Теория вероятностей и математическая статистика
Теория
вероятностей и математическая статистика
1.ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
.1 Сходимость последовательностей случайных
величин и вероятностных распределений
В теории вероятностей приходится иметь дело с
разными видами сходимости случайных величин. Рассмотрим следующие основные виды
сходимости: по вероятности, с вероятностью единица, среднем порядка р, по
распределению.
Пусть 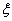 ,
, 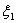 ,
, 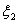 … - случайные величины, заданные на
некотором вероятностном пространстве (
… - случайные величины, заданные на
некотором вероятностном пространстве ( , Ф , P).
, Ф , P).
Определение 1. Последовательность
случайных величин , …
называется сходящейся по вероятности к случайной величине 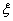 (обозначение:
(обозначение:
 ), если для
любого
), если для
любого 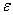 > 0
> 0
{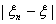 >}
>}  0, n
0, n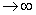 .
.
Определение 2. Последовательность
случайных величин , , …
называется сходящейся с вероятностью единица (почти наверное, почти всюду) к
случайной величине , если
{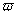 :
: 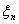
 } = 0,
} = 0,
т.е. если множество исходов , для
которых () не
сходятся к (), имеет
нулевую вероятность.
Этот вид сходимости обозначают
следующим образом: 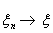 , или
, или 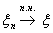 , или
, или 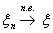 .
.
Определение 3. Последовательность
случайных величин , , …
называется сходящейся в среднем порядка р, 0 < p < 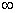 , если
, если
 0, n.
0, n.
Определение 4. Последовательность
случайных величин , ,…
называется сходящейся по распределению к случайной величине (обозначение:
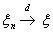 ), если для
любой ограниченной непрерывной функции
), если для
любой ограниченной непрерывной функции 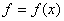
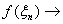 M
M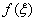 , n.
, n.
Сходимость по распределению
случайных величин определяется только в терминах сходимости их функций распределения.
Поэтому об этом виде сходимости имеет смысл говорить и тогда, когда случайные
величины заданы на разных вероятностных пространствах.
Теорема 1.
а) Для того чтобы (Р-п.н.),
необходимо и достаточно, чтобы для любого > 0
{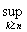
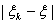
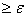 } 0, n.
} 0, n.
) Последовательность {} фундаментальна с вероятностью единица тогда и только тогда, когда для любого > 0.
фундаментальна с вероятностью единица тогда и только тогда, когда для любого > 0.
{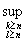
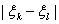 } 0, n.
} 0, n.
Доказательство.
а) Пусть А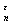 = {: |- | }, А
= {: |- | }, А =
=  А
А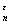
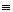
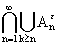 . Тогда
. Тогда
{: }=  =
= 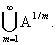
Но
(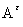 ) =
) = 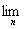 P (
P (  ),
),
Поэтому утверждение а) является
результатом следующей цепочки импликаций:
Р{: }= 0  P(
P( 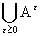 ) = 0
) = 0 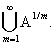 = 0 Р(А
= 0 Р(А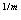 ) = 0, m
) = 0, m 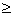 1 P(A) = 0, > 0 P(
1 P(A) = 0, > 0 P(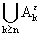 ) 0, n 0, > 0 P{ } 0,
) 0, n 0, > 0 P{ } 0,
n 0, > 0.) Обозначим 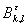 = {:
= {: 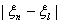 },
}, 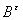 =
= 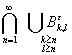 . Тогда {: {()} не
фундаментальна } =
. Тогда {: {()} не
фундаментальна } =  и так же,
как в а) показывается, что {: {()} не фундаментальна } = 0 P{ } 0, n.
и так же,
как в а) показывается, что {: {()} не фундаментальна } = 0 P{ } 0, n.
Теорема доказана
Теорема 2. ( критерий Коши
сходимости почти наверно)
Для того чтобы последовательность
случайных величин {} была
сходящейся с вероятностью единица (к некоторой случайной величине ),
необходимо и достаточно, чтобы она была фундаментальна с вероятностью единица.
Доказательство.
Если , то 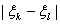

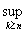
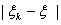 +
+ 
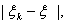
откуда вытекает необходимость
условия теоремы.
Пусть теперь последовательность {}
фундаментальна с вероятностью единица. Обозначим  L = {: {()} не фундаментальная}. Тогда для
всех
L = {: {()} не фундаментальная}. Тогда для
всех 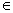
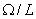 числовая
последовательность {} является
фундаментальной и, согласно критерию Коши для числовых последовательностей,
существует
числовая
последовательность {} является
фундаментальной и, согласно критерию Коши для числовых последовательностей,
существует 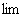 (). Положим
(). Положим
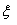 () =
() = 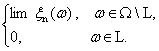
Так определенная функция является
случайной величиной и .
Теорема доказана.
.2 Метод характеристических функций
Метод характеристических функций является одним
из основных средств аналитического аппарата теории вероятностей. Наряду со
случайными величинами (принимающими действительные значения) теория
характеристических функций требует привлечения комплекснозначных случайных
величин.
Многие из определений и свойств, относящихся к
случайным величинам, легко переносятся и на комплексный случай. Так,
математическое ожидание Мξ
комплекснозначной случайной величины ζ=ξ+ίη
считается
определенным, если определены математические ожидания Мξ
и Мη.
В этом случае по определению полагаем Мζ
= Мξ
+ ίМη.
Из определения независимости случайных элементов следует, что комплекснозначные
величины ζ1
=ξ1+ίη1
, ζ2=ξ2+ίη2
независимы тогда и только тогда, когда независимы пары случайных величин (ξ1
, η1)
и (ξ2
, η2),
или, что то же самое, независимы σ-алгебры
Fξ1,
η1 и Fξ2, η2.
