Физическая организация различных файловых систем
Министерство образования и науки
Российской Федерации
Федеральное агентство по образованию
Государственное образовательное
учреждение
Высшего профессионального образования
"Северо-Кавказский
государственный технический университет"
Курсовая работа
по дисциплине:
"Теоретические основы
компьютерной безопасности"
на тему:
"Физическая организация
различных файловых систем"
Выполнил: Студент Марков Д.М.
Группа БАС-081, 3 курс
Проверил: к. т. н., доцент Гайчук Д.В.
г. Ставрополь, 2011
Содержание
Введение
1. Теоретическая часть
1.1 Организация хранения информации на накопителях
1.2 Цели и задачи файловой системы
1.3 Физическая организация и адресация файла
1.4 Физическая организация файловой системы FAT
1.6 Физическая организация файловой системы NTFS
1.5 Физическая организация файловых систем ext2, ext3, ext4
2. Аналитическая часть
2.1 Общие сведения о матричных принтерах
2.2 Проектирование символов для матричных принтеров
2.3 Проектирование символов
Заключение
Список использованной литературы
Приложение 1
Приложение 2
Приложение 3
Приложение 4
Введение
В современной жизни, нередко необходимо созданный в
электронном варианте текст или результаты какой-то другой работы перенести на
бумажный носитель. Для выполнения данной задачи служит принтер, различают
матричные, лазерные и струйные принтеры.
Матричные принтеры обладают рядом недостатков: высокий шум
при работе, низкая скорость печати, отсутствие возможности печати в цвете, но,
несмотря на данные недостатки, данные принтеры до сих пор находят достаточно
широкое применение, так как данные принтеры обладают невысокой стоимостью,
простотой эксплуатации и высокой надёжностью в работе. Кроме того матричные
принтеры позволяют печатать практически на любой бумаге.
Как правило, для обеспечения возможности использования
принтера в прикладных программных пакетах используются специально разработанные
программы управления (драйверы). Такие программы осуществляют операции по
преобразованию данных и выводу их на принтер.
Для разработки драйверов необходимо знать сам
язык управления принтером (набор команд), специфических для конкретного
принтера. Команды управления принтером позволяют задать размер символов,
воспроизводимых при печати, расстояние между строками текста, начертание
отдельных литер и другие параметры.
Целью курсовой работы является ознакомление с приемами
управления работой печатающих устройств в MS-DOS.
Задачей курсовой работы является формирование новых символов
для матричного принтера, разработка команд для загрузки символов в оперативную
память принтера и программы, реализующей процесс печати новых символов.
1.
Теоретическая часть
1.1
Организация хранения информации на накопителях
Жесткий диск состоит из одной или нескольких стеклянных или
металлических пластин, каждая из которых покрыта с одной или двух сторон
магнитным материалом. Таким образом, диск в общем случае состоит из пакета
пластин (рисунок 1).
На каждой стороне каждой пластины размечены тонкие
концентрические кольца - дорожки (traks), на которых хранятся данные.
Количество дорожек зависит от типа диска. Нумерация дорожек начинается с 0 от
внешнего края к центру диска. Когда диск вращается, элемент, называемый
головкой, считывает двоичные данные с магнитной дорожки или записывает их на
магнитную дорожку.
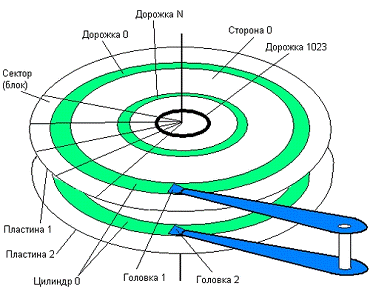
Рисунок 1 - Схема устройства жесткого диска
Головка может позиционироваться над заданной дорожкой.
Головки перемещаются над поверхностью диска дискретными шагами, каждый шаг
соответствует сдвигу на одну дорожку. Запись на диск осуществляется благодаря
способности головки изменять магнитные свойства дорожки. Для поиска информации
головка должна перемещаться по радиусу диска. Обычно все головки закреплены на
едином перемещающем механизме и двигаются синхронно. Поэтому, когда головка
фиксируется на заданной дорожке одной поверхности, все остальные головки
останавливаются над дорожками с такими же номерами.
Совокупность дорожек одного радиуса на всех поверхностях всех
пластин пакета называется цилиндром (cylinder). Каждая дорожка разбивается на
фрагменты, называемые секторами (sectors), или блоками (blocks), так что все дорожки
имеют равное число секторов, в которые можно максимально записать одно и то же
число байт (иногда внешняя дорожка имеет несколько дополнительных секторов,
используемых для замены поврежденных секторов в режиме горячего
резервирования).
Сектор имеет фиксированный для конкретной системы размер,
выражающийся степенью двойки. Чаще всего размер сектора составляет 512 байт.
Учитывая, что дорожки разного радиуса имеют одинаковое число секторов,
плотность записи становится тем выше, чем ближе дорожка к центру.
Сектор - наименьшая адресуемая единица обмена данными
дискового устройства с оперативной памятью. Для того чтобы контроллер мог найти
на диске нужный сектор, необходимо задать ему все составляющие адреса сектора:
номер цилиндра, номер поверхности и номер сектора. Так как прикладной программе
в общем случае нужен не сектор, а некоторое количество байт, не обязательно
кратное размеру сектора, то типичный запрос включает чтение нескольких секторов,
содержащих требуемую информацию, и одного или двух секторов, содержащих наряду
с требуемыми данными избыточные (рисунок 2).
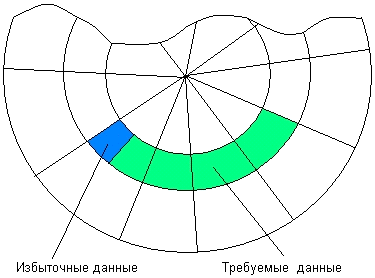
Рисунок 2 - Считывание избыточных данных при обмене с диском
Операционная система при работе с диском использует, как
правило, собственную единицу дискового пространства, называемую кластером
(cluster). При создании файла место на диске ему выделяется кластерами.
Например, если файл имеет размер 2560 байт, а размер кластера в файловой системе
определен в 1024 байта, то файлу будет выделено на диске 3 кластера.
Дорожки и секторы создаются в результате выполнения процедуры
физического, или низкоуровневого, форматирования диска, предшествующей
использованию диска. Для определения границ блоков на диск записывается
идентификационная информация. Низкоуровневый формат диска не зависит от типа
операционной системы, которая этот диск будет использовать.
Разметку диска под конкретный тип файловой системы выполняют
процедуры высокоуровневого, или логического, форматирования. При
высокоуровневом форматировании определяется размер кластера и на диск
записывается информация, необходимая для работы файловой системы, в том числе
информация о доступном и неиспользуемом пространстве, о границах областей, отведенных
под файлы и каталоги, информация о поврежденных областях. Кроме того, на диск
записывается загрузчик операционной системы.
Прежде чем форматировать диск под определенную файловую
систему, он может быть разбит на разделы.
Раздел - это непрерывная часть физического диска, которую
операционная система представляет пользователю как логическое устройство
(используются также названия логический диск и логический раздел). Во многих
операционных системах используется термин "том" (volume). В разных ОС
толкование этого термина имеет свои нюансы, но чаще всего он обозначает
логическое устройство, отформатированное под конкретную файловую систему.
Логическое устройство функционирует так, как если бы это был
отдельный физический диск. Именно с логическими устройствами работает
пользователь, обращаясь к ним по символьным именам, используя, например,
обозначения А, В, С, SYS и т.п. Операционные системы разного типа используют
единое для всех них представление о разделах, но создают на его основе
логические устройства, специфические для каждого типа ОС. Так же как файловая
система, с которой работает одна ОС, в общем случае не может интерпретироваться
ОС другого типа, логические устройства не могут быть использованы операционными
системами разного типа. На каждом логическом устройстве может создаваться
только одна файловая система.
На разных логических устройствах одного и того же физического
диска могут располагаться файловые системы разного типа. На рисунке 3 показан
пример диска, разбитого на три раздела, в которых установлены две файловых
системы NTFS (разделы С и Е) и одна файловая система FAT (раздел D).
