Программа частотного словаря сочетаний слов
Курсовая
работа
«Программа
частотного словаря сочетаний слов»
Техническое задание
Требуется разработать программу
дляформирования частотного словаря сочетаний пар словдля некоторого текста.
Программа должна обеспечивать следующие функции:
- обработка текстов,
полученных методом копирования-вставки или расположенных в текстовом файле
(разрешена работа с файлами, имеющими расширения.txt и.rtf);
- возможность
пользователю самостоятельно определять символы, являющиеся разделителями слов;
- составление словаря
словосочетаний по заданному тексту (под словосочетанием подразумеваются два
слова, расположенные рядом в одном предложении);
- сохранение
созданного в результате работы программы словаря в файл одного из текстовых
форматов (.txtили.rtf);
- возможность
сортировки словосочетаний словаря по алфавиту и по частоте их употребления в
тексте;
- поиск
словосочетания и частоты его употребления в словаре;
- отсутствие различий
между символами верхнего и нижнего регистра в ходе обработки текста и словаря.
Введение
Задача создания программы,
обладающей функционалом, определяемым заданием, предполагает решение более
простых подзадач:
- возможность
обработки текста из файла;
- формирование из
заданного текста списка словосочетаний, в котором каждый элемент соответствует
некоторому слову из текста;
- возможность
перемещения словаря в файл текстового формата;
- поиск
словосочетания в словаре;
- сортировка
словосочетаний в словаре по заданному признаку;
- нечувствительность
к регистру.
1.
Теоретическая часть
приложение
тестирование интерфейс пользователь
Сортировкой или упорядочением массива называется расположение его
элементов по возрастанию (или убыванию). [1] Если не все элементы различны, то
надо говорить о неубывающем (или невозрастающем) порядке. Критерии оценки
эффективности этих алгоритмов могут включать следующие параметры:
· количество
шагов алгоритма, необходимых для упорядочения;
· количество
сравнений элементов;
· количество
перестановок, выполняемых при сортировке. [1]
Самым простым методом сортировки
является так называемый метод «пузырька». Чтобы уяснить его идею,
представьте, что массив (таблица) расположен вертикально. Элементы с большим
значением всплывают вверх наподобие больших пузырьков. При первом проходе вдоль
массива, начиная проход «снизу», берется первый элемент и поочередно
сравнивается с последующими. При этом:
· если
встречается более «легкий» (с меньшим значением) элемент, то они меняются
местами;
· при
встрече с более «тяжелым» элементом, последний становится «эталоном» для сравнения,
и все следующие сравниваются с ним.
В результате наибольший элемент
оказывается в самом верху массива.
Во время второго прохода вдоль
массива находится второй по величине элемент, который помещается под элементом,
найденным при первом проходе, т.е. на вторую сверху позицию, и т.д.
Заметим, что при втором и
последующих проходах, нет необходимости рассматривать ранее «всплывшие»
элементы, т.к. они заведомо больше оставшихся. Другими словами, во время j-го
прохода не проверяются элементы, стоящие на позициях выше j.
Алгоритм данной сортировки считается
учебным и практически не применяется вне учебной литературы, вместо него на
практике применяются более эффективные алгоритмы сортировки. В то же время
метод сортировки обменами лежит в основе некоторых более совершенных
алгоритмов, таких как шейкерная сортировка и пирамидальная сортировка.
[1]
Шейкерная сортировка
(сортировка перестановками) -
разновидность пузырьковой сортировки. Анализируя метод пузырьковой сортировки
можно отметить два обстоятельства.
Во-первых, если при движении по
части массива перестановки не происходят, то эта часть массива уже
отсортирована и, следовательно, ее можно исключить из рассмотрения. [1]
Во-вторых, при движении от конца
массива к началу минимальный элемент «всплывает» на первую позицию, а
максимальный элемент сдвигается только на одну позицию вправо. [1]
Эти две идеи приводят к следующим
модификациям в методе пузырьковой сортировки. Границы рабочей части массива
(т.е. части массива, где происходит движение) устанавливаются в месте
последнего обмена на каждой итерации. Массив просматривается поочередно справа
налево и слева направо.
Лучший случай для этой сортировки -
отсортированный массив (О(n)), худший - отсортированный в обратном порядке (O (n²)). [1]
Пирамидальная - алгоритм сортировки, работающий в худшем, в среднем и в лучшем
случае (то есть гарантированно) заΘ (n log n) операций при сортировке n элементов. Количество
применяемой служебной памяти не зависит от размера массива (то есть, O(1)). [1]
Может рассматриваться как
усовершенствованная сортировка пузырьком, в которой элемент всплывает
(min-heap) / тонет (max-heap) по многим путям.
