Создание приложения 'Подсчет частоты введенных слов в текстовом файле'
Оглавление
Введение
Анализ предметной области
Проектирование
Блок-схемы
Отладка и тестирование
Сопровождение
Заключение
Список литературы
Приложение
Введение
В настоящее время человечество является высокоразвитым обществом с
множеством технологий упрощающими жизнь в той или иной степени. Перед
обществом, как и раньше, могут встать различные важные проблемы, для решения
которых необходим сбор статистических данных (например, социологических опрос).
Статистическое исследование, как и любое другое исследование, может
играть очень важную роль в науке или в какой-либо другой области.
Статистическое исследование позволяет людям предусмотреть возможные разрешения
различных ситуаций, возможно даже, на основе предыдущих исследований.
С помощью его можно решать очень большой круг вопросов и
задач, анализируя полученные данные и давая конкретные рекомендации для
разрешения проблемы.
Таким образом, роль социологического исследования в процессе
изучения общества трудно переоценить, поэтому именно оно и будет рассмотрено в данной курсовой работе на примере
разработки приложения «Подсчет частоты введенных слов в текстовом файле».
Данная
программа может использоваться в филологических исследованиях текстов больших
объемов. С её помощью можно узнать, как часто применяется то или иное слово в
тексте, таким образом составляя статистику использования того или иного слова. Таким образом, программе
можно найти применение в области лексической семантики.
Одна из целей исторического метода лексической семантики отличить
исконные слова от заимствованных и установить время, причину заимствований и их
роль для развития данного языка. С синхронической точки зрения для многих слов
это сделать довольно трудно, а часто и невозможно, тогда как при историческом
подходе генетическая связь между родственными словами, а также источник
заимствований чужих слов и выражений становятся очевидными и
аргументированными. Одним из важных критериев древности слова служит частота
его использования в языке: чем чаще слово, тем оно древнее.
Согласно некоторым исследования при чтении, правильно выбрав и хорошо
запомнив около 80 наиболее обычных, самых частотных слов, можно понять около 50% простого текста;
200 слов покроют примерно 60%;
- 300 слов - 65%;
- 400 слов - 70%;
- 800 слов - примерно 80%;
- 1500 - 2000 слов - около 90%;
- и 8000 слов покроют практически около 99 процентов письменного текста.
Очевидно, что статистику собранную программой для каждого конкретного
текста можно применить в соответствии с результатами исследований.
Для реализации поставленной цели можно выделить несколько пунктов:
)Выделить возможные области применения приложения и разобраться в
возможных аспектах и особенностях найденных областей применения;
)Составить алгоритм работы приложения;
)Разработать приложение на языке программирования Си;
)Протестировать приложение;
)Устранить возможные ошибки в работе приложения;
)Составить описание работы с приложением для пользователей.
Разбор областей применения приводится в разделе «Анализ предметной
области», алгоритм работы приложения представлен в виде блок-схем функций
программы. По третьему пункту приводится исходный код программы с подробными
комментариями. Тестирование приложения представлено в виде скриншотов консоли и
содержимого текстовых документов.
После тестирования приводится подробная инструкция работы с консольным
приложением для пользователей.
Финальный вариант приложения предназначен для людей, работающих в
лингвистических и филологических направлениях.
В работе использовано 4-ре источника литературы, основным из них является
«Программирование на языке Си» (Подбельский В.В., Фомин С.С. 2004. - 600 с.:
ил)
Работа состоит из 4-х частей.
В первой части производится анализ предметной области;
Во второй описывается проектирование приложения;
В третьей приводятся результаты тестирования приложения;
В четвёртой части находится описание работы с приложением.
Анализ
предметной области
При анализе данной области было выделено 3 возможных варианта приложений,
с помощью которых можно реализовать полностью или частично поставленные задачи.
Сначала рассмотрим варианты приложений с частичной возможностью
реализации поставленной задачи:
)Любой текстовый редактор с функцией поиска по словам.
