Программная реализация шифра замены та его дешифрование
Программная
реализация шифра замены та его дешифрование
Оглавление
Теоретические сведения
Шифр подстано́вки
Шифры простой замены
Примеры шифров простой замены
Безопасность шифров простой замены
Частотный анализ
Частотные характеристики текстовых сообщений
Код программы
Экспериментальные данные
Вывод
Теоретические
сведения
Шифр подстановки
Шифр подстановки каждый символ открытого текста
заменяет на некоторый другой. В классической криптографии различают четыре типа
шифра подстановки:
Одноалфавитный шифр подстановки (шифр простой
замены) - шифр, при котором каждый символ открытого текста заменяется на
некоторый, фиксированный при данном ключе символ того же алфавита.
Однозвучный шифр подстановки похож на
одноалфавитный за исключением того, что символ открытого текста может быть
заменен одним из нескольких возможных символов.
Полиграммный шифр подстановки заменяет не один
символ, а целую группу. Примеры: шифр Плейфера, шифр Хилла.
Многоалфавитный шифр подстановки состоит из
нескольких шифров простой замены. Примеры: шифр Виженера, шифр Бофора,
одноразовый блокнот.
Наиболее известными и часто используемыми
шифрами являются шифры замены. Они характеризуются тем, что отдельные части
сообщения (буквы, слова, ...) заменяются на какие-либо другие буквы, числа,
символы и т.д. При этом замена осуществляется так, чтобы потом по шифрованному
сообщению можно было однозначно восстановить передаваемое сообщение.
Пусть, например, зашифровывается сообщение на
русском языке и при этом замене подлежит каждая буква сообщения. Формально в
этом случае шифр замены можно описать следующим образом. Для каждой буквы 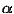 исходного
алфавита строится некоторое множество символов
исходного
алфавита строится некоторое множество символов  так,
что множества и
так,
что множества и  попарно
не пересекаются при
попарно
не пересекаются при 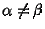 , то есть любые два
различные множества не содержат одинаковых элементов. Множество называется
множеством шифробозначений для буквы .
, то есть любые два
различные множества не содержат одинаковых элементов. Множество называется
множеством шифробозначений для буквы .
Таблица
|
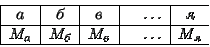
|
(1)
|
является ключом шифра замены. Зная ее, можно
осуществить как зашифрование, так и расшифрование.
При зашифровании каждая буква открытого
сообщения, начиная с первой, заменяется любым символом из множества . Если в
сообщении содержится несколько букв , то каждая из них заменяется на
любой символ из . За счет
этого с помощью одного ключа (<#"511505.files/image006.gif">,
 ,
,
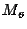 ,
...,
,
..., 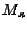 попарно
не пересекаются, то по каждому символу шифрованного сообщения можно однозначно
определить, какому множеству он принадлежит, и, следовательно, какую букву
открытого сообщения он заменяет. Поэтому расшифрование возможно и открытое
сообщение определяется единственным образом.
попарно
не пересекаются, то по каждому символу шифрованного сообщения можно однозначно
определить, какому множеству он принадлежит, и, следовательно, какую букву
открытого сообщения он заменяет. Поэтому расшифрование возможно и открытое
сообщение определяется единственным образом.
Шифры простой
замены
В шифрах простой замены замена производится
только над одним единственным символом. Для наглядной демонстрации шифра
простой замены достаточно выписать под заданным алфавитом тот же алфавит но в
другом порядке или например со смещением. Записанный таким образом алфавит
называют алфавитом замены.
Примеры шифров простой замены
Шифр Атбаш
Шифр простой замены, использованный для
еврейского алфавита и получивший оттуда свое название. Шифрование происходит
заменой первой буквы алфавита на последнюю, второй на предпоследнюю (алеф
(первая буква) заменяется на тав (последнюю), бет (вторая) заменяется на шин
(предпоследняя); из этих сочетаний шифр и получил свое название). Шифр Атбаш для
английского алфавита:
Исходный алфавит: A B C D E F G H I J K L M N O
P Q R S T U V W X Y Z
Алфавит замены: Z Y X W V U T S R Q P O N M L K
J I H G F E D C B A
Шифр с использованием кодового слова
Шифр с использованием кодового слова является
одним из самых простых как в реализации так и в расшифровывании. Идея
заключается в том что выбирается кодовое слово, которое пишется впереди, затем
выписываются остальные буквы алфавита в своем порядке. Шифр с использованием
кодового слова WORD.
Исходный алфавит: A B C D E F G H I J K L M N O
P Q R S T U V W X Y Z
Алфавит замены: W O R D A B C E F G H I J K L M
N P Q S T U V X Y Z
Как мы видим при использовании короткого
кодового слова мы получаем очень и очень простую замену. Так же мы не можем
использовать в качестве кодового слова слова с повторяющимися буквами, так как
это приведет к неоднозначности расшифровки, то есть двум различным буквам
исходного алфавита будет соответствовать одна и та же буква шифрованного
текста.
Часто состоит
из одного элемента. Например, в романе Ж. Верна ``Путешествие к центру Земли''
в руки профессора Лиденброка попадает пергамент с рукописью из знаков
рунического письма. Каждое множество состоит
из одного элемента. Элемент каждого множества выбирается из набора символов
вида
|

