б) оценить тесноту связи с помощью показателей корреляции и
коэффициента детерминации;
в) оценить качество линейного уравнения с помощью средней
ошибки аппроксимации;
г) дать оценку силу связи с помощью среднего коэффициента
эластичности и бета-коэффициента;
д) оценить статистическую надёжность результатов
регрессионного моделирования с помощью F-критерия Фишера;
. Проверить результаты, полученные в п.2 с помощью ППП
Excel. Рассчитать параметры
показательной парной регрессии. Проверить результаты с помощью ППП Excel. Оценить статистическую
надёжность указанной модели с помощью F-критерия Фишера.
. Обоснованно выбрать лучшую модель и рассчитать по
ней прогнозное значение результата, если прогнозное значение фактора
увеличиться на 5 % от среднего уровня. Определить доверительный интервал
прогноза при уровне значимости γ=0,05.
1. Построим поле корреляции,
для чего отложим на плоскости в прямоугольной системе координат точки (xi,yi) (рис.1)
2. Для расчёта параметров
линейной регрессии строим расчётную таблицу (табл.2.)
|
№
|
x
|
y
|
yx
|
x2
|
y2
|
y
|
y -
y
|
100
|Ai|
|
(y -
y)2
|
(x -
x)2
|
(y -
y)2
|
(y - y)2
|
|
1
|
97
|
213
|
20661
|
9409
|
45369
|
206,067
|
6,933077
|
3,255
|
48,068
|
87,111
|
214,630
|
465,840
|
|
2
|
79
|
175
|
13825
|
6241
|
30625
|
177,813
|
-2,81286
|
1,607
|
7,912
|
75,111
|
185,064
|
269,507
|
|
3
|
86
|
200
|
17200
|
7396
|
40000
|
188,801
|
11,19945
|
5,600
|
125,428
|
2,778
|
6,844
|
73,674
|
|
4
|
77
|
168
|
12936
|
5929
|
28224
|
174,674
|
-6,67352
|
3,972
|
44,536
|
113,778
|
280,333
|
548,340
|
|
5
|
104
|
204
|
21216
|
10816
|
41616
|
217,055
|
-13,0546
|
6,399
|
170,423
|
266,778
|
657,304
|
158,340
|
|
6
|
69
|
150
|
10350
|
4761
|
22500
|
162,116
|
-12,1162
|
8,077
|
146,801
|
348,444
|
858,520
|
1715,340
|
|
7
|
100
|
190
|
19000
|
10000
|
36100
|
210,776
|
-20,7759
|
10,935
|
431,639
|
152,111
|
374,781
|
2,007
|
|
8
|
93
|
205
|
19065
|
8649
|
42025
|
199,788
|
5,211758
|
2,542
|
27,162
|
28,444
|
70,083
|
184,507
|
|
9
|
81
|
186
|
15066
|
6561
|
34596
|
180,952
|
5,047802
|
2,714
|
25,480
|
44,444
|
109,505
|
29,340
|
|
10
|
102
|
231
|
23562
|
10404
|
53361
|
213,915
|
17,08473
|
7,396
|
291,888
|
205,444
|
506,187
|
1566,840
|
|
11
|
74
|
180
|
13320
|
5476
|
32400
|
169,965
|
10,035
|
5,575
|
100,711
|
186,778
|
460,195
|
130,340
|
|
12
|
90
|
195
|
17550
|
8100
|
38025
|
195,079
|
-0,07923
|
0,041
|
0,006
|
5,444
|
13,414
|
12,840
|
|
Итого
|
1052
|
2297
|
203751
|
93742
|
444841
|
2297
|
0,000
|
58,114
|
1420,055
|
1516,6667
|
3736,862
|
5156,917
|
|
Среднее
значение
|
87,667
|
191,417
|
16979,250
|
7811,833
|
37070,083
|
191,417
|
0,000
|
4,843
|
118,338
|
126,389
|
311,405
|
429,743
|
|
σ
|
11,242
|
20,730
|
|
|
|
|
|
|
|
|
|
|
|
σ2
|
126,389
|
429,743
|
|
|
|
|
|
|
|
|
|
|
а. Построим линейное уравнение парной регрессии y по x. Используя данные
таблицы 2, имеем
β =  =
=
α = y - β * x = 191,417-1,570*87,667=53,809
Тогда линейное уравнение парной регрессии имеет вид:
y = 53,809+1,570 * x.
Оно показывает, что с увеличением среднедушевого прожиточного
минимума на 1 руб. среднедневная зарплата возрастает в среднем на 1,570 руб.
