Исследование эхокомпенсатора и улучшение его характеристик в режиме одновременного разговора абонентов
Введение
В настоящее время все более и более значимыми становятся электронные
средства коммуникации. Телевидение, телефония и глобальные телекоммуникационные
сети сделали грандиозный шаг вперед, превратившись из несовершенных
любительских разработок в вещи, без которых не мыслит себя, наверное, любой
цивилизованный человек. Из-за небывалого развития телекоммуникационных
устройств, более ранние разработки порой «не успевают» за прогрессом. Поэтому
приходится искать методы, чтобы обеспечить нормальную работу и совместимость
между новейшими технологиями и технологиями, которые считались вершиной
развития десятилетия назад. Так, например аналоговая телефония постепенно
вытесняется цифровой . Но, несмотря на свои недостатки, она все же процветает,
и будет существовать еще через многие годы. Проблема эхо-сигнала в телефонных
линиях - лишь одна из многочисленных проблем, существующих на сегодняшний день
в телефонии. Связана она с особенностями физической организации телефонных
линий, изменять которую экономически нецелесообразно. Поэтому разрабатываются
специальные методы и устройства, которые позволяют подавлять эхо-сигналы.
Наибольшим успехом в вопросах эхокомпенсации пользуются адаптивные методы [1,
5].
Применение адаптивных фильтров в системах связи оказалось весьма
плодотворным. Этому способствовало несколько причин:
·
прогресс
полупроводниковой технологии, особенно в области сверхбольших интегральных
схем, дал возможность создания адаптивных фильтров при приемлемых коммерческих
затратах;
·
рост систем
передачи данных создал необходимость в применении адаптивной фильтрации для
преодоления искажений передачи, присущих существующим телефонным сетям;
·
улучшение систем
передачи речи для тех случаев, когда отраженные сигналы вызывают существенное
искажение передачи звука или нестабильность [1].
В последнем случае говорят об эхо-сигналах, возникающих из-за того, что
передаваемые сигналы вследствие взаимосвязей попадают в обратный канал и
возвращаются вновь к своему источнику. Наиболее общей причиной возникновения обратных
связей является несогласованность полных сопротивлений дифференциальных систем
на стыке двухпроводных систем с четырехпроводными. Полное согласование
сопротивлений практически невозможно, поскольку коммутируемая сеть содержит
множество различных абонентских и соединительных линий, каждая из которых имеет
свое сопротивление [2].
Степень раздражающего воздействия эха, испытываемого говорящим, зависит
как от величины обратного сигнала, так и от его задержки. При установлении
соединений на короткие расстояния задержка мала, и эхо проявляется как
естественное слияние сигналов в ухе говорящего. Однако при возрастании задержки
необходимо принимать меры к подавлению эха с тем, чтобы минимизировать
раздражающий эффект.
Одним из возможных способов подавления эхо-сигналов является применение
эхокомпенсатора устанавливаемого в четырехпроводной части цепи [3, 4]. Его
основное назначение - сформировать искусственную копию эха и вычесть ее из
просочившегося эхо-сигнала, который возвращается через дифференциальную систему
к дальнему абоненту [1, 2, 5, 6].
Среди основных требований, предъявляемых к эхокомпенсаторам
рекомендациями МСЭ [3], выделим следующие:
·
слабое ухудшение
подавления эхо-сигнала, при одновременном разговоре абонентов;
·
уверенное
детектирование двойного разговора.
Выделение этих требований не случайно, т. к. поведение общепринятых
адаптивных алгоритмов в условиях одновременного присутствия сигналов от двух
абонентов может существенно отличаться от поведения в условиях присутствия
сигнала только от одного абонента. Кроме того, в состав эхокомпенсатора входит
не только адаптивный фильтр, но также и детектор двойного разговора (ДДР), в
его работе возможны ошибки [7, 8], которые влияют на процесс адаптации и могут
привести к неправильной работе алгоритма перестройки коэффициентов адаптивного
фильтра и изменению оценки эхо-тракта.
Зависимость величины изменения оценки эхо-тракта от соотношения амплитуд
сигналов абонентов, параметров используемых алгоритмов и параметров эхо-тракта
ранее не исследовалась, что затрудняет разработку новых алгоритмов перестройки
коэффициентов, которые могли бы улучшить работу эхокомпенсатора в режиме
двойного разговора.
Целью работы является исследование эхокомпенсатора и улучшение его
характеристик в режиме одновременного разговора абонентов. Исследуется
зависимость расстройки коэффициентов адаптивного фильтра от величины шага
подстройки адаптивного алгоритма, соотношения амплитуд сигналов абонентов,
параметров эхо-тракта. Предлагается новый робастный адаптивный алгоритм, позволяющий
уменьшить искажения коэффициентов адаптивного фильтра, вызванные неточностями в
работе ДДР. Приводятся результаты исследования процессов в эхокомпенсаторе,
когда сигналы дальнего и ближнего абонентов являются как детерминированными,
так и случайными. Для задания случайных сигналов используется схема задания
сигналов предложенная в рекомендации G. 165 [3].
Важным этапом в разработке новых алгоритмов является их реализация в виде
конечного устройства.
1. Общие сведения о эхокомпенсации
Причиной эха в телефонных каналах является аналоговое устройство,
называемое дифференциальной системой (hybrid) (см. рис. 1). Оно используется
для разбиения дуплексного канала на два симплексных, и содержит в себе пару
трансформаторов. [8]
В связи с просачиванием тока в диффсистеме, часть принимаемого сигнала
отражается обратно к своему источнику. Это отражение вкупе с задержками,
происходящими при передаче сигналов, вызывает следующее явление: говорящий
слышит эхо собственного голоса, что (субъективно) очень неприятно.
Данный эхокомпенсатор выполнен на базе алгоритма с использованием
поблочно адаптируемого линейного фильтра. Имеются нелинейный процессор (NLP)
для подавления остаточной ошибки эхокомпенсации, детектор двойного разговора,
механизм изменения скорости адаптации в случае наличия гармонических сигналов и
пр.
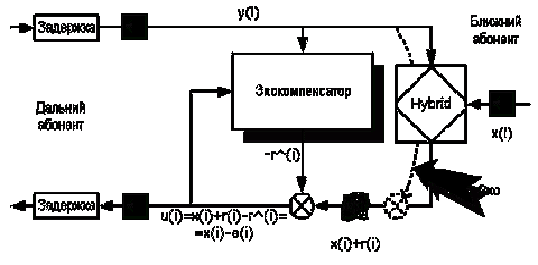
Рис. 1. Простейший эхокомпенсатор
Сигнал y(i) является сигналом дальнего абонента (Far), сигнал x(i) является
сигналом ближнего абонента (Near),
сигнал u(i) является выходным сигналом эхокомпенсатора (Out). Эхокомпенсатор имеет два входа, на
один из которых подаётся сигнал ближнего абонента, на другой - сигнал дальнего
абонента. Если мы подробней рассмотрим сам ЭК (рис. 2), то видим что основой
является адаптивный фильтр и так как он работает в реальном времени, то ему
соответственно нужен наиболее быстрый алгоритм, к примеру можно использовать
быстрое преобразование фурье(БПФ). Чтобы этот фильтр отличал встречный сигнал
от эха, стоит детектор встречного разговора(DBP), также в данной модели стоят шумоподавитель(SH) для подавления постороних шумов и
нелинейный процессор(NP)
для управления процессом. Проследим собственно за ходом сигнала V(n), этот сигнал поступает на шумоподавитель и впоследущем на
детектор встречного разговора(для временной записи для анализа) и на сумматор в
виде сигнала y(n), где после идёт через процессор к абоненту, впоследующем от
абонента идёт сигнал x(n) обратно и попадает на адаптивный
фильтр и детектор. С детектора идёт на адаптивный алгоритм перестановки
коэфициентов КИХ-фильтра, на котом одновременно есть пришедший обратный сигнал,
прошедший обработку БПФ. В результате из фильтра выходит сигнал, который
обрабатывается обратным преобразованием Фурье(ОБПФ) и этот сигнал y*(n) поступает на сумматор и вычинается из сигнала y(n), в результате мы получаем ошибку e(n)=y(n)-y*(n), которая поступает на анализ
адаптивного алгоритма перестановки коэфициентов КИХ-фильтра , который
подстраивает коэфициенты КИХ-фильтра таким образом чтобы ошибка была минимальной,
в результате мы и получим эхоподавление [9].
