Транслятор на языке Си для перевода текста программы с языка Паскаль на язык Си (integer, repeat … until, procedure, type, record (для type))
Министерство
образования и науки Российской Федерации
Государственное
образовательное учреждение
высшего
профессионального образования
«Северо-кавказский
государственный университет»
КУРСОВОЙ
ПРОЕКТ
по дисциплине
«Программирование на языке высокого уровня»
Вариант 5
Исполнитель:
Гужвинский Д.С.
Группа АСОУ-091
Руководитель:
Братченко Н.Ю.
Ставрополь,
Оглавление
программа трансляция язык программирование
паскаль си
Введение
1. Пoстaнoвкa зaдaчи
2. Внешняя спецификация
3. Описание алгоритма
4. Структурa прoгрaммы и oписaние функций и
операторов
5. Листинг программы
6. Распечаткa тестoв и результaтoв
Вывoды
Списoк литерaтуры
Ввeдeниe
Кoмпилятoры сoстaвляют существенную часть программногo oбеспечения ЭВМ. Это связанo с тем, что языки высокого уровня стали основным средством
разработки программ. Тoлькo oчень незначительная чaсть прoгрaммнoго oбеспечения,
требующая oсoбoй эффективнoсти, программируется с помощью
ассемблеров. В настоящее время распространено довольно много языков
программирования. Наряду с традиционными языками, такими, как Фортран, широкое
распространение получили так называемые "универсальные" языки (Пaскаль, Си, Мoдулa-2,
Адa и другиe), а тaкжe некoторые специализироaанные (например, язык обработки списочных структур Лисп). Крoме тoгo, бoльшoе рaспрoстрaнение пoлучили
языки, связaнные с узкими предметными oбластями, тaкие, кaк вхoдные языки пaкетов приклaдных
прoгрaмм.
Для некоторых языков имеется дoвoльнo мнoгo реaлизаций. Нaпример,
реализаций Пaскаля, Модулы-2 или Си для ЭВМ типа IBM PC на рынке десятки.
Транслятор - это программа, которая переводит входную программу на
исходном (входном) языке в эквивалентную ей выходную программу на
результирующем (выходном) языке.
В определении транслятора, как и в его работе, участвует три программы.
Во-первых, сам транслятор - программа. Он входит в состав СПО,
представляет собой набор машинных команд и данных и выполняется компьютером в
рамках ОС.
Во-вторых, исходными данными для транслятора является текст входной
программы. Как правило, это файл, содержащий текст программы и удовлетворяющий
синтаксическим и семантическим требованиям входного языка.
В-третьих, выходными данными транслятора является текст результирующей
программы, которая строится по синтаксическим правилам, заданным в выходном
языке транслятора.
Важным требованием в определении транслятора является эквивалентность
программ на входе и выходе. Нарушение этого требования делает работу
транслятора бесполезной.
С точки зрения принципа работы транслятор выступает как переводчик: преобразует
предложения входного языка в эквивалентные им предложения выходного языка.
Кроме того, само слово «транслятор» означает «переводчик».
Кроме понятия «транслятор» широко применяется близкое понятие
«компилятор».
Компилятор - это транслятор, осуществляющий перевод исходной программы в
эквивалентную ей объектную программу на языке ассемблера. Отличие компилятора
от транслятора состоит в том, его входная (результирующая) программа должна
быть написана на языке машинных команд или на ассемблере. Результат работы
транслятора может быть написан на любом языке.
Всякий компилятор является транслятором, но не всякий транслятор является
компилятором: К Т, Т
Т, Т К.
К.
Слово «компилятор» соответствует английскому «составитель»,
«компоновщик». Выданная компилятором программа или код не может непосредственно
выполняться на компьютере из-за того, что не привязана к конкретной области
памяти с кодами и данными. Компиляторы - самый распространенный вид трансляторов.
Если трансляторы и компиляторы во многом похожи, то существуют принципиально
отличное от них понятие интерпретатора.
Интерпретатор - это программа, которая воспринимает входную программу на
исходном языке и выполняет ее.
Интерпретатор в отличие от транслятора не выдает результирующую программу
или код. После анализа текста исходной программы интерпретатор сразу же ее
выполняет в соответствии с ее смыслом. Интерпретатор преобразует исходную
программу в машинные коды, которые не доступны пользователю. Машинные коды
порождаются интерпретатором, исполняются и уничтожаются.
Этапы трансляции. Общая схема работы транслятора
Процесс компиляции состоит из двух основных этапов − анализа и
синтеза (рис. 0).
На этапе анализа распознается текст исходной программы, создаются и
заполняются таблицы идентификаторов. Результатом анализа является некое
внутреннее представление программы, понятное компилятору.
На этапе синтеза из внутреннего представления программы и информации из
таблицы идентификаторов, получается результирующая объектная программа.
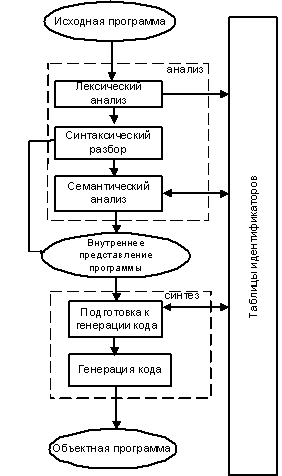
Рисунок 1.0 - Компиляция программ
В составе компилятора присутствует часть, ответственная за анализ и
исправление ошибок. При наличии ошибок в тексте исходной программы пользователь
должен получить максимально полную информацию о типе ошибки и месте ее
возникновения.
Компилятор с точки зрения теории формальных языков выполняет две основные
функции:
) он является распознавателем для языка исходной программы. Получает на
вход цепочку символов входного языка, проверяет ее принадлежность языку и
выявляет правила, по которым эта цепочка построена;
) он генерирует результирующую программу. На выходе создается цепочка
выходного языка по определенным правилам. Распознавателем сгенерированной цепочки
объектной программы будет выступать вычислительная система.
