Анализ защищенности программного обеспечения
Министерство
образования и науки Российской Федерации
Федеральное
государственное бюджетное образовательное
учреждение
высшего профессионального образования
«Сочинский
государственный университет»
Институт
информационных технологий и математики
Кафедра общей
математики и информатики
УТВЕРЖДАЮ
Заведующий кафедрой
___________ А. Р. Симонян
« » ___________ 2012 г.
АНАЛИЗ
ЗАЩИЩЕННОСТИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Выпускная
квалификационная работа
по
специальности 050201
Научный руководитель:
кандидат технических наук,
доцент кафедры общей математики и информатики
_________ С. Ж. Симаворян
« » __________ 2012 г.
Выполнил:
студент группы 07-МИ
_________ Л. Р. Зарандия
« » _________ 2012 г.
Содержание
Введение
ГЛАВА 1.
БЕЗОПАСНОСТЬ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ.
1.1 Угрозы
безопасности программного обеспечения и примеры их реализации
1.1.1
Классификация угроз.
1.1.2
Используемая терминология.
1.2. Жизненный
цикл программного обеспечения
1.2.1 Стандарты
жизненного цикла ПО
1.3 Принципы
обеспечения безопасности программного обеспечения
1.3.1
Классификация средств атаки на средства защиты программного обеспечения
1.3.2 Основные
принципы обеспечения безопасности ПО.
1.4 Оценка
качества программного обеспечения
1.4.1
Показатели сопровождения программного обеспечения
1.4.2
Показатели надежности
1.4.3
Показатели удобства применения программного обеспечения
1.4.4
Показатели эффективности программного обеспечения
1.4.5
Показатели универсальности программного обеспечения
1.4.6
Показатели корректности программного обеспечения
1.5 Постановка
задачи оценки защищенности ПО
ГЛАВА 2. МЕТОДЫ
ЗАЩИТЫ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ, ИХ ОЦЕНКА И АНАЛИЗ ЗАЩИЩЕННОСТИ.
2.1 Методы
технологической защиты ПО и их оценка эффективности.
2.1.1Аппаратные
средства защиты программного обеспечения
2.1.2
Программные средства защиты программного обеспечения
2.2 Методы
обеспечения эксплуатационной безопасности ПО.
2.2.1 Методы и
средства защиты программ от компьютерных вирусов
2.2.2 Методы
защиты программного обеспечения от средств исследования программ
2.3 Правовая
поддержка процессов разработки и применения ПО.
2.3.1 Стандарты
в области информационной безопасности
2.4 Оценка
защищенности ПО
2.4.1 Качества
систем защиты программного обеспечения
2.4.2 Методы
анализа и оценки безопасности ПО
Заключение
Литература
Введение
В настоящее время значительное внимание уделяется проблеме возможного
наличия в программном обеспечении (ПО) функциональных возможностей, способных
привести к последствиям и тем самым нанести ущерб правообладателю или
потребителю. Особую актуальность данная проблема приобретает для ПО,
используемого для обработки информации, к которой предъявляются требования по
безопасности. Одним из наиболее значимых факторов угрозы нарушения безопасности
информации, является наличие уязвимостей в ПО, реализующем процессы обработки
информации. Под уязвимостью понимается программный код, выполнение которого
может нарушить безопасность обрабатываемой информации при появлении
определенных условий. При этом наличие уязвимости может быть обусловлено как ошибками
разработчика, так и его умышленными действиями. В связи с этим серьезные усилия
специалистов сосредоточены на разработке и совершенствовании подходов к
исследованиям ПО на предмет отсутствия в нем уязвимостей. Оценка влияния
информационных воздействий на ПО является важнейшей частью общего процесса
выявления уязвимостей и выделена в отдельное направление.
Оценка защищенности информационных технологий определяется, в первую
очередь, наличием законодательных актов и нормативно-технических документов по
обеспечению безопасности информационных технологий. Критерии оценки
безопасности информационных технологий занимают среди них особое место. Только
стандартизованные критерии позволяют проводить сравнительный анализ и
сопоставимую оценку изделий информационных технологий.
Проблемы защиты программного обеспечение в области контроля над его
использованием и дальнейшим распространением в настоящее время принято решать
при помощи программно-технических средств - систем защиты ПО. В то же время для
обхода и отключения подобных систем защиты существует множество
инструментальных средств. Возникает задача сопоставить возможности средств
защиты ПО с возможностями средств их преодоления. Результаты такого анализа
будут полезны для оценки рисков при производстве программных продуктов, а так
же планировании и оценке уровня стойкости систем защиты ПО.
У системы защиты ПО существуют ряд основных проблем, с которыми она
должна справляться:
· кража интеллектуальной собственности или
конфиденциальных данных содержащихся в программе (в том числе восстановление
логики работы программы);
· несанкционированное использование либо распространение ПО
(кража, копирование, пиратство);
· несанкционированная модификация ПО;
Рассмотрим подробнее эти методы атаки на программное обеспечение.
Пиратство - вид деятельности, связанный с неправомерным
распространением или использованием ПО. Существует множество способов
проведения таких атак, среди которых (но не ограничиваясь ими) можно выделить
следующие:
· неправомерное копирование - перенос программы на другой
компьютер и ее выполнение на нем в случае, если это не разрешено лицензией.
Следует отметить, что для противодействия этой атаке важно сделать невозможным
не столько копирование программы, сколько ее выполнение на другом
компьютере. Этот вид атаки мало распространен в связи с несовместимостью с
современной бизнес-моделью распространения ПО;
· неправомерное использование - выполнение программы (либо
использование ее результатов) пользователем, которому автор или владелец не
предоставил разрешения на выполнение;
· нарушение требований лицензии на ПО;
· перепродажа программного продукта от своего имени.
Незаконное копирование и перепродажа ПО, а также несанкционированное его
использование лицами, которые не имеют на это права, ежегодно обходится
производителям, по разным оценкам, потерями от 10 до 12 млрд. долларов. По
данным Business Software Alliance, 36% всего используемого в мире ПО
является пиратским. Можно утверждать, что пиратство - основная проблема для
разработчиков и распространителей коммерческого ПО. Это подтверждается и
обилием решений для противостояния пиратству. За всю историю коммерческого ПО
были придуманы тысячи способов (как программных, так и аппаратных) защиты ПО от
нелегального использования и распространения.
Кража интеллектуальной собственности или конфиденциальных
данных - это целенаправленный процесс
анализа кода ПО с целью извлечения из него определенных функциональных
возможностей, а также раскрытия алгоритмов или данных, используемых в
программе, которые могут представлять интерес для атакующего. Анализируя
извлеченные из программы данные, атакующий (называемый также обратным
проектировщиком, или реверс - инженером) может получить доступ к
алгоритмам программы. Возможно, некоторые из этих алгоритмов защищены патентами
или просто должны сохраняться в секрете (например, по причине манипулирования
секретными ключами).
Основными инструментами реверс-инженера являются дизассемблер и отладчик
(большинство современных реализаций объединяют эти инструменты в одном продукте).
Дизассемблер позволяет по выполняемому коду восстановить исходный код программы
в виде инструкций на языке ассемблера, а в некоторых случаях - и в виде
программы на языке более высокого уровня (например, С). Отладчик позволяет
загрузить программу «внутрь себя» и контролировать ход ее выполнения (выполнять
инструкции программы «по шагам», предоставлять доступ к ее адресному
пространству, отслеживать обращения к разным участкам памяти). Следует
отметить, что реверс-инженер может обойтись и без этих средств, просто
рассматривая программу как «черный ящик», подавая ей на вход специальным
образом сформированные данные и анализируя выходные данные. Однако анализ по
методу «черного ящика» крайне неэффективен ввиду его малой производительности.
Поскольку этот метод практически не используется при взломе программ, вопрос
противодействия ему не будем рассматривать.
Стоить отметить, что обратный анализ программ, написанных на языках,
которые компилируются в промежуточный интерпретируемый код (например, Java, C# и другие CLR-языки),
на порядок проще программ, написанных на языках, компилирующихся в машинный
код, поскольку в исполняемый код таких программ записывается информация про их
семантическую структуру (об их классах, полях, методах и т.д.). В связи с
возросшей популярностью таких языков программирования (и, в частности, .NET Framework) задача защиты программ, написанных
с их использованием, становится все более актуальной.
Модификация кода программы - преднамеренное или непреднамеренное изменение
выполняемого кода программы, приводящее к отклонениям программы от нормального
хода выполнения. Например, атакующий может изменить процедуру проверки
лицензионного ключа так, чтобы для любого переданного значения она возвращала TRUE, и, таким образом, программа бы
считала любое значение лицензионного ключа корректным. Кроме того, атакующий
может добавить в программу - жертву код, отсылающий конфиденциальную информацию
об окружении, в котором она выполняется, на его компьютер. Способность
программы определять, что она была изменена, очень важна, так как изменения,
внесенные в программу, могут привести к самым печальным последствиям (например,
в случае, если программа обслуживает больницу, электростанцию или другую
критическую службу). Отдельно стоит отметить, что подобные атаки могут быть
выполнены компьютерными вирусами, заражающими исполняемый код. Если программа
сумеет противостоять заражению (или определить, что она была заражена), это
сможет существенно снизить темпы распространения вирусной эпидемии.
Следует отметить, что вышеперечисленные виды атак не являются
независимыми друг от друга. Скорее, даже наоборот - они очень тесно переплетены
между собой. Так, проблема создания генератора ключей (пиратство) опирается на
исследование, каким образом в программе выполняется проверка лицензионного
ключа (реверс-инженерию); еще один подход софтверных пиратов - удаление из
программы кода проверки лицензионного ключа - связан с модификацией кода.
Поэтому рассматривать атаки независимо друг от друга не имеет смысла, нужно
сконцентрироваться на методах, обеспечивающих максимальное противодействие всем
видам атак одновременно.
ГЛАВА 1. БЕЗОПАСНОСТЬ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
.1 Угрозы
безопасности программного обеспечения и примеры их
реализации
Угрозы безопасности информации и программного обеспечения возникают как в
процессе их эксплуатации, так и при создании этих систем, что особенно
характерно для процесса разработки ПО.
При решении проблемы повышения уровня защищенности информационных
ресурсов необходимо исходить из того, что наиболее вероятным информационным
объектом воздействия будет выступать программное обеспечение, составляющее
основу комплекса средств получения, семантической переработки, распределения и
хранения данных.
Построение надежной защиты компьютерной системы невозможно без
предварительного анализа возможных угроз безопасности системы. Этот анализ
должен включать в себя:
• выявление характера хранящейся в системе информации, выделение
наиболее опасных угроз (несанкционированное чтение, несанкционированное
изменение и т.д.);
• оценку затрат времени и средств на вскрытие системы, допустимых
для злоумышленников;
• оценку ценности информации, хранящейся в системе;
• построение модели злоумышленника (другими словами, определение
того, от кого нужно защищаться - от постороннего лица, пользователя системы,
администратора и т.д.);
• оценку допустимых затрат времени, средств и ресурсов системы на
организацию ее защиты.
1.1.1
Классификация угроз
Угрозами информационной безопасности называются потенциальные источники
нежелательных событий, которые могут нанести ущерб ресурсам информационной
системы. Все угрозы безопасности, направленные против программных и технических
средств информационной системы, в конечном итоге оказывают влияние на
безопасность информационных ресурсов и приводят к нарушению основных свойств
хранимой и обрабатываемой информации. Как правило, угрозы информационной
безопасности различаются по способу их реализации.
Исходя из этого можно выделить следующие основные классы угроз
безопасности, направленных против информационных ресурсов:
• угрозы, реализуемые либо воздействием на программное обеспечение
и конфигурационную информацию системы, либо посредством некорректного
использования системного и прикладного программного обеспечения;
• угрозы, связанные с выходом из строя технических средств
системы, приводящим к полному или частичному разрушению информации, хранящейся
и обрабатываемой в системе;
• угрозы, обусловленные человеческим фактором и связанные с
некорректным использованием сотрудниками программного обеспечения или с
воздействием на технические средства, в большей степени зависят от действий и
"особенностей" морального поведения сотрудников;
• Угрозы с использованием программных средств. Наиболее
многочисленный класс угроз конфиденциальности, целостности и доступности
информационных ресурсов связан с получением внутренними и внешними нарушителями
логического доступа к информации с использованием возможностей, предоставляемых
общесистемным и прикладным программным обеспечением. Большинство рассматриваемых
в этом классе угроз реализуется путем локальных или удаленных атак на
информационные ресурсы системы внутренними и внешними нарушителями. Результатом
осуществления этих угроз становится несанкционированный доступ к данным,
управляющей информации, хранящейся на рабочем месте администратора системы,
конфигурационной информации технических средств, а также к сведениям,
передаваемым по каналам связи.
В этом классе выделяются следующие основные угрозы:
• угрозы техническим средствам
• несанкционированный доступ к приложению;
• внедрение вредоносного программного обеспечения;
• злоупотребление системными ресурсами;
• отказ от подтверждения авторства передаваемой информации;
• сбои системного и сетевого программного обеспечения;
• сбои прикладного программного обеспечения.
Наиболее уязвимы с точки зрения защищенности информационных ресурсов
являются так называемые критические компьютерные системы. Под критическими
компьютерными системами будем понимать сложные компьютеризированные
организационно - технические и технические системы, блокировка или нарушение
функционирования которых потенциально приводит к потере устойчивости
организационных систем государственного управления и контроля, утрате
обороноспособности государства, разрушению системы финансового обращения, дезорганизации
систем энергетического и коммуникационно - транспортного обеспечения
государства, глобальным экологическим и техногенным катастрофам.
.1.2
Используемая терминология
Разработка терминологии в области обеспечения безопасности ПО является
базисом для формирования нормативно-правового обеспечения и концептуальных
основ по рассматриваемой проблеме. Единая терминологическая база является
ключом к единству взглядов в области, информационной безопасности, стимулирует
скорейшее развитие методов и средств защиты ПО. Термины освещают основные
понятия, используемые в рассматриваемой области на данный период времени.
Определения освещают толкование конкретных форм, методов и средств обеспечения
информационной безопасности.
Непреднамеренный дефект - объективно и (или) субъективно образованный дефект,
приводящий к получению неверных решений (результатов) или нарушению
функционирования КС.
Преднамеренный дефект - криминальный дефект, внесенный субъектом для
целенаправленного нарушения и (или) разрушения информационного ресурса.
Программная закладка - совокупность операторов и (или) операндов, преднамеренно в
завуалированной форме включаемую в состав выполняемого кода программного
компонента на любом этапе его разработки. Программная закладка реализует
определенный несанкционированный алгоритм с целью ограничения или блокирования
выполнения программным компонентом требуемых функций при определенных условиях
вычислительного процесса, задаваемого семантикой перерабатываемых программным
компонентом данных, либо с целью снабжения программного компонента не
предусмотренными спецификацией функциями, которые могут быть выполнены при
строго определенных условиях протекания вычислительного процесса.
Алгоритмическая закладка - преднамеренное искажение какой-либо части алгоритма
решения задачи, либо построение его таким образом, что в результате конечной
программной реализации этого алгоритма программа будет иметь ограничения на
выполнение требуемых функций, заданных спецификацией, или вовсе их не выполнять
при определенных условиях, задаваемого семантикой перерабатываемых программой
данных.
Несанкционированный доступ - действия, приводящие к нарушению безопасности
информационного ресурса и получению секретных сведений.
Нарушитель (нарушители) - субъект (субъекты), совершающие несанкционированный
доступ к информационному ресурсу.
Модель угроз - вербальная, математическая, имитационная или натурная
модель, формализующая параметры внутренних и внешних угроз безопасности ПО.
Оценка безопасности ПО - процесс получения количественных или качественных
показателей информационной безопасности при учете преднамеренных и
непреднамеренных дефектов в системе.
Технологическая безопасность - свойство программного обеспечения
и информации не быть преднамеренно искаженными и (или) начиненными избыточными
модулями (структурами) диверсионного назначения на этапе создания.
Эксплуатационная безопасность - свойство программного обеспечения
и информации не быть несанкционированно искаженными (измененными) на этапе
эксплуатации.
Дизассемблирование - способ преобразования кода исполняемых модулей в язык
программирования, понятный человеку - Assembler.
Декомпиляция - преобразование исполняемого модуля приложения программный
код на языке высокого уровня и получение представления приложения, близкого к исходному
коду.
.2
Жизненный цикл программного обеспечения
Жизненный цикл программного обеспечения - период времени, который
начинается с момента принятия решения о необходимости создания программного
продукта и заканчивается в момент его полного изъятия из эксплуатации.
(Стандарт IEEE Std 610.12)
Необходимость определения этапов жизненного цикла (ЖЦ) ПО обусловлена
стремлением разработчиков к повышению качества ПО за счет оптимального
управления разработкой и использования разнообразных механизмов контроля
качества на каждом этапе, начиная от постановки задачи и заканчивая авторским
сопровождением ПО. Наиболее общим представлением жизненного цикла ПО является
модель в виде базовых этапов - процессов, к которым относятся:
• системный анализ и обоснование требований к ПО;
• предварительное (эскизное) и детальное (техническое)
проектирование ПО;
• разработка программных компонент, их комплексирование и отладка
ПО в целом;
• испытания, опытная эксплуатация и тиражирование ПО;
• регулярная эксплуатация ПО, поддержка эксплуатации и анализ
результатов;
• сопровождение ПО, его модификация и совершенствование, создание
новых версий.
Данная модель является общепринятой и соответствует как отечественным
нормативным документам в области разработки программного обеспечения, так и
зарубежным. С точки зрения обеспечения технологической безопасности
целесообразно рассмотреть более подробно особенности представления этапов ЖЦ в
зарубежных моделях, так как именно зарубежные программные средства являются
наиболее вероятным носителем программных дефектов диверсионного типа.
1.2.1
Стандарты
жизненного цикла ПО
• ГОСТ 34.601-90
• ISO/IEC 12207:1995 (российский аналог - ГОСТ Р ИСО/МЭК 12207-99)
Графическое представление моделей ЖЦ позволяет наглядно выделить их
особенности и некоторые свойства процессов.
Первоначально была создана каскадная модель ЖЦ, в которой крупные этапы
начинались друг за другом с использованием результатов предыдущих работ. Она
предусматривает последовательное выполнение всех этапов проекта в строго
фиксированном порядке. Переход на следующий этап означает полное завершение
работ на предыдущем этапе. Требования, определенные на стадии формирования
требований, строго документируются в виде технического задания и фиксируются на
все время разработки проекта. Каждая стадия завершается выпуском полного
комплекта документации, достаточной для того, чтобы разработка могла быть
продолжена другой командой разработчиков. Неточность какого-либо требования или
некорректная его интерпретация в результате приводит к тому, что приходится
«откатываться» к ранней фазе проекта и требуемая переработка не просто выбивает
проектную команду из графика, но приводит часто к качественному росту затрат и,
не исключено, к прекращению проекта в той форме, в которой он изначально
задумывался. Основное заблуждение авторов водопадной модели состоит в
предположениях, что проект проходит через весь процесс один раз,
спроектированная архитектура хороша и проста в использовании, проект
осуществления разумен, а ошибки в реализации легко устраняются по мере
тестирования. Эта модель исходит из того, что все ошибки будут сосредоточены в
реализации, а потому их устранение происходит равномерно во время тестирования
компонентов и системы. Таким образом, водопадная модель для крупных проектов
мало реалистична и может быть эффективно использована только для создания
небольших систем.[7]
Наиболее специфической является спиралевидная модель ЖЦ. В этой модели
внимание концентрируется на итерационном процессе начальных этапов
проектирования. На этих этапах последовательно создаются концепции,
спецификации требований, предварительный и детальный проект. На каждом витке
уточняется содержание работ и концентрируется облик создаваемого ПО,
оценивается качество полученных результатов и планируются работы следующей итерации. На каждой итерации оцениваются:
• риск превышения сроков и стоимости проекта;
• необходимость выполнения ещё одной итерации;
• степень полноты и точности понимания требований к системе;
• целесообразность прекращения проекта.
Стандартизация ЖЦ ПО проводится по трем направлениям. Первое направление
организуется и стимулируется Международной организацией по стандартизации (ISO
- International Standard Organization) и Международной комиссией по
электротехнике (IEC - International Electro-technical Commission). На этом
уровне осуществляется стандартизация наиболее общих технологических процессов,
имеющих значение для международной кооперации. Второе направление активно
развивается в США Институтом инженеров электротехники и радиоэлектроники (IEEE
- Institute of Electrotechnical and Electronics Engineers) совместно с
Американским национальным институтом стандартизации (American Na-tional
Standards Institute-ANSI). Стандарты ISO/IEC и ANSI/IEEE в основном имеют
рекомендательный характер. Третье направление стимулируется Министерством
обороны США (Department of Defense-DOD). Стандарты DOD имеют обязательный
характер для фирм, работающих по заказу Министерства обороны США.
Для проектирования ПО сложной системы, особенно системы реального
времени, целесообразно использовать общесистемную модель ЖЦ, основанную на
объединении всех известных работ в рамках рассмотренных базовых процессов. Эта
модель предназначена для использования при планировании, составлении рабочих
графиков, управлении различными программными проектами.
Совокупность этапов данной модели ЖЦ целесообразно делить на две части,
существенно различающихся особенностями процессов, технико-экономическими
характеристиками и влияющими на них факторами.
В первой части ЖЦ производится системный анализ, проектирование,
разработка, тестирование и испытания ПО. Номенклатура работ, их трудоемкость,
длительность и другие характеристики на этих этапах существенно зависят от
объекта и среды разработки. Изучение подобных зависимостей для различных
классов ПО позволяет прогнозировать состав и основные характеристики графиков
работ для новых версий ПО.
Вторая часть ЖЦ, отражающая поддержку эксплуатации и сопровождения ПО,
относительно слабо связана с характеристиками объекта и среды разработки.
Номенклатура работ на этих этапах более стабильна, а их трудоемкость и
длительность могут существенно изменяться, и зависят от массовости применения
ПО. Для любой модели ЖЦ обеспечение высокого качества программных комплексов
возможно лишь при использовании регламентированного технологического процесса
на каждом из этих этапов. Такой процесс поддерживается средствами автоматизации
разработки, которые целесообразно выбирать из имеющихся или создавать с учетом
объекта разработки и адекватного ему перечня работ.
.3
Принципы обеспечения безопасности программного
обеспечения
Один
из возможных подходов к созданию модели технологической безопасности ПО может
основываться на обобщенной концепции технологической безопасности компьютерной
инфосферы [8] <#"564481.files/image001.gif">
Схема угроз технологической безопасности ПО
Составление модели угроз технологической безопасности ПО должно включать
в себя следующие элементы: матрицу чувствительности к «вариациям» ПО (то есть к
появлению искажений), энтропийный портрет ПО (то есть описание «темных»
запутанных участков ПО), реестр камуфлирующих условий для конкретного ПО,
справочные данные о разработчиках и реальный (либо реконструированный) замысел
злоумышленников по поражению этого ПО. В таблице приведен пример типового
реестра угроз для сложных программных комплексов.
|
ПРОЕКТИРОВАНИЕ Проектные решения Злоумышленный выбор нерациональных
алгоритмов работы. Облегчение внесения закладок и затруднение их
обнаружения. Используемые информационные технологии Внедрение
информационных технологий или их элементов, содержащих программные закладки.
Внедрение неоптимальных информационных технологий. Используемые
аппаратно-технические средства Поставка вычислительных средств,
содержащих программные, аппаратные или программно-аппаратные закладки.
Поставка вычислительных средств с низкими эксплуатационными характеристиками.
|
|
КОДИРОВАНИЕ Архитектура программной системы,
взаимодействие ее с внешней средой и взаимодействие подпрограмм программной
системы Доступ
к «чужим» подпрограммам и данным. Нерациональная организация вычислительного
процесса. Неправильная организация динамически формируемых команд или
параллельных вычислительных процессов. Неправильная организация
переадресации команд, запись злоумышленной информации в используемые
программной системой или другими программами ячейки памяти. Функции и
назначение кодируемой части программной системы, взаимодействие этой части с
другими подпрограммами Формирование программной закладки,
воздействующей на другие части программной системы. Организация
замаскированного спускового механизма программной закладки. Формирование
программной закладки, изменяющей структуру программной системы. Технология
записи программного обеспечения и исходных данных. Поставка программного
обеспечения и технических средств со встроенными дефектами.
|
|
ОТЛАДКА И ИСПЫТАНИЯ Назначение, функционирование,
архитектура программной системы Встраивание программной закладки как в отдельные
подпрограммы, так и в управляющую программу программной системы.
Формирование программной закладки с динамически формируемыми командами.
Неправильная организация переадресации отдельных команд программной системы. Сведения
о процессе испытаний (набор тестовых данных, используемые вычислительные
средства, подразделения и лица, проводящие испытания, используемые модели) Формирование
набора тестовых данных, не позволяющих выявить программную закладку.
Поставка вычислительных средств, содержащих программные, аппаратные или
программно-аппаратные закладки. Формирование программной закладки, не
обнаруживаемой с помощью используемой модели объекта в силу ее неадекватности
описываемому объекту.
|
|
КОНТРОЛЬ Используемые процедуры и методы контроля Формирование
спускового механизма программной закладки, не включающего ее при контроле на
безопасность. Маскировка программной закладки путем внесения в программную
систему ложных «непреднамеренных» дефектов. Формирование программных закладок
в ветвях программной системы, не проверяемых при контроле. Формирование
программных закладок, не позволяющих выявить их внедрение в программную
систему путем контрольного суммирования. Поставка программного обеспечения и
вычислительной техники, содержащих программные, аппаратные и
программно-аппаратные закладки. Сведения об обнаруженных при контроле
программных закладках Разработка новых программных закладок при доработке
программной системы. Сведения об обнаруженных незлоумышленных дефектах и
программных закладках Сведения о доработках программной системы и
подразделениях, их осуществляющих Сведения о среде функционирования
программной системы и ее изменениях. Сведения о функционировании программной
системы, доступе к ее загрузочному модулю и исходным данным, алгоритмах
проверки сохранности программной системы и данных.
|
Вариант общей структуры набора потенциальных угроз безопасности
информации и ПО на этапе эксплуатации приведен в таблице
|
Угрозы нарушения безопасности ПО
|
|
Случайные
|
Преднамеренные
|
|
Пассивные
|
Активные
|
|
Не выявленные ошибки программного обеспечения; отказы и
сбои технических средств; ошибки операторов; старение носителей информации;
разрушение информации под воздействием физических факторов (аварии,
неправильная эксплуатация и т.п.).
|
Маскировка несанкционированных запросов под запросы ОС;
обход программ разграничения доступа; чтение конфиденциальных данных из
источников информации; подключение к каналам связи с целью получения
информации («подслушивание» и/или «ретрансляция»); анализ трафика;
использование терминалов и ЭВМ других операторов; намеренный вызов случайных факторов.
|
Незаконное применение ключей разграничения доступа; обход
программ разграничения доступа; вывод из строя подсистемы регистрации и
учета; уничтожение ключей шифрования и паролей; подключение к каналам связи с
целью модификации, уничтожения, задержки и переупорядочивания данных;
несанкционированное копирование, распространение и использование программных
средств; намеренный вызов случайных факторов.
|
Рассмотрим основное содержание данной таблицы. Угрозы, носящие случайный
характер и связанные с отказами, сбоями аппаратуры, ошибками операторов и т.п.
предполагают нарушение заданного собственником информации алгоритма, программы
ее обработки или искажение содержания этой информации. Субъективный фактор
появления таких угроз обусловлен ограниченной надежностью работы человека и
проявляется в виде ошибок (дефектов) в выполнении операций формализации
алгоритма функциональных преобразований или описания алгоритма на некотором
языке, понятном вычислительной системе.
После окончательного синтеза модели угроз разрабатываются практические
рекомендации и методики по ее использованию для конкретного объекта
информационной защиты, а также механизмы оценки адекватности модели и реальной
информационной ситуации и оценки эффективности ее применения при эксплуатации.
Принципиальное различие подходов к синтезу моделей угроз технологической и
эксплуатационной безопасности ПО заключается в различных мотивах поведения
потенциального нарушителя информационных ресурсов, принципах, методах и
средствах воздействия на ПО на различных этапах его жизненного цикла.
.3.1
Классификация средств атаки на средства защиты программного обеспечения

