Итерационный решатель для несимметричных матриц на основе аддитивного метода Шварца для машин с распределенной памятью
СОДЕРЖАНИЕ
1.
ВВЕДЕНИЕ
.
РЕСУРСЫ
.1
Вычислительный кластер
.2
Библиотеки
3. МЕТОД GMRES (THE GENERALIZED
MINIMUM RESIDUAL)
4.
ПЕРЕОБУСЛОВЛЕННЫЙ МЕТОД GMRES
.1
Параллельный переобуславливатель
.2
Параллельный переобусловленный метод с распределенной памятью
.3
Сетевой закон Амдала
.
ЧИСЛЕННЫЕ ЭКСПЕРИМЕНТЫ
.
РЕЗУЛЬТАТЫ
.
ЗАКЛЮЧЕНИЕ
.
СПИСОК ЛИТЕРАТУРЫ
1. ВВЕДЕНИЕ
В результате
сеточных аппроксимаций уравнений в частных производных могут возникнуть большие
разреженные системы линейных уравнений (СЛАУ): Ax = b. В
больших системах число неизвестных вполне может достигать ~ 107 ÷
108. Разреженной система является, если
количество ненулевых элементов данной матрицы A размерности n×n
составляет величину
O(n). Для хранения матриц такого типа используется специальный метод CSR, который будет рассмотрен подробнее.
Такие задачи, как правило, трудно решать без распараллеливания процесса
вычислений с использованием кластеров - многопроцессорных ЭВМ с распределенной
памятью.
В данной работе рассмотрено создание эффективного параллельного алгоритма
переобусловленного метода GMRES
(General Minimum Residual Method) для несимметрических блочных трехдиагональных систем
линейных алгебраических уравнений с использованием кластеров. В качестве основы
для распараллеливаемого алгоритма был выбран аддитивный метод Шварца[4,5]. Этот
метод основывается на декомпозиции физической расчетной области в рамках
некоторой итерационной процедуры. При реализации данного метода возникают
проблемы при «склейке» решений в подобластях. Эти проблемы связаны со способом
взаимодействия процессоров и способом передачи информации, а также с
необходимостью минимизировать количество арифметических действий.
Первый пункт данной работы посвящен используемым в ней ресурсам. К этим
ресурсам относятся библиотека MPI, предназначенная для разработки параллельного
кода, и библиотека Intel® Math Kernel Library, в которую входит прямой решатель
PARDISO, функция умножения матрицы на вектор DCSRMV и функция умножения двух
матриц DCSRMM. Также в пункте 1 описаны характеристики
кластера, на котором тестировалась программа.
Во втором пункте описан общий вид системы линейных алгебраических
уравнений, возникающий в результате сеточных аппроксимаций уравнений в частных
производных. Также в этом пункте описан специальный метод хранения разреженных
матриц CSR и метод GMRES, который лег
в основу данной работы.
К упомянутым ранее проблемам, возникающим при «склейке» решений в
подобластях, относится вычисление переобуславливателя, умножение матрицы на
вектор и вычисление скалярного произведения при перекрывании подобластей в
методе декомпозиции области. Этому посвящен четвертый пункт работы, в котором
описан параллельный алгоритм переобусловленного метода GMRES: параметры метода, способ распределения данных по
процессорам, построение параллельного переобуславливателя.
2. РЕСУРСЫ
.1 Вычислительный кластер
Кластер hpc7000 (рис.1) объединяет 8
двухпроцессорных узлов с общей памятью. Узел (рис.2) содержит два процессора Intel Xeon 5355 по четыре ядра каждый. Ядра в процессоре попарно
динамически разделяют кэш 2-го уровня. Два ядра, в зависимости от взаимного
расположения, могут обмениваться информацией либо через кэш 2 уровня, либо
через шину FSB. Все 8 ядер для чтения/записи данных
в ОЗУ, а так же для синхронизации одних и тех же данных в разных кэшах
используют двойную независимую шину.
