|
Процесс
|
Время появления
|
Время активности
|
|
P1
|
0.0
|
7
|
|
P2
|
2.0
|
4
|
|
P3
|
4.0
|
1
|
|
P4
|
5.0
|
4
|
Схема их диспетчеризации по
стратегии SJF без прерывания процессов приведена на рисунке 5.
Схема диспетчеризации процессов по стратегии
SJF без прерывания.
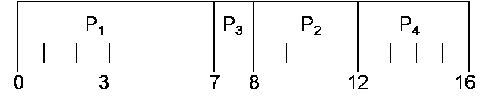
Рисунок 5
В данном случае среднее время
ожидания = (0 + 6 + 3 + 7)/4 = 4.
Теперь применим к тем же процессам
стратегию SJF с прерыванием и проанализируем, как изменится среднее время
ожидания. Результат применения стратегии изображен на рисунке 6.
Схема диспетчеризации процессов по
стратегии SJF с прерываниями.

Рисунок 6
В данном случае принцип прерывания
процесса в момент поступления в систему более короткого процесса применяется
несколько раз:
- в
момент 2 прерывается процесс 1 и начинает исполняться более короткий процесс 2;
- в
момент 4 прерывается процесс 2 и начинает исполняться более короткий процесс 3.
Из диаграммы видно, что, вследствие
применения принципа прерывания процессов, периоды непрерывного выполнения
процесса на процессоре могут быть не смежными и перемежаться с периодами
выполнения других процессов.
В данном случае среднее время
ожидания = (9 + 1 + 0 +2)/4 = 3, т.е. оно, как и следовало предполагать,
оказалось меньше, чем без применения принципа прерывания процессов.
3. Использование SJF на практике
.1 Реализация стратегии
диспетчеризации SJF
И вот уже объяснив суть Shortest Job First, хотелось бы показать, где собственно используется данная
стратегия. Покажем на примере перевода элементов данных из одного источника в
другой. Это стратегия существенно снижает среднее время ожидания.
Например, группа читателей ждут,
пока элементы станут доступными в определенном пункте назначения. Автор с
ограниченными возможностями подключения (недостаточная пропускная способность,
недостача ресурсов сервера или длиннолатентная (latency перевод с англ.
задержка) ссылка для его читателей) влияет на издателя, который дает доступ к
элементам читателям.
Это работа мотивированна работой
инфраструктуры типичной Веб-публикации на сегодняшний день, где содержание
элемента автора загружается на AWeb сервер, а не непосредственно к читателю. Если объем данных
элементов больше чем пропускная способность линии - как в случае отправки
изображения с высоким разрешением или длинных видеоролики, загружаемых через
широкополосное соединение или через беспроводную связь мобильного устройства,
то автор будет заинтересован в сокращении времени, пока его элементы станут
доступны читателям. Принцип работы Веб-публикации подробно показан на рисунке
7. Набор элементов (θ i) загружен на сайт издателя. Издатель информирует автора о
популярности(Pi) каждого элемента в отдельности.
Принцип работы Веб-публикации
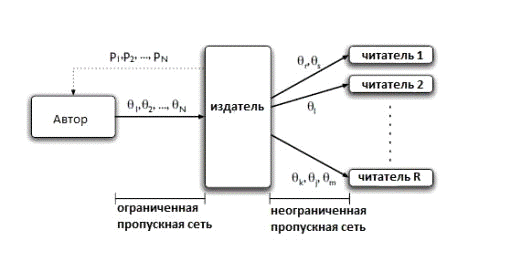
Рисунок 7
Конкретные примеры этого являются
веб-бытовые услуги общего доступа к файлам как. Mac и Steamload, которые позволяют
пользователям обмениваться большими файлами, а так же вести хостинг для
мультимедийного контента. Содержание распределительной сети (такие как Akamai и интернет Mirror Image) в которой большие
файлы копируются на серверы находящиеся в географической близости для
пользователей, в том числе и для автора (если у него ограниченная пропускная
способность). Если файлы копируются «По требованию», например, по популярности,
то для этого файла уделяется производительность, уменьшается время ожидания.
Наша стратегия состоит в том, что бы уменьшить время работы (SJF), сделать алгоритм для
передачи элемента и рассортировать по популярности. Планировщик вычисляет,
основываясь на размерах файлов; сколько читателей запрашивали этот файл.
Несколько запросов от одного читателя рассматривается как один.
Мы считаем, что для каждого автора
есть конечное множество элементов данных для загрузки. Издатель знает
количество элементов (например, получив список всех элементов) и имеет
возможность сохранить их все. Кроме того, мы предлагаем неограниченные
возможности связи между читателями и издателем, но ограниченные возможности
связи между издателем и автором. Таким образом, читатель имеет доступ к любому
элементу, он становится доступным для читателя, как только полностью будет
загружен на издателя. Время между первым запросом и завершении загрузки назовем
как «Время ожидания». Установка всего процесса подробно показана на рисунке 7,
где набор элементов показан как (θ i), а популярность показана как (Pi).
