Анализ временных рядов
АНАЛИЗ ВРЕМЕННЫХ РЯДОВ
Поскольку условия ведения бизнеса изменяются с
течением времени, предпринимателям и менеджерам для успешного ведения своей
предпринимательской деятельности требуется предвидеть с той или иной степенью
надежности будущие события. В период роста цен на энергоносители, промышленники
должны уметь прогнозировать потребление электрической энергии
Анализ временных рядов - это анализ, основанный на
исходном предположении, согласно которому случившееся в прошлом служит
достаточно надежным указанием на то, что произойдет в будущем. Это также можно
назвать проектированием тенденций.
Временные ряды и их характеристики
Временной ряд представляет собой последовательность
данных, описывающих объект в последовательные моменты времени. В отличие от
анализа случайных выборок, анализ временных рядов основывается на
предположении, что последовательные данные наблюдаются через равные промежутки.
Существует две основные цели анализа временных рядов:
определение природы ряда и прогнозирование, т.е. предсказание будущих значений
временного ряда по настоящим и прошлым значениям. Обе цели требуют, чтобы
модель ряда была определена и более или менее формально описана. Как только
модель определена, с ее помощью можно интерпретировать рассматриваемые данные -
например, использовать ее для анализа наличия сезонного изменения цен на
товары. Затем можно экстраполировать ряд на основе найденной модели, т.е.
предсказать его будущие значения.
Как и большинство других видов анализа, анализ
временных радов предполагает, что данные содержат систематическую составляющую
(обычно включающую несколько компонент) и случайный шум (ошибку), который
затрудняет обнаружение регулярных компонент. Большинство методов исследования
временных рядов включает различные способы фильтрации шума, позволяющие увидеть
регулярную составляющую более отчетливо.
Большинство регулярных составляющих временных рядов
принадлежит к двум классам: они являются либо трендом, либо сезонной
составляющей. Тренд представляет собой общую систематическую линейную или
нелинейную компоненту, закономерно изменяющуюся во времени. Сезонная
составляющая - это периодически повторяющаяся компонента. Оба эти вида
регулярных компонент часто имеются в рядах одновременно. Например, потребление
завода может возрастать из года в год (тренд), но при этом они могут содержать
и сезонную составляющую (например, на 30% в зимний период возрастает
потребление относительно летнего периода). В табл. 1 приведено сравнение
компонент, влияющих на значения временного ряда.
Таблица 1. Факторы, влияющие на значения временного ряда
|
Компонента
|
Классификация
|
Определение
|
Причины
|
Продолжитель-ность
|
|
Тренд
|
Систематическая
|
Общая устойчивая
долговременная тенденция
|
Изменения в технологии,
численности населения, благосостоянии, системе ценностей
|
Несколько лет
|
|
Циклическая
|
Систематическая
|
Повторяющиеся спады и
подъемы, проходящие 4 фазы: пик, рецессия, депрессия, подъем
|
Взаимодействие
множественных комбинаций факторов, влияющих на экономику
|
Обычно 2-10 лет с
изменяющейся интенсивностью
|
|
Сезонная
|
Систематическая
|
Достаточно регулярные
периодические флуктуации, происходящие в каждом 12-месячном периоде из года в
год
|
Погодные условия.
|
В течение 12 месяцев
(квартальные и месячные наблюдения)
|
|
Нерегулярная
|
Случайная
|
Остаточная флуктация,
рассматривающаяся как «сезонная с ошибкой» и остающаяся после того, как
учтены систематические эффекты
|
Случайные вариации данных,
вызванные непредвиденными событиями
|
Обычно короткой
продолжительности и не повторяющиеся
|
Декомпозиция временных рядов
временной ряд сглаживание регрессионный
Основным положением, на котором базируется использование временных рядов
для прогнозирования, является то, что факторы, влияющие на полученные данные,
воздействовали некоторым образом на наблюдаемый процесс в прошлом и настоящем,
и предполагается, что они будут действовать схожим образом и в не очень далеком
будущем. Поэтому основной целью анализа временных рядов будет разложение их на
составные компоненты (декомпозиция) с целью прогноза дальнейшего поведения
системы и выработки рациональных управленческих решений.