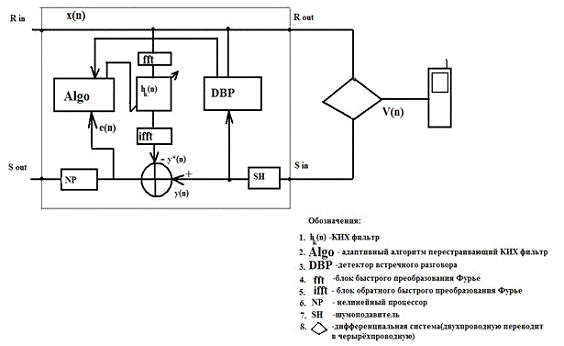
Рис. 2. Более подробная схема эхокомпенсатора
Эхокомпенсатор является встроенным устройством и для его реализации
используется сигнальный процессор (СП), который в последующем программируется
под заданный алгоритм.
1.1 Быстрое преобразование Фурье (БПФ) 1. 2. 1 Физический
смысл БПФ
Для чего нужно быстрое преобразование Фурье или вообще дискретное
преобразование Фурье (ДПФ)? Давайте попробуем разобраться. Пусть у нас есть
функция синуса x = sin(t) на рис. 3.

Рис. 3. функция синуса x = sin(t)
Максимальная амплитуда этого колебания равна 1. Если умножить его на
некоторый коэффициент A, то получим тот же график, растянутый по вертикали в A
раз: x = Asin(t).
Период колебания равен 2π. Если мы хотим увеличить период до
T, то надо умножить переменную t на коэффициент. Это вызовет растяжение графика
по горизонтали: x = A sin(2πt/T).
Частота колебания обратно периоду: ν = 1/T. Также говорят о круговой частоте,
которая вычисляется по формуле: ω= 2πν =
2πT. Откуда: x = A
sin(ωt).
И, наконец, есть фаза, обозначаемая как φ. Она определяет сдвиг графика
колебания влево. В результате сочетания всех этих параметров получается гармоническое
колебание или просто гармоника на рис. 4.

Рис. 4. Гармонические колебания
Очень похоже выглядит и выражение гармоники через косинус на рис. 5.

Рис. 5 гармоника через косинус
Большой разницы нет. Достаточно изменить фазу на π/2, чтобы перейти от синуса к косинусу
и обратно. Далее будем подразумевать под гармоникой функцию косинуса:
x = A cos(2πt/T + φ) = A cos(2πνt
+ φ) = A cos(ωt
+ φ) (1)
В природе и технике колебания, описываемые подобной функцией чрезвычайно
распространены. Например, маятник, струна, водные и звуковые волны и прочее, и
прочее.
Преобразуем (1) по формуле косинуса суммы:
x = A cos φ cos(2πt/T) - A sin φ sin(2πt/T) (2)
Выделим в (2) элементы, независимые от t, и обозначим их как Re и Im
(3-4):
x = Re cos(2πt/T) - Im sin(2πt / T) (3) = A cos φ, Im = A sin φ (4)
По величинам Re и Im можно однозначно восстановить амплитуду и фазу
исходной гармоники:
 и
и 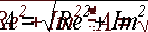 (5)
(5)
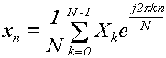 (6)
(6)
Выполним над этой формулой следующие действия: разложим каждое
комплексное Xk на мнимую и действительную составляющие Xk = Rek + j Imk;
разложим экспоненту по формуле Эйлера на синус и косинус действительного
аргумента; перемножим; внесем 1/N под знак суммы и перегруппируем элементы в
две суммы:
Оставим эту формулу пока в стороне и рассмотрим очень распространенную
ситуацию. Пусть у нас есть звуковое или какое-то иное колебание в виде функции
x = f(t). Пусть это колебание было записано в виде графика для отрезка времени
[0, T]. Для обработки компьютером нужно выполнить дискретизацию. Отрезок
делится на N-1 частей и сохраняются значения функции x0, x1, x2, . . . , xN для
N точек на границах отрезков t0 = 0, t1 = T/N, t2 = 2T/N, . . . , tn =nT/N, . .
. , tN = T.
В результате прямого дискретного преобразования Фурье [2] были получены N
значений для Xk:
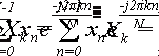 (8)
(8)
Теперь, если применить обратное дискретное преобразование Фурье, то
получится исходная последовательность {x}. Исходная последовательность состояла
из действительных чисел, а последовательность {X} в общем случае комплексная.
Теперь вернемся к формуле (7). Слева стоит действительное число xn, а справа -
две суммы, одна из которых помножена на мнимую единицу j. Сами же суммы состоят
из действительных слагаемых. Отсюда следует, что вторая сумма равна нулю, если
исходная последовательность {x} была действительной. Отбросим ее и получим:
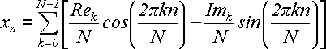 (9)
(9)
Поскольку при дискретизации мы брали tn = nT/N и xn = f(tn), то можем
выполнить замену: n = tnN/T. Следовательно, в синусе и косинусе вместо 2πkn/N
можно написать 2πktn/T. В результате получим:
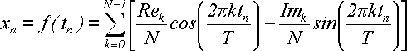 (10)
(10)
Сопоставим эту формулу с формулами (11) и (12) для гармоники:
x = A cos(2πt/T + φ) = A cos(2πνt + φ) = A cos(ωt + φ) (11) = Re cos(2πt/T) - Im sin(2πt / T) (12)
Мы видим, что сумма (9) представляет собой сумму из N гармонических
колебаний разной частоты, фазы и амплитуды (13):
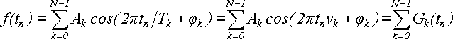 (13)
(13)
Далее будем функцию
Gk(t) = Ak cos(2πtk/T + φk) (14)
называть k-й гармоникой.
Амплитуда, фаза, частота и период каждой из гармоник связаны с
коэффициентами Xk формулами:
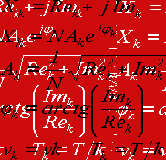
Итак, физический смысл дискретного преобразования Фурье состоит в том,
чтобы представить некоторый дискретный сигнал в виде суммы гармоник. Параметры
каждой гармоники вычисляются прямым преобразованием, а сумма гармоник -
обратным.
Общий принцип БПФ
Одна из причин того, что анализ Фурье [7] играет такую важную роль в
цифровой обработке сигналов, заключается в существовании эффективных алгоритмов
дискретного преобразования Фурье. Вспомним, что дискретное преобразование Фурье
(ДПФ) определяется выражением
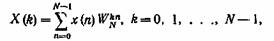 ( 15)
( 15)
где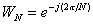 . Обратное дискретное преобразование
Фурье (ОДПФ) имеет вид
. Обратное дискретное преобразование
Фурье (ОДПФ) имеет вид
В (15) и ( 16)как х(n), так X(k) могут быть комплексными. Выражения в (15)
и (16)отличаются только знаком экспоненты от WN и скалярным коэффициентом 1/N.
Поэтому рассуждения, касающиеся вычислительных процедур для (15), применимы с
очевидными изменениями к (16).
Чтобы проиллюстрировать важность эффективных вычислительных алгоритмов,
поучительно сначала рассмотреть непосредственное вычисление ДПФ. Так как х(n)
может быть комплексным, то можно записать
Отсюда видно, что для каждого значения k при непосредственном вычислении
X(k) требуется 4N умножений и (4N-2) сложений действительных чисел. Так как
X(k) должно вычисляться для N различных значений k, непосредственное вычисление
дискретного преобразования Фурье последовательности х(n) требует 4N2 умножений
и N(4N-2) сложений действительных чисел или N2 умножений и N(N- 1) сложений
комплексных чисел. Вдобавок к умножениям и сложениям при выполнении вычисления
ДПФ на универсальных или специализированных цифровых вычислительных . машинах
требуются, конечно, средства для хранения значений последовательности х(n) и
коэффициентов и средства обращения к памяти. Так как количество запоминаний
и обращений к памяти в вычислительных алгоритмах обычно пропорционально числу
арифметических операций, то оно считается разумной мерой сложности
вычислительного алгоритма или времени, необходимого для вычислений. Таким
образом, приемлемой мерой эффективности непосредственного вычисления
дискретного преобразования Фурье является тот факт, что оно требует 4N2
умножений и N (4N-2) сложений действительных чисел. Так как количество
вычислений, а следовательно, и время вычислений приблизительно-пропорциональны
N/2, то ясно, что при прямом методе необходимое число арифметических операций
становится очень большим при больших значениях N. По этой причине представляют
значительный интерес вычислительные процедуры, уменьшающие количество умножений
и сложений.
