Построение эконометрических моделей, представленных различными типами временных рядов
БЕЛОРУССКИЙ
ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Экономический
факультет
Кафедра
банковской и финансовой экономики
Курсовой
проект
Построение
эконометрических моделей, представленных различными типами временных рядов
Студентки 3 курса
отделения «Финансы и кредит»
Ряшницевой Юлии Дмитриевны
Научный руководитель
преподаватель
Абакумова Ю.Г.
Минск,
2007 г.
Содержание
Введение
.
Теоретический раздел
.
Аналитический раздел
Заключение
Список
использованной литературы
Приложения
ВВЕДЕНИЕ
Целью исследования является эконометрическое
моделирование денежного агрегата М0, в зависимости от валового внутреннего
продукта (GNP), индекса потребительских цен (IPC).
Зависимость между выбранными
экономическими показателями известна из макроэкономической теории, так
например, можно выбрать в качестве основной формулу обмена 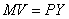 , где
, где  (
(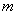 денежный
мультипликатор),
денежный
мультипликатор), 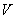 - скорость обращения денег по
доходу,
- скорость обращения денег по
доходу,  уровень
цен,
уровень
цен,  - реальный ВВП. Так же она
подтверждается в работах множества исследователей, построенными на основе
эмпирических статданных эконометрическими моделями для разных стран.
- реальный ВВП. Так же она
подтверждается в работах множества исследователей, построенными на основе
эмпирических статданных эконометрическими моделями для разных стран.
При построении эконометрической
модели зависимости денежного агрегата M0 от ВВП(GNP) и индекса потребительских
цен (CPI) в Республики Беларусь использовались данные за 2005-2006 года по
месяцам (данные в Приложении 1).
При построении эконометрических
моделей необходимо учитывать является ли временные ряды стационарными.
Ряд 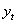 называется строго стационарным,
если совместное распределение m наблюдений
называется строго стационарным,
если совместное распределение m наблюдений 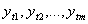 не зависит от сдвига по времени, то
есть совпадает с распределением
не зависит от сдвига по времени, то
есть совпадает с распределением  для любых m,t,t2,…,tm.
для любых m,t,t2,…,tm.
Ряд называется слабо стационарным, если
его средняя, дисперсия и ковариация не зависит от времени:


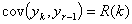
Если нарушается хотя бы одно из этих
условий то ряд становиться нестационарным.
Временные ряды бывают:
нестационарными по среднему
нестационарными по дисперсии.
Временной ряд является
нестационарным по среднему, если его математическое ожидание изменяется во
времени в соответствии с некоторым детерминированным или вероятностным
значением. Для описания таких временных рядов используют модели с детерминированным
трендом.
Траектории временных рядов с разными
типами трендов отличаются друг от друга. Временной ряд с детерминированным
трендом имеет линию тренда в качестве некоторой центральной линии с достаточно
частыми колебаниями выше и ниже этой линии. Такие ряды принято называть TS
рядами или стационарными относительно тренда.
Для временного ряда, который помимо
детерминированного, содержит стохастический тренд характерны длительные
пребывания значений выше или ниже центральной линии, причем отклонение может
быть достаточно значительным, в этом случае линия детерминированного тренда
перестанет играть роль центральной линии, вокруг которой колеблется траектория
процесса. Такие виды принято называть DS рядами или стационарными относительно
взятия разностей.
Дисперсия временного ряда
экономического показателя может зависеть от времени, тогда имеет место
гетероскидастичность и данный временной ряд является нестационарным по
дисперсии.
Для построения эконометрических
моделей, представленных различными типами временных рядов использовались
следующие обозначения:
|
Временной
ряд
|
Обозначение
|
|
Денежный
агрегат М0, млрд. руб.
|
М0
|
|
ВВП,
млрд. руб.