Двумя простейшими моделями, в которых переменная временного ряда Y раскладывается на трендовую,
циклическую, сезонную и нерегулярную компоненту, являются аддитивная модель и
мультипликативная.
Модель, которая трактует каждое значение временного ряда как сумму
указанных выше компонент, называется аддитивной. Согласно этой модели любое
значение временного ряда представляется в виде:
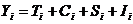
где Yi, -
значение временного ряда, а Ti , Ci, Si, Ii, -
соответственно значения трендовой, циклической, сезонной и нерегулярной
компонент в любой точке ряда.
Аддитивная модель применима в тех случаях, когда
анализируемый временной ряд имеет приблизительно одинаковые изменения на протяжении
всей длительности ряда.
Наиболее фундаментальной является классическая
мультипликативная модель временного ряда, широко используемая при анализе
ежемесячных, ежеквартальных и ежегодных данных и потому чаще всего применяемая
в экономических исследованиях.
В классической мультипликативной модели временных
рядов определяется, что наблюдаемое значение в любой точке временного ряда
является произведением трех факторов - тренда, циклической и нерегулярной
компонент (в случае короткошаговых наблюдений - четырех, здесь добавляется еще
и сезонная компонента), и любое значение ряда может быть представлено в виде:
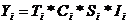 , где
, где
где
Yi, - значение временного ряда, а Ti, Ci, Si, Ii, -
соответственно значения трендовой, циклической, сезонной и нерегулярной
компонент в любой точке ряда.
Анализ тренда
Не существует "автоматического" способа
обнаружения тренда во временном ряду. Однако если тренд является монотонным
(устойчиво возрастает или убывает), то анализировать такой ряд обычно нетрудно.
Если временные ряды содержат значительную ошибку, то первым шагом выделения
тренда является сглаживание.
Сглаживание всегда включает некоторый способ
локального усреднения данных, при котором несистематические компоненты взаимно
погашают друг друга. Самый общий метод сглаживания - скользящее среднее, в
котором каждый член ряда заменяется простым или взвешенным средним т соседних
членов, где т - ширина "окна". Также для выделения тренда широко
используется метод экспоненциального сглаживания.
Многие монотонные временные ряды можно хорошо описать
линейной функцией. Если же имеется явная монотонная нелинейная компонента, то
данные вначале следует преобразовать таким образом, чтобы устранить эту
нелинейность. Чаще всего для этой цели используют логарифмическое,
экспоненциальное или (не так часто) полиномиальное преобразование данных.
Метод экспоненциального сглаживания
Простая и логически ясная модель временного ряда имеет
следующий вид:
Yt = b + et
где b - константа, et - случайная ошибка. Константа b
относительно стабильна на каждом временном интервале, но может также медленно
изменяться со временем. Один из интуитивно ясных способов выделения значения b
из данных состоит в том, чтобы использовать сглаживание скользящим средним, в
котором последним наблюдениям приписываются большие веса, чем предпоследним,
предпоследним большие веса, чем пред-предпоследним, и т.д. Простое
экспоненциальное сглаживание именно так и построено. Здесь более старым
наблюдениям приписываются экспоненциально убывающие веса, при этом, в отличие
от скользящего среднего, учитываются все предшествующие наблюдения ряда, а не
только те, которые попали в определенное окно. Точная формула простого
экспоненциального сглаживания имеет вид:
St = a yt + (1 - a) St-1
Когда эта формула применяется рекурсивно, каждое новое
сглаженное значение (которое является также прогнозом) вычисляется как
взвешенное среднее текущего наблюдения и сглаженного ряда. Очевидно, результат
сглаживания зависит от параметра a. Если a равен 1, то предыдущие наблюдения
полностью игнорируются. Если a равен 0, то игнорируются текущие
наблюдения. Значения a между 0 и 1 дают промежуточные
результаты. Эмпирические исследования показали, что простое экспоненциальное
сглаживание весьма часто дает достаточно точный прогноз.
На практике обычно рекомендуется брать a меньше
0,30. Однако выбор a больше 0,30 иногда дает более точный прогноз. Это значит,
что лучше все же оценивать оптимальное значение a по реальным данным, чем использовать
общие рекомендации.
