Численные расчёты динамики генных сетей на основе редукции графов в рамках синхронной булевой модели
Численные
расчёты динамики генных сетей на основе редукции графов в рамках синхронной
булевой модели
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
1. ПОСТАНОВКА
ЗАДАЧИ
1.1
Описание предметной области
1.1.1 Генная
сеть
.1.2 Модели
регуляции генов
.1.3 Синхронная
булева модель
.1.4 Динамика
сети
1.2 Постановка
задачи
.3 Существующие
методы решения
2. РЕШЕНИЕ
ЗАДАЧИ
2.1 Формальная
постановка задачи
.2 Алгоритм
перебора
.3 Редукция
сети
.4 Помодульный
анализ
.5 Оценка
сложности
3. РЕАЛИЗАЦИЯ
3.1 Выбранные
средства
.2 Функционирование
программного средства
3.2.1 Входные
данные
.2.2 Схема
работы программы
.2.3 Выходные
данные
3.3 Интерфейс
.4 Тестирование
ЗАКЛЮЧЕНИЕ
ЛИТЕРАТУРА
ВВЕДЕНИЕ
Живые системы имеют чрезвычайно сложное
внутреннее строение. Уникальным свойством таких систем является способность к
самовоспроизведению и к эффективному существованию в изменяющихся условиях
внешней среды. Исключительно важная роль в функционировании живых систем
принадлежит генным сетям, которые обеспечивают выполнение жизненно важных функций
организмов. Обычно генные сети состоят из десятков и сотен элементов, которые
объединяются между собой посредством сложных нелинейных процессов.
В данной работе рассмотрена синхронная булева
модель генной сети. В рамках этой модели сеть представляется в виде графа,
каждой вершине которого сопоставлен определённый ген (булева переменная,
задающая активность гена) и некоторая булева функция, задающая состояние гена в
следующий момент времени в зависимости от состояния всей сети.
Была поставлена задача разработать и реализовать
алгоритм, позволяющий в рамках данной модели провести анализ динамики генной
сети, то есть выявить все её стационарные и циклические устойчивые состояния.
Существующие методы решения задачи имеют высокие требования времени и памяти,
что делает исследование больших сетей практически невозможным, поэтому было
решено разработать методы, позволяющие работать с пространствами размерности
меньше исходного. В процессе выполнения задачи были проведены следующие работы:
1) Изучена новая предметная область теории
функционирования генных сетей и написан обзор;
2) Рассмотрены существующие методы решения
задачи, выявлены их недостатки;
) Определены требования к решению;
) Разработан и формально описан новый
метод решения задачи, использующий иерархическую декомпозицию сети:
· Разработан подход иерархической
декомпозиции графа;
· Разработан алгоритм помодульного
расчёта динамики сети;
5) Проведена оценка сложности и эффективности
алгоритмов;
6) Создано программное средство,
реализующее разработанные алгоритмы;
) Проведена отладка и тестирование
программного средства на наборе случайно сгенерированных сетей, практически
показана эффективность разработанного средства;
) Проведены исследования реально
существующих больших сетей;
) Подведены итоги работы.
Программное средство реализовано на языке C++ в
среде разработки Microsoft Visual Studio 2008, тестирование проводилось на
следующей вычислительной платформе: AMD Athlon™ 64 X2 Dual Core Processor 5600+
(2.90 GHz), 2.00 GB Ram, Windows 7 x86.
Полученное программное средство позволяет
корректно рассчитать все устойчивые состояния генной сети, заданной графом
преобразования, используя иерархическое разбиение графа на модули. Средства,
используемые ранее для исследования динамики генных сетей в рамках синхронной
булевой модели, специализируются на поиске лишь неподвижных точек системы
(SAT-, ROBDD-подходы). Применяя редукцию и декомпозицию графов, удалось
существенно снизить затраты, что сделало исследование крупных сетей реальным. В
будущем планируется дальнейшая оптимизация решения задачи. Актуальность и
новизна работы состоит в том, что, получив полные данные о динамике сети, можно
приступить к анализу её устойчивости - исследовать реакцию сети на внешние
воздействия, исследовать поведение сети при мутациях, выделить группы
регуляторных генов, оказывающих ключевое влияние на поведение сети. Ранее
подобные исследования велись, исходя только из структуры, не затрагивая
реальные динамические свойства сети.