Сортировка пирамидой использует
сортирующее дерево. Сортирующее дерево - это такое двоичное дерево, у которого
выполнены условия:
1. Каждый лист имеет глубину
либо 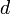 , либо
, либо  , - максимальная глубина дерева.
, - максимальная глубина дерева.
2. Значение в любой вершине
больше, чем значения её потомков.
Удобная структура данных для
сортирующего дерева - такой массив Array, что Array[1] - элемент в корне, а
потомки элемента Array[i] - Array[2i] и Array [2i+1].
Алгоритм сортировки будет состоять
из двух основных шагов:
. Выстраиваем элементы массива в
виде сортирующего дерева:
Array[i] ≥
Array[2i][i] ≥ Array [2i+1], при n/2 ≥ i ≥ 1.
Этот шаг требует  операций.
операций.
. Будем удалять элементы из корня по
одному за раз и перестраивать дерево. То есть на первом шаге обмениваем
Array[1] и Array[n], преобразовываем Array[1], Array[2], …, Array [n-1] в
сортирующее дерево. Затемпереставляем Array[1] и Array [n-1], преобразуем
Array[1], Array[2], …, Array [n-2] в сортирующее дерево. Процесс продолжается
до тех пор, пока в сортирующем дереве не останется один элемент. Тогда
Array[1], Array[2], …, Array[n] - упорядоченная последовательность. [1] Этот
шаг требует  операций.
операций.
Выбор алгоритма сортировки
перестановкамиобусловлен его простотой и быстродействием по сравнению с остальными
описанными выше алгоритмами.
В основе алгоритма лежит обмен
соседних элементов массива. Каждый элемент массива, начиная с первого,
сравнивается со следующим, и если он больше следующего, то элементы меняются
местами. Таким образом, элементы с меньшим значением продвигаются к началу
массива (всплывают), а элементы с большим значением - к концу массива (тонут).
Поэтому данный метод сортировки обменом иногда называют методом «пузырька».
Этот процесс повторяется столько раз, сколько элементов в массиве, минус
единица. [3]
На рис. 1.1 цифрой 1 обозначено
исходное состояние массива и перестановки на первом проходе, цифрой 2 -
состояние после перестановок на первом проходе и перестановки на втором
проходе, и т.д.

Рис. 1.1. Сортировка перестановками
Процедура сортировки, запускается
нажатием кнопки Сортировка (Button1). Значения элементов массива
вводятся из ячеек компонента stringGrid1. Во время сортировки, после выполнения
очередного цикла обменов элементов массива, программа выводит массив в поле
метки Label2.
Листинг 1.1. Сортировка
массива методом обмена [3]
procedure TForm1. Button1Click (Sender: TObject);
const=5;
var:array [1..SIZE] of integer;
k:integer; // текущий элемент
массива:integer; // индекс для ввода и вывода массива:boolean; // TRUE, если в
текущем цикле были обмены:integer; // буфер для обмена элементами массива
begin
// вводмассива
for i:=1 to SIZE do[i]:= StrToInt (StringGrid1. Cells
[i-1, 0]);
label2.caption:='';
// сортировка массива repeat:=FALSE;
// пусть в текущем цикле нет обменов
for k:=l to SIZE-1 doa[k]
> a [k+l] then
begin // обменяем k-й и k+1-й элементы
buf:= a[k]; a[k]:= a
[k+l]; a [k+l]:= buf;:= TRUE;
end;
// выводмассива
for i:=l to SIZE do.caption:=label2.caption+' '+IntTostr
(a[i]);.caption:=label2.caption+#13;
// массивотсортирован.caption:=label2.caption
+#13+'Maccив отсортирован.';
end;
Следует отметить, что максимальное
необходимое количество циклов проверки соседних элементов массива равно
количеству элементов массива минус один. Вместе с тем возможно, что массив
реально будет упорядочен за меньшее число циклов. Например, последовательность
чисел 5 1 2 3 4, если ее рассматривать как представление массива, будет
упорядочена за один цикл, и выполнение оставшихся трех циклов не будет иметь
смысла.