На практике оптимальный параметр сглаживания часто
ищется с использованием процедуры поиска на сетке. Возможный диапазон значений
параметра разбивается сеткой с определенным шагом. Например, рассматривается
сетка значений от a = 0,1 до a = 0,9 с шагом 0,1. Затем выбирается
такое значение a, для которого сумма квадратов (или средних квадратов)
остатков (наблюдаемые значения минус прогнозы на шаг вперед) является
минимальной.Excel располагает функцией Exponential Smoothing (Экспоненциальное
сглаживание), которая обычно используется для сглаживания уровней эмпирической
временного ряда на основе метода простого экспоненциального сглаживания. Для
вызова этой функции необходимо на панели меню выбрать команду Tools
Data Analysis. На экране раскроется окно
Data Analysis, в котором следует выбрать значение Exponential Smoothing
(Экспоненциальное сглаживание). В результате появится диалоговое окно
Exponential Smoothing.
В диалоговом окне Exponential Smoothing задаются
практически те же параметры, что и в рассмотренном выше диалоговом окне Moving
Average.
1.
Input Range
(Входные данные) - в это поле вводится диапазон ячеек, содержащих значения
исследуемого параметра.
2.
Labels (Метки) -
данный флажок опции устанавливается в том случае, если первая строка (столбец)
во входном диапазоне содержит заголовок. Если заголовок отсутствует, флажок
следует сбросить. В этом случае для данных выходного диапазона будут
автоматически созданы стандартные названия.
3.
Damping factor
(Фактор затухания) - в это поле вводится значение выбранного коэффициента
экспоненциального сглаживания а. По умолчанию принимаете значение а = 0,3.
4.
Output options
(Параметры вывода) - в этой группе, помимо указания диапазона ячеек для
выходных данных в поле Output Range (Выходной диапазон), можно также
потребовать автоматически построить график, для чего необходимо установить
флажок опции Chart Output (Вывод графика), и рассчитать стандартные
погрешности, для чего нужно установить флажок опции Standart Erroг (Стандартные
погрешности).
Расчеты методом экспоненциального сглаживания:
Исходные данные
|
Часы
|
Дни
|
|
11 янв
|
18 янв
|
25 янв
|
1 фев
|
8 фев
|
15 фев
|
1 мар
|
22 мар
|
|
0-1
|
2339,4
|
3017,7
|
2940
|
2749,95
|
3314,9
|
4866,8
|
2722,7
|
2545,2
|
2439,2
|
|
1-2
|
2326,8
|
2995,65
|
2948,4
|
2711,1
|
3012,5
|
4668,3
|
2688
|
2624
|
2485,4
|
|
2-3
|
2299,5
|
3176,25
|
2932,65
|
2667
|
4617,9
|
6073,2
|
2606,1
|
3069,2
|
4088,7
|
|
3-4
|
2401,35
|
5946,15
|
4217,85
|
2689,05
|
4887,8
|
5534,6
|
2502,2
|
4624,2
|
4750,2
|
|
4-5
|
3271,8
|
5199,6
|
7604,1
|
3895,5
|
6694,8
|
7817,3
|
3707,6
|
6971
|
6825
|
|
5-6
|
4884,6
|
8877,75
|
7786,8
|
5827,5
|
9041,6
|
9198
|
5596,5
|
7004,6
|
7614,6
|
|
6-7
|
5570,25
|
10731
|
8721,3
|
6427,05
|
8712,9
|
7892,9
|
6190,8
|
7344,8
|
|
7-8
|
5663,7
|
8967