1.
ПОСТАНОВКА ЗАДАЧИ
генный граф булевая модель
1.1 Описание предметной области
1.1.1 Генная сеть
Все происходящие в организме процессы
(биохимические, физиологические и др.) осуществляются за счет координированной
экспрессии различных групп генов.
Каждая такая группа составляет основу конкретной
генной сети, отвечающей за выполнение определенной функции клетки, органа,
организма. Под генной сетью при этом понимается совокупность координированно
экспрессирующихся генов, их белковых продуктов и взаимосвязей между ними.
В генной сети можно выделить несколько обязательных
типов компонентов, таких, как:
1) Группы координированно
экспрессирующихся генов (ядро сети);
2) Белки, кодируемые этими генами
(выполняющие как определенные структурные, транспортные, биохимические, так и
регуляторные функции);
) Отрицательные и положительные обратные
связи, стабилизирующие параметры генной сети на определенном уровне или,
напротив, отклоняющие их от исходного значения;
) Низкомолекулярные соединения
(метаболиты и др.) и различные внешние сигналы, обеспечивающие переключение состояний
генной сети.
Белки синтезируются в результате биологического
процесса, называемого "экспрессией генов". Каждый ген в каждой клетке
"кодирует" определенный белок. В ходе своей экспрессии гены
регулируют активность друг друга, поэтому пространственно-временное
распределение концентрации белков в клетке возникает как результат нелинейных
взаимодействий между генами.
Поэтому модель, описывающую динамику
пространственных функций концентраций белков, можно назвать моделью регуляции
генов или моделью экспрессии генов.
1.1.2 Модели регуляции генов
Существуют следующие классы моделей
функционирования генной сети:
1) Континуальная модель - в этой модели
концентрации белков (продуктов экспрессии генов) являются непрерывными
функциями времени и дискретными функциями пространственной переменной; динамика
таких функций описывается с помощью обыкновенных дифференциальных уравнений. К
этому же классу можно отнести модели, в которых концентрации белков также
непрерывны по пространству и являются решением уравнений в частных производных.
Функции синтеза и распада белка в уравнениях строятся на основе имеющихся
знаний об общих механизмах процесса экспрессии генов и химической кинетики.
Диффузия моделируется, как правило, на основе закона Фика или дополнительно с
учетом возможных нелокальных эффектов.
2) Логическая модель - этот класс включает
в себя модели генной регуляции, уравнения которых основаны на булевой логике и
ее различных модификациях. В логических моделях состояние гена описывается
булевой переменной, значение 1 которой соответствует состоянию гена, в котором
он активен (кодирует белок), а значение 0 - состоянию, в котором ген неактивен
(белок не синтезируется). Динамика такой переменной описывается с помощью
булевых функций. Логические модели позволяют лишь качественно описывать
экспрессию генов, то есть решения для функций концентрации белков, кодируемых
генами, представляют собой дискретные уровни в пространстве и времени.
1.1.3
Синхронная булева модель
В данной работе будет использоваться синхронная
булева модель. В рамках этой модели генная сеть представима в виде графа
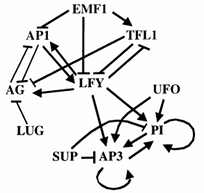
Рис 1. Граф генной сети Arabidopsis Thaliana.
В нём каждая вершина представляет конкретный
ген, а дуги представляют отрицательные и положительные обратные связи между
генами.
Каждой вершине графа сопоставлены:
1) Логическая переменная, выражающая
состояние гена в настоящий момент времени;
2) Логическая функция, выражающая будущее
состояние гена, определяемое действием регулирующих его генов.
Все вершины меняют значения одновременно в
зависимости от состояний регулирующих их генов, следовательно, можно
представить преобразование для каждой вершины как булеву функцию
где xi - значение i-й вершины графа.
Так как логические переменные принимают значения
0 и 1, можно представить состояние сети в виде булева вектора v, i-й компоненте
которого соответствует состояние i-й вершины графа.
