Исследование динамических рядов значений экономических показателей
Исследование динамических
рядов значений экономических показателей
1.
Теоретическая часть
.1
Общие сведения о методе скользящей средней
Скользящее среднее - один из распространенных методов
сглаживания временных рядов. Данный метод широко используется для отображения
изменений биржевых котировок, цен, годовых колебаний температур и т.д. Метод
так же может быть весьма полезен в цифровой обработке сигналов для устранения
высокочастотных составляющих и шумов, то есть он может быть использован в
качестве фильтра низких частот.
Пусть имеется оцифрованный сигнал S(n), где n - номер отчета
в выборке сигнала. Применив метод скользящего среднего получаем сигнал F(n).
Общая формула для вычисления скользящего среднего:
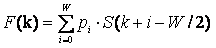 , (1)
, (1)
где W - ширина области усреднения, pi - весовые коэффициенты.
Суть метода заключается в замене точки выборки средним
значением соседствующих точек в заданной окрестности. В общем случае для
усреднения используются весовые коэффициенты, которые могут быть различными по
значению.
Частным случаем формулы 1 является простое скользящее
среднее, являющееся результатом усреднения значений в окрестности точки S(k).
Весовые коэффициенты для простого скользящего среднего pi=1/W. Таким образом,
формула 1 принимает вид:
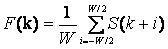 , (2)
, (2)
Простое скользящее среднее прекрасно подходит для устранения
высокочастотных шумовых составляющих из сигнала при его обработке, когда к
фильтру не предъявляется высоких требований по фазофо-частотной характеристике,
крутизне среза и т.д. Например, при устранении шумов перед декодированием из
оцифрованного сигнала информации.
Главным достоинством алгоритма простого скользящего среднего
являются простота его реализации и нетребовательность к вычислительным ресурсом
по сравнению с цифровыми фильтрами, реализующимися дискретной линейной
сверткой.
Если рассмотреть формулу 1, можно заметить, что она является
описанием КИХ-фильтра, где весовые коэффициенты pi являются импульсной
характеристикой. Трудоемкость вычисления результата КИХ-фильтрации определяется
количеством коэффициентов импульсной характеристики (Nh) и количеством
семплов(отсчетов) в выборке сигнала (Ns). Тогда для вычисления одного
результирующего отсчета потребуется произвести Nh операций умножения и Nh
операций сложения. Для вычисления результирующей (отфильтрованной) выборки
необходимо произвести Nh·Ns операций умножения и Nh·Ns операций сложения. При
реализации систем реального времени такая трудоемкость зачастую бывает
неприемлемой. Если рассмотреть формулу 2 то несложно подсчитать, что для
вычисления одного результирующего семпла потребуется Nh операций сложения и
всего одна операция умножения. Для вычисления результирующей (отфильтрованной)
выборки необходимо произвести Nh·Ns операций сложения и Ns операций умножения.
Таким образом, реализация алгоритма по формуле 2 дает прирост в
производительности на время Nh·ts, где ts - время, затрачиваемое на выполнение
одной операции умножения.
Алгоритм вычисления скользящего среднего можно далее оптимизировать
по трудоемкости, а следовательно по времени выполнения за счет сокращения
операций сложения, если учесть тот факт, что для применения фильтра
суммирование по W отчетам можно провести только один раз для нахождения
элемента
F(k)= SUM(k)/W, (3)
где
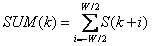 (4)
(4)
Тогда последующий элемент может быть вычислен по формуле
F (k+1) = (SUM(k) + S (k+ W/2 + 1) - S (k - W/2))
/ W (5)
Пояснение к формуле (5) представленно на рисунке 1.
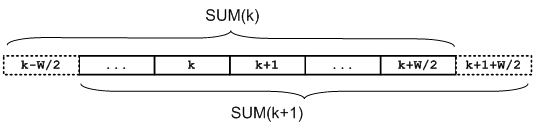
Рисунок 1 - Оптимизация нахождения сумм
Таким образом, на первой итерации алгоритма необходимо
провести Nh операций сложения, а на последующих Ns итерациях - всего по две
операции сложения.