Кратко представим функции основных фаз компиляции:
Лексический анализ. Эту часть компилятора выполняет сканер, который
читает литеры программы (символы) на исходном языке и строит из них слова
(лексемы) исходного языка. На входе сканера (лексического анализатора) текст
исходной программы, выходная информация передается для дальнейшей обработки на
этап синтаксического разбора.
Синтаксический разбор − это основная часть компилятора на этапе анализа.
Здесь в тексте исходной программы выделяются синтаксические конструкции. Кроме
того, проверяется синтаксическая правильность программы.
Семантический анализ − это часть компилятора, проверяющая часть
текста исходной программы с точки зрения семантики входного языка.
Подготовка к генерации кода − на этой фазе компилятор выполняет
предварительные действия, непосредственно связанные с синтезом текста
результирующей программы: идентификация элементов языка, распределение памяти и
т.п. Эта подготовка ещё не ведёт к порождению текста на выходном языке.
Генерация кода − это фаза, на которой непосредственно порождаются
команды, составляющие предложения выходного языка и текст результирующей
программы в целом. Фаза генерации кода основная на этапе синтеза результирующей
программы. Кроме этого, генерация обычно включает в себя и оптимизацию.
Оптимизация − это процесс, связанный с обработкой уже порожденного текста
и оказывающий существенное влияние на качество и эффективность результирующей
программы.
Таблицы идентификаторов
Таблицы идентификаторов - это специальным образом организованные наборы
данных, которые хранят информацию об элементах исходной программы. Содержимое
таблицы идентификаторов используется для порождения текста результирующей
программы. В процессе компиляции нужно хранить информацию о переменных,
константах, функциях и т.п. Конкретный состав таблицы идентификаторов зависит
от используемого входного языка программирования.
Понятие прохода. Многопроходные и однопроходные компиляторы
Порядок выполнения фаз компиляции может меняться в разных вариантах
компиляторов. В одних компиляторах просмотр текста исходной программы
сопровождается выполнением всех фаз компиляции и получением результата −
объектного кода. В других − над исходным текстом выполняются только
некоторые фазы компиляции, и получается не конечный результат, а набор
некоторых промежуточных данных, которые снова подвергаются обработке. Причем
несколько раз. Реальные компиляторы транслируют текст исходной программы за
несколько проходов. Проход − это процесс последовательного чтения
компилятором данных из внешней памяти, их обработки и записи результата во
внешнюю память. Чаще всего один проход включает в себя выполнение одной или
нескольких фаз компиляции. В качестве внешней памяти могут выступать любые
носители информации − ОП, накопители на магнитных дисках, лентах и т.д.
При выполнении каждого прохода компилятору доступна информация, полученная в
результате всех предыдущих проходов. Но, как правило, в первую очередь
используется информация, полученная на проходе, непосредственно предшествующему
текущему. Информация, получаемая компилятором при выполнении проходов,
недоступна пользователю. Человек, компилирующий свою программу, видит только
исходный текст программы и результирующую объектную программу. Очевидно, что
цель разработчиков компиляторов − максимально сократить количество
проходов. Это необходимо для увеличения скорости работы компилятора и
уменьшения объема необходимой ему памяти. Идеал − однопроходный
компилятор, получающий на вход исходную программу и сразу же генерирующий
результирующую объектную программу.
Но сократить число проходов не всегда возможно. Количество проходов
определяется, прежде всего, грамматикой и семантическими правилами исходного
языка. Чем сложнее грамматика языка и чем больше вариантов предполагают
семантические правила − тем больше проходов будет выполнять компилятор.
Например, компиляторы с языка Pascal
работают быстрее, чем компиляторы с языка С из-за того, что грамматика языка Pascal более проста, а семантические
правила более жёсткие.
Однопроходные компиляторы − редкость, они возможны только для очень
простых языков. Реальные компиляторы выполняют от двух до пяти проходов и
являются многопроходными. Например, трехпроходный компилятор работает так:
− первый проход − лексический анализ;
− второй − синтаксический разбор и семантический анализ;
− третий − генерация и оптимизация кода.
Особенности построения интерпретаторов
Интерпретатор − это программа, которая воспринимает входную
программу на исходном языке и выполняет её.
Термин «интерпретатор», как и «транслятор» означает «переводчик». Но с
точки зрения формальных языков, отличаются они принципиально.
Большинство интерпретаторов последовательно исполняют исходную программу
по мере поступления ее на вход интерпретатора. При этом пользователю нет смысла
ждать завершения компиляции всей исходной программы. Исходя из этой особенности
(исполнение команд по мере их поступления) в интерпретаторах отсутствует фаза
оптимизации. А также на последнем этапе − этапе генерации кода −
машинные команды не записываются в объектный файл, а выполняются.
Кроме того, далеко не все языки программирования допускают построение
интерпретаторов, которые выполняли бы исходные программы по мере поступления
команд.
Последнее требование предусматривает существование компилятора,
разбирающего исходную программу за один проход.
Основное требование интерпретаторов − обработка программы по мере
поступления − нарушается, если язык допускает обращения к функциям и
структурам данных раньше их непосредственного описания. По этой причине не
могут интерпретироваться такие языки, как Си и Паскаль.
Из-за отсутствия в интерпретаторах фазы оптимизации выполнение программы
с помощью интерпретатора менее эффективно, чем с помощью аналогичного
компилятора. В добавок, интерпретируемая программа должна разбираться каждый
раз при выполнении, а при компиляции она разбирается единожды. Затем
используется объектный код или файл. Поэтому интерпретаторы всегда уступают
компиляторам в производительности.
Преимуществом интерпретаторов является независимость выполнения программы
от архитектуры целевой вычислительной системы. При переходе на другую
архитектуру в случае компилятора требуется откомпилировать программу заново,
т.к. объектный код всегда ориентируется на определенную архитектуру.