Наряду с пространством L2
действительных случайных величин с конечным вторым моментом можно ввести в
рассмотрение гильбертово пространство комплекснозначных случайных величин ζ=ξ+ίη
с
М |ζ|2<∞,
где |ζ|2=
ξ2+η2,
и скалярным произведением (ξ1
,
ξ2)= Мζ1ζ2¯,
где ζ2¯-
комплексно-сопряженная случайная величина.
При алгебраических операциях векторы
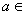 Rn
рассматриваются как алгебраические столбцы,
Rn
рассматриваются как алгебраические столбцы,
 ,
,
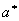 - как вектор-строки, a*
- (а1,а2,…,аn). Если
- как вектор-строки, a*
- (а1,а2,…,аn). Если 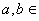 Rn
, то под их скалярным произведением (a,b) будет пониматься величина
Rn
, то под их скалярным произведением (a,b) будет пониматься величина  . Ясно, что
. Ясно, что 
Если аRn и R=||rij||
- матрица порядка nхn, то
 =
=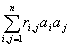 . (1)
. (1)
Определение 1. Пусть F = F(х1,….,хn)
- n-мерная функция распределения в (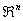 ,
, 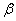 ( )). Ее
характеристической функцией называется функция
( )). Ее
характеристической функцией называется функция
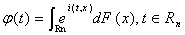 . (2)
. (2)
Определение 2. Если ξ = (ξ1,…,ξn) - случайный
вектор, определенный на вероятностном пространстве 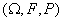 со
значениями в
со
значениями в 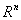 , то его
характеристической функцией называется функция
, то его
характеристической функцией называется функция
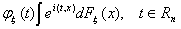 (3)
(3)
где Fξ = Fξ(х1,….,хn)
- функция распределения вектора ξ=(ξ1, … , ξn).
Если функция распределения F(х)
имеет плотность f = f(х), то тогда
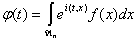 .
.
В этом случае характеристическая
функция 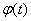 есть не что
иное, как преобразование Фурье функции f(x).
есть не что
иное, как преобразование Фурье функции f(x).
Из (3) вытекает, что
характеристическую функцию φξ(t)
случайного вектора можно определить также равенством
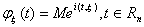 . (4)
. (4)
Основные свойства характеристических
функций (в случае n=1).
Пусть ξ = ξ(ω) - случайная
величина, Fξ
=
Fξ
(х)
- её функция распределения и  - характеристическая функция.
- характеристическая функция.
Следует отметить, что если 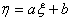 , то
, то 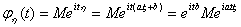 .
.
Поэтому
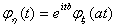 . (5)
. (5)
Далее, если ξ1, ξ2, … , ξn -
независимые с. в. и Sn= ξ1+ξ2 +… + ξn, то
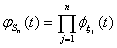 (6)
(6)
В самом деле, 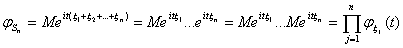 ,
,
где воспользовались тем, что математическое
ожидание произведения независимых (ограниченных) случайных величин равно
произведению их математических ожиданий.
Свойство (6) является ключевым при
доказательстве предельных теорем для сумм независимых случайных величин методом
характеристических функций. В этой связи, функция распределения 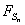 выражается
через функции распределения отдельных слагаемых уже значительно более сложным
образом, а именно,
выражается
через функции распределения отдельных слагаемых уже значительно более сложным
образом, а именно, 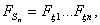 где знак *
означает свертку распределений.
где знак *
означает свертку распределений.
С каждой функцией распределения в  можно
связать случайную величину, имеющую эту функцию в качестве своей функции
распределения. Поэтому при изложении свойств характеристических функций можно
ограничиться рассмотрением характеристических функций
можно
связать случайную величину, имеющую эту функцию в качестве своей функции
распределения. Поэтому при изложении свойств характеристических функций можно
ограничиться рассмотрением характеристических функций  случайных
величин
случайных
величин 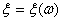 .
.
Имеют место следующие свойства:
) |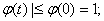
) равномерно
непрерывна по 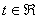 ;
;
)  ;
;
) является
действительнозначной функцией тогда и только тогда, когда распределение F
симметрично
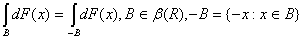
) если для некоторого n ≥
1 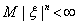 , то при
всех
, то при
всех 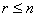 существуют
производные
существуют
производные 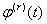 и
и 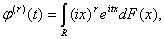

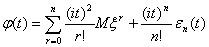 ,
,
где 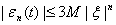 и
и 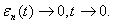
) Если существует и является
конечной 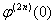 , то
, то 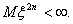
) Пусть для всех n ≥
1 и 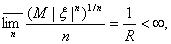
тогда при всех |t|<R
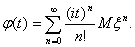
Следующая теорема показывает, что
характеристическая функция однозначно определяет функцию распределения.
Теорема 2 (единственности). Пусть F
и G - две функции распределения, имеющие одну и ту же характеристическую функцию,
то есть для всех
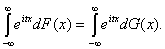
Тогда 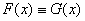 .
.
Теорема говорит о том, что функция
распределения F = F(х) однозначно восстанавливается по своей характеристической
функции 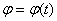 . Следующая
теорема дает явное представление функции F через
. Следующая
теорема дает явное представление функции F через 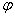 .
.
Теорема 3 (формула обобщения). Пусть
F = F(х) - функция распределения и 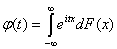 - ее характеристическая функция.
- ее характеристическая функция.
а) Для любых двух точек a, b (a <
b), где функция F = F(х) непрерывна,
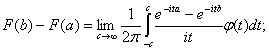
) Если 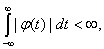 то функция
распределения F(х) имеет плотность f(x),
то функция
распределения F(х) имеет плотность f(x),
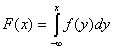
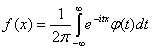 .
.
Теорема 4. Для того чтобы компоненты
случайного вектора 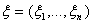 были
независимы, необходимо и достаточно, чтобы его характеристическая функция была
произведением характеристических функций компонент:
были
независимы, необходимо и достаточно, чтобы его характеристическая функция была
произведением характеристических функций компонент:
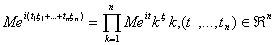 .