Поэтому в программу введена
логическая переменная changed, которой перед выполнением очередного цикла
присваивается значение FALSE. Процесс сортировки (цикл repeat) завершается,
если после выполнения очередного цикла проверки соседних элементов массива
(цикл for) ни один элемент массива не был обменен с соседним, и, следовательно,
массив уже упорядочен.
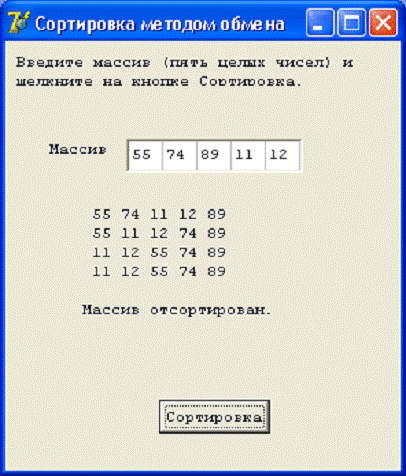
Рис. 1.2. Этапы сортировки массива
методом обмена после завершения процесса сортировки
Для организации поиска в массиве
могут быть использованы различные алгоритмы.
Линейный,
последовательный поиск - алгоритм
нахождения заданного значения произвольной функции на некотором отрезке. [2]
Данный алгоритм является простейшим алгоритмом поиска и в отличие, например, от
двоичного, не накладывает никаких ограничений на функцию и имеет простейшую
реализацию. Поиск значения функции осуществляется простым сравнением очередного
рассматриваемого значения (как правило поиск происходит слева направо, то есть
от меньших значений аргумента к большим) и, если значения совпадают (с той или
иной точностью), то поиск считается завершённым. [2]
Если отрезок имеет длину N, то найти
решение с точностью до  можно
за время
можно
за время  . Т.о. асимптотическая сложность алгоритма - . В связи с малой эффективностью по сравнению с другими
алгоритмами линейный поиск обычно используют только если отрезок поиска
содержит очень мало элементов, тем не менее линейный поиск не требует
дополнительной памяти или обработки / анализа функции, так что может работать в
потоковом режиме при непосредственном получении данных из любого источника. Так
же, линейный поиск часто используется в виде линейных алгоритмов поиска
максимума / минимума.
. Т.о. асимптотическая сложность алгоритма - . В связи с малой эффективностью по сравнению с другими
алгоритмами линейный поиск обычно используют только если отрезок поиска
содержит очень мало элементов, тем не менее линейный поиск не требует
дополнительной памяти или обработки / анализа функции, так что может работать в
потоковом режиме при непосредственном получении данных из любого источника. Так
же, линейный поиск часто используется в виде линейных алгоритмов поиска
максимума / минимума.
Двоичный (бинарный)
поиск (также известен как метод деления
пополам и дихотомия) - классический алгоритм поиска элемента в отсортированном
массиве (векторе), использующий дробление массива на половины. [4]
Частным случаем двоичного поиска
является метод бисекции, который применяется для поиска корней заданной
непрерывной функции на заданном отрезке.
Листинг 1.2.
Двоичныйпоискэлементавмассиве. [5]
functionRecurceFind (L, R: Integer): Integer;
var: Integer;
begin
if R < L then
begin:=L; // Result:= -1 еслипоискточный
Exit;
end;:= (L + R) div 2;
if A[M] = X then
begin:= M;;
end;
if A[M] > X then:=RecurceFind (L, M - 1)
else:=RecurceFind (M + 1, R)
end;
begin:=RecurceFind (Low(A), High(A));
end;
Выбор алгоритма двоичного поиска обусловлен
простотой и быстродействием по сравнению с приведенным выше алгоритмом
линейного поиска.
2. Описание
использованных структур данных
Массив - упорядоченный набор данных,
для хранения данных одного типа, идентифицируемых с помощью одного или
нескольких индексов. В простейшем случае массив имеет постоянную длину и хранит
единицы данных одного и того же типа.
Количество используемых индексов массива
может быть различным. Массивы с одним индексом называют одномерными, с двумя -
двумерными и т.д. Одномерный массив нестрого соответствует вектору в
математике, двумерный - матрице.