2б. Учитывая:
σx = 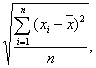 σy =
σy = 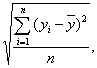
оценим тесноту линейной связи с помощью линейного коэффициента
парной корреляции:
rxy = β * 
Найдём коэффициент детерминации:
R2 = r2xy = 0,7246
Это означает, что 72% вариации заработной платы y объясняется вариацией фактора х - среднедушевого
прожиточного минимума.
в. Для оценки качества полученной модели найдём среднюю ошибку
аппроксимации:

В среднем, расчётные значения отклоняются от фактических на
4,8428%. Качество построенной модели оценивается как хорошее, т.к. значение 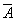 - менее 8%.
- менее 8%.
г. Для оценки силы связи признаков y и х найдём средний коэффициент эластичности:
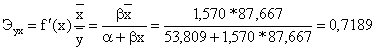
Таким образом, в среднем на 0,72% по совокупности изменится
среднедневная зарплата от своей средней величины при изменении среднедушевого
прожиточного минимума в день одного трудоспособного на 1%. Бета-коэффициент:
β yx = β *
показывает, что среднее квадратическое отклонение
среднедневной зарплаты изменится в среднем на 85% от своего значения при
изменении прожиточного минимума в день одного трудоспособного на величину его
квадратического отклонения.
д. Для оценки статистической надёжности результатов
используем F
- критерий Фишера.
Выдвигаем нулевую гипотезу Но о статистической
незначимости полученного линейного уравнения.
Рассчитаем фактическое значение F - критерия при заданном
уровне значимости γ = 0,05
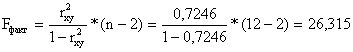
Сравнивая табличное Fтабл = 4,96 и фактическое Fфакт = 26,315 значения, отмечаем, что Fтабл < Fфакт ,
что указывает на необходимость отвергнуть выдвинутую гипотезу Но.
2е. Оценку статистической значимости параметров регрессии
проведём с помощью t- статистики Стьюдента и путём расчёта
доверительного интервала для каждого из показателей.
Выдвигаем гипотезу Но о статистически незначимом
отличии показателей регрессии от нуля: α = β = rxy = 0.
Табличное значение t- статистики tтабл для степеней свободы
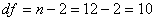
при заданном уровне значимости γ = 0,10 составляет 1,8.
Определим величину случайных ошибок:
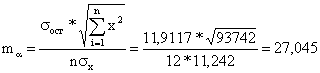
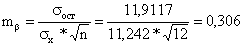
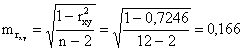
Найдём соответствующие фактические значения t-критерия Стьюдента:
 ,
, 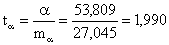
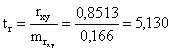
Фактические значения t -
статистики превосходят табличное значение tтабл = 1,8
tβ = 5,130 > tтабл , tα = 1,990 > tтабл , tr = 5,130 > tтабл
поэтому гипотеза Но о статистически незначимом отличии
показателей регрессии от нуля отклоняется, т.е. параметры α, β, rxy не случайно отличаются от нуля, а
статистически значимы.
Для расчёта доверительных интервалов для
параметров α и β определим их предельные
ошибки
 ,
,
 .
.
Доверительные интервалы
для параметры a:
(5,128; 102,490)
для параметры β: (1,019; 2,120)
С вероятностью
r = 1 - γ = 1 - 0,05 = 0,95
можно утверждать, что параметр β, находясь в указанных
границах, не принимают нулевых значений, т.е. не являются статистически
незначимыми и существенно отличны от нуля.
3. Проверим результаты, поученные в пункте 2 с помощью ППП Excel.
Параметры парной регрессии вида y=a+bx определяет встроенная
статистическая функция ЛИНЕЙН. Результат вычисления функции ЛИНЕЙН представлен
на рисунке 2:
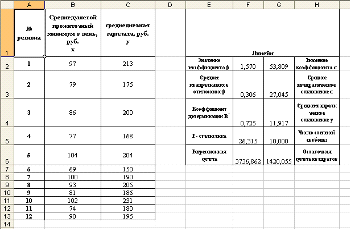
Рис. 2. Результат вычисления функции ЛИНЕЙН
С помощью инструмента анализа данных Регрессия, помимо
результатов регрессионной статистики, дисперсионного анализа и доверительных
интервалов можно получить остатки и графики подбора линии регрессии, остатков и
номинальной вероятности.
Результаты регрессионного анализа для данных задачи
представлены на рисунке 3.