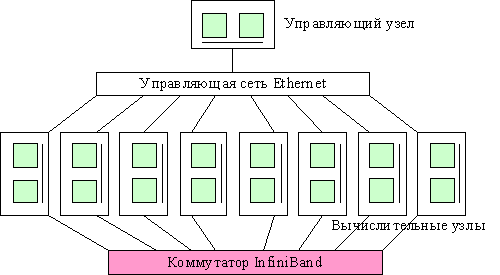
Рис.
2.1.1 Схема кластера hpc7000

Рис.
2.1.2 Схема вычислительного узла кластера hpc7000
На кластере hpc7000
установлено следующее программное обеспечение.
. Операционная система RedHat Linux (RHEL 5u1),
. Компиляторы Intel 10.1.015, Intel MKL 10.0.3.020, Intel MPI 3.1.038,
Intel Trace Analyzer & Collector 7.1.029
Вычислительные узлы соединены высокоскоростным коммутатором InfiniBand. Управляющая сеть Ethernet используется для постановки задач в
очередь и управления кластером. Некоторые характеристики кластера hpc7000 приведены в табл. 1.
Таблица 2.1.1
|
Характеристика
|
Значение
|
|
Название кластера
|
hpc7000
|
|
Количество вычислительных
узлов в кластере
|
64
|
|
Количество процессоров в
узле
|
2
|
|
Количество ядер в
процессоре
|
4
|
|
Итого ядер в кластере
|
512
|
|
Техпроцесс
|
65 нм
|
|
Процессор
|
Intel Xeon 5355
|
|
Тактовая частота процессора
|
2.66 ГГц
|
|
Пиковая производительность процессора
|
42.56 ГФлопс
|
|
Пиковая производительность
кластера
|
5,45 Тфлопс
|
|
Частота шины
|
1.33 ГГц
|
|
Пропускная способность шины
|
160 Мб/с
|
|
Кэш первого уровня
|
2×32 Кб
на ядро
|
|
Кэш второго уровня
|
2 по 2 Мб на 4 ядра
|
|
ОЗУ
|
16 Гб
|
|
Пропускная способность
памяти
|
10.66 Мб/с
|
.2 Библиотеки
В данной работе используются несколько готовых библиотек:
1) Intel(R) MPI Library 3.1 for Linux.
2) Intel®MKL.
Message
Passing Interface[6] (MPI, интерфейс передачи сообщений) - программный
интерфейс для передачи информации <#"587436.files/image003.gif"> процессов, то процессы нумеруются внутри группы
целыми числами от  до
до 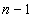 . Таким
образом, отправитель или получатель, определенные в операции посылки или
приема, всегда обращается к номеру процесса в группе.
. Таким
образом, отправитель или получатель, определенные в операции посылки или
приема, всегда обращается к номеру процесса в группе.
Все
операции взаимодействия, описанные в MPI, можно разделить на две группы: парные
и коллективные. Операции взаимодействия могут быть как синхронными, так и
асинхронными.
Парные
операции взаимодействия осуществляются только между двумя процессами. При этом
взаимодействие осуществляется, только если один процесс инициализировал
пересылку (например, вызовом функции MPI_Send), а второй инициализировал прием
(например, вызовом функции MPI_Recv).
Коллективные
операции взаимодействия осуществляются между всеми процессами. К ним относятся
операции коллективного вычисления (минимум, максимум, сумма и другие, в том
числе и определяемые пользователем операции).
Из библиотеки Intel®MKL взяты три процедуры: DCSRMV, DCSRMM и PARDISO.
PARDISO - Средство параллельного прямого решения разреженных
матриц.
DCSRMV
представляет собой алгоритм перемножения разреженной матрицы на вектор с
двойной точностью.
DCSRMM
представляет собой алгоритм перемножения двух разреженных матриц с двойной
точностью.