и средства обращения к памяти. Так как количество запоминаний
и обращений к памяти в вычислительных алгоритмах обычно пропорционально числу
арифметических операций, то оно считается разумной мерой сложности
вычислительного алгоритма или времени, необходимого для вычислений. Таким
образом, приемлемой мерой эффективности непосредственного вычисления
дискретного преобразования Фурье является тот факт, что оно требует 4N2
умножений и N (4N-2) сложений действительных чисел. Так как количество
вычислений, а следовательно, и время вычислений приблизительно-пропорциональны
N/2, то ясно, что при прямом методе необходимое число арифметических операций
становится очень большим при больших значениях N. По этой причине представляют
значительный интерес вычислительные процедуры, уменьшающие количество умножений
и сложений.
Большинство подходов к улучшению эффективности вычисления ДПФ использует
следующие свойства величин
) =()* (18)
=()* (18)
) =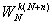 =
=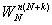 (19)
(19)
Например, используя первое свойство, т. е. свойство симметрии функции cos
и sin, можно сгруппировать слагаемые в ( 17)следующим образом:
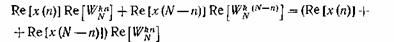 (20)
(20)
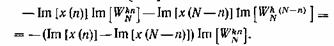 (21)
(21)
Аналогичную группировку можно произвести для других слагаемых в ( 17).
Посредством этого метода число умножений можно сократить приблизительно вдвое.
Можно также использовать тот факт, что для определенных значений произведения
kn функции sin и cos принимают значения 1 или 0, при которых не требуется
умножение. Однако при сокращениях такого типа количеств вычислений все еще
остается приблизительно пропорциональным N2. К счастью, второе свойство, т. е.
периодичность комплексной последовательности, позволяет достигнуть существенно
большего сокращения количества вычислений.
Вычислительные алгоритмы, использующие как симметрию, так и периодичность
последовательности, были известны задолго до появления быстродействующих ЭВМ В
то время приветствовалась любая схема, уменьшающая количество ручных вычислений
даже в 2 раза. Рунге (Runge) , а позже Даниэльсон (Danielson) и Лапцош
(Lanczos) описали алгоритмы, при которых количество вычислений было
приблизительно пропорционально N Log N, а не N2. Однако это различие не было
слишком: важным для тех малых значений N, которые можно было осуществить при
ручных вычислениях. В 1965 г. Кули (Cooley) и Тьюки (Tukey) опубликовали
алгоритм вычисления дискретного преобразования Фурье, применимый при составном
N, т. е. когда N является произведением двух или большего числа целых чисел.
Опубликование этой статьи вызвало значительный интерес к дискретному
преобразованию Фурье при обработке сигналов и привело к открытию ряда
вычислительных алгоритмов, которые стали известны под названием алгоритмы
быстрого преобразования Фурье (БПФ). В целом все множество таких алгоритмов
часто называется БПФ . Основной принцип всех этих алгоритмов заключается в
разложении операции вычисления дискретного преобразования Фурье
последовательности длины N на вычисление преобразований Фурье с меньшим числом
точек. Способы, которыми осуществляется этот принцип, приводят к различным
алгоритмам. Все они сравнимы по эффективности. Первый, названный прореживанием
по времени, получил такое название от того, что в процессе вычислений х(n)
(индекс n часто ассоциируется со временем) разлагается на уменьшающиеся
подпоследовательности. Во втором общем классе алгоритмов последовательность
коэффициентов дискретного преобразования Фурье X(k) разлагается на меньшие
подпоследовательности, откуда идет название прореживание по частоте.
В этой главе будет рассмотрен ряд алгоритмов вычисления дискретного
преобразования Фурье, которые отличаются друг от друга по эффективности, но все
они более эффективны, чем прямое вычисление по ( 17). Первым будет рассмотрен
метод Герцеля (Gortzel) , который требует количества вычислений, пропорционального
N2, но с меньшим, чем при прямом методе, коэффициентом пропорциональности.
Наибольшее внимание будет уделено алгоритмам БПФ, т. е. алгоритмам, при которых
количество вычислений приблизительно пропорционально N log N. Мы не будем
стараться рассмотреть все алгоритмы, но проиллюстрируем общие принципы всех
алгоритмов этого типа, рассматривая детально только несколько из наиболее часто
используемых схем [7].
Алгоритм предварительной перестановки
теперь рассмотрим конкретную реализацию БПФ . Пусть имеется N=2T
элементов последовательности x{N} и надо получить последовательность X{N}.
Прежде всего, нам придется разделить x{N} на две последовательности: четные и
нечетные элементы. Затем точно так же поступить с каждой последовательностью.
Этот итерационный процесс закончится, когда останутся последовательности длиной
по 2 элемента.
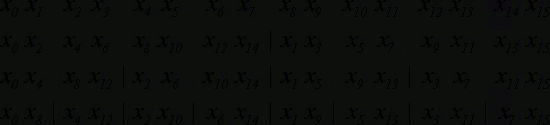
Рис. 7. Пример процесса для N=16
Итого выполняется (log2N)-1 итераций.
Рассмотрим двоичное представление номеров элементов и занимаемых ими
мест. Элемент с номером 0 (двоичное 0000) после всех перестановок занимает
позицию 0 (0000), элемент 8 (1000) - позицию 1 (0001), элемент 4 (0100) -
позицию 2 (0010), элемент 12 (1100) - позицию 3 (0011). И так далее. Нетрудно
заметить связь между двоичным представлением позиции до перестановок и после
всех перестановок: они зеркально симметричны. Двоичное представление конечной
позиции получается из двоичного представления начальной позиции перестановкой
битов в обратном порядке. И наоборот.
Этот факт не является случайностью для конкретного N=16, а является
закономерностью. На первом шаге четные элементы с номером n переместились в
позицию n/2, а нечетные из позиции в позицию N/2+(n-1)/2. Где n=0, 1, …, N-1.
Таким образом, новая позиция вычисляется из старой позиции с помощью функции:
(n, N) = [n/2] + N{n/2}
Здесь как обычно [x] означает целую часть числа, а {x} - дробную.
В ассемблере эта операция называется циклическим сдвигом вправо (ror),
если N - это степень двойки. Название операции происходит из того факта, что
берется двоичное представление числа n, затем все биты, кроме младшего (самого
правого) перемещаются на 1 позицию вправо. А младший бит перемещается на
освободившееся место самого старшего (самого левого) бита рис. 8.
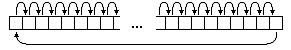
Рис. 8. перемещение младшего бита на освободившееся место самого старшего
Дальнейшие разбиения выполняются аналогично. На каждом следующем шаге
количество последовательностей удваивается, а число элементов в каждой из них
уменьшается вдвое. Операции ror подвергаются уже не все биты, а только
несколько младших (правых). Старшие же j-1 битов остаются нетронутыми
(зафиксированными), где j - номер шага рис. 9.

Рис. 9.
Что происходит с номерами позиций при таких последовательных операциях?
Давайте проследим за произвольным битом номера позиции. Пусть этот бит
находился в j-м двоичном разряде, если за 0-й разряд принять самый младший
(самый правый). Бит будет последовательно сдвигаться вправо на каждом шаге до
тех пор, пока не окажется в самой правой позиции. Это случится после j-го шага.
На следующем, j+1-м шаге будет зафиксировано j старших битов и тот бит, за
которым мы следим, переместится в разряд с номером T-j-1. После чего окажется
зафиксированным и останется на месте. Но именно такое перемещение - из разряда
j в разряд T-j-1 и необходимо для зеркальной перестановки бит. Что и
требовалось доказать.
Теперь, мы убедились в том, что перестановка элементов действительно
осуществляется по принципу, при котором в номерах позиций происходит в свою
очередь другая перестановка: зеркальная перестановка двоичных разрядов. Это
позволит нам получить простой алгоритм:
(I = 1; I < N-1; I++)
Некоторую проблему представляет собой операция обратной перестановки бит
номера позиции reverse(), которая не реализована ни в популярной архитектуре
Intel, ни в наиболее распространенных языках программирования. Приходится
реализовывать ее через другие битовые операции. Ниже приведен алгоритм функции
перестановки T младших битов в числе I:
unsigned int reverse(unsigned int I, int T)
{ int Shift = T - 1; unsigned int LowMask = 1; unsigned int
HighMask = 1 << Shift; unsigned int R; for(R = 0; Shift >= 0; LowMask
<<= 1, HighMask >>= 1, Shift -= 2) R |= ((I & LowMask) <<
Shift) | ((I & HighMask) >> Shift); return R;
}
Пояснения к алгоритму. В переменных LowMask и HighMask хранятся маски,
выделяющие два переставляемых бита. Первая маска в двоичном представлении
выглядит как 0000…001 и в цикле изменяется, сдвигая единицу каждый раз на 1
разряд влево:
. . . 001
. . . 010
. . . 100
Вторая маска (HighMask) принимает последовательно значения:
. . . 000
. . . 000
. . . 000
каждую итерацию сдвигая единичный бит на 1 разряд вправо. Эти два сдвига
осуществляются инструкциями LowMask <<= 1 и HighMask >>= 1.
