|
|
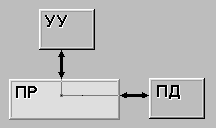
ОКОД(SISD) (single instruction stream / single data stream) – одиночный
поток команд и одиночный поток данных. К этому классу относятся, прежде
всего, классические последовательные машины, или иначе, машины
фон-неймановского типа, например, PDP-11 или VAX 11/780. В таких машинах есть
только один поток команд, все команды обрабатываются последовательно друг за
другом и каждая команда инициирует одну операцию с одним потоком данных. Не
имеет значения тот факт, что для увеличения скорости обработки команд и
скорости выполнения арифметических операций может применяться конвейерная
обработка – как машина CDC 6600 со скалярными функциональными устройствами,
так и CDC 7600 с конвейерными попадают в этот класс.
|
|
|
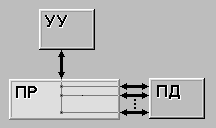
ОКМД(SIMD) (single instruction stream / multiple data stream) – одиночный
поток команд и множественный поток данных. В архитектурах подобного рода
сохраняется один поток команд, включающий, в отличие от предыдущего класса,
векторные команды. Это позволяет выполнять одну арифметическую операцию сразу
над многими данными – элементами вектора. Способ выполнения векторных
операций не оговаривается, поэтому обработка элементов вектора может
производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью
конвейера, как, например, в машине CRAY-1.
|
|

|
МКОД(MISD) (multiple instruction stream / single data stream) – множественный
поток команд и одиночный поток данных. Определение подразумевает наличие в
архитектуре многих процессоров, обрабатывающих один и тот же поток данных.
Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до
сих пор не смогли представить убедительный пример реально существующей
вычислительной системы, построенной на данном принципе. Ряд исследователей
относят конвейерные машины к данному классу, однако это не нашло окончательного
признания в научном сообществе. Будем считать, что пока данный класс пуст.
|
|
|
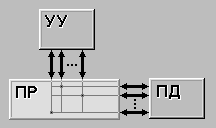
МКМД(MIMD) (multiple instruction stream / multiple data stream) – множественный
поток команд и множественный поток данных. Этот класс предполагает, что в
вычислительной системе есть несколько устройств обработки команд,
объединенных в единый комплекс и работающих каждое со своим потоком команд и
данных.
|
Итак,
что же собой представляет каждый класс? В ОКОД(SISD), как уже говорилось,
входят однопроцессорные последовательные компьютеры например на базе Intel 80486.
Однако, критиками подмечено, что в этот класс можно включить и
векторно-конвейерные машины, если рассматривать вектор как одно неделимое
данное для соответствующей команды. В таком случае в этот класс попадут и такие
системы, как CRAY-1.
Бесспорными
представителями класса ОКМД(SIMD) считаются матрицы процессоров: ILLIAC IV, ICL
DAP, Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах
единое управляющее устройство контролирует множество процессорных элементов.
Каждый процессорный элемент получает от устройства управления в каждый
фиксированный момент времени одинаковую команду и выполняет ее над своими
локальными данными. Для классических процессорных матриц никаких вопросов не
возникает, однако в этот же класс можно включить и векторно-конвейерные машины,
например, CRAY-1. В этом случае каждый элемент вектора надо рассматривать как
отдельный элемент потока данных.
Но
не всё так просто. В последнее время к типу выполнения ОКМД (скорее к типу
выполнения, а не к архитектуре) относят и расширения ОКОД-процессоров (или тех
процессоров, которые при довольно отвлечённом рассмотрении выглядят как ОКОД)
расширенных методом выполнения команд «ОКМД-в-регистре», когда длинный регистр
делится на одинаковое количество полей (обычно 2n, n=1..3), над которыми
в течении одно машинного такта выполняется одна и та же команда, как над
несколькими регистрами, но с целью экономии доступа к памяти все значения
загружаются одновременно в этот регистр. Схема эта чрезвычайно популярна: Intel
MMX/SSE/SSE2, AMD 3DNow!, SPARC VIS.
Класс
МКМД(MIMD) чрезвычайно широк, поскольку включает в себя всевозможные
мультипроцессорные системы: Cm*, C.mmp, CRAY Y-MP, Denelcor
HEP, BBN Butterfly, Intel Paragon, CRAY T3D и многие
другие. Интересно то, что если конвейерную обработку рассматривать как
выполнение множества команд (операций ступеней конвейера) не над одиночным
векторным потоком данных, а над множественным скалярным потоком, то все
рассмотренные выше векторно-конвейерные компьютеры можно расположить и в данном
классе.
