|
#"550601.files/image001.gif">
Рисунок 1.1 - Навигация по онтологии и ее
редактирование с помощью инструмента OntoEdit
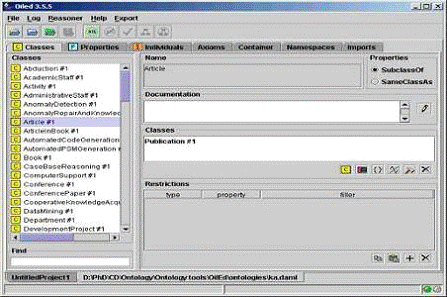
Рисунок 1.2 - Редактирование онтологии с помощью
инструмента OilEd
WebOnto - разработан для Tadzebao - инструмента
исследования онтологий и предназначен для поддержки совместного просмотра,
создания и редактирования онтологий. Его цели - простота использования,
предоставление средств масштабирования для построения больших онтологий. [8]
Для моделирования онтологий WebOnto использует
язык OCML (Operational Conceptual Modeling Language). В WebOnto пользователь
может создавать структуры, включая классы с множественным наследованием, что
можно выполнять графически. Все слоты наследуются корректно. Инструмент
проверяет вновь вводимые данные контролем целостности кода OCML.
Инструмент имеет ряд полезных особенностей:
сохранение структурных диаграмм, раздельный просмотр отношений, классов, правил
и т.д. Другие возможности включают совместную работу нескольких пользователей
над онтологией, использование диаграмм, функций передачи и приёма и др.является
Web-браузером для баз знаний LOOM. Он состоит из двух основных модулей: сервера
онтологий и Web-браузера для редактирования и просмотра онтологий LOOM с
помощью HTML-форм, обеспечивая для них графический интерфейс. OntoSaurus также
предоставляет ограниченные средства редактирования, но его основная функция -
просмотр онтологий. Но для построения сложных онтологий нужно понимать язык
LOOM. Большинство пользователей строят онтологию на языке LOOM в другом
редакторе, а затем для просмотра и редактирования импортируют его в OntoSaurus.
В OntoSaurus реализованы все возможности языка LOOM. Обеспечиваются
автоматический контроль совместимости, дедуктивная поддержка рассуждения и
некоторые другие функции. [10]
Конструктор онтологий ODE (Ontological Design
Environment), который взаимодействует с пользователями на концептуальном уровне
в отличие от инструментов, подобно OntoSaurus, общающихся на символьном уровне.
Мотивом для ODE послужило то, что людям проще формулировать онтологии на
концептуальном уровне. ODE обеспечивает пользователей набором таблиц для
заполнения (концептов, атрибутов, отношений) и автоматически генерирует для них
код в LOOM, Ontolingua и FLogic. ODE составляет часть методологии полного
жизненного цикла построения онтологии согласно Methontology. Инструмент получил
свое дальнейшее развитие в WebODE, который интегрирует все сервисы ODE в одну
архитектуру, сохраняет свои онтологии в реляционной базе данных, обеспечивает
дополнительные сервисы (машину вывода, построение аксиом, сбор онтологий,
генерацию каталогов). [11]- инструмент поддержки проектирования моделей знаний
согласно методологии CommonKADS. Онтологии составляют часть таких моделей
знаний (другая часть - модели вывода). Модели CommonKADS определены в CML
(Conceptual Modeling Language). KADS22 - интерактивный графический интерфейс
для CML со следующими функциональными возможностями: синтаксический анализ
файлов CML, печать, просмотр гипертекста, поиск, генерация глоссария и
генерация HTML. [15]
Дальнейшее развитие в рамках проекта DWQ (Data
Warehouse Quality) ведет к инструменту i.com, инструментальному средству
поддержки концептуальной стадии проекта интегрированных информационных систем.
i.com использует расширенную модель данных сущностей-связей (EER - Extended
Entity-Relationship Model) дополнив ее ограничениями многомерной агрегации и
промежуточных схем.
Инструмент і.com полностью интегрирован с мощным
сервером рассуждения на основе DL. i.com служит главным образом для
интеллектуального концептуального моделирования. [16]
1.2 Инструменты для отображения и объединения
онтологий
Сегодня онтологии доступны в разных
представлениях. Но, что делать, когда мы находим несколько онтологий, которые
бы хотели использовать, но они не соответствуют друг другу.
Инструменты объединения онтологий помогают
пользователям найти сходство и различие между исходными онтологиями и создают
результирующую онтологию, которая содержит элементы исходных онтологий. Для
достижения этой цели они автоматически определяют соответствия между концептами
в исходных онтологиях или обеспечивают среду, где пользователь может легко
найти и определить эти соответствия. Эти инструменты известны как инструменты
отображения, выравнивания и объединения онтологий, так как они выполняют
сходные операции для процессов отображения, выравнивания и объединения.
Отображение (mapping) онтологии заключается в
нахождении семанитечких связей подобных элементов из разных онтологий.
Выравнивание (alignment) онтологий состоит в том, чтобы установить различные
виды соответствия (или связи) между двумя онтологиями, а затем повторно
сохранить исходные онтологии и таким образом, в дальнейшем использовать
информацию друг друга. Объединение (merging) онтологий - генерация одной
согласованной онтологии из двух исходных [17].
Исследователи разных областей информатики
работают над автоматическим или поддерживаемым инструментально объединением
онтологий (или иерархии классов, или объектно-ориентированных схем, или схем
баз данных - определенная терминология изменяется в зависимости от области
применения). Однако и автоматическое объединение онтологий, и создание инструментальных
средств, которые бы управляли пользователем в этом процессе, находятся на
ранних стадиях развития. В этом разделе представлен обзор некоторых из
существующих подходов.
Инструментальные средства, которые имеют дело с
нахождением соответствия между онтологиями, классифицируются:
- для объединения двух онтологий с
целью создания одной новой (PROMPT, Chimaera, OntoMerge);
- для определения функции
преобразования из одной онтологии в другую (OntoMorph);
- для определения отображения между
концептами в двух онтологиях, находя пары соответствующих концептов (например,
OBSERVER, FCA-Merge);
- для определения правил отображения
для связи только релевантных частей исходных онтологий (ONION). [18]-
дополнение к системе Protégé, реализованное
в виде плагина, служит для объединения и группировки онтологий. При объединении
двух отологий PROMPT создает список предлагаемых операций. Операция может
состоять, например, из объединения двух терминов или копирования терминов в
новую онтологию. Пользователь может выполнить операцию, выбирая одну из
предлагаемых или определяя непосредственно операцию. [18]выполняет выбранную
операцию и дополнительные изменения, вызванные этой операцией. Потом список
предлагаемых операций модифицируется и создается список конфликтов и возможных
решений этих конфликтов. Это повторяется до тех пор, пока не будет готова новая
онтология (Рис. 1.3).- интерактивный инструмент для объединения, основанный на
редакторе онтологий Ontolingua. Chimaera позволяет пользователю объединять
онтологии, разработанные в различных формализмах. Пользователь может
запрашивать анализ или руководство от Chimaera в любой момент в течение
процесса объединения, и инструмент направит его на те места в онтологии, где
требуется его вмешательство. В своих предложениях Chimaera главным образом
полагается на то, из какой онтологии прибыли концепты, основываясь на их
именах. Chimaera оставляет решение о том, что делать пользователю и не делает
никаких предложений самостоятельно. Единственное таксономическое отношение,
которое рассматривает Chimaera - отношение подкласс - суперкласс. Chimaera
самый близкий к PROMPT. Однако поскольку он использует в своем анализе только
иерархию класса, он пропускает многие из соответствий, которые находит PROMPT.
Эти соответствия включают предложения по объединению слотов с подобными
именами, которые относятся к объединенным классам, объединению доменов слотов,
которые были объединены и т. д. [19]
В OntoMerge объединенная онтология есть
объединение двух исходных онтологий и набора аксиом соединения. Первый шаг в
процессе объединения в OntoMerge состоит в трансляции обеих онтологий к общему
синтаксическому представлению на разработанном авторами языке.
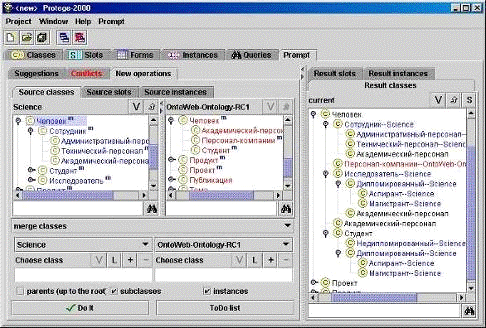
Рисунок 1.3 - Пример объединения двух онтологий
при помощи инструмента Protégé и
плагина Prompt
Затем инженер онтологии определяет аксиомы
соединения, содержащие термины из обеих онтологий. Процесс трансляции
экземпляров выглядит следующим образом: все экземпляры в исходных онтологиях,
рассматриваются как находящиеся в объединенной онтологии. Затем на основе
инструкций в исходных онтологиях и аксиом соединения машина вывода сделает
заключение, таким образом, создавая новые данные в объединенной онтологии.
OntoMerge предоставляет инструменты для трансляции данных-экземпляров в
объединенную онтологию. [20]определяет набор операторов преобразования, которые
можно применить к онтологии. Затем человек-эксперт использует начальный список
пар и исходных онтологий для определения набора операторов, которые должны
примениться к исходным онтологиям для устранения различий между ними, и
OntoMorph применяет эти операторы. Таким образом, совокупность операций может
выполняться за один шаг. Однако, человек-эксперт не получает никакого
руководства за исключением начального списка пар. [21]
Система OBSERVER применяет DL для ответа на
запросы, используя несколько онтологий и информацию об отображении между ними.
Вначале пользователи определяют набор межонтологических отношений. Система
помогает справиться с этой задачей, находя синонимы в исходных онтологиях.
Определив отображения, пользователи могут формулировать запросы в терминах DL с
помощью собственной онтологии. Затем OBSERVER использует информацию отображения
для формулировки запросов к исходным онтологиям. OBSERVER в значительной
степени полагается на тот факт, что описания в онтологиях и запросах являются
содержательными. [22]Merge - метод для сравнения онтологий, которые имеют набор
общих экземпляров или набор общих документов, аннотируемых с помощью концептов
исходных онтологий. Основываясь на этой информации, FCA-Merge использует
математические методы из Formal Concept Analysis для того чтобы произвести
решетку концептов, связывающую концепты исходных онтологий. Алгоритм предлагает
отношения эквивалентности и подкласс-суперкласс. Затем инженер онтологии может
анализировать результат и использовать его как руководство для создания
объединенной онтологии. Однако предположение, что две объединяемые онтологии
используют общий набор экземпляров или имеют набор документов, в котором каждый
документ аннотируется терминами обоих источников слишком жесткое и на практике
такая ситуация происходит редко. В качестве альтернативы, авторы предлагают
использовать методы обработки естественного языка для аннотации набора
документов концептами из этих двух онтологий. [23]
Система ONION (ONtology compositION) основана на
алгебре онтологии. Поэтому, она предоставляет инструменты для определения
правил артикуляции (соединения) между онтологиями. Правила артикуляции обычно
учитывают только релевантные части исходных онтологий. Для того чтобы
предложить соединение, ONION использует и лексические методы, и методы на
основе графов. Метод нахождения лексического подобия между именами концептов
использует словари и методы семантической индексации, основанные на
местонахождении группы слов в тексте. [24]
.3 Сравнительный анализ инструментов построения,
редактирования и отображения онтологий
Инструменты построения онтологий можно разделить
на два типа: разработанные для редактирования онтологий на определенном языке
онтологий и интегрированные наращиваемые инструментальные сайты
(Web-приложения, на основе форм HTML и/или Java-апплетов), большинство из
которых не зависит от языка представления.
Следует подчеркнуть, что большинство из
рассмотренных инструментальных средств разрабатываются университетскими
исследовательскими группами, которые предоставляют открытый код, либо
предлагают свободный доступ к функциям. Однако наиболее перспективные из них
передаются коммерческим компаниям (например, OntoEdit Professional -
лицензированный продукт).
Инструменты OntoEdit, WebODE и KADS22 дают
поддержку методологиям построения онтологий, соответственно On-To-Knowledge,
METHONTOLOGY и CommonKADS, что не мешает им использоваться в других
методологиях или вообще без них.
Касаясь технического аспекта, а именно
архитектуры программного обеспечения (локальная, клиент-серверная,
n-уровневая), расширяемости, языков программирования на которых реализованы
инструменты, способов хранения онтологий (в файлах или базах данных), необходимо
отметить следующее.
