Процесс анализа информационных массивов
СОДЕРЖАНИЕ
Введение
1. Априорный анализ исходных статистических данных
1.1 Обобщение
исходных данных
1.2 Оценка
однородности совокупности
1.3 Оценка
характера распределения совокупности исходных данных
2. Моделирование связи социально-экономических явлений
2.1 Отбор факторных признаков
2.2 Построение модели связи и оценка ее существенности
2.3 Интерпретация модели связи (уравнения регрессии)
Заключение
Список
использованных источников
ВВЕДЕНИЕ
В
современном обществе важную роль в механизме управления экономикой выполняет
статистика. Независимо от уровня и стадии экономического развития, характера
политической системы, статистика на протяжении сотен лет своего существования
всегда выступала как необходимый и эффективный инструмент государственного
управления и одновременно как наука, исследующая количественную сторону
массовых явлений. Выполняя самые разнообразные функции сбора, систематизации и
анализа сведений, характеризующих экономическое и социальное развитие общества,
она всегда играла роль главного поставщика факторов для управленческих,
научно-исследовательских и прикладных практических нужд различного рода
структур, организаций и населения.
В настоящее
время под термином «статистика» чаще всего понимают следующее.
Статистика
- одна из общественных наук, имеющая целью сбор, упорядочивание, анализ и
сопоставление числового представления фактов, относящихся к самым разнообразным
массовым явлениям. Это вместе с тем учение о системе показателей, т.е.
количественных характеристик, дающих всестороннее представление об общественных
явлениях, о национальном хозяйстве в целом и отдельных его отраслях.
Статистика
- это эффективное орудие, инструмент познания, используемый в естественных и
общественных науках для установления тех специфических закономерностей, которые
действуют в конкретных массовых явлениях, изучаемых данной наукой.
Статистика
- это также одна из форм практической деятельности людей, цель которой - сбор,
обработка и анализ массовых данных о тех или иных явлениях.
Одной из
основных задач статистики является оценка наиболее существенных
причинно-следственных связей между различными процессами и явлениями, а также
воздействия одних факторов на другие. Она осуществляется через моделирование
взаимосвязей с помощью корреляционно–регрессионного анализа, который является
одним из основных в широком спектре статистических методов первичной обработки,
анализа и прогнозирования экономических данных.
Таким
образом, целью данной курсовой работы является проведение комплексного анализа
данных о предприятиях автомобильного транспорта Тюменской области и выявление
причинно-следственных связей с помощью статистических методов.
Задачами
курсовой работы являются:
1)
проведение априорного анализа данных по предприятиям;
2)
моделирование связи между показателями предприятий.
Объекты
исследования – предприятия автомобильного транспорта Тюменской области.
В работе
приведены теоретические данные о методике анализа статистических данных и
выявления причинно-следственных связей, на основе которой был произведен анализ
данных по предприятиям автомобильного транспорта по Тюменской области.
1.
АПРИОРНЫЙ
анализ исходных статистических данных
Анализ
статистических данных начинается с априорного анализа. Априорным (от лат. a priori – из предшествующего)
называется анализ, предшествующий непосредственному математико-статистическому
анализу и проверяющий предпосылки его реализации.
Этапы
априорного анализа включают:
·
обобщение исходных данных: построение вариационных рядов по
каждому из исследуемых показателей. Графическое изображение построенных рядов
распределения в виде гистограммы, полигона, кумуляты;
·
оценку однородности совокупности (на основе метода группировок,
показателей вариации, анализа аномальных наблюдений на основе λ- и
q-статистик);
·
оценку характера распределения совокупности исходных данных с
помощью средней, моды, медианы, показателей вариации.
1.1
Обобщение исходных данных
В качестве
объектов исследования были выбраны предприятия автомобильного транспорта
Тюменской области (ОАО «ТюменьАвтоТранс», ЗАО "Автотранспортное
предприятие", ООО "Автоуниверсал-Трак", ОАО "СПАТО",
ООО "РБА-Тюмень", ООО «ГлавАвтоТранс», ООО «Тюмень
ТрансКонтиненталь», ООО «АванТрансСервис», АК «Ространсавто», ТД «Русойл», ООО
«Континент», ОАО «Тюменские моторостроители», ЗАО
"Сибавтоспецтехника", ООО «Урал-Тюмень», ООО «Спецтехника-Тюмень»,
ООО «Тракт-Запчасть-Сервис», ООО «СпецАвто», ООО «Сибинтком», ОАО
«Тюменнефтеспецтранс»). Основными видами деятельности предприятий являются
производство, поставки и ремонт автобусов, автомобилей, авто и спецтехники.
Предприятия
исследуются для выяснения и формирования практических выводов об эффективности
их деятельности и предложений, направленных на улучшение деятельности
предприятий, на ликвидацию имеющихся недостатков.
В качестве
исходных данных были выбраны показатели доходов и расходов по обычным видам
деятельности предприятий.
Задача данного
исследования – сравнить показатели предприятий, для выяснения наличия и степени
зависимости между ними.
Далее
представлена таблица с исходными данными по 19 предприятиям (табл. 1.1).