1.3.2
Основные принципы обеспечения безопасности ПО.
В качестве объекта обеспечения технологической и эксплуатационной
безопасности ПО рассматривается вся совокупность его компонентов в рамках
конкретной. В качестве доминирующей должна использоваться стратегия сквозного
тотального контроля технологического и эксплуатационного этапов жизненного
цикла компонентов ПО. Совокупность мероприятий по обеспечению технологической и
эксплуатационной безопасности компонентов ПО должна носить, по возможности,
конфиденциальный характер. Необходимо обеспечить постоянный, комплексный и
действенный контроль за деятельностью разработчиков и пользователей компонентов
ПО. Кроме общих принципов, обычно необходимо конкретизировать принципы
обеспечения безопасности ПО на каждом этапе его жизненного цикла. Далее
приводятся один из вариантов разработки таких принципов.
Принципы обеспечения технологической безопасности при
обосновании, планировании работ и проектном анализе ПО.
Принципы обеспечения безопасности ПО на данном этапе включают следующие
принципы:
Комплексности обеспечения безопасности ПО, предполагающей рассмотрение проблемы
безопасности информационно - вычислительных процессов с учетом всех структур
КС, возможных каналов утечки информации и несанкционированного доступа к ней,
времени и условий их возникновения, комплексного применения организационных и
технических мероприятий.
Планируемости применения средств безопасности программ, предполагающей перенос акцента на
совместное системное проектирование ПО и средств его безопасности, планирование
их использования в предполагаемых условиях эксплуатации.
Обоснованности средств обеспечения безопасности ПО, заключающейся в глубоком
научно-обоснованном подходе к принятию проектных решений по оценке степени
безопасности, прогнозированию угроз безопасности, всесторонней априорной оценке
показателей средств защиты.
Достаточности защищенности программ, отражающей необходимость поиска
наиболее эффективных и надежных мер безопасности при одновременной минимизации
их стоимости.
Гибкости управления защитой программ, требующей от системы контроля и
управления обеспечением безопасности ПО способности к диагностированию,
опережающей нейтрализации, оперативному и эффективному устранению возникающих
угроз.
Заблаговременности разработки средств обеспечения
безопасности и контроля производства ПО, заключающейся в предупредительном характере мер
обеспечения технологической безопасности работ в интересах недопущения снижения
эффективности системы безопасности процесса создания ПО.
Документируемости технологии создания программ, подразумевающей разработку пакета
нормативно-технических документов по контролю программных средств на наличие
преднамеренных дефектов.
Принципы достижения технологической безопасности ПО в
процессе его разработки Принципы обеспечения безопасности ПО на данном этапе включают следующие
принципы:
Регламентации технологических этапов разработки ПО, включающей упорядоченные фазы
промежуточного контроля, спецификацию программных модулей и стандартизацию
функций и формата представления данных.
Автоматизации средств контроля управляющих и вычислительных
программ на наличие
преднамеренных дефектов.
Создания типовой общей информационной базы алгоритмов,
исходных текстов и программных средств, позволяющих выявлять преднамеренные программные дефекты.
Последовательной многоуровневой фильтрации программных
модулей в процессе
их создания с применением функционального дублирования разработок и поэтапного
контроля.
Типизации алгоритмов, программ и средств информационной
безопасности,
обеспечивающей информационную, технологическую и программную совместимость, на
основе максимальной их унификации по всем компонентам и интерфейсам.
Централизованного управления базами данных проектов ПО и администрирование технологии
их разработки с жестким разграничением функций, ограничением доступа в
соответствии со средствами диагностики, контроля и защиты.
Блокирования несанкционированного доступа соисполнителей и абонентов
государственных и негосударственных сетей связи, подключенных к стендам для
разработки программ.
Статистического учета и ведения системных журналов о всех процессах разработки ПО с целью
контроля технологической безопасности. Использования только сертифицированных и
выбранных в качестве единых инструментальных средств разработки программ для
новых технологий обработки информации и перспективных архитектур вычислительных
систем. программа компьютер вирус информационный
безопасность
Принципы обеспечения технологической безопасности на этапах
стендовых и приемосдаточных испытаний
Принципы обеспечения безопасности ПО на данном этапе включают принципы:
Тестирования ПО на основе разработки комплексов тестов, параметризуемых
на конкретные классы программ с возможностью функционального и статистического
контроля в широком диапазоне изменения входных и выходных данных.
Проведения натурных испытаний программ при экстремальных нагрузках с
имитацией воздействия активных дефектов.
Осуществления «фильтрации» программных комплексов с целью выявления возможных
преднамеренных дефектов определенного назначения на базе создания моделей угроз
и соответствующих сканирующих программных средств. Разработки и экспериментальной
отработки средств верификации программных изделий.
Проведения стендовых испытаний ПО для определения непреднамеренных
программных ошибок проектирования и ошибок разработчика, приводящих к
невыполнению целевых функций программ, а также выявление потенциально «узких»
мест в программных средствах для разрушительного воздействия. Отработки средств
защиты от несанкционированного воздействия нарушителей на ПО.
Сертификации программных изделий по требованиям безопасности с выпуском сертификата соответствия
этого изделия требованиям технического задания.
Принципы обеспечения безопасности при эксплуатации
программного обеспечения Принципы обеспечения безопасности ПО на данном этапе включают принципы:
Сохранения эталонов и ограничения доступа к ним программных средств, недопущение
внесения изменений в эталоны. Профилактического выборочного тестирования и
полного сканирования программных средств на наличие преднамеренных дефектов.
Идентификации ПО на момент ввода его в эксплуатацию в соответствии с предполагаемыми
угрозами безопасности ПО и его контроль.
Обеспечения модификации программных изделий во время их эксплуатации путем
замены отдельных модулей без изменения общей структуры и связей с другими
модулями.
Строгого учета и каталогизации всех сопровождаемых программных
средств, а также собираемой, обрабатываемой и хранимой информации.
Статистического анализа информации обо всех процессах, рабочих
операциях, отступлениях от режимов штатного функционирования ПО.
Гибкого применения дополнительных средств защиты ПО в случае выявления новых,
непрогнозируемых угроз информационной
безопасности.
.4 Оценка
качества программного обеспечения
Согласно ГОСТ 28195-89 качеством программного обеспечения называ-ется
совокупность потребительских свойств ПО, характеризующих способность
программного обеспечения удовлетворять потребность пользователей в обработке
данных в соответствии с назначением. [15]
Оценка качества ПО чаще всего проводится экспертными методами на основе
технического задания и спецификации на разработку оцениваемого ПО и интуитивных
представлений о том, каким должно быть данное ПО для успешного исполнения
требуемых функций. К экспертизе привлекались специалисты в области применения
оцениваемого ПО или будущие пользователи данного ПО. Недостатками такогометода
являются, во-первых, необходимость индивидуального подхода к оценке качества
каждого конкретного ПО и, во-вторых, неоднозначность и субъективность оценки. В
настоящее время, оценка качества конкретного ПО производится путем раздельной
оценки некоторой совокупности показателей качества оцениваемого ПО и
последующим суммированием полученных оценок, в результате которого получается
общая оценка качества. Формализации показателей качества посвящена группа
нормативных документов. Существует международный стандарт ISO 9126:1991 , в
котором выделены характеристики (показатели качества), позволяющие оценивать ПО
с точки зрения пользователя, разработчика и управляющего проектом. Всего в
международном стандарте рекомендуется шесть основных показателей качества ПО,
каждый из которых детализирован несколькими характеристиками. Аналогом
международного стандарта IS09126:1991 является российский стандарт ГОСТ
28195-89. Он близок к международному стандарту по структуре и идеологии, хотя
номенклатура показателей несколько отличается от номенклатуры показателей
качества, предложенной в международном стандарте.
Оценка показателей качества ПО может производиться различными методами,
учитывающими специфику каждого конкретного показателя. Основными из них
являются:
• метод экспертных оценок;
• оценки с применением различных математических методов (так
называемые метрики программ);
• эвристические методы, выработанные практикой.
Несмотря на довольно большое количество метрик программ (несколько
сотен), измеряемых с помощью инструментальных программных средств, метрология
программного обеспечения на настоящий момент развита достаточно слабо.
Например, используя существующие метрики, пока невозможно однозначно оценить
уровень качества анализируемой программы без дополнительного применения
экспертных методов.
Все существующие на сегодняшний день показатели качества ПО можно
разделить на следующие классы:
) Показатели сопровождения - структурная и информационная
сложность ПО, структурность ПО, наглядность, повторяемость.
) Показатели надежности.
) Показатели удобства работы - легкость освоения, доступность
эксплуатационной программной документации, удобство эксплуатации и
обслуживания.
) Показатели эффективности - уровень автоматизации, временная
эффективность, ресурсоемкость.
) Показатели универсальности - гибкость, мобильность,
модифицируемость.
) Показатели корректности - логическая корректность, полнота
реализации, согласованность, проверенность.
Дадим подробный анализ перечисленных показателей качества ПО и методов,
используемых для их оценки.
.4.1
Показатели сопровождения программного обеспечения
Показатели сопровождения ПО характеризуют технологические аспекты,
обеспечивающие простоту поиска и устранения ошибок в программе и программной
документации и поддержания ПО в актуальном состоянии.
Оценку структурной (топологической) и информационной сложности ПО в
настоящее время проводят различными способами, которые можно разделить на
метрики сложности потока управления и метрики сложности потока данных [16].
Метрики сложности потока управления связывают сложность ПО со сложностью
структуры передач управления при работе оцениваемого ПО. Оценку сложности
потока управления проводят с помощью следующих методов:
а) Метрика Холстеда.
Метрика Холстеда [17] используется для численной оценки сложности
программы. Исходными данными для нее являются:
• количество уникальных операндов в программе;
• количество операторов в программе;
• общее количество операторов данного языка программирования.
Метрика Холстеда заключается в следующем.
Введем обозначения:
 - число
уникальных операторов в программе,
- число
уникальных операторов в программе,
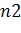 - число
уникальных операндов, в программе,
- число
уникальных операндов, в программе,
 -
словарь программы,
-
словарь программы,
 - общее
число операторов в программе,
- общее
число операторов в программе,
 - общее число операндов в программе,
- общее число операндов в программе,
 - длина
программы.
- длина
программы.
Тогда
объем программы  вычисляется
по формуле:
вычисляется
по формуле:
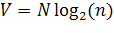
Длину
программы и словарь программы связывает следующая зависимость:

Значение
расчетной длины, значительно отличающееся от измеренной длины, указывает на
наличие в программе избыточных конструкций (несовершенств). Холстед приводит
шесть классов несовершенств:
• дополняющие друг друга операции;
• синонимические операнды;
• неоднозначные операнды;
• наличие общих подвыражений;
• ненужное присваивание;
• нефакторизированные выражения.
Потенциальный объем ПО вычисляется по формуле:
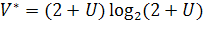
где
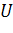 - число
входных и выходных данных программы.
- число
входных и выходных данных программы.
Данный
показатель целесообразно применять для оценки неструктурированных компонентов,
поскольку сложность структурной программы коррелирует с ее размером. Уровень  программы
вычисляется формуле:
программы
вычисляется формуле:

По
уровню программы можно судить об избыточности программы. При этом более
качественные (неизбыточные) программы имеют большее значение уровня.
Зависимости,
используемые в метрике Холстеда, вытекают из положений теории информации.
Используя метрику Холстеда, можно оценить теоретическую длину конкретной
программы, ее объём, избыточность реализации алгоритма и численно оценить
уровень языка программирования, на котором написана программа. Важно отметить,
что эта оценка будет достаточно правдоподобной. Правдоподобность такой оценки
подтверждается проведенным корреляционным и регрессионным анализом на примере
типичных программных модулей. [18]
б)
Метрика Маккейба.
Метрика
Маккейба [19] использует графовое представление структуры программы -
структурное дерево программы (СДП) и структуры передач управления при ее работе
между операторами, или, на более высоком уровне, между модулями - управляющий
граф программы (УГП). Такое представление позволяет оценить сложность программы
различными методами. Например, методами алгебры графов оценивают связность
построенного УГП и, таким образом, оценивают степень отличия данного УГП от
графа типа «дерево», что характеризует структурную сложность программы  :
:
где: 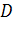 -
количество ребер в графе вызовов модулей (УГП);
-
количество ребер в графе вызовов модулей (УГП);
 -
количество вершин в УГП.
-
количество вершин в УГП.
Для
структурированной программы характерна простая структура УГП (дерево).
Сложность
программы по Маккейбу (цикломатическое число СДП программы, или модуля)
оценивается по следующей формуле:

где:  - число
дуг в графе логической структуры модуля (СДП);
- число
дуг в графе логической структуры модуля (СДП);
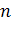 - число
вершин в графе.
- число
вершин в графе.
Цикломатическое
число  численно равно минимальному количеству тестовых путей,
необходимых для покрытия каждой дуги графа логической структуры модуля хотя бы
один раз. Этот показатель может быть использован также для оценки сложности и
трудоемкости тестирования ПО.
численно равно минимальному количеству тестовых путей,
необходимых для покрытия каждой дуги графа логической структуры модуля хотя бы
один раз. Этот показатель может быть использован также для оценки сложности и
трудоемкости тестирования ПО.
Метрика
Маккейба исследована в современных работах. Например, в [20] сложность
программы оценивается по количеству тестов, необходимых для покрытия всего УГП
программы. В построенном УГП программы выделяются вычислительные траектории
(ВТ), т.е. полная последовательность всех операторов со значениями их операндов
и вычислительные пути, т.е. совокупность всех ВТ, имеющих идентичную
последовательность одних и тех же операторов. Вводится понятие неизбыточного
теста программы - такого теста И, что существует покрытая им вычислительная
траектория в УГП, не покрытая ни одним из предыдущих тестов. Тогда, сложность
программы измеряется как трудоемкость тестирования, или минимальное число
неизбыточных тестов, покрывающие все вычислительные траектории УГП. Существуют
также автоматизированные системы, позволяющие строить УГП и оценивать
количество тестов, необходимых для полного покрытия данного УГП, и, таким
образом, автоматически оценивать сложность ПО. Недостатком таких
автоматизированных систем является следующее. По мере увеличения сложности
оцениваемого ПО количество вычислительных ресурсов, необходимых для работы
автоматизированной системы, резко возрастает из-за резкого увеличения
количества вычислительных траекторий в УГП.
Существуют
усовершенствованные метрики, основанные на метрике Маккейба, например, метрика
Майерса[21].
в)
Метрика Джилба.
Метрика
Джилба [16] оценивает сложность программы. Она основана на подсчете количества
условных конструкций типа  и,
несмотря на простоту, дает хорошие результаты. В работе [16] эта метрика
дополнена учетом максимального уровня вложенности базовых структурных конструкций
(следование, условие, цикл).
и,
несмотря на простоту, дает хорошие результаты. В работе [16] эта метрика
дополнена учетом максимального уровня вложенности базовых структурных конструкций
(следование, условие, цикл).
Метрики
сложности потока данных связывают сложность ПО со сложностью структуры потоков
данных, передаваемых в процессе работе оцениваемого ПО. Сложность потока данных
может оцениваться различными методами.
Проанализируем
эти методы.
Метрика
«модуль - глобальная переменная» оценивает сложность программы, связывает
сложность программ с обращениями к глобальным переменным.
Метрика
со спеном оценивает сложность программы. Спен - это число утверждений,
содержащих данный идентификатор между его первым и последним появлением в
программе. Таким образом, данная метрика связывает количество переменных в
программе и количество обращений к ним со сложностью самой программы.
г) Метрика Чепина [19] оценивает сложность
программы. В данной метрике все переменные разбиваются на четыре класса по
характеру использования - переменные, используемые для расчета, модифицируемые
или создаваемые внутри программы, управляющие и паразитные. Далее по формуле
вычисляется значение метрики. Существуют несколько вариантов этой метрики. Рассмотрим более простой, а с точки зрения
практического использования - достаточно эффективный вариант этой метрики.
Все
множество переменных, составляющих список ввода-вывода, разбивается на четыре
функциональные группы.
. Множество
« » -
вводимые переменные для расчетов и для обеспечения вывода. Примером может
служить используемая в программах лексического анализатора переменная,
содержащая строку исходного текста программы, то есть сама переменная не
модифицируется, а только содержит исходную информацию.
» -
вводимые переменные для расчетов и для обеспечения вывода. Примером может
служить используемая в программах лексического анализатора переменная,
содержащая строку исходного текста программы, то есть сама переменная не
модифицируется, а только содержит исходную информацию.
. Множество
« » -
модифицируемые или создаваемые внутри программы переменные.
» -
модифицируемые или создаваемые внутри программы переменные.
. Множество
«» -
переменные, участвующие в управлении работой программного модуля (управляющие
переменные).
. Множество
« » - не
используемые в программе («паразитные») переменные. Поскольку каждая переменная
может выполнять одновременно несколько функций, необходимо учитывать ее в
каждой соответствующей функциональной группе.
» - не
используемые в программе («паразитные») переменные. Поскольку каждая переменная
может выполнять одновременно несколько функций, необходимо учитывать ее в
каждой соответствующей функциональной группе.
Далее вводится значение метрики Чепина:

где:
 -
весовые коэффициенты.
-
весовые коэффициенты.
Весовые
коэффициенты использованы для отражения различного влияния на сложность
программы каждой функциональной группы. По мнению автора метрики наибольший
вес, равный трем, имеет функциональная группа С, так как она влияет на поток
управления программы. Весовые коэффициенты остальных групп распределяются
следующим образом: 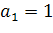 ;
;  ;
;  ;
;  . Весовой
коэффициент группы T не равен нулю, поскольку «паразитные» переменные не
увеличивают сложности потока данных программы, но иногда затрудняют ее
понимание. С учетом весовых коэффициентов выражение примет вид:
. Весовой
коэффициент группы T не равен нулю, поскольку «паразитные» переменные не
увеличивают сложности потока данных программы, но иногда затрудняют ее
понимание. С учетом весовых коэффициентов выражение примет вид:

Структурность
Структурность
ПО - это организация всех взаимосвязанных частей ПО в единое целое с
использованием логических структур «следование», «условие», «цикл». Основы
структурной технологии проектирования ПО изложены в работе [22]. Необходимость
оценки данного показателя связана с тем, что от структурности ПО напрямую
зависит удобство сопровождения и модификации ПО. Кроме того, при строгом
соблюдении технологии структурного проектирования ПО, количество ошибок в нем
значительно снижается. Существует несколько метрик для оценки структурности ПО,
например, метрика структурности программы, основанная на оценке линеарности УГП
- «подсчете точек пересечения» дуг графа программы . Полученная оценка
линеарности УГП может использоваться для оценки меры неструктурированности
программы. Данное предположение основано на том, что структурные конструкции
при представлении их управляющим графом планарны и, таким образом, точка
пересечения дуг в УГП появляется только при наличии неструктурной конструкции.
Следовательно, по их количеству можно оценить неструктурированность программы.
Наглядность
Наглядность
ПО - это наличие и представление в наиболее легко воспринимаемом виде исходных
текстов ПО, полное их описание в соответствующих программных документах. Оценка
наглядности ПО требует привлечения наук, изучающих психологию человека и/или
экспертных оценок. Данное понятие пока формализовать невозможно, но существуют
методики косвенной оценки наглядности, например, оценка уровня комментированности
программы :

где:
 -
количество комментированных строк исходного текста программы;
-
количество комментированных строк исходного текста программы;
 - общее
количество строк исходного текста программы.
- общее
количество строк исходного текста программы.
На
основе практического опыта принято считать, что для наглядности исходных
текстов программы требуется  , т.е. на
каждые десять строк программы должен приходиться хотя бы один комментарий.
, т.е. на
каждые десять строк программы должен приходиться хотя бы один комментарий.
Используя
оценку уровня языковых средств, применяемых в программе, можно также косвенно
оценивать наглядность данной программы.
Наглядность
ПО можно также косвенно оценить по его структурности. При этом более
структурированное ПО имеет более высокую наглядность.
Повторяемость
Повторяемость
ПО - это степень использования типовых проектных решений, или компонентов,
входящих в ПО. Оценивается на основе статистики об использовании типовых
решений и модулей, входящих в состав ПО, собранной в процессе разработки
данного ПО.
1.4.2
Показатели надежности
Надежность ПО - это способность ПО в конкретных областях применения
выполнять заданные функции в соответствии с программными документами в условиях
возникновения отклонений в среде функционирования, вызванных сбоями технических
средств, ошибками во входных данных, ошибками обслуживания и другими
дестабилизирующими воздействиями [15]. В понятии надежности ПО обычно выделяют
два понятия[23]:
• работоспособность ПО, т.е. способность ПО выполнять свои функции
в соответствии с программными документами;
• устойчивость функционирования ПО, т.е. способность ПО выполнять
свои функции в условиях возникновения сбоев и отклонений в среде
функционирования.
Сравнительно недавно начали появляться методы оценки надежности,
разработанные специально для оценки надежности ПО. Они используют понятие
математической модели надежности программы (МНП). МНП - это математическое
выражение, связывающее один или несколько показателей надежности ПО с
непосредственно измеренным параметром, характеризующим ПО в некоторой среде.
Иными словами, это предельно абстрагированная математическая модель программы,
в которой отсутствуют детали, не влияющие на надежность. Это заметно упрощает
процедуру оценки надежности программы [24].
Среди МНП можно выделить следующие:
• априорные МНП (АМН);
• эмпирические МНП (ЭМН);
• полные (ПМН).
В основе АМН лежат такие характеристики ПО, как объем, сложность и
характеристики процесса создания. С помощью АМН можно оценить показатели
надежности ПО до начала его испытаний. Существующие
на сегодняшний день АМН пока не позволяют применить их на практике, в основном,
это оценка сложности разрабатываемого ПО, например, по метрике Холстеда, и
попытка связать ее с надежностью будущего ПО. Точная взаимосвязь сложности ПО с
его надежностью пока неясна. Так как главным, если не единственным источником
ошибок является программист, то здесь необходимо привлекать дисциплины,
изучающие самого человека.
В ЭМН используется информация, полученная в процессе функционирования ПО
(отладки и т.д.). Эмпирические МНП делятся на:
• непрерывные ЭМН. Если ЭМН имеет в качестве одного из аргументов
время, то такая модель называется непрерывной ЭМН (НЭМН).
• дискретной ЭМН (ДЭМН), если время отсутствует, а используется
порядковый номер испытания.
Для получения необходимой для ЭМН информации пользуются результатами
отладки ПО в процессе разработки, результатами бета-тестирования (тестирования
предварительной или окончательной версии ПО в условиях, близких к реальным,
группой специально подготовленных пользователей - бета-тестеров).
Непрерывные эмпирические математические модели надежности ПО характерны
тем, что в список их аргументов, входит время работы ПО, но это не совсем
корректно отражает работу ПО на современных компьютерах, так как они работают
фиксированными дискретными порциями времени - тактами.
В
настоящее время наиболее известной НЭМН является модель Шумана. Согласно
этой модели интенсивность отказов определяется тем, насколько часто в процессе
выполнения программы приходится сталкиваться с дефектами. То есть,
интенсивность отказов зависит от количества обнаруженных дефектов. Если
допустить, что интенсивность отказов пропорциональна количеству обнаруженных
ошибок, то можно получить экспоненциальную модель. В этой модели
предполагается, что зависимость интенсивность проявления ошибок остается
постоянной до тех пор, пока не исправлен дефект в программе, вызывающий эти
ошибки (первичная ошибка). Если каждая обнаруженная ошибка исправляется, то
значения промежутков времени между их проявлениями изменяются по
экспоненциальному закону. Исследования, проведенные на ряде комплексов крупных
программ, показали, что распределение числа накопленных ошибок от
времени  их
обнаружения хорошо аппроксимируется экспонентой. Значение коэффициента
корреляции примерно равно 0,85. Пропорциональность частот обнаружения ошибок и
их исправления можно объяснить тем, что исправления сами могут вносить
дополнительные ошибки, и тем, что внесенное исправление может исправлять сразу
несколько связанных ошибок. Эта гипотеза хорошо подтверждается статистическими
исследованиями, проведенными при разработке крупных комплексов ПО. При этих
допущениях получим:
их
обнаружения хорошо аппроксимируется экспонентой. Значение коэффициента
корреляции примерно равно 0,85. Пропорциональность частот обнаружения ошибок и
их исправления можно объяснить тем, что исправления сами могут вносить
дополнительные ошибки, и тем, что внесенное исправление может исправлять сразу
несколько связанных ошибок. Эта гипотеза хорошо подтверждается статистическими
исследованиями, проведенными при разработке крупных комплексов ПО. При этих
допущениях получим:

где:
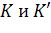 -
коэффициенты пропорциональности, учитывающие масштаб времени, используемого при
описании процесса обнаружения ошибок,
-
коэффициенты пропорциональности, учитывающие масштаб времени, используемого при
описании процесса обнаружения ошибок,
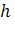 -
интенсивность проявления ошибок при нормальном функционировании ПО,
-
интенсивность проявления ошибок при нормальном функционировании ПО,
 - число
оставшихся ошибок,
- число
оставшихся ошибок,
- число
обнаруженных ошибок,
 - общее
число ошибок в программе,
- общее
число ошибок в программе,  .
.
Зависимость
значений наработки на проявление ошибки от количества устраненных ошибок и
аппроксимация этих данных экспонентой показана на рисунке.

Пусть
 = 1, то
есть время отладки соответствует реальному времени, тогда получим:
= 1, то
есть время отладки соответствует реальному времени, тогда получим:

Отсюда
число обнаруженных ошибок вычисляется по формуле:

а
число оставшихся в ПО первичных ошибок при времени отладки равно:
равно:

Эти
выводы согласуются со статистикой, собранной при разработке больших комплексов
ПО. Их можно использовать для расчета требуемого времени отладки для достижения
нужной степени тестированности ПО. Если известны все моменты обнаружения
ошибок, и в эти моменты обнаруживается и устраняется одна первичная ошибка, то
по собранной статистике можно корректировать коэффициенты ,
добиваясь большего соответствия экспоненциальной МНП характеристикам реального
ПО.[29]
Существует
еще ряд других НЭМН, например, модели Вейса, Формана, Хетагурова, Минаева.
В
общем случае ни одна из существующих на сегодняшний день НЭМН неприменима для
правдоподобной оценки надежности ПО. Однако в отдельных случаях некоторые из
НЭМН все же можно использовать для оценки надежности ПО.
В
отличие от НЭМН в список аргументов ДЭМН входит не время функционирования ПО, а
порядковый номер прогона программы. Одной из первых ДЭМН является модель
Коркорэна. В ней учитывается номер испытания, в котором наблюдался  дефект
-го типа. Выявленный дефект устраняется с вероятностью
дефект
-го типа. Выявленный дефект устраняется с вероятностью  (для -го
типа). Тогда, надежность программы рассчитывается по формуле:
(для -го
типа). Тогда, надежность программы рассчитывается по формуле:

где:  - число
успешных испытаний,
- число
успешных испытаний,
k - априори
известное число типов дефектов,


Значение
вероятности должно
оцениваться на основе априорной информации, или данных предшествующего периода
функционирования.
В
современном производстве МНП пока не получили широкого распространения. Оценка
надежности ПО ведется в основном с помощью тестирования, что ведет к некоторой
неопределенности понятия «надежность» конкретного ПО. В связи с этим появилась
юридическая практика распространения и продажи ПО по принципу «как есть» («as is»). Согласно этому принципу фирма-изготовитель ПО не
несет ответственности ни за возможные ошибки, содержащиеся в данном ПО, ни за
возможные их побочные эффекты (сбои и зависания компьютеров, или даже
необратимую потерю содержимого носителей информации).
В
соответствии с вышеизложенным можно сделать вывод о том, что разработка реально
применимых МНП является актуальной задачей.
1.4.3
Показатели удобства применения программного обеспечения
Под удобством применения ПО понимаются свойства ПО, способствующие
быстрому освоению, применению и эксплуатации ПО с минимальными трудозатратами с
учетом характера решаемых задач и требований к квалификации обслуживающего
персонала. Рассмотрим следующие показатели:
• Легкость освоения ПО - это представление программной
документации и программы в виде, способствующем пониманию логики
функционирования программы в целом и ее частей. Практически не поддается
формализации и оценивается, в основном, при помощи экспертной оценки. Для
повышения качества ПО по данному показателю требуется привлечение к его
разработке специалистов в области инженерной психологии, эргономики,
дизайнеров, художников.
• Доступность эксплуатационных программных документов - понятность,
наглядность и простота описания в эксплуатационных программных документах (ПД).
Для понятия качества ПД характерны некоторые особенности качества ПО:
- Понятность. ( понятен читающему его человеку)
- Завершенность. (содержатся все элементы, перечисленные
в его оглавлении, и с достаточной точностью и полнотой отражает аспекты
принятых технических решений)
- Осмысленность. (не содержит избыточной информации)
- Согласованность. (содержит единую нотацию,
терминологию, символику, смысловую связь внутри себя, с другими документами и с
ПО)
- Самоопределенность. (его взаимосвязанные части, разделы
и подразделы, организованы в единое целое определенным образом).
- Полнота. (соответствует требованиями к
структуре и содержанию документа.)
- Идентифицируемость. (содержит всю информацию о полном
наименовании документа, дате завершения его разработки и о его разработчике)
• Удобство эксплуатации и обслуживания - это соответствие процесса
обработки данных и форм представления результатов характеру решаемых задач. Трудно
поддается формализации оценке, поэтому оценивается при помощи методов
экспертной оценки и бета-тестирования.
.4.4
Показатели эффективности программного обеспечения
Показатели эффективности характеризуют степень удовлетворения потребности
пользователя в обработке данных с учетом экономических, вычислительных и
людских ресурсов. Включает следующее:
• Уровень автоматизации - степень автоматизации функций процесса
обработки данных с учетом рациональности функциональной структуры программы с
точки зрения взаимодействия с ней пользователя и использования вычислительных
ресурсов.
• Временная эффективность ПО - способность ПО выполнять заданные
действия в интервал времени, отвечающий указанным требованиям. Данный
показатель особенно важен для систем реального времени и ПО, применяемого для
управлениями особо ответственными объектами.
• Ресурсоемкость ПО - минимально возможные вычислительные ресурсы
и число обслуживающего персонала для эксплуатации данного ПО. Оценивается путем
практических испытаний ПО в условиях, близких к реальной эксплуатации, или в
течение пробного периода эксплуатации.
1.4.5
Показатели универсальности программного обеспечения
Эти показатели характеризуют адаптируемость ПО к новым функциональным
требованиям, возникающим вследствие изменения области применения, или других
условий функционирования. Включает следующее:
• Гибкость. Характеризует возможности использования ПО в различных
областях применения.
• Мобильность. Характеризует возможность применения ПО на ЭВМ
аналогичного класса. Примером такого ПО является ПО, написанное для
операционных систем (ОС) UNIX-клона, например, Linux, FreeBSD, Solaris.
Подавляющее большинство ПО для этих ОС распространяется в виде исходных текстов
на языках С, Perl, Python, LISP и компилируется только при инсталляции на
конкретную ЭВМ.
• Модифицируемость ПО характеризует простоту внесений необходимых
изменений и доработок в программу в процессе ее эксплуатации.
1.4.6
Показатели корректности программного обеспечения
Показатели корректности ПО характеризуют степень соответствия ПО
требованиям, установленным в техническом задании (ТЗ), требованиям к обработке
данных и общесистемным требованиям. Включает следующее:
• Логическая корректность
• Полнота реализации
• Согласованность
• Проверенность
Рассмотрим подробнее все эти показатели.
Логическая корректность ПО - функциональное и программное соответствие процесса
обработки данных общесистемным требованиям. Характеризует неидеальность
реализации алгоритма из-за ограниченности возможностей аппаратных средств, для
которых написано ПО. Самой точной и надежной оценкой корректности является
полная верификация - перебор всех возможных наборов данных и сравнение
результатов работы программы на каждом наборе данных с эталоном.[16] Однако,
при большом наборе данных такой подход требует огромных временных и денежных
затрат. Поэтому для особо ответственного ПО применяют частичную верификацию.
Ведется создание автоматических верификаторов. Здесь возникает еще одна
проблема - создание эталонных результатов, с которыми будут сравниваться
результаты работы верифицируемого ПО и проверка его корректности. Для оценки
корректности также применяются выработанные практикой эвристические методы.
Кратко их проанализируем.
Метод Миллса. В программу специально вводится некоторое количество ошибок
для последующей отладки специалистами. После отладки количество найденных
введенных ошибок сопоставляется с количеством найденных собственных ошибок
программы, и делается вывод о количестве еще оставшихся ошибок.
Метод «штурма». Для отладки одного из модулей ПО
привлекается весь коллектив разработчиков, все найденные ошибки учитываются.
Таким образом, после такой отладки данный модуль станет практически
безошибочным. Интенсивность ошибок по длине тестируемого модуля вычисляется по
формуле:

где: В - число обнаруженных ошибок;
N - длина тестируемого модуля.
Тогда, коэффициент тестированности модуля равен:

Оценка
общего количества ошибок во всем ПО равна:

Полнота
реализации. Характеризует полноту
реализации заданных функций ПО и достаточность их описания в программной
документации. Точно оценить полноту реализации алгоритма невозможно, так как
всегда существует возможность того, что на некотором наборе данных программа не
выполнит заданного алгоритма. Оценивается практическими испытаниями. Для особо
ответственного ПО данный показатель может оцениваться частичной верификацией.
Также,
существует оценка полноты реализации заданного алгоритма обработки данных в
процессе разработки ПО,  :
:
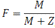
где: -
количество реализованных модулей,
 -
количество еще не реализованных модулей («модулей-заглушек»).
-
количество еще не реализованных модулей («модулей-заглушек»).
Согласованность. Согласованность ПО - однозначное, непротиворечивое
описанию использование тождественных объектов, функций, терминов, определений,
идентификаторов и т.д. в различных частях текста программы и в программных документов.
Оценивается экспертной оценкой самой программы и программных документов.
Проверенность.
Проверенность ПО - полнота проверки
возможных маршрутов выполнения программы в процессе тестирования. Проверенность
можно оценивать по отношению числа модулей, отработавших в процессе
тестирования, к общему числу модулей:

где:  - число
модулей, отработавших в процессе тестирования,
- число
модулей, отработавших в процессе тестирования,
 - общее
число модулей.
- общее
число модулей.
Таким
образом, можно сделать вывод о том, что качество некоторого ПО можно оценить,
оценив тем или иным способом каждый из показателей качества в отдельности.
Затем по их совокупности вывести интегральную оценку, которая и будет отражать
понятие качества данного ПО.
Разработка
метода экспертных оценок показателей качества
Для
оценки таких трудно формализуемых показателей качества, как легкость освоения
ПО и удобство обслуживания и эксплуатации ПО, часто применяются методы
экспертных оценок. Показатели качества ПО оцениваются группой экспертов. Под
экспертом понимается лицо, которое на основании ознакомления с заданием и
вопросами, касающимися этого задания, может определить относительную важность
нескольких параметров или переменных. Так как каждый отдельный эксперт может
быть пристрастным, оптимистичным или, наоборот, пессимистичным и др., то для
сглаживания любых индивидуальных особенностей экспертов и снижения возможной
субъективности оценки, предпочтительным является метод оценивания ПО несколькими
экспертами. С увеличением числа экспертов достоверность общей оценки
возрастает.
Как
правило, при высокой квалификации и большом опыте экспертов достигается высокая
степень достоверности оценки. Это достигается благодаря усреднению
субъективности каждого из экспертов при обобщении всех оценок и преобладании,
соответственно, объективной стороны оценок экспертов. Для формализации и
суммирования результатов экспертной оценки, применяются различные методики.
Чаще других применяется методика экспертной оценки с применением нечетких
множеств.
В
данной методике подход к оценке показателей качества основан на понятии
нечеткого множества Л.Заде [26]. Формализация нечетких понятий по Заде
предполагает отказ от основного положения теории множеств об однозначной принадлежности
элемента некоторому множеству. Нечеткое множество  определяется
как совокупность упорядоченных пар, составленных из элементов
определяется
как совокупность упорядоченных пар, составленных из элементов  , и соответствующих степеней принадлежности
, и соответствующих степеней принадлежности  и
обозначается следующим образом:
и
обозначается следующим образом:

где:
 - функция
принадлежности, выражающая степень принадлежности элемента х к множеству ;
- функция
принадлежности, выражающая степень принадлежности элемента х к множеству ;
 - область определения функции принадлежности
- область определения функции принадлежности 
Функция
принадлежности 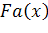 является специальной характеристической функцией
нечеткого множества А и принимает значения из интервала [0; 1]. Область
определения функций
принадлежности, рассматриваемых в данной методике, определяется метрикой
показателя качества и для общности представляется интервалом [0; 1], на котором
введена сетка точек действительной числовой оси, расположенных с шагом 0,005
(сетка может быть иной).
является специальной характеристической функцией
нечеткого множества А и принимает значения из интервала [0; 1]. Область
определения функций
принадлежности, рассматриваемых в данной методике, определяется метрикой
показателя качества и для общности представляется интервалом [0; 1], на котором
введена сетка точек действительной числовой оси, расположенных с шагом 0,005
(сетка может быть иной).
В
процессе получения оценок используются нечеткие числа (L-R)-типа,
определенные на интервале [0; 1].
Нечеткое
число может быть задано с помощью функции принадлежности (L-R)-типа
следующим образом:



где:  -
невозрастающие функции на множестве неотрицательных действительных чисел,
-
невозрастающие функции на множестве неотрицательных действительных чисел,
 - среднее значение (четкое число),
- среднее значение (четкое число),
 - левый и
правый коэффициенты нечеткости соответственно.
- левый и
правый коэффициенты нечеткости соответственно.
Нечеткое
число записывается в виде тройки:  Нечеткое
число является характеристикой ПО по определенному показателю качества
(нечеткое значение показателя качества).
Нечеткое
число является характеристикой ПО по определенному показателю качества
(нечеткое значение показателя качества).
Процесс
формирования мнения эксперта состоит в выборе этого мнения и его уточнении в
зависимости от уверенности эксперта. В процессе формирования мнений для
формализации их значений экспертами используются лингвистические переменные.
Лингвистическая переменная представляет собой значение показателя качества
данного ПО, выражающее мнение эксперта или пользователя, и может принимать
фиксированный набор лингвистических значений, отражающих различные оценки ПО по
отношению к показателю качества. Каждому лингвистическому значению
соответствует нечеткое число (L-R)-типа. При этом а - мода нечеткого числа
отражает значение мнения эксперта , а коэффициенты нечеткости соответствуют
степени уверенности эксперта (пользователя) в своем мнении. Возможный вариант
набора лингвистических значений следующий:
• очень хорошо (очень высокие требования);
• хорошо (высокие);
• почти хорошо (почти высокие);
• между хорошим и средним (высоким и средним);
• чуть более среднего;
• среднее;
• чуть менее среднего;
• между средним и плохим (средним и низким);
• почти плохо (почти низкие);
• плохо (низкие);
• очень плохо (очень низкие требования).
Каждому
лингвистическому значению соответствует стандартное нечеткое число  , например, в одной из реализаций данной методики,
лингвистическим значениям соответствуют следующие нечеткие числа:
, например, в одной из реализаций данной методики,
лингвистическим значениям соответствуют следующие нечеткие числа:
(1,0.045,0.045)
- очень хорошо;
(1,0.1025,0.1025)
- хорошо;
(0.875,
0.08,0.08) - почти хорошо;
(0.75,
0.07, 0.07) -между хорошим и средним;
(0.625,0.06,0.06)
- чуть более среднего;
(0.5,0.045,0.045)
- среднее;
(0.375,
0.06,0.06) - чуть менее среднего;
(0.25,
0.07,0.07) -между средним и плохим;
(0.125,
0.08,0.08) - почти плохо;
(0,0.1025,0.1025)
-плохо;
(0,0.045,0.045)
- очень плохо,
Эксперт
должен выбрать одно из лингвистических значений, соответствующих его мнению об
объекте оценивания. Уточнить свое мнение эксперт может, изменив моду, уточнить
уверенность во мнении - изменив коэффициенты слева и справа. Например, если
эксперт уверен в своем выборе, то он должен уменьшить коэффициенты, если не
уверен - то увеличить. Полученные тройки нечетких чисел являются исходными
данными для построения функции принадлежности.
Значения
функций принадлежности находятся по формуле:
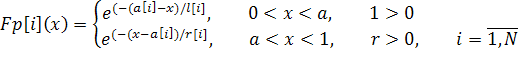
При
оценке показателя качества группой экспертов строятся функции принадлежности,
отражающие мнения каждого эксперта. Каждому эксперту приписывается коэффициент
компетентности (по умолчанию равный единице).
Обобщенная
функция принадлежности по всем экспертам получается с использованием меры
согласованности мнений экспертов:

где
 - функция принадлежности, отражающая мнение i-го
эксперта.
- функция принадлежности, отражающая мнение i-го
эксперта.
Обобщенная
функция принадлежности вычисляется следующим образом:

где
 -
коэффициент компетентности i-го эксперта.
-
коэффициент компетентности i-го эксперта.
Полученные
нечеткие оценки показателей оцениваемого ПО сравниваются с нечеткими оценками
требований к ПО такого рода. Требования к качеству ПО формируются
потенциальными пользователями, знающими условия эксплуатации оцениваемого ПО.
Обработка мнений пользователей происходит аналогично обработке мнений экспертов-специалистов.
1.5
Постановка задачи оценки защищенности ПО
Для повышения эффективности оценки защищенности, ее ускорения и
удешевления необходимо разработать методику, позволяющую преодолеть недостатки
подхода к оценке защищенности, недооценку ее роли в обеспечении требуемого
уровня качества СПО, подмену тестирования уязвимостей процедурами типа проверки
работоспособности на контрольном примере и т. п. Данная методика оценки
защищенности, должна предусматривать:
• знание назначения испытываемого СПО, условий его
функционирования и требований к нему со стороны пользователей;
• автоматизацию всех наиболее трудоемких процессов и прежде всего
моделирование среды функционирования, включая искажающие воздействия;
• ясное представление цели и последовательности испытания;
• целенаправленность и неизбыточность испытания, исключающие или
минимизирующие повторение однородных процедур при одних и тех же условиях
функционирования испытываемого СПО;
• систематический контроль за ходом, регулярное ведение протокола
и журнала испытания;
• четкое, последовательное определение и исполнение плана
испытания;
• четкое сопоставление имеющихся ресурсов с предполагаемым объемом
испытания;
• возможность обеспечения, а также объективной количественной
оценки полноты и достоверности результатов испытания на всех этапах.
Несмотря на высокую сложность, оценка защищенности ПО должна быть
проведена в сжатые сроки, однако в настоящее время данная задача не является
формализованной. С целью формализации и повышения достоверности оценки защищенности
ПО при проведении испытаний необходимо разработать методику оценки
защищенности, основанную на методах анализа уязвимостей программного
обеспечения, что должно и включать три этапа: подготовка, непосредственное
тестирование и анализ результатов тестирования.
ГЛАВА 2.
МЕТОДЫ ЗАЩИТЫ ПРОГРАММНОГО
ОБЕСПЕЧЕНИЯ,
ИХ ОЦЕНКА И АНАЛИЗ ЗАЩИЩЕННОСТИ
.1 Методы
технологической защиты ПО и их оценка
эффективности
Методы защиты можно разделить на программные, аппаратные и
программно-аппаратные. К программным относятся методы, реализуемые чисто
софтверным путём, в них не затрагиваются физические характеристики носителей
информации, специальное оборудование и т.п. К аппаратным относятся методы,
использующие специальное оборудование (например, электронные ключи, подключаемые
к портам компьютера) или физические особенности носителей информации
(компакт-дисков, дискет), чтобы идентифицировать оригинальную версию программы
и защитить продукт от нелегального использования.
.1.1Аппаратные
средства защиты программного обеспечения
Аппаратные
ключи защиты
Основой данной технологии является специализированная микросхема, либо
защищённый от считывания микроконтроллер, имеющие уникальные для каждого ключа
алгоритмы работы. Ключ представляет собой плату, защищённую корпусом, в
архитектуру которой обязательно входят микросхемы памяти и, иногда,
микропроцессор. Ключ может подключаться в слот расширения материнской платы
ISA, или же к LPT, COM, PCMCIA, USB-порту компьютера. В его программное
обеспечение входит модуль, который встраивается в защищаемое ПО (таким образом
данное программное обеспечение "привязывается" к ключу, а не к
конкретному компьютеру), и драйвера под различные операционные системы. Ключи в
большинстве своём основаны на одной из трёх моделей существующих аппаратных
реализаций: на основе FLASH-памяти, PIC или ASIC-чипов. Помимо этого, в
некоторые ключи встраиваются дополнительные возможности в виде
энергонезависимой памяти, таймеров, выбора алгоритма кодирования данных.
Принцип действия электронных ключей. Ключ присоединяется к определённому
интерфейсу компьютера. Далее защищённая программа через специальный драйвер
отправляет ему информацию, которая обрабатывается в соответствии с заданным
алгоритмом и возвращается обратно. Если ответ ключа правильный, то программа
продолжает свою работу. В противном случае она может выполнять определенные
разработчиками действия, например, переключаться в демонстрационный режим,
блокируя доступ к определённым функциям.
Существуют специальные ключи, способные осуществлять лицензирования
(ограничения числа работающих в сети копий программы) защищенного приложения по
сети. В этом случае достаточно одного ключа на всю локальную сеть. Ключ
устанавливается на любой рабочей станции или сервере сети. защищенные
приложения обращаются к ключу по локальной сети. Преимущество в том, для работы
с приложением в пределах локальной сети им не нужно носить с собой электронный
ключ.
На российском рынке наиболее известны следующие линейки продуктов (в
алфавитном порядке): CodeMeter от WIBU-SYSTEMS, Guardant от компании «Актив»,
HASP от Aladdin, LOCK от Astroma Ltd., Rockey от Feitian, SenseLock от Seculab
и др.
Аппаратные ключи защиты можно классифицировать по
нескольким признакам:
• типы подключения (ключи на порт принтера (LPT), последовательный
порт (СОМ), USB-порт и ключи, подключаемые к специальной плате, вставляемой в
компьютер);
• удобство и функциональность программного обеспечения;
• языки программирования (поддержка языков нужна для того, чтобы
программист смог более эффективно использовать ключ для защиты разрабатываемой
программы);
• список поддерживаемых аппаратных платформ и операционных систем;
• применимость ключа для сетевого лицензирования программного
обеспечения;
• по архитектуре можно подразделить на ключи с памятью (без
микропроцессора) и ключи с микропроцессором (и памятью).
Виды ключей:
Ключи с памятью
Это, наверное, самый простой тип ключей. Ключи с памятью имеют
определенное число ячеек, из которых разрешено считывание. В некоторые из этих
ячеек также может производиться запись. Обычно в ячейках, недоступных для
записи, хранится уникальный идентификатор ключа.
Когда-то давно существовали ключи, в которых перезаписываемой памяти не
было вообще, а программисту для считывания был доступен только идентификатор
ключа. Но очевидно, что на ключах с такой функциональностью построить серьезную
защиту просто невозможно.
Правда, и ключи с памятью не способны противостоять эмуляции. Достаточно
один раз прочитать всю память и сохранить ее в эмуляторе. После этого правильно
эмулировать ответы на все запросы к ключу не составит большого труда.
Таким образом, аппаратные ключи с памятью в заданных условиях не способны
дать никаких преимуществ по сравнению с чисто программными системами.
Ключи с неизвестным алгоритмом
Многие современные аппаратные ключи содержат секретную функцию
преобразования данных, на которой и основывается секретность ключа. Иногда
программисту предоставляется возможность выбрать константы, являющиеся
параметрами преобразования, но сам алгоритм остается неизвестным.
Проверка наличия ключа должна выполняться следующим образом. При
разработке защиты программист делает несколько запросов к алгоритму и
запоминает полученные ответы. Эти ответы в какой-то форме кодируются в
программе. Во время выполнения программа повторяет те же запросы и сравнивает
полученные ответы с сохраненными значениями. Если обнаруживается несовпадение,
значит, программа получает ответ не от оригинального ключа.
Эта схема имеет один существенный недостаток. Так как защищенная
программа имеет конечный размер, то количество правильных ответов, которые она
может хранить, также является конечным. А это значит, что существует
возможность построения табличного эмулятора, который будет знать правильные
ответы на все запросы, результат которых может проверить программа.
В рекомендациях по защите программ с помощью аппаратных ключей даются
советы, как сделать фиктивные запросы со случайными данными так, чтобы
затруднить построение эмулятора. Однако если программа при запуске делает 100
запросов, результат которых может быть проверен, и 100 случайных запросов,
результат которых не проверяется, то, запустив программу 10 раз, очень легко
выделить действительные запросы, повторившиеся 10 раз, и отсечь все фиктивные,
встретившиеся по 1-2 раза.
Конечно, не стоит всегда проверять наличие ключа выполнением одной и той
же серии запросов с проверкой. Лучше выполнять проверки в разных частях
программы и в разное время. Это может значительно усложнить сбор статистики для
отсечения фиктивных запросов.
Но не стоит забывать, что можно проанализировать программу и попытаться в
дизассемблере найти все обращения к ключу. Это поможет выяснить, ответы на
какие из запросов проверяются, и построить компактную таблицу для эмуляции. Так
что ключи с неизвестным алгоритмом могут затруднить, но не могут предотвратить
построение эмулятора для конкретной версии конкретной программы. Зато при
переходе к новой версии, если перечень проверки программой ответов на запросы
будет изменен, придется заново выполнять сбор статистики или анализ программы.
Атрибуты алгоритмов
В некоторых ключах алгоритму могут сопутствовать дополнительные атрибуты.
Так, например, в ключах Sentinel SuperPro алгоритм может быть защищен паролем и
начинает работать только после того, как будет выполнена активация, в ходе
которой правильный пароль должен быть передан ключу.
Активация позволяет разработчику предусмотреть возможность изменения
функциональности ключа на стороне пользователя. То есть программа может иметь
несколько версий (например базовую, расширенную и профессиональную), и в ключе
изначально активированы только те алгоритмы, которые необходимы для
функционирования базовой версии. Если пользователь решит перейти к более полной
версии, разработчик пришлет ему инструкции по активации алгоритмов,
соответствующих расширенной или профессиональной версии.
Однако все достоинства алгоритмов, активируемых по паролю, опираются на
секретность пароля, а не на свойствах аппаратного ключа. Следовательно,
аналогичная защита может быть реализована чисто программными средствами. Другой
тип атрибутов алгоритмов, поддерживаемых ключами Sentinel SuperPro, - это
счетчики. С активным алгоритмом может быть связан счетчик, изначально имеющий
ненулевое значение. Программа при каждом запуске (или выполнении определенной
операции, например при экспорте данных) вызывает специальную функцию API-ключа,
уменьшающую значение счетчика на единицу. Как только счетчик принимает нулевое
значение, алгоритм деактивируется и перестает работать.
Однако данная схема не способна помешать применению эмулятора. Противник
может перехватывать и предотвращать все попытки уменьшения значения счетчика.
Следовательно, алгоритм никогда не будет деактивирован, и в распоряжении
противника будет неограниченное время для сбора данных, необходимых для
табличной эмуляции.
Противостоять эмуляции может счетчик, значения которого уменьшается при
каждом обращении к алгоритму. Но в этом случае возникает опасность, что из-за
сбоев в работе программы или операционной системы иногда значение счетчика
будет уменьшаться без совершения программой полезных действий. Причина проблемы
в том, что обращение к алгоритму должно производиться до того, как программа
совершит полезную работу, а счетчик должен уменьшаться только в том случае,
если работа выполнена успешно. Но автоматическое уменьшение счетчика при
обращении к алгоритму такую функциональность не обеспечивает - количество
оставшихся попыток уменьшается независимо от успеха выполнения операции.
Ключи с таймером
Некоторые производители аппаратных ключей предлагают модели, имеющие
встроенный таймер. Но для того, чтобы таймер мог работать в то время, когда
ключ не подключен к компьютеру, необходим встроенный источник питания. Среднее
время жизни батареи, питающей таймер, составляет 4 года, и после ее разрядки
ключ перестанет правильно функционировать. Возможно, именно из-за сравнительно
короткого времени жизни ключи с таймером применяются довольно редко. Но как
таймер может помочь усилить защищенность?
Ключи HASP Time предоставляют возможность узнавать текущее время,
установленное на встроенных в ключ часах. И защищенная программа может
использовать ключ для того, чтобы отследить окончание тестового периода. Но
очевидно, что эмулятор позволяет возвращать любые показания таймера, т. е.
аппаратная часть никак не повышает стойкость защиты. Хорошей комбинацией
является алгоритм, связанный с таймером. Если алгоритм может быть деактивирован
в определенный день и час, очень легко будет реализовывать демонстрационные
версии программ, ограниченные по времени.
Но, к сожалению, ни один из двух самых популярных в России разработчиков
аппаратных ключей не предоставляет такой возможности. Ключи HASP, производимые
компанией Aladdin, не поддерживают активацию и деактивацию алгоритмов. А ключи
Sentinel SuperPro, разработанные в Rainbow Technologies, не содержат таймера.
Ключи с известным алгоритмом
В некоторых ключах программисту, реализующему защиту, предоставляется
возможность выбрать из множества возможных преобразований данных, реализуемых
ключом, одно конкретное преобразование. Причем подразумевается, что программист
знает все детали выбранного преобразования и может повторить обратное
преобразование в чисто программной системе. Например, аппаратный ключ реализует
симметричный алгоритм шифрования, а программист имеет возможность выбирать
используемый ключ шифрования. Разумеется, ни у кого не должно быть возможности
прочитать значение ключа шифрования из аппаратного ключа.
В такой схеме программа может передавать данные на вход аппаратного ключа
и получать в ответ результат шифрования на выбранном ключе Но тут возникает
дилемма. Если в программе отсутствует ключ шифрования, то возвращаемые данные
можно проверять только табличным способом, а значит, в ограниченном объеме.
Фактически имеем аппаратный ключ с неизвестным программе алгоритмом. Если же
ключ шифрования известен программе, то можно проверить правильность обработки
любого объема данных, но при этом существует возможность извлечения ключа
шифрования и построения эмулятора.
Так что аппаратное выполнение симметричного алгоритма шифрования с
известным ключом не дает ничего нового с точки зрения защиты. Но есть еще и
асимметричные алгоритмы.
Когда ключ реализует асимметричный алгоритм шифрования, программисту не
обязательно знать используемый секретный ключ. Даже можно сказать, что
отсутствие возможности создать программную копию аппаратного асимметричного
шифрующего устройства не сужает, а расширяет область возможных применений, т.к.
сокращается перечень возможных способов компрометации секретного ключа. В любом
случае, для проверки того, что аппаратный ключ присутствует и правильно
выполняет вычисления, достаточно знать открытый ключ.
Эта схема не может быть обойдена только эмуляцией, т. к. для построения
полного эмулятора требуется по открытому ключу шифрования вычислить секретный
ключ. А это математически сложная задача, не имеющая эффективного решения.
Однако остается возможность подмены открытого ключа в программе, и если
такая подмена пройдет незамеченной, построить программный эмулятор не составит
труда. Так что асимметричные алгоритмы, реализованные на аппаратном уровне,
способны обеспечить некопируемость защищенной программы, но только в том
случае, если удастся предотвратить подмену открытого ключа шифрования.
Ключи с программируемым алгоритмом
Очень интересным решением с точки зрения стойкости защиты являются
аппаратные ключи, в которых может быть реализован произвольный алгоритм.
Сложность алгоритма ограничивается только объемом памяти и системой команд
ключа.
В этом случае для защиты программы важная часть вычислений
переносится в ключ, а значит, для анализа и взлома не будет возможным
запротоколировать правильные ответы на все запросы или восстановить алгоритм по
функции проверки. Ведь проверка, как таковая, может вообще не выполняться -
результаты, возвращаемые ключом, являются промежуточными величинами в
вычислении какой-то сложной функции, а подаваемые на вход значения зависят не
от программы, а от обрабатываемых данных.
Главное - это реализовать в ключе такую функцию, чтобы не
было возможным по контексту догадаться, какие именно операции производятся в
ключе.
Обход защиты
Задача злоумышленника - заставить защищённую программу работать в
условиях отсутствия легального ключа, подсоединённого к компьютеру. Не вдаваясь
очень глубоко в технические подробности, будем исходить из предположения, что у
злоумышленника есть следующие возможности:
• Перехватывать все обращения к ключу;
• Протоколировать и анализировать эти обращения;
• Посылать запросы к ключу и получать на них ответы;
• Протоколировать и анализировать эти ответы;
• Посылать ответы от имени ключа и др.
Такие широкие возможности противника можно объяснить тем, что он имеет
доступ ко всем открытым интерфейсам, документации, драйверам и может их
анализировать на практике с привлечением любых средств.
Для того чтобы заставить программу работать так, как она работала бы с
ключом, можно или внести исправления в программу (взломать её программный
модуль), или эмулировать наличие ключа путем перехвата вызовов библиотеки API
обмена с ключом.
Стоит отметить, что современные электронные ключи (к примеру, ключи
Guardant поколения Sign и современные ключи HASP HL) обеспечивают стойкое
шифрование протокола обмена электронный ключ - библиотека API работы с ключом.
В результате наиболее уязвимыми местами остаются точки вызовов функций этого
API в приложении и логика обработки их результата.
Эмуляция ключа
При эмуляции никакого воздействия на код программы не происходит, и
эмулятор, если его удается построить, просто повторяет все поведение реального
ключа. Эмуляторы строятся на основе анализа перехваченных запросов приложения и
ответов ключа на них. Они могут быть как табличными (содержать в себе все
необходимые для работы программы ответы на запросы к электронному ключу), так и
полными (полностью эмулируют работу ключа, так как взломщикам стал известен внутренний
алгоритм работы).
Построить полный эмулятор современного электронного ключа - это
достаточно трудоёмкий процесс, требующий большого количества времени и
существенных инвестиций. Ранее злоумышленникам это удавалось: например,
компания Aladdin признаёт, что в 1999 году злоумышленникам удалось разработать
довольно корректно работающий эмулятор ключа HASP3 и HASP4. Это стало возможным
благодаря тому, что ключ использовал проприетарный алгоритм кодирования,
который был взломан. Сейчас большинство ключей используют публичные
крипотоалгоритмы, поэтому злоумышленники предпочитают атаковать какой-то
конкретный защищённый продукт, а не защитный механизм в общем виде. Для
современных систем защиты HASP и Guardant эмуляторов в свободном доступе нет,
так как используется публичная криптография.
Информации о полной эмуляции современных ключей Guardant не встречалось.
Существующие табличные эмуляторы реализованы только для конкретных приложений.
Возможность их создания была обусловлена неиспользованием (или неграмотным
использованием) основного функционала электронных ключей разработчиками защит.
Так же отсутствует какая-либо информация о полной или хотя бы частичной
эмуляции ключей LOCK, либо о каких-либо других способах обхода этой защиты.
Взлом программного модуля
Злоумышленник исследует логику самой программы, с той целью, чтобы,
проанализировав весь код приложения, выделить блок защиты и деактивировать его.
Взлом программ осуществляется с помощью отладки (или пошагового исполнения),
декомпиляции и дампа оперативной памяти. Эти способы анализа исполняемого кода
программы чаще всего используются злоумышленниками в комплексе.
Отладка осуществляется с помощью специальной программы - отладчика,
который позволяет по шагам исполнять любое приложение, эмулируя для него операционную
среду. Важной функцией отладчика является способность устанавливать точки (или
условия) остановки исполнения кода. С помощью них злоумышленнику проще
отслеживать места в коде, в которых реализованы обращения к ключу (например,
остановка выполнения на сообщении типа «Ключ отсутствует! Проверьте наличие
ключа в USB-интерфейсе»).
Дизассемблирование - способ преобразования кода исполняемых модулей в
язык программирования, понятный человеку - Assembler. В этом случае
злоумышленник получает распечатку (листинг) того, что делает приложение.
Декомпиляция - преобразование исполняемого модуля приложения программный
код на языке высокого уровня и получение представления приложения, близкого к
исходному коду. Может быть проведена только для некоторых языков программирования
(в частности, для .NET приложений, создаваемых на языке C# и распространяемых в
байт-коде - интерпретируемом языке относительно высокого уровня).
Суть атаки с помощью дапма памяти заключается в считывании содержимого
оперативной памяти в момент, когда приложение начало нормально исполняться. В
результате злоумышленник получает рабочий код (или интересующую его часть) в
"чистом виде" (если, к примеру, код приложения был зашифрован и
расшифровывается только частично, в процессе исполнения того или иного
участка). Главное для злоумышленника - верно выбрать момент.
Отметим, что существует немало способов противодействия отладке, и
разработчики защиты используют их: нелинейность кода, (многопоточность),
недетерминированную последовательность исполнения, «замусоривание» кода,
(бесполезными функциями, выполняющими сложные операции, с целью запутать
злоумышленника), использование несовершенства самих отладчиков и др.
Практика использования
На практике в подавляющем большинстве случаев программисты не используют
все возможности, предоставляемые аппаратными ключами. Так, на пример, очень
часто в алгоритмических ключах с памятью используется только память, не говоря
уже о случаях, когда все проверки наличия ключа производятся в одной функции,
которая возвращает результат в виде логического значения. И для получения
полнофункциональной версии программы даже не требуется ключ - достаточно
исправить функцию проверки чтобы она всегда возвращала состояние,
соответствующее наличию ключа. Некоторые ключи (например Sentinel SuperPro)
имеют довольно сложную систему разграничения доступа. Ключи Sentinel SuperPro
поддерживают пароли для активации алгоритмов, выбираемые при программировании,
и раздельные пароли для записи и перезаписи, одинаковые для всех ключей одной серии,
поставляемых одному разработчику. И очень часто в теле программы оказывается
пароль перезаписи, который позволяет противник перепрограммировать ключ по
своему усмотрению.
Ключи HASP Time, напротив, не имеют разграничения доступа - для того
чтобы изменить время в ключе, нужно знать те же самые пароли, которые
используются для чтения времени. То есть злоумышленнику для продления периода
работоспособности программы, ограниченной по времени, достаточно отвести назад
часы в ключе, и ничто не мешает ему это сделать. Некоторые неизвестные
алгоритмы, реализованные в ключах, были подвергнуты анализу. Так был
восстановлен алгоритм функции SeedCode, используемый в ключах HASP. А по
некоторым сообщениям в Интернете, не являются больше секретными и алгоритмы,
реализуемые ключами Sentinel SuperPro, и даже новые алгоритмы кодирования и
декодирования в ключах HASP4.
Ключи с асимметричными алгоритмами выпускаются уже многими
производителями, но позиционируются как устройства для идентификации и
аутентификации, а не для защиты информации.
Ключи с программируемым алгоритмом, напротив, не выпускаются крупными
производителями ключей и, следовательно, практически не применяются. Возможно,
это обусловлено тем, что они получаются слишком дорогими или слишком сложными
для использования.
Выводы
Утверждение, что аппаратные ключи способны остановить компьютерное
пиратство, является мифом, многие годы распространяемым производителями ключей.
Для хорошо подготовленного противника ключ редко является серьезным
препятствием.
К тому же, часто программисты слепо доверяют автоматизированным средствам
защиты, поставляемым в составе SDK-ключа, и не прикладывают самостоятельных
усилий для усиления защиты. Обещания производителей создают иллюзию
защищенности, но на самом деле практически для всех автоматизированных средств
защиты давно разработаны эффективные способы нейтрализации защитных механизмов.
Большая часть защитных механизмов, применяемых в современных ключах,
оказывается работоспособной только в предположении, что противник не сможет
обеспечить эмуляцию ключа, т. е. реализуются на программном уровне.
Следовательно, почти всегда тот же уровень защиты может быть достигнут без
привлечения аппаратных средств.
Защита при
помощи компакт дисков
Как правило, этот способ защиты применяется для защиты программ,
записанных на этом же компакт-диске, являющимся одновременно ключевым. Для
защиты от копирования используется:
• запись информации в неиспользуемых секторах;
• проверка расположения и содержимого «сбойных» секторов;
• проверка скорости чтения отдельных секторов.
Первые
два метода бесполезны при снятии полного образа с диска. Третий метод более
надёжный. Он используется, например, в защите StarForce. В этой защите также
делается попытка проверить возможность записи на вставленный диск. Если запись
возможна, то диск считается нелицензионным. Но существуют программы, которые
могут эмулировать диски с учётом геометрии расположения данных, тем самым
обходя эту защиту, и, к тому же, возможно записать диск CD-R с её учётом, и он
будет признаваться лицензионным. Также возможно скрыть тип диска, чтобы CD-R
или CD-RW был виден как обычный CD-ROM. Но и системы защиты тоже (используя
специальный драйвер) борются с ними, пытаясь обнаружить наличие эмуляции. В
настоящее время наибольшую известность в мире имеют системы защиты от
копирования SecuROM, StarForce
<javascript:function()%7breturn%20false%7d;>, SafeDisc, CD-RX
<javascript:function()%7breturn%20false%7d;> и Tages.[1]
SecuROM
Эта технология, разработанная специалистами корпорации Sony, сочетает в
себе использование специальной цифровой метки и шифрования. В процессе
мастеринга на стеклянную матрицу наносится электронная метка, уникальная для
каждой партии дисков. Метку нельзя скопировать при записи на диски CD-R,
жесткий диск компьютера и при заводском тиражировании. SecuROM прозрачна для
пользователей: для активации защищенных ею дисков не требуется вводить пароли
или ключи, поскольку идентификация происходит автоматически при запуске
содержащихся на диске приложений. В случае использования нелегальной копии
приложение будет заблокировано, а на экране появится сообщение об ошибке.Но
несмотря на все ухищрения разработчиков SecuROM, защищенные ею диски можно
легко скопировать при помощи утилиты CloneCD.[2]
StarForce
Проверка подлинности диска состоит из нескольких этапов. Сначала читается
информация о диске, установленном в приводе, и проверяется его метка тома.
Затем выполняется 8 запросов на чтение случайных одиночных секторов с номерами
в диапазоне от 1 до 65 536. Результаты чтения никак не используются, и, скорее
всего, эти действия нужны для разгона диска до номинальной скорости вращения.
Затем еще раз читается (но уже не проверяется) информация о диске. Все
перечисленное выше проходит через драйвер файловой системы CDFS, никак не
защищено от анализа и, следовательно, наверняка не влияет на процесс
аутентификации.
Все остальные обращения к диску идут на более низком уровне. В той версии
StarForce, анализ которой проводится, обращения адресовались драйверу
устройства Cdrom и представляли собой SCSI-команды. Последовательность этих
команд такова.
. Чтение содержания диска (Table Of Content, TOC).
. Чтение одиночных секторов с номерами 16, 17, 17 (дважды читается
17-ый сектор).
. Чтение одиночных секторов с номерами 173117, 173099, 173081,
173063, 173045, 173027, 173009, 172991, 172973.
. Чтение случайных 17 блоков по 8 секторов с номерами первого
читаемого сектора в диапазоне примерно от 168100 до 173200.
. SCSI-команда с кодом ОхВВ, описание которой не удалось найти в
документации, но которая, скорее всего, отвечает за управление скоростью
вращения привода.
. Чтение одиночного сектора с номером 173117.
Причем если с первой попытки диск не опознан как оригинальный, то шаги 3
и 4 повторяются в цикле. Значит, после выполнения шага 4 вся информация, необходимая
для аутентификации диска, уже получена.
Разберем подробнее, зачем может потребоваться каждый из шагов.
Чтение ТОС, скорее всего, требуется для определения номера сектора, с
которого начинается последняя сессия мультисессионного диска. Так как сессия
всего одна, то в 16 и 17 секторах как раз и хранятся описания структуры тома
(метка тома, количество секторов, адрес директории диска и т. д.). А повторное
чтение сектора 17, скорее всего, используется для того, чтобы примерно оценить
порядок времени, затрачиваемого на один оборот диска. Разница времени между
двумя чтениями одного сектора должна быть кратна длительности оборота диска.
В последовательности номеров секторов 173117, 173099, 173081, 173063,
173045, 173027, 173009, 172991, 172973 легко усматривается закономерность -
каждое следующее значение на 18 меньше предыдущего. Число 18 тоже явно не
случайное - на том радиусе диска, где размещаются сектора с указанными
номерами, на один виток спирали помещается примерно 18 секторов. А чтение
секторов в порядке убывания номера с большой вероятностью используется для
того, чтобы предотвратить чтение с предупреждением, когда привод считывает во
внутренний буфер не только заданные сектора, но и несколько последующих, на
случай если данные читаются последовательно.
Получив значения восьми интервалов (между девятью операциями чтения) и
зная длительность и периодов обращения диска (полученную повторным чтением
сектора), можно с большой точностью определить скорость вращения диска.
А дальше выполняется 17 чтений блоков со случайными номерами с целью
измерения 16 интервалов времени. Если все интервалы соответствуют нужному
значению, то диск признается подлинным. Если же отклонения от ожидаемых величин
превышают некоторое пороговое значение, то проводится повторное вычисление
скорости вращения и повторное измерение задержек между чтением блоков по 8
секторов.[1]
Способ обхода защиты
Чтобы заставить StarForce поверить, что в приводе стоит оригинальный
диск, надо совсем не много: чтобы задержки между чтениями соответствовали
ожидаемым. А для этого необходимо знать точные характеристики диска: радиус, на
котором начинается спираль, и размер сектора. Для определения этих величин
можно провести те же самые измерения, что проводит StarForce при проверке
диска, а затем варьировать начальный радиус и размер сектора, пока не будут
найдены оптимальные значения. Критерием оптимальности, например, может служить
сумма отклонений разностей углов, и углов, полученных из замеренных интервалов.
Современное оборудование (во всяком случае, оборудование бытового класса)
действительно не позволяет создавать копии защищенного диска, но написание
эмулятора, способного обмануть StarForce, не представляет сверхсложной задачи.
Достаточно перехватывать обращения к драйверу CD-ROM и в случае, если
выполняется команда чтения, делать временною задержку, какую мог бы иметь
оригинальный диск, и только после этого возвращать управление вызывающей
программе., несомненно, является неординарной защитой. Ее исключительность
заключается хотя бы в том, что до сих пор не существует надежного способа
быстро создавать работоспособные копии защищенных дисков.[1]
.1.2
Программные средства защиты программного обеспечения
Под программными методами защиты информации понимается комплекс
специальных алгоритмов и компонентов общего программного обеспечения
вычислительных систем, предназначенных для выполнения функций контроля,
разграничения доступа и исключения несанкционированного доступа [3].
Существующие системы защиты программного обеспечения можно
классифицировать по ряду признаков, среди которых можно выделить:
• метод установки;
• используемые механизмы защиты;
• принцип функционирования.
• Системы защиты ПО по методу установки можно подразделить
на:
• системы, устанавливаемые на скомпилированные модули ПО;
• системы, встраиваемые в исходный код ПО до компиляции;
• комбинированные.
Системы первого типа наиболее удобны для производителя ПО, так как легко
можно защитить уже полностью готовое и оттестированное ПО, а потому и наиболее
популярны. В то же время стойкость этих систем достаточно низка (в зависимости
от принципа действия СЗ), так как для обхода защиты достаточно определить точку
завершения работы «конверта» защиты и передачи управления защищенной программе,
а затем принудительно ее сохранить в незащищенном виде.
Системы второго типа неудобны для производителя ПО, так как возникает
необходимость обучать персонал работе с программным интерфейсом (API) системы
защиты с вытекающими отсюда денежными и временными затратами. Кроме того,
усложняется процесс тестирования ПО и снижается его надежность, так как кроме
самого ПО ошибки может содержать API системы защиты или процедуры, его
использующие. Но такие системы являются более стойкими к атакам, потому что
здесь исчезает четкая граница между системой защиты и как таковым ПО.
Наиболее живучими являются комбинированные системы защиты. Сохраняя
достоинства и недостатки систем второго типа, они максимально затрудняют анализ
и дезактивацию своих алгоритмов.
По используемым механизмам защиты системы защиты можно
классифицировать на:
• системы, использующие сложные логические механизмы;
• системы, использующие шифрование защищаемого ПО;
• комбинированные системы.
Системы первого типа используют различные методы и приёмы,
ориентированные на затруднение дизассемблирования, отладки и анализа алгоритма
системы защиты и защищаемого ПО. Этот тип системы защиты наименее стоек к
атакам, так как для преодоления защиты достаточно проанализировать логику
процедур проверки и должным образом их модифицировать.
Более стойкими являются системы второго типа. Для дезактивации таких
защит необходимо определение ключа дешифрации ПО. Самыми стойкими к атакам
являются комбинированные системы.
Для защиты ПО используется ряд методов, таких как:
• Алгоритмы запутывания (обфускация)- используются хаотические
переходы в разные части кода, внедрение ложных процедур - «пустышек», холостые
циклы, искажение количества реальных параметров процедур ПО, разброс участков
кода по разным областям ОЗУ и т.п.
• Алгоритмы шифрования данных - программа шифруется, а затем
расшифровывается по мере выполнения.
• Метод проверки целостности программного кода - проверка
на изменения в коде программы;
• Эмуляция процессоров - создается виртуальный процессор
и/или операционная система (не обязательно существующие) и программа-переводчик
из системы команд IBM в систему команд созданного процессора или ОС, после
такого перевода ПО может выполняться только при помощи эмулятора, что резко
затрудняет исследование алгоритма ПО.
• Выполнение на сервере.
По принципу функционирования СЗ можно подразделить на:
• упаковщики/шифраторы;
• СЗ от несанкционированного копирования;
• СЗ от несанкционированного доступа (НСД).
Алгоритмы
запутывания (обфускация).
Обфускация ("obfuscation" - запутывание), это один из методов
защиты программного кода, который позволяет усложнить процесс реверсивной
инженерии кода защищаемого программного продукта.
Обфускация может применяться не только для защиты ПО, она имеет более
широкое применение, например она, может быть использована создателями вирусов,
для защиты их творений и т.д.
Суть процесса обфускации заключается в том, чтобы запутать программный
код и устранить большинство логических связей в нем, то есть трансформировать
его так, чтобы он был очень труден для изучения и модификации посторонними
лицами (будь то взломщики, или программисты которые собираются узнать
уникальный алгоритм работы защищаемой программы).
Из этого следует, что обфускация одна не предназначена для обеспечения
наиболее полной и эффективной защиты программных продуктов, так как она не
предоставляет возможности предотвращения нелегального использования
программного продукта. Поэтому обфускацию обычно используют вместе с одним из
существующих методов защиты (шифрование программного кода и т.д.), это
позволяет значительно повысить уровень защиты ПП в целом.
Обфускация соответствует принципу экономической целесообразности, так как
ее использование не сильно, увеличивает стоимость программного продукта, и
позволяет при этом снизить потери от пиратства, и уменьшить возможность
плагиата в результате кражи уникального алгоритма работы защищаемого
программного продукта.
Существуют различные определения процесса обфускации. Рассматривая данный
процесс с точки зрения защиты ПО, и трансформации кода программы без
возможности в последствии вернуться к его первоначальному виду (трансформация
"в одну сторону"), можно дать такое определение:
Определение. Пусть "TR" будет трансформирующим процессом,
тогда при "PR1 =TR=> PR2" программа "PR2" будет
представлять собой трансформированный код программы "PR1". Процесс
трансформации "TR" будет считаться процессом обфускации если, будут
удовлетворены такие требования:
• код программы "PR2" в результате трансформации будет
существенно отличаться от кода программы "PR1", но при этом он будет
выполнять те же функции что и код программы "PR1", а также будет
работоспособным.
• изучение принципа работы, то есть процесс реверсивной инженерии,
программы "PR2" будет более сложным, трудоемким, и будет занимать
больше времени, чем программы "PR1".
• при каждом процессе трансформации одного и того же кода
программы "PR1", код программ "PR2" будут различны.
• создание программы детрансформирующей программу "PR2"
в ее наиболее похожий первоначальный вид, будет неэффективно.
Программный код может быть представлен в двоичном виде
(последовательность байтов представляющих собой так называемый машинный код,
который получается после компиляции исходного кода программы) или исходном виде
(текст содержащий последовательность инструкций какого-то языка
программирования, который понятен человеку, этот текст в последствии будет
подвержен компиляции или интерпретации на компьютере пользователя).
Процесс обфускации может быть осуществлен над любым из выше перечисленных
видов представления программного кода, поэтому принято выделять следующие
уровни процесса обфускации:
• низший уровень, когда процесс обфускации осуществляется над
ассемблерным кодом программы, или даже непосредственно над двоичным файлом
программы хранящим машинный код.
• высший уровень, когда процесс обфускации осуществляется над
исходным кодом программы написанном на языке высокого уровня.
• Осуществление обфускации на низшем уровне считается менее
комплексным процессом, но при этом более трудно реализуемым по ряду причин.
Одна из этих причин заключается в том, что должны быть учтены особенности
работы большинства процессоров, так как способ обфускации, приемлемый на одной
архитектуре, может оказаться неприемлемым на другой.
Также на сегодняшний день процесс низкоуровневой обфускации исследован
мало.
Большинство существующих алгоритмов и методов обфускации могут быть
применены для осуществления процесса обфускации как на низшем, так и на высшем
уровне.
Также иногда может быть неэффективно, подвергать обфускации весь код
программы (например, из-за того, что в результате может значительно снизится
время выполнения программы), в таких случаях целесообразно осуществлять
обфускацию только наиболее важных участков кода.
Оценка процесса обфускации
Существует много методов определения эффективности применения того или
иного процесса обфускации, к конкретному программному коду.
Эти методы принято разделять на две группы: аналитические и эмпирические.
Аналитические методы основываются на трех величинах характеризующих насколько
эффективен тот или иной процесс обфускации:
• Устойчивость - указывает на степень сложности осуществления
реверсивной инженерии над кодом прошедшим процесс обфускации.
• Эластичность - указывает на то насколько хорошо данный процесс
обфускации, защитит программный код от применения деобфускаторов.
• Стоимость преобразования - позволяет оценить, насколько больше
требуется системных ресурсов для выполнения кода прошедшего процесс обфускации,
чем для выполнения оригинального кода программы.
Их наиболее эффективно применять при сравнении различных алгоритмов
обфускации, но при этом они не могут дать абсолютного ответа на вопрос
насколько эффективно применение того или иного алгоритма, именно к данному
программному коду.
Эмпирические же методы могут дать приемлемый ответ на такой вопрос, т.к.
они основываются на статистических данных получаемых в результате исследований.
Для проведения одного из таких исследований нужна группа людей (как можно лучше
знакомых, с реверсивной инженерией), фрагмент кода защищаемой программы, и
набор различных алгоритмов обфускации.
Результаты такого исследования будут включать в себя минимальное
количество времени, которое потребовалось группе людей, для того чтобы изучить
каждый фрагмент кода прошедшего один из алгоритмов обфускации.
Виды обфускации
В статьях [4] и [5] предлагается следующая классификация преобразований,
производимых в процессе обфускации:
. Преобразования форматирования, или лексические преобразования.
К этому классу относятся преобразования, затрудняющие визуальное
восприятие программы. Они включают в себя удаление отступов, комментариев,
замену имён идентификаторов произвольными наборами символов и прочее.
Лексические преобразования не рассматриваются в рамках данной работы.
. Преобразования структур данных.
Этот класс включает в себя преобразования, изменяющие структуры данных, с
которыми работает программа. Примерами таких преобразований могут служить
изменение иерархии наследования классов, объединение скалярных переменных
одного типа в массив.
. Преобразования потока управления программы.
К этому классу относится методы обфускации, изменяющие последовательность
выполнения отдельных фрагментов программы. В их числе вставка тел функций на
место их вызова, добавление «непрозрачных предикатов», недостижимого кода,
избыточного кода.
. Преобразования потока данных программы.
В этот класс входят преобразования, влияющие на зависимости по данным
между переменными в программе. Сюда относится добавление фиктивных
зависимостей, внесение избыточности в обработку данных, изменение времени жизни
переменных и многое другое.
Лексическая обфускация или преобразования форматирования
Обфускация такого вида включает в себя следующие методы:
• удаление всех комментариев в коде программы, или изменение их на
дезинформирующие;
• удаление различных пробелов, отступов, которые обычно используют
для лучшего визуального восприятия кода программы;
• замену имен идентификаторов (имен переменных, массивов,
структур, функций, процедур и т.д.), на произвольные длинные наборы символов,
которые трудно воспринимать человеку.
Эти методы направлены только на усложнение анализа кода программы
человеком. Отсутствие комментариев не влияет существенно на анализ (их могло
вообще не быть на стадии создания кода исследуемой программы). Форматирование
текста программы в удобный для восприятия вид может быть легко проведено
вручную или с помощью автоматических средств. Имена идентификаторов так же
могут быть изменены в процессе деобфускации на удобные и значимые для
исследователя.
Обфускация управления
Обфускация управления направлена на преобразование графа потоков
управления программы с целью изменить порядок вызываемых функций, добавить
новые функции или убрать существующие, заменив их несколькими новыми.
Многие методы этого вида обфускации используют так называемые
непрозрачные предикаты. В качестве таких предикатов выступают
последовательности операций, результат работы которых сложно определить.
Определение. Непрозрачной переменной V назовем переменную, вводимую при
обфускации программы и удовлетворяющую следующим свойствам:
. На стадии обфускации программы значение переменной V можно
определить по самой программе и по дополнительной информации, доступной на этой
стадии, но отсутствующей в тексте программы;
. По тексту обфусцированной программы установить значение
переменной V сложно.
Аналогично определяется непрозрачный предикат - предикат Р считается
непрозрачным предикатом, если его результат известен только в процессе
обфускации, то есть после осуществления процесса обфускации, определение
значения такого предиката становится трудным. Предикат возвращает значения из
множества {истина, ложь}.
Обозначим через PT
• непрозрачный предикат, возвращающий всегда истинное значение,
через PF
• непрозрачный предикат, возвращающий всегда ложное значение, и
через P?
• непрозрачный предикат, который может вернуть как истинное, так и
ложное значение.
Тривиальным непрозрачным предикатом назовем такой предикат, значение
которого можно установить локальным статическим анализом кода программы. Слабым
непрозрачным предикатом назовем предикат, значение которого можно определить
глобальным статическим анализом всей программы. Применение таких предикатов
несущественно запутывает программу. Ниже представлен фрагмент кода, в котором
вводится тривиальный непрозрачный предикат.
{v,a=5,b=6;=a+b;
if (b>5) …//всегда
истина
…
if (random(1,5)<0) … //всегда ложно
}
Внесение недостижимого кода.
Метод обфускации, в котором удобно использовать непрозрачные предикаты.
Данный метод состоит в том, что в программу добавляются новые инструкции,
которые на самом деле никогда не выполняются (ни при каком наборе входных
параметров). Несмотря на то, что вносимые инструкции реально никогда не
исполняются, то есть являются недостижимыми, задача статического определения
достижимости кода является алгоритмически неразрешимой. Этот факт не позволяет
статическому анализатору в некоторых случаях, например при использовании
достаточно сложных непрозрачных предикатов, отбросить добавленные инструкции
как недостижимые. Простой пример использования непрозрачного предиката при
добавлении недостижимого кода - размещение этого кода в функциональном блоке
условного оператора, который вычисляет значение предиката PF.
Поскольку значение всегда ложное, то функциональный блок условного оператора
никогда не выполнится.
Внесение мёртвого кода.
Назовем мёртвым такой код, выполнение которого никак не влияет на
результат работы программы. Тривиальный пример мертвой инструкции - NOP,
инструкция, которая ничего не делает. Менее тривиальный пример - расширение
арифметических операций: прибавление, равного нулю слагаемого, умножение на
равный единице множитель и т.д. В отличие от недостижимого кода, который не
исполняется никогда, мёртвый код может исполняться, поэтому при использовании
этого метода нужно учитывать все последствия выполнения вносимого кода. В этом
методе также можно использовать непрозрачные предикаты, вставляя в мертвый код
условный оператор, проверяющий значение PF. Это комбинирование недостижимого и
мёртвого кода, поскольку сама проверка ложного условия является мертвой
инструкцией. При этом изменяется как граф потоков управления, так и граф
потоков данных.
Клонирование кода.
Этот метод состоит в том, что создается несколько копий участков кода,
которые затем связываются непрозрачными предикатами типа P?. Затем к копиям
применяются другие методы обфускации, делающие копии непохожими друг на друга,
и хотя на самом деле неважно, какая из копий выполнится, проделанные
преобразования существенно усложняют анализ графа потоков управления. На
рисунке слева представлена схема клонирования кода с использованием непрозрачного
предиката.
Клонирование кода (слева) и внесение недостижимого кода
(справа).
Введение «блока-диспетчера». Данный метод направлен на
существенное изменение графа потоков управления программы. Другое
распространенное название этого метода - «уплощение», приведение графа к
плоскому виду. Метод состоит в том, что управление из одного функционального
блока в другой передается не непосредственно, а через введенный в процессе
обфускации «диспетчер». При этом граф потоков управления становится плоским.
Граф потоков данных также существенно изменяется, поскольку потоки данных всех
функциональных блоков начинают влиять друг на друга через «диспетчер».
Фактически, данный метод сводит задачу анализа графа потоков управления к задаче
анализа графа потоков данных.