3. МЕТОД GMRES (THE GENERALIZED
MINIMUM RESIDUAL)
Рассмотрим СЛАУ
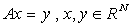 (3.1)
(3.1)
где
А - вещественная, блочная, трехдиагональная, несимметричная матрица.
Отметим,
что в нашем случае матрица состоит из р блоков.
 (3.2)
(3.2)
Массив values хранит все ненулевые элементы
разреженной матрицы, i-ый
элемент массива columns хранит
номер столбца i-го элемента массива values, а k-ый элемент массива rowIndex хранит порядковый номер в массиве values того ненулевого элемента, с которого начинается k-я строка. Последний элемент массива rowIndex хранит количество всех ненулевых
элементов.
Одним из эффективных методов решения подобных задач является метод GMRES(The Generalized Minimum Residual)[7]
Алгоритм GMRES:
1. r0
:= b - Ax0, β := || r0||2, v1 := r0/β
2. Определяем
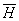 m := 0,
m := 0, 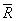 m = E
m = E
3. Для
каждого i = 1, 2, …, m
a. Вычисляем wi := Avi
b. Для каждого j = 1, …, i
Вычисляем hji := (wi, vj)
Пересчитаем wi := wi - hjivj
c. hi+1,i := ||wi||2.
Если hi+1,i = 0, то m := i, на
шаг 4
d. vi+1 := wi/hi+1,i
Приведем матрицу H к
верхнетреугольному виду. Определим ортогональную матрицу

 (3.3)
(3.3)
где
ci = 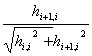 , si =
, si = 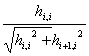 .
.
Также
определим вектор gm = βe1
Rm :=
RmΩi
Hm :=
Ωi*Hm;
gm := Ωigm
4. Вычисляем ym := Hm-1gm

Рис. 3.1 Схема метода GMRES
Для улучшения сходимости метода обобщенных невязок применяют
переобуславливатель.
Алгоритм
переобусловленного метода GMRES отличается от алгоритма метода GMRES
тем, что на каждой итерации необходимо выполнять операцию  . Поэтому при построении
. Поэтому при построении 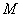 следует учитывать следующие критерии:
следует учитывать следующие критерии:
· Матрица должна хорошо аппроксимировать матрицу 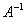 , чтобы обеспечить значительное уменьшение числа
итераций метода обобщенных невязок.
, чтобы обеспечить значительное уменьшение числа
итераций метода обобщенных невязок.
· Скорость
вычисления переобуславливателя должна быть достаточно высокой, чтобы увеличение
вычислительной нагрузки на одну итерацию могло быть компенсировано за счёт
уменьшения числа итераций.
4. ПЕРЕОБУСЛОВЛЕННЫЙ МЕТОД GMRES
.1 Параллельный переобуславливатель
При построении параллельного переобуславливателя в методе GMRES требуется соблюдать определенные
условия. Во-первых, необходимо учитывать факторы, которые влияют на
целесообразность использования переобуславливателя. Эти факторы были описаны
выше, в главе “Формулировка метода”. Помимо этого, существуют условия, которые
необходимо соблюдать для создания эффективных параллельных алгоритмов.
· Необходимо, чтобы каждый компьютер мог независимо от других
рассчитать необходимую ему часть переобуславливателя.
· Метод не должен зависеть от числа компьютеров в кластере.
Один из эффективных методов удовлетворяющих этим условиям является аддитивный
метод Шварца[4,5].
Пусть А - вещественная, блочная, положительно определенная
матрица. Обозначим через Ci i-ю
подматрицу, содержащая 4 блока матрицы A:
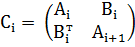
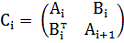 (4.1.1)
(4.1.1)
Тогда
переобуславливатель  записывается в виде суммы
записывается в виде суммы
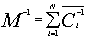 (4.1.2)
(4.1.2)
Где
 обратная к подматрице
обратная к подматрице 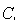 матрица,
расширенная нулями до размерности матрицы A.
матрица,
расширенная нулями до размерности матрицы A.
