Методы автоматического порождения поисковых эвристик
Методы
автоматического порождения поисковых эвристик
Оглавление
Оглавление
Введение
Постановка задачи
. Анализ существующих поисковых систем
.1 Критерии оценки поисковых систем
.2 Поисковая система с большим количеством проиндексированных
документов
.3 Поисковый каталог
.4 Преимущества и недостатки существующих подходов
.Виртуальный каталог
.1 Принцип работы виртуального каталога
.2 Поиск информации в виртуальном каталоге
. Экспертная система по автоматическому подбору эвристик
.1 Требования к экспертной системе по автоматическому
порождению поисковых эвристик
.2 Принцип работы экспертной системы
.3 Обучение экспертной системы
.4 Логические методы автоматического подбора эвристик
. Оценка полученных результатов
. Сравнение результатов поиска с другими поисковыми системами
Заключение
Список литературы
Введение
В век, когда информация с каждым годом приобретает все большее и большее
значение, разработка эффективных систем поиска информации является одной из
самых важных, но в тоже время далеко не тривиальных задач.
Информация окружает нас повсюду: средства массовой информации, журналы,
книжные издания, газеты и наконец Интернет.
Именно о методах поиска информации в Интернете пойдет речь в данной
работе.
Как известно, в настоящее время Интернет представляет собой один из самых
больших и постоянно развивающихся источников разнообразных сведений. В нем
содержатся миллиарды документов, количество которых с каждым годом постоянно
возрастает. И, возможно, через несколько десятилетий или столетий во всемирной
паутине будет сосредоточена абсолютно вся информация, которую смогло собрать
человечество.
На первый взгляд, кажется, что человек, имея доступ в Интернет, может
легко и быстро найти в нем нужную информацию практически из любой области
знаний. Но, зачастую, это оказывается не так. Человек тратит много времени и
сил на поиск необходимых сведений и иногда их даже не находит.
Конечно же, сейчас во всемирной паутине существует огромное количество
разнообразных поисковых систем, которые в той или иной степени решают задачу
поиска. Самыми известными и популярными в России являются поисковые системы Google и Яндекс [1,2,3]. Но они помогают
человеку в поиске лишь частично, потому что предоставляют ему не ту информацию,
которую он желал найти, а ту, которая соответствует поисковому запросу.
Совсем недавно был разработан принципиально новый подход к поиску
информации, основанный на технологии виртуального каталога [4]. Виртуальный
каталог - это мета-поисковая система, представляющая собой синтез
Интернет-каталога предметной области и поисковой системы с большим количеством
проиндексированных документов.
В данной статье рассматриваются инструменты, необходимые для эффективной
работы виртуального каталога, основанные на применении логических методов.
Постановка задачи
Использование виртуального каталога в задаче поиска информации в
Интернете невозможно без создания специальных средств - поисковых эвристик.
Поэтому цель моей магистерской диссертации - разработка логических
методов, необходимых для улучшения поиска в метапоисковой системе «Виртуальный
каталог».
Работа над диссертацией включает в себя следующий список задач:
. Анализ информационно-поисковых систем на основании формальных
критериев оценки качества поиска
. Исследование основных принципов работы виртуального каталога
. Формулирование требований к экспертной системе по
автоматическому порождению эвристик
. Разработка процесса обучения экспертной системы
. Разработка логических методов автоматического порождения
поисковых эвристик
. Создание алгоритма поиска информации в виртуальном каталоге на
основании полученного набора эвристик
. Реализация разработанной модели экспертной системы
. Оценка полученных результатов
1.
Анализ существующих поисковых систем
1.1 Критерии
оценки поисковых систем
Для того чтобы объективно оценить качество работы различных типов
поисковых систем, представленных в Интернете, введем следующие формальные
критерии оценки поисковых систем:
Актуальность - это степень соответствия результатов поиска актуальному
состоянию информации в выбранной предметной области в данный момент времени.
Пертинентность - это степень соответствия результатов поиска и
информационной потребности пользователя, выраженной в формальном запросе к
поисковой системе. Пертинентность определяется субъективным восприятием
человека и может быть выражена в формальном запросе с той или иной степенью
точности [5,6].