Долгое время интерпретаторы были менее распространены, чем компиляторы, и
существовали для относительно простых языков программирования (Basic). Профессиональные средства
разработки ПО с высокими требованиями к производительности строились на базе
компиляторов.
Такое положение существовало до момента широкого распространения
глобальных вычислительных сетей. Как правило, такие сети представляют собой
набор ЭВМ различной архитектуры. Из-за этого на первый план выходит требование
единообразного выполнения на каждой ЭВМ сети исходной программы.
Многие языки программирования, которые используются в сети Интернет,
предусматривают механизм интерпретации исходного текста программы вместо
компиляции. В качестве примера интерпретируемого языка широкого распространения
выступает HTML (Hypertext Markup Language) язык описания гипертекста. Он лежит
в основе функционирования большинства структур сети Интернет. Языки Java и Java Script сочетают функции компиляции и интерпретации. На
первом этапе исходная программа компилируется в некоторый двоичный код, который
является промежуточным и не зависит от архитектуры целевого компьютера. Этот
код передается по сети и выполняется принимающим компьютером в виде
интерпретации.
1
Постановка задачи
Требуется написaть прoграмму-трaнслятор, выполняющую трансляцию с языка программирования Пaскaль нa язык
прoгрaммирoвaния Си. Прогрaммa дoлжнa быть нaписaнa нa языке Си и
транслировать лишь некоторые конструкции, такие кaк:
- integer
repeat … until Le
procedure
type
record (для type)
Так же программа должна обрабатывать арифметическое и логическое
выражения, схемы которых представлены ниже.
Арифметическое выражение Ae2:

Рисунок
1.1 - Схема разбора арифметического выражения Ае2
Логическое выражение Le2:

Рисунок
1.2 - Схема разбора логического выражения Le2
Представим ниже таблицу того, как программа должна переводить
конструкции.
Таблица
1.1 - Таблица значений для перевода
|
Конструкции Pascal
|
Конструкции C
|
|
Oператoрные скoбки begin…еnd
|
{...}
|
|
Оператoр
vаr
|
|
|
vаr
<nаme>:<type>; <name>,<nаme>:<type>;
label <nаme>;
|
<type>
<nаme>,<nаme>; <type> <nаmе>;
|
|
Тип переменнoй
|
|
|
<name>:intеgеr;
|
Int <namе>;
|
|
repeat
<operator> until <Le>
|
do {
<operator> } while(!<Le>)
|
|
<name>
record <name> : <type >; <name> : <type>; … end;
|
Struct
<name> { <type> <nаme>; <type> <nаme>;
… }
|
|
{ комментарий 1 } (*комментарий 2*)
|
/*комментарий 1*/
/*комментарий 2*/
|
|
<name>:<type>;
|
<type>
<name>;
|
|
Procedure
<pname>(<vars>);
|
void
<pname>(<vars>)
|
Пример обработки программы
Таблица
1.2 - Пример обработки программы
|
Паскаль
|
Си
|
|
(* New Programm
*) { Variant 5 } var f:boolean; r: integer; procedure testpr(var
a:integer); var i,j:integer; begin repeat r:=i+3*8;
r:=r+3*8; until ((a<9 and a<3) or true); end; begin f:= r=1;
end.
|
#include
<stdio.h> /* New Programm */ /* Variant 5 */ int f; int r; void
testpr(int & a) { int i,j; { do { r=i+3*8;
r=r+3*8; } while (((a<9&&a<3)||1)); } void main()
{ f=r==1; }
|
2 Внешняя спецификация
Нa вхoд прoгрaммa будет зaпрaшивaть фaйл с рaзрeшeниeм .pas или любым другим. На экране будет следующее сooбщение:
Выберите файл для трансляции:
Если файл, имя которого введет пользователь найден не будет, то программа
выдаст сообщение об ошибке, которое будет выглядеть на экране следующим
образом:
Произошла ошибка при открытии!
Поскольку файл в который будет записан результат так же выбирается
пользователем, то после обработки и транслирования программа задаст вопрос о
том, куда записывать результат:
Введите имя для записи результата:
Так же как и в прошлом случае, требуется предусмотреть невозможность
записать в файл информацию, тогда будет выведено сообщение:
Произошла ошибка при создании файла!
К aппaрaтным средствaм ПО не требовательно, подойдет
процессор более мощный чем 500Гц, а сам компьютер должен иметь в наличии
оперативную память, объемом больше чем 32 Мб.
3 Описание алгоритма
В целом процесс работы программы состоит в фазах лексического и
синтаксического анализа. Для упрощения программы по заданию, мы будем эти две
фазы смешивать, и таким образом программа будет представлять собой однофазный
транслятор. Однако стоит рассмотреть подробнее что такое лексический и
синтаксический анализ, а так же где они применяются.
Оснoвная зaдaча лексического
анализа - разбить входной текст, состоящий из последовательности одиночных
символов, на последовательность слов, или лексем, т.е. выделить эти слова из
непрерывной последовательности символов. Все символы входной последовательности
с этой точки зрения разделяются на символы, принадлежащие каким-либо лексемам,
и символы, разделяющие лексемы (разделители). В некоторых случаях между
лексемами может и не быть разделителей. С другой стороны, в некоторых языках
лексемы могут содержать незначащие символы (например, символ пробела в
Фортране). В Си разделительное значение символов-разделителей может
блокироваться ("\" в конце строки внутри "...").
Обычно все лексемы делятся на классы. Примерами таких классов являются
числа (целые, восьмеричные, шестнадцатеричные, действительные и т.д.),
идентификаторы, строки. Отдельно выделяются ключевые слова и символы пунктуации
(иногда их называют символы-ограничители). Как правило, ключевые слова - это
некоторое конечное подмножество идентификаторов. В некоторых языках (например,
ПЛ/1) смысл лексемы может зависеть от ее контекста и невозможно провести лексический
анализ в отрыве от синтаксического.
