Понятия и расчеты в математической статистике
1.
Какая
шкала называется шкалой отношений? Приведите примеры
Шкала отношений или шкала
равных отношений - наиболее часто используемая в естественных науках и, прежде
всего, в физике. Это еще более гибкая шкала, здесь кроме определения равенства,
рангового порядка, равенства интервалов известно еще и равенство отношений.
Шкала отношений позволяет определить не только, на сколько больше (меньше) один
объект другого в отношении измеряемого свойства, но и во сколько раз больше
(меньше).
Например, для четырех
объектов с откликами 3, 4, 6 и 8 выполняется отношение 3/4 = 6/8. Это
обусловлено тем, что в шкала отношений в отличие от интервальной шкалы, нулевое
значение отклика указывает на полное отсутствие измеряемого свойства.
2.
Стратифицированная,
или расслоенная, выборка
(stratified sampling) — это процесс, состоящий из двух
этапов, в котором совокупность делится на подгруппы (слои, страты, strata). Слои должны взаимно исключать и взаимно дополнять один
другого, чтобы каждый элемент совокупности относился к одному и только одному
слою, и ни один элемент не был упущен. Далее, из каждого слоя случайным образом
выбираются элементы, при этом обычно используется метод простой случайной
выборки. Формально, выбор элементов из каждого слоя может осуществляться только
с помощью SRS. Однако на практике иногда применяется
систематический отбор и другие вероятностные выборочные методы. Отличие
стратифицированной выборки от квотной состоит в том, что элементы в ней
выбираются скорее случайно, а не из удобства или на основании мнения
исследователя. Главная задача стратифицированной выборки — увеличение точности
без увеличения затрат.
Стратификационный метод
обеспечивает наличие в выборке всех важных подгрупп. Это особенно важно, если
исследуемая характеристика неравномерно распределена среди элементов
генеральной совокупности. Например, распределение дохода семей неравномерно,
так как годовой доход большинства семей составляет меньше 50 тысяч долларов, и
лишь немногие семьи имеют годовой доход, равный 125 тысяч долларов и выше. Если
применить простую случайную выборку, семьи с доходом 125 тысяч долларов и выше
могут не быть адекватно представлены. Стратифицированная выборка позволяет
обеспечить соответствующее количество таких семей в выборке. Она сочетает в
себе простоту метода SRS с
возможностью повышения точности. Поэтому данный метод формирования выборки
3. Медиана
один из показателей
центра распределения для порядковых и количественных переменных; обозначается Ме.
Представляет собой значение переменной, которое делит выборку пополам таким
образом, чтобы для 50% объектов из выборки значения переменной не превосходили Ме,
а для других 50% объектов - были не меньше, чем Ме.
4. Охарактеризуйте понятие «мощность
критерия»
Для определения понятия мощности
критерия введем понятие альтернативной гипотезы H1,
т.е. гипотезы, которая выполняется, если не выполняется нулевая гипотеза H0.
Тогда в терминах правильности или ошибочности принятия H0 и H1
можно указать четыре потенциально возможных результата применения
критерия к выборке, представленные в табл. 3. Как мы видим мощность критерия -
это вероятность принятия при применении данного критерия альтернативной
гипотезы H1 при условии, что она верна. Очевидно, что при
фиксированной ошибке 1-го рода (ее мы задаем сами, и она не зависит от свойств
критерия) критерий будет тем лучше, чем больше его мощность (т.е. чем меньше
ошибка 2-го рода).
Проведем следующие
рассмотрения для того, чтобы формально определить понятие мощности критерия.
Критерий разбивает выборочное пространство 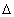 на два
дополнительных множества
на два
дополнительных множества  ( множество
точек, для которых гипотеза принимается ) и
( множество
точек, для которых гипотеза принимается ) и 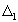 . ( множество
точек, для которых гипотеза отвергается ). Множество называют областью
принятия гипотезы , а - областью ее
отклонения или критической областью . Вероятность попадания выборки в
критическую область при заданной функции распеределения, называют функцией
мощности критерия . Если альтернативной к испытуемой является простая
гипотеза, то она однозначно определяет распеределение. Значение функции
мощности для этого распределения называют мощностью критерия .
