переменными (с учетом шкал);
· дисперсионный
анализ (однофакторный, двухфакторный);
· регрессионный анализ:
определение парной линейной и нелинейной регрессии, определение множественной линейной
регрессии, проверка адекватности модели и значимости коэффициентов регрессии;
· корреляционный анализ:
расчет коэффициентов парной и множественной корреляции, проверка значимости
коэффициента корреляции, расчет коэффициента детерминации, расчет матриц парной
корреляции и расширенной матрицы.
Также планируется возможность построения имитационных
моделей, наполнение этого модуля методами будет происходить позже остальных.
На рисунке 3 представлена схема наполнения пакета.
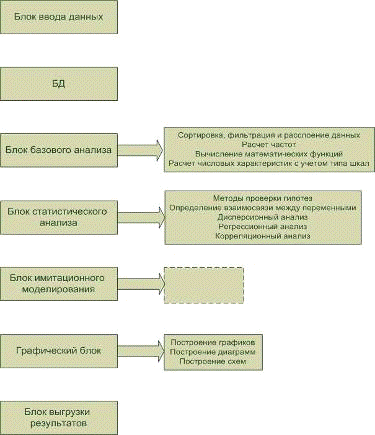
Рисунок 3 - Схема наполнения пакета
Передача информации, то есть связь между блоками пакета будет
осуществляться по схеме, которую можно наблюдать на рисунке 4.
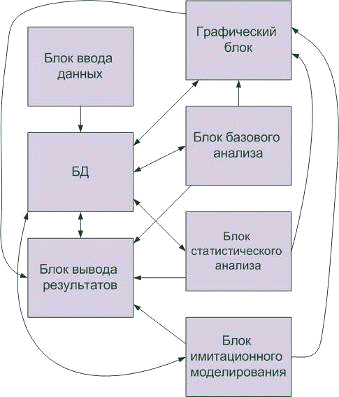
Рисунок 4 - Схема взаимодействия компонентов системы
4. План
реализации пакета
Над разработкой пакета трудится команда разработчиков:
ведущие разработчики, которые занимаются написанием основной части пакета,
созданием БД и сведением всех частей пакета в релизы, и разработчики, пишущие
модули и библиотеки, реализующие различные методы работы с данными, а также
интерфейс. Руководитель и координатор проекта следят за своевременным
исполнением плана и осуществляют связь между разработчиками.
На рисунке 5 представлена диаграмма последовательности
процесса разработки нашего пакета.
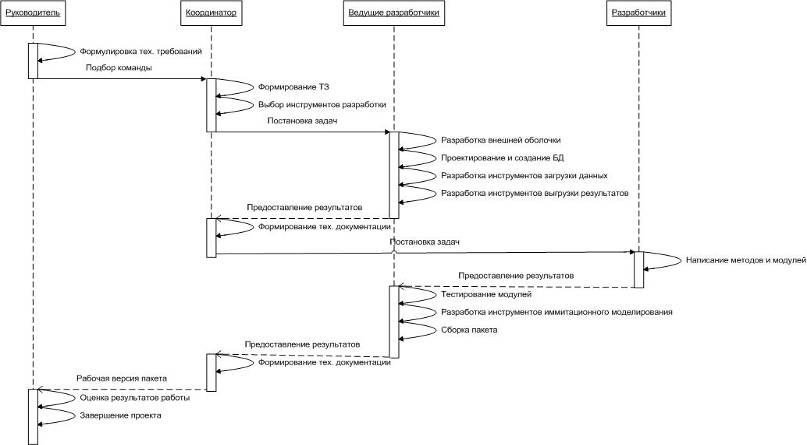
Рисунок 5 - Диаграмма последовательности процесса разработки
пакета
5. Управление
версиями
Наличие нескольких разработчиков порождает проблему
взаимодействия между ними, а также проблему тестирования и сборки различных
промежуточных версий пакета без риска потерять уже готовые компоненты
программы, затереть функционирующие модули нерабочими.
Для решения этой проблемы программисты всего мира достаточно
давно используют так называемые системы контроля версий (СКВ, Version Control System, VCS) - программное
обеспечение для облегчения работы с изменяющейся информацией. Такие системы
наиболее широко используются при разработке программного обеспечения для
хранения исходных кодов разрабатываемой программы. Однако они могут с успехом
применяться и в других областях, в которых ведётся работа с большим количеством
непрерывно изменяющихся электронных документов.