Этот принцип имеет смысл когда автор
загружает процессы на издателя и процессы не требуют сложных расчетов.
Например, когда мы переносим содержимое жесткого диска с объемом 500-Гб через Gigabit Ethernet и передачи нескольких
десятков видео, каждое по 10 Мб, через ADSL соединение
(максимальная скорость передачи 128 кбит/с), оба потребуют больше часа на
передачу. Время передачи такое же как, передача несколько широкоформатных
изображении «raw» (перевод с англ сырой), в 8-мегапиксельной камере, через
беспроводной сети 3G. Мы не берем в счет пропускную способность канала, но вместо
этого экспортируем с более широким спектром время передачи, которые могут
связаны с конкретными сценариями, которые перечислены выше.
Мы предлагаем два варианта
расписания стратегии. Первый из них, является статистическим, в смысле, что
популярность данных элементов фиксирована и известна до начала загрузки.
Доказано что планирование SJF на основе отношения размера приводит к минимальному времени
ожидания.
Вторая стратегия, позволяет
запрашивать данные во время загрузки. С помощью симулятора, мы покажем, что в
этом случае планирования SJF на отношении размера файла и популярности, что снижает общее
время ожидания, чем планирование на основе размера и популярности поодиночке. И
на основе данных их симулятора, мы обнаружили что он снижает общее врем когда
только у нас мало элементов (не более шести элементов).
3.2 Статический способ
процессор обслуживание задание
стратегия
В этом случае мы предполагаем, что
популярность каждого элемента фиксирована и известна до начала передачи. Это
означает, что планировщику нужно принять решение только один раз, в начале
передачи. Репликация файлов из перегруженного сервера для удаленного сервера
распространения контента является примером такого сценария. Так как исходный
сервер отвечает на рост популярности определенных файлов, его шаблон доступа
может быть использован для статистических решений планирования. Определения и
доказательства в этом разделе может служить в отправной точке для обсуждения
следующих секции динамического планирования.
Рассмотрим множество ϴ, где N задач (элементы будут загружены):
Формула (1)
ϴ=(θ1, θ2,… θn).
Если время начинается в то время,
когда множество ϴ готово к передаче в издательство, и если время fi, когда задача θi была загружена, то среднее время ожидания (AWT average waiting time) для всех задач этого
множества при графике σ:
формула AWT(2)
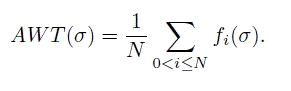
Это определение AWT выражает среднее время
ожидания для каждого запроса, основываясь на том, сколько ждет читатель до
начала загрузки. Для учета элементов запрашиваемых больше чем одним читателем,
мы включаем популярность pi элемента θi. То есть количество читателей
обслужено им. Выражено здесь на рисунке 9:
Формула AWT (по популярности) (3)

И вместо нахождения среднего по
количеству задач, N, усреднить от общего количества ожидающих запросов M рисунок 10:
Усреднить от общего количества

Обратите внимание, что при р = 1 ∀ я, то (3) эквивалентно
(2). Не запрошенные элементы (р = 0) не включены в ожидание времени, так что
никто не ждет их. Мы предполагаем, что их передача откладывается до тех пор
пока не передадутся запрошенные элементы.
Заключение
Мы рассмотрели изменения кратчайшего
алгоритма работы первого для планирования передачи набора данных элементов
автора с ограниченными возможностями подключения. Мы посмотрели затраты времени
с каждой точки зрения, по сути наша стратегия способствует уменьшению времени
ожидания наиболее популярных и наименьшего: они становятся доступными как можно
скорее, тем самым снижая время ожидания читателей.
Мы доказали, что элементы
планирования данных, разместив по популярности и по размеру, и минимизирует
среднее время ожидания (AWT), как определенно в (2), при pi не меняется со временем
и планируем, один раз до начала передачи. Мы показали, как этот алгоритм
работает лучше, чем обычный простой SJF который использует в качестве вычислительных затрат только размер
элемента. Кроме того, мы обнаружили, что если элементов много (больше шести),
то наша формула не поможет производительности. В будущем мы надеемся, что
получиться увеличить количество элементов
Исходя их всех вышеизложенных
формул, можно увидеть, что стратегия Shortest Job First существенно уменьшает среднее время ожидания. И реализует движок
работы многих веб сайтов, веб-публикации и серверов, таких как youtube.com, tweeter.com, depositfiles.com и т.д.