Предложенная
схема классификации вплоть до настоящего времени является самой применяемой при
начальной характеристике того или иного компьютера. Если говорится, что
компьютер принадлежит классу ОКМД(SIMD) или МКМД(MIMD), то сразу становится
понятным базовый принцип его работы, и в некоторых случаях этого бывает
достаточно. Однако видны и явные недостатки. В частности, некоторые
заслуживающие внимания архитектуры, например dataflow и векторно–конвейерные
машины, четко не вписываются в данную классификацию. Другой недостаток – это
чрезмерная заполненность класса МКМД(MIMD). Необходимо средство, более
избирательно систематизирующее архитектуры, которые по Флинну попадают в один
класс, но совершенно различны по числу процессоров, природе и топологии связи
между ними, по способу организации памяти и, конечно же, по технологии
программирования.
Наличие
пустого класса МКОД (MISD) не стоит считать недостатком схемы. Такие классы, по
мнению некоторых исследователей в области классификации архитектур, могут стать
чрезвычайно полезными для разработки принципиально новых концепций в теории и
практике построения вычислительных систем.
3.2
Классификация Фенга
В 1972 году
Т. Фенг предложил классифицировать вычислительные системы на основе двух
простых характеристик. Первая – число бит n в машинном слове, обрабатываемых
параллельно при выполнении машинных инструкций. Практически во всех современных
компьютерах это число совпадает с длиной машинного слова. Вторая характеристика
равна числу слов m, обрабатываемых одновременно данной вычислительной системой.
Немного изменив терминологию, функционирование любого компьютера можно
представить как параллельную обработку n битовых слоев, на каждом из которых
независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую характеристику
обычно называют шириной битового слоя.
Если
рассмотреть предельные верхние значения данных характеристик, то каждую
вычислительную систему C можно описать парой чисел (n, m) и представить точкой
на плоскости в системе координат длина слова – ширина битового слоя. Площадь
прямоугольника со сторонами n и m определяет интегральную характеристику
потенциала параллельности P архитектуры и носит название максимальной
степени параллелизма вычислительной системы: P(C)=mn. По существу, данное
значение есть ничто иное, как пиковая производительность, выраженная в других
единицах. В период появления данной классификации, а это начало 70-х годов, еще
казалось возможным перенести понятие пиковой производительности как
универсального средства сравнения и описания потенциальных возможностей
компьютеров с традиционных последовательных машин на параллельные. Понимание
того факта, что пиковая производительность сама по себе не столь важна, пришло
позднее, и данный подход отражает, естественно, степень осмысления специфики
параллельных вычислений того времени.
Рассмотрим компьютер Advanced Scientific Computer фирмы Texas Instruments (TI ASC). В основном
режиме он работает с 64-х разрядным словом, причем все разряды обрабатываются
параллельно. Арифметико-логическое устройство имеет четыре одновременно
работающих конвейера, содержащих по восемь ступеней. Такая организация дает
4x8=32 бита в каждом битовом слое, и значит компьютер TI ASC может быть
представлен в виде (64,32).
На основе
введенных понятий все вычислительные системы в зависимости от способа обработки
информации, заложенного в их архитектуру, можно разделить на четыре класса.
·
Разрядно-последовательные пословно-последовательные (n=m=1). В
каждый момент времени такие компьютеры обрабатывают только один двоичный разряд.
Представителем данного класса служит давняя система MINIMA с естественным
описанием (1,1).
·
Разрядно-параллельные пословно-последовательные (n>1, m=1).
Большинство классических последовательных компьютеров, так же как и многие
вычислительные системы, эксплуатируемые до сих пор, принадлежит к данному
классу: IBM 701 с описанием (36,1), PDP-11 (16,1), IBM 360/50 и VAX 11/780 – обе
с описанием (32,1).
·
Разрядно-последовательные пословно-параллельные (n = 1, m > 1).
Как правило вычислительные системы данного класса состоят из большого числа
одноразрядных процессорных элементов, каждый из которых может независимо от
остальных обрабатывать свои данные. Типичными примерами служат STARAN (1, 256)
и MPP (1,16384) фирмы Goodyear Aerospace, прототип известной системы ILLIAC IV
компьютер SOLOMON (1, 1024) и ICL DAP (1, 4096).