.
Теорема Бохнера-Хинчина.
Пусть -
непрерывная функция, 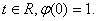 Для того,
чтобы была
характеристической, необходимо и достаточно, чтобы она была
неотрицательно-определенной, то есть для любых действительных t1, …
, tn и любых комплексных чисел
Для того,
чтобы была
характеристической, необходимо и достаточно, чтобы она была
неотрицательно-определенной, то есть для любых действительных t1, …
, tn и любых комплексных чисел 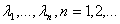
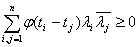 .
.
Теорема 5. Пусть  - характеристическая
функция случайной величины .
- характеристическая
функция случайной величины .
а) Если 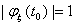 для
некоторого
для
некоторого 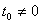 , то
случайная величина является
решетчатой с шагом
, то
случайная величина является
решетчатой с шагом 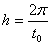 , то есть
, то есть
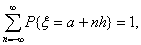
) Если 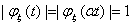 для двух
различных точек
для двух
различных точек 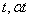 , где
, где 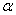 -
иррациональное число, то случайная величина ξ является вырожденной:
-
иррациональное число, то случайная величина ξ является вырожденной:
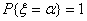 ,
,
где а - некоторая константа.
с) Если 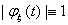 , то
случайная величина ξ
вырождена.
, то
случайная величина ξ
вырождена.
1.3 Центральная
предельная теорема для независимых одинаково распределенных
случайных
величин
Пусть {} -
последовательность независимых, одинаково распределенных случайных
величин. Математическое ожидание M= a,
дисперсия D= 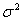 , S
, S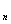 =
= 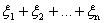 , а Ф(х) -
функция распределения нормального закона с параметрами (0,1). Введем еще
последовательность случайных величин
, а Ф(х) -
функция распределения нормального закона с параметрами (0,1). Введем еще
последовательность случайных величин
= 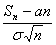 .
.
Теорема. Если 0 <<, то при n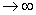 P(< x) Ф(х)
равномерно относительно х (
P(< x) Ф(х)
равномерно относительно х (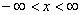 ).
).
В этом случае
последовательность {} называется
асимптотически нормальной.
Из того, что М= 1 и из
теорем непрерывности вытекает, что наряду со слабой сходимостью 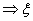 ,
, 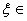 Ф
Ф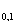 М f() Mf() для любой
непрерывной ограниченной f имеет место
также сходимость М f() Mf() для любой
непрерывной f,
такой, что |f(x)|
< c(1+|x|
М f() Mf() для любой
непрерывной ограниченной f имеет место
также сходимость М f() Mf() для любой
непрерывной f,
такой, что |f(x)|
< c(1+|x|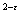 ) при
каком-нибудь
) при
каком-нибудь 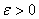 .
.
Доказательство.
Равномерная сходимость здесь
является следствием слабой сходимости и непрерывности Ф(х). Далее, без
ограничения общности можно считать а = 0, так как иначе можно было бы
рассмотреть последовательность {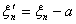 }
}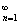 , при этом последовательность {} не
изменилась бы. Стало быть, для доказательства требуемой сходимости достаточно
показать, что
, при этом последовательность {} не
изменилась бы. Стало быть, для доказательства требуемой сходимости достаточно
показать, что  (t) e
(t) e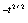 ,когда а =
0. Имеем
,когда а =
0. Имеем
(t) =  , где =(t).
, где =(t).
Так как существует М , то
существует
, то
существует 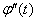 и
справедливо разложение
и
справедливо разложение
= 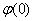 + t
+ t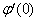 +
+ 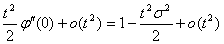 ,
,
Следовательно, при n
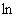
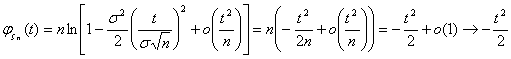
Теорема доказана.
1.4 Основные задачи математической статистики их
краткая характеристика
Установление закономерностей, которым подчинены
массовые случайные явления, основано на изучении статистических данных -
результатах наблюдений. Первая задача математической статистики - указать
способы сбора и группировки статистических сведений. Вторая задача математической
статистики - разработать методы анализа статистических данных, в зависимости от
целей исследования.
При решении любой задачи математической
статистики располагают двумя источниками информации. Первый и наиболее
определенный(явный) - это результат наблюдений (эксперимента) в виде выборки из
некоторой генеральной совокупности скалярной или векторной случайной величины.
При этом объем выборки n может быть фиксирован, а может и увеличиваться в ходе
эксперимента (т. е. могут использоваться так называемые последовательные
процедуры статистического анализа).
Второй источник - это вся априорная информация
об интересующих свойствах изучаемого объекта, которая накоплена к текущему
моменту. Формально объем априорной информации отражается в той исходной
статистической модели, которую выбирают при решении задачи. Однако и о
приближенном в обычном смысле определении вероятности события по результатам
опытов говорить не приходится. Под приближенным определением какой-либо
величины обычно подразумевают, что можно указать пределы погрешностей, из
которых ошибка не выйдет. Частота же события случайна при любом числе опытов
из-за случайности результатов отдельных опытов. Из-за случайности результатов
отдельных опытов частота может значительно отклоняться от вероятности события.
Поэтому, определяя неизвестную вероятность события как частоту этого события
при большом числе опытов, не можем указать пределы погрешности и гарантировать,
что ошибка не выйдет из этих пределов. Поэтому в математической статистике
обычно говорят не о приближенных значениях неизвестных величин, а об их
подходящих значениях, оценках.