4.2 Параллельный переобусловленный метод с распределенной памятью
BLOCKS - параметр метода декомпозиции, который задает количество BLOCKS+1 подобластей и количество BLOCKS подматриц вида Ci (4.1.1). Для равномерного разбиения
параметр декомпозиции должен быть кратен числу MPI процессам.
eps - параметр, отвечающий за остановку данного итерационного метода. Метод
останавливается, когда относительная евклидова норма невязки достигает значения
меньшего eps.
Матрица А распадается по процессорам следующим образом: на каждом i-ом процессоре (i=0, …,p-2) хранится
часть матрицы А в виде отдельных блочных 2*2 подматриц вида Ci (4.1.1) с блоком Ai+1. Для i=p-1, на процессоре хранится только подматрица Сp-1.
Также на каждом (в том числе и последнем) процессоре хранятся, соответственно,
части вектора начального приближения и вектора правой части: (Xi, Xi+1) и (Yi, Yi+1).
, 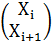 ,
, 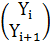 , (4.2.1)
, (4.2.1)
Умножение
матрицы на вектор и построение переобуславливателя являются самыми трудоемкими
процедурами в методе GMRES.
Умножение
матрицы А на вектор Х осуществляется следующим образом. Пусть
Сi (4.2.1) - часть матрицы А, хранящаяся на i-ом
процессоре. При этом компоненты вектора Х согласованы на разных
процессорах (под согласованностью мы понимаем, что компонента Xi+1
на i-ом процессоре равна Xi+1
на (i+1)-ом). На каждом процессоре
выполняем следующую операцию:
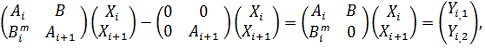
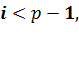
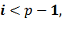
 (4.2.2)
(4.2.2)
Результат
этой операции на i-ом процессоре обозначим 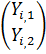

Умножение
матрицы на вектор осуществляется с помощью процедуры DCSRMV из
библиотеки Intel®MKL[5]. Для того, чтобы получить результирующий вектор, i-ый
процессор комбинирует данные с (i-1)-м и (i+1)-м с помощью процедуры MPI: MPI_SEND
и MPI_RECIVE[6](рис.4.2.1).

Рис.
4.2.1
Переобуславливатель
М действует на вектор Х следующим образом. Пусть данные
распределены, как описано выше. Тогда на каждом процессоре с помощью прямого
решателя PARDISO из библиотеки Intel®MKL[5]
решается следующая система:
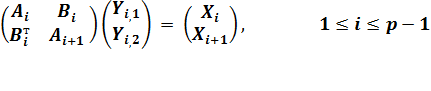
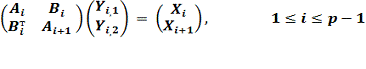 (4.2.3)
(4.2.3)
Результирующий
вектор собирается аналогично, как и в случае с умножением матрицы на вектор,
т.е. i-ый процессор комбинирует данные с (i-1)-м и (i+1)-м с помощью процедуры MPI: MPI_SEND
и MPI_RECIVE[6] (рис. 4.2.2).

Рис.
4.2.2 Действие переобуславливателя М на вектор X
Вычисление
скалярного произведение выполняется следующим образом: На первом MPI
процессе считается скалярное произведение всей части вектора, принадлежащего
процессу. На остальных процессах считается скалярное произведения только той
части вектора, которая не пересекается с частью вектора, принадлежащего
предыдущему процессу. Затем, на каждом процессе выполняется суммирование всех
частей скалярного произведения, которые уже были вычислены на остальных
процессах. Таким образом, получили скалярное произведение векторов, которое выполняется
с помощью процедуры MPI MPI_ALLREDUСE.[6]
4.3
Сетевой закон Амдала
кластер линейный уравнение переобуславливатель
Одной
из главных характеристик параллельных систем является ускорение 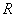 параллельной системы [2], которое определяется
выражением:
параллельной системы [2], которое определяется
выражением:
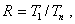 (4.3.1)
(4.3.1)
где
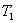 - время решения задачи на однопроцессорной системе;
- время решения задачи на однопроцессорной системе;
 - время
решения той же задачи на
- время
решения той же задачи на  - процессорной системе.