1.2
Общие сведения о корреляционном анализе и коэффициенте линейной парной
корреляции
Корреляционный анализ - совокупность методов исследования
параметров многомерного признака, позволяющая по выборке из генеральной
совокупности сделать статистические выводы о мерах статистической зависимости
между компонентами исследуемого признака.
В данном учебном пособии рассмотрены основные элементы
анализа структуры и тесноты статистической связи между анализируемыми
переменными, т.е. задачи корреляционного анализа.
Основное содержание корреляционного анализа составляют
методы, которые позволяют ответить на вопросы:
· «существует ли связь
между исследуемыми переменными?»;
· «какова структура связей
между параметрами исследуемого многомерного признака?»;
· «как измерить тесноту
связей?».
В задачах корреляционного анализа под структурой связей
понимается лишь факт наличия или отсутствия связи, а не форма этой зависимости.
Рассмотрим описание общей схемы взаимосвязи параметров при
статистическом исследовании зависимостей, приведенной на рисунке.
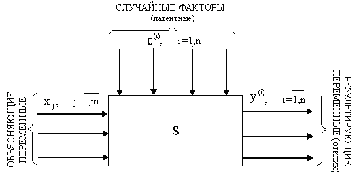
Общая схема взаимосвязи параметров при статистическом
исследовании зависимостей
Здесь S - модель исследуемого реального объекта, реализующая
механизм преобразования входных переменных в отклик, хj, 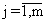 - входные переменные,
описывающие условия функционирования объекта (некоторые из них могут быть
подвергнуты регулированию). Эти факторы часто называют независимыми,
предикторными или объясняющими.
- входные переменные,
описывающие условия функционирования объекта (некоторые из них могут быть
подвергнуты регулированию). Эти факторы часто называют независимыми,
предикторными или объясняющими.
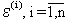 - случайные, остаточные компоненты, влияние
которых на y(i) трудно учесть (измерить). К ним относятся также
случайные ошибки в измерении анализируемых параметров. Такие компоненты
называют еще латентными или просто «остатками».
- случайные, остаточные компоненты, влияние
которых на y(i) трудно учесть (измерить). К ним относятся также
случайные ошибки в измерении анализируемых параметров. Такие компоненты
называют еще латентными или просто «остатками».
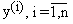 - выходные переменные (отклик), характеризующие
результат функционирования объекта. Еще их называют объясняемыми переменными.
- выходные переменные (отклик), характеризующие
результат функционирования объекта. Еще их называют объясняемыми переменными.
Далее будем пользоваться введенными понятиями.
При исследовании статистической связи между компонентами
многомерного признака исследователю приходится решать следующие задачи:
· выбор подходящего
измерителя связи с учетом специфики и природы анализируемых переменных;
· точечное или интервальное
оценивание измерителя связи по выборочным данным, полученным в результате
эксперимента;
· проверка гипотезы о
значимости (статистически значимом отличии значения корреляционной
характеристики от нуля) анализируемого измерителя связи;
· анализ структуры связей
между компонентами многомерного признака.
Все это задачи корреляционного анализа. В качестве
измерителей степени тесноты парных связей между количественными переменными
могут использоваться индекс корреляции, коэффициент корреляции (иногда
используют термин «коэффициент корреляции Пирсона»), корреляционное отношение,
частный коэффициент корреляции, применяемый для исследования частных или
«очищенных» связей, освобожденных от опосредованного одновременного влияния на
исследуемую парную связь других переменных.
Если статистическая информация о многомерном признаке
представлена не в количественной, а в порядковой шкале, то измерение парных
связей осуществляется посредством ранговых выборочных измерителей связи -
коэффициентов корреляции Кендалла и Спирмэна.
Измерение степени тесноты множественной связи между
количественными переменными возможно с помощью множественного коэффициента корреляции
(или коэффициента детерминации), а между порядковыми переменными - с помощью
коэффициента конкордации.
При таком многообразии измерителей статистической связи
важной становится задача выбора адекватного ее измерителя.
Применимость того или иного измерителя определяется как
формой представления исходной статистической информации (количественные или
порядковые признаки), так и формой связи (линейная, нелинейная). От грамотного
выбора адекватного измерителя связи зависит достоверность статистических выводов,
распространяемых на исследуемую многомерную генеральную совокупность.