Список литературы
1. В.О. Сафонов. Основы современных операционных систем.
http://www.untuit.ru
2. Simone Lupetti, Dmitrii Zagorodnov. Data popularity and
shortest-job-first scheduling of network transfer. IKT 2010 project number
146986/431. University of Tromso
Приложение
КОД ПРОГРАММЫ SJF НА ЯЗЫКЕ С++
# include<stdio.h>
#
include<alloc.h>node
{int
process_no;btime;node *link;
};append (struct node
**, int, int);display (struct node *, int);chart (struct node **);main()
{clrscr();node *p;=
NULL; /* Empty Linked list */i=1, time;ans = 'y';(ans!= 'n')
{printf («\nEnter Burst
Time For Process No.%d:», i);(«%d»,&time);(&p, i, time);(«Any More
Process (Y/N)?»);= getche();++;
}();();(«\nThe Order Of
Execution Of Process For SJF Algorithm Will be: -»);(p, 1);();(«\nThe Waiting
Time Of Process For SJF Algorithm Will be: -»);(p, 2);();(&p);();
}append (struct node
**q, int i, int time)
{struct node *r,*temp =
*q;= (struct node *) malloc (sizeof(struct node));>process_no = i;>btime
= time;
/* If list is empty or
new data to be inserted b4 the first node */(*q==NULL || (*q)->btime >
time)
{*q = r;
(*q)->link = temp;
}
{/* traverse the entire
linked listsearch the position the new node to be inserted */(temp!= NULL)
{if (temp->btime
<=time &&(temp->link->btime > time || temp->link
==NULL))
{r->link =
temp->link;>link = r;>link = NULL;
}= temp->link;
}
}
}display (struct node
*q, int kk)
{struct node
*temp;wtime, avg=0, total = 0, count=0;= q;i;(«\n»);(«\n\t\t % c», 218);(i=1;
i<33; i++)
{if (i==17)(«%c»,
194);(«%c», 196);
}(«%c», 191);(kk==1)
{printf («\n\t\t % c
PROCESS NO. %c BURST TIME %c\n», 179,179,179);
}(kk==2)
{printf («\n\t\t % c
PROCESS NO. %c WAIT TIME %c\n», 179,179,179);
}(«\t\t % c», 195);(i=1;
i<33; i++)
{if (i==17)(«%c»,
197);(«%c», 196);
}(«%c»,
180);(temp!=NULL)
{count++;(kk==1)
{printf («\n\t\t % c %d.
%c %3d %c», 179, temp->process_no, 179, temp->btime, 179);
}(kk==2)
{if (temp ==q) /* First
Process In The Ready Queue */
{wtime = 0;+=
temp->btime;+=wtime;
}
{wtime = total;+=
temp->btime;+=wtime;
}(«\n\t\t % c %d. %c %3d
%c», 179, temp->process_no, 179, wtime, 179);
}=temp->link;
}(«\n\t\t % c»,
192);(i=1; i<33; i++)
{if (i==17)(«%c»,
193);(«%c», 196);
}(«%c», 217);(kk==2)
{printf («\nThe Average
Waiting Time (%d % c % d) =%.2f», avg, 246, count, float (avg/float(count)));
}
}chart (struct node **q)
{(«\n»);(«\nThe Glant
Chart Is As Follows:-\n»);node *temp,*temp1,*temp2,*temp3,*temp4;= *q; temp1 =
*q; temp2 = *q; temp3 = *q; temp4=*q;sum = 0; float sfactor;(temp4!=NULL)
{sum+=temp4->btime;=
temp4->link;
}(sum<80)
{sfactor = 1.0;
}
{sfactor = (sum %
80)/float(sum);
}i, k=0;(«%d»,
k);(temp3!= NULL)
{if((sfactor*temp3->btime)
== 0)
{goto harsh;
}(i=-1;
i<=(sfactor*temp3->btime); i++)
{printf(«»);
}+=temp3->btime;(«%d»,
k);:=temp3->link;
}(«\n»);(temp!=NULL)
{if (temp == *q)
{(«%c % c»,
218,196);((sfactor*temp->btime) == 0)
{goto last;
}(i=-1;
i<=(sfactor*temp->btime); i++)
{printf («%c», 196);
}(temp->link!= NULL)
{printf («%c», 194);
}
{printf («%c», 191);
}
}
{if((sfactor*temp->btime)
== 0)
{goto last;
}(i=-1;
i<=(sfactor*temp->btime); i++)
}(temp->link!= NULL)
{printf («%c», 194);
}
{printf («%c», 191);
}
}:= temp->link;
}(«\n»);(«%c»,
179);(temp1!= NULL)
{if((sfactor*temp1->btime)
== 0)
{goto last1;
}(i=0;
i<=(sfactor*temp1->btime); i++)
{if (i==int
(sfactor*temp1->btime)/2)
{printf («P % d»,
temp1->process_no);
}(«»);
}(«%c», 179);:=
temp1->link;
}(«\n»);(temp2!=NULL)
{if (temp2 == *q)
{printf («%c % c»,
192,196);((sfactor*temp2->btime) == 0)
{goto last2;
}(i=-1;
i<=(sfactor*temp2->btime); i++)
{printf («%c», 196);
}(temp2->link!= NULL)
{printf («%c», 193);
}
{printf («%c», 217);
}
}
{if((sfactor*temp2->btime)
== 0)
{goto last2;
}(i=-1;
i<=(sfactor*temp2->btime); i++)
{printf («%c», 196);
}(temp2->link!= NULL)
{printf («%c», 193);
}
{printf («%c», 217);
}
}:=temp2->link;
}
}