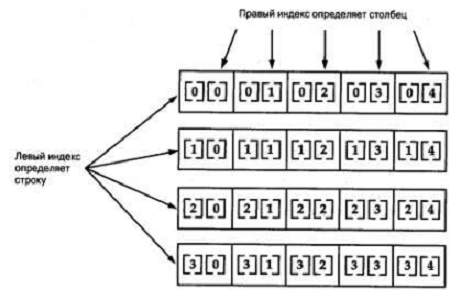
Рис. 2.1. Схематическое изображение
двумерного массива
В приложении массив используется для
хранения словосочетаний и частоты их повторений в тексте. Каждому элементу в
массиве соответствует некоторое словосочетание. В процессе подсчета и удаления
повторяющихся словосочетаний в каждый элемент массива добавляется количество
повторений соответствующего словосочетания. Выбор массива строк в качестве
структуры данных для хранения словаря обусловлен простотой использования.
3. Описание
процедур
и
функций
procedureTForm1. Button1Click (Sender:
TObject)
Данная процедура позволяет выбрать
файл для работы из файловой системы Windows. При этом открывается диалоговое окно с каталогом. Делается это с
помощью переменной типа TOpenDialog. Свойство Filter позволило создать ограничение на открытие файлов. Программа
открывает только файлы с расширением.txtи.rtf. Путь к выбранному файлу записывается в глобальную переменную Failтипа String, после чего открывается
файл по указанному пути, и содержание файла копируется в поле МЕМО1.
procedure TForm1.
Button2Click (Sender: TObject):
ДаннаяпроцедуранаподобииprocedureTForm1. Button1Click (Sender:TObject) открывает файл настройки с разделителями и выводит его в MEMO3.
procedureTForm1. Button3Click (Sender: TObject):
Данная процедура выполняет основную
задачу программы - создает словарь. На первом этапе работы процедуры создается
массив разделителей razd, получаемый из поля MEMO3. Затем текст из MEMO1 построчно считывается в переменную строкового типа s. Если какой-либо символ
этой строки оказывается равным одному из разделителей, то слово записывается в
массив строк slova, где каждому слову соответствует один из элементов массива. Далее
из пар элементов массива slova формируется массив frazi, элементами которого являются все словосочетания текста. После
этого запускается алгоритм поиска одинаковых словосочетаний. При наличии
некоторого числа одинаковых элементов в массиве fraziпроисходит удаление всех
одинаковых элементов за исключением проверяемого и увеличение счетчика на
количество найденных элементов. После обхода по всему массиву в проверяемый
элемент дописывается значение счетчика, отображающее частоту употребления
словосочетания в тексте и переход к проверке следующего словосочетания. Далее
происходит сортировка (методом перестановок) полученного словаря по алфавиту.
На входе процедуры подается текст из
MEMO1. На выходе в MEMO2 выводится отсортированный словарь вида <кол-во
повторений> ‘…….’<словосочетание>.
procedure TForm1.
Button4Click (Sender: TObject):
Данная процедура позволяет сохранять
полученный ранее словарь в текстовой файл. В ней также открывается диалоговое
окно с каталогом файловой системы. Используется переменная типа TSaveDialog. Путь к файлу
записывается в переменную Slvrтипа String. Информация для записи в файл берется из поля MEMO2.
procedureTForm1. Button5Click (Sender: TObject):
Данная процедура выполняет
сортировку словаря методом перестановок. Если значение свойстваIndexItemкомпонента RadioGroupравно 0, то словарь
сортируется по алфавиту, иначе по частоте.
procedure TForm1.
Button6Click (Sender: TObject)):
Данная процедура осуществляет
двоичный поиск по словарю. На входе подается словарь frazi, на выходе в Labelзаписывается результат
поиска.
4. Описание
структуры приложения и интерфейса пользователя
Задача была реализована на языке Delphiв интегрированной среде
Embarcadero RAD Studio XE2. Приложение состоит из одного модуля Unit1. В основной форме
данной программы определены три компонента текстового ввода, кнопка открытия
файла, кнопка открытия файла с настройками, кнопка создания словаря, кнопка
сохранения словаря и поле для ввода слов для поиска (рис. 4.1)
Рис. 4.1. Главное окно программы
Для работы программы необходимо,
чтобы в полях «Исходный текст» и «Список разделителей» были
символы. Для этого можно пользоваться соответствующими кнопками открытия файлов
или вводить текст непосредственно в поле (рис. 4.2).
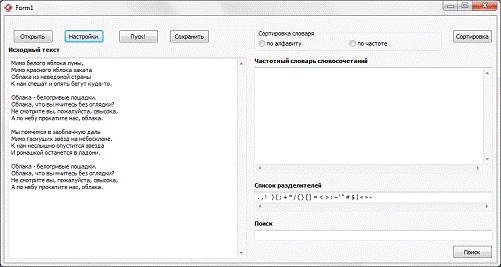
Рис. 4.2. Ввод обрабатываемого
текста и списка разделителей.