Предварительный анализ структуры связи между компонентами
исследуемого многомерного признака, представленного выборкой из генеральной
совокупности, осуществляют с помощью корреляционных полей.
Под корреляционным полем (диаграммой рассеяния) переменных
(u, v) понимается графическое представление результатов измерений (u1,
v1), …, (ui, vi), …, (un, vn),
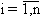 этих переменных в
плоскости (u, v). На основании анализа корреляционного поля легко решить вопрос
о наличии или отсутствии связи, проследить характер связи (линейная,
нелинейная, функциональная или стохастическая) и ее тенденцию (положительная,
отрицательная).
этих переменных в
плоскости (u, v). На основании анализа корреляционного поля легко решить вопрос
о наличии или отсутствии связи, проследить характер связи (линейная,
нелинейная, функциональная или стохастическая) и ее тенденцию (положительная,
отрицательная).
1.3
Общие сведения о регрессионном анализе и методе наименьших квадратов
Метод наименьших квадратов - метод нахождения оптимальных
параметров линейной регрессии, таких, что сумма квадратов ошибок (регрессионных
остатков) минимальна. Метод заключается в минимизации расстояния 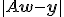 между двумя векторами -
вектором восстановленных значений зависимой переменной и вектором фактических
значений зависимой переменной.
между двумя векторами -
вектором восстановленных значений зависимой переменной и вектором фактических
значений зависимой переменной.
Метод наименьших квадратов является одним из наиболее
распространенных и наиболее разработанных вследствие своей простоты и
эффективности методов оценки параметров линейных эконометрических моделей.
Вместе с тем, при его применении следует соблюдать определенную осторожность,
поскольку построенные с его использованием модели могут не удовлетворять целому
ряду требований к качеству их параметров и, вследствие этого, недостаточно
«хорошо» отображать закономерности развития процесса 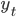 .
.
Рассмотрим процедуру оценки параметров линейной
эконометрической модели с помощью метода наименьших квадратов более подробно.
Такая модель в общем виде может быть представлена уравнением (1.2):
yt = a0 + a1 х1t + … + an хnt + εt.
Исходными данными при оценке параметров a0, a1,…,
an является вектор значений зависимой переменной y = (y1,
y2,…, yT)' и матрица значений независимых переменных

в которой первый столбец, состоящий из единиц, соответствует
коэффициенту модели 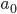 .
.
Название свое метод наименьших квадратов получил, исходя из
основного принципа, которому должны удовлетворять полученные на его основе
оценки параметров: сумма квадратов ошибки модели должна быть минимальной.
Регрессионный анализ - это статистический метод исследования
зависимости случайной величины у от переменных (аргументов) хj
(j = 1, 2,…, k), рассматриваемых в регрессионном анализе как
неслучайные величины независимо от истинного закона распределения xj.
Обычно предполагается, что случайная величина у имеет
нормальный закон распределения с условным математическим ожиданием  = φ(x1,…, хk), являющимся функцией от аргументов хj
и с постоянной, не зависящей от аргументов дисперсией σ2.
= φ(x1,…, хk), являющимся функцией от аргументов хj
и с постоянной, не зависящей от аргументов дисперсией σ2.
Для проведения регрессионного анализа из (k + 1) - мерной генеральной
совокупности (у, x1, х2,…, хj,…, хk) берется выборка объемом n,
и каждое i-е наблюдение (объект) характеризуется значениями переменных (уi, xi1, хi2,…, хij,…, xik), где хij
- значение j-й переменной для i-го наблюдения (i = 1, 2,…, n), уi
- значение результативного признака для i-го наблюдения.
Наиболее часто используемая множественная линейная модель
регрессионного анализа имеет вид
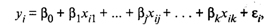 (6)
(6)
где βj - параметры
регрессионной модели;
εj - случайные ошибки
наблюдения, не зависимые друг от друга, имеют нулевую среднюю и дисперсию σ2.
Отметим, что модель (6) справедлива для всех i = 1,2,…, n,
линейна относительно неизвестных параметров β0, β1,…, βj, …, βk и аргументов.