Таблица
1.1
Показатели
доходов и расходов по обычным видам деятельности предприятий, тыс. руб.
|
Номер предприятия
|
Выручка от продажи товаров, продукции, работ, услуг
|
Себестоимость проданных товаров, продукции, работ, услуг
|
Коммерческие и управленческие расходы
|
|
1
|
21903
|
8109
|
13697
|
|
2
|
76581
|
46692
|
28889
|
|
3
|
116565
|
71378
|
43834
|
|
4
|
139317
|
83304
|
54508
|
|
5
|
35475
|
24126
|
11042
|
|
6
|
78417
|
50729
|
26413
|
|
7
|
149687
|
102338
|
44716
|
|
8
|
287056
|
218436
|
65048
|
|
9
|
82279
|
66579
|
20556
|
|
10
|
158161
|
108977
|
37419
|
|
11
|
225792
|
157775
|
56192
|
|
12
|
297921
|
222019
|
73114
|
|
13
|
33702
|
14860
|
19372
|
|
14
|
139722
|
90233
|
42770
|
|
15
|
221771
|
155565
|
60932
|
|
16
|
374199
|
284117
|
81486
|
|
17
|
176430
|
163552
|
11529
|
|
18
|
244843
|
223176
|
22200
|
|
19
|
395322
|
360237
|
32614
|
|
Итого
|
3255143
|
2452202
|
746331
|
Вначале необходимо
построить ряды распределения предприятий по каждому из признаков.
Один из
вариантов стандартной процедуры группировки по количественным признакам для
определения числа групп является формула Г. Стерджесса (формула (1.1)):
 (1.1)
(1.1)
где N – число групп.
Из расчета
по формуле (1.1) n = 5. Следовательно, предприятия делятся на
5 групп с интервалом группировки (шагом) h = 74684, вычисляемым по формуле (1.2):
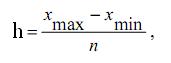 (1.2)
(1.2)
где xmax и xmin – максимальное и
минимальное значения признака в совокупности.
Но с учетом округления h = 100000, и предприятия разбиваются на
4 группы. Ряд распределения предприятий по величине выручки от продажи товаров, продукции,
работ, услуг представлен в таблице 1.2.
Таблица 1.2
Распределение
предприятий по величине выручки
|
Группы предприятий по выручке от продажи товаров, продукции,
работ, услуг, тыс. руб.
|
Число предприятий
|
Удельный вес, % к итогу
|
|
21903 – 121903
|
7
|
36,8
|
|
121903 – 221903
|
6
|
31,6
|
|
221903 – 321903
|
4
|
21,1
|
|
321903 – 421903
|
2
|
10,5
|
|
Итого
|
19
|
100,0
|
Из таблицы
1.2 видно, что большинство предприятий имеет выручку не более 221903 тыс. руб.
Для наглядного
представления рядов распределения используют их графическое изображение в виде
гистограммы, полигона и кумуляты.
Гистограмма
– столбиковая диаграмма, для построения которой на оси абсцисс откладывают отрезки,
равные величине интервалов вариационного ряда.
Полигон –
это вид диаграммы в которой при помощи отрезков соединяются точки середин
координат сторон прямоугольника.
Кумулята –
это линейное построения диаграммы по накопленным частотам, которые определяются
последовательным суммированием частот. Накопление частоты показывают сколько
единиц совокупности имеют значения признака не больше чем рассматриваемое
значение.
Ряд
распределения по величине выручки от продаж представлен графически на рис.1.1,
рис.1.2 и рис.1.3.
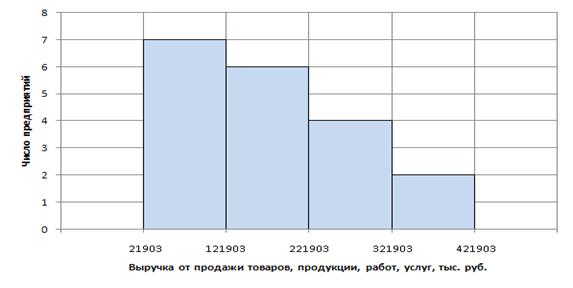
Рис.1.1
Гистограмма распределения предприятий по величине выручки
Гистограмма
является изображением интервального ряда распределения. Для изображения
дискретного ряда строится полигон.

Рис.1.2
Полигон распределения предприятий по величине выручки
По рис.1.1
и рис.1.2 видно, что распределение имеет ветвь, уходящую вправо. Нет ярко
выраженной вершины.
Кумулята
строится также для дискретного ряда. Она показывает, сколько единиц
совокупности имеют значения признака не больше чем рассматриваемое значение.
 Рис.1.3 Кумулята распределения предприятий по величине выручки
Рис.1.3 Кумулята распределения предприятий по величине выручки
Затем
строятся группировки предприятий по остальным признакам, с использованием формул (1.1) и (1.2), и
изображаются графически.
Предприятия
распределяются по величине себестоимости проданных
товаров, продукции, работ, услуг на пять групп. Интервал группировки:
h = (360237 - 8109) / 5 = 70426 ≈
100000.
Учитывая,
что h округлили, предприятия следует разбить на 4 группы (табл. 1.3).
Таблица
1.3
Распределение
предприятий по величине себестоимости проданных товаров, продукции, работ,
услуг
|
Группы предприятий по себестоимости проданных товаров, продукции, работ, услуг,
тыс. руб.
|
Число предприятий
|
Удельный вес, % к итогу
|
|
8109 – 108109
|
10
|
52,6
|
|
108109 – 208109
|
4
|
21,1
|
|
208109 – 308109
|
4
|
21,1
|
|
308109 – 408109
|
1
|
5,2
|
|
Итого
|
19
|
100,0
|
Себестоимости
проданных товаров, продукции, работ, услуг у большинства предприятий не
превышает 108109 тыс. руб. Предприятие с себестоимостью в пределах от 308109 до
408109 тыс. руб. выбивается из общего ряда, и является аномальным для этого
распределения.