Примером данного приложения может служить «Microsoft Word 2010»(Рис №1)
Рис №1. Окно поиска «Microsoft Word 2010»
Из минусов данного решения можно отметить, что данный способ является
очень затратным по времени, так как одновременно можно получить частоту только
для одного слова.
)Браузер со встроенной поддержкой поиска на странице.
В качестве примера рассмотрим браузер «Google Chrome»(Рис №2)

Рис №2.
Окно поиска
«Google Chrome»
Минусами такого способа являются:
· Поиск только по одному слову одновременно;
· Необходимость переноса текста в txt- или html-формат;
· Поиск лишь по буквенным сочетаниям.
В качестве
примера приложения, на котором можно реализовать поставленные задачи полностью
рассмотрим «LitFrequencyMeter»(Рис №3,№4,№5):
Данная
программа позволяет определить число слов и знаков в тексте, сделать выборку
для анализа, исключив отдельные знаки и союзы, и определить число выбранных для
анализа слов и знаков, создать статистику, расположив слова и знаки в
алфавитном порядке. Возможен также графический вывод статистики.

Рис №3. Интерфейс LitFrequencyMeter
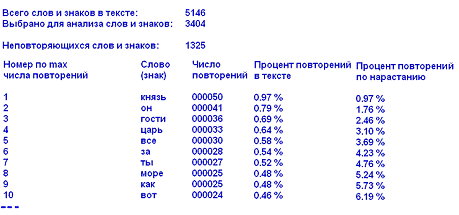
Рис №4. Вывод статистики в LitFrequencyMeter
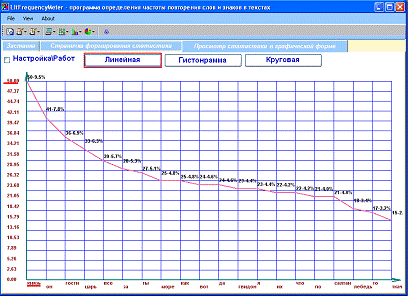
Рис №5. Графическое представление статистики в LitFrequencyMeter
В данной части производилось описание анализа предметной области, в результате
было рассмотрено два варианта частичной реализации поставленной цели (а именно,
приложения «Google Chrome» и «Microsoft Word 2010») и один
вариант полностью соотвествующий исходным требованиям (приложение «LitFrequencyMeter»). Исходя из полученных результатов,
можно сказать, что наиболее удобным для использования приложениея является «LitFrequencyMeter». Тем не менее, стоит отметить, что
существует очень мало профессиональных решений послностью соотвествующих
поставленной цели.
Проектирование
Для создания приложения «Подсчет частоты введенных слов в текстовом
файле» была выбрана среда Dev-C++ 4.9.9.2.
Программу можно представить в виде схемы(Рис №6):
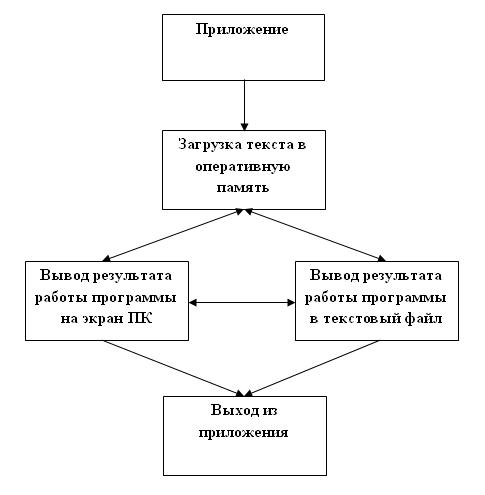
Рис №6.Схематическое представление программы.
На представленной выше схеме можно увидить поэтапную работу приложения.
Обратите внимание на то, что загрузка текста в приложение является обязательным
условием для его работы, так же из схемы видно, что результат работы программы
можно вывести как в файл, так и в окно консоли.