регресионный корреляция детерминация
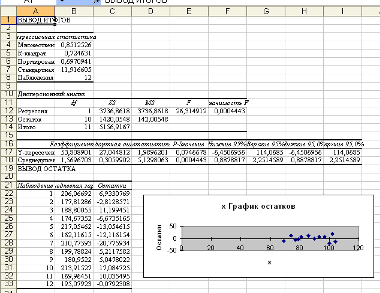
Рис. 3. Результаты применения инструмента Регрессия
Сравнивая полученные вручную и с помощью ППП Excel данные, убеждаемся в
правильности выполненных действий.
. Построению показательной модели
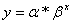 (1)
(1)
предшествует процедура линеаризации переменных.
Прологарифмируем обе части уравнения (1), получим:
ln y = ln α + x * ln β (2)
ведём обозначения
Y = ln y, C = ln α , B = ln β
Тогда уравнение (2) запишется в виде:
Y = C + B * x. (3)
Параметры полученной линейной модели (3) рассчитываем
аналогично тому, как это было сделано ранее. Используем данные расчётной
таблицы 3.
Таблица 3
|
№
|
x
|
Y
|
Yx
|
x2
|
Y2
|
Y
|
Y -Y
|
100
|Ai|
|
(Y -
Y)2
|
(x -
x)
|
(Y -
Y)2
|
(Y -
Y)2
|
|
1
|
97
|
5,361
|
520,045
|
9409
|
28,743
|
5,327
|
0,644
|
0,001
|
87,111
|
0,006
|
0,013
|
|
2
|
79
|
5,165
|
408,018
|
6241
|
26,675
|
5,176
|
-0,011
|
0,212
|
0,000
|
75,111
|
0,005
|
0,007
|
|
3
|
86
|
5,298
|
455,655
|
7396
|
28,072
|
5,234
|
0,064
|
1,205
|
0,004
|
2,778
|
0,000
|
0,002
|
|
4
|
77
|
5,124
|
394,545
|
5929
|
26,255
|
5,159
|
-0,035
|
0,682
|
0,001
|
113,778
|
0,008
|
0,015
|
|
5
|
104
|
5,318
|
553,084
|
10816
|
28,282
|
5,386
|
-0,067
|
1,267
|
0,005
|
266,778
|
0,019
|
0,005
|
|
6
|
69
|
5,011
|
345,734
|
4761
|
25,106
|
5,092
|
-0,081
|
1,620
|
0,007
|
348,444
|
0,025
|
0,057
|
|
7
|
100
|
5,247
|
524,702
|
10000
|
27,531
|
5,352
|
-0,105
|
1,999
|
0,011
|
152,111
|
0,011
|
0,000
|
|
8
|
93
|
5,323
|
495,040
|
8649
|
28,334
|
5,293
|
0,030
|
0,560
|
0,001
|
28,444
|
0,002
|
0,006
|
|
9
|
81
|
5,226
|
423,285
|
6561
|
27,308
|
5,192
|
0,033
|
0,636
|
0,001
|
44,444
|
0,003
|
0,001
|
|
10
|
102
|
5,442
|
555,127
|
10404
|
29,620
|
5,369
|
0,074
|
1,354
|
0,005
|
205,444
|
0,014
|
0,038
|
|
11
|
74
|
5,193
|
384,279
|
5476
|
26,967
|
5,134
|
0,059
|
1,140
|
0,004
|
186,778
|
0,013
|
0,003
|
|
12
|
90
|
5,273
|
474,570
|
8100
|
27,805
|
5,268
|
0,005
|
0,094
|
0,000
|
5,444
|
0,000
|
0,001
|
|
Итого
|
1052
|
62,981
|
5534,0855
|
93742
|
330,700
|
62,981
|
0,000
|
11,415
|
0,040
|
1516,667
|
0,107
|
0,147
|
|
Среднее
значение
|
87,667
|
5,248
|
461,174
|
7811,833
|
27,558
|
5,248
|
0,000
|
0,951
|
|
|
|
|
|
σ
|
11,242
|
0,110
|
|
|
|
|
|
|
|
|
|
|
|
σ2
|
126,389
|
0,012
|
|
|
|
|
|
|
|
|
|
|
Построим линейное уравнение парной регрессии Y по X. Используя данные
таблицы 3, имеем:
 ,
,
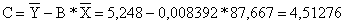 .
.
Получим линейное уравнение регрессии:
Y = 4,51276+0,008392* х (4)
Тесноту полученной линейной модели характеризует линейный
коэффициент парной корреляции:
rxY = β * 
Коэффициент детерминации при этом равен:
R2 = r2xy = 0,853822 =
0,7290
Это означает, что 73% вариации фактора Y объясняется вариацией
фактора х. Средняя ошибка линейной аппроксимации составляет:

Проведя потенцирование уравнения (4), получим искомую нелинейную
(показательную) модель
y =91,1733*1,00843x (5)
Результаты вычисления параметров показательной кривой (1)
можно проверить с помощью ППП Excel, для чего используем встроенную статистическую
функцию ЛГРФПРИБЛ. Порядок вычисления аналогичен применению функции ЛИНЕЙН.
