Кодирование речевого сигнала
СОДЕРЖАНИЕ
Перечень сокращений
Введение
. Обзор источников и анализ состояния вопроса
.1 Критерий разработки кодирующих устройств
.2 Кодирование PCM
.3 Кодирование DPCM
.4 LPC кодеры
.5 Кодирование GSM 6.10
.6 Кодирование CELP
.7 Кодирование MP-MLQ
.8 Оценка качества сигнала
. Теоретический анализ исследуемых вопросов
.1 Постановка проблемы, формулировка задачи
.2 Теоретический анализ существующих алгоритмов спектра
.2.1 Задача спектрального оценивания
.2.2 Авторегрессионное спектральное оценивание
.2.2.1 Оценивание корреляционной функции - метод Юла-Уалкера.
.2.2.2 Методы оценивания коэффициентов отражения.
.2.2.3 Геометрический алгоритм
.2.2.4 Гармонический алгоритм Берга
2.3 Рассмотрение вопросов анализа и способа обработки речевых
сигналов
2.3.1 Речевой сигнал
.3.2 Обработка сигналов
.3.3 Цифровая обработка речи
.3.4 Кодирование речи
.3.5 Системы синтеза речи
.3.5.1 Ограничение на синтез речи
.3.5.2 Методы синтеза
.4 Форматы звуковых файлов
.4.1 MIDI - формат
.4.2 MP3 - формат
.4.3 WAV - формат
. Разработка алгоритма
.1 Кодек речи CELP. Общие положения
.2 Кодирование сигнала
.3 Определение периода основного тона
.4 Стохастическая и адаптивная кодовые книги
.5 Определение среднеквадратической ошибки предсказания во
временной области
.6 Синтезирование сигнала
. Анализ полученных данных
. Экономическая часть
.1 Характеристика программного продукта
.2 Планирование выполнения работ и построение линейного
графика выполнения НИР
.3 Расчет сметной стоимости научно-технической продукции
.4 Оценка научно-технического и экономического уровня НИР
.5 Выводы по оценке научно-технического и экономического
уровня НИР
. Разработка вопросов охраны труда
.1 Анализ условий труда
.2 Техника безопасности
.3 Производственная санитария и гигиена труда
.4 Пожарная профилактика
Выводы
Перечень ссылок
ПЕРЕЧЕНЬ СОКРАЩЕНИЙ
- analysis-by-synthesis- Code division multiple access- Code Excited
Linear Predictive- Differential Pulse Code Modulation- Embedded Adaptive
Differential Pulse Code Modulation- European Telecommunication Standards
Institute- Global System for Mobile- International Telecommunication Union-
Interactive Multimedia AssociationCELP - Low-Delay Code-Excited Linear
Prediction- Linear Predicative Coding- Line Spectrum Pair- Long-Term
Prediction- mean opinion score- Musical Instrument Digital Interface- Multi
Pulse Linear Predictive CodingMLQ - Multipulse Maximum Likelihood Quantization-
predictive code-excited linear prediction- Pulse Code ModulationLTP - Regular
Pulse Excitation Long Term Predictor- LPC - Regular-Pulse Excitation/Linear
Predicative Coding- Short-Term Prediction- Vector Sum Excited Linear Prediction
АКФ - автокорреляционная функция
АР - авторегрессия
ИКМ - импульсно-кодовая модуляция
ЛАБ - лаборант
ИНЖ - инженер
И.П. - исполнитель-программист
КЕО - коэффициент естественного освещения
НИЛ - научно исследовательская лаборатория
НИР - научно
исследовательская работа
ОВПФ - опасные и вредные производственные факторы
ОУ - осветительные устройства
ПОТ - период
основного тона
ПС - производственная среда
РФ - решетчатый фильтр
С.Н.С - старший научный сотрудник
СПМ - спектральная плотность мощности
ФОП - фонд оплаты труда
ЧМС -
человек-машина-среда
ВВЕДЕНИЕ
Обмен голосовой информацией по сетям передачи данных обретает все большую
популярность. Интерес обусловлен более низкой стоимостью международных и
междугородных переговоров по сравнению с обычными телефонными сетями. В
корпоративных сетях экономия достигается за счет более эффективного
использования арендованных каналов связи, по которым можно передавать не только
данные, но и голос (естественно, в цифровом формате).
Сегодня появляются все новые и новые конфигурации систем передачи на базе
разнородного оборудования. Многие стараются оптимизировать создаваемые системы
передачи по различным критериям - цене, набору "высоких технологий",
компактности аппаратных средств, удобству эксплуатации и другим.
При разработке любой новой технологии исследователи должны добиваться
технологического совершенства, с одной стороны, и низкой стоимости реализации -
с другой. Применительно к методам кодирования речи понятие совершенства
подразумевает высокое качество сигнала и малую временную задержку. Стоимость
реализации определяют такие факторы, как общая сложность системы и скорость
битового потока, необходимая для достижения определенного качества сигнала.
Для того чтобы грамотно выбрать речевой кодек, достаточно представления
об используемом в нем методе (на котором базируется алгоритм кодирования) и о
процессе согласования сигнала, полученного после цифровой обработки
(оцифровки), с цифровым каналом связи.
Данным проектом рассматривается кодирование речевого сигнала методом CELP
(Сode Excited Linear Prediction), стандарт G.723.1, поскольку, согласно MOS
(mean opinion score - средняя субъективная оценка), этот стандарт является
наиболее предпочтительным среди существующих методов кодирования с точки зрения
соотношения качество речи / скорость потока.
Разработка вопросов охраны труда является логичным и обоснованным
продолжением основной части пояснительной записки дипломной работы.
Проектирование лабораторного макета невозможно без рассмотрения условий
эксплуатирования данного устройства. Целью раздела пояснительной записки
"Разработка вопросов охраны труда" является анализ опасных и вредных
факторов. Из них выбирается наиболее опасный фактор , влияющий на работу и
жизненную деятельность обслуживающего персонала .С их помощью разрабатываются
мероприятия и рассчитываются средства защиты направленные на обеспечение
нормальных условий. Указываются меры по пожарной безопасности
1. ОБЗОР ИСТОЧНИКОВ И АНАЛИЗ СОСТОЯНИЯ ВОПРОСА
.1 Критерий разработки кодирующих
устройств
При разработке любой новой технологии исследователи должны добиваться
технологического совершенства, с одной стороны, и низкой стоимости реализации -
с другой. Применительно к методам кодирования речи понятие совершенства
подразумевает высокое качество сигнала и малую временную задержку. Стоимость
реализации определяют такие факторы, как общая сложность системы и скорость
битового потока, необходимая для достижения определенного качества сигнала.
Сегодня появляются все новые и новые конфигурации систем передачи на базе
разнородного оборудования. Возникает задача согласования компонентов
оборудования, необходимого для заданных схем организации связи. При этом многие
стараются оптимизировать создаваемые системы передачи по различным критериям -
цене, набору "высоких технологий", компактности аппаратных средств,
удобству эксплуатации и другим.
Для того чтобы грамотно выбрать речевой кодек, достаточно представления
об используемом в нем методе (на котором базируется алгоритм кодирования) и о
процессе согласования сигнала, полученного после цифровой обработки
(оцифровки), с цифровым каналом связи.
Человек различает звук в диапазоне от 20 Гц до 20 кГц, но необходимый для
восприятия речи диапазон существенно уже. Подавляющая часть информации при
разговоре передается на частотах до 4 кГц. Для точного восстановления
аналогового сигнала приемником передающая сторона должна брать отсчеты не менее
двух раз за период максимальной частоты (теорема Котельникова - Найквиста).
Принимая максимальную частоту равной 4000 Гц и 8-разрядное представление
амплитуды, получим, что после преобразования в цифровую форму передача голоса
требует пропускной способности:
(отсчет/период) * 4000 (период/с) * 8 (бит) = 64 000 (бит/с).
Это достаточно широкий цифровой канал, требующий существенных
капиталовложений. А при необходимости одновременного установления нескольких
голосовых соединений первоначальные затраты пропорционально возрастают. Поэтому
голос чаще всего передается в сжатом виде.
Компрессионные алгоритмы условно разделяют на сжимающие без потерь (так
называемые конструктивные) и с потерями (или деструктивные) качества. Поскольку
сжатие без потерь не слишком эффективно в отношении голосовой информации,
наибольшее распространение получили деструктивные алгоритмы. Они обеспечивают
высокие степени сжатия (до 12-13 раз по сравнению с несжатым голосом) при
незначительной потере качества. Наиболее популярны алгоритмы с “линейным предсказанием”,
использующие сплайн-функции первого порядка для аппроксимации исходного сигнала
(серии CELP и SELP): ACELP (G.723.1a) - 5,3 кбит/с, СS-ACELP (G.729) - 8
кбит/с, СV-SELP - 8 и 16 кбит/с, LD-CELP. Хорошее качество при высоких степенях
компрессии обеспечивают также алгоритмы серии MP-MLQ (Multipulse Maximum
Likelihood Quantization), в частности алгоритм G.723.1b - 6,3 кбит/с.
1.2 Кодирование PCM
Международный стандарт кодирования для передачи речи в телефонном канале
PCM был принят ITU (International Telecommunication Union, Международный
телекоммуникационный союз) в 1960 г. под названием G.711 в качестве
международного стандарта кодирования речи для телефонного канала. Временной
интервал для PCM со скоростью 64 Кбит/с формирует базовый строительный блок для
современных общественных телефонных служб и оборудования, такого как
мультиплексоры каналов.
Термин PCM (Pulse Code Modulation, импульсно-кодовая модуляция ИКМ) был
впервые использован при разработке стандарта передачи цифрового аудио. PCM не
относится к какому-либо виду сжатия, он отображает квантование и дискретизацию
аналогового сигнала. Диапазон значений, которых может достигнуть сигнал
(диапазон квантования) разделяется на сегменты, каждому из которых
присваивается уникальное кодовое слово (последовательность бит). При оцифровке
сигнала каждому его значению ставится в соответствие кодовое слово сегмента, в
который он попал. Значения сигнала берутся через одинаковые интервалы времени,
т.о. весь сигнал во времени может быть записан как последовательность бит.
Ниже представлен пример PCM-кодирования при 7 уровнях квантования и 11
значениях дискретизации (рисунок 1.1):
Квантование и дискретизация сигнала Восстановление сигнала
|
0
|
000
|
|
1
|
001
|
|
2
|
010
|
|
3
|
011
|
|
4
|
100
|
|
5
|
101
|
|
6
|
110
|
|
7
|
111
|
Рисунок 1.1 - PCM-кодирование
Один из способов компрессии - уменьшение уровней квантования, например
соединением двух соседних сегментов в один. Сигнал по-прежнему имеет похожий
контур, но шум квантования значительно больше.
Сжатый сигнал кодируется последовательностью: 10 11 11 00 01 10 11 10 01
01 10, всего 22 бита, т.е. сжатие составило 1,5:1. Похожий метод используется в
стандарте сжатия A-Law.
Второй основной метод сжатия - уменьшение количества уровней
дискретизации, например замена двух соседних значений одним средним, таким
образом частота дискретизации уменьшается вдвое, что приводит к потере высоких
частот в сигнале (рисунок 1.2):
Рисунок
1.2 - Уменьшение количества уровней дискретизации при PCM-кодировании
Хотя
PCM-сигнал со скоростью 64 Кбит/с и гарантирует качество речи аналогового
телефонного сигнала, ограниченная общая ширина канала, особенно в спутниковых и
радиочастотных системах, вынуждает снижать скорость битовых потоков, отводимых
для каждого речевого сигнала. С этой точки зрения весьма эффективны алгоритмы
сжатия речи, дополняющие PCM-кодирование математическими функциями, такими как
фильтры, квантизаторы и предсказатели. Они манипулируют PCM-сигналом так, чтобы
передавать его более эффективным способом, обеспечивая тем не менее точное
воспроизведение сигнала на приемном конце.
С
возрастанием потребностей в пропускной способности канала были разработаны
новые технологии сжатия речи с целью минимизировать скорость передачи цифровых
потоков с сохранением приемлемых качества сигнала, сложности реализации
алгоритма и временных задержек.
1.3 Кодирование DPCM
(Differential
PCM) - дифференциальная ИКМ. В данном методе кодовые слова отображают не
значения уровней сигнала, а разницу между ними. Например, при оцифровке одной
линии в изображении с использванием DPCM кодовым словом может являться различие
в яркости между текущей точкой и соседней слева. Существует множество типов
сигналов с малыми различиями в соседних уровнях. Если к ним применить DPCM, то
кодовые слова, содержащие разницу в уровнях, будут встречаться гораздо чаще,
чем другие, а значит и лучше сжиматься.это простеший пример кодирования с
предсказанием, так как фактически происходит предсказание следующего значения
на основании текущего. Если предсказание верно, то в результате образуется
очень короткое кодовое слово, иначе оно будет длиннее чем в “чистом” PCM.
Типичным
примером сигнала, хорошо поддающимся DPCM кодированию, является
фотоизображение, которое в основном содержит плавные переходы тона. Другой
пример - аудио сигнал с узкополосным спектром.
Ниже
представлены 2 гистограммы (уровень/количество в изображении) одного
изображения, закодированного с помощью PCM и DPCM (рисунок 1.3).
Диапазон
кодовых слов значительно меньше, таким образом можно добиться постоянного
коэффициента сжатия. На практике DPCM обычно используется совместно с одним из
видов сжатия с потерями, например в JPEG, или Adaptive (адаптивная) DPCM -
широко распространенный метод сжатия звуковых сигналов. В данном методе размер
шага квантования адаптируется к текущей скорости изменения сжимаемого сигнала
(метод основан на том, что в аналоговом сигнале, передающем речь, невозможны
резкие скачки интенсивности, поэтому если кодировать не саму амплитуду сигнала,
а ее изменение по сравнению с предыдущим значением, то можно обойтись меньшим
числом разрядов). Существует несколько видов ADPCM, одним из самых
распространенных является стандарт IMA ADPCM (Interactive Multimedia
Association), который определяет сжатие PCM с 16 до 4 бит на уровень в реальном
масштабе времени. Преимуществом метода является минимальная загрузка
процессора, недостаток - слабо различимый шум квантования и средняя степень
сжатия 4:1.