1.1.4 Динамика сети
Генные сети контролируют все основные процессы,
протекающие в живых системах:
· Поддерживают в организме устойчивые
состояния, характеризующиеся постоянством концентраций веществ (гомеостаз,
стационарные состояния);
· Обеспечивают периодические
незатухающие колебания концентраций определенных групп веществ (осцилляции,
циклы);
· Контролируют необратимые процессы:
развитие, рост, дифференцировка, апоптоз.

Рис 2. Динамика генной сети.
На рисунке показан устойчивый циклический режим
(верхний график) и стационарное состояние (нижний график). Сеть принимает то
или иное устойчивое состояние в зависимости от начальных данных.
Для булевой модели множество всех состояний сети
конечно, и представимо в виде графа. Вершины графа соответствуют состояниям, а
дуги - переходам из одного состояния в другое согласно преобразованию,
заданному булевыми функциями:
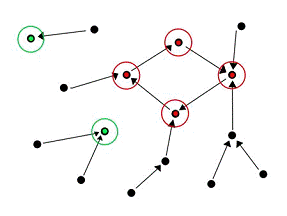
Рис 3. Конфигурационное пространство генной
сети.
На рисунке обведены устойчивые состояния сети
(две стационарные точки и цикл длины 4).
1.2 Постановка задачи
Требуется разработать и реализовать алгоритм,
позволяющий построить полную динамическую картину синхронной булевой модели
генной сети. Под построением динамической картины понимается выделение таких
состояний сети, как:
· Неподвижные точки - состояния, не
меняющиеся при преобразовании;
· Циклы - цепочки состояний,
замыкающиеся на себе в ходе преобразования;
· Области притяжения - состояния,
через некоторое количество преобразований переходящие в циклы или неподвижные
точки.
Необходимо, чтобы все группы состояний были
выделены корректно (без потери устойчивых состояний).
1.3 Существующие методы решения
1) SAT-подход.
Основной минус SAT-подхода состоит в том, что с
его помощью удается быстро найти одно конкретное решение SAT-задачи. При поиске
новых решений (например, при перечислении неподвижных точек) информацию о
найденных приходится учитывать, добавляя к КНФ запрещающие
ограничения-дизъюнкты. Однако в общем случае число решений может не
ограничиваться никаким полиномом от длины входа.
2) ROBDD-подход.
ROBDD (Reduced Ordered Binary Decision Diagram)
- этот подход на текущий момент популярен в верификации моделей программ, но
возможно его применение и к задаче поиска неподвижных точек автоматных
отображений. Применение этого подхода оправдано для графов с небольшим
количеством вершин (меньше 100), и по скорости этот подход сильно проигрывает
SAT-подходу. Это объясняется тем, что ROBDD-графы являются более медленными
структурами данных, чем КНФ. С другой стороны, успешное построение ROBDD даёт
полную информацию о неподвижных точках рассматриваемого отображения.
3) Моделирование поведения сети для
случайных начальных данных.
Часто для исследования динамических свойств сети
формируют случайно сгенерированный набор начальных состояний сети и для каждого
начального состояния моделируют процесс регуляции генов. Результатом таких
исследований служит набор устойчивых состояний, которые приняла сеть. Эти
данные помогают составить частичную динамическую картину сети.
4) Полный перебор состояний сети.
Полный перебор состояний сети - очень
ресурсоёмкий процесс. Существующие программные средства, нацеленные на
построение полной динамической картины, не справляются с анализом динамики
больших сетей.
.4 Требования к решению задачи
В ходе исследования поставленной задачи и существующих
решений в данной области, были выработаны следующие требования к
разрабатываемым алгоритмам и программному средству:
· Возможность по заданному графу
преобразования найти все устойчивые состояния сети (неподвижные точки и циклы);
· Удобное представление результатов,
возможность настройки вывода;
· Отсутствие потерь решений в ходе
расчётов;
· Допустимое время работы программы и
допустимые размеры потребляемой памяти для больших сетей;
· Бесперебойность работы;
· Возможность настройки работы
программы.
2.
РЕШЕНИЕ ЗАДАЧИ
2.1 Формальная постановка задачи
Пусть L = {0,1}n - множество всех
булевых векторов размерности n. Рассмотрим на нём отображения F: L → L,
переводящие вектор v в вектор F(v): если v = (x1, .. , xn),
то F(v) = (f1(x1, .. , xn), .. , fn(x1,
.. , xn)), где gi - некоторые булевы функции.