Как следует из (6), коэффициент регрессии Bj показывает, на какую
величину в среднем изменится результативный признак у, если переменную хj
увеличить на единицу измерения, т.е. является нормативным коэффициентом.
В матричной форме регрессионная модель имеет вид
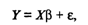 (7)
(7)
где Y - случайный вектор-столбец размерности п
х 1 наблюдаемых значений результативного признака (у1, у2,….
уn); Х - матрица размерности п х (k + 1) наблюдаемых
значений аргументов, элемент матрицы х, рассматривается как неслучайная
величина (i = 1, 2,…, n; j=0,1,…, k; x0i, = 1); β - вектор-столбец размерности (k + 1) х 1 неизвестных,
подлежащих оценке параметров модели (коэффициентов регрессии); ε - случайный вектор-столбец размерности п х 1 ошибок наблюдений
(остатков). Компоненты вектора εi не зависимы друг от
друга, имеют нормальный закон распределения с нулевым математическим ожиданием
(Mεi = 0) и неизвестной
постоянной σ2 (Dεi = σ2).
На практике рекомендуется, чтобы значение п превышало
k не менее чем в три раза.
В модели (7)
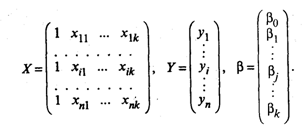
В первом столбце матрицы Х указываются единицы при
наличии свободного члена в модели (6). Здесь предполагается, что существует
переменная x0, которая во всех наблюдениях принимает значения,
равные единице.
Основная задача регрессионного анализа заключается в
нахождении по выборке объемом п оценки неизвестных коэффициентов
регрессии β0, β1, …, βk модели (6) или вектора β в (7).
Так как в регрессионном анализе хj
рассматриваются как неслучайные величины, a Mεi = 0, то согласно (6) уравнение регрессии имеет
вид
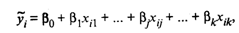 (8)
(8)
для всех i = 1, 2,…, п, или в матричной форме:
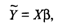 (9)
(9)
где 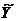 - вектор-столбец с элементами 1…, i,…, n.
- вектор-столбец с элементами 1…, i,…, n.
Для оценки вектора-столбца β
наиболее
часто используют метод наименьших квадратов, согласно которому в качестве
оценки принимают вектор-столбец b, который минимизирует сумму квадратов
отклонений наблюдаемых значений уi от модельных значений i, т.е. квадратичную форму:
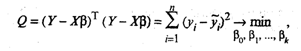
где символом «Т» обозначена транспонированная матрица.
Наблюдаемые и модельные значения результативного признака у
показаны на рис. 1.
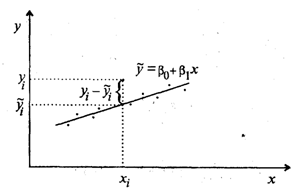
Рис. 2. Наблюдаемые и модельные значения результативного
признака у
Дифференцируя, с учетом (9) и (8), квадратичную форму Q по β0, β1, …, βk и приравнивая частные производные к нулю,
получим систему нормальных уравнений
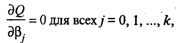
решая которую получим вектор-столбец оценок b, где b
= (b0, b1,…, bk)T. Согласно методу
наименьших квадратов, вектор-столбец оценок коэффициентов регрессии получается
по формуле
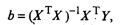 (11)
(11)
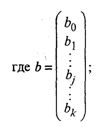
ХT - транспонированная
матрица X;
(ХTХ)-1 - матрица, обратная
матрице ХTХ.
Зная вектор-столбец b оценок коэффициентов регрессии,
найдем оценку  уравнения регрессии
уравнения регрессии
 (12)
(12)
или в матричном виде:
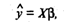
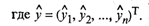
Оценка ковариационной матрицы вектора коэффициентов регрессии
b определяется выражением
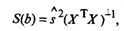 (13)
(13)
где
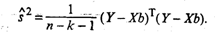 (14)
(14)
Учитывая, что на главной диагонали ковариационной матрицы
находятся дисперсии коэффициентов регрессии, имеем
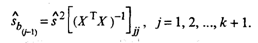 (15)
(15)
Значимость уравнения регрессии, т.е. гипотеза Н0:
β = 0 (β0,= β1 = βk = 0), проверяется по F-критерию,
наблюдаемое значение которого определяется по формуле
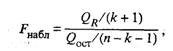 (16)
(16)
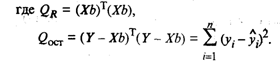
По таблице F-распределения для заданных α, v 1 = k + l, v2 = n - k - l находят Fкр.