Более ранние инструменты Ontolingua, OntoSaurus
и WebOnto имеют клиент-серверную архитектуру. Protégé,
OntoEdit и OilEd имеют 3-х уровневую архитектуру, где
существует четкое разделение между хранением онтологий, модулями бизнес-логики
логики приложений и приложениями интерфейса пользователя. Эти инструменты
обладают большими возможностями по наращиванию (например, при помощи плагинов).
Большинство инструментов хранит свои онтологии в текстовых файлах, что
ограничивает размер онтологий. Только Protégé и
WebODE могут хранить свои онтологии в базах данных и таким образом управлять
большими онтологиями. Наконец, большинство инструментов реализовано на Java.
Выше уже говорилось о том, что модели знания
инструментов определяют компоненты, которые должны использоваться при
построении онтологии. Большинство инструментов представляет онтологии,
комбинируя фреймы и логику первого порядка (First Order Logic - FOL). Однако
это еще не означает, что они могут представлять одни и те же компоненты с одним
и тем же количеством информации. Только два из перечисленных инструментов,
OilEd и OntoSaurus, основаны на дескриптивной логике (DL).
Далее остановимся на некоторых свойствах
редакторов онтологий. Интерфейс пользователя редакторов онтологий может быть
Web-приложением, на основе форм HTML (Ontolingua, OntoSaurus и WebODE) и/или
Java-апплетов (WebOnto) или локальным приложением (Protégé,
OntoEdit, OilEd).
Все редакторы онтологий за исключением OilEd,
Ontolingua и OntoSaurus обеспечивают графические средства редактирования и
просмотра онтологий, где классы обычно представлены узлами на графах, а
отношения - дугами между ними. Дополнительно к этим графическим функциям,
OilEd, OntoEdit Professional, Protégé и
WebODE предоставляют некоторую поддержку в написании формальных аксиом и
сложных выражений., Ontolingua, OntoSaurus, WebODE и WebOnto поддерживают
совместную разработку онтологий, предоставляя отдельным пользователям или
группам пользователей разрешение на доступ и написание различных наборов
онтологий.
Разнообразие инструментов для отображения и
объединения онтологий делает сложным их непосредственное сравнение. Фактически,
когда разработчик должен решить вопрос, какой инструмент является наиболее
подходящим, все будет зависеть от конкретной задачи. Например, если
объединяемые онтологии совместно используют набор экземпляров, то лучше всех
может работать FCA-Merge. Если онтологии имеют экземпляры, но совместно их не
используют, и многие значения слотов содержат текст, лучшим выбором может стать
GLUE. Если только части онтологий должны быть отображены, можно было бы выбрать
инструмент ONION. Если онтологии имеют очень ограниченную структуру, а концепты
имеют подробные определения на естественном языке (одном), инструментальные
средства ISI/USC могут обеспечивать лучшие ответы. Если экземпляры вообще не
доступны, и онтологии содержат много отношений между концептами, лучше всех
может работать Prompt.
1.4 Проекты, использующие онтологии
В сфере информационного поиска заслуживает
упоминания европейский исследовательский проект под названием CROSSMARC.
Участники этого проекта делают упор на необходимости широкого использования
онтологий для разделения отраслевых и общепонятийных знаний, считая, что это
облегчит извлечение информации из различных источников, сузит поисковые запросы
и улучшит качество выдаваемых результатов [3]. Эта задача оказывается смежной с
задачей автоматической рубрикации текстов, в ходе которой производится
распределение текстов по рубрикам на основе автоматических методов и
использования онтологий.
В области машинного перевода известна система
OntoLearn, используемая при переводе многословных терминов с английского языка
на итальянский. Система автоматически выделяет и строит предметные онтологии.
Промежуточные онтологические построения используются для прямого машинного
перевода [3]. Можно привести также пример системы машинного перевода,
разработанной в Университете Sains в Малайзии [4]. Она осуществляет снятие
неоднозначности со слов, используя тексты определений и структурную информацию
из онтологий.
IAMTC (Interlingual Annotation of
Multilingual Text Corpora) можно
отнести
к
системам
понимания
языка.
Этот
многосторонний проект занимается аннотацией шести больших параллельных корпусов
с целью извлечения межъязыковых соответствий. Система использует 110 000
записей онтологии OMEGA для частеречной разметки и дальнейшего анализа
естественного языка. Для понимания естественного языка могут использоваться
также аксиомы и умозаключения, содержащиеся в онтологиях, помогает и большой
набор отдельных примеров, экземпляров.[5]
Онтологии могут также лежать в основе различных
вопросно-ответных систем и способствовать улучшению анализа запросов и точности
ответов. Можно привести пример демонстрационной вопросно-ответной системы YAWA
[7]. Она по запросу выдает информацию о главах государств и правительств стран
мира, так же обладает сведениями о том, кто занимает указанную должность в
данной стране. Кроме этих связей, в нее заложены знания о соотношении названия
и основной функции (глава государства и/или правительства) высших
государственных должностей в отдельно взятой стране в зависимости от типа
системы государственного управления. Таким образом, при выдаче ответов по
запросу система учитывает заложенные в нее сведения об окружающей
действительности: набор понятий, отношений между ними, ограничений на отношения
и список конкретных экземпляров.
Существует целое направление работ в сфере
электронной коммерции, где онтологии предоставляют классификацию товаров и
услуг и обеспечивают наличие стандартизованного представления информации. Таким
образом, происходит систематизация понятий области бизнеса, упорядочение их
описаний. Онтологии предоставляют эффективный доступ к информации, дают
возможность лучше понять данную информацию и, следовательно, произвести её
более широкий и сложный анализ [6].
Еще один пример использования онтологий
представляет собой система понимания языка, разработанная в НПЦ «Интелтек
Плюс». Сейчас уже «создана и внедряется в Совете Федерации Федерального
Собрания Российской Федерации первая очередь информационной системы
"Семантический контроль текстов редактируемых документов"... Она
используется специалистами Управления информационного и документационного
обеспечения аппарата Совета Федерации для проверки правильности расшифровки стенограмм
и проверки редакций различных типов документов на предмет их соответствия
эталонным словарям и базам данных». Эта система занимается поиском
несоответствий в текстах редактируемых документов на основе эталонного описания
предметной области, содержащегося в онтологии [8]. К таким несоответствиям
авторы относят «ошибочные должности сотрудников организаций, ссылки на
устаревшие структурные подразделения организаций, неправильные телефонные
номера должностных лиц». Таким образом, они стремятся выявить «неэквивалентность
факта, выявленного при анализе текста, имеющимся в базе знаний фактам». В
данном случае под базой знаний понимается онтология, снабженная конкретными
экземплярами. После извлечения знаний из текстов, модуль логического вывода
сверяет их с данными в онтологии, проверяя наличие связей между элементами,
отслеживая правильность этих связей, и таким образом подтверждает или
опровергает достоверность фактов и отмечает нарушение семантических связей.
Онтологии занимают ключевую позицию во многих
лингвистических комплексах, так, например, InfoMap широко использует
иерархические структуры в работе с текстами на естественном языке. Целью
данного проекта являлось извлечение значения слов на базе их употребления в
тексте [9]. В рамках данного проекта при группировке понятий и значений
используется верхняя зона WordNet, а также анализ корпусов текстов путем
извлечения кластеров слов автоматически. Затем эти данные используются для
подбора вероятных родовых терминов в группах слов, то есть для формирования
таксономий. Также возможно применение результатов данных процедур для сравнения
структуры групп в параллельных текстах на разных языках, что позволяет улучшать
качество машинного перевода и уточнять переводы слов в рамках многоязычной
лексикографии.
Существует большое количество проектов в области
медицины, использующих онтологии в своих приложениях. Так, можно привести
пример проекта MuchMore, являющего частью InfoMap, описанного ранее,
занимающего разработкой методов организации информации на различных языках и в
частности медицинской области знания [10] Их исследование основывается на
использовании иерархии понятий для предметных областей, и следовательно
технологиях извлечения многоязычных терминов и отношений. Их продукт помогает
осуществлять поиск документов на различных языках по медицинской области
знания. Медицинская область знания очень перспективна в этой сфере, так как для
нее уже создано большое количество онтологий и структурированных источников
знания, а также присутствует множество текстов на данной области, требующих
обработки. Это тексты, описывающие карты больных, случаи заболеваний, общие
описания разных болезней и многие другие. Проект MuchMore помогает выстроить
взаимосвязи между всеми типами текстов в данной области. В задачи этого исследования
входит:
- сокращение «пропасти» между
медицинской документацией и многоязычными данными путем автоматического
извлечения дескрипторов и составления метаописаний истории болезней для
последующего использования в других источниках. Организация информации в
онтологии помогает в дальнейшем быстро строить экспертные системы и приложения
для работы с данными;
- устранение языкового барьера при
поиске информации. Использование онтологий позволяет эффективно искать
информацию на нескольких языках, тем самым значительно облегчая работу
специалистов. Также это дает возможность сравнивать описания аналогичных
случаев на разных языках и проводить более содержательные исследования [10].
Следующее перспективное направление развития
онтологий используется при семантической разметке текста. Учет семантических
категорий, описанных в онтологии, позволяет сделать разметку корпусов более
точной, уменьшить неоднозначность, так как в шаблоны, по которым производится
разметка, связаны в категориями в онтологии. Такая семантическая разметка в
дальнейшем позволяет проводить семантический анализ текста, различные
статистические исследования, извлекать межъязыковые соответствия [11].
Еще одним современным проектом, широко
использующим онтологии является компания Онтос, разрабатывающая различные
семантические технологии. При помощи их систем, основанных на обработке текстов
на естественном языке (NLP), пользователь может генерировать и хранить
релевантные знания, необходимые для различных задач. Данные системы
ориентированы на пользователя, которому надо обрабатывать большие массивы
информации, извлекать структурированную информацию.[12] Для решения данных
задач возможно использование продуктов Онтоса, обеспечивающих автоматическую
обработку необходимых неструктурированных данных и получения прямого доступа к
аналитическим (обработанным) данным. Как упоминается на сайте компании, их
системы успешно решают следующие задачи:
- поддержка принятия решений при
проведении исследований;
- визуализация информации с помощью
семантических сетей;
- автоматическая генерация
семантических аннотаций из неструктурированного текста;
- дайджестирование больших документов
на базе их семантического содержания;
- резюмирование больших объемов
аннотированного текста;
- поддержка мета-данных в соответствии
со стандартами RDF/OWL;
- семантический поиск с применением
технологии триплетов (Объект - Отношение - Объект). [12]
Так, один из продуктов компании, OntosMiner,
анализирует текст на естественном языке, используя семантические правила
онтологий. Результатом работы данной системы становится распознавание объектов
и связей между ними и добавление их как аннотации к соответствующим фрагментам
текста. [13]
Еще одним аналогичным проектом является RCO
(Russian Context Optimizer). С помощью современных технологий исследователи
строят онтологии, семантические представления. Продукты и технологии RCO
позволяют решать такие прикладные задачи как составление содержательного
портрета текста, извлечение именованных объектов, связей и фактов из массивов
неструктурированных данных, анализ тональности текста, выявление заимствований,
обнаружение дубликатов. Использование онтологий помогает при поиске заранее
неизвестной информации, относящейся к некоторой теме, позволяя выдать
пользователю возможные «подсказки» для уточнения запроса. Также онтологии
служат основой для решения различных аналитических задач, позволяя исследовать
окружение выбранного объекта, находить цепочки и группы связности во множестве
объектов. [14]
Также в этой связи стоит упомянуть проект
«Галактика ZOOM». Эта система предоставляет различные возможности для
специалистов разных уровней: руководителей, аналитиков, маркетологов,
специалистов по PR, сотрудников служб безопасности. Как упоминается на сайте,
их разработки могут использоваться для поиска информации, выявления сути
текста, сравнения документов и исследования документов с учетом динамики во
времени. [15]
Онтологии получили широкое распространения и для
моделирования организационной структуры предприятий. Онтологическое
представление знаний о субъектах экономической деятельности, которые входят в
состав какой-либо системы, можно использовать для объединения их информационных
ресурсов в единое информационное пространство. Онтология предприятия включает в
себя организационную онтологию, описывающую организационно-функциональную
структуру предприятия: состав штатного расписания (работники, администрация,
обслуживающий персонал), партнеры, ресурсы и т. п. и отношения между ними, а
также онтологию по технологиям, описывающую терминологию технологий. Разработанные
онтологии позволяют сотрудникам одной отрасли или корпорации использовать общую
терминологию и избежать взаимных недоразумений, которые могут усложнить
сотрудничество и привести к серьезным убыткам. [16]
В качестве примера практического использования
онтологических моделей технологий можно привести систему ONTOLOGIC,
предназначенную для создания и поддержки распределенных систем
нормативно-справочной информации (НСИ), ведения словарей, справочников и
классификаторов и поддержки системы кодирования объектов учета. Онтология
обеспечивает непротиворечивое накопление любого количества информации в
стандартной структуре классификации. Такой подход гарантирует однозначную
идентификацию ресурсов независимо от различных трактовок их наименований разными
производителями. При использовании данной системы осуществляется эффективный
контроль и верификация данных, проверки корректности, полноты и
непротиворечивости данных как на этапе анализа и нормализации существующих
данных, так и при занесении новых элементов данных. [17]
2. ПОСТАНОВКА ЗАДАЧИ
Согласно определению Т. Грубера, онтология - это
спецификация концептуализации предметной области [1]. Это формальное и
декларативное представление, которое включает словарь понятий и соответствующих
им терминов предметной области, а также логические выражения (аксиомы), которые
описывают множество отношений между понятиями. Для описания отношений в
онтологиях используются весь арсенал формальных моделей и языков, разработанных
в области искусственного интеллекта - исчисление предикатов, системы продукций,
семантические сети, фреймы и т.п. Таким образом, термин “онтология” оказался
близок по значению к термину “искусственный интеллект”, а термин
“онтологический инжиниринг” явился синонимом термина “инженерия знаний”. На
сегодняшний день существует не менее десятка зарубежных систем, относимых к
классу инструментов онтологического инжиниринга, которые поддерживают различные
формализмы для описания знаний и используют различные машины вывода из этих
знаний. Наиболее известные из них - это Protégé, CYC,
KAON2, OntoEdit. Среди уже разработанных онтологий
наиболее известными и объемными являются CYC и SUMO.