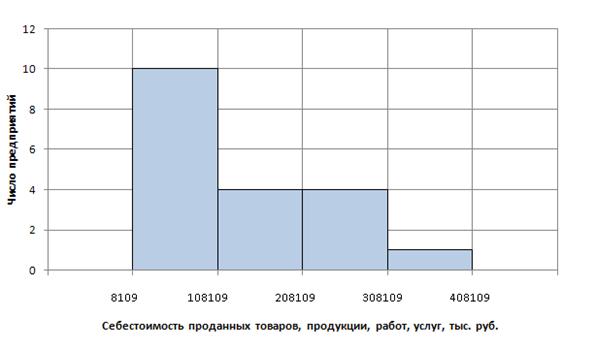
Рис.1.4
Гистограмма распределения предприятий по себестоимости проданных товаров, продукции, работ, услуг

Рис.1.5
Полигон распределения предприятий по себестоимости проданных товаров, продукции, работ, услуг
Графическое
изображение ряда себестоимости (рис.1.4, рис.1.5.) показывает, что ряд имеет плоскую
вершину и ветвь, уходящую вправо, как и ряд распределения выручки.

Рис.1.6
Кумулята распределения предприятий по себестоимости проданных товаров, продукции, работ, услуг
Предприятия
распределяются по величине коммерческих и управленческих расходов на пять групп (табл. 1.4). Интервал группировки:
h = (81486 – 11042) / 5 = 14089 ≈
15000.
Таблица
1.4
Распределение
предприятий по величине коммерческих и
управленческих расходов
|
Группы предприятий по величине коммерческих и управленческих расходов, тыс. руб.
|
Число предприятий
|
Удельный вес, % к итогу
|
|
11042 – 26042
|
6
|
31,6
|
|
26042 – 41042
|
4
|
21,1
|
|
41042 – 56042
|
3
|
15,8
|
|
56042 – 71042
|
4
|
21,1
|
|
71042 – 86042
|
2
|
10,5
|
|
Итого
|
19
|
100,0
|
Самая большая группа
предприятий имеет меньшие расходы, в отличие от других групп.
В графическом
изображении это выглядит следующим образом.

Рис.1.7
Гистограмма распределения предприятий по величине коммерческих и управленческих расходов

Рис.1.8
Полигон распределения предприятий по величине коммерческих и управленческих расходов
По графикам
видно, что распределение предприятий по расходам имеет схожие характеристики с
распределением предприятий по себестоимости, отличается только количеством
групп.

Рис.1.9
Кумулята распределения предприятий по величине коммерческих и управленческих расходов
После
сбора, группировки и поверхностного анализа данных следует провести более
углубленный анализ.
1.2
Оценка однородности совокупности
априорный анализ
статистический совокупность распределение
Для оценки однородности
совокупности используют различные методы, такие как: группировка, расчет
показателей вариации (дисперсия, коэффициент вариации), анализ аномальных
наблюдений на основе l- и q-статистик.
На основе
группировки и ее графического изображения (рис.1.1 – рис.1.9) можно
предположить, что ряды распределения по трем признакам не являются однородными.
Но вместе с тем, следует иметь виду, что при незначительном объеме выборки (n
< 50) слишком углубленный анализ гистограммы может привести к неверным выводам,
поскольку слабо выраженные «горбики и ямы» частот могут быть обусловлены не
основными факторами, определяющими распределение единиц по группам, а просто
случайными отклонениями вариантов от  .
.
После
анализа аномальных наблюдений на основе l- статистики, выявляется аномальность значений, соответствующих 13
предприятию, а также аномальность показателей выручки и расходов 9 предприятия.
В данной
работе последующий анализ будет проводится с учетом аномальности, вызванной
объективно существующими причинами.
Причины
появления в совокупности аномальных наблюдений могут быть:
1) внешние, возникающие в результате
технических ошибок;
2) внутренние, объективно существующие.
Для
дальнейшего анализа формы распределения используют показатели вариации. Показатели
вариации делятся на абсолютные и относительные. К абсолютным относятся размах
колебаний, среднее линейное отклонение, дисперсия, среднее квадратическое
отклонение и квартильное отклонение. Коэффициент осцилляции, относительное
линейное отклонение, коэффициент вариации и относительный показатель
квартильной вариации – относительные показатели.
В данной
курсовой работе для характеристики однородности совокупности рассчитывались
такие показатели, как дисперсия, среднее квадратическое отклонение и
коэффициент вариации.
Дисперсия –
это средний квадрат отклонений индивидуальных значений признака от средней
величины. Дисперсия не только является основной мерой колеблемости признака, но
также используется для построения показателей тесноты корреляционной связи, при
оценке результатов выборочных наблюдений и т.д.
Для
сгруппированных данных она вычисляется по формуле (1.3):
 ,
,
(1.3)
где xi – i-ый вариант осредняемого признака;
–
выборочная средняя величина или средняя агрегатная;
ni – частота, то есть число, показывающее сколько раз встречаются
варианты из данного интервала, или вес i-го варианта;
n – число объектов совокупности.