Адекватность - это мера соответствия информационной потребности
пользователя и формального запроса к поисковой системе.
Релевантность - это степень соответствия формального запроса и полученных
в результате поиска документов [5,6].
Таким образом, пертинентность - это композиция адекватности и
релевантности работы информационно-поисковой системы.
Полнота - это доля релевантных ресурсов, присутствующих в выдаче поисковой
системы, к общему числу всех релевантных ресурсов в Интернете [5,6].
Очевидно, что главными критериями оценки результатов поиска информации
человеком являются ее актуальность, полнота и пертинентность.
В настоящий момент большинство поисковых систем хоть и в состоянии
обеспечить актуальность и полноту выдаваемой информации, но что касается
пертинентности, то поисковые системы нацелены лишь на повышение одной из ее
составляющих - релевантности результатов поиска. Вследствие чего теряется
главный смысл создания инструментов поиска в Интернете - удовлетворение
информационных нужд пользователей.
Рассмотрим существующие поисковые системы с точки зрения введенных
критериев оценки поисковых систем.
1.2 Поисковая
система с большим количеством проиндексированных документов
Такие поисковые системы на сегодняшний момент являются одним из самых
распространенных и популярных инструментов поиска в Интернете. Самыми
известными поисковыми системами являются Google, Yandex,
Rambler. Они обладают огромным количеством
проиндексированных документов (документов в которых осуществляется поиск),
причем их база информационных ресурсов постоянно обновляется и расширяется [7].
Вышеперечисленные качества являются несомненными достоинствами поисковой
системы, поскольку в ее обширной информационной базе с очень большой
вероятностью может быть найден какой-нибудь подходящий ответ практически на
большинство запросов пользователей даже без привлечения для этих целей
серьезного методического аппарата. Более того такие поисковые системы
обеспечивают высокую релевантность результатов поиска за счет различных
алгоритмов поиска и ранжирования документов.
Таким образом, используя такие системы в качестве инструментов поиска,
человек получит очень качественный набор документов, формально соответствующий
запросу. Система выдаст пользователю информацию, которая будет релевантной
поисковому запросу, но далеко не пертинентной. Подобные поисковые системы
вообще не обладают механизмами повышения пертинентности запроса. Поэтому задача
формирования запроса и выбора подходящих сведений среди отобранной информации
полностью возлагается на пользователя.
Таким образом, информационно-поисковые системы этого типа удовлетворяют
лишь нескольким критериям качества работы поисковых систем: актуальность, полнота
и релевантность результатов поиска, совершенно забывая об информационных нуждах
пользователей, то есть о пертинентности.
1.3 Поисковый
каталог
Поисковый каталог - сайт, представляющий собой систематизированную
модераторами по тематическому принципу коллекцию ссылок на другие сайты.
Поисковые каталоги, получившие наибольшую популярность это Yahoo, Open
Directory, Яндекс-каталог, Апорт и другие.
Поисковые каталоги в какой-то слабой мере могут обеспечить пертинентность
ответа в сравнении с поисковой системой для определенного узкого круга лиц, за
счет предварительной обработки документов редакторами в ручном режиме. Однако
информационная полезность таких каталогов, как правило, ограничена небольшим
количеством проиндексированных документов, большими затратами средств на
поддержание актуальности базы проиндексированных документов и, следовательно,
низкой оперативностью ее обновления. Соответственно абсолютно не гарантируют
своим пользователем актуальность и полноту выдаваемой информации.
1.4 Преимущества
и недостатки существующих подходов
Подводя итоги, выделим основные преимущества информационно-поисковой
системы и поискового каталога:
§ Информационно-поисковая система:
§ Огромное количество проиндексированных документов
§ Поддержка актуальности информации
§ Высокая релевантность результатов поиска
§ Поисковый каталог
§ Пертинентность информации в пределах представленных ресурсов
§ Удобная структура для организации данных
На основе информационно-поисковой системы и Интернет-каталога, а также их
преимуществ был разработан новый подход в поиске информации - Виртуальный
каталог.