Рисунок 1.3 - Распределение уровней при PCM и DPCM кодировании
Метод адаптивной дифференциальной импульсно-кодовой модуляции ADPCM,
принятый в качестве стандарта в 1984 г. под названием G.726, воспроизводит речь
почти с такой же субъективной оценкой качества, как и PCM, используя только 32
Кбит/с.является основой стандарта ITU G.727, который определяет преобразование
речи методом EADPCM - Embedded Adaptive Differential Pulse Code Modulation
(вложенная адаптивная дифференциальная импульсно-кодовая модуляция). Согласно
данному стандарту, речевой сигнал преобразуется в цифровой вид методом АДИКМ.
Затем формируется речевой кадр, состоящий из блоков бит, причем первый блок
содержит старшие биты всех закодированных отсчетов, второй блок - следующие по
убыванию старшинства биты и т.д. В пределах блока, биты упорядочиваются
согласно номеру отсчета, который они определяют. Особенность этого метода
заключается в том, что некритичная к удалению информация расположена в
позициях, где она может быть легко отвергнута (в конце кадра).и ADPCM - методы
кодирования волновой функции речевого сигнала. Это означает, что они
рассматривают входной речевой сигнал как чисто аналоговый. Однако для получения
высокого качества сигнала при скоростях ниже 32 Кбит/с такое кодирование
неэффективно. Природа человеческой речи и ее восприятия должна быть учтена в
алгоритме кодирования.
1.4 LPC кодеры
Все методы кодирования, основанные на определенных предположениях о форме
сигнала, не подходят при передаче сигнала с резкими скачками амплитуды. Именно
такой вид имеет сигнал, генерируемый модемами или факсимильными аппаратами,
поэтому аппаратура, поддерживающая сжатие, должна автоматически распознавать
такие сигналы и обрабатывать их иначе, чем речевой трафик. Преобразование
речевого сигнала методом ADPCM дает хорошее качество воспроизведения речи на
скоростях до 32 кбит/c. Уменьшение скорости ведет к существенному ухудшению
качества речи.
Наиболее эффективными являются кодеры на основе метода линейного предсказания
речи (linear predictive coding - LPC). Кодеры данного типа работают уже с
целыми блоками подготовленных отсчетов. Для каждого блока алгоритм LPC
вычисляет и передает частоту основного тона, его амплитуду, флаг речевого или
неречевого происхождения сигнала и другие параметры. Затем из значений этих
параметров формируется речевой кадр, готовый для передачи. При таком подходе к
кодированию речи, во-первых, возрастают требования к вычислительным мощностям,
а во-вторых, увеличивается задержка при передаче, поскольку кодирование
применяется не к отдельным значениям, а к некоторому их набору, который перед
началом преобразования следует накопить в определенном буфере.
Первые реализации LPC, такие как LPC-вокодер, способствовали передаче
данных на низких скоростях - 2,4 и 4,8 Кбит/с. На скорости 2,4 Кбит/с
обеспечивается приемлемый уровень разборчивости речи, но качество,
естественность и распознаваемость недостаточны. И поскольку этот метод сильно
зависит от точного воспроизведения человеческой речи, его реализации, такие как
LPC-вокодер, не подходят для сигналов неречевого происхождения, попадающих в
голосовую полосу частот.
Более сложные методы сжатия речи основаны на применении метода линейного
предсказания речи в сочетании с элементами кодирования формы сигнала. В этих
алгоритмах используется кодирование с обратной связью, когда при передаче
сигнала осуществляется оптимизация кода (алгоритмы используют замкнутый
LPC-кодер, называемый также "анализ через синтез" -
analysis-by-synthesis - AbS). Закодировав сигнал, процессор пытается
восстановить его форму и сравнивает результат с исходным сигналом, после чего
начинает варьировать параметры кодирования, добиваясь наилучшего совпадения.
Достигнув такого совпадения, аппаратура передает полученный код по линиям связи.
На противоположном конце происходит восстановление речевого сигнала. Ясно, что
для использования такого метода требуются еще более серьезные вычислительные
мощности.
1.5 Кодирование GSM 6.10
Данный метод сжатия является частью телекоммуникационного протокола GSM
(Global System for Mobile), самого популярного протокола для цифровых мобильных
телефонов в Европе. GSM является телефонным стандартом, определенным
Европейским Институтом Телекоммуникационных Стандартов (European
Telecommunication Standards Institute ETSI). Для сжатия звука используется
часть стандарта, относящаяся к сжатию речи GSM 06.10 RPE-LTP “Regular Pulse
Excitation Long Term Predictor” - метод регулярного импульсного возбуждения
(Regular Pulse Excitation - RPE), используемый в европейских сотовых системах
на 13,2 Кбит/с
Исходными данными для GSM являются кадры из 160 знаковых 13-битных
линейных PCM значений при частоте 8 кГц. Один кадр составляет 20 мс, что
примерно равно одному гортанному периоду звучания речи человека с низким
голосом, или 10 периодам с высоким. Это достаточно короткий промежуток времени,
во время которого голосовая волна изменяется несильно. Время кодирования в
сумме с длиной кадра определяют задержку обработки при общении.
Кодировщик сжимает исходный кадр из 160 значений в один кадр размером 260
бит. Секунда речи при этом составляет 1625 байт, мегабайт сжатой информации
содержит 10 минут речи.
Кодек состоит из двух типов фильтров - STP (short-term predictor)
линейно-предсказывающий коротковременной фильтр, и LTP (long-term predictor)
длинновременной. Выходные данные фильтров зависят не только от одного входного
значения, но и от предыдущего состояния: когда последовательность значений
проходит через фильтр, он возбуждается ею. Упаковщик GSM 6.10 моделирует
анатомическую систему речи человека с помощью двух фильтров и начального
возбуждения. STP, который является первой стадией обработки при сжатии и
последней при распаковке, выполняет роль голосового и носового тракта. Он
возбуждается выходом длинновременного предсказывающего фильтра LTP, который
преобразует свои входные данные - возбуждение остаточным импульсом RPE - в
смесь гортанной волны и безголосового шума.
Линейное предсказание состоит в том, что когда фильтр возбуждается
неизвестной смесью гортанной волны и шума, он синтезирует речь, которая должна
сжиматься. Фильтр предсказывает свои выходные данные в виде взвешенных сумм
(линейной комбинации) предыдущих выходных данных. Для каждого кадра, состоящего
из значений речевого сигнала S[], вычисляется массив весов LPC[P] таких, что
S[n] примерно равно LPC[0]*S[n-1]+LPC[1]*S[n-2]+…+LPC[P-1]*S[n-P] для всех
значений S[n]. Количество весов P обычно лежит в пределах 8..14, в GSM
используется P=8.
При коротковременном анализе кодирования вычисляется остаточный сигнал,
который будет возбуждать коротковременную стадию синтеза при декодировании, в
виде блоков из 40 значений. Процедура LTP анализа масштабирует данные значения,
вычитает их из исходного сигнала и проводит ряд дополнительных стадий
обработки. Декодирование происходит в обратном порядке - сигнал проходит через
LTP фильтр, затем через STP, в результате чего происходит синтез речи.
Таким образом, кодек GSM 6.10 (Microsoft) предоставляет сжатие в реальном
времени, хорошее качество и слышимость восстановленной после кодирования речи,
и достаточную степень компрессии примерно 6:1.
1.6 Кодирование CELP
В последнее время большую популярность приобрели кодеры CELP (Сode
Excited Linear Prediction), разновидностями которых являются SELP, LD-CELP,
V-CELP и A-CELP. Эти высокоэффективные кодеры обеспечивают отличное качество
звука при низких скоростях (2,4-8 кбит/с). Для кодирования погрешности
предсказания в них используются кодовые книги, состоящие из блоков с конечным
числом символов. Перечисленные разновидности кодеров различаются способами
формирования и хранения этих последовательностей. Чаще всего последовательность
хранится в сжатом виде. Дополнительные буквы в названии кодера (LD, V и др.)
указывают на способ реализации предсказателя, синтеза квантователя или кодовой
книги.
Одной из самых распространенных разновидностей кодирования является метод
LD-CELP - Low-Delay Code-Excited Linear Prediction (метод линейного
предсказания с кодовым возбуждением и низкой задержкой). Он позволяет достичь
удовлетворительного качества воспроизведения при пропускной способности 16
кбит/с. Этот метод был стандартизован ITU в 1992 г. как алгоритм кодирования
речи G.728. Алгоритм применяется к цифровой последовательности, получаемой в
результате аналого-цифрового преобразования речевого сигнала с 16-разрядным
разрешением.
Широкое распространение для различных приложений получило и множество
нестандартных методов кодирования, в частности варианты адаптивного кодирования
с предсказанием (adaptive predictive coding - APC), разработанные в лабораториях
компании Bell; метод линейного предсказания с векторным возбуждением
(vector-sum-excited linear prediction - VSELP), предложенный фирмой Motorola в
качестве стандарта для цифровых сотовых систем США, работающих на скорости 8
Кбит/с; метод линейного предсказания с предиктивным кодовым возбуждением
(predictive code-excited linear prediction - PCELP), созданный DSP Group в 1992
г. и встроенный фирмой RAD Data Communications в модульные мультиплексоры
доступа.
1.7 Кодирование MP-MLQ
Если не учитывать критерии сложности и задержки, то главные достижения в
кодерах сигналов таковы: улучшение качества сигнала при определенной скорости и
получение заданного качества сигнала при низких скоростях. Для коммерческих
приложений, где качество передачи речи, характерное для PCM, служит эталоном,
следует особо выделить задачу получения приемлемого звучания на все более
низких скоростях. Это особенно важно для кодирующих устройств в беспроводных
телекоммуникационных системах, которые используют ограниченные по пропускной способности
радиочастотные и спутниковые каналы.
В марте 1995 г. Международный союз по электросвязи (International
Telecommunications Union - ITU) выбрал метод сжатия речи для своих будущих
стандартов в области мультимедиа и видеотелефонов, подключаемых к коммутируемым
телефонным сетям. Стандарт сжатия G.723 частично базируется на новом методе
сжатия речи (Multipulse Maximum Likelihood Quantization - MP-MLQ),
разработанном израильской фирмой AudioCodes, создателем передовых речевых и
факсимильных технологий, и ее корпоративным партнером - американской фирмой DSP
Group.
Метод MP-MLQ относится к семейству алгоритмов AbS. Речевой кодер MP-MLQ
использует LPC-анализатор 10-го порядка и работает на скоростях 4,8; 6,4; 7,2 и
8,0 Кбит/с. Его структура поддерживает перепрограммирование "на лету"
для одной или нескольких скоростей. Масштабируемость алгоритма MP-MLQ позволяет
разрабатывать производные реализации для скоростей вплоть до 4,0 Кбит/с и более
низких коммуникационных задержек (до 20 мс), осуществлять кодирование на
нескольких скоростях и с переменной скоростью, выполнять многоканальную
обработку (благодаря низкой вычислительной нагрузке - менее 10 MIPS) и
достигать высокого качества на 8 Кбит/с.
.8 Оценка качества сигнала
Поскольку человек как получатель информации является ключевым элементом
любой телекоммуникационной системы, качество сигнала оценивается по его
субъективному восприятию речи. Качество сигнала измеряется часто по
пятибалльной шкале MOS (mean opinion score - средняя субъективная оценка). Оценка
по шкале MOS определяется путем обработки оценок, даваемых группами слушателей
нескольким речевым сигналам, воспроизводимым различными громкоговорителями.
Каждый слушатель выносит оценку каждого сигнала: 1 - плохо, 2 - слабо, 3 -
разборчиво, 4 - хорошо, 5 - отлично. Затем результаты усредняются.
Таблица 1.1 - Показатели MOS основных алгоритмов кодирования речи
|
Название алгоритма
|
MOS
|
|
G.711 (PCM; 64 кбит/c)
|
4,1
|
|
G.726 (ADPCM; 32 кбит/c)
|
3,8
|
|
G.728 (LD-CELP; 16 кбит/c)
|
3,6
|
|
G.723.1 (ACELP; 5,3 кбит/c)
|
3,7
|
|
G.723.1 (MP-MLQ; 6,3
кбит/c)
|
3,9
|
Наиболее предпочтительным среди приведенных методов кодирования с точки
зрения соотношения качество речи / скорость потока является алгоритм G.723.1
(Таблица 1.1).
. ТЕОРЕТИЧЕСКИЙ АНАЛИЗ ИССЛЕДУЕМОГО ВОПРОСА
2.1 Постановка проблемы, формулировка задачи
На настоящее время существует большое количество алгоритмов и групп
алгоритмов, которые, так или иначе, решают основную задачу кодирования речи
методом “Анализ через синтез”. Основной вклад сделан такими исследователями как:
Голд Б. (Gold B.), Рабинер Л. (Rabiner L.R.), Бартлетт M. (Bartlett M.S.)
Однако каждый из алгоритмов имеет свою область приложения. Например,
градиентные адаптивные авторегрессионные методы не могут быть применены к
обработке данных с быстро меняющимся во времени спектром. Классические методы
имеют широкую область применения, но проигрывают авторегрессионным и методах,
основанных на собственных значениях, по качеству оценивания. Но в реальном
масштабе времени использование последних затруднено из-за вычислительной
сложности.
Более того, применение каждого из методов обычно требует выбора значений
параметров (выбор окна данных и корреляционного окна в классических методах,
порядка модели в авторегрессионном алгоритме и алгоритме линейного
предсказания) и правильный выбор требует экспериментальных результатов с каждым
классом алгоритмов.
Таким образом, имеется следующая задача: на основе существующих
алгоритмов проанализировать возможность их применения как к последовательной
обработке сигналов в реальном времени, так и к блочной обработке и оценить
качество получаемых результатов. Критериями «качества» оценки является
сравнение сигнала на основе полученных графических и звуковых результатов
проделанной работы. В идеальном варианте они должны бать сопоставимы с
исходниками, т.е. теми сигналами, которые были поданы на вход нашего проектного
программного устройства.
Из вышесказанного сформулируем следующие подзадачи:) теоретическое и
практическое исследование алгоритмов блочной обработки;
б) анализ классических алгоритмов блочной обработки всей
последовательности;
с) анализ алгоритмов обработки сигналов в реальном масштабе времени.
Кроме этих теоретических проблем, существует ряд практических вопросов,
специфичных для обработки сигналов в реальном времени. Среди них выделим:
Необходимость в «одновременном» выполнении следующих основных этапов
обработки данных:
а) непосредственное получение последовательности входных данных (цифровые
отсчеты аудио-сигнала, речевого сигнала);
б) обработка получаемых отсчетов сигнала;
в) представление обработанной информации;
г) возможность контролировать процесс обработки информации.
Ограничение длительности интервала выборки поступающих данных
вычислительными ресурсами
Ограничение длительности интервала выборки характером сигнала
Если первый вопрос очевиден в рамках обработки данных в реальном времени,
то второй и третий вопросы требуют осмысления причин этих ограничений.
Экспериментальные входные данные будем формировать следующим образом:
а) для анализа классических алгоритмов блочной обработки всей
последовательности в части применения окон данных и корреляционных окон
эксперимент и подсчет основных характеристик окон будем производить над
дискретизированными отсчетами соответствующих функций;
б) для анализа алгоритмов обработки сигналов в реальном масштабе времени
используем аудио и речевой сигналы.
Выходными данными экспериментов будем считать:
а) для задачи анализа алгоритмов блочной обработки всей
последовательности отсчетов:
) оценку спектра сигнала, по которому можно судить о качестве
применяемого метода, сравнивая истинный спектр сформированного сигнала с
полученной оценкой;
) вычислительные и временные затраты метода;
б) для анализа сигналов в реальном масштабе времени: спектральная
плотность мощности (функция, зависящая в этом эксперименте также и от времени).
Для оценки составляющих в спектре сигнала в данный момент времени.
2.2 Теоретический анализ существующих алгоритмов
спектра
.2.1 Задача спектрального оценивания
Задача спектрального оценивания подразумевает оценивание некоторой
функции частоты. О характеристиках спектральной оценки судят по тому, насколько
хорошо она согласуется с известным спектром тест-сигнала в некоторой
непрерывной области частот.
Спектральная оценка, получаемая по конечной записи данных, характеризует
некоторое предположение относительно той истинной спектральной функции, которая
была бы получена, если бы в нашем распоряжении имелась запись данных
бесконечной длины. Именно поэтому поведение и характеристики спектральных
оценок должны описываться с помощью статистических терминов. Общепринятыми
статистическими критериями качества оценки являются ее смещение и дисперсия.
Аналитическое определение этих величин обычно наталкивается на определенные
математические трудности, поэтому на практике просто совмещают графики
нескольких реализаций спектральной оценки и визуально определяют смещение и
дисперсию как функции частоты. Те области совмещенных графиков спектральных
оценок, где экспериментально определенное значение дисперсии велико, будут
свидетельствовать о том, что спектральные особенности, видимые в спектре
отдельной реализации, не могут считаться статистически значимыми. С другой
стороны, особенности совмещенных спектров в тех областях, где эта дисперсия
мала, с большой достоверностью могут быть соотнесены с действительными
частотными составляющими анализируемого сигнала. Однако в случае коротких
записей данных часто не удается получить несколько спектральных оценок, да и
сам статистический анализ отдельных спектральных оценок, полученных по коротким
записям данных, в общем, случае представляет собой весьма трудную проблему.
2.2.2 Авторегрессионное спектральное оценивание
Одна из причин применения параметрических моделей случайных и процессов и
построения на их основе методов получения оценок спектральной плотности
мощности обусловлена увеличением точности оценок по сравнению с классическими
методами. Еще одна важная причина - более высокое спектральное разрешение.
Далее рассматриваются следующие методы: метод Юла-Уалкера оценивания
авторегрессионных параметров по последовательности оценок автокорреляционной
функции и метод Берга оценивания авторегрессионных параметров по
последовательности оценок коэффициентов отражения.
Модель временного ряда (называемая модели авторегрессии-скользящего
среднего (АРСС) в случае входной последовательности - белого шума), которая
пригодна для аппроксимации многих встречающихся на практике детерминированных и
стохастических процессов с дискретным временем, описывается следующим
разностным уравнением
 . (2.1)
. (2.1)
Системная
функция  , связывающая вход и выход этого фильтра имеет
рациональную форму
, связывающая вход и выход этого фильтра имеет
рациональную форму
 . (2.2)
. (2.2)
Если
в качестве входной последовательности использовать белый шум, то приходим к
АРСС-модели. Спектральную плотность для АРСС-модели получаем, подставляя  , что дает
, что дает
 , (2.3)
, (2.3)
где
 ,
,
 ,
,  , а
, а  -
дисперсия
-
дисперсия
возбуждающего
белого шума
В
частных случаях для авторегрессионной модели и модели скользящего среднего
получаем соответственно
 , (2.4)
, (2.4)
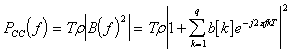 . (2.5)
. (2.5)
2.2.2.1 Оценивание корреляционной функции -
метод Юла-Уалкера
Из соотношения, связывающего параметры АРСС-модели с порядком
авторегрессии p и скользящего среднего q
 . (2.6)
. (2.6)
Поскольку полагается, что u[k] - белый шум, то
 ,
,  , (2.7)
, (2.7)
 , m>q, (2.8)
, m>q, (2.8)
 , m<0. (2.9)
, m<0. (2.9)
В частном случае для авторегрессионных параметров, получаем
,  , (2.10)
, (2.10)
 , m=0, (2.11)
, m=0, (2.11)
, m<0. (2.12)
В матричном виде эти соотношения выглядят следующим образом