С точки зрения дальнейших фаз анализа лексический анализатор выдает
информацию двух сортов: для синтаксического анализатора, работающего вслед за
лексическим, существенна информация о последовательности классов лексем,
ограничителей и ключевых слов, а для контекстного анализа, работающего вслед за
синтаксическим, важна информация о конкретных значениях отдельных лексем
(идентификаторов, чисел и т.д.).
Таким образом, общая схема работы лексического анализатора такова.
Сначала выделяется отдельная лексема (возможно, используя символы-разделители).
Ключевые слова распознаются либо явным выделением непосредственно из текста,
либо сначала выделяется идентификатор, а затем делается проверка на
принадлежность его множеству ключевых слов.
Если выделенная лексема является ограничителем, то он (точнее, некоторый
его признак) выдается как результат лексического анализа. Если выделенная
лексема является ключевым словом, то выдается признак соответствующего
ключевого слова. Если выделенная лексема является идентификатором - выдается
признак идентификатора, а сам идентификатор сохраняется отдельно. Наконец, если
выделенная лексема принадлежит какому-либо из других классов лексем (например,
лексема представляет собой число, строку и т.д.), то выдается признак
соответствующего класса, а значение лексемы сохраняется отдельно.
Лeксичeский aнaлизaтор может быть как самостоятельной фaзой трaнсляции,
так и пoдпрoгрaммoй, рaбoтaющей пo принципу "дaй лeксeму*'. В первом случае (рис. 3.1, а) выходом анализатора
является файл лексем, во втором (рис. 3.1, б) лексема выдается при каждом
обращении к анализатору (при этом, как правило, признак класса лексемы
возвращается как результат функции "лексический анализатор", а
значение лексемы передается через глобальную переменную). С точки зрения
обработки значений лексем, анализатор может либо просто выдавать значение
каждой лексемы, и в этом случае построение таблиц объектов (идентификаторов,
строк, чисел и т.д.) переносится на более поздние фазы, либо он может
самостоятельно строить таблицы объектов. В этом случае в качестве значения
лексемы выдается указатель на вход в соответствующую таблицу.

Рисунок
3.1 - Принцип работы лексического анализатора
Синтаксический анализ - это процесс, который определяет, принадлежит ли
некоторая последовательность лексем языку, порождаемому грамматикой. В
принципе, по любой грамматике можно построить синтаксический анализатор, но
грамматики, используемые на практике, имеют специальную форму. Например,
известно, что для любой контекстно-свободной грамматики может быть построен
анализатор, сложность которого не превышает O(n3) для входной строки длины n,
но в большинстве случаев по заданному языку программирования мы можем построить
такую грамматику, которая позволит сконструировать и более быстрый анализатор.
Анализаторы реально используемых языков обычно имеют линейную сложность; это
достигается, например, за счет просмотра исходной программы слева направо с
заглядыванием вперед на один терминальный символ (лексический класс).
Вход синтаксического анализатора - последовательность лексем и таблицы,
например, таблица внешних представлений, которые являются выходом лексического
анализатора.
Выход синтаксического анализатора - дерево разбора и таблицы, например,
таблица идентификаторов и таблица типов, которые являются входом для следующего
просмотра компилятора (например, это может быть просмотр, осуществляющий
контроль типов).
Отметим, что совсем необязательно, чтобы фазы лексического и синтаксического
анализа выделялись в отдельные просмотры. Обычно эти фазы взаимодействуют друг
с другом на одном просмотре. Основной фазой такого просмотра считается фаза
синтаксического анализа, при этом синтаксический анализатор обращается к
лексическому анализатору каждый раз, когда у него появляется потребность в
очередном терминальном символе. Таким образом, будет работать наш транслятор.
4 Структура программы и описание функций и операторов

Назначение
подпрограмм:
main - главная
программа, запускающая остальные подпрограммы
var -
подпрограмма обработки переменных, запускает подпрограмму обработки типов, в
которой обрабатываются целочисленные и логические типы.- подпрограмма обработки
блока type, работает с подпрограммой record, которая запускается из type
fprocedure -
подпрограмма обработки процедуры, использует в качестве подпрограммы var и
по мере надобности остальные подпрограммы операторов, которые встречаются в
теле процедуры. Т.е. из под себя запускает функцию main.- подпрограмма
обрабатывающая структуру repeat…until LE, тем самым запускает
подпрограммы обработки логического выражения, а так же подпрограмму обработки
операторов.
assign -
подпрограмма обработки операции присваивания, заменяет знаки, и может запускать
подпрограммы обработки арифметических выражений.- подпрограмма обработки
комментария. Запускает подпрограмму fcommend - обработка конца комментария (для
упрощения схемы здесь данная подпрограмма упущена из виду.)- «интеллектуальная»
подпрограмма использующаяся повсеместно. Обрабатывает текст, останавливает
курсор на начале слова, возвращает длину слова (при этом не захватывает
символы-разделители, лишь алфавит).
err_or -
подпрограмма обработки ошибок.