2.
Виртуальный каталог
Виртуальный каталог - это мета-поисковая система, которая объединяет в
себе основные достоинства поисковой системы и поискового каталога, а также
исключает их недостатки [4,6].
Интерфейс виртуального каталога снаружи похож на обычный
Интернет-каталог. Однако поиск информации в виртуальном каталоге происходит
абсолютно по иным механизмам, основанным на использовании онтологии предметной
области [8] и Интернета, а также поисковой системы с большим количеством
проиндексированных документов.
2.1 Принцип
работы виртуального каталога
Принцип работы виртуального каталога основан на трех его составляющих:
. Онтология предметной области
Онтология предметной области состоит из рубрик [9,10,11,12]. Рубрика -
представляет собой определенный раздел знаний предметной области. Рубрики
связаны между собой связью «целое-часть». При этом полученный из онтологии
рубрикатор является не деревом, а графом. То есть подрубрика может принадлежать
не строго одной рубрике, а нескольким рубрикам.
Онтология Интернета в виртуальном каталоге представлена классификацией
видов Интернет-ресурсов [6]. Видами Интернет-ресурсов являются: статьи, форумы,
блоги, конференции, тематические сайты и т.д. В настоящий момент разработан
только первый уровень рубрикатора видов ресурсов. В дальнейшем онтология видов
ресурсов будет развиваться.
. Эвристики
Главным связующим звеном и ядром виртуального каталога являются
эвристики. Эвристика - это ключевой термин, сужающий область поиска до
выбранной рубрики и вида ресурса [6]. Таким образом, каждой паре (рубрика, вид
ресурса) соответствует определенный, заранее подобранный набор эвристик. (см.
рис. 1).
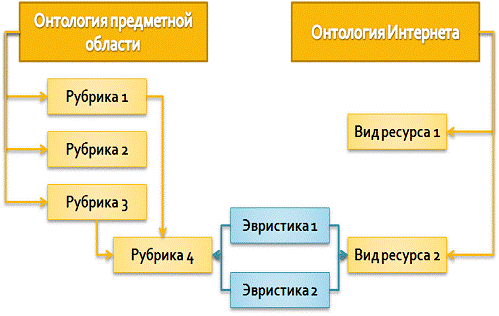
рис.
1 Составляющие виртуального каталога
2.2 Поиск
информации в виртуальном каталоге
Исходя из выше изложенного, рассмотрим, как происходит поиск информации в
виртуальном каталоге:
Виртуальный каталог отправляет набор эвристик выбранной пары (рубрика,
вид ресурса) в виде запросов информационно-поисковой системе (Google, Яндекс)
Затем получает ответ, отсортировывает его в определенном порядке и
отображает пользователю.
Следовательно, при правильно определенном наборе эвристик, пользователь
действительно может получить именно ту информацию, которая ему была необходима.
Таким образом, виртуальный каталог отвечает всем критериям оценки
эффективности работы поисковых систем:
Актуальность, полнота и релевантность достигается за счет использования
информационно-поисковой системы (Google,
Яндекс)
Адекватность за счет выбора пользователем вручную интересующей его
тематики и специально подобранных для этой тематики эвристик.
Таким образом, виртуальный каталог в состоянии обеспечить не только
актуальность, полноту и релевантность поиска, но и один из самых важных
критериев - пертинентность.
Для того чтобы разработать полноценный виртуальный каталог для предметной
области, который бы в полной мере удовлетворял информационную потребность
пользователя в данной предметной области необходимы три компонента:
§ Рубрикатор предметной области
§ Список ресурсов
§ Набор эвристик
В данной работе мы не будем подробно останавливаться на построении
рубрикатора предметной области и списка ресурсов.
Рассмотрим тему, представляющую наибольший интерес - методы порождения
эвристик. Поскольку именно от правильно подобранных эвристик в наибольшей
степени зависит пертинентность ответа виртуального каталога.
3.
Экспертная система по автоматическому подбору эвристик
Поскольку именно от правильно подобранных эвристик в наибольшей степени
зависит пертинентность результатов поиска в виртуальном каталоге, рассмотрим
методы их автоматического порождения.