|
GDP
|
|
Индекс
потребительских цен, %
|
CPI
|
1.Теоретический раздел:
Эконометрические модели, представленные
различными типами временных рядов можно построить с помощью таких тестов как:
.тест Бреуша - Годфри, который указывает на
наличие или отсутствие автокорреляции в модели. Тест Бреуша-Годфри применяется
для больших выборок и высоких порядков авторегрессий случайных отклонений
AR(p):
εi = ρ1εi-1 + ρ2εi-2
+
ρ3εt-3+… + ρpεi-p - ut, i=1,…,n
Проверка автокорреляции сводится к проверке
гипотез
H0 : ρ1 = ρ2 =…= ρp=0: ρj ≠
0
Тест Бреуша-Годфри сводится к следующему:
оценить исходную регрессионную модель и получить
остатки εi;
построить и оценить модель εi
на
все регрессоры исходной модели плюс ei-1, ei-2, …, ei-p:
ei = α0 + α1xi1+ …+ αim +
γ1ei-1
+
γ2ei-2
+…+ γpei-p + ut;
определяется коэффициент детерминации
вспомогательного уравнения:
if (n-p)R2 < χ2α, n-p , то
принимается гипотеза H0
(n-p)R2 > χ2α, n-p , то
принимается гипотеза H1.
Тест Бреуша-Годфри применяется в
авторегрессионных моделях для зависимой переменной y, в моделях скользящего
среднего для случайных отклонений εi= εi-1 +
λ1ui-1 + +λ2ui-2 + … +
λpui-p, величина p априорна неизвестным и оценивается
экспертным путем с использованием информационных критериев Акаики и Шварца.
. тест Уайта, который указывает на наличие или
отсутствие гетероскедастичности в эконометрической модели. Процедура проверки
критерия Уайта состоит из:
Построения обычной линейной регрессионной модели
и нахождение остатков
Построения дополнительной модели, где в качестве
независимых переменных используются те же регрессоры, что и в п. 1, а так же их
квадраты, попарные произведения и константа. В качестве зависимой - квадраты
остатков исходной модели
Подсчета статистики критерия: W = TR2,
где T - объем выборки. Если гипотеза
H0: 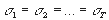 верна, то
статистика W имеет распределение 2 с l-1 степенями свободы (l - число регрессоров
во второй модели).
верна, то
статистика W имеет распределение 2 с l-1 степенями свободы (l - число регрессоров
во второй модели).
.тест ADF, с помощью которого можно
проверить остатки эконометрической модели на стационарность. Тест Дики-Фуллера
В тесте Дики-Фуллера для определения
наличия “единичного корня” используют 3 типа моделей:

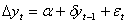
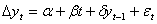
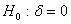 следовательно имеем модель
“единичного корня” и нестационарен.
следовательно имеем модель
“единичного корня” и нестационарен.
Расширенный тест Дики-Фуллера
Этот тест есть модификация теста
Дики-Фуллера и используется в таких случаях, когда предполагается наличие
автокорреляционных остатков 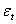 , что может повлиять на
объективность результатов теста. В таком случае в правую часть соответствующей
регрессии вводят лаговые разности, например:
, что может повлиять на
объективность результатов теста. В таком случае в правую часть соответствующей
регрессии вводят лаговые разности, например:
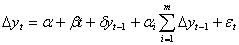

Для определения статистической
значимости коэффициента 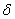 нельзя
использовать привычную статистику Стьюдента, вместо t-статистики используется
нельзя
использовать привычную статистику Стьюдента, вместо t-статистики используется 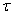 - статистика
со специально подсчитанными критическими точками Маккиннона для уровней
значимости
- статистика
со специально подсчитанными критическими точками Маккиннона для уровней
значимости  = 0,01;
0,05; 0,10. Критическая область левосторонняя.
= 0,01;
0,05; 0,10. Критическая область левосторонняя.
. тест Жака-Бера. Критерий Жака-Бера
используется для проверки гипотезы о том, что исследуемая выборка xS является
выборкой нормально распределенной случайной величины с неизвестным
математическим ожиданием и дисперсией. Как правило, этот критерий применяется
перед тем, как использовать методы параметрической статистики, требующие
нормальности исследуемых случайных величин. Для проверки случайной величины на
нормальность используется тот факт, что у нормального распределения коэффициент
асимметрии и эксцесс равны нолю - отклонение этих величин от нулевого значения
может служить мерой отклонения распределения от нормального. На основе выборки
строится статистика Жака-Бера
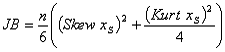
(здесь n - размер выборки), после
чего по таблице квантилей распределения вычисляется p-значение, соответствующее
полученному значению JB. Следует отметить, что при росте n статистика Жака-Бера
сходится к распределению хи-квадрат с двумя степенями свободы, поэтому в
практике иногда используют таблицу квантилей распределения хи-квадрат. Однако
это является ошибкой - сходимость слишком медленная и неравномерная.