Для того чтобы предоставить пользователю полное взаимодействие с
программой необходимо реализовать меню, а также реализовать вывод ошибки при
введении пути на несуществующий файл. Необходимо предусмотреть сигнальный
вывод, при запросе пользователя на вывод результата работы программы при
отсутствии обрабатываемого файла в памяти программы. Для удобства пользователя
указывается полный путь к файлу.
Результат можно вывести как экран ПК, так и в отдельный текстовый файл,
путь к которому указывается полностью.
Блок-схемы
В данном
разделе приводятся блок-схемы различных функций программы с их описаниями
(более полные описания приводятся в главе «Отладка и тестирование»).
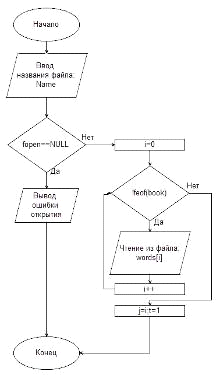
Ниже
представленна блок-схема функции Read
(чтение данных из файла), на ней видно, каким именно образом осуществляется
обработка ошибок и запись в файл:
На данной блок-схеме представлен алгоритм подсчёта обработанных слов
функции Scan:
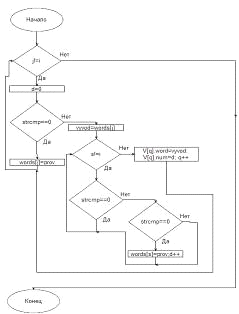
Рис №8. Блок-схема функции Scan
Следующая блок-схема показывает, каким именно образом происход очистка
слов от различных знаков препинания и машинных символов:
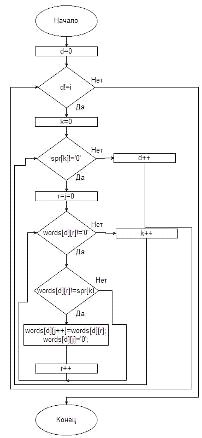
Рис №9. Блок-схема функции Delete
Ниже представленна блок-схема главной функции (части программы,
отвечающей за взаимодействие с пользователем):
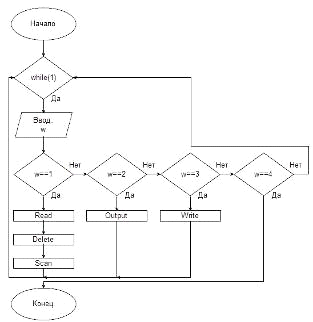
Рис №10.
Блок-схема главной функции
программа
приложение подсчет текстовый
Отладка и тестирование
#include <stdio.h>
- описание стандартных функций ввода и вывода
#include <string.h>
- описание функций для работы со строками
#include <conio.h>
- описание функций для работы с клавиатурой и монитором
#include <stdlib.h>
- описание функций контроля выполнения программы
#include <locale.h>
- описание функций связанных с локализацией программы
int t=0,e,g; - объявление глобальных переменных с типом int
char words[500000][50];
- объявление глобального массива строк
typedef struct Count{ - описание структуры и ввод нового
имени структуры
char word[50]; -
объявление строковой переменной внутри структуры
int num; - объявление
переменной с типом int внутри
структуры
}CNT; - имя-синоним структуры
CNT V[500000]; -
объявление структуры заданного типа
void Read(int*j) - прототип функции чтения с файла с параметром указателем
типа int
{
int i; - объявление
переменной типа int внутри функции
char name[50]; -
объявление строковой переменной внутри функции
FILE *book; - объявление указателя на файл
clrscr();
- очистка экрана
printf("Vvedite nazvanie faila i put' k nemy\n"); - сообщение о вводе имени и пути к файлу
scanf("%s",&name); - ввод пути и имени файла
if ((book=fopen(name,"r"))==NULL) - открытие файла в режиме чтение и условие на
проверку существования введённого пользователем файла. Если файл не существую -
программа возвращает сообщение об ошибке
{printf("Fail nevojmojno otkryt'\n");
- сообщение об ошибке
getch();}
- ожидание нажатия клавиши
else {
- если условие не выполняет, то следует выполнение данного
оператора("Obrabotka..."); - сообщение о работе программы
for(i=0;!feof(book);i++) { - цикл считывания с файла
данных. Запись начинается с нулевого элемента в глобальный массив строк words. После каждого считанного слова
выполняется инкрементирование i.