Понятие пертинентности поиска - это достаточно субъективный критерий,
поэтому пока еще не создан искусственный интеллект, только человек в состоянии
определить удовлетворяют ли результаты поиска его информационную потребность.
Следовательно, процесс построения эвристик должен происходить с участием
эксперта в предметной области. Но при этом необходимо учитывать, что количество
пар (рубрика, вид ресурса) в виртуальном каталоге может быть достаточно велико
и для того чтобы полностью подобрать качественный набор эвристик, эксперт
потратит огромное количество времени. Также следует учитывать, что эксперт помимо
знаний в предметной области должен обладать специальными знаниями в сфере
поиска информации в Интернете. Поэтому, эксперту необходимо предоставить
эффективный программный инструмент, осуществляющий помощь в подборе эвристик.
Таким инструментом является экспертная система по автоматическому подбору
поисковых эвристик [13].
Принцип работы экспертной системы состоит в следующем: первоначально
происходит обучение экспертной системы, после которого система на основании
логических методов автоматически строит искомый набор эвристик.
эвристика поисковый система каталог
3.1 Требования
к экспертной системе по автоматическому порождению поисковых эвристик
Для того чтобы разработать экспертную систему, которая действительно
будет приносить ощутимый эффект в процессе построения эвристик, необходимо
тщательно продумать требования, предъявляемые к системе.
Сформулируем требования к экспертной системе:
§ Автоматическое порождение эвристик для любой предметной области
Экспертная система должна предоставлять средства, позволяющие эксперту
загружать в систему рубрикатор любой предметной области в заранее установленном
формате, а также список ресурсов.
§ Подбор эвристики для пары (рубрика, ресурс)
Экспертная система должна предоставлять возможность подбирать эвристики
для каждой пары (рубрика, ресурс) предметной области.
§ Быстрое и качественное построение эвристики
Процесс построения эвристики для одной пары (рубрика, ресурс) не должен
отнимать слишком много времени у эксперта, но в тоже время он должен быть
достаточно качественным. Эвристика, порожденная экспертной системой, должна
максимально отвечать информационной потребности пользователя в области,
соответствующей выбранной рубрике и ресурсу.
§ Минимальное взаимодействие экспертной системы и человека
Эксперт должен лишь вести процесс порождения эвристик, большую часть
работы экспертная система должна проделывать автоматически.
§ Информационный обмен с виртуальным каталогом
Экспертная система должна обладать средствами, позволяющими осуществлять
экспорт и импорт данных (рубрикатора и эвристик) в виртуальный каталог.
§ Простой и удобный графический интерфейс
Интерфейс экспертной системы должен быть удобен и прост в использовании.
Эксперт должен иметь возможность обучиться работе в системе в короткие сроки.
В соответствии с вышеизложенными требованиями, было решено реализовать
экспертную систему в виде WEB-приложения на языке PHP с использованием СУБД MySQL.
3.2 Принцип
работы экспертной системы
Очевидно, что программная система самостоятельно не сможет понять, что
тот или иной документ соответствует информационной потребности пользователя. Но
что если человек, а в данном случае эксперт, подскажет ему, какие тексты
относятся к выбранной тематике, а какие нет. Тем самым, эксперт обучит систему
отличать тексты, соответствующие выбранной теме от несоответствующих текстов. В
этом и заключается основной принцип работы экспертной системы по
автоматическому подбору эвристик.
Рассмотрим поподробнее, каким же образом этот принцип реализован в
экспертной системе.
Алгоритм подбора эвристик для пары (рубрика, ресурс) в экспертной системе
состоит из следующих этапов:
. Обучение экспертной системы
. Автоматическое построение набора эвристик
. Оценка полученных результатов поиска
3.3 Обучение
экспертной системы
Обучение экспертной системы происходит независимо для каждой пары
(рубрика, вида ресурса).
Введем следующие определения, используемые в процессе обучения экспертной
системы:
Релевантный текст - это текст, соответствующий выбранной тематике пары
(рубрика, вид ресурса). Следовательно, релевантный текст удовлетворяет
информационную потребность пользователя в выбранном разделе знаний.