После этого можно будет нажать кнопку
«Пуск!» и в поле «Частотный словарь словосочетаний» появится
информация (рис. 4.3).

Рис. 4.3. Составленный словарь
словосочетаний
Полученный словарь можно
отсортировать по частоте или по алфавиту, выбрав соответствующий пункт в поле
«Сортировка словаря» инажав кнопку «Сортировка» (рис. 4.4).

Рис. 4.4. Сортировка по частоте
Поиск словосочетания по словарю
осуществляется путем ввода в поле «Поиск» требуемой фразы и клика на
кнопку «Поиск» или нажатия кнопки Enterна клавиатуре.
Результаты поиска выводятся под полем «Поиск» (рис. 4.5).
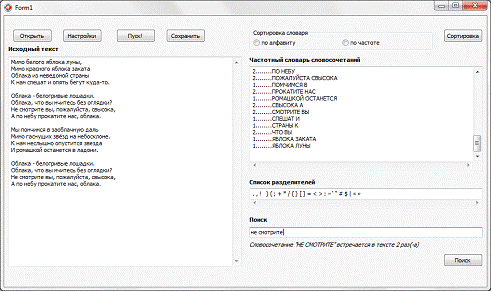
Рис. 4.5. Поиск словосочетания «не
смотрите»
Полученный словарь можно сохранить в
файл с помощью кнопки «Сохранить» (рис. 4.6).
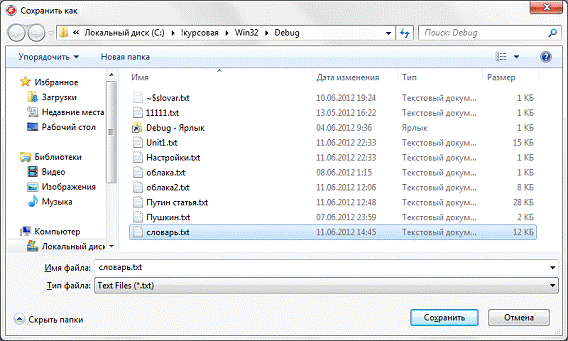
Рис. 4.6. Сохоанение словаря на
жестком диске
При сохранении файла необходимо
через точку в имени файла указать его расширение (.txt или.rtf).
. Системные
требования и имеющиеся ограничения
1. Операционная система: MSWindowsXP/Vista/7 с
установленнымFramework (версии 2.0 и старше). Количество необходимой памяти: 8
Мб ОЗУ, 8 Мб свободного места на жёстком диске.
. В процессе работы
приложения не учитывается регистр.
. Программа обрабатывает
тексты, занимающие не более 32 Кб памяти в силу ограничений компонента Memo.
.
Тестирование приложения
Тестирование заключалось в проверке
работоспособности приложения вне зависимости от объема введенного текста.
Результаты тестирования приведены в рисунках 4.1-4.3.
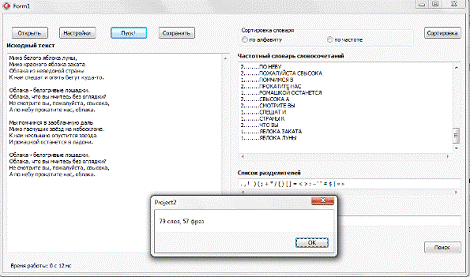
Рис. 6.1 Текст, состоящий и 79 слов

Рис. 6.2 Текст, состоящий из 2146
слов
Рис. 6.3 Текст, состоящий из 3910
слов
. Анализ
временных характеристик и выводы
При помощи команды «showmessage» произведен
тестпроизводительности алгоритма на разных объёмах входных данных. Тествыдавал информацию
о количественных характеристиках работы алгоритма, таких как объем
обрабатываемого текста (таб. 6.1) и количество словосочетаний, перестановок при
сортировке и обходов частей массива при поиске (таб. 6.2).Ссылаясь на
результаты тестирования, можно сделать вывод, что время составления словаря
линейно зависит от количества входящей информации.