Переменная Shift показывает расстояние (в разрядах) между переставляемыми
битами. Сначала оно равно T-1 и каждую итерацию уменьшается на 2. Цикл
прекращается, когда расстояние становится меньше или равно нулю.
Операция I & LowMask выделяет первый бит, затем он сдвигается на
место второго (<<Shift). Операция I & HighMask выделяет второй бит,
затем он сдвигается на место первого (>>Shift). После чего оба бита
записываются в переменную R операцией "|".
Вместо того чтобы переставлять биты позиций местами, можно применить и
другой метод. Для этого надо вести отсчет 0, 1, 2, …, N/2-1 уже с обратным
следованием битов. Опять-таки, ни в ассемблере Intel, ни в распространенных
языках программирования не реализованы операции над обратным битовым
представлением. Но алгоритм приращения на единицу известен, и его можно
реализовать программно. Вот пример для T=4.
I = 0;
J = 0;
for(J1 = 0; J1 < 2; J4++, J ^= 1) for(J2 =
0; J2 < 2; J3++, J ^=
2) for(J4 = 0; J4
< 2; J4++, J ^= 4) for(J8 = 0; J8 < 2; J8++, J ^= 8) { if (I < J) { S = x[I]; x[I] = x[J]; x[J] = S; // перестановка элементов xIи xJ } I++; }
В этом алгоритме используется тот общеизвестный факт, что при увеличении
числа от 0 до бесконечности (с приращением на единицу) каждый бит меняется с 0
на 1 и обратно с определенной периодичностью: младший бит - каждый раз,
следующий - каждый второй раз, следующий - каждый четвертый и так далее.
Эта периодичность реализована в виде T вложенных циклов, в каждом из
которых один из битов позиции J переключается туда и обратно с помощью операции
XOR (В C/C++ она записывается как ^=). Позиция I использует обычный инкремент
I++, уже встроенный в язык программирования.
Данный алгоритм имеет тот недостаток, что требует разного числа вложенных
циклов в зависимости от T. На практике это не очень плохо, поскольку T обычно
ограничено некоторым разумным пределом (16. . 20), так что можно написать
столько вариантов алгоритма, сколько нужно. Тем не менее, это делает программу
громоздкой. Ниже я предлагаю вариант этого алгоритма, который эмулирует
вложенные циклы через стеки Index и Mask. int Index[MAX_T];
int Mask[MAX_T];R;(I = 0; I < T; I++)
{ Index[I] = 0; Mask[I] = 1 << (T - I - 1);
} = 0; (I = 0; I < N; I++)
{ if (I < J) { S = x[I]; x[I] = x[J]; x[J] = S; // перестановка элементов xI и xJ } for(R = 0; R < T;
R++) { J ^= Mask[R]; if (Index[R] ^= 1) // эквивалентно Index[R] ^= 1; if (Index[R] != 0) break; }
}
Величина MAX_T определяет максимальное значение для T и в наихудшем
случае равна разрядности целочисленных переменных ЭВМ. Этот алгоритм, может
быть, чуть медленнее, чем предыдущий, но дает экономию по объему кода.
И, наконец, последний алгоритм. Он использует классический подход к
многоразрядным битовым операциям: надо разделить 32-бита на 4 байта, выполнить
перестановку в каждом из них, после чего переставить сами байты.
Перестановку бит в одном байте уже можно делать по таблице. Для нее нужно
заранее приготовить массив reverse256 из 256 элементов. Этот массив будет
содержать 8-битовые числа. Записываем туда числа от 0 до 255 и переставляем в
каждом порядок битов.
Теперь этот массив применим для последней реализации функции reverse:
unsigned int reverse(unsigned int I, int T)
{ unsigned int R; unsigned char *Ic = (unsigned char*)
&I; unsigned char *Rc = (unsigned char*) &R; Rc[0] = reverse256[Ic[3]];
Rc[1] = reverse256[Ic[2]]; Rc[2] = reverse256[Ic[1]]; Rc[3] =
reverse256[Ic[0]]; R >>= (32 - T); Return R;
}
Обращения к массиву reverse256 переставляют в обратном порядке биты в
каждом байте. Указатели Ic и Ir позволяют обратиться к отдельным байтам
32-битных чисел I и R и переставить в обратном порядке байты. Сдвиг числа R
вправо в конце алгоритма устраняет различия между перестановкой 32 бит и
перестановкой T бит. Ниже приводится наглядная геометрическая иллюстрация
алгоритма, где стрелками показаны перестановки битов, байтов и сдвиг.
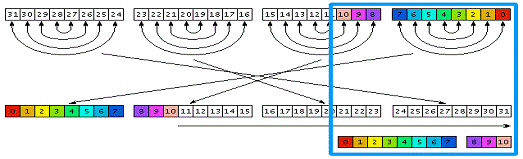
Рис. 10. геометрическая иллюстрация алгоритма
Оценим сложность описанных алгоритмов. Понятно, что все они
пропорциональны N с каким-то коэффициентом. Точное значение коэффициента
зависит от конкретной ЭВМ. Во всех случаях мы имеем N перестановок со
сравнением I и J, которое предотвращает повторную перестановку некоторых
элементов. Рядом присутствует некоторый обрамляющий код, применяющий достаточно
быстрые операции над целыми числами: присваивания, сравнения, индексации,
битовые операциии и условные переходы. Среди них в архитектуре Intel наиболее
накладны переходы. Поэтому я бы рекомендовал последний алгоритм. Он содержит
всего N переходов, а не 2N как в алгоритме со вложенными циклами или их
эмуляцией и не NT как в самом первом алгоритме.
С другой стороны, предварительная перестановка занимает мало времени по
сравнению с последующими операциями, использующими (N/2)log2N умножений комплексных
чисел. В таком случае тоже есть смысл выбрать не самый короткий, но самый
простой и наглядный алгоритм - последний описанный. Вот его окончательный вид с
небольшой оптимизацией:
static unsigned
char reverse256[]= { 0x00, 0x80, 0x40, 0xC0, 0x20, 0xA0, 0x60, 0xE0, 0x10, 0x90, 0x50, 0xD0, 0x30, 0xB0, 0x70, 0xF0, 0x08, 0x88, 0x48, 0xC8, 0x28, 0xA8, 0x68, 0xE8, 0x18, 0x98, 0x58, 0xD8, 0x38, 0xB8, 0x78, 0xF8, 0x04, 0x84, 0x44, 0xC4, 0x24, 0xA4, 0x64, 0xE4, 0x14, 0x94, 0x54, 0xD4, 0x34, 0xB4, 0x74, 0xF4, 0x0C, 0x8C, 0x4C, 0xCC, 0x2C, 0xAC, 0x6C, 0xEC, 0x1C, 0x9C, 0x5C, 0xDC, 0x3C, 0xBC, 0x7C, 0xFC, 0x02, 0x82, 0x42, 0xC2, 0x22, 0xA2, 0x62, 0xE2, 0x12, 0x92, 0x52, 0xD2, 0x32, 0xB2, 0x72, 0xF2, 0x0A, 0x8A, 0x4A, 0xCA, 0x2A, 0xAA, 0x6A, 0xEA, 0x1A, 0x9A, 0x5A, 0xDA, 0x3A, 0xBA, 0x7A, 0xFA, 0x06, 0x86, 0x46, 0xC6, 0x26, 0xA6, 0x66, 0xE6, 0x16, 0x96, 0x56, 0xD6, 0x36, 0xB6, 0x76, 0xF6, 0x0E, 0x8E, 0x4E, 0xCE, 0x2E, 0xAE, 0x6E, 0xEE, 0x1E, 0x9E, 0x5E, 0xDE, 0x3E, 0xBE, 0x7E, 0xFE, 0x01, 0x81, 0x41, 0xC1, 0x21, 0xA1, 0x61, 0xE1, 0x11, 0x91, 0x51, 0xD1, 0x31, 0xB1, 0x71, 0xF1, 0x09, 0x89, 0x49, 0xC9, 0x29, 0xA9, 0x69, 0xE9, 0x19, 0x99, 0x59, 0xD9, 0x39, 0xB9, 0x79, 0xF9, 0x05, 0x85, 0x45, 0xC5, 0x25, 0xA5, 0x65, 0xE5, 0x15, 0x95, 0x55, 0xD5, 0x35, 0xB5, 0x75, 0xF5, 0x0D, 0x8D, 0x4D, 0xCD, 0x2D, 0xAD, 0x6D, 0xED, 0x1D, 0x9D, 0x5D, 0xDD, 0x3D, 0xBD, 0x7D, 0xFD, 0x03, 0x83, 0x43, 0xC3, 0x23, 0xA3, 0x63, 0xE3, 0x13, 0x93, 0x53, 0xD3, 0x33, 0xB3, 0x73, 0xF3, 0x0B, 0x8B, 0x4B, 0xCB, 0x2B, 0xAB, 0x6B, 0xEB, 0x1B, 0x9B, 0x5B, 0xDB, 0x3B, 0xBB, 0x7B, 0xFB, 0x07, 0x87, 0x47, 0xC7, 0x27, 0xA7, 0x67, 0xE7, 0x17, 0x97, 0x57, 0xD7, 0x37, 0xB7, 0x77, 0xF7, 0x0F, 0x8F, 0x4F, 0xCF, 0x2F, 0xAF, 0x6F, 0xEF, 0x1F, 0x9F, 0x5F, 0xDF, 0x3F, 0xBF, 0x7F, 0xFF,
{ Jc[0] = reverse256[Ic[3]]; Jc[1] = reverse256[Ic[2]]; Jc[2]
= reverse256[Ic[1]]; Jc[3] = reverse256[Ic[0]]; J >>= (32 - T); if (I
< J) { S = x[I]; x[I] = x[J]; x[J] = S; }
}
1. 2 Основной цикл алгоритма
Напомним основные формулы:
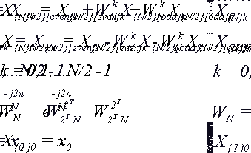 (22)
(22)
На рис. 11 проиллюстрирован второй этап вычисления ДПФ. Линиями сверху
вниз показано использование элементов для вычисления значений новых элементов.