·
Разрядно-параллельные пословно-параллельные (n > 1, m > 1). Большая часть существующих параллельных вычислительных систем, обрабатывая одновременно
mn двоичных разрядов, принадлежит именно к этому классу: ILLIAC IV (64, 64), TI
ASC (64, 32), C.mmp (16, 16), CDC 6600 (60, 10), BBN Butterfly GP1000 (32,
256).
Недостатки
предложенной классификации достаточно очевидны и связаны со способом вычисления
ширины битового слоя m. По существу Фенг не делает никакого различия между
процессорными матрицами, векторно-конвейерными и многопроцессорными системами.
Не делается акцент на том, за счет чего компьютер может одновременно
обрабатывать более одного слова: множественности функциональных устройств, их
конвейерности или же какого-то числа независимых процессоров. Если в системе N
независимых процессоров имеют каждый по F конвейерных функциональных устройств
с длиной конвейера L, то для вычисления ширины битового слоя надо просто найти
произведение данных характеристик. Конечно же, опираясь на данную
классификацию, достаточно трудно (а иногда и невозможно) осознать специфику той
или иной вычислительной системы. Однако достоинством является введение
единой числовой метрики для всех типов компьютеров, которая вместе с
описанием потенциала вычислительных возможностей конкретной архитектуры
позволяет сравнить любые два компьютера между собой.
3.3
Классификация Хокни
Р. Хокни
– известный английский специалист в области параллельных вычислительных систем,
разработал свой подход к классификации, введенной им для систематизации
компьютеров, попадающих в класс MIMD по систематике Флинна.
Как
отмечалось выше (см. классификацию Флинна), класс MIMD чрезвычайно широк,
причем наряду с большим числом компьютеров он объединяет и целое множество
различных типов архитектур. Хокни, пытаясь систематизировать архитектуры внутри
этого класса, получил иерархическую структуру, представленную на рисунке:
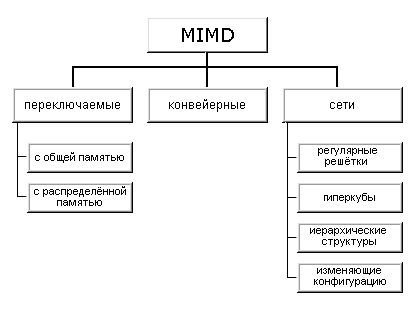
Основная
идея классификации состоит в следующем. Множественный поток команд может быть
обработан двумя способами: либо одним конвейерным устройством обработки,
работающем в режиме разделения времени для отдельных потоков, либо каждый поток
обрабатывается своим собственным устройством. Первая возможность используется в
MIMD компьютерах, которые автор называет конвейерными (например, процессорные
модули в Denelcor HEP). Архитектуры, использующие вторую возможность, в свою
очередь опять делятся на два класса:
·
MIMD компьютеры, в которых возможна прямая связь каждого
процессора с каждым, реализуемая с помощью переключателя;
·
MIMD компьютеры, в которых прямая связь каждого процессора
возможна только с ближайшими соседями по сети, а взаимодействие удаленных
процессоров поддерживается специальной системой маршрутизации через
процессоры-посредники.
Многие
современные вычислительные системы имеют как общую разделяемую память, так и
распределенную локальную. Такие системы автор рассматривает как гибридные MIMD
c переключателем.
При
рассмотрении MIMD машин с сетевой структурой считается, что все они имеют
распределенную память, а дальнейшая классификация проводится в соответствии с
топологией сети: звездообразная сеть (lCAP), регулярные решетки разной
размерности (Intel Paragon, CRAY T3D), гиперкубы (NCube, Intel iPCS), сети с
иерархической структурой, такой, как деревья, пирамиды, кластеры (Cm*,
CEDAR) и, наконец, сети, изменяющие свою конфигурацию.
Заметим,
что если архитектура компьютера спроектирована с использованием нескольких
сетей с различной топологией, то, по всей видимости, по аналогии с гибридными
MIMD с переключателями, их стоит назвать гибридными сетевыми MIMD, а
использующие идеи разных классов – просто гибридными MIMD. Типичным
представителем последней группы, в частности, является компьютер Connection
Machine 2, имеющим на внешнем уровне топологию гиперкуба, каждый узел которого
является кластером процессоров с полной связью.