Таб. 6.1 Зависимость времени
составления словаря от объема текста
|
Объем текста
|
Время
|
|
100 строк
|
15
|
|
200 строк
|
31
|
|
500 строк
|
109
|
|
1000 строк
|
203
|
Таб. 6.2 Кол-во перестановок при
сортировке и обходов при поиске.
|
Объем словаря
|
Время сортировки
|
Кол-во перестановок при сортировке
|
Кол-во обходов при поиске
|
|
200
|
15
|
92
|
6
|
|
400
|
47
|
858
|
7
|
|
660
|
78
|
4120
|
8
|
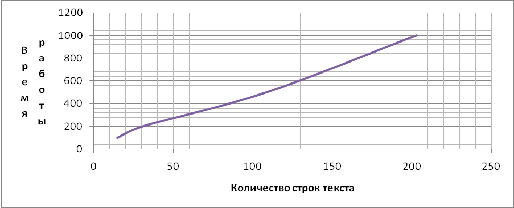
Рис. 7.1 Зависимость
времени составления словаря от объема введенного текста
Результаты тестирования
отражают практически линейную зависимость времени сортировки словаря и
количество обходов частей списка словосочетаний при поиске в зависимости от его
величины, что свидетельствует о правильности составления алгоритма сортировки
перестановками.
Линейная зависимость
первых двух графиков является подтверждением правильности реализации
проверяемых алгоритмов.
Нелинейность последнего
графика обусловлена тем, что кол-во словосочетаний зависит не только от объема
текста, но и от количества предложений в нем
Заключение
приложение
тестирование интерфейс пользователь
В соответствии с заданием, мною была
разработана программа, имеющая дружественный графический интерфейс, и
предоставляющая возможность создания частотного словаря словосочетаний и
дальнейшей его обработки. В ходе работы были рассмотрены алгоритмы бинарного
поиска и сортировки методом перестановки.
Список литературы
1. А.Я. Архангельский. Программирование в Delphi. - Москва: Изд-во
Бином-Пресс, 2003-1152 с.
2. Е.П. Марков. Программирование в Delphi 7. - Санкт-Петербург:
Изд-во БХВ-Петербург, 2005 - 784 с.
. Сортировка методом обмена // Уроки программированияURL:http://progclub.ru/? param=book&name=delphi7_dlya_nachinaushih&dir=glava5&file=index14 (дата обращения:
20.05.2012).
. Двоичный поиск // Википедия - свободная энциклопедия URL:
http://ru.wikipedia.org/wiki/Двоичный поиск (дата обращения: 20.05.2012).
. Двоичный поиск // Delphiпрограммирование URL:
http://www.delphisources.ru/pages/faq/base/binary_int_array_search.html (дата
обращения: 20.05.2012).
. DelphiTOpenDialog // DelphiпрограммированиеURL:
http://www.delphisources.ru/pages/faq/faq_delphi_basics/TOpenDialog.php.html
(Дата обращения: 20.05.2012).
. Delphi TSaveDialog // DelphiпрограммированиеURL: http://www.delphisources.ru/pages/faq/faq_delphi_basics/TSaveDialog.php.html (Дата
обращения: 20.05.2012).
Приложение. Текст
программы
unitUnit1;
interface
uses
Winapi. Windows, Winapi.
Messages, System. SysUtils, System. Variants, System. Classes, Vcl. Graphics,.
Controls, Vcl. Forms, Vcl. Dialogs, Vcl. StdCtrls, Vcl. ExtCtrls;
= class(TForm): TMemo;:
TMemo;: TButton;: TButton;: TButton;: TButton;: TEdit;: TLabel;: TLabel;:
TLabel;: TMemo;: TButton;: TRadioGroup;: TButton;: TLabel;: TLabel;:
TLabel;Button1Click (Sender: TObject);Button2Click (Sender:
TObject);Button4Click (Sender: TObject);Button3Click (Sender:
TObject);Button6Click (Sender: TObject);Button5Click (Sender:
TObject);Edit1KeyPress (Sender: TObject; var Key: Char);
{Private declarations}
{Public declarations};
: TForm1;, Slvr,
Razdel:string;: array of string;
{$R *.dfm}
TForm1. Button1Click
(Sender: TObject); // Открыть: TOpenDialog;: TextFile;:string;
. Clear;. Lines. Add ('
');:= TOpenDialog. Create(self);. InitialDir:= GetCurrentDir;
// Только разрешенные существующие
файлы могут быть выбраны
openDialog. Options:= [ofFileMustExist];
openDialog. Filter:=
'Text
Files|*.txt;*.rtf';
// Диалоготкрытияфайла.