Все разделы одного диска имеют одинаковый размер блока,
определенный для данного диска в результате низкоуровневого форматирования.
Однако в результате высокоуровневого форматирования в разных разделах одного и
того же диска, представленных разными логическими устройствами, могут быть
установлены файловые системы, в которых определены кластеры отличающихся
размеров.
Операционная система может поддерживать разные статусы
разделов, особым образом отмечая разделы, которые могут быть использованы для
загрузки модулей операционной системы, и разделы, в которых можно устанавливать
только приложения и хранить файлы данных. Один из разделов диска помечается как
загружаемый (или активный). Именно из этого раздела считывается загрузчик
операционной системы.
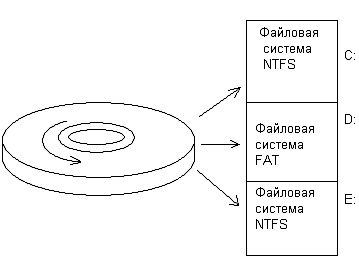
Рисунок 3 - Разбиение диска на разделы
1.2 Цели и
задачи файловой системы
Файл - это именованная область внешней памяти, в которую можно
записывать и из которой можно считывать данные. Файлы хранятся в памяти,
независящей от энергопитания, обычно - на магнитных дисках.
Файловая система (далее по тексту ФС) - это часть
операционной системы, включающая:
- совокупность всех файлов на диске;
- наборы структур данных, используемых для
управления файлами, такие, например, как каталоги файлов, дескрипторы файлов,
таблицы распределения свободного и занятого пространства на диске;
файловая система печатающее устройство
- комплекс системных программных средств,
реализующих различные операции над файлами, такие как создание, уничтожение,
чтение, запись, именование и поиск файлов.
Файловая система позволяет программам обходиться набором
достаточно простых операций для выполнения действий над некоторым абстрактным
объектом, представляющим файл. При этом программистам не нужно иметь дело с
деталями действительного расположения данных на диске, буферизацией данных и
другими низкоуровневыми проблемами передачи данных с долговременного
запоминающего устройства. Все эти функции файловая система берет на себя.
Файловая система распределяет дисковую память, поддерживает именование файлов,
отображает имена файлов в соответствующие адреса во внешней памяти,
обеспечивает доступ к данным, поддерживает разделение, защиту и восстановление
файлов.
Таким образом, файловая система играет роль промежуточного
слоя, экранирующего все сложности физической организации долговременного
хранилища данных, и создающего для программ более простую логическую модель
этого хранилища, а также предоставляя им набор удобных в использовании команд
для манипулирования файлами.
Задачи, решаемые ФС, зависят от способа организации
вычислительного процесса в целом. Самый простой тип - это ФС в
однопользовательских и однопрограммных ОС, к числу которых относится, например,
MS-DOS. Основные функции ОС в такой ФС нацелены на решение следующих задач:
- именование файлов;
- программный интерфейс для приложений;
- отображения логической модели файловой
системы на физическую организацию хранилища данных;
- устойчивость файловой системы к сбоям
питания, ошибкам аппаратных и программных средств.
Задачи ФС усложняются в операционных однопользовательских
мультипрограммных ОС, которые, хотя и предназначены для работы одного
пользователя, но дают ему возможность запускать одновременно несколько
процессов. К перечисленным выше задачам добавляется новая задача совместного
доступа к файлу из нескольких процессов. Файл в этом случае является
разделяемым ресурсом, а значит, файловая система должна решать весь комплекс
проблем, связанных с такими ресурсами. В частности, в ФС должны быть
предусмотрены средства блокировки файла и его частей, предотвращения гонок,
исключение тупиков, согласование копий и т.п.
В многопользовательских системах появляется еще одна задача:
защита файлов одного пользователя от несанкционированного доступа другого
пользователя и ещё более сложными становятся функции ФС, которая работает в
составе сетевой ОС.
1.3
Физическая организация и адресация файла
Важным компонентом физической организации файловой системы
является физическая организация файла, то есть способ размещения файла на
диске. Основными критериями эффективности физической организации файлов
являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового
пространства;
- максимально возможный размер файла.
Непрерывное размещение - простейший вариант физической
организации (рисунок 4, а), при котором файлу предоставляется
последовательность кластеров диска, образующих непрерывный участок дисковой
памяти. Основным достоинством этого метода является высокая скорость доступа,
так как затраты на поиск и считывание кластеров файла минимальны. Также
минимален объем адресной информации - достаточно хранить только номер первого
кластера и объем файла. Данная физическая организация максимально возможный
размер файла не ограничивает. Однако этот вариант имеет существенные
недостатки, которые затрудняют его применимость на практике, несмотря на всю
его логическую простоту. Файл может постоянно изменяться и изменять свой
размер, при этом область под файл будет выделена в момент его создания, и
следовательно дальнейшее увеличение объема невозможно, т.к. скорее всего
следующие кластеры будут заняты другими файлами. Ещё одной проблемой является
фрагментация, т.к. в результате многочисленных операций добавления и удаления
файлов пространство диска со временем будет похоже на "лоскутное
одеяло", что приведёт к тому, что суммарный объем свободной памяти может
быть очень большим, а выбрать место для размещения файла целиком невозможно.
Поэтому на практике используются методы, в которых файл размещается в
нескольких, в общем случае несмежных областях диска.
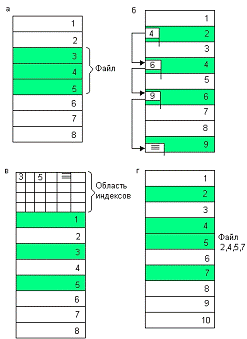
Рисунок 4 - Физическая организация файла: непрерывное
размещение (а); связанный список кластеров (б); связанный список индексов (в);
перечень номеров кластеров (г)
Следующий способ физической организации - размещение файла в
виде связанного списка кластеров дисковой памяти (рисунок 4, б). При таком
способе в начале каждого кластера содержится указатель на следующий кластер. В
этом случае адресная информация минимальна: расположение файла может быть
задано одним числом - номером первого кластера. В отличие от предыдущего
способа каждый кластер может быть присоединен к цепочке кластеров какого-либо
файла, следовательно, фрагментация на уровне кластеров отсутствует. Файл может
изменять свой размер во время своего существования, наращивая число кластеров.
Недостатком является сложность реализации доступа к произвольно заданному месту
файла - чтобы прочитать пятый по порядку кластер файла, необходимо
последовательно прочитать четыре первых кластера, прослеживая цепочку номеров
кластеров. Кроме того, при этом способе количество данных файла, содержащихся в
одном кластере, не равно степени двойки (одно слово израсходовано на номер
следующего кластера), а многие программы читают данные кластерами, размер
которых равен степени двойки.
Популярным способом, применяемым, например, в файловой
системе FAT, является использование связанного списка индексов (рисунок 4, в).
Файлу выделяется память в виде связанного списка кластеров. Номер первого
кластера запоминается в записи каталога, где хранятся характеристики этого
файла. Остальная адресная информация отделена от кластеров файла. С каждым
кластером диска связывается некоторый элемент - индекс. Индексы располагаются в
отдельной области диска - в MS-DOS это таблица FAT (File Allocation Table),
занимающая один кластер. Когда память свободна, все индексы имеют нулевое
значение. Если некоторый кластер N назначен некоторому файлу, то индекс этого
кластера становится равным, либо номеру М следующего кластера данного файла,
либо принимает специальное значение, являющееся признаком того, что этот
кластер является для файла последним. Индекс же предыдущего кластера файла
принимает значение N, указывая на вновь назначенный кластер.
При такой физической организации сохраняются все достоинства
предыдущего способа: минимальность адресной информации, отсутствие
фрагментации, отсутствие проблем при изменении размера. Кроме того, данный
способ обладает дополнительными преимуществами. Во-первых, для доступа к
произвольному кластеру файла не требуется последовательно считывать его
кластеры, достаточно прочитать только секторы диска, содержащие таблицу индексов,
отсчитать нужное количество кластеров файла по цепочке и определить номер
нужного кластера. Во-вторых, данные файла заполняют кластер целиком, а значит,
имеют объем, равный степени двойки.