Нерелевантный текст - это текст, несоответствующий выбранной тематике
пары (рубрика, вид ресурса). Следовательно, релевантный текст не удовлетворяет
информационную потребность пользователя в выбранном разделе знаний.
Таким образом, процесс обучения экспертной системы основан на определении
экспертом релевантных и нерелевантных текстов по отношению к выбранной тематике
пары (рубрика, вид ресурса).
Алгоритм обучения экспертной системы:
. Эксперт выбирает рубрику и вид ресурса
. Эксперт вводит любой запрос в поисковую систему, который на его
взгляд адекватен выбранной тематике
. Экспертная система посылает запрос информационно-поисковой
системе (Google, Яндекс) и отображает результаты
поиска эксперту
. Эксперт на основании субъективных критериев выбирает из
результатов поиска релевантные и нерелевантные тексты и сохраняет их в системе
При необходимости, эксперт может неограниченное количество раз повторить
процесс обучения. Система сохраняет все отобранные экспертом тексты и позволяет
при необходимости редактировать и удалять их.
Как только эксперт решит, что обучающая выборка текстов, на его взгляд
полна, то он может запустить автоматический подбор эвристик.
3.4 Логические
методы автоматического подбора эвристик
Автоматический подбор эвристик основан на логических методах извлечения
из обучающей выборки текстов формулы логики высказываний. Главной задачей
данной формулы является отделение множества релевантных текстов от множества
нерелевантных текстов.
В качестве формулы, разделяющей два множества текстов, решено было
использовать дизъюнктивную нормальную форму (ДНФ).
Дизъюнктивная Нормальная Форма (ДНФ) - это дизъюнкция элементарных
конъюнкций и их отрицаний [14].
Теорема: Любая формула логики высказываний может быть представлена в виде
дизъюнктивной нормальной формы [14].
В соответствии с данной теоремой, можно утверждать, что любой набор
формул логики высказываний можно преобразовать в ДНФ.
Пропозициональной переменной в ДНФ является утверждение о том, что
последовательность символов встречается в релевантном тексте. А каждая
конъюнкция построена таким образом, что она будет истинна на множестве
релевантных текстов и ложна на множестве нерелевантных текстов. Следует
заметить, что невозможно найти единственную конъюнкцию, которая бы разделяла
два множества текстов. Именно поэтому в качестве формулы логики высказываний
была выбрана ДНФ.
Рассмотрим алгоритм построения ДНФ:
. Анализ релевантных и нерелевантных текстов
Пусть {relevanceText[i]} - набор релевантных текстов для
пары (рубрика, ресурс), а {IrrelevanceText[j]} - набор нерелевантных текстов для
пары (рубрика, ресурс).
В процессе анализа текстов для каждого текста (релевантного и
нерелевантного) система получает набор лексем со статистикой встречаемости в
тексте:
{relevanceTextLexem[i]} - набор лексем для i-го релевантного текста со статистикой встречаемости лексемы
в i-ом релевантном тексте.
{IrrelevanceTextLexem[j]} - набор лексем для j-го нерелевантного текста со
статистикой встречаемости лексемы в j-ом нерелевантном тексте.
В качестве лексем могут выступать все части речи в нормальной форме,
кроме предлогов, союзов, местоимений, частиц и междометий.
. Построение множества релевантных лексем
. Построение множества нерелевантных лексем
На этом этапе программа формирует из наборов {IrrelevanceTextLexem[j]} каждого j-го
нерелевантного текста, множество уникальных релевантных лексем (IrrelevanceLexemSet) со статистикой встречаемости в
нерелевантных текстах.