 . (2.13)
. (2.13)
Таким
образом, если задана автокорреляционная последовательность для  , то АР-параметры можно найти в результате решения
последнего матричного соотношения (называемого нормальными уравнениями
Юла-Уалкера).
, то АР-параметры можно найти в результате решения
последнего матричного соотношения (называемого нормальными уравнениями
Юла-Уалкера).
Наиболее
очевидным подходом к авторегрессионному оцениванию является решение нормальных
уравнений Юла-Уалкера, в которые вместо значений неизвестной автокорреляционной
функции подставляем их оценки.
2.2.2.2 Методы оценивания коэффициентов отражения
Рекурсивное
решение уравнений Юла-Уалкера методом Левинсона связывает АР-параметры порядка
p c параметрами порядка p-1 выражением
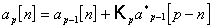 , где
n=1,2,..p-1. (2.14)
, где
n=1,2,..p-1. (2.14)
Коэффициент
отражения 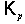 определяется по известным значениям автокорреляционной
функции
определяется по известным значениям автокорреляционной
функции
 , (2.15)
, (2.15)
 , где
, где  . (2.16)
. (2.16)
Из
всех величин только непосредственно зависит от автокорреляционной
функции. В разное время предлагалось несколько различных процедур оценки
коэффициента отражения, рассмотрим некоторые из них.
2.2.2.3 Геометрический алгоритм
Ошибки
линейного предсказания вперед и назад определяются соответственно следующими
выражениями
 , (2.17)
, (2.17)
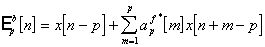 . (2.18)
. (2.18)
Рекурсивные
выражения, связывающие ошибки линейного предсказания моделей порядков p и p-1,
определяются простой подстановкой  и
и  в рекурсивное соотношение для авторегрессионных
параметров
в рекурсивное соотношение для авторегрессионных
параметров
 , (2.19)
, (2.19)
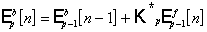 . (2.20)
. (2.20)
Несложно показать, что коэффициент отражения обладает следующим свойством
(является коэффициентом частной корреляции между ошибками линейного
предсказания вперед и назад)
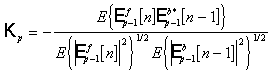 . (2.21)
. (2.21)
Используя оценки взаимной корреляции и автокорреляции ошибок предсказания
вперед и назад, получим
 . (2.22)
. (2.22)
Таким
образом, геометрический алгоритм использует алгоритм Левинсона, в котором
вместо обычного коэффициента отражения, вычисляемого по известной
автокорреляционной функции, используется его оценка 
Окончательный
вид выражений геометрического алгоритма
 , где
n=1,2,..p-1 , (2.23)
, где
n=1,2,..p-1 , (2.23)
 , (2.24)
, (2.24)
 ,
, 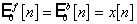 , (2.25)
, (2.25)
 , (2.26)
, (2.26)
, где  . (2.27)
. (2.27)
.2.2.4 Гармонический алгоритм
Берга
Алгоритм Берга идентичен геометрическому, однако оценка коэффициента
отражения находится из других соображений, а именно: при каждом значений
параметра p в нем минимизируется арифметическое среднее мощности ошибок
линейного предсказания вперед и назад), есть выборочная дисперсия ошибки
предсказания)
 . (2.28)
. (2.28)
Приравнивая
производные к нулю, имеем оценку для
 . (2.29)
. (2.29)
Некоторым обобщением является взвешивание среднего квадрата ошибки
предсказания для уменьшения частотного смещения, наблюдаемого при использовании
базового метода Берга
 , (2.30)
, (2.30)
что приводит к следующей оценке
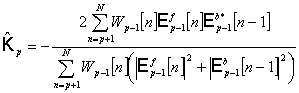 . (2.31)
. (2.31)
2.3 Рассмотрение вопросов анализа и способа
обработки речевых сигналов
.3.1 Речевой сигнал
Рассмотрев алгоритмы решения поставленной задачи, углубимся в теорию
описания исследуемого вида сигнала. Речь предназначена для общения. Возможности
речи с этой точки зрения можно характеризовать по-разному. Один из
количественных подходов основан на теории информации, разработанной Шенноном. В
соответствии с этой теорией речь можно описать ее информационным содержанием
или информацией.
Другой способ описания речи заключается в представлении ее в виде
сигнала, т. е. акустического колебания. Хотя идеи, теории информации играют
важную роль при построении сложных систем связи, Наиболее полезными на практике
являются представления речи в виде колебания или в виде некоторой
параметрической модели. Речевое общение начинается с того, что в мозгу диктора
возникает в а6страктной форме некоторое сообщение. В процессе речеобразования
это сообщение преобразуется в речевое колебание. Информация, содержащаяся в
сообщении, представлена в акустическом колебании весьма сложным образом.
Сообщение сначала преобразуется в последовательности нервных импульсов,
управляющих артикуляторным аппаратом (т. е. перемещением языка, губ, голосовых
связок и т. д.). В результате воздействия нервных импульсов артикуляторный
аппарат приходит в движение, результатом которого является акустическое речевое
колебание, несущее информацию об исходном сообщении. Сообщение, передаваемое с
помощью речевого сигнала, является дискретным, т. е. может (быть представлено в
виде последовательности символов из конечного их числа. Символы, из которых
составлен речевой сигнал, называются фонемами. В каждом языке имеется присущее
ему множество фонем, обычно от 30 до 50. Например, в английском языке можно
выделить 42 фонемы.
Особый интерес представляет оценка скорости передачи информации,
содержащейся в речевом сигнале. Грубая оценка получается из того, что
физические ограничения на перемещение элементов артикуляторного аппарата
позволяют человеку произносить в среднем 10 фонем в секунду. Если фонемы
представить числами в двоичной системе счисления, то для всех фонем английского
языка более чем достаточно шестизначного двоичного кода. Принимая среднюю
скорость произнесения равной 10 фонемам в секунду и пренебрегая корреляцией
между соседними фонемами, получим, что скорость передачи информации составляет
60 бит/с. Другими словами, при нормальном темпе произнесения письменный
эквивалент речевого сигнала содержит 60 бит/с. Эта оценка, однако, не учитывает
таких факторов, как индивидуальность и эмоциональное состояние диктора,
скорость произнесения, громкость речи и т. д.
В системах речевой связи сигнал передается, хранится и обрабатывается
различными способами. Задачи техники обусловливают применение различных форм
представления речевого сигнала, Однако во всех случаях им присущи следующие
особенности:
) сохранение информационного содержания речевого сигнала;
) представление речевого сигнала в форме, удобной для передачи и
хранения, или в виде, позволяющем легко, и достаточно гибко (преобразовывать
речевой сигнал без существенных информационных потерь. Представление речевого
сигнала должно быть таким, чтобы его информационное содержание легко воспринималось
автоматически с помощью машины или при прослушивании человеком. Представление
речевого сигнала (но не его информационного содержания) может потребовать от
500 до. 106 бит/с. При разработке способа представления речевого сигнала
существенное влияние оказывают методы обработки сигнала.
2.3.2 Обработка сигналов
Задача обработки сигналов схематически представлена на
рисунке 2.1. В случае речевых сигналов источником информации является человек.
Измерению или наблюдению обычно подвергается
акустическое колебание. Обработка сигнала предполагает в первую очередь
формирование описания на основе некоторой модели с последующим преобразованием
полученного представления в требуемую форму.
Последним шагом в процессе обработки является выделение и использование информационного
содержания сигнала. Этот шаг может осуществляться путем прослушивания сигнала
человеком или его автоматической обработки. В качестве примера можно
рассмотреть систему идентификации диктора из заданного ансамбля дикторов, в
которой используется представление речевого сигнала в виде зависящего от
времени спектра. Одним из возможных преобразований сигнала в этих условиях
является усреднение спектра по всей фразе, сравнение среднего спектра с
эталонами, имеющимися для каждого диктора, и затем выбор соответствующего
диктора на основе полученных мер сходства спектров. Для данного примера
информационным содержанием сигнала являются признаки индивидуальности диктора.
Таким образом, обработка сигнала в общем случае предусматривает решение двух
основных задач: получить общее представление сигнала либо в форме речевого
колебания, либо в виде параметров и преобразовать полученное представление в
более удобную для решаемой задачи форму.

Рисунок 2.1 - Схема обработки информации
2.3.3 Цифровая обработка речи
При рассмотрении вопросов применения цифровой обработки речевых сигналов
к задачам связи полезно сконцентрировать внимание на трех основных
направлениях: представлении речевых сигналов в цифровой форме, цифровой реализации
аналоговых методов обработки и методах, основанных исключительно на цифровой
обработке.

Рисунок 2.2 - Способы представления речевого сигнала
Представление речевых сигналов в цифровой форме является, конечно, одним
из центральных вопросов. По полосе частот сигнал может быть представлен в виде
последовательности равноотстоящих отсчетов, взятых с достаточно высокой
частотой. Таким образом, процедура дискретизации лежит в основе теории и
приложений цифровой обработки. Существует ряд способов дискретного
представления речевых сигналов. Как показано на рисунке 2.2, эти способы могут
быть разбиты на две большие группы - цифровое и параметрическое представление
речевого колебания. Цифровое представление речевого колебания, как это следует
из названия, основано на сохранении формы колебания в процессе дискретизации и
квантований. Параметрическое представление базируется на описании речевого
сигнала, как выходного отклика модели речеобразования.

Рисунок 2.3 - Диапазон скоростей передачи при различном представлении
речевого сигнала
На первом этапе построения параметрического представления речевое
колебание подвергается дискретизации и квантованию, а затем обрабатывается для
получения параметров модели. Параметры модели обычно разделяются на параметры
возбуждения (относящиеся к источнику звуков речи) и параметры голосового тракта
(относящиеся непосредственно к отдельным звукам речи).
На рисунке 2.3 представлены результаты сравнительного анализа различных
цифровых представлений по требуемой скорости передачи информации. Пунктирная
линия, проходящая через точку 15 кбит/с, отделяет группу цифровых представлений
речевого колебания (слева) от параметрических представлений (справа), которые
обладают меньшим информационным объемом. Как следует из рисунка, требуемая
скорость передачи изменяется от 75 бит/с (что примерно соответствует скорости
передачи письменного эквивалента речи) до 200000 бит/с и более при простейшем
цифровом представлении речевого колебания. Таким образом, в зависимости от типа
цифрового представления сигнала требуемая для его передачи скорость может
изменяться примерно в 3000 раз. Конечно, скорость передачи: далеко не
единственный фактор, определяющий выбор типа цифрового представления. Другими
факторами являются стоимость, гибкость цифрового представления, качество
восприятия речи и т. д.