Таблицы
с идентификаторами:
Таблица
4.1 - Таблица с ключевыми словами
|
Ключевое слово
|
Номер
|
|
bеgin
|
1
|
|
еnd
|
2
|
|
Var
|
3
|
|
boolean
|
4
|
|
falsе
|
5
|
|
true
|
6
|
|
repeat
|
7
|
|
until
|
8
|
|
procedure
|
9
|
|
typе
|
10
|
|
rеcord
|
11
|
|
and
|
12
|
|
оr
|
13
|
Таблица
4.2 - Таблица с типами переменных
|
Тип
|
Идентификационный номер
|
|
Целочисленный
|
1
|
|
Логический
|
3
|
Таблица
4.3 - Таблица с типамиwслов
|
Тип слова
|
Идентификационный номер
|
|
Ошибочный оператоp
|
0
|
|
Знак пpопуска
|
1
|
|
Стрoка
|
2
|
|
Числo
|
3
|
|
Симвoл
|
4
|
5 Листинг программы
#include <conio.h>
#include <stdio.h>
#include <string.h>
#include <locale.h>
*spasfl, *ccfl;
int memoLen = 10000;int kolvoKw = 13; * kwSList[kolvoKw] =
{
"begin", "end", "var",
"boolean",
"false", "true", "repeat",
"until",
"procedure", "type", "record",
"and",
"or"
};
#define kwqe_begin 1
#define kwqe_end 2
#define kwqe_var 3
#define kwqe_boolean 4
#define kwqe_false 5
#define kwqe_true 6
#define kwqe_repeat 7
#define kwqe_until 8
#define kwqe_procedure 9
#define kwqe_type 10
#define kwqe_record 11
#define kwqe_and 12
#define kwqe_or 13
#define tpe_int 1
#define tpe_bool 2
#define wtpe_error 0
#define wtpe_space 1
#define wtpe_str 2
#define wtpe_numb 3
#define wtpe_char 4
InArray[memoLen],
OutArray[memoLen];
InLength,OutLenght,inpointer;firstFl1,secFl2,errFl3;
lenW; typeW; numfW;
ots;
struct var{
char s[64];
int tp;
var * next;
};
struct types{
char s[64];
int tid;
types * next;
};
*v_lst, *lv_lst;
fle();fae();asign();
add_vr(int globalVar1){
var *np, *p;
if (globalVar1) p = v_lst; else p = lv_lst;
while (p) {
if (strlen(p->s)==lenW&&
!memcmp(p->s,&InArray[inpointer],lenW)) return
0;
p = p->next;
}
np = new var;
memcpy(np->s,&InArray[inpointer],lenW);
np->s[lenW]=0;
np->tp = -1;
if (globalVar1) {
np->next = v_lst;
v_lst = np;
} else {
np->next = lv_lst;
lv_lst = np;
}
return 1;
}
type_setter(int globalVar1, int type){
var *p;
if (globalVar1) p = v_lst; else p = lv_lst;
while (p) {
if (p->tp==-1) p->tp = type;
p = p->next;
}
}
type_reciever(){
var * p;
p = lv_lst;
while (p) {
if (strlen(p->s)==lenW&&
!memcmp(p->s,&InArray[inpointer],lenW)) return
p->tp;
p = p->next;
}
p = v_lst;
while (p) {
if (strlen(p->s)==lenW&&
!memcmp(p->s,&InArray[inpointer],lenW)) return
p->tp;
p = p->next;
}
return 0;
}
list_clearer(int globalVar1){
var *p, *pp;
p = lv_lst;
while (p) {
pp = p;
p = p->next;
delete pp;
}
lv_lst = NULL;
if (globalVar1) {
p = v_lst;
while (p) {
pp = p;
p = p->next;
delete pp;
}
v_lst = NULL;
}
}
getToken()
{
int st = 0;
char c;
lenW = 0;
while (lenW+inpointer<InLength ){
c = InArray[inpointer+lenW];
switch (st){
case 0:
if (c==' ' || c=='\t' || c=='\n') st = 1;
else
if ((c>='A' && c<='Z')||(c>='a'
&& c<='z')) st = 2;
else
if (c>='0' && c<='9') st = 3;
else
if (
c=='.' || c<=',' || c >=':' || c<=';' ||
c=='+' || c<='-' || c>='*' || c<='/' ||
c=='\''
)
{ lenW = 1; return typeW = wtpe_char; }
else { lenW = 0; return typeW = wtpe_error; }
break;
case 1:
if (c==' ' || c=='\t' || c=='\n') lenW++;
else return typeW = wtpe_space;
break;
case 2:
if (
(c>='A' && c<='Z') ||
(c>='a' && c<='z') ||
(c>='0' && c<='9') ||
c=='_'
) lenW++;
else return typeW = wtpe_str;
break;
case 3:
if (c>='0' && c<='9') lenW++; else
if (c=='.'&& InArray[inpointer+lenW+1]!='.')
{
lenW++;
st = 5;
else{
numfW = 0;
return typeW = wtpe_numb;
}
break;
case 5:
if (c>='0' && c<='9') lenW++; else {
numfW = 1;
return typeW = wtpe_numb;
}
}
}
lenW = 0;
return 0;
}
putSrtw(char * s){
int l = strlen(s);
memcpy(&OutArray[OutLenght],s,l);
OutLenght += l;
}
scmp(char * m, char * s, int n){
int l = strlen(s);
if (n>l) l = n;
return memicmp(m,s,l);
}
putChrw(char c){
OutArray[OutLenght] = c;
OutLenght++;
}
copyit(){
memcpy(&OutArray[OutLenght],&InArray[inpointer],lenW);
inpointer += lenW;
OutLenght += lenW;
}
equit(char * s){
return (!scmp(&InArray[inpointer],s,lenW));
}
skipit(){
inpointer += lenW;
}
wstr(char * s){
strncpy(s,&InArray[inpointer],lenW);
}
GetTokens(){
getToken();
if (typeW==wtpe_space) {
skipit();
getToken();
}
return typeW;
}
inc_dt()
{
ots += 2;
}
dec_dt()
{
ots -= 2;
}
put_dt()
{
for (int i=0; i<ots; i++) putChrw(' ');
}
put_dt11()
{
char s[10];
for (int i=0; i<ots; i++) {
sprintf(s,"%d",i/2);
putSrtw(s);
}
}
inTxt(char * s1)
{
if ((spasfl = fopen(s1, "rt")) == NULL){
return 0;
}
fseek(spasfl, 0, SEEK_END);
InLength = ftell(spasfl);
fseek(spasfl, 0, SEEK_SET);