. ( множество
точек, для которых гипотеза отвергается ). Множество называют областью
принятия гипотезы , а - областью ее
отклонения или критической областью . Вероятность попадания выборки в
критическую область при заданной функции распеределения, называют функцией
мощности критерия . Если альтернативной к испытуемой является простая
гипотеза, то она однозначно определяет распеределение. Значение функции
мощности для этого распределения называют мощностью критерия .
Вернемся к рассмотрению примера с оценкой вероятности правильной классификации. Ошибка
первого рода состоит в том, что, когда вероятность правильной классификации
действительно равна 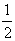 , число
правильных классифкаций
, число
правильных классифкаций 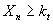 . Значение
ошибки первого рода может быть вычислено следующим образом:
. Значение
ошибки первого рода может быть вычислено следующим образом:
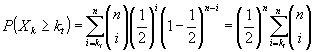
Ошибка второго рода
состоит в том, что при вероятности правильной классификации 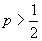 , число
правильных классификаций
, число
правильных классификаций 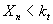 . Эта
вероятность вычисляется по формуле:
. Эта
вероятность вычисляется по формуле:
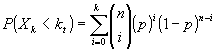
 Если задан уровень значимости
Если задан уровень значимости 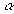 , то пороговое
значение
, то пороговое
значение 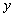 , задающее
критическую область, определяется из неравенства:
, задающее
критическую область, определяется из неравенства:
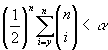
Функция мощности критерия
- это вероятность попадания в критическую область:
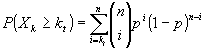
Пусть теперь
альтернативной гипотезой для 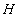 :
: 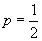 будет простая
гипотеза
будет простая
гипотеза 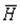 :
: 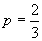 ., тогда
мощность критерия, равная вероятности попадания в критическую область, когда
верна альтернативная гипотеза, вычисляется бы по формуле.
., тогда
мощность критерия, равная вероятности попадания в критическую область, когда
верна альтернативная гипотеза, вычисляется бы по формуле.
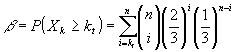 .
.
Вероятность ошибки
второго рода равна в этом случае равна 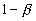 .
.
5. Охарактеризуйте термин процентили
Процентиль (этот термин был впервые использован
Галтоном в 1885 г.) распределения - это такое число xp, что значения
p-й части совокупности меньше или равны xp. Например, 25-я процентиль
(также называемая квантилью 0.25 или нижней квартилью)
переменной - это такое значение (xp), что 25% (p) значений
переменной попадают ниже этого значения.
Аналогичным образом
вычисляется 75-я процентиль (также называемая квантилью 0.75 или верхней квартилью) - такое значение, ниже
которого попадают 75% значений переменной. Способ расчета процентилей
можно задать на вкладке Общие настройки в диалоговом окне Параметры
по умолчанию (это окно вызывается нажатием кнопки Опции в меню Сервис).
6. Если коэффициент корреляции
положителен, то между исследуемыми величинами есть прямая зависимость
7.
Когда необходимо
использовать понятие «зона значимости»?
Понятие «зона значимости
« используется при оценке испытаний при использовании различных критериев
(например. G-критерий), когда получаемое число
попадает в зону. Когда принимается альтернативная гипотеза.
8. Решить задачу, используя парный критерий
тенденций Т-Вилкоксона
У 19 испытуемых
определили количество ошибок при выполнении корректурной пробы до и после
коррекционных упражнений. Психолог определяет будет ли уменьшаться количество
ошибок внимания у респондентов после специальных коррекционных упражнений.
|
До
|
24
|
12
|
42
|
30
|
40
|
55
|
50
|
52
|
50
|
22
|
|
после
|
22
|
12
|
41
|
31
|
32
|
44
|
50
|
32
|
32
|
21
|
|
До
|
33
|
78
|
79
|
25
|
28
|
16
|
17
|
12
|
25
|
|
После
|
34
|
56
|
78
|
23
|
22
|
16
|
18
|
25
|
Решение
1. проверим выполнимость
ограничений: 5 ≤ 19 ≤ 50;
2. запишем данные в
таблицу и сделаем необходимые вычисления:
|
№ испыт.