Цикл работает до тех пор, пока команда feof не вернёт 1. Feof проверяет выполнение условия окончания файла и в
случае невыполнения возвращает 0
fscanf(book,"%s",&words[i]);} - считывание слов с файла
fclose(book); - закрытие обработанного файла
*j=i; - процесс присваивания
t=1; -
процесс присваивания глобальной переменной значения 1. Ввод данной переменной
обусловлен тем, что вывод результатов программы невозможен до тех пор, пока не
будет считана информация с файла. Функции на вывод результатов работают только
при положительном значении t
}}
int Scan(CNT*V,int*i) - прототип функции типа int подсчёта введённых слов с файла с
параметрами-указателями на структуру и переменную типа int
{
int j,d,s,q=0; - объявление
переменных типа int
char vyvod[50],prov[]="::null::"; - объявление строковых переменных
for(j=0;j!=*i;j++) { - цикл обработки всех считанных
слов
d=0; -
счётчик количества слов
if (strcmp(words[j],prov)==0) {continue;} - условие проверяет соответствует
ли слово из массива строк words[j] заранее заданной строке prov. Если данное условие выполняется, то
цикл пропускает текущую итерации.
else {
- если условие не выполняется, то следует выполнение данного оператора
strcpy(vyvod,words[j]); -
в строку vyvod копируется строка words[j]. Далее эта строка будет сравнивать со строками из массива
строк words и заносится в структуру CNT V как уникальная. Все повторные совпадения данного слова будут
заменяться на значение строки prov
“::null::”. Напоминаю, что предыдущий цикл
прерывает итерацию при встрече данного значения, что позволяет избежать
подсчёта лишнего слова.
for(s=0;s!=*i;s++) { - цикл сравнения массива строк
с заданной строкой vyvod
if (strcmp(vyvod,words[s])==0) {d++; strcpy(words[s],prov);}} - если
слово встреченное в массиве строк words равно заданному слову, то происходит его затирание словом prov и инкрементирование счётчика
strcpy(V[q].word,vyvod); V[q].num=d; q++;}} - копирование
заданного слова и количество его повторений в структуру STR V("\a\a\a"); - 3 звуковых сигнала по окончанию
обработки
return q; - возвращение
функцией значения q с типом int
}
void Delete(int*i) - прототип функции удаления из слов знаков препинания с параметром-указателем
на переменную типа int
{
char spr[]="!<«[]»>:,.?;'";
- объявление строковой переменной
int k,r,j,d; - объявление
переменной с типом int
for(d=0;d!=*i;d++) { - цикл удаления знаков
препинания из слов, проходит по всему массиву строк words
for(k=0;spr[k]!='\0';k++) { - цикл чтения знаков из
заданной строки, работает до тех пор, пока не достигнет нуль-терминатора
for(r=j=0;words[d][r]!='\0';r++) -
цикл сравнения символов из массива строк words со строкой spr
if (words[d][r]!=spr[k]) - условие проверяет совпадает ли данный символ с символом
из строки spr, после чего сдвигает символы строки.