Рисунок 2.4 - Области применения речевой связи
Наиболее важным фактором, определяющий выбор цифрового представления
сигнала и методов цифровой обработки, является специфика решаемой прикладной
задачи. На рисунке 2.4 приведено несколько примеров из обширной области
передачи и обработки речевых сигналов. Полезно кратко рассмотреть каждый из них
для того, чтобы методы обработки были более понятными.
2.3.4 Кодирование речи
Необходимость кодирования речевой информации возникла не так давно, но на
сегодняшний момент, в связи с бурным развитием техники связи, особенно
мобильной связи, решение этой проблемы имеет большое значение при разработке
систем связи.
Одним из наиболее ранних и наиболее важных примеров применения обработки
речевого сигнала является вокодер или кодер голоса (voice-coder), созданный
Дадли в 1930-х гг. Целью разработки вокодера являлось уменьшение полосы частот,
необходимой для передачи речи. Эта задача актуальна и в настоящее время,
несмотря на наличие широкополосных спутниковых, СВЧ и оптических систем связи.
Кроме того, необходимы дешевые и как можно более низкоскоростные
преобразователи речи в цифровую форму для их использования в цифровых
телефонных сетях связи. Одной из положительных сторон применения цифровых
систем является возможность обеспечения скрытности передачи.
.3.5 Системы синтеза речи
Большой интерес к системам синтеза речи объясняется необходимостью
разработки способа экономического хранения речевого сигнала в системах речевого
ответа. Подобная система реализует цифровой алгоритм автоматического сообщения
голосом информации, которую запрашивает пользователь с клавиатуры пульта или
специального терминала. Поскольку пультом может служить обычный телефонный
аппарат с кнопочным набором, система речевого ответа может широко
использоваться в коммутируемых телефонных сетях без установки какого-либо
дополнительного оборудования.
2.3.5.1 Ограничение на синтез речи
Существуют различные методы синтеза речи. Выбор того или иного метода
определяется различными ограничениями. Рассмотрим 4 вида ограничений, которые
влияют на выбор метода синтеза.
а) Задача.
Возможности синтезированной речи зависят от того, в какой области она
будет применятся. Когда необходимо произносить ограниченное число фраз (и их
произнесение линейно не меняется), необходимый речевой материал просто
записывается на пленку. С другой стороны, если задача состоит в синтезе
речевого сигнала в реальном масштабе времени, используется совершенно другой
ряд методик.
б) Голосовой аппарат человека.
Все системы синтеза речи должны производить на выходе какую-то речевую
волну, но это не произвольный сигнал. Чтобы получить речевую волну
определенного качества, сигнал должен пройти путь от источника в речевом
тракте, который возбуждает действие артикуляторных органов, которые действуют
как изменяющиеся во времени фильтры. Артикуляторные органы также накладывают
ограничения на скорость изменения сигнала. Они также имеют функцию сглаживания:
гладкого сцепления отдельных базовых фонетических единиц в сложный речевой
поток.
в) Структура языка.
Ряд возможных звуковых сочетаний определяется природой той или иной
языковой структуры. Было обнаружено, что единицы и структуры, используемые
лингвистами для описания и объяснения языка, могут также использоваться для характеристики
и построения речевой волны. Таким образом, при построении выходной речевой
волны используются основные фонологические законы, правила ударения,
морфологические и синтаксические структуры, фонотактические ограничения.
г) Технология.
Возможности успешно моделировать и создавать устройства для синтеза речи
в сильной степени зависят от состояния технико-технологической стороны дела.
Речевая наука сделала большой шаг вперед благодаря появлению различных
технологий, в том числе: рентгенография, кинематография, теория фильтров и
спектров, а главным образом - цифровые компьютеры. С приходом интегральных
сетевых технологий с постоянно возрастающими возможностями стало возможно
построение мощных, компактных, недорогих устройств, действующих в реальном времени.
Этот факт, вместе с основательными знаниями алгоритмов синтеза речи,
стимулировал дальнейшее развитие систем синтеза речи и переход их в
практическую жизнь, где они находят широкое применение.
2.3.5.2 Методы синтеза
Различные подходы могут быть сгруппированы по областям их применения, по
сложности их воплощения.
Синтезаторы делят на два типа: с ограниченным и неограниченным словарем.
В устройствах с ограниченным словарем речь хранится в виде слов и предложений,
которые выводятся в определенной последовательности при синтезе речевого
сообщения. Речевые единицы, используемые в синтезаторах подобного типа,
произносятся диктором заранее, а затем преобразуются в цифровую форму, что
достигается с помощью различных методов кодирования, позволяющих компрессировать
речевую информацию и хранить ее в памяти синтезирующего устройства. Существует
несколько методов записи и компоновки речи.
а) Волновой метод кодирования.
Самый легкий путь - просто записать материал на пленку и по необходимости
проигрывать. Этот способ обеспечивает высокое качество синтезируемой речи, т.к.
позволяет воспроизводить форму естественного речевого сигнала. Однако этот путь
синтеза не позволяет реализовать построение новой фразы, т.к. не
предусматривает обращение к различным ячейкам памяти и вызов из памяти нужных
слов. В зависимости от используемой технологии этот способ может представлять
задержки в доступе и иметь ограничения, связанные с возможностями записи.
Никаких знаний об устройстве речевого тракта и структуре языка не требуется. Единственно
серьезное ограничение в данном случае имеет объем памяти. Существуют способы
кодирования речевого сигнала в цифровой форме, позволяющие в несколько раз
уплотнять информацию: простая модуляция данных, импульсно-кодовая модуляция,
адаптивная дельтовая модуляция, адаптивное предиктивное кодирование. Данные
способы могут уменьшить скорость передачи данных от 50кбит/сек (нормальный
вариант) до 10кбит/сек, в то время как качество речи сохраняется. Естественно,
сложность операций кодирования и декодирования увеличивается со снижением числа
бит в секунду. Такие системы хороши, когда словарь сообщений небольшой и
фиксированный. В случае же, когда требуется соединить сообщения в более
длинное, сгенерировать высококачественную речь трудно, т.к. значения параметров
речевой волны нельзя изменить, а они могут не подойти в новом контексте. Во
всех системах синтеза речи устанавливается некоторый компромисс между качеством
речи и гибкостью системы. Увеличение гибкости неизбежно ведет к усложнению
вычислений.
б) Параметрическое представление.
С целью дальнейшего уменьшения требуемой памяти для хранения и
обеспечения необходимой гибкости было разработано несколько способов, которые
абстрагируются от речевой волны как таковой, а представляют ее в виде набора
параметров. Эти параметры отражают наиболее характерную информацию либо во
временной, либо в частотной области. Например, речевая волна может быть
сформирована сложением отдельных гармоник заданной высоты и заданными
спектральными выступами на данной частоте. Альтернативный путь состоит в том,
чтобы форму речевого тракта описать в терминах акустики и искусственным путем
создать набор резонансов. Этот метод синтеза экономичнее волнового, т.к.
требует значительно меньшего объема памяти, но при этом он требует больше вычислений,
чтобы воспроизвести исходный речевой сигнал. Данный способ дает возможность
манипулировать теми параметрами, которые отвечают за качество речи (значение
формант, ширина полос, частота основного тона, амплитуда сигнала). Это дает
возможность склеивать сигналы, так что переходы на границах совершенно не
заметны. Изменения таких параметров как частота основного тона на протяжении
всего сообщения дают возможность существенно изменять интонацию и временные
характеристики сообщения. Наиболее популярным в настоящее время методами
кодирования в устройствах, использующих параметрическое представление сигналов,
является метод, основанный на формантных резонансах и метод линейного
предсказания (LPC - linear predictive coding). Для синтеза используются единицы
речи различной длины: параграфы, предложения, фразы, слова, слоги, полуслоги,
дифоны. Чем меньше единица синтеза, тем меньшее их количество требуется для
синтеза. При этом требуется больше вычислений, и возникают трудности
коартикуляции на стыках. Преимущества этого метода: гибкость, немного памяти
для хранения исходного материала, сохранение индивидуальных характеристик
диктора. Требуется соответствующая цифровая техника и знание моделей
речеобразования, при этом, лингвистическая структура языка не используется.
в) Синтез по правилам.
Описанные выше методы синтеза ориентированы на такие речевые единицы, как
слова, предварительно введенные в устройство с голоса диктора. Данный принцип
лежит в основе функционирования синтезаторов с ограниченным словарем. В синтезаторах
с неограниченным словарем элементами речи являются фонемы или слоги, поэтому в
них применяется метод синтеза по правилам, а не простая компоновка. Данный
метод весьма перспективен, т.к. обеспечивает работу с любым необходимым
словарем, однако качество речи значительно ниже, чем при использовании метода
компоновки.
При синтезе речи по правилам также используются волновой и
параметрический методы кодирования, но уже на уровне слогов.
Метод параметрического представления требует компромисса между качеством
речи и возможностью изменять параметры. Исследователи обнаружили, что для
синтеза речи высокого качества необходимо иметь несколько различных
произношений единицы синтеза (например, слога), что ведет к увеличению словаря
исходных единиц без каких бы то ни было сведений о контекстной ситуации,
оправдывающей тот или иной выбор. По этой причине процесс синтеза получает еще
более абстрактный характер и переходит от параметрического представления к
разработке набора правил, по которым вычисляются необходимые параметры на
основе вводного фонетического описания. Это вводное представление содержит само
по себе мало информации. Это обычно имена фонетических сегментов (например,
гласные и согласные) со знаками ударения, обозначениями тона и временных характеристик.
Таким образом, метод синтеза по правилам использует малоинформационное описание
на входе (менее 100 бит/сек). Этот метод дает полную свободу моделирования
параметров, но необходимо подчеркнуть, что правила моделирования несовершенны.
Синтезированная речь хуже натуральной, тем не менее, она удовлетворяет тестам
по разборчивости и понятности. На уровне предложения и параграфа правила
предоставляют необходимую степень свободы для создания плавного речевого
потока.
.4 Форматы звуковых файлов
Поскольку в ходе выполнения работы придется иметь дело с записью звуковых
сигналов и последующей их оцифровке, то было бы целесообразно рассмотреть
форматы звуковых файлов.
2.4.1 MIDI - формат
Musical Instrument Digital Interface (сокращенно MIDI) - цифровой интерфейс
музыкальных инструментов. Создан в 1982 году ведущими производителями
электронных музыкальных инструментов - Yamaha, Roland, Korg, E-mu и др.
Изначально был предназначен для замены принятого в то время управления
музыкальными инструментами при помощи аналоговых сигналов управлением при
помощи информационных сообщений, передаваемых по цифровому интерфейсу.
Впоследствии стал стандартом де-факто в области электронных музыкальных
инструментов и компьютерных модулей синтеза.
2.4.2 MP3 - формат
MP3 - сокращение от MPEG Layer3. Это один из цифровых форматов хранения
аудио, разработанный Fraunhofer IIS и THOMPSON (1992г.), позднее утвержденный
как часть стандартов сжатого видео и аудио MPEG1 и MPEG2. Данная схема является
самой сложной из семейства MPEG Layer 1/2/3. Она требует больших затрат
машинного времени для кодирования по сравнению с остальными и обеспечивает
более высокое качество кодирования. Используется главным образом для передачи
аудио в реальном времени по сетевым каналам и для кодирования CD Audio.
2.4.3 WAV - формат
Формат аудио-файла, представляющий произвольный звук как он есть - в виде
цифрового представления исходного звукового колебания или звуковой волны
(wave), отчего в ряде случаев технология создания таких файлов, именуется
wave-технологией. Позволяет работать со звуками любого вида, любой формы и
длительности.

Рисунок 2.5 - Графическое представление WAV-файла
Форма сигнала формата WAV представлена на рисунке 2.5, здесь: А -
амплитуда звуковой волны, Т - время ее распространения. Графическое
представление WAV-файла очень удобно и часто используется в звуковых редакторах
и программах-секвенсорах для работы с ними и последующего преобразования (об
этом речь пойдет в следующей главе). Данный формат был разработан компанией
Microsoft и немудрено, что все стандартные звуки Windows имеют расширение WAV.
Характерно еще и то, что эти файлы являются, как бы «промежуточными
результатом», работы программ -«грабберов» и пихоакустических процессоров, для
оцифровки треков СD и дальнейшего их сжатия. Но из-за того, что несжатые
«полнометражные» музыкальные композиции в формате WAV имеют огромные размеры
(30-50 МБ), они практически не используются. Их вытеснила музыка в MP3. Однако
из-за своей простоты и возможности представления произвольного звука, для
проведения работы по кодированию речевого сигнала методом “Анализ через синтез”
я буду использовать именно этот формат записи речевого сигнала.
3. РАЗРАБОТКА АЛГОРИТМА
3.1 Кодек речи CELP. Общие положения
В первом разделе было отмечено, что предпочтительным среди существующих
методов кодирования с точки зрения соотношения качество речи/скорость потока
является алгоритм G.723.1 или иными словами - алгоритм CELP. Следовательно,
кодирование речи будет осуществляться по этому алгоритму.
Метод кодирования CELP основан на линейной авторегрессионной модели
процесса формирования и восприятия речи и входит в группу методов “анализ через
синтез”, реализующих современные и эффективные алгоритмы сжатия речевых
сигналов. Алгоритмы данного класса занимают промежуточное положение между
кодерами формы сигнала, в которых сохраняется форма колебания речевого сигнала
в процессе его дискретизации и квантования, и параметрическими вокодерами,
основанными на процедурах оценки и кодирования небольшого числа параметров
речи, объединяя преимущества каждого из них.
Линейная авторегрессионная модель процесса формирования речевых сигналов
с локально постоянными на интервалах 10..30 мс параметрами получила в настоящее
время наибольшее распространение. Для этой модели
 (3.1)
(3.1)
где
 - последовательность отсчетов речевого сигнала;
- последовательность отсчетов речевого сигнала;
 -
коэффициенты линейного предсказания, характеризующие свойства голосового
тракта;
-
коэффициенты линейного предсказания, характеризующие свойства голосового
тракта;
 -
порождающая последовательность или сигнал возбуждения голосового тракта;
-
порождающая последовательность или сигнал возбуждения голосового тракта;
 - порядок
модели.
- порядок
модели.
Величина
 (3.2)
(3.2)
называется предсказанием случайной величины. Разность между текущим
значением отсчета и его предсказанием называется ошибкой предсказания
 (3.3)
(3.3)
Величина
характеризует, по существу, максимальную точность предсказания
текущего отсчета, а ее статистические свойства определяют выбор порядка модели
АР.
.
На рисунке 3.1 представлен АР фильтр предсказания (обеляющий фильтр), алгоритм
действия которого описывается выражением (3.3).

Рисунок 3.1 - Авторегрессионный фильтр предсказания
Он
состоит из линий задержки, усилителей
с коэффициентами усиления  ,
, и сумматора. Ошибки предсказания на выходе этого будут
отчетами белого шума, а точнее некоррелированным процессом.
и сумматора. Ошибки предсказания на выходе этого будут
отчетами белого шума, а точнее некоррелированным процессом.
Генерация
случайного процесса осуществляется методом порождающего случайного процесса.
Порождающий процесс в виде белого шума, обычно с гауссовой функцией
распределения, пропускается через формирующий фильтр, параметры которого
определяются соответствующей моделью АР. генератор процесса АР, показанный на
рисунке 3.2.

Рисунок 3.2 - Генератор процесса авторегрессии
Авторегрессионная модель речевого сигнала описывает его достаточно
высокой степенью точности и позволяет применять развитый математический аппарат
линейного предсказания. При этом обеспечивается более высокое качество
декодированной речи, устойчивость к входному акустическому шуму и ошибкам в
канале связи по сравнению с ситемами с иными принципами кодирования.
В рамках данной модели наиболее перспективным методом кодирования
считается метод “анализа через синтез” с использованием многоимпульсного
возбуждения. Новизна многоимпульсного возбуждения заключается в том, что в
сигнале остатка линейного предсказания выбираются такие его значения, которые
наиболее важны для повышения качества синтезированной речи. При этом
используемая в процедуре анализа через синтез схема кодирования, помимо учета
ошибок квантования, включает критерии субъективной оценки качества речевого
сигнала, что обеспечивает естественное звучание синтезированной речи.
Метод анализа через синтез использует синтезатор (декодер) речевого
сигнала, как составную часть устройства кодирования. При этом задача анализа
сводится к процедуре оценки передаваемых в канал связи параметров речи,
проводимой в соответствии с некоторым критерием рассоглосованием между исходным
и декодированным сигналами.
Обобщенная блок-схема CELP представлена ни рисунке 3.3.