|
Замер 1
|
Замер 2
|
di = «после» - «до»
|
|di|
|
Ранг |di|
|
Ранг «нетип.»
|
|
1
|
24
|
22
|
-2
|
2
|
7,5
|
7,5
|
|
2
|
12
|
12
|
0
|
0
|
|
|
|
3
|
42
|
41
|
-1
|
1
|
3,5
|
3,5
|
|
4
|
30
|
31
|
1
|
1
|
3.5
|
|
|
5
|
40
|
32
|
-8
|
8
|
12
|
12
|
|
6
|
55
|
44
|
-11
|
11
|
13
|
13
|
|
7
|
50
|
50
|
0
|
0
|
|
|
|
8
|
52
|
32
|
-20
|
20
|
15
|
15
|
|
9
|
50
|
32
|
-18
|
18
|
14
|
|
10
|
22
|
21
|
-1
|
1
|
3,5
|
3,5
|
|
11
|
33
|
34
|
1
|
1
|
3,5
|
|
|
12
|
78
|
56
|
-22
|
22
|
16
|
16
|
|
13
|
79
|
78
|
-1
|
1
|
3,5
|
3,5
|
|
14
|
25
|
23
|
-2
|
2
|
7.5
|
7.5
|
|
15
|
28
|
22
|
-6
|
6
|
3,5
|
3,5
|
|
16
|
16
|
12
|
-4
|
4
|
3,5
|
3,5
|
|
17
|
17
|
16
|
-1
|
1
|
3,5
|
3,5
|
|
18
|
12
|
18
|
6
|
6
|
3,5
|
|
|
19
|
25
|
25
|
0
|
0
|
|
|
|
Суммы
|
-
|
-
|
-
|
151
|
106
|
Исключим нулевые сдвиги и
подсчитаем новый объем выборки: n.= 19-3
= 16;
3. запишем модули сдвигов
в ряд по возрастанию и укажем их места в этом ряду, а затем припишем
соответствующие ранги:
|
№ испыт.
|
|di|
|
Ранг |di|
|
|
1
|
1
|
3,5
|
|
2
|
1
|
3,5
|
|
3
|
1
|
3,5
|
|
4
|
1
|
3,5
|
|
5
|
1
|
3,5
|
|
6
|
1
|
3,5
|
|
7
|
2
|
7,5
|
|
8
|
2
|
7,5
|
|
9
|
4
|
9
|
|
10
|
6
|
10
|
|
11
|
6
|
11
|
|
12
|
8
|
12
|
|
13
|
11
|
13
|
|
14
|
18
|
14
|
|
15
|
20
|
15
|
|
16
|
22
|
16
|
|
Суммы
|
|
151
|
4. определим, какие
сдвиги являются «типичными», а какие - «нетипичными». Положительных сдвигов
больше, их шесть, значит, они «типичные». Отрицательных - меньше, их всего два,
значит, они «нетипичные»;
5. сформулируем гипотезы:
Н 0: интенсивность сдвига
в типичном направлении не превосходит интенсивность сдвига в нетипичном
направлении;
Н 1: интенсивность сдвига
в типичном направлении превосходит интенсивность сдвига в нетипичном
направлении.
6. подсчитаем Т эмп. = ∑
R нетип. = 106;
7. по числу n и таблице 2 приложения найдем Т кр.
(p ≤ 0,05) = 5 и Т кр. (p ≤ 0,0 1) = 1. Построим ось значимости и отметим на ней
все найденные значения:
зона
значимости зона неопределенности зона не значимости
T кр. (p ≤ 0,01) Т эмп. T кр. (p ≤ 0,05)
Так как Т эмп. < Т кр.
(p ≤ 0,05), то Н 0 отвергается и
принимается Н 1, на уровне значимости p ≤
0,05, то есть сдвиг в типичном направлении более интенсивен, чем сдвиг в
нетипичном направлении, что мы можем утверждать с вероятностью, большей 95 %.
Ответ
Обучение можно считать
эффективным (с вероятностью, большей 95 %).