Задача оценивания неизвестных
параметров возникает в тех случаях, когда функция распределения генеральной
совокупности известна с точностью до параметра 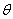 . В этом случае необходимо найти
такую статистику
. В этом случае необходимо найти
такую статистику 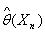 , выборочное
значение
, выборочное
значение 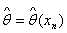 которой для
рассматриваемой реализации xn случайной выборки можно было бы
считать приближенным значением параметра . Статистику , выборочное значение
которой для
рассматриваемой реализации xn случайной выборки можно было бы
считать приближенным значением параметра . Статистику , выборочное значение 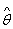 которой для
любой реализации xn принимают за приближенное значение неизвестного
параметра , называют
его точечной оценкой или просто оценкой, а - значением точечной оценки.
Точечная оценка должна удовлетворять вполне определенным требованиям для того,
чтобы её выборочное значение соответствовало истинному значению
параметра .
которой для
любой реализации xn принимают за приближенное значение неизвестного
параметра , называют
его точечной оценкой или просто оценкой, а - значением точечной оценки.
Точечная оценка должна удовлетворять вполне определенным требованиям для того,
чтобы её выборочное значение соответствовало истинному значению
параметра .
Возможным является и иной подход к
решению рассматриваемой задачи: найти такие статистики 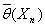 и
и 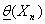 ,чтобы с
вероятностью γ
выполнялось
неравенство:
,чтобы с
вероятностью γ
выполнялось
неравенство:
P { 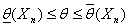 } = γ
} = γ
В этом случае говорят об
интервальной оценке для . Интервал
(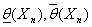 )
)
называют доверительным интервалом
для с коэффициентом
доверия γ.
Оценив по результатам опытов ту или
иную статистическую характеристику, возникает вопрос: насколько согласуется с
опытными данными предположение (гипотеза) о том, что неизвестная характеристика
имеет именно то значение, которое получено в результате её оценивания? Так
возникает второй важный класс задач математической статистики - задачи проверки
гипотез.
В некотором смысле задача проверки
статистической гипотезы является обратной к задаче оценивания параметра. При
оценивании параметра мы ничего не знаем о его истинном значении. При проверке
статистической гипотезы из каких-то соображений предполагается известным его
значение и необходимо по результатам эксперимента проверить данное
предположение.
Во многих задачах математической статистики
рассматриваются последовательности случайных величин 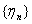 , сходящиеся
в том или ином смысле к некоторому пределу
, сходящиеся
в том или ином смысле к некоторому пределу 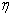 (случайной величине или константе),
когда
(случайной величине или константе),
когда 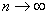 .
.
Таким образом, основными задачами
математической статистики являются разработка методов нахождения оценок и
исследования точности их приближения к оцениваемым характеристикам и разработка
методов проверки гипотез.
.5 Проверка статистических гипотез: основные
понятия
Задача разработки рациональных
методов проверки статистических гипотез - одна из основных задач математической
статистики. Статистической гипотезой (или просто гипотезой) называют любое
утверждение о виде или свойствах распределения наблюдаемых в эксперименте
случайных величин.
Пусть имеется выборка 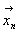 , являющаяся
реализацией случайной выборки
, являющаяся
реализацией случайной выборки 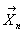 из генеральной совокупности
из генеральной совокупности 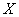 , плотность
распределения которой
, плотность
распределения которой 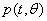 зависит от
неизвестного параметра .
зависит от
неизвестного параметра .
Статистические гипотезы
относительно неизвестного истинного значения параметра называют
параметрическими гипотезами. При этом если - скаляр, то речь идет об
однопараметрических гипотезах, а если вектор - то о многопараметрических
гипотезах.
Статистическую гипотезу 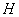 называют
простой, если она имеет вид
называют
простой, если она имеет вид

Статистическую гипотезу называют
сложной, если она имеет вид
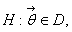
где 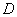 - некоторое
множество значений параметра , состоящее более чем из одного
элемента.
- некоторое
множество значений параметра , состоящее более чем из одного
элемента.
В случае проверки двух
простых статистических гипотез вида
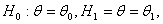
где 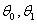 - два
заданных (различных ) значения параметра, первую гипотезу
- два
заданных (различных ) значения параметра, первую гипотезу 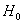 обычно
называют основной, а вторую
обычно
называют основной, а вторую 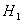 - альтернативной, или конкурирующей
гипотезой.
- альтернативной, или конкурирующей
гипотезой.
Критерием, или статистическим
критерием, проверки гипотез называют правило, по которому по данным выборки принимается
решение о справедливости либо первой, либо второй гипотезы.
Критерий задают с помощью
критического множества  ,
являющегося подмножеством выборочного пространства
,
являющегося подмножеством выборочного пространства 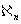 случайной
выборки . Решение
принимают следующим образом:
случайной
выборки . Решение
принимают следующим образом:
) если выборка принадлежит
критическому множеству , то
отвергают основную гипотезу и принимают альтернативную гипотезу
;
) если выборка не
принадлежит критическому множеству (т. е. принадлежит дополнению 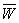 множества до
выборочного пространства ), то
отвергают альтернативную гипотезу и принимают основную гипотезу .
множества до
выборочного пространства ), то
отвергают альтернативную гипотезу и принимают основную гипотезу .
При использовании любого критерия
возможны ошибки следующих видов:
1) принять гипотезу , когда
верна - ошибка
первого рода;
) принять гипотезу , когда
верна - ошибка
второго рода.
Вероятности совершения ошибок
первого и второго рода обозначают и :
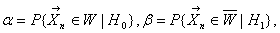
где 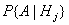 -
вероятность события
-
вероятность события 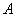 при
условии, что справедлива гипотеза
при
условии, что справедлива гипотеза 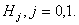 Указанные вероятности вычисляют с
использованием функции плотности распределения случайной выборки :
Указанные вероятности вычисляют с
использованием функции плотности распределения случайной выборки :
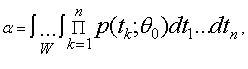
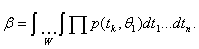
Вероятность совершения ошибки
первого рода также
называют уровнем значимости критерия.