Необходимо отметить, что при отсутствии фрагментации на
уровне кластеров на диске все равно имеется определенное количество областей
памяти небольшого размера, которые невозможно использовать, то есть
фрагментация все же существует. Эти фрагменты представляют собой неиспользуемые
части последних кластеров, назначенных файлам, поскольку объем файла в общем
случае не кратен размеру кластера.
Еще один способ задания физического расположения файла
заключается в простом перечислении номеров кластеров, занимаемых этим файлом
(рисунок 4, г). Этот перечень и служит адресом файла. Недостаток данного
способа очевиден: длина адреса зависит от размера файла и для большого файла
может составить значительную величину. Достоинством же является высокая
скорость доступа к произвольному кластеру файла, так как здесь применяется
прямая адресация, которая исключает просмотр цепочки указателей при поиске
адреса произвольного кластера файла. Фрагментация на уровне кластеров в этом
способе также отсутствует.
Метод перечисления адресов кластеров файла задействован в
файловой системе NTFS. Здесь он дополнен достаточно естественным приемом,
сокращающим объем адресной информации: адресуются не кластеры файла, а
непрерывные области, состоящие из смежных кластеров диска. Каждая такая
область, называемая отрезком (run), или экстентом (extent), описывается с
помощью двух чисел: начального номера кластера и количества кластеров в
отрезке. Для того чтобы корректно принимать решение о выделении файлу набора
кластеров, файловая система должна отслеживать информацию о состоянии всех
кластеров диска: свободен/занят. Эта информация может храниться как отдельно от
адресной информации файлов, так и вместе с ней.
1.4
Физическая организация файловой системы FAT
Логический раздел, отформатированный под файловую систему
FAT, состоит из следующих областей (рисунок 5).
- Загрузочный сектор содержит программу
начальной загрузки операционной системы. Вид этой программы зависит от типа
операционной системы, которая будет загружаться из этого раздела.
- Основная копия FAT содержит информацию о
размещении файлов и каталогов на диске.
- Резервная копия FAT.
- Корневой каталог занимает фиксированную
область размером в 32 сектора (16 Кбайт), что позволяет хранить 512 записей о
файлах и каталогах, так как каждая запись каталога состоит из 32 байт.
- Область данных предназначена для
размещения всех файлов и всех каталогов, кроме корневого каталога.

Рисунок 5 - Физическая структура файловой системы FAT
Файловая система FAT поддерживает всего два типа файлов:
обычный файл и каталог. Файловая система распределяет память только из области
данных, причем использует в качестве минимальной единицы дискового пространства
кластер.
Таблица FAT (как основная копия, так и резервная) состоит из
массива индексных указателей, количество которых равно количеству кластеров
области данных. Между кластерами и индексными указателями имеется взаимно
однозначное соответствие - нулевой указатель соответствует нулевому кластеру и
т.д.
Индексный указатель может принимать следующие значения,
характеризующие состояние связанного с ним кластера:
- кластер свободен (не используется);
- кластер используется файлом и не является
последним кластером файла; в этом случае индексный указатель содержит номер
следующего кластера файла;
- последний кластер файла;
- дефектный кластер;
- резервный кластер.
Таблица FAT является общей для всех файлов раздела. В
исходном состоянии (после форматирования) все кластеры раздела свободны и все
индексные указатели (кроме тех, которые соответствуют резервным и дефектным
блокам) принимают значение "кластер свободен". При размещении файла
ОС просматривает FAT, начиная с начала, и ищет первый свободный индексный
указатель. После его обнаружения в поле записи каталога "номер первого
кластера" фиксируется номер этого указателя. В кластер с этим номером
записываются данные файла, он становится первым кластером файла. Если файл
умещается в одном кластере, то в указатель, соответствующий данному кластеру,
заносится специальное значение "последний кластер файла". Если же
размер файла больше одного кластера, то ОС продолжает просмотр FAT и ищет
следующий указатель на свободный кластер. После его обнаружения в предыдущий
указатель заносится номер этого кластера, который теперь становится следующим
кластером файла. Процесс повторяется до тех пор, пока не будут размещены все
данные файла. Таким образом, создается связный список всех кластеров файла.
В начальный период после форматирования файлы будут
размещаться в последовательных кластерах области данных, однако после
определенного количества удалений файлов кластеры одного файла окажутся в
произвольных местах области данных, чередуясь с кластерами других файлов
(рисунок 6).
Размер таблицы FAT и разрядность используемых в ней индексных
указателей определяется количеством кластеров в области данных. Для уменьшения
потерь из-за фрагментации желательно кластеры делать небольшими, а для
сокращения объема адресной информации и повышения скорости обмена наоборот -
чем больше, тем лучше. При форматировании диска под файловую систему FAT обычно
выбирается компромиссное решение, и размеры кластеров выбираются из диапазона
от 1 до 128 секторов, или от 512 байт до 64 Кбайт.
Очевидно, что разрядность индексного указателя должна быть
такой, чтобы в нем можно было задать максимальный номер кластера для диска
определенного объема. Существует несколько разновидностей FAT, отличающихся
разрядностью индексных указателей, которая и используется в качестве условного
обозначения: FAT12, FAT16 и FAT32. В файловой системе FAT12 используются
12-разрядные указатели, что позволяет поддерживать до 4096 кластеров в области
данных диска, в FAT16 - 16-разрядные указатели для 65 536 кластеров и в FAT32 -
32-разрядные для более чем 4 миллиардов кластеров.
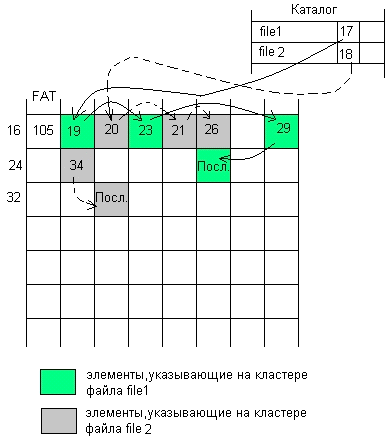
Рисунок 6 - Списки указателей файлов в FAT
Таблица FAT при фиксированной разрядности индексных
указателей имеет переменный размер, зависящий от объема области данных диска.
При удалении файла из файловой системы FAT в первый байт
соответствующей записи каталога заносится специальный признак, свидетельствующий
о том, что эта запись свободна, а во все индексные указатели файла заносится
признак "кластер свободен". Остальные данные в записи каталога, в том
числе номер первого кластера файла, остаются нетронутыми, что оставляет шансы
для восстановления ошибочно удаленного файла.
Резервная копия FAT всегда синхронизируется с основной копией
при любых операциях с файлами, поэтому резервную копию нельзя использовать для
отмены ошибочных действий пользователя, выглядевших с точки зрения системы
вполне корректными. Резервная копия может быть полезна только в том случае,
когда секторы основной памяти оказываются физически поврежденными и не
читаются.
Используемый в FAT метод хранения адресной информации о
файлах не отличается большой надежностью - при разрыве списка индексных
указателей в одном месте, например из-за сбоя в работе программного кода ОС по
причине внешних электромагнитных помех, теряется информация обо всех
последующих кластерах файла.
1.6
Физическая организация файловой системы NTFS
Файловая система NTFS была разработана в качестве основной
файловой системы для ОС Windows NT в начале 90-х годов.
Основными отличительными свойствами NTFS являются:
- поддержка больших файлов (теоретически до
16 Терабайт) и больших дисков (264 байт);
- восстанавливаемость после сбоев и отказов
программ и аппаратуры управления дисками;
- высокая скорость операций, в том числе и
для больших дисков;
- низкий уровень фрагментации, в том числе и
для больших дисков;
- гибкая структура, допускающая развитие за
счет добавления новых типов записей и атрибутов файлов с сохранением
совместимости с предыдущими версиями ФС;
- устойчивость к отказам дисковых
накопителей;
- поддержка длинных символьных имен;
- контроль доступа к каталогам и отдельным
файлам.
В отличие от разделов FAT все пространство тома NTFS
представляет собой либо файл, либо часть файла. Основой структуры тома NTFS
является главная таблица файлов (Master File Table, MFT), которая содержит, по
крайней мере, одну запись для каждого файла тома, включая одну запись для самой
себя. Каждая запись MFT имеет фиксированную длину, зависящую от объема диска, -
1,2 или 4 Кбайт. Для большинства дисков, используемых сегодня, размер записи
MFT равен 2 Кбайт, который далее будет считаться размером записи по умолчанию.