На место совпавшего символа ставится нуль-терминатор
{words[d][j++]=words[d][r];}
words[d][j]='\0';}
}
}
void Output(CNT*V,int*i,int q) - прототип функции вывода результатов работы программы на
экран с параметрами-указателями на структуру и переменными типа int
{
int j; - объявление
переменной типа int
if (t!=1) { - проверка на заполнение
массива строк
printf("Snachala nyjno prochitat'
fail\n");("Press any key to escape for menu");}{ - если условие не выполнено, то
действует данный оператор
clrscr();
- очистка экрана
printf("slovo '%s' - kol-vo:
%d\n",V[j].word,V[j].num);}("Vsego slov - %d",*i);} - вывод количества всех слов
getch();
- ожидание нажатия клавиши
}
void Write(CNT*V,int*i,int q) - прототип функции записи в файл результатов работы
программы с параметрами-указателями на структуру и переменными типа int
{
int j; - объявление
переменной с типом int
char name[50]; -
объявление строковой переменной
FILE *book; - объявление указателя на файл
clrscr();
- очистка экрана
if (t!=1) { - проверка условия на
заполнения массива строк
printf("Snachala nyjno prochitat'
fail\n");("Press any key to escape for menu");}{("Vvedite
nazvanie faila i put' k nemy\n"); - вывод сообщения о вводе пути и названия файла("%s",&name); - ввод пути и названия файла
book=fopen(name,"wt");
- открытие файла в режиме записи
for(j=0;j!=q;j++) { - цикл записи результатов
работы программы
fprintf(book,"slovo '%s' - kol-vo:
%d\n",V[j].word,V[j].num);} - запись
в файл(book,"Vsego slov - %d",*i); - запись общего количества слов в
файл
fclose(book);} - закрытие файла
getch();
- ожидание нажатия клавиши
}
int main() -
объявление главной функции
{
int w; - объявление
переменной типа int
setlocale(LC_ALL,"Russian");
- подключение кириллицы в консоли
while(1){
- цикл с рекурсией
clrscr();
- очистка экрана
printf("=============================\n"); - вывод сообщения
printf("
Kursovoi proekt\n");
printf("Vypolnil student gryppy 12-94\n");("
Romanov A.S.\n");("=============================\n");
printf(" M E N U\n"); - вывод меню
printf("1:Read from
file\n");("2:Rezult\n");("3:Write in
file\n");("4:Exit\n");("%d",&w); - ввод значения
w(w) { - оператор выбора1: Read(&e); Delete(&e); g=Scan(V,&e); break; - выполнение функций2: Output(V,&e,g); break;3: Write(V,&e,g); break;
case 4: exit(0);} - выход из программы
}
}
В программном коде использовано 6 функций(чтение из файла, обработка
данных, занесение данных в структуру, вывод результата на экран, вывод
результата в файл, меню в главной функции). Для работы программы необходим как
минимум один файл - необходимо считать данные. Также есть возможно вывести
результаты работы программы в тот же файл.
Для проверки разработанного приложения проведём тестирование её работы.
Все тесты были проведены на базе группы пользователей.
Тест №1
Проверка работы функции удаления знаков препинания из слов.
В качестве тестового текста возьмём следующие предложения(Рис №11):
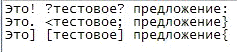
Рис №11. Тест №1.
Исходя из заданного текста, можно предположить, что ожидаемым результатом
работы программы будет вывод 3-х уникальных слов.
Проверка(Рис №12):
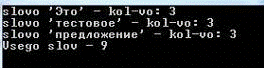
Рис №12. Тест №1.Проверка удаления знаков препинания
Как видно из скриншота консоли, программа полностью справилась с первым
тестом.
Тест №2.
Проверка работы счётчика общего вхождения слов.
В качестве текста возьмём часть введения. Узнаем количество слов
фрагмента при помощи Microsoft Word(Рис №13):

Рис №13. Тест №2. Подсчёт слов при помощи «Microsoft Word 2010»
Тест №2Поместим данный фрагмент в текстовый файл и сравним с результатом
работы приложения(Рис №14):
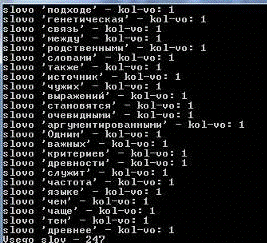
Рис №14. Тест №2.Проверка подсчёта общего количества слов
Результаты показывают, что программа справилась со вторым тестом.
Тест №3.
Проверка работы счётчика вхождения уникальных слов.