Гипотеза H0 отклоняется с вероятностью α, если Fнабл > Fкр. Из этого
следует, что уравнение является значимым, т.е. хотя бы один из коэффициентов
регрессии отличен от нуля.
Для проверки значимости отдельных коэффициентов регрессии,
т.е. гипотезы Н0: βj = 0, где j = 1, 2,…, k,
используют t-критерий и вычисляют tнабл(bj) = bj / 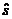 bj. По таблице t-распределения для
заданного α и v = п - k - 1
находят tкр.
bj. По таблице t-распределения для
заданного α и v = п - k - 1
находят tкр.
Гипотеза H0 отвергается с вероятностью α, если tнабл > tкр. Из этого следует, что
соответствующий коэффициент регрессии βj значим, т.е. βj ≠ 0. В противном случае
коэффициент регрессии незначим и соответствующая переменная в модель не
включается. Тогда реализуется алгоритм пошагового регрессионного анализа,
состоящий в том, что исключается одна из незначительных переменных, которой
соответствует минимальное по абсолютной величине значение tнабл. После этого вновь
проводят регрессионный анализ с числом факторов, уменьшенным на единицу.
Алгоритм заканчивается получением уравнения регрессии со значимыми
коэффициентами.
Существуют и другие алгоритмы пошагового регрессионного
анализа, например с последовательным включением факторов.
Наряду с точечными оценками bj генеральных
коэффициентов регрессии βj регрессионный анализ
позволяет получать и интервальные оценки последних с доверительной вероятностью
γ.
Интервальная оценка с доверительной вероятностью γ для параметра βj имеет вид
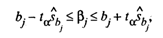 (17)
(17)
где tα находят по таблице t-распределения при
вероятности α = 1 - γ и числе степеней свободы v = п - k - 1.
Интервальная оценка для уравнения регрессии в точке, определяемой
вектором-столбцом начальных условий X0 = (1, x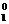 , x
, x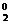 ,…, x
,…, x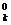 )T записывается в виде
)T записывается в виде
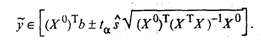 (18)
(18)
Интервал предсказания n+1 с доверительной
вероятностью у определяется как
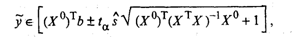 (19)
(19)
где tα определяется по таблице t-распределения при α = 1 - γ и числе степеней свободы v
= п - k - 1.
По мере удаления вектора начальных условий х0
от вектора средних 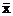 ширина доверительного интервала при заданном
значении γ будет увеличиваться (рис. 2), где = (1,
ширина доверительного интервала при заданном
значении γ будет увеличиваться (рис. 2), где = (1, 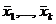 ).
).
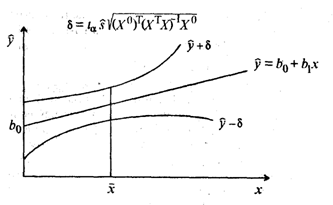
Рис. 3. Точечная 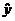 и интервальная
и интервальная 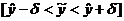 оценки уравнения
регрессии
оценки уравнения
регрессии 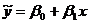
2.