|
(2)
|
В рассказе А. Конан Дойла ``Пляшущие человечки''
каждый символ изображает пляшущего человечка в самых различных позах
|

|
(3)
|
На первый взгляд кажется, что чем хитрее
символы, тем труднее вскрыть сообщение, не имея ключа. Это, конечно, не так.
Если каждому символу однозначно сопоставить какую-либо букву или число, то
легко перейти к зашифрованному сообщению из букв или чисел. В романе Ж. Верна
``Путешествие к центру Земли'' каждый рунический знак был заменен на
соответствующую букву немецкого языка, что облегчило восстановление открытого
сообщения. С точки зрения криптографов использование различных сложных символов
не усложняет шифра. Однако, если зашифрованное сообщение состоит из букв или
цифр, то вскрывать такое сообщение удобнее.
В данной расчетно-графической работе, я
использовал, созданный программно, случайный алфавит.
Безопасность шифров
простой замены
Главный недостаток этого метода шифрования это
то, что последние буквы алфавита (которые имеют низкие коэффициенты при
частотном анализе) имеют тенденцию оставаться в конце. Более защищенный способ
построить алфавит замены состоит в том, чтобы выполнить колоночное перемещение
(перемещение столбцов) в алфавите, используя ключевое слово, но это не часто
делается. Несмотря на то, что число возможных ключей является очень большим
(26! = 2^88.4), этот вид шифра может быть легко взломанным. Согласно расстоянию
уникальности английского языка, 27.6 букв от зашифрованного текста должно быть
достаточно чтобы взломать шифр простой замены. На практике, обычно достаточно
около 50 символов для взлома, хотя некоторые шифротексты могут быть взломаны и
с меньшим количеством символов, если найдены какие-либо нестандартные
структуры. Но при равномерном распределении символов в тексте может
потребоваться куда более длинные шифротексты для взлома.
Расстояние уникальности - термин, используемый в
криптографии, обращающейся к длине оригинального шифротекста, которого должно
быть достаточно для взлома шифра.
Частотный анализ - это один из методов
криптоанализа шифротекстов. В частности это процедура кодирования, основанная
на систематической замене одних букв другими, поскольку средняя частота, с
которой встречаются буквы какого-либо языка, более или менее постоянна.
Утверждается, что для какого-либо языка частота
встречаемости отдельных букв в осмысленном тексте есть устойчивая величина.
Устойчивыми также являются комбинации двух, трех (биграммы, триграммы) и
четырех букв. Этот факт, в частности, использовался в криптографии для вскрытия
шифров.
Метод частотного анализа известен уже больше
тысячи лет. Тайные шифры встречаются в детективах, приключенческих книгах. У
Эдгара По - «Золотой жук», у Конан Дойля - «Пляшущие человечки», у Жюль Верна
«Дети капитана Гранта» и т.д
Частотный анализ играет чрезвычайно важную роль
при взломе шифров, а также при расшифровки древних надписей. Возможно, наиболее
известным результатом в этой области служит расшифровка египетских иероглифов
Дж.-Ф.Шампольоном в 1822 году. Ключом к расшифровке послужил камень Розетты. На
камне один текст записан тремя способами: иероглифическим, демотическим и
по-гречески.
Безусловно, при использовании компьютера
частотный анализ значительно ускоряется. Поэтому большинство ранних методов
шифрования устарели. Не будем забывать, что некоторые из первых компьютеров
предназначались для взламывания немецких кодов во время Второй мировой войны.
Хотя частотный анализ является мощным средством,
шифрование до сих пор остаётся эффективным на практике, так как многие
потенциальные криптоаналитики не знакомы с этой техникой. Взлом сообщения без
частотного анализа обычно требует знания используемого шифра, то есть в
основном является следствием шпионажа, взятки, кражи или измены для его
определения.
Вероятность появления отдельных букв, а также их
порядок в словах и фразах естественного языка подчиняются статистическим
закономерностям: например, пара стоящих рядом букв «ся» в русском языке более
вероятна, чем «цы», а «оь» не встречается вовсе. Анализируя достаточно длинный
текст, зашифрованный методом замены, можно по частотам появления символов