Очень удобно то, что два элемента на определенных позициях в массиве дают два
элемента на тех же местах. Только принадлежать они будут уже другим, более
длинным массивам, размещенным на месте прежних, более коротких. Это позволяет
обойтись одним массивом данных для исходных данных, результата и хранения
промежуточных результатов для всех T итераций.
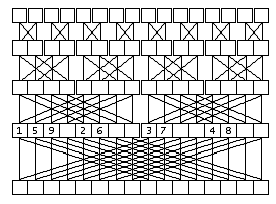
Рис. 11. второй этап вычисления ДПФ
Итак, вот действия, которые нужно выполнить после первичной перестановки
элементов.
#define T 4
#define Nmax (2 << T)Q, Temp, j(0, 1);complex
x[Nmax];double pi2 = 2 * 3. 1415926535897932384626433832795;N, Nd2, k, mpNd2,
m; (N = 2, Nd2 = 1; N <= Nmax; Nd2 = N, N += N)
{ for(k = 0; k < Nd2; k++) { W = exp(-j*pi2*k/N); for(m =
k; m < Nmax; m += N) { mpNd2 = m + Nd2; Temp = W * x[mpNd2]; x[mpNd2] = x[m]
- Temp; x[m] = x[m] + Temp; } }
}
Переменная Nmax содержит полную длину массива данных и окончательное
количество элементов ДПФ. В таблице показано соответствие между выражениями в
формуле (22) и переменными в программе.
Внешний цикл - это основные итерации. На каждой из них 2Nmax/N ДПФ
(длиной по N/2 элементов каждое) преобразуются в Nmax/N ДПФ (длиной по N
элементов каждое).
Следующий цикл по k представляет собой цикл синхронного вычисления
элементов с индексами k и k + N/2 во всех результирующих ДПФ.
Самый внутренний цикл перебирает Nmax/N штук ДПФ одно за другим.
Именно так, а не иначе: сначала вычисляются элементы с номерами 0 и N/2,
во всех ДПФ в количестве Nmax/N штук, потом с номерами 1 и N/2 + 1 и так далее.
На рис. 4 показана последовательность вычислений для N = 8. Такая
последовательность обеспечивает однократное вычисление .
Обратите внимание, что x[mpNd2] вычисляется раньше, чем x[k], чтобы
значение x[k] не было модифицировано прежде, чем будет использовано.
Алгоритм обратного дискретного преобразования Фурье отличается только
тем, что вместо -j надо использовать +j и после всех вычислений поделить каждое
x[k] на Nmax.
Для справки: произведение, сумма и экспонента для комплексных чисел
вычисляются по формулам:
(x, y)(x', y')=(xx'-yy')(xy'+x'y)
(x, y)+(x', y')=(x+x')(y+y') jv=(cos v, - sinv)
где v - действительное число [7].
1. 3 БПФ для произвольного N
эхокомпенсатор преобразование фурье дискретный
Ранее мы рассмотрели случаи, когда число элементов преобразования равно
степени двойки. К сожалению, на данный момент не существует столь же
эффективного алгоритма вычисления ДПФ для произвольного N. Однако, существует
алгоритм, который значительно лучше "лобового" решения задачи. Он
требует, чтобы N было четным. Допустим, что N = M 2T = M L. Число L - целая
степень двойки, числа M и T - положительные целые.
Сложность этого алгоритма равна N2 / L + Nlog2L. Как видите, этот
алгоритм тем эффективнее, чем больше L, то есть, чем больше число элементов N
"похоже" на степень двойки. В худшем случае, когда L = 2, он лишь
немногим лучше "лобового" решения, которое имеет сложность N2.
Тем не менее, на практике нам часто полезен именно описанный алгоритм.
Допустим, у нас имеется оцифрованный звуковой сигнал, длиной в 2001 отсчет, и
мы хотим узнать его спектр. Если мы применим обычный алгоритм, то нам придется
отрезать "лишний" кусок сигнала, размером почти в его половину,
уменьшив число отсчетов до 1024. Но в таком случае мы потеряем гармоники,
которые, возможно, возникли только ближе к концу сигнала. Другой вариант:
дополнить исходный сигнал до 2048 отсчетов - тоже плох. В самом деле: чем его
дополнить? Если нулями, то в результате мы приобретем множество лишних гармоник
из-за резкого скачка сигнала вниз на 2001-м отсчете. Совершенно неясно, как
интерполировать сигнал на дополнительные 47 отсчетов так, чтобы не появились
новые, ненужные гармоники (шумы). И только новый алгоритм решает эту проблему.
С помощью него мы можем "отрезать" совсем небольшой кусочек, в 1
отсчет, взяв L = 16 и получив ускорение в 16 раз! Либо мы можем пожертвовать
кусочком чуть длиннее, взяв L еще больше. Для реальных сигналов невелика
вероятность, что на этом маленьком отрезке спектр резко изменится, так что результат
получится вполне удовлетворительный.
Теперь рассмотрим сам алгоритм. Его главной частью является уже знакомый
нам алгоритм "fft" для N, равного степени двойки. Этот алгоритм [1]
лишь немного модифицирован. Из исходной последовательности длиной N выбирается
L элементов, начиная от элемента с номером h (0 ≤ h < M) и с шагом M.
В результате получается последовательность из L элементов. Так как L у нас -
степень двойки, мы можем применить к полученной последовательности обычный
алгоритм БПФ. Результаты преобразования записываются в те же ячейки, откуда
были взяты. Изменение алгоритма заключается всего лишь в том, что каждый раз
вместо g-го элемента берется элемент с номером h + gM, то есть, выполняется
замена индексов по формуле:
→ h + gM (23)
Позднее мы еще дополнительно оптимизируем этот алгоритм, а пока выпишем
его результат в виде формулы:
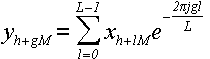 (24)
(24)
Где g = 0, 1, . . . , L - 1. Как видите, по сравнению с формулой (1) мы
выполнили замену переменных: k → g, n → l, N → L и сделали
преобразование индексов по формуле (23) .
На первом этапе модифицированный алгоритм БПФ применяется ко всем
элементам исходной последовательности. Для этого вычисление по формуле (20)
выполняется для h = 0, 1, . . . , M - 1. Каждое такое вычисление меняет L
элементов с индексами h, h + M, h + 2M, . . . , h + (L - 1)M. Таким образом,
вызвав M раз этот алгоритм [2], мы изменим все N = ML элементов заданной
последовательности:
Шаг 0: элементы с номерами 0, M, 2M, . . . (L-1)M
Шаг 1: элементы с номерами 1, 1 + M, 1 + 2M, . . . 1 + (L-1)M
Шаг 2: элементы с номерами 2, 2 + M, 2 + 2M, . . . 2 + (L-1)M
. . .