3.4
Классификация Шнайдера
В 1988 году
Л. Шнайдер (L. Snyder) предложил новый подход к описанию архитектур
параллельных вычислительных систем, попадающих в класс SIMD систематики Флинна.
Основная идея заключается в выделении этапов выборки и непосредственно
исполнения в потоках команд и данных. Именно разделение потоков на адреса и их
содержимое позволяет описать такие ранее «неудобные» для классификации
архитектуры, как компьютеры с длинным командным словом, систолические массивы и
целый ряд других.
Пусть S
произвольный поток ссылок. Последовательность адресов потока S,
обозначаемая Sa, – это последовательность, чей i-й элемент – набор,
сформированный из адресов i-х элементов каждой последовательности из S: потока
S, обозначаемая Sv, – это последовательность, чей i-й элемент
– набор, образованный слиянием наборов значений i-х элементов каждой
последовательности из S.
Если Sx
– последовательность элементов, где каждый элемент – набор из n чисел, то для
обозначения «ширины» последовательности будем пользоваться обозначением: w(Sx)
= n.
Каждую пару
(I, D) с потоком команд I и потоком данных D будем
называть вычислительным шаблоном, а все компьютеры будем разбивать на
классы в зависимости от того, какой шаблон они могут исполнить. В самом деле,
компьютер может исполнить шаблон (I, D), если он в состоянии:
·
выдать w(Ia) адресов команд для одновременной выборки
из памяти;
·
декодировать и проинтерпретировать одновременно w(Iv)
команд;
·
выдать одновременно w(Da) адресов операндов и
·
выполнить одновременно w(Dv) операций над различными
данными.
Если все
эти условия выполнены, то компьютер может быть описан следующим образом: Iw(Ia)w(Iv)Dw(Da)w(Dv).
Поэтому
описание однопроцессорной машины с фон-неймановской архитектурой будет
выглядеть так: I1,1D1,1.
Теперь
возьмем две машины из класса SIMD: Goodyear Aerospace MPP и ILLIAC IV, причем
не будем принимать во внимание разницу в способах обработки данных отдельными
процессорными элементами. Единственный поток команд означает I = 1 для обеих
машин. По тем же соображениям, использованным только что для последовательной
машины, для потока команд получаем равенство w(Ia) = w(Iv)
= 1. Далее, вспомним, что для доступа к операндам устройство управления MPP
рассылает один и тот же адрес всем процессорным элементам, поэтому в этой
терминологии MPP имеет единственную последовательность в потоке данных, т.е. D
= 1. Однако затем выборка данных из памяти и последующая обработка
осуществляется в каждом процессорном элементе, поэтому w(Dv)=16384,
а вся система MPP может быть описана так: I1,1D1,16384.
В ILLIAC IV
устройство управления, так же, как и в MPP, рассылает один и тот же адрес всем
процессорным элементам, однако каждый из них может получить свой уникальный
адрес, добавляя содержимое локального индексного регистра. Это означает, что D
= 64 и в системе присутствуют 64 потока адресов данных, определяющих одиночные
потоки операндов, т.е. w(Da) = w(Dv) = 64. Суммируя
сказанное, приходим к описанию ILLIAC IV: I1,1D64,64.
Для более
четкой классификации Шнайдер вводит три предиката для обозначения значений,
которые могут принимать величины w(Ia), w(Iv), w(Da)
и w(Dv):
s – предикат
«равен 1»;
с – предикат
«от 1 до некоторой (небольшой) константы»;
m – предикат
«от 1 до произвольно большого конечного числа».
В этих
обозначениях, например, фон-неймановская машина принадлежит к классу IssDss.
Несмотря на то, что и 'c' и 'm' в принципе не имеют определенной верхней
границы, они отражают разные свойства архитектуры компьютера. Описатель 'c'
предполагает жесткие ограничения сверху со стороны аппаратуры, и соответствующий
параметр не может быть значительно увеличен относительно простыми средствами.