произвести обратную замену и восстановить исходный текст.
Частотный метод породил требование равномерного
распределения символов в шифртексте. Сегодня принципы частотного анализа широко
применяются в программах по подбору паролей и позволяют на несколько порядков
сократить время поиска.
Частотные
характеристики текстовых сообщений
Как упоминалось выше, важными характеристиками
текста являются повторяемость букв (количество различных букв в каждом языке
ограничено), пар букв, т.е.m (m-грамм), сочетаемость букв друг с другом,
чередование гласных и согласных и некоторые другие особенности. Примечательно,
что эти характеристики являются достаточно устойчивыми.
Идея состоит в подсчете чисел вхождений каждой
nm возможных m-грамм в достаточно длинных открытых текстах T=t1t2...tl,
составленных из букв алфавита {a1, a2, ..., an}. При этом просматриваются подряд
идущие m-граммы текста:t2...tm, t2t3... tm+1, ..., ti-m+1tl-m+2...tl.
Если L (ai1ai2 ... aim ) - число появлений
m-граммы ai1ai2...aim в тексте T, а L - общее число подсчитанных m-грамм, то
при достаточно больших L частоты L (ai1ai2 ... aim )/ L, для данной m-граммы
мало отличаются друг от друга.
В силу этого, относительную частоту считают
приближением вероятности P (ai1ai2...aim) появления данной m-граммы в случайно
выбранном месте текста (такой подход принят при статистическом определении
вероятности).
В общем смысле частоту букв в процентном
выражении можно определить следующим образом: подсчитывается сколько раз она
встречается в шифро-тексте, затем полученное число делится на общее число
символов шифро-текста; для выражения в процентном выражении, еще умножается на
100.
Но существует некоторая разница значений частот,
которая объясняется тем, что частоты существенно зависят не только от длины
текста, но и от характера текста. Например, текст может быть технического
содержания, где редкая буква Ф может стать довольно частой. Поэтому для
надежного определения средней частоты букв желательно иметь набор различных
текстов. шифрование замена подстановка
Код программы
Шифратор
//---------------------------------------------------------------------------
#include <vcl.h>
#pragma hdrstop
#include "Unit1.h"
//---------------------------------------------------------------------------
#pragma package(smart_init)
#pragma resource "*.dfm"*Form1;
//---------------------------------------------------------------------------
__fastcall TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{->Text=" ";->Text="
";->Text=" ";->Text=" ";
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button1Click(TObject *Sender)
{abc="абвгдежзийклмнопрстухфцчшщъыьэюя
";nabc, t="",k="",
o="0";str="",str2="";nom[33];len;key="";->Text=Now().TimeString();=Edit1->Text;=t[7]+t[8];n=StrToInt(k);->Text=n;->Text=abc;(int
i=1;i<=33;i++)
{nom[i]=((2*i+n))%33;
if(nom[i]==0) nom[i]=33;}
for(int i=1;i<=abc.Length();i++)
{int m=nom[i];
nabc=nabc+abc[m];}->Text=nabc;=Memo1->Text.LowerCase();=str.Length();
//Label2->Caption=IntToStr(len);
for(int i=1;i<=len; i++)
{ Memo2->Text=" ";
//Memo1->Text=" ";
for(int j=1;j<=abc.Length();j++)
{
if(str[i]==abc[j])=key + nabc[j];
}
}->Text=key;=Memo2->Text;=str.Length();
//Label1->Caption=IntToStr(len);
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button2Click(TObject *Sender)
{->Lines->LoadFromFile("C:\\лоад.txt");
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button3Click(TObject *Sender)
{save="C:\\сейв.txt";
Memo2->Lines->SaveToFile(save);
}
//---------------------------------------------------------------------------
//---------------------------------------------------------------------------
__fastcall TForm1::Button4Click(TObject *Sender)
{>MessageBox("расчетно-графическая
работа. выполнил студент ИИДС 349 Мищенко А.С.","About",MB_OK);
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button5Click(TObject *Sender)
{();
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button6Click(TObject *Sender)
{->Text="" ;->Text=""
;
}
//---------------------------------------------------------------------------
Дешифратор
//---------------------------------------------------------------------------
#include <vcl.h>