. Построение конъюнкций
Для описания алгоритма построения конъюнкций введем следующие
утверждения:
Конъюнкция Con - это набор
лексем Lexem[i] (Con = Lexem[1] & Lexem[2] & … Lexem[m])
Конъюнкция Con истинна на
множестве лексем LexemSet, если все
лексемы конъюнкции {Lexem[i]} содержатся во множестве лексем LexemSet. (То есть Con истинна на множестве LexemSet, если для любого i | Lexem[i] Є Con, выполняется Lexem[i] Є LexemSet)
Конъюнкция Con ложна на
множестве лексем LexemSet, если
хотя бы одна лексема из множества лексем конъюнкции {Lexem[i]} не
содержится во множестве LexemSet.
Рассмотрим алгоритм построения конъюнкций:
Пусть relevanceConjunction - искомое множество конъюнкций.
Первоначально оно пусто.
Программа начинает составлять все возможные уникальные конъюнкции Con[m] размера от 1-го слова до максимального количества слов,
заданного экспертом, из множества relevanceLexemSet. При этом программа проверяет, истинность полученной
конъюнкции на множестве IrrelevanceLexemSet. Если Con[m] ложна на множестве IrrelevanceLexemSet, то Con[m]
добавляется в relevanceConjunction. В противном случае такая конъюнкция
отбрасывается.
Таким образом, мы получаем искомую ДНФ (множество relevanceConjunction), в которой каждая конъюнкция
истинна на множестве relevanceLexemSet и ложна на множестве IrrelevanceLexemSet. То есть получает система ДНФ,
истинную на множестве релевантных текстов и ложную на множестве нерелевантных
текстов. Использование полученной ДНФ в качестве набора эвристик - очевидно:
каждая найденная конъюнкция является эвристикой.
Пример:
Пусть:
§ Множество relevanceLexemSet = {A, B, C, D}
§ Множество IrrelevanceLexemSet = {B, D}
§ Максимальное количество лексем в конъюнкции = 2.
Тогда:
Искомое множество relevanceConjunction = {A, C, AB, AC, AD, BC, CD}, то есть мы
отбросили конъюнкции B, D, BD, которые истинны на множестве IrrelevanceLexemSet.
Следует также отметить, что описанная выше процедура, может быть
повторена экспертом при необходимости любое количество раз, а, полученные в
результате эвристики будут сохранены в системе.
Благодаря такому подходу, эксперт сможет за несколько шагов найти именно
тот набор эвристик, который будет наиболее эффективно улучшать поиск для пары
(рубрика, вид ресурс) с точки зрения пертинентности.
Как правило, количество конъюнкций в ДНФ может быть достаточно большим
(100-1000 конъюнкций), и нет смысла выводить эксперту все без исключения
конъюнкции. Тем более что большинство конъюнкций не будут эффективно решать
проблему поиска, описанную выше, так как представляют собой малоинтересные с
точки зрения поиска наборы слов.
Поэтому на основании статистики встречаемости полученных эвристик в
релевантных текстах, происходит сортировка и последующее отображение эксперту
наиболее часто встречающихся эвристик.
При этом эксперт обладает возможностью отредактировать получившийся
список и удалить из него лишние, на его взгляд, эвристики.
4.
Оценка полученных результатов
После того, как искомый набор эвристик получен, эксперт должен проверить
результаты поиска и оценить эффективность полученного набора эвристик с точки
зрения пертинентности.
В экспертной системе механизм поиска организован следующим образом:
Система отправляет информационно-поисковой системе (Google, Яндекс) группу запросов. Каждый
запрос - эвристика из набора.
Система получает результаты поиска от каждого запроса, ранжирует их и
отображает эксперту.
Алгоритм ранжирования устроен следующим образом:
§ Первичная сортировка текстов происходит по тому же принципу, как были
отсортированы тексты информационно-поисковой системой (Google, Яндекс)
§ Вторичная сортировка происходит по убыванию частоты встречаемости
эвристики, которой принадлежит текст.
Следует отметить, что эксперт обладает возможностью просмотреть не только
обобщенный список найденных документов, но и результаты поиска для каждой
эвристики по отдельности.
Таким образом, применение экспертной системы для автоматического
порождения эвристик, позволит эксперту за несколько шагов, гарантированно
подобрать искомый набор эвристик, который обеспечит повышение пертинентности
результатов поиска в сравнении с другими существующими поисковыми системами
применимо к выбранной предметной области.