Блок-диспетчер.
Обфускация данных
Обфускация данных направлена на изменение графа потоков данных, а также
на трансформацию хранилищ данных и самих типов данных. Примером трансформации типа
данных может служить двоично-десятичный код - форма записи целых чисел, когда
каждый десятичный разряд числа записывается в виде его четырёхбитного двоичного
кода. Таким образом, целочисленная переменная будет содержать значение,
традиционная интерпретация которого отлична от принятой в программе.
Изменение интерпретации значения бит.
Изменение времени жизни и области видимости переменных.
Если в различных блоках кода используются локальные переменные, и блоки
выполняются независимо друг от друга, то несколько локальных переменных можно
заменить одной или несколькими глобальными. Это породит новые потоки данных,
существенно связывающие различные первоначально независимые функциональные
блоки.
Разделение и объединение переменных.
Для усложнения используемых структур данных в программе можно применять
соединение независимых данных или разделение зависимых. Две или более
переменных v1,...,vk могут быть
объединены в одну переменную V, если их общий размер (v1,...,vk)
не превышает размер переменной V. При этом создастся новый поток данных,
соответствующий переменной V, на который влияют отношением типа «запись» потоки
данных переменных v1,...,vk. Обратно, переменные
фиксированного диапазона могут быть разделены на две и более переменных. Для
этого переменную V, имеющую тип Xtype, разделяют на k
переменных v1,...,vk типа Ytype,
то есть V = v1,...,vk. Потом создается
набор функций, позволяющих извлекать переменную типа Xtype из переменных
типа Ytype и записывать переменную типа Xtype в переменные типа Ytype.
При этом создаются несколько потоков данных, на которые поток данных переменной
V влияет отношением «запись».
Реструктурирование массивов данных.
Традиционный порядок следования элементов в массиве можно изменить на порядок,
вычисляемый по сложной формуле. Также, по аналогии с предыдущим методом,
массивы данных можно разделять на подмассивы, либо объединять несколько
массивов в один большой. Можно увеличить размерность массива, например, вместо
большого одномерного массива использовать двумерный массив вдвое меньшей длины.
Соответственно, обратный метод - разворачивание многомерных массивов в
одномерные. На рисунке продемонстрировано комбинирование нескольких методов
реструктуризации массивов данных.
А