В данной работе были построены:
. Коинтегрированная модель- модель
построенная из нестационарных рядов, интегрированных одного порядка.
. Модель приростов. Модель прироста
строится, временные ряды, входящие в первоначальную модель являются
интегрированными первого порядка.
. Модель первых лагов (1)
. Модель первых лагов (2) -модель в
первых лагах без данных показателей.
. ECM(1)- модель коррекции ошибок.
. Аналитический раздел
Анализ моделей
Построим модель зависимости
денежного агрегата M0 от ВВП(GNP) и индекса потребительских цен (CPI) в
Республики Беларусь за 2005-2006 года по месяцам (данные в Приложении 1).
Первоначально проверим временные
ряды на стационарность:
|
Ряд
|
ADF
ТЕСТ
|
Итог
|
|
Спецификация
|
ADF
статистика
|
Критическая
точка
|
|
|
GDP
|
T,1
|
-2,28
|
-3,63
|
I(1)
|
|
∆GDP
|
C,1
|
-5,12
|
-3,01
|
I(0)
|
|
CPI
|
T,2
|
-1,77
|
-3,64
|
I(1)
|
|
∆
CPI
|
C,1
|
-3.63
|
-3,00
|
I(0)
|
|
M0
|
C,1
|
-1,58
|
-3,00
|
I(1)
|
|
∆
M0
|
N,0
|
-4,52
|
-1,96
|
I(0)
|
Несмотря на то, что ряды не стационарны, они
являются интегрированными одного порядка, поэтому мы можем строить по ним
модель.
Модель построенная из нестационарных рядов,
интегрированных одного порядка, называется коинтегрированной моделью. Построим
коинтегрированную модель и оценим ее качество:
|
Variable
|
Coefficient
|
Std.
Error
|
t-Statistic
|
Prob.
|
|
C
|
-30355.73
|
3525.950
|
-8.609234
|
0.0000
|
|
GNP
|
0.369014
|
0.058231
|
6.337061
|
0.0000
|
|
CPI
|
274.9362
|
29.76776
|
9.236041
|
0.0000
|
R-squared = 0.803368Watson stat =
1.238616statistic = 42.89929(F-statistic) = 0.000000
По построенным данным видно, что P-вероятность и
t-статистика показывают значимость коэффициентов модели, включая свободный
член. Коэффициент детерминации, F- статистика и ее вероятность указывают на
статистическую значимость и адекватность построенной модели.
Теперь перейдем к предпосылкам нарушения МНК.
Начнем со статистки Дарбина - Уотсона и теста Бреуша - Годфри на наличие
автокорреляции в модели:
|
Breusch-Godfrey Serial Correlation
LM Test:
|
|
F-statistic
|
2.917086
|
Probability
|
0.103122
|
|
Obs*R-squared
|
3.054929
|
Probability
|
0.080493
|
По статистике Дарбина - Уотсона невозможно
сделать вывод о наличие автокорреляции, однако тест Бреуша - Годфри указывает
на ее присутствие, следовательно, мы принимаем гипотезу о наличие
автокорреляции в данной модели.
Теперь перейдем к тесту Уайта и оценим данную
модель на наличие гетероскедастичности:
|
White
Heteroskedasticity Test:
|
|
F-statistic
|
2.023071
|
Probability
|
0.123816
|
|
Obs*R-squared
|
8.634731
|
Probability
|
0.124551
|
Тест Уайта указывает на отсутствие в данной
модели гетероскедастичности.
Теперь перейдем к анализу случайных отклонений в
данной модели: проведем проверку на стационарность и нормальное распределение:
В первую очередь проверим остатки на
стационарность с помощью теста ADF:
|
ADF
Test Statistic
|
-3.321477
|
1%
Critical Value*
|
-2.6700
|
|
|
5%
Critical Value
|
-1.9566
|
|
|
10%
Critical Value
|
-1.6235
|
Была взята спецификация N,0. По данному тесту
можно сделать вывод о том, что наличие стационарности случайных отклонений
данной модели подтверждается.