Шаг M-1: элементы с номерами M - 1, M - 1 + M, M - 1 + 2M, . . . M - 1 +
(L-1)M
На втором этапе заводится новый массив размером в N элементов, и к нему
применяется формула:
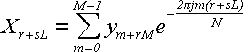 (25)
(25)
В двойном цикле величина s проходит значения 0. . M - 1, а величина r
проходит значения 0. . L - 1. Общее число итераций, таким образом, равно ML =
N. Каждая итерация требует суммирования M элементов. То есть, общее количество
слагаемых равно NM. На предварительном этапе [1] мы M раз применили обычный
алгоритм БПФ для L элементов, который, как мы уже знаем, имеет сложность L
log2L. Таким образом, общая сложность алгоритма равна:
NM + L log2L = N(N/L) + ML log2L = N2/L + N log2L (26)
Тем самым, мы доказали формулу сложности, приведенную в начале главы.
Теперь нам осталось доказать только то, что формула (2. 7)действительно
дает ДПФ. Для этого подставим формулу (2. 6)в формулу (2. 7):
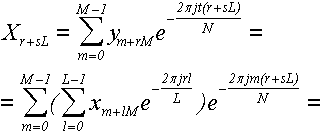 (27)
(27)
поскольку выражение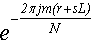 не зависит от l, то мы его можем внести под знак внутренней
суммы (28):
не зависит от l, то мы его можем внести под знак внутренней
суммы (28):
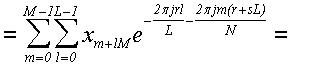 (28)
(28)
теперь учтем, что L = N/M, чтобы привести выражение в показателе степени
к общему знаменателю и упростить (29):
 (29)
(29)
теперь воспользуемся Теоремой 0, чтобы добавить полезный множитель,
равный единице (30):
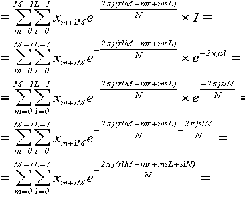 (30)
(30)
теперь воспользуемся равенством N = ML, чтобы разбить сумму в числителе
на множители (31):
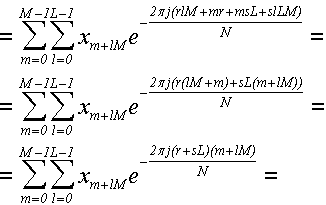 (31)
(31)
теперь выполним замену переменных r + sL → k, m + lM → n:
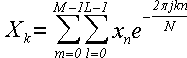 (32)
(32)
Эта сумма эквивалентна сумме (1), с точностью до перемены мест слагаемых.
В самом деле, если n = m + lM, m = 0. . M - 1, l = 0. . L - 1, N = LM, то
переменная n по мере суммирования принимает все значения от 0 до N - 1 ровно по
одному разу. Что и требовалось доказать [7-8] .
1. 4 Рекомендации МСЭ G. 165 применяемые для создания
эхокомпенсатора
Эхокомпенсаторы - речевые обслуживающие устройства, размещенные в
4-хпроводной части цепи и используемые для уменьшения эха с помощью вычитания
предполагаемого эха из эхоцепи. Они могут быть охарактеризованы независимо от
пути передачи или от вычитания эха аналоговым или цифровым средством.
Рекомендация МСЭ G. 165
применяется для создания эхокомпенсаторов, использующих цифровые или аналоговые
технологии, и предназначается для использования в международной сети.
Эхокомпенсаторы, разработанные в этой рекомендации, будут совместимы с любой
сетью.
Тесты в рекомендации МСЭ G. 165
основываются на исполнении шума в ограниченной полосе. Эхокомпенсаторы рис. 12,
проходящие эти тесты, могут также выполняться на речи. Разработчики и
пользователи эхокомпенсаторов гарантируют требуемое речевое исполнение.
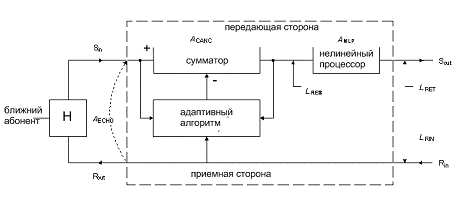
Рис. 12. эхокомпенсатор по рекомендации G. 165
Определения, связанные с эхокомпенсаторами.
L -
относительный уровень мощности сигнала, выраженный в 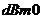 .
.
А
- ослабление или потеря сигнала, выраженная в 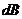 .
.
Н
регистр
Регистр
в эхокомпенсаторе, в котором хранится импульсная характеристика модели
эхотракта.
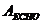 -
затухание эхосигнала (потеря возвращенного эха)
-
затухание эхосигнала (потеря возвращенного эха)
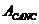 -
подавление (оценка эхосигнала)
-
подавление (оценка эхосигнала)
Ослабление
эхосигнала после прохождения через передающую сторону эхокомпенсатора.
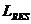 -
уровень остаточного эха
-
уровень остаточного эха
Уровень
эхо-сигнала, который остается в точке 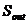
 операции эхокомпенсации после неполного подавления
эхосигнала. Он связан с уровнем приема входного сигнала
операции эхокомпенсации после неполного подавления
эхосигнала. Он связан с уровнем приема входного сигнала 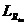 :
:

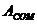 -
комбинированная потеря
-
комбинированная потеря
Сумма
потери эха, потерь компенсации, и потерь нелинейной обработки. Эта потеря
связывает с 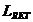 :
:
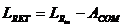 , где
, где 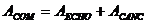
Эхо
в любой 2-хпроводной или комбинации 2-хпроводной и 4-хпроводной телефонной
сети, вызывает полную неразборчивость речи. Эхокомпенсатор может настроиться,
чтобы уменьшить эхо до сносного уровня. Эхо, присутствующее в точке  эхокомпенсатора - это искаженная и задержанная копия
поступающей речи от дальнего абонента, т. е. эхо - поступающая речь,
модифицированная эхотрактом. Эхотракт обычно описывается импульсной
характеристикой (ИХ) рис. 13. Типичная ИХ эхотракта имеет небольшой участок с
отличными от нуля отсчетами длительностью 4-8 мс из-за ограничения полосы и
многочисленных отражений, а большая ее часть равна нулю (чистая задержка tr) и
фактически представляет собой отсчеты, формирующие линию задержки. Их сумма -
задержка эхотракта td. Величины задержки и дисперсии будут меняться в
зависимости от свойств эхотракта.
эхокомпенсатора - это искаженная и задержанная копия
поступающей речи от дальнего абонента, т. е. эхо - поступающая речь,
модифицированная эхотрактом. Эхотракт обычно описывается импульсной
характеристикой (ИХ) рис. 13. Типичная ИХ эхотракта имеет небольшой участок с
отличными от нуля отсчетами длительностью 4-8 мс из-за ограничения полосы и
многочисленных отражений, а большая ее часть равна нулю (чистая задержка tr) и
фактически представляет собой отсчеты, формирующие линию задержки. Их сумма -
задержка эхотракта td. Величины задержки и дисперсии будут меняться в
зависимости от свойств эхотракта.
Для корректной обработки сигнала адаптивный фильтр должен иметь длительность
ИХ, равную либо большую, чем длительность ИХ эхотракта.
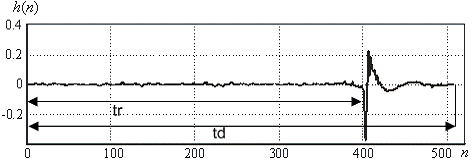
Рис. 13. Пример импульсной характеристики эхотракта
Эхокомпенсаторы,
разработанные в рекомендации Международного Cоюза
Электросвязи ITU-T G. 165, будут выполнены правильно для потери эха () 6 дБ или больше. Для меньше,
чем 6 дБ, они все же могут работать, но с плохим исполнением.
Эхокомпенсаторы
могут синтезировать копию импульсной характеристики эхотракта. Многие
эхокомпенсаторы моделируют эхотракт, используя представление выборочных данных,
дискретизированных с частотой Найквиста (8000Гц). Такой эхокомпенсатор,
правильно функционируя, должен иметь достаточную емкость для требуемого количества
отсчетов. Успешно демонстрируются эхокомпенсаторы, имеющие емкость от 8 до 64
мс. Максимальная задержка td эхотракта в сети, в которой эхокомпенсатор
используется, определяет его требуемую емкость. Обычно, меньшее количество
ячеек памяти не сможет осуществить требуемый синтез эхотракта; в то же время
большее число ячеек памяти будет создавать нежелательный дополнительный шум
благодаря тому, что неиспользованные ячейки из-за оценки шума обычно ненулевые.
Признано,
что эхокомпенсатор представляет собой дополнительный параллельный эхо-тракт.