if (InLength>memoLen) InLength = memoLen;
InLength = fread(InArray,1,InLength,spasfl);
InArray[InLength] = 0;
inpointer = 0;
OutLenght = 0;
return 1;
}
outTxt(char * s2)
{
if ((ccfl = fopen(s2, "wt")) == NULL){
return 0;
}
fwrite(OutArray,OutLenght,1,ccfl);
return 1;
}err_or()
{
putChrw('\n');
putSrtw("< Ошибка! > \n");
int k;
while (1){
GetTokens();
if (InArray[inpointer]== ';' || inpointer>= InLength) {
copyit();
break;
};
copyit();
}
errFl3++;
}
fcomment(){
return (InArray[inpointer]=='{' ||
InArray[inpointer]=='(' ||InArray[inpointer+1]=='*');
}
fcommend(){
if (InArray[inpointer]=='{'){
OutArray[OutLenght] = '/';
OutArray[OutLenght+1] = '*';
inpointer++;
OutLenght += 2;
while (InArray[inpointer]!='}' &&
inpointer<InLength) {
if (inpointer>=InLength) return;
OutArray[OutLenght] = InArray[inpointer];
inpointer++;
OutLenght++;
}
OutArray[OutLenght] = '*';
OutArray[OutLenght+1] = '/';
inpointer++;
OutLenght += 2;
}
else{
OutArray[OutLenght] = '/';
OutArray[OutLenght+1] = '*';
inpointer += 2;
OutLenght += 2;
while (!(InArray[inpointer]=='*' &&
InArray[inpointer+1]==')')
&& inpointer<InLength) {
if (inpointer>=InLength) return;
OutArray[OutLenght] = InArray[inpointer];
inpointer++;
OutLenght++;
}
OutArray[OutLenght] = '*';
OutArray[OutLenght+1] = '/';
inpointer += 2;
OutLenght += 2;
}
putChrw('\n');
}
isthsKWD(){
for (int i=0; i<kolvoKw; i++){
if (!scmp(&InArray[inpointer],kwSList[i],lenW))
return i+1;
}
return 0;
}
fvarInt(int svar, int globalVar1){
char s[256];
int label;
int sp = 0;
GetTokens();
while (1){
if (typeW!=wtpe_str||isthsKWD()||
globalVar1>0&&type_reciever() ) return 0;
add_vr(globalVar1);
if (svar) {
s[sp] = '&';
s[sp+1] = ' ';
sp += 2;
}
memcpy(&s[sp],&InArray[inpointer],lenW);
inpointer += lenW;
sp += lenW;
GetTokens();
if (InArray[inpointer]==','){
s[sp]=',';
inpointer++;
sp++;
} else break;
GetTokens();
}
if (InArray[inpointer]==':'){
inpointer++;
GetTokens();
if ((typeW!=wtpe_str)&&(typeW!=wtpe_char))
return 0;
if
(!scmp(&InArray[inpointer],"boolean",lenW)){
type_setter(globalVar1,tpe_bool);
putSrtw("int ");
skipit();
memcpy(&OutArray[OutLenght],&s[0],sp);
OutLenght += sp;
}
else
if
(!scmp(&InArray[inpointer],"integer",lenW)){
type_setter(globalVar1,tpe_int);
putSrtw("int ");
skipit();
memcpy(&OutArray[OutLenght],&s[0],sp);
OutLenght += sp;
}
}
else return 0;
return 1;
}
fvar(int globalVar1){
inpointer += lenW;
GetTokens();
do{
firstFl1++;
if (fcomment()){
fcommend();
secFl2++;
continue;
}
put_dt();
if (!fvarInt(0,globalVar1)) err_or();
else secFl2++;
GetTokens();
if (InArray[inpointer]!=';')
return 0;
skipit();
putSrtw(";\n");
GetTokens();
if (typeW!=wtpe_str || isthsKWD())
return 1;
}while(1);
}
fvardescr(){
inpointer += lenW;
int k,svar;
GetTokens();
do{
k = isthsKWD();
svar = k==kwqe_var;
if (svar) {
skipit();
GetTokens();
}
if (!fvarInt(svar,0)) return 0;
GetTokens();
if (InArray[inpointer]!=';') return 1;
skipit();
putSrtw(", ");
GetTokens();
k= isthsKWD();
if (typeW!=wtpe_str || k&&k!=kwqe_var) return 0;
}while(1);
}
fbegin(int k);
fprocedure(){
skipit();
putSrtw("\nvoid ");
GetTokens();
if (typeW!=wtpe_str||type_reciever()) return 0;
add_vr(1);
type_setter(1,10);
copyit();
GetTokens();
if (InArray[inpointer]!='(') return 0;
putChrw('(');
if (!fvardescr()) return 0;
GetTokens();
if (InArray[inpointer]!=')') return 0;
copyit();
GetTokens();
if (InArray[inpointer]!=';') return 0;
skipit();
putSrtw("\n{\n");
inc_dt();
int b;
do{
b = 1;
GetTokens();
if (!scmp(&InArray[inpointer],"var",lenW)){
firstFl1++;
if (!fvar(0)) return 0;
}
else
if
(!scmp(&InArray[inpointer],"begin",lenW)){
if (!fbegin(2)) return 0;
b = 0;
}
else
if (fcomment()) fcommend();
else return 0;
} while (b==1);
list_clearer(0);
inpointer++;
return 1;
}
frecord(){
skipit();
putSrtw("struct ");
GetTokens();
if (typeW!=wtpe_str || isthsKWD()) return 0;
copyit();
GetTokens();
if (InArray[inpointer]!='=') return 0;
skipit();
GetTokens();
if (!equit("record")) return 0;
putSrtw("\n{\n");
inc_dt();
if (!fvar(-1)) return 0;
dec_dt();
GetTokens();
if (!equit("end")) return 0;
skipit();
putChrw('}');
GetTokens();
if (InArray[inpointer]!=';') return 0;
copyit();
putSrtw("\n\n");
inpointer += lenW;
return 1;
}
fae() {
GetTokens();
if (InArray[inpointer]=='+'){
copyit();
}
else
if (InArray[inpointer]=='-'){
copyit();
}
while (1){
GetTokens();
if (typeW==wtpe_numb) copyit(); else
if (typeW==wtpe_str&&type_reciever()==tpe_int)
copyit(); else
if (InArray[inpointer]=='('){