Теперь посмотрим на нормальное распределение
остатков с помощью теста Жака-Бера:
(JB)= 0,59
Тест Жака-бера указывает на нормальное
распределение случайных отклонений в данной модели.
Анализируя данную модель можно сделать следующий
вывод:
по P-вероятности и t- статистике коэффициенты
данной модели являются статистическизначимыми, также статистически значимой
является и сама модель по коэффициенту детерминации, F- статистике и ее
вероятности;
переходя к предпосылкам нарушения МНК, можно
отметить, что в данной модели отсутствует гетероскедастичность, но при этом
присутствует автокорреляция, что снижает эффективность оценок данной модели;
остатки в данной модели являются стационарными и
имеют нормальное распределение, что является достаточно важным условием
построения качественной модели.
Так как временные ряды, входящие в
первоначальную модель, являются интегрированными первого порядка, построим
модель приростов и оценим ее качество:
|
Variable
|
Coefficient
|
Std.
Error
|
t-Statistic
|
Prob.
|
|
C
|
174.3703
|
41.27483
|
4.224616
|
0.0004
|
|
D(GNP)
|
0.061228
|
0.052202
|
1.172913
|
0.2546
|
|
D(CPI)
|
726.3547
|
94.81866
|
7.660461
|
0.0000
|
squared = 0.805893Watson stat =
2.006428statistic = 41.51797(F-statistic) = 0.000000
По построенным данным видно, что P-вероятность и
t-статистика показывают значимость коэффициента индекса потребительских цен и
незначимость коэффициента при ВВП, однако возьмем погрешность в 25%, что
позволит сделать вывод о статистической значимости коэффициентов данной модели.
Коэффициент детерминации, F- статистика и ее вероятность указывают на
статистическую значимость и адекватность построенной модели.
Теперь перейдем к предпосылкам нарушения МНК.
Начнем со статистки Дарбина - Уотсона и теста Бреуша - Годфри на наличие
автокорреляции в модели:
Breusch-Godfrey
Serial Correlation LM Test:
|
F-statistic
|
0.088849
|
Probability
|
0.768880
|
|
Obs*R-squared
|
0.107054
|
Probability
|
0.743524
|
По статистике Дарбина - Уотсона и тесту Бреуша -
Годфри отчетливо видно отсутствие автокорреляции в данной модели.
Теперь перейдем к тесту Уайта и оценим данную
модель на наличие гетероскедастичности:
|
White
Heteroskedasticity Test:
|
|
F-statistic
|
0.499788
|
Probability
|
0.736247
|
|
Obs*R-squared
|
2.299121
|
Probability
|
0.680929
|
Тест Уайта указывает на отсутствие в данной
модели гетероскедастичности.
Теперь перейдем к анализу случайных отклонений в
данной модели: проведем проверку на стационарность и нормальное распределение:
В первую очередь проверим остатки на
стационарность с помощью теста ADF:
|
ADF
Test Statistic
|
-4.797725
|
1%
Critical Value*
|
-2.6756
|
|
|
5%
Critical Value
|
-1.9574
|
|
|
10%
Critical Value
|
-1.6238
|
Была взята спецификация N,0. По данному тесту
можно сделать вывод о том, что наличие стационарности случайных отклонений
данной модели подтверждается.
теперь посмотрим на нормальное распределение
остатков с помощью теста Жака-Бера:
(JB)= 0,7398
Тест Жака-бера указывает на нормальное
распределение случайных отклонений в данной модели.
Анализируя данную модель можно сделать следующий
вывод:
по P-вероятности и t- статистике коэффициенты
данной модели являются статистически значимыми на уровне значимости 25%, также
статистически значимой является и сама модель по коэффициенту детерминации, F-
статистике и ее вероятности;
переходя к предпосылкам нарушения МНК, можно
отметить, что в данной модели отсутствует как гетероскедастичность, так и
автокорреляция, что указывает на эффективность и несмещенность оценок данной
модели;
остатки в данной модели являются стационарными и
имеют нормальное распределение, что является достаточно важным условием
построения качественной модели.
Теперь перейдем к построению модели в первых
лагах:
|
Variable
|
Coefficient
|
Std.