Результат вычисления функции ЛГРФПРИБ представлен на рисунке
4:
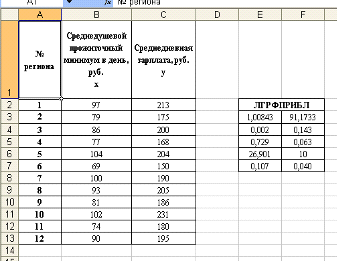
Рис. 4. Результат вычисления функции ЛГРФПРИБЛ
Для расчёта индекса корреляции ρxy нелинейной регрессии
воспользуемся вспомогательной таблицей 4.
Таблица 4
|
№
|
x
|
y
|
y
|
(y -
y)2
|
(x -
x)2
|
(y - y)2
|
|
1
|
97
|
213
|
206,067
|
48,068
|
87,111
|
465,840
|
|
2
|
79
|
175
|
177,813
|
7,912
|
75,111
|
269,507
|
|
3
|
86
|
200
|
188,801
|
125,428
|
2,778
|
73,674
|
|
4
|
77
|
168
|
174,674
|
44,536
|
113,778
|
548,340
|
|
5
|
104
|
204
|
217,055
|
170,423
|
266,778
|
158,340
|
|
6
|
69
|
150
|
162,116
|
146,801
|
348,444
|
1715,340
|
|
7
|
100
|
190
|
210,776
|
431,639
|
152,111
|
2,007
|
|
8
|
93
|
205
|
199,788
|
27,162
|
28,444
|
184,507
|
|
9
|
81
|
186
|
180,952
|
25,480
|
44,444
|
29,340
|
|
10
|
102
|
231
|
213,915
|
291,888
|
205,444
|
1566,840
|
|
11
|
74
|
180
|
169,965
|
100,711
|
186,778
|
130,340
|
|
12
|
90
|
195
|
195,079
|
0,006
|
5,444
|
12,840
|
|
Итого
|
1052
|
2297
|
2297
|
1420,055
|
1516,6667
|
5156,917
|
|
Среднее
значение
|
87,667
|
191,417
|
191,417
|
118,338
|
126,389
|
429,743
|
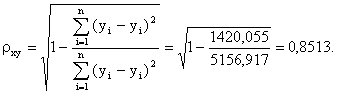
Найдём коэффициент детерминации
R2 = ρxy = 0,85132= 0,7246
Это означает, что 72% вариации заработной платы y объясняется вариацией фактора x - среднедушевого прожиточного минимума.
Рассчитываем фактическое значение F-критерия при заданном уровне значимости γ = 0,05:
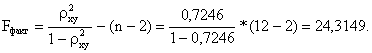
Сравнивая табличное Fтабл = 4,96 и фактическое Fфакт = 24,3149 значения, отмечаем, что
Fтабл < Fфакт ,
что указывает на необходимость отвергнуть выдвинутую гипотезу Но
о статистически незначимых параметрах уравнения (5).
. Так как коэффициенты детерминации, соответствующие линейной и
показательной моделям практически равны (около 72% вариации заработной платы y объясняется вариацией фактора x - среднедушевого прожиточного минимума в обеих моделях), то нет
весомых оснований отдать предпочтение какой-либо модели. Тем не менее,
прогнозное значение результата рассчитаем по показательной модели (R2лин
= 0,7246 = R2показ
= 0,7246).
По условию задачи прогнозное значение фактора выше его среднего
уровня х = 87,677 на 5%, тогда оно составит:
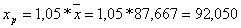
и прогнозное значение зарплаты при этом составит:
ŷ р = 91,1733*1,00843x=91,1733*1,0084392,05=197,3982
Найдём ошибку прогноза:
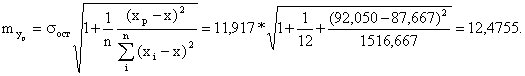
и доверительный интервал прогноза при уровне значимости γ = 0,05.