Величину 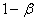 , равную
вероятности отвергнуть основную гипотезу , когда она верна, называют
мощностью критерия.
, равную
вероятности отвергнуть основную гипотезу , когда она верна, называют
мощностью критерия.
1.6 Критерий независимости 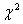
Имеется выборка ((X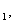 Y
Y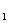 ), …, (XY)) из
двумерного распределения
), …, (XY)) из
двумерного распределения
L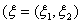 с
неизвестной функцией распределения
с
неизвестной функцией распределения 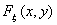 , для которой требуется проверить
гипотезу H
, для которой требуется проверить
гипотезу H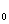 :
:  , где
, где 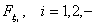 некоторые
одномерные функции распределения.
некоторые
одномерные функции распределения.
Простой критерий согласия для
гипотезы H можно
построить, основываясь на методике . Эту методику применяют для
дискретных моделей с конечным числом исходов, поэтому условимся считать, что
случайная величина принимает
конечное число s некоторых значений, которые будем
обозначать буквами 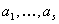 , а вторая
компонента - k значений
, а вторая
компонента - k значений  . Если
исходная модель имеет другую структуру, то предварительно группируют возможные
значения случайных величин отдельно по первой и второй компонентам. В этом
случае множество разбивается
на s интервалов
. Если
исходная модель имеет другую структуру, то предварительно группируют возможные
значения случайных величин отдельно по первой и второй компонентам. В этом
случае множество разбивается
на s интервалов 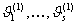 , множество
значение - на k интервалов
, множество
значение - на k интервалов 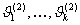 , а само
множество значений
, а само
множество значений 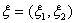 - на N=sk
прямоугольников
- на N=sk
прямоугольников 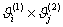 .
.
Обозначим через 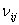 число
наблюдений пары
число
наблюдений пары 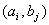 (число
элементов выборки, принадлежащих прямоугольнику
(число
элементов выборки, принадлежащих прямоугольнику 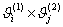 , если данные группируются), так что
, если данные группируются), так что
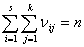 . Результаты
наблюдений удобно расположить в виде таблицы сопряженности двух знаков( табл.
1.1) . В приложениях и обычно означают два признака, по которым производится
классификация результатов наблюдения.
. Результаты
наблюдений удобно расположить в виде таблицы сопряженности двух знаков( табл.
1.1) . В приложениях и обычно означают два признака, по которым производится
классификация результатов наблюдения.
Пусть 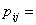 Р
Р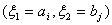 , i=1,…,s, j=1,…,k. Тогда
гипотеза независимости означает, что существует s+k постоянных
, i=1,…,s, j=1,…,k. Тогда
гипотеза независимости означает, что существует s+k постоянных 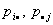 таких, что
таких, что 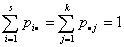 и
и 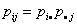 , т.е.
, т.е.
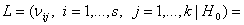
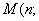 p
p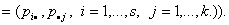
Таблица 1.1
Таким образом, гипотеза H сводится к
утверждению, что частоты (число их
равно N = sk)
распределены по полиномиальному закону с вероятностями исходов, имеющими
указанную специфическую структуру (вектор вероятностей исходов р определяется
значениями r=s+k-2
неизвестных параметров 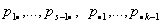 .
.
Для проверки этой гипотезы, найдем
оценки максимального правдоподобия для определяющих рассматриваемую схему
неизвестных параметров. Если справедлива нулевая гипотеза, то функция
правдоподобия имеет вид L(p)=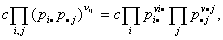 где
множитель с от неизвестных параметров не зависит. Отсюда по методу
неопределенных множителей Лагранжа получаем, что искомые оценки имеют вид
где
множитель с от неизвестных параметров не зависит. Отсюда по методу
неопределенных множителей Лагранжа получаем, что искомые оценки имеют вид 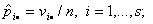
 Следовательно, статистика
Следовательно, статистика
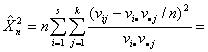
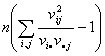
L( )
)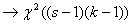 при , поскольку
число степеней свободы в предельном распределении равно N-1-r=sk-1-(s+k-2)=(s-1)(k-1).
при , поскольку
число степеней свободы в предельном распределении равно N-1-r=sk-1-(s+k-2)=(s-1)(k-1).
Итак, при достаточно больших n можно
использовать следующее правило проверки гипотезы: гипотезу Н отвергают
тогда и только тогда, когда вычисленное по фактическим данным значение t статистики 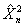 удовлетворяет
неравенству
удовлетворяет
неравенству 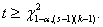
Этот критерий имеет асимптотически (
при ) заданный
уровень значимости и
называется критерием независимости .
2. ПРАКТИЧЕСКАЯ ЧАСТЬ
.1 Решения задач о типах сходимости
1. Доказать, что из
сходимости почти наверное следует сходимость по вероятности. Приведите
контрольный пример, показывающий, что обратное утверждение неверно.
Решение. Пусть
последовательность случайных величин 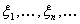 сходится к случайной величине x почти
наверное. Значит, для любого ε > 0
сходится к случайной величине x почти
наверное. Значит, для любого ε > 0
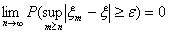
Так как 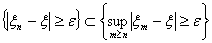 , то
, то

и из сходимости xn к x почти
наверное вытекает, что xn
сходится к x по
вероятности, так как в этом случае
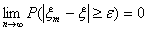
Но обратное утверждение не
верно. Пусть -
последовательность независимых случайных величин, имеющих одну и ту же функцию
распределения F(x), равную нулю при х ≤ 0 и равную 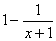 при х > 0. Рассмотрим
последовательность
при х > 0. Рассмотрим
последовательность
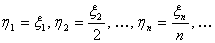 .
.