- процессорной системе.
Пусть
 ,
,
где
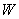 - общее число операций в задаче,
- общее число операций в задаче, 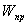 - число операций, которые можно выполнить параллельно,
- число операций, которые можно выполнить параллельно,
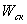 - число скалярных (нераспараллеливаемых) операций.
- число скалярных (нераспараллеливаемых) операций.
Обозначим
через 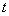 время выполнения одной операции. Тогда из (4.3.1)
получаем известный закон Амдала [2]:
время выполнения одной операции. Тогда из (4.3.1)
получаем известный закон Амдала [2]:
где
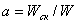 - удельный вес скалярных операций.
- удельный вес скалярных операций.
Закон
Амдала определяет принципиально важные для параллельных вычислений положения:
. Ускорение
зависит от потенциального параллелизма задачи (величина 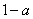 ) и параметров аппаратуры (число процессоров ).
) и параметров аппаратуры (число процессоров ).
. Предельное
ускорение определяется свойствами задачи.
Данный вариант закона Амдала не отражает потерь времени на
межпроцессорный обмен сообщениями. Эти потери могут не только снизить ускорение
вычислений, но и замедлить вычисления по сравнению с однопроцессорным
вариантом. Поэтому необходима некоторая модернизация выражения (4.3.2).
Перепишем (4.3.2) следующим образом [2]:
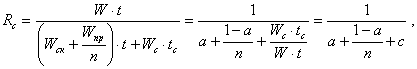 (4.3.3)
(4.3.3)
где
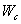 - количество передач данных;
- количество передач данных;
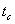 - время
одной передачи данных;
- время
одной передачи данных;
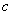 -
коэффициент сетевой деградации вычислений.
-
коэффициент сетевой деградации вычислений.
Выражение
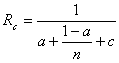 (4.3.4)
(4.3.4)
и
является сетевым законом Амдала. Этот закон определяет следующие особенности
многопроцессорных вычислений [2]:
Коэффициент
сетевой деградации вычислений :
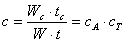 (4.3.5)
(4.3.5)
определяет
объем вычислений, приходящихся на одну передачу данных (по затратам времени).
При этом  - определяет алгоритмическую составляющую коэффициента
деградации, обусловленную свойствами алгоритма, а
- определяет алгоритмическую составляющую коэффициента
деградации, обусловленную свойствами алгоритма, а 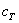 - техническую составляющую, которая зависит от
соотношения технического быстродействия процессора и аппаратуры сети. Таким
образом, для повышения скорости вычислений следует воздействовать на обе
составляющие коэффициента деградации. Для многих задач и сетей коэффициенты и могут
быть вычислены аналитически и заранее, хотя они определяются множеством
факторов: алгоритмом задачи, размером данных, реализацией функций обмена
библиотеки MPI, использованием разделяемой памяти и техническими характеристиками
коммуникационных сред и протоколов. В данной работе, мы будем определять
величины в законе Амдала экспериментальным путём, поскольку теоретическая
оценка затруднена использованием закрытых кодов из коммерческих библиотек.
- техническую составляющую, которая зависит от
соотношения технического быстродействия процессора и аппаратуры сети. Таким
образом, для повышения скорости вычислений следует воздействовать на обе
составляющие коэффициента деградации. Для многих задач и сетей коэффициенты и могут
быть вычислены аналитически и заранее, хотя они определяются множеством
факторов: алгоритмом задачи, размером данных, реализацией функций обмена
библиотеки MPI, использованием разделяемой памяти и техническими характеристиками
коммуникационных сред и протоколов. В данной работе, мы будем определять
величины в законе Амдала экспериментальным путём, поскольку теоретическая
оценка затруднена использованием закрытых кодов из коммерческих библиотек.