|
10382,4
|
6527,85
|
9871,1
|
10224
|
6347,3
|
6872,3
|
6831,3
|
|
8-9
|
5326,65
|
7518
|
8738,1
|
5864,25
|
8889,3
|
9358,7
|
5922
|
7801,5
|
9282
|
|
9-10
|
4995,9
|
7187,25
|
9088,8
|
5717,25
|
7862,4
|
9493,1
|
5644,8
|
7410,9
|
5930,4
|
|
10-11
|
5199,6
|
10454,9
|
10179,8
|
6176,1
|
9911
|
7933,8
|
6049,1
|
6722,1
|
8808,5
|
|
11-12
|
5181,75
|
9904,65
|
11008,2
|
5926,2
|
9860,6
|
8286,6
|
5981,9
|
6776,7
|
7896
|
|
12-13
|
4773,3
|
8817,9
|
9752,4
|
5149,2
|
8884,1
|
9216,9
|
5113,5
|
5598,6
|
6343,1
|
|
13-14
|
4228,35
|
7460,25
|
8566,95
|
4572,75
|
6190,8
|
8202,6
|
4293,5
|
4013,1
|
7730,1
|
3675
|
5815,95
|
8400
|
3832,5
|
4960,2
|
8649,9
|
3832,5
|
3490,2
|
7196,7
|
|
15-16
|
3435,6
|
6978,3
|
5176,5
|
3409,35
|
5690
|
6489
|
3450,3
|
3137,4
|
4313,4
|
|
16-17
|
3268,65
|
5940,9
|
7411,95
|
3231,9
|
6159,3
|
7291,2
|
3145,8
|
3038,7
|
5296,2
|
|
17-18
|
3124,8
|
6421,8
|
7770
|
3109,05
|
5844,3
|
6724,2
|
2949,5
|
2816,1
|
5076,8
|
|
18-19
|
3106,95
|
6925,8
|
6032,25
|
2969,4
|
5165
|
6671,7
|
2924,3
|
2967,3
|
6160,4
|
|
19-20
|
2996,7
|
6166,65
|
7503,3
|
2954,7
|
4006,8
|
5466,3
|
2774,1
|
2660,7
|
4948,7
|
|
20-21
|
2964,15
|
6378,75
|
4205,25
|
2926,35
|
3791,6
|
6762
|
2645
|
2410,8
|
3137,4
|
|
21-22
|
3893,4
|
4597,95
|
2916,9
|
6689,6
|
4381,7
|
2678,6
|
2352
|
2677,5
|
|
22-23
|
2752,05
|
6466,95
|
6280,05
|
2870,7
|
3899,7
|
4241
|
2710,1
|
2915,9
|
2585,1
|
|
23-24
|
2656,5
|
5902,05
|
6107,85
|
2930,55
|
3612
|
3806,3
|
2920,1
|
2525,3
|
2565,2
|
Прогноз потребления на 29 марта 2010:
График 1. Прогнозирование потребления за 0-1 час
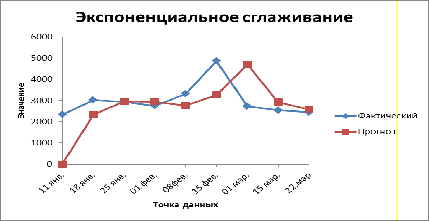
Анологичным образом как указано выше расчитываем
прогнозируемое значение потребленияпо часам
Прогноз.
|
Час
|
Потребление, кВт
|
Час
|
Потребление, кВт
|
|
0-1
|
2453,558 (2359,35)
|
12-13
|
6177,997 (5304,6)
|
|
1-2
|
2501,712 (2361,45)
|
13-14
|
6728,012 (4034,1)
|
|
2-3
|
3985,421(3476,55)
|
14-15
|
6215,624027 (3267,6)
|
|
3-4
|
4593,973 (3754,8)
|
15-16
|
4060,24189 (2969,4)
|
|
4-5
|
6672,213 (5800,2)
|
16-17
|
4726,783039 (2767,8)
|
|
5-6
|
7394,439 (8497,65)
|
17-18
|
4501,625718 (2667)
|
|
6-7
|
6802,418 (7248,85)
|
18-19
|
5284,417904 (2431,8)
|
|
7-8
|
6892,322 (7136,85)
|
19-20
|
4333,632471 (2339,4)
|
|
8-9
|
20-21
|
3050,722833 (2321,55)
|
|
9-10
|
6302,982 (8678,25)
|
21-22
|
2171,839846 (2178,75)
|
|
10-11
|
8182,47 (8470,35)
|
22-23
|
2091,830857 (2325,75)
|
|
11-12
|
7557,47 (8570,1)
|
23-24
|
2081,204949 (2560,95)
|
Проведем анализ временных рядов при помощи пакета Eviews для получения прогноза потребления
электрической энергии.
1. Постановка задачи
Имеются данные о почасовом потреблении электроэнергии. Данные приведены
за период от первого января 2008 года по 31 октября 2010 года (зависимая
переменная). Были собраны статистические данные.