Примером может служить число инструкций, упакованных в командном слове VLIW
компьютера. С другой стороны, описатель 'm' используется тогда, когда
обозначаемая величина может быть легко изменена, т.е. другими словами,
компьютер по данному параметру масштабируем. Например, относительная проста в
увеличении числа процессорных элементов в системе MPP является основанием для
того, чтобы отнести ее к классу IssDsm. Конечно же,
различие между 'c' и 'm' в достаточной мере условное и, как правило, порождает
массу вопросов. В частности, как описать машину, в которой процессоры связаны
через общую шину? С одной стороны, нет никаких принципиальных ограничений на
число подключаемых процессоров. Однако каждый дополнительный процессор
увеличивает загруженность шины, и при достижении некоторого порога подключение
новых процессоров бессмысленно. Как описать такую систему, 'c' или 'm'? Автор
оставляет данный вопрос открытым.
На основе
указанных предикатов можно выделить следующие классы компьютеров:
·
IssDss – фон-неймановские машины;
·
IssDsc – фон-неймановские машины, в которых
заложена возможность выбирать данные, расположенные с разным смещением
относительно одного и того же адреса, над которыми будет выполнена одна и та же
операция. Примером могут служить компьютеры, имеющие команды, типа
одновременного выполнения двух операций сложения над данными в формате
полуслова, расположенными по указанному адресу.
·
IssDsm – SIMD компьютеры без возможности
получения уникального адреса для данных в каждом процессорном элементе,
включающие MPP, Connection Machine 1 так же, как и систолические массивы.
·
IssDcc – многомерные SIMD машины – фон-неймановские
машины, способные расщеплять поток данных на независимые потоки операндов;
·
IssDmm – это SIMD компьютеры, имеющие
возможность независимой модификации адресов операндов в каждом процессорном
элементе, например, ILLIAC IV и Connection Machine 2.
·
IscDcc – вычислительные системы, выбирающие
и исполняющие одновременно несколько команд, для доступа к которым используется
один адрес. Типичным примером являются компьютеры с длинным командным словом
(VLIW).
·
IccDcc – многомерные MIMD машины.
Фон-неймановские машины, которые могут расщеплять свой цикл выборки / выполнения
с целью обработки параллельно нескольких независимых команд.
·
ImmDmm – к этому классу относятся все
компьютеры типа MIMD.
Достаточно
ясно, что не нужно рассматривать все возможные комбинации описателей 's', 'c' и
'm', так как архитектура реальных компьютеров накладывает ряд вполне разумных
ограничений. Очевидно, что число адресов w(Sa) не должно превышать
числа возвращенных значений w(Sv), которое компьютер может
обработать. Отсюда следуют неравенства: w(Ia) <= w(Iv)
и w(Da) <= w(Dv). Другим естественным предположением
является тот факт, что число выполняемых команд не должно превышать числа
обрабатываемых данных: w(Iv) <= w(Dv).
Подводя
итог, можно отметить два положительных момента в классификации Шнайдера: более
избирательная систематизация SIMD компьютеров и возможность описания
нетрадиционных архитектур типа систолических массивов или компьютеров с длинным
командным словом. Однако почти все вычислительные системы типа MIMD опять
попали в один и тот же класс ImmDmm. Это и не удивительно,
так как критерий классификации, основанный лишь на потоках команд и данных без
учета распределенности памяти и топологии межпроцессорной связи, слишком слаб
для подобных систем.
3.5
Классификация Скилликорна
В 1989 году
была сделана очередная попытка расширить классификацию Флинна и, тем самым,
преодолеть ее недостатки. Д. Скилликорн разработал подход, пригодный для
описания свойств многопроцессорных систем и некоторых нетрадиционных
архитектур, в частности dataflow и reduction machine.
Предлагается
рассматривать архитектуру любого компьютера, как абстрактную структуру,
состоящую из четырех компонент:
·
процессор команд (IP – Instruction Processor) – функциональное устройство,
работающее, как интерпретатор команд; в системе, вообще говоря, может отсутствовать;
·
процессор данных (DP – Data Processor) – функциональное устройство, работающее как
преобразователь данных, в соответствии с арифметическими операциями;
·
иерархия памяти (IM – Instruction Memory, DM – Data Memory) – запоминающее
устройство, в котором хранятся данные и команды, пересылаемые между
процессорами;
·
переключатель – абстрактное устройство, обеспечивающее связь между процессорами
и памятью.