Рисунок 3.3 - Блок-схема кодека речи CELP
Где STP - (short-term predictor) линейно-предсказывающий коротковременной
фильтр; LTP - (long-term predictor) линейно-предсказывающий долговременной
фильтр; dp1, dp2 - ошибки прямого предсказания; bp1, bp2 - ошибки обратного
предсказания; m - порядок модели; ПОТ - период основного тона; K1, K2 -
коэффициенты отражения; Xn - входной сигнал; X`n - синтезированный сигнал.
- наиболее эффективно применяется при передаче речевого сигнала в
диапазоне скоростей от 4 до 16 кбит/с.
По существу, в алгоритме CELP производится векторное квантование
последовательности Xn, т.е. позиции выборок и их амплитуды в сигнале многоимпульсного
возбуждения оптимизируются одновременно. При этом отрезок (сегмент) сигнала
возбуждения выбирается из предварительно сформированной постоянной совокупности
- кодовой книги, содержащей достаточно большое количество реализаций, например,
некоррелированного гауссового шума. Выбранная реализация усиливается и подается
на вход фильтра LTP.
В канал связи передаются номер (индекс) элемента кодовой книги с
соответствующим коэффициентом усиления, параметры синтезатора основного тона, а
также коэффициенты линейного предсказания, характеризующие состояние голосового
тракта.
Являясь одной из самой распространенных, схема с линейным предсказанием и
возбуждением от кода, CELP является лучшей схемой AbS-LPC для низких скоростей.
В CELP имеется линейный фильтр с изменяющимися во времени параметрами для
выделения грубой и точной спектральной информации. Возбуждение выполняется
путем перебора всех векторов из возбуждающей кодовой книги. Хотя CELP является
сложным методом, он способен синтезировать речь с высоким качеством даже на
низких скоростях.
3.2 Кодирование сигнала

Рисунок 3.4 - Анализирующий решетчатый фильтр
На вход фильтра STP подается речевой сигнал Xn. При этом для
предсказателя нулевого порядка
d0=b0=Xn. (3.4)
Далее процесс идет по схеме, представленой на рисунке 3.4. В линию
задержки подставляем -1, а ошибки предсказания и коэффициенты отражения
рассчитываем по формулам, приведенным в разделе 2.
Если решетчатая форма фильтра будет использовать коэффициенты отражения
K1 , значения которых меньше единицы, форма фильтра будет минимально фазовой. В
этом случае после каждой ступени предсказания значения прямого, обратного остатков
предсказания будут становится все меньше и меньше.
Эти условия будут выполняться, если коэффициенты отражения будут
определятся по методу Берга, в основе которого лежит минимизация суммы среднего
квадрата прямого и обратного остатков предсказания.выхода фильтра снимаем
ошибки предсказания dp и bp, коэффициенты и отражения K1.
Эти параметры, а также период основного тона, который был определен в
блоке ПОТ, поступают на фильтр LTP. При этом для предсказателя нулевого порядка
=dp_STP,
b0=bp_STP, (3.5)
где dp_STP - ошибки прямого предсказания dp с фильтра STP;_STP - ошибки
обратного предсказания bp с фильтра STP.
Далее процесс идет также как описано выше, но в первую линию задержки
ставим найденный ПОТ и выбираем порядок модели p=3. Снижение порядка модели
позволит нам дообелить шум.
Поскольку наилучшее значение порядка фильтра заранее, как правило, не
известно, на практике обычно приходится испытывать несколько порядков модели.
Базируясь на этом, вводят тот или иной критерий ошибки, по которому затем определяется
требуемый порядок модели. Если порядок модели выбран слишком малым, получаются
сильно сглаженные спектральные оценки, если излишне большим - увеличивается
разрешение, но в оценке появляются ложные спектральные пики. Таким образом,
применительно к авторегрессионному спектральному оцениванию выбор порядка
модели эквивалентен компромиссу между разрешением и величиной дисперсии для
классических методов спектрального оценивания. Интуитивно ясно, что следует
увеличивать порядок АР-модели до тех пор, пока вычисляемая ошибка предсказания
не достигнет минимума.
С выхода STP снимаем ошибки предсказания dp и коэффициенты отражения К2.
3.3 Определение периода основного тона
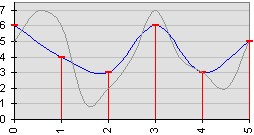
Этой частью работы занимался мой напарник. Оценивание периода (или
частоты) основного тона является одной из наиболее важных задач в обработке
речи. Предложен ряд способов ее решения. Все они обладают ограничениями и можно
с уверенностью сказать, что в настоящее время отсутствует метод выделения
основного тона, обеспечивающий удовлетворительные результаты для различных
дикторов, в разных областях применения и условиях эксплуатации.
Были рассмотрены 3 метода определения ПОТ:
Кепстральный метод;
Разностный метод;
Метод АКФ.
ПОТ рассчитывается между блоками STP и LPT и используется для нахождения
ошибки предсказания фильтра LPT.
3.4 Стохастическая и адаптивная кодовые книги
Основным узлом CELP-кодера является стохастическая кодовая книга, которая
содержит последовательность векторов возбуждения. Выбор сигнала возбуждения из
кодовой книги состоит из выбора оптимального индекса возбуждения Uk и
относящегося к нему такого усиления gk, чтобы синтезированная речь в наибольшей
степени соответствовала исходной (оригинальной) речи и приводила бы к
минимизации взвешенного остатка предсказания.
Стохастическая кодовая книга содержит последовательности с белым
гауссовским распределеием, с нулевым средним значением и единичной дисперсией.
Основанием для использования стохастической кодовой книги является тот факт,
что в системах с CELP-кодерами одновременно используются долговременный - LTP и
кратковременный - STP-предикторы. При этом в сигнале остатка предсказания еn
практически устранены все корреляционные связи, поэтому еn имеет гауссовский
характер с нулевым математическим ожиданием и единичной дисперсией.
Преимущество при использовании стохастической кодовой книги заключается в
том, что ее формирование обходится без процесса «обучения» на реальных речевых
сигналах, как это происходит при создании детерминированной кодовой книги.
Поиск оптимальных векторов в стохастической кодовой книге осуществляется
иерархическим (бинарным древовидным) методом. При этом требуется достаточно
большой объем вычислений. Поэтому возникает естественное желание сократить
объем вычислений. Очень простой, но достаточно эффективный метод уменьшения
объема вычислений получается посредством двухстороннего ограничения около
нулевого уровня возможных векторов стохастической кодовой книги, при котором
стохастическая книга будет принимать значения -1, 0, +1. Это так называемый
алгебраический способ образования кодовой книги. В этом способе кодовые слова
имеют равную энергию, поэтому нет необходимости вычислять энергетический член
||gkUk||2 .Это простой и эффективный путь уменьшения объема вычислений. При
этом за время кадра будет возникать от 77% до 90% нулевых значений, т.е.
разреженность кодовой книги будет составлять 77% - 90%, а это приводит к
существенному сокращению вычислений и улучшению качества речи. При
90-процентном ограничении около нулевого уровня объем вычислении составляет в
среднем 2,1N+0,1N2 на один кодовый вектор, где N - количество выборок речевого
сигнала в одном векторе.
Кодовая книга с ограничением около нулевою уровня дополнительно
упрощается посредством ограничения ненулевых вводов до -1 или до +1. Это
обеспечивает улучшение качества речи по сравнению с простой гауссовской книгой.
В противоположность результатам, полученным для стохастической кодовой
книги, ограничение около нулевого уровня адаптивной кодовое книги ухудшает
качество речи, поэтому такое ограничение для адаптивной кодовой книги не
рекомендуется.
Дальнейшее увеличение скорости поиска вектора в стохастической кодовой
книге может быть получено за счет перекрывающихся или совмещающихся векторов.
Уровень совмещения определяется сдвигом на определенное число выборок речевого
сигнала двух соседних векторов. Обычно этот сдвиг составляет от одной до
четырех выборок, чаще всего до двух выборок речевого сигнала. Для
стохастической кодовой книги сочетание совмещающихся векторов и двухстороннего
ограничения около нулевого уровня сигнала оказывает особенно положительное
воздействие, так как при этом сокращается вычислительная сложность, экономится
память и одновременно улучшается качество речи.
Реализация стохастической кодовой книга со сдвигом на две выборки и
90-процентным ограничением около нулевого уровня для кодовой книги размером
1024 вектора при длине кадра в 60 выборок для поиска векторов требует 14 млн.
операций в секунду.
Размер кодовой книги сказывается на качестве речевого сигнала: чем больше
размер книги, тем выше качество речи. Но уже при кодовой книге на 256 .
векторов качество речи можно считать приемлемым, а на 1024 вектора качество
речи получается хорошим.
В кодовой книге хранится набор всевозможных последовательностей сигналов
возбуждения. При поступлении сигнала возбуждения Uk(z) на выходе фильтров
1/Р(z)(LPT) и 1/Ф(z)(STP) формируется синтезированный речевой сигнал:
 , (3.6)
, (3.6)
где gk - масштабный коэффициент вектора возбуждения, т.е. коэффициент
усиления.
Для получения минимальной разности между исходным речевым сигналом и
синтезированным сигналом используется критерий минимизации среднеквадратичной
ошибки. Данный критерий может быть определен либо в частотной, либо во
временной области.
Использование метода векторного квантования является более эффективным
при работе с двумя кодовыми книгами; одна книга для образования спектра, другая
- для образования сигнала возбуждения.
Для
формирования кодовой книги огибающей спектра используются либо коэффициенты
отношения логарифма площади  , либо
линейные спектральные пары - LSP. Последние являются наиболее
предпочтительными. Наличие двух книг, стохастической и адаптивной, позволяет
сократить объем памяти. Назначение адаптивной кодовой книги состоит в
устранении периодичности в речевом сигнале.
, либо
линейные спектральные пары - LSP. Последние являются наиболее
предпочтительными. Наличие двух книг, стохастической и адаптивной, позволяет
сократить объем памяти. Назначение адаптивной кодовой книги состоит в
устранении периодичности в речевом сигнале.
Для
устранения периодичности из сигнала предполагается, что в адаптивной кодовой
книге должна содержаться информация предшествующего кадра. При нахождении
оптимального вектора возбуждения учитываются векторы предыстории. В
вокализованной речи выбранные векторы-кандидаты представляют целые числа
периодов основного тона, устраненные из текущего кадра. В невокализованной речи
адаптивная кодовая книга содержит множество перекрывающихся случайных
последовательностей. Использование перекрывающихся или совмещающихся случайных
последовательностей значительно сокращает потребность в памяти, при этом
адаптивная кодовая книга строится достаточно легко. Адаптивная кодовая книга
используется при «замкнутой» петле (ПОТ).
3.5 Определение среднеквадратической ошибки
предсказания во временной области
Сигнал
возбуждения получается при пропускании шума из кодовой книге через два фильтра:
сначала через фильтр долговременного предсказания LTP, а затем через фильтр
кратковременного предсказания STP. При этом получается сигнал Ui(n). После
этого производится взвешивание Ui(n) и получаем Uwi(n).
Согласно
теореме Парсеваля минимизация средней квадратической ошибки в частотной области
соответствует ее минимизации во временной области
 , (3.7)
, (3.7)
где L - число отсчетов речевого сигнала, используемых для определения
вектора возбуждения Uwi, хранящегося в кодовой книге.
Минимизация Ewi означает поиск вектора оптимального возбуждения Uwi(n),
наиболее близкого к сигналу остатка предсказания xw(n). С этой целью
производная Ewi относительно коэффициента усиления Gi, приравнивается нулю. В
результате получаем
 , (3.8)
, (3.8)
где Rxu(i) - корреляция между остатком предсказания xw(n) и сигналом
возбуждения Uwi(n)
 . (3.9)
. (3.9)
 -
энергия сигнала возбуждения
-
энергия сигнала возбуждения  , равная
, равная
 . (3.10)
. (3.10)
Используя определения Rxu(i) и Ruu(i) (3.7) перепишем в виде
 . (3.11)
. (3.11)
Поскольку
 не зависит от испытуемого кодового слова, минимизация
не зависит от испытуемого кодового слова, минимизация
 равносильна максимизации второго члена последнего
выражения. Используя (3.8), его можно переписать в виде
равносильна максимизации второго члена последнего
выражения. Используя (3.8), его можно переписать в виде
 . (3.12)
. (3.12)
Эта
операция производится 512 раз (размерность кодовой книги). При прохождении
полностью кодовой книги выбирается вектор с максимальным значением  . Индекс i и коэффициента усиления Gi, соответствующий
максимальному значению передаются на приемную сторону.
. Индекс i и коэффициента усиления Gi, соответствующий
максимальному значению передаются на приемную сторону.
3.6 Синтезирование сигнала
Синтез производится по схеме, представленной на рисунке 3.5. Алгоритм
обработки в фильтрах долговременного и кратковременного предсказания такой же
как был рассмотрен на этапе кодирования. Просто все действия мы выполняем в
обратном порядке. Декодер сотового телефона по принятым данным восстанавливает
речевой сигнал. РФ с прямым прохождением сигнала и РФ с обратной связью,
имеющие одинаковые коэффициенты отражения, выполняют инверсные операции над
входным сигналом. Если на вход РФ с прямым прохождением сигнала подается
коррелированный случайный процесс, то на выходе получаем ошибку предсказания
типа белого шума. В случае же когда на вход РФ с обратной связью подается
случайный процесс типа белого шума, то на выходе формируется коррелированный
случайный процесс X`n.