В качестве текста возьмём часть введения. Узнаем количество слов
фрагмента при помощи Microsoft Word:
За тестовый материал возьмём следующий текст(Рис №15):

Рис №15. Тест №3.Проверка подсчёта слов
Посмотрим на результат работы программы(Рис №16):
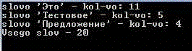
Рис №16. Тест №3. Проверка подсчёта слов
Исходя из результатов вышеприведённых тестов, можно сказать, что
программа успешно справилась со всеми тестами. И может быть использована
студентами, преподавателями и людьми, работающими в лингвистических и
филологических направлениях.
Сопровождение
Для корректной работы программы необходимо 35 кб свободного места на
жёстком диске. Количество требуемой оперативной памяти варьируется в
зависимости от объёма обрабатываемого текста:
Для 100 слов(~555 знаков) - 1024 кб;
Для 1000 слов(~5699 знаков) - 1084 кб;
Для 70000 слов(~441 962 знаков) - 5272 кб;
Для 543000 слов(~3 560 607 знаков) - 28 523 кб;
Следует учитывать, что от объёма текста также зависит и время, требуемое
на обработку программой. В случае с 70000 слов примерное время обработки
составило 6 секунд, в случае с 543000 слов - 1 минуту 9 секунд. Программа
предназначена для работы на операционных системах Microsoft Windows любой разрядности. Для работы с консолью обязательно
наличие клавиатуры.
При запуске программы появляется консоль с действиями, предлагаемыми на
выбор пользователю(Рис №17):
Рис №17. Работа с приложением №1.
При выборе второго и третьего пункта, без загруженного в память программы
текста, пользователь получает следующее сообщение(Рис №18)

Рис №18. Работа с приложением №2.
В случае выбора пользователем первого пункта, предлагается ввести полный
путь к файлу. Если файл не существует или путь неверен, то пользователь получит
сообщение следующего вида(Рис №19):

Рис №19. Работа с приложением №3.
В случае правильного ввода(Рис №20):
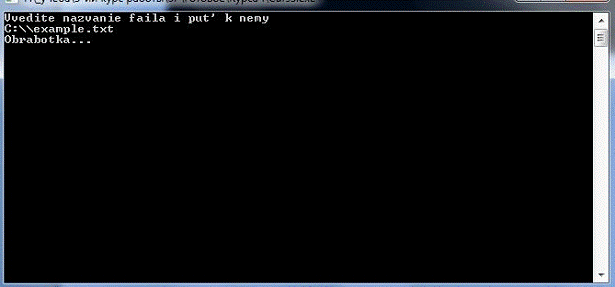
Рис №20. Работа с приложением №4.
После окончания обработки выводится 3 звуковых сигнала.
Когда текст обработан, можно выбрать 2-ой или 3-ий пункт в меню.
пункт(Рис №21):
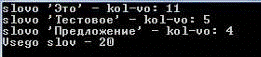
Рис №21. Работа с приложением №5.
-ий пункт(Рис №22):

Рис №22. Работа с приложением №6.
При выборе 4-го пункта программа закрывается.
В данном разделе были описаны минимальные системные требования для работы
приложения и подробно описаны все возможные варианты взаимодействия
пользователя с программой. К каждому текстовому описанию действия выполняемого
пользователем приводится графическая иллюстрация.
Заключение
При
выполнении данной курсовой работы были рассмотрены 4 источника литературы и 1
электронный ресурс соответсвующие предметной области, так же было рассмотрено 3
приложения, которые частично или полностью соответсвуют поставленной цели.
В ходе выполнения курсовой работы были выполнены следующие задачи:
)Выделены возможные области применения разработанного приложения
(филологические и лингвистические исследования), было рассмотрено 3 варианта
готовых решений (текстовые редакторы, браузеры, приложение
«LitFrequencyMeter»);
)Был составлен алгоритм приложения, представленный в виде схемы и
блок-схем в разделе «Проектирование»
)Разработан программный код на языке программирования Си. В работе он
представлен с подробными комментариями.