Все файлы на томе NTFS идентифицируются номером файла,
который определяется позицией файла в MFT.
Весь том NTFS состоит из последовательности кластеров, что
отличает эту файловую систему от рассмотренных ранее, где на кластеры делилась
только область данных. Порядковый номер кластера в томе NTFS называется
логическим номером кластера (Logical Cluster Number, LCN). Файл NTFS также
состоит из последовательности кластеров, при этом порядковый номер кластера
внутри файла называется виртуальным номером кластера (Virtual Cluster Number,
VCN).
Базовая единица распределения дискового пространства для
файловой системы NTFS - непрерывная область кластеров, называемая отрезком. В
качестве адреса отрезка NTFS использует логический номер его первого кластера,
а также количество кластеров в отрезке k, то есть пара (LCN, k). Таким образом,
часть файла, помещенная в отрезок и начинающаяся с виртуального кластера VCN,
характеризуется адресом, состоящим из трех чисел: (VCN, LCN, k).
Для хранения номера кластера в NTFS используются 64-разрядные
указатели, что дает возможность поддерживать тома и файлы размером до 264
кластеров. При размере кластера в 4 Кбайт это позволяет использовать тома и
файлы, состоящие из 64 миллиардов килобайт.
Структура тома NTFS показана на рисунке 8. Загрузочный блок
тома NTFS располагается в начале тома, а его копия - в середине тома.
Загрузочный блок содержит стандартный блок параметров BIOS, количество блоков в
томе, а также начальный логический номер кластера основной копии MFT и
зеркальную копию MFT.
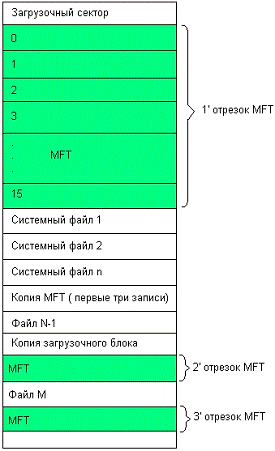
Рисунок 8 - Структура тома NTFS
Далее располагается первый отрезок MFT, содержащий 16
стандартных, создаваемых при форматировании записей о системных файлах NTFS.
Назначение этих файлов описано в показанной ниже таблице MFT (таблица 1).
|
Номер записи
|
Системный файл
|
Имя файла
|
Назначение
файла
|
|
0
|
Главная таблица
файлов
|
$Mft
|
Содержит полный
список файлов тома NTFS
|
|
1
|
Копия главной
таблицы файлов
|
SMftMirr
|
Зеркальная
копия первых трех записей MFT
|
|
2
|
Файл журнала
|
SLogFile
|
Список
транзакций, который используется для восстановления файловой системы после
сбоев
|
|
3
|
Том
|
SVolume
|
Имя тома,
версия NTFS и другая информация о томе
|
|
4
|
Таблица
определения атрибутов
|
SAttrDef
|
Таблица имен,
номеров и описаний атрибутов
|
|
5
|
Индекс
корневого каталога
|
$.
|
Корневой
каталог
|
|
6
|
Битовая карта
кластеров
|
SBitmap
|
Разметка
использованных кластеров тома
|
|
7
|
Загрузочный
сектор раздела
|
SBoot
|
Адрес
загрузочного сектора раздела
|
|
8
|
Файл плохих
кластеров
|
SBadClus
|
Файл,
содержащий список всех обнаруженных на томе плохих кластеров
|
|
9
|
Таблица квот
|
SQuota
|
Квоты
используемого пространства на диске для каждого пользователя
|
|
10
|
Таблица
преобразования регистра символов
|
SUpcase
|
Используется
для преобразования регистра символов для кодировки Unicode
|
|
11-15
|
Зарезервированы
для будущего использования
|
|
|
В NTFS файл целиком размещается в записи таблицы MFT, если
это позволяет сделать его размер. В том же случае, когда размер файла больше
размера записи MFT, в запись помещаются только некоторые атрибуты файла, а
остальная часть файла размещается в отдельном отрезке тома (или нескольких
отрезках). Часть файла, размещаемая в записи MFT, называется резидентной
частью, а остальные части - нерезидентными. Адресная информация об отрезках,
содержащих нерезидентные части файла, размещается в атрибутах резидентной
части.
Некоторые системные файлы являются полностью резидентными, а
некоторые имеют и нерезидентные части, которые располагаются после первого
отрезка MFT. Нулевая запись MFT содержит описание самой MFT, в том числе и
такой ее важный атрибут, как адреса всех ее отрезков. После форматирования MFT
состоит из одного отрезка, но после создания первого несистемного файла для
хранения его атрибутов требуется еще один отрезок, так как изначально
непрерывная последовательность кластеров MFT уже завершена системными файлами.
Из приведенного описания видно, что сама таблица MFT
рассматривается как файл, к которому применим метод размещения в томе в виде
набора произвольно расположенных нескольких отрезков.
Каждый файл и каталог на томе NTFS состоит из набора
атрибутов. Важно отметить, что имя файла и его данные также рассматриваются как
атрибуты файла, то есть в трактовке NTFS, кроме атрибутов у файла нет никаких
других компонентов.
Каждый атрибут файла NTFS состоит из полей: тип атрибута,
длина атрибута, значение атрибута и, возможно, имя атрибута. Тип атрибута,
длина и имя образуют заголовок атрибута.
Имеется системный набор атрибутов, определяемых структурой
тома NTFS. Системные атрибуты имеют фиксированные имена и коды их типа, а также
определенный формат. Могут применяться также атрибуты, определяемые
пользователями. Их имена, типы и форматы задаются исключительно пользователем.
Атрибуты файлов упорядочены по убыванию кода атрибута, причем атрибут одного и
того же типа может повторяться несколько раз. Существуют два способа хранения
атрибутов файла - резидентное хранение в записях таблицы MFT и нерезидентное
хранение вне ее, во внешних отрезках. Таким образом, резидентная часть файла
состоит из резидентных атрибутов, а нерезидентная - из нерезидентных атрибутов.
Сортировка может осуществляться только по резидентным атрибутам.
Системный набор включает следующие атрибуты:
- Attribute List (список атрибутов) - список
атрибутов, из которых состоит файл; содержит ссылки на номер записи MFT, где
расположен каждый атрибут; этот редко используемый атрибут нужен только в том
случае, если атрибуты файла не умещаются в основной записи и занимают
дополнительные записи MFT;
- File Name (имя файла) - этот атрибут
содержит длинное имя файла в формате Unicode, а также номер входа в таблице MFT
для родительского каталога; если этот файл содержится в нескольких каталогах,
то у него будет несколько атрибутов типа File Name; этот атрибут всегда должен
быть резидентным;
- MS-DOS Name (имя MS-DOS) - этот атрибут
содержит имя файла в формате 8.3;
- Version (версия) - атрибут содержит номер
последней версии файла;
- Security Descriptor (дескриптор
безопасности) - этот атрибут содержит информацию о защите файла: список прав
доступа ACL и поле аудита, которое определяет, какого рода операции над этим
файлом нужно регистрировать;
- Volume Version (версия тома) - версия
тома, используется только в системных файлах тома;
- Volume Name (имя тома) - имя тома;
- Data (данные) - содержит обычные данные
файла;
- MFT bitmap (битовая карта MFT) - этот
атрибут содержит карту использования блоков на томе;
- Index Root (корень индекса) - корень
В-дерева, используемого для поиска файлов в каталоге;
- Index Allocation (размещение индекса) -
нерезидентные части индексного списка В-дерева;
- Standard Information (стандартная
информация) - этот атрибут хранит всю остальную стандартную информацию о файле,
которую трудно связать с каким-либо другим атрибутом файла, например, время
создания файла, время обновления и другие.
Файлы NTFS в зависимости от способа размещения делятся на
небольшие, большие, очень большие и сверхбольшие.
Небольшие файлы (small). Если файл имеет небольшой размер, то
он может целиком располагаться внутри одной записи MFT, имеющей, например,
размер 2 Кбайт. Небольшие файлы NTFS состоят, по крайней мере, из следующих
атрибутов (рисунок 9):
- стандартная информация (SI - standard
information);
- имя файла (FN - file name);
- данные (Data);
- дескриптор безопасности (SD - security
descriptor).