Практическая часть
.1
Построение графиков изменения значений показателей по данным варианта
Сформируем таблицу исходных данных
|
Xi
|
Yi
|
|
0
|
20
|
28
|
|
1
|
21
|
21
|
|
2
|
22
|
41
|
|
3
|
23
|
27
|
|
4
|
24
|
35
|
|
5
|
24
|
46
|
|
6
|
25
|
56
|
|
7
|
27
|
52
|
|
8
|
27
|
59
|
|
9
|
27
|
63
|
|
10
|
32
|
72
|
|
11
|
32
|
76
|
|
12
|
32
|
88
|
|
13
|
33
|
87
|
|
14
|
34
|
82
|
|
15
|
34
|
100
|
|
16
|
35
|
95
|
|
17
|
36
|
108
|
|
18
|
39
|
106
|
|
19
|
39
|
113
|
2.2
Обработка динамических рядов методом скользящей средней и построение графиков
скользящий корреляция график средний
Рассчитаем сглаживание в данной таблице по первому показателю
|
Xi
|
Расчет
скользящих средних
|
Сглаженный
показатель
|
|
0
|
21
|
21
|
21
|
|
1
|
23
|
(21+23+20):3
|
21,33333333
|
|
2
|
20
|
(23+20+24):3
|
22,33333333
|
|
3
|
24
|
(20+24+22):3
|
22
|
|
4
|
22
|
(24+22+24):3
|
23,33333333
|
|
5
|
24
|
(22+24+24):3
|
24,33333333
|
|
6
|
27
|
(24+27+25):3
|
25,33333333
|
|
7
|
25
|
(27+25+27):3
|
26,33333333
|
|
8
|
27
|
(25+27+27):3
|
26,33333333
|
|
9
|
27
|
(27+27+32):3
|
28,66666667
|
|
10
|
32
|
(27+32+32):3
|
30,33333333
|
|
11
|
32
|
(32+32+34):3
|
32,66666667
|
|
12
|
34
|
(32+34+33):3
|
33
|
|
13
|
33
|
(34+33+32):3
|
33
|
|
14
|
32
|
(33+32+35):3
|
33,33333333
|
|
15
|
35
|
(32+35+34):3
|
33,66666667
|
|
16
|
34
|
(35+34+39):3
|
36
|
|
17
|
39
|
(34+39+36):3
|
36,33333333
|
|
18
|
36
|
(39+36+39):3
|
38
|
|
19
|
39
|
39
|
39
|
Построим график с результатами расчетов
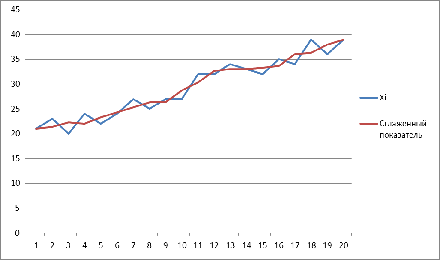
Рассчитаем сглаживание в данной таблице по второму показателю
|
YiРасчет
скользящих среднихСглаженный показатель
|
|
|
|
|
0
|
21
|
21
|
21
|
|
1
|
27
|
(21+27+28):3
|
25,33333333
|
|
2
|
28
|
(27+28+35):3
|
30
|
|
3
|
35
|
(28+35+41):3
|
34,66666667
|
|
4
|
41
|
(35+41+46):3
|
40,66666667
|
|
5
|
46
|
(41+46+52):3
|
46,33333333
|
|
6
|
52
|
(46+52+56):3
|
51,33333333
|
|
7
|
56
|
(52+56+59):3
|
55,66666667
|
|
8
|
59
|
(56+59+63):3
|
59,33333333
|
|
9
|
63
|
(59+63+72):3
|
64,66666667
|
|
10
|
72
|
(63+72+76):3
|
70,33333333
|
|
11
|
76
|
(72+76+82):3
|
76,66666667
|
|
12
|
82
|
(76+82+87):3
|
81,66666667
|
|
13
|
87
|
(82+87+88):3