Системы управления версиями делятся на централизованные и
децентрализованные (распределённые).
Традиционные системы управления версиями используют
централизованную модель, когда имеется единое хранилище документов, управляемое
специальным сервером, который и выполняет большую часть функций по управлению
версиями. Пользователь, работающий с документами, должен сначала получить
нужную ему версию документа из хранилища; обычно создаётся локальная копия
документа, т. н. "рабочая копия". Может быть получена последняя
версия или любая из предыдущих, которая может быть выбрана по номеру версии или
дате создания, иногда и по другим признакам. После того, как в документ внесены
нужные изменения, новая версия помещается в хранилище. В отличие от простого
сохранения файла, предыдущая версия не стирается, а тоже остаётся в хранилище и
может быть оттуда получена в любое время. Сервер может использовать т. н.
дельта-компрессию - такой способ хранения документов, при котором сохраняются
только изменения между последовательными версиями, что позволяет уменьшить
объём хранимых данных. Поскольку обычно наиболее востребованной является
последняя версия файла, система может при сохранении новой версии сохранять её
целиком, заменяя в хранилище последнюю ранее сохранённую версию на разницу
между этой и последней версией. Некоторые системы (например, ClearCase) поддерживают сохранение
версий обоих видов: большинство версий сохраняется в виде дельт, но
периодически (по специальной команде администратора) выполняется сохранение
версий всех файлов в полном виде; такой подход обеспечивает максимально полное
восстановление истории в случае повреждения репозитория.
Часто бывает, что над одним проектом одновременно работают
несколько человек. Если два человека изменяют один и тот же файл, то один из
них может случайно отменить изменения, сделанные другим. Системы управления
версиями отслеживают такие конфликты и предлагают средства их решения.
Большинство систем может автоматически объединить (слить) изменения, сделанные
разными разработчиками. Однако такое автоматическое объединение изменений,
обычно, возможно только для текстовых файлов и при условии, что изменялись
разные (непересекающиеся) части этого файла. Такое ограничение связано с тем,
что большинство систем управления версиями ориентированы на поддержку процесса
разработки программного обеспечения, а исходные коды программ хранятся в
текстовых файлах. Если автоматическое объединение выполнить не удалось, система
может предложить решить проблему вручную.
Многие системы управления версиями предоставляют ряд других
возможностей:
· позволяют создавать
разные варианты одного документа, т. н. ветки, с общей историей изменений до
точки ветвления и с разными - после неё;
· дают возможность узнать,
кто и когда добавил или изменил конкретный набор строк в файле;
· ведут журнал изменений, в
который пользователи могут записывать пояснения о том, что и почему они изменили
в данной версии;
· контролируют права
доступа пользователей, разрешая или запрещая чтение или изменение данных, в
зависимости от того, кто запрашивает это действие.
Каждая система управления версиями имеет свои специфические
особенности в наборе команд, порядке работы пользователей и администрировании.
Тем не менее, общий порядок работы для большинства VCS совершенно стереотипен.
Общие принципы правильного использования VCS немногочисленны и едины
для любых разработок и систем управления версиями.

Рисунок 6 - Схема работы централизованных систем контроля
версий
. Любые рабочие, тестовые или демонстрационные версии
проекта собираются только из репозитория системы. "Персональные"
сборки, включающие ещё не зафиксированные изменения, могут делать только
разработчики для целей промежуточного тестирования. Таким образом,
гарантируется, что репозиторий содержит всё необходимое для создания рабочей
версии проекта.
2. Текущая версия главной ветви всегда корректна. Не
допускается фиксация в главной ветви неполных или не прошедших хотя бы
предварительное тестирования изменений. В любой момент сборка проекта,
проведённая из текущей версии, должна быть успешной.
. Любое значимое изменение должно оформляться как
отдельная ветвь. Промежуточные результаты работы разработчика фиксируются в эту
ветвь. После завершения работы над изменением ветвь объединяется со стволом.
Исключения допускаются только для мелких изменений, работа над которыми ведётся
одним разработчиком в течение не более чем одного рабочего дня.
. Версии проекта помечаются тэгами. Выделенная и
помеченная тэгом версия более никогда не изменяется.