Для оценки
влияния различных факторов, обуславливающих вариацию признака, рассчитывается
дисперсия по каждому из показателей. Для этого строятся расчетные таблицы:
Таблица 1.5
Расчетная
таблица для вычисления дисперсии по величине выручки от продажи товаров,
продукции, работ, услуг
|
Группы предприятий по выручке от продажи, тыс. руб.
|
Число предприятий ni
|
Середина интервала xi
|
xini
|
xi - 
|
(xi - )2ni
|
|
21903 – 121903
|
7
|
71903
|
503321
|
-105263
|
29462326870
|
|
121903 – 221903
|
6
|
171903
|
1031418
|
-5263,2
|
126204986,1
|
|
221903 – 321903
|
4
|
271903
|
1087612
|
94736,8
|
9600277008
|
|
321903 – 421903
|
2
|
371903
|
743806
|
194736,8
|
26844875346
|
|
Итого
|
19
|
|
3366157
|
|
66033684211
|
Средняя
выборочная вычисляется по формуле (1.4):
=  (1.4)
(1.4)
Отсюда = 177166,1.
По таблице
1.5 видно, что значения признака отклоняются от средней выборочной в основном в
отрицательную сторону.
С помощью
формулы (1.3) находится дисперсия, σ2 = 3422825485.
Таблица
1.6
Расчетная
таблица для вычисления дисперсии по величине себестоимости
проданных товаров, продукции, работ, услуг
|
Группы предприятий по себестоимости проданных товаров,
продукции, работ, услуг, тыс. руб.
|
Число предприятий ni
|
Середина интервала xi
|
xini
|
xi -
|
(xi - )2ni
|
|
8109 – 108109
|
10
|
58109
|
581090
|
-78947,4
|
16526869806
|
|
108109 – 208109
|
4
|
158109
|
632436
|
21052,6
|
1472853186
|
|
208109 – 308109
|
4
|
258109
|
1032436
|
121052,6
|
12354958449
|
|
308109 – 408109
|
1
|
358109
|
358109
|
221052,6
|
9471265928
|
|
Итого
|
19
|
|
2604071
|
|
39825947368
|
= 137056,4
σ2
= 2096102493
Значения
себестоимости в основном не превышают среднюю выборочную.
Таблица
1.7
Расчетная
таблица для вычисления дисперсии по величине коммерческих и
управленческих расходов
|
Группы предприятий по величине коммерческих и управленческих
расходов, тыс. руб.
|
Число предприятий ni
|
Середина интервала xi
|
xini
|
xi -
|
(xi - )2ni
|
|
11042 – 26042
|
6
|
18542
|
111252
|
-22894,7
|
13437138350
|
|
26042 – 41042
|
4
|
33542
|
-7894,7
|
134307479,2
|
|
41042 – 56042
|
4
|
48542
|
194168
|
7105,26
|
81939058,2
|
|
56042 – 71042
|
3
|
63542
|
190626
|
22105,26
|
865927977,8
|
|
71042 – 86042
|
2
|
78542
|
157084
|
37105,26
|
1053601108
|
|
Итого
|
19
|
|
787298
|
|
3479489474
|
= 41436,7
σ2
= 183131024,9
По таблице
видно, что значения признака отклоняются от средней выборочной также в основном
в отрицательную сторону.
Наиболее
часто применяемый показатель относительной колеблемости – коэффициент вариации
(формула (1.5)):
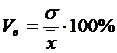 (1.5)
(1.5)
Для того
чтобы рассчитать коэффициент вариации для группы предприятий по величине выручки от продажи товаров, продукции, работ, услуг нужно рассчитать среднее квадратическое отклонение σ по формуле
(1.6):
 (1.6)
(1.6)
Среднее
квадратическое отклонение σ = 58504,92,
то есть величина выручки в среднем отклоняется на 58504,92 тыс. руб.
Исходя из
этого, коэффициент вариации равен:
Vв = (58504, 92 / 177166,1) * 100% = 33 %
Величина Vв
оценивает интенсивность колебаний вариантов относительно их средней величины.
Принята следующая оценочная шкала колеблемости признака:
– 0% < Vв
≤40% – колеблемость незначительная;
– 40% <
Vв ≤ 60% – колеблемость средняя (умеренная);
– Vв
> 60% – колеблемость значительная.
Для
нормальных и близких к нормальному распределений показатель Vв
служит индикатором однородности совокупности: принято считать, что при
выполнимости неравенства
Vв
≤ 33%,
совокупность
является количественно однородной по данному признаку. Так как коэффициент
вариации не превышает 33%, то можно считать совокупность предприятий по выручке
достаточно однородной.
Коэффициент
вариации для остальных признаков равен:
1)
Для группы предприятий по себестоимости проданных товаров,
продукции, работ, услуг Vв = 33,4%. Колеблемость незначительная.
2)
Для группы предприятий по величине
коммерческих и управленческих расходов Vв = 32,7%. Колеблемость незначительная. Совокупность можно считать
однородной.
Так как
коэффициент вариации группировки предприятий по себестоимости незначительно превышает
33%, то можно сказать, что совокупность достаточно однородна, а превышение
можно объяснить небольшим объемом выборки, аномальностью некоторых значений и
влиянием внешних и внутренних факторов.
1.3
Оценка характера распределения
совокупности исходных данных
Выявление
общего характера распределения предполагает оценку не только степени его
однородности, но и его симметричности, остро- или плосковершинности.
Простейшей
мерой ассиметричности распределения является отклонение между характеристиками
центра распределения. Поскольку в симметричном распределении = Me = Mo, то чем заметнее
ассиметрия, тем больше отклонение ( - Mo). В связи с этим простейший
показатель ассиметрии, коэффициент К. Пирсона, рассчитывается так, формула
(1.7):
 ,(1.7)
,(1.7)
где – средняя арифметическая ряда распределения;
Mo – мода (наиболее часто встречающееся значение признака у единиц
данной совокупности).