Разработано большое количество онтологий в
различных предметных областях, но мир очень быстро изменяется, идет развитие
новых отраслей, существующие онтологии требуют постоянного пополнения и
усовершенствования. На данном этапе появляются идеи использования
автоматических и полуавтоматических методов для интеграции онтологий.
Основной задачей работы является исследования существующих
подходов к отображению онтологий. Отображение онтологий является неотъемлемой
частью большинства задач согласования онтологий, таких как слияние,
выравнивание онтологий, модификация одной онтологии для достижения однородности
с другой и так далее. Актуальность работы состоит в том, что данное направление
интенсивно развивается в современном мире. Многие ученые работают над созданием
автоматических и полу-автоматических систем отображения онтологий, которые
будут работать с минимальным воздействием на них человеческого фактора.
Исходя из поставленной основной задачи
исследований, в работе необходимо решить, следующие подзадачи:
- провести сравнительный анализ
инструментов для работы с онтологиями: построение и редактирование;
- провести детальный анализ
инструментов для отображения и объединения онтологий;
- изучить основные подходы к
отображению онтологий;
- проанализировать существующие методы
и модели отображения, а также проекты в которых они используются.
Для примера необходимо выделить несколько
основных алгоритмов отображения, протестировать на реальных онтологиях и на
основе полученных результатов, предоставить детальный анализ по их
использованию.
На сегодняшний день, нет методов полностью
автоматического отображения, а под ним предполагают такую организацию этого
процесса, при которой первоначальный перечень терминов предметной области и
структура их взаимосвязей автоматически выявляются программными средствами на
основании статистической обработки результатов лингвистического анализа коллекции
текстов, после чего верифицируются и структурируются экспертом в соответствии с
его имплицитной моделью знаний и прагматическими требованиями прикладной
системы, для которой разрабатывается онтология.
3. МЕТОДЫ ОТОБРАЖЕНИЯ ОНТОЛОГИЙ
В основном к задачам отображения подходят с
практической точки зрения, в зависимости от поставленной цели перед
разработчиком. Поэтому нет единственно правильного определения отображения
онтологий. Кудрявцев определяет отображение онтологий (ontology mapping), как
деятельность по установлению соответствия между несколькими онтологиями [24]. В
работах J. Euzenat и P. Shvaiko отображение рассматривают, как направленный
вариант выравнивания онтологий (оntology аlignment). Процесс построения правил
отображения понятий одной онтологии в понятия другой, либо как результат этого
процесса, то есть, множество правил отображения одинакового направления, таких
что элементы отображаемой онтологии присутствуют в нём максимум единожды. [25]
На основе выше упомянутых определений, под отображением онтологий будем
понимать, процесс, при котором понятия одной онтологии выражаются через понятия
другой. Корректно термин отображения рассматривать в двух ракурсах:
как
процесс отображения одной онтологии в другую или как результат такого процесса,
то есть множество функций отображения понятий одной онтологии в понятия другой.
[26]
Отображение онтологий является неотъемлемой
частью большинства задач согласования онтологий, таких как слияние,
выравнивание онтологий, модификация одной онтологии для достижения однородности
с другой и так далее.
Модели данных, используемые сегодня в качестве
онтологических, либо неформальны, либо
включают достаточно простые средства спецификации для возможности использования
автоматического формального вывода, довольствуясь описаниями структурных
спецификаций понятий и простых ограничений над ними.
Поэтому
большинство методов, используемых для
отображения онтологий, предварительно
связывают понятия по вербальной информации (именам
понятий, определениям), и затем на основе полученных связей оперируют со
структурными спецификациями, оценивая их близость,
обнаруживая
и устраняя разного рода конфликты.
Проблема отображения онтологий является
актуальной с самого начала использования онтологий при создании информационных
систем.
Анализ
состояния исследований соответствующих методов показал, что эта тема
исследована до сих пор недостаточно глубоко. Разрабатываемые методы, в
основном, неформальны и имеют
множество открытых вопросов.
Принципы и методы отображения онтологий остаются
предметом дискуссий, при создании систем
вопросы отображения онтологий до сих пор предпочитают избегать.
Наименее
исследованы методы отображения онтологий, разработанных
в неоднородных онтологических моделях. Говоря о неоднородных онтологиях, мы
подразумеваем, что две (или более)
онтологии по-разному описывают одну и ту же предметную область или близкие
предметные области с точки зрения разных сообществ.
Онтология
задаёт подразумеваемую семантику для понятий предметной области и определяет
онтологический контекст, в котором работает
сообщество. . В результате,
семантика понятий в контекстах, описанных разными онтологиями, может быть
сходной при различных подходах к описанию их структуры: составу, ограничениям и
степени детализации.
.1 Ручное отображение онтологий. Методы
ручного отображения онтологий
Ручное отображение онтологий - деятельность по
установлению соответствия между несколькими онтологиями [24].
Проблема отображения онтологий заключается в
том, что:
. Сущности (классы, свойства, связи, объекты)
имеющие одинаковые имена могут иметь разный смысл;
. Сущности (классы, свойства, связи, объекты)
имеющие одинаковый смысл могут иметь разные имена.
Отображение онтологий разделяется на 2
подзадачи:
. Локальное отображение сущностей,
подразумевающее независимую установку соответствий между двумя сущностями,
рассматриваемых онтологий;
. Глобальное отображение сущностей, в рамках
которого, подразумевается пересмотр (пересчет) локальных отображений с учетом
отображений всех остальных
элементов.
Для обеспечения максимальной точности
отображения сущностей при ручном режиме отображения выделяют 4 основных метода:
) Лингвистический/Лексический/Текстовый анализ
сущностей онтологий
На данном этапе определяется сходство между
сущностями на основе сравнения имен сущностей (оценка количества совпадающих
символов, общие части слов, например, «Цели» и «Целевые установки») или путем
анализа синонимичных терминов. Для выявления синонимичных терминов могут
использоваться существующие словари общей и профессиональной лексики,
тезаурусы. Данный вид анализа можно считать исходным для установления
соответствия между сущностями.
) Структурный анализ сущностей онтологий
.1) Анализ внутренней структуры сущностей
онтологий
В данном случае оценка сходства производится на
основе анализа доменов и областей допустимых значений для атрибутов и связей.
Методы анализа внутренней структуры иногда называются методами на основе
ограничений. Сущностей со схожей внутренней структурой, а также свойств с
похожими доменом и областью значений может быть достаточно много, поэтому
данные методы используются только для формирования кластеров сходных понятий и
требуют сочетания с другими методами.
.2) Анализ внешней структуры сущностей онтологий
А) Анализ сходства по иерархическим связям
сущностей онтологий
Оценка схожести двух сущностей двух онтологий
может быть основана на позициях данных сущностей в иерархии классов. Если две
сущности двух онтологий схожи, то их «соседи» также как-то схожи. Такое
утверждение может использоваться по-разному и порождает ряд возможных критериев
(признаков) для сходства двух сущностей:
- Их прямые супер-сущности (или все
супер-сущности) уже являются схожими;
- их сущности-братья (или все их
сущности-братья) уже являются схожими;
- их прямые сущности-потомки (или все
их сущности-потомки) уже являются схожими;
- все их сущности-листья (сущности, не
имеющие потомков, находящиеся в дереве, корнем которой является рассматриваемая
сущность) уже являются схожими;
- все (или большинство) сущности на
пути от корня к рассматриваемой сущности уже являются схожими.
Б) Анализ сходства по перекрестным связям
сущностей онтологий
Определение сходства между сущностями может быть
основано также на анализе связей сущностей. Если класс А1 связан с классом В1
связью типа R1 в одной онтологии, а класс A2 связан с В2 связью типа R2 в
другой онтологии, и если известно, что В1 и В2 - схожи, R1 и R2 - схожи, можно
предположить схожесть А1 и А2. Подобным образом можно говорить и сходстве типов
связей - R1 и R2 если известно, что А1 и А2 - схожи, В1 и В2 - схожи. Таким
образом оценивается схожесть элементов онтологии в работе.
) Экстенсиональный (статистический) анализ
сущностей онтологий
Для оценки экстенсионального соответствия
классов используются существующие экземпляры классов. Для установки соответствия
между сущностями используются следующие диагностические правила:
- С1 эквивалентен С2 - невозможно
найти объект О1:С1, такой что не О1:С2 и наоборот.
- С1 подкласс С2 - невозможно найти
объект О1:С1, такой что О1:С2 и С1 не эквивалентен С2.
Анализ экстенсионала позволяет также
идентифицировать классы-роли, когда возникает два разных класса для описания
одного экстенсионала.
) Логический анализ сущностей онтологий
Логический анализ основан на выявлении родовых
классов сопоставляемых классов и анализе наложенных на них ограничений.
Ограничением данного метода является потребность
в «якорях» - сущностях которые либо заведомо эквивалентны в двух сопоставляемых
онтологиях, либо являются разделяемыми сущностями в некоторой сторонней
онтологии.
После получения локальных соответствий между
сущностями определяется глобальное соответствие между сущностями.
Практические рекомендации по расстановке
приоритетов между результатами различных способов локального анализа:
При наличие баз знаний, включающих в себя
экземпляры отображаемых онтологий, приоритетное значение имеют результаты
экстенсионального анализа. При наличие «якорей» в отображаемых онтологиях
приоритетное значение имеют результаты логического анализа.
Однако результаты любого анализа следует
согласовывать с результатами, полученными с использованием других видов
анализа. Особенно важно такое согласование при установке соответствия между
классами ролями, исполнители которых (экстенсионал) могут выполнять
одновременно несколько ролей.
Метод ориентирован на «ручную» интеграцию
онтологий путем поиска компромисса и согласования мнений, традиционные метрики
сходства сущностей отображаемых онтологий не рассчитываются.
3.2 Автоматическое отображение онтологий
программный онтология алгоритм
Развитие онтологий начинает приобретать более
массовый характер, и в настоящее время в этой области есть ряд масштабных
проектов. Разработано большое количество онтологий в различных предметных
областях, но возникает вопрос, как гарантировать их соответствие текущему
положению вещей, как быть уверенным, что они точны и полны, а также как
обеспечить достаточную детальность представляемых данных. В связи с тем, что
мир очень быстро изменяется, идет развитие новых отраслей, существующие
онтологии требуют постоянного пополнения и усовершенствования. На данном этапе
появляются идеи использования автоматических и полуавтоматических методов для
не только обновления онтологий, но даже для их создания.
В большинстве случаев проблемой автоматического
извлечения знаний из онтологий становится большое количество «шума», который
надо эффективно отсеивать. В связи с этим иногда наряду с автоматическими
методами используют последующую ручную обработку результатов отображения для
получения данных большей точности.
Общие требования, предъявляемые к системам
автоматического отображения онтологий:
- Минимальный контроль - сведение к
минимуму или исключение вообще участия человека.
- Универсальность - применимость к
неоднородным онтологиям, т.е. написанным на разных языках (RDF, RDF(S), OWL),
вне зависимости от их размера, возможность трансляции.
- Точность - отображенная онтология
должна содержать как можно меньше ошибок.
Выполнение данных требований, возможно, позволит
построить эффективную систему автоматического отображения онтологий, пока же
все существующие системы нуждаются в доработках и улучшениях или же успешно
работают лишь применительно к замкнутым областям знания [28].