Эта последовательность
сходится к нулю по вероятности, так как
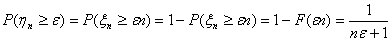
стремится к нулю при любом
фиксированном ε
и
. Однако
сходимость к нулю почти наверное иметь место не будет. Действительно
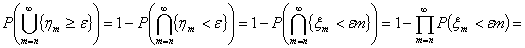
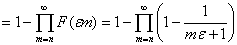
стремится к единице, то есть
с вероятностью 1 при любых и n в последовательности  найдутся
реализации, превосходящие ε.
найдутся
реализации, превосходящие ε.
Отметим, что при наличии некоторых
дополнительных условий, накладываемых на величины xn,
сходимость по вероятности влечет сходимость почти наверное.
. Пусть xn -
монотонная последовательность. Доказать, что в этом случае сходимость xn к x по
вероятности влечет за собой сходимость xn к x с
вероятностью 1.
Решение. Пусть xn -
монотонно убывающая последовательность, то есть 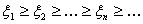 . Для
упрощения наших рассуждений будем считать, что x º 0, xn ³ 0 при всех
n. Пусть xn
сходится к x по
вероятности, однако сходимость почти наверное не имеет место. Тогда существует ε > 0, такое, что
при всех n
. Для
упрощения наших рассуждений будем считать, что x º 0, xn ³ 0 при всех
n. Пусть xn
сходится к x по
вероятности, однако сходимость почти наверное не имеет место. Тогда существует ε > 0, такое, что
при всех n
Но 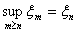 и сказанное
означает, что при всех n
и сказанное
означает, что при всех n
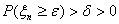
что противоречит сходимости xn к x по
вероятности. Таким образом, для монотонной последовательности xn,
сходящийся к x по
вероятности, имеет место и сходимость с вероятностью 1 (почти наверное).
. Пусть последовательность xn сходится
к x по
вероятности. Доказать, что из этой последовательности можно выделить
последовательность 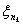 ,
сходящуюся к x с
вероятностью 1 при
,
сходящуюся к x с
вероятностью 1 при 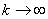 .
.
Решение. Пусть  - некоторая
последовательность положительных чисел, причем
- некоторая
последовательность положительных чисел, причем 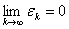 , и
, и  - такие положительные числа, что
ряд
- такие положительные числа, что
ряд 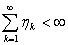 . Построим
последовательность индексов n1<n2<…<nk<…
,
выбирая nk
так, чтобы
. Построим
последовательность индексов n1<n2<…<nk<…
,
выбирая nk
так, чтобы
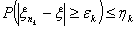
Тогда ряд
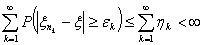 ,
,
Так как ряд  сходится,
то при любом ε
> 0 остаток
ряда
сходится,
то при любом ε
> 0 остаток
ряда 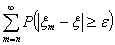 стремится к
нулю. Но тогда стремится к нулю и
стремится к
нулю. Но тогда стремится к нулю и
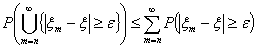 ,
,
то есть 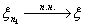 .
.
. Доказать, что из сходимости
в среднем какого либо положительного порядка следует сходимость по вероятности.
Приведите пример, показывающий, что обратное утверждение неверно.
Решение. Пусть
последовательность xn сходится
к величине x в
среднем порядка р > 0, то есть
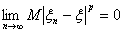 .
.
Воспользуемся обобщенным
неравенством Чебышева: для произвольных ε > 0 и р > 0
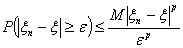 .
.
Устремив и учитывая,
что 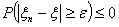 , получим,
что
, получим,
что
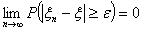 ,
,
то есть xn сходится
к x по
вероятности.
Однако сходимость по
вероятности не влечет за собой сходимость в среднем порядка р > 0. Это
показывает следующий пример. Рассмотрим вероятностное пространство áW, F , Rñ,
где F = B[0,
1]
- борелевская s-алгебра,
R -
мера Лебега.
Определим последовательность
случайных величин следующим
образом:
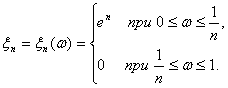
Последовательность xn сходится
к 0 по вероятности, так как
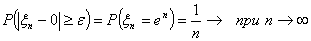 ,
,
но при любом р > 0
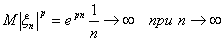 ,
,
то есть сходимость в среднем
иметь не будет.
. Пусть 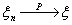 , при чем
для всех n
, при чем
для всех n 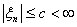 . Доказать,
что в этом случае xn сходится
к x в
среднеквадратическом.
. Доказать,
что в этом случае xn сходится
к x в
среднеквадратическом.
Решение. Заметим, 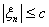 , то и
, то и 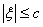 . Получим
оценку для
. Получим
оценку для 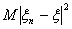 . Рассмотрим
случайную величину
. Рассмотрим
случайную величину 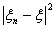 . Пусть ε -
произвольное
положительное число. Тогда
. Пусть ε -
произвольное
положительное число. Тогда  при
при 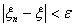 и
и  при
при 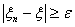 .
.
Значит,
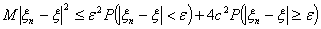 .
.
Если , то 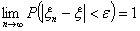 и .
Следовательно,
и .
Следовательно,  . А
поскольку ε
сколь
угодно мало и
. А
поскольку ε
сколь
угодно мало и 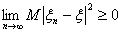 , то
, то 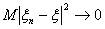 при , то есть
при , то есть  в
среднеквадратическом.
в
среднеквадратическом.
. Доказать, что если xn сходится
к x по
вероятности, то имеет место слабая сходимость 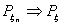 . Приведите контрольный пример,
показывающий, что обратное утверждение неверно.
. Приведите контрольный пример,
показывающий, что обратное утверждение неверно.
Решение. Докажем, что если , то 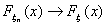 в каждой
точке х, являющейся точкой непрерывности
в каждой
точке х, являющейся точкой непрерывности  (это необходимое и достаточное
условие слабой сходимости ),
(это необходимое и достаточное
условие слабой сходимости ), 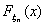 - функция
распределения величины xn, а - величины x.