Если импульсная характеристика модели эхотракта сильно отличается от импульсной
характеристики эхотракта, то остаточное эхо может быть больше, чем эхо в точке из-за эхотракта. Эхотракты изменяются, когда
эхокомпенсатор используется в последующих связях. Когда речевой сигнал подается
в точку  , эхокомпенсатор должен адаптироваться или сойтись к
новому эхотракту, и желательно довольно быстро, т. е. около полсекунды. Также
остаточное эхо должно быть небольшим по сравнению с уровнем полученного
речевого сигнала и характеристиками эхотракта.
, эхокомпенсатор должен адаптироваться или сойтись к
новому эхотракту, и желательно довольно быстро, т. е. около полсекунды. Также
остаточное эхо должно быть небольшим по сравнению с уровнем полученного
речевого сигнала и характеристиками эхотракта.
Тесты и рекомендации для исполнения с входными сигналами, поданными в
приемной и передающей сторонах эхокомпенсатора.
В тестах предполагается, что нелинейный процессор может быть блокирован,
что буфер импульсного отклика эхотракта (Н регистр) может быть очищен
(обнулиться), и что адаптацию можно запретить. Исполнение эхокомпенсатора.
Требования
изложены в описаниях тестов, сделанных для подачи сигналов в точки и эхокомпенсатора
и измерения сигналов. Схема для проведения тестов показана на
рис. 14.
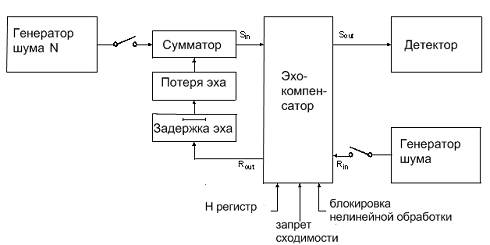
Рис. 14. Схема для проведения тестов из рекомендации МСЭ ITU-T G. 165
Шум с ограниченной полосой используется как поданный входной тестовый
сигнал. Затухание эха не зависит от частоты.
Основная
цель эхокомпенсатора - управлять эхом речевого сигнала. Это создается
синтезированием копии импульсной характеристики эхотракта и использованием ее
для генерации оценки эха, которая вычитается из фактической эхоцепи. Синтез
должен быть выполнен с использованием речевого входного сигнала. Из-за
трудности определения речевого тестового сигнала, следующие тесты - типовые и
полагаются на использование ограниченного шума в первую очередь для удобства и
повторяемости измерений. Речевые сигналы не использованы в тестах. Тест №1
определяет устойчивый уровень остаточного и возвращенного эха. Этот тест
предполагает проверку того, что устойчивое состояние подавления (оценки
эхосигнала) способно создать достаточно низкий уровень
остаточного эхосигнала .
Требование.
При
условии, что Н регистр первоначально обнуляется и нелинейный процессор
заблокирован, для значений уровня полученного входного сигнала 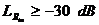 и
и 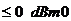 , для
всех величин потери эха больше равно 6 дБ, задержки эхотракта
, для
всех величин потери эха больше равно 6 дБ, задержки эхотракта 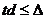 мс (
мс (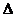 представляет задержку эхотракта
представляет задержку эхотракта 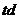 , для
которого разрабатывается эхокомпенсатор), уровень остаточного эхосигнала должен быть меньше или равен зависимости, показанной
на рис. 15.
, для
которого разрабатывается эхокомпенсатор), уровень остаточного эхосигнала должен быть меньше или равен зависимости, показанной
на рис. 15.
Тест
№2 - тест на сходимость.
Этот
тест предполагает проверку того, что эхокомпенсатор сходится быстро для всех
комбинаций уровней входного сигнала, эхотрактов и изменений определенного
эхотракта и что уровень возвращенного эха достаточно низок. Тест также
проверяет, достаточно ли значение устойчивого состояние подавления (ERLE) для создания уровня остаточного эха, который
достаточно низок для разрешения использование нелинейной обработки. В общем,
если все другие переменные не изменяются, более высокий уровень ERLE
или меньшая величина предусмотрят меньшую зависимость от функционирования
нелинейного процессора.
Н
регистр первоначально очищается и адаптация блокируется. Детектор двойного
разговора включается в режим двойного разговора с применением сигналов и . Сигнал
в точке удаляется и одновременно адаптация разблокируется.
Степень адаптации, измеренная уровнем возвращенного эха , будет зависеть от характеристик сходимости
эхокомпенсатора и времени обнаружения двойного разговора.
Задача
теста - очистить Н регистр и заблокировать адаптацию. Сигнал 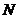 прилагается к уровню
прилагается к уровню  и сигнал
прилагается к точке. Потом удаляется
и одновременно адаптация блокируется рис. 16.
и сигнал
прилагается к точке. Потом удаляется
и одновременно адаптация блокируется рис. 16.
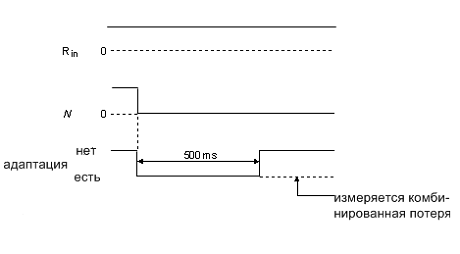
Рис. 16. Проведение теста №2
Спустя
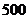 мс блокировка адаптации и измерение уровня
возвращенного эха . Нелинейный процессор должен быть разблокирован.
мс блокировка адаптации и измерение уровня
возвращенного эха . Нелинейный процессор должен быть разблокирован.
Требование.
При
условии, что Н регистр первоначально обнуляется, для всех величин 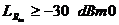 и , и в
течение мс и для всех величин потери эха
и , и в
течение мс и для всех величин потери эха 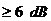 и задержка эхотракта мс.
Комбинированная потеря (
и задержка эхотракта мс.
Комбинированная потеря (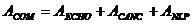 ) будет больше равно 27 дБ.
) будет больше равно 27 дБ.
Тест
№3 - исполнение по условию двойного разговора.
Две
части этого теста предполагают тестировать исполнение компенсатора по различным
условиям. В тестах делается предположение, что с обнаружением двойного
разговора измерения переходят к блокированию или замедлению адаптации, чтобы
избежать чрезмерное затухание в компенсаторе.
Тест
№3а предполагает проверку того, что детектирование (обнаружение двойного
разговора) не так чувствительно при условии, когда эхо и низкий уровень
речевого сигнала от ближнего абонента ложно вызывают операцию детектора
двойного разговора в протяженности, когда адаптация не происходит. Задача теста
- очистить Н регистр; затем для некоторой величины задержки эха и потери эха,
сигнал прилагается к т. . Одновременно рис. 17 сигнал с помехами, который
достаточно низок в уровне, несерьезно препятствующий способности эхокомпенсатора
сходиться, подается в т. . Этот сигнал не должен заставить детектор двойного
разговора (детектор двойного разговора (ДДР) служит для избежания расхождения
эхокомпенсатора во время одновременного разговора обоих абонентов)
активизироваться, должны происходить адаптация и компенсация. Спустя 1 секунду
адаптация тормозит и остаточное эхо измеряется.
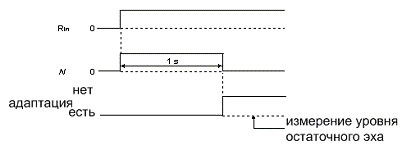
Рис.
17. Регистр Н первоначально обращается в ноль для всех величин 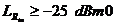 и
и  ,
, 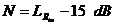 ,
, 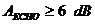 и
задержка эхотракта, мс, сходимость должна произойти в течение 1 сек. и должен быть
и
задержка эхотракта, мс, сходимость должна произойти в течение 1 сек. и должен быть 
Тест
№3b предполагает проверку того, что детектор двойного
разговора достаточно чувствителен и действует достаточно быстро, чтобы
предотвратить большое расхождение во время двойного разговора. Задача теста -
полная сходимость эхокомпенсатора для данного эхотракта. Сигнал после подается
в точку . Одновременно рис. 18 сигнал подается в точку , он
имеет уровень больше, чем . Это должно заставить детектор двойного разговора
включиться в работу. Спустя некоторое произвольное время адаптация блокируется
и измеряется остаточное эхо.
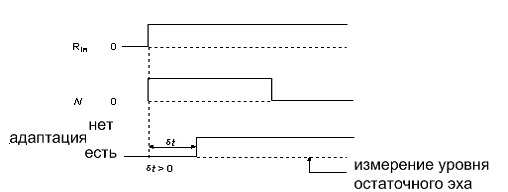
рис.
18. сигнал подается в точку
Требование.