Error
|
t-Statistic
|
Prob.
|
|
C
|
-7539.345
|
4672.073
|
-1.613704
|
0.1250
|
|
GNP
|
0.032422
|
0.055271
|
0.586602
|
0.5652
|
|
CPI
|
762.8445
|
93.41302
|
8.166362
|
0.0000
|
|
M0(-1)
|
0.758026
|
0.130516
|
5.807924
|
0.0000
|
|
GNP(-1)
|
-0.002924
|
0.054900
|
-0.053264
|
0.9581
|
|
CPI(-1)
|
-689.5790
|
117.3987
|
-5.873824
|
0.0000
|
R-squared = 0.957834Watson stat =
2.699912statistic = 77.23275(F-statistic) = 0.000000
По построенным данным видно, что P-вероятность и
t-статистика показывают значимость коэффициентов, исключая коэффициенты при ВВП
и ВВП в первом лаге. Коэффициент детерминации, F- статистика и ее вероятность
указывают на статистическую значимость и адекватность построенной модели.
Теперь перейдем к предпосылкам нарушения МНК.
Начнем со статистки Дарбина - Уотсона и теста Бреуша - Годфри на наличие
автокорреляции в модели:
|
Breusch-Godfrey Serial Correlation
LM Test:
|
|
F-statistic
|
3.571374
|
Probability
|
0.077041
|
|
Obs*R-squared
|
4.197028
|
Probability
|
0.040495
|
По статистике Дарбина - Уотсона и тесту Бреуша -
Годфри отчетливо видно отсутствие автокорреляции в данной модели.
Теперь перейдем к тесту Уайта и оценим данную
модель на наличие гетероскедастичности:
|
White
Heteroskedasticity Test:
|
|
F-statistic
|
0.903717
|
Probability
|
0.557476
|
|
Obs*R-squared
|
9.880366
|
Probability
|
0.451051
|
Тест Уайта указывает на отсутствие в данной
модели гетероскедастичности.
Теперь перейдем к анализу случайных отклонений в
данной модели: проведем проверку на стационарность и нормальное распределение:
В первую очередь проверим остатки на
стационарность с помощью теста ADF:
|
ADF
Test Statistic
|
-6.807388
|
1%
Critical Value*
|
-2.6756
|
|
|
5%
Critical Value
|
-1.9574
|
|
|
10%
Critical Value
|
-1.6238
|
Была взята спецификация N,0. По данному тесту
можно сделать вывод о том, что наличие стационарности случайных отклонений
данной модели подтверждается.
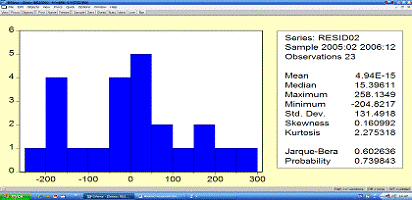
Теперь посмотрим на нормальное распределение
остатков с помощью теста Жака-Бера:
(JB)= 0,4653
Тест Жака-бера указывает на нормальное
распределение случайных отклонений в данной модели.
Анализируя данную модель можно сделать следующий
вывод:
по P-вероятности и t- статистике коэффициенты
данной модели являются статистически значимыми, исключая коэффициенты при ВВП и
ВВП в первом лаге, также статистически значимой является и сама модель по
коэффициенту детерминации, F- статистике и ее вероятности;
переходя к предпосылкам нарушения МНК, можно
отметить, что в данной модели отсутствует как гетероскедастичность, так и
автокорреляция, что указывает на эффективность и несмещенность оценок данной
модели;
остатки в данной модели являются стационарными и
имеют нормальное распределение, что является достаточно важным условием
построения качественной модели.
Так как в модели незначимыми оказались
коэффициенты при ВВП и ВВп в первом лаге попробуем построить модель в первых
лагах без данных показателей и оценим ее качество:
|
Variable
|
Coefficient
|
Std.