5.
ЧИСЛЕННЫЕ ЭКСПЕРИМЕНТЫ
В
соответствии с описанной в работе теорией, параллельный алгоритм был реализован
на вычислительном кластере HP BladeSystem c7000(см. пункт 1.2), находящемся в
НГУ. Тестирование проводилось на СЛАУ, возникающей при сеточном решении
уравнения Пуассона с конвекцией в одномерном и двумерном случае с равномерной
аппроксимирующей сеткой. Тестирование MPI алгоритма проводилось на разных
размерностях N и с различным параметром декомпозиции BLOCKS на
нескольких узлах.
Рассмотрим
сначала одномерную задачу, N = 1 000 000. Используется разбиение на 120, 240 и 300
блоков, параметр сетки eps = 10Е-4. На рис. 5.1 изображена зависимость времени
работы алгоритма от числа процессов. На графике показано, что время достигает
своего минимума на восьми процессах, причем, на меньших разбиениях время
меньше.
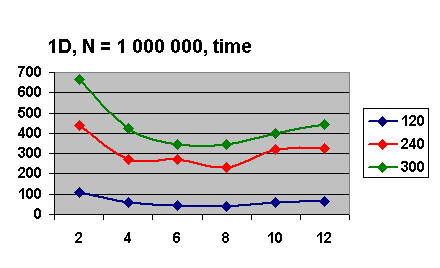
Рис. 5.1
Для двумерной задачи рассматривалось разбиение на 120, 480 и 840 блоков.
Значительное отличие во времени работы алгоритма в одномерном и двумерном
случае связано с тем, что число итераций в двумерном случае меньше в несколько
раз.
При N = 1 000 000 и eps = 10E-4 график зависимости времени работы алгоритма от числа
процессов изображен на рис 5.2. На графике показано, что значение параметра BLOCKS при таком eps на двумерной задаче незначительно
влияет на время работы.

Рис. 5.2
При уменьшении eps
до 10E-6 и при N = 1 000 000 число итераций возрастает, соответственно, время
работы алгоритма увеличивается. При различных значениях параметра BLOCKS, временные линии существенно отличаются.
Это можно проследить на рис.5.3.
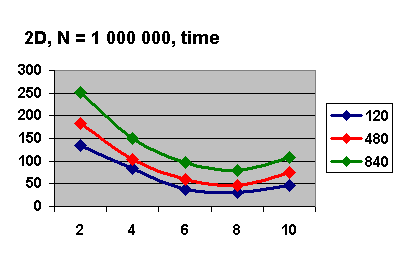
Рис. 5.3
График требуемой памяти на каждом узле(в Мб) в зависимости от их числа
изображен на рис. 5.4. Стоит отметить, что основная часть выделенной памяти на
каждом узле отводится для PARDISO,
что есть неотъемлемая часть переобуславливателя.
Обозначим отношение времени работы параллельной части алгоритма ко всему
времени работы через c.
На рис. 5.5 изображена зависимость. с от числа процессов. Несмотря на
то, что время работы алгоритма уменьшается (рис. 5.3), линии на рис.5.5. идут
вверх, что свидетельствует об увеличении временных затрат на параллельную
часть, особенно на десяти процессах.
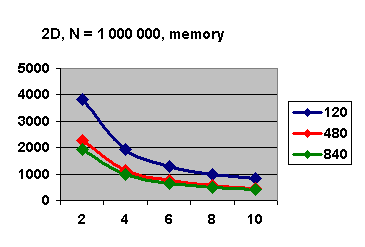
Рис. 5.4
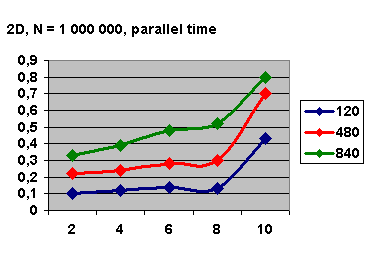
Рис. 5.5
При увеличении размерности N до 2
250 000 аналогичные графики изображены на рис. 5.6 - 5.8. На рис. 5.6. видно,
что минимальное время работы алгоритма на каждом разбиении (120, 480 и 840)
имеет место на 8 процессах.