На первом этапе отображения необходимо найти
отправную точку, назовем ее связующим звеном двух онтологий, старта алгоритма.
Выделяют несколько методов ее обнаружения:
- текстовые совпадения;
- совпадения иерархических отношений;
- совпадение форматов и данных.
Под текстовыми совпадениями подразумевается
идентичность имен понятий (здесь также учитываются родственные слова), текстовых
определений (сравнение строк, исключение стоп-слов и др.). Иерархическое
совпадение предусматривает поиск общих вышестоящих понятий, фильтрацию
неоднозначностей, нахождение семантического расстояния. Под фильтрацией
неоднозначностей, следует понимать, выбросы зашумленных данных, не совпадение
названий понятий в двух онтологиях. Выбор семантического расстояния зависит от
поставленной задачи и конечного результата. Совпадение форматов и данных
опирается на внутри понятийные отношения и ограничения на заполнение слотов.
После отработки алгоритмов используется функция, которая учитывает результаты
всех процедур и выдает общий коэффициент совпадения. Нахождение связующего
звена включает в себя также процедуру валидации, т.е. сверка заданных
требований с полученным результатом, в ходе которой происходит проверка с
учетом иерархических связей соотносимых понятий. Эта процедура пытается найти
несоответствия понятий, цикличность отображения, проверить наследование свойств
[27].
Для выявления идентичности понятий используются
специально созданные критерии. Так, комплексный критерий, предложенный Н.
Гуарино, проверяет сходство по нескольким параметрам:
- материал: идентичность материала, из
которого сделаны экземпляры сравниваемых понятий;
- топологический: идентичность формы
экземпляров сравниваемых понятий;
- морфологический: те части, из
которых состоят экземпляры сравниваемых понятий;
- функциональный: использование;
- меронимический: экземпляры понятий;
- социальный: социальная роль [27].
Учитываются также возможные стандартные
метонимические переносы, которые делают онтологию более гибкой и расширяют
возможность нахождения близких по содержанию понятий.
Метонимия (греч. «переименование) механизм речи,
состоящий в переносе названия с одного класса объектов или единичного объекта
на другой класс или отдельный предмет, ассоциируемый с данным по смежности,
сопредельности, принадлежности или иному виду контакта; например: выпить две
чашки кофе, где чашка («сосуд») означает меру жидкости. Действие механизма
метонимии приводит к появлению нового значения или контекстно - обусловленному
изменению значения слова. Основой метонимии могут служить отношения между
однородными и неоднородными категориями, например предметами и их признаками
(действиями). Регулярные отношения между предметами или действием и предметом
определяют контактное положение соответствующих им слов в тексте. В этом случае
метонимия часто возникает за счет эллипсиса (сокращения текста); например:
Слушать музыку Шопена и Слушать Шопена.
Описанные методы являются полуавтоматическими,
то есть сначала автоматически генерируются варианты соответствий, а потом
вручную в несколько этапов происходит соединение онтологий. Статистика
показала, что эти процедуры обладают достаточно высокой степенью точности и
дают хорошие результаты [27]. Так, использование подобных автоматических
алгоритмов отображения при построении онтологии SENSUS дало более 90% точности.
Онтология разрабатывалась группой исследователей по компьютерной обработке
естественного
языка, основным направлением которой является машинный перевод и реферирование
текста.
При отображении онтологий может возникнуть ряд
проблем, которые может быть достаточно сложно решать автоматическими методами.
Так эксперты в разных областях могут отсылать к одному и тому же понятию и
понимать его различным образом. Проблемы возникают и тогда, когда одно и то же
слово используется для обозначения различных понятий в каждом отдельном поле.
Решением такой проблемы может быть более тесная коммуникация составителей
онтологий, а также использование более широких онтологий, применимых к
различным областям знания.
.3 Методы автоматического отображения онтологий
Выбор предпочтительных методов к отображению
онтологий должен производиться в первую очередь не из соображений эффективного
обнаружения совпадений в именах или структурных описаниях понятий, хотя это
также необходимо. Основной критерий отображения понятий онтологии - близость и
непротиворечивость подразумеваемой понятийной семантики.
. Если предположить, что хорошо
специфицированные онтологии точно отражают семантику понятий, то важны
формальные методы, доказательно сохраняющие семантику при отображении понятий
друг в друга.
. Необходимо иметь на вооружении методы,
позволяющие находить сходства и различия в понятийной семантике, вне
зависимости от сходства и различия в описаниях их структуры.
Эти
методы должны быть также формальными, чтобы с высокой долей уверенности
обосновывать связи понятий.
Существуют 4 основных подхода автоматического
отображения:
) Отношение уточнения спецификаций сущностей
онтологий.
Формальный критерий корректности отображения
спецификаций, в том числе,
спецификаций
абстрактных типов данных и онтологических понятий, представляемых средствами
абстрактных типов данных. Таким критерием является отношение уточнения
спецификаций, пришедшее из теории программирования. Установленное между
спецификациями, отношение уточнения
означает, что уточняющую спецификацию гарантированно можно использовать вместо
уточняемой, не замечая подмены.
Данное отношение определяется для абстрактных типов данных формально,
поэтому
утверждение об уточнении спецификаций можно доказывать. В зависимости от
сложности модели данных доказательство уточнения может быть автоматическим или
интерактивным.
Частным случаем уточнения спецификаций является
отношение поглощения, устанавливаемое на экстенсионалах понятий. Оно означает,
что все экземпляры класса поглощаемого понятия являются также экземплярами
поглощающего. Это отношение играет важнейшую роль в сегодняшних онтологиях, и
возможность его автоматического доказательства является основных критерием при
разработке современных онтологических моделей, призванных быть понимаемыми и
человеком, и машиной.
Поэтому
учитывая тенденции и разрешимость онтологических моделей,
в
рассуждениях в большинстве случаев достаточно использовать поглощение.
В
частности, для отображения
онтологий в современных онтологических моделях отношение поглощения понятий
резонно использовать в качестве основного критерия. В целом, отношение
уточнения может устанавливаться между понятиями как при разработке одной
онтологии, так и при
согласовании разных онтологий.
Формально обоснованные отношения уточнения
понятий гарантируют корректность отображения понятий одной онтологии в другую.
В этом случае, предполагая, что изначально спецификации онтологических понятий
достаточно отражают их понятийную семантику, можно быть уверенным, что
семантика понятий при отображении сохранена.
Данный подход работает со спецификациями
онтологии как со схемами. Предположение о достаточности спецификаций для
отражения семантики понятий здесь существенно. Поэтому помимо формальных
подходов работы с онтологиями, необходимы
подходы,
выявляющие
сходства и конфликты понятий на основании информации о понятиях сверх описания
их
структуры и ограничений.
) Метаонтологии и онтологии верхнего уровня.
Помимо формальных методов работы со
спецификациями сущностей онтологий для описания семантики онтологических
понятий согласовываемых онтологий, желательно иметь спецификации,
рассматривающие понятия каждой из онтологий с некоторой общей точки зрения.
Реализацией такого подхода может стать применение метаонтологии, связанной с
обеими согласовываемыми онтологиями.
Метаонтология может содержать описание:
− обобщённой метамодели,
на
основе которой можно построить большинство онтологических моделей; такая
метаонтология оказывается особенно полезна при отображении онтологий,
разработанных в разных онтологических моделях;
− более абстрактной онтологии,
из
понятий которой строится большинство разновидностей сущностей, встречающихся в
предметной области.
Метаонтология должна стать подложкой под
согласовываемые онтологии. Если онтологии изначально не описаны одной и той же
метаонтологией, соотносить элементы спецификаций с понятиями метаонтологии
можно специально для решения задачи отображения. При необходимости
качественного отображения онтологий данный подход может оказаться затратным, но
дающим хороший результат. Принцип формирования подложки следующий.
Каждое понятие из согласовываемых онтологий
(а
также, если возможно, каждое отношение или свойство) должно стать экземпляром
некоторого понятия метаонтологии. Если семантически подходящего понятия в
метаонтологии нет, то создаётся служебное понятие (оно
будет являться подпонятием понятия метаонтологии),
являющееся
выражением, описывающим в
терминах понятий метаонтологии необходимую семантику.
И
элемент спецификации онтологии становится экземпляром служебного понятия. Таким
образом, в классах, определяемых
понятиями метаонтологии или служебными понятиями, в
качестве экземпляров окажутся элементы спецификаций согласовываемых онтологий,
распределённые по классам в зависимости от их семантики с точки зрения
метаонтологии.
Такой принцип построения подложки на
метаонтологии позволяет сделать независимыми друг от друга спецификации в
терминах метаонтологии и собственно спецификации онтологий, так как эти
спецификации находятся на разных уровнях иерархии классификации. К слову, по
той же причине нет ограничений на одновременное использование нескольких
метаонтологий, рассматривающих онтологии с разных ракурсов предметных областей.
Сформированные спецификации в терминах
метаонтологии можно использовать:
− для проверки корректности отображения
понятий;
− при семантическом поиске релевантных
понятий для дальнейшего отображения.
В этих задачах поглощающее
(уточняющее)
понятие
должно находиться с поглощаемым (уточняемым)
в одном классе (включая его
подклассы), соответствующем понятию метаонтологии или служебного понятия.
Описанный подход берёт своё начало ещё в
концептуальном моделировании, где важность метауровней была осознана
изначально. В онтологическом моделировании актуальность такого подхода только
возрастает.
Другой подход к формированию подложки использует
общую онтологию верхнего уровня, содержащую наиболее общие понятия,
используемые в любых предметных областях (например, DOLCE).
Согласовываемые
онтологии встраиваются в иерархию понятия/подпонятия онтологии верхнего уровня
(при
таком подходе её некорректно называть метаонтологией). Этот путь более сложен,
он включает задачу интеграции каждой
онтологии в онтологию верхнего уровня и может приводить к изменению изначальных
онтологий для совместимости их с онтологией верхнего уровня. Однако и он
позволяет избежать некорректных отображений понятий между онтологиями.
) Фундаментальные метасвойства.
Онтология представляет собой набор свойств и
отношений, которые являются утверждениями об объекте. В онтологии уделяется
большое внимание различным видам свойств понятий. С элементами онтологии может
быть связан набор фундаментальных метасвойств, с
точки зрения которых можно оценить любое понятие или отношение:
− существенность - неотъемлемость свойства
сущности;
− строгость - принадлежность существенного
свойства сущности в любом воображаемом контексте или мире;
− идентификация - является ли утверждение об
объекте идентифицирующим его свойством;
− собственная идентификация -
несёт
ли эту идентификацию само утверждение, либо оно наследует её из других свойств
или сущностей;
− неизменность - может ли свойство
меняться во времени;
− зависимость - может ли сущность
существовать без других;
− постоянство - как долго сущность
остаётся таковой;
− объединение - существование экземпляров
понятия как целых сущностей в отношении часть/целое,
и
другие.
Формальное определение подобных метасвойств
предполагает некоторые ограничения, которые должны выполняться при их
использовании с различными сущностями. Некоторые из этих метасвойств совместимы
друг с другом, другие исключают друг друга. Для свойства q,
поглощающего
свойство p, верны следующие ограничения:
− если q строгое для любых сущностей, то p
также строгое для любых сущностей;
− если q несёт критерий идентификации
сущностей, то и p также;
− если q несёт критерий объединения, то и
p также;
− если q не несёт объединение, то и p
также;
− всякая сущность должна быть значением
наиболее общего свойства, несущего его идентификацию, и другие.
В частности, при построении таксономии
поглощения между понятиями, некоторые метасвойства более специфических понятий
должны наследоваться, и обнаружение
конфликтов метасвойств понятий в иерархии будет означать некорректность
построения таксономии. На подобных
правилах основан инструмент проверки и коррекции онтологий OntoClean.
Те же ограничения должны выполняться и для
связей,
выявленных
между понятиями, принадлежащими
разным онтологиям. Соответственно их
можно использовать для обнаружения семантических конфликтов в результатах
отображения онтологий. Если метасвойства связанных понятий из двух онтологий
противоречат друг другу, это означает,
что
отображение было составлено некорректно, и понятия имеют разную семантику.
На основе метасвойств различных видов можно
проводить и другие, более сложные
рассуждения, полезные в задаче отображения онтологий.
Родовые понятия онтологии могут отражать
идентификацию объектов реального мира, образовывать типы. Видовые - создавать
категории объектов. Ролевые - относиться к
ролям объектов реального мира. Ролевые
понятия могут быть подпонятиями родовых. Видовые понятия могут быть
подпонятиями ролевых или родовых понятий. Если касаться метасвойств отношений
часть/целое, совокупность всех частей составляет целое,
это
может быть использовано для предположения связи понятий. Если часть является
неотъемлемой, целое может быть идентифицировано по части. Если целое является
инвариантным, то части можно идентифицировать по целому. Все эти знания могут
быть использованы для корректного отображения понятий между онтологиями.