Execute:=openDialog. FileName;(Tekst, Fail);(Tekst);
not eof(Tekst) do(Tekst,
s);. Lines. Add(s);;. Lines. Delete(0);
;
;
TForm1. Button2Click
(Sender: TObject); // Настройки: TOpenDialog;: TextFile;:string;
Memo3. Lines. Count=0
then Memo3. Lines. Add('');:= TOpenDialog. Create(self);. InitialDir:= GetCurrentDir;
//
Только разрешенные существующие файлы могут быть выбраны
openDialog. Options:= [ofFileMustExist];
// Разрешено выбрать только.txt и.rtf файлы
openDialog. Filter:=
'Text
Files|*.txt;*.rtf';
// Диалоготкрытияфайла.
Execute:=openDialog. FileName;(Tekst, Razdel);(Tekst);
not eof(Tekst) do(Tekst,
s);. Lines. Add(s);;. Lines. Delete(0);
;;TForm1. Button3Click
(Sender: TObject); // Пуск
, p, j, k, e, p1, h, x,
t: integer;: array of string;: array of char;, s1: string;: string;:boolean;
. Clear; (slova, 0); // обнуление словаря
setlength (razd, 0); // обнуления списка разделителей
i:=0;:=0;:=1;
////////////////////////////
:=memo3. Lines[0]; // j<= length(s) do // //
setLength (razd, p+1); //
razd[p]:=s[j]; // // создание массива с разделителями
p:=p+1; // :=j+2; // ;
//
///////////////////////////
(razd, length(razd)+1);[length(razd) - 1]:= #13;(razd, length(razd)+1);[length(razd)
- 1]:= #9;
:= 0;
j:= 1;
i:= 0;
t:=GetTickCount(); // начало замера времени
whilei<>memo1.
Lines. Count do:= memo1. Lines[i]; // просмотрi-й строки
(' ', s)=1 do delete (s,
1,1); // удаляемотступы
{Чтобы символ '-' не определялся как
слово}
h:= 1;h<=length(s) -
2 dop1:= 0 to length(razd) - 1 dos[h]='-' then if s [h+1]=razd[p1] then(s, h,
1);:= h+1;;
whilelength (s)>0 do // если конец строки, то переход на следующую
begin
k:= 0;
e:= -1;
{Проверка строки на наличие
разделителя}
while k<=
length(razd) - 1 do(s[j]= razd[k]) then e:= 1;:=
k+1
end;
ife>0 then // если проверяемый символ оказался разделителем
begin
// Заносим слово в массив 'slova'
//////////////////////////////////////////////////////////////////////////
// s[j]='.' then s1:= copy (s, 1, j) else if s[j]='!' // s1:= copy (s, 1, j)
else if s[j]='?' then s1:= copy (s, 1, j) // s1:= copy (s, 1, j-1); // 1:= AnsiUpperCase(s1); // перевод всех букв в слове в верхний регистр //
if (length (s1)=0) or
(s1='-') then begin j:= j+1; delete (s, 1,1); end // begin // (slova, p+1); //
[p]:=s1; // := p+1; // (s, 1, j); // :=1; end; end; end // j:= j+1; // ; //
i:= i+1; //
end; //
//////////////////////////////////////////////////////////////////////////
{Очистка слов от оставшихся
разделителей}
For i:=0 to
length(slova) - 1 dok:=0 to length(razd) - 1 do(razd[k], slova[i])>0 do
delete (slova[i], pos (razd[k], slova[i]), 1);
{Составляем фразы из полученных
слов}
p:= 0; i:= 0;<=
Length(slova) - 2 do:= pos ('.', slova[i]);j=0 then if pos ('!', slova[i])=0
then if pos ('?', slova[i])=0 then[i]<>'' then if slova [i+1]<>''
then(frazi, p+1);[p]:=slova[i]+' '+slova [i+1];:= p+1;;:= i+1;;
{Удаление оставшихся знаков
препинания}
fori:= 0 toLength(frazi) - 1 do
begin:= frazi[i];:=
length (s);s[j]='.' then delete (s, j, 1) else if s[j]='!'delete (s, j, 1) else
if s[j]='?' then delete (s, j, 1); [i]:= s;