Представим сеть как ориентированный граф
размерности n, веса рёбер которого равны -1 или 1 (отрицательные или
положительные связи соответственно), а значения xi вершин принимают
значения 0 и 1. Тогда множеством всех возможных состояний сети будет являться
множество всех булевых векторов размерности n, то есть L = {0,1}n.
Классифицируем векторы множества L: цепочка (v1,
v2, .. , vk) называется циклом длины k, если для любого i
из [2, k] vi = F(vi-1), и v1 = F(vk),
то есть её векторы в результате k преобразований отображаются в себя. Цикл
длины 1 называется неподвижной точкой. Векторы, не принадлежащие к циклам,
называются областями притяжения.
Задача: пусть задан граф G
преобразования F(v),
требуется для данной сети выделить все обозначенные выше классы векторов.
.2 Алгоритм перебора
Конфигурационное пространство (множество всех
состояний сети) дискретно и представимо в виде графа, вершинами которого
являются состояния, а дугами - переходы согласно заданному преобразованию F.
Отождествим вектор v = (x1, x2,
.. , xn) числу v, равному десятичному представлению этого вектора, и
построим задающий преобразование массив V, такой, что V[v] = F(v). Тогда
алгоритм поиска циклов будет выглядеть так:
1. Задаём дополнительный массив T, в
котором для каждой точки будет храниться её тип (отрицательное число -
принадлежность к зоне притяжения, положительное - принадлежность к циклу).
Изначально массив заполнен специальными значениями, которые обозначают, что
точка ещё не обработана.
2. Задаём множество посещённых вершин с
логарифмической скоростью поиска (visited), изначально оно пустое.
. Выбираем ещё не обработанную стартовую
точку v (T[v] = 0).
. Помечаем точку посещённой. Применяем
заданное преобразование к этой точке (на этот момент мы уже имеем
преобразованное пространство, поэтому преобразование точки v сходится к поиску
w = V[v]).
. Если точка w уже обработана (T[w] !=
0), то помечаем всю цепочку от стартовой вершины до w типом этой точки (T[w]).
Если точка w не обработана (T[w] = 0), но посещена (принадлежит visited), то
помечаем цепочку от стартовой до w значением -w, а от w и до конца - значением
+w. Если точка w не посещена, то продолжаем, возвращаясь к пункту 4.
. Если после обработки последней цепочки
не все вершины посещены, переходим к пункту 3.
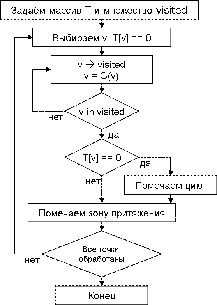
Рис. 4. Блок-схема алгоритма поиска циклов
перебором.
В итоге у нас будет заполнен массив T, в котором
будет содержаться информация о каждой точке - принадлежит она к зоне притяжения
или к циклу, и если к циклу, то к какому.
Сложность данного алгоритма: O(n·2n).
Слабое место перебора - ресурсоёмкость. На таблице приведены минимальные
требования алгоритма к выделению памяти в зависимости от размера сети:
Таблица 1. Затраты памяти при прямом переборе.
|
n
|
2n
|
sizeof(V),
KB
|
sizeof(T),
KB
|
Итого,
MB
|
|
8
|
256
|
0,25
|
0,5
|
0,0007
|
|
16
|
65
536
|
128
|
0,375
|
|
24
|
16
777 216
|
49
152
|
98
304
|
144
|
|
32
|
4
294 967 296
|
16
777 216
|
33
554 432
|
49
152
|
Как мы видим, анализ больших сетей прямым
перебором попросту невозможен.
.3 Редукция сети
Были разработаны методы, позволяющие работать с
конфигурационными пространствами размерности меньше исходного.
) Поточечная редукция сети.
Для заданного графа проводится удаление и
слияние вершин, непосредственно не влияющих на динамику сети. Редукция графа
логируется и после анализа динамики редуцированного графа данные
восстанавливаются до оригинальной размерности.