Из-за того что файл может иметь переменное количество
атрибутов, а также из-за переменного размера атрибутов нельзя наверняка
утверждать, что файл уместится внутри записи. Однако обычно файлы размером
менее 1500 байт помещаются внутри записи MFT (размером 2 Кбайт).

Рисунок 9 - Небольшой файл NTFS
Большие файлы (large). Если данные файла не помещаются в одну
запись MFT, то этот факт отражается в заголовке атрибута Data, который
содержит признак того, что этот атрибут является нерезидентным, то есть
находится в отрезках вне таблицы MFT. В этом случае атрибут Data содержит
адресную информацию (LCN, VCN, k) каждого отрезка данных (рисунок 10).
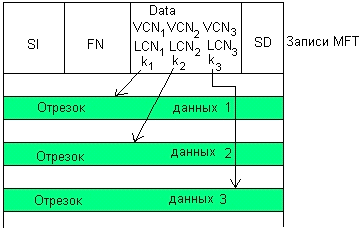
Рисунок 10 - Большой файл
Очень большие файлы (huge). Если файл настолько велик, что
его атрибут данных, хранящий адреса нерезидентных отрезков данных, не
помещается в одной записи, то этот атрибут помещается в другую запись MFT, а
ссылка на такой атрибут помещается в основную запись файла (рисунок 11). Эта
ссылка содержится в атрибуте Attribute List. Сам атрибут данных по-прежнему
содержит адреса нерезидентных отрезков данных.
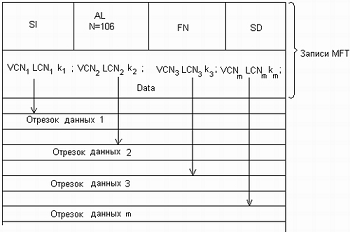
Рисунок 11 - Очень большой файл
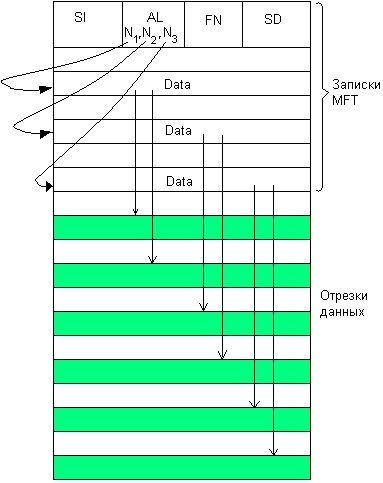
Рисунок 12 - Сверхбольшой файл
Сверхбольшие файлы (extremely huge). Для сверхбольших файлов
в атрибуте Attribute List можно указать несколько атрибутов, расположенных в
дополнительных записях MFT (рисунок 12). Кроме того, можно использовать двойную
косвенную адресацию, когда нерезидентный атрибут будет ссылаться на другие
нерезидентные атрибуты, поэтому в NTFS не может быть атрибутов, слишком большой
для системы длины.
Каждый каталог NTFS представляет собой один вход в таблицу
MFT, который содержит атрибут Index Root. Индекс содержит список файлов, входящих
в каталог. Индексы позволяют сортировать файлы для ускорения поиска,
основанного на значении определенного атрибута. Обычно в файловых системах
файлы сортируются по имени. NTFS позволяет использовать для сортировки любой
атрибут, если он хранится в резидентной форме.
Имеются две формы хранения списка файлов.
Небольшие каталоги (small indexes). Если количество файлов в
каталоге невелико, то список файлов может быть резидентным в записи в MFT,
являющейся каталогом (рисунок 13). Для резидентного хранения списка
используется единственный атрибут - Index Root. Список файлов содержит значения
атрибутов файла. По умолчанию - это имя файла, а также номер записи MTF,
содержащей начальную запись файла.

Рисунок 13 - Небольшой каталог
Большие каталоги (large indexes). По мере того как каталог
растет, список файлов может потребовать нерезидентной формы хранения. Однако
начальная часть списка всегда остается резидентной в корневой записи каталога в
таблице MFT (рисунок 14). Имена файлов резидентной части списка файлов являются
узлами, так называемого В-дерева (двоичного дерева). Остальные части списка
файлов размещаются вне MFT. Для их поиска используется специальный атрибут
Index Allocation, представляющий собой адреса отрезков, хранящих остальные
части списка файлов каталога. Одни части списков являются листьями дерева, а
другие являются промежуточными узлами, то есть содержат наряду с именами файлов
атрибут Index Allocation, указывающий на списки файлов более низких уровней.

Рисунок 14 - Большой каталог
Узлы двоичного дерева делят весь список файлов на несколько
групп. Имя каждого файла-узла является именем последнего файла в
соответствующей группе.
Поиск в каталоге уникального имени файла, которым в NTFS
является номер основной записи о файле в MFT, по его символьному имени
происходит следующим образом. Сначала искомое символьное имя сравнивается с
именем первого узла в резидентной части индекса. Если искомое имя меньше, то
это означает, что его нужно искать в первой нерезидентной группе, для чего из
атрибута Index Allocation извлекается адрес отрезка (VCNj, LCNj Kj), хранящего имена файлов
первой группы. Среди имен этой группы поиск осуществляется прямым перебором
имен и сравнением до полного совпадения всех символов искомого имени с
хранящимся в каталоге именем. При совпадении из каталога извлекается номер
основной записи о файле в MFT и остальные характеристики файла берутся уже
оттуда.
Если же искомое имя больше имени первого узла резидентной
части индекса, то его сравнивают с именем второго узла, и если искомое имя
меньше, то описанная процедура применяется ко второй нерезидентной группе имен,
и т.д.
В результате вместо перебора большого количества имен (в
худшем случае - всех имен каталога) выполняется сравнение с гораздо меньшим
количеством имен узлов и имен в одной из групп каталога.
Если одна из групп каталога становится слишком большой, то ее
также делят на группы, последние имена каждой новой группы оставляют в исходном
нерезидентном атрибуте Index Root, а все остальные имена новых групп переносят
в новые нерезидентные атрибуты типа Index Root (на рисунке этот случай не
показан). К исходному нерезидентному атрибуту Index Root добавляется атрибут
размещения индекса, указывающий на отрезки индекса новых групп. Если теперь при
поиске искомого имени в нерезидентной части индекса первого уровня какое-либо
сравнение показывает, что искомое имя оказывается меньше, чем одно из
хранящихся там имен, то это говорит о том, что в данном атрибуте точного
сравнения имени уже быть не может и нужно перейти к подгруппе имен следующего
уровня дерева.
1.5
Физическая организация файловых систем ext2, ext3, ext4
Как и в любой файловой системе UNIX, в составе ext2 можно
выделить следующие составляющие:
- блоки и группы блоков;
- индексный дескриптор;
- суперблок.
Всё пространство раздела диска разбивается на блоки
фиксированного размера, кратные размеру сектора: 1024, 2048, 4096 или 8192
байт. Размер блока указывается при создании файловой системы на разделе диска.
Меньший размер блока позволяет сэкономить место на жёстком диске, но также
ограничивает максимальный размер файловой системы. Все блоки имеют порядковые
номера. С целью уменьшения фрагментации и количества перемещений головок
жёсткого диска при чтении больших массивов данных блоки объединяются в группы
блоков.
Базовым понятием файловой системы является индексный
дескриптор, или inode (англ. information node). Это специальная структура,
которая содержит информацию об атрибутах и физическом расположении файла.
Индексные дескрипторы объединены в таблицу, которая содержится в начале каждой
группы блоков.
|
Суперблок
(Superblock)
|
|
Описание группы
блоков (Group Description)
|
|
Битовая карта
блоков (Block Bitmap)
|
|
Битовая карта
индексных дескрипторов (Inode Bitmap)
|
|
Таблица
индексных дескрипторов (Inode Table)
|
|
Данные (Data)
|
Рисунок 15 - Обобщенная структурная схема ФС ext2
Суперблок - основной элемент файловой системы ext2. Он
содержит общую информацию о файловой системе:
- общее число блоков и индексных
дескрипторов в файловой системе,
- число свободных блоков и индексных
дескрипторов в файловой системе,
- размер блока файловой системы,
- количество блоков и индексных дескрипторов
в группе блоков,
- размер индексного дескриптора,
- идентификатор файловой системы.