end;
{Подсчет и удаление одинаковых фраз}
h:= High(frazi);:=
0;<= h do begin:=frazi[i];:= 1;j:= h downtoi + 1 do begin[j] = S then
begin(e);k:= j to h - 1 do frazi[k]:= frazi [k + 1];(h);;;:= length
(frazi[i]);(' ', frazi[i])<>p then[i]:= IntToStr(e) + '……..' + Sbegin x:=
i+1;;(i);;(frazi, h + 1);
{Чистка словаря отсловосочетаний с
пустыми строками вместо слов}
k:=0;k <= length(frazi)
- 1 do:= length (frazi[k]);(' ', frazi[k])=p then begin for i:=K+1 to
Length(frazi) - 1 do[i-1]:= frazi[i];(frazi, Length(frazi) - 1); end; inc(k);
;
t:=GetTickCount() - t; // конец замера времени
{Сортировка фраз по алфавиту}
repeat
priz:=false;
fori:= 0 to
length(frazi) - 2 do:= pos ('.', frazi[i])+8;:= pos ('.', frazi [i+1])+8;:=
copy (frazi[i], p, length (frazi[i]));:= copy (frazi [i+1], p1, length
(frazi[i+1]));(s>s1) then:= frazi[i];[i]:= frazi
[i+1];[i+1]:=buf;:=true;;;=false;
{Вывод словаря в мемо}
Memo2. Clear;
fori:= 0 to
length(frazi) - 1 do. Lines. Add (' ');. Lines[i]:=frazi[i];;. Caption:=
'Времяработы t='+inttostr(t);;
TForm1. Button4Click
(Sender: TObject); // Сохранить:TSaveDialog;:= TSaveDialog. Create(self);.
InitialDir:= GetCurrentDir;
// Отображение диалог сохранения
файла
ifsaveDialog. Execute:=saveDialog.
FileName;. Lines. SaveToFile(Slvr);;;
TForm1. Button5Click
(Sender: TObject); // Сортировка, p, p1: integer;, s, s1: string;:boolean;
{Сортировкапоалфавиту}RadioGroup1.
ItemIndex=0 then begin:=false;:= 0 to length(frazi) - 2 do:= pos ('.',
frazi[i])+8;:= pos ('.', frazi [i+1])+8;:= copy (frazi[i], p, length
(frazi[i]));:= copy (frazi [i+1], p1, length (frazi[i+1]));(s>s1) then:=
frazi[i];[i]:= frazi [i+1];[i+1]:=buf;:=true;;;=false;
{Вывод в мемо}. Clear;:=
0 to length(frazi) - 1 do. Lines. Add (' ');. Lines[i]:=frazi[i];;
begin
{Сортировкапочастоте}:=false;:=
0 to length(frazi) - 2 do:= pos ('.', frazi[i]);:= pos ('.', frazi [i+1]);
:= copy (frazi[i], 1,
p-1);:= copy (frazi [i+1], 1, p-1);p<p1 then begin
:= frazi[i];[i]:= frazi
[i+1];[i+1]:=buf;:=true;;(s<s1) and (p=p1) then:= frazi[i];[i]:= frazi
[i+1];[i+1]:=buf;:=true;;;=false;
{Вывод в мемо}. Clear;:=
0 to length(frazi) - 1 do. Lines. Add (' ');.lines[i]:= frazi[i];; end;;
TForm1. Button6Click
(Sender: TObject); // Поиск:string;, k, j, p, p1:integer;, s1, buf:
string;:boolean;. Caption:='';:=false;:= 0 to length(frazi) - 2 do:= pos ('.',
frazi[i])+8;:= pos ('.', frazi [i+1])+8;:= copy (frazi[i], p, length
(frazi[i]));:= copy (frazi [i+1], p1, length (frazi[i+1]));(s>s1) then:=
frazi[i];[i]:= frazi [i+1];[i+1]:=buf;:=true;;;=false;:=AnsiUpperCase (edit1.
Text);:=0; j:=length(frazi) - 1;:=0;<= j do:= i + (j - i) div 2;:= pos ('.',
frazi[k])+8;:= copy (frazi[k], p, length (frazi[k]));:= copy (frazi[k], 1,
p-9);> s then:= k + 1if obr< s then:= k - 1;;
s= obr then1. Caption:='Словосочетание «'+s+'» встречается в тексте '+s1+' раз(-а)'
elseLabel1. Caption:='Словосочетание не найдено';
if Edit1. Text='' then
label1. Caption:='';;
procedure TForm1.
Edit1KeyPress (Sender: TObject; var Key: Char);Key = #13 then
Button6Click(Button6);;.