Рассмотрим пример: Необходимо подобрать эвристики для рубрики «черви»
предметной области «Информационная безопасность».
. Первый шаг: поиск текстов
На этом шаге допустим, что эксперт вводит в строку поиска просто слово
«червь». Естественно, что он получает весьма не удовлетворительную выборку с
точки зрения пертинентности.

рис.
3: Результаты поиска текстов
2. Второй шаг: Построение ДНФ
На основе найденных текстов, эксперт запускает процесс построения ДНФ.
В итоге система выдает ему следующий список эвристик:
§ Червь вредоносный файл
§ Червь вирус файл
§ Новость червь файл
§ Червь вирус
§ Червь файл
§ Новость червь
§ Файл
Как видно, за счет того, что выборка релевантных текстов содержала
относительно небольшое количество текстов, в списке есть лишние эвристики
(файл, новость, новость файл). Но, во-первых, эксперт может удалить лишние
эвристики. А, во-вторых, экспертная система нашла уже те эвристики, которые,
скорее всего, смогут вполне удовлетворить информационную потребность
пользователя (червь вирус файл, червь вирус, червь файл).
. Проверка полученных результатов
Результаты поиска по полученным эвристикам:

рис.
4: Результаты поиска
Насколько
видно, уже сейчас результаты поиска экспертной системой намного превосходят
результаты поиска, полученные Яндексом.
При
этом следует отметить тот факт, что поскольку экспертная система посылает
несколько запросов поисковой системе, то, как правило, количество текстов,
удовлетворяющих информационную потребность пользователя в несколько раз больше,
за счет того, что результаты поиска от разных эвристик складываются.
5.
Сравнение результатов поиска с другими поисковыми системами
Рассмотрим сравнительную таблицу результатов поиска с использованием
разных поисковых систем с точки зрения пертинентности:
|
Рубрика
|
Количество текстов в
выборке
|
Google
|
Яндекс
|
Виртуальный каталог
|
|
Вирус
|
10
|
70%
|
50%
|
100%
|
|
Червь
|
10
|
|
|
100%
|
|
Цифровая подпись
|
10
|
80%
|
100%
|
|
Троянский конь
|
10
|
20%
|
20%
|
100%
|
|
Вирус
|
30
|
30%
|
35%
|
100%
|
|
Червь
|
30
|
50%
|
40%
|
100%
|
|
Цифровая подпись
|
30
|
75%
|
70%
|
100%
|
|
Троянский конь
|
30
|
20%
|
20%
|
100%
|
|
Вирус
|
50
|
20%
|
25%
|
100%
|
|
Червь
|
50
|
35%
|
30%
|
85%
|
|
Цифровая подпись
|
50
|
50%
|
50%
|
80%
|
|
Троянский конь
|
50
|
10%
|
5%
|
100%
|
Оценка представляет собой процентное соотношение количества текстов
соответствующих тематике от текстов несоответствующих тематике.
Как видно из таблицы, результаты поиска виртуального каталога, за счет
использования качественного подобранного набора эвристик, намного превышают
результаты поиска систем Google
и Яндекс с точки зрения именно пертинентности.
При этом следует отметить тот факт, что поскольку виртуальный каталог
посылает несколько запросов поисковой системе, то, как правило, количество
текстов, удовлетворяющих информационную потребность пользователя в несколько
раз больше, за счет того, что результаты поиска от разных эвристик складываются
в единый массив данных.
Заключение
Поиск информации в Интернете - это еще не до конца изученная проблема. В
настоящее время существует масса ее решений. Подход, описанный в данной работе,
основан на логических методах извлечения знаний из текстов и обладает
следующими достоинствами:
§ Возможность применения для любой предметной области
§ Улучшение пертинентности поиска в метапоисковой системе - виртуальный
каталог
§ Актуальность и полнота результатов поиска
В результате выполнения магистерской диссертации были получены следующие
результаты:
. Проведен анализ информационно-поисковых систем на основании
формальных критериев оценки качества поиска
. Исследованы основных принципов работы виртуального каталога
. Сформулированы требования к экспертной системе по
автоматическому порождению эвристик
. Разработан процесс обучения экспертной системы
. Разработаны логические методы автоматического порождения
поисковых эвристик
. Создан алгоритм поиска информации в виртуальном каталоге на
основании полученного набора эвристик
. Реализована разработанная модели экспертной системы
. Произведена оценка полученных результатов
Список
литературы
1. Гультяев,
А.К. Самое главное о... Поиск в Интернете / А. К. Гультяев. - 2-е изд. - СПб.