B1 B2
Метод
шифрования программного кода
Используется, для того чтобы предотвратить вмешательство в программу, а
также усложнить изучение взломщиком того, как устроена программа, как она работает,
как в ней реализован метод защиты и т.д.
Данный метод защиты предусматривает зашифровывание кода программы, после
чего она в зашифрованном виде поставляется конечным пользователям (иногда
эффективно зашифровывать только наиболее важные, критические, участки кода, а
не весь код программы). Когда пользователь запускает такую программу, вначале
будет запущена процедура расшифровки программы, которой потребуется ключ, с
помощью которого будет расшифрована запускаемая программа.
Ключ для шифрования кода должен быть надежно защищен. В идеале, он должен
отличаться для каждого пользователя программы. Однако такой подход является
неприемлемым для продуктов с большим количеством пользователей, поскольку
предполагает, что каждому пользователю будет выдаваться отдельная копия
продукта, зашифрованная ключом этого пользователя. Поэтому более удобным
вариантом является использование общего ключа и его хранение в недоступном
месте (например, на смарт-карте или сервере приложений). Еще одним подходом к
хранению ключа является его генерация в ходе выполнения программы, однако такой
подход более уязвим к реверс-инженерии.
Можно выделить два подхода к расшифровке выполняемого кода: расшифровка
всего кода при запуске программы и поэтапная расшифровка необходимых участков кода
непосредственно перед их выполнением с последующей обратной зашифровкой.
Слабостью первого подхода является возможность снять копию участка памяти,
содержащего расшифрованную программу, поэтому этот подход крайне ненадежен. Для
того чтобы получить программу в незашифрованном виде, атакующему нужно
выполнить все зашифрованные фрагменты, для каждого фрагмента снимая дамп
памяти. При большом количестве зашифрованных фрагментов эта задача становится
практически невыполнимой.
Шифрование программного кода также может применяться и для защиты кода от
модификации. При шифровании некоторого участка кода совместно с данными этого
участка кода можно поместить контрольную сумму его байт. Таким образом, если
злоумышленник внесет изменения в шифртекст (например, с экспериментальной
целью), контрольная сумма при расшифровке не совпадет с оригинальной и эти
изменения можно будет отследить. Определенный интерес представляет метод на
основании саморасшифровывающегося кода. Данный метод не предполагает
наличия некоторого фиксированного ключа. Программный код разбивается на
участки, которые шифруются независимо друг от друга. В процессе выполнения
программы каждый следующий участок расшифровывается ключом, полученным
применением некоторой функции к байтам предыдущего. Очевидно, что этот метод не
предоставляет защиты от неавторизованного выполнения кода, а только от реверс -
инженерии и модификации выполняемого кода.
Метод
проверки целостности кода программы.
Целостность программного кода может быть нарушена по разным причинам.
Во-первых, внести изменения в код может вирус, внедрившийся в программу.
Во-вторых, изменения могут быть преднамеренно внесены недоброжелателем
(например, таким способом он может отключить систему проверки лицензионного
кода либо попытаться удалить из программы водяной знак). В любом случае
выполнение измененного программного кода нежелательно по причине невозможности
гарантировать правильность его работы. Для предотвращения выполнения программы
в случае, если ее код был модифицирован, в программу можно добавить специальный
проверочный код, который, в случае обнаружения изменений в коде программы,
будет ее аварийно завершать. На этот код будут возложены такие задачи:
. обнаружить, что программа была модифицирована,
. если это возможно, исправить обнаруженные изменения, в противном
случае обеспечить аварийное завершение программы.
В идеальном случае обнаружение изменения в коде и соответствующее этому
обнаружению аварийное завершение программы должны быть широко распределены во
времени и коде программы, чтобы запутать потенциального атакующего. Очевидно,
что код < if (tampered()) i = 1 / 0 > не обеспечивает достаточной защиты в связи с
возможностью тривиального обнаружения и устранения.
Следующие два способа являются наиболее используемыми для проверки программы
на наличие внесенных изменений:
1. исследовать исполняемый код программы и проверить, совпадает ли
он с оригинальным. Для этого можно использовать некоторую одностороннюю
хэш-функцию (напр., SHA1). Проверять
можно не весь код, а только части, для которых неизменность является критичной.
2. исследовать правильность промежуточных результатов, получаемых в
программе. Этот подход известен как проверка программы (program verification). Кроме рассматриваемых целей, этот
метод также может использоваться для верификации или тестирования программы на
этапе разработки и является самым применяемым для решения задачи обнаружения
изменений в программе.
Для проверки приложения на неизменность предлагается использовать
множество объектов - троек <тестер, интервал, корректор>. Тестером
называется подпрограмма, вычисляющая хэш-функцию от некоторого интервала
(участка кода) программы и сравнивающая его с оригиналом. В процессе выполнения
тестеры запускаются и проверяют правильность интервала, за который они
отвечают, путем сравнения оригинального значения хэш-функции и действительного.
В случае, если значения не совпадают, программа через некоторое время аварийно
завершается. Корректоры необходимы для безопасного хранения оригинальных
значений хэш-функции. Корректоры могут быть как константами (т.е. просто
массивом байт), так и подпрограммами, конструирующими оригинальное значение.
Очевидно, второй подход обеспечивает большую защиту.
Использование каскадного подхода и создание зависимостей между тестерами
поможет усложнить защиту, обеспечиваемую тестерами. В этом случае
злоумышленнику для снятия защиты даже только с одного интервала потребуется
обнаружение и уничтожение всех тестеров, находящихся в коде программы.
Разберем еще один подход, похожий на рассмотренный выше. Ответственными
за целостность приложения являются стражники (guards) - подпрограммы, выполняющие проверку целостности
данных. Отличием их от тестеров является возможность восстановления измененных
участков кода. Для исправления изменений используются коды, исправляющие
ошибки.
Несмотря на то, что на основе подхода, использующего проверки участков
выполняемого кода, можно построить достаточно сложную систему защиты программы
от модификации, этот подход имеет один серьезный концептуальный недостаток.
Поскольку проверка целостности выполняется на уровне программного кода, то
после внедрения защиты код программы не может быть изменен. Это приводит к
достаточно большим неудобствам - например, к невозможности оптимизации (сжатия)
программного кода с сохранением семантики, невозможности добавить к программе
цифровую подпись. Кроме того, поскольку тестеры следят за целостностью лексики,
в то время как в первую очередь стоит задача обеспечить целостность семантики,
возникает проблема анализа и оценки уровня обеспечиваемой защиты.
У этого подхода имеются и другие недостатки. Например, операция чтения
программой своего собственного кода (характерная для приложений, проверяющих
свою целостность вышеописанным образом) является редко выполняемой, а потому
легко обнаружимой. Поэтому более предпочтительны методы, проверяющие
целостность семантической структуры программы.
Один
из таких методов, названный забывчивым хэшированием (oblivious hashing). В качестве объекта проверки предлагается
использовать не бинарный код, а след выполнения программы (функции,
участка программы и т.п.). Программа (функция, участок) представляется в виде
последовательности абстрактных машинных инструкций  которые
обращаются для чтения и записи к участкам памяти
которые
обращаются для чтения и записи к участкам памяти 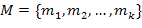 , начального состояния памяти
, начального состояния памяти  ,
счетчика инструкций C и его начального значения
,
счетчика инструкций C и его начального значения  . Следом
некоторого участка программы называется пятерка
. Следом
некоторого участка программы называется пятерка 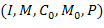 , где
, где  -
некоторый входной параметр, который влияет на выполнение участка программы. В
процессе выполнения участка программы вычисляется хэш-функция от его следа.
Поскольку след отражает семантику участка программы, полученное значение хэш -
функции по сути является цифровой подписью, выполненной над поведением этого
участка. Изменение как кода, так и данных, с которыми оперирует участок,
приведет к несовпадению полученного при проверке значения хэш-функции с
оригинальным значением, что позволит определить наличие изменений в программе.
-
некоторый входной параметр, который влияет на выполнение участка программы. В
процессе выполнения участка программы вычисляется хэш-функция от его следа.
Поскольку след отражает семантику участка программы, полученное значение хэш -
функции по сути является цифровой подписью, выполненной над поведением этого
участка. Изменение как кода, так и данных, с которыми оперирует участок,
приведет к несовпадению полученного при проверке значения хэш-функции с
оригинальным значением, что позволит определить наличие изменений в программе.
Недостатком
данного подхода является его неуниверсальность. Так, проверку методом
забывчивого хэширования невозможно реализовать для участков программы,
оперирующих случайными данными (такими, как текущее время, положение указателя
мыши и т.п.), или данными, множество значений которых очень велико. Это
существенно ограничивает множество подпрограмм, для которых можно применить
этот метод.
Итак,
защита от модификации кода программы является неотъемлемой частью общей задачи
защиты клиентского программного обеспечения. Кроме того, программа, обладающая
возможностью обнаружить изменения в своем коде, является более безопасной и в
случае выполнения. Программа, не отслеживающая изменений в своем коде,
потенциально может представлять угрозу как для себя, так и для других программ,
выполняющимся с ней в одном окружении.
Основными
атаками на алгоритмы защиты от модификации, оперирующие бинарным кодом
программы, являются удаление проверочного кода и подмена хранимых внутри программы
оригинальных значений хэш-функции. Из этого следует, что и проверочный код, и
оригинальные значения хэш-функций должны быть хорошо защищены от воздействия.
Для этих целей можно использовать запутывание (обфускация), помещение
проверочного кода/данных на защищенный носитель и т.п. Атаки на алгоритмы,
проверяющие целостность семантической структуры программы, являются гораздо
более сложными, в первую очередь из-за сложности их обнаружения.
Электронная
цифровая подпись
Основные определения, обозначения и алгоритмы.
Для реализации схем электронной цифровой подписи (или просто
цифровой подписи) требуются три следующих эффективно функционирующих алгоритма:
• Ak - алгоритм генерации секретного и открытого
ключей для подписи кода программы, а также проверки подписи, - s и p
соответственно;
• As - алгоритм генерации (проставления) подписи
с использованием секретного ключа s;
• Ap - алгоритм проверки (верификации) подписи с
использованием открытого ключа p.
Алгоритмы должны быть разработаны так, чтобы выполнялось основное
принципиальное свойство, - свойство невозможности получения нарушителем
алгоритма As из алгоритма Ap.
Таким образом, если Ak - алгоритм генерации ключей,
тогда определим значения (s,p)=Ak(α,β) как указанные выше сгенерированные
ключи, где α - некоторый параметр безопасности (как правило, длина
ключей), а β - параметр, характеризующий случайный характер работы
алгоритма Ak при каждом его вызове.
Ключ s хранится в секрете, а открытый ключ p делается
общедоступным. Это делается, как правило, путем помещения открытых ключей
пользователей в открытый сертифицированный справочник. Сертификация открытых
ключей справочника выполняется некоторым дополнительным надежным элементом,
которому все пользователи системы доверяют обработку этих ключей. Обычно этот
элемент называют Центром обеспечения безопасности или Центром доверия.
Непосредственно процесс подписи осуществляется посредством алгоритма As.
В этом случае значениеc=As(m) - есть подпись кода программы m,
полученная при помощи алгоритма As и ключа s.
Процесс верификации выполняется следующим образом. Пусть m* и c*
- код программы и подпись для этого кода соответственно, Ap -
алгоритм верификации. Тогда, выбрав из справочника общедоступный открытый ключ p,
можно выполнить алгоритм верификации: b=Ap(m*,c*), где
предикат b {true,false}. Если b=true, то код m*
действительно соответствует подписи c*, полученной при помощи секретного
ключа s, который, в свою очередь, соответствует открытому ключу p,
то есть m=m*, c=c* и наоборот еслиb=false, то код
программы ложен и (или) код подписан ложным ключом.
{true,false}. Если b=true, то код m*
действительно соответствует подписи c*, полученной при помощи секретного
ключа s, который, в свою очередь, соответствует открытому ключу p,
то есть m=m*, c=c* и наоборот еслиb=false, то код
программы ложен и (или) код подписан ложным ключом.
Примеры схем электронной цифровой подписи. К наиболее известным схемам цифровой
подписи с прикладной точки зрения относятся схемы RSA, схемы Рабина-Уильямса,
Эль-Гамаля, Шнорра и Фиата-Шамира, а также схема электронной цифровой подписи
отечественного стандарта ГОСТ Р 34.10-94.
Рассмотрим несколько подробнее наиболее известные схемы цифровой подписи:
Подпись
RSA: Вход: Числа  , где
, где  и
и  -
большие l-разрядные простые числа,
-
большие l-разрядные простые числа,  .
Открытый ключ
.
Открытый ключ  ,
секретный ключ
,
секретный ключ  , такой,
что
, такой,
что  и
наибольший общий делитель
и
наибольший общий делитель  , где
, где 
Генерация ключей:(d,(e,n))=Ak(l,b).
Подпись:As: 1.md(mod n) c, где c - подпись кода программы m.
c, где c - подпись кода программы m.
Верификация:Ap: 1.[c*]e(mod n)m**,
2.если m**=m*, подпись верна.
Подпись
Эль-Гамаля: Вход: Числа и  , где -
простое l-разрядное число, а -
первообразный корень по модулю .
Секретный ключ ,
открытый ключ
, где -
простое l-разрядное число, а -
первообразный корень по модулю .
Секретный ключ ,
открытый ключ  , такой,
что
, такой,
что  , m
- подписываемый код программы.
, m
- подписываемый код программы.
Генерация ключей:(d,(e,g,p))=Ak(l,b).
Подпись: As: 1.rgk(mod p), где kRZp-1;
2.находится такое c, что m[kc+dr](mod p-1),
где (c,r) - подпись кода m.
Верификация:Ap: 1.если gm*=errc*(mod
p), то подпись верна.
Подпись стандарта ГОСТ Р 34.10-94.
Вход: Числа  где -
простое l-разрядное число, -
первообразный корень по модулю
где -
простое l-разрядное число, -
первообразный корень по модулю  а -
большой простой делитель
а -
большой простой делитель  . Пусть
также
. Пусть
также  .
Секретный ключ подписи
.
Секретный ключ подписи 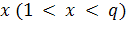 и
открытый ключ
и
открытый ключ  .
.
Генерация ключей:(x,(g,p,q,y))=Ak(l,b).
Подпись: Ax: 1.r[gk(mod p)](mod q), где kRZq.
.s[xr+km)](mod q), где m=h(M) -рассматривается как
значение хэш-функции h, соответствующей отечественному стандарту на функцию
хэширования сообщений ГОСТ Р 34.11-94. Таким образом, пара (r,s) - есть подпись
кода программы M.
Верификация: Ay: 1.vm-1(mod q).
2.u[gsvy-rv(mod p)](mod q);
3.Если u=r, то (r,s) - есть подпись кода программы M, где m=h(M).
Под стойкостью схемы цифровой подписи понимается стойкость в
теоретико-сложностном смысле, то есть, как отсутствие эффективных алгоритмов ее
подделки и (или) раскрытия. По-видимому, до сих пор основной является следующая
классификация:
• атака с открытым ключом, когда противник знает только
открытый ключ схемы;
• атака на основе известного открытого текста (известного
кода программы), когда противник получает подписи для некоторого
(ограниченного) количества известных ему кодов (при этом противник никак не
может повлиять на выбор этих кодов);
• атака на основе выбранного открытого текста, когда
противник может получить подписи для некоторого ограниченного количества
выбранных им кодов программы (предполагается, что коды выбираются независимо от
открытого ключа, например, до того как открытый ключ станет известен);
• адаптивная атака на основе выбранного открытого текста,
когда противник выбирает коды программы последовательно, зная открытый ключ и
зная на каждом шаге подписи для всех ранее выбранных кодов.
Атаки перечислены таким образом, что каждая последующая сильнее предыдущей.
Угрозами для схем цифровой подписи являются раскрытие схемы или подделка
подписи. Определяются следующие типы угроз:
• полного раскрытия, когда противник в состоянии вычислить
секретный ключ подписи;
• универсальной подделки, когда противник находит алгоритм,
функционально эквивалентный алгоритму вычисления подписи;
• селективной подделки, когда осуществляется подделка
подписи для кода программы, выбранного противником априори;
• экзистенциональной подделки, когда осуществляется
подделка подписи хотя бы для одного кода программы (при этом противник не
контролирует выбор этого кода, которое может быть вообще случайным или
бессмысленным).
Угрозы перечислены в порядке ослабления. Стойкость схемы электронной
подписи определяется относительно пары (тип атаки, угроза).
Если принять вышеописанную классификацию атак и угроз, то наиболее
привлекательной является схема цифровой подписи, стойкая против самой слабой из
угроз, в предположении, что противник может провести самую сильную из всех
атак. В этом случае, такая схема должна быть стойкой против экзистенциональной
подделки с адаптивной атакой на основе выбранного открытого текста.
Метод
эмуляции процессора в защите ПО
Суть метода такова: некоторые функции, модули, или программа целиком,
компилируются под некий виртуальный процессор, с неизвестной потенциальному
взломщику системой команд и архитектурой. Выполнение обеспечивает встраиваемый
в результирующий код симулятор. Таким образом, задача реинжиниринга защищенных
фрагментов сводится к изучению архитектуры симулятора, симулируемого им
процессора, созданию дизассемблера для последнего, и, наконец, анализу
дизассемблированого кода. Задача эта нетривиальна даже для специалиста,
имеющего хорошие знания и опыт в работе с архитектурой целевой машины. Взломщик
же не имеет доступа ни к описанию архитектуры виртуального процессора, ни к
информации по организации используемого симулятора. Стоимость взлома
существенно возрастает.
Почему же, учитывая высокую теоретическую эффективность, данный метод до
сих пор не используется повсеместно? Видимо по двум основным причинам.
Во-первых, метод имеет особенности, что сужает области его потенциального
применения - об этом будет сказано ниже. Во-вторых, и, возможно, это более
серьезная причина, сложность (а следовательно и стоимость) реализации метода
весьма высока. Если же учесть принципиальную возможность утечки информации о
только что созданной системе, которая моментально приведет к ее неэффективности
и обесцениванию, становится понятно, почему фирмы-производители защитного ПО не
спешат реализовывать этот метод. Стоит, однако, отметить, что с теми или иными
вариациями и ограничениями данный метод все же реализован в таких новейших
продуктах как StarForce3, NeoGuard, VMProtect и др. Видимо таких продуктов
будет становиться все больше и больше, а существующие будут развиваться, т.к.
появляющиеся реализации подтверждают высокую эффективность метода, хоть и имеют
пока слабые стороны.
Одним из недостатков метода является высокая стоимость его реализации,
однако она может быть заметно снижена. В основе системы защиты, реализующей
данный метод, мог бы лежать компилятор с языка высокого уровня. Необходимо
машинно-зависимая фаза в любом компиляторе всего одна - кодогенерация, от
зависимостей в других фазах, как правило, можно избавиться.
Если же компилятор изначально разрабатывается как мультиплатформенный, в
нем, как правило, максимально упрощен процесс перенастройки на другую целевую
платформу. Например, это может быть достигнуто автоматической генерацией
кодогенератора по специальному описанию целевой машины. В этом случае
разработчикам для смены платформы достаточно лишь изменить это описание. Но
даже если собственного компилятора нет, можно воспользоваться свободно
распространяемыми с открытым кодом.
А чтобы максимально упростить для пользователя работу с описываемой
системой защиты, ее можно снабдить механизмами встраивания в популярные среды
разработки. В этом случае схема работы такого комплекса могла бы выглядеть так,
как изображено на рисунке.
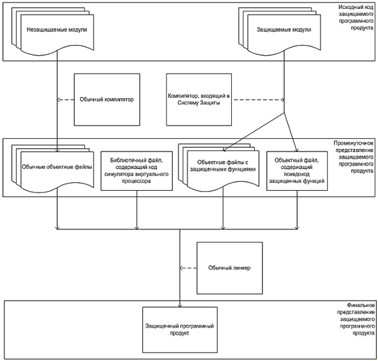
Соответственно, функционирование защищенного таким способом образом
продукта происходило бы по следующей схеме

Специфика использования компилятора налагает ряд особых требований к
виртуальному процессору, тем не менее все они могут быть легко реализованы.
Требований немного - нужно лишь обеспечить возможность доступа к внешней,
относительно виртуальной машины, памяти, а так же возможность вызова внешних
функций - это необходимо для взаимодействия защищенного и незащищенного кода. В
остальном архитектура виртуального процессора может быть совершенно
произвольной, и чем запутаннее и оригинальней она будет, тем более высокий
уровень защиты будет достигнут.
Сам компилятор, кроме изменения кодогенерационной фазы, нужно доработать
для приобретения им возможностей:
• Различать обращения к внутренней и внешней памяти относительно
виртуального процессора (в том числе и вызовы функций)
• Создавать для каждой защищаемой функции так называемую оболочку,
выполняющуюся на реальном процессоре, с вызовом защищенной функции через
симулятор
Последнюю возможность следует описать подробнее. Как было отражено в
схеме, функционал защищенных функций будет реализован через вызов симулятора, с
указанием, какую из защищенных функций нужно интерпритировать. Однако, до
этого, необходимо выполнить специальный код, подготавливающий для защищенной
функции параметры - "переместить" их с реальных регистров и памяти на
виртуальные, способом, соответствующим архитектуре виртуального процессора.
Всем этим будут заниматься специальные функции, сгенерированные нашим
компилятором - "оболочки". Оболочки, в свою очередь, будут
использовать специальные функции симулятора для доступа к виртуальным регистрам
и памяти. Характерно, что наш компилятор будет генерировать оболочки на языке
высокого уровня, которые, в свою очередь, будут компилироваться стандартным
компилятором, использующимся пользователем для сборки незащищенной части своего
проекта. Итак, вызов защищенной функции из незащищенного модуля может выглядеть
так, как изображено на рисунке

Конечно, конкретная реализация метода виртуального процессора может быть
несколько отличной от описываемой, как и схема работы защищенного им продукта.
Тем не менее, описанный вариант вполне жизнеспособен, и, кроме того,
относительно прост.
Сердце защищенного продукта - симулятор. Он будет включаться в любую
сборку защищенного продукта. Однако не будем подробно рассматривать его
реализацию, т.к. специальных требований к нему практически не предъявляется -
он должен лишь симулировать архитектуру нашего виртуального процессора, включая
операции доступа к внешней памяти. Стоит, однако, отметить, что с учетом
специфики его применения, необходимо максимально автоматизировать процесс
перенастройки симулятора на новые виртуальные архитектуры.
Недостатки же метода - следствие его достоинств:
• Скорость работы перенесенного в виртуальную среду кода в разы
(ориентировочно в 10-50, в зависимости от архитектуры виртуального процессора и
симулятора) ниже, чем кода оригинального
• Объем защищенной программы, как правило, будет несколько выше,
чем незащищенной
Впрочем, последний недостаток несущественен, т.к. размер увеличится
незначительно, а в некоторых случаях может даже снижаться. Первый же недостаток
принципиален, и налагает некоторые очевидные ограничения на использование
метода.
Рассмотренный метод защиты ПО весьма эффективен, учитывая то, что затраты
на его разработку можно существенно сократить. Однако, особенности метода не
позволяют рекомендовать его для защиты программ полностью. Так, метод не может
применяться для защиты функций, критичных ко времени выполнения, а так же
функций, замедление работы которых может заметно снизить эффективность
использования программы пользователем. Тем не менее, аккуратное применение
данного метода позволяет добиться очень высокого уровня защиты от изучения.
Всвязи с этим, основной областью его применения видится повышение стойкости к
изучению отдельных алгоритмов других систем защиты ПО. Кроме того, метод применим
для защиты нересурсоемких алгоритмов, а так же для сокрытия содержания в
защищаемой программе некоторых специальных данных, например, сведений об
авторстве.
Выполнение
на стороне сервера.
Данный метод защиты основан на технологии клиент-сервер, он позволяет
предотвратить отсылку кода программы пользователям, которые будут с ней
работать, так как сама программа храниться, и выполняется на сервере, а
пользователи используя клиентскую часть этой программы, получают результаты ее
выполнения.