Данный подход некоторым образом связан с
предыдущим описанным подходом отображения онтологий, использующим общую
онтологию верхнего уровня для согласовываемых онтологий. Ведь фундаментальным
понятиям онтологии верхнего уровня соответствуют вполне определённые наборы
значений метасвойств. И эти метасвойства также задают требования к понятиям
согласовываемых онтологий. Таким
образом,
при
совместном использовании онтологии верхнего уровня и фундаментальных
метасвойств понятий появляются дополнительные возможности контроля с помощью
метасвойств корректности отнесения понятий онтологий в качестве подпонятий к
понятиям онтологии верхнего уровня.
) Экземпляры экстенсионалов понятий.
Последний подход из представленных методов
обнаружения сходств и конфликтов понятийной семантики, связан с экземплярами
классов понятий онтологий. Такими экземплярами могут становиться:
− объекты, соответствующие сущностям реального
мира;
− примеры моделей реального мира;
− хорошо классифицированные с помощью
онтологий данные.
На основе принадлежности экземпляров одним и тем
же понятиям разных онтологий можно заниматься поиском релевантных понятий.
Обратная задача - проверка экстенсиональной составляющей связанных понятий из
согласовываемых онтологий. Существование хотя бы одного примера модели, в
которой сущности не принадлежат одновременно классам,
соответствующим
эквивалентным понятиям согласовываемых онтологий, приводит к конфликту и ставит
под сомнение корректность установленной связи между понятиями.
Данный
экстенсиональный подход к проверке отображения онтологий
«по
образцу» может быть реализован формальным образом.
Применяя существующие, даже формальные,
методики, невозможно автоматически отображать онтологии,
созданные
разными рабочими группами. Поэтому первым требованием к работе экспертов по
согласованию отображенных онтологий является вовлечение в работу и в дискуссию
экспертов-представителей каждой из выбранных онтологий.
Необходимость вовлечения экспертов доказывается
тем, что при формальности представленных подходов в каждом из них присутствуют
предположения, не доказуемые формально:
− о достаточности отражения семантики
понятий спецификациями онтологий;
− о корректном описании понятий в терминах
метаонтологий;
− о корректной оценке значений
метасвойств, связанных с понятиями;
−о корректном отнесении сущностей
реального мира или информационных объектов к определённым понятиям.
Эксперт в области своей компетенции может принимать
ответственные решения, связанные с
перечисленными выше проблемами: пояснять
семантику понятий, не выраженную в спецификациях, выражать понятия своей
онтологии в терминах метаонтологий, декларировать фундаментальные свойства
понятий, предлагать примеры моделей реального мира и решать, как они выражаются
в терминах его онтологии. Семантические различия похожих понятий могут
выясняться зачастую только в процессе дискуссий, на основе применения к
выбранным онтологиям одной и той же метаинформации о понятиях. Каждый из
представленных подходов может помочь экспертам эффективно обнаруживать скрытые
конфликты при отображении онтологий. Реализация
этих подходов может быть не только компьютеризированной. Они могут быть полезны
экспертам в качестве:
− регламента обсуждений и дискуссий в ходе
совместной работы по отображению онтологий;
− автоматизированной системы поддержки
совместной работы экспертов по отображению онтологий в интерактивном режиме.
Таким образом, система поддержки отображения
онтологий должна обеспечивать не столько работу автоматизированных методов,
результаты
которых должен контролировать эксперт, сколько
совместное применение различных методов верификации отображений в ходе работы
нескольких экспертов - представителей конкретных онтологий.
При согласовании отображенных пересекающихся
областей сталкиваются продуманные решения, и
находить консенсус между ними бывает непросто. Интенсивно
занимаясь оценкой различных алгоритмов выравнивания онтологий, исследователи,
тем не менее, понимают ограничения этих подходов и отмечают необходимость и
перспективность разработок, позволяющих
оптимально поддерживать интеллектуальную работу экспертов при согласовании
онтологий [4].
.4 Проекты, использующие методы автоматического
и ручного отображения.
Подход Similarity Flooding (SF) работает с
помеченными графами, основным принципом
поиска связанных понятий является предположение, что элементы двух онтологий
подобны, если подобны их смежные элементы. Предположение
о близости двух элементов далее распространяется по их соседям.
Инициализирующие
предположения о близости вершин находятся простым сравнением имён.
Для
улучшения результатов инициализирующих данных используется внешний источник
типа WordNet, без его привлечения
качество работы метода сильно страдает.позиционируется как система
сопоставления схем, однако также упоминается постоянно, когда речь идёт об
интеграции онтологий. Проект транслирует понятия в логические формулы и
сопоставляет понятия онтологий первым делом с использованием WordNet. Решатель
SAT используется для проверки отношений эквивалентности,
включения,
пересечения.
В проекте OLA утверждается,
что
методы оценки расстояния строк имеют большую производительность и эффективность
в сравнении методами оценки близости определений, основанными на использовании
внешних источников, в частности WordNet, за счёт времени обращения к внешним
источникам. OLA основан на оценке
терминологических и структурных расстояний между понятиями онтологий численно в
интервале от 0 до 1. Близость представляется как множество формул,
каждая
переменная которой представляет подобие сущностей.
Определения
формул соответствуют определению функции близости и определениям онтологических
сущностей. Проект работает с онтологиями в модели OWL Light.- инструмент для
выравнивания структурных онтологий в модели OWL DL
с
использованием методов оценки близости. Обе онтологии преобразуются в графы
DL-GRAPH, затем вычисляется
локальное подобие лингвистическими и структурными методами, а затем оценивается
семантическая близость.
В подходе QOM замечено, что на время работы
алгоритма поиска отображения непосредственно влияет количество вероятных пар.
Здесь применяется эвристический метод оценки структуры онтологий,
позволяющий
уменьшить количество кандидатов на отображение. На этапе оценки близости QOM
избегает полной попарной оценки деревьев онтологии и ограничивает число
дорогостоящих сравнений. Там, где
используются итерации, ограничивается их
количество, утверждая на тестах, что
дальнейшие итерации не сильно влияют на результат. Констатируется,
что
оптимизация операций уменьшает качество отображения,
а
использование комбинации подходов его увеличивает. В целом, QOM
показывает
неплохие результаты при разнице во времени работы на порядок относительно
других методов.Merge - метод для сравнения
онтологий, которые имеют набор общих экземпляров или набор общих документов,
аннотируемых с помощью концептов исходных онтологий. Основываясь на этой
информации, система производит
решетку понятий, связывающую концепты исходных онтологий.
Алгоритм
предлагает отношения эквивалентности и подкласса. Затем
эксперт анализирует результат и использует его как руководство для создания
объединенной онтологии. Однако предположение, что
две объединяемые онтологии используют общий набор экземпляров или имеют набор
документов, представительных для данной проблемной области,
и
каждый документ должен аннотироваться терминами обоих источников слишком
жесткое и на практике такая ситуация происходит редко. В качестве альтернативы,
авторы предлагают использовать методы обработки естественного языка для
аннотации набора документов понятиями этих двух онтологий.
Проект GLUE представляет оригинальный подход к
связыванию онтологий, использующий
обучающиеся машины для предположения близости элементов онтологий по данным
экземпляров понятий. Онтологии определяются как таксономии понятий с
атрибутами. Во время фазы обучения находятся шаблоны и правила сопоставления
элементов онтологий. Точность
предположения зависит от качества обучения. Используется
несколько машин обучения и метаобучатель, взвешивающий
их результаты в соответствии с тем, какие
результаты выдавал конкретный подход во время обучения. Для многих онтологий не
существует данных, состоящих из экземпляров понятий,
в
этом случае метод не применим.
4. ИНТЕГРИРОВАННЫЙ ПОДХОД К РЕШЕНИЮ ПРОБЛЕМЫ
ОТОБРАЖЕНИЯ ОНТОЛОГИЙ
Создание промышленных систем, основанных на
онтологиях, требует методов и инструментов, как для построения онтологий, так и
для целого ряда задач, связанных с их сопровождением. Для построения онтологий
с середины 90-х годов прошлого века начали создаваться среды разработки
онтологий. В последующие годы параллельно с развитием средств разработки
онтологий появились средства редактирования и сопровождения онтологий, средства
отображения, выравнивания и объединения онтологий, а также средства
аннотирования онтологий. Таким образом, к настоящему времени сформировалась
целая инженерия онтологий [29].
Одним из центральных понятий инженерии онтологий
является понятие «отображение онтологий» (ontology mapping), под которым понимается
деятельность по установлению соответствия между несколькими онтологиями или,
другими словами, нахождение семантических связей подобных элементов из разных
онтологий. С наиболее общей точки зрения важность задачи отображения онтологий
обусловлена тем фактом, что мощность знаний, заключенных в онтологиях,
проявляется в полной мере только в том случае, когда удается учесть взаимосвязи
независимых онтологий - установление факта подобия сущностей в разных
онтологиях означает извлечение из этих онтологий дополнительных знаний [30].
Близкой к проблеме отображения онтологий
является проблема выравнивания онтологий (ontology alignment), которая
заключается в том, чтобы установить различные виды соответствия между двумя
онтологиями, а затем сохранить исходные онтологии вместе с информацией о
найденных соответствиях с тем, чтобы в дальнейшем использовать информацию о
взаимосвязях онтологий. Отметим также, что на основе отображения онтологий
решается задача интеграции онтологий (ontology merging) - задача создания новой
онтологии или ее фрагментов из двух и более исходных онтологий [30].
Онтологический инжиниринг подразумевает глубокий
структурный анализ предметной области. Приведем простейший алгоритм
онтологического инжиниринга:
- выделение концептов - базовых
понятий данной предметной области;
- определение «высоты дерева
онтологий» - количество уровней абстракции;
- распределение концептов по уровням;
- построение связей между концептами -
определение отношений и взаимодействий базовых понятий;
- консультации с различными
специалистами для исключения противоречий и неточностей [31].
В основе онтологического анализа лежит описание
системы (например корпорации) в терминах сущностей, отношений между ними и
преобразование сущностей, которое выполняется в процессе решения определенной
задачи.
Основной характерной чертой этого подхода
является, в частности, разделение реального мира на составляющие и классы
объектов и определение их онтологий, или же совокупности фундаментальных
свойств, которые определяют их изменения и поведение. Эти подходы и методологии
базируются на следующих принципах проектирования и реализации онтологии.
Ясность - онтология должна эффективно передавать
смысл введенных терминов, ее определения должны быть объективны, а для их
объективизации должен использоваться четко фиксированный формализм.
Согласованность - все определения должны быть
логически непротиворечивы, а те утверждения, которые выводимы в онтологии, не
должны противоречить ее аксиомам.
Расширяемость - необходимо проектировать онтологию
так, чтобы ее словари терминов можно было расширять без ревизии уже
существующих понятий.
Минимум влияния кодирования - концептуализация
онтологии должна быть специфицирована на уровне представления, а не символьного
кодирования.
Минимум онтологических обязательств - онтология
должна содержать только наиболее существенные предположения о моделируемой ПО,
чтобы оставлять свободу расширения и специализации [32].
.1 Критерии подобия концептов онтологий
Задача отображения онтологий возникает во многих
областях науки и техники, например, при организации понятийного контроля знаний
субъекта обучения в интеллектуальной обучающей системе, при моделировании
организаций в задачах организационного проектирования, при проектировании
персонифицированных информационных ресурсов над Wеb-сайтами со
слабоструктурированными данными, при построении цифровых (электронных)
библиотек.
В работе рассмотрены критерии и мультикритерии
подобия онтологий. На этой основе дан обзор методов автоматического отображения
онтологий. Рассматриваемые критерии подобия онтологий построены на основе
подобия сущностей соответствующих семантических сетей, дескриптивной логики,
ограничений и правил и пр. Все критерии являются транзитивными: если А подобно
В, и В подобно С, то А подобно С. Таким образом, рассматриваемые критерии можно
использовать для установления подобия более, чем двух онтологий.
Для иллюстраций в работе используется язык
описания онтологий OWL (Web Ontology Language).
Компоненты, из которых состоит онтология,
зависят от используемой модели онтологии. Обычно онтология описывается с
помощью
- концептов (понятий, классов,
сущностей, категорий),
- атрибутов концептов (слотов,
свойств, ролей),
- отношений между концептами (связей,
зависимостей, функций),
- дополнительных ограничений (аксиом,
фасет).
Элементы предметной области (элементы данного
концепта) называются экземплярами. Зависимость между концептами, которая
включает в себя необходимое условие и следствие выполнения этого условия,
называется правилом. Онтология вместе с множеством соответствующих экземпляров
составляет базу знаний.