Второй тип систем управления версиями - распределённые,
известные также как Distributed Version Control System, DVCS. Такие системы
используют распределённую модель вместо традиционной клиент-серверной. Они, в
общем случае, не нуждаются в централизованном хранилище: вся история изменения
документов хранится на каждом компьютере, в локальном хранилище, и при
необходимости отдельные фрагменты истории локального хранилища синхронизируются
с аналогичным хранилищем на другом компьютере. В некоторых таких системах
локальное хранилище располагается непосредственно в каталогах рабочей копии.
Когда пользователь такой системы выполняет обычные действия,
такие как извлечение определённой версии документа, создание новой версии и
тому подобное, он работает со своей локальной копией хранилища. По мере
внесения изменений, хранилища, принадлежащие разным разработчикам, начинают
различаться, и возникает необходимость в их синхронизации. Такая синхронизация
может осуществляться с помощью обмена патчами или так называемыми наборами
изменений (англ. change sets) между пользователями.
Описанная модель логически аналогична созданию отдельной
ветки для каждого разработчика в классической системе управления версиями (в
некоторых распределённых системах перед началом работы с локальным хранилищем
нужно создать новую ветвь). Отличие состоит в том, что до момента синхронизации
другие разработчики этой ветви не видят. Пока разработчик изменяет только свою
ветвь, его работа не влияет на других участников проекта и наоборот. По
завершении обособленной части работы, внесённые в ветви изменения сливают с
основной (общей) ветвью. Как при слиянии ветвей, так и при синхронизации разных
хранилищ возможны конфликты версий. На этот случай во всех системах
предусмотрены те или иные методы обнаружения и разрешения конфликтов слияния.

Рисунок 7 - Схема работы распределенных систем контроля
версий
С точки зрения пользователя распределённая система отличается
необходимостью создавать локальный репозиторий и наличием в командном языке
двух дополнительных команд: команды получения репозитория от удалённого
компьютера (poll) и передачи своего репозитория на удалённый компьютер (push). Первая команда
выполняет слияние изменений удалённого и локального репозиториев с помещением
результата в локальный репозиторий; вторая - наоборот, выполняет слияние
изменений двух репозиториев с помещением результата в удалённый репозиторий.
Как правило, команды слияния в распределённых системах позволяют выбрать, какие
наборы изменений будут передаваться в другой репозиторий или извлекаться из
него, исправлять конфликты слияния непосредственно в ходе операции или после её
неудачного завершения, повторять или возобновлять неоконченное слияние. Обычно
передача своих изменений в чужой репозиторий (push) завершается удачно
только при условии отсутствия конфликтов. Если конфликты возникают,
пользователь должен сначала слить версии в своём репозитории (выполнить poll), и лишь затем
передавать их другим.
Обычно рекомендуется организовывать работу с системой так,
чтобы пользователи всегда или преимущественно выполняли слияние у себя в
репозитории. То есть, в отличие от централизованных систем, где пользователи
передают свои изменения на центральный сервер, когда считают нужным, в
распределённых системах более естественным является порядок, когда слияние
версий инициирует тот, кому нужно получить его результат (например, разработчик,
управляющий сборочным сервером).
Основные преимущества распределённых систем - их гибкость и
значительно большая (по сравнению с централизованными системами) автономия
отдельного рабочего места. Каждый компьютер разработчика является, фактически,
самостоятельным и полнофункциональным сервером, из таких компьютеров можно
построить произвольную по структуре и уровню сложности систему, задав (как
техническими, так и административными мерами) желаемый порядок синхронизации.
При этом каждый разработчик может вести работу независимо, так, как ему удобно,
изменяя и сохраняя промежуточные версии документов, пользуясь всеми
возможностями системы (в том числе доступом к истории изменений) даже в
отсутствие сетевого соединения с сервером. Связь с сервером или другими
разработчиками требуется исключительно для проведения синхронизации, при этом
обмен наборами изменений может осуществляться по различным схемам.
Исходя из того, что разработка нашего пакета ведётся не в
офисе, и встречи разработчиков будут происходить не слишком часто, для нашей
работы лучше использовать распределённую систему контроля версий.
В настоящее время наибольшую популярность имеют две таких
системы: Git и Mercurial. Также достаточно известны системы Darcs, BitKeeper, Bazaar и Monotone.
Git была создана самим Линусом Торвальдсом для
управления разработкой ядра Linux. Первая версия появилась в 2005 году. Примерами
проектов, использующих Git, являются ядро Linux, Drupal, Cairo, GNU Core Utilities, Mesa, Wine, Chromium, Compiz Fusion, FlightGear, jQuery и некоторые дистрибутивы
Linux. Программа является
свободной и выпущена под лицензией GNU GPL версии 2.