Выполнение на стороне сервера
Клиентскую часть можно распространять бесплатно, это позволит
пользователям платить только за использование серверной части.
Часто данный метод защиты используется в различных программах-сценариях,
которые располагаются на WEB серверах, и выполняют общие операции, например,
контролируют работу других программ (front-end), а также передают им, какие
либо данные для обработки.
Недостатком данного метода является то, что он устанавливает зависимость
пропускной способности сети и тех данных, с которыми будет работать программа
(соответственно работа с мультимедиа данными требует наиболее максимальной
пропускной способности сети). Поэтому данный метод наиболее эффективен для
простых программ (сценариев), потребность в которых очень большая среди
пользователей. Однако, и здесь возникает ряд проблем, связанных с
безопасностью:
• стойкость такой защиты зависит, прежде всего, от защищенности
серверов, на которых он исполняется (речь идет о Интернет-безопасности)
• важно обеспечение конфиденциальности запросов, аутентификации
пользователей, целостности ресурса (возможности «горячего» резервирования), и
доступности решения в целом
Возникают
также вопросы доверия сервису (в том числе правовые), так как ему фактически «в
открытом виде» передаются как само ПО, так и данные, которые оно обрабатывает
(к примеру, персональные данные
<#"564481.files/image122.gif"> означает
степень зависимости нормального функционирования защищенного ПО от наличия
информации, содержащейся или генерируемой системой защиты ПО.
означает
степень зависимости нормального функционирования защищенного ПО от наличия
информации, содержащейся или генерируемой системой защиты ПО.
Для
оценки информационной интегрированности мы предлагаем использовать отношение
объема данных 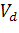 ,
передаваемых системой защиты ПО в защищенное ПО в процессе сеанса работы
защищенного ПО, к времени этого сеанса
,
передаваемых системой защиты ПО в защищенное ПО в процессе сеанса работы
защищенного ПО, к времени этого сеанса 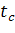 :
:

Другие
показатели качества систем защиты ПО предлагается оценивать методами,
аналогичными для программного обеспечения общего назначения.
Рассмотрим показатели качества ПО в применении к системам защиты ПО.
Удобство применения систем защиты программного обеспечения.
Выше было показано что данный показатель качества оценивает: легкость
освоения, доступность эксплуатационной программной документации, удобство
эксплуатации и обслуживания. Отметим, что из-за функциональных особенностей
систем защиты данные показатели качества не имеют смысла в отношении конечного
пользователя защищенного ПО. Исключением являются навесные системы защиты ПО,
для которых показатели удобства применения систем защиты имеют смысл в
отношении их промежуточного пользователя - разработчика защищаемого ПО.
Показатели эффективности систем защиты программного
обеспечения.
Из показателей эффективности для систем защиты ПО большое значение имеют:
временная эффективность и ресурсоемкость. Это объясняется тем, что система
защиты при своем функционировании «отбирает» машинные ресурсы у защищаемого ПО,
влияя, таким образом, на показатели его временной эффективности и
ресурсоемкости. Следовательно, при оценке качества системы защиты ПО данные
показатели требуют тщательных оценок, например, путем практических испытаний.
Показатели универсальности систем защиты программного
обеспечения.
Из всех показателей универсальности на качество систем защиты ПО
наибольшее влияние оказывают: гибкость, мобильность и модифицируемость.
Гибкость систем защиты ПО.
Как было отмечено в главе 1, гибкость характеризуют возможности
использования ПО в различных областях.
По отношению к системам защиты ПО под гибкостью будем понимать
возможность применения систем защиты для использования с различными видами ПО.
Требуемую гибкость системы защиты ПО необходимо обеспечить уже на стадии
технического задания на его разработку. Отметим, что данный показатель имеет
большое значение для оценки качества систем защиты навесного типа.
Мобильность систем защиты ПО.
Степень мобильности систем защиты ПО (то есть возможности их переработки
для применения на ЭВМ аналогичного класса) во многом зависит от вида
оцениваемой системы защиты ПО и способа ее разработки. Например, различные
способы защиты алгоритма от отладчиков и дизассемблеров, как правило, вообще
непереносимы, и их применение в системе защиты ухудшают ее мобильность. В
целом, для оценки мобильности систем защиты ПО применимы вышеописанные методы.
Модифицируемость систем защиты ПО.
Этот показатель для систем защиты ПО характеризуется теми же свойствами,
что и для ПО обычного назначения. Исключением могут быть случаи сознательного
усложнения реализации алгоритма для затруднения его понимания. Следовательно,
оценка данного показателями системы защиты ПО возможна методами, аналогичными
для программного обеспечения общего назначения.
Рассмотрев особенности систем защиты ПО можно отметить, что их
вспомогательный характер, с одной стороны, и характерные для них специфические
особенности построения структуры и функционирования, с другой стороны, хотя и
допускают применение набора показателей качества ПО и методов их оценки,
описанных в главе 1, но при этом требуют некоторых изменений и доработки
применительно к указанной специфике. Это потребует дальнейших исследований,
выходящих за рамки данной работы.
2.4.2
Методы анализа и оценки безопасности ПО
На базе средств обнаружения элементов разрушающих программных средств
(РПС) - от простейших антивирусных программ-сканеров до сложных отладчиков и
дизассемблеров - анализаторов и выработался набор методов, которыми
осуществляется анализ безопасности ПО.
Разделим методы, используемые для анализа и оценки безопасности ПО, на
две категории: контрольно-испытательные и логико-аналитические (см. рисунок). В
основу данного разделения положены принципиальные различия в точке зрения на
исследуемый объект (программу). Контрольно-испытательные методы анализа рассматривают РПС через призму
фиксации факта нарушения безопасного состояния системы, а логико-аналитические
- через призму доказательства наличия отношения эквивалентности между моделью
исследуемой программы и моделью РПС.
В такой классификации тип используемых для анализа средств не принимается
во внимание - в этом ее преимущество по сравнению, например, с разделением на
статический и динамический анализ.
Комплексная система исследования безопасности ПО должна включать как
контрольно-испытательные, так и логико-аналитические методы анализа, используя
преимущества каждого их них. С методической точки зрения логико-аналитические
методы выглядят более предпочтительными, т.к. позволяют оценить надежность
полученных результатов и проследить последовательность (путем обратных
рассуждений) их получения. Однако эти методы пока еще мало развиты и,
несомненно, более трудоемки, чем контрольно-испытательные.
Контрольно-испытательные методы анализа безопасности
программного обеспечения
Контрольно-испытательные
методы - это методы, в которых критерием безопасности программы служит факт
регистрации в ходе тестирования программы нарушения требований по безопасности,
предъявляемых в системе предполагаемого применения исследуемой программы [10]
<#"564481.files/image126.gif"> зависящих
от множества аргументов
зависящих
от множества аргументов 
Это
множество состоит из двух подмножеств:
• подмножества ограничений на использование ресурсов аппаратуры и
операционной системы, например оперативной памяти, процессорного времени,
ресурсов ОС, возможностей интерфейса и других ресурсов;
• подмножества ограничений, регламентирующих доступ к объектам,
содержащим данные (информацию), то есть областям памяти, файлам и т.д.
Для
доказательства того, что исследуемая программа удовлетворяет требованиям по
безопасности, предъявляемым на предполагаемом объекте эксплуатации, необходимо
доказать, что программа не нарушает ни одного из условий, входящих в . Для
этого необходимо определить множество параметров  ,
контролируемых при тестовых запусках программы. Параметры, входящие в это
множество определяются используемыми системами тестирования. Множество
контролируемых параметров должно быть выбрано таким образом, что по множеству
измеренных значений параметров можно было получить множество значений аргументов .
,
контролируемых при тестовых запусках программы. Параметры, входящие в это
множество определяются используемыми системами тестирования. Множество
контролируемых параметров должно быть выбрано таким образом, что по множеству
измеренных значений параметров можно было получить множество значений аргументов .
После
проведения испытаний по вектору полученных значений параметров 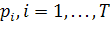 можно
построить вектор значений аргументов
можно
построить вектор значений аргументов 
Тогда
задача анализа безопасности формализуется следующим образом.
Программа
не содержит РПС, если для любого ее испытания  множество
предикатов
множество
предикатов  истинно.
истинно.
Очевидно,
что результат выполнения программы зависит от входных данных, окружения и т.д.,
поэтому при ограничении ресурсов, необходимых для проведения испытаний,
контрольно-испытательные методы не ограничиваются тестовыми запусками и
применяют механизмы экстраполяции результатов испытаний, включают в себя методы
символического тестирования и другие методы, заимствованные из достаточно
проработанной теории верификации (тестирования правильности) программы.
Рассмотрим
схему анализа безопасности программы контрольно-испытательным методом.
Контрольно-испытательные методы анализа безопасности начинаются с
определения набора контролируемых параметров среды или программы. Затем
необходимо составить программу испытаний, осуществить их и проверить требования
к безопасности, предъявляемые к данной программе в предполагаемой среде
эксплуатации, на запротоколированных действиях программы и изменениях в
операционной среде, а также используя методы экстраполяции результатов и
стохастические методы.
Наибольшую трудность здесь представляет определение набора критичных с
точки зрения безопасности параметров программы. Они очень сильно зависят от
специфики операционной системы и определяются путем экспертных оценок. Кроме
того в условиях ограниченных объемов испытаний, заключение о выполнении или
невыполнении требований безопасности как правило будет носить вероятностный
характер.
Логико-аналитические методы контроля безопасности программ
При проведении анализа безопасности с помощью логико-аналитических
методов (см. рисунок) строится модель программы и формально доказывается
эквивалентность модели исследуемой программы и модели РПС.
В простейшем случае в качестве модели программы может выступать ее
битовый образ, в качестве моделей вирусов множество их сигнатур, а
доказательство эквивалентности состоит в поиске сигнатур вирусов в программе.
Более сложные методы используют формальные модели, основанные на совокупности признаков,
свойственных той или иной группе РПС.
Формальная постановка задачи анализа безопасности логико-аналитическими
методами может быть сформулирована следующим образом.
Выбирается некоторая система моделирования программ, представленная
множеством моделей всех программ - Z. В выбранной системе исследуемая
программа представляется своей моделью М, принадлежащей множеству Z.
Должно быть задано множество моделей РПС V={vi|i=1,...,N},
полученное либо путем построения моделей всех известных РПС, либо путем порождения
множества моделей всех возможных (в рамках данной модели) РПС. Множество V
является подмножеством множества Z. Кроме того, должно быть задано
отношение эквивалентности определяющее наличие РПС в модели программы,
обозначим его Е(x,y). Это отношение выражает тождественность программы x
и РПС y, где x - модель программы, y - модель РПС, и y
принадлежит множеству V.
Тогда задача анализа безопасности сводится к доказательству того, что
модель исследуемой программы М принадлежит отношению E(M,v), где v
принадлежит множеству V.
Для проведения логико-аналитического анализа безопасности программы
необходимо, во-первых, выбрать способ представления и получения моделей
программы и РПС. После этого необходимо построить модель исследуемой программы
и попытаться доказать ее принадлежность к отношению эквивалентности, задающему
множество РПС.
На основании полученных результатов можно сделать заключение о степени
безопасности программы. Ключевыми понятиями здесь являются "способ
представления" и "модель программы". Дело в том, что на
компьютерную программу можно смотреть с очень многих точек зрения - это и
алгоритм, который она реализует, и последовательность команд процессора, и
файл, содержащий последовательность байтов и т.д. Все эти понятия образуют
иерархию моделей компьютерных программ. Можно выбрать модель любого уровня
модели и способ ее представления, необходимо только чтобы модель РПС и
программы были заданы одним и тем же способом, с использованием понятий одного
уровня. Другой серьезной проблемой является создание формальных моделей
программ, или хотя бы определенных классов РПС. Механизм задания отношения
между программой и РПС определяется способом представления модели. Наиболее
перспективным здесь представляется использование семантических графов и объектно-ориентированных
моделей.
В целом полный процесс анализа ПО включает в себя три вида анализа:
• лексический верификационный анализ;
• синтаксический верификационный анализ;
• семантический анализ программ.
Каждый из видов анализа представляет собой законченное исследование
программ согласно своей специализации.
Результаты исследования могут иметь как самостоятельное значение, так и
коррелироваться с результатами полного процесса анализа.
Лексический верификационный анализ предполагает поиск распознавания и
классификацию различных лексем объекта исследования (программа),
представленного в исполняемых кодах. При этом лексемами являются сигнатуры. В
данном случае осуществляется поиск сигнатур следующих классов:
• сигнатуры вирусов;
• сигнатуры элементов РПС;
• сигнатуры (лексемы) "подозрительных функций";
• сигнатуры штатных процедур использования системных ресурсов и
внешних устройств.
Поиск лексем (сигнатур) реализуется с помощью специальных
про-грамм-сканеров.
Синтаксический верификационный анализ предполагает поиск, распознавание и
классификацию синтаксических структур РПС, а также построение
структурно-алгоритмической модели самой программы.
Решение задач поиска и распознавания синтаксических структур РПС имеет
самостоятельное значение для верификационного анализа программ, поскольку
позволяет осуществлять поиск элементов РПС, не имеющих сигнатуры.
Структурно-алгоритмическая модель программы необходима для реализации
следующего вида анализа - семантического.
Семантический анализ предполагает исследование программы изучения смысла
составляющих ее функций (процедур) в аспекте операционной среды компьютерной
системы. В отличие от предыдущих видов анализа, основанных на статическом
исследовании, семантический анализ нацелен на изучение динамики программы - ее
взаимодействия с окружающей средой. Процесс исследования осуществляется в
виртуальной операционной среде с полным контролем действий программы и
отслеживанием алгоритма ее работы по структурно-алгоритмической модели.
Семантический анализ является наиболее эффективным видом анализа, но и
самым трудоемким. По этой причине методика сочетает в себе три перечисленных
выше анализа. Выработанные критерии позволяют разумно сочетать различные виды
анализа, существенно сокращая время исследования, не снижая его качества.
Оценка технологической безопасности системы защиты ПО.
Следует заметить, что реальные условия испытаний систем защиты программ
всегда существенно отличаются от тех, которые требуются для представительного
измерения уровня безопасности ПО. Например, тестовые прогоны выполняются на
выбранных определенным образом входных наборах данных.
Будем производить выбор с учетом сокращения времени поиска
соответствующей ошибки. При этом выбор должен быть основан на опыте и интуиции
испытателей, либо осуществлен с учетом функциональных возможностей, которые
должна обеспечивать программа, или возможностей соответствующих методик
испытаний. Следовательно, контрольные примеры, как правило, не являются
представительными с точки зрения моделирования реальных условий работы системы
защиты программы.
Алгоритм оценки величины R, предусматривающий использование результатов испытаний, состоит из
следующих шагов:
1. Определение множества E входных массивов.
2. Выделение в Е подмножеств  ,
связанных с отдельными ветвями программы.
,
связанных с отдельными ветвями программы.
3. Определение для каждого в
предполагаемых условиях функционирования значений вероятности 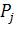 .
.
4. Определение подмножества для
каждого входного набора данных, используемого в контрольных примерах.
5. Выявление проверенных пар и непроверенных в ходе
испытаний сегментов и пар сегментов.
6. Определение для каждого j величины
 где
значение коэффициента определяется
в соответствии со следующими правилами (см. Табл.).
где
значение коэффициента определяется
в соответствии со следующими правилами (см. Табл.).
7. Оценка R вычисляется
по формуле:
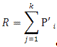
где k: - общее число ветвей программы.
Таблица
значений коэффициента
|
значение коэффициента Мощность подмножества (количество сегментов)
|
|
|
0,99
|
более одного конкретного примера
|
|
0,95
|
один конкретный пример
|
|
0,90
|
ни одного контрольного примера, но в процессе проверки
программы были найдены все сегменты и все сегментные пары ветви 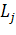
|
|
0,80
|
в ходе испытаний были опробованы все сегменты, но не все
сегментные пары
|
|

|
m сегментов (1< m <4) ветви не были опробованы в ходе испытаний
|
|
0
|
более чем 4 сегмента не были опробованы в процессе
испытаний
|
Приведенные
выше параметры ; были
определены на основе анализа теоретических результатов исследования и
экспериментальных результатов тестирования различных программ. Для того, чтобы
получить более точные оценки величины R необходимо
провести измерения с использованием подходящего метода формирования выборки.
Оценка
технологической безопасности системы защиты программного обеспечения
осуществляется посредством проверки условия  где
где  -
установленная нормативными документами граница безопасности ПО. Отметим также,
что для систем защиты критических приложений граница
-
установленная нормативными документами граница безопасности ПО. Отметим также,
что для систем защиты критических приложений граница  .
.
В
заключение отметим, что на этапе эксплуатации программных комплексов особое
значение приобретают вопросы эксплуатационной безопасности, т.е. свойства
программного обеспечения и информации не быть несанкционирование искаженными. В
этой связи должна производиться оценка надежности систем защиты программных
комплексов сточки зрения эксплуатационной безопасности с помощью различных
методик, включая предложенные в настоящей работе. На основании анализа уязвимых
мест и после составления полного перечня угроз для данного конкретного объекта
информационной защиты необходимо осуществить переход к неформализованному или
формализованному описанию модели угроз эксплуатационной безопасности системы
защиты ПО. Такая модель, в свою очередь, должна являться составной частью
обобщенной модели обеспечения безопасности информации и ПО объекта защиты. На практике
часто используют неформализованное описание модели угроз, т.к. структура,
состав и функциональность современных компьютерных систем управления носят
многоуровневый, сложный и распределенный характер, а действия потенциального
нарушителя информационных и функциональных ресурсов трудно поддаются
формализации.
Задача
разработки обобщенной модели обеспечения безопасности информации, систем защиты
ПО и ПО объекта защиты может явиться предметом будущих научных исследований
Заключение
Количество
и уровень деструктивности угроз безопасности для программных комплексов
компьютерных систем как со стороны внешних, так и со стороны внутренних
источников угроз постоянно возрастает. Это объясняется стремительным развитием
компьютерных и телекоммуникационных средств, глобальных информационных систем,
необходимостью разработки для них сложного программного обеспечения с применение
современных средств автоматизации процесса проектирования программ. Кроме того,
это объясняется значительным или даже резким повышением в последнее время
активности деятельности хакеров и групп хакеров, атакующих компьютерные
системы, криминальных групп компьютерных взломщиков, различных специальных
подразделений и служб, осуществляющих свою деятельность в области создания
средств воздействия на критически уязвимые объекты информатизации.
В
настоящей работе излагаются научно-практические основы обеспечения безопасности
программного обеспечения компьютерных систем, рассматриваются методы и средства
защиты программ от воздействия разрушающих программных средств на различных
этапах их жизненного цикла.
Значительная
часть материала посвящена выявлению и анализу угроз безопасности программного
обеспечения, рассмотрению основ формирования моделей угроз и их вербальному
описанию, методов и средств обеспечения технологической и эксплуатационной
безопасности программ.
Необходимой
составляющей проблемы обеспечения информационной безопасности программного
обеспечения является общегосударственная система стандартов и других
нормативных и методических документов по безопасности информации (ознакомиться
с большей их частью можно в главе 4), а также международные стандарты и
рекомендации по управлению качеством программного обеспечения, которые
позволяет предъявить к создаваемым и эксплуатируемым программных комплексам
требуемый уровень реализации защитных функций.
Изложенный
материал, поможет при изучении технологии проектирования систем обеспечения
безопасности программного обеспечения избежать многих ошибок, которые могут
существенно повлиять на качество проекта и эффективность конечной системы в
целом при ее реализации на объектах информатизации различного назначения.
Литература:
1. Дмитрий
Скляров "Искусство защиты и взлома информации" ©
"БХВ-ПЕТЕРБУРГ", 2004
. http://www.cdrinfo.com
. Расторгуев
С.П. Программные методы защиты информации в компьютерах и сетях.
. Чернов
А. В. Анализ запутывающих преобразований программ / Библиотека аналитической
информации [Электронный ресурс]
http://www.citforum.ru/security/articles/analysis/
. Чернов
А. В. Исследование и разработка методологии маскировки программ: дис. ... канд.
физ.-мат. наук /Моск. гос. ун-т им. М. В. Ломоносова. - М., 2003. - 133
с
. А.
В. Анисимов. Подходы к защите программного обеспечения от атак злонамеренного
хоста. УДК 681.3:004.056
. Мирошниченко
Е. А. Технологии программирования: учебное пособие / Е. А. Мирошниченко. - 2-е
изд., испр. и доп. - Томск: Изд-во Томского политехнического университета,
2008. - 128 с.
. Ефимов
А.И., Пальчун Б.П. О технологической безопасности компьютерной инфосферы//
Вопросы защиты информации. - 1995.- №3(30).
. Белкин
П.Ю. Новое поколение вирусов принципы работы и методы защиты// Защита
информации. - 1997.- №2.-С.35-40
. Зегжда
Д.П., Шмаков Э.М. Проблема анализа безопасности программного обеспечения//
Безопасность информационных технологий. - 1995.- №2.- С.28-33.
. Тейер
Т., Липов М., Нельсон Э. Надежность программного обеспечения. - М.: Мир, 1981.
. Расторгуев
СП., Дмитриевский Н.Н. Искусство защиты и «раздевания» программ. - М.:
«Софтмаркет», 1991.
. Роббинс
Д. Отладка приложений Microsoft .NET и Microsoft Windows. - М.: «Русская
редакция», 2004. - 736 с.
. Касперски
К, Техника и философия хакерских атак. Изд.2. - М.: Солон-Р, 2005.
. ГОСТ
28195-89: Оценка качества программных средств. Общие положения. - М.:
Издательство стандартов, 1989.
. Изосимов
А.В., Рыжко А.Л. Метрическая оценка качества программ. - М.: Изд. МАИ, 1989.
. Цивин
СВ. Методы защиты программных средств вне доверенной вы-числительной среды:
Автореф. дисс. к.т.н. - Пенза, 2000. - 21 с.
. Мадан
В.И. Исследование и анализ количественных характеристик качества программ:
Автореф. дисс, к,ф-м.н., Украинский институт кибернетики, 1992.
19. McCabe
T. A complexity measure //IEEE Transactions on Software Engineering, 1976, V.SE
2, № 4, P.308-320.
20. Шимаров
В.А. Методы инструментального контроля качества программ на основе структуры
передач управления: Автореф. дисс. к.ф-м.н. - АН БССР, Ин-т математики,
Минск, 1989.
. Майерс
Г. Надежность программного обеспечения. Пер. с англ. под ред. В.Ш. Кауфмана.
- М.: Мир, 1980
. Дал
У., Дейкстра Э., Хоор К. Структурное программирование. - М
. Липаев
В.В. Надежность ПО АСУ. - М.: Энергоиздат, 1981.
. Воробьев
С.Г., Копыльцов А.В, Пальчун Б.Н., Юсупов P.M. Методы и модели оценки
качества ПО. Ин-т информатики и автоматизации. - СПб.:1992.
. Липаев
В.В. Отладка сложных программ. Методы, Средства. Технологии, - М,: Энергоатомиздат,
1993,
. Заде
Л. Понятие лингвистической переменной и его применение к понятию приближенных
решений. - М.: Мир, 1976.