Суперблок находится в 1024 байтах от начала раздела. От
целостности суперблока напрямую зависит работоспособность файловой системы.
Операционная система создаёт несколько резервных копий суперблока на случай
повреждения раздела. В следующем блоке после суперблока располагается
глобальная дескрипторная таблица - описание групп блоков, представляющее собой
массив, содержащий общую информацию обо всех группах блоков раздела.
Все блоки раздела ext2 разбиваются на группы блоков. Для
каждой группы создаётся отдельная запись в глобальной дескрипторной таблице, в
которой хранятся основные параметры:
- номер блока в битовой карте блоков,
- номер блока в битовой карте inode,
- номер блока в таблице inode,
- число свободных блоков в группе,
- число индексных дескрипторов, содержащих
каталоги.
Битовая карта блоков - это структура, каждый бит которой
показывает, отведён ли соответствующий ему блок какому-либо файлу. Если бит
равен 1, то блок занят. Аналогичную функцию выполняет битовая карта индексных дескрипторов,
которая показывает, какие именно индексные дескрипторы заняты, а какие нет.
Ядро Linux, используя число индексных дескрипторов, содержащих каталоги,
пытается равномерно распределить inode каталогов по группам, а inode файлов
старается по возможности переместить в группу с родительским каталогом. Все
оставшееся место, обозначенное в таблице как данные, отводится для хранения
файлов.
Файловая система ext2 использует следующую схему адресации
блоков файла. Для хранения адреса файла выделено 15 полей, каждое из которых
состоит из 4 байт. Если файл умещается в 12 блоков, то номера соответствующих
кластеров непосредственно перечисляются в первых двенадцати полях адреса. Если
размер файла превышает 12 блоков, то следующее поле содержит адрес кластера, в
котором могут быть расположены номера следующих блоков файла. Таким образом,
13-е поле используется для косвенной адресации.
При максимальном размере блока в 4096 байт кластер,
соответствующий 13-му полю, может содержать до 1024 номеров следующих блоков файла.
Если размер файла превышает 12+1024 блоков, то используется 14-е поле, в
котором находится адрес кластера, содержащего 1024 номеров кластеров, каждый из
которых ссылается на 1024 блока файла. Здесь применяется уже двойная косвенная
адресация. И наконец, если файл включает более 12+1024+1048576 блоков, то
используется последнее 15-е поле для тройной косвенной адресации.
Данная система адресации позволяет при максимальном размере
блока в 4096 байт иметь файлы, размер которых превышает 2 ТБ.
ext3 или ext3fs - журналируемая файловая
система, используемая в операционных системах на ядре Linux. Основана на ФС
ext2.
Основное отличие от ext2 состоит в том, что ext3
журналируема, то есть в ней предусмотрена запись некоторых данных, позволяющих
восстановить файловую систему при сбоях в работе компьютера.
Стандартом предусмотрено три режима журналирования:
- writeback: в журнал записываются только
метаданные файловой системы, то есть информация о её изменении. Не может
гарантировать целостности данных, но уже заметно сокращает время проверки по
сравнению с ext2;
- ordered: то же, что и writeback, но запись
данных в файл производится гарантированно до записи информации о изменении
этого файла. Немного снижает производительность, также не может гарантировать
целостности данных (хотя и увеличивает вероятность их сохранности при
дописывании в конец существующего файла);
- journal: полное журналирование как
метаданных ФС, так и пользовательских данных. Самый медленный, но и самый
безопасный режим; может гарантировать целостность данных при хранении журнала
на отдельном разделе (а лучше - на отдельном жёстком диске).
Файловая система ext3 может поддерживать файлы размером до 1
ТБ. С Linux-ядром 2.4 объём файловой системы ограничен максимальным размером
блочного устройства, что составляет 2 терабайта. В Linux 2.6 (для 32-разрядных
процессоров) максимальный размер блочных устройств составляет 16 ТБ, однако
ext3 поддерживает только до 4 ТБ.
ext4 - файловая система, основанная на ext3 и
совместимая с ней (прямо и обратно). Отличается от ext3 поддержкой extent'ов,
групп смежных физических блоков, управляемых как единое целое; повышенной
скоростью проверки целостности и рядом других усовершенствований.
Новые возможности ext4 (в сравнении с ext3):
) Использование экстентов. В файловой системе ext3
адресация данных выполнялась традиционным образом, поблочно. Такой способ
адресации становится менее эффективным с ростом размера файлов. Экстенты
позволяют адресовать большое количество (до 128 MB) последовательно идущих
блоков одним дескриптором. До 4х указателей на экстенты может размещаться
непосредственно в inode, что достаточно для файлов маленького и среднего
размера.
2) 48-битные номера блоков. При размере блока 4K это
позволяет адресовать до одного экзабайта (248*4KB = 250*1KB
= 260 B = 1 EB).
) Выделение блоков группами (multiblock allocation).
Файловая система хранит не только информацию о местоположении свободных блоков,
но и количество свободных блоков, идущих друг за другом. При выделении места
файловая система находит такой фрагмент, в который данные могут быть записаны
без фрагментации. Это снижает уровень фрагментации файловой системы в целом.
) Отложенное выделение блоков (delayed allocation).
Выделение блоков для хранения данных файла происходят непосредственно перед
физической записью на диск (например, при вызове sync), а не при вызове write.
В результате, операции выделения блоков можно делать не по одной, а группами,
что в свою очередь минимизирует фрагментацию и ускоряет процесс выделения
блоков. С другой стороны, увеличивает риск потери данных в случае внезапного
пропадания питания.
) Превышен лимит в 32000 каталогов.
) Резервирование inode'ов при создании каталога
(directory inodes reservation). При создании каталога резервируется несколько
inode'ов. Впоследствии, при создании файлов в этом каталоге сначала
используются зарезервированные inode'ы, и если таких не осталось, выполняется
обычная процедура.
) Размер inode. Размер inode (по умолчанию) увеличен с
128 до 256 байтов. Это дало возможность реализовать те преимущества, которые
перечислены ниже.
) Временные метки с наносекундной точностью
(nanosecond timestamps). Более высокая точность времён, хранящихся в inode.
Диапазон хранящихся времён тоже расширен: если раньше верхней границей
хранимого времени было 18 января 2038 года, то теперь это 25 апреля 2514 года.
) Версия inode. В inode появился номер, который
увеличивается при каждом изменении inode файла.
) Хранение расширенных атрибутов в inode (EA in
inode). Хранение расширенных атрибутов, таких как ACL, атрибутов SELinux и
прочих, позволяет повысить производительность. Атрибуты, для которых
недостаточно места в inode, хранятся в отдельном блоке размером 4KB.
) Контрольное суммирование в журнале (Journal
checksumming). Контрольные суммы журнальных транзакций. Позволяют лучше найти и
(иногда) исправить ошибки при проверке целостности системы после сбоя.
) Предварительное выделение (persistent
preallocation). Сейчас для того, чтобы приложению гарантированно занять место в
файловой системе, оно заполняет его нулями. В ext4 появилась возможность
зарезервировать множество блоков для записи и не тратить на инициализацию
лишнее время. Если приложение попробует прочитать данные, оно получит сообщение
о том, что они не проинициализированы. Таким образом, несанкционированно прочитать
удалённые данные не получится.
) Дефрагментация без размонтирования (online
Defragmentation).
) Неинициализированные блоки (uninitialised groups).
Позволяет ускорить проверку файловой системы. Блоки, отмеченные как
неиспользуемые, проверяются группами, и детальная проверка производится, только
если проверка группы показала, что внутри есть повреждения.
2.
Аналитическая часть
2.1 Общие
сведения о матричных принтерах
Матричный принтер (Dot-Matrix-Printer) -
старейший из ныне применяемых типов принтеров, был изобретён в 1964 году
корпорацией Seiko Epson.