При
правосторонней асимметрии Asn > 0, при левосторонней Asn <0. Если Asn = 0, вариационный ряд
симметричен.
Показатель
ассиметрии также можно рассчитать с помощью центрального момента третьего порядка
(формула (1.8)):
 ,(1.8)
,(1.8)
где μ3 – центральный момент третьего порядка.
Центральный
момент  рассчитывается
по формуле (1.9):
рассчитывается
по формуле (1.9):
 .(1.9)
.(1.9)
Центральный
момент первого порядка всегда равен нулю. Центральный момент второго порядка
представляет собой дисперсию. Центральный момент третьего порядка равен нулю в
симметричном распределении. Центральный момент четвертого порядка применяется
при вычислении показателя эксцесса.
Если
рассчитать показатель ассиметрии ряда распределения выручки через центральный
момент третьего порядка, то получится такой результат:
As = (10005540,2*103)
/ (19*995847754,2) = 0,53;
As = 0,53
> 0, это значит, что в ряду распределения преобладают варианты, которые
больше, чем средняя, то есть ряд положительно ассиметричен.
Для оценки
существенности показателя ассиметрии находится средняя квадратическая ошибка,
которая зависит от объема наблюдений, по формуле (1.10):
σAs =  = 0,495.
= 0,495.
(1.10)
Так как
отношение  = 1,2 <
3, ассиметрия несущественна, ее наличие может быть объяснено влиянием различных
случайных обстоятельств.
= 1,2 <
3, ассиметрия несущественна, ее наличие может быть объяснено влиянием различных
случайных обстоятельств.
Для оценки
крутизны распределения вычисляется показатель эксцесса по формуле (1.11):
 ,
,
(1.11)
Показатель эксцесса
ряда распределения выручки равен:
Ek = (4057850999*103)
/ (19*99446750716) = 2,248 – 3 = -0,85.
При
симметричном распределении Ek = 0. Если Ek > 0, распределение
является островершинным; если Ek < 0 – плосковершинным.
В
частности, большая отрицательная величина Ek означает преобладание у признака крайних
значений, причем одновременно и более низких, и более высоких. При этом в центральной
части распределения может образоваться «впадина», превращающая распределение в двухвершинное
(U-образной формы), что является индикатором неоднородности совокупности.
Исходя из
этого, можно говорить о плосковершинности ряда распределения выручки.
Оценка
существенности показателя эксцесса равна 0,85, это значит, что эксцесс
несущественен.
Для ряда
распределения предприятий по себестоимости проданных товаров, продукции, работ:
As = (13013850,4*103)
/ (19*858154723,4) = 0,8.
Для ряда
распределения предприятий по величине коммерческих и управленческих расходов:
As = (62040,2*103)
/ (19*8343127,4) = 0,39.
Что
означает, что ряды распределения этих признаков имеют правостороннюю
скошенность.
Эксцесс для
групп предприятий по себестоимости:
Ek = (3635894445*103)
/ (19*81549404931) – 3 = -0,65.
Эксцесс для
групп предприятий по расходам:
Ek = (6181726,6*103)
/ (19*169214861,8) – 3 = -1,08.
Так как
эксцессы этих рядов распределений меньше нуля, то ряды распределения являются
плосковершинными (рис 1.5, рис.1.8).
Исходя из
показателей ассиметрии и эксцесса, можно предположить, что распределение
значений признаков не является нормальным.
Априорный анализ исходных
данных показал, что совокупности предприятий по признакам являются достаточно однородными,
но отклоняются от нормального распределения. Это может быть объяснено
различными внешними факторами, как расположение предприятий, клиентура,
конкуренты, экономическое и политическое устройство и др.
2.
Моделирование
связи социально-экономических явлений
После
априорного анализа исходных статистических данных следует моделирование связи
социально-экономических явлений.
Моделирование
предполагает:
·
отбор факторных признаков
·
построение модели связи и оценка ее существенности
·
интерпретацию модели связи (уравнения регрессии)
2.1
Отбор факторных признаков
Признаки,
обуславливающие изменение других, связанных с ними признаков, называют
факторными, или просто факторами. Признаки, изменяющиеся под воздействием
факторных признаков, называют результативными.
Для
выявления наличия связи между признаками, ее характера и направления в
статистике используются методы приведения параллельных данных, аналитических
группировок, графический, корреляционный и регрессионный.
Метод
приведения параллельных данных основан на сопоставлении двух или нескольких
рядов статистических величин.
В таблице
2.1 предприятия ранжированы по величине себестоимости
проданных товаров, продукции, работ, услуг.
Таблица
2.1
Показатели
доходов и расходов по обычным видам деятельности предприятий, ранжированные по
величине себестоимости, тыс. руб.
|
Номер предприятия
|
Себестоимость проданных товаров, продукции, работ, услуг
|
Выручка от продажи товаров, продукции, работ, услуг
|
Коммерческие и управленческие расходы
|
|
1
|
2
|
3
|
4
|
|
1
|
8109
|
21903
|
13697
|
|
13
|
14860
|
33702
|
19372
|
|
5
|
24126
|
35475
|
11042
|
|
2
|
46692
|
76581
|
28889
|
|
6
|
50729
|
78417
|
26413
|
|
9
|
66579
|
82279
|
20556
|
|
3
|
71378
|
116565
|
43834
|
|
4
|
83304
|
139317
|
54508
|
|
14
|
90233
|
139722
|
42770
|
|
7
|
102338
|
149687
|
44716
|
|
10
|
108977
|
158161
|
37419
|
|
15
|
155565
|
221771
|
60932
|
|
11
|
157775
|
225792
|
56192
|
|
17
|
163552
|
176430
|
11529
|
|
8
|
218436
|
287056
|
65048
|
|
12
|
222019
|
297921
|
73114
|
|
18
|
223176
|
244843
|
22200
|
|
16
|
284117
|
374199
|
81486
|
|
19
|
360237
|
395322
|
32614
|
|
Итого
|
2452202
|
3255143
|
746331
|
Отсюда
видно, что с увеличением себестоимости увеличивается и выручка от продаж, хотя
в отдельных случаях такая зависимость не наблюдается. Это говорит о возможном
наличии прямой корреляционной связи. Связь между величиной коммерческих и
управленческих расходов и другими признаками не наблюдается.