Цель исследования: изучить процесс построения и анализа эконометрической
модели в пакете Econometric Views, составить, рассчитать и
проанализировать модель данной проблемы; проверить адекватность модели реальной
ситуации на числовых данных в среде Eviews.
Подтвердить правильность предположения о влиянии данных факторов с
использованием математической модели и статистических данных.
В итоге будет выявлена статистическая значимость (незначимость) выбранных
факторов.
. Статистический материал приведен в приложении.
. Построение и анализ данных в EViews
Ввод исходных данных
Данная работа осуществляется в пакете Econometric Views. Начальным этапом является ввод данных.
Создаем новый рабочий файл. В строке главного меню
выбираем File/New/Workfile, после чего откроется диалоговое
окно.
Ввод исходных данных
Данная работа осуществляется в пакете Econometric Views. Начальным этапом является ввод данных.
Создаем новый рабочий файл. В строке главного меню выбираем File/New/Workfile, после чего откроется диалоговое
окно (рис.1):

Рис. 1
В пакете допускается восемь типов данных:
Годовые (Annual) - годы 20 века идентифицируются по последним двум цифрам
(97 эквивалентно 1997), для данных, относящихся к 21 веку необходима полная
идентификация (например, 2020);
Полугодовые (Semi-annual) - 1999:1, 2001:2 (формат - год и номер
полугодия);
Квартальные (Quarterly) - 1992:1, 2005:3 (формат - год и номер квартала);
Ежемесячные (Monthly) - 1956:1, 1990:11 (формат - год и номер месяца);
Недельные (Weekly);
Дневные (5 day weeks);
Дневные (7 day weeks);
Недатированные или нерегулярные (Undated or irregular) - допускают работу
с данными, строго не привязанными к определенным временным периодам;
Воспользуемся типом (weekly
(7 day weeks)). В окнах Start date и End date вводим соответственно начальную (1:01:2010) и
конечную (11:01:2010) даты наблюдения данные у нас известны только за 10
месяцев 2010 года, но мы при вводе даты вводим конечную дату 11:01:2010 для
получения прогноза. Нажав кнопку ОК, создастся рабочий файл, содержащий вектор
коэффициентов C и серию Resid (рис.2):
Проанализируем данные за период с 1го января 2010 года
до 30 сентября 2010года.
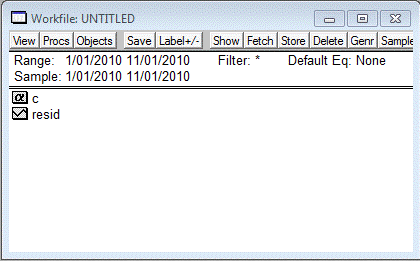
Рис. 2
Первый заключается в импорте данных из файла.
Осуществляется это следующим образом. В строке главного меню выберем File/
Import/Read Text-Lotus-Excel. Появится окно (рис. 3):

Рис. 3
В этом окне С - вектор, который будет содержать
коэффициенты уравнения, построенного в процессе работы с Eviews, Resid - вектор
остатков.
Для того чтобы просмотреть итоговую таблицу,
необходимо, выделив переменные, выбрать опцию Open->as Group (рис. 4)

Рис. 4
Построение регрессионной модели
Просмотр числовых характеристик переменных
Для просмотра числовых характеристик отмеченных переменных необходимо
выбрать в рабочем файле View/Descriptive Stats/Common Sample. В результате
появится окно (рис.6):
Далее в расчетах мы будем смотреть только нулевого
часа потребление, так как для остальных часов все строится аналогичным образом.
Во первых нам необходимо проверить все данные на тренд.
Для этого проделаем следующие операции New object->eqation
(рис. 5).

Рис. 5
В следующем меню укажем «ser01 @trend с» (без ковычек)
рис.6
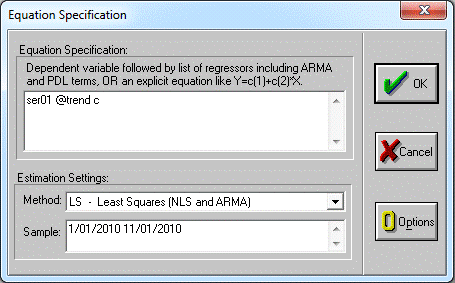
Рис. 6
На вновь появившемся файле мы видим, как уже
говорилось выше мы проводим прогноз только по первому часу, для остальных часов
все проводится аналогичным образом. Далее открывается окно в котором указано
следующее (см. рис.7):

Рис. 7
Как видно из рисунка 7 R-squared (квадрат коэффициента
корреляции Пирсона) < 0,3 это говорит об отсутствии тренда.