Принцип работы матричного принтера
следующий. Изображение формируется с помощью печатающей головки, которая
представляет собой один или два ряда вертикально расположенных тонких иголок
(игольчатая матрица), приводимых в действие электромагнитами. Головка
устанавливается на ракетке и передвигается построчно вдоль листа, при этом
иголки в нужный момент времени ударяют через красящую ленту по бумаге, формируя
точечное изображение. Этот тип принтеров называется SIDM (англ. Serial Impact
Dot Matrix - последовательные ударно-матричные принтеры).
Существуют принтеры с 9, 12, 14, 18 и 24
иголками в головке. Основное распространение получили 9-ти (дешевые модели) и
24-х игольчатые принтеры. Качество печати и скорость графической печати зависят
от числа иголок: больше иголок - больше точек. Качество печати в 9-ти
игольчатых принтерах улучшается при печати информации не в один, а в два или
четыре прохода печатающей головки вдоль печатаемой строки. Более качественная и
быстрая печать обеспечивается 24-игольчатыми принтерами, называемыми LQ (англ.
Letter Quality - качество пишущей машинки). Однако эти принтеры не только более
дорогостоящи, но и менее надежны, а также замена вышедших из строя печатающих
головок представляет определенные трудности.
Существуют монохромные пятицветные
матричные принтеры, в которых используется 4 цветная CMYK лента. Смена цвета
производится смещением ленты вверх-вниз относительно печатающей головки.
Для перемещения красящей ленты используется
передаточный механизм, использующий движение каретки. За перемещение каретки
отвечает шаговой двигатель. Еще один шаговой двигатель отвечает за перемещение
бумагоопорного валика. Именно поэтому скорость печати матричных принтеров
невысока. В зависимости от выбранного качества печати и модели принтера
скорость печати составляет от 10 до 60 секунд на страницу. Скорость печати
матричных принтеров измеряется в CPS (англ. characters per second - символах в
секунду).
Матричные принтеры оборудованы внутренней
памятью (буфером) для хранения данных, полученных от персонального компьютера.
Объем памяти недорогих принтеров составляет от 4 до 64 Кбайт. Хотя существуют
модели, имеющие и больший объем памяти (например, Seikosha SP-2415 имеет буфер
размером 175 Кбайт).
2.2
Проектирование символов для матричных принтеров
Матричные принтеры поставляются с несколькими типовыми
начертаниями символов (прямое, полужирное, наклонное) и несколькими вариантами
литер (престиж, оратор, скрипт и пр.), позволяющих воспроизводить тексты с
латинским алфавитом. Такие шрифты называют встроенными.
Описание встроенных шрифтов хранится в постоянном
запоминающем устройстве принтера и в любой момент доступно для применения.
Однако не всегда стандартный набор символов достаточен для воспроизведения
нужного текста. Особенно это характерно для документов специализированного
характера, требующих некоторых специфических знаков (например, символов
русского или других национальных алфавитов, условные обозначения географических
элементов, знаков диаграмм шахматных позиций и т.п.). Для этих случаев в
системе команд принтера предусматривается возможность конструирования
недостающих символов, сохранения их в оперативной памяти принтера и
воспроизведения в момент печати. Шрифты подобного вида называют загружаемыми.
Загружаемые шрифты становятся доступными только после
размещения их описания в оперативную памяти принтера н могут воспроизводиться
только до конца текущего сеанса (до выключения питания принтера) или до момента
загрузки в оперативную память принтера описания другого шрифта.
Проектирование и воспроизведение произвольных литер состоит
нз следующих этапов:
. Сначала изображается кривая, образующую литеру.
. Далее рассчитываются данные, необходимые для описания
кривой.
. Затем эти данные посылаются в оперативную память принтера
для связи описание символа с определенным кодом.
. Принтеру дается команда напечатать данную литеру вместо
той, которую он воспроизводит в соответствии с описанием для этого же кода из
постоянной памяти.
Рассмотрим механизм формирования символов на примере принтера
Epson LX1050. Этот матричный принтер имеет печатающую головку с 24 иголками и
может воспроизводить символы в нескольких режимах. В каждом из режимов
допускается конструирование символов с помощью матриц различной ширины и высоты
(таблица 2). Минимальная ширина символов - 5.
Таблица 2 - Таблица соответствия размеров матриц режимам
принтера
|
Режим
|
Ширина
|
Высота
|
|
Draft
|
9
|
24
|
|
LQ
pica
|
29
|
24
|
|
LO
elite
|
23
|
24
|
|
LQ
semi-condensed
|
15
|
24
|
|
LQ
proportional
|
37
|
24
|
|
Draft
super subscript
|
7
|
16
|
|
LQ
super subscript
|
23
|
16
|
|
LQ
prop, super subscript
|
23
|
16
|
|
Размер матрицы
для воспроизведения символов
|
Положение
иголок для печати символов А
|
|
Номера иголок
|
|
|
* * * * * * * *
* *
|
1
|
* * * * * *
|
|
* * * * * * * *
* *
|
2
|
* * * * * * *
|
|
* * * * * * * *
* *
|
3
|
* * * *
|
|
* * * * * * * *
* *
|
4
|
* * * *
|
|
* * * * * * * *
* *
|
5
|
* * * *
|
|
* * * * * * * *
* *
|
* * * * * * *
* *
|
|
* * * * * * * *
* *
|
7
|
* * * *
|
|
* * * * * * * *
* *
|
8
|
* * * *
|
|
* * * * * * * *
* *
|
9
|
* * * *
|
|
1 2 3 4 5 6 7 8
9 10
|
|
1 2 3 4 5 6 7 8
9 10
|
|
Номера позиций
|
|
Номера позиции
|
|
|
|
|
Рисунок 16 - Пример формирования матрицы для печати
символа "А"
Символ представляет собой матрицу, в которой темные ячейки
соответствуют выпячиваемым иголкам, а светлые - утапливаемым. Такая матрица
может быть закодирована. Каждой строке матрицы присвоен номер. Все строки
матрицы разбиты на три группы, внутри каждой из которых нумерация повторяется.
Каждый столбец матрицы кодируется тремя байтами, соответствующими одной из
групп строк. Значение каждого из трех байтов, кодирующих столбец, определяется
суммой, присвоенной строкам, на пересечении которых с данным столбцом размещен
знак"*" (рисунок 2).
Кроме кодированного описания внешнего вида символа,
необходимо задать три параметра, определяющих ширину символа и его положение
относительно других символов при печати. Каждый из этих параметров предшествует
описанию внешнего вида символа и задается байтом информации. Первый параметр (m0) определяет расстояние
слева, второй параметр (ml) - ширину самого символа, третий параметр (m2) - расстояние справа от
других символов.
При описании символа количество колонок (ml), образующих символ, и
общее пространство (m0+ml+m2) занимаемое символом, не должны превышать значений,
представленных в таблице 3.
Таблица 3 - Таблица соответствия значения количества колонок
и общего пространства режимам принтера
|
Режим
|
ml
|
m0+ml+m2
|
|
Draft
|
9
|
12
|
|
LQ
pica
|
29
|
36
|
|
LO
elite
|
23
|
30
|
|
LQ
semi-condensed
|
15
|
24
|
|
LQ
proportional
|
37
|
42
|
|
Draft
super subscript
|
7
|
12
|
|
LQ
super subscript
|
23
|
36
|
|
LQ
prop, super subscript
|
23
|
42
|
В соответствии с условием поставленной задачи рассматриваемым
режимом матричного принтера является LQ semi-condensed, следовательно, матрица
имеет размеры в ширину 15 позиции и в высоту 24 иголки. Ширину отступов от
символа слева (m0) и справа (m2) выберем равным двум иголкам, общее пространство
символа m0+ml+m2=2+15+2=19, что не превышает максимального значения 24.
Чтобы связать описание символа с соответствующим кодом,
необходимо послать на принтер набор команд, указывающих режим, номер кода
загружаемого символа, три байта общего описания символа (m0, ml, m2) и байты
описания столбцов матрицы. Данные операции прослеживаются на примере листингов
приложений.
Заданием на курсовую работу было проектирование даты своего
рождения (9.10.1991), т.е.9,".", 1, 0.
2.3
Проектирование символов
Проектирование символа "9"
1. На клеточном поле 15х24 изображается кривая проектируемого
символа, затем на ее основе проектируется матрица (Рисунок 17).