) Декомпозиция сети
Для уменьшения анализируемых пространств,
происходит разбиение исходного графа на модули. Так как вершины графа
взаимодействуют между собой и влияют на динамику друг друга, для возможности
помодульного анализа было принято решение разбивать граф на модули следующим
образом:
· Первый (стартовый) модуль - подграф,
не имеющий никаких входящих дуг извне, в силу независимости этого фрагмента
сети можно корректно рассчитать его динамику;
· Второй модуль - подграф, в который
извне входят дуги только из первого модуля;
· Третий модуль - подграф, в который
извне входят дуги только из первых двух модулей;
· Последний модуль - подграф, в
который входят все оставшиеся вершины исходного графа.
Формально иерархическое разбиение можно описать
так:
Пусть задан ориентированный граф G =
(M, E), где M - множество вершин графа, E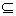 M×M - множество дуг. Тогда
результатом разбиения будет набор подграфов Gi = (Mi, Ei), i
M×M - множество дуг. Тогда
результатом разбиения будет набор подграфов Gi = (Mi, Ei), i  {1, .. , m}, таких,
что
{1, .. , m}, таких,
что
 a,bMi: (a,b)E
a,bMi: (a,b)E  (a,b)Ei
(a,b)Ei
bMi: (a,b)Ei a
Маска полученного разбиения
сохраняется и используется для дальнейшего анализа динамики сети.
2.4 Помодульный анализ
Согласно разбиению выделим в исходной сети
стартовый модуль. На вершины этого модуля не влияют никакие элементы извне,
следовательно, можно корректно рассчитать динамику этого модуля. Расчёт
проводится по описанному выше алгоритму перебора.
После расчёта мы имеем набор циклов и стартового
модуля. Согласно полученному ранее разбиению выделим следующий модуль для
анализа - такой фрагмент сети, в который извне входят дуги только из стартового
модуля.
Назовём виртуальными вершины, принадлежащие
стартовому модулю, из которых выходят дуги, ведущие в новый модуль.
Для каждого цикла стартового модуля (далее будем
называть его базовым циклом) проведём анализ динамики нового модуля.
После первоначальных расчётов известна динамика
стартового модуля и динамика виртуальных вершин в частности, поэтому можно
задать значение каждой из этих вершин некоторыми периодическими функциями g1(t),
.. , gk(t),
где k - количество таких вершин, а период функций равен длине базового цикла.

Рис. 5. Переход к анализу следующего модуля.
Тогда для модуля преобразование F
будет зависеть не только от преобразуемого вектора v, но и от времени, то есть
будет иметь вид v = F(v, t).
Расширим алгоритм перебора, использовавшийся для анализа динамики стартового
модуля, для расчётов на новом модуле. Теперь состояние сети помимо значений
компонент вектора будет задавать и величина (t mod h), где h - длина базового
цикла, то есть количество состояний увеличится в h раз.
Тогда в существующем алгоритме произойдут
следующие изменения: будет введена целочисленная переменная t, увеличивающаяся
с каждым преобразованием; вместо одного массива T, содержащего типы точек,
будет h массивов Ti; множество посещённых точек visited будет
хранить помимо самих точек так же момент времени, в который они были посещены.
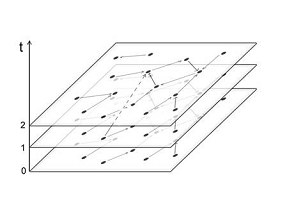
Рис. 6. Увеличение множества состояний модуля.
В результате расчётов мы получим набор циклов в
рассматриваемом модуле. Так как этот модуль имеет общие вершины со стартовым
модулем, можно простейшим образом присоединить к каждому циклу набора поведение
остальных вершин стартового модуля (из базового цикла). Таким образом, мы будем
иметь данные о динамике объединения этого и стартового модуля. Теперь можно
принять стартовым это объединение, выделить новый модуль и провести расчёт по
приведённому выше алгоритму. Продолжать это до тех пор, пока не будут захвачены
все вершины исходного графа.
.5 Оценка сложности
Удаётся избежать работы с конфигурационным
пространством размерности 2n, перейдя к меньшим размерностям
анализируемых модулей.