Статистическую
связь между двумя признаками можно изобразить графически. За x обозначается факторный
признак, в данном случае себестоимость. За у обозначается результативный
признак – выручка.
 Рис. 2.1 Зависимость величины выручки от себестоимости
Рис. 2.1 Зависимость величины выручки от себестоимости
Линия,
соединенная точками, называется «ломаная регрессии». Число точек ломаной
регрессии соответствует числу предприятий.
Точнее определить
наличие и тесноту связи можно с помощью различных показателей. Зная показатели,
можно выявить те факторы, которые в данных конкретных условиях являются
решающими и главным образом воздействуют на формирование величины
результативного признака.
К
показателям тесноты связи относится линейный коэффициент корреляции.
В
статистической теории разработаны и на практике применяются различные
модификации формул расчета данного коэффициента:
 ,(2.1)
,(2.1)
где x – факторный признак;
y – результативный признак.
Выполнив
несложные преобразования можно получить следующую формулу (2.2):
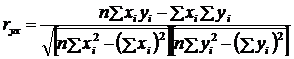 .(2.2)
.(2.2)
При
пользовании этой формулой отпадает необходимость вычислять отклонения
индивидуальных значений признаков от средней величины, что исключает ошибку в
расчетах при округлении средних величин.
Линейный
коэффициент корреляции может принимать любые значения в пределах от -1 до +1.
Чем ближе коэффициент корреляции по абсолютной величине к 1, тем теснее связь
между признаками. Знак при линейном коэффициенте корреляции указывает на
направление связи - прямой зависимости соответствует знак плюс, обратной – знак
минус.
На основе
данных таблицы 1.1(2.1), с помощью формулы (2.2), было определено два
коэффициента корреляции.
Во-первых,
коэффициент корреляции, показывающий степень тесноты связи между себестоимостью
и выручкой от продаж.
Пусть x1 – величина себестоимости проданных
товаров, продукции, работ, услуг. Тогда, y – величина выручки от продажи товаров, продукции, работ, услуг.
Отсюда r = 0,98, связь является прямой и очень
сильной. Что значит, с увеличением себестоимости увеличивается и выручка.
Во-вторых,
рассчитан коэффициент корреляции, показывающий степень тесноты связи между
расходами и выручкой от продаж. В данной ситуации x2 – величина коммерческих и управленческих расходов, а y – величина выручки от продажи товаров, продукции, работ, услуг.
Коэффициент
корреляции равен 0,66, что говорит о прямой связи между признаками.
Тесноту
связи между факторными признаками можно также рассчитать по формуле (2.1),
заменяя результативный признак на факторный:
 .
.
(2.3)
 = 0,51.
= 0,51.
Полученная
величина свидетельствует о наличии прямой зависимости между значениями
себестоимости и расходов.
Для
наглядности была построена матрица парных коэффициентов корреляции:
y – величина выручки от продажи товаров,
продукции, работ, услуг;
x1 – величина себестоимости проданных товаров, продукции, работ, услуг;
x2 – величина коммерческих и
управленческих расходов.
Таблица
2.2
Матрица
парных коэффициентов корреляции
|
y
|
x1
|
x2
|
|
y
|
1,00
|
0,98
|
0,66
|
|
x1
|
0,98
|
1,00
|
0,51
|
|
x2
|
0,66
|
0,51
|
1,00
|
Матрица
парных коэффициентов корреляции показывает, что результативный показатель
наиболее тесно связан с показателем x1.
Так как
существует линейная связь между результативным и двумя факторными признаками, а
также между парой факторных признаков, то имеет смысл рассчитать множественный
коэффициент корреляции.
В данной
работе множественный коэффициент корреляции был вычислен по формуле (2.4):
 .(2.4)
.(2.4)
 = 0,99.
= 0,99.
Связь между
показателями сильная, факторы x1 и x2 практически полностью обуславливают величину y.
При
построении модели связи, или регрессии, может возникнуть проблема
мультиколлинеарности (наличие сильной корреляции между независимыми
переменными, входящими в уравнение регрессии). Мультиколлинеарность существенно
искажает результаты исследования.
Наиболее
распространенный метод выявления коллинеарности основан на анализе парных
коэффициентов корреляции. Он состоит в том, что две или несколько переменных
признаются коллинеарными (мультиколлинеарными), если парные коэффициенты
корреляции больше определенной величины. На практике наиболее часто считают,
что два аргумента коллинеарны, если парный коэффициент корреляции между ними по
абсолютной величине больше 0,8.
В данном
примере парный коэффициент корреляции не превышает величины 0,8 (= 0,51), что говорит об отсутствии
явления мультиколлинеарности.