Error
|
t-Statistic
|
Prob.
|
|
C
|
-5806.533
|
1416.786
|
-4.098385
|
0.0006
|
|
CPI
|
797.7339
|
68.30743
|
11.67858
|
0.0000
|
|
CPI(-1)
|
-739.2640
|
67.97107
|
0.0000
|
|
M0(-1)
|
0.797769
|
0.064184
|
12.42942
|
0.0000
|
|
R-squared
|
0.956968
|
Mean
dependent var
|
1966.091
|
|
Adjusted
R-squared
|
0.950173
|
S.D.
dependent var
|
464.8887
|
|
S.E.
of regression
|
103.7721
|
Akaike
info criterion
|
12.27904
|
|
Sum
squared resid
|
204604.2
|
Schwarz
criterion
|
12.47652
|
|
Log
likelihood
|
-137.2090
|
F-statistic
|
140.8431
|
|
Durbin-Watson
stat
|
2.734840
|
Prob(F-statistic)
|
0.000000
|
squared = 0.956968Watson stat = 2.734840statistic
= 140.8431(F-statistic) = 0.000000
По построенным данным видно, что P-вероятность и
t-статистика показывают значимость коэффициентов. Коэффициент детерминации, F-
статистика и ее вероятность указывают на статистическую значимость и
адекватность построенной модели.
Теперь перейдем к предпосылкам нарушения МНК.
Начнем со статистки Дарбина - Уотсона и теста Бреуша - Годфри на наличие
автокорреляции в модели:
|
Breusch-Godfrey Serial Correlation
LM Test:
|
|
F-statistic
|
3.784356
|
Probability
|
0.067523
|
|
Obs*R-squared
|
3.995536
|
Probability
|
0.045621
|
По статистике Дарбина - Уотсона четко не видно
есть ли автокорреляция в данной модели, однако тест Бреуша - Годфри показывает
отсутствие автокорреляции в данной модели, следовательно принимаем гипотезу об
отсутствии автокорреляции.
Теперь перейдем к тесту Уайта и оценим данную
модель на наличие гетероскедастичности:
|
White
Heteroskedasticity Test:
|
|
F-statistic
|
1.611071
|
Probability
|
0.207967
|
|
Obs*R-squared
|
8.662204
|
Probability
|
0.193486
|
Тест Уайта указывает на отсутствие в данной
модели гетероскедастичности.
Теперь перейдем к анализу случайных отклонений в
данной модели: проведем проверку на стационарность и нормальное распределение:
В первую очередь проверим остатки на
стационарность с помощью теста ADF:
|
ADF
Test Statistic
|
-6.923127
|
1%
Critical Value*
|
-2.6756
|
|
|
5%
Critical Value
|
-1.9574
|
|
|
10%
Critical Value
|
-1.6238
|
Была взята спецификация N,0. По данному тесту
можно сделать вывод о том, что наличие стационарности случайных отклонений
данной модели подтверждается.
теперь Посмотрим на нормальное распределение
остатков с помощью теста Жака-Бера:
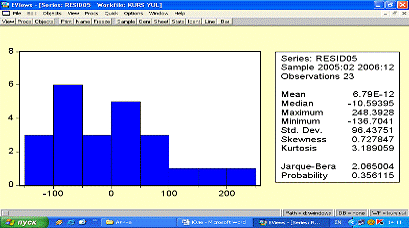
(JB)= 0,3561
Тест Жака-бера указывает на нормальное
распределение случайных отклонений в данной модели.
Анализируя данную модель можно сделать следующий
вывод:
по P-вероятности и t- статистике коэффициенты
данной модели являются статистически значимыми, также статистически значимой
является и сама модель по коэффициенту детерминации, F- статистике и ее
вероятности;
переходя к предпосылкам нарушения МНК, можно
отметить, что в данной модели отсутствует как гетероскедастичность, так и
автокорреляция, что указывает на эффективность и несмещенность оценок данной
модели;
остатки в данной модели являются стационарными и
имеют нормальное распределение, что является достаточно важным условием
построения качественной модели.
Наконец, построим модель коррекции ошибок (ECM)
и оценим ее качество:
|
Variable
|
Coefficient
|
Std.