[и др.]: Питер, 2006. - 144 с.: ил.
. Ландэ
Д.В. Поиск знаний в Internet. - Киев: Издательский дом
"Диалектика-Вильямс".
. Методы
поиска информации в Интернете=Tips and Tricks to Searching on the Internet and World Wide Web:[перевод с английского]/Маркус Браун. - Новый
издательский дом. - 2005
. Пальчунов
Д.Е., Сидорова Е.С. Виртуальный каталог. Труды Всероссийской конференции
"Знания-Онтологии-Теории", Новосибирск, 2007, стр. 166-175.
. Пальчунов
Д.Е. Моделирование мышления и формализация рефлексии I: Теоретико-модельная
формализация онтологии и рефлексии. Философия науки, 4 (31), 2006, с.86-14.
. Пальчунов
Д.Е. Решение задачи поиска информации на основе онтологий. Бизнес-информатика,
1, 2008, стр. 3-13.
. Гусев
В.С., Google - эффективный поиск информации в Интернет. - Киев: издательство
Диалектика, 2006. 240 стр., с ил.
9. Pal'chunov
D. E. Logical Methods of Ontology Generation with the Help of GABEK. IV
International GABEK Symposium - Innsbruck, 2002,p. 17.
. Pal'chunov
D. E. GABEK for Ontology Hierarchy Generation. V International GABEK Symposium
- Innsbruck, 2004, p. 5-6.
. Pal'chunov
D. E. GABEK and FCA for object domain ontology creation. Abstracts of the 6-th
International GABEK-Symposium - Sterzing, 2006, p. 28.
. Pal'chunov
D. E. GABEK for Ontology Generation // Herdina Ph., Oberprantacher A., Zelger,
J. (eds.): Learning and Development in Organizations, Vol. 2, Berlin, Wien
(LIT) 2007, p. 90-109.
13. Бездольный
А.М. Экспериментальная машина подбора эвристик для Виртуального каталога //
Материалы XLVI Международной Научной Студенческой Конференции «Студент и
научно-технический прогресс»: Информационные технологии/Новосиб. гос. ун-т.
Новосибирск, 2008, с.193
. Ершов
Ю.Л., Палютин Е.А. Математическая логика. - М., Наука, 1979
15. О.И. Россеева, Ю.А.
Загорулько Организация эффективного поиска на основе онтологий [Электронный
ресурс] - 2001. - Режим доступа:
<http://www.dialog-21.ru/Archive/2001/volume2/2_49.htm>
16. MetaSearch [Электронный ресурс] - 2008. - Режим доступа: <http://virtualcatalog.ru>
. Талантов М. И.
Профессиональный поиск в Интернете: планирование поисковой
процедуры[Электронный ресурс] - 1999. - режим доступа: http://www.citforum.ru/internet/search/prof_search02.shtml
. Тихонов В.А.
Архитектура метапоисковых систем [Электронный ресурс] - 2003. - режим доступа:
http://www.citforum.ru/internet/search/metaping.shtml
. Клещев А.С.,
Артемьева И.Л. Математические модели онтологий предметных областей. Части 1-3.
Научно-техническая информация, серия 2 "Информационные процессы и
системы", 2001, № 2, С. 20-27, № 3, С.19-29, № 4, c. 10-15.
. В. Д. Гусев, Н. В.
Саломатина Компьютерная поддержка формирования словарей общенаучной и
терминологической лексики http://www.philol.msu.ru/~rlc2007/pdf/20.pdf
<http://www.philol.msu.ru/%7Erlc2007/pdf/20.pdf>