#pragma hdrstop
#include "Unit1.h"
#include "Unit2.h"
//---------------------------------------------------------------------------
#pragma package(smart_init)
#pragma resource "*.dfm"*Form1;str1,
str2, str3, abc, abc2;lenstr1, lenstr2;
//---------------------------------------------------------------------------
__fastcall TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button2Click(TObject *Sender)
{();
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button1Click(TObject *Sender)
str1=Memo1->Lines->Text;
lenstr1=str1.Length();
str2=Memo2->Lines->Text;
lenstr2=str2.Length();
// Label2->Caption=IntToStr(lenstr1);
//Label6->Caption=IntToStr(lenstr2);i=0,
abc3[33], abc4[33];
for(i;i<33;i++)
{abc3[i]=0;
abc4[i]=0;
StringGrid1->Cells[i][0]=abc[i+1];
StringGrid1->Cells[i][2]=abc[i+1];}j=1;
for(j;j<34;j++)
for(i=1; i<=lenstr1;i++)
if(str1[i]==abc[j] || str1[i]==abc2[j])
abc3[j-1]++;(j=1;j<34;j++)
for(i=1; i<=lenstr2;i++)
if(str2[i]==abc[j] || str2[i]==abc2[j])
abc4[j-1]++;(i=0;i<33;i++)
{StringGrid1->Cells[i][1]=abc3[i];
StringGrid1->Cells[i][3]=abc4[i];}
}__fastcall
TForm1::Button3Click(TObject *Sender)
{int i, j, t1, t2;
AnsiString temp;(i=0;i<33;i++)
for(j=0;j<33;j++)
{t1=StrToInt(StringGrid1->Cells[i][1]);
t2=StrToInt(StringGrid1->Cells[j][1]);
if(t1<t2){temp=StringGrid1->Cells[i][0];
StringGrid1->Cells[i][0]=StringGrid1->Cells[j][0];
StringGrid1->Cells[j][0]=temp;
StringGrid1->Cells[i][1]=IntToStr(t2);
StringGrid1->Cells[j][1]=IntToStr(t1);}
t1=StrToInt(StringGrid1->Cells[i][3]);
t2=StrToInt(StringGrid1->Cells[j][3]);
if(t1<t2){temp=StringGrid1->Cells[i][2];
StringGrid1->Cells[i][2]=StringGrid1->Cells[j][2];
StringGrid1->Cells[j][2]=temp;
StringGrid1->Cells[i][3]=IntToStr(t2);
StringGrid1->Cells[j][3]=IntToStr(t1);}
}
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::FormCreate(TObject *Sender)
{="абвгдежзийклмнопрстуфхцчшщъыьэюя
";="АБВШДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ ";
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button4Click(TObject *Sender)
{str3="";
int i, j;
AnsiString temp;
for(i=1;i<=lenstr2;i++)
for(j=0;j<33;j++)
{temp=StringGrid1->Cells[j][2];
if(temp==str2[i])
{temp=StringGrid1->Cells[j][0];
str3=str3+temp;}
}->Lines->Text=str3;
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button5Click(TObject *Sender)
{
//SaveDialog1->FileName="lab3";
//SaveDialog1->InitialDir=GetCurrentDir();
//SaveDialog1->Execute();
//Memo3->Lines->SaveToFile("lab3.txt");
Memo1->Text=""
;->Text="" ;->Text="" ;
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button6Click(TObject *Sender)
{
AnsiString load="C:\\лоад.txt";
Memo1->Lines->LoadFromFile(load);
}
void __fastcall
TForm1::Button7Click(TObject *Sender)
{
AnsiString load="C:\\сейв.txt";
Memo2->Lines->LoadFromFile(load);
}
//---------------------------------------------------------------------------
void __fastcall
TForm1::Button8Click(TObject *Sender)
{>MessageBox("расчетно-графическая
работа. выполнил студент ИИДС 349 Мищенко А.С.","About",MB_OK);
}
//---------------------------------------------------------------------------
Экспериментальные данные
Работа шифратора
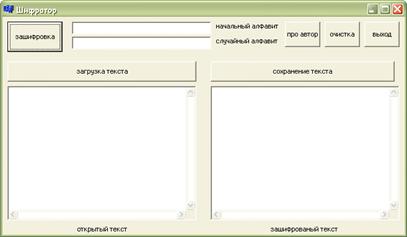
Рис. 1 форма
программы
Рис. 2 загрузка
открытого текста

Рис. 3 зашифровка
текста с использованием случайного алфавита

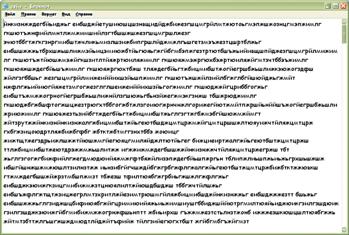
Рис. 4 сохранение
шифро-текста

Рис. 5 сведения об авторе
Работа дешифратора
Рис. 6 форма дешифратора

Рис. 7 загрузка
исходного текста
Рис .8 загрузка сохраненного шифро-текста

Рис. 9 подсчет символов в открытом и шифрованном
сообщениях

Рис. 10 сортировка
символов по возрастанию

Рис. 11 применение
частотного анализа текста

Рис. 12 сведения об авторе
Вывод
в данной работе я программно реализовал
шифрование текста с помощью шифра замены. Работа шифратора основана на
использовании случайно сформированного алфавита. Каждый символ исходного
алфавита заменяется символом случайного алфавита. Дешифратор основан на
применении частотного анализа текста. Программа подсчитывает количество
символов в шифро-тексте и сравнивает с количеством символов в открытом тексте,
после чего выводит результат анализа в другое поле.