Подобие некоторых сущностей x, y
определяется с помощью функции подобия sim(x,y)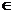 [0,1], которая обладает следующими
свойствами : [0,1], которая обладает следующими
свойствами :
- sim (x,y)=1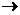 x=y (объекты x, y идентичны); x=y (объекты x, y идентичны);
- sim(x,y)=0 (объекты x, y совершенно разные и не
имеют схожих характеристик);
- sim(x,y)=1 (свойство возвратности функции
подобия);
- sim(x,y)=sim(y,x) (свойство симметричности
функции подобия).
Пусть O1, O2 -
рассматриваемые онтологии, bi,jOi - некоторая сущность
онтологии Oi, i=1,2. Подобие сущностей b1,2, b2,1
означает, что sim(b1,2, b2,1)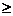 t, где t -
пороговая величина (уровень подобия, уровень отсечения). t, где t -
пороговая величина (уровень подобия, уровень отсечения).
Отображение онтологии O1
на онтологию O2 означает попытку найти для каждого из концептов
онтологии O1 подобный ему концепт в онтологии O2. Другими
словами, отобразить онтологию O1 на онтологию O2 означает
отобразить каждую из сущностей b1,2 онтологии O1 на
соответствующую сущность b2,1 онтологии O2.
Если онтология O2 есть
отображение онтологии O1, то этот факт записывается в
виде map(O1)= O2.
В работе было выделено 19 критериев
подобия для автоматического отображения онтологий:
) Критерии на основе подобия
идентификаторов или URI сущностей.
Критерий L1. Первым из
критериев этого класса является критерий на основе идентификаторов сущностей
(меток). Критерий формулируется следующим образом: если метки двух сущностей
подобны, то эти сущности подобны. Вместо имен сущностей могут сравниваться
имена их синонимов (с использованием существующих словарей общей и
профессиональной лексики или тезаурусов).
Критерий L2. Критерий
строится на основе идентификаторов сущностей, уникальных для каждой из
сущностей, например, URI (Uniform Resource Identifier) и формулируется
следующим образом: если две сущности имеют подобные URI, то эти сущности
подобны.
) Критерии на основе семантической
сети онтологии.
Критерий L3. Поскольку
сущности состоят в отношениях с другими сущностями через свои атрибуты, имеет
место следующий критерий подобия: если атрибуты двух сущностей подобны, то эти
сущности подобны.
Критерий L4. Ограничить
отношения между сущностями можно путем задания области применения (domain) и
диапазона (range) соответствующих атрибутов сущностей. Это обстоятельство
позволяет сформировать следующий критерий подобия отношений: если область применения
и диапазон двух отношений подобны, то такие отношения подобны.
) Критерии на основе дескриптивной
логики.
Критерии данного класса охватывают
онтологии, которые обладают сложностью, достаточной для их описания
дескриптивными логиками.
Здесь «умные люди», «книги» и «умный
человек» - концепты; «читают» - отношение; «Сергей» - экземпляр. Экземпляр
«Сергей» наследует отношение родительского понятия. Пример дескриптивной логики
на языке OWL имеет вид, который изображен на рисунке.
Таблица 4.1 - Пример дескриптивной
логики
|
Отношение
двух концептов
|
Отношение
экземпляра и концепта
|
Отношение
экземпляра и концепта
|
|
умные
люди читают книги
|
Сергей
читает книги
|
Сергей
- умный человек
|
Критерий L5 формируется, исходя из
посыла, что подобные концепты с большой вероятностью имеют подобные
родительские понятия: если родительские понятия двух концептов подобны, то сами
концепты также подобны.
Критерий L6 основан на подобии
дочерних понятий: если дочерние понятия сравниваемых концептов подобны, то эти
концепты также подобны.

Рисунок 4.1 - Пример дескриптивной логики
написанный на языке OWL
Критерий L7 основан на подобии
концептов, относящихся к тому же уровню иерархии понятий: если концепты имеют
подобные концепты того же уровня иерархии, то они также подобны.
Критерии L8 , L9 строятся
на основе подобия атрибутов дочерних и родительских сущностей:
- если подобны атрибуты дочерних
сущностей, то атрибуты родительских сущностей также подобны (L8);
- если подобны атрибуты родительских сущностей,
то атрибуты дочерних сущностей также подобны (L9).
Критерий L10. Поскольку, как
отмечалось выше, экземпляр представляет собой элемент соответствующего
концепта, он наследует все атрибуты этого концепта. Поэтому имеет место
следующий критерий подобия: если концепты включают в себя подобные экземпляры,
то эти концепты подобны.
Критерий L11 является обратным по
отношению к критерию L10 и записывается в виде: если экземпляры
принадлежат подобным концептам, то эти экземпляры подобны.
Критерий L12 близок к критерию
подобия L10 и формулируется следующим образом: если концепты имеют
схожую малую/большую часть экземпляров, эти понятия подобны. В отличие от
критерия L10,подобие в данном критерии определяется подобием
структуры дочерних элементов, а не уровнем подобия самих элементов.
Критерий L13 имеет следующую
формулировку: если два экземпляра связаны с некоторым другим экземпляром
подобными отношениями, то эти экземпляры подобны. Критерий L14
является обратным по отношению к критерию L13 и формулируется следующим
образом: если некоторое отношение связывает экземпляры с одним и тем же
экземпляром, то сравниваемые отношения могут быть подобны.
) Критерии на основе ограничений.
Критерий L15 основан на использовании
отношений вида «SameClassAs» и «SameIndividualAs»: если две сущности связаны
между собой отношением «sameClassAs» или отношением «sameIndividualAs», то эти
сущности подобны.
Критерий L16 основан на использовании
отношений вида «EquivalentClass», «EquivalentProperty», «SameAs»: если две
сущности связаны между собой отношениями «EquivalentClass»,
«EquivalentProperty», «SameAs», то эти сущности подобны.
) Критерии на основе правил.
Подобными называются правила, которые имеют
подобные условия, а также подобные следствия выполнения правила.
Критерий L17 имеет вид: если две
сущности связаны между собой подобными правилами, то эти сущности подобны.
Рассмотренные выше критерии подобия онтологий
используют свойства общего определения онтологий. Кроме этого, возможны
онтологии, которые используют особый словарь. Если этот словарь строго
определен и общедоступен, то он также может быть использован для формирования
критериев подобия онтологий.
В качестве примера рассмотрим SWAP-системы, в
которых каждому файлу присваивается уникальный хэш-код. Для таких систем имеют
место критерии L18 , L19:
- если хэш-коды двух элементов
одинаковы, то и элементы подобны;
- файлы одинакового MIME-type подобны,
как минимум, по формату.
Чаще всего в качестве мультикритерия подобия
используется аддитивная свертка критериев L1 - L19 - т.е.
их взвешенная сумма
 , (4.1) , (4.1)
где b1,2O1,
b2,1O2
- сущности онтологий О1 О2, соответственно;
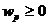 - весовой коэффициент критерия - весовой коэффициент критерия 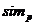 . .
4.2 Меры семантической близости концептов
онтологий
Онтология - это спецификация концептуализации
предметной области (ПО). Онтология состоит из организованных в иерархию
понятий,
отношений
между понятиями и атрибутов понятий, а также аксиом и правил вывода. Понятия
представляют множества экземпляров. Понятия, экземпляры, отношения и атрибуты
будем называть онтологическими термами.
Меры близости онтологических термов используют
различные семантические характеристики сравниваемых термов - их свойства
(атрибуты и отношения с другими термами), взаимное положение в
онтологических
иерархиях. В работе рассматриваются меры семантической близости, предполагающие
однозначную интерпретацию термов для одной онтологии.
Онтологический подход обеспечивает новый уровень
в решении задач поиска и интеграции информации. Запрос пользователя, как
правило, не полностью отражает его интерес, так как пользователь, с одной
стороны, не знает всех терминов и структур данных, заложенных в систему, с
другой -
не
всегда точно выражает, что он
ищет. Использование семантической близости дает возможность расширять запросы и
ранжировать результаты
запросов. Другими словами, терм c может быть представлен как размытое
(нечеткое) множество, включающее (кроме этого терма) семантически близкие термы
со значением семантической близости выше заданного порога, причем семантическая
близость определяет принадлежность к нечеткому множеству: с+ = {1/с, S(с,с1)/с1,
S(c,c2)/c2,
…,
S(c,cn)/cn}.
При интеграции информации, например при операциях
над онтологиями, использование мер близости позволяет автоматически находить
семантически близкие понятия, принадлежащие к разным системам концептуализации.
Ключевым моментом в решении задачах поиска и
интеграции является разработка количественных оценок семантической близости. В
работе представлен обзор методов, которые используют
знания, заложенные в онтологии, для оценок семантической близости термов.
В основу многих онтологических мер близости
положен теоретико-множественный подход Тверски [1], определяющий меру близости
двух объектов, основанную на
сопоставлении свойств (feature matching). Мера близости S(a,b) между объектами
a и b
является
функцией
трех
аргументов A∩B, A-B, B-A, где A и B - множества свойств этих объектов,
должна удовлетворять аксиомам монотонности, независимости, разрешимости и
инвариантности и определяется формулой (contrast model):
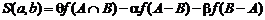 (4.2) (4.2)
В развитие модели Тверски была построена ratio
model:
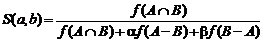 (4.3) (4.3)
В большинстве методов вычисления мер близости
используется ratio model, а в качестве
функции f - мощность множества-аргумента.
Близость двух понятий
онтологии
может быть оценена по положению вершин, соответствующих этим понятиям в
таксономической иерархии (IS-A). Простейшая мера близости такого рода основана
на длине кратчайшего пути, измеряемого числом вершин (или ребер) в пути между
двумя соответствующими вершинами таксономии [2], с учетом глубины
таксономической
иерархии
[3]
- чем меньше длина пути между вершинами, тем они ближе:
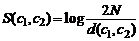 ,
(4.4) ,
(4.4)
где N - глубина дерева, d(c1, c2)
- длина кратчайшего пути между вершинами.
Предложена мера близости, учитывающая только глубины
вершин понятий:
 ,
(4.5) ,
(4.5)
где N(LCS)
- глубина наименьшей общей родовой вершины - ближайшего общего родителя (least
common subsumer - LCS), N(c1) и N(c2) - глубины вершин.
Предложена мера близости, учитывающая два параметра:
длину кратчайшего пути между вершинами и глубину LCS-вершины
-
с учетом их весов a и b. Наибольшая корреляция с экспертными оценками получена
при применении формулы:
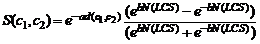 ,
(4.6) ,
(4.6)
где d и N -
длина кратчайшего пути между вершинами и глубина
LCS-вершины.
При оценке семантической близости понятий
предлагается ограничивать конфигурацию пути: длину пути и
количество
перегибов. Предполагается, что
два понятия семантически близки, если соединены достаточно коротким путем,
который имеет малое количество перегибов. Рассматриваются пути либо, состоящие
из совокупности иерархических отношений, направленных в одну сторону (например,
последовательность
отношений от потомка к предку), либо включающие ровно один перегиб.
Для измерения близости используется
семантическое расстояние SemDist, инверсное семантической близости: чем больше
семантическое расстояние, тем меньше семантическая
близость. Вводится понятие общей специфичности двух вершин CSpec:
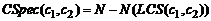 ,
(4.7) ,
(4.7)
где N - глубина таксономического дерева. Чем
меньше специфичность двух вершин, тем больше информации они разделяют и
близость их больше.
Семантическое расстояние является функцией двух
параметров - длины кратчайшего пути между вершинами и общей специфичности двух
вершин:
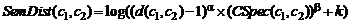 ,
(4.8) ,
(4.8)
где α >
0, β
>
0; k ≥ 1 - константа (обеспечивает нелинейность и положительность
SemDist), d(с1, с2) - длина кратчайшего пути между двумя
вершинами.
Вводится информационное
содержание понятия IC (information content), которое вычисляется как частота
встречаемости понятия и его подпонятий в стандартном корпусе текстов и
трактуется как величина вероятности P(с). Если с2 - родитель для с1,
то P(с1) ≤ P(с2). Чем абстрактнее понятие, тем меньше
величина его IC. В [10] близость между двумя понятиями оценивается по IC
ближайшего родителя сравниваемых понятий. Вместо глубины вершин используется их
IC -
«взвешенная»
глубина. Таксономическая мера близости понятий определяется через так называемую
«верхнюю котопию» (UC - upwards cotopy), содержащую все суперпонятия заданной
вершины:
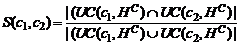 (4.9) (4.9)
Предлагается асимметричная мера семантической
близости. В зависимости от направления прохождения
ребрам
придается разный вес, так как потомок более подобен родителю, чем родитель
потомку.