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
Рисунок 17 - Матрица символа "9"
. Каждый столбец матрицы кодируется тремя байтами (таблица
3).
Таблица 3 - Значение кодирующих байтов матрицы для символа
"9"
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
байт 1
|
0
|
0
|
63
|
32
|
32
|
32
|
32
|
32
|
32
|
32
|
32
|
63
|
63
|
0
|
0
|
|
байт 2
|
0
|
0
|
224
|
96
|
96
|
96
|
96
|
96
|
96
|
96
|
96
|
255
|
255
|
0
|
0
|
|
байт 3
|
0
|
0
|
12
|
12
|
12
|
12
|
12
|
12
|
12
|
12
|
12
|
252
|
252
|
0
|
0
|
3. Затем в оперативную память принтера передается данные,
связанные с кодом литеры, и подается команда печати спроектированного символа
(Приложение 1).
Проектирование символов".", "1",
"0" осуществляется аналогично.
Проектирование символа". "
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
Рисунок 18 - Матрица символа". "
Таблица 4 - Значение кодирующих байтов матрицы для
символа". "
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
байт 1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
байт 2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
байт 3
|
0
|
0
|
0
|
0
|
0
|
0
|
28
|
28
|
28
|
0
|
0
|
0
|
0
|
0
|
0
|
Листинг третьего этапа проектирования приведен в приложении
2.
Проектирование символа "1"
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
Рисунок 19 - Матрица символа "1"
Таблица 5 - Значение кодирующих байтов матрицы для символа
"1"
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
байт 1
|
0
|
0
|
0
|
0
|
0
|
1
|
3
|
7
|
14
|
28
|
56
|
63
|
63
|
0
|
0
|
|
байт 2
|
0
|
0
|
0
|
0
|
0
|
128
|
128
|
0
|
0
|
0
|
0
|
255
|
0
|
0
|
|
байт 3
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
252
|
252
|
0
|
0
|
Листинг проектирования приведен в приложении 3.
Проектирование символа "0"
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
128
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
32
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
Рисунок 20 - Матрица символа "0"
Таблица 6 - Значение кодирующих байтов матрицы для символа
"0"
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
байт 1
|
0
|
0
|
63
|
63
|
48
|
48
|
48
|
48
|
48
|
48
|
48
|
63
|
63
|
0
|
0
|
|
байт 2
|
0
|
0
|
255
|
255
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
255
|
255
|
0
|
0
|
|
байт 3
|
0
|
0
|
252
|
252
|
12
|
12
|
12
|
12
|
12
|
12
|
12
|
252
|
252
|
0
|
0
|
Листинг проектирования приведен в приложении 4.
Заключение
В теоретической части работы были рассмотрены физические
основы файловых систем, которые используются сегодня на большинстве
персональных компьютеров. Каждая файловая система обладает как своими
достоинствами, так и недостатками, которые были рассмотрены в соответствующих
разделах.
Понимание физической организации различных файловых систем
позволяет выбирать ту или иную файловую систему для выполнения поставленных
задач, так для работы с накопителями небольшого объёма лучше подойдёт файловая
система FAT, а для накопителей большого объёма лучше использовать файловые
системы NTFS или ext4.
В аналитической части были углублены знания по управлению
печатающими устройствами. Были изучены механизмы печати отдельных литер,
управляющие команды, позволяющие осуществить вывод символов на печать. Получены
практические навыки расширения диапазона используемых для печати символов путем
конструирования недостающих знаков, кодирования их описания и подачи на принтер
набора управляющих команд.
Также в аналитической части была выполнена поставленная задача:
формирование новых символов, разработка команд для их загрузки в оперативную
память принтера и программы, реализующей вывод данных символов на печать -
разработаны начертания символов, позволяющих вывести на печать дату моего
рождения (9.10.1991), и реализован их вывод на языке программирования QBasic.
Список
использованной литературы
1.
В.Г. Олифер, Н.А. Олифер. Сетевые операционные системы. - СПб.: Питер, 2002.
.
М. Тим Джонс. Анатомия ext4 - IBM, 17 февраля 2009.
.
Виктор Хименко. Устройство файловой системы ext2fs. "Файлы, файлы,
файлы". Мир ПК, 2000.
.
Гайчук Д.В., Подопригора Н.Б. Методические указания к выполнению курсовой
работы по дисциплине "Безопасность операционных систем" для студентов
специальности 090105 "Комплексное обеспечение информационной безопасности
автоматизированных систем", Ставрополь, 15 мая 2006.
.
И.И. Попов, Т.Л. Партыка. Операционные системы, среды и оболочки. - Инфра-М,
2006.
.
Борланд, Р. Знакомство с Microsoft Windows 98 - 1997.
.
Кэрриэ Б. Криминалистический анализ файловых систем. - СПб.: Питер, 2007.
Приложение 1
Листинг вывода на печать символа "9" на языке QBASIC
LPRINTCHR$ (27); "xl";
LPRINT CHR$ (27); "&"; CHR$ (0); CHR$ (20);
CHRS (20);
RESTORE 1540
FOR N=20 TO 20
1040 READ LS: LPRTNT CHR$ (LS);
READ CW: LPRTNT CHR$ (CW);
READ RS: LPRTNT CHR$ (RS);
FOR M=l TOCW*3
READ MM
LPRINT CHR$ (MM);
NEXT M
NEXTN
'Symbol'
DATA 2,15,2
DATA 0, 0, 0, 0, 0, 0, 63, 224, 12, 32, 96, 12,
32, 96, 12
DATA 32, 96, 12, 32, 96, 12, 32, 96, 12, 32, 96,
12, 32, 96, 12
DATA 32, 96, 12, 63, 255, 252, 63, 255, 252, 0,
0, 0, 0, 0, 0
Приложение
2
Листинг вывода на печать символа"." на языке QBASIC
1000 LPRINTCHR$ (27); "xl";
LPRINT CHR$ (27); "&"; CHR$ (0);
CHR$ (20); CHRS (20);
RESTORE 1540
FOR N=20 TO 20
READ LS: LPRTNT CHR$ (LS);
READ CW: LPRTNT CHR$ (CW);
READ RS: LPRTNT CHR$ (RS);
FOR M=l TOCW*3
READ MM
LPRINT CHR$ (MM);
NEXT M
NEXTN
'Symbol'
DATA 2,15,2
DATA 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
1570 DATA 0, 0, 0, 0, 0, 28, 28, 28, 0, 0, 0, 0, 0, 0, 0
1580 DATA 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
Приложение
3
Листинг вывода на печать символа "1" на языке QBASIC
1000 LPRINTCHR$ (27); "xl";
LPRINT CHR$ (27); "&"; CHR$ (0);
CHR$ (20); CHRS (20);
RESTORE 1540
FOR N=20 TO 20
1040 READ LS: LPRTNT CHR$ (LS);
READ CW: LPRTNT CHR$ (CW);
READ RS: LPRTNT CHR$ (RS);
FOR M=l TOCW*3
READ MM
LPRINT CHR$ (MM);
NEXT M
NEXTN
'Symbol'
DATA 2,15,2
DATA 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
1570 DATA 1, 128, 0, 3, 128, 0, 7, 0, 0, 14, 0, 0, 28, 0, 0
1580 DATA 56, 0, 0, 63, 255, 252, 63, 255, 252, 0, 0, 0, 0, 0, 0
Приложение
4
Листинг вывода на печать символа "0" на языке QBASIC
1000 LPRINTCHR$ (27); "xl";
LPRINT CHR$ (27); "&"; CHR$ (0);
CHR$ (20); CHRS (20);
RESTORE 1540
FOR N=20 TO 20
READ LS: LPRTNT CHR$ (LS);
READ CW: LPRTNT CHR$ (CW);
READ RS: LPRTNT CHR$ (RS);
FOR M=l TOCW*3
READ MM
LPRINT CHR$ (MM);
NEXT M
NEXTN
'Symbol'
DATA 2,15,2
DATA 0, 0, 0, 0, 0, 0, 63, 255, 252, 63, 255, 252, 48, 0, 12
DATA 48, 0, 12, 48, 0, 12, 48, 0, 12, 48, 0, 12, 48, 0, 12
DATA 48, 0, 12, 63, 255, 252, 63, 255, 252, 0, 0, 0, 0, 0,
0