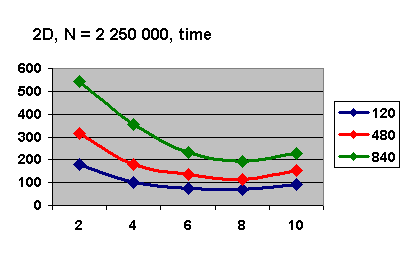
Рис. 5.6
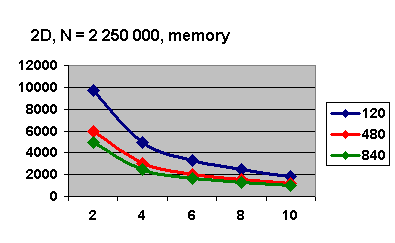
Рис. 5.7
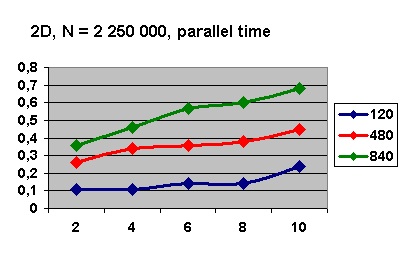
Рис. 5.8
6. РЕЗУЛЬТАТЫ
В данной работе был реализован параллельный алгоритм для решения СЛАУ на
машинах с распределенной памятью. Были рассмотрены одномерный и двумерный
случаи задачи Пуассона с конвекцией. Тестирование проводилось на разных
размерностях N и при различных параметрах eps и BLOCKS. Предполагалось, что параллельный алгоритм даст
выигрыш по времени, что и было подтверждено в ходе численных экспериментов.
7. ЗАКЛЮЧЕНИЕ
Цель данной работы заключалась в разработке и реализации параллельного
метода для решения задачи линейной алгебры Ах=b с несимметричной
матрицей A. Проблема создания параллельного кода наиболее
актуальна в случаях, когда необходимо решать СЛАУ с сотнями миллионов
неизвестных(n~107-108), потому как решение подобных задач
на одном компьютере требует большого количества времени. Для систем меньшей
размерности подобные методы также позволяют получить существенное сокращение
времени решения.
В рамках метода декомпозиции области и на основании описанного в данной
работе переобусловленного метода обобщенных невязок была реализована и
протестирована параллельная программа, использующая встроенные библиотеки
Интела.
Тестирование показало хорошую параллельность метода, уменьшение времени
при увеличении числа узлов на кластере.
Таким образом, можно считать цель данной работы выполненной.
8. СПИСОК ЛИТЕРАТУРЫ
1. Мацокин А.М. Конспект лекций:
Вычислительные методы линейной алгебры. (http://mmfd.nsu.ru/def_koi.htm)
2. Программирование
для многопроцессорных систем в стандарте MPI: Пособие / Г. И. Шпаковский, Н. В. Серикова. - Мн.: БГУ,
2002..
. Ю.М.Лаевский,
А.М.Мацокин. Методы декомпозиции решения эллиптических и параболических краевых
задач. - СибЖВМ, 1999, т.2, © 4, 361-372.
4. Мацокин
А.М., Непомнящих С.В. Метод альтернирования Шварца в подпространстве //
Известия высш. учебных заведений. Математика.1985. N. 10, P.
61-66.
5. Intel(R)
Math Kernel Library (Intel(R) MKL) Documentation
(http://software.intel.com/ru-ru/intel-mkl/)
6. Корнеев
В.Д. Параллельное программирование в MPI. - Новосибирск 2002.
7. Yousef
Saad. Iterative methods for sparse linear system.