|
85,66666667
|
|
14
|
88
|
(87+88+95):3
|
90
|
|
15
|
95
|
(88+95+100):3
|
94,33333333
|
|
16
|
100
|
(95+100+106):3
|
100,3333333
|
|
17
|
106
|
(100+106+108):3
|
104,6666667
|
|
18
|
108
|
(106+108+113):3
|
109
|
113
|
113
|
113
|
Построим график с результатами расчетов
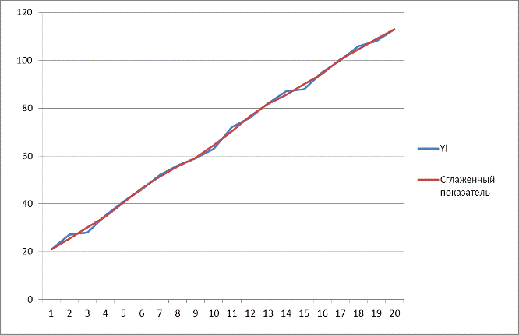
2.3 Расчет коэффициента линейной парной
корреляции по заданным значениям рядов
Исходные данные
|
A
|
B
|
C
|
|
1
|
|
Xi
|
Yi
|
|
2
|
0
|
21
|
21
|
|
3
|
1
|
23
|
27
|
|
4
|
2
|
20
|
28
|
|
5
|
3
|
24
|
35
|
|
6
|
4
|
22
|
41
|
|
7
|
5
|
24
|
46
|
|
8
|
6
|
27
|
52
|
|
9
|
7
|
25
|
56
|
|
10
|
8
|
27
|
59
|
|
11
|
9
|
27
|
63
|
|
12
|
10
|
32
|
72
|
|
13
|
11
|
32
|
76
|
|
14
|
12
|
34
|
82
|
|
15
|
13
|
33
|
87
|
|
16
|
14
|
32
|
88
|
|
17
|
15
|
35
|
95
|
|
18
|
16
|
34
|
100
|
|
19
|
17
|
39
|
106
|
|
20
|
18
|
36
|
108
|
|
21
|
19
|
39
|
113
|
Сделаем некоторые расчеты
|
Xi
|
(Xi-X!)
|
(Xi-X!)^2
|
Yi
|
(Yi-Y!)
|
(Yi-Y!)^2
|
(Xi-X!)*(Yi-Y!)
|
|
21
|
-8,3
|
68,89
|
21
|
-46,75
|
2186
|
388,025
|
|
23
|
-6,3
|
39,69
|
27
|
-40,75
|
1661
|
256,725
|
|
20
|
-9,3
|
86,49
|
28
|
-39,75
|
1580
|
369,675
|
|
24
|
-5,3
|
28,09
|
35
|
-32,75
|
1073
|
173,575
|
|
22
|
-7,3
|
53,29
|
41
|
-26,75
|
716
|
195,275
|
|
24
|
-5,3
|
28,09
|
46
|
-21,75
|
473
|
115,275
|
|
27
|
-2,3
|
5,29
|
52
|
-15,75
|
248
|
36,225
|
|
25
|
-4,3
|
18,49
|
56
|
-11,75
|
138
|
50,525
|
|
27
|
-2,3
|
5,29
|
59
|
-8,75
|
77
|
20,125
|
|
27
|
-2,3
|
5,29
|
63
|
-4,75
|
23
|
10,925
|
|
32
|
2,7
|
7,29
|
72
|
4,25
|
18
|
11,475
|
|
32
|
2,7
|
7,29
|
76
|
8,25
|
68
|
22,275
|
|
34
|
4,7
|
22,09
|
82
|
14,25
|
203
|
66,975
|
|
33
|
3,7
|
13,69
|
87
|
19,25
|
371
|
71,225
|
|
32
|
2,7
|
7,29
|
88
|
20,25
|
410
|
54,675
|
|
35
|
5,7
|
32,49
|
95
|
27,25
|
743
|
155,325
|
|
34
|
4,7
|
22,09
|
100
|
32,25
|
1040
|
151,575
|
|
39
|
9,7
|
94,09
|
106
|
38,25
|
1463
|
371,025
|
|
36
|
6,7
|
44,89
|
108
|
40,25
|
1620
|
269,675
|
|
39
|
9,7
|
94,09
|
113
|
45,25
|
2048
|
438,925
|
|
29,3
|
|
684,2
|
67,75
|
|
16156
|
3230
|
Рассчитывали по формулам
|
F
|
G
|
H
|
I
|
J
|
K
|
L
|
|
2
|
Xi
|
(Xi-X!)
|
(Xi-X!)^2
|
Yi
|
(Yi-Y!)
|
(Yi-Y!)^2
|
(Xi-X!)*(Yi-Y!)