- функция
распределения величины xn, а - величины x.
Пусть х - точка непрерывности
функции F.
Если 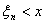 , то
справедливо по крайней мере одно из неравенств
, то
справедливо по крайней мере одно из неравенств 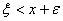 или
или 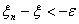 . Тогда
. Тогда
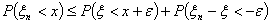 .
.
Аналогично, при 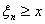 справедливо
хотя бы одно из неравенств
справедливо
хотя бы одно из неравенств 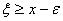 или
или  и
и
 ,
,
Или
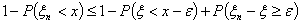 .
.
Откуда
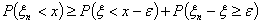 .
.
Если , то для
сколь угодно малого ε > 0 существует
такое N, что при всех п > N
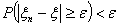 .
.
Тогда
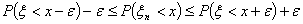
С другой стороны, если х -
точка непрерывности то можно найти такое ε > 0, что для
сколь угодно малого
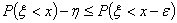
и
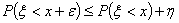 .
.
Значит, для сколь угодно
малых ε
и
существует
такое N, что при п >N
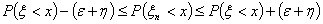 ,
,
или
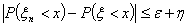 ,
,
или, что то же самое,
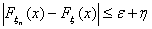 .
.
Это означает, что во всех
точках непрерывности 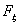 имеет место
сходимость и .
Следовательно, из сходимости по вероятности вытекает слабая сходимость.
имеет место
сходимость и .
Следовательно, из сходимости по вероятности вытекает слабая сходимость.
Обратное утверждение, вообще
говоря, не имеет места. Чтобы убедиться в этом, возьмем последовательность
случайных величин 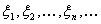 ,, не равных
с вероятностью 1 постоянным и имеющих одну и ту же функцию распределения F(x).
Считаем, что при всех п величины и независимы. Очевидно, слабая
сходимость имеет
место, так как у всех членов последовательности одна и та же функция
распределения. Рассмотрим
,, не равных
с вероятностью 1 постоянным и имеющих одну и ту же функцию распределения F(x).
Считаем, что при всех п величины и независимы. Очевидно, слабая
сходимость имеет
место, так как у всех членов последовательности одна и та же функция
распределения. Рассмотрим 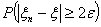 :
:
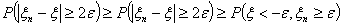
|Из независимости и
одинаковой распределенности величин , следует, что
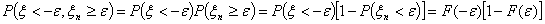 .
.
то есть
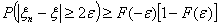
Выберем среди всех функций
распределений невырожденных случайных величин такую F(x),
что 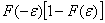 будет
отлично от нуля при всех достаточно малых ε. Тогда
не
стремится к нулю при неограниченном росте п и сходимость по вероятности иметь
место не будет.
будет
отлично от нуля при всех достаточно малых ε. Тогда
не
стремится к нулю при неограниченном росте п и сходимость по вероятности иметь
место не будет.
7. Пусть имеет место слабая
сходимость , где с вероятностью
1 есть постоянная. Доказать, что в этом случае будет сходиться к по
вероятности.
Решение. Пусть с
вероятностью 1 равно а. Тогда слабая сходимость означает сходимость при любых 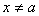 . Так как
. Так как 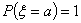 , то
, то 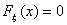 при
при 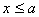 и
и 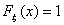 при
при 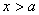 . То есть
. То есть 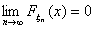 при
при 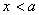 и
и 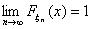 при . Отсюда
следует, что для любого ε > 0 вероятности
при . Отсюда
следует, что для любого ε > 0 вероятности
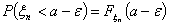 и
и 
стремятся к нулю при . Это
значит, что

стремится к нулю при , то есть сходиться к
по
вероятности.
Задача 1.
Значение гамма-функции Г(x) при x= вычисляется
методом Монте-Карло. Найдем минимальное число испытаний необходимых для того,
что бы с вероятностью 0,95 можно было ожидать, что относительная погрешность
вычислений будет меньше одного процента.
вычисляется
методом Монте-Карло. Найдем минимальное число испытаний необходимых для того,
что бы с вероятностью 0,95 можно было ожидать, что относительная погрешность
вычислений будет меньше одного процента.
Решение
Для 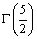 с точностью
до
с точностью
до  имеем
имеем
 .
.
Известно, что
 . (1)
. (1)
Сделав в (1)
замену 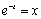 , приходим к
интегралу по конечному промежутку:
, приходим к
интегралу по конечному промежутку:
 .
.
У нас 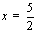 , поэтому
, поэтому
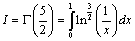 .
.
Как видно, 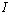 представимо
в виде
представимо
в виде 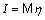 , где
, где  , а
, а 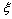 распределена
равномерно на
распределена
равномерно на 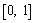 . Пусть
произведено
. Пусть
произведено 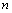 статистических
испытаний. Тогда статистическим аналогом является величина
статистических
испытаний. Тогда статистическим аналогом является величина
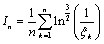 ,
,
где 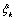 ,
, 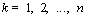 , -
независимые случайные величины с равномерным на распределением. При этом
, -
независимые случайные величины с равномерным на распределением. При этом
 ;
;
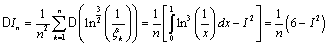 ,
,
т.к. 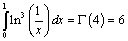
Из ЦПТ следует, что 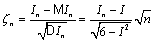 асимптотически
нормальна с параметрами
асимптотически
нормальна с параметрами 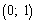 .
.
Далее, по условию задачи 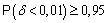 , т.е.
, т.е.
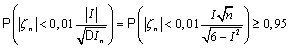 .
.
Значит,
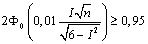 ,
,
откуда
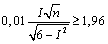 ,
, 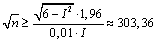 .
.
Значит, минимальное
количество испытаний, обеспечивающее с вероятностью  относительную
погрешность вычисления не более
относительную
погрешность вычисления не более  равно
равно 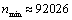 .