Предельная ошибка прогноза, которая в 95% случаев не будет
превышена, составит:
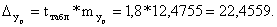
Доверительный интервал прогноза
(174,9423; 219,8541)
Задача: “ Анализ и
прогнозирования временных рядов ”
В таблице каждого варианта заданы
временные ряды:
Таблица 5
|
Y
|
X1
|
X2
|
X3
|
X4
|
X5
|
|
128
|
1
|
5,1
|
15
|
8,1
|
67
|
|
136
|
2
|
4,5
|
14,8
|
8,6
|
71
|
|
140
|
3
|
4,6
|
15,2
|
9
|
73
|
|
155
|
4
|
7
|
9,4
|
65
|
|
163
|
5
|
4,5
|
15,5
|
9,1
|
79
|
|
168
|
6
|
3,9
|
16
|
9,6
|
81
|
|
172
|
7
|
5,1
|
18,1
|
9,9
|
90
|
|
176
|
8
|
3,6
|
13
|
10
|
92
|
|
178
|
9
|
3,8
|
15,8
|
10,5
|
126
|
|
182
|
10
|
3,8
|
16,9
|
10,8
|
102
|
|
184
|
11
|
5
|
16,3
|
9,9
|
94
|
|
183
|
12
|
5,5
|
16,1
|
11
|
96
|
|
219
|
13
|
3
|
15,4
|
9,6
|
91
|
|
220
|
14
|
4
|
15,7
|
11
|
101
|
|
206
|
15
|
4,5
|
16
|
9,6
|
103
|
|
211
|
16
|
10,3
|
15,1
|
10,2
|
104
|
|
230
|
17
|
12,7
|
15,5
|
10
|
88
|
|
241
|
18
|
13,8
|
15,8
|
8,2
|
101
|
|
254
|
19
|
15
|
16
|
8,6
|
105
|
|
258
|
20
|
15
|
15,5
|
8
|
108
|
-объем реализации продукции фирмы.
Следующие рядыХ1 - время,
Х2- расходы на рекламу,
Х3- цена товара,
Х4 - средняя цена конкурентов,
Х5 - индекс потребительских
расходов являются рядами независимых переменных.
Требуется:
1.Вычислить матрицу коэффициентов парной корреляции
и про
анализировать тесноту связи между показателями.
2.Выбрать вид линейной модели регрессии, включив в
нее два
фактора. Обосновать исключение из модели трех других факторов.
3.Аналитическими методами
а) оценить параметры и качество
модели,
б) вычислить среднюю ошибку аппроксимации,
в) вычислить множественный
коэффициент детерминации.
4.С целью проверки полученных результатов провести
регрессионный анализ выбранной модели с помощью Excel.
5.Проанализировать влияние факторов на зависимую
переменную (вычислить соответствующие коэффициенты эластичности и
6.Р-
коэффициенты, пояснить смысл полученных результатов).
7.Выбрать с помощью Excel наилучший вид тренда
временных
рядов, соответствующих оставленным в модели переменным. По полученным
зависимостям вычислить их прогнозные значения на два
шага вперед.
8.Определить точечные и интервальные прогнозные
оценки объема реализации продукции фирмы Y на два шага вперед.
Решение:
В данном примере число наблюдений n=20, факторных признаков m=5.
1. Корреляционный анализ
Найдём матрицу коэффициентов парной корреляции с помощью Excel: Сервис 4
Анализ данных На новом рабочем листе получаем результаты вычислений - таблицу
значений коэффициентов парной корреляции (рис.5).
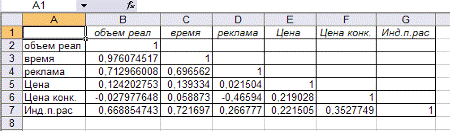
Рисунок .5. Результаты корреляционного анализа
. Выбор вида модели
- Анализ матрицы коэффициентов парной корреляции
показывает, что зависимая переменная, т.е. объём реализации, имеет тесную
связь:
с индексом
с индексом потребительских расходов ryX5=0,6688,
- с расходами на рекламу ryX2=0,712,
- со временем ryX1=0,976
Однако X1 и X5 тесно связаны между собой rX1X5=0,721,
что свидетельствует о наличии коллинеарности. Из этих двух
переменных оставим в модели X5 - индекс потребительских расходов. Переменные Х1
(время), Х3 (цена товара), Х4(цена конкурента) также исключаем из модели, т.к.
связь их с результативным признаком Y (объёмом реализации) невысокая.
После исключения незначимых факторов имеем n = 20, k = 2.