Рисунок 3.5 - Генератор на решетчатом фильтре с обратной связью
4. АНАЛИЗ ПОЛУЧЕННЫХ ДАННЫХ
Кодирование и декодирование слитной речи в реальном масштабе времени
требует большого количества операций с секунду (вплоть до16 мнл. оп./с) при
применении кодовой книги. В дипломной работе были кодированы и декодированы
методом «анализ через синтез» отдельные фонемы и слова небольшой длительности.
Фонемы можно разделить на следующие классы:
. Гласные - «а», «о», «у» и т.д.
. Полугласные - «л», «р»
. Согласные
носовые - «н», «м»;
взрывные, вокализованные - «б», «д», «г»;
взрывные, невокализованные - «т», «к», «п»;
фрикативные, вокализованные - «в», «з», «ж»;
фрикативные, невокализованные - «ф», «с», «ш»;
аффрикаты - «ц», «ч», «й».
Выборки этих фонем были получены путем оцифровки с частотой 8000 Гц их
протяженного произношения одним диктором.
Наиболее полно фонемы можно охарактеризовать их спектрами и временными
диаграммами. Фонемы «и», «л», «м», «щ» являются наиболее характерными.
Временные диаграммы кодированного и декодированного сигнала представлены на
рисунках 4.1 - 4.4. Спектральная плотность мощности приведена на рисунках 4.5 -
4.8.
а)
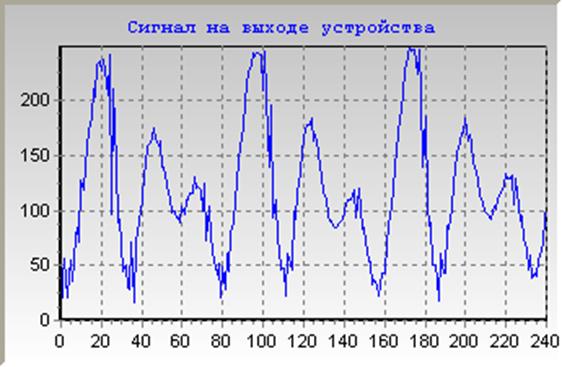
б)
Рисунок 4.1 - Временная диаграмма входного (а) и выходного сигнала (б)
для фонемы «и»

а)

б)
Рисунок 4.2 - Временная диаграмма входного (а) и выходного сигнала (б)
для фонемы «л»
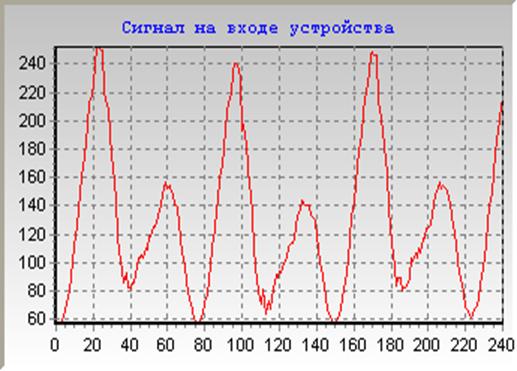
а)

б)
Рисунок 4.3 - Временная диаграмма входного (а) и выходного сигнала (б)
для фонемы «м»

а)
кодирование речь файл звуковой

б)
Рисунок 4.4 - Временная диаграмма входного (а) и выходного сигнала (б)
для фонемы «щ»

Рисунок 4.5 - Спектр входного (а) и выходного сигнала (б) для фонемы «и»

Рисунок 4.6 - Спектр входного (а) и выходного сигнала (б) для фонемы «л»

Рисунок 4.7 - Спектр входного (а) и выходного сигнала (б) для фонемы «м»
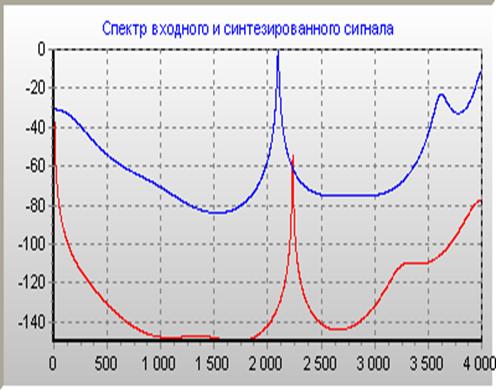
Рисунок 4.8 - Спектр входного (а) и выходного сигнала (б) для фонемы «щ»
Как видно из графиков, СПМ фонем имеет сложный характер. СПМ имеет
несколько мод на формантных частотах, причем, некоторые из них, могут иметь
значительную ширину полосы (фонема «щ»).
Для проверки правильности модели был сгенерирован и обработан звук
частотой 500 Гц. Временная диаграмма и спектр сигналов представлены на рисунках
4.9, 4.10. Как видно из рисунка 4.10 у процесса после декодирования сохранилась
та же центральная частота (500 Гц), но появилась вторая мода на частоте 800 Гц.

Рисунок 4.9 - Временная диаграмма звука частотой 500 Гц: а) входной
(красная линия); б) выходной (черная линия)

Рисунок 4.10 - спектр звука частотой 500 Гц: а) входной (красная линия);
б) выходной (черная линия)
Многомодовый характер спектров фонем, а также значительная ширина
отдельных мод, требует использования АР модели достаточно высокого порядка.
Точность представления линейной моделью фонемы существенным образом зависит от
порядка модели. В программе предусмотрен выбор порядка модели авторегрессии для
построения СПМ ( от 8-го до 20-го). Достоинством применения параметрического
метода определения спектральной плотности мощности является то, что спектр
определяется малым числом параметров (всего 15 коэффициентов авторегрессии), по
сравнению с традиционным преобразованием Фурье.
Все эксперименты проводились для порядка модели m=15, ПОТ определялся
разностным методом. Синтезированный сигнал получился схожим с исходным
голосовым сигналом. Однако есть неточности - это говорит о том, что очень
трудно подобрать порядок модели и метод оценивания ПОТ для различных голосовых
диапазонов и тембров голоса.
5. ЭКОНОМИЧЕСКАЯ ЧАСТЬ
.1 Характеристика программного продукта
Модель имеет полную совместимость с Windows 98 (Windows 2000 и Windows
XP), позволяет решать несколько задач одновременно, имеет удобную форму для
ввода параметров и вывода результатов исследования в графическом виде.
Программный продукт является универсальным в проектируемой области и
позволяет легко расширять базу расчетов, используя объектно-ориентированную
среду разработки приложений - Delphi6.
Разработка программного обеспечения велась в интересах кафедры РЭС. Один
экземпляр программы является необходимым и достаточным для организации
автоматизированного рабочего места инженера или научного работника.
Распространение разработанного пакета пока не предусматривается
Работы по научно-исследовательским разработкам (НИР) выполняет временный
творческий коллектив в составе 4 человек - исполнитель-программист (и.п.),
инженер (инж.), лаборант (лаб.), старший научный сотрудник (с.н.с.).
5.2 Планирование выполнения работ и построение
линейного графика выполнения НИР
Составим календарный план проведения научных работ в полном соответствии
с темой и содержанием дипломной работы, который представлен в таблице 5.1.
Таблица 5.1 - Календарный план проведения научно-исследовательских работ
|
№ п\п
|
Виды работ
|
Исполнители
|
Трудоемкость
|
|
|
|
в %
|
Чел. дни
|
|
1
|
2
|
3
|
4
|
5
|
|
1. РАЗРАБОТКА И ВЫБОР
НАПРАВЛЕНИЯ ИССЛЕДОВАНИЯ
|
|
|
|
|
1
|
Составление задания НИР
|
и.п. с.н.с. инж.
|
1,2
|
0,5 0,5 0,5
|
|
2
|
Сбор информационных
материалов
|
и.п. с.н.с.
|
2,1
|
2,1 2,1
|
|
3
|
Составление обзора по теме
|
и.п. лаб.
|
12,3
|
4,5 2,2
|
|
4
|
Разработка общей
методологии проведения исследований
|
и.п. инж. лаб.
|
13,6
|
9 4 2
|
|
2. ТЕОРЕТИЧЕСКИЕ И
ЭКСПЕРИМЕНТАЛЬНЫЕ ИССЛЕДОВАНИЯ
|
|
|
|
|
5
|
Исследование алгоритмов
спектрального оценивания
|
и.п.
|
6,2
|
9,2
|
|
6
|
Рассмотрение вопросов
анализа и способа обработки речевых сигналов. Создание прикладной программы.
|
и.п. лаб.
|
12,1
|
4,2 3,3
|
|
7
|
Определение периода
основного тона. И внедрение его в алгоритм обработки сигнала.
|
инж. и.п.
|
3,4
|
15 1,6
|
|
8
|
Рассмотрение форматов
звукового файла. Выбор оптимального формата. Оцифровка файла типа WAV
|
и.п. лаб.
|
10,3
|
3,3 1
|
|
9
|
Моделирование процесса
кодирования и последующего синтеза сигнала на проектируемом программном
продукте
|
и.п. лаб. инж.
|
18,7
|
1,6 1,6 1,6
|
|
10
|
Сравнение результатов
синтеза с входным WAV-файлом
|
и.п. с.н.с лаб.
|
1,3
|
4,1 4,1 4,1
|
|
3. ОБОБЩЕНИЯ, ВЫВОДЫ И
ПРЕДЛОЖЕНИЯ
|
|
|
|
|
11
|
Обобщение результатов
работы
|
и.п. с.н.с
|
9,4
|
5 1,6
|
|
12
|
Определение возможности
использования проведенного исследования
|
и.п.
|
3,1
|
1
|
|
13
|
Написание отчета по НИР
|
и.п.
|
6,3
|
13,3
|
|
14
|
ВСЕГО
|
|
100
|
103
|
Примем такие условные обозначения: 01 - исполнитель-программист, 02 -
старший научный сотрудник, 03 - инженер, 04 - лаборант.
Таблица 5.2 - данные для линейного графика проведения НИР
|
№ вида работы
|
Виды работ
|
Коды исполнителей
|
Количество человек
|
Продолжительность работы
|
|
1
|
2
|
3
|
5
|
6
|
|
1
|
Составление задания НИР
|
01,02,03
|
3
|
1
|
|
2
|
Сбор информационных
материалов
|
01,02
|
2
|
2
|
|
3
|
Составление обзора по теме
|
01,04
|
2
|
4
|
|
4
|
Разработка общей
методологии проведения исследований
|
01,03,04
|
3
|
5
|
|
5
|
Исследование алгоритмов
спектрального оценивания
|
01
|
1
|
10
|
|
6
|
Рассмотрение вопросов
анализа и способа обработки речевых сигналов. Создание прикладной программы.
|
01,04
|
2
|
4
|
|
7
|
Определение периода
основного тона. И внедрение его в алгоритм обработки сигнала.
|
01,03
|
2
|
9
|
|
8
|
Рассмотрение форматов
звукового файла. Выбор оптимального формата. Оцифровка файла типа WAV
|
01,04
|
2
|
2
|
|
9
|
Моделирование процесса
кодирования и последующего синтеза сигнала
|
01,02,04
|
3
|
2
|
|
10
|
Сравнение результатов
синтеза с входным WAV-файлом
|
01,02,04
|
3
|
4
|
|
|
11
|
Обобщение результатов
работы
|
01,02
|
2
|
4
|
|
|
12
|
Опред. Возможности
использования прове-денного исследования
|
01
|
1
|
1
|
|
|
13
|
Написание отчета по НИР
|
01
|
1
|
4
|
|
|
Итого
|
|
|
52
|
|
|
|
|
|
|
|
|
|
|
По результатам выше приведенной таблицы построим график проведения
научно-исследовательской работы. График приведен на рисунке 5.1, на нем
черточками указано количество исполнителей работы, N - виды работ, d - дни.
Поскольку работу выполняло несколько сотрудников, работающих одновременно
над различными этапами, то имеем сокращение длительности выполнения НИР до 52
вместо запланированных 65 дней.
Для определения трудоемкости НИР использован метод, когда трудоемкость
одного из этапов определяется прямым счетом, затем определяется процентное
соотношение каждого из этапов НИР, далее находится трудоемкость всех остальных
этапов.
Количество исполнителей определяется по этапу и по видам работ, исходя из
конкретных условий.
Длительность исполнителей определяется по этапу и по видам работ, исходя
из конкретных условий.