.
Задача 2
Рассматривается последовательность
из 2000 независимых одинаково распределенных случайных величин с математическим
ожиданием, равным 4, и дисперсией, равной 1,8. Среднее арифметическое этих
величин есть случайная величина . Определить вероятность того, что
случайная величина примет
значение в интервале (3,94; 4,12).
Решение
Пусть , …,,…- последовательность независимых
случайных величин, имеющих одинаковое распределение с M=a=4 и D==1,8. Тогда
к последовательности {} применима
ЦПТ. Случайная величина 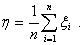
Вероятность того, что примет
значение в интервале (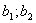 ):
):
P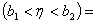 P
P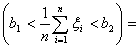 P
P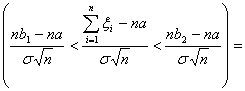
=P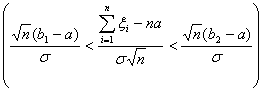
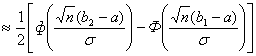 .
.
При n=2000, 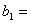 3,94 и
3,94 и 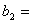 4,12 получим
4,12 получим
P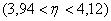
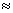
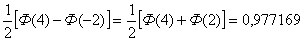
.3 Проверка гипотез критерием
независимости
Задача 1.
В результате проведенного
исследования было установлено, что у 782 светлоглазых отцов сыновья тоже имеют
светлые глаза, а 89 светлоглазых отцов сыновья - темноглазые. У 50 темноглазых
отцов сыновья также темноглазые, а у 79 темноглазых отцов сыновья -
светлоглазые. Имеется ли зависимость между цветом глаз отцов и цветом глаз их
сыновей? Уровень доверия принять равным 0,99.
Решение
Для решения данной задачи
воспользуемся таблицей сопряженности двух признаков.
Таблица 2.1
|
Дети
|
Отцы
|
Сумма
|
|
Светлоглазые
|
Темноглазые
|
|
|
Светлоглазые
|
782
|
79
|
861
|
|
Темноглазые
|
89
|
50
|
139
|
|
Сумма
|
871
|
129
|
1000
|
H: нет
зависимости между цветом глаз детей и отцов.
H: есть
зависимость между цветом глаз детей и отцов.
Статистика вычисляется за следующей
формулой
~ 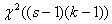
s=k=2 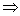
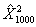 =90,6052 с 1
ступеней свободы
=90,6052 с 1
ступеней свободы
Вычисление сделаны в программе Mathematica 6.
По таблицам распределения находим,
что 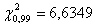 .
.
Поскольку >  , то
гипотезу H, про
отсутствия зависимости между цветом глаз отцов и детей, при уровне значимости
, то
гипотезу H, про
отсутствия зависимости между цветом глаз отцов и детей, при уровне значимости 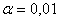 , следует
отклонить и принять альтернативную гипотезу H.
, следует
отклонить и принять альтернативную гипотезу H.
Задача 2.
Утверждается, что результат действия
лекарства зависит от способа применения. Проверьте это утверждение по данным,
представленным в табл. 2.2 Уровень доверия принять равным 0,95.
Таблица 2.2
|
Результат
|
Способ
применения
|
В
|
С
|
|
Неблагоприятный
|
11
|
17
|
16
|
|
Благоприятный
|
20
|
23
|
19
|
Решение.
Для решения данной задачи воспользуемся таблицей
сопряженности двух признаков.
Таблица 2.3
|
Результат
|
Способ
применения
|
Сумма
|
|
А
|
В
|
С
|
|
|
Неблагоприятный
|
11
|
17
|
16
|
44
|
|
Благоприятный
|
20
|
23
|
19
|
62
|
|
Сумма
|
31
|
40
|
35
|
106
|
H: результат
действия лекарств не зависит от способа применения
H: результат
действия лекарств зависит от способа применения
Статистика вычисляется за следующей
формулой
~
s=2, k=3, 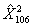 =0,734626 c 2 ступенями
свободы.
=0,734626 c 2 ступенями
свободы.
Вычисление сделаны в программе Mathematica 6
По таблицам распределения находим,
что 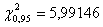 .
.
Поскольку < 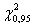 , то
гипотезу H, про
отсутствия зависимости действия лекарств от способа применения, при уровне
значимости
, то
гипотезу H, про
отсутствия зависимости действия лекарств от способа применения, при уровне
значимости 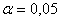 , следует
принять.
, следует
принять.
Заключение
В данной работе приведены
теоретические выкладки из раздела «Критерий независимости », а также
«Предельные теоремы теории вероятностей», курсу «Теория вероятностей и
математическая статистика». В ходе выполнения работы на практике были проверены
критерий независимости ; также для
заданных последовательностей независимых случайных величин было проверено
выполнение центральной предельной теоремы.
Данная работа помогла
усовершенствовать мои знания с данных разделов теории вероятностей, работы с
литературными источниками, твердо владеть техникой проверки критерия
независимости .
вероятностная
статистическая гипотеза теорема
Перечень ссылок
1. Сборник задач с теории
вероятности с решением. Уч. пособие / Под ред. В.В. Семенца. - Харьков: ХТУРЕ,
2000. - 320с.
. Гихман И.И., Скороход А.В.,
Ядренко М.И. Теория вероятностей и математическая статистика. - К.: Вища шк.,
1979. - 408 с.
. Ивченко Г.И., Медведев Ю.И.,
Математическая статистика: Учеб. пособие для втузов. - М.: Высш. шк., 1984. -
248с., .
. Математическая статистика: Учеб.
для вузов/ В.Б. Горяинов, И.В. Павлов, Г.М. Цветкова и др.; Под ред. В.С.
Зарубина, А.П. Крищенко. - М.: Изд-во МГТУ им. Н.Э. Баумана, 2001. - 424с.