При всех достоинствах Git, таких как высокая
производительность, интеграция с другими VCS и удобное встраивание в
скрипты, система сложнее в освоении, чем Mercurial. При этом команды Git ориентированы на набор
изменений, а не на файлы, что непривычно и не всегда удобно.
Mercurial изначально разрабатывалсь для эффективной работы
с очень большими репозиториями кода. Mercurial первоначально был написан для Linux, позже портирован под Windows, Mac OS X и большинство Unix-систем.
· без проблем работает на Windows и UNIX;
· стабилен;
· имеет большой
список возможностей;
· имеет множество утилит
для интеграции с разнообразными средами разработки и оболочками (в том числе
хорошо интегрируется с MS Visual Studio);
· использует
минимум ресурсов;
· имеет
множество плагинов.
Система Mercurial написана на Python, хотя чувствительные к
производительности части выполнены в качестве Python-расширений на C. Значительное количество
проектов по разработке свободного программного обеспечения использует Mercurial в качестве основной
системы контроля версий. В их числе: Mozilla, OpenOffice.org, OpenJDK, Netbeans, OpenSolaris, ALSA, Xen.
Mercurial прежде всего консольная программа, но имеет
графические оболочки. Большинство пользователей применяют TortoiseHg, что обусловлено её
поддержкой авторами Mercurial, возможностью интеграции в проводник Windows и в Gnome/Nautilus, а также сходство с TortoiseSVN. Внешний вид
TortoiseHg представлен на рисунке 8.
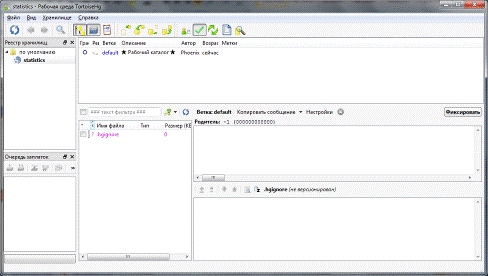
Рисунок 8 - Интерфейс TortoiseHg
Заключение
В ходе данной работы был выполнен общий обзор созданного
проекта разработки статистического пакета прикладных программ.
В ходе работы были решены следующие задачи:
· проведён обзор аналогов проектируемой
системы;
· разработана
структура пакета;
· разработан
план реализации проекта;
· выбраны
инструменты разработки.
Таким образом был создан проект разработки статистического
пакета, удовлетворяющего нашим требованиям.
При следовании этому проекту мы получим пакет, который
покроет большинство нужд студентов различных специальностей в подобном
программном обеспечении, сэкономив тем самым институту деньги на покупку
коммерческих аналогов, а также станет своего рода тренажером для студентов,
занимающихся программированием, что обеспечит пакету долгосрочное развитие.
Список
литературы
1. Г.Н.
Смирнова, А.А. Сорокин, Ю.Ф. Тельнов. Проектирование экономических
информационных систем. Учебник. - М.; Финансы и статистика, 2001.
2. Вендров
А.М. Проектирование программного обеспечения экономических информационных
систем: Учебник. - М.: Финансы и статистика, 2003.
. С.В.
Черемных, И.Ю. Семенов, В.С. Ручкин. Структурный анализ систем:
IDEF-технологии. - М.; Финансы и статистика, 2001.
. А.
Бююль, П. Цёфель. SPSS: искусство обработки информации. Анализ статистических
данных. - М.; Диасофт, 2005.
. Э.
Троелсен. Язык программирования C# 2010 и платформа.net 4. - М.; Вильямс, 2011.
6. Блог "Brain IT!
О программировании и около" - http://brain-it. blogspot.com
<http://brain-it.blogspot.com>
7. Version
Control System Comparison - http://better-scm.
shlomifish.org/comparison/comparison.html
<http://better-scm.shlomifish.org/comparison/comparison.html>
8. Руководство по использованию Mercurial - http://mercurial.
selenic.com/wiki/RussianTutorial
<http://mercurial.selenic.com/wiki/RussianTutorial>
9. Перевод статьи Steve Losh: A Git User’s Guide to
Mercurial Queues - http://pqr7.
wordpress.com/2011/01/07/a-git-users-guide-to-mercurial-queues/
<http://pqr7.wordpress.com/2011/01/07/a-git-users-guide-to-mercurial-queues/>