Рисунок 5.1 - Линейный график выполнения НИР
Длительность проведения работ по каждому этапу определяется по формуле:
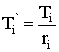 (5.1)
(5.1)
где Ti - трудоемкость работ по этапу, человеко-дней- количество
исполнителей по этапу.
При построении линейного графика выполнения работ, календарный график
рассчитывается по пятидневкам, (13 пятидневок).
5.3 Расчет сметной стоимости научно-технической
продукции
Затраты на проведение НИР относятся к предпроизводственным. Это
одноразовые затраты на все работы, которые выполняются по теме диплома всеми
исполнителями НИР.
Затраты определяются путем составления калькуляции плановой себестоимости
по статьям: материалы; спецоборудование для научных и экспериментальных работ;
начисления на ФОП; другие прямые затраты; накладные расходы.
Для выполнения дипломной работы необходимо приобрести набор канцелярских
принадлежностей. При выполнении работы, стоимость данных изделий вносится в
смету НИР. Расчет стоимости материалов и покупных изделий приведен в таблице
5.3
Таблица 5.3 - Расчет затрат по материалам
|
Наименование
|
Единицы измерения
|
Норма расхода
|
Цена единицы, грн.
|
Стоимость, грн.
|
|
1
|
2
|
3
|
4
|
5
|
|
Пишущие принадлежности
|
Шт
|
3
|
0,8
|
2,4
|
|
Бумага формата А1
|
Шт
|
5
|
3
|
15
|
|
Бумага формата А4
|
Шт
|
200
|
0,03
|
6
|
|
Дискеты
|
Шт
|
5
|
2
|
10
|
|
Итого
|
|
|
|
38,4
|
|
Транспортно -
заготовительные расходы (7%)
|
2,7
|
|
Всего
|
41,1
|
|
|
|
|
|
|
В таблице 5.4 представлено спецоборудование для научных и
экспериментальных работ, которое необходимо для выполнения данной НИР на время
проведения работ.
Таблица 5.4 - Затраты по спецоборудованию
|
Наименование
|
Кол-во ед., шт
|
Цена за ед., грн.
|
Общая стоимость
|
Время исполне-ния, лет
|
Норма аморт., %
|
Сумма аморт., грн/г
|
Итого расход, грн.
|
|
Intel CELERON 700
|
1
|
2400
|
2400
|
0,03
|
25
|
600
|
18
|
1
|
1100
|
1100
|
0,03
|
25
|
275
|
8,3
|
|
Принтер Canon S200
|
1
|
356
|
350
|
0.03
|
25
|
87,5
|
2,6
|
|
Итого
|
28,9
|
Расчет заработной платы производится исходя из должностных окладов. Согласно
таблицы 5.1, в разработке темы принимают участие 4 исполнителя с должностными
окладами:
1) исполнитель-программист - 290 грн.;
2) инженер - 180 грн.;
) старший научный сотрудник - 310 грн.;
) лаборант - 150 грн.
Для расчета основной заработной платы используем, в качестве исходных
данных, трудоемкость определенных видов работ (таблица 5.1).
Средняя заработная плата за один рабочий день определяется для каждой
категории работников, исходя из месячного оклада и количества рабочих дней в
месяце.
Таблица 5.5 - Основная заработная плата
|
Этапы темы
|
Исп.-прогр.
|
Инженер
|
Ст.научн.сотр.
|
Лаборант
|
Всего
|
|
дни
|
сумма
|
дни
|
сумма
|
дни
|
сумма
|
дни
|
сумма
|
дни
|
сумма
|
|
I
|
16,1
|
222,3
|
4,5
|
38,6
|
2,6
|
38,4
|
4,2
|
30
|
27,4
|
329,3
|
|
II
|
24
|
331,4
|
16.6
|
142,3
|
4.1
|
60,5
|
10
|
71,4
|
57.4
|
605,6
|
|
III
|
19.3
|
266,5
|
0
|
0
|
1.6
|
23,6
|
0
|
0
|
20.9
|
290,1
|
|
Итого
|
59,4
|
820,2
|
21,1
|
180,9
|
8,3
|
122,5
|
14,2
|
101,4
|
105,7
|
1225
|
|
Основная заработная плата,
грн.(ОЗП)
|
1225
|
|
Дополнительная заработная
плата, грн (8% от ОЗП)
|
98
|
К другим прямым затратам отнесем затраты на приобретение и подготовку
материалов, специальной научно-технической информации и др., которые
определяются прямым счетом. Накладные расходы составят 70% от фонда оплаты
труда (ФОТ). На основании выше перечисленных расчетов составим калькуляцию
плановой себестоимости НИР, представленную в таблице 5.6.
Определим договорную цену по формуле:
 (5.2)
(5.2)
где Nk - нормативная рентабельность, %;доп - коэффициент, учитывающий
заработную плату обслуживающих и управленческих подразделений;
Таблица 5.6 - Калькуляция плановой себестоимости проведения НИР
|
Статьи калькуляции затрат
|
Сумма, грн.
|
|
Материалы
|
41,1
|
|
Специальное оборудование
для НИР
|
28,9
|
|
Основная заработная плата
|
1225
|
|
Дополнительная заработная
плата
|
98
|
|
Отчисления в социальное
страхование (4% от ФОТ)
|
49
|
|
Отчисления в пенсионный
фонд (32% от ФОТ)
|
392
|
|
Фонд занятости (1,5% от
ФОТ)
|
18,4
|
|
Другие прямые затраты
|
80
|
|
Накладные расходы (70% от
ФОТ)
|
906,5
|
|
Всего затрат
|
2838,9
|
 (4.3)
(4.3)
где ФОТобщ - общий фонд оплаты труда предприятия;
ФОТнир - ФОТ подразделений, непосредственно занятых проведением НИР.
Тогда
Кдоп=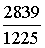 =2,3.
=2,3.
Ц=2838,9+ =3684,15
=3684,15
Прибыль:
П=Ц-С;
G=845,25 грн.
Оптовая
цена: себестоимость 1,25 = 3548,6 грн.
Отпускная
цена НИР с НДС=20% равна 4258,32 грн.
5.4 Оценка научно-технического и экономического
уровня НИР
Оценка
научно-технического и экономического уровня НИР может быть подсчитана с помощью
формулы
 (5.4)
(5.4)
где I - важность работы;сл - технологическая сложность выполнения
работы;р - результативность НИР;- показатель использования результатов НИР;нир
- стоимость НИР;нир - время проведения НИР.
Важность работы оценивается по ее назначению. Численно может принимать
значение I=2..5. Данная НИР направлена на создание кодека речи с целью
уплотнения сигнала и увеличения объема передачи информации, а также как
следствие - удешевление связи. Это важная задача для современной науки, поэтому
важность работы оценивается 4.
Технологическая сложность выполнения работы принимает значение 1..3. При
разработке проекта использовалось оборудование, которое поставлено на серийное
производство. Коэффициент сложности 2.
Результативность НИР определяется по полноте поставленной задачи,
принимает значение 1..4. Поставленная задача была решена полностью - оценка 4.
Показатель использования результатов принимает значение 0..3. В нашем
случае 3.
Стоимость НИР 2838 грн.
Время проведения разработки составило 0,142 года (52 дня).
Итак, мы имеем:=4;сл=2;р=4;=3;нир=2938 грн.;нир=0.142 года.
Подставив все эти значения в выражение 5.4, получим:нир=1,23
5.5 Выводы по оценке научно-технического и
экономического уровня НИР
Проведя экономические расчеты, мы получили Uнир=1,23. Поскольку значение
> 1 программы кодирования речи методом “Анализ через синтез” является
целесообразной.
6. РАЗРАБОТКА ВОПРОСОВ ОХРАНЫ ТРУДА
6.1 Анализ условий труда
Проектирование разработанной системы велось в помещении
научно-исследовательской лаборатории (НИЛ), оборудованной ПЭВМ.
Размер НИЛ составляет 5х6х3.5 м. Помещение выполнено из железобетона. В
рассматриваемом помещении трехфазная четырехпроводная сеть напряжением 380/220
В с глухозаземленной нейтралью, частотой 50 Гц.
Для системы «Человек Машина Среда» можно выделить следующие элементы:
а) «человек»- 4 оператора ЭВМ;
б) «машина»- 4 ПЭВМ, которые запитаны от электрической сети переменного
тока 220 В частотой 50 Гц;
с) «среда»- производственное помещение с вышеперечисленными параметрами.
Согласно ДНАОП 0.00-1.31-99 (т. к. данное помещение оборудовано для
работы на ЭВМ) для одного работающего площадь производственного помещения 6 м2,
объем воздушного пространства 19.5 м2. Следовательно, помещение удовлетворяет
этим требованиям.
Люди, работающие в помещении, совместно с оборудованием, образует систему
«Человек Машина Среда» (ЧМС), в которой при определенных условиях могут
возникать следующие опасности: анормальный микроклимат, выполнение тяжелой
умственной работы, информационная опасность, несоответствие показателей
освещения характеристикам человека, опасность поражения электрическим током.
Существует два подхода к описанию объектов: структурный и функциональный.
При структурном подходе элементами описания служат отдельные физические части
объекта - люди, машины, устройства и т. д. При функциональном подходе
элементами описания являются действия, операции и пр. Подходы, сочетающие
различным образом указанные два основных, называют функционально-структурными.
Применительно к системе ЧМС при структурном подходе в качестве элементов
выделяются человек-оператор и управляемая им техника (в данном случае ЭВМ), а
при функциональном подходе - операции, осуществляемые человеком и техникой.
Основной особенностью системы защиты является то, что на результат ее
работы влияет как поведение людей, так и состояние техники. Поэтому для нее
характерен равноэлементный подход к анализу объекта исследования, когда человек
и техника рассматриваются как равнозначные элементы системы.
В общем виде, взаимодействие работающих с производственной средой можно
представить в виде некоторой кибернетической системы ЧМС (рисунок 6.1), которая
показывает основные факторы, воздействующие на человека со стороны
производственной среды. Под «машиной» в системе ЧМС понимается совокупность
технических средств, используемых человеком оператором. В нашем случае это ЭВМ.
«Человек-оператор» - это человек, осуществляющий трудовую деятельность,
основу которой составляет управление объектом (процессом) с помощью
информационной модели.

Рисунок 6.1 - Функциональная схема системы ЧМС
Согласно данной схеме проводится анализ условий жизнедеятельности
человека с целью разработки защитных мер, обеспечивающих его безопасность.
Разработка вопросов охраны труда производится для помещения вычислительного
центра.
Таблица 6.1- Функциональные связи в системе ЧМС
|
Номер связи
|
Описание связи
|
|
1
|
Воздействие одного человека
на другого
|
|
2
|
Взаимообмен информации
между машинами
|
|
3
|
Информация от человека о
результате состояния предмета труда
|
|
4
|
Выдача т прием информации о
состоянии труда машиной
|
|
5
|
Информация о состоянии
предмета труда и среде, получаемая человеком от машины
|
|
6
|
Влияние среды на состояние
организма человека
|
|
7
|
Влияние среды на состояние
машины
|
|
8
|
Влияние человека, как
биологического объекта на среду
|
|
9
|
Воздействие машины на среду
|
Согласно ГОСТ 12.0.003-74 опасные и вредные производственные факторы
подразделяют по природе действия на группы:
·
физические;
·
химические;
·
биологические;
·
психофизиологические.
Для данного помещения характерны две группы из выше перечисленных -
физические и психофизиологические, которые способны значительно снижать, а при
длительном воздействии и приводить к потере работоспособности работающего
персонала.
К физической группе относятся такие факторы как:
·
повышенная и
пониженная температура воздуха рабочей зоны;
·
повышенный
уровень шума на рабочем месте;
·
повышенное
значение напряжения в электрической цепи, замыкание которой может произойти
через тело человека;
·
повышенная или
пониженная влажность воздуха;
·
повышенный
уровень электромагнитных излучений;
·
отсутствие или
недостаток естественного освещения;
·
недостаточная
освещенность рабочей зоны.
Так как питание оборудования осуществляется от сети, напряжением 220В,
возникает опасный вредный фактор - повышенное напряжение в электрической цепи,
замыкание которой может произойти через тело человека, такая опасность может
произойти при случайном прикосновении к токоведущим частям оборудования и
неисправности защитной изоляции. Источником шума является принтер или другое
печатающее устройство, вентиляторы систем охлаждения ЭВМ. Результатом действия
повышенной или пониженной температуры воздуха рабочей зоны является быстрая
утомляемость. Источником повышенной или пониженной температуры рабочей зоны
являются климатические условия. Источником электромагнитных излучений являются
мониторы: переменное электромагнитное излучение отклоняющих систем
видеомониторов, рентгеновское излучение видеомониторов. При отсутствии или
недостатке естественного света, также как и при недостаточной освещенности
рабочей зоны может возникнуть быстрая утомляемость и головная боль. Отсутствие
и недостаток естественного света происходит из-за неправильно организованного
освещения.
К психофизической группе относятся такие факторы:
·
умственное
перенапряжение;
·
перенапряжение
зрительных анализаторов;
·
монотонность
труда.
Сохранность зрения человека, состояния его нервной системы и безопасность
на производстве в значительной мере зависят от условий освещения. От освещения
зависят также производительность труда и точность выполняемых операций.
Правильно организованное освещение обеспечивает возможность нормальной
производственной деятельности. Здание, где установлена ПЭВМ, на которой
предполагается внедрить АРМ, расположено в четвертом поясе светового климата. В
помещении используется естественное освещение в светлое время суток и
искусственное освещение в темное время суток.
Помимо полезных функций обеспечения человека продукта труда может
генерировать и нежелательные для человека опасные и вредные производственные
факторы (ОВПФ). Причем при определенном уровне ОВПФ психофизиологические
возможности человека уже не могут обеспечить поддержание производственной среды
(ПС) в желаемом состоянии. ОВПФ воздействуют как на человека, так и на
аппаратуру. Такие факторы как электромагнитные поля, электрический ток,
освещение и шум воздействуют только на человека, а воздух рабочей зоны и
пожарная опасность - и на человека, и на машину. Опасность поражения человека
электрическим током, освещенность, воздух рабочей зоны и пожарная опасность
являются опасными факторами.
Проанализируем все возможные опасные и вредные производственные факторы.
Результаты анализа ОВПФ приведены в таблице 6.2.
При анализе воздуха рабочей зоны необходимо учитывать то, что воздушная
среда характеризуется химическим составом и метеорологическими условиями.
Показателями, характеризующими микроклимат являются температура, относительная
влажность, скорость движения воздуха и интенсивность теплового излучения. В
зависимости от энергозатрат организма (ГОСТ12.1.005 - 88) (работа производится
сидя или связанна с ходьбой и сопровождается некоторым физическим напряжением)
предусмотрена Iб категория работ, при которой энергозатраты организма
составляют около 150 ккал/ч. Поддержание на заданном уровне параметров,
определяющих микроклимат - температуру, влажность и скорость движения воздуха,
осуществляется с помощью кондиционера типа БК-1500. В холодный период года -
использование системы отопления помещения.
При анализе освещения необходимо учесть, что в лаборатории используется
естественное освещение, которое нормируется по значению коэффициента
естественного освещения (КЕО) и искусственное освещение, которое нормируется
освещенностью поверхности (СНиП II - 4 - 79).
Таблица 6.2 - Оценка факторов производственной среды и трудового процесса
|
Факторы производственной
среды
|
Значение фактора (ПДК,ПДУ)
|
3 класс - опасные и вредные
условия, характер труда
|
Продолжи-тельность действия
фактора, в % за смену
|
|
Норма
|
Факт
|
1 ст
|
2 ст
|
3 ст
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
|
Вредные химические
вещества: 1класс опасности
|
-
|
-
|
-
|
-
|
-
|
-
|
|
2 класс опасности
|
-
|
-
|
-
|
-
|
-
|
-
|
|
3 класс опасности
|
-
|
-
|
-
|
-
|
-
|
-
|
|
Вибрация
|
-
|
-
|
-
|
-
|
-
|
-
|
|
Шум
|
60 дБ
|
60 дБ
|
-
|
-
|
-
|
100
|
|
Инфразвук
|
-
|
-
|
-
|
-
|
-
|
-
|
|
Ультразвук
|
-
|
-
|
-
|
-
|
-
|
-
|
|
Неонизирующие излучения: а) электр. сост. 0,06 - 3 МГц 3 - 30 МГц
|
50 20
|
35 10
|
-
|
-
|
-
|
75
|
|
б) магнитные 0,06 - 3 МГц 3 - 30 МГц
|
5 -
|
2 -
|
-
|
-
|
-
|
75
|
|
Рентгеновское излучение
|
-
|
-
|
-
|
-
|
-
|
-
|
|
Микроклимат: Температура воздуха
|
23 - 25
|
15
|
-
|
-
|
-
|
100
|
|
Скорость движения воздуха
|
до 1
|
до 1
|
-
|
-
|
-
|
100
|
|
Относительная влажность
|
40 - 60
|
40
|
-
|
-
|
-
|
100
|
|
Атмосферное давление
|
-
|
-
|
-
|
-
|
-
|
-
|
|
Освещение: - естественное,
%
|
1,9
|
1,8
|
+
|
-
|
-
|
до 100 летом
|
|
- искусственное, лк
|
300
|
150
|
+
|
-
|
-
|
до 100 зимой
|
|
Тяжесть труда:
|
|
|
|
|
|
|
|
- мелкие стереотипные
движения кистей и пальцев рук
|
До 40000 накл. полож. до
300.
|
до 30000
|
-
|
-
|
-
|
90
|
|
- рабочая поза (пребывание
в наклонном положении в течении смены)
|
-
|
-
|
-
|
-
|
-
|
-
|
|
- наклоны корпуса ( раз за
смену )
|
-
|
-
|
-
|
-
|
-
|
|
- перемещение в
пространстве, км за смену
|
до 10 км
|
до 7 км
|
-
|
-
|
-
|
100
|
|
Напряженность труда а)
внимание: -продолжительность
сосредоточения, %
|
до 75
|
до 75
|
-
|
-
|
-
|
80
|
|
-плотность сигналов в
среднем за час
|
-
|
-
|
-
|
-
|
-
|
-
|
|
б) напряженность
анализаторов: - зрение (категория
работ)
|
точная
|
точная
|
-
|
-
|
-
|
70
|
|
- слух (разборчивость, % )
|
-
|
-
|
-
|
-
|
-
|
-
|
|
в) эмоциональное и
интеллектуальное напряжение
|
Работа по гра-фику
|
Работа по гра-фику
|
-
|
-
|
-
|
100 %
|
|
г) монотонность труда -
количество элементов в повторяющихся операциях
|
-
|
-
|
-
|
-
|
-
|
-
|
|
- длительность выполнения
повторяющихся операций
|
-
|
-
|
-
|
-
|
-
|
-
|
|
- время наблюдения за ходом
производственного процесса без активных действий
|
-
|
-
|
-
|
-
|
-
|
-
|
|
13. Сменность
|
Однос- менн. работа
|
Однос- менн. работа
|
-
|
-
|
-
|
-
|
|
|
|
|
|
|
|
|
|
Уровень шума, создаваемый в помещении при эксплуатации аппаратуры, не
более 60 дБ. Согласно ГОСТ 12. 1. 003 - 83 для помещений уровень звука и
эквивалентные уровни звука не должны превышать 50 дБ по шкале А. Так как
уровень шума аппаратуры не выходит за регламентированный, то никакой защиты не требуется
[21].
К основным причинам возникновения условий, при которых появляется
возможность поражения обслуживающего персонала электрическим током относятся:
случайные прикосновения к токоведущим частям;
возникновение аварийных режимов в электроустановках;
нарушение правил эксплуатации.
В соответствии с ГОСТ 12.1.019-79 в электроустановках применяются
следующие технические защитные меры:
) малые напряжения;
) электрическое разделение сетей;
) контроль и профилактика повреждений изоляции;
) компенсация емкостной составляющей тока замыкания на землю;
) обеспечение недоступности токоведущих частей;
) защитное заземление;
) зануление;
) двойная изоляция;
) защитное отключение.
Питание аппаратуры поступает через понижающий трансформатор от трехфазной
сети с заземленной нейтралью напряжением до 1000 В. В соответствии с ГОСТ 12.
1. 030 - 81 в электроустановках напряжением до 1000 В с заземленной нейтралью
для надежной защиты людей от поражения электрическим током применяется
зануление, обеспечивающее автоматическое отключение участка сети, на котором
произошел пробой на корпус. При занулении корпуса электрооборудование
соединяется не с заземлителями, а с нулевым проводом. Пробой на зануляемый
корпус равносилен однофазному короткому замыканию, в результате которого срабатывает
токовая защита и отключает поврежденный участок сети, что недопустимо в системе
связи. Поэтому аппаратура связи заземляется.
ОВПФ: отсутствие или недостаток искусственного света, согласно СНиП
II-4-79, не удовлетворяет требованиям. Недостаточная освещенность рабочей зоны
является доминирующим фактором, который может повлиять на условия.
6.2 Техника безопасности
В рассматриваемом помещении трехфазная сеть напряжением 220/380 В с
глухозаземленной нейтралью, частотой 50 Гц. По периметру помещения проводится
шина занyления, соединенная с защитным нулевым проводом, который повторно
заземлен. К шине подсоединены корпуса приборов и оборудования.
Согласно ПУЭ (ГОСТ 12.1.030-81 ССБТ. “Электробезопасность. Защитное
заземление, зануление”), рассматриваемое помещение по степени опасности
поражения электрическим током относится к категории без повышенной опасности,
так как в помещении отсутствует сырость (относительная влажность воздуха до
60%) и токопроводящие полы (пол деревянный), токопроводящая пыль, отсутствует
высокая температура.
Зануление превращает замыкание на корпус ПЭВМ или принтера в однофазное
короткое замыкание и отключение повреждённого участка сети осуществляется
автоматом защиты, ток срабатывания у которого должен превышать в 5-7 раз
максимальный ток, потребляемый электрооборудованием в помещении №306, но быть
меньше в 1,4 раза тока короткого замыкания. Время отключения повреждённого
участка сети должно быть не более 0,1 - 0,2 секунды.
Согласно требованиям ДНАОП 0.00 - 4.12 - 94, необходимо проводить
вводный, первичный на рабочем месте, повторный, а при необходимости внеплановый
и целевой инструктажи.
·
Вводный
инструктаж необходимо проводить при поступлении на работу. Инструктаж
организует и проводит служба охраны труда, факт инструктажа фиксируется в
журнале вводного инструктажа.
·
Первичный
инструктаж необходимо проводить непосредственно на рабочем месте. Факт
инструктажа необходимо фиксировать в журнале первичного инструктажа.
·
Внеплановый
инструктаж следует проводить при изменении условий труда, введение в
эксплуатацию новой техники, а также при несчастных случаях.
·
Целевой
инструктаж необходимо проводить при выполнении работ, несвязанных с их
основными обязанностями.
На рабочем месте, проводится ответственным за технику безопасности. Факт
инструктажа фиксируется в соответствующем документе.
Содержание всех инструктажей должно соответствовать ДНАОП 0.00 - 4.12 -
94 .
6.3 Производственная санитария и гигиена труда
Категория работ по энергозатратам организма Iа (легкая физическая работа).
для данной категории работ, согласно стандарту ГОСТ 12.1.005-88 [3] должны
поддерживаться метеорологические условия, приведенные в таблице 6.3
Таблица 6.3
|
Период года
|
Допустимые
|
|
температура на рабочих
местах,0С
|
относительная влажность
воздуха, %
|
Скорость движения воздуха,
м/с
|
|
верхняя
|
нижняя
|
|
|
|
Холодный
|
25
|
21
|
75
|
0.1
|
|
Теплый
|
28
|
25
|
21
|
0.1 - 0.2
|
Шум на рабочем месте создается внутренними источниками: преобразователями
напряжения и другими техническими средствами, а так же шумами, проникающие
извне. Для снижения шума следует
ослабить шум самих источников, предусмотрев применение в их конструкциях
акустические экраны, прокладки из резины;
ослабить шум за счет звукопоглощения поверхности окружающих конструкций.
Допустимый уровень шума для данного рабочего места (рабочее место в
помещении лаборатории) - 60 Дб.
Освещение помещения и рабочего места должно быть мягким, без блеска. Для
искусственного освещения помещения используют люминисцентные лампы, у которых
большая световая отдача, малая яркость светящейся поверхности, близкий к
естественному спектральный состав излучения. Согласно санитарным нормам и
правилам СНиП II - 4 - 99 [8] рекомендуемая освещенность 300 лк.
Из выше приведенной таблицы 6.1 по оценке ОВПФ видно, что доминирующим
фактором, который может повлиять на условия труда - это недостаточная
искусственная освещённость рабочей зоны. Проектом предлагается провести расчет
освещенности, применение которого приведет соответствующий ОВПФ к норме.
Общее освещение обеспечивают осветительные устройства ( ОУ ) с
люминесцентными лампами.
Выбор типа светильников и применяемых в них ламп проводится с учётом
среды в помещении, характера работ. Используемые ОУ типа ЦСП ( 1В ) - 2*40
климатического исполнения УЧ. В каждый светильник установлены две лампы ЛБ
40-4. Мощность потребляемая одной лампой, составляет 40 Вт.; световой поток -
2355 лм.; продолжительность горения 15000 ч..
Расчёт выполняется по методу коэффициента использования светового потока.
Необходимое число светильников в ряду определяется по формуле
 , (6.1)
, (6.1)
где ЕН - нормируемое значение освещённости, ЕН = 300 ЛК.;
КЗ - коэффициент запаса, КЗ = 1,5;- коэффициент неравномерности
освещённости для люминесцентных ламп Z = 1,1;- площадь помещения, S = 30 м2;-
число рядов светильников;
ФСВ - световой поток светильника;
КИ - коэффициент использования светового потока;
КЗТ - коэффициент затемнения, КЗТ = 0,8.
Для определения коэффициента использования светового потока КИ находим
индекс помещения i и предположительно оцениваем коэффициенты отражения
поверхностей помещения: потолка - pn, стен - рс, расчётной поверхности или пола
- рр.
Индекс помещения рассчитаем по формуле