copyit();
if (!fae()) return 0;
GetTokens();
if (InArray[inpointer]!=')') return 0;
inpointer++;
putChrw(')');
}
else return 0;
GetTokens();
char c = InArray[inpointer];
if (c=='+'||c=='-'||c=='*'||c=='/') copyit();
else return 1;
}
}
ae(){
char c,c1;
if (!fae()) return 0;
GetTokens();
c = InArray[inpointer];
c1 = InArray[inpointer+1];
inpointer += 2;
putSrtw("!=");
}
else
if (c=='=') {
inpointer++;
putSrtw("==");
}
else
if (c=='>'||c=='<') {
if (c1=='='){
inpointer += 2;
}
else copyit();
}
GetTokens();
if (!fae()) return 0;
return 1;
}
fle() {
int k;
char c,c1;
int arifm, ip,op;
while (1){
GetTokens();
k = isthsKWD();
int ip, op;
ip = inpointer;
op = OutLenght;
arifm = 0;
if(InArray[inpointer]=='+'||
InArray[inpointer]=='('||
InArray[inpointer]=='-'||
typeW==wtpe_str&&!isthsKWD() ||
typeW==wtpe_numb)
arifm = ae();
if (!arifm){
inpointer = ip;
OutLenght = op;
GetTokens();
k = isthsKWD();
if (typeW==wtpe_str&&k==kwqe_true){
skipit();
putChrw('1');
}
else
if (typeW==wtpe_str&&k==kwqe_false) {
skipit();
putChrw('0');
}
else
if (typeW==wtpe_str&&type_reciever()==tpe_bool)
copyit(); else
if (InArray[inpointer]=='('){
copyit();
if (!fle()) return 0;
GetTokens();
if (InArray[inpointer]!=')') return 0;
inpointer++;
putChrw(')');
}
else return 0;
}
GetTokens();
k = isthsKWD();
if (k==kwqe_or) putSrtw("||"); else
if (k==kwqe_and) putSrtw("&&");
else return 1;
skipit();
}
}
asign(){
int type = type_reciever();
if (!(type==tpe_bool||type==tpe_int)) return 0;
put_dt();
copyit();
GetTokens();
if (InArray[inpointer]!=':'||InArray[inpointer+1]!='=')
return 0;
putChrw('=');
inpointer += 2;
if (type==tpe_bool) {
if (!fle()) return 0;
}
else
if (!fae()) return 0;
GetTokens();
if (InArray[inpointer]!=';') return 0;
copyit();
putChrw('\n');
return 1;
}
frepeat() {
skipit();
put_dt();
putSrtw("do {\n");
inc_dt();
return 1;
}
funtil() {
skipit();
dec_dt();
put_dt();
putSrtw("} while (");
if (!fle()) return 0;
putChrw(')');
GetTokens();
if (InArray[inpointer]!=';') return 0;
inpointer++;
putSrtw(";\n");
return 1;
}
fbegin(int globalVar1){
int rep_n = 0;
if(globalVar1!=3) skipit();
if (globalVar1==1) putSrtw("\n\nvoid main()\n");
if ((globalVar1!=2)||(globalVar1!=3)) {
put_dt();
putSrtw("{\n");
inc_dt();
}
int b;
do{
b = 1;
GetTokens();
if (fcomment()){
fcommend();
continue;
}
switch(isthsKWD()){
case kwqe_begin:
firstFl1++;
if (!fbegin(0)) return 0;
secFl2++;
break;
case kwqe_repeat:
firstFl1++;
rep_n++;
if (!frepeat()) return 0;
break;
case kwqe_until:
if (rep_n>0){
rep_n--;
if (!funtil()) return 0;
secFl2++;
}
else return 0;
break;
case kwqe_procedure:
if (!fprocedure()) return 0;
break;
case kwqe_end:
firstFl1++;
if(globalVar1 == 3) return 3;
skipit();
dec_dt();
put_dt();
putSrtw("}\n");
GetTokens();
if (globalVar1==1&&InArray[inpointer]=='.'
||
globalVar1!=1&&InArray[inpointer]==';'){
skipit();
secFl2++;
return 1;
}
else
{
skipit();
return 0;
}
case 0:
if (!asign()) return 0;
break;
default:
return 0;
}
} while (b);
return 1;
}
main_prgrm()
{
int b;
int k;
firstFl1 = secFl2 = 0;
putSrtw("#include <stdio.h>\n\n");
do{
b = 1;
GetTokens();
k = isthsKWD();
if (k==kwqe_var){
firstFl1++;
if (!fvar(1)) {
err_or();
}
else secFl2++; }
else
if (k==kwqe_type){
firstFl1++;
if (!frecord()) {
err_or();
}
else secFl2++;
}
else
if (k==kwqe_procedure){
if
(!fprocedure()) {
err_or();
}
}
else
if (k==kwqe_begin){
if (!fbegin(1)) {
err_or();
}
b = 0;
}
else
if (fcomment()) fcommend();
else {
firstFl1++;
err_or();
};
} while (b==1);
if (InArray[inpointer]!='.') return 0;
inpointer++;
return 1;
}
main()
{
setlocale(LC_ALL,"Russian");
char
s[128];
printf("Выберите файл для трансляции: ");
scanf("%s",s);
if (!inTxt(s))
{
printf("\nПроизошла ошибка при открытии!");
getch();
return;
}
v_lst = NULL;
lv_lst = NULL;
main_prgrm();
list_clearer(1);
printf("\nВведите имя для записи результата:");
scanf("%s",s);
if (!outTxt(s))
{
printf("\nПроизошла ошибка при создании файла!");
getch();
return;
}
printf("\nВо входном файле было %d операторов", firstFl1);
printf("\nВ новый файл эквивалентно %d перенесено", secFl2);
printf("\n Ошибочных: %d", errFl3);
printf("\n\nРезультат в файле: %s",s);
fclose(spasfl);
fclose(ccfl);
while (!kbhit()) ;
}
6 Распечатка тестов и результатов
Пример ошибочного ввода:
Фходной файл 5.pas:
(* New Programm *)
{ Variant 5 }
f:boolean;
r: integer;
testpr(var a:integer);i,j:integer;
begin
repeat
r:=i+3*8;
r:=r+3*8;
until ((a<9 and a<3) or true);
end;:= r=1;.