Эхокомпенсатор
первоначально в состоянии полной сходимости для всех величин 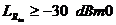 и , и для
всех величин
и , и для
всех величин 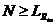 и для всех величин потери эха, и задержка эхотракта мс,
уровень остаточного эха после одновременной подачи и для
некоторого промежутка времени не должен увеличиваться больше, чем на 10 дБ
относительно устойчивого состояния (рис. 7). Тест №4 - Тест на степень
просачивания.
и для всех величин потери эха, и задержка эхотракта мс,
уровень остаточного эха после одновременной подачи и для
некоторого промежутка времени не должен увеличиваться больше, чем на 10 дБ
относительно устойчивого состояния (рис. 7). Тест №4 - Тест на степень
просачивания.
Этот тест предполагает проверку того, что время просачивания не слишком
маленькое, т. е. что содержимое Н регистра не обращается в ноль слишком быстро.
Задача
теста состоит в том, чтобы полностью сходился эхокомпенсатор для данного
эхотракта и чтобы затем удалить все сигналы из эхокомпенсатора. Спустя 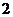 минуты содержимое Н регистра обнуляется, сигнал
подается в точку и измеряется остаточное эхо (см. рис. 11).
минуты содержимое Н регистра обнуляется, сигнал
подается в точку и измеряется остаточное эхо (см. рис. 11).
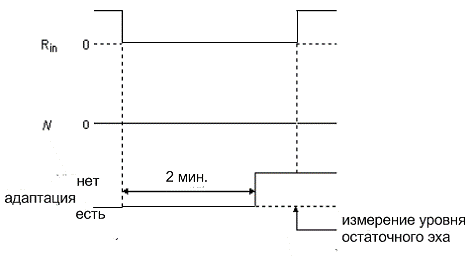
Рис. 19. Тест №4
Требование.
Для
эхокомпенсатора первоначально в состоянии полной сходимости для всех величин и 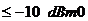 , спустя минуты после удаления сигнала в точке , уровень остаточного эха не должен увеличиваться
больше чем на
, спустя минуты после удаления сигнала в точке , уровень остаточного эха не должен увеличиваться
больше чем на  от устойчивого уровня рис. 19.
от устойчивого уровня рис. 19.
Тест№5
- тест на бесконечную сходимость потери возвращенного эха.
Тест
предполагает проверку того, что эхокомпенсатор имеет некоторые возможности
(средства) для предотвращения нежелательной генерации эха. Это может
происходить, когда Н регистр содержит модель эхотракта, любую из
предшествующего или текущей связи, и эхотракт открывается (цепь эха исчезает),
пока сигнал подан в точку .
Задача
теста - чтобы полостью сходился эхокомпенсатор для данного эхотракта. Эхотракт
после прерывается, пока сигнал подается в точку . Спустя
500 мс прерывания эхотракта должен быть измерен возвращенный эхосигнал в точке рис. 20.
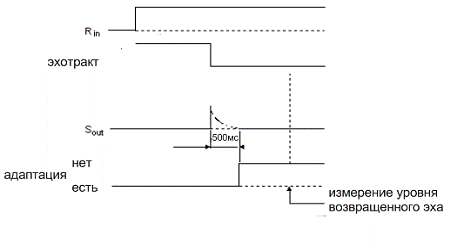
Рис. 20. тест № 5
Требование.
С
эхокомпенсатором первоначально в полностью сходящемся состоянии для всех
величин потери эха и для всех величин и
, уровень возвращенного эха, спустя мс должен быть 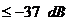 [6].
[6].
2. Тестирование эхокомпенсатора
Протестируем наш эхокомпенсатор по стандарту G. 165:
Тест
№1 определим устойчивый уровень остаточного и возвращенного эха. Этот тест
предполагает проверку того, что устойчивое состояние подавления (оценки
эхосигнала) способно создать достаточно низкий уровень
остаточного эхосигнала .
Требование.
При
условии, что Н регистр первоначально обнуляется и нелинейный процессор
заблокирован, для значений уровня полученного входного сигнала и , для
всех величин потери эха , задержки эхотракта мс ( представляет задержку эхотракта , для которого разрабатывается эхокомпенсатор),
уровень остаточного эхосигнала должен
быть меньше или равен зависимости, показанной на рис. 21.
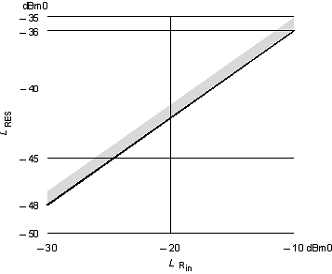
Рис.
21. Зависимость между уровнем принятого входного сигнала (LRin)
и уровнем остаточного эха (LRES)
Уровень
возвращенного эха должен быть меньше 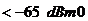 для всех
величин и .
для всех
величин и .
При
проведении первого теста для блочного Фурье метода наименьших квадратов (БФМНК)
и для сравнения нормализованого метода наименьших квадратов(НМНК) получили
такие результаты рис. 22:
То
есть, мы получили, что наш эхокомпенсатор соответствует поставленым требваниям
и при малых отсчётах практически не возникает разницы в выборе алгоритма МНК,
но при дальнейшем увеличении отсчётов НМНК лучше компенсирует эхо чем БФМНК.
Тест
№2 - тест на сходимость. Этот тест предполагает проверку того, что
эхокомпенсатор сходится быстро для всех комбинаций уровней входного сигнала,
эхотрактов и изменений определенного эхотракта и что уровень возвращенного эха
достаточно низок. Тест также проверяет, достаточно ли значение устойчивого
состояние подавления (ERLE) для создания уровня остаточного эха, который
достаточно низок для разрешения использование нелинейной обработки. В общем,
если все другие переменные не изменяются, более высокий уровень ERLE
или меньшая величина предусмотрят меньшую зависимость от функционирования
нелинейного процессора.
Н
регистр первоначально очищается и адаптация блокируется. Детектор двойного
разговора включается в режим двойного разговора с применением сигналов и . Сигнал
в точке удаляется и одновременно адаптация разблокируется.
Степень адаптации, измеренная уровнем возвращенного эха , будет зависеть от характеристик сходимости
эхокомпенсатора и времени обнаружения двойного разговора.
Задача
теста - очистить Н регистр и заблокировать адаптацию. Сигнал прилагается к уровню и сигнал
прилагается к точке.
Спустя
мс блокировка адаптации и измерение уровня
возвращенного эха . Нелинейный процессор должен быть разблокирован.
При
условии, что Н регистр первоначально обнуляется, для всех величин и , и в
течение мс и для всех величин потери эха и задержка эхотракта мс.
Комбинированная потеря () будет 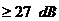 .
.
То
есть и при тесте №2 мы получили, что наш эхокомпенсатор соответствует
поставленным требованиям и при малых отсчётах практически не возникает разницы
в выборе алгоритма МНК, но при дальнейшем увеличении отсчётов НМНК лучше
компенсирует эхо чем БФМНК.
Заключение
В данной работе было рассмотрено применение адаптивных методов обработки
в вопросах эхокомпенсации в телефонии. Были проведены исследования, касающиеся
поведения наиболее распространенного адаптивного метода - БПФ в ситуации
двойного разговора.
Полученные в ходе данной работы результаты могут найти применение в
разработке и модификации существующих систем эхокомпенсации в телефонной связи,
а также при разработке алгоритмов цифровой обработки данных на базе сигнальных
процессоров TMS320.
В дальнейшем приобретенные знания и опыт исследований мы хотели бы
применить на практике, то есть на сигнальных процессорах TMS320.
Литература
1.
Адаптивные
фильтры. / Под ред. К. Ф. Н. Коуэна и П. М. Гранта: Пер. с англ. / Под. ред. С.
М. Ряковского. - М. : Мир, 1988. 392 с.
2.
Беллами Дж.
Цифровая телефония: Пер. с англ. Э. Б. Ершовой, Э. В. Кордонского - М. : Радио
и связь, 1986. 544 с.
3.
ITU-T
Recommendation G. 165. Echo cancellers. 1993.
4.
Брюханов Ю. А. ,
Цифровые цепи и сигналы: Учеб. пособие. Ярославль, 1999. 152 с.
5.
Уидроу Б. ,
Стирнз С. Адаптивная обработка сигналов: Пер. с англ. под. ред. В. В.
Шахгильдяна - М. : Радио и связь, 1989. 440 с.
6.
Gansler
T. , Gay S. L. , Sondhi M. M. , Double-Talk Robust Fast Converging Algorithms
for Network Echo Cancellation // IEEE Workshop on Applications of Signal
Processing to Audio and Acoustics. 1999. P. W99-1-W99-4.
http://psi-logic.
narod. ru/fft <http://psi-logic.narod.ru/fft> Echocompensation and noise
suppression for speech recognition applications (Dr. Walter Stammler, Matthias
Schulz and Frank Scheppach). 2000.