Функции
процессора команд во многом схожи с функциями устройств управления
последовательных машин и, согласно Д. Скилликорну, сводятся к следующим:
·
на основе своего состояния и полученной от DP информации IP
определяет адрес команды, которая будет выполняться следующей;
·
осуществляет доступ к IM для выборки команды;
·
получает и декодирует выбранную команду;
·
сообщает DP команду, которую надо выполнить;
·
определяет адреса операндов и посылает их в DP;
·
получает от DP информацию о результате выполнения команды.
Функции
процессора данных делают его, во многом, похожим на арифметическое устройство
традиционных процессоров:
·
DP получает от IP команду, которую надо выполнить;
·
получает от IP адреса операндов;
·
выбирает операнды из DM;
·
выполняет команду;
·
запоминает результат в DM;
·
возвращает в IP информацию о состоянии после выполнения команды.
В терминах
таким образом определенных основных частей компьютера структуру традиционной
фон-неймановской архитектуры можно представить в следующем виде:
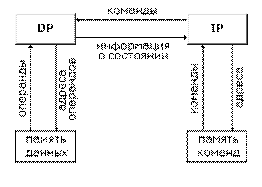
Это один из
самых простых видов архитектуры, не содержащих переключателей. Для описания
параллельных вычислительных систем автор зафиксировал четыре типа
переключателей, без какой-либо явной связи с типом устройств, которые они
соединяют:
·
1–1 – переключатель такого типа связывает пару функциональных
устройств;
·
n-n – переключатель связывает i-е устройство из одного множества
устройств с i-м устройством из другого множества, т.е. фиксирует попарную
связь;
·
1-n – переключатель соединяет одно выделенное устройство со всеми
функциональными устройствами из некоторого набора;
·
nxn – каждое функциональное устройство одного множества может быть
связано с любым устройством другого множества, и наоборот.
Примеров
подобных переключателей можно привести очень много. Так, все матричные
процессоры имеют переключатель типа 1-n для связи единственного процессора
команд со всеми процессорами данных. В компьютерах семейства Connection Machine
каждый процессор данных имеет свою локальную память, следовательно, связь будет
описываться как n-n. В тоже время, каждый процессор команд может связаться с
любым другим процессором, поэтому данная связь будет описана как nxn.
Классификация
Д. Скилликорна состоит из двух уровней. На первом уровне она проводится на
основе восьми характеристик:
1.
количество процессоров команд (IP);
2.
число запоминающих устройств (модулей памяти) команд (IM);
3.
тип переключателя между IP и IM;
4.
количество процессоров данных (DP);
5.
число запоминающих устройств (модулей памяти) данных (DM);
6.
тип переключателя между DP и DM;
7.
тип переключателя между IP и DP;
8.
тип переключателя между DP и DP.
(1, 1, 1–1,
n, n, n-n, 1-n, nxn),
а условное
изображение архитектуры приведено на следующем рисунке:
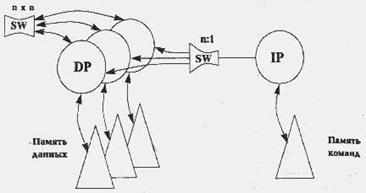
Для
сильно связанных мультипроцессоров (BBN Butterfly, C.mmp) ситуация иная. Такие
системы состоят из множества процессоров, соединенных с модулями памяти с
помощью динамического переключателя. Задержка при доступе любого процессора к
любому модулю памяти примерно одинакова. Связь и синхронизация между
процессорами осуществляется через общие (разделяемые) переменные. Описание
таких машин в рамках данной классификации выглядит так: (n, n, n-n, n, n, nxn,
n-n, нет), а саму архитектуру можно изобразить так, как на следующем рисунке:
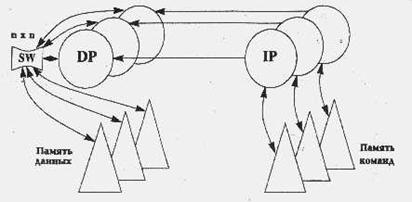
Используя
введенные характеристики и предполагая, что рассмотрение количественных
характеристик можно ограничить только тремя возможными вариантами значений: 0,
1 и n (т.е. больше одного), можно получить 28 классов архитектур.