Количество обработанных состояний уменьшается с
2n до
n0
+ 2n1 *∑h0j + .. + 2n(k-1)*∑h(k-2)j,
где k - количество модулей, nj -
размерность j-го модуля, ∑hji - сумма длин циклов в j-м
модуле.
Сложность оценивается по доминирующей сложности
анализа наибольшего модуля:
(m·2m), m = max(ni).
Размер памяти, выделяемый при вычислениях, зависит
от размера рассчитываемого в данный момент модуля и длины «родительского»
цикла, для которого ведётся расчёт. При достаточно малых количествах вершин в
модулях эта величина будет незначительна по сравнению с потреблением памяти
алгоритмом, проводящем расчёты без разбиения.
3.
РЕАЛИЗАЦИЯ
3.1 Выбранные средства
Для разработки были выбраны:
· Язык C++;
· Среда разработки Microsoft Visual
Studio 2008;
· Инструмент для визуализации графов
GraphViz.
В ходе разработки были дополнительно написаны
следующие инструменты:
· Генератор случайных графов
преобразований по заданным характеристикам;
· Программа для приведения к КНФ
системы булевых уравнений, определяющих преобразование, заданное графом;
· Программа, упорядочивающая вершины
графа в нужном порядке, удаляющая указанные вершины и исследующая граф на
некорректные дуги;
· Программа, строящая гистограмму
расстояний Хэмминга по выборке векторов.
3.2 Функционирование программного средства
3.2.1 Входные данные
Входной файл содержит граф размерности n,
задающий преобразование:
В первой строке файла содержится число n,
последующие строки имеют вид:
j k
обозначающий дугу типа k (-1 или 1) из вершины i
в вершину j. Нумерация вершин начинается с нуля.
Сопутствующий файл задаёт декомпозицию графа:
В первой строке файла содержится количество
модулей M, последующие M пар строк имеют вид:
i1
a2 .. ani
где ni - размер i-го модуля, a1
.. ani - вершины, входящие в i-й модуль.
3.2.2 Схема работы программы
2. Считывание графа и маски разбиения.
. Анализ стартового модуля.
. Последовательный анализ модулей: расчёт
динамики i-го модуля для каждого цикла предыдущего модуля: передача i-му модулю
данных об этом цикле; расчёт динамики по определённому выше алгоритму;
сохранение данных и переход к следующему модулю.
. Объединение результатов.
. Вывод решения.
Подробная блок-схема работы программы приведена
в конце работы (см. Приложение).
3.2.3 Выходные данные
После расчётов данные об аттракторах хранятся
отдельно для каждого модуля: помимо непосредственно последовательностей
векторов, принадлежащих циклу, для каждого аттрактора ранится ссылка на его
«родительский» цикл из предыдущего модуля.
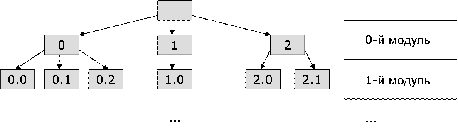
Рис. 7. Структура хранения данных.
Таким образом, данные хранятся в виде дерева, и
для объединения результатов достаточно для каждого цикла последнего модуля
достроить цикл для исходной сети, двигаясь по дереву вверх.
Данные сохраняются в текстовый файл в
определённом формате: есть возможность сохранить как список всех аттракторов,
так и результаты анализа каждого модуля и связи между ними.
3.3 Интерфейс
Программное средство представляет из себя
консольное приложение, параметры которого задаются в командной строке:
Таблица 2. Параметры запуска программы.
|
Параметр
|
Описание
|
Значение по умолчанию
|
|
-graph <filename>
|
Имя файла, содержащего граф
преобразования.
|
net.graph
|
|
-mask <filename>
|
Имя файла, содержащего маску
разбиения.
|
net.mask
|
|
-method decomp -method complete
-method both
|
Способ поиска решений: decomp - с
использованием декомпозиции; complete - полным перебором состояний (при этом
не нужно указывать файл с маской разбиения); both - поиск обоими методами
(для сравнения результатов при тестировании).
|
decomp
|
|
-log <filename>
|
Имя файла, в который будет
производиться логирование.