Модель приобретает вид:

3. Оценка параметров и качества модели
На основе метода наименьших квадратов проведём оценку
параметров регрессии по формуле
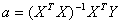 . (1)
. (1)
При этом используем данные, приведённые в таблице 6
Таблица 6
|
Y
|
Х0
|
X2
|
X5
|
|
объем реал
|
|
реклама
|
Инд.п.рас
|
|
128
|
1
|
5,1
|
67
|
|
136
|
1
|
4,5
|
71
|
|
140
|
1
|
4,6
|
73
|
|
155
|
1
|
7
|
65
|
|
163
|
1
|
4,5
|
79
|
|
168
|
1
|
3,9
|
81
|
|
172
|
1
|
5,1
|
90
|
|
176
|
1
|
3,6
|
92
|
|
178
|
1
|
3,8
|
126
|
|
182
|
1
|
3,8
|
102
|
|
184
|
1
|
5
|
94
|
|
183
|
1
|
5,5
|
96
|
|
219
|
1
|
3
|
91
|
|
220
|
1
|
4
|
101
|
|
206
|
1
|
4,5
|
103
|
|
211
|
1
|
10,3
|
104
|
|
230
|
1
|
12,7
|
88
|
|
241
|
1
|
13,8
|
101
|
|
254
|
1
|
15
|
105
|
|
258
|
1
|
15
|
108
|
Непосредственное вычисление вектора оценок параметров
регрессии а согласно формуле (1) весьма громоздко.
Задача существенно упрощается при использовании средств Excel. Операции, предписанные
формулой (1) целесообразно проводить с помощью следующих встроенных в Excel функций
¨ МУМНОЖ - умножение матриц;
¨ ТРАНСП - транспортирование матриц;
¨ МОБР - вычисление обратной матрицы.
После вычислений имеем:
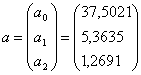
Уравнение регрессии зависимости объёма реализации от затрат на
рекламу и индекса потребительских расходов можно записать в виде
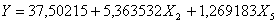
Рис. 6. Результат вычислений - вектор оценок параметров регрессии
а
Расчётные значения Y определяются
путём последовательной подстановки в эту модель значений факторов, взятых для
каждого момента времени t.
1. Регрессионный анализ
При проведения регрессионного анализа с помощью Excel получили
(рис.7)
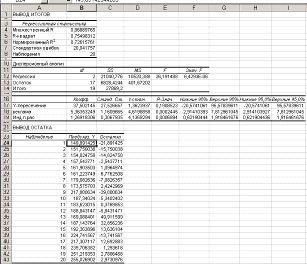
Рис.7. Результаты регрессионного анализа, проведённого с
помощью Excel
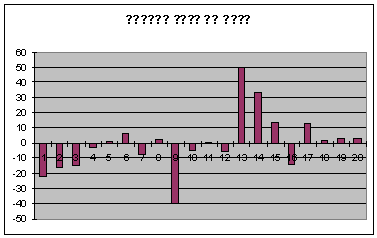
Рис. 8. График остатков
. Оценка качества модели
В таблице «Вывод остатка» (рис.7) приведены вычисленные по
модели значения Y и значения остаточной компоненты е.
Исследование на наличие автокорреляции остатков проведём с
помощью d
- критерия Дарбина - Уотсона. Для определения величины d - критерия воспользуемся
расчётной таблицей 7.
Таблица 7
|
Набл.
|
Y
|
Предск.Y
|
ε( t )
|
ε2( t )
|
(ε( t )-ε( t-1 ))2
|
ε( t )*ε( t-1 )
|
( Y -Ycр )2
|
|
1
|
128
|
149,891
|
-21,891
|
479,235
|
|
|
3868,840
|
|
2
|
136
|
151,750
|
-15,750
|
248,064
|
37,717
|
344,791
|
2937,640
|
|
3
|
140
|
154,825
|
-14,825
|
219,773
|
0,856
|
233,490
|
2520,040
|
|
4
|
155
|
157,544
|
-2,544
|
6,471
|
150,823
|
37,711
|
1239,040
|
|
5
|
163
|
161,904
|
1,096
|
1,202
|
13,252
|
-2,789
|
739,840
|
|
6
|
168
|
161,224
|
6,776
|
45,918
|
32,260
|
7,430
|
492,840
|
|
7
|
172
|
179,083
|
-7,083
|
50,164
|
192,069
|
-47,994
|
331,240
|
|
8
|
176
|
173,576
|
2,424
|
5,877
|
90,382
|
-17,170
|
201,640
|
|
9
|
178
|
217,801
|
-39,801
|
1584,090
|
1782,945
|
-96,489
|
148,840
|
|
10
|
182
|
187,340
|
-5,340
|
28,518
|
1187,519
|
212,545
|
67,240
|
|
11
|
184
|
183,623
|
0,377
|
0,142
|
32,687
|
-2,013
|
38,440
|
|
12
|
183
|
188,843
|
-5,843
|
34,142
|
-2,203
|
51,840
|
|
13
|
219
|
169,088
|
49,912
|
2491,168
|
3108,592
|
-291,641
|
829,440
|
|
14
|
220
|
187,144
|
32,856
|
1079,532
|
290,885
|
1639,907
|
888,040
|
|
15
|
206
|
192,364
|
13,636
|
185,943
|
369,413
|
448,031
|
249,640
|
|
16
|
211
|
224,742
|
-13,742
|
188,831
|
749,537
|
-187,381
|
432,640
|
|
17
|
230
|
217,307
|
12,693
|
161,109
|
698,780
|
-174,420
|
1584,040
|
|
18
|
241
|
239,706
|
1,294
|
1,673
|
129,943
|
16,420
|
2580,640
|
|
19
|
254
|
251,219
|
2,781
|
7,732
|
2,211
|
3,597
|
4070,440
|
|
20
|
258
|
255,027
|
2,973
|
8,839
|
0,037
|
8,267
|
4596,840
|
|
Сумма
|
3804,000
|
3804,000
|
0,000
|
6349,190
|
8908,597
|
2130,089
|
24000,360
|
Имеем
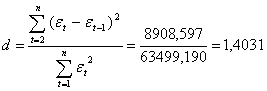 .