В классах 1–5
находятся компьютеры типа dataflow и reduction, не имеющие процессоров команд в
обычном понимании этого слова. Класс 6 это классическая фон-неймановская
последовательная машина. Все разновидности матричных процессоров содержатся в
классах 7–10. Классы 11 и 12 отвечают компьютерам типа MISD классификации
Флинна и на настоящий момент, по мнению автора, пусты. Классы с 13-го по 28-й
занимают всевозможные варианты мультипроцессоров, причем в 13–20 классах
находятся машины с достаточно привычной архитектурой, в то время, как
архитектура классов 21–28 пока выглядит экзотично.
На втором
уровне классификации Д. Скилликорн просто уточняет описание, сделанное на
первом уровне, добавляя возможность конвейерной обработки в процессорах команд
и данных.
В конце
данного описания имеет смысл привести сформулированные автором три цели,
которым должна служить хорошо построенная классификация:
·
облегчать понимание того, что достигнуто на сегодняшний день в
области архитектур вычислительных систем, и какие архитектуры имеют лучшие
перспективы в будущем;
·
подсказывать новые пути организации архитектур – речь идет о тех
классах, которые в настоящее время по разным причинам пусты;
·
показывать, за счет каких структурных особенностей достигается
увеличение производительности различных вычислительных систем; с этой точки
зрения, классификация может служить моделью для анализа производительности.
3.6
Классификация Дункана
В работе Р. Дункан
излагает свой взгляд на проблему классификации архитектур параллельных
вычислительных систем, причем сразу определяет тот набор требований, на который,
с его точки зрения, может опираться искомая классификация:
·
Из класса параллельных машин должны быть исключены те, в которых
параллелизм заложен лишь на самом низком уровне, включая:
o
конвейеризацию на этапе подготовки и выполнения команды
(instruction pipelining), т.е. частичное перекрытие таких этапов, как
дешифрация команды, вычисление адресов операндов, выборка операндов, выполнение
команды и сохранение результата;
o
наличие в архитектуре нескольких функциональных устройств,
работающих независимо, в частности, возможность параллельного выполнения
логических и арифметических операций;
o
наличие отдельных процессоров ввода / вывода, работающих
независимо и параллельно с основными процессорами.
Причины
исключения перечисленных выше особенностей автор объясняет следующим образом.
Если рассматривать компьютеры, использующие только параллелизм низкого уровня,
наравне со всеми остальными, то, во-первых, практически все существующие
системы будут классифицированы как «параллельные» (что заведомо не будет позитивным
фактором для классификации), и, во-вторых, такие машины будут плохо вписываться
в любую модель или концепцию, отражающую параллелизм высокого уровня.
·
Классификация должна быть согласованной с классификацией Флинна,
показавшей правильность выбора идеи потоков команд и данных.
·
Классификация должна описывать архитектуры, которые однозначно не
укладываются в систематику Флинна, но, тем не менее, относятся к параллельным
архитектурам (например, векторно-конвейерные).
Учитывая
вышеизложенные требования, Дункан дает неформальное определение параллельной
архитектуры, причем именно неформальность дала ему возможность включить в
данный класс компьютеры, которые ранее не вписывались в систематику Флинна.
Итак, параллельная архитектура – это такой способ организации
вычислительной системы, при котором допускается, чтобы множество процессоров
(простых или сложных) могло бы работать одновременно, взаимодействуя по мере
надобности друг с другом. Следуя этому определению, все разнообразие
параллельных архитектур Дункан систематизирует так, как показано на рисунке:
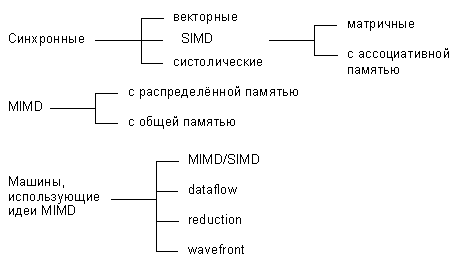
По существу
систематика очень простая: процессоры системы работают либо синхронно, либо
независимо друг от друга, либо в архитектуру системы заложена та или иная
модификация идеи MIMD. На следующем уровне происходит детализация в рамках
каждого из этих трех классов. Дадим небольшое пояснение лишь к тем из них,
которые на сегодняшний день не столь широко известны.
Систолические
архитектуры (их чаще называют
систолическими массивами) представляют собой множество процессоров,
объединенных регулярным образом (например, система WARP). Обращение к памяти
может осуществляться только через определенные процессоры на границе массива.
Выборка операндов из памяти и передача данных по массиву осуществляется в одном
и том же темпе. Направление передачи данных между процессорами фиксировано.