2.2 Построение модели
связи и оценка ее существенности
Как было
выяснено в предыдущем пункте, зависимость результативного признака от факторных
является прямолинейной. Факторные признаки не являются мультиколлинеарными и
практически полностью обуславливают результативный признак, следовательно, все
признаки необходимо включить в модель. Поэтому связь будет описываться такой
моделью связи (2.5):
 ,(2.5)
,(2.5)
где  и
и  – коэффициенты регрессии.
– коэффициенты регрессии.
Система
нормальных уравнений:
 (2.6)
(2.6)
Подставив
данные из таблицы 2.1 в эту систему, получается:

Отсюда: a0 = -2132,16; a1 = 1,005433; a2 = 1,080124;

Расчеты
показали, что с увеличением себестоимости проданных товаров, продукции, работ,
услуг на 1 тыс. руб. и коммерческих, управленческих расходов на 1 тыс. руб.
величина выручки от продажи возрастает соответственно в среднем на 1,0054 и 1,0801 тыс. руб.
Далее
необходимо проверить адекватность модели, построенной на основе уравнений
регрессии.
Во-первых,
нужно проверить значимость каждого коэффициента регрессии. Значимость
коэффициента регрессии осуществляется с помощью t-критерия Стьюдента (2.7):
 ,
,
(2.7)
где 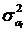 -дисперсия
коэффициента регрессии.
-дисперсия
коэффициента регрессии.
Параметр
модели признается статистически значимым, если
tp > tkp(α; ν=n-k-1),
где α – уровень значимости;
ν –
число степеней свободы.
Величина может быть определена по формуле
(2.8):
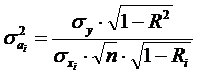 ,(2.8)
,(2.8)
где R – множественный коэффициент корреляции по y;
Ri – множественный коэффициент
корреляции по фактору xi с остальными факторами.
В данной
работе Ri = , так как рассматриваются всего два факторных
признака.
По формуле
(2.8):
 ;
;
 .
.
Теперь по
формуле (2.7) определяются значения t-критерия.
 ;
;
 .
.
Оба рассчитанных
критерия превышают табличное значение, tkp= 2,12 (0,05; ν=16).
Параметры модели являются статистически значимыми.
Во-вторых,
проверяется адекватность уравнения регрессии с помощью расчета F-критерия Фишера (2.9):
 .(2.9)
.(2.9)
Гипотеза о
незначимости коэффициента множественной корреляции ( = 0) отвергается, если
= 0) отвергается, если  .
.
 ;
;
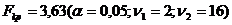 .
.
Гипотеза
отклоняется, так как  . С вероятностью
. С вероятностью  можно сделать заключение о статистической
значимости уравнения в целом и показателя тесноты связи .
можно сделать заключение о статистической
значимости уравнения в целом и показателя тесноты связи .
2.3 Интерпретация
модели связи (уравнения регрессии)
Оценить
долю каждого из факторов в изменении уровня результативного показателя можно по
параметрам уравнения регрессии. Это может быть сделано путем прямой оценки по
величине коэффициентов регрессии, а также по коэффициентам эластичности  , стандартизированным
частным коэффициентам регрессии β–коэффициентам и Δ–коэффициентам.
, стандартизированным
частным коэффициентам регрессии β–коэффициентам и Δ–коэффициентам.
Коэффициенты
уравнения множественной регрессии показывают абсолютный размер влияния факторов
на уровень результативного показателя и характеризуют степень влияния каждого
фактора на анализируемый показатель при фиксированном (среднем) уровне других
факторов, входящих в модель. Чем больше величина коэффициента регрессии, тем
значительнее влияние данного признака на моделируемый. Как было выяснено в
пункте 2.2, увеличение себестоимости проданных
товаров, продукции, работ, услуг на 1 тыс. руб. приводит к увеличению выручки в
среднем на 1,0054 тыс. руб. А с увеличением коммерческих, управленческих
расходов на 1 тыс. руб. величина выручки от продажи возрастает соответственно в
среднем на 1,0801 тыс.
руб. a1< a2 , влияние x2 чуть более существенно, чем влияние x1 на y.
С целью
расширения возможностей экономического анализа используются показатели
относительных величин, например, частные коэффициенты эластичности,
определяемые по формуле (2.10):
 ,(2.10)
,(2.10)
где 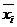 - среднее значение соответствующего факторного
признака;
- среднее значение соответствующего факторного
признака;
 - среднее значение результативного признака;
- среднее значение результативного признака;
 - коэффициент регрессии при соответствующем
факторном признаке.
- коэффициент регрессии при соответствующем
факторном признаке.
Коэффициент
эластичности показывает, на сколько процентов в среднем изменится значение
результативного признака при изменении факторного признака на 1%.
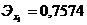 ;
;
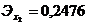 .
.
Это
означает, что при росте себестоимости проданных товаров, продукции, работ и
услуг на 1%, величина выручки от продажи возрастет на 0,7574%. А при росте
коммерческих и управленческих расходов на 1 %, выручка увеличится на 0,2476%.
По значениям коэффициентов эластичности видно, что первый факторный признак x1 имеет большее влияние на результативный, чем второй факторный
признак x2.
β – коэффициенты
показывают, на какую часть среднего квадратического отклонения  изменится зависимая переменная y с изменением соответствующего фактора xi на величину
среднеквадратического отклонения (
изменится зависимая переменная y с изменением соответствующего фактора xi на величину
среднеквадратического отклонения ( ).
).