.
В качестве критических табличных уровней при n=20, двух объясняющих факторах при уровне значимости γ = 0,05 возьмём величины dL= 1,10 и dU= 1,54 (из приложения). Расчётное значение
d = 1,4031 попало в интервал от dL= 1,10 до dU= 1,54.
|
Есть положитель-ная автокорреляция
остатков. Н0 отклоняется. С вероятностью (γ-1) принимается Н1.
|
Зона
неопределённости
|
Нет оснований
отклонять Н0 (автокорреляция остатков отсутствует)
|
Зона
неопределённости
|
Есть отрицательная
автокорреляция остатков. Н0 отклоняется. С вероятностью (γ-1) принимается Н1*.
|
|
0
|
dL
d dU
|
2
|
4 - dL
|
4
|
Рис. 9. Сравнение расчётного значения d - критерия Дарбина -
Уотсона с критическими значениями dL и dU
Так как расчётное значение d - критерия Дарбина -
Уотсона попало в зону неопределенности, то нельзя сделать окончательный вывод
об автокорреляции остатков по этому критерию.
Для определения степени автокорреляции вычислим коэффициент
автокорреляции и проверим его значимость при помощи критерия стандартной
ошибки. Стандартная ошибка коэффициента корреляции рассчитывается по формуле:
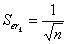
Коэффициенты автокорреляции случайных данных должны обладать
выборочным распределением, приближающимся к нормальному с нулевым
математическим ожиданием и средним квадратическим отклонением, равным

Если коэффициент автокорреляции первого порядка r1 находится в интервале
,96 * 0,224< r1 < 1,96 * 0,224
то можно считать, что данные не показывают наличие автокорреляции
первого порядка.
Используя расчетную таблицу 7, получаем:

Так как
0,439 < r1 = 0,3355 < 0,439,
то свойство независимости остатков выполняется.
Вычислим для построенной модели множественный коэффициент
детерминации
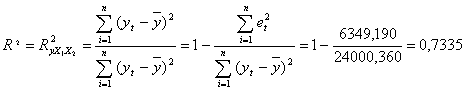
Множественный коэффициент детерминации показывает долю вариации
результативного признака под воздействием включенных в модель факторов Х2
и Х5. Т.о., около 73 % вариации зависимой переменной (объема реализации)
в построенной модели обусловлено влиянием включенных факторов Х2
(реклама) и Х5 (индекс потребительских расходов).
Проверку значимости уравнения регрессии проведем на основе F-критерия Фишера
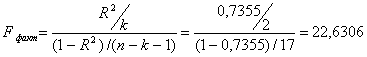
Табличное значение F-критерия при
доверительной вероятности 0,95, степенями свободы
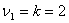
 и
и
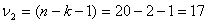
составляет Fтабл= 3,5915.
Поскольку Fфакт= 22,6306 > Fтабл= 3,5915,
то уравнение регрессии следует признать адекватным.
Значимость коэффициентов уравнения регрессии а1 и
а2 оценим с использованием F-критерия Стьюдента:
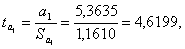

Табличное значение, t-критерия
Стьюдента при уровне значимости 0,05 и степенях свободы (20 - 2 - 1) = 17
составляет tта6л = 2,1.
Так как
ta1 4,6199 > tта6л = 2,1,
ta2 4,1369 > tта6л = 2,1
то отвергаем гипотезу о незначимости коэффициентов уравнения
регрессии а1 и а2.