Каждый процессор за интервал времени выполняет небольшую инвариантную
последовательность действий.
Гибридные
MIMD/SIMD архитектуры, dataflow, reduction и wavefront вычислительные системы
осуществляют параллельную обработку информации на основе асинхронного
управления, как и MIMD системы. Но они выделены в отдельную группу, поскольку
все имеют ряд специфических особенностей, которыми не обладают системы,
традиционно относящиеся к MIMD.
MIMD/SIMD – типично гибридная архитектура. Она предполагает, что в MIMD
системе можно выделить группу процессоров, представляющую собой подсистему,
работающую в режиме SIMD (PASM, Non-Von). Такие системы отличаются
относительной гибкостью, поскольку допускают реконфигурацию в соответствии с
особенностями решаемой прикладной задачи.
Остальные
три вида архитектур используют нетрадиционные модели вычислений. Dataflow
используют модель, в которой команда может выполнятся сразу же, как только
вычислены необходимые операнды. Таким образом, последовательность выполнения
команд определяется зависимостью по данным, которая может быть выражена,
например, в форме графа.
Модель
вычислений, применяемая в reduction машинах иная и состоит в следующем:
команда становится доступной для выполнения тогда и только тогда, когда
результат ее работы требуется другой, доступной для выполнения, команде в
качестве операнда.
Wavefront
array архитектура объединяет в себе идею
систолической обработки данных и модель вычислений, используемой в dataflow. В
данной архитектуре процессоры объединяются в модули и фиксируются связи, по
которым процессоры могут взаимодействовать друг с другом. Однако, в
противоположность ритмичной работе систолических массивов, данная архитектура
использует асинхронный механизм связи с подтверждением (handshaking), из-за
чего «фронт волны» вычислений может менять свою форму по мере прохождения по
всему множеству процессоров.
Заключение
Наиболее
перспективным и динамичным направлением увеличения скорости решения прикладных
задач является широкое внедрение идей параллелизма в работу вычислительных
систем. К настоящему времени спроектированы и опробованы сотни различных
компьютеров, использующих в своей архитектуре тот или иной вид параллельной
обработки данных. Идея распараллеливания вычислений основана на том, что
большинство задач может быть разделено на набор меньших задач, которые могут
быть решены одновременно. Обычно параллельные вычисления требуют координации
действий. Параллельные вычисления существуют в нескольких формах: параллелизм
на уровне битов, параллелизм на уровне инструкций, параллелизм данных,
параллелизм задач. Параллельные вычисления использовались много лет в основном
в высокопроизводительных вычислениях, но в последнее время к ним возрос интерес
вследствие существования физических ограничений на рост тактовой частоты
процессоров. Параллельные вычисления стали доминирующей парадигмой в
архитектуре компьютеров, в основном в форме многоядерных процессоров.
Попытки
систематизировать все множество архитектур начались после опубликования М. Флинном
первого варианта классификации вычислительных систем в конце 60-х годов и
непрерывно продолжаются по сей день. Классификация очень важна для лучшего
понимания исследуемой предметной области, однако нахождение удачной классификации
может иметь целый ряд существенных следствий. Классификация должна помогать
разобраться с тем, что представляет собой каждая архитектура, как они
взаимосвязаны между собой, что необходимо учитывать для написания действительно
эффективных программ или же на какой класс архитектур следует ориентироваться
для решения требуемого класса задач. Одновременно удачная классификация могла
бы подсказать возможные пути совершенствования компьютеров и в этом смысле она
должна быть достаточно содержательной. Трудно рассчитывать на нахождение
нетривиальных «белых пятен», например, в классификации по стоимости, однако
размышления о возможной систематике с точки зрения простоты и технологичности
программирования могут оказаться чрезвычайно полезными для определения
направлений поиска новых архитектур.
Список
литературы
1.
Вл.В. Воеводин, А.П. Капитонова. «Методы описания и
классификации вычислительных систем». Издательство МГУ, 1994
2.
Хокни Р., Джессхоуп К. Параллельные ЭВМ. Архитектура,
программирование и алгоритмы. М.: Радио и связь. 1986. 392 с.
3.
Головкин Б.А. Параллельные вычислительные системы. М.:
Наука. 1980. 520 с.
4.
Валях Е. Последовательно-параллельные вычисления. М.: Мир. 1985.
456 с.