|
log.txt
|
|
-stat simple -stat full -stat
decomp
|
Формат вывода статистики: simple -
вывод только количества циклов и неподвижных точек в сети (без объединения
результатов); full - полная статистика (вывод всех аттракторов сети); decomp
- вывод статистики отдельно по каждому модулю (без объединения результатов).
|
full
|
|
-output <filename>
|
Имя выходного файла.
|
output.txt
|
|
-debug
|
Режим отладки, в котором подробная
информация о ходе работы программы выводится в консоль.
|
|
3.4 Тестирование
Был сформирован ряд случайно сгенерированных
тестовых графов с количеством дуг, входящих в каждую вершину, равным 2
(согласно аргументам, приведённым в [1], NK-автомат при K=2 есть адекватная
модель молекулярно-генетических систем управления биологических клеточных
организмов). Для проверки корректности полученных результатов, был произведён
поиск решений двумя методами: с использованием декомпозиции и перебором без
разбиения. На графике показана зависимость среднего времени работы программы от
размера графа:

Рис. 8.
Результаты тестирования.
Как видно,
разбиение графа позволяет существенно снизить временные затраты, что делает
возможным исследование реально существующих больших сетей.
В рамках
работы был успешно проведён анализ динамики сети реакции на стресс кишечной
палочки (E.coli), состоящей из 73 вершин. В результате после поточечной
редукции был получен набор более чем из 130 тысяч решений. Полученные данные
могут быть использованы в будущем для анализа устойчивости данной сети.
ЗАКЛЮЧЕНИЕ
При выполнении работы была решена
задача разработки и реализации алгоритмов численных расчётов динамики генных
сетей на основе редукции графов в рамках синхронной булевой модели, и были
получены следующие результаты:
1) Изучена
новая предметная область теории функционирования генных сетей и написан обзор;
рассмотрены существующие методы решения задачи, выявлены их недостатки;
2) Разработан
и формально описан новый метод решения задачи, использующий иерархическую
декомпозицию сети:
· Разработан подход иерархической
декомпозиции графа;
· Разработан алгоритм
помодульного расчёта динамики сети.
3) Создано
и отлажено программное средство, реализующее разработанные алгоритмы;
4) Практически
показана эффективность разработанного средства: проведено тестирование
программного средства на наборе случайно сгенерированных сетей, проведены
исследования реально существующих больших сетей.
Полученное программное средство
позволяет корректно рассчитать все устойчивые состояния генной сети, заданной
графом преобразования, используя иерархическое разбиение графа на модули.
Тестирование показало значительный выигрыш расчётов с использованием
декомпозиции относительно существующих программных средств.
В будущем планируется приступить к
разработке алгоритмов анализа устойчивости сетей на основе полученных данных об
их динамике:
· Исследование поведения сети при
возмущениях (изменении компонент вектора состояния);
· Исследование поведения сети при
исключении элементов или перестройке связей;
· Определение ключевых
регуляторов сети - элементов, оказывающих ключевое влияние на поведение сети.
Сформулированный метод можно также
применять для решения задач разрешимости систем булевых уравнений и
адаптировать для решения похожих задач, приводимых к задаче расчёта динамики
булевых сетей.
Работа была представлена на XLIX
Международной научной студенческой конференции «Студент и научно-технический
прогресс» (МНСК-2011) на подсекции биоинформатики.
ЛИТЕРАТУРА
генный граф булевая
модель
1. B.K.
Sawhill, S.A.Kauffman. Phase transitions in logic networks // Working paper,
Sana Fe Institute. 1997.
2. Luiz
Mendoza, Denis Thieffry, Elena R. Alvarez-Buylla. Genetic control of flower
morphogenesis in Arabidopsis thaliana: logic analysis // Bioinformatics vol.
15. 1999. C. 593-606.
3. Колчанов
Н.А., Ананько Е.А., Колпаков Ф.А. и др. Генные сети // Мол. биология. 2000. Т.
34, №4. С. 533-544.
4. Евдокимов
А.А., Кочемазов С.Е., Семенов А.А. Применение символьных вычислений к
исследованию дискретных моделей некоторых классов генных сетей //
Вычислительные технологии. 2011. Т. 16. № 1. С. 30-47
ПРИЛОЖЕНИЕ