Психолог провёл
эксперимент, в котором выяснилось, что из 23 учащихся математической спецшколы
15 справились с заданием, а из 28 обычной школы с теми же заданиями справилось
11 человек. Можно ли считать, что различия в успешности решения заданий
учащимися спецшколы и обычной школы достоверны?
Решение
1. проверим
выполнимость ограничений:
(n 1 = 23 > 5 и n 2 = 28 > 5);
2. разделим
группы детей на части с помощью признака «справился с заданием» и «не справился
с заданием». Заполним таблицу:
|
|
«Есть эффект»
|
«Нет эффекта»
|
Сумма
|
|
Спецшкола
|
15
|
8
|
23
|
|
Обычная школа
|
11
|
17
|
28
|
3. подсчитываем
процентные доли количества детей, «справившихся с заданием» в экспериментальной
и контрольной группах. В экспериментальной группе 23 человека, которые
составляют 100 %, из них справились с заданием 15 человек, они составляют 60 %.
Значит, не
справились с заданием в экспериментальной группе 100 % -60 % =40 %.
Аналогично, в
контрольной группе 28 человек, которые составляют 100 %, из них справились с
заданием 11 человек, которые составляют 39%.
Тогда доля,
не справившихся с заданием в контрольной группе равна 61 %.
Заполним
четырехклеточную таблицу:
|
|
«Есть эффект»
|
«Нет эффекта»
|
|
Спецшкола
|
60 %
|
40 %
|
|
Обычная школа
|
39 %
|
61 %
|
Отсюда видно, что ни одна
из процентных долей не равна нулю.
4. Сформулируем гипотезы:
Н 0: доля испытуемых в
экспериментальной группе, у которых «есть эффект», не превосходит доли таких же
испытуемых в контрольной группе;
Н 1: доля испытуемых в
экспериментальной группе, у которых «есть эффект», превосходит долю таких же испытуемых
в контрольной группе.
5. по таблице 3.1
приложения найти значения φ 1 и φ 2 по процентному содержанию тех
испытуемых, у которых «есть эффект»:
φ 1 (60%) = 1,772;
φ 2 (39%) = 1,369.
6. подсчитаем
φ эмп. = (φ1 –
φ2) √ n 1* n 2 = (1,772 – 1,369) √ 23 * 28 = 1,43;
n1 + n2 23 + 28
7. по таблице 3.2
приложения найдем уровень значимости различия процентных долей: φ эмп. =
1,43 соответствует уровню значимости p = 0,09.
Для практики этот уровень
мал, поэтому следует сравнить φ эмп. с φ кр. (p ≤ 0,05) = 1,64 и φ кр. (p ≤ 0,01) = 2,31 (их тоже найти по таблице 3.2
приложения).
Ось значимости имеет
следующий вид:
зона
значимости зона неопределенности зона не значимости
1,34 1,64 2,31
φ эмп. φ кр. (p ≤ 0,05) φ
кр. (p = 0,01)
Так как φ эмп. <
φ кр. (p ≤ 0,05), а тем более φ
эмп. < φ кр. (p ≤ 0,01), то
принимается Н 0 с вероятностью ≥ 99 %.
Доля детей в
экспериментальной группе, которые справились с заданием, не выше, чем доля
таких детей в контрольной группе. Статистически такой процент различий
недостаточен (хотя, на первый взгляд, разница в показателях у них большая - 20
%).
Ответ
Различия в результатах
групп статистически незначительны.
10.
Охарактеризуйте
понятие «регрессионный анализ»
Задачи регрессионного
анализа лежат в сфере установления формы зависимости, определения функции
регрессии, использования уравнения для оценки неизвестных значении зависимой
переменной.
Метод множественной
регрессии использовался для оценки функции спроса.
Экономические временные ряды исследовались для выявления
бизнес-циклов и циклических процессов в экономике. В динамике различных
элементов экономики имеются такие показатели, изменение которых развивается с
опережением некоторых других показателей, и поэтому они могут рассматриваться
как предвестники соответствующих изменений отстающих показателей (основа
концепции экономических барометров), позволяя решать задачу прогноза.