)Приложение было протестировано на базе группы пользователей.
)В ходе работы были выявлены и устранены следующие ошибки (в работе
представлен финальный вариант):
Одно и тоже слово со знаком препинания и без считывалось программой как
разные слова. Данный недостаток устранён при помощи введения функции Delete;
Приложение позволяло выбрать второй и третий пункт без загруженного
текста. Данный недостаток устранён при помощи проверки условия заполнения
массива строк (подобнее рассматривается в разделе «Программный код»);
Максимальный объём слов, считываемых программой - 600 000. Данный
недостаток можно устранить, изменив код программы, но для этого необходим
исходный код.
)Составлено подробное описание работы приложения для пользователей. Для наглядности
описание содержит скриншоты консоли.
Вследствие этого можно считать, что выполнена поставленная цель данной
работы - разработка приложения «Подсчет частоты введенных слов в текстовом
файле».
Финальное приложение предполагает использование людьми, занятыми в
филологической или лингвистической направленнастях. Аналогично, данное
приложение может быть использовано студентами и преподавателями для проведения
некоторых статистических исследований.
Список
литературы
1. Гришмановский
П.В., Даниленко И.Н. Курсовое проектирование. Разработка программного
обеспечения. Методические указания к выполнению курсовых проектов для студентов
специальностей 210100 «Управление и информатика в технических системах» и
220400 «Программное обеспечение вычислительной техники и автоматизированных
систем». Сургут: Издательство СурГУ, 2004. - 23с.
. Подбельский
В.В., Фомин С.С. Программирование на языке Си: Учеб. пособие. - 2-е доп. изд. -
М.: Финансы и статистика, 2004. - 600 с.: ил.
. Поляков
К.Ю. Практический курс программирования на Си: свободно-распространяемый
интернет - учебник в формате PDF.
. Поляков
К.Ю. Презентации по практическому курсу программирования на Си: Хранение и
обработка данных - Си, Проектирование программ - Си, Численные методы - Си,
Целочисленные алгоритмы - Си, Динамические структуры данных - Си. 2008-2009.
5. www.cyberforum.ru. Электронный ресурс.
6. www.stackoverflow.com
<http://www.stackoverflow.com>.
Электронный ресурс.
Приложение
Листинг
программы
1. #include <stdio.h>
. #include <string.h>
. #include <conio.h>
. #include <stdlib.h>
. #include <locale.h>
6. int t=0,e,g,n;
. char words[700000][50],name1[50];
. typedef struct Count{
. char word[50];
. int num;
. }CNT;
. CNT V[700000];
13. void SravnNum(char prov[50],int*ok)
. {
. int i,j;
. char numbers[]="0123456789";
. *ok=0;
. for(i=0;prov[i]!='\0';i++) {
. for(j=0;numbers[j]!='\0';j++) {
. if (prov[i]==numbers[j]) {
. *ok=1; break;}}}}
22. void SravnAlp(char prov[50],int*ok)
. {
. int i,j,p=0,d=0,mass[50][100];
. char alphabet[]="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
. *ok=0;
. for(i=0;prov[i]!='\0';i++) {
. for(j=0;alphabet[j]!='\0';j++) {
. if (prov[i]==alphabet[j]) {
. p=1; break;}}}
. if (p==1)
. for(j=0;alphabet[j]!='\0';j++) {
. if (prov[i]==alphabet[j]) {