Error
|
t-Statistic
|
Prob.
|
|
C
|
146.1541
|
38.78456
|
3.768357
|
0.0013
|
|
D(GNP)
|
0.100672
|
0.049539
|
2.032195
|
0.0564
|
|
D(CPI)
|
639.3349
|
92.25471
|
6.930106
|
0.0000
|
|
RESID01(-1)
|
-0.342437
|
0.141123
|
-2.426512
|
0.0254
|
|
R-squared
|
0.851815
|
Mean
dependent var
|
-8.647826
|
|
Adjusted
R-squared
|
0.828417
|
S.D.
dependent var
|
298.4544
|
|
S.E.
of regression
|
123.6276
|
Akaike
info criterion
|
12.62920
|
|
Sum
squared resid
|
290391.8
|
Schwarz
criterion
|
12.82667
|
|
Log
likelihood
|
-141.2357
|
F-statistic
|
36.40590
|
|
Durbin-Watson
stat
|
1.985892
|
Prob(F-statistic)
|
0.000000
|
squared = 0.851815Watson stat =
1.985892statistic =36.40590(F-statistic) = 0.000000
По построенным данным видно, что P-вероятность и
t-статистика показывают значимость коэффициентов при уровне значимости 6%.
Коэффициент детерминации, F- статистика и ее вероятность указывают на
статистическую значимость и адекватность построенной модели.
Теперь перейдем к предпосылкам нарушения МНК.
Начнем со статистки Дарбина - Уотсона и теста Бреуша - Годфри на наличие
автокорреляции в модели:
|
Breusch-Godfrey Serial Correlation
LM Test:
|
|
F-statistic
|
0.025444
|
Probability
|
0.875042
|
|
Obs*R-squared
|
0.032466
|
Probability
|
0.857009
|
По статистике Дарбина - Уотсона и тесту Бреуша -
Годфри отчетливо видно отсутствие автокорреляции в данной модели.
Теперь перейдем к тесту Уайта и оценим данную
модель на наличие гетероскедастичности:
|
White
Heteroskedasticity Test:
|
|
F-statistic
|
0.240344
|
Probability
|
0.956403
|
|
Obs*R-squared
|
1.901579
|
Probability
|
0.928524
|
Тест Уайта указывает на отсутствие в данной
модели гетероскедастичности.
Теперь перейдем к анализу случайных отклонений в
данной модели: проведем проверку на стационарность и нормальное распределение:
В первую очередь проверим остатки на
стационарность с помощью теста ADF:
|
ADF
Test Statistic
|
-4.564575
|
1%
Critical Value*
|
-2.6756
|
|
|
5%
Critical Value
|
-1.9574
|
|
|
10%
Critical Value
|
-1.6238
|
Была взята спецификация N,0. По данному тесту
можно сделать вывод о том, что наличие стационарности случайных отклонений
данной модели подтверждается.
Теперь посмотрим на нормальное распределение
остатков с помощью теста Жака-Бера:
(JB)= 0,882
Тест Жака-бера указывает на нормальное
распределение случайных отклонений в данной модели.
Анализируя данную модель можно сделать следующий
вывод:
по P-вероятности и t- статистике коэффициенты
данной модели являются статистически значимыми при уровне значимости 6%, также
статистически значимой является и сама модель по коэффициенту детерминации, F-
статистике и ее вероятности;
переходя к предпосылкам нарушения МНК, можно
отметить, что в данной модели отсутствует как гетероскедастичность, так и
автокорреляция, что указывает на эффективность и несмещенность оценок данной
модели;
остатки в данной модели являются стационарными и
имеют нормальное распределение, что является достаточно важным условием
построения качественной модели.
Заключение
Одним из традиционных подходов к исследованию
макроэкономических процессов является подход, основанный на использовании
эконометрических моделей. Эконометрические модели позволяют решать достаточно
широкий круг задач исследования: анализ причинно-следственных связей между
экономическими переменными; прогнозирование значений экономических переменных;
построение и выбор вариантов (сценариев) экономической политики на основе
имитационных экспериментов с моделью. Моделирование и прогнозирование
макроэкономических процессов является, несомненно, актуальной проблемой и для
белорусской экономики. В данной работе были построены эконометрические модели,
которые отразили зависимость денежного агрегата M0 от валового внутреннего
продукта и индекса цен Республики Беларусь за период 2005-2006 год.
Список использованной литературы:
Eviews
5.1. User Guide. - QMS
«Эконометрика»
Бородич С.А.
www.nbrb.by
<#"580782.files/image025.gif">
Модель приростов
модель Первых лагов(1)

Модель в первых лагов (2)
(1)