. Влияние факторов на зависимую переменную
Проанализируем влияние включенных в модель факторов на зависимую
переменную по модели. Учитывая, что коэффициенты регрессии невозможно использовать
для непосредственной оценки влияния факторов на зависимую переменную из-за
различия единиц измерения, вычислим соответствующие коэффициенты эластичности, β - коэффициенты:
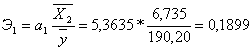 ,
,
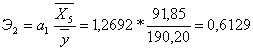 ,
,
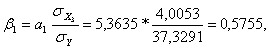

Таким образом, при увеличении расходов на рекламу на 1 % величина объема
реализации изменится приблизительно на 0,2 %, при увеличении потребительских
расходов на 1 % величина объема реализации изменится на 0,61 %.
Кроме того, при увеличении затрат на рекламу на 4,0053 ед. объем
реализации увеличится на 22 тыс. руб. (0,5755*37,3291 ≈ 22), при
увеличении потребительских расходов на 15,1568 ед. объем реализации увеличится
на 19 ед. (0,5153*37,3291 ≈ 19).
. Точечное и интервальное прогнозирование
Найдем точечные и интервальные прогнозные оценки объема реализации
на два квартала вперед.
Для построения прогноза результативного признака Y и оценок прогноза необходимо определить прогнозные
значения, включенных в модель факторов Х2 и Х5. Построим
линию тренда для временного ряда «Индекс потребительских расходов» (рис. 10).
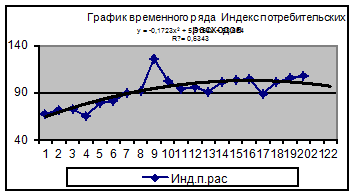
Рис.10. Результат построения тренда и прогнозирования по тренду
для временного ряда «Индекс потребительских расходов»
В качестве аппроксимирующей функции выбран полином второй
степени - парабола:
Х5 = 58,664+5,5154t - 0,1723t2
по которой построен прогноз на два шага вперед, причем
прогнозные значения на 21-ый и 22-ой периоды соответственно составляют:
Х5(21) = 58,664 + 5,5154*21 - 0,1723*212
=98,5031,
Х5(22) = 58,664 + 5,5154*22 - 0,1723*222
=96,6096.
Построим линию тренда для временного ряда «Затраты на
рекламу» (рис. 11).
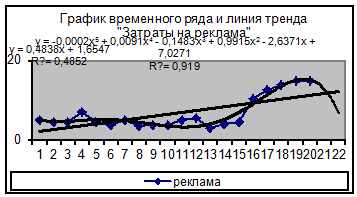
Рис.11. Результат построения тренда и прогнозирования по тренду
для временного ряда «Затраты на рекламу»
Для фактора Х2 «реклама» выбираем полиномиальную модель
пятой степени (этой модели соответствует наибольшее значение коэффициента
детерминации):
Х2 = -0,0002*t5+0,0091*t4-0,148*t3+0,991*t2-2,6371*t+7,0271.
Полиномы высоких порядков редко используются при прогнозировании
экономических показателей. В этом случае при вычислении прогнозных оценок
коэффициентов модели необходимо учитывать большое число знаков после запятой.
Прогнозные значения на 21-ый и 22-ой периоды соответственно
составляют:
Х2(21= -0,0002*215+0,0091*214-0,148*213+0,991*212-2,6371*21+7,0271=-28,9921,
Х2(22)= = -0,0002*225+0,0091*224-0,148*223+0,991*222-2,6371*22+7,0271=-46,2459
Для получения прогнозных оценок переменной Y по модели
подставим в неё найденные прогнозные значения факторов X2 и
X5, получим
Ŷ(21) 
Ŷ(22) 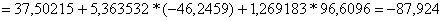
Доверительный интервал прогноза имеет границы:
верхняя граница прогноза: Ŷ(n+1)+U(l),
нижняя граница прогноза: Ŷ(n+1)-U(l),
где 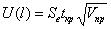 ,
, 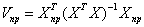 .
.
Имеем
 ,
,
tкр=2,11
(по таблице при γ=0,05 и
числе степеней свободы 17),
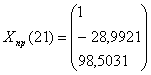 ,
, 
Тогда с использованием Excel,
имеем
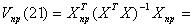 4,4560
4,4560
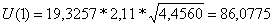
и


Результаты прогнозных оценок модели регрессии представим в
таблице прогнозов (табл.8)
|
Упреждение
|
Прогноз
|
Нижняя граница
|
Верхняя граница
|
|
1
|
7,0205
|
93,0979
|
-79,0569
|
|
2
|
-87,924
|
38,3778
|
-214,2258
|
Список литературы
1. Гордон
В.А., Шмаркова Л.И. Методические указания по выполнению контрольной № 1 по
дисциплине «Эконометрика» Орёл, 2003
2. Гордон
В.А., Шмаркова Л.И. Методические указания по выполнению контрольной № 2 по
дисциплине «Эконометрика» Орёл, 2003