Недостатком большинства мер, основанных на
онтологических структурах, является симметричность
(экспертные оценки показывают, что мера близости не всегда симметрична). Кроме
того, эти меры независимы от контекста и чувствительны к структуре иерархии.
Предлагаются меры близости,
основанные
на неиерархических («горизонтальных») отношениях
и атрибутах. Оценка близости
понятий, использующая горизонтальные отношения, опирается
на
предположение, что если два понятия
имеют одно и то же отношение с третьим, то они ближе, чем два
понятия,
которые имеют это же отношение с различными понятиями, т. е. близость двух
понятий зависит от близости понятий, с которыми они имеют отношения. Таким
образом, мера близости вычисляется рекурсивно. Атрибутивная мера близости
основана на близости значений общих атрибутов понятий. Атрибуты можно
рассматривать как отношения, диапазоны которых литералы, числа, строки и другие
типы данных. В качестве меры близости для строковых данных можно использовать
пронормированное редакторское расстояние [15], для чисел - инверсию разности,
пронормированную максимальным значением атрибута.
Гибридные меры являются свертками перечисленных
мер близости понятий. Чем полнее будут учитываться характеристики двух
сущностей с разных точек зрения, тем более качественную меру близости можно
получить. В связи с этим наиболее перспективными представляются именно
гибридные меры, сочетающие несколько подходов.
Чаще всего в гибридных мерах используется аддитивная
свертка:
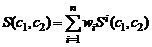 ,
(4.10) ,
(4.10)
где 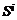 -
мера близости по определенному критерию, вес wi определяет
относительную важность критерия, сумма весов равна 1, n - число критериев. -
мера близости по определенному критерию, вес wi определяет
относительную важность критерия, сумма весов равна 1, n - число критериев.
Распространенная модификация аддитивной свертки
основана на использовании сигмоидальной функции, которая позволяет повысить
веса мер, имеющих большие значения, и практически пренебречь мерами с малыми
значениями (sig(x)=1/(1+e-ax), a > 0):
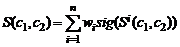 (4.11) (4.11)
Веса могут определяться интерактивно экспертами
и/или пользователями, а также автоматически с помощью обучаемой нейронной сети
[16] или генетического алгоритма [17].
Трудности сравнения разных онтологий
ПО
(различных концептуализаций одной и той же ПО) заключаются в различии
используемых лексиконов и в различных путях концептуализации
и
ее представления. Отображение онтологии О1 на онтологию О2
означает попытку найти для каждого из концептов онтологии О1 подобный
ему концепт в онтологии О2.
Гибридная мера, предложенная в
[13],
содержит оценку близости экземпляров, состоящую из трех частей -
таксономической, реляционной и атрибутивной:
 (4.12) (4.12)
Таксономии двух онтологий связываются через
«мосты» («якоря») - вершины, соответствующие эквивалентным понятиям, которые
определяются с использованием синсетов (множеств синонимов) из MeSH (Medicine
Subject headings) и WordNet. Параметры таксономической меры близости
рассчитываются с учетом введенных мостов: ближайшим общим родителем (LCS) для
сравниваемых понятий из разных онтологий O1 и O2 является
ближайший общий родитель первого элемента сравниваемой пары и
вершины-моста.
Для вычисления кросс-онтологической меры
близости таксономии двух онтологий связываются через вводимую top-вершину обеих
иерархий. Близость понятий в двух онтологиях вычисляется с учетом лексической
близости терминов, соответствующих сравниваемым вершинам,
семантической
близости соседних (в заданном радиусе окрестности вершины в иерархии) вершин, а
также
близости
различимых свойств понятий, соответствующих сравниваемым
вершинам.
Мера близости между термами разных онтологий
разбивается на элементарные критерии: лексическая близость, близость свойств,
близость доменов и диапазонов отношений,
близость родительских/дочерних понятий и т. д. Расчет
близости
между понятиями в разных онтологиях является итерационным процессом, поскольку
многие из рассмотренных критериев близости двух понятий основываются на
близости других сущностей. На первой итерации используются критерии близости,
которые не основываются на других критериях, например лексическая близость.
Рассматриваются методы измерения близости между
онтологиями на двух уровнях - вербальном и концептуальном.
На вербальном уровне происходит сравнение
лексиконов двух онтологий, на концептуальном - сравнение таксономий понятий и
других отношений двух онтологий.
Ранжирование ответов на запросы к Web-порталу
сводится к сравнению пар баз знаний
(онтологий) - каждого результата запроса (QKBi), который
интерпретируется
как база знаний, и портала (KB). Базы
знаний
результата
и портала имеют один лексикон и одни понятия, поэтому сравниваются только
отношения. Ранжирование производится по значению близости результата к порталу,
причем понятие близости между двумя базами знаний сводится к близости
отношений:
(QKBi, KB) = 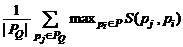 ,
(4.13) ,
(4.13)
где PQ - множество отношений базы
знаний результата запроса QKBi, P - множество отношений базы знаний
портала, S(pj, pi) - близость двух n-арных отношений pj
и pi .
Меры семантической близости используются в
широком спектре задач. Эффективность применения той или иной меры зависит как
от задачи, так и от пользователя. Этот вопрос не рассматривается в известной
авторам данного обзора литературе и ожидает своего исследования.
Интерактивный интерфейс при задании запроса
поможет пользователю определить свои предпочтения при выборе меры семантической
близости.
.3 Семантическое расстояние
Измерение семантических расстояний, или
количественная оценка семантических связей в системе языка - это
исследовательская задача, для решения которой существует необходимый и
достаточный теоретический аппарат, однако ее практические решения далеки от
совершенства.
Измерение семантических расстояний на уровне
лексикона и речевых произведений возможно лишь в том случае, если выполняются
следующие условия:
·
существует
семантическое описание тех единиц, теснота связи между которыми подлежит
измерению;
·
существует
подробное описание разнообразных семантических отношений, связывающих языковые
единицы и их комплексы;
·
используемый
математический аппарат (теория множеств, топология, математическая статистика и
пр.) адаптирован с учетом качественной природы измеряемых отношений.
В существующих исследованиях по измерению
семантических расстояний задействованы два подхода: парадигматический и
синтагматический.
1) Парадигматический подход предполагает
измерение семантических расстояний в лексиконе. Исходный тезис таков:
семантическую близость следует определять, опираясь на данные о значении,
хранящиеся «внутри» языкового знака, а не за его пределами.
Определив лексикон языка как сложным образом
упорядоченное множество классов слов, связанных парадигматическими отношениями
(семантических полей или группировок иного толка, например,
лексико-семантических групп, синонимических рядов), и описав значения единиц
данных классов с помощью набора неких семантических признаков, можно применить
к описанию языкового материала несложный математический аппарат. Класс
лексических единиц при этом интерпретируется как n-мерное метрическое
пространство, в котором каждое из значений лексем можно задать как точку или
вектор. Для пары лексем расстояние определяется через число совпадающих или
различающихся семантических признаков в их значениях. С данной целью могут быть
использованы мера Хэмминга, мера Евклида, разнообразные коэффициенты ассоциации
и пр. Каждому из семантических признаков, описывающих значения лексических
единиц класса, может быть приписан вес, отражающий важность той или иной семы в
иерархии. Не менее эффективно представление класса лексем в виде матрицы (в
строках такой матрицы содержатся признаковые описания значений слов, в столбцах
- возможные реализации семантических признаков), в виде таблицы расстояний или
сети (в узлах сети располагаются лексемы, связывающие их дуги могут иметь метку
типа семантического расстояния, т.е. содержать указание на какое-либо из
парадигматических отношений: синонимия, антонимия, конверсия, гипонимия,
меронимия и т.д., а также количественного значения семантического расстояния).
При всем изяществе и простоте данного решения все же остается неясным:
·
какие
меры лучше приспособлены для той или иной цели: мера, учитывающая расхождения
между сравниваемыми объектами по всевозможным признакам (мера Хэмминга, мера
Евклида и пр.) или мера, пренебрегающая периферийными признакам сравниваемых
объектов и учитывающая расхождение по основному признаку, особенно если у него
много значений (мера Чебышева); мера, учитывающая расхождения между
сравниваемыми объектами по всевозможным признакам, но значение которой во
многом определяется значением доминирующего признака (мера Евклида) или мера,
значение которой в одинаковой степени определяется всеми признаками,
рассматриваемыми как равноправные (мера Хэмминга) и пр.
·
по
каким признакам необходимо сравнивать те языковые единицы, связи между которыми
подлежат измерению: выделяя денотативные признаки означаемого для знака, можно
определять близость слов на основе сравнения соответствующих им понятий;
выделяя сигнификативные признаки означаемого для знака, можно определять
близость слов на основе сравнения их внутриязыкового содержания;
·
как
формировать признаковое пространство: какими должны быть признаки - бинарными,
тернарными, n-арными, каким должно быть их количество, должно ли признаковое
пространство быть структурировано по иерархическому принципу, как определять
веса признаков, насколько точными должны быть измерения и пр.
2) Синтагматический подход предполагает
измерение семантических расстояний в тексте и между текстами. Исходный тезис
таков: обращение к корпусу позволяет использовать данные о значении слова,
хранящиеся «вне» языкового знака, и определять содержательную близость
лексических единиц, сопоставляя их синтагматические свойства. Данный подход
вполне согласуется с теорией значения как употребления, с идеей неаддитивного
сложения смыслов (речь идет о реализации в тексте отношения семантического
согласования, т.е. о дублировании в контексте той семантической информации,
которая содержится в слове). Синтагматический подход лежит в основе процедуры
латентного семантического анализа (ЛСА). ЛСА - это статистический метод
извлечения и анализа текстовой информации, не требующий предварительного
создания лексикографических описаний, семантических сетей, обращения к базам
знаний, концептуальным иерархиям и пр. В основе метода ЛСА лежит гипотеза о
том, что между отдельными словами и обобщенным контекстом (предложениями,
абзацами и целыми текстами), в которых они встречаются, существуют неявные
(латентные) взаимосвязи, обуславливающие совокупность взаимных
ограничений. ЛСА активно используется для
формирования групп близких по значению слов на основе статистического анализа
их сочетаемости с элементами контекста, однако отношение содержательной
соотнесенности понимается при этом очень широко, и сейчас еще рано говорить об
ЛСА как о точном инструменте семантического исследования.
При парадигматическом подходе необходимо
аргументированно задать метрическое пространство и сформировать множество
признаков, на основе которых будут производиться семантические измерения, также
необходимо выбрать оптимальную меру. При синтагматическом подходе необходимо
обращаться к представительному корпусу текстов, снабженному в том числе
и семантической исследовательской информацией, и
учитывать не только вероятность/частоту встречаемости сравниваемых единиц в том
или ином контексте/конструкции, но и частоту самой конструкции.
Необходимо признать продуктивность совмещения
парадигматического и синтагматического подходов и привлечь внимание
исследователей к корпусам текстов как к богатейшему источнику информации для
измерения семантических расстояний.
Исследования в области изучения семантического
расстояния среди отечественных ученых и зарубежных значительно отличаются, их
нельзя признать достаточными но по разным причинам. Отечественные работы об
измерении семантических расстояний предоставляют методологическую базу для
подобных исследований и обосновывают предлагаемые решения с точки зрения
лингвистической теории. Зарубежные работы об измерении семантических расстояний
сфокусированы на подготовке формального аппарата для осуществления исследований
и обосновывают предлагаемые подходы с точки зрения практических решений и
возможных областей применения полученных результатов.
4.4 Быстрый алгоритм отображения для простых
онтологий
- направлен на быстроту выполнения операции
промежуточных методов, уменьшая эффективность и точность отображения. Данный
алгоритм включает в себя 6 методов, выполняющихся последовательно, для
отображения онтологии (Рис.4.2)

Рисунок 4.2 - Процесс отображения
) Feature Engineering - функция
трансляции онтологий, т.е. преобразование к одному форматы, обычно приводят к
формату RDF(S), т.к. он считается стандартным при работе с онтологиями.
) Selection of Next Search Steps. - выбор
следующего шага поиска кандидатов. Выбор экспертом алгоритма поиска
семантической близости и семантического расстояния между парами концептов, в
зависимости от поставленной цели {(e, f)|e є O1, f є O2}.
) Similarity Computation - вычисление
подобия, определение сходств между сущностями, вычисляется на этапе
сопоставления онтологий.
) Similarity Aggregation - объединение
сущностей в одну систему, подтверждение отображения связей. Среди пар совпавших
сущностей выбирается та у которой мера схожести больше, порог был выбран равный
0,5.
) Interpretation - сопоставление названий
понятий, присвоение выбранному классу синтезированное имя от двух других.
) Iteration - итерация, проходит в
несколько этапов и останавливается, когда не может найти новых отображений.