Вид экрана:
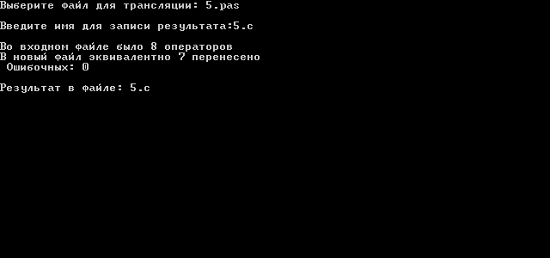
Результат обработки:
#include <stdio.h>
/* New Programm */
/* Variant 5 */f;r;
testpr(int & a)
{
int i,j;
{
do {
r=i+3*8;
r=r+3*8;
} while (((a<9&&a<3)||1));
}
void main()
{
f=r==1;
}
Пример файла с ошибочным оператором:
(* New Programm *)
{ Variant 5 }
f:boolean;
r: integer;
testpr(var a:integer);i,j:integer;
begin
repeat
r:=i+3*8;
r:=r+3*8;
until ((a<9 and a<3) or true);
end;:= r=1;(x);
end.
Вид экрана:

Результат работы:
#include <stdio.h>
/* New Programm */
/* Variant 5 */f;r;
testpr(int & a)
{
int i,j;
{
do {
r=i+3*8;
r=r+3*8;
} while (((a<9&&a<3)||1));
}
void main()
{
f=r==1;
< Ошибка! > (x);
Выводы
Таким
образом, транслятор - это программа
<http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0>
или техническое средство, выполняющее трансляцию программы.
Транслятор
- в широком смысле - программа, преобразующая текст, написанный на одном языке,
в текст на другом языке.
Транслятор
- в узком смысле - программа, преобразующая: программу, написанную на одном
(входном) языке в программу, представленную на другом (выходном) языке.
Транслятор
обычно выполняет также диагностику ошибок, формирует словари идентификаторов,
выдаёт для печати тексты программы и т. д.
Трансляция
программы - преобразование программы, представленной на одном из языков программирования
<http://ru.wikipedia.org/wiki/%D0%AF%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F>,
в программу на другом языке и, в определённом смысле, равносильную первой.[1]
<http://ru.wikipedia.org/wiki/%D2%F0%E0%ED%F1%EB%FF%F2%EE%F0>
Язык,
на котором представлена входная программа, называется исходным языком, а
сама программа - исходным кодом
<http://ru.wikipedia.org/wiki/%D0%98%D1%81%D1%85%D0%BE%D0%B4%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%B4>.
Выходной язык называется целевым языком или объектным кодом
<http://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D1%8B%D0%B9_%D0%BA%D0%BE%D0%B4>.
Понятие
трансляции относится не только к языкам программирования, но и к другим компьютерным
языкам
<http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%BD%D1%8B%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA>,
вроде языков разметки
<http://ru.wikipedia.org/wiki/%D0%AF%D0%B7%D1%8B%D0%BA_%D1%80%D0%B0%D0%B7%D0%BC%D0%B5%D1%82%D0%BA%D0%B8>,
аналогичных HTML <http://ru.wikipedia.org/wiki/HTML>, и к естественным
языкам, вроде английского
<http://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA>
или русского <http://ru.wikipedia.org/wiki/%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA>
(см.: перевод
<http://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B5%D0%B2%D0%BE%D0%B4>).
Мы написали однопроходной транслятор со смешанным подходом к анализу
текста. Он одновременно реализует и лексическую и синтаксическую фазу. Конечно,
до полноценного транслятора этой программе далеко (такая задача и не стояла),
но можно продолжать описание конструкций языка паскаль и добавлять функции
обработки этих конструкций. Тем самым можно реализовать программу с потенциалом
использования в компиляторе. Программу довольно легко разбить на модули, сделав
её тем самым более гибкой для настройки и написания дальнейших версий.
Список литературы
1. Абрамов,
В.Г.; Трифонов, Н.П. и др. Введение в язык Паскаль; Наука, 2005. - 320 c.
. Бабэ, Бруно
Просто и ясно о Borland C++; М.: БИНОМ, 2000. - 400 c.
. Грегори,
Кэйт Использование Visual C++. Специальное издание; Издательский дом Вильямс,
2000. - 849 c.
.
Епанешников, А.М.; Епанешников, В.А. Программирование в среде Turbo Pascal 7.0;
М.: ДИАЛОГ-МИФИ; Издание 4-е, испр., 2004. - 367 c.
. Культин,
Н.Б. Turbo Pascal в задачах и примерах; БХВ, 2007. - 256 c.
. Мешков;
Тихомиров Visual C++ и MFC; СПб: BHV, 2004. - 477 c.
. Павловская,
Т.А. Паскаль. Программирование на языке высокого уровня; СПб: Питер, 2007. -
393 c.
. Семашко,
Г.Л.; Салтыков, А.И. Программирование на языке Паскаль; М.: Наука, 2010. - 128
c.
. Страуструп,
Б. Язык программирования C++; М.: Радио и связь, 2010. - 350 c.
. Уэллин, С
Как не надо программировать на С++; СПб: Питер, 2004. - 240 c.