. d++;}}}
. if (d!=i) {*ok=1;}
. }}
38. void Read(int*j)
. {
. int i,ok=0,ok1=0;
. FILE *book;
. clrscr();
. printf("Vvedite nazvanie faila i put' k
nemy\n");
. scanf("%s",&name1);
. if ((book=fopen(name1,"r"))==NULL)
. {printf("Fail nevojmojno otkryt'\n");
. getch();}
. else {
. printf("Vvedite minal'nyu dliny slova\n");
. scanf("%d",&n);
. printf("Obrabotka...");
. for(i=0;!feof(book);) {
. fscanf(book,"%s",&words[i]);
. if (strlen(words[i])<n)
. {continue;}
. else SravnNum(words[i],&ok);
. SravnAlp(words[i],&ok1);
. if (ok==0 && ok1==0) {i++;}}
. fclose(book);
. *j=i;
. t=1;}
. }
63. int Scan(CNT*V,int*i)
. {
. int j,d,s,q=0;
. char vyvod[50],prov[]="::null::";
. for(j=0;j!=*i;j++) {
. d=0;
. if (strcmp(words[j],prov)==0) {continue;}
. else {
. strcpy(vyvod,words[j]);
. for(s=0;s!=*i;s++) {
. if (strcmp(vyvod,words[s])==0) {d++;
strcpy(words[s],prov);}}
. strcpy(V[q].word,vyvod); V[q].num=d; q++;}}
. if (t=1){
. printf("\a\a\a");}
. return q;
. }
79. void Delete(int*i)
. {
. char spr[]="!<[{()}]« »>:,.?;";
. int k,r,j,d;
. for(d=0;d!=*i;d++) {
. for(k=0;spr[k]!='\0';k++) {
. for(r=j=0;words[d][r]!='\0';r++)
. if (words[d][r]!=spr[k])
. {words[d][j++]=words[d][r];}
. words[d][j]='\0';}
. }
. }
91. void Output(CNT*V,int*i,int q)
. {
. int j;
. if (t!=1) {
. clrscr();
. printf("Snachala nyjno prochitat'
fail\n");
. printf("Press any key to escape for
menu");}
. else{
. clrscr();
. for(j=0;j!=q;j++) {
. printf("slovo '%s' - kol-vo:
%d\n",V[j].word,V[j].num);}
. printf("Vsego slov - %d\n",*i);
. getch();
. }
106. void Write(CNT*V,int*i,int q)
. {
. int j;
. char name[50];
. FILE *book;
. clrscr();
. if (t!=1) {
. printf("Snachala nyjno prochitat'
fail\n");
. printf("Press any key to escape for
menu");}
. else{
. printf("Vvedite nazvanie faila i put' k
nemy\n");
. scanf("%s",&name);
. book=fopen(name,"wt");
. fprintf(book,"imya vhodnogo faila:
%s\n",name1);
. fprintf(book,"minimal'naya dlina slov:
%d\n",n);
. for(j=0;j!=q;j++) {
. fprintf(book,"slovo '%s'\t kol-vo:
%d\n",V[j].word,V[j].num);}
. fprintf(book,"Vsego slov\t %d\n",*i);
. fprintf(book,"Unikal'nyh slov\t %d",q);
. fclose(book);}
. getch();
. }
128. void Sort(CNT*V,int q)
. {
. int i,j,a;
. char b[50];
. for(i=0; i<q-1; i++){
. for(j=i+1; j<q; j++){
. if(strcmpi(V[i].word,V[j].word)>0){
. strcpy(b,V[i].word);
. strcpy(V[i].word,V[j].word);
. strcpy(V[j].word,b);
. a=V[i].num;
. V[i].num=V[j].num;
. V[j].num=a;}}}
. }
142. int main()
. {
. int w;
. setlocale(LC_ALL,"Russian");
. while(1){
. clrscr();
. printf("=============================\n");
. printf(" Kursovoi proekt\n");
. printf("Vypolnil student gryppy 12-94\n");
. printf(" Romanov A.S.\n");
. printf("=============================\n");
153. printf(" M E N U\n");
154. printf("1:Read from file\n");
. printf("2:Rezult\n");
. printf("3:Write in file\n");
. printf("4:Exit\n");
. scanf("%d",&w);
. switch(w) {
. case 1: Read(&e); Delete(&e);
g=Scan(V,&e); break;
. case 2: Sort(V,g); Output(V,&e,g); break;
. case 3: Sort(V,g); Write(V,&e,g); break;
163. case 4: exit(0);}
. }
. }