|
|
3
|
21
|
=F3-$F$23
|
=G3^2
|
21
|
=I3-$I$23
|
=J3^2
|
=G3*J3
|
|
4
|
23
|
=F4-$F$23
|
=G4^2
|
27
|
=I4-$I$23
|
=J4^2
|
=G4*J4
|
|
5
|
20
|
=F5-$F$23
|
=G5^2
|
28
|
=I5-$I$23
|
=J5^2
|
=G5*J5
|
|
6
|
24
|
=F6-$F$23
|
=G6^2
|
35
|
=I6-$I$23
|
=J6^2
|
=G6*J6
|
|
7
|
22
|
=F7-$F$23
|
=G7^2
|
41
|
=I7-$I$23
|
=J7^2
|
=G7*J7
|
|
8
|
24
|
=F8-$F$23
|
=G8^2
|
46
|
=I8-$I$23
|
=J8^2
|
=G8*J8
|
|
9
|
27
|
=F9-$F$23
|
=G9^2
|
52
|
=I9-$I$23
|
=J9^2
|
=G9*J9
|
|
10
|
25
|
=F10-$F$23
|
=G10^2
|
56
|
=I10-$I$23
|
=J10^2
|
=G10*J10
|
|
011
|
27
|
=F11-$F$23
|
=G11^2
|
59
|
=I11-$I$23
|
=J11^2
|
=G11*J11
|
|
12
|
27
|
=F12-$F$23
|
=G12^2
|
63
|
=I12-$I$23
|
=J12^2
|
=G12*J12
|
|
13
|
32
|
=F13-$F$23
|
=G13^2
|
72
|
=I13-$I$23
|
=J13^2
|
=G13*J13
|
32
|
=F14-$F$23
|
=G14^2
|
76
|
=I14-$I$23
|
=J14^2
|
=G14*J14
|
|
15
|
34
|
=F15-$F$23
|
=G15^2
|
82
|
=I15-$I$23
|
=J15^2
|
=G15*J15
|
|
16
|
33
|
=F16-$F$23
|
=G16^2
|
87
|
=I16-$I$23
|
=J16^2
|
=G16*J16
|
|
17
|
32
|
=F17-$F$23
|
=G17^2
|
88
|
=I17-$I$23
|
=J17^2
|
=G17*J17
|
|
18
|
35
|
=F18-$F$23
|
=G18^2
|
95
|
=I18-$I$23
|
=J18^2
|
=G18*J18
|
|
19
|
34
|
=F19-$F$23
|
=G19^2
|
100
|
=I19-$I$23
|
=J19^2
|
=G19*J19
|
|
20
|
39
|
=F20-$F$23
|
=G20^2
|
106
|
=I20-$I$23
|
=J20^2
|
=G20*J20
|
|
21
|
36
|
=F21-$F$23
|
=G21^2
|
108
|
=I21-$I$23
|
=J21^2
|
=G21*J21
|
|
22
|
39
|
=F22-$F$23
|
=G22^2
|
113
|
=I22-$I$23
|
=J22^2
|
=G22*J22
|
|
23
|
=СРЗНАЧ
(F3:F22)
|
|
=СУММ (H3:H22)
|
=СРЗНАЧ
(I3:I22)
|
|
=СУММ (K3:K22)
|
=СУММ (L3:L22)
|
Рассчитываем эмпирическую величину коэффициента корреляции по
формуле расчета коэффициента корреляции Браве-Пирсона:
r=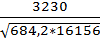 = 0,971359947
= 0,971359947
т.к. rф = 0,971359947 > 0, то между данными выборок наблюдается
прямая положительная взаимосвязь.
Т.к.
значения коэффициента корреляции находится в пределах 0,99 < rф =
0,971359947 < 0,7, то наблюдается высокая степень взаимосвязи.
Заключение
В процессе выполнения курсовой работы я научился применять
метод скользящих средних и метод наименьших квадратов, а так же выявлять наилучшие
модели аппроксимаций.
С помощью программы Microsoft office Exel мы проводили расчеты и
построения графиков.
Список источников
1. «Исследование
операций в экономике», Учебное пособие для вузов, под ред. Кремера Н.Ш. -
М.:Банки и биржи, ЮНИТИ, 1997
2. Качала
В.В. Основы теории систем и системного анализа. Учебное пособие для вузов. М.:
Горячая линия - Телеком, 2007