Этот
коэффициент можно рассчитать по формуле (2.11):
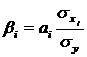 .(2.11)
.(2.11)
Бета-коэффициенты,
рассчитанные для данной модели, показывают, что при увеличении на одно среднее
квадратическое отклонение величины себестоимости и расходов, величина выручки в
среднем увеличивается на 0,8766 (β1=0,8766) и на 0,2076 (β2=0,2076)
средних квадратических отклонений соответственно.
С помощью
частных коэффициентов эластичности и с помощью бета – коэффициентов можно
проранжировать факторы по степени их влияния на зависимую переменную, то есть
сопоставить их между собой по величине этого влияния. Но с помощью бета – коэффициентов
нельзя непосредственно оценить долю влияния каждого фактора в суммарном влиянии
всех факторов. Для этой цели используются дельта – коэффициенты (2.12):
 (2.12)
(2.12)
Расчет
дельта – коэффициентов привел к таким результатам:
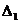 = 0,8623;
= 0,8623;
 = 0,1372.
= 0,1372.
Наибольшее
влияние на выручку от продажи товаров, продукции,
работ, услуг оказывает величина себестоимости – 86,23
%, а величина расходов оказывает влияние в размере 13,72%. Следовательно, себестоимость
имеет намного более значительное влияние на выручку, нежели расходы.
ЗАКЛЮЧЕНИЕ
Комплексный
анализ статистической информации и выявление причинно-следственных связей имеет
большое значения для оценки деятельности предприятий, отраслей или экономики
городов и стран. Такой анализ помогает выявить наиболее существенные факторы,
которые оказывают влияние на деятельность, на основе их построить наиболее
эффективную стратегию развития.
В данной
курсовой работе был проведен анализ статистических данных по нескольким
предприятиям автомобильного транспорта Тюменской области.
Был
проведен первоначальный анализ по трем признакам: выручке от продажи товаров,
продукции, работ, услуг, себестоимости и коммерческим, управленческим расходам.
Были построены группировки по каждому из признаков. Были оценены однородность и
характеристики распределений совокупностей. Результаты привели к выводам о том,
что совокупности по признакам являются достаточно однородными, а отклонения
признаков (островершинность, скошенность вправо) могут быть объяснены малым
объемом выборки, возможными ошибками, допущенными в исследовании и различными
внутренними и внешними обстоятельствами (структура предприятий, персонал, цели
и задачи предприятий, уровень технологий, законодательство, потребители,
конкуренты, и др.). Анализ связи между признаками привел к выводам, что связь
существенная. Что можно было предположить на основе логики экономического
анализа. Построенная модель связи является значимой, то есть довольно хорошо
отражает зависимость признаков.
Общий
анализ показал, что основную массу составляют мелкие и средние предприятия.
Доходы и расходы от основных видов деятельности являются показателями
успешности фирм. Выручка предприятий напрямую зависит от себестоимости и
расходов. Чем больше себестоимость продукции и расходы, тем выручка
значительнее. То есть при увеличении себестоимости и расходов на управление и
коммерческих, поток клиентов, или цена продукции будет увеличиваться, что
приведет к росту выручки. И если показатель себестоимости увеличится в большей
степени, чем показатель коммерческих и управленческих расходов, то величина
выручки вырастет значительнее, так как себестоимость имеет большее влияние на
выручку. При этом и себестоимость, и расходы практически полностью обуславливают
величину выручки.
Таким
образом, по результатам данного исследования были выявлены наиболее
значительные признаки, влияющие на прибыльность предприятий.
СПИСОК
ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1.
Бакланов Г.И., Адамов В.Е., Устинов В.Е. Статистика промышленности.
4-е изд. перераб. и доп. – М.: Статистика, 1982.
2.
Бакланов В.И. Как статистика изучает эффективность и качество
продукции в промышленности. – М.: Статистика, 1978. – 119с.
3.
Герасимович А.И. Математическая статистика: Учеб. пособие. – 2-е изд.,
перераб. и доп. – Мн.: Выш. шк., 1983. – 279с.
4.
Еремина Н.М., Маршалова В. П. Статистика труда: Учебник. – 4-е
изд., перераб. и доп. – М.: Финансы и статистика, 1988. – 248с.
5.
Ефимова М.Р., Петрова Е. В., Румянцев В. Н. Общая теория
статистики: Учебник. – М.: ИНФРА - М, 1998. – 416с.
6.
Кремер Н.Ш., Теория вероятностей и математическая статистика:
Учебник для вузов. – 2-е изд., перераб. и доп. – М.: ЮНИТИ-ДАНА, 2006. – 573с.
7.
Основы экономической деятельности предприятия: Учебное пособие/
Под ред. Л.Н. Рудневой. – Тюмень: ТюмГНГУ, 1999. – 120с.
8.
Практикум по общей теории статистики: Учеб. пособие / Н.Н. Ряузов,
Н.С. Партешко, А.И. Харламов и др.: Под ред. Н. Н. Ряузова. – 2-е изд.,
перераб. и доп. – М.: Финансы и статистика, 1981. – 278с.
9.
Практикум по теории статистики: Учеб. пособие / Р. А. Шмойлова,
В.Г. Минашкин, Н.А. Садовникова.: под ред. Р. А. Шмойловой. – 3-е изд. – М.:
Финансы и статистика, 2008. – 416с.
10.
Статистика: Учеб. пособие / Л.П. Харченко, В.Г. Долженкова, В.Г.
Ионин и др.: под ред. канд. экон. Наук В.Г. Ионин. – 2-е изд., перераб. и доп.
– М.: ИНФРА - М, 2006. – 334с.