Для сравнения двух сущностей из разных
онтологий, рассматриваются их характеристики. Это используется, чтоб определить
одинаковые они или нет. Изначально, предполагается, что сущности с одинаковыми
характеристиками эквивалентно. Вес и характеристику сущностей определяет
эксперт предметной области. Под характеристиками понимают:
- идентификаторы - уникальные значения
сущностей онтологий URI или имена RDF;
- простейшие элементы RDF(S): такие
как свойства или отношения подклассов;
- производные характеристики, которые
продлевают или ограничивают простейшие элементы RDF(S), т.е. не общие, а более
специфические подклассы.
 (4.4) (4.4)
- String
Similarity - подобие строк - основывается на измерении расстояния Левенштейна,
числовое значение находится на интервале [0,1]
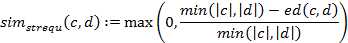 (4.5) (4.5)
- Dice
Coefficient - вероятностный коэффициент - сравнивает два набора сущностей.
 (4.6) (4.6)
- SimSet - установление
подобия - служит для определения, на сколько две сущности похожи между собой.
Каждая сущность описывается, как вектор, представляющий сходство с другими
сущностями. Чем меньше расстояние между векторами, тем больше они походи между
собой. К векторам применяется многомерное шкалирование, значение вектора - мера
схожести, полученная на предыдущем этапе. Результатом будет вычисление значения
косинуса между векторами.
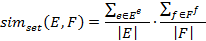 (4.7) (4.7)
- Подобие
множеств пар схожих концептов вычисляется по формуле:
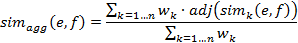 (4.8) (4.8)
где, Wk - вес для каждой меры
сходства;- функция преобразования исходных значений подобия в интервал [0,1]
Для оценки результатов работы алгоритма, были
выбраны стандартные метрики:
- точность (р), вычисляется, как
отношение количества правильных отображений к общему количеству отображений;
- память (r) (перезапись, recall),
вычисляется, как отношение количества правильных отображений к существующему
количеству отображений;
- f-мера - проверка точности и
правильности работы алгоритма. Формула сочетает в себе два предыдущих значения.
 (4.9) (4.9)
где, в - фактор, который количественно
определяет значение точности и памяти относительно друг друга, по умолчанию,
данный фактор принят равным 1.
Результаты, полученные при тестировании
алгоритма QOM. На вход подавались две онтологии описывающие предметную область:
транспортные средства. На рисунке 4.3 желтым цветам выделены классы онтологий,
зеленым - свойства классов, розовым - экземпляры, пунктирной линией связи
отображения концептов.
.5 Отображение сложных онтологий с помощью
алгоритма повышенной точности
Алгоритм AUTOMS состоит
из синтеза 5 методов, которые используются при отображении онтологий. При
последовательном выполнении представленных методов алгоритм показал наибольшую
точность выполнения. Методы интегрированы с AUTOMS выполняются в определенной
последовательности: отображения проектируются по методу эксплуатации
последующих методов, таким образом, строятся новые отображения. AUTOMS
изначально базируется на методе лексического согласования, который первый
применяется в последовательности методов.
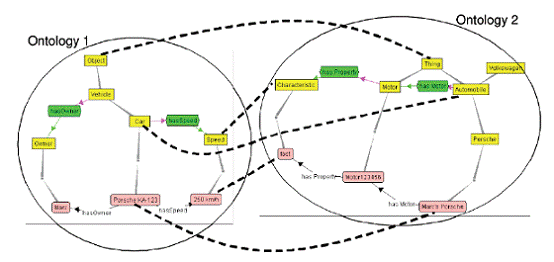
Рисунок 4.3 - Отображение связей между
концептами
Результат, который выводит программа, показан на
рисунке 4.4.

Рисунок 4.4 - Результат работы алгоритма
Алгоритм использует лексическую информацию
относительно имен, меток и комментариев к онтологическим концептам и свойствам,
для того чтоб вычислить их сходства. Хотя имена считаются наиболее высшими,
комментарии тоже рассмотрены. Алгоритм кластеризации делит данные на кластеры,
а затем в пространстве кластеров ищет, куда отнести концепт (при мощи жадного
алгоритма). Каждый кластер представляет собой модель, которая определенна в
виде дерева Хаффмана. Оно постепенно строится, используя динамический алгоритм,
который генерирует текущую строку и обновляет кластер. Алгоритм Хаффмана -
адаптивный жадный алгоритм оптимального префиксного кодирования алфавита с
минимальной избыточностью. В его основе лежит метод кодирования состоящий из
двух основных этапов: построение оптимального кодового дерева и построение
отображения код-символ на основе построенного дерева.
Чтобы решить будет ли строка добавлена в
кластер, алгоритм использует оценочную функцию, меру компактности и
однородности кластера. Оценочная функция - CCDiff - определяется, как разница
длины выбранной строки, которая является членом кластера и длинной кластера,
учитывая рассматриваемую строку (новую). Функция объединяет строки, имеющие тот
же набор символов, что и строки в кластере (например: Pentium III и P III). OWL
строка принадлежит к определенному кластеру, когда ее CCDiff имеет определенный
порог, который меньше порога CCDiff всех существующих строк в кластере.
Основываясь на экспериментах с использованием лексического метода, порог
подобия ([0;1]) был установлен 0,986. Новый кластер создается, если не один из
кандидатов (строк) не отнесен к существующим кластерам. Этот алгоритм можно
использовать, даже при отсутствии начальных кластеров.
Наравне с вычислением лексического
согласования пар, следует вычислять семантический морфизм (S - морфизм),
который является технической основой структурного метода. Морфизм -
отображения, сохраняющие групповую структуру. Бывает линейным и непрерывным.
Непрерывное отображение или непрерывная функция - это такое отображение
<#"550601.files/image033.gif">
Рисунок 4.5 - Тестовая онтология №1
Во второй класс делится на подклассы:
повседневная одежда, одежда для бизнеса, вечерняя и спортивная. Которая, в свою
очередь, подразделяется по категориям названий одежды.
Рисунок 4.6 - Тестовая онтология №2
Предлагаемый интегрированный подход к проблеме
отображения онтологий, который учитывает сложность предметной области и сравниваемых
онтологий.
Для простых онтологий характеризуемых хорошо
структурированной предметной областью, предлагается использовать алгоритм QOM,
а для слабо структурированных и сложно формализованных - интегрированный
алгоритм AUTOMS. Оба алгоритма построили онтологии, но с разной точностью.
Полученные результаты позволяют сделать вывод о том, что для достижения большей
точности отображения онтологий в слабо структурированных и сложно формализуемых
предметных областях, целесообразно использовать подход на основе
унифицированной модели, которая включает в себя декларативные описания основных
понятий характеризующих определенную предметную область. Унифицированный
«взгляд» разработчиков на решаемую проблему.
ВЫВОДЫ
В данной магистерской работе был проведен анализ
предметной области, сравнительный анализ инструментов создания и
редактирования, отображения и объединения онтологий, детальный анализ подходов
к отображению онтологий, выявлены основные методы и алгоритмы построения
отображений. Большинство из рассмотренных инструментальных средств
разрабатываются университетскими исследовательскими группами, которые
предоставляют открытый код, либо предлагают свободный доступ к функциям.
Наиболее перспективные из них передаются коммерческим компаниям (например, OntoEdit
Professional - лицензированный продукт).
В результате анализа основных подходов к
проблеме отображения онтологий, получены данные, свидетельствующие о том, что
на сегодняшний день не существует автоматических методов отображения онтологий.
Во всех известных проектах, включающих задачу отображения онтологий,
обязательно присутствует участие эксперта или группы экспертов, специалистов в
исследуемой предметной области, которые координируют связи между концептами
сравниваемых онтологий. Таким образом, все предлагаемые походы являются
полуавтоматическими.
В рамках исследуемой работы предложен
интегрированный подход к проблеме отображения онтологий, который учитывает
сложность предметной области и сравниваемых онтологий. Для простых онтологий
характеризуемых хорошо структурированной предметной областью, предлагается
использовать алгоритм QOM, а для слабо структурированных и сложно
формализованных - интегрированный алгоритм AUTOMS.
Рассмотрены основные методы в алгоритме AUTOMS,
эффективность двух подходов, была показана на 2х тестовых онтологиях.
Полученные результаты позволяют сделать вывод о том, что для достижения большей
точности отображения онтологий в слабо структурированных и сложно формализуемых
предметных областях, целесообразно использовать подход на основе
унифицированной модели, которая включает в себя декларативные описания основных
понятий характеризующих определенную предметную область. Унифицированный
«взгляд» разработчиков на решаемую проблему («сверху», «снизу», «сбоку»).
Такая декларативная модель позволила бы
разработчикам придерживаться единого взгляда на проблему и соответственно
строить онтологии предметных областей максимально похожими друг на друга.
ПЕРЕЧЕНЬ ИСПОЛЬЗОВАННЫХ
ИСТОЧНИКОВ
1.
Doan, A.H., J. Madhavan, P. Domingos, A.
Halevy: Learning to Map between Ontologies on the Semantic Web. WWW 2002
.
J. Euzenat, D. Loup, M. Touzani, P. Valtchev. Ontology Alignment with OLA.
Proc. of the 3rd EON Workshop, 3rd Intl. Semantic Web Conference, Hiroshima,
2004
.
J. Euzenat, P. Shvaiko. Ontology Matching. Springer-Verlag, New York, 2007
.
S. M. Falconer, N. F. Noy, M.-A. Storey. Towards Understanding the Needs of
Cognitive Support for Ontology Mapping. International Workshop on Ontology
Matching, Athens, 2006
.
F. Giunchiglia, P. Shvaiko, and M. Yatskevich:. Semantic Schema Matching. In
Proc. of CoopIS’05, volume 3760 of LNCS, pages 347-360, 2005
.
Guarino, N. and Welty, C. (2004), ‘‘An overview of OntoClean’’, in Staab, S.
and Studer, R. (Eds), Handbook on Ontologies, Springer, Berlin, pp. 151-72
.
I. Horrocks, U. Sattler, S. Tobies. Practical reasoning for very expressive
description logics.
Logic Journal of IGPL, 8(3), 2000
.
L. Kalinichenko, M. Missikoff, F. Schiappelli, N. Skvortsov. Ontological
Modeling. RCDL'2003. St.-Petersburg, 2003
.
J. Madhavan, P. A. Bernstein, E. Rahm. Generic Schema Matching with Cupid. In
Proc. of the 27th Conference on Very Large Databases, 2001
.
N. Noy, M. Musen. The PROMPT Suite: Interactive Tools For Ontology Merging And
Mapping. Stanford Medical Informatics, Stanford University, 2003
.
P. Shvaiko & J. Euzenat. Schema and ontology matching. Tutorial. ESWC’05,
2005
.
G. Stumme, A. Medche. FCA-Merge: Bottom-up merging of ontologies. IJCAI’01,
Seattle, WA, 2000
.
J. Tang, J. Li, B. Liang, X. Huang, Y. Li, and K. Wang. Using Bayesian Decision
for Ontology Mapping. Journal of Web Semantics, Vol(4) 4:243-262, 2006
.
S. Zghal, S. Ben Yahia, E
Mephu Nguifo, Y. Slimani. SODA: an OWL-DL based ontology matching system In
Proceedings of the first French Conference on Ontology (JFO 2007), Sousse, 2007
15.
М. Р. Когаловский, Л. А. Калиниченко. Концептуальное моделирование в
технологиях баз данных и онтологические модели. Симпозиум «Онтологическое
моделирование», Звенигород, М: ИПИ РАН, 2008
.
Кудрявцев Д. В. Практические методы отображения и интеграции онтологий. Семинар
Знания и онтологии *Elsewhere*, КИИ-2008, Дубна, 2008 104
Nikolay
Skvortsov
.
Н. А. Скворцов. Использование системы интерактивного доказательства для
отображения онтологий. RCDL'2006, Суздаль. - Ярославль: Ярославский
государственный университет им. П. Г. Демидова, 2006. - С. 65-69.
.
Н. А.
Скворцов.
Вопросы
согласования онтологических моделей и онтологических контекстов.
Симпозиум
«Онтологическое моделирование», М: ИПИ
РАН, 2008
.
Н. А. Скворцов, С. А. Ступников. Использование онтологии верхнего уровня для
отображения информационных моделей. RCDL'2008, Дубна:
ОИЯИ,
2008 - С.
122-127
.
DOLCE: a Descriptive Ontology for Linguistic and Cognitive Engineering.
http://www.loa-cnr.it/DOLCE.html
.
NeOn Glossary of Activities. Neon Project, 2007
Похожие работы на - Исследование основных подходов к автоматическому отображению онтологий
|