 , (6.2)
, (6.2)
где А - длина помещения;
В - ширина помещения;- расчётная высота подвеса светильников над рабочей
поверхностью.
= H-h1-h2
где H - высота помещения;- свес - расстояние от светильников до
перекрытия;- высота рабочей поверхности:р = 3,5-0,2-0,8 =2,5 м.=
(5*6)/(2,5*(5+6)) = 1,1
Для рассчитанного индекса помещения и коэффициентов отражения
поверхностей помещения: pn = 70%, рс = 50%, рр = 10% коэффициент использования
КИ =0,39.
Так как качественные показатели освещения зависят от отношения расстояния
между ОУ и их рядами к hp, рекомендуется расстояние L между рядами светильников
выбирать в соответствии с формулой
= hp*L, (6.3)
где L -
наивыгоднейшее отношение, L = 0,77.= 2,5*0,77 = 1,93 м.
Номинальный световой поток лампы ЛД - 40 ФЛ = 2355 лм., тогда световой
поток излучаемый светильником УСП (1В) - 2*40 определяется по формуле
ФСВ =1,85*ФЛ. (6.4)
ФСВ = 1,85*2355 = 4356,75 лм.
Расстояние между стеной и крайним светильником определяется по формуле
l = 0,3*L. (6.5)
= 0,3*1,93 =0,579м.
Располагаем светильники вдоль длинной стороны B помещения. Число рядов
определяем по формуле
n = A/L. (6.6)
= 5/1,93 = 3.
Число светильников в ряду определяем по формуле (6.1):=(300*1,5*30*1,1) /
(3*4356,75*0,39*0,8) »4;=4.
Следовательно в ряду по 4 светильника.
При длине одного светильника lсв=1,33 м, растояние между светильниками
определяется по формуле:
 . (6.7)
. (6.7)
Следовательно R=(6-3×1.33)/(3+1)=0,5м.
На рисунке 6.2 приведен план размещения светильников в помещении.

Рисунок 6.2 - Расположение светильников в помещении
6.4 Пожарная профилактика
Как известно, пожар может возникнуть при взаимодействии горючих веществ,
кислорода и источника возгорания. В помещении лаборатории присутствуют все три
основные фактора, что могут обусловить пожар.
Горючими компонентами в лаборатории есть строительные материалы, для
акустической и эстетической обработки помещения, дверь, пол, изоляция силовых и
сигнальных кабелей, обмотки радиотехнических деталей. Источником воспламенения
в лаборатории могут быть электрические схемы, прибори, которые применяются для
технического обслуживания, приспособления електропитания, кондиционеры воздуха,
где в результате разных нарушений создаются перегретые элементы, электрическая
дуга или искра, которая способствует разжиганию горючих материалов.
Наше помещение представляет собой комнату на втором этаже железобетонного
здания. Помещение отвечает всем нормам пожаробезопасности и огнестойкости.
Помещение относится к классу П- IIа, т.к в помещении содержатся твердые
горючие волоконные вещества. Согласно СНиП 2.01.02-85 «Противопожарные нормы,
проектирование зданий и сооружений», здание и помещение относится к первой
степени огнестойкости, так как несущие и ограждающие конструкции выполнены из
железобетона и искусственных каменных материалов. По пожароопасности здания
относят к категории В, т.к. в помещении обращаются сгораемые вещества и
материалы.
Противопожарные мероприятия должны иметь комплексный характер, то есть
учитывать много аспектов этого вопроса.
Электрические приспособления должны, по возможности, быть выполнены из
негорючих материалов. Так, например, поливинилхлоридная изоляция это материал,
который хуже зажигается, чем полиэтиленовый. Все элементы электронных приспособлений
должны работать в допустимых режимах нагрузки, так как при их повышении
элементы схемы могут розогреваться. Так, например, нельзя включать в источник
питания нагрузки большей мощности, чем предусмотрено.
Кабельные линии оказываются наиболее пожароопасным местом в лаборатории.
Для снижения возгораемости и способности распространения огня, покроем кабель
пожарозащитным покрытием. От трансформаторных подстанций и генераторных
помещений к разделительным щиткам кабели проложим в металлических газовых
трубах.
При монтажно-сборочных и ремонтно-профилактических работах создается
высокая опасность возникновения пожара. Поэтому, при таких работах необходимо
четко выполнять правила пожарной безопасности. А именно:
нельзя оставлять паяльник на воспламеняющейся конструкции;
промывку деталей и модулей горючими жидкостями надо выполнять в
специальных помещениях, оборудованных проточно-вытяжной вентиляцией;
зажигательные жидкости надо хранить в металлических ящиках или сейфах, в
количестве, которая не превышает дневную норму.
Рабочее место стола студента покроем плитой из негорючего
диэлектрического материалла. Временнаю сеть от переносных приборов до источника
питания проложим по кратчайшему пути. Розетки будем монтировать на негорючих
пластинах и оснащають предохранителями.
Организационно-технические мероприятия по пожарной безопасности включают
в себя следующее:
·
инструктаж по
пожарной безопасности;
·
разработку
мероприятий по действиям работников на случай возникновения пожара и
организации эвакуации;
·
применением
плакатов наглядной агитации по пожарной безопасности.
В лабораториях и помещениях для сервисной аппаратуры необходимо
предусмотреть огнетушитель типа ОУБ в количестве 1 штуки на 28м? и ящик с песком.
Огнетушащим веществом является тетрафтордибром-метан, которым можно
гасить электрические устройства и приборы под напряжением.
Расположим в помещении 2 огнетушителя (поскольку площадь помещения 30 м2)
и ящик с песком.
Автоматическая система защиты обнаруживает пожар при помощи сигнальных
датчиков, передает сигнал тревоги в пожарную охрану. Для защиты лаборатории
наиболее пригодные бытовые осведомители типа РИД-1, с радиоизотропной
установкой охранно-пожарной сигнализацией типа РУОП-1. Используются также
осведомители типа ДИП-1, ДИП-2 и другие. Количество датчиков должно быть 4 на
20м?.
Огнетушитель, а также ящик с песком находится в лаборатории возле входной
двери.
План эвакуации людей из лаборатории при пожаре изображено на рисунке 6.3.

- огнетушитель; 2 - ящик с песком.
Рисунок 6.3 - Схема эвакуации при пожаре
ВЫВОДЫ
На базе кодека CELP был разработан алгоритм кодирования речи, с
использованием кодовой книги. Это позволило снизить скорость передачи цифрового
потока данных до 4.8 кбит/с. Близость спектра и временной диаграммы выходного
(синтезированного) сигнала с входным речевым сигналом (как было показано в
разделе 4) свидетельствует о хорошем качестве алгоритма и построенному на нем
программного продукта. Однако не полное сходство исследуемых сигналов говорит о
том, что необходимо еще искать оптимальный алгоритм определения ПОТ, а также
разрабатывать метод варьирования порядком модели фильтра.
Проведя оценку научно-технического и экономического уровня НИР был сделан
вывод о целесообразности выполнения дипломной работы. Данный кодек является
выгодным с точки зрения оценки цена/качество.
При разработке вопросов охраны труда был выявлен доминирующий фактор,
который может повлиять на условия труда - это недостаточная освещенность.
Произведен расчет для устранения этого фактора.
ПЕРЕЧЕНЬ ССЫЛОК
1. Бондарев
В., Трестер Г., Чернега В. Цифровая обработка сигналов. - Севастополь: СевГТУ,
1999, 397 с.
. Коротаев
Г.А. Эффективный алгоритм кодирования речевого сигнала на скорости 4,8 кбит/с и
ниже // Зарубежная Радиоэлектроника. 1996 № 3. с . 53-68.
. Коротаев
Г.А. Анализ и синтез речевого сигнала методом линейного предсказания //
Зарубежная Радиоэлектроника. 1990 № 3. с . - .
. Коротаев
Г.А. Некоторые аспекты линейного предсказания при анализе и синтезе речевого
сигнала // Зарубежная Радиоэлектроника. 1991 № 7. с . -
. Правила
охраны труда при эксплуатации электронно-вычислительных машин.- Утверждены
Комитетом по надзору за охраной труда Министерства труда и социальной политики
Украины, приказ от 10.02.1999 №21.
.
ГОСТ12.0.003-74 ССБТ. Опасные и вредные производственные факторы.
Классификация.
. ДНАОП
0.03.3.18-85. Временные санитарные нормы и правила для работников
вычислительных центров.
. ДНАОП
0.03.3.14-85. Санитарные нормы допустимых уровней шума на рабочих местах.
. Охрана
труда в электроустановках: Учебник для вузов / Под ред. Б.А. Князевского.- М.:
Энергия, 1983.-319 с.
. ГОСТ
12.1.004-91 ССБТ. Пожарная безопасность. Общие требования.
.
Методические указания по технико-экономическому обоснованию дипломных проектов
для студентов специальностей 7.090701, 7.090702, 7.090703 (РТ, АРТ, МРП).
Составители: доц. Светличная А.Г., доц. Скибицкая В.И.