Далее строим корелограмму для этого не обходимо сделать следующие
процедуры View/correlogram.
Полученные результаты рис. 8.

Рис. 8
В большинстве оказывают существенное влияние на модель только первые семь
лагов. В первой серии под подозрение сразу попадают 1, 6 и 7 лаги. Проверяем их
для этого необходимо сделать следующее, Заново создать equation и прописать там номера лагов рис. 8.
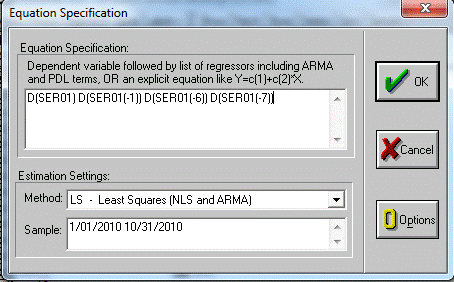
Получаем при этом рис. 9
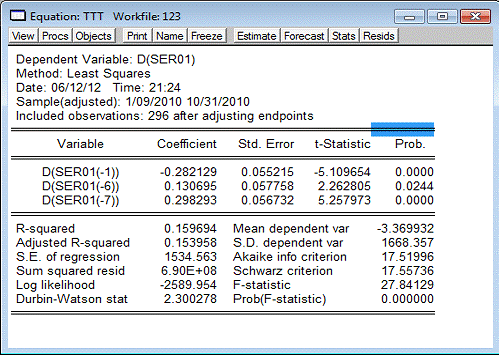
Рис. 9
Далее при помощи Forecast прогнозируем на нулевой час за 01.11.2010
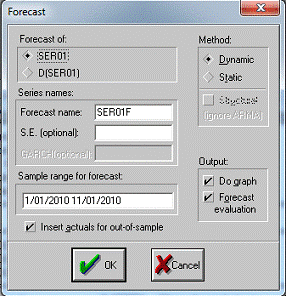
Рис. 10
Получаем результат прогноза на нулевой час 01.11.2010 года в новом файле
который называется Ser01F рис. 11
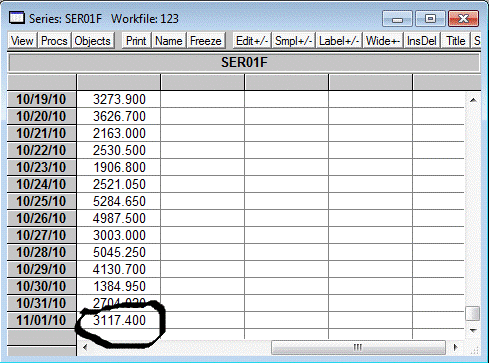
Рис. 11
Аналогичным образом повторяем процедуру еще 23 раза и получаем результат
почасового потребления на 1.01.11.
И получаем результат
Прогноз
|
Час
|
Потребление, кВт
|
Час
|
Потребление, кВт
|
|
0-1
|
3177,9
|
12-13
|
7146,3
|
|
1-2
|
4425,225
|
13-14
|
5936,175
|
|
2-3
|
2766,225
|
14-15
|
6789,3
|
|
3-4
|
3719,4
|
15-16
|
5237,4
|
|
4-5
|
4848,375
|
16-17
|
6528,9
|
|
5-6
|
5396,475
|
17-18
|
4877,775
|
|
6-7
|
6477,45
|
18-19
|
4344,775
|
|
7-8
|
7379,4
|
19-20
|
3416,175
|
|
8-9
|
6854,4
|
20-21
|
4754,4
|
|
9-10
|
6175,575
|
21-22
|
3199,875
|
|
10-11
|
7095,375
|
22-23
|
4867,275
|
|
11-12
|
7427,7
|
23-24
|
3